BAB 2
TINJAUAN PUSTAKA
2.1. Sistem Pendukung Keputusan
Sistem Pendukung Keputusan (SPK) atau dikenal Decision Support System(DSS)
adalah sistem informasi interaktif yang menyediakan informasi, pemodelan dan
pemanipulasian data yang digunakan untuk membantu pengambilan keputusan pada
situasi yang semiterstruktur dan situasi yang tidak terstruktur dimana tak seorangpun
tahu secara pasti bagaimana keputusan seharusnya dibuat (Kadir, 2003).
2.1.1 Karakteristik Sistem Pendukung Keputusan
Adapun yang menjadi karakteristik SPK (Kadir, 2003) :
1. Menawarkan keluwesan, kemudahan beradaptasi, dan tanggapan yang cepat.
2. Memungkinkan pemakai memulai dan mengendalikan masukan dan keluaran.
3. Dapat dioperasikan dengan sedikit atau tanpa bantuan pemrogram profesional.
4. Menyediakan dukungan untuk keputusan dan permasalahan yang solusinya tak
dapat ditentukan di depan.
5. Menggunakan analisis data dan perangkat pemodelan yang canggih.
2.1.2 Arsitektur Sistem Pendukung Keputusan
Menurut Kusrini (2009), aplikasi SPK bisa terdiri dari beberapa subsistem, yaitu :
1. Subsistem manajemen data
Subsistem ini memasukkan satu database yang berisi data yang relevan untuk
suatu situasi dan dikelola oleh perangkat lunak yang disebut sistem manajemen
2. Subsistem manajemen model
Merupakan paket perangkat lunak yang memasukkan model keuangan, statistik,
ilmu manajemen, atau model kuantitatif lain yang memberikan kapabilitas
analitik dan manajemen perangkat lunak yang tepat.
3. Subsistem antarmuka pengguna
Pengguna berkomunikasi dengan dan memerintahkan sistem pendukung
keputusan melalui subsistem tersebut. Pengguna adalah bagian yang
dipertimbangkan dari sistem.
4. Subsistem manajemen berbasis pengetahuan
Subsistem tersebut mendukung semua subsistem lain atau bertindak langsung
sebagai suatu komponen independen dan bersifat opsional.
2.1.3 Pandangan Pengguna Sistem Pendukung Keputusan
Pandangan pengguna SPK adalah salah satu yang mempengaruhi motivasi
penggunaan SPK. Hubungan antara pandangan pengguna SPK dan motivasi
penggunaan SPK diharapkan haruslah positif. Karena itu, motivasi untuk
menggunakan SPK diharapkakn meningkat ketika SPK dirasakan menjadi lebih
efektif ataupun efisien, atau lebih mudah penggunaannya. (Jao, 2010). Adapun yang
menjadi pandangan pengguna tersebut adalah :
1. Keefektifan
Pengguna mungkin memposisikan keefektifan dan penggunaan lebih sedikit
usaha untuk mencapai target mereka ketika sadar akan keuntungan dari
meningkatkan hasil keputusan. Akibatnya, pertimbangan pengguna terhadap
hasil keputusan akan menuju kepada peningkatan penggunaan SPK.
2. Efisiensi
Sebuah SPK dikatakan efisien jika dapat membantu pengguna dalam membuat
keputusan dalam waktu yang singkat.
3. Usaha
Penelitian menunjukkan bahwa peningkatan penggunaan SPK meningkat ketika
sebuah SPK mengurangi usaha yang digunakan untuk mengimplementasi
strategi yang membutuhkan usaha penuh, dan ketika penggunaan SPK
2.2 Android
Android merupakan sebuah sistem operasi perangkat mobile berbasis linux yang
mencakup sistem operasi, middleware, dan aplikasi. Untuk mengembangkan Android,
dibentuk OHA (Open Handset Aliance), konsorsium dari 34 perusahaan peranti keras
(Hardware), peranti lunak (Software), dan telekomunikasi, termasuk Google, HTC,
Intel, Motorola, Qualcomm, T-Mobile, dan Nvidia. Pada tanggal 5 November 2007,
Android dirilis pertama kali. Android bersama OHA menyatakan mendukung
pengembangan open source pada perangkat mobile.
Sekitar bulan September 2007, Google mengenalkan Nexus One, salah satu
jenis smartphone yang menggunakan Android sebagai sistem operasinya yang
diproduksi oleh HTC Corp. dan tersedia di pasaran pada tanggal 5 Januari 2008. Sejak
saat itu, Android berkembang pesat dan bersaing dengan Apple dalam sistem operasi
untuk PC Tablet. Terdapat dua jenis distributor sistem operasi Android. Pertama yang
mendapat dukungan penuh dari Google atau GMS (Google Mail Services), dan kedua
adalah yang benar-benar bebas distribusinya, tanpa dukungan langsung Google, atau
dikenal sebagai OHD (Open Handset Distribution). Hingga 14 Oktober 2013, Android
sudah merilis 31 versi mulai dari versi Beta yang belum memakai versi angka sampai
Kitkat versi 4.4. Semakin versi tinggi, fiturnya semakin canggih dan banyak.
2.3 Algoritma C4.5
Algoritma C4.5 adalah perluasan dari algoritma ID3 yang diciptakan Quinlan untuk
menghasilkan decision tree. Algoritma ini menggunakan konsep information gain atau
entropy reduction untuk memilih optimal split. C4.5 secara rekursif memeriksa setiap
decision node, memilih optimal split, sampai tak ada lagi kemungkinan melakukan
split (Larose & Larose, 2014).
Algoritma C4.5 adalah salah satu metode untuk membuat decision tree
berdasarkan data training yang telah disediakan (Adyatama, 2013). Teknik
pengklasifikasian C4.5 menggunakan entropy dan information gain untuk perluasan
pohon(tree) (Florence & Savithri, 2013). Secara umum proses algoritma C4.5 untuk
membangun pohon keputusan adalah sebagai berikut (Kusrini, 2009) :
1. Pilih atribut sebagai akar
2. Buat cabang untuk masing-masing nilai
4. Ulangi proses untuk masing-masing cabang sampai semua kasus selesai.
Untuk memilih atribut sebagai akar, didasarkan pada nilai gain tertinggi dari
atribut-atribut yang ada. Untuk menghitung gain digunakan rumus :
��� �, � = � � � � − ∑��� × � � � ��
�
�=
Keterangan :
S : Himpunan Kasus
A : Atribut
n : Jumlah Partisi Atribut A
Si : Jumlah Kasus pada Partisi ke-i
S : Jumlah Kasus dalam S
� � � � = ∑ − � × � � �
�
�=
Keterangan :
S : Himpunan Kasus
A : Fitur
N : Jumlah partisi S
pi : Proporsi dari Si terhadap S
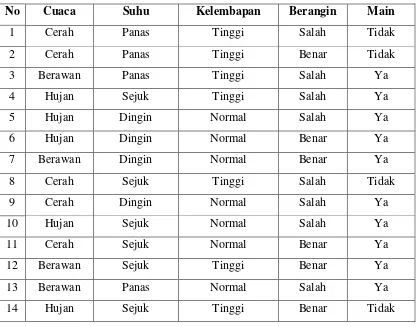
Contoh kasus yang terjadi adalah untuk menyelesaikan kasus pertandingan tenis akan
dilakukan atau tidak, berdasarkan keadaan cuaca, suhu, kelembapan, dan angin seperti
Tabel 2.1 Data Set Kasus Penentuan Pelaksanaan Pertandingan
No Cuaca Suhu Kelembapan Berangin Main
1 Cerah Panas Tinggi Salah Tidak
2 Cerah Panas Tinggi Benar Tidak
3 Berawan Panas Tinggi Salah Ya
4 Hujan Sejuk Tinggi Salah Ya
5 Hujan Dingin Normal Salah Ya
6 Hujan Dingin Normal Benar Ya
7 Berawan Dingin Normal Benar Ya
8 Cerah Sejuk Tinggi Salah Tidak
9 Cerah Dingin Normal Salah Ya
10 Hujan Sejuk Normal Salah Ya
11 Cerah Sejuk Normal Benar Ya
12 Berawan Sejuk Tinggi Benar Ya
13 Berawan Panas Normal Salah Ya
14 Hujan Sejuk Tinggi Benar Tidak
Kemudian hitung entropy dengan rumus :
� � � � = ∑ − � × � � �
�
�=
Maka didapat :
� � � � = − ( ) × � � ( ) + − ( ) × � � ( ) = ,
Tabel 2.2 Hasil Perhitungan Entropy pada Data Set
Total Kasus Sum(Ya) Sum(Tidak) Entropy Total
Setelah mendapatkan entropy dari keseluruhan kasus pada Tabel 2.2, lakukan analisis
pada setiap atribut dan nilai-nilainya dan hitung entropynya.
Hitung gain setiap atribut dengan rumus :
��� �, � = � � � � − ∑��� × � � � ��
�
�=
��� � ��� = , − (( ) × + ( ) × , + ( ) × , )
��� � ��� = ,
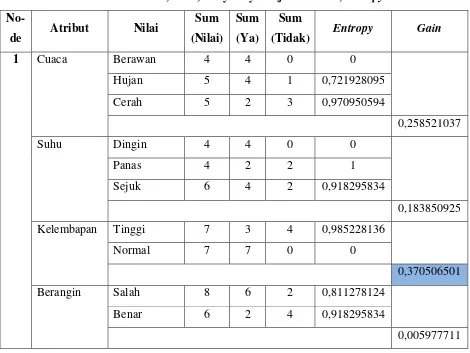
Kemudian, hitung gain masing-masing atribut suhu, kelembapan, dan berangin. Hasil
perhitungan dari masing-masing atribut terlihat pada Tabel 2.3.
Tabel 2.3 Analisis Atribut, Nilai, Banyaknya Kejadian Nilai, Entropy dan Gain
No-(Tidak) Entropy Gain
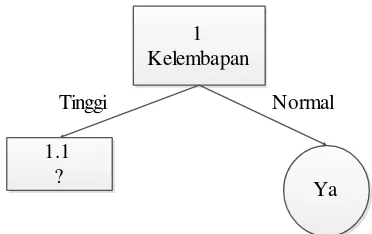
Pada Gambar 2.1 di bawah dapat dilihat kelembapan sebagai node akar karena
kelembapan adalah atribut dengan nilai gain paling tinggi. Berdasarkan pembentukan
pohon keputusan, node 1.1 akan dianalisis lebih lanjut.
Gambar 2.1 Pohon Keputusan Node 1 (root node)
Untuk mempermudah, tabel awal difilter dengan mengambil data yang memiliki
kelembapan = tinggi sehingga didapat data pada Tabel 2.4.
Tabel 2.4 Data dengan Kelembapan = Tinggi
No Cuaca Suhu Kelembapan Berangin Main
1 Cerah Panas Tinggi Salah Tidak
2 Cerah Panas Tinggi Benar Tidak
3 Berawan Panas Tinggi Salah Ya
4 Hujan Sejuk Tinggi Salah Ya
5 Cerah Sejuk Tinggi Salah Tidak
6 Berawan Sejuk Tinggi Benar Ya
7 Hujan Sejuk Tinggi Benar Tidak
Lalu data di Tabel 2.4 dianalisis dan dihitung lagi nilai entropy atribut Kelembapan
Tinggi seperti terlihat pada Tabel 2.5.
Tabel 2.5 Hasil Perhitungan Entropy Atribut Kelembapan Tinggi Kelembapan
Tinggi Sum (Ya) Sum (Tidak) Entropy
7 3 4 0,985228136
1 Kelembapan
1.1 ?
Ya
Lakukan lagi analisis terhadap atribut yang tersisa dan hitung nilai entropynya
masing-masing. Hasil analisis dapat dilihat pada Tabel 2.6.Setelah itu, tentukan pilih
atribut yang memiliki gain tertinggi untuk dibuatkan node berikutnya (node 1.1)
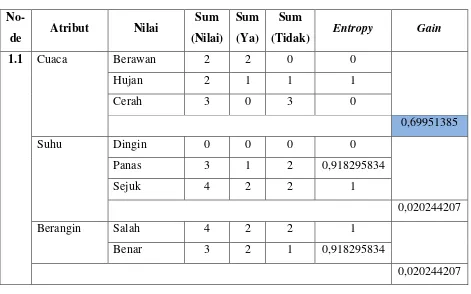
Tabel 2.6 Analisis Atribut untuk Node 1.1
No-(Tidak) Entropy Gain
1.1 Cuaca Berawan 2 2 0 0
adalah Berawan dan Cerah. Maka akan didapat pohon keputusan seperti pada Gambar
2.2.
Untuk menganalisis node 1.1.2, lakukan lagi langkah yang sama seperti sebelumnya.
Hasilnya ditampilkan pada Tabel 2.7, Tabel 2.8, Tabel 2.9 dan terbentuklah pohon
keputusan seperti pada Gambar 2.3.
Tabel 2.7 Hasil Analisis Node 1.1.2
No Cuaca Suhu Kelembapan Berangin Main
1. Hujan Sejuk Tinggi Salah Ya
2. Hujan Sejuk Tinggi Benar Tidak
Tabel 2.8 Hasil Perhitungan Entropy Atribut Kelembapan Tinggi dan Hujan Kelembapan
Tinggi dan Hujan Sum (Ya) Sum (Tidak) Entropy
2 1 1 1
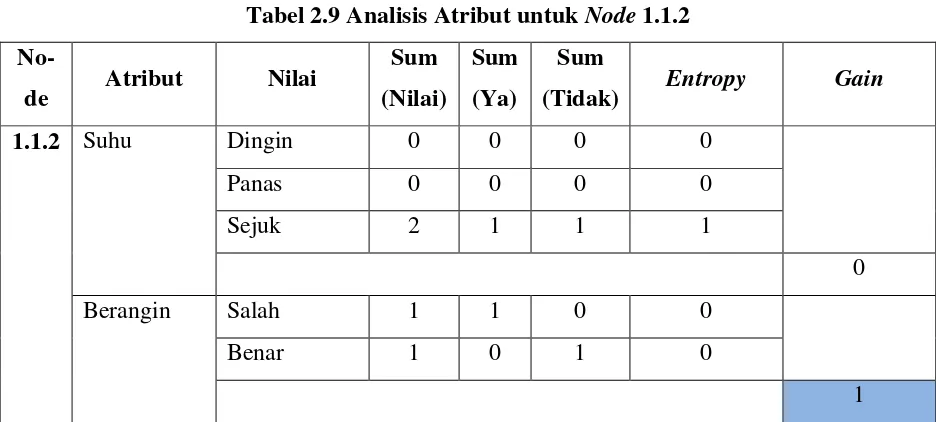
Tabel 2.9 Analisis Atribut untuk Node 1.1.2
No-de Atribut Nilai
Sum (Nilai)
Sum (Ya)
Sum
(Tidak) Entropy Gain
1.1.2 Suhu Dingin 0 0 0 0
Panas 0 0 0 0
Sejuk 2 1 1 1
0
Berangin Salah 1 1 0 0
Benar 1 0 1 0
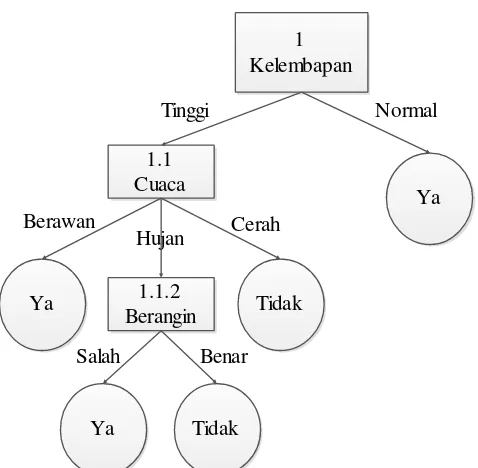
Gambar 2.3 Pohon Keputusan Akhir
Dari Gambar 2.3 didapat pola keputusan (rules), yaitu :
IF Kelembapan = Normal THEN Main = Ya
IF Kelembapan = Tinggi ^ Cuaca = Berawan THEN Main = Ya
IF Kelembapan = Tinggi ^ Cuaca = Cerah THEN Main = Tidak
IF Kelembapan = Tinggi ^ Cuaca = Hujan ^ Berangin = Salah THEN Main = Ya
IF Kelembapan = Tinggi ^ Cuaca = Hujan ^ Berangin = Benar THEN Main = Tidak 1
Kelembapan
1.1 Cuaca
1.1.2 Berangin
Ya
Tidak Ya
Tidak Ya
Tinggi Normal
Berawan
Hujan Cerah