Rekomendasi Penjurusan di SMU YSKI dengan Algoritma K-Means
Rosita Herawati[email protected] Abstract
This research is tIllking about grouping senior high school students into 2 or 3 different groups. This research is located in SMA YSKI Semarang. The process of grouping students in this school is quite complicated. It is because of the diversity of the elements which is used to determine the student into groups. K-Means Algorithm is used to clustering students based on characteristics of each groups. As a system which able to recommend student into a group, then K-Means done in nested loops. This nested process done for catch any possibility if a student falls into 2 or 3 different groups. Every loops will grouping student into cluster in accordance with the characteristics of every groups.
Keywords: penjurusan siswa SMA, K-Means, clustering
1. Pendahuluan
Setiap tahun ajaran baru, semua Sekolah Menengah Atas (SMA) di Indonesia melakukan proses penjurusan bagi siswanya. Setiap SMA memiliki minimal 2 kelas penjurusan. Penjurusan yang umum ada di SMA adalah IPA dari IPS. Namun ada pula SMA yang memiliki jurusan Bahasa sebagai pilihan ketiga yang dapat diambil oleh siswa. Penjurusan ini dilakukan saat siswa naik kelas XI (sebelas).
Penjurusan di SMA dimaksudkan untuk mengarahkan siswa sesuai minat dan bakatnya. Dengan adanya penjurusan, siswa diharapkan lebih fokus belajar. Penjurusan sejak dini ini, juga dapat mempermudah siswa memilih dan mempersiapkan bidang yang ingin ditekuninya ketika melanjutkan studi ke perguruan tinggi.
Penelitian ini berangkat dari ketertarikan peneliti pada proses penjurusan yang dilakukan di SMA YSKl Semarang. Proses penjurusan di SMA ini cukup rumit. Elemen yang digunakan untuk menentukan jurusan bagi setiap siswa cukup beragam. Ada 3 (tiga) jurusan yang ditawarkan. Namun, setiap jurusan memiliki kriteria yang berbeda-beda.
Melihat kerumitan proses penjurusan ini, peneliti mencoba untuk melakukannya dengan pendekatan yg berbeda. Algoritma
K-Means menjadi pilihan untuk mengurai kerumitan proses penjurusan ini. Algoritma K-Means dipilih karena sederhana dan mudah diimplementasikan. Algoritma ini cukup populer untuk digunakan dalam kasus clustering atau pengelompokkan, seperti halnya proses penjurusan di SMA. Penelitian 1m diharapkan dapat memberikan kemudahan bagi pengelola SMA. YSKI dalam melakukan proses penjurusan di setiap tahunnya.
2. Tinjauan Pustaka
Knowledge discovery in Database
(KDD) merupakan salah satu cabang dari
data mining. KDD merupakan proses
ekstrasi data dan pencarian polaJpengetahuan penting/potensial yang terdapat dari sekumpulan data yang besarlbanyak. Pola ini nantinya diolah menjadi informasi yang dapat mencerminkan kumpulan data secara menyeluruh. Salah satu metode yang diterapkan dalam KDD adalah clustering. Clustering merupakan metode untuk membagi data ke dalam kelompok-kelompok yang mempunyai karakteristik yang sarna.
Algoritma K-Means (J.B. MacQueen, 1976) adalah salah satu algoritma clustering yang paling dasar. Algoritma lUI
mengelompokkan data secara tegas berdasarkan ciri yang melekat pada data.
Artinya, algoritma ini tidak mengizinkan data berada di dua atau lebih kelompok. Data yang memiliki tingkat kemiripan yang tinggi akan dikumpulkan dalam satu kelompok. Sementara yang tidak mmp akan dikelompokkan secara terpisah.
Ide pokok dari algoritma K-Means sangat sederhana dan mudah untuk diterapkan. Huruf "K" pada nama algoritma tnl sebetulnya mencenninkan jumlah cluster/kelompok. Sementara "Means" merupakan nilai rata-rata dari suatu cluster. Jadi untuk menerapkan algoritma K-Means
1m,
yang perlu dilakukan hanyalah menentukan angka rata-rata sebanyak K. Angka-angka tersebut diambil dari nilai rata-rata semua data yang ada di setiap cluster. Sementara, untuk menentukan apakah suatu data masuk ke dalam kelompok yang mana, dilakukan perhitungan selisih antara data tersebut dengan rata-rata tiap cluster.Hitung jarak obyek ke
pusat
Kelompokkan obyek berdasar jarak minimum
Gambar 2.1 Flowchart K-Means [1]
Selisih jarak antar data del)gan rata-rata tiap cluster mencerminkan tingkat kemiripan. Semakin kecil selisih jarak, maka dianggap tingkat kemiripannya tinggi. Dan dapat dikelompokan menjadi satu. Namun sebaliknya, jika selisih jarak semakin jauh/besar, maka akan dianggap tidak mirip.
Dan akan dikelompokkan secara terpisah. Ada berbagai macam metode yang dapat digunakan untuk menghitung selisih jarak. Antara lain Eucledian distance, Mahalanobis distance, Manhattan distance, dan Normalised Cosines distance [2]. Metode yang paling populer dan akan digunakan dalam penelitian
1m
adalah dengan menggunakan Eucledian distance.n
d(x,
y)
=
IIx -
YII2
=
L
(Xi - Yt)2
t=lGambar 2.2 Rumus Eucledian distance
3. Metodologi Penelitian
Tahapan pertama dari penelitian ini adalah melakukan studi literature mengenai algoritma yang akan digunakan, yaitu
K-Means. Selanjutnya peneliti melakukan pengumpulan data-data yang dibutuhkan dalam proses penjurusan di SMU. Metode yang digunakan dalam mengumpulkan data adalah observasi dan wawancara. Dalam tahapan ini, peneliti mengumpulkan nilai siswa sebagai alat ujicoba, serta syarat -dan aturan yang berlaku dalam proses penjuruan di SMUYSKI.
Penelitian ini menggunakan teknik
object oriented approach. Object oriented approach membangun sistem dari kumpulan object-object yang unik dan independent,
yang ditemukanldisarikan dari permasalahan yang ada serta memfokuskan pada data dan proses yang dimiliki oleh setiap o.bject serta interaksi yang terjadi antar object-object tersebut.
Tahapan penelitian menggunakan dengan' menggunakan Object oriented
approach terdiri dari dua bagian yaitu Object Oriented Analysis dan Object Oriented Design. Object Oriented Analysis (OOA) fokus pada spesifikasi kebutuhan sistem dan menganalisis domain dari sistem tersebut. Pada tahap ini, kebutuhan user dan dugaanlpemikiran programmer harus sarnalsepaharn. Oleh karena itu, perlu didefinisik.anldigarnbarkan dengan jelas visi dan batasan dari sistem yang akan dibuat. Sementara Object Oriented Design fokus pada implementasi kebutuhan sistem yang sudah diidentifikasi pada proses OOA.
4. Basil Penelitian dan Pembahasan 4.1 Analisis Sistem
Pada tahapan studi literatur dan pengumpulan data, ditemukan beberapa syarat / kriteria yang harus dipenuhi dalarn proses penjurusan. Kriteria-kriteria tersebut adalah [4]:
1. Penjurusan dilakukan pada siswa kelas XI (sebelas). Atau lebih tepatnya saat siswa naik ke kelas XI.
2. Penjurusan dilakukan dengan memperhitungkan 30% nilai semester I (satu) dan 70% nilai semester IT (dua). Nilai yang dimaksud adalah nilai saat siswa belajar di kelas X (sepuluh).
3. Setiap siswa akan dijuruskan kedalarn 3 kelompok jurusan yaitu, IPA, IPS dan Bahasa.
4. Jurusan IPA, mensyaratkan nilai mata pelajaran yang menjadi ciri jurusan (Kimia, Fisika, Biologi, dan Matematika) hams diatas atau sarna dengan KKM (Kriteria Ketuntasan Mengajar). Nilai KKM ditentukan oleh pengelola sekolah. Selain itu rata-rata dari keempat mata pelajaran tersebut diatas minimal 75. 5. Jurusan IPS memiliki kriteria yang sarna
dengan jurusan IPA, narnun mata pelajaran yang menjadi eiri jurusan adalah Ekonomi, Geografi, Sosiologi, Matematika.
6. Sementara pada jurusan Bahasa juga hams memenuhi syarat yang sarna. Mata pelajaran yang menjadi ciri jurusan adalah
Bahasa Asing, Bahasa Indonesia dan Bahasa Inggris.
7. Jika siswa tidak memenuhi kriteria penilaian diatas, maka penjurusan siswa akan didasarkan pada tes minat dan bakat. Penentuan penjurusan ini akan dilakukan secara manual.
4.2 Desain Sistem
Berdasarkan hasil observasi dan data yang ada, maka diarnbil kesimpulan bahwa jumlah cluster yang harus dialokasikan adalah 3 (tiga). Ketiga cluster tersebut akan mewakili IPA, IPS dan Bahasa. Siswa-siswa kelas XI akan dibagi kedalarn 3 cluster diatas.
Sementara nilai rapor akan menjadi objek/data yang akan diolah dengan algoritma K-Means. Nilai rapor akan digunakan sebagai nilai yang akan dihitung jaraknya dengan nilai pusat. Pada awalnya, nilai pusat ditetapkan secara random. Ada 20 (dua puluh) mata pelajaran untuk siswa kelas X. Narnun tidak semua nilai mata pelajaran yang ada dalarn rapor diolah. Hanya matakuliah yang menjadi ciri tiap jurusan yang akan dihitung.
Tahapan yang harus dilalui sebelum menjalankan algoritma K-Means adalah menghitung 30% nilai semester I dan 70% nilai semester II. Perhitungan ini dilakukan untuk setiap mata pelajaran yang merupakan ciri tiap jurusan. Tahap selanjutnya adalah dengan membandingkan total nilai dari perhitungan tahap satu dengan KKM (Kriteria Ketuntasan Mengajar). Hal ini dilakukan karena terdapat kriteria yang mensyaratkan nilai mata pelajaran yang menjadi ciri jurusan harus diatas atau sarna dengan KKM. Nilai perhitungan sarnpai dengan tahap ini belum dapat digunakan untuk melakukan clustering. Seluruh nilai yang menjadi ciri tiap jurusan hams dihitung dulu rata-ratanya. Rata-rata dari perhitungan yang terakhir ini lah yang akan menjadi data utarnaipenentu objek, dalarn hal ini siswa, untuk diletakkan pada cluster tertentu.
Dalarn tahapan pertarna di atas, temyata banyak ditemukan kemungkinan seorang
siswa meOlenuhi semua atau sebagian kriteria penjurusan dari sekolah. Artinya.
dimungkinkan bagi seorang siswa. dengan tingkat kecerdasan yang tinggi. mampu memenuhi kriteria jurusan IPA. IPS dan sekaligus Bahasa. Namun. K-Means tidak mengizinkan objek berada di dua atau lebih kelompok. Objek yang Olemiliki tingkat
semester I dan
n.
Sementara Gambar 4.2 berikutini
menampilkan hasil dati 3 (tiga) proses yang sudah dijelaskan eli bagian Desain Sistem. Sebagai sistem yang dapat mendukung pengambilankeputusan, sistem
ini'menunjukkan basil 3 clustering·
Sekaligus
~~~~~~_a~"~::Z""':T""'f''''':'m'f.''"''''Cil!:~='=''''
LBO. MIa! Rapqrtkeroiripan yang tinggi akan dikumpulkan TglA<lpar :[Jf.~:.:]f;IC
TtmAJarM:~
dalam satu keloOlpok. Sementara yang tidak samester : OC:::III
;;'inti:
l!l::.::-jj!mirip akan dikeloOlpokkan secara terpisah.
-Dengan Olemperhatikan kedua hal tersebut ::==~I/-AIAIWI_120" dan tujuan dari penelitian ini. yaitu untuk !,,:'~a:'NYIIIU::""_w.1U";d
memberikan rekomendasi. maka dilakukan modiflkasi pada algoritma K-Means.
Pada penelitian ini algoritma K-Means tidak diterapkan untuk keseluruhan
data.
Namun dilakukan pemecahan. Data dipecah 3 (tiga). Dan setiap pecahan dilakukan setiap step algoritma. Tujuan dari pemecahan ini adalah untuk mendapatkan kemungkinan dimana siswa memenuhi setiap kriteria penjurusan. Singga. pada data pertama akan mencoba melakukan clustering berdasarkan ciri jurusan lPA. Hasil dati clustering ini akan disimpan sementara. Proses selanjutnya mela.kukan clustering untuk IPS. Dan hasilnya juga disimpan sementara. Begitu pHa pada proses terakhir yang akan menyimpan clustering untuk jurusan Bahasa. Dengan demikian seorang siswa, dimungkinkan masuk dalam tiap cluster.
Sebagai sistem yang akan mendukung pengambilan keputusan, sistem ini akan menampilkan seluruh hasil dari 3 proses diatas. Selain menampilkan hasil clustering. proses diatas juga akan mendokumentasikan hasil rata-rata tiap cluster. Tujuannya adalah memberikan gambaran bagi pengelola untuk menentukanlmengelompokkan siswa secara manual.
4.3 Implementasi Sistem
Berdasarkan ranCangan desain sistem. maka diimplementasikan sebuah sistem yang dapat membantu pengelola mengambil keputusan.
Halaman Leger Nilai Rapor I (Gambar 4.1) diatas menampilkan semua nHai
Gambar 4.1 Bal8J]Jl8D Lager NiIai Rapor 1
Gambar4.2
Pada baris pertama Gambar 4.2 terlihat bahwa siswa hanya masuk 1 (satu) cluster saja yaitu IPS. Sementara baris berikutnya menampilkan 3 (tiga) cluster sekaligus. Hal ini menunjukkan bahwa siswa, dengan nilai yang telah dicapainya selama 1 (satu) tabun mampu memenuhi semua kriteria
penjurusan. Dan ketika 3 (tiga) kali proses clustering dengan algoritma K-Means, siswa ini termasuk objek yang diclusterkan kedalam 3 cluster yang berbeda pada tiap prosesnya.
Dengan menampilkan semua kemungkinan siswa masuk dalam cluster yang berbeda beserta rata-ratanya, akan mempermudah pengelola sekolah untuk mengambil keputusan. Seorang siswa mungkin saja dapat masuk ke dalam semua cluster, namun dengan mempertimbangkan rata-rata yang ada, seorang siswa dapat saja diarahkan untuk mengambil jurusan yang sesuai. Pertimbangan dimungkinkan juga dengan melihat hasil test minat dan bakat yang telah dilakukan. N amun hasil test minat dan bakat tidak ter-"capture" dalam sistem lID, sehingga proses penjurusan akan dilakukan secara manual.
S. Kesimpulan dan Saran
Algoritma K -Means eukup mudah untuk diterapkan dalam proses penjurusan siswa SMA YSKI Memanfaatkan K-Means dengan sedikit memodiflkasi eukup efektif untuk digunakan mengelompokkan siswa dalam 3 kelas penjurusan. Modiflkasi dilakukan dengan melakukan proses algoritma K-Means sebanyak 3 (tiga) kali. Setiap proses akan mengclusterkan siswa sesuai dengan eiri jurusan.
Proses penjurusan ini eukup rumit, hal
ID1 disebabkan karen a banyaknya
elemenlnilai yang digunakan sebagai kriteria
penjurusan. Kerumitan ini diurai dengan melakukan perhitungan untuk setiap nilai mata pelajaran yang merupakan eiri jurusan terlebih dahulu. Kemudian mengambil rata-rata dari perhitungan pertama dan menggunakannya sebagai data yang dihitung dalam algoritma K-Means.
Pada penelitian ini algoritma K-Means harns dimodiflkasi terlebih dahulu dan diulang hingga 3 (tiga) kali agar dapat memberikan rekomendasi penjurusan. Meskipun hasil rekomendasi dapat dieapai, namun alangkah lebih baiknya jika dalam penelitian selanjutnya digunakan algoritma yang lain, yang dapat melakukan elusterisasi objek kedalam 2 atau lebih cluster tanpa harns dilakukan perulangan.
Daftar Pustaka
[1] Andayani, Sri, Pembentukan cluster dalam Knowledge Discovery in Database dengan Algoritma K-Means, UNY, 2007
[2] Wiliem, Arnold, Metode Clustering: K-means, http://pengolahancitra.eom, diakses 20Mei 2012
[3] What is K-Mean Clustering?,
http://people.revoledu.eom/kardiltutoriallkM eanlWhatIs.htm, diakses 20 Mei 2012
[4] YSKI, Panduan Akademik SMA Kristen YSKI Semarang Tahun Pelajaran 201112012, YSKI, Semarang, 2011
Pencarian GambaI' di Dalam
FoDder delllgan
Input Gambar Terpotong
Shlnta Esilf'n WahYUllllil!llgmm19 Hironimu.sLeolll~
l,2,3Fakultas llrnu Komputer Unika Soegijapranata [email protected]
Abstract
Habits of computer users are storing data with poor management, this causes the data search process becomes more difficult. Software on a computer that is commonly used for searching process use "key" in the form of text. This research try to find a picturre based on picture input
using template metcing method. Template matching method compare input picture with every picture on the directory file
Keyword: Template matching, image, image searching, image matching
1. Pendahwwm
Semakin murahnya media penyimpanan seperti harddisk, flashdisk membuat setiap orang mampu membeli media penyimpanan dengan kapasitas besar.
Dengan besarnya penyimpanan mengakibatkan untuk menyimpan semua data media penyimpanan yang dimiliki,
kapasitas keinginan ke dalam Kebiasaan pengguna komputer adalah menyimpan data-data dengan manajemen yang kurang baik, sehingga menyebabkan kesulitan pada saat akan menemukan data tersebut kembali.
Beberapa perangkat lunak pada komputer yang disediakan biasanya digunakan untuk mencari data yang berupa file dengan masukan pencarian "key" berupa text. Key data text digunakan untuk mencari file yang berupa dokumen ataupun file yang berupa gambar (image I citra).
Dalam penelitian ini akan dibuat sebuah sistem sederhana yang akan digunakan untuk pencarian sebuah file gambar di dalam sebuah folder maupun direktori. Masukan sistem berupa file gambar yang tidak utuh.
Penelitian ini dilakukan untuk menyelesaikan permasalahan mencari gambar yang terpotong pada sekumpulan garnbar-garnbar yang ada didalarn folder. 2. l'iHujauam Pustaka
2.1 Image
Suatu image adalah fungsi intensitas 2 dimensi I(x, y), dimana x dan y adalah
koordinat spasial dan
f
pada titik (x, y)merupakan tingkat kecerahan (brightness) suatu image pada suatu titik. Suatu image diperoleh dari penangkapan kekuatan sinar yang dipantulkan oleh objek.
hnage sebagai output alat perekaman, seperti kamera, dapat bersifat analog ataupun digital. hnage Analog adalah citra yang masih dalam bentuk sinyal analog, seperti hasil pengambilan gambar oleh kamera atau citra tampilan eli layar TV ataupun monitor (sinyal video).
Suatu image digital merupakGm representasi 2-D array sample diskrit suatu image kontinu f(x,y). Amplitudo setiap sample di kuantisasi untuk menyatakan bilangan hingga bit. Setiap elemen array 2-D sample disebut suatu pixel.
Tingkat ketajaman/resolusi w~a
pada image digital tergantung pada jumlah "bit" yang digunakan oleh komputer untuk merepresentasikan setiap pixel tersebut. Tipe yang sering digunakan untuk merepresentasikan citra adalah "8-bit citra" (256 colors (0 untuk hitam - 255 untuk putih).
2.2 Template Matching
Template matching merupakan sebuah metode yang bias a digunakan untuk mengklasiflkasikan sebuah object.
Template matching dilakukan dengan membandingkan data dari dalam image template dengan gambar yang sarna. Metode template matching yang biasa dilakukan adalah sebagai berikut :
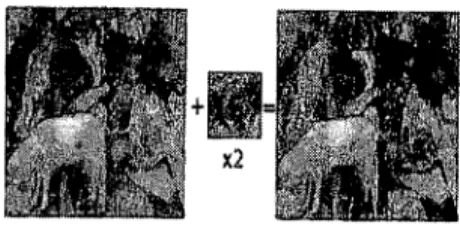
Gambar 2.1: Proses image Matching
Pencarian potongan dilakukan hanya pada sebuah file gambar. Pencarian dilakukan dengan membandingkan template dari pojok kiri atas ke kanan dan ke bawah, seperti yang terlihat dalam gambar 2.2
U kuran tempI ate yang digun akan biasan ya tidak terlalu besar. Cara Gambar 2.2: Proses iterasi image
matching
memb andingkan template adalah menggeser template per pixel ke kanan sampai dengan akhir image baru geser satu pixel ke bawah. 3. Metodologi Penelitian
Penelitian dilakukan dengan membuat sebuah perangkat lunak sederhana yang digunakan sebagai alat untuk menganalisa pencarian gambar dengan metode template matching. Metode template matching membandingkan gambar input dengan sekelompok data gambar yang tersimpan di dalam sebuah folder. Sebelum dilakukan proses matching terlebih dahulu dilakukan proses perubahan dari gambar asli yang berupa gambar dengan dimensi RGB ke dalam gambar satu dimensi yang disebut grayscale. Proses matching gambar didasarkan pada ukuran gambar input yang digunakan sebagai template. Setelah diperoleh ukuran template, setiap gambar di dalam folder, akan dibagi berdasarkan
~kuran template yang diperoleh dari gambar
mput. Proses matching dilakukan antara template dengan gambar yang dicari.
Setelah sistem dibangun akan dilakukan proses percobaan dan pengujian. Skema pengujian dilakukan dengan melakukan percobaan 5 kelompok masukan yang berbeda yaitu
1. Gambar masukan berukuran kedl. 2. Gambar masukan berukuran sedang 3. Gambar masukan berukuran besar 4. Gambar masukan dikenakan noise 5. Gambar masukan dikenakan rotasi Setelah proses pengujian kemudian dilakukan analisa terhadap output yang dihasilkan oleh sistem. Selain hasil yang berupa gambar, sistem juga memberikan hasil berupa prosentase kemiripan dari image yang berhasil ditemukan dibandingkan dengan total pixel dari image masukan yaitg digunakan sebagai template.
Pada penelitian ini proses pencarian gambar didasarkan pada ukuran template, proses pergeseran pada saat membandingkan template dengan image asli juga dilakukan sesuai dengan luas template bukan geser per pixel. Pergeseran dilakukan sesuai dengan luas file yang dibandingkan dibagi luas template seperti ditunjukkan pada gambar 4.Berisi metode yang dipakai dalam penelitian yang sudah dilakukan
4. Basil Penelitian dan Pembahasan
4.1 Rancangan Sistem
Sistem dikembangkan dengan menggunakan PHP. Sistem akan menerima masukan berupa gambar yang akan dicari, selain gambar yang dieari, sistem juga akan menerima masukan berupa folder yang diperkirakan berisi gambar yang dicari. Alur proses mencari kemiripan gambar sebagai berikut:
1. Gambar masukan diubah terlebih dahulu menjadi gambar grayscale yaitu gambar abu-abu yang hanya mempunyai sebuah channel warna dengan range nilai antara 0 - 255. Perubahan dari gambar RGB ke
gambar Grayscale dengan menggunakan perhitungan average untuk masing-masing channel. Kemudian hasilnya akan disimpan ke dalam pixel bam yang hanya 1 channel.
2. Dati file masukan disimpan ukuran dati file tersebut untuk digunakan sebagai template
3. Setiap file eli dalam folder akan dibandingkan dengan template gambar (gambar masukan). Cara memebandingkan template dengan gambarnya dati ujung kiri atas gambar menuju ke kanan kemudian kembali ke ujung kiri dikolom berikutnya.
4. HasH perhitungan kemiripan dibandingkan untuk tiap file. HasH kemiripan yang maksimal akan disimpan sebagai hasil keluaran dati sistem.
5. Sistem akan menampilkan hasil· perhitungan kemiripan yang paling maksimal ke dalam layar. Berisi hasil penelitian dan pembahasannya
4.2 Hasil Pengujian :
1. Gambar masukan berukuran kecil Pada proses pengujian yang pertama dilakukan pada 6 buah masukan image yang berukuran kurang dati 100 x 100 pixel dengan semua image pada template yang berukuran lebih dati 100 x 100 pixel
1[' albllen 1 : nll!llsllil JPlelDlguD.jimm nlllIMllge IIlIMIlS\llll!m1Dl lbIeJr1U1llruJl'2JDl lk.ecllil
Ukuran input Ukuran hasil Prosentase kemiripan 35 x 38 106 x 120 72,55% 32x 34 106 x 120 1,47% 74x 75 225 x 225 4,39% 52x 57 251 x 201 10.02% 70x 70 225 x 225 4,30% 65 x 75 204 x 204 1,18%
Hastl dan 6 percobaan pada skema percobaan yang pertama 4 percobaan sukses dan 2 percobaan tidak berhasil menemukan
image yang cocok dengan image yang dican. Berdasarkan 4 data yang berhasil ditemukan di dalam folder, keempat image masukan adalah potongan image yang berada pada posisi ujung dari gambar (pojok). Dilihat dati prosentase kemiripan dati data image yang berhasil ditemukan didalam folder rata-rata nilai prosentasenya kecil. Hal ini disebabkan karena template yang digunakan untuk membandingkan juga kecil.
2. Gambar masukan berukuran sedang Pada pengujian yang kedua image masukan diambil mendekati setengah dati ukuran image yang sebenamya. Pada pengujian yang kedua ini juga melibatkan 6 image masukan.
ThbeH :2 : IIMnsJiII. JPlelDlgunjimm ilnInage 1IlIMIlS1!llIlm1Dl lbI em lk.IUl Jl'2JDl S edlaJm ag
Ukuran input Ukuran hasil Prosentase kemicipan 112 x 152 315 x 160 22,53% 167 x 96 225 X 225 69,71% 82X57 102 X 102 18,05% 185 X 87 225 x 225 3,83% 76 X 193 251 X 201 9,55% 89X50 102 X 102 7,73%
..
Dan penguJlan yang kedua dan enam percobaan lima percobaan berhasil menemukan file yang dicati, kegagalan hanya 1 kali. Kalo diamati dati file masukan yang gagal dapat dilihat bahwa image yang dipotong tidak berada pada posisi ujung dati image yang ada di folder (image asli). Beberapa pengujian yang berhasil dilakukan menghasilkan prosentase yang relatif besar, hal ini dikarenakan jumlah pixel image masukan yang digunakan sebagai template.
3. Gambar masukan berukuran besar Pengujian yang ketiga melibatkan 6 me masukan. Pada pengujian yang ketiga, image masukan berukuran besar atau hampir mendekati ukuran file aslinya.
Tabel 3 : basil pengujian image masukan berukuran besar
Ukuran input Ukuran hasil Prosentase kemiripan 182 X 160 225 X 225 66,94% 146 X 175 251 X 201 26,89% 145 x 145 315 x 160 12,30% 123 x 204 204 x 204 39,30% 160 x 160 160 x 160 3,74% 146 x 275 205 x 246 76,11% Pada pengujian yang ketiga dari enarn percobaan 3 yang berhasil dan 3 yang gagal. Pada percobaan yang kedua gagal dikarenakan image masukan diarnbil pada posisi tengah dari image asli. Pada percobaan yang kelima gagal karena ada image di dalarn folder yang ukurannya sarna persis dengan ukuran image masukan (template) sehingga apabila kedua image tersebut dijadikan image grayscale maka kemungkinan miripnya menjadi lebih besar.
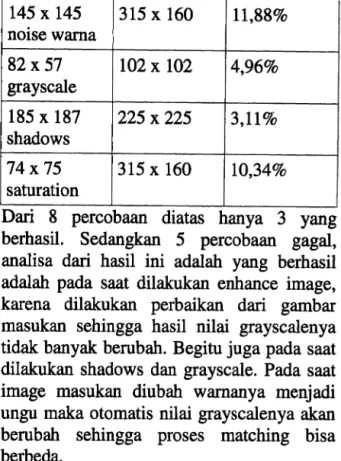
4. Garnbar masukan dikenakan noise Pada pengujian yang keempat, image inputan yang digunakan sebagai template selain hanya berupa bagian dari image asH juga dikenakan noise untuk masing-masing image masukan. Ada yang diubah warnanya, dibuat lebih terang, ditarnbah noise dan sebagainya. Pada pengujian yang ke 4 ini dilakukan 8 percobaan.
Tabel 4 : basil pengujian image masukan dikenakan noise
Ukuran input Ukuran hasil Prosentase kemiripan 146 x 175 204 x 204 0,32% warna ungu 32x 34 106 x 120 1,37% enhance 59 x 64 160 x 160 11,22% saturation 222 x 115 251 x 201 2,87% noise warna 145 x 145 315 x 160 11,88% noise warna 82x 57 102 x 102 4,96% grayscale 185 x 187 225 x 225 3,11% shadows 74x 75 315 x 160 10,34% saturation
Dari 8 percobaan diatas hanya 3 yang berhasil. Sedangkan 5 percobaan gagal, analisa dari hasil ini adalah yang berhasil adalah pada saat dilakukan enhance image, karena dilakukan perbaikan dari garnbar masukan sehingga hasil nilai grayscalenya tidak banyak berubah. Begitu juga pada saat dilakukan shadows dan grayscale. Pada saat image masukan diubah warnanya menjadi ungu maka otomatis nilai grayscalenya akan berubah sehingga proses matching bisa berbeda.
5. Garnbar masukan dikenakan rotasi Pada pengujian yang ketiga dilakukan terhadap image masukan yang dirotasi. Percobaan ini untuk mengukur seberapa besar toleransi metode L'Ilage matching terhadap proses rotasi. Proses rotasi dilakukan terhadap 8 buah image masukan. Tabel 5 : basil pengujian image masukan dikenakan rotasi
Ukuran input Ukuran hasil Prosentase kemiripan 146 x 175 205 x 246 76,11% 175 x 146 205 x 246 37,67% 146 x 175 251 x 201 37,06% 123 x 204 204 x 204 39,30% 204 x 123 205 x 246 33,84% 204 x 123 205 x 246 36,85% 123 x 204 251 x 201 34,63%
Dari 8 percobaan hanya 3 yang berhasIl, yang 5 percobaan tidak berhasil karena posisi nilai pixel dari tempat berbeda dari image aslinya.
Secara umum ketidak berhasilan proses pencarian adalah :
Pergeseran pencarian berdasarkan luas dari template sehingga tidak bisa presisi untuk dalam proses pencariannya, selain itu juga proses matching berdasarkan posisi masing-masing pixel pada template dan image yang ada di folder. Ukuran template dan ukuran image asli mempengaruhi hasil pencarian. Terdapat beberapa bagian dari image asli yang tidak dibandingkan, hal ini disebabkan karena jumlah membandingkan template dengan bagian-bagian dari image asli diperoleh dari pembagian luas file image di dalam folder dengan luas template yang dibulatkan.
5. Kesimpulan dan Saran
Kesimpulan yang dapat diambil dari penelitian ini adalah :
Posisi potongan image masukan yang berhasil ditemukan adalah potongan yang ada diposisi ujung baik atas, samping maupun bawah dari image asli. Ukuran template dan ukuran image asli mempengaruhi hasil pencarian. Posisi derajat (rotasi) image masukan dengan image asli mempengaruhi hasil pencarian. Nilai
grayscale yang sarna juga mempengaruhi hasil pencarian.
Berdasarkan hasH penelitian ini perlu dilakukan penelitian berikutnya dengan menarnbahkan metode untuk proses matching yaitu menambahkan parameter dominan wama untuk hasil proses matching yang sudah dilakukan. Selain menambah metode yang bisa dilakukan adalah memberi toleransi dalam membandingkan nilai di dalam template dan nilai dari file asli.
Daftar Pustaka
[1] Rafael C. Gonzalez dan Richard E. Woods, 2008, Digital Image Processing, Pearson Prentise Hall, New Jersey.
[2] Definisi Grayscale
http://en.wikipedia.org/wiki/Grayscale diakses tanggal 01 Juni 2012
[3] Template Matching
http://opencv.itseez.comldoc/tutorialslimgproclhi stograms/template matching/template matching. html diakses tanggal 05 J uni 2012
[4] Template matching
http://opencv.itseez.comldoc/tutorials/imgproclhi stograms/template matching/template matching. html diakses tanggal 05 Juni 2012
![Gambar 2.1 Flowchart K-Means [1]](https://thumb-ap.123doks.com/thumbv2/123dok/2145456.2706202/2.847.120.411.564.1083/gambar-flowchart-k-means.webp)
![Gambar 4.1 Bal8J]Jl8D Lager NiIai Rapor 1](https://thumb-ap.123doks.com/thumbv2/123dok/2145456.2706202/4.859.452.803.121.994/gambar-bal-j-jl-d-lager-niiai-rapor.webp)