OPTIMASI CLUSTERING MENGGUNAKAN PARTICLE
SWARM OPTIMIZATION PADA SISTEM IDENTIFIKASI
TUMBUHAN OBAT BERBASIS CITRA
FRANKI YUSUF BISILISIN
SEKOLAH PASCASARJANA
INSTITUT PERTANIAN BOGOR
PERNYATAAN MENGENAI TESIS DAN
SUMBER INFORMASI SERTA PELIMPAHAN HAK CIPTA
Dengan ini saya menyatakan bahwa tesis berjudul Optimasi Clustering menggunakan Particle Swarm Optimization pada Sistem Identifikasi Tumbuhan Obat berbasis Citra adalah benar karya saya dengan arahan dari komisi pembimbing dan belum diajukan dalam bentuk apa pun kepada perguruan tinggi mana pun. Sumber informasi yang berasal atau dikutip dari karya yang diterbitkan maupun tidak diterbitkan dari penulis lain telah disebutkan dalam teks dan dicantumkan dalam Daftar Pustaka di bagian akhir tesis ini.
Dengan ini saya melimpahkan hak cipta dari karya tulis saya kepada Institut Pertanian Bogor.
Bogor, Maret 2014
Franki Yusuf Bisilisin NIM G651110591
Pelimpahan hak cipta atas karya tulis dari penelitian kerjasama dengan pihak luar
RINGKASAN
FRANKI YUSUF BISILISIN. Optimasi Clustering menggunakan Particle Swarm Optimization pada Sistem Identifikasi Tumbuhan Obat berbasis Citra. Komisi Pembimbing YENI HERDIYENI dan BIB PARUHUM SILALAHI.
Indonesia merupakan negara dengan tingkat keanekaragaman hayati yang tinggi dan terdapat 22.500 spesies tumbuhan obat. Presentase pemanfaatan tumbuhan obat oleh masyarakat Indonesia hanya sebesar 4,4% atau sebanyak 1000 spesies. Pengetahuan masyarakat yang rendah tentang tumbuhan obat merupakan salah satu penyebab dari minimnya pemanfaatan tumbuhan obat di Indonesia. Peningkatan pengetahuan masyarakat dapat dibantu dengan dikembangkannya sistem identifikasi tumbuhan obat. Pada penelitian ini, metode ekstraksi ciri yang digunakan untuk sistem identifikasi tumbuhan obat adalah fuzzy local binary pattern (FLBP). Data citra yang digunakan adalah sebanyak 1.440 citra daun.
Teknik unsupervised learning yakni clustering diusulkan untuk membandingkan hasil identifikasi tumbuhan obat dengan teknik klasifikasi. Metode clustering yang digunakan adalah k-means clustering dan fuzzy c-means clustering. Kelemahan utama dari kedua metode adalah hasil sensitif terhadap pemilihan pusat cluster awal dan perhitungan solusi lokal untuk mencapai kondisi optimal. Penelitian ini menerapkan metode particle swarm optimization (PSO) untuk mengatasi kelemahan dari k-meansclustering dan fuzzy c-means clustering. Penerapan metode PSO pada sistem identifikasi bertujuan untuk meningkatkan hasil identifikasi tumbuhan obat. Penelitian ini membangun empat model clustering, diantaranya k-means clustering, fuzzy c-means clustering, PSO based k-means clustering dan PSO based fuzzy c-means clustering. Pengembangan model clustering menggunakan bahasa pemrograman C++.
Evaluasi model clustering menggunakan nilai akurasi menunjukkan bahwa metode PSO mampu meningkatkan hasil identifikasi pada k-meansclustering dan fuzzy c-means clustering. K-means clustering menghasilkan akurasi 41,67% dan PSO based k-means clustering 48%. Fuzzy c-means clustering menghasilkan akurasi 50% dan PSO based fuzzy c-means clustering 52,33%. Evaluasi model
clustering menggunakan waktu komputasi menunjukkan adanya penambahan
waktu pada metode PSO. Penambahan algoritme menyebabkan pengolahan data semakin banyak. Waktu komputasi pada metode k-means clustering 291,3 detik dan metode PSO based k-means clustering 403,3 detik. Waktu komputasi pada metode fuzzy c-means clustering 59,65 detik dan metode PSO based fuzzy c-means clustering 60,1 detik. Metode PSO based fuzzy c-means clustering merupakan metode yang lebih baik karena menghasilkan akurasi yang tinggi dan waktu komputasi yang lebih cepat.
SUMMARY
FRANKI YUSUF BISILISIN. Clustering Optimization using Particle Swarm Optimization for Medicinal Plant Identification System based on Digital Image. Supervised by YENI HERDIYENI and BIB PARUHUM SILALAHI.
Indonesia is a country with a high level of biodiversity and there are 22,500 species of medicinal plants. The percentage of medicinal plant used by Indonesian people is only 4.4% or as much as 1,000 species. The people’s lack of knowledge becomes one of the cause of this low use of medicinal plant in Indonesia. People’s insight about medicinal plant can be increased by developing an identification system of medicinal plant. In this research, we used fuzzy local binary pattern (FLBP) to extract the feature. The number of digital image that used in this research are 1,440 leaf image.
Unsupervised learning technique known as clustering is proposed to compare the results of the identification of medicinal plants with classification techniques. Clustering methods used is the k-means clustering and fuzzy c-means clustering. The disadvantages of both method is that the results are sensitive to the selection of initial cluster centers and the calculation of local solutions to achieve optimal conditions. This research applied a particle swarm optimization (PSO) method to overcome the weaknesses of k-means clustering and fuzzy c-means clustering. The application of PSO method in the identification system as a purpose to improve the identification of medicinal plants. This research builds four models of clustering is the k-means clustering, fuzzy c-means clustering, PSO based k-means clustering and PSO-based fuzzy c-means clustering. The development of clustering model using C++ programming language.
Evaluation model of clustering using an accuracy value indicates that the PSO method can improve the identification of the k-means clustering and fuzzy c-means clustering. Accuracy of k-c-means clustering resulted 41.67% and PSO-based k-means clustering is 48%. Accuracy of fuzzy c-means clustering resulted in 50% and PSO based fuzzy c-means clustering is 52.33%. Evaluation of clustering models using computational time indicates the addition of time on the PSO method. The addition of algorithms led to growing number of data processing. Computation time on k-means clustering 291.3 seconds and PSO based k-means clustering 403.3 seconds. Computation time on fuzzy c-means clustering 59.65 seconds and PSO based fuzzy c-means clustering 60.1 seconds. PSO based fuzzy c-means clustering is a better method for generating high accuracy and faster computing time.
© Hak Cipta Milik IPB, Tahun 2014
Hak Cipta Dilindungi Undang-Undang
Dilarang mengutip sebagian atau seluruh karya tulis ini tanpa mencantumkan atau menyebutkan sumbernya. Pengutipan hanya untuk kepentingan pendidikan, penelitian, penulisan karya ilmiah, penyusunan laporan, penulisan kritik, atau tinjauan suatu masalah; dan pengutipan tersebut tidak merugikan kepentingan IPB
OPTIMASI CLUSTERING MENGGUNAKAN PARTICLE
SWARM OPTIMIZATION PADA SISTEM IDENTIFIKASI
TUMBUHAN OBAT BERBASIS CITRA
FRANKI YUSUF BISILISIN
Tesis
sebagai salah satu syarat untuk memperoleh gelar Magister Komputer
pada
Program Studi Ilmu Komputer
SEKOLAH PASCASARJANA
INSTITUT PERTANIAN BOGOR
Judul Tesis : Optimasi Clustering menggunakan Particle Swarm Optimization pada Sistem Identifikasi Tumbuhan Obat berbasis Citra
Nama : Franki Yusuf Bisilisin
NIM : G651110591
Disetujui oleh
Komisi Pembimbing
Dr Yeni Herdiyeni, SSi, MKom Dr Ir Bib Paruhum Silalahi, MKom
Ketua Anggota
Diketahui oleh
Ketua Program Studi Dekan Sekolah Pascasarjana
Ilmu Komputer
Dr Eng Wisnu Ananta Kusuma, ST, MT Dr Ir Dahrul Syah, MScAgr
PRAKATA
Puji dan syukur penulis panjatkan kepada Tuhan Yang Maha Esa atas segala karunia-Nya sehingga karya ilmiah ini berhasil diselesaikan. Tema yang dipilih dalam penelitian yang dilaksanakan sejak bulan September 2012 adalah Optimasi Clustering menggunakan Particle Swarm Optimization pada Sistem Identifikasi Tumbuhan Obat berbasis Citra.
Terima kasih penulis ucapkan kepada Ibu Dr Yeni Herdiyeni, SSi, MKom dan Bapak Dr Ir Bib Paruhum Silalahi, MKom selaku pembimbing, serta Bapak Dr Ir Agus Buono, MSi, MKom selaku penguji dalam ujian tesis. Di samping itu, penghargaan penulis sampaikan kepada Yayasan Uyelewun Indonesia melalui beasiswa atas pemberian fasilitas baik pembiayaan maupun sarana/prasarana selama penyusunan karya ilmiah ini. Ungkapan terima kasih juga disampaikan kepada kedua orangtua, Bapak Niander Mesak Bisilisin (Alm) dan Ibu Juliana Carolin Bisilisin-Tafui atas doa, dukungan moral dan materi, kakak tercinta Susan Imelda Bisilisin, SE bersama suami Simsoni Sodak dan anak Ester Juliani Sodak, kakak tersayang Ricky Yuland Bisilisin, AMd bersama istri Wely Dortia Lay, SE dan anak Samuel Cavilano Bisilisin serta seluruh keluarga, atas segala doa dan kasih sayangnya. Terima kasih kepada seluruh dosen dan staf akademik Ilmu Komputer Institut Pertanian Bogor, teman-teman angkatan XIII Program Studi Ilmu Komputer (khususnya lima sekawan) atas kebersamaan dan bantuannya selama kuliah dan penyelesaian penelitian ini.
Penulis juga mengucapkan terima kasih kepada semua pihak yang telah membantu selama penyelesaian karya ilmiah ini yang tidak dapat disebutkan satu-persatu. Semoga karya ini bermanfaat. Kritik dan saran sangat penulis harapkan demi kesempurnaan karya ini di kemudian hari.
Bogor, Maret 2014
i
DAFTAR ISI
DAFTAR TABEL ii
DAFTAR GAMBAR ii
DAFTAR LAMPIRAN iii
1 PENDAHULUAN 1
Latar Belakang 1
Tujuan Penelitian 2
Manfaat Penelitian 2
Ruang Lingkup 2
2 TINJAUAN PUSTAKA 3
Fitur Tekstur 3
Local Binary Pattern (LBP) 3
Fuzzy Local Binary Pattern (FLBP) 4
K-MeansClustering 6
Fuzzy C-MeansClustering 7
Particle Swarm Optimization (PSO) 8
PSO basedK-Means Clustering 10
PSO basedFuzzyC-Means Clustering 12
3 METODE 14
Alat dan Bahan 14
Metode Penelitian 14
4 HASIL DAN PEMBAHASAN 17
Hasil Praproses 17
Ekstraksi Fitur FLBP 17
Hasil Percobaan 17
5 SIMPULAN DAN SARAN 27
Simpulan 27
Saran 27
DAFTAR PUSTAKA 28
ii
DAFTAR TABEL
1 Operator LBP 15
2 Penentuan clusterk-means clustering 18
3 Penentuan clusterfuzzy c-means clustering 20
4 Penentuan cluster PSO basedk-means clustering 21 5 Penentuan cluster PSO basedfuzzyc-means clustering 22
DAFTAR GAMBAR
1 Skema komputasi LBP 3
2 Ukuran operator LBP 4
3 Fungsi keanggotaan 0( ) dan 1( )sebagai fungsi dari Δpi 5
4 Skema perhitungan FLBP dengan F=10 6
5 Algoritme K-means 7
6 Algoritme Fuzzy C-Means 8
7 Algoritme Particle Swarm Optimization 10
8 Algoritme PSO basedk-means clustering 12
9Algoritme PSO basedfuzzyc-means clustering 13
10 Metode penelitian 14
11 Hasil praproses citra tumbuhan obat 17
12 Histogram FLBP pada citra Psidium guajava L. 17 13 Grafik perbandingan akurasi per spesies k-means clustering 19 14 Contoh citra latih dan citra uji spesies 9 (Kemangi) 19 15 Kesalahan identifikasi spesies citra k-means clustering 19 16 Grafik perbandingan akurasi per spesies fuzzy c-means clustering 20 17 Contoh citra latih dan citra uji spesies 2 (Jarak Pagar) 20 18 Kesalahan identifikasi spesies citra fuzzy c-means clustering 21 19 Grafik perbandingan akurasi per spesies PSO based k-means clustering 21 20 Contoh citra latih dan citra uji spesies 2 (Jarak Pagar) dan spesies 26
(Cincau Hitam) 22
21 Kesalahan identifikasi spesies citra PSO based k-means clustering 22 22 Grafik perbandingan akurasi per spesies PSO based fuzzy c-means clustering23 23 Contoh citra latih dan citra uji spesies 2 (Jarak Pagar), spesies 20 (Sosor
Bebek), spesies 26 (Cincau Hitam) dan spesies 29 (Jambu Biji) 23 24 Kesalahan identifikasi spesies citra PSO based fuzzy 24
25 Perbandingan evaluasi akurasi 24
iii
DAFTAR LAMPIRAN
1 Data Tumbuhan Obat 29
2 Purityk-means clustering 32
3 Purityfuzzy c-means clustering 33
4 PurityPSO based k-means clustering 34
1
PENDAHULUAN
Latar Belakang
Indonesia merupakan negara dengan tingkat keanekaragaman hayati yang tinggi. Groombridge dan Jenkins (2002) mencatat bahwa terdapat 22.500 spesies tumbuhan obat di Indonesia. Jumlah spesies yang telah dimanfaatkan sebagai tumbuhan obat sebanyak 1000 spesies. Hal ini menunjukkan bahwa jumlah persentase tumbuhan obat yang telah dimanfaatkan hanya sebesar 4.4% dari sumber daya tumbuhan obat yang tersedia. Salah satu penyebab kurangnya pemanfaatan tumbuhan obat adalah minimnya pengetahuan masyarakat mengenai potensi tumbuhan obat. Peningkatan pengetahuan masyarakat tentang tumbuhan obat dapat dibantu dengan dikembangkannya sistem identifikasi tumbuhan obat.
Teknologi identifikasi secara otomatis diperlukan untuk mempercepat proses identifikasi dengan menggunakan organ vegetatif seperti daun. Sistem identifikasi terdiri dari dua teknik yaitu teknik klasifikasi dan teknik clustering. Adapun penelitian menggunakan teknik klasifikasi yang sudah dilakukan, salah satunya pada penelitian Herdiyeni dan Wahyuni (2012) menggunakan metode ekstraksi fitur fuzzy local binary pattern (FLBP) dan metode klasifikasi probabilistic neural network (PNN) untuk identifikasi tumbuhan obat. Sistem identifikasi telah dikembangkan di dalam aplikasi mobile berbasis Android. Pengembangan sistem bertujuan untuk memudahkan pengguna dalam mengidentifikasi tumbuhan obat. Teknik klasifikasi merupakan supervised learning yaitu teknik yang memerlukan pelabelan data sebelum pembelajaran. Label tersebut menunjukkan kelas observasi dan data baru diklasifikasikan berdasarkan training set. Pada penelitian ini digunakan teknik clustering. Teknik clustering merupakan unsupervised learning yaitu label kelas dari data training tidak diketahui. Data tersebut diberikan pengukuran, observasi dan lain-lain dengan tujuan mengetahui keberadaan data dalam kelas atau cluster. Dengan menggunakan teknik clustering, akan dilihat perbandingan hasil identifikasi tumbuhan obat dengan teknik klasifikasi.
Menurut Ghahramani (2004), teknik unsupervised learning dapat dianggap sebagai teknik untuk menemukan pola. Pola tersebut dapat berupa pengamatan, item data atau fitur vektor. Teknik unsupervised learning memungkinkan untuk mempelajari model dengan jumlah data yang banyak dan lebih kompleks. Clustering merupakan salah satu teknik unsupervised learning. Menurut Jain et al. (1999), clustering adalah ilmu yang mempelajari hubungan antara satu data dengan data yang lain kemudian mengelompokkannya menjadi satu kategori tertentu. Metode clustering yang paling banyak digunakan adalah metode k-means clustering dan fuzzy c-means clustering. Kelemahan utama dari kedua metode adalah hasil sensitif terhadap pemilihan pusat cluster awal dan perhitungan solusi lokal untuk mencapai kondisi optimal. Menurut Panchal et al. (2009), pemilihan pusat cluster awal dan perhitungan solusi lokal mempengaruhi proses dari kedua metode dan hasil partisi data.
2
pada ruang pencarian solusi sehingga menemukan solusi global. Salah satu teknik optimasi dengan pendekatan metaheuristik yang dapat digunakan untuk memaksimalkan kinerja dari metode k-means clustering dan fuzzy c-means clustering adalah particle swarm optimization (PSO). Dengan teknik ini, pemilihan pusat cluster baru tidak melihat dari perhitungan solusi lokal saja tetapi perhitungan juga dilihat dari solusi global. Dalam penelitian Panchal et al. (2009), PSO dapat digunakan untuk menemukan pusat cluster baru sesuai dengan jumlah cluster yang sudah ditentukan. Algoritme dimodifikasi menggunakan metode k-means clustering dan fuzzy c-means clustering untuk pengelompokan awal, kemudian PSO memperbaiki kelompok data yang dibentuk oleh kedua metode tersebut.
Pada penelitian ini, kelemahan pemilihan pusat cluster awal dan perhitungan solusi lokal pada metode k-means clustering dan fuzzy c-means
clustering akan di optimasi menggunakan PSO. Penerapan metode PSO
diharapkan mampu mengatasi kelemahan tersebut dan meningkatkan hasil identifikasi tumbuhan obat. Nilai akurasi dan waktu komputasi digunakan untuk mengukur seberapa baik metode PSO yang diterapkan.
Tujuan Penelitian
Penelitian ini bertujuan melakukan optimasi k-meansclustering dan fuzzy c-meansclustering menggunakan metode particle swarm optimization (PSO) untuk meningkatkan hasil identifikasi tumbuhan obat.
Manfaat Penelitian
Penelitian ini diharapkan untuk meningkatkan hasil identifikasi tumbuhan obat berbasis citra menggunakan teknik optimasi particle swarm optimization pada k-meansclustering dan fuzzyc-meansclustering secara otomatis.
Ruang Lingkup
Ruang lingkup penelitian ini adalah:
1. Data yang digunakan adalah 30 spesies citra daun tumbuhan obat di Indonesia. 2. Metode Particle Swarm Optimization dimodifikasi berdasarkan algoritme
2
TINJAUAN PUSTAKA
Fitur Tekstur
Fitur tekstur merupakan gambaran visualisasi dari sebuah objek. Tekstur dapat dicirikan sebagai variasi intensitas pencahayaan pada sebuah citra. Analisis tekstur memiliki peranan yang cukup penting dalam aplikasi pengolahan citra digital. Meskipun warna merupakan hal yang penting dalam mendeskripsikan citra akan tetapi informasi warna tidak cukup untuk mendeskripsikan suatu citra. Informasi yang terkandung pada tekstur adalah area, kekasaran, regularity, linearitas dan frekuensi (Maenpaa 2003).
Local Binary Pattern (LBP)
Analisis tekstur digunakan di sebagian besar aplikasi seperti remote sensing, pengolahan citra pada biomedical, visual inspection dan identifikasi citra. Sejak 1970-an penelitian dan pengembangan metode ekstraksi fitur telah banyak diusulkan. Metode local binary pattern (LBP) merupakan salah satu metode untuk merepresentasikan tekstur berdasarkan pola biner (binary pattern). Metode LBP cukup efektif di dalam menggambarkan pola tekstur lokal dari citra (Keramidas et al. 2011).
Menurut Iakovidis et al. (2008) proses local binary pattern (LBP) merepresentasikan tekstur lokal disekitar tekstur pusat berdasarkan operator ketetanggaan LBP. Setiap pola tekstur LBP direpresentasikan oleh sembilan elemen � = � ,�0,�1,…,�7 ,� merupakan nilai piksel pusat dan � 0 7 merupakan nilai piksel sekelilingnya (circular sampling). Nilai circular sampling dapat dicirikan oleh nilai biner 0 7 seperti terlihat pada gambar 1(b) dan didefinisikan pada Persamaan 1.
= 0 ∆� < 0 Gambar 1 Skema komputasi LBP
(Iakovidis et al. 2008)
4
Nilai biner yang dihasilkan kemudian akan dikonversi ke nilai desimal untuk mendapatkan nilai LBP, didefinisikan pada Persamaan 2.
� �= 7=0 . 2 ,� � ∈ 0,255
Nilai-nilai LBP yang dihasilkan akan direpresentasikan melalui histogram. Histogram akan menunjukkan frekuensi kemunculan dari setiap nilai LBP.
Menurut Ahonen dan Pietikainen (2008) operator LBP dapat dikembangkan dengan menggunakan berbagai ukuran sampling points dan radius (Gambar 2). Pengamatan piksel ketetanggaan, akan digunakan notasi �,� dimana � merupakan sampling points dan � merupakan radius. Nilai LBP dihasilkan sesuai dengan operator LBP yang digunakan. Semakin kecil radius dan semakin besar sampling points yang digunakan maka semakin banyak piksel yang diolah untuk mendapatkan nilai LBP.
(8.1) (16,2) (8,2) Gambar 2 Ukuran operator LBP
(Ahonen dan Pietikainen 2008)
Fuzzy Local Binary Pattern (FLBP)
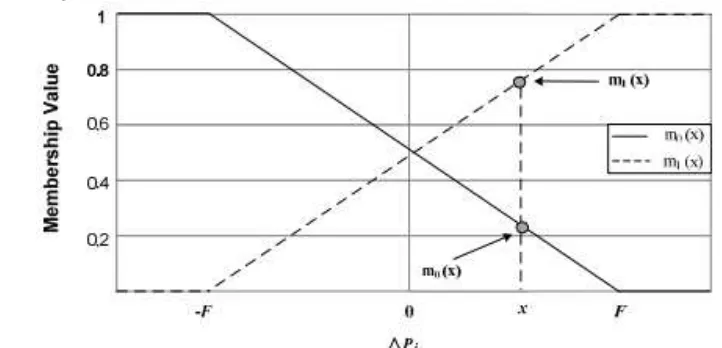
Fuzzification pada proses LBP adalah transformasi variabel input menjadi variabel fuzzy berdasarkan pada sekumpulan fuzzy rule (Iakovidis et al. 2008). Berdasarkan penelitian Iakovidis et al. (2008), penelitian ini menggunakan dua fuzzy rule untuk menentukan representasi nilai biner dan mencari nilai fuzzy. Penentuan nilai fuzzy berdasarkan deskripsi selisih antara nilai circular sampling � dan piksel pusat � (Δ�) yaitu : dapat ditentukan (Gambar 3). Fungsi keanggotaan 0( ) mendefinisikan derajat
5
1 =
0 , ∆� �
�+Δ�
2.� , − � < ∆� < �
1 , ∆� −�
Fungsi keanggotaan 0( ) dan 1( ) , � ∈ 0,255 merepresentasikan threshold FLBP (F) yang mengontrol derajat ketidakpastian. Semakin besar nilai threshold yang digunakan maka semakin banyak nilai piksel yang diolah di dalam rentang fuzzy. Penentuan nilai threshold berdasarkan dari tekstur citra yang diekstraksi. Citra yang memiliki tekstur homogeny cukup menggunakan nilai threshold yang kecil, sedangkan citra yang memiliki tekstur heterogen menggunakan nilai threshold yang lebih besar. Penggunaan threshold yang besar mempengaruhi waktu komputasi pada saat proses ekstraksi fitur.
Gambar 3 Fungsi keanggotaan 0( ) dan 1( )sebagai fungsi dari Δpi (Iakovidis et al. 2008)
Metode LBP original hanya menghasilkan satu kode LBP saja, sedangkan dengan metode FLBP akan menghasilkan satu atau lebih kode LBP. Nilai-nilai LBP yang dihasilkan FLBP memiliki tingkat kontribusi yang berbeda, bergantung pada nilai-nilai fungsi keanggotaan 0 dan 1( ) yang dihasilkan. Untuk ketetanggaan 3×3, kontribusi CLBP dari setiap kode LBP pada histogram FLBP
didefinisikan pada Persamaan 5 (Iakovidis et al. 2008).
� � = ( )
7
=0
Total kontribusi ketetanggaan 3×3 ke dalam bin histogram FLBP, didefinisikan pada Persamaan 6.
� � = 1
255
� �=0
4)
5)
6) (4)
(5)
6
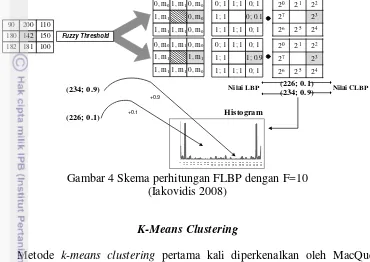
Kode LBP tersebut akan direpresentasikan dengan histogram yang dihitung dengan menjumlahkan kontribusi � � dari setiap nilai LBP seperti ditunjukkan pada Gambar 4.
Gambar 4 Skema perhitungan FLBP dengan F=10 (Iakovidis 2008)
K-MeansClustering
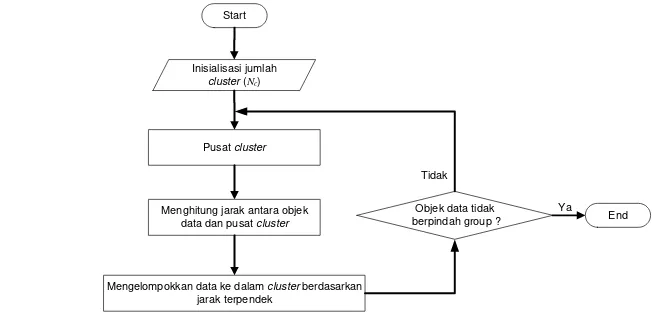
Metode k-means clustering pertama kali diperkenalkan oleh MacQueen (1976). K-means clustering adalah algoritme untuk mengklasifikasikan atau mengelompokkan data berdasarkan atribut-atribut atau fitur-fitur ke dalam beberapa jumlah kelompok secara tepat, dimana Nc adalah pusat cluster.
Algoritme ini dimulai dengan menentukan pusat cluster awal secara acak, kemudian objek data dalam dataset dikelompokkan ke pusat cluster berdasarkan jarak yang terdekat antara objek data dan pusat cluster.
Prosedur algoritme k-meansclustering adalah sebagai berikut : 1. Jumlah cluster(� ).
Jumlah cluster merupakan hal yang sangat penting, sehingga penentuan jumlah cluster yang digunakan untuk mengelompokkan data juga harus diperhatikan.
2. Mendefinisikan pusat cluster awal.
Pada langkah ini, ditentukan posisi titik awal sebagai pusat cluster data sebanyak � titik data secara random.
3. Mengelompokkan data ke dalam cluster.
7
Perhitungan jarak pada algoritme ini dilakukan untuk masing-masing data ke setiap pusat cluster. Sehingga jika terdapat � data dan � pusat cluster maka akan dihasilkan sebanyak (� � ) perhitungan jarak. Selanjutnya, dari hasil perhitungan jarak data dengan pusat cluster, akan dicari nilai minimum untuk masing-masing data. Nilai minimum menunjukkan bahwa data lebih dekat dengan pusat cluster tersebut, sehingga data akan lebih tepat ditempatkan ke dalam cluster, didefinisikan pada Persamaan 8.
Proses algoritme k-means clustering berhenti ketika beberapa kriteria terpenuhi, yaitu jumlah iterasi sudah mencapai nilai maksimum atau tidak ada perubahan keanggotaan cluster. Alur kerja algoritme k-means clustering, seperti ditunjukkan pada Gambar 5.
Start
End
Mengelompokkan data ke dalam cluster berdasarkan jarak terpendek
Gambar 5 Algoritme K-means
Fuzzy C-MeansClustering (FCM)
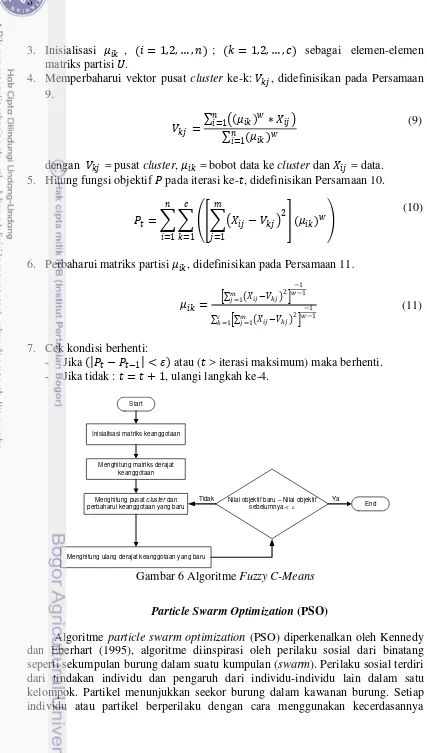
Metode fuzzy c-means pertama kali diperkenalkan oleh Bezdek pada tahun 1984. Fuzzy c-means adalah suatu teknik pengelompokkan data dimana keberadaan tiap-tiap data dalam suatu cluster ditentukan oleh nilai keanggotaan. Alur kerja algoritme fuzzyc-meansclustering, seperti ditunjukkan pada Gambar 6. Prosedur algoritme fuzzy c-means clustering (Kusumadewi dan Purnomo 2010) adalah sebagai berikut :
1. Data input �, berupa matriks berukuran ( = jumlah sampel data, = atribut setiap data). � = data sampel ke- ( = 1,2,…, ), atribut ke- ( = 1,2,…, ).
2. Tentukan jumlah cluster , pangkat , iterasi maksimum, error terkecil yang diharapkan �, fungsi objektif awal �0 = 0 dan iterasi awal = 1.
8
3. Inisialisasi � , ( = 1,2,…, ) ; ( = 1,2,…, ) sebagai elemen-elemen matriks partisi .
4. Memperbaharui vektor pusat cluster ke-k: , didefinisikan pada Persamaan 9.
= � ∗ � =1
� =1
dengan = pusat cluster, � = bobot data ke cluster dan � = data. 5. Hitung fungsi objektif � pada iterasi ke- , didefinisikan Persamaan 10.
� = � − 2
=1
� =1
=1
6. Perbaharui matriks partisi � , didefinisikan pada Persamaan 11.
� = � −
Menghitung ulang derajat keanggotaan yang baru Menghitung matriks derajat
keanggotaan
Menghitung pusat cluster dan perbaharui keanggotaan yang baru
Nilai objektif baru – Nilai objektif sebelumnya < e
Tidak Ya
Inisialisasi matriks keanggotaan
Gambar 6 Algoritme Fuzzy C-Means
Particle Swarm Optimization (PSO)
Algoritme particle swarm optimization (PSO) diperkenalkan oleh Kennedy dan Eberhart (1995), algoritme diinspirasi oleh perilaku sosial dari binatang seperti sekumpulan burung dalam suatu kumpulan (swarm). Perilaku sosial terdiri dari tindakan individu dan pengaruh dari individu-individu lain dalam satu kelompok. Partikel menunjukkan seekor burung dalam kawanan burung. Setiap individu atau partikel berperilaku dengan cara menggunakan kecerdasannya (9)
(10)
9
(intelligence) sendiri dan juga dipengaruhi perilaku kelompok kolektifnya. Dengan demikian, jika satu partikel atau seekor burung menemukan jalan yang tepat atau pendek menuju sumber makanan, sisa kelompok yang lain juga akan dapat segera mengikuti jalan tersebut meskipun lokasi mereka jauh di kelompok tersebut (Santosa dan Willy 2011).
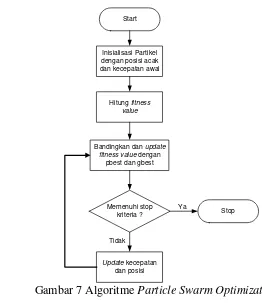
Berbeda dengan teknik komputasi evolusioner lainnya, setiap partikel di dalam PSO juga berhubungan dengan suatu kecepatan (velocity). Partikel-partikel tersebut bergerak melalui penelusuran ruang dengan kecepatan dinamis yang disesuaikan menurut perilaku historisnya. Oleh karena itu, partikel-partikel mempunyai kecenderungan untuk bergerak ke area penelusuran yang lebih baik setelah melewati proses penelusuran. Pada algoritme PSO, vektor kecepatan diperbaharui untuk masing-masing partikel, kemudian menjumlahkan vektor kecepatan tersebut ke posisi partikel. Proses memperbaharui kecepatan dipengaruhi oleh kedua solusi yaitu melakukan penyesuaian posisi terbaik dari partikel (local best) dan penyesuaian terhadap partikel terbaik dari seluruh kawanan (global best). Pada tiap iterasi setiap solusi yang direpresentasikan oleh posisi partikel, dievaluasi dengan cara memasukkan solusi tersebut kedalam fitness function. Alur kerja algoritme Particle Swarm Optimization terlihat pada Gambar 7.
Prosedur algoritme PSO adalah sebagai berikut :
1. Inisialisasi populasi dari partikel-partikel dengan posisi dan kecepatan secara acak dalam suatu ruang dimensi penelusuran.
2. Evaluasi nilai fitness dari masing-masing partikel berdasarkan posisinya. 3. Membandingkan evaluasi fitness partikel dengan Pbestnya. Jika nilai yang ada
lebih baik dibandingkan dengan nilai Pbestnya, maka Pbest di set sama dengan nilai tersebut dan Pi sama dengan lokasi partikel yang ada Xi dalam ruang dimensional d.
4. Identifikasi nilai terbaik secara keseluruhan (Gbest) yang dimiliki oleh setiap partikel dalam populasi.
5. Setelah mendapatkan nilai Pbest dan Gbest tersebut, partikel memperbaharui kecepatan dan posisinya masing-masing, didefinisikan pada Persamaan 12 dan 13.
10
Gambar 7 Algoritme Particle Swarm Optimization
PSO basedK-Means Clustering
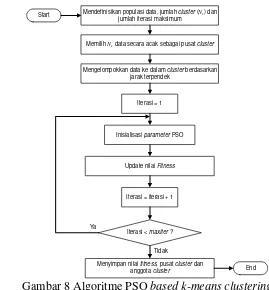
Algoritme PSO based k-means clustering merupakan gabungan dari algoritme k-means clustering dengan algoritme PSO. PSO based k-means clustering digunakan untuk proses pengelompokkan data dan proses penemuan pusat cluster terbaik. Pengelompokkan data menggunakan algoritme PSO based k-means clustering menunjukkan hasil yang lebih baik dari metode k-means clustering (Van der Merwe dan Engelbrecht 2003). Di dalam konteks clustering, satu partikel merepresentasikan satu titik data pusat cluster. Setiap partikel = 1,…, ,…, � , dengan mengacu pada − vektor pusat cluster dari partikel ke - . Alur kerja algoritme PSO based k-means clustering seperti ditunjukkan pada Gambar 8. Berikut ini adalah langkah-langkah dalam algoritme PSO basedk-means clustering :
1. Mendefinisikan jumlah cluster (Nc), populasi data dan jumlah iterasi
maksimum
2. Mendefinisikan pusat cluster awal 3. Mengelompokkan data ke dalam cluster
Pada langkah ini, data dimasukkan ke dalam salah satu cluster yang mempunyai jarak terdekat antara pusat cluster dengan data, didefinisikan pada Persamaan (7).
4. Perhitungan nilai fitness
Kualitas dari setiap partikel diukur, didefinisikan pada Persamaan 14
11
dengan adalah nilai maksimum piksel dalam set citra ( = 2 −1 untuk s-bit citra); Z adalah matriks yang mewakili pengolahan piksel citra ke cluster partikel i. Setiap elemen menunjukkan jika piksel adalah milik cluster partikel i. Nilai �1dan �2 ditentukan oleh user. Juga,
, = max
=1,… , � , /
�
adalah nilai rata-rata maksimum jarak Euclidean dari partikel untuk masing-masing kelas partikel dan
= min
1, 2, 1≠2 1, 2
adalah jarak Euclidean minimum antara setiap pasang cluster.
Fungsi fitness tersebut memiliki tujuan yang dilakukan secara bersamaan, terdiri atas:
- Meminimalkan intra-distance yaitu jarak antara data dengan masing-masing pusat cluster, seperti yang diukur dengan , .
- Memaksimalkan inter-distance yaitu jarak antara setiap pusat cluster, seperti yang diukur dengan .
5. Gbest PSO basedk-means clustering
Untuk mencari nilai gbest dalam algoritme PSO based k-means clustering, nilai fitness dari setiap pusat cluster akan dicari yang paling optimal (minimum), didefinisikan pada Persamaan (14). Langkah selanjutnya adalah data akan dikelompokkan sebagai berikut :
1. Inisialisasi setiap partikel (Nc) secara acak
2. Untukt=1 sampaitmax lakukan
(a) Untuk setiap partikel i lakukan (b) Untuk setiap data
i. Hitung jarak Euclidean , untuk semua pusat cluster Cij
ii. Tentukan ke cluster sehingga , = minimum iii. Hitung nilai fitness, didefinikan pada Persamaan (14) (c) Updatepbest dan gbest
(d) Update pusat cluster, didefinisikan pada Persamaan (12) dan (13). dengan tmax adalah jumlah iterasi maksimum.
12
Start
End Mendefinisikan populasi data, jumlah cluster (Nc) dan
jumlah iterasi maksimum
Memilih Nc data secara acak sebagai pusat cluster
Mengelompokkan data ke dalam cluster berdasarkan jarak terpendek
Iterasi = 1
Inisialisasi parameter PSO
Update nilai Fitness
Iterasi = iterasi + 1
Menyimpan nilai fitness, pusat cluster dan anggota cluster
Iterasi < maxiter ?
Tidak Ya
Gambar 8 Algoritme PSO basedk-means clustering
PSO basedFuzzyC-Means Clustering
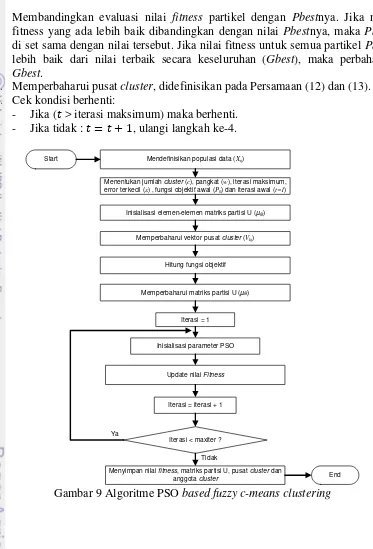
Algoritme PSO based fuzzy c-means clustering merupakan gabungan dari algoritme fuzzy c-means clustering dengan algoritme PSO. Algoritme ini diperkenalkan untuk mengatasi permasalahan solusi lokal dari pengelompokkan data menggunakan metode fuzzy c-means clustering tradisional (Panchal et al. 2009). Vektor = 1, 2,…, , menunjukkan pusat cluster. Satu partikel merepresentasikan satu titik data pusat cluster dengan mengacu pada − vektor pusat cluster. Alur kerja algoritme PSO based fuzzy c-means clustering seperti ditunjukkan pada Gambar 9. Berikut ini adalah langkah-langkah dalam algoritme PSO basedfuzzy c-means clustering :
1. Data input �, berupa matriks berukuran ( = jumlah sampel data, = atribut setiap data). � = data sampel ke- ( = 1,2,…, ), atribut ke- ( = 1,2,…, ).
2. Tentukan jumlah cluster , pangkat , iterasi maksimum, error terkecil yang diharapkan �, fungsi objektif awal �0 = 0 dan iterasi awal = 1.
3. Inisialisasi � , ( = 1,2,…, ) ; ( = 1,2,…, ) sebagai elemen-elemen matriks partisi .
4. Memperbaharui vektor pusat cluster ke-k: , didefinisikan pada Persamaan 9.
5. Hitung fungsi objektif � pada iterasi ke- , didefinisikan pada Persamaan 10. 6. Perbaharui matriks partisi � , didefinisikan pada Persamaan 11.
13
� = min
1, 2,…, � −
=1
Membandingkan evaluasi nilai fitness partikel dengan Pbestnya. Jika nilai fitness yang ada lebih baik dibandingkan dengan nilai Pbestnya, maka Pbest di set sama dengan nilai tersebut. Jika nilai fitness untuk semua partikel Pbest lebih baik dari nilai terbaik secara keseluruhan (Gbest), maka perbaharui Gbest.
8. Memperbaharui pusat cluster, didefinisikan pada Persamaan (12) dan (13). 9. Cek kondisi berhenti:
- Jika ( > iterasi maksimum) maka berhenti. - Jika tidak : = + 1, ulangi langkah ke-4.
Start
End Mendefinisikan populasi data (Xij)
Menentukan jumlah cluster (c), pangkat (w), iterasi maksimum, error terkecil (e) , fungsi objektif awal (P0) dan iterasi awal (t=1)
Inisialisasi elemen-elemen matriks partisi U (µik)
Iterasi = 1
Inisialisasi parameter PSO
Update nilai Fitness
Iterasi = iterasi + 1
Menyimpan nilai fitness, matriks partisi U, pusat cluster dan anggota cluster
Iterasi < maxiter ?
Tidak Ya
Memperbaharui vektor pusat cluster (Vkj)
Hitung fungsi objektif
Memperbaharui matriks partisi U (µik)
Gambar 9Algoritme PSO basedfuzzyc-means clustering
3
METODE
Alat dan Bahan
Penelitian ini menggunakan alat laptop dengan spesifikasi Processor AMD
E-300 APU with Radeon™ HD Graphics 1,3 GHz, memori DDR3 RAM 2.00 GB
dan harddisk 500 GB. Perangkat lunak yang digunakan adalah Sistem Operasi Windows7, Microsoft Word 2007, Microsoft Excel 2007, CodeBlocks 10.05 dan OpenCV. Adapun bahan yang digunakan dalam penelitian ini adalah data citra daun tumbuhan obat.
Metode Penelitian
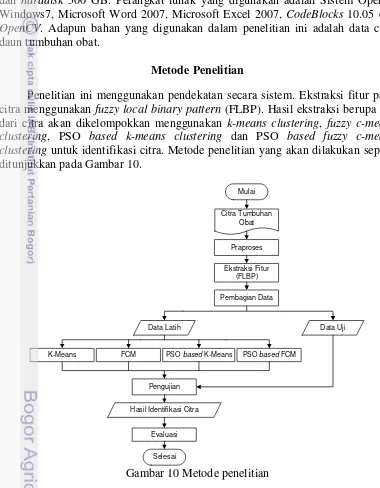
Penelitian ini menggunakan pendekatan secara sistem. Ekstraksi fitur pada citra menggunakan fuzzy local binary pattern (FLBP). Hasil ekstraksi berupa ciri dari citra akan dikelompokkan menggunakan k-means clustering, fuzzy c-means clustering, PSO based k-means clustering dan PSO based fuzzy c-means clustering untuk identifikasi citra. Metode penelitian yang akan dilakukan seperti ditunjukkan pada Gambar 10.
Citra Tumbuhan Obat
Praproses
Ekstraksi Fitur (FLBP)
Pembagian Data
K-Means PSO based K-Means
Pengujian
Evaluasi
Mulai
Selesai
FCM PSO based FCM
Data Latih Data Uji
Hasil Identifikasi Citra
Gambar 10 Metode penelitian
Data Citra Tumbuhan Obat
15
(DSC-W55, 7210 Supernova, Canon Digital Axus 95 IS, Samsung PL100, dan EX-Z35). Total citra daun tumbuhan obat yang digunakan adalah 1 440 yang terdiri atas 30 spesies dengan masing-masing spesies terdiri atas 48 citra. Data citra tumbuhan obat seperti ditunjukkan pada Lampiran 1.
Praproses
Praproses adalah tahap awal dari proses identifikasi tumbuhan obat. Proses yang dilakukan pada tahap ini adalah mengganti latar belakang citra daun dengan warna putih. Ukuran citra diperkecil menjadi 270x240 piksel. Mode warna citra diubah menjadi grayscale sebagai input untuk proses ekstraksi fitur.
Ekstraksi fitur dengan Fuzzy Local Binary Pattern
Ekstraksi fitur menggunakan metode �� ��,�. Langkah pertama untuk mendapatkan informasi tekstur dari suatu citra adalah dengan menentukan operator LBP dan threshold FLBP. Setelah penentuan operator dan threshold, citra akan dibagi ke dalam beberapa blok (local region) sesuai dengan operator circular neighborhood (�,�), yaitu sampling point (�) dan radius (�) yang digunakan. Selanjutnya adalah proses scanning citra (convolution) menggunakan local region untuk mendapatkan nilai LBP dari setiap local region. Nilai LBP akan direpresentasikan melalui histogram FLBP. Histogram tersebut menggambarkan frekuensi dari kontribusi nilai LBP yang muncul pada sebuah citra. Operator LBP seperti ditunjukkan pada Tabel 1. Pada penelitian ini, operator LBP yang digunakan adalah operator (8,2) dengan nilai threshold 4.
Tabel 1 Operator LBP
(�,�) Ukuran blok (piksel) Kuantisasi sudut
(8,1) (3 3) 450
(8,2) (5 5) 450
Pembagian Data Latih dan Data Uji
Pada tahap ini, jumlah vektor data citra daun tumbuhan obat dibagi menjadi 2 bagian, yaitu data latih dan data uji. Data latih digunakan sebagai masukan untuk pelatihan dengan metode k-means clustering, fuzzyc-means clustering, PSO based k-means clustering dan PSO based fuzzy c-means clustering. Data uji digunakan untuk menguji model hasil pelatihan. Pengujian bertujuan mengetahui kemampuan dari masing-masing model dalam mengelompokkan data spesies tumbuhan obat. Pengelompokkan data dilakukan dengan membagi komposisi untuk data latih sebesar 80% dan data uji sebesar 20%. Dengan komposisi tersebut, jumlah data untuk data latih adalah 38 citra dan jumlah data untuk data uji adalah 10 citra.
Pembuatan Model
16
clustering, PSO based k-means clustering dan PSO based fuzzy c-means clustering.
Pengujian
Pengujian untuk model k-means clustering, fuzzy c-means clustering, PSO based k-means clustering dan PSO based fuzzy c-means clustering dilakukan dengan menggunakan metode pengukuran jarak Euclidean, dihitung dengan Persamaan (7). Pengujian tersebut menggunakan data uji sebagai masukan untuk setiap model yang telah diperoleh.
Evaluasi Model
Pengujian data dilakukan untuk menilai tingkat keberhasilan pengelompokkan data citra uji oleh sistem. Evaluasi dari kinerja model clustering didasarkan pada banyaknya data uji yang diprediksi secara benar oleh model. Hasil perhitungan clustering data uji ditampilkan dalam tabel purity. Purity merupakan salah satu teknik utama dalam mengukur kualitas anggota dari sebuah cluster (Sripada 2011). Purity mengukur kebaikan suatu cluster dilihat dari tingkat homogenitas anggota cluster yang didefinisikan pada Persamaan 16.
= 1
� (�)
dengan
� = jumlah anggota keseluruhan dari sebuah cluster (�) = jumlah anggota terbanyak dari sebuah cluster
Tabel purity diproses untuk mendapatkan nilai akurasi. Nilai akurasi merupakan nilai perbandingan antara jumlah data yang berhasil diprediksi dengan jumlah total data pengujian. Akurasi didefinisikan pada Persamaan 17.
= 100%
Evaluasi juga dilakukan dengan mengukur efisiensi waktu komputasi dari masing-masing metode yang digunakan. Efisiensi waktu diukur berdasarkan total running time dalam proses pengelompokkan spesies tumbuhan obat.
4
HASIL DAN PEMBAHASAN
Hasil Praproses
Praproses dilakukan dengan tujuan mempercepat waktu pengolahan data citra. Praproses data citra tumbuhan obat dilakukan dengan cara memperkecil ukuran citra menjadi 270 240 dan mengubah mode warna citra menjadi grayscale. Hasil dari praproses seperti pada Gambar 11.
Psidium guajava L.
Gambar 11 Hasil praproses citra tumbuhan obat
Ekstraksi Fitur FLBP
Citra grayscale hasil praproses digunakan sebagai masukan pada proses ekstraksi FLBPP,R. Ekstraksi dilakukan menggunakan ukuran circular neighborhood. Ciri FLBP yang dihasilkan, diekstrak menggunakan nilai threshold FLBP fuzzifikasi (F) yaitu 4 dengan operator LBP (8.2).
Ekstraksi FLBP menghasilkan histogram frekuensi nilai LBP. Histogram merupakan pertambahan kontribusi dari nilai LBP yang dihasilkan. Panjang bin yang dihasilkan pada histogram FLBPP,R bergantung pada jumlah sampling points (P) yang digunakan, yaitu 2P. Pada penelitian ini, jumlah P yang digunakan adalah 8 sehingga jumlah bin pada histogram FLBPP,R sebanyak 28 = 256 bin. Contoh histogram Psidium guajava L ditunjukan pada Gambar 12.
Gambar 12 Histogram FLBP pada citra Psidium guajava L.
Hasil Percobaan
Metode k-means clustering, fuzzy c-means clustering, PSO based k-means
clustering dan PSO based fuzzy c-means clustering digunakan untuk
mengelompokkan spesies tumbuhan obat. Hasil pengelompokkan spesies
0
105 112 119 126 133 140 147 154 161 168 175 182 189 196 203 210 217 224 231 238 245 252
18
tumbuhan obat menggunakan keempat metode menghasilkan output berupa kelompok cluster. Pengukuran kualitas clustering untuk masing-masing metode menggunakan akurasi dan waktu komputasi.
Analisis Hasil Percobaan
Tahap pembuatan model untuk metode k-means clustering, fuzzy c-means clustering, PSO based k-means clustering dan PSO based fuzzy c-means clustering menggunakan data latih sebanyak 1.140 citra dan pengujian dengan data uji sebanyak 300 citra. Proses pengelompokkan data menggunakan 30 pusat cluster. Jumlah ini diperoleh berdasarkan spesies tumbuhan obat berjumlah 30.
Proses kerja metode k-means clustering dan fuzzyc-means clustering adalah mengelompokkan citra sesuai dengan spesies tumbuhan obat. Metode PSO based k-means clustering digunakan untuk mengoptimasi hasil pengelompokkan data dari metode k-means clustering dan PSO based fuzzy c-means clustering digunakan untuk mengoptimasi hasil pengelompokkan data dari metode fuzzy c-means clustering. PSO based k-means clustering dan PSO based fuzzy c-means clustering pada penelitian ini menggunakan parameter learning rate c1=1,49 dan
c2=1,49, nilai r1=0,5 dan r2=0,5, untuk bobot inertia(w)=0,72 dengan kecepatan
maksimum(Vmax)=2 (Omran et al. 2005).
Kesalahan identifikasi terlihat dari banyaknya citra yang dikelompokkan kedalam spesies yang sama dan juga pada spesies yang berbeda. Hal ini menunjukkan spesies tumbuhan obat mempunyai informasi tekstur daun yang hampir sama. Pengaruh dari kesalahan identifikasi adalah nilai akurasi yang diperoleh rendah.
Evaluasi hasil k-means clustering
Evaluasi model untuk metode k-means clustering menunjukkan jumlah citra yang berhasil diidentifikasi sebanyak 125 citra. Jumlah citra yang teridentifikasi diperoleh berdasarkan nilai purity. Penentuan cluster untuk setiap spesies citra ditunjukan pada Tabel 2 dan Lampiran 2.
Tabel 2 Penentuan clusterk-means clustering
Perhitungan akurasi dapat dilihat sebagai berikut.
= 125
300× 100% = 41,67%
Perbandingan akurasi untuk masing-masing spesies tumbuhan obat yang teridentifikasi terlihat pada Gambar 13.
Spesies 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30
Purity(Max) 0.6 0.7 0.6 0.4 0.4 0.6 0.8 0.7 1 0.8 0.3 0.5 0.4 0.2 0.3 0.6 0.2 0.4 0.4 0.9 0.6 0.5 0.3 0.4 0.3 0.6 0.3 0.4 0.7 0.3
19
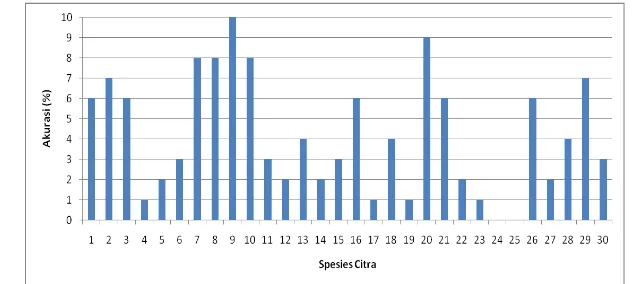
Gambar 13 Grafik perbandingan akurasi per spesies k-means clustering
Grafik pada Gambar 13 menunjukkan bahwa ada 28 spesies citra yang mampu teridentifikasi. Spesies 9 (Kemangi) merupakan spesies yang berhasil teridentifikasi dengan tingkat akurasi 100%. Contoh citra latih dan citra uji spesies 9 terlihat pada Gambar 14.
Gambar 14 Contoh citra latih dan citra uji spesies 9 (Kemangi)
Spesies 24 (Kumis Kucing) dan 25 (Kemuning) yang tidak teridentifikasi dan menghasilkan akurasi 0%. Kesalahan identifikasi menyebabkan spesies 24 (Bidani) dikenali sebagai spesies 18 (Som Jawa). Hal ini menunjukkan spesies tumbuhan obat tersebut mempunyai informasi tekstur daun (ciri) yang hampir sama. Kesalahan identifikasi yang kedua adalah spesies 25 (Kemuning) dikenali sebagai spesies 21 (Nanas Kerang). Informasi ciri dari kedua spesies tersebut menunjukkan adanya kemiripan yang berdampak pada hasil akurasi yang diperoleh rendah. Contoh citra kesalahan identifikasi spesies 24 dan 25 terlihat pada Gambar 15.
Gambar 15 Kesalahan identifikasi spesies citra k-means clustering
Waktu komputasi yang diperoleh untuk pembuatan model k-means clustering yaitu 291,3 detik.
Evaluasi hasil fuzzy c-means clustering
Evaluasi model untuk metode fuzzy c-means clustering menunjukkan jumlah citra yang berhasil diidentifikasi sebanyak 150 citra. Jumlah citra yang teridentifikasi diperoleh berdasarkan nilai purity. Penentuan cluster untuk setiap spesies citra ditunjukan pada Tabel 3 dan Lampiran 3.
Data Latih Data Uji
20
Tabel 3 Penentuan clusterfuzzy c-means clustering
Perhitungan akurasi dapat dilihat sebagai berikut.
= 150
300× 100% = 50%
Perbandingan akurasi untuk masing-masing spesies tumbuhan obat yang teridentifikasi terlihat pada Gambar 16.
Gambar 16 Grafik perbandingan akurasi per spesies fuzzy c-means clustering
Grafik pada Gambar 16 menunjukkan bahwa ada 28 spesies citra yang mampu teridentifikasi. Spesies 2 (Jarak Pagar) merupakan spesies yang berhasil teridentifikasi dengan tingkat akurasi 100%. Contoh citra latih dan citra uji spesies 2 terlihat pada Gambar 17.
Gambar 17 Contoh citra latih dan citra uji spesies 2 (Jarak Pagar)
Spesies 14 (Tabat Barito) dan 27 (Sambang Darah) tidak teridentifikasi dan menghasilkan akurasi 0%. Kesalahan identifikasi menyebabkan spesies 14 (Tabat Barito) dikenali sebagai spesies 2 (Jarak Pagar). Hal ini menunjukkan spesies tumbuhan obat tersebut mempunyai informasi tekstur daun (ciri) yang hampir sama. Kesalahan identifikasi yang kedua adalah spesies 27 (Sambang Darah) dikenali sebagai spesies 30 (Handeleum). Informasi ciri dari kedua spesies tersebut menunjukkan adanya kemiripan yang berdampak pada hasil akurasi yang diperoleh rendah. Contoh citra kesalahan identifikasi spesies 14 dan 27 terlihat pada Gambar 18.
Spesies 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 Purity (Max) 0.4 1 0.6 0.3 0.5 0.9 0.8 0.8 0.9 0.7 0.3 0.4 0.5 0.2 0.4 0.6 0.2 0.6 0.6 0.9 0.4 0.4 0.4 0.3 0.1 0.6 0.4 0.7 0.9 0.5 Cluster 1 2 3 4 5 6 7 8 9 10 11 21 12 13 15 16 17 18 19 20 30 22 23 24 25 26 14 28 29 27
21
Gambar 18 Kesalahan identifikasi spesies citra fuzzy c-means clustering
Waktu komputasi yang diperoleh untuk pembuatan model fuzzy c-means clustering yaitu 59,65 detik.
Evaluasi hasil PSO based k-means clustering
Evaluasi model untuk metode PSO based k-means clustering menunjukkan jumlah citra yang berhasil diidentifikasi sebanyak 144 citra. Jumlah citra yang teridentifikasi diperoleh berdasarkan nilai purity. Penentuan cluster untuk setiap spesies citra ditunjukan pada Tabel 4 dan Lampiran 4.
Tabel 4 Penentuan cluster PSO basedk-means clustering
Perhitungan akurasi dapat dilihat sebagai berikut.
= 144
300× 100% = 48%
Perbandingan akurasi untuk masing-masing spesies tumbuhan obat yang teridentifikasi terlihat pada Gambar 19.
Gambar 19 Grafik perbandingan akurasi per spesies PSO based k-means clustering
Grafik pada Gambar 19 menunjukkan bahwa ada 29 spesies citra yang mampu teridentifikasi. Spesies 2 (Jarak Pagar) dan Spesies 26 (Cincau Hitam) merupakan spesies yang berhasil teridentifikasi dengan tingkat akurasi 100%. Contoh citra latih dan citra uji spesies 2 dan 26 terlihat pada Gambar 20.
Spesies 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 Purity (Max) 0.5 1 0.6 0.3 0.3 0.8 0.8 0.6 0.8 0.7 0.3 0.4 0.3 0.2 0.4 0.6 0.2 0.6 0.6 0.9 0.4 0.5 0.3 0.5 0.2 1 0.3 0.7 0.5 0.2 Cluster 1 2 3 4 5 6 7 8 9 10 11 14 13 12 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30
22
Gambar 20 Contoh citra latih dan citra uji spesies 2 (Jarak Pagar) dan spesies 26 (Cincau Hitam)
Spesies 12 (Bidani) tidak teridentifikasi dan menghasilkan akurasi 0%. Kesalahan identifikasi menyebabkan spesies 12 (Bidani) dikenali sebagai spesies 20 (Sosor Bebek). Hal ini menunjukkan spesies tumbuhan obat tersebut mempunyai informasi tekstur daun (ciri) yang hampir sama. Informasi ciri dari spesies tersebut menunjukkan adanya kemiripan yang berdampak pada hasil akurasi yang diperoleh rendah. Contoh citra kesalahan identifikasi spesies 12 terlihat pada Gambar 21.
Gambar 21 Kesalahan identifikasi spesies citra PSO based k-means clustering
Waktu komputasi yang diperoleh untuk pembuatan model PSO based k-means clustering yaitu 403,3 detik.
Evaluasi hasil PSO based fuzzy c-means clustering
Evaluasi model untuk metode PSO based fuzzy c-means clustering menunjukkan jumlah citra yang berhasil diidentifikasi sebanyak 157 citra. Jumlah citra yang teridentifikasi diperoleh berdasarkan nilai purity. Penentuan cluster untuk setiap spesies citra ditunjukan pada Tabel 5 dan Lampiran 5.
Tabel 5 Penentuan cluster PSO basedfuzzyc-means clustering
Perhitungan akurasi dapat dilihat sebagai berikut.
= 157
300× 100% = 52,33%
Perbandingan akurasi untuk masing-masing spesies tumbuhan obat yang teridentifikasi terlihat pada Gambar 22.
Spesies 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 Purity (Max) 0.4 1 0.7 0.3 0.5 0.9 0.8 0.8 0.9 0.7 0.3 0.4 0.4 0.2 0.4 0.6 0.2 0.6 0.6 1 0.4 0.4 0.3 0.3 0.1 1 0.3 0.7 1 0.5 Cluster 1 2 3 4 5 6 7 8 9 10 11 21 12 13 15 16 17 18 19 20 30 22 23 24 25 26 14 28 29 27
Data Latih Data Uji
Spesies 2 (Jarak Pagar)
Spesies 26 (Cincau Hitam)
23
Gambar 22 Grafik perbandingan akurasi per spesies PSO based fuzzy c-means clustering
Grafik pada Gambar 22 menunjukkan bahwa ada 28 spesies citra yang mampu teridentifikasi. Spesies 2 (Jarak Pagar), Spesies 20 (Sosor Bebek), Spesies 26 (Cincau Hitam) dan Spesies 29 (Jambu Biji) merupakan spesies yang berhasil teridentifikasi dengan tingkat akurasi 100%. Contoh citra latih dan citra uji spesies 2, 20, 26 dan 29 terlihat pada Gambar 23.
Gambar 23 Contoh citra latih dan citra uji spesies 2 (Jarak Pagar), spesies 20 (Sosor Bebek), spesies 26 (Cincau Hitam) dan spesies 29 (Jambu Biji)
Spesies 14 (Tabat Barito) dan Spesies 27 (Sambang Darah) tidak teridentifikasi dan menghasilkan akurasi 0%. Kesalahan identifikasi menyebabkan spesies 14 (Tabat Barito) dikenali sebagai spesies 2 (Jarak Pagar) dan spesies 27 (Sambang Darah) dikenali sebagai spesies 30 (Handeleum). Hal ini menunjukkan spesies tumbuhan obat tersebut mempunyai informasi tekstur daun (ciri) yang hampir sama. Informasi ciri dari spesies tersebut menunjukkan adanya kemiripan yang berdampak pada hasil akurasi yang diperoleh rendah. Contoh citra kesalahan identifikasi spesies 14 dan 27 terlihat pada Gambar 24.
Spesies 2 (Jarak Pagar)
Spesies 26 (Cincau Hitam)
Spesies 20 (Sosor Bebek)
Spesies 29 (Jambu Biji)
24
Gambar 24 Kesalahan identifikasi spesies citra PSO based fuzzy c-means clustering
Waktu komputasi yang diperoleh untuk pembuatan model PSO based k-means clustering yaitu 60,1 detik.
Perbandingan kinerja hasil percobaan
Pembuatan model untuk masing-masing metode dilakukan untuk mengetahui teknik yang paling baik dalam mengelompokkan spesies tumbuhan obat. Pada setiap percobaan yang dilakukan, akurasi dan waktu komputasi mempengaruhi pemilihan metode yang akan digunakan dalam sistem identifikasi tumbuhan obat. Dari hasil analisis pada setiap percobaan, perbandingan evaluasi untuk nilai akurasi seperti ditunjukkan pada Gambar 25.
Gambar 25 Perbandingan evaluasi akurasi
Perbandingan evaluasi untuk akurasi pada Gambar 25 menunjukkan metode k-means clustering menghasilkan akurasi paling rendah yaitu 41,67%. Metode tersebut di optimasi dengan metode PSO based k-means clustering dan menghasilkan akurasi sebesar 48%. Evaluasi pada metode fuzzy c-means clustering memperoleh akurasi sebesar 50%. Metode tersebut di optimasi dengan metode PSO based fuzzy c-means clustering dan menghasilkan akurasi tertinggi yaitu 52,33%. Hal tersebut menunjukkan adanya peningkatan akurasi, karena metode PSO based k-means clustering dan PSO based fuzzy c-means clustering mampu memperbaiki pengelompokkan data yang diperoleh metode k-means clustering dan fuzzyc-means clustering.
Perbandingan evaluasi untuk waktu komputasi pada setiap percobaan seperti ditunjukkan pada Gambar 26.
25
Gambar 26 Perbandingan evaluasi waktu komputasi
Perbandingan evaluasi waktu komputasi pada Gambar 26 menunjukkan adanya penambahan waktu pada metode PSO based k-means clustering dan PSO based fuzzy c-means clustering dari metode k-means clustering dan fuzzy c-means
clustering. Penambahan algoritme menyebabkan pengolahan data semakin
banyak. Hal tersebut berdampak pada waktu komputasi yang semakin lama. Waktu komputasi yang diperoleh metode k-means clustering 291,3 detik dan metode PSO basedk-means clustering 403,3 detik. Peningkatan waktu komputasi pada metode PSO based k-means clustering cukup signifikan atau sekitar 2 kali dari metode standar k-means clustering. Waktu komputasi yang diperoleh metode fuzzy c-means clustering 59,65 detik dan metode PSO based fuzzy c-means clustering 60,1 detik. Hal ini menunjukkan peningkatan waktu komputasi PSO based fuzzy c-means clustering tidak terlalu signifikan dari metode standar fuzzy c-means clustering.
Pengaruh metode PSO dalam proses optimasi clustering menunjukkan adanya peningkatan hasil identifikasi spesies tumbuhan obat. Penggunaan metode PSO dalam optimasi metode k-means clustering mempunyai pengaruh yang cukup besar karena mampu meningkatkan akurasi sekitar 6,33%. Pada penggunaan metode PSO dalam optimasi metode fuzzy c-means clustering mempunyai pengaruh yang tidak terlalu besar karena hanya meningkatkan akurasi sekitar 2,33%.
Pemilihan Metode Sistem Identifikasi Tumbuhan Obat
26
5
SIMPULAN DAN SARAN
Simpulan
Simpulan dari hasil penelitian ini adalah:
1. Optimasi metode k-means clustering dan fuzzy c-means clustering menggunakan metode PSO pada proses identifikasi spesies tumbuhan obat berhasil diimplementasikan. Setiap metode menggunakan data masukan hasil ekstraksi fitur citra dengan FLBP berupa vektor ciri dari spesies tumbuhan obat.
2. Metode k-means clustering memperoleh akurasi 41,67% dan fuzzy c-means clustering sebesar 50%. Metode PSO yang dimodifikasi untuk mengoptimasi k-means clustering dan fuzzy c-means clustering mampu meningkatkan akurasi identifikasi spesies tumbuhan obat. Metode PSO based k-means clustering memperoleh akurasi 48% dan metode PSO based fuzzy c-means clustering memperoleh akurasi 52,33%.
3. Waktu komputasi yang semakin lama pada metode PSO based k-means clustering dan PSO based fuzzy c-means clustering disebabkan karena adanya penambahan algoritme. Hal ini berdampak pada pengolahan data yang semakin banyak.
4. Pengaruh metode PSO dalam proses optimasi metode clustering menunjukkan adanya peningkatan hasil identifikasi spesies tumbuhan obat.
Saran
Penelitian selanjutnya diharapkan melakukan optimasi pemilihan pusat
cluster awal sehingga mendapatkan hasil yang optimal dalam proses
DAFTAR PUSTAKA
Ahonen T, Pietikainen M. 2004. Face Recognition with Local Binary Pattern. Springer Verlag Berlin Heidelberg. ECCV, LNCS 3021:469-481.
Bezdek JC, Ehrlich R, Full W. 1984. FCM : The Fuzzy C-Means Clustering Algorithm. Computers & Geoscience Vol. 10, No. 2-3, pp. 191-203, 1984. Ghahramani Z. 2004. Unsupervised Learning. Advanced Lectures on Machine
Learning. LNAI 3176. Springer-Verlag.
Groombridge B, Jenkins MD. 2002. World Atlas of Biodiversity. Earth’s Living Resources in the 21st Century. UNEP-WCMC, Cambridge.
Herdiyeni Y, Wahyuni NKS. 2012. Mobile Application for Indonesian Medicinal Plants Identification using Fuzzy Local Binary Pattern and Fuzzy Color Histogram. International Conference on Advanced Computer Science and Information System ISBN: 978-979-1421-15-7.
Iakovidis DK, Eystratios G, Keramidas EG, Maroulis D. 2008. Fuzzy Local Binary Patterns for Ultrasound Texture Characterization. ICIAR, LNCS 5112, pp. 750-759, 2008.
Jain AK, Murty MN, Flynn PJ. 1999. Data Clustering : A Review. ACM Computing Surveys. Vol. 31, No. 3, 1999.
Kennedy J, Ebenhart RC. 1995. Particle Swarm Optimization. Sixth International Symposium on Micro Machine and Human Science. 0-7803-2676-8. 1995 IEEE.
Keramidas EG, Iakovidis DK, Maroulis D. 2011. Fuzzy Binary Patterns for Uncertainty-aware Texture Representation. Jurnal. Electronic Letters on Computer Vision and Image Analysis. ELCVIA ISSN: 1577-5097.
Kusumadewi S, Purnomo H. 2010. Aplikasi Logika Fuzzy untuk Pendukung Keputusan. Yogyakarta(ID) : Graha Ilmu.
MacQueen JB. 1967. Some Methods for Classification and Analysis of Multivariate Observations. Western Management Science Institute. Task No. 047-041.
Mäenpää T. 2003. The Local Binary Pattern Approach to Texture Analysis. University of Oulu. ISBN 951-42-7076-2.
Omran M, Engelbrecht AP, Salman A. 2005. Particle Swarm Optimization Method for Image Clustering. 19, 297 (2005). DOI: 10.1142/S0218001405004083
Panchal VK, Kundra H, Kaur J. 2009. Comparative Study of Particle Swarm Optimization based Unsupervised Clustering Techniques. International Jurnal of Computer Science and Network Security. Vol. 9 No. 10, 2009.
Santosa B, Willy P. 2011. Metoda Metaheuristik Konsep dan Implementasi. Surabaya(ID) : Guna Widya.
Sripada SC. 2011. Comparison of Purity and Entropy of K-Means Clustering and Fuzzy C-Means Clustering. Indian Journal of Computer Science and Engineering, 2(3), pp.343–346.
30
(Ficus deloidea L.) Mengatasi stroke.
15 Nandang Gendis air seni, dan bau badan.
Lampiran 2 Purityk-means clustering
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30
1 2 0 0 4 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 4 0 0
2 0 7 0 0 0 0 0 0 0 0 0 0 0 1 0 1 0 0 0 0 0 0 1 0 0 0 0 0 0 0
3 1 0 6 0 0 0 0 0 0 0 0 0 0 0 0 0 0 3 0 0 0 0 0 0 1 0 3 1 0 0
4 0 0 0 1 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 2 0 0 0 0 0 0 0 0 0
5 0 0 0 0 2 0 0 0 0 0 0 0 2 0 0 0 2 0 1 0 0 0 0 0 0 0 0 0 0 0
6 0 0 0 0 0 3 0 0 0 0 1 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0
7 0 0 0 0 0 0 1 0 0 0 0 0 0 1 0 0 1 0 1 0 0 1 0 0 0 0 0 0 0 0
8 1 0 1 0 0 0 0 7 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0
9 0 0 0 0 0 0 0 3 10 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0
10 0 0 0 0 0 6 0 0 0 8 1 0 0 1 0 0 0 0 4 0 0 0 0 0 1 0 0 0 0 0
11 0 0 0 1 0 0 0 0 0 0 1 0 0 0 3 0 0 0 0 0 0 0 0 1 0 0 2 0 0 0
12 0 0 0 0 0 0 1 0 0 0 1 0 1 2 0 0 0 0 0 0 0 1 0 1 2 0 0 0 0 1
13 0 0 0 0 0 0 0 0 0 0 1 0 1 2 0 0 0 0 0 0 0 0 0 0 0 0 0 0 7 0
14 0 0 0 0 4 0 8 0 0 0 0 0 0 1 0 0 2 0 0 0 0 5 2 0 0 0 0 0 0 0
15 0 0 0 0 0 0 0 0 0 0 0 0 0 0 3 0 0 1 0 0 0 0 0 2 0 0 0 0 0 0
16 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 6 0 0 0 0 0 0 0 0 0 0 0 0 0 0
17 0 0 0 0 1 0 0 0 0 0 0 0 1 0 0 0 1 0 1 0 0 0 3 0 0 2 0 0 0 0
18 0 0 0 0 0 0 0 0 0 0 0 0 0 0 1 0 0 4 0 0 0 0 0 4 0 0 0 1 0 0
19 0 0 0 0 0 0 0 0 0 2 0 0 0 0 0 0 1 0 1 0 0 0 0 0 0 2 0 0 0 0
20 0 0 0 0 0 0 0 0 0 0 0 5 0 0 0 0 0 0 0 9 0 0 0 0 0 0 2 0 0 3
21 0 0 0 1 0 1 0 0 0 0 0 0 0 0 0 0 0 0 0 0 1 1 0 0 0 0 0 0 0 0
22 0 0 0 0 0 0 0 0 0 0 0 0 0 1 0 0 0 0 0 0 0 2 1 0 0 0 0 0 0 0
23 0 3 0 0 0 0 0 0 0 0 0 0 0 0 0 0 1 0 0 0 0 0 1 0 0 0 0 0 0 0
24 0 0 0 0 0 0 0 0 0 0 0 2 0 0 1 0 0 1 0 0 0 0 0 1 1 0 0 0 0 0
25 0 0 0 0 3 0 0 0 0 0 3 1 0 1 0 0 2 0 2 0 0 0 0 0 0 0 0 0 0 0
26 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 2 0 0 6 0 0 0 0
27 0 0 0 0 0 0 0 0 0 0 1 1 1 0 0 0 0 1 0 0 1 0 0 1 1 0 0 0 0 3
28 6 0 2 3 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 2 4 0 0
29 0 0 0 0 0 0 0 0 0 0 0 0 4 0 1 3 0 0 0 1 0 0 0 0 1 0 0 0 3 0
30 0 0 1 0 0 0 0 0 0 0 1 1 0 0 1 0 0 0 0 0 6 0 0 0 3 0 1 0 0 3
Purity (Max) 0.6 0.7 0.6 0.4 0.4 0.6 0.8 0.7 1 0.8 0.3 0.5 0.4 0.2 0.3 0.6 0.2 0.4 0.4 0.9 0.6 0.5 0.3 0.4 0.3 0.6 0.3 0.4 0.7 0.3
Cluster 28 2 3 4 5 6 14 8 9 10 25 24 29 12 15 16 17 18 19 20 30 22 23 7 21 26 11 1 13 27
Cluster Citra
33
Lampiran 3 Purityfuzzy c-means clustering
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30
1 4 0 0 3 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 1 2 0 0
2 0 10 0 0 0 0 0 0 0 0 0 0 0 2 0 1 1 0 0 0 0 0 2 0 0 3 0 0 0 0
3 2 0 6 0 0 0 0 0 0 0 0 0 0 0 0 0 0 1 0 0 1 0 0 0 1 0 1 0 0 2
4 0 0 0 2 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0
5 0 0 0 0 5 0 0 0 0 0 0 0 1 0 0 0 1 0 1 0 0 0 0 0 0 0 0 0 0 0
6 0 0 0 0 0 9 0 0 0 1 0 0 0 0 0 0 0 0 0 0 2 0 0 0 0 0 0 0 0 0
7 0 0 0 0 1 0 8 0 0 0 0 0 0 0 0 0 1 0 0 0 0 1 0 0 0 0 0 0 0 0
8 4 0 0 0 0 0 0 8 1 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0
9 0 0 0 0 0 0 0 2 9 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0
10 0 0 0 0 0 0 0 0 0 7 1 0 0 1 0 0 0 0 2 0 0 0 0 0 1 0 0 0 0 0
11 0 0 0 0 0 0 0 0 0 0 3 1 1 1 1 1 0 0 0 0 0 0 0 0 0 0 0 0 0 0
12 0 0 0 0 0 0 0 0 0 0 0 0 5 2 1 0 0 0 0 0 0 1 0 0 1 0 0 0 0 1
13 0 0 0 0 0 0 0 0 0 0 1 0 1 0 0 0 0 0 0 0 0 0 0 0 1 0 0 0 1 0
14 0 0 0 0 2 0 2 0 0 0 0 0 0 0 0 0 2 0 0 0 0 4 2 0 0 0 0 0 0 0
15 0 0 0 1 0 0 0 0 0 0 0 0 0 0 4 0 0 1 0 0 1 0 0 3 1 0 1 0 0 1
16 0 0 0 0 0 0 0 0 0 0 0 0 0 1 0 6 0 0 0 0 0 0 0 0 0 0 0 0 0 0
17 0 0 0 0 1 0 0 0 0 0 0 0 0 0 0 0 2 0 0 0 0 0 0 0 0 1 0 0 0 0
18 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 6 0 0 0 0 0 3 0 0 0 0 0 0
19 0 0 0 0 0 0 0 0 0 2 2 0 0 0 0 0 2 0 6 0 0 0 0 0 0 0 0 0 0 0
20 0 0 0 0 0 0 0 0 0 0 0 4 0 0 0 0 0 0 0 9 1 0 0 0 0 0 0 0 0 0
21 0 0 0 0 0 1 0 0 0 0 0 1 0 0 0 0 0 1 0 0 0 0 0 0 0 0 0 0 0 0
22 0 0 0 0 0 0 0 0 0 0 0 0 0 1 0 0 0 0 0 0 1 4 1 0 0 0 0 0 0 0
23 0 0 0 0 1 0 0 0 0 0 0 0 1 0 0 0 0 0 0 0 0 0 1 0 0 0 0 0 0 0
24 0 0 0 0 0 0 0 0 0 0 0 2 0 0 2 0 0 1 0 0 0 0 0 3 1 0 2 0 0 0
25 0 0 0 0 0 0 0 0 0 0 1 0 0 1 1 0 0 0 1 0 0 0 0 0 1 0 0 0 0 0
26 0 0 0 0 0 0 0 0 0 0 0 0 1 0 0 0 1 0 0 0 0 0 4 0 0 6 0 0 0 0
27 0 0 2 2 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 1 0 4 1 0 5
28 0 0 2 2 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 1 7 0 0
29 0 0 0 0 0 0 0 0 0 0 1 0 0 1 0 2 0 0 0 1 0 0 0 0 1 0 0 0 9 0
30 0 0 0 0 0 0 0 0 0 0 1 2 0 0 1 0 0 0 0 0 4 0 0 1 1 0 0 0 0 1
Purity (Max) 0.4 1 0.6 0.3 0.5 0.9 0.8 0.8 0.9 0.7 0.3 0.4 0.5 0.2 0.4 0.6 0.2 0.6 0.6 0.9 0.4 0.4 0.4 0.3 0.1 0.6 0.4 0.7 0.9 0.5
Cluster 1 2 3 4 5 6 7 8 9 10 11 21 12 13 15 16 17 18 19 20 30 22 23 24 25 26 14 28 29 27
Cluster Citra