32
BAB IV
HASIL PENELITIAN DAN PEMBAHASAN
4.1. Hasil Penelitian
Penerapan algoritma Naïve Bayes dan Backward Elimination pada zona yang terjangkit COVID-19 di Jawa Barat Dataset dimaksudkan untuk mengetahui dan mendapatan hasil akurasi lebih baik pada klasifikasi deteksi zona COVID-19 dari penelitian – penelitian sebelumnya. Hasil akurasi optimal atau tidak akan didapatkan atau tidak, hasilnya akan terlihat pada hasil eksperimen. Eksperimen pada algoritma Naïve Bayes dan Backward Elimination akan dilakukan menggunakan metode
validasi Split Validation.
4.1.1. Hasil Eksperimen Naïve Bayes Tanpa Backward Elimination
Pada Tahap ini adalah proses eksperimen tahap pertama yaitu pengujian model menggunakan Software Rapidminer terhadap model Naïve Bayes tanpa berbasis Backward Elimination. zona yang terjangkit COVID-19 Dataset yang merupakan
dataset yang telah disiapkan untuk diimplementasikan pada proses uji model, kemudian diujikan pada algoritma Naïve Bayes tanpa Backward Elimination. Setelah dilakukan uji model maka diperoleh hasil sepereti pada table IV.1
Tabel IV.1
Hasil Akurasi Model Naïve Bayes tanpa Backward Elimination
No Model (Algoritma) Akurasi
1 Naïve Bayes 59.26 %
33
Sumber : (Hamzah, 2020)
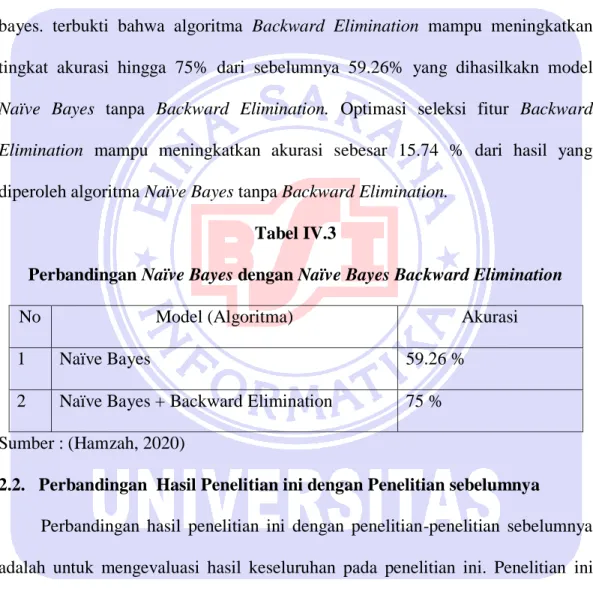
Gambar IV.1 Confusion Matrix Naïve Bayes tanpa Backward Elimination Pada tabel IV.1 hasil akurasi yang diperoleh untuk klasifikasi dari zona yang terjangkit COVID-19 Dataset menggunakan metode naïve bayes tanpa backward elimination sebesar 59.26 %.
4.1.2. Hasil Eksperimen Naïve Bayes Berbasis Backward Elimination
Pada tahap ini akan dilakukan ekperimen dengan penerapan optimasi seleksi fitur Backward Elimination pada model Naïve Bayes. Backward Elimination adalah salah satu seleksi fitur yang dapat memilih atribut-atribut terbaik sehingga mampu meningkatkan tingkat akurasi pada dataset yang diujikan. Setelah eksperimen dilakukan maka hasilnya pada tabel IV.2.
Tabel IV.2
Hasil Akurasi Model Naïve Bayes dan Backward Elimination
No Model (Algoritma) Akurasi
1 Naïve Bayes dan Backward Elimination 75 % Sumber : (Hamzah, 2020)
Sumber : (Hamzah, 2020)
Gambar IV.2 Confusion Matrix Naïve Bayes dengan Backward Elimination Pada tabel IV.2 hasil akurasi yang diperoleh dengan penerapan Backward Elimination pada naïve bayes berhasil ditingkatkan dengan hasil akurasi 75%.
4.2. Pembahasan
Pada tahap ini adalah tahap untuk mengevaluasi hasil dari ekperimen yang dilakukan pada eksperimen tahap satu dan eksperimen tahap dua. Kedua eksperimen dilakukan pada Software Rapidminer yang sudah terimplementasi model Backward Elimination. Pada eksperimen tahap satu diperoleh hasil yang belum maksimal, kemudian pada tahap kedua hasil akurasi dapat meningkat.
4.2.1. Perbandingan Algoritma Naïve Bayes dengan Algoritma Naïve Bayes menggunakan Backward Elimination
Pada tahap ini dilakukan evaluasi terhadap algoritma naïve bayes tanpa backward elimination dengan algoritma naïve bayes menggunakan backward
elimination. Tujuan pada evaluasi ini adalah untuk melihat apakah optimasi
backward elimination dapat meningkatkan hasil akurasi pada algoritma naïve bayes. terbukti bahwa algoritma Backward Elimination mampu meningkatkan tingkat akurasi hingga 75% dari sebelumnya 59.26% yang dihasilkakn model Naïve Bayes tanpa Backward Elimination. Optimasi seleksi fitur Backward
Elimination mampu meningkatkan akurasi sebesar 15.74 % dari hasil yang
diperoleh algoritma Naïve Bayes tanpa Backward Elimination. Tabel IV.3
Perbandingan Naïve Bayes dengan Naïve Bayes Backward Elimination
No Model (Algoritma) Akurasi
1 Naïve Bayes 59.26 %
2 Naïve Bayes + Backward Elimination 75 % Sumber : (Hamzah, 2020)
4.2.2. Perbandingan Hasil Penelitian ini dengan Penelitian sebelumnya Perbandingan hasil penelitian ini dengan penelitian-penelitian sebelumnya adalah untuk mengevaluasi hasil keseluruhan pada penelitian ini. Penelitian ini adalah penelitian lanjutan dari penelitian – penelitian sebelumnya dengan metode yang sama, yaitu naïve bayes dengan naïve bayes dan backward elimination. Seperti yang terlihat pada tabel IV.4 Perbandingan Hasil Penelitian dibawah ini.
Tabel IV. 4
Perbandingan Hasil penelitian
No Judul Penelitian Algoritma Akurasi
1
Optimasi Naive Bayes
Menggunakan Particle Swarm Optimization Untuk Meningkatkan
Akurasi Deteksi Autisme Spectrum Disorder (Agustina, 2017) Naïve Bayes 92,91% Naïve Bayes + Particle Swarm Optimization 98,51% 2
Klasifikasi Nasabah Ansurasnsi Jiwa Menggunakan Algoritma Naïve Bayes berbasis Backward
Elimination (Gorontalo & Bayes,
2017) Naïve Bayes 83,02 % Naïve Bayes + Backward Elimination 85,89 % 3
Klasifikasi Penyakit Autis Pada Anak Menggunakan Metode Naïve Bayes dan Backward Elimination
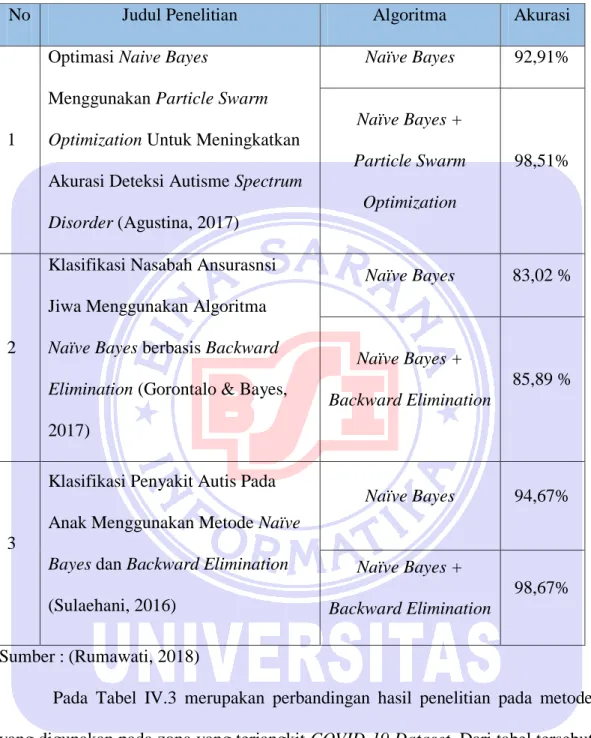
(Sulaehani, 2016) Naïve Bayes 94,67% Naïve Bayes + Backward Elimination 98,67% Sumber : (Rumawati, 2018)
Pada Tabel IV.3 merupakan perbandingan hasil penelitian pada metode yang digunakan pada zona yang terjangkit COVID-19 Dataset. Dari tabel tersebut terbukti bahwa kedua penelitian yang hanya menggunakan metode naïve bayes saja tidak mengahasilkan akursi yang optimal, Maka dilakukan pengoptimasian dari metode naïve bayes pada penelitian keduanya bertujuan untuk meningkatkan hasil akurasi. Terbukti optimasi PSO ataupun Backward Elimination masing-masing mampu meningkatkan akurasi pada dataset. Dari tabel diatas terbukti
bahwa naïve bayes dan backward elimination berhasil meningkatkan hasil akurasi terbaik dengan 75 %.
4.2.3. Perhitungan Manual Algoritma Naive Bayes
Untuk mencari nilai prediksi pada data testing dalam pemodelan Naive Bayes, dilakukan dengan cara menghitung prior probabilities dan conditional
probabilities untuk mencari hasil perhitungan posterior probabilities
masing-masing class. Hasil perhitungan prior probabilities dan conditional probabilities untuk seluruh data zona yang terjangkit COVID-19 Dataset.
Sumber : (PIKOBAR, 2020)
Gambar IV. 3 Tampilan Status Zona Larangan COVID-19 Di Jawa Barat Berikut adalah contoh klasifikasi dengan menggunakan perhitungan manual untuk salah satu data testing dengan menggunakan seluruh dataset sebagai data training.
Rumus Mean :
X
=
∑
X = rata-rata hitung
xi = nilai sampel ke-i
Zona Merah : ODP : 2,603.333333333333 PDP : : = 702 Positif Aktif : = 239.3333333 Sembuh : = 84 Meninggal : = 13.66666667 Zona Kuning : ODP : = 1980.78947 PDP = 320.105263 Positif Aktif : = 70.89473684 Sembuh : = 17.57895 Meninggal : = 5.157894737 Zona Biru : ODP : = 1027.6 PDP : = 41.8 Positif Aktif = 27.4 Sembuh = 6.6
Meninggal : = 1
Tabel IV. 5 Perhitungan Mean
Mean
Status ODP PDP Positif Aktif Sembuh Meninggal Zona Merah 2603.33333 702 239.3333333 84 13.66666667 Zona Kuning 1980.78947 320.105263 70.89473684 17.57895 5.157894737 Zona Biru 1027.6 41.8 27.4 6.6 1 Sumber : (Hamzah, 2020)
Rumus Standar Deviasi (gurupendidikan, 2020) :
√∑ ( )
σ = varians atau ragam untuk populasi xi = Titik tengah x = Rata-rata (mean) n = Jumlah data √( ) ( ) ( ) ( ) ( ) = = 4.270831
Tabel IV. 6 Perhitungan Standar Deviasi
Standar Deviasi
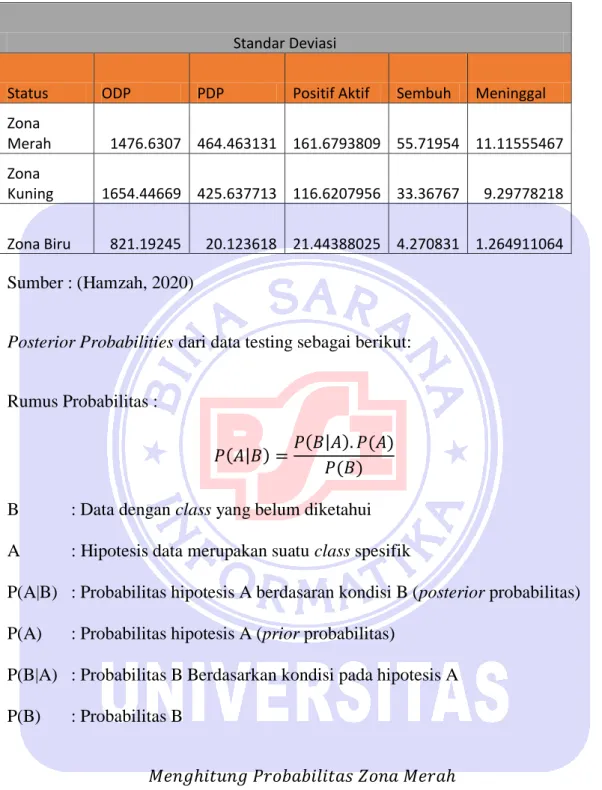
Status ODP PDP Positif Aktif Sembuh Meninggal Zona Merah 1476.6307 464.463131 161.6793809 55.71954 11.11555467 Zona Kuning 1654.44669 425.637713 116.6207956 33.36767 9.29778218 Zona Biru 821.19245 20.123618 21.44388025 4.270831 1.264911064 Sumber : (Hamzah, 2020)
Posterior Probabilities dari data testing sebagai berikut:
Rumus Probabilitas :
( | ) ( | ) ( ) ( ) B : Data dengan class yang belum diketahui A : Hipotesis data merupakan suatu class spesifik
P(A|B) : Probabilitas hipotesis A berdasaran kondisi B (posterior probabilitas) P(A) : Probabilitas hipotesis A (prior probabilitas)
P(B|A) : Probabilitas B Berdasarkan kondisi pada hipotesis A P(B) : Probabilitas B
( | ) = 0.111111111
( | ) = 0.185185185
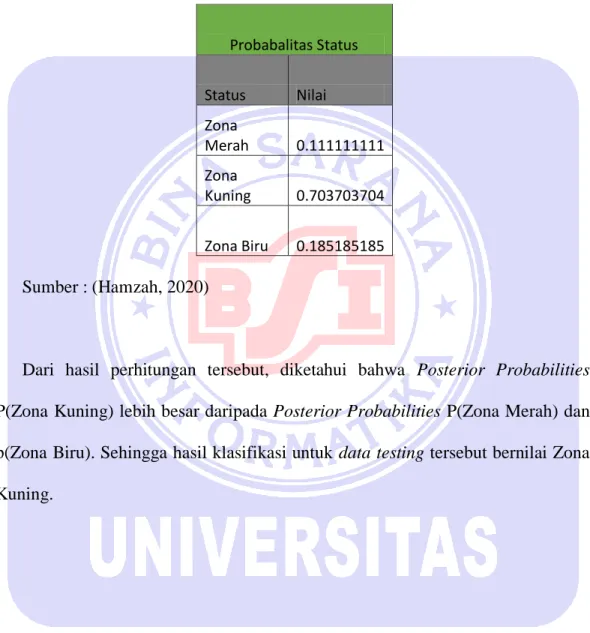
Tabel IV. 7 Probabilitas Status
Probabalitas Status Status Nilai Zona Merah 0.111111111 Zona Kuning 0.703703704 Zona Biru 0.185185185 Sumber : (Hamzah, 2020)
Dari hasil perhitungan tersebut, diketahui bahwa Posterior Probabilities P(Zona Kuning) lebih besar daripada Posterior Probabilities P(Zona Merah) dan p(Zona Biru). Sehingga hasil klasifikasi untuk data testing tersebut bernilai Zona Kuning.
4.3 Implementasi Aplikasi Web
1. Tampilan awal dari Dashboard Status Zona Terjangkit COVID-19 seperti gambar dibawah berikut ini :
Sumber : (Hamzah, 2020)
Gambar IV. 4 Tampilan Status Zona Larangan COVID-19
2. Tampilan selanjutnya adalah Daftar data yang berisi variabel – Variabel. Sebagian contohnya seperti gambar dibawah ini :
Sumber : (Hamzah, 2020)
3. Selanjutnya tampilan pilihan jumlah yang akan di kalkulasi, seperti yang terlihat pada gambar IV.6.
Sumber : (Hamzah, 2020)
Gambar IV. 6 Tampilan Kalkulasi Status Zona COVID-19
4. Kemudian setelah memilih nama Daerah, jumlah ODP, PDP, Positif Aktif, Sembuh, dan Meninggal. klik kalkulasi inputkan pilihan data.
Sumber : (Hamzah, 2020)
4.4 Manfaat Penelitian
Berdasarkan pengujian pada pemodelan data mining untuk zona yang terjangkit COVID-19 Dataset, diketahui algoritma naïve bayes dan backward elimination dengan kelompok 6 atribut dapat dijadikan alternatif untuk pemodelan
klasifikasi data mining pada zona yang terjangkit COVID-19 Dataset.
Penelitian ini berhasil menemukan model data mining yang mampu mengklasifikasikan zona yang terjangkit COVID-19 Dataset dengan tingkat akurasi yang lebih tinggi dari penelitian sebelumnya. Peningkatan akurasi model pembelajaran dapat dilakukan dengan model penelitian dan algoritma pemodelan yang berbeda. Namun, terbentuknya model tidak menandakan telah terselesaikannya proyek, perlu untuk menggunakan model yang dibuat sesuai dengan tujuan data mining.