Diskless Cluster Berbasis Job Scheduler Condor
Menggunakan Diskless Remote Boot in Linux
Muhammad Syaifuddin Zuhri¹, Mochamad Hariadi²,I Ketut Eddy Purnama³
Abstrak—Dengan perkembangan teknologi yang sangat cepat, kartu jaringan semakin murah dan cepat 100 Mbits/s ethernet merupakan sesuatu yang biasa sekarang dan dalam beberapa tahun kedepan teknologi gigabit akan menjadi standar jaringan. Dengan kartu jaringan berkecepatan tinggi, kecepatan akses remote disk akan dapat menyamai kecepatan akses local disk yang mana menyebabkan teknologi komputer tanpa harddisk (diskless) dapat diimplementasikan dalam jaringan lokal. Selain itu teknologi tanpa hard diskdapat mengurangi biaya untuk upgrade software dan biaya administrasi sistem seperti backup, recovery yang dipusatkan pada server.
Pada penelitian ini kami akan membangun sebuah cluster linux berteknologi diskless atau tanpa harddisk dengan menggunakan Diskless Remote Boot in Linux (DRBL) pada undedicated cluster. Semua node dapat digabungkan menjadi sebuah lingkungan komputasi yang besar. Untuk mengoptimalkan kemampuan komputasi tersebut, kami menggunakan condor sebagai job scheduleruntuk membangun lingkungn High-Throughput Computing (HTC) pada diskless cluster yang telah dibangun. Condor dapat memanajemen secara efektif workstation yang berkomunikasi melalui jaringan. Kelebihan condor adalah kemampuan untuk memanfaatkan secara efektif sumber daya yang tidak terdedikasi.
Kata Kunci—diskless,upgrade software,server,Diskless Remote Boot in Linux,node,job scheduler,High-Throughput Computing,diskless cluster,workstation.
I. PENDAHULUAN
D
ENGAN semakin berkembangnya teknologi ,maka kebutuhan masyarakat akan komputasi akan semakin besar , perkembangan kebutuhan akan komputasi akan berkembang sejalan dengan kesadaran masyarakat terhadap manfaat komputer dalam berbagai bidang. Untuk melakukan komputasi yang besar biasanya digunakan super komputer, namun cara ini dianggap belum efektif mengingat harga super komputer yang masih sangat mahal. Maka muncul ide cluster computing, dimana beberapa komputer dihubungkan menggunakan jaringan untuk saling bekerja sama melakukan tugas tertentu.Semakin berkembangnya kebutuhan akan cluster computing terhadap komputasi yang besar menyebabkan semakin besarnya sumber daya yang dibutuhkan. Hal ini menyebabkan permasalahan efisiensi pada instalasi dan perawatan komputer-komputer node eksekusi, semakin besar sumber daya komputer-komputer yang dibutuhkan semakin sulit perawatan cluster tersebut. Muncul ide pemanfaatan teknologi Pre-boot eXecution
(1) Muhammad Syaifuddin Zuhri, Bidang Studi Teknik Komputer & Telematika, Jurusan Teknik Elektro ITS Surabaya.
(2) Mochammad Hariadi, ST., M.Sc., Ph.D., Dosen Pembimbing 1, Bidang Studi Teknik Komputer & Telematika, Jurusan Teknik Elektro ITS Surabaya. (2) Dr. I Ketut Eddy Purnama, ST., MT., Dosen Pembimbing 2, Bidang Studi Teknik Komputer & Telematika, Jurusan Teknik Elektro ITS Surabaya.
Environment (PXE) pada komputer cluster, dimana boot system pada node-node cluster diambil dari PXE server sehingga tidak diperlukan instalasi sistem operasi pada node. Dengan pemanfaatan teknologi PXE akan meningkatkan efisiensi karena tidak diperlukan instalasi pada setiap node yang ada juga penambahan node dapat dilakukan dengan lebih baik. Diskless Remote Boot in Linux (DRBL) merupakan salah satu aplikasi PXE yang digunakan pada diskless clustering. Alasan pemilihan DRBL sebagai sistem diskless pada cluster adalah kemampuan DRBL sebagai salah satu sistem booting over network yang dapat digunakan untuk membuat diskless cluster dalam waktu yang cukup singkat.
HTC (High Throughput Computing) merupakan komputer yang didedikasikan untuk melakukan tugas komputasi yang banyak dan sangat panjang, dan orientasinya adalah keberhasilan dalam melakukan tugas tersebut (tanpa memperdulikan waktu yang dibutuhkan). Condor merupakan suatu sistem yang menyediakan layanan High Throughput Computing (HTC). Condor mengelola sumber daya komputer yang ada pada condor pool dengan cara menggabungkan workstation yang tersebar banyak dan berada pada tempat yang berbeda-beda (tapi tetap dalam satu jaringan), menjadi satu cluster yang siap melakukan proses komputasi.
II. DASARTEORI
A. Pre-boot eXecution Environment (PXE)
Pre-boot eXecution Environment (PXE)didefinisikan sebuah dasar dari standar Industri Protokol Internet dan servis-servis yang secara luas digunakan di industri, yaitu TCP/IP, DHCP, dan TFTP. Standarisasi ini dalam bentuk interaksi server dan klien[5]. PXE bekerja pada kartu interface jaringan (Network Iinterface Card) di PC, dan membuat NIC sebagai perangkat boot. PXE membooting klien PC dari jaringan dengan mentransfer "boot image file" dari server. File ini dapat menjadi sistem operasi untuk PC klien atau agen pra-OS yang melakukan tugas manajemen klien. Karena PXE tidak dikhususkan untuk sistem operasi tertentu ,maka PXE dapat digunakan untuk menjalankan berbagai macam sistem operasi.Protokol PXE kurang lebih merupakan sebuah kombinasi dari DHCP dan TFTP, meskipun dengan sedikit modifikasi dari keduanya. DHCP digunakan untuk menentukan lokasi yang boot server yang sesuai, dengan TFTP digunakan untuk men-download bootstrap awal program dan file-file tambahan. Gambar 1 menunjukkan tahapan kerja protokol PXE. Berikut langkah kerja protokol PXE :
1) klien mengirimkan DHCP Discover secara broadcast pada port 67
2) DHCP sever membalas dengan mengirimkan DHCP Offer pada klien menggunakan port 68
3) PXE klien menerima DHCP Offer dari server yang berisi:
a) alamat ip klien b) list boot server
c) discovery control option d) Multicast Discovery IP address
4) klien memilih ip address pada DHCPOffer dan mengirimkan DHCP Request ke server
5) klien melakukan koneksi dengan BOOT server 6) BOOT server mengirimkan DHCPACK
7) klien men-download file eksekusi menggunakan standart TFTPatau MTFTP
8) klien menentukan apakah authentikasi diperlukan atau tidak
9) klien melakukan eksekusi pada file eksekusi yang telah di-download
Gambar 1. Tahapan Kerja PXE[5]
B. DRBL (Diskless Remote Boot in Linux)
DRBL (Diskless Remote Boot in Linux) adalah sebuah software gratis, open source solusi untuk memanage sistem operasi linux pada banyak klien. Dengan menggunakan DRBL dapat menghemat banyak waktu yang dihabiskan untuk menjalankan banyak klien. Cukup dengan menginstall pada satu server maka dapat mengkonfigurasi seluruh klien. DRBL Menyediakan lingkungan tanpa harddisk atau tanpa sistem bagi mesin klien. DRBL dapat bekerja pada debian, Ubuntu, Mandriva, Red Hat, Fedora, CentOS dan SuSE. DRBL menggunakan sumber hardware yang terdistribusi dan membuatnya mungkin untuk klien mengakses secara penuh local hardware-nya sendiri. Didalamnya juga terserta Clonezilla, sebuah alat partisi dan klonning disk yang mirip dengan Symantec Ghost[4].
DRBL mempunyai beberapa fitur :
• Dapat bekerja berdampingan dengan OS lain. • Mudah dalam Installasi.
• Menghemat hardware, dana atau biaya perbaikan. Condor adalah sistem penjadwalan job yang dikembangkan oleh Condor research project di University of
Wisconsin-Madison Department of Computer Sciences, mulai 20 tahun yang lalu. Condor dapat berjalan di berbagai arsitektur dan sistem operasi. Condor bertugas melakukan pengaturan beban kerja dari job yang melakukan komputasi secara intensif.
C. Condor
Condor menamakan dirinya sebagai sistem High-Throughput Computing (HTC) yaitu sistem komputasi yang menitikberatkan pada banyaknya hasil yang didapat dalam periode tertentu, misalnya mingguan atau bulanan. Berbeda dengan sistem High Performance Computing (HPC) yang menghitung kekuatannya berdasarkan satuan FLOPS (Floating Point Operations per Second). High-throughput computing (HTC) berusaha untuk menyediakan kekuatan komputasi dalam jumlah besar dengan cara mengutilisasi secara efisien sumber daya yang tersedia dalam jaringan.
Selain mendukung HTC, Condor juga mendukung Opportunistic Computing yaitu kemampuan meng-utilisasi sumber daya semaksimal mungkin meskipun ketersediaannya tidak 100%. Condor mampu mengubah suatu workstation yang pada siang hari digunakan untuk kegiatan akademik menjadi sumber daya komputasi pada malam hari, atau memanfaatkan sumber daya yang idle ketika ditinggal pemiliknya untuk rapat atau makan siang. Hal ini dimungkinkan dengan adanya fitur condor yang sangat menarik yaitu checkpointing, dimana proses yang sedang berjalan dapat dihentikan sementara (ketika sumber daya dipakai atau mengalami kerusakan) dan kemudian dilanjutkan kembali di waktu yang akan datang. Proses yang dijalankan lagi ini tidak perlu menggunakan mesin yang sama seperti sebelumnya. inilah fitur penting Condor.
Condor juga menyediakan lingkungan komputasi paralel seperti MPI dengan tersedianya universe parallel pada Condor, universe ini merupakan lingkungan eksekusi Condor untuk program-program paralel. Selain itu juga terdapat universe lain yaitu: standard, vanilla, PVM, MPI, Globus/Grid, java, scheduler. Dalam melaksanakan tugasnya, Condor dibagi atas beberapa daemon yang saling bekerja sama, antara lain: condor_master, condor_startd, condor_starter, condor_schedd, condor_shadow, condor_collector, condor_negotiator.
III. DISAIN DANIMPLEMENTASISISTEM
Desain jaringan pada penelitian ini menggunakan jaringan privateyang dibentuk dari aplikasi yang terdapat pada DRBL server , dimana semua node berkomunikasi dengan jaringan lain melalui gateway DRBL server . Pada DRBL server dan headnode memiliki dua ip dimana ip 10.122.67.0/24 digunakan untuk mengakses jaringan luar, sedangkan ip 10.122.100.0/24 merupakan ip alias untuk jaringan yang digunakan. Gambar 2 menunjukkan desain jaringan diskless clusteryang dibuat.
DRBL difungsikan sebagai server dengan menggunakan hostname drbl.drbl.grid.computer.ee.its.ac.id dengan alamat ip 10.122.67.98 untuk jaringan ITS dan ip 10.122.100.1 sebagai ip alias untuk jaringan yang digunakan. Selain menjadi DRBL server, juga berfungsi sebagai DNS , NFS, DHCP, dan PXE
server. Servis-servis tersebut dibutuhkan untuk menunjang tugas DRBL server sebagai diskless server.
Headnode difungsikan sebagai central manager dan mesin submitter pada condor cluster, dengan menggunakan hostname node1.drbl.grid.computer.ee.its.ac.id dengan alamatip 10.122.67.96 sebagai ip jaringan ITS dan alamat ip 10.122.100.2 untuk jaringan private yang digunakan. Headnode difungsikan untuk manajemen job pada condor cluster serta untuk mensubmit job yang akan dikerjakan.
Gambar 2. Desain jaringan
IV. IMPLEMENTASISISTEM
High throughput computing (HTC) berbasis DRBL merupakan gabungan antara cluster, diskless, dan job scheduler. Pada penelitian ini operating system yang digunakan adalah debian lenny, untuk diskless server menggunakan DRBL, dan manajemen job menggunakan job scheduler Condor. Dalam implementasi High Throughput Computing (HTC) berbasis DRBL ini terdapat beberapa tahapan yang harus dilakukan sesuai dengan urutan yang ditentukan, antara lain:
1) Instalasi dan konfigurasi DNS. 2) Instalasi dan konfigurasi NTP klien.
3) Instalasi library, compiler,daemon dan render engine yang digunakan.
4) Instalasi dan konfigurasi DRBL. 5) Konfigurasi NFS server dan klien. 6) Instalasi dan konfigurasi Condor. 7) Instalasi dan konfigurasi ganglia.
V. PENGUJIANSISTEM
Dalam bab ini akan dibahas mengenai pengujian dari softwaredan hardware yang telah direalisasikan dengan tujuan untuk mengetahui apakah fungsi tiap-tiap bagian dari sistem yang direncanakan telah bekerja dengan baik dan sesuai dengan yang diharapkan.
Untuk menguji Diskless cluster berbasis job scheduler condor ini, maka dilakukan beberapa macam pengujian, antara lain:
A. Pengujian rendering dengan node eksekusi seragam Pada pengujian ini condor dijalankan pada 4 buah komputer yang memiliki spesifikasi yang seragam yaitu menggunakan prosessor Inteldan memory 512 MB.
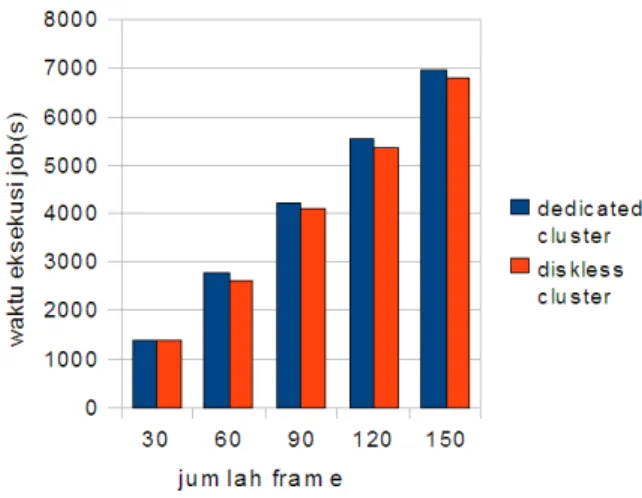
Gambar 3. perbandingan waktu eksekusi job dedicated dan diskless cluster seragam
Dari pengujian yang telah dilakukan pada dedicated cluster dan diskless cluster dengan spesifikasi node seragam dapat diketahui bahwa diskless cluster membutuhkan waktu eksekusi job yang hampir sama dengan waktu eksekusi job pada dedicated cluster. Sedangkan pada pengujian rendering sebanyak 150 frame diskless cluster membutuhkan waktu eksekusi job lebih sedikit daripada dedicated cluster. Perbandingan waktu eksekusi job pada dedicated cluster dan diskless cluster dapat dilihat pada Gambar 3 .
B. Pengujian rendering dengan node eksekusi memiliki memory berbeda
Pada pengujian ini condor dijalankan pada 4 buah komputer yang memiliki spesifikasi sebagai berikut: 2 buah komputer prosessor Intel dan memory 512 MB, 2 buah komputer prosessor Inteldan memory 1024 MB.
Gambar 4. Perbandingan waktu eksekusi dedicated dan diskless cluster memoryberbeda
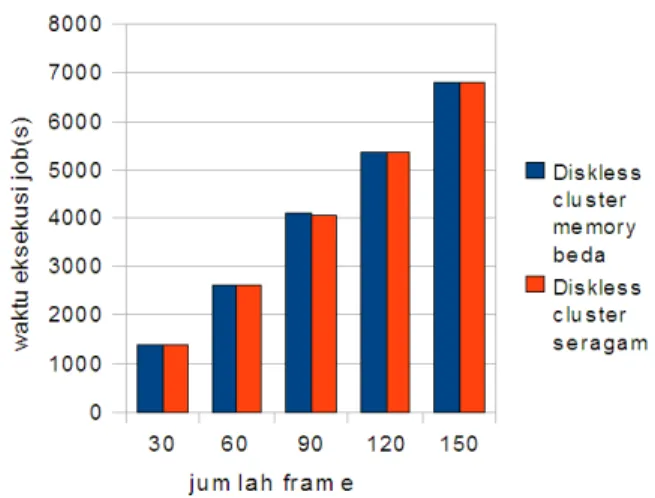
Gambar 5. Perbandingan waktu eksekusi diskless cluster seragam dan memorybeda
Dari pengujian yang telah dilakukan pada dedicated cluster dan diskless cluster dengan spesifikasi memory berbeda dapat diketahui bahwa waktu eksekusi job rendering pada diskless cluster lebih cepat daripada dedicated cluster. Hal ini dapat dilihat pada Gambar 4. Pada Gambar 5 kita dapat mengetahui bahwa waktu eksekusi job rendering pada diskless cluster dengan spesifikasi seragam dan dengan besar memory berbeda hampir sama, sehingga dapat diketahui pada eksekusi job rendering besar memory fisik tidak berpengaruh besar dengan lama waktu eksekusi job.
C. Pengujian rendering dengan node eksekusi memiliki prosessor berbeda
Pada pengujian ini condor dijalankan pada 6 buah komputer yang memiliki spesifikasi sebagai berikut: 2 buah komputer prosessor Intel dan memory 512 MB, 2 buah komputer prosessor Intel dan memory 1024 MB, dan 2 buah komputer prosessor VIAdan memory 512 MB. Sedangkan untuk diskless dan dedicated cluster prosessor seragam menggunakan 6 buah komputer yang memiliki spesifikasi sebagai berikut: 4 buah komputer prosessor Intel dan memory 512 MB, 2 buah komputer prosessor Intel dan memory 1024 MB.
Gambar 6. Perbandingan lama waktu eksekusi dedicated dan diskless cluster
Pada Gambar 6 dapat diketahui bahwa implementasi diskless cluster dengan node eksekusi memiliki prosessor seragam membutuhkan waktu eksekusi job paling sedikit dibandingkan diskless cluster dengan prosessor berbeda dan dedicated cluster dengan prosessor seragam. Hal ini dikarenakan pada diskless cluster sumber daya CPU pada node eksekusi dapat digunakan secara lebih optimal dibandingkan dedicated cluster karena CPU pada node eksekusi tidak digunakan untuk memanajemen sumber daya harddisk lokal dan servis yang lebih sedikit (minimum) dibandingkan dedicated cluster. Diskless cluster dengan prosessor beda membutuhkan waktu paling lama karena prosessor VIA yang digunakan memiliki frekuensi yang lebih kecil daripada prosessor Intel, selain itu image yang digunakan pada node VIA adalah image server yang menggunakan prosessor intel sehingga pada Condor node VIA dikenali sebagai node eksekusidengan prosessor Intel sehingga node VIA tidak dapat bekerja dengan optimal.
D. Pengujian ketahanan sistem
Pada pengujian ini condor dijalankan pada 6 buah komputer yang memiliki spesifikasi sebagai berikut: 2 buah komputer prosessor Intel dan memory 512 MB, 2 buah komputer prosessor Intel dan memory 1024 MB, dan 2 buah komputer prosessor VIA dan memory 512 MB. Berikut pengujian ketahanan sistem pada diskless cluster yang dibuat:
• Headnode mati
Pada pengujian ini headnode dimatikan selama 2 menit, yaitu ketika job pada Condor masih terdapat 86 frame dari 150 frameyang disubmitkan.
Tabel I
DISTRIBUSI JOB PENGUJIAN HEADNODE MATI
node distribusi job
node0-111 33 node0-112 33 node0-114 33 node0-118 33 node0-125 9 node0-127 9
Dapat dilihat pada Tabel I distribusi job pada cluster. Dari data pada Tabel I diketahui bahwa saat headnode dimatikan maka job akan diubah ke kondisi idle oleh central manager dan ketika headnode dinyalakan kembali maka job akan dieksekusi kembali. Pada pengujian ini didapatkan waktu rendering total cluster adalah 6882 detik.
• DRBL sever mati
Pada pengujian ini DRBL server dimatikan selama 10 menit, yaitu ketika job pada Condor masih terdapat 60 frame dari 150 frame yang disubmitkan.
Tabel II
DISTRIBUSI JOB PENGUJIANDRBLSERVER MATI
node distribusi job
node0-111 33 node0-112 32 node0-114 33 node0-118 33 node0-125 9 node0-127 10
Dapat dilihat pada Tabel II distribusi job pada cluster.Pada pengujian ini node tidak bekerja saat DRBL server dalam kondisi mati, ketika DRBL server kembali dinyalakan node akan menunggu beberapa waktu untuk me-load kembali file sistem pada server dan kembali mengeksekusi job.
• Listrik mati
Pada pengujian ini diskless cluster mengeksekusi job rendering sebanyak 150 frame, pada pertengahan proses eksekusi sistem mengalami black out (lampu mati) selama hampir 1 detik.
Tabel III
DISTRIBUSI PEMBAGIAN JOB PENGUJIAN LISTRIK MATI
node distribusi pembagian job
node0-111 35 node0-112 35 node0-114 35 node0-118 25 + 1 gagal node0-125 9 node0-127 10
Dapat dilihat pada Tabel III distribusi job pada cluster. Pada pengujian ini job ke 81 mengalami kegagalan eksekusi dan tidak dapat dipindah ke node lain sehingga tidak dikerjakan, selain itu setelah mengalami black out (lampu mati) node0-118 mengalami masalah hardware yaitu penurunan kinerja NIC sehingga kemampuan komputasinya turun drastis. Pada pengujian ini waktu proses rendering total pada cluster selama 7114 detik.
E. Pengujian Beban Cluster
Gambar 7. Beban CPU Condor diskless cluster dengan 6 node
Pada Gambar 7 menunjukkan beban CPU total pada cluster, pada eksekusi job ini menggunakan 75 persen dari total CPU pada cluster. Warna kuning pada Gambar 7 menunjukkan besar CPU yang digunakan untuk proses rendering, sedangkan warna merah menunjukkan total beban yang dikerjakan tiap nodepada diskless cluster untuk menjalankan servis-servisnya, dan warna biru menunjukkan beban CPU yang digunakan untuk menjalankan servis dengan owner user tertentu (bukan root).
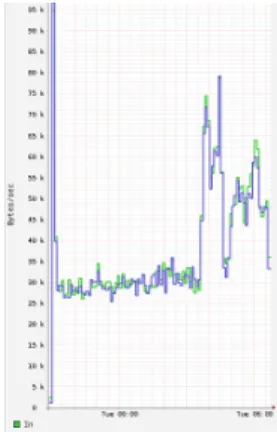
Gambar 8. Beban Jaringan Condor diskless cluster dengan 6 node
Pada Gambar 8 kondisi awal central manager(headnode) akan membagikan frame pada node eksekusi dan mentransfer data jika diperlukan sehingga beban jaringan awal besar, pada saat node eksekusi selesai merender gambar tiap frame maka node eksekusi akan mengirimkan kembali hasil eksekusi job ke central manager(headnode) sehingga cluster akan menggunakan beban jaringan dengan besar yang hampir sama dan secara terus-menerus. Dari data yang didapatkan dapat diketahui bahwa proses eksekusi job rendering sebanyak 2200 frame ini memanfaatkan sumber daya CPU dari komputer, sedangkan beban jaringan pada saat eksekusi job berkisar antara 35 KBps.
VI. PENUTUP
A. Kesimpulan
Setelah melakukan tahapan implementasi dan pengujian sistem, maka diperoleh beberapa kesimpulan, antara lain :
• Diskless clustermenggunakan DRBL pada node seragam membutuhkan waktu eksekusi job yang hampir sama dengan waktu eksekusi job pada dedicated cluster seragam, dimana pada pengujian rendering 30 sampai 120 frame diskless cluster lebih lambat sekitar 10 detik dan pada rendering 150 frame diskless cluster lebih cepat 100 detik daripada dedicated cluster.
• Diskless cluster menggunakan DRBL pada node dengan memoryberbeda memiliki waktu eksekusi job yang lebih cepat sekitar 10 detik untuk job 30, 60 dan 100 frame dan lebih cepat sampai 200 detik untuk job 90, 120, 150 frame atau rata-rata sekitar 2,85 persen dibandingkan dedicated cluster memoryberbeda.
• Perbedaan besar memory fisik pada diskless cluster tidak berpengaruh besar terhadap lama waktu eksekusi job
rendering pada diskless cluster dimana untuk waktu eksekusi diskless cluster seragam untuk job dengan 90 frame lebih lambat 44 detik sedangkan untuk 30,60,120,dan 150 frame lebih lambat kurang dari 5 detik dibandingkan dengan diskless cluster dengan memory berbeda.
• Pada diskless cluster dengan prosessor seragam memiliki lama waktu eksekusi job lebih cepat rata-rata sekitar 30,59 persen dibandingkan diskless cluster dengan prosessor berbeda dan lebih cepat rata-rata sekitar 7,1 persen dibandingkan dedicated cluster dengan prosessor seragam.
• Pada diskless cluster dengan prosessor berbeda, diskless clustermengalami masalah yang diakibatkan penggunaan node VIA yang memiliki spesifikasi berbeda dengan DRBL server sehingga node VIA dikenali sebagai node dengan prosessor Intel pada Condor pool.
• Perbedaan tipe prosessor pada diskless cluster menggunakan DRBL berpengaruh besar terhadap lama waktu eksekusi job rendering yang dikerjakan, hal ini menyebabkan turunnya kinerja diskless cluster dengan rata-rata sekitar 30,59 persen bila dibandingkan dengan diskless cluster dengan prosessor seragam. B. Saran
Pada penelitian ini image sistem operasi yang digunakan oleh semua node eksekusi sama, hal ini menyebabkan timbulnya permasalahan pada node dengan prosessor yang berbeda dengan DRBL server sehinggga kinerja node kurang optimal. Pada penelitian selanjutnya disarankan untuk menggunakan image sistem operasi yang berbeda-beda untuk setiap node sehingga masalah perbedaan spesifikasi hardware dan arsitektur komputer pada node dapat diselesaikan.
DAFTARPUSTAKA
[1] Ian Foster, 2002. What is the Grid? A Three Point Checklist. Grid Today, http://www-fp.mcs.anl.gov/~foster/Articles/ WhatIsTheGrid.pdf. [2] Joshy Joseph and Craig Fellenstein, 2003. Grid Computing. Prentice
Hall.
[3] Karen R. Sollins, 1992. THE TFTP PROTOCOL (REVISION 2). Massachusetts Institute of Technology Laboratory for Computer Science 545 Technology Square Cambridge, MA 02139-1986
[4] Steven Shiau, dkk, 2009. Diskless Remote Boot in Linux (DRBL). http://drbl.sourceforge.net/
[5] SYSTEMSOFT, 1999. Preboot Execution Environment (PXE) Specification. Intel Corporation,
[6] Chao-Tung Yang, Ping-I Chen, Sung-Yi Chen, Hao-Yu Tung: A Jobs Allocation Strategy for Multiple DRBL Diskless Linux Clusters with Condor Schedulers. GCC 2006: 54-57
[7] James H. Laros III and Lee H. Ward: Implementing Scalable Disk-less Clusters Using the Network File System (NFS) . Proceedings of the 4th Symposium of the Los Alamos Computer Science Institute: LACSI 2003, 27-29, October 2003
[8] Lukmanul H., 2007. Desain dan Implementasi High Throughput Computing Environment Menggunakan Condor. Unpublised under graduate research Departement of Electrical Engineering Institut of Technology Sepuluh November
[9] Toni K., 2008.Desain dan Implementasi Sistem Manajemen Grid Menggunakan Condor-G.Unpublised under graduate research Departement of Electrical Engineering Institut of Technology Sepuluh November
[10] Hendy C., 2009.Virtual Cluster On Demand Berbasis Diskless Remote Boot in Linux (DRBL).Unpublised under graduate research Departement of Electrical Engineering Institut of Technology Sepuluh November
[11] http://grid.ee.its.ac.id/
[12] Condor Team., 2009. Condor® Version 7.3.2 Manual. University of Wisconsin–Madison
Muhammad Syaifuddin Zuhri dilahirkan di Jombang pada tanggal 27 Agustus 1988, merupakan anak pertama dari tiga bersaudara. Ia menempuh pendidikan pertama kali di TK Muslimat Jagalan Jombang, kemudian melanjutkan pendidikan dasar di MIN Kauman Utara Jombang, pendidikan menengah di MTsN Tambak Beras Jombang, dan pendidikan menengah atas di SMA Negeri 2 Jombang. Setelah lulus SMA, ia memilih untuk melanjutkan pendidikan tingginya di Jurusan Teknik Elektro, Fakultas Teknologi Industri ITS.
Saat di bangku kuliah, penulis aktif pada berbagai macam kegiatan kemahasiswaan diantaranya adalah asisten dosen di Laboratorium jaring Komputer dan Multimedia (Lab. B-201) . Dalam Pengabdian dan menimba ilmu di Lab tersebut sempat juga sebagai koordinator Praktikum Rangkaian Digital Lab B201. Dari berbagai kegiatan tersebut, penulis akhirnya tertarik pada bidang-bidang teknologi informasi, utamanya Grid Computing dan sampai sekarang penulis aktif dalam bidang tersebut.
![Gambar 1. Tahapan Kerja PXE[5]](https://thumb-ap.123doks.com/thumbv2/123dok/4073756.3039316/2.918.125.399.463.681/gambar-tahapan-kerja-pxe.webp)