commit to user
i
APLIKASI ALGORITMA CART
UNTUK MENGKLASIFIKASIKAN DATA NASABAH
ASURANSI JIWA BERSAMA BUMIPUTERA 1912 SURAKARTA
oleh
LAILA KURNIA DAMAYANTI
M0106014
SKRIPSI
ditulis dan diajukan untuk memenuhi sebagian persyaratan
memperoleh gelar Sarjana Sains Matematika
FAKULTAS MATEMATIKA DAN ILMU PENGETAHUAN ALAM
UNIVERSITAS SEBELAS MARET
SURAKARTA
commit to user ii
SKRIPSI
APLIKASI ALGORITMA CART
UNTUK MENGKLASIFIKASIKAN DATA NASABAH ASURANSI JIWA BERSAMA BUMIPUTERA 1912 SURAKARTA
yang disiapkan dan disusun oleh LAILA KURNIA DAMAYANTI
M0106014
dibimbing oleh
Pembimbing I, Pembimbing II,
Irwan Susanto, DEA Drs. Pangadi, M.Si.
NIP. 19710511 199512 1 001 NIP. 19571012 199103 1 001
telah dipertahankan di depan Dewan Penguji
pada hari Jumat tanggal 29 April 2011
dan dinyatakan telah memenuhi syarat
Anggota Tim Penguji Tanda Tangan
1. Winita Sulandari, M.Si 1.
………
NIP. 19780814 200501 2 002
2. Dr. Sutanto, DEA 2.
………
NIP. 19710302 199603 1 001
Surakarta, Mei 2011
Disahkan oleh
Fakultas Matematika dan Ilmu Pengetahuan Alam
Dekan
Prof. Drs. Sutarno, M.Sc, Ph.D
commit to user iii
ABSTRAK
Laila Kurnia Damayanti, 2011. APLIKASI ALGORITMA CART UNTUK
MENGKLASIFIKASIKAN DATA NASABAH ASURANSI JIWA BERSAMA
BUMIPUTERA 1912 SURAKARTA. Fakultas Matematika dan Ilmu Pengetahuan Alam, Universitas Sebelas Maret.
Masalah klasifikasi sering dijumpai dalam kehidupan sehari-hari, baik mengenai data sosial, industri, kesehatan, perusahaan maupun perbankan. Masalah
tersebut dapat diselesaikan dengan metode klasifikasi. Algoritma CART
(Classification and Regression Trees) merupakan metode statistik nonparametrik yang berguna untuk memperoleh kelompok data yang akurat dalam analisis klasifikasi. Data nasabah Asuransi Jiwa Bersama Bumiputera mempunyai banyak atribut yang bertipe kategorik (nominal maupun ordinal) yang tidak mudah untuk
ditangani. Algoritma CART merupakan salah satu metode yang cocok untuk
mengatasi masalah tersebut dengan kelebihan-kelebihan yang dimilikinya. Algoritma
CART diaplikasikan untuk mengklasifikasikan nasabah AJB Bumiputera 1912
Surakarta. Selanjutnya pola status pembayaran nasabah dapat dicari untuk menentukan calon nasabah yang akan datang.
Proses pembentukan pohon klasifikasi terbagi menjadi 4 tahapan yaitu pembentukan pohon, pelabelan kelas, proses pemangkasan pohon klasifikasi dan pemilihan pohon klasifikasi optimal. Data nasabah dibagi menjadi dua kelompok data yaitu data learning dan data testing. Dalam skripsi ini dilakukan tiga kombinasi proporsi data learning dan data testing yaitu: (1) pembagian data learning dan data testing dengan proporsi data learning > data testing (70%: 30%), (2) pembagian data learning dan data testing dengan proporsi data learning = data testing (50% : 50%), (3) pembagian data learning dan data testing dengan proporsi data learning < data testing (40% : 60%).
Hasil penelitian menunjukkan bahwa untuk membuat model yang akan digunakan untuk mengklasifikasikan data baru maka pohon klasifikasi optimal yang
digunakan adalah pohon pada kondisi pertama dengan proporsi data learning dan data
testing sebesar 70%:30%, dimana nilai ketepatan data testingnya tertinggi yaitu sebesar 83.65 %. Dengan Algoritma CART dapat dikatakan bahwa status pembayaran nasabah dikategorikan tidak lancar jika cara bayar dilakukan secara bulanan. Sedangkan status pembayaran dikategorikan lancar jika cara bayar dilakukan secara setengah tahunan atau tahunan.
commit to user iv
ABSTRACT
Laila Kurnia Damayanti, 2011. THE APPLICATION OF CART ALGORITHM TO
CLASSIFY DATA OF CUSTOMERS MUTUAL LIFE INSURANCE BUMIPUTERA 1912 IN SURAKARTA. Faculty of Mathematics and Natural Sciences, Sebelas Maret University.
. In everyday life, the problem of classification is very frequently found, both in social data, industrial, healthcare, corporate and banking. These problems can be solved by the method of classification. Algorithm CART (Classification and Regression Trees) is a nonparametric statistical method that is useful to obtain accurate sets of data in the classification analysis. The data of customers Mutual Life Insurance Bumiputera had many attributes that type of categorical (nominal or ordinal) is not easy to handle. CART algorithm is a suitable method to resolve the issue with the advantages it is had. The CART algorithm is applies to classify customers Mutual Life Insurance Bumiputera 1912 in Surakarta. Further to note patterns generated customer payment status to determine which prospective customers will come.
The tree classification building divided into four step i.e. the splitting nodes and class assignment, stop the split, the tree pruning classification and the optimal selection tree classification. In this paper is applies three combinations of proportions of learning data and testing data are: (1) the distribution of learning data and testing data with the proportion of learning data higher than data testing (70%: 30%), (2) the distribution of learning data and testing data with the proportion of data learning is equal testing data (50%: 50%), (3) data sharing learning and testing data with the proportion of learning data lower than data testing (40%: 60%).
The results shows that in order to create a model that will be used to classify new data, the optimal classification tree is a tree that is used in the first condition that the proportion of learning data and testing data is equal 70%:30%, where the highest value testing data accuracy that is equal to 83.65%. With CART algorithm can describe that under the monthly payment basis customer payment status is classified as stagnating. While categorized as no constrain payment status if payment is done half-way annual or annual.
commit to user v
MOTTO
“Sesungguhnya sesudah kesulitan itu ada kemudahan, maka apabila kamu telah
selesai (dari suatu urusan), kerjakanlah dengan sungguh-sungguh (urusan) yang lain”
commit to user vi
PERSEMBAHAN
Karya ini penulis kupersembahkan untuk :
Orang tuaku tercinta
Kakak dan adikku tersayang
My special person
Teman-temanku dan sahabat-sahabatku tercinta
commit to user vii
KATA PENGANTAR
Alhamdulillahi Rabbil’alamin. Puji syukur penulis panjatkan kehadirat Allah SWT
yang telah memberikan nikmat, rahmat, dan hidayahNya sehingga penulis dapat
menyelesaikan skripsi ini. Penulis juga tidak lupa mengucapkan terima kasih kepada
beberapa pihak yang telah banyak memberikan masukan untuk perbaikan penulisan skripsi
ini, khususnya kepada
1. Bapak Irwan Susanto, DEA dan Drs. Pangadi, M.Si. selaku Pembimbing I dan
Pembimbing II yang telah memberikan bimbingan, nasehat, kritik dan saran selama
penyusunan skripsi ini.
2. Bapak Drs. Sutrima, M.Si yang telah memberikan semangat, bimbingan, nasehat,
kritik dan saran dalam penyusunan skripsi ini.
3. Bapak, Ibu, Kakak, serta Adikku atas doa, kasih sayang, perhatian dan segalanya
yang telah menjadikan penulis selalu semangat dan termotivasi untuk melakukan
yang terbaik.
4. Sahabat-sahabat tercinta Hayu, Tya, Linda, Dewanti serta Mas Cica terima kasih atas
dukungan, support serta bimbingan yang telah diberikan dalam menyelesaikan
skripsi ini.
Selanjutnya, semoga skripsi ini dapat bermanfaat bagi pihak yang membutuhkan.
Surakarta, April 2011
commit to user
2.1.1. Teori Probabilitas….……… 4
2.1.2. Analisi Klasifikasi……… 7
2.1.3. Masalah Umum Klasifikasi...………... 8
2.1.4. Algoritma CART………….………. 11
2.1.5. Struktur atau Bentuk Pohon Klasifikasi…………...……… 12
2.1.6. Binary Recursive Partitioning….….……….... 14
commit to user ix
2.1.7.1 Proses Pemecahan Node………..
2.1.7.2 Pelabelan Kelas (Class Assignment)………
2.1.7.3 Proses Penghentian Pemecahan………...
2.1.7.4 Proses pemangkasan Pohon………. 2.1.7.5 Pohon Klasifikasi Optimal………...
2.1.8. Predictive Accuracy……….
16
2.1.9. Interpretasi Pohon Klasifikasi…..……… 30
2.2. Kerangka Pemikiran ………... 32
BAB III METODE PENELITIAN ……….. 33
3.1. Sumber Data……… 3.2. Metode Analisis Data ……….. 33 34 BAB IV PEMBAHASAN ……… 36
commit to user x
DAFTAR TABEL
Tabel 4.1. Variabel Independen dan Variabel Dependen ………... 36
Tabel 4.2. Kriteria Pemilah Terbaik Root NodeKondisi Pertama ………. 38
Tabel 4.3. Tree Sequence Kondisi Pertama ……… 44
Tabel 4.4. Tingkat Akurasi Pohon Optimal Dengan Data Learning
Kondisi Pertama ………. 45
Tabel 4.5. Tingkat Akurasi Pohon Optimal Dengan Data Testing
Kondisi Pertama ………. 46
Tabel 4.6. Kriteria Pemilah Terbaik Root NodeKondisi Kedua ……… 47
Tabel 4.7. Tree Sequence Kondisi Kedua ………... 53
Tabel 4.8. Tingkat Akurasi Pohon Optimal Dengan Data Learning
Kondisi Kedua ……… 54
Tabel 4.9. Tingkat Akurasi Pohon Optimal Dengan Data Testing
Kondisi Kedua ……… 55
Tabel 4.10. Kriteria Pemilah Terbaik Root NodeKondisi Ketiga………
Tabel 4.11. Tree Sequence Kondisi Ketiga...
Tabel 4.12. Tingkat Akurasi Pohon Optimal Dengan Data Learning
Kondisi Ketiga...
Tabel 4.13. Tingkat Akurasi Pohon Optimal Dengan Data Testing
Kondisi Ketiga...
Tabel 4.14. Nilai Ketepatan dari Ketiga Kondisi ……….
56
62
63
64
commit to user
Gambar 4.3. Pohon Klasifikasi Maksimal Kondisi Pertama ……….. 40
Gambar 4.4. Pohon Klasifikasi Kondisi Pertama yang Akan Dipangkas ……...
Gambar 4.5. Node 36 Pada Kondisi Pertama yang Akan Dipangkas...
Gambar 4.6. Pemilahan Root Node Kondisi Kedua...
Gambar 4.7. Terminal Node 23 dan 24 Kondisi Kedua...
Gambar 4.8. Pohon Klasifikasi Maksimal Kondisi Kedua...
Gambar 4.9. Pohon Klasifikasi Kondisi Kedua yang Akan Dipangkas………...
Gambar 4.10. Node 8 Pada Kondisi Kedua yang Akan Dipangkas………..
Gambar 4.11. Pemilahan Root Node Kondisi Ketiga………
Gambar 4.12. Terminal Node 10 dan 11 Kondisi Ketiga………..
Gambar 4.13. Pohon Klasifikasi Maksimal Kondisi Ketiga...
Gambar 4.14. Pohon Klasifikasi Kondisi Ketiga yang Akan Dipangkas……….
Gambar 4.15. Node 9 Pada Kondisi Ketiga Yang Akan Dipangkas ………
commit to user xii
DAFTAR NOTASI
x : Variabel independen
y : Variabel dependen
� : Probabilitas prior untuk kelas ke-j
R*(T) : Probabilitas terjadinya kesalahan untuk seluruh terminal node t
R(T) : Estimator R*(T)
� : Fungsi impurity
i(t) : Ukuran impurity untuk nodet
∆ , : Fungsi penurunan keragaman pada node t dengan kriteria pemecah s
: Impurity nodet
� : Impurity tree (Pohon Klasifikasi T)
� : Pohon klasifikasi maksimal
� : Node complexity
� : Banyak terminal node
Rα (T) : Ukuran ongkos kompleksitas untuk pohon klasifikasi T
T : Penduga sampel uji untuk Pohon klasifikasi T
� : Penduga validasi silang lipat V untuk pohon klasifikasi T
R*(d) : Proporsi misclassification yang sebenarnya
R(d) : Estimator R*(d)
Rts(d) : Proporsi misclassification dengan metode Test Sample Estimate
commit to user
1
BAB I
PENDAHULUAN
1.1Latar Belakang Masalah
Masalah klasifikasi sering dijumpai pada kehidupan sehari-hari, baik
mengenai data sosial, data industri, data kesehatan, data perusahaan maupun data
perbankan. Masalah tersebut dapat diselesaikan dengan metode klasifikasi. Menurut
Webb dan Yohannes [8] metode klasifikasi dapat dilakukan dengan pendekatan
parametrik dan nonparametrik. Dalam pendekatan parametrik terdapat beberapa
metode klasifikasi yang sering digunakan antara lain : Analisis Regresi Logistik,
Analisis Diskriminan dan Analisis Regresi Probit. Analisis Regresi Logistik dan
Analisis Regresi Probit memiliki kelemahan, yaitu nilai yang dihasilkan model
Regresi Logistik dan Regresi Probit berupa nilai probabilitas yang dirasa kurang
praktis. Pada Analisis Diskriminan, data diharuskan memenuhi beberapa asumsi yaitu
data harus berdistribusi normal dan matriks kovarian yang sama untuk setiap
populasi, Breiman et.al. [1].
Dengan adanya keterbatasan metode klasifikasi parametrik, maka digunakan
pendekatan nonparametrik. Metode nonparametrik tidak bergantung pada asumsi
tertentu sehingga memberikan fleksibilitas yang lebih besar dalam menganalisa data
tetapi tetap mempunyai tingkat akurasi yang tinggi dan mudah dalam penggunaannya.
Ada beberapa metode klasifikasi dengan pendekatan nonparametrik yang sering
digunakan, salah satunya adalah metode klasifikasi berstruktur pohon yang
diperkenalkan oleh Leo Breiman, et.al. [1] yaitu Classification and Regression Trees
(CART). Algoritma CART memiliki banyak keunggulan dibandingkan dengan metode
lain seperti, variabel-variabel dalam CART baik variabel dependen maupun
independen tidak menggunakan asumsi distribusi tertentu, variabel independennya
dapat bertipe kategorik (nominal atau ordinal) maupun kontinu, tidak berlaku adanya
commit to user
Masalah klasifikasi juga di alami dalam bidang asuransi, khususnya AJB
Bumiputera 1912 Surakarta. Asuransi Jiwa Bersama Bumiputera 1912 telah
mengumpulkan data nasabah sekian tahun lamanya sehingga mencapai data dalam
jumlah yang besar. Data tersebut mempunyai banyak atribut bertipe kategorik
(nominal atau ordinal). Untuk menganalisisnya diperlukan pengetahuan yang tidak
mudah, dimana bisa menangani masalah data yang terjadi di AJB Bumiputera
tersebut.
Masalah yang muncul dalam AJB Bumiputera Surakarta adalah apabila ingin
mengelompokkan nasabah yang lancar membayar premi dan tidak lancar membayar
premi. Jika mengelompokkan nasabah yang tidak lancar membayar premi ke dalam
kelompok nasabah yang lancar membayar premi merupakan kesalahan yang dapat
berakibat cukup fatal. Lancar tidaknya pembayaran premi nasabahnya sangat penting
bagi pihak Bumiputera 1912 Surakarta karena sangat berpengaruh terhadap kinerja
serta eksistensinya dalam kehidupan sehari-hari. Untuk itu diperlukan suatu cara agar
dapat mengetahui bagaimana pola nasabah yang dikatakan lancar maupun tidak
lancar sehingga dapat membantu pihak Bumiputera dalam mengklasifikasikan
nasabahnya. Dengan demikian pihak Bumiputera dapat mempertimbangkan nasabah
yang akan nantinya akan diterima ataupun ditolak dengan hasil analisis tersebut.
Berdasarkan uraian di atas, penulis tertarik untuk melakukan penelitian
terhadap perusahaan asuransi khususnya AJB Bumiputera 1912 Surakarta dengan
mengaplikasikan Algoritma Classification and Regression Tress (CART) dalam data
nasabah, sehingga dapat dicari pola status nasabah untuk dapat dijadikan bahan
analisis perusahaan dalam menentukan calon nasabah di masa yang akan datang.
1.2Rumusan Masalah
Berdasarkan latar belakang masalah, rumusan masalah yang dikemukakan adalah
1. bagaimana implementasi algoritma CART dalam mengklasifikasi atau
commit to user
2. bagaimana pola nasabah yang dihasilkan untuk menentukan calon nasabah yang
akan datang.
1.3Batasan Masalah
Classification and Regression Trees (CART) terdiri dari dua metode yang
berbeda yaitu pohon klasifikasi dan pohon regresi. Dalam skripsi ini pembahasan
hanya dilakukan pada pembentukan pohon klasifikasi.
1.4Tujuan Penelitian
Tujuan penelitian ini adalah
1. mengklasifikasikan atau mengelompokkan data nasabah AJB Bumiputera 1912
Surakarta dengan menggunakan algoritma CART .
2. menentukan pola nasabah yang dihasilkan untuk menentukan calon nasabah yang
akan datang.
1.5Manfaat Penelitian
Dengan dilakukannya penelitian tentang klasifikasi data nasabah AJB
Bumiputera 1912 Surakarta diharapkan dapat menambah pengetahuan tentang peran
nyata statistika dalam bidang keuangan khususnya asuransi. Hasil penelitian ini juga
diharapkan dapat membantu semua pihak, khususnya pihak AJB Bumiputera 1912
Surakarta dalam mengklasifikasikan nasabahnya dan mengetahui pola yang terjadi
berdasarkan klasifikasi yang didapatkan dari hasil analisis sehingga dapat menjadi
sumbangan informasi untuk menentukan nasabah mana yang akan diterima ataupun
commit to user
4
BAB II
LANDASAN TEORI
2.1Tinjauan Pustaka
Pada bagian ini diberikan beberapa definisi, teorema dan pengertian yang
mendasari dilakukannya penelitian ini, meliputi teori probabilitas, masalah umum
klasifikasi, algoritma CART, struktur pohon klasifikasi CART, binary recursive
partitioning, langkah kerja CART, predictive accuracy, dan interpretasi pohon
klasifikasi.
2.1.1 Teori Probabilitas
Teori probabilitas memberikan peranan yang sangat penting dalam membuat
sebuah pohon klasifikasi dengan menggunakan algoritma CART ini.
Definisi 2.1. (Wapole dan Myers, 1986) Bila suatu percobaan mempunyai N hasil
percobaan yang berbeda dan masing-masing mempunyai kemungkinan yang sama
untuk terjadi, dan bila tepat n diantara hasil percobaan itu menyusun kejadian A,
maka peluang kejadian A adalah
=
Menurut Walpole dan Myers [7] kaidah-kaidah probabilitas yang banyak digunakan
dalam membuat sebuah pohon klasifikasi, antara lain adalah
1. kaidah penjumlahan
a. kaidah penjumlahan dua kejadian yang saling terpisah.
Bila A dan B saling terpisah, maka
= +
b. kaidah penjumlahan n buah kejadian yang saling terpisah.
Bila 1, 2,⋯, kejadian-kejadian yang saling terpisah, maka
commit to user
c. bila A dan ′ adalah dua kejadian yang satu merupakan komplemen
lainnya maka
+ ′ = 1
2. kaidah peluang bersyarat
peluang bersyarat B, bila A diketahui dilambangkan dengan | .
didefinisikan sebagai
| = ( )
( ) , > 0
3. kaidah penggandaan
a. kaidah penggandaan khusus
Bila kejadian A dan B saling bebas maka
Probabilitas dalam CART
Dalam learning sampleℒ dengan banyaknya kelas adalah j, diberikan
N : banyaknya objek atau cases pada learning sampleℒ
Nj : banyaknya objek atau cases pada kelas j
dengan
commit to user
Probabilitas prior merupakan informasi awal mengenai proporsi atau
perbandingan banyaknya objek pada tiap-tiap kelas dalam ℒ . Nilai probabilitas prior
ini diestimasi dari proporsi yang diperoleh dari data. Menurut Webb dan
Yohannes [8] setidaknya ada 2 jenis dari probabilitas prior dalam CART yaitu
1. priors data, mengasumsikan bahwa proporsi banyaknya objek dalam suatu
kelas yang terdapat dalam sampel sama dengan yang terdapat dalam
populasinya. Prior data diestimasi oleh (� ) = .
2. priors equal, mengasumsikan bahwa proporsi banyaknya objek tiap-tiap kelas
adalah sama. Diestimasikan P(kelas1) = P(kelas 2) = 1
2
.
Dalam sebuah node t, diberikan :
∶ Banyaknya objek atau cases dalam ℒ yang mana 0 ∈ (banyaknya objek
dalam node t
∶ Banyaknya objek atau cases kelas j yang berada dalam node t
( )
∶proporsi objek-objek dalam kelas j yang berada di node t
, : probabilitas bahwa sebuah objek adalah anggota kelas j dan berada dalam
node t
sehingga
, =� .
= . ( )
, = ( ) . (2.1)
Jika adalah probabilitas beberapa objek akan berada dalam node t, maka
commit to user
berada dalam node t, maka berdasarkan persamaan (2.2) diperoleh
| = ( , )
Analisis klasifikasi yaitu suatu analisis untuk memisahkan objek-objek ke
dalam dua kelas atau lebih serta menentukan atau mengalokasikan objek-objek baru
ke dalam kelas-kelas tersebut. Jadi, ada dua fungsi dalam analisis klasifikasi, yaitu
1. fungsi partisi, yaitu memisahkan objek-objek ke dalam dua kelas atau lebih
berdasarkan aturan klasifikasi tertentu.
2. fungsi prediksi, yaitu untuk mengalokasikan objek-objek baru (belum diketahui
kelasnya) ke dalam kelas-kelas tersebut.
Untuk melakukan kedua fungsi tersebut digunakan suatu alat klasifikasi
yaitu classifier dengan cara-cara atau metode yang sistematis. Beberapa contoh
classifier diantaranya adalah Analisis Diskriminan, Regresi Logistik, K-th Nearest
Neighbor, Kernel Density Estimation, Neural Network, dan Classification and
Regression Trees (CART). Classifier memisahkan objek-objek ke dalam
commit to user
1, 2, 3,…, yang selanjutnya disebut dengan variabel independen sedangkan
variabel yang memuat kelas-kelas dari objek disebut variabel dependen =
{ 1, 2,⋯, } dimana ∶ kelas ke- ; = 1, 2,⋯, .
Definisi 2.2. (Breiman et al, 1993) Classifier adalah partisi dari ke
dalam himpunan bagian 1,⋯, dengan = sedemikian sehingga untuk
setiap � objek tersebut diprediksikan ke dalam kelas j.
= { ∶ = }
Classifier dibentuk berdasarkan data terdahulu atau observasi pada masa
lampau (past experience). Data-data terdahulu ini terhimpun dalam satu bentuk
susunan yang disebut dengan Learning Sample atau Training sample. Learning
Sample terdiri dari variabel-variabel independen dan variabel dependen pada kolom
dan objek-objek (cases) sebanyak N pada baris.
Definisi 2.3. (Breiman et al, 1993) Learning sampleterdiri dari data
( 1, 1), ( 2, 2),⋯, ( , ) dengan � dan � 1,⋯, , = 1, 2,⋯, ,
dengan N adalah banyaknya objek (case).
Learning sample dinotasilan dengan
ℒ= { 1 , 1 , 2 , 2 ,⋯, , .
2.1.3 Masalah Umum Klasifikasi (Misclassification, Rebstitution Estimate dan
Misclassification Cost)
Classification rules (aturan klasifikasi) sebagai hasil akhir dari pohon
klasifikasi yang terbentuk, nantinya akan digunakan untuk melakukan prediksi.
Aturan klasifikasi ini tidaklah sepenuhnya terhindar dari kesalahan (error). Bentuk
kesalahannya adalah kesalahan dalam mengklasifikasikan objek baru ke dalam suatu
commit to user
kelas 2 padahal yang sebenarnya objek tersebut termasuk dalam kelas 1. Begitu pula
sebaliknya sebuah objek diklasifikasikan ke dalam kelas 1, padahal sebenarnya objek
itu termasuk dalam kelas 2.
Dalam CART untuk mengidentifikasi misclassification ini digunakan
resubstitution estimate. Dalam perhitungannya resubstitution estimate menggunakan
semua objek yang terdapat dalam ℒ.
Definisi 2.4. (Breiman et al, 1993) Resubstitution estimate ( ) adalah probabilitas
atau peluang terjadinya misclassification di dalam sebuah node t tertentu.
= 1−maks ( | ).
Definisi 2.5. (Breiman et al, 1993) Resubstitution estimate ( ) adalah probabilitas
atau peluang terjadinya misclassification yang dialami beberapa objek dalam
learning sample jika objek tersebut berada dalam sebuah node t tertentu. = . ( )
dengan ( ) adalah probabilitas beberapa objek akan berada dalam nodet.
Definisi 2.6. (Breiman et al, 1993) Resubstitution estimate (�) adalah probabilitas
atau peluang terjadinya misclassification yang dialami beberapa objek untuk
keseluruhan terminal node t atau peluang terjadinya misclassification yang
disebabkan oleh pohon klasifikasi yang terbentuk
dengan
� = ( )
t ∈ �
� adalah himpunan semua terminal node.
Konsep yang berkaitan dengan misclassification yaitu cost (misclassification
cost). Konsep misclassification cost muncul karena dalam beberapa masalah
klasifikasi tidaklah realistis untuk memberikan besar resiko yang sama terhadap
kesalahan klasifikasi ini. Mungkin saja resiko melakukan kesalahan klasifikasi
commit to user
melakukan kesalahan klasifikasi sebuah objek anggota kelas 2 menjadi anggota kelas
1 atau sebaliknya.
Sebagai contoh dalam diagnosis suatu penyakit, menyatakan seorang pasien
dalam kategori ”tidak fatal” padahal keadaan sebenarnya “fatal” jelas lebih beresiko daripada menyatakan bahwa ia “fatal” padahal keadaan sebenarnya “tidak fatal”.
Definisi 2.7. (Breiman et al, 1993) ( | ) adalah besar cost untuk terjadinya
misclassification sebuah objek kelas j sebagai objek kelas i, dengan | > 0, ≠
dan | = 0, = .
Besar cost dari misclassification ini biasa dituliskan dalam bentuk cost matriks.
Kelas Sebenarnya
1 2
Hasil Prediksi 1 0 C(1|2)
2 C(2|1) 0
Misal diketahui sebuah node t dengan probabilitas | tertentu, = 1, 2,⋯, jika
diketahui sebuah objek berada dalam node t tersebut dan diklasifikasikan ke dalam
kelas i, maka estimasi rata-rata ongkos kesalahan klasifikasi (expected
misclassification cost) adalah
| | .
Selanjutnya didefinisikan resubstitution estimate ( ) berdasarkan expected
misclassification cost ini.
Definisi 2.8. (Breiman et al, 1993) Resubstitution estimate ( ) berdasarkan
expected misclassification cost di dalam sebuah node t adalah
commit to user
Dengan mendefinisikan = � = t∈ � .
Jika dipunyai nilai | = 1 ≠ | = 0 untuk = maka
diperoleh
| | = | .
Berdasarkan persamaan (2.3) maka diperoleh
| | = 1− ( | )
sehingga
= min | |
= min 1− | .
Nilai min (1− | ) akan diperoleh apabila | maksimum, sehingga dapat
dituliskan pula = 1−max ( | ), yang identik dengan definisi 2.4.
Berdasarkan hasil di atas, definisi 2.5 adalah resubstitution estimate dalam
sebuah node t apabila semua nilai | = 1 atau sama untuk semua ≠ .
2.1.4 Algoritma CART
Algoritma CART adalah sebuah metode statistik nonparametrik yang
digunakan untuk melakukan analisis klasifikasi. Algoritma CART pertama kali
diperkenalkan pada tahun 1993 oleh ilmuwan Amerika Serikat yaitu Breiman, et al.
Algoritma CART terdiri dari dua analisis yaitu pohon klasifikasi dan pohon regresi.
Jika variabel dependen yang dimiliki bertipe kategorik (nominal atau ordinal), maka
CART menghasilkan pohon klasifikasi sedangkan jika variabel dependen yang
dimiliki bertipe kontinu atau numerik (interval atau rasio) maka CART akan
menghasilkan pohon regresi. Pohon CART dikatakan binary decision tree karena
commit to user
dalam dua child nodes secara berulang-ulang diawali dengan root node. Dalam
skripsi ini pembahasan dikhususkan pada pohon klasifikasi.
Menurut Lewis [3] beberapa keunggulan CART dibanding dengan metode
statistik yang lain (khususnya parametrik) diantaranya adalah
1. variabel-variabel dalam CART baik variabel independen maupun dependen tidak
mendasarkan atau mengasumsikan distribusi populasinya pada distribusi
probabilitas tertentu. Sehingga CART termasuk dalam kelompok metode statistik
nonparametrik.
2. variabel–variabel independen dalam CART bisa bertipe kategorik (nominal atau
ordinal) tanpa diperlukannya pembuatan variabel dummy ataupun juga bisa
bertipe kontinu.
3. CART mampu untuk mengatasi missing value.
4. CART tidak terpengaruh oleh adanya outlier, kolinearitas, dan heteroskedastisitas
diantara variabel independennya.
5. dalam CART tidak berlaku adanya transformasi data. Data-data asli yang dirubah
ke dalam bentuk apapun tidak akan mempengaruhi dalam pembentukan pohon
klasifikasinya.
6. interpretasi dari pohon klasifikasi yang dihasilkan oleh CART sangat mudah
dipahami oleh para pengguna.
2.1.5 Struktur atau Bentuk Pohon Klasifikasi CART
Algoritma CART termasuk dalam anggota analisis klasifikasi yang disebut
decision trees karena proses analisis dari CART digambarkan dalam bentuk atau
struktur yang menyerupai sebuah pohon, lebih tepatnya pohon klasifikasi yang
berbentuk biner. Biner di sini bararti bahwa setiap pemecahan parent node
commit to user
= Root Node = nonterminal node = branch = terminal node
X1 > a
X2 > b
X2≤ b
Gambar 2.1 Pohon Klasifikasi CART
Keterangan Gambar 2.1 :
1. Root Node digambarkan dengan lingkaran. Merupakan nonterminal node paling
awal atau paling atas dan tempat inisialisasi learning sample yang dimiliki.
Inisialisasi disini menyangkut beberapa objek atau cases yang dimiliki oleh
tiap-tiap kelas.
2. Branch digambarkan dengan 2 garis lurus yang merupakan cabang dari root node.
Branch merupakan tempat kriteria pemecahan dari masing-masing nonterminal
node. Sebagai contoh : kriteria pemecahan pertama (split 1) pada branch kiri
commit to user
3. Nonterminal nodes digambarkan dengan lingkaran. Merupakan subset atau
himpunan bagian dari nonterminal node di atasnya yang memenuhi kriteria
pemecahan tertentu.
Sebagai contoh : objek-objek yang berada dalam nonterminal node 5 merupakan
subset atau himpunan bagian dari objek-objek yang berada dalam nonterminal
node 2 yang memenuhi kriteria pemecahan 2 > .
4. Terminal nodes, digambarkan dengan persegi. Merupakan node tempat
diprediksikannya sebuah objek pada kelas tertentu (class labeled).
Sebagai contoh : jika ada beberapa objek yang masuk dalam terminal node 6,
maka objek-objek tersebut akan dimasukkan kedalam kelas 4.
5. Node 4dan 5 merupakan child node dari node 2, sedangkan node 2merupakan
child node dari root node 1. Begitu pun sebaliknya root node 1 merupakan
parent node untuk node 2 dan node 3, node 2 merupakan parent node untuk
node 4 dan 5 , sedangkan node 3 merupakan parent node untuk node 6 dan
node 7 , dst.
2.1.6 Binary Recursive Partitioning
Teknik atau proses kerja dari CART dalam membuat sebuah pohon klasifikasi
dikenal dengan istilah Binary Recursive Partitioning. Proses disebut binary karena
setiap parent node akan selalu mengalami pemecahan ke dalam tepat dua child node.
Sedangkan recursive berarti bahwa proses pemecahan tersebut akan diulang kembali
pada setiap child nodes hasil pemecahan terdahulu, sehingga child nodes tersebut
sekarang menjadi parent nodes. Proses pemecahan ini akan terus dilakukan sampai
tidak ada kesempatan lagi untuk melakukan pemecahan berikutnya. Dan istilah
partitioning mengartikan bahwa learning sample yang dimiliki dipecah ke dalam
bagian-bagian atau partisi-partisi yang lebih kecil.
Kriteria pemecahan didasarkan pada nilai-nilai dari variabel independen yang
variabel-commit to user
Gambar 2.2. Proses Partisi
variabel independen 1, 2,⋯, . Proses binary recursive partitioning bisa
diilustrasikan sebagai proses pembagian dari ruang berdimensi dari
variabel-variabel independen ke dalam partisi-partisi yang berbentuk persegi panjang dan
tidak saling bertumpang tindih. Idenya adalah membagi ruang berdimensi dari
variabel-variabel independen tadi ke dalam beberapa partisi yang mana
masing-masing partisi berisi objek-objek yang homogen atau seragam. Homogen di sini
maksudnya adalah objek-objek tersebut merupakan anggota satu kelas yang sama.
Walaupun pada kenyataannya keadaan seperti ini tidaklah mutlak diperoleh. Proses
splitting akan berlanjut sampai didapatkan pohon klasifikasi yang paling besar atau
maksimal (proses splitting tidak bisa dilakukan lagi)
Untuk memperjelas proses partisi, akan diberikan contoh pemilahan pada
Gambar 2.2. Pada Gambar 2.2 terlihat proses partisi node 1 dipilah dengan kriteria
commit to user
dari kriteria sedangkan node 3 terbentuk akibat kriteria pemecahan > .
Kemudian proses partisi berlanjut pada node 3, dengan kriteria pemecahan
dan > . Node 4 terbentuk karena memenuhi kriteria dan node 5 terbentuk
karena kriteria > .
2.1.7 Langkah Kerja CART
Menurut Lewis [3] pada dasarnya dalam membuat sebuah pohon klasifikasi,
CART bekerja dalam empat langkah utama. Langkah pertama adalah tree building
process yaitu proses pembentukan dan pembuatan pohon klasifikasi. Terdiri dari
proses splitting nodes yaitu proses pemecahan parent nodes menjadi dua buah child
node melalui aturan pemecahan tertentu dan dilakukan secara berulang-ulang serta
proses pelabelan kelas yaitu proses mengidentifikasi node-node yang terbentuk pada
suatu kelas tertentu melalui aturan pengidentifikasian. Langkah kedua adalah proses
penghentian pembuatan atau pembentukan pohon klasifikasi (stopping the trees
building process). Pada tahap ini pohon terakhir atau maximal tree (� ) telah
terbentuk. Langkah ketiga adalah pruning the tree yaitu proses pemangkasan atau
pemotongan � menjadi pohon yang lebih kecil (T). Selanjutnya langkah terakhir
adalah proses optimal tree selection yaitu pemilihan atau penentuan pohon klasifikasi
yang optimal.
2.1.7.1 Proses Pemecahan Node
Proses pemecahan pada masing-masing parent node didasarkan pada
goodness of split criterion (kriteria pemecahan terbaik). Kriteria pemecahan terbaik
ini dibentuk berdasarkan fungsi impurity (fungsi keragaman).
Definisi 2.9. (Breiman et al, 1993) Fungsi impurity adalah sebuah fungsi � yang
didefinisikanoleh ( 1, 2,⋯, ) ; 0 = 1, = 1, 2,⋯, .
Fungsi impurity �memenuhi kriteria:
commit to user
measure (ukuran impurity) i(t) dari beberapa node t sebagai
=� 1| , 2| ,⋯, | .
Definisi 2.11. (Breiman et al, 1993) Diberikan impurity measure i(t), maka Gini
Diversity Index (Indek Keragaman Gini) adalah :
= | | (2.4)
≠
Dalam sebuah node t, andaikan terdapat 1, 2 ⋯, kelas. Untuk j = 1 dan i adalah
kelas-kelas lainnya maka (2.4) dapat dituliskan
| |
Begitu pula untuk j = 2 dan i adalah kelas-kelas lainnya maka (2.4) dapat dituliskan
commit to user
Sehingga untuk j kelas secara umum, didapatkan :
| | =
≠
( | − 2( | ))
= | − 2 |
= 1− 2 | .
Sehingga berdasarkan (2.4) Gini Diversity Index dapat dituliskan
= 1− 2 | .
Rumus (2.4) hanya berlaku apabila besar cost untuk resiko kesalahan
klasifikasi masing-masing kelas sama, C(1|2) = C(1|3) = C(i|j) jika besar cost berbeda
maka (2.4) dituliskan
= | | .
≠
Definisi 2.12. (Breiman et al, 1993) Jika sebuah split s dalam node t dibagi ke dalam
dengan proporsi banyaknya objek yang masuk dalam adalah , dan dengan
proporsi banyaknya objek yang masuk dalam adalah , maka didefinisikan
decrease impurity (pengurangan keragaman)
∆ , = − − (2.6)
Nilai ∆ , digunakan sebagai uji goodness of split criterion (kriteria uji
pemecahan terbaik). Suatu split s akan digunakan untuk memecah nodet menjadi dua
buah node yaitu node dan jika s memaksimalkan nilai
∆ ∗, = max∆ , .
Berdasarkan (2.6) ∆ , akan maksimum apabila diperoleh dan
commit to user
node baru yang keragamannya lebih kecil (homogen) apabila dibandingkan dengan
node awalnya (parent node). Misalkan sebuah pohon klasifikasi telah terbentuk dan
memiliki sekumpulan atau himpunan terminal nodes� , didefinisikan impurity node
I(t), dengan
= .
Didefinisikan pula tree impurity � , dengan
� = =
∈� ∈�
sehingga didapatkan hasil sebagai berikut
∆ , = − − .
Proposisi 2.1. Pemilihan split s yang memaksimalkan ∆ , ekuivalen dengan
pemilihan split s yang meminimalkan tree impurity .
2.1.7.2 Pelabelan Kelas
Pelabelan kelas adalah proses pengidentifikasian tiap nodes pada suatu kelas
tertentu. Pelabelan kelas tidak hanya diberlakukan untuk terminal nodes saja,
nonterminal nodes bahkan root node mengalami proses ini. Hal ini dikarenakan
setiap nonterminal nodes memiliki kesempatan untuk menjadi terminal nodes.
Sehingga proses pelabelan kelas akan terus dilakukan selama proses splitting masih
berlanjut.
Walaupun semua nodes mengalami proses ini, tentu saja diantaranya yang
paling membutuhkan proses ini adalah terminal nodes, karena terminal nodes adalah
nodes yang sangat penting dalam memprediksi suatu objek pada kelas tertentu jika
objek tersebut berada pada terminal nodes tersebut. Misalkan sebuah pohon
klasifikasi telah terbentuk dan memiliki terminal nodes � .
Definisi 2.13. (Breiman et al, 1993) Class assignment rule mengidentifikasikan
sebuah kelas ∈{1, 2,⋯, } pada setiap terminal node ∈ � . Kelas yang
commit to user
Ada dua aturan pelabelan kelas, masing-masing aturan berdasarkan kepada
dua macam misclassification cost yang berbeda. Kedua aturan itu diterangkan pada
definisi-definisi berikut
Definisi 2.14. (Breiman et al, 1993) Class assignment rule ∗( ) didefinisikan
apabila | = max | ∗ =
Aturan ini disebut the plurality rule (aturan keragaman) dan berdasarkan nilai
misclassification cost yang sama pada setiap kelas.
Definisi 2.15. (Breiman et al, 1993) Didefinisikan class assignment rule ∗( ), ∗ =
0 apabila 0 meminimalkan | ( | )
Aturan ini berdasarkan nilai misclassification cost yang berbeda untuk tiap kelas
| > 0 jika ≠ dan | = 0 jika = .
Resubstitution estimate adalah konsekuensi logis dari proses pelabelan kelas
ini. Resubstitution estimate adalah probabilitas terjadinya misclassification yang
dialami beberapa objek-objek tersebut pada nodet tertentu. Proses splitting pada node
t menyatakan yang kecil pada kedua node baru yang terbentuk. Hal ini
dibuktikan melalui proposisi berikut.
Proposisi 2.2. (Breiman, et al, 1993) Untuk setiap pemecahan node t menjadi dan
berlaku
( ) ( ) + .
2.1.7.3. Proses Penghentian Pemecahan
Menurut Vayssieres [4], proses splitting atau pembuatan pohon klasifikasi
akan berhenti apabila sudah tidak dimungkinkan lagi dilakukan proses pemecahan.
Proses pemecahan akan berhenti apabila hanya tersisa satu objek saja yang ada dalam
node terakhir atau semua objek yang berada di dalam sebuah node merupakan
anggota kelas yang sama (homogen). Kemudian , bernilai 0 atau 1. = 0,
dan resubstitution estimate � untuk nilai misclassification sama dengan 0. Pada
commit to user
terakhir atau yang tidak mengalami pemecahan lagi sebagai akibat dari kondisi di atas
akan menjadi terminal nodes dan diidentifikasikan pada suatu kelas tertentu sesuai
dengan class assignment rule yang telah dijelaskan sebelum ini. Pohon klasifikasi
yang terbentuk sebagai hasil dari proses ini dinamakan “maximal tree” (� ).
2.1.7.4. Proses Pemangkasan Pohon
Maximal tree (� ) yang dihasilkan dari proses tree building dapat
mengakibatkan dua masalah, Webb dan Yohannes [8] :
1. Meskipun � memiliki tingkat akurasi yang tinggi dengan nilai
misclassification rate atau misclassification cost yang kecil bahkan bernilai
nol (dihitung dengan metode resubstitution estimate), namun � dapat
menyebabkan over-fitting atau pencocokan nilai yang terlalu kompleks pada
data-data baru. Hal ini dikarenakan terlalu banyak variabel independen yang
digunakan untuk melakukan prediksi terhadap data baru tersebut.
2. Sebagai akibat dari point 1, � akan sulit untuk dipahami atau
diinterpretasikan. Sehingga � akan lebih cepat dikatakan sebagai complex
tree yang kompleksitasnya ditentukan dari banyaknya terminal node yang
dimiliki.
Proses pemangkasan pohon dimaksudkan untuk menghilangkan kedua
masalah tersebut dengan memotong atau memangkas � menjadi beberapa pohon
klasifikasi (T) yang ukurannya lebih kecil (subtrees). Untuk mempermudah dalam
memahami proses pemangkasan ini, berikut diberikan penjelasan awal mengenai
proses ini.
Sebuah node ′ disebut descendan (anak) dari node t dan node t disebut
ancestor dari node ′ jika kedua node ini bisa dihubungkan oleh jalur-jalur yang
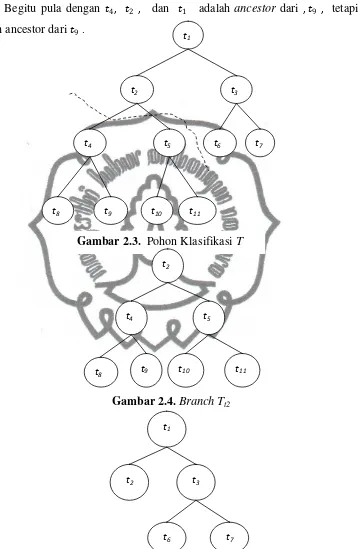
bergerak dari atas ke bawah (node t berada di atas node ′). Pada Gambar 2.3 pohon
commit to user t1
t2 t3
t4 t5 t6 t7
t8 t9 t10 t11
Gambar 2.3. Pohon Klasifikasi T
t2
t4 t5
t8 t9 t10 t11
Gambar 2.4.Branch Tt2
t1
t2 t3
t7 t6
Gambar 2.5. Pohon Klasifikasi T –Tt2 ( pruned subtree )
(Breiman et al., 1993)
dan 7 . Begitu pula dengan 4, 2 , dan 1 adalah ancestor dari , 9 , tetapi 3
commit to user
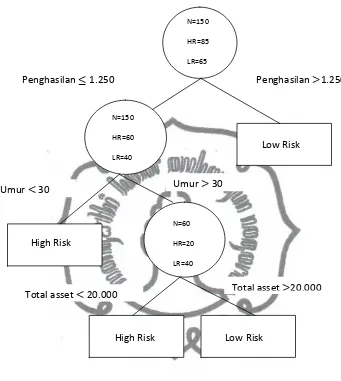
Definisi 2.16. (Breiman et al, 1993) Suatu branch � dari T dengan root node (node
akar) ∈ � terdiri dari node t itu sendiri dengan semua descendant dari t dalam T.
Sebagai contoh pada gambar 2.4. branch �2.
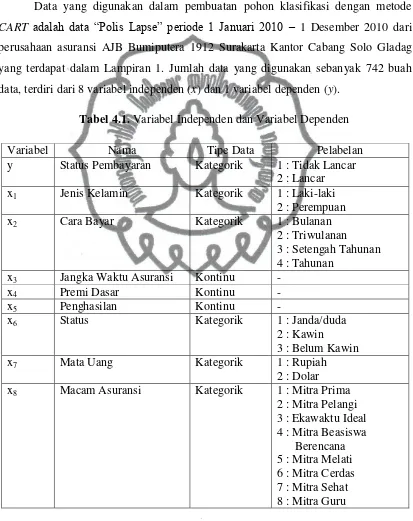
Definisi 2.17. (Breiman et al, 1993) Pruning (pemangkasan) sebuah branch � dari
sebuah pohon T akan menghapus atau menghasilkan semua descendant t dari T
kecuali root nodenya (t itu sendiri).
Sebagai contoh pada Gambar 2.5. pohon klasifikasi� − �2.
Definisi 2.18. (Breiman et al, 1993) Jika �′ diperoleh dari � sebagai hasil dari
pemangkasan suatu branch, maka �′ disebut pruned subtree dari T dan dinotasikan
dengan �′ <�. Sebagai catatan �′ dan T memiliki root node (node akar) yang sama.
Sebagai contoh gambar pohon klasifikasi � − �2 menunjukkan pruned subtree.
Metode yang digunakan dalam proses pemangkasan pohon berdasarkan pada
minimal cost complexity pruning.
� = = ( )
∈� ∈�
� adalah tree misclassification cost atau tree resubtitution cost, sedangkan ( )
disebut node misclassification cost.
Definisi 2.19. (Breiman et al, 1993) Diketahui subtree �<� didefinisikan
complexity (kompleksitas) dari subtree ini adalah � , yaitu banyaknya terminal
nodes yang dimiliki T, � 0 adalah complexity parameter atau node complexity dan
cost complexity measure (ukuran ongkos kompleksitas) �(�), maka
� � = � +� � .
Nilai � bisa diartikan sebagai penalty setiap terminal node berdasarkan
kompleksitasnya, semakin besar nilai � maka ukuran tree yang dihasilkan akan kecil,
sebaliknya jika nilai � kecil maka kompleksitas nodenya juga kecil sehingga ukuran
tree yang dihasilkan akan besar. Sehingga contoh sebuah � memiliki terminal
node yang berisi hanya satu objek atau homogen sehingga sehingga nilai � untuk
commit to user
Nilai � akan terus meningkat selama proses pruning berlangsung dan akan mencapai
nilai terbesar pada saat terminal node sama dengan root node.
Cost complexity pruning menentukan suatu pohon bagian �(�) yang
meminimumkan � � pada seluruh pohon bagian, atau untuk setiap nilai �, dicari
pohon bagian � � <� yang meminimumkan � � yaitu
� � � = min�<� � � .
Proses pemangkasan pohon klasifikasi dimulai dengan mengambil yang
merupakan right child node dan yang merupakan left child node dari � yang
dihasilkan dari parent node t. jika diperoleh dua child node dan parent node yang
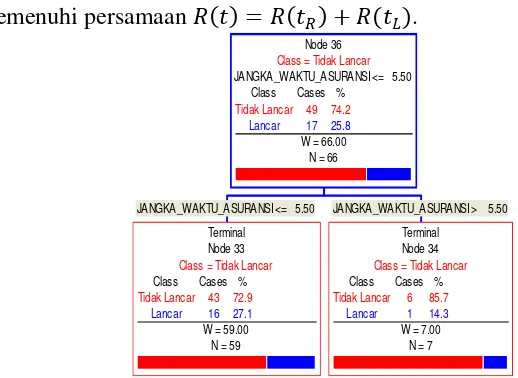
memenuhi persamaan = + ( ) maka child node dan dipangkas.
Hasilnya adalah pohon �1 yang memenuhi kriteria �1 = (� ). Proses tersebut
diulang sampai tidak ada lagi pemangkasan yang mungkin terjadi. Dan diperoleh
urutan sebagai berikut �1,�2,⋯, 1 , �1 > �2 > ⋯> { 1} . Dengan urutan �
sebagai berikut �1 = 0 <�2 < �3 <⋯ <� .
2.1.7.5. Pohon Klasifikasi Optimal
Pohon klasifikasi yang terbentuk dapat berukuran besar dan kompleks dalam
mengambarkan struktur data. Sehingga perlu dilakukan suatu pemangkasan, yaitu
suatu penilaian ukuran sebuah pohon tanpa mengorbankan kebaikan ketepatan
melalui pengurangan simpul pohon sehingga dicapai penghematan gambaran.
Pemangkasan dilakukan dengan memangkas bagian pohon yang kurang penting
sehingga didapat pohon optimal.
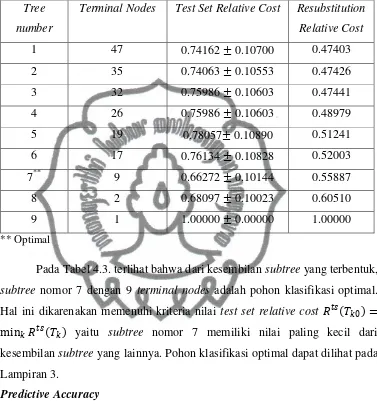
Metode pemangkasan pohon sebelumnya menghasilkan urutan subtree
�1 > �2 > ⋯> { 1} karena pohon klasifikasi yang dihasilkan begitu banyak maka
permasalahan sekarang adalah bagaimana caranya menentukan pohon klasifikasi
yang optimum. Jika menggunakan resubtitution estimate
� = = ( )
commit to user
Maka �1 akan terpilih sebagai pohon optimum, karena nilai resubtitution estimate
dari �1 pasti paling kecil. Oleh karena itu metode resubtitution estimate merupakan
metode yang bias untuk mengestimasi true misclassification cost. Ada dua metode
tak bias untuk mengestimasi nilai true misclassification cost yaitu penduga uji sample
(test sample estimate) dan penduga validasi silang lipat V (cross validation V-fold
estimate).
1. Test Sample Estimate
Test sample digunakan jika ukuran data besar (ℒ besar). Bagilah ℒ menjadi
ℒ1dan ℒ2. Misal ℒ1sebanyak (1) objek dan ℒ2 sebanyak (2) objek. Buatlah �
menggunakan ℒ1 dan pangkas hingga diperoleh � =�1 > �2 >�3 > ⋯> { } .
Gunakan ℒ2 pada masing-masing tree dan hitunglah berapa banyak objek yang
mengalami kesalahan klasifikasi (misclassification). Untuk lebih jelasnya dinotasikan
(2)
adalah banyaknya objek anggota kelas j dalam ℒ2. Untuk setiap T pada �
hitunglah nilai (2) yaitu banyaknya kelas j dalam ℒ2 yang diklasifikasikan sebagai
commit to user
Test sample estimate dapat digunakan untuk memilih pohon klasifikasi yang optimum
dari � , misal tree optimum adalah �0
� 0 = min � .
2. V-Fold Cross Validation Estimates
Cross validation digunakan apabila ukuran sampel kecil. Dalam V-Fold Cross
Validation , learning sample ℒ dibagi secara acak ke dalam V bagian, ℒ , v = 1, 2,
⋯, V. setiap bagian berisi objek dalam jumlah yang sama (mendekati sama). Learning
sample ke-v adalah ℒ( )= ℒ − ℒ , = 1, 2,⋯,�. Dengan demikian ℒ( )berisi
(�−1)
� dari total objek. Biasanya diambil � = 10, sehingga ℒ( ) berisi
9 10
objek dari ℒ.
Dalam V-Fold Cross Validation ada V pohon klasifikasi tambahan yang
dibuat bersamaan dengan pohon klasifikasi utama yang menggunakan ℒ. Ke-V pohon
klasifikasi tambahan tersebut dibuat dengan learning sample ℒ( ). Dimulai dengan
membuat V maksimal tree , �( ) , = 1, 2,⋯,� seperti halnya � . Untuk setiap
nilai complexity parameter atau node complexity �, dibuat �(�),�( )� dibuat oleh
ℒ( ) tanpa melibatkan ℒ sisanya (1/10 dari ℒ) ℒ ini digunakan sebagai test sample
pada masing-masing �( )�.
Untuk setiap , , didefinisikan
= ( )
dengan ( ): banyaknya objek anggota kelas j dalam ℒ( )yang diklasifikasikan
sebagai kelas i oleh �( )�.
∶ jumlah keseluruhan dari objek-objek kelas j yang diklasifikasikan
commit to user
Oleh karena setiap objek muncul sekali dan hanya sekali ℒ( )maka jumlah
keseluruhan objek kelas j di dalam seluruh test sample adalah sama dengan
banyaknya objek kelas j dalam ℒ,
| =
= ( | ) |
�(�) = ( )� .
Jika probabilitas prior diestimasi oleh � = , maka menjadi
�(�) =
1
( | ) .
Untuk memilih pohon klasifikasi yang optimum dari � , misal pohon klasifikasi
yang optimum itu adalah � 0 maka
� 0 = min � .
2.1.8 Predictive Accuracy
Konsep misclassification yang telah dijelaskan pada bagian terdahulu,
membawa kepada konsep yang lebih penting lagi dalam membangun sebuah pohon
klasifikasi dengan menggunakan algoritma CART ini. Predictive accuracy merupakan
metode yang digunakan dalam CART untuk menguji tingkat keakurasian atau
kehandalan (validitas) dari pohon klasifikasi yang terbentuk dalam melakukan tugas
prediksinya yaitu untuk mengalokasikan objek-objek baru ke dalam kelas-kelas
tertentu.
Algoritma CART tidak menggunakan covariates-nya terhadap probabilitas
distribusi tertentu, sehingga tidak dimungkinkan untuk melakukan uji-uji hipotesis.
Metode yang digunakan untuk menguji tingkat keakurasian ini yaitu dengan cara
menguji langsung pohon klasifikasi yang terbentuk terhadap sekumpulan data yang
commit to user
proporsi banyaknya objek yang mengalami kesalahan klasifikasi (misclassification).
Semakin kecil proporsi misclassification yang terjadi, semakin akurat pohon
klasifikasi yang terbentuk dalam melakukan prediksi. Begitu juga sebaliknya,
semakin besar proporsi misclassification semakin tidak akurat pohon klasifikasi yang
terbentuk dalam melakukan prediksinya.
Proporsi misclassification yang sebenarnya (populasi) adalah
∗ = ( ( )≠ )
dengan
∶ fungsi klasifikasi atau aturan klasifikasi (classification rules) dari pohon
klasifikasi yang terbentuk dengan menggunakan algoritma CART. Objek a
termasuk dalam kelas j jika ∈ � maka = .
Breiman, et al [1] memperkenalkan tiga prosedur dalam menguji tingkat
keakurasian pohon klasifikasi yang terbentuk ini.
1. Resubstitition Estimate, dinotasikan dengan . Konsep resubstitution
estimate yang sudah diperkenalkan pada bagian terdahulu lebih menekankan pada
sebuah pohon klasifikasi masih dalam proses pembuatan. Sedangkan konsep
resubstitution estimate pada bagian ini lebih menekankan pada saat pohon
klasifikasi telah terbentuk,
= 1 ≠ .
=1
Cara kerja :
1. Buat pohon klasifikasi dari learning sampleℒ dengan aturan klasifikasi yang
terbentuk .
2. Operasikan pada learning sampleℒ.
3. Hitung proporsi banyaknya objek yang salah terklasifikasikan (misclassified).
4. Nilai proporsi misclassification ini adalah nilai sebagai estimator bagi
commit to user
2. Test Sample Estimate, dinotasikan dengan dan digunakan apabila ukuran
sampel besar,
2. Gunakan ℒ1 untuk membuat pohon klasifikasi dengan aturan klasifikasi yang
terbentuk yaitu .
2. Buat pohon klasifikasi dengan menggunakan V-1 subsampel, sehingga
terbentuk aturan klasifikasi . Subsampel yang tersisa (ℒ�) digunakan
sebagai test sample.
commit to user
4. Ulangi langkah 2 dan 3 dengan menggunakan semua subsampel untuk
membuat pohon klasifikasi kedua kecuali subsampel ℒ�−1. ℒ�−1 sekarang
menjadi test sample dan diperoleh �−1 .
Proses ini diulang terus sampai tiap-tiap subsample digunakan sebagai test
sample.
5. Hitung �
� = 1
� (�) �
�=1
� ini digunakan sebagai estimator bagi ∗ .
Metode resubstitution estimate merupakan metode yang paling lemah. Hal ini
dikarenakan test sample yang digunakan adalah learning sample yang digunakan
untuk membuat pohon klasifikasi itu sendiri sehingga menyebabkan nilai proporsi
misclassification yang terbentuk selalu rendah (underestimate).
Dalam penelitian ini digunakan metode Test Sample Estimate dalam menguji
tingkat keakurasian pohon klasifikasi yang terbentuk karena jumlah sample yang
digunakan besar.
2.1.9 Interpretasi Pohon Klasifikasi
Interpretasi dari pohon klasifikasi yang telah terbentuk disajikan dalam suatu
aturan hubungan (association rules) yang disebut dengan classification rules.
Classification rules adalah aturan pengklasifikasian yang berbentuk if… then…
commit to user
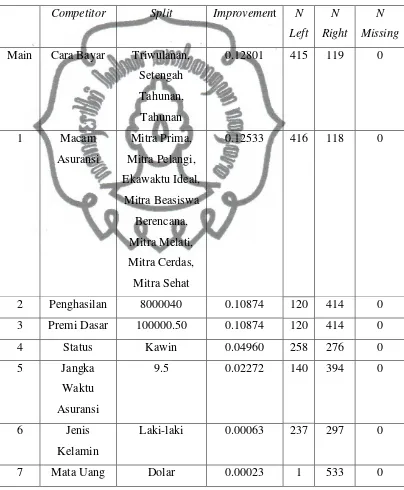
Gambar 4.7. Contoh Pohon Klasifikasi CART
1. jika penghasilan > 1.250 maka kelas Low Risk,
Penghasilan 1.250 Penghasilan >1.250 N=150 Total asset 20.000
High Risk Low Risk N=150
HR=85
commit to user 2.2Kerangka Pemikiran
Dengan mengacu pada tinjauan pustaka di atas dapat disusun suatu kerangka
pemikiran yang mendasari penulisan skripsi ini. Dalam CART variabel dependen
dapat bertipe kategorik (nominal atau ordinal) dan bertipe kontinu atau numerik
(interval atau rasio), untuk variabel dependen yang bertipe kategorik (nominal atau
ordinal) digunakan CART yang menghasilkan classification trees (pohon klasifikasi),
dan dengan pohon klasifikasi tersebut dapat mengklasifikasikan atau
mengelompokkan data nasabah AJB Bumiputera 1912 Surakarta sehingga dapat
dicari pola status nasabah dalam pengambilan keputusan untuk menentukan calon
commit to user
33
BAB III
METODE PENELITIAN
3.1 Sumber Data
Dalam penelitian ini, data yang digunakan adalah data sekunder yang diambil
dari data “Polis Lapse” periode 1 Januari 2010 – 1 Desember 2010 dari perusahaan
asuransi AJB Bumiputera 1912 Surakarta Kantor Cabang Solo Gladag. Penelitian
pada skripsi ini menggunakan data sebanyak 742 dengan variabel dependennya
adalah nasabah dengan kategori status pembayaran tidak lancar dan lancar, sedangkan
variabel independennya yaitu jenis kelamin, cara bayar, jangka waktu asuransi, premi
dasar, penghasilan, status, mata uang dan macam asuransi.
Berdasarkan data yang diperoleh, dilakukan pembuatan pohon klasifikasi
dengan algoritma CART menggunakan bantuan Software Salford Predictive Miner
CART Pro Ex 6.0. Pada pohon klasifikasi, data nasabah dengan status pembayaran
lancar dan tidak lancar dibagi menjadi dua kelompok data yaitu data learning dan
data testing. Karena tidak ada aturan khusus mengenai pembagian proporsi antara
data learning dan data testing maka pada penelitian ini dilakukan tiga kombinasi
proporsi data learning dan data testing yaitu: (1) pembagian data learning dan data
testing dengan proporsi data learning > data testing (70%: 30%), (2) pembagian data
learning dan data testing dengan proporsi data learning = data testing (50% : 50%),
(3) pembagian data learning dan data testing dengan proporsi data learning < data
testing (40% : 60%).
Masing-masing kombinasi data dihitung ketepatan klasifikasi untuk data
testing. Selanjutnya dipilih satu kombinasi proporsi data learning dan data testing
yang memiliki ketepatan klasifikasi data testing terbesar untuk analisis selanjutnya.
Ketepatan klasifikasi pada data testing dijadikan dasar karena dapat menggambarkan
commit to user 3.2 Metode Analisis Data
Penelitian ini dilaksanakan dengan metode studi kasus, yaitu dilakukan
dengan menerapkan teori untuk menganalisis data. Berikut diberikan langkah-langkah
yang dilakukan dalam penelitian ini.
1. Mengumpulkan data dengan mengambil data sekunder dari AJB Bumiputera
1912 Surakarta yaitu data “Polis Lapse” periode 1 Januari 2010 – 1 Desember
2010 dari perusahaan asuransi AJB Bumiputera 1912 Surakarta Kantor Cabang
Solo Gladag.
2. Menentukan variabel dependen dan variabel independen dalam analisis.
Variabel dependennya adalah nasabah dengan kategori tidak lancar dan lancar
sedangkan variabel independennya meliputi adalah jenis kelamin, cara
pembayaran premi (Cara Bayar), jangka waktu asuransi, premi dasar,
penghasilan, status, jenis mata uang (mata uang), macam asuransi.
3. Melakukan pembuatan pohon klasifikasi dengan algoritma CART dengan
menggunakan Software Salford Predictive Miner CART Pro Ex 6.0. dengan
tahap-tahap sebagai berikut
a. Tahap I : Pembentukan atau pembuatan pohon
Langkah 1 : proses splitting nodes
Memilih variabel terbaik dengan nilai improvement atau ∆ , tertinggi
sebagai kriteria dalam memilih variabel yang digunakan untuk memecah
sebuah node.
Langkah 2 : proses class assignment.
Pemberian label kelas pada node-node yang telah terbentuk dimana kelas
yang diidentifikasikan pada node t adalah kelas yang mempunyai
probabilitas paling tinggi daripada kelas lainnya.
b. Tahap II : Proses penghentian pembuatan atau pembentukan pohon
commit to user
Proses splitting node akan berenti karena pada ujung pohon klasifikasi
terdapat terminal node dimana anggotanya terdapat pada kelas yang sama.
c. Tahap III : Pruning the tree yaitu proses pemangkasan atau pemotongan
� menjadi pohon yang lebih kecil (T).
Proses pemangkasan pohon akan terjadi apabila dua child node dan parent
node memenuhi persamaan = + ( ), dimana adalah
parent node, adalah right child node, dan ( ) adalah left child
node.
d. Tahap IV : Proses optimal tree selection yaitu pemilihan atau penentuan
pohon klasifikasi yang optimal.
Pemilihan pohon klasifikasi optimal berdasarkan pada subtree yang
mempunyai nilai test set relative cost terkecil.
4. Menguji tingkat keakuratan pohon dalam mengelompokkan data learning
maupun data testing selanjutnya memilih pohon yang menghasilkan tingkat
akurasi pohon optimal tertinggi .
5. Menginterpretasikan hasil pohon klasifikasi algoritma CART dengan tingkat
akurasi pohon optimal tertinggi dengan data testing sebagai berikut
a. Setiap parent node akan membentuk sekelompok child node dibawahnya
yang akhirnya akan terbentuk segmen-segmen.
b. Kemudian segmen-segmen tersebut diinterpretasi berdasarkan
commit to user
36
BAB IV
PEMBAHASAN
4.1. Deskripsi data
Data yang digunakan dalam pembuatan pohon klasifikasi dengan metode
CART adalah data “Polis Lapse” periode 1 Januari 2010 – 1 Desember 2010 dari
perusahaan asuransi AJB Bumiputera 1912 Surakarta Kantor Cabang Solo Gladag
yang terdapat dalam Lampiran 1. Jumlah data yang digunakan sebanyak 742 buah
data, terdiri dari 8 variabel independen (x) dan 1 variabel dependen (y).
Tabel 4.1. Variabel Independen dan Variabel Dependen
Variabel Nama Tipe Data Pelabelan
y Status Pembayaran Kategorik 1 : Tidak Lancar
2 : Lancar
x1 Jenis Kelamin Kategorik 1 : Laki-laki
2 : Perempuan
x2 Cara Bayar Kategorik 1 : Bulanan
commit to user
Variabel dependen yang digunakan terbagi menjadi dua kelas yaitu kelas tidak
lancar dan kelas lancar.
Data ini diolah dengan menggunakan paket softwareCART Pro Ex 6.0 produk
dari Salford Systems (http://www.salford-systems.com). Ada tiga kondisi yang
digunakan untuk membuat pohon klasifikasi dengan menggunakan algoritma CART.
1. Kondisi pertama adalah pembagian data menjadi dua bagian yaitu data
learning dan data testing dengan proporsi data learning > data testing
(70%:30%).
2. Kondisi kedua adalah pembagian data menjadi dua bagian yaitu data learning
dan data testing dengan proporsi data learning = data testing (50%:50%).
3. Kondisi ketiga pembagian data menjadi dua bagian yaitu data learning dan
data testing dengan proporsi data learning < data testing (40%:60%).
4.2. Hasil Analisis CART
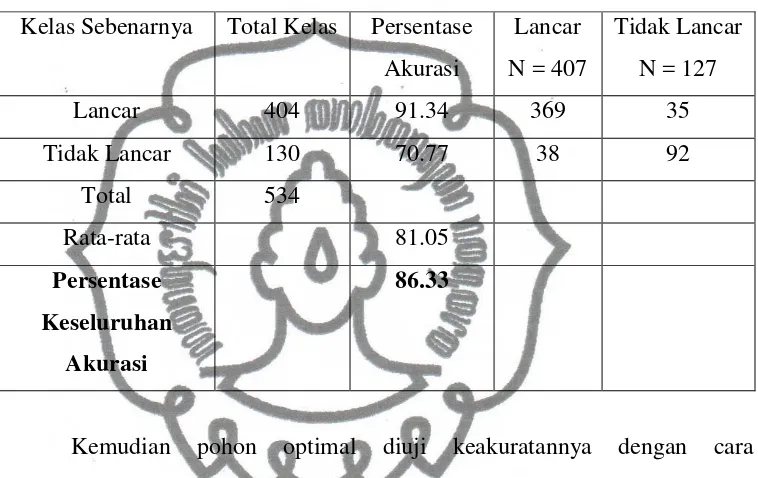
4.2.1. Pembentukan Pohon Klasifikasi Kondisi Pertama
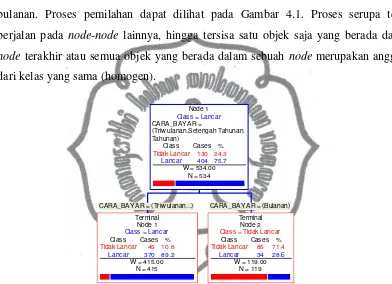
1. Proses Splitting Node
Pada kondisi pertama pembagian data menjadi dua bagian (data
learning dan data testing) dengan proporsi 70%:30%. Dengan demikian data
learning berjumlah 534buah data, sedangkan data testing berjumlah 208 buah
data. Sebelum dilakukan proses splitting node, terlebih dahulu memilih
variabel pemilah terbaik dari kedelapan variabel independen. Pemilahan
variabel berdasarkan kriteria goodness of split. Suatu split s akan digunakan
untuk memecah node t menjadi dua buah node yaitu node dan node
jika s memaksimalkan nilai ∆ ∗, = max ∆ , , dimana ∆ ∗, adalah
nilai yang paling maksimal/tertinggi dari ∆ , . Root node dipecah dengan