Power Dari Uji Kenormalan Data
Dosen Jurusan Teknik Mesin-Fakultas Teknologi Industri, Universitas Kristen Petra Center for Quality Improvement
Jl. Siwalankerto 121-131, Surabaya 60293 [email protected]
Abstrak
Salah satu asumsi dasar yang seringkali dipakai pada aplikasi Six Sigma adalah kenormalan data. Teknik goodness of fit telah banyak dikembangkan untuk mengukur dan membatasi penyimpangan terhadap distribusi normal yang dipakai. Di antara teknik yang telah dikembangkan, yang banyak dipakai adalah Pearson Chi-square test, Kolmogorov-Smirnov test, Cramer-von Mises test, dan Anderson-Darling test.
Dalam makalah ini penulis membandingkan kemampuan keempat uji kenormalan tersebut dalam mengidentifikasi data yang tidak berdistribusi normal. Dalam penelitian ini distribusi dari sumber data yang diujikan adalah uniform dan lognormal. Ukuran sampel yang dipakai adalah 20, 30, dan 40 dengan replikasi sebanyak 100 kali. Penulis memakai tingkat signifikansi sebesar 1%, 5%, dan 10%.
Metode Anderson-Darling menunjukkan superioritas dibandingkan metode-metode yang lain dalam mendeteksi ketidaknormalan, baik untuk data yang berasal dari distribusi lognormal maupun distribusi uninform. Metode Anderson-Darling dan Kolmogorov-Smirnov lebih praktis dalam penggunaannya karena sudah tersedia dalam software Minitab. Namun kepraktisan ini tidak diimbangi dengan fleksibilitas dari Minitab untuk kondisi di mana salah satu atau kedua parameter diketahui.
Kata kunci: goodness of fit test, resiko beta error, Pearson Chi-square, Kolmogorov-Smirnov, Cramer-von Mises, Anderson-Darling
Abstract
One basic assumption frequently used in Six Sigma applications is normality of data. Goodness of fit techniques have been developed to measure and limit deviation from normality. Among those developed techniques that are frequently applied are Pearson Chi-square test, Kolmogorov-Smirnov test, Cramer-von Mises test, and Anderson-Darling test.
In this paper the author compares performance of those four normality tests in detecting non-normality of data generated from non-normal distribution. In this research distributions of generated data are uniform and lognormal. Sample size of 20, 30, and 40 are used with 100 replications. Significance levels of 1%, 5%, and 10% are used in this research.
Anderson-Darling method shows its superiority compared to other methods in detecting non-normality, both for data generated from lognormal distribution and for data generated from uniform distribution. Anderson-Darling and Kolmogorov-Smirnov methods are more practical to use because they are
available in Minitab software. But, their practicality is not accompanied by flexibility of Minitab to accommodate a situation where one or both parameters are known.
Keywords: goodness of fit test, resiko beta error, Pearson Chi-square, Kolmogorov-Smirnov, Cramer-von Mises, Anderson-Darling
1. Latar belakang
Distribusi yang paling sering dipakai dalam aplikasi Six Sigma adalah distribusi normal. Kebanyakan data diasumsikan berditribusi normal setelah diuji kenormalannya. Namun asumsi ini sangat beresiko bila uji kenormalan yang dipakai gagal mendeteksi penyimpangan terhadap distribusi normal yang sangat besar. Para peneliti dan para praktisi di bidang kualitas biasanya melakukan uji kenormalan data dengan memakai beberapa metode yang ada, seperti Anderson-Darling test, Kolmogorov-Smirnov test, Pearson Chi-square test, dan Cramer-von Mises test. Selain keempat metode tersebut, masih ada beberapa metode, seperti metode grafis, Shapiro-Wilk test, dan Fisher’s cumulat test. Namun penulis tidak melakukan pengujian pada ketiga metode terakhir karena metode-metode tersebut kurang populer dibandingkan keempat yang terdahulu.
2. Metode uji kenormalan 2.1. Anderson-Darling test
Metode ini termasuk dalam salah satu uji kenormalan yang mengukur penyimpangan dari empirical distribution function (EDF) terhadap cumulative distribution function (CDF) yang diasumsikan, dalam hal ini adalah distribusi normal. Bila ada n pengamatan diurutkan x(i), maka
EDF Fn(x) didefinisikan sebagai:
, 1, 2, 3, … , (1)
dimana N(x(i) ≤ x) adalah jumlah pengamatan berurut yang kurang dari atau sama dengan x.
Untuk n pengamatan diurutkan x(i), statistik uji Anderson-Darling adalah:
∑ 2 1 ln ln 1 (2)
Nilai A2 hasil perhitungan ini dibandingkan nilai kritis yang besarnya adalah 1.092, 0.787, dan 0.656 untuk α sebesar 1%, 5%, dan 10% dengan scaling factor (1 + 4/n – 25/n2), dimana n adalah jumlah pengamatan [1]. Untuk pengujian dengan metode Anderson-Darling, penulis memakai software Minitab yang akan memberikan informasi mengenai nilai A2 hitung dan p-value.
2.2.Kolmogorov-Smirnov test
Metode Kolmogorov-Smirnov, yang merupakan uji kenormalan paling populer, didasarkan pada nilai D yang didefinisikan sebagai berikut:
sup | | (3)
Pada hakekatnya D adalah nilai deviasi absolut maksimum antara Fn (x) dan F0 (x) [2]. Nilai D
ini selanjutnya dibandingkan dengan nilai D kritis untuk ukuran tes α. Stephens memberikan nilai kritis tersebut untuk berbagai kondisi pengujian [1]. Untuk α = 1%, nilai D kritis adalah 1.035*(√n – 0.01 + 0.85/√n). Sedangkan untuk α = 5% dan α = 10%, nilai D kritis berturut-turut sebesar 0.895*(√n – 0.01 + 0.85/√n) dan 0.819*(√n – 0.01 + 0.85/√n). Software Minitab dapat dipakai untuk melakukan pengujian kenormalan data. Output dari Minitab memberikan nilai statistik D, yang dituliskan sebagai KS, dan p-value.
2.3. Cramer-von Mises test
Metode Cramer-von Mises termasuk statistik EDF yang berbasis ukuran kuadratik sebagaimana metode Anderson-Darling. Statistik uji Cramer-von Mises diberikan oleh rumus:
(4)
Untuk kepraktisan, bila n pengamatan x(i) sudah diurutkan, maka rumus (5) bias dipakai.
∑ . (5)
Nilai W2 hasil perhitungan dibandingkan dengan nilai kritis, yang besarnya berturut-turut adalah 0.178*(1 + 0.5/n), 0.126*(1 + 0.5/n), dan 0.104*(1 + 0.5/n) untuk α sebesar 1%, 5%, dan 10% [1]. Tabel 1 memberikan nilai kritis W2 untuk jumlah sampel 20, 30 dan 40 dan α = 1%, 5%, dan 10%.
Tabel 1. Harga nilai kritis W2 untuk n = 20, 30, 40 dan α = 1%, 5%, 10%
n = 20 n = 30 n = 40
α = 1% α = 5% α = 10% α = 1% α = 5% α = 10% α = 1% α = 5% α = 10% W2 0.1825 0.1292 0.1066 0.1810 0.1281 0.1057 0.1802 0.1276 0.1053
2.4. Pearson Chi-square test
Metode Pearson Chi-square termasuk uji kenormalan yang berbasis statistik uji X2. Statistik X2 diberikan oleh persamaan:
∑ (6)
dimana Ei adalah frekuensi pengamatan sampel yang diharapkan berada dalam kelas i bila
frekuensi sampel dalam setiap kelas interval mengikuti distribusi yang diduga. Sementara, Oi
statistik uji X2 adalah distribusi χ2 dengan derajat kebebasan (k-c-1), dimana k adalah jumlah kelas interval yang tidak kosong dan c adalah jumlah parameter yang akan diestimasi. Dalam eksperimen ini, penulis memakai c = 2 karena ada dua parameter yang akan diestimasi, yaitu mean dan standar deviasi dari distribusi yang diduga.
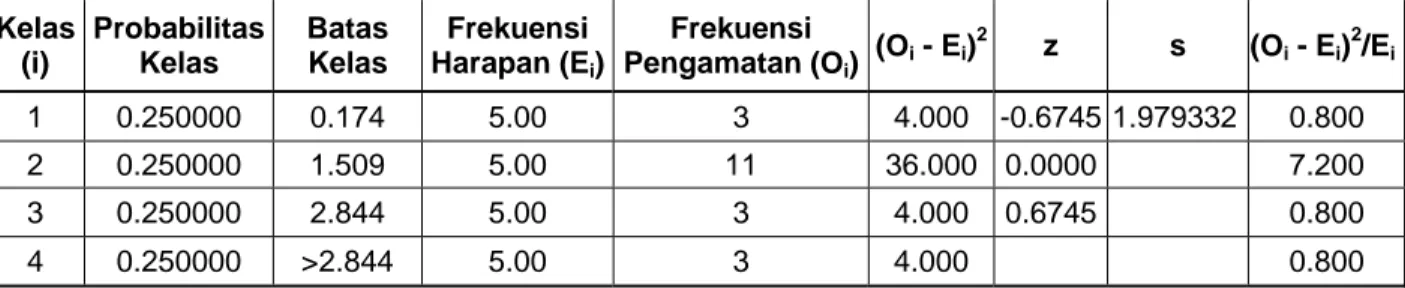
Penulis melakukan eksperimen uji kenormalan dengan metode Pearson Chi-square dengan bantuan software Microsoft Excel. Bagaimana eksperimen dilakukan untuk data di Tabel 2 dengan metode ini digambarkan di Tabel 3. X2 hitung yang didapat dari data ini adalah 9.60. Nilai α yang diperoleh untuk X2 = 9.60 dengan memakai perintah CHIDIST(9.60,1) adalah sebesar 0.19%. Derajat kebebasan yang dipakai adalah 1 karena jumlah kelas interval k = 4, dan c = 2.
Tabel 2 Data Sampel Yang Didapat Dari Distribusi Lognormal
Data # Data Terurut Data # Data Terurut Data # Data Terurut Data # Data Terurut
1 0.086769 6 0.310121 11 0.696137 16 1.952232
2 0.115637 7 0.311585 12 0.781144 17 2.629553
3 0.171858 8 0.450829 13 0.875442 18 3.810904
4 0.188831 9 0.621640 14 1.073498 19 6.459452
5 0.297202 10 0.631605 15 1.656088 20 7.057198
Tabel 3. Uji Kenormalan Dengan Metode Pearson Chi-Square
Kelas (i) Probabilitas Kelas Batas Kelas Frekuensi Harapan (Ei) Frekuensi Pengamatan (Oi) (Oi - Ei) 2 z s (Oi - Ei) 2 /Ei 1 0.250000 0.174 5.00 3 4.000 -0.6745 1.979332 0.800 2 0.250000 1.509 5.00 11 36.000 0.0000 7.200 3 0.250000 2.844 5.00 3 4.000 0.6745 0.800 4 0.250000 >2.844 5.00 3 4.000 0.800 3. Rancangan eksperimen
Keempat metode di atas akan diuji untuk mendeteksi ketidaknormalan data yang dihasilkan dari distribusi lognormal dan uniform. Kedua distribusi tersebut dipilih karena sifat keduanya yang ekstrim. Distribusi uniform biasanya sulit dibedakan dari distribusi normal karena penyimpangannya biasanya tidak ekstrim. Sedangkan, distribusi lognormal dengan location dan scale value tertentu sangat berbeda bentuknya dari distribusi normal. Pengujian terhadap keempat metode dilakukan dengan memakai sampel sebesar 20, 30, dan 40. Setiap kombinasi distribusi dan ukuran sampel dicoba sebanyak 100 replikasi. Rancangan eksperimen pengujian kinerja metode uji kenormalan yang telah didiskusikan di atas digambarkan pada Tabel 4.
Tabel 4. Rancangan Eksperimen Pengujian Kinerja Uji Kenormalan
n Alpha Lognormal Uniform
AD KS PCS CvM AD KS PCS CvM 20 α = 1% α = 5% α = 10% 30 α = 1% α = 5% α = 10% 40 α = 1% α = 5% α = 10%
Catatan: AD = Anderson-Darling, KS = Kolmogorov-Smirnov, PCS = Pearson Chi-square, CvM = Cramer-von Mises
Dalam setiap eksperimen, penulis akan mencatat apakah metode tersebut mendeteksi ketidaknormalan data yang disajikan. Berapa kali metode tersebut menolak asumsi kenormalan data dari 100 replikasi yang dilakukan memberikan gambaran terhadap power dari metode tersebut.
4. Analisa data dan pembahasan
Tabel 5. memberikan hasil ekpserimen pengujian keempat metode uji kenormalan data di atas. Tampak dari tabel tersebut superioritas dari metode Anderson-Darling, khususnya untuk data yang berasal dari distribusi lognormal. Demikian pula untuk data yang berdistribusi uniform, kinerja atau power dari metode Anderson-Darling(AD) tetap lebih unggul dibandingkan dengan ketiga metode yang lain, meskipun masih kurang memuaskan untuk ukuran sampel 20. Berada di urutan kedua adalah metode Cramer-von Mises (CvM). Dibandingkan dengan Anderson-Darling, power dari Cramer-von Mises hanya terpaut sedikit untuk distribusi lognormal. Perbedaan kinerja metode AD dan CvM pada ukuran sampel 30 dan 40 tidak signifikan karena p-value dari perbandingan kedua proporsi adalah sebesar 0.470. Perbedaan terbesar terjadi pada n = 20 dan α = 1%, yaitu 0.83 dan 0.76. Uji proporsi dari kedua hasil menunjukkan perbedaan tersebut juga tidak signifikan karena p-value masih sebesar 0.218. Untuk ditribusi uniform, perbedaan power dari metode Cramer-von Mises dibandingkan metode Anderson-Darling agak jauh bedanya. Uji proporsi yang dilakukan untuk kinerja metode AD dan CvM pada n = 30 dan 40 serta α = 5% dan 10% menunjukkan hasil yang cukup signifikan, yaitu dengan p-value sebesar 0.083.
Tabel 5. Hasil Eksperimen Pengujian Kinerja Uji Kenormalan
n Alpha Lognormal Uniform
AD KS PCS CvM AD KS PCS CvM 20 α = 1% 0.83 0.61 0.41 0.76 0.03 0.00 0.01 0.02 α = 5% 0.90 0.79 0.60 0.85 0.15 0.07 0.02 0.09 α = 10% 0.95 0.85 0.76 0.91 0.22 0.19 0.14 0.17 30 α = 1% 0.97 0.83 0.76 0.95 0.08 0.01 0.01 0.05
α = 5% 0.97 0.94 0.87 0.97 0.33 0.16 0.05 0.17 α = 10% 0.99 0.95 0.88 0.97 0.48 0.26 0.16 0.36 40 α = 1% 0.97 0.90 0.97 0.97 0.15 0.04 0.02 0.07 α = 5% 0.99 0.95 0.97 0.97 0.50 0.20 0.09 0.36 α = 10% 1.00 0.98 0.98 0.98 0.69 0.33 0.14 0.56
1. Data yang ditampilkan adalah power dari metode uji, yaitu persentase menolak asumsi kenormalan dari100 kali pengujian.
2. Kotak yang diarsir adalah hasil terbaik untuk setiap ukuran sampel dan alpha level.
Untuk ditribusi lognormal, kinerja terburuk diberikan oleh metode Pearson Chi-square (PCS) pada ukuran sampel 20 dan 30. Tetapi pada ukuran sampel 40, kinerja PCS sudah setara dengan kinerja metode CvM. Untuk distribusi uniform, kinerja PCS juga tetap yang terburuk.
Tabel 5 juga menunjukkan bahwa lebih sulit mendeteksi ketidaknormalan data yang berasal dari distribusi uniform dibandingkan distribusi lognormal. Sedangkan untuk data yang berasal dari distribusi lognormal dengan ukuran sampel sebesar 30 atau lebih, metode AD dan CvM hampir selalu dapat mendeteksi ketidaknormalannya.
Dari segi kepraktisan, metode KS dan AD lebih praktis karena Minitab sudah menyediakan fungsi. Namun fungsi yang sudah tersedia di Minitab tidak mengakomodasi situasi lain, misalnya bila salah satu atau kedua parameter sudah diketahui dari data masa lalu. Artinya, Minitab hanya menyediakan fungsi uji normalitas untuk data yang tidak diketahui mean dan standar deviasinya. Sementara itu, untuk metode Cramer-von Mises dan Pearson Chi-square penulis harus melakukan perhitungan dengan memakai Excel. Dengan demikian, penulis bisa mengontrol rumus mana yang akan dipakai sesuai dengan kondisi yang terjadi. Dalam percobaan ini, meskipun penulis dengan sengaja memilih besarnya mean dan standar deviasi pada saat memproduksi data secara acak, penulis memilih untuk tidak memasukkan nilai mean dan standar deviasi tersebut agar distribusi normal yang dipakai sebagai pembanding lebih sesuai dengan data yang dibangkitkan. Kondisi ini lebih mewakili situasi di lapangan, yaitu mean dan standar deviasi dari populasi yang akan diuji tidak diketahui.
5. Kesimpulan
• Metode Anderson-Darling menunjukkan superioritas dibandingkan metode-metode yang lain.
• Untuk ukuran sampel 30 atau lebih, ketidaknormalan data yang berasal dari distribusi lognormal hampir selalu terdeteksi. Jumlah sampel lebih dari 30 lebih disarankan untuk memperbesar peluang mendeteksi ketidaknormalan.
• Data yang berasal dari distribusi uniform lebih susah dideteksi ketidaknormalannya.
• Metode Anderson-Darling dan Kolmogorov-Smirnov lebih praktis pengujiannya karena fungsi tersebut sudah tersedia di software Mintab.
6. Daftar rujukan
[1] Stephens, M.A. (1974) “EDF statistics for goodness of fit and some comparisons”, Journal of the American Statistical Association, Vol. 69, No. 347, pp. 730-737.
[2] Tang, L.C., T.N. Goh, H.S. Yam dan Timothy Yoap (2006) Six Sigma: Advanced Tools for Black Belts and Master Black Belts, John Wiley & Sons, Ltd., pp. 153-170.
[3] Anderson, T.W. dan D.A. Darling (1952) “Asymptotic theory of certain ‘goodness of fit’ criteria based on stochastic process”, Annals of Mathematical Statistics, Vol. 23, pp. 193-212.
[4] Feller, W. (1948) “On the Kolmogorov-Smirnov limit theorems for empirical distributions”, Annals of Mathematical Statistics, Vol. 19, pp. 177-189.