Fakultas Ilmu Komputer
1932
Optimasi Pemodelan Regresi Linier Berganda Pada Prediksi Jumlah
Kecelakaan Sepeda Motor Dengan Algoritme Genetika
Sema Yuni Fraticasari1, Dian Eka Ratnawati2, Randy Cahya Wihandika3
Program Studi Teknik Informatika, Fakultas Ilmu Komputer, Universitas Brawijaya Email: 1[email protected], 2[email protected], 3[email protected]
Abstrak
Kecelakaan lalu lintas dari tahun ke tahun semakin meningkat menurut catatan Badan Pusat Statistika dari tahun 1992 hingga tahun 2003. Menurut, World Health Organization (WHO) mencatatat bahwa hampir 3.400 orang per hari meninggal dunia karena kecalakaan lalu lintas. Kota Surabaya merupakan salah satu kota metropolitan yang ada di Indonesia. Pertumbuhan penduduk cukup pesat karena kota Surabaya juga sebagai ibu kota provinsi Jawa Timur. Sistem memprediksi daerah yang sering terjadi kecelakaan lalu lintas berdasarkan parameter yang digunakan antara lain panjang jalan, lebar badan volume, kecepatan, jumlah lajur, jumlah arah, pembatas/median, akses persil dan lebar bahu dengan menggunakan regresi linier berganda yang dioptimasi dengan algoritme genetika. Pada algoritme genetika menggunakan bilangan riil dengan panjang kromosom 10 gen. Metode crossover
yang digunakan extended intermediate crossover sedangkan mutasi menggunakan random mutation, serta seleksi menggunakan elitism selection. Dari hasil uji coba yang dilakukan menghasilkan ukuran populasi yaitu 125, kombinasi cr dan mr yang terbaik yaitu 0,6:0,4 dan generasi terbaik sebanyak 700. Perbandingan tingkat error tanpa optimasi menunjukkan nilai error yang lebih rendah yaitu 0,5% dibandingkan dengan regresi yang menghasilkan nilai error sebesar 1,5 %.
Kata kunci: kecelakaan, prediksi, regresi linier, algoritme genetika
Abstract
Traffic accidents are increasing from year to year according to the Badan Pusat Stastistika record from 1992 to 2003. According to the World Health Organization (WHO), it noted that nearly 3,400 people per day died due to traffic accidents. Surabaya is one of the metropolitan cities in Indonesia. Population growth is quite fast because the city of Surabaya is also the capital of East Java province. The system predicts the area of frequent traffic accidents based on the parameters used such as the length of the road, the width of the volume body, the velocity, the number of lanes, the number of directions, the boundary / median, the plot access and the shoulder width by using linear regression optimized with the genetic algorithm. The genetic algorithm uses real numbers with 10 of gene chromosome lengths. The crossover method used by the extended intermediate crossover while the mutation uses random mutation, and the selection uses elitism selection. From the results of the experiments conducted to produce population is 125, the best combination of cr and mr is 0,6:0,4 and the best generation is 700. Comparison of error rate by showing a lower error value of 0,5% compared with regression Which results in an error value is 1,5%.
Keywords: traffic accidents, prediction, linear regression, genetic algorithm
1. PENDAHULUAN
Pada saat ini jumlah kecelakaan lalu lintas menjadi sorotan di Indonesia. Badan Pusat Statistika telah mencatat angka kecelakaan lalu lintas yang terjadi di Indonesia dari tahun 1992 hingga tahun 2013 mengalami kenaikan (Statistika, 2014). Ini terjadinya karena seiring dengan pertumbuhan jumlah kendaraan semakin
mencatat bahwa hampir 3.400 orang per hari meninggal dunia karena kecelakaan lalu lintas. Selain itu, dari laporan kecelakaan kepaa polisi lalu lintas yang ditampilkan per triwulan rata jumlah kejadian laka masih diatas angka 20.000 kejadian bahkan hampir mencapai 30.000 kejadian.
Angka kecelakaan lalu lintas yang terus meningkat membuat berbagai pihak mencari solusi untuk mencegah terjadinya kecelakaan lalu lintas. Agar terjadi relevan antara solusi yang dihasilkan dengan masalah yang ada, maka diperlukan informasi yang dapat menunjang dari data kecelakaan lalu lintas yang selama ini terjadi. Kepolisian Negara Republik Indonesia memiliki data-data kecelakaan lalu lintas lalu lintas yang telah terjadi. Dari data-data tersebut dapat digali untuk menghasilkan informasi-informasi yang ada di dalamnya. Untuk memudahkan pengolahan data diperlukan suatu metode komputasi data mining agar menghasilkan suatu model yang dapat digunakan untuk memprediksi suatu kejadiaan.
Kota Surabaya merupakan salah satu kota metropolitan yang ada di Indonesia. Pertumbuhan penduduk cukup pesat karena kota Surabaya juga sebagai ibu kota provinsi Jawa Timur. Sistem memprediksi daerah yang sering terjadi kecelakaan lalu lintas berdasarkan parameter yang digunakan antara lain panjang jalan, lebar badan volume, kecepatan, jumlah lajur, jumlah arah, pembatas/median, akses persil dan lebar bahu. Parameter tersebut digunakan untuk memberikan informasi, sehingga dapat di cari solusi pencegahan kecelakaan lalu lintas.
Dari permasalahan yang ada maka dibuat model dengan persamaan regresi linear yang terdiri dari variabel terikat (Y) dan variabel bebas (X) yang dioptimasi dengan algoritme genetika. Alasan mengapa dilakukan optimasi? Karena hasil prediksi dari regresi linier masih menghasilkan error yang cukup tinggi, sehingga dilakukan optimasi pemodelan regresi linier yang diharapkan dapat mengurangi tingkat
error. Dari beberapa jurnal telah menggunakan pemodelan regresi linear menggunakan algoritme genetika untuk menyelesaikan suatu masalah. Salah satunya pada penelitian yang telah dilakukan Arini Indah Permatasari pada tahun 2015 dengan melakukan optimasi pemodelan regresi linear dengan menggunakan algoritme genetika untuk memprediksi jumlah pemakaian kWh listrik di kota Batu. Dari penelitian itu menghasilkan parameter tebaik
yaitu ukuran populasi sebanyak 140, generasi terbaik sebanyak 1250 dengan kombinasi Cr dan Mr yaitu 0.7 dan 0.3 dan menghasilkan nilai
fitness 0.8317476. Untuk perbandingan tingkat
error regresi linear sebesar 860685.5 dan tingkat
error algoritme genetika sebesar 552476.2. Hasil akhir dari percobaan ini yaitu koefisien yang menjadi model regresi (Permatasari, 2015).
Selain itu, penelitian yang juga menggunakan algoritme genetika untuk pemodelan persamaan regresi linear juga dilakukan oleh Fiki Azkiya untuk memprediksi berat badan ideal. Dari penelitian tersebut menghasilkan model persamaan regresi yang terbaik untuk menghitung berat badan sehingga menghasilkan berat badan ideal. Penelitian ini tersebut menggunakan pengkodean riil dengan panjang kromosom 5 dimana pada gen pertama sebagai konstanta dan gen kedua hingga kelima sebagai koefisien (Azkiya, 2015).
2. DASAR TEORI
2.1. Kecelakaan Lalu Lintas
Kecelakaan lalu lintas menurut UU No. 22 Tahun 2009 menjelaskan bahwa suatu peristiwa yang terjadi di jalan yang tidak diduga dan tidak disengaja dengan melibatkan antara pengguna jalan yang mengakibatkan korban dan/atau kerugian harta benda (Undang-Undang, 2009). Pada suatu peristiwa kecelakaan pasti mengandung dilakukan dengan tidak sengaja. Dengan peristiwa yang tidak sengaja sehingga menimbulkan perasaan terkejut, heran dan mengalami trauma pada seseorang yang mengalami peristiwa tersebut (Fajar, 2015). Lain halnya pada peristiwa yang terjadi dengan disengaja dan telah direncanakan sebelumnya, maka peristiwa tersebut tidak termasuk pada kecelakaan lalu lintas. Tetapi termasuk dalam tindak kriminal.
2.2 Regresi Linier
Menurut Sir Francis Galton pada tahun 1886 telah mengemukakan pendapatnya melalui kajian yang dilakukan bahwa tinggi badan anak-anak mengikuti tinggi badan orangtua yang tinggi. Dari situ, Galton memperkenalkan regresi untuk memprediksi variable. Ada beberapa ahli statistik mengembangkan dengan istilah regresi berganda (multiple regression) untuk memproses beberapa variabel digunakan untuk memprediksi variable yang lainnya.
merupakan suatu metode statistika yang menjelaskan tentang model antara dua variable atau lebih. Suatu model hubungan antara variabel terikat (dependen) yang dinotasikan dengan variabel Y dengan satu atau lebih variabel bebas (independen) yang dinotasikan dengan variabel X, sehingga menghasilkan nilai estimasi serta memprediksi nilai rata-rata variabel terikat berdasarkan variabel bebas (Permatasari, 2015). Untuk mengetahui hubungan antara variabel bebas dengan menggunakan regresi linier dapat menggunakan dua bentuk, yaitu:
1. Analisis regresi sederhana (simple analysis regresi)
2. Analisis regresi berganda (multiple analysis regresi)
Adapun perbedaan dari analisis regresi sederhana dengan analisis regresi berganda yaitu terletak pada variabel bebas. Analisis regresi sederhana hanya menggunakan satu variabel bebas dan variabel tak bebas. Sedangkan, analisis regresi berganda menggunakan dua atau lebih variabel bebas dan satu variabel tak bebas.
2.3. Algoritme Genetika
Algoritme genetika merupakan cabang dari algortima evolusi dengan tujuan untuk mendapatkan nilai yang optimum. Algoritme genetika merupakan cabang yang paling popular dan dapat diterapkan pada masalah yang kompleks (Mahmudy, 2015). Teknik pencarian algoritme genetika diadopsi dari proses evolusi alam dengan proses seleksi makhluk hidup dalam sebuah populasi (Zukhri, 2014).
Seperti halnya makhluk hidup, dalam algortima genetika terdiri atas beberapa individu yang berkumpul sehingga membentuk populasi. Individu-individu yang ada pada algoritme genetika disebut kromosom. Kromosom merupakan representasi dari suatu malasah yang akan diselesaikan yang berbentuk kode. Pemetaan proses alamiah ke dalam proses komputasi dapat dilihat pada Tabel 1 (Zukhri, 2014):
Tabel 1. Pemetaan Proses Alamiah ke Proses Komputasi
Proses Alamiah Proses Komputasi
Individu Penyelesaian masalah
Populasi Himpunan penyelesaian
Fitness Kualitas penyelesaian
Kromosom Kode / representasi penyelesaian
Gen Bagian dari representasi
penyelesaian
Pertumbuhan Pengkodean representasi
penyelesaian
Crossover Operator genetika
Mutasi Operator genetika
Seleksi Alam Menyeleksi penyelesaian
masalah (sementara)
berdasarkan kualitasnya
Pada buku Algoritme Genetika mengutip dari penelitian Cole pada tahun 1998, bahwa dalam algoritme genetika proses untuk kromosom-kromosom sebagai populasi oleh operator genetika terjadi secara berulang. Awal mulanya, menentukan populasi awal secara acak sesuai dengan masalah yang ada. Selanjutnya, melakukan reproduksi dengan 2 cara yaitu
crossover dan mutasi. Setelah itu, mencari nilai fitness dari masing-masing kromosom.
Terdapat lima komponen yang utama untuk menyelesaikan algoritme genetika, yaitu sebegai berikut (Michalewicz, 2013):
1. Representasi Kromosom.
2. Populasi Awal.
3. Evaluasi mengurutkan berdasarkan nilai fitness yang ditentukan.
4. Operator genetika yang dapat mengubah komposisi genetika dari
offspring selama reproduksi.
5. Nilai-nilai parameter algoritme genetika.
3. METODOLOGI
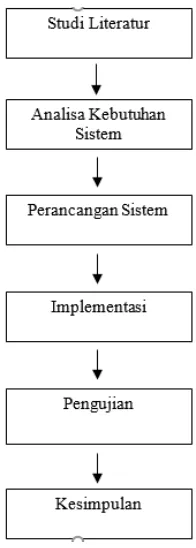
penelitian yang akan digunakan untuk menyelesaikan penelitian ini seperti Gambar 1.
Gambar 1. Tahapan Metodologi Penelitian
3.1. Studi Literatur
Pada tahap ini dilakukan pendalaman mengenai algoritme yang digunakan dalam penelitian. Algoritme ini digunakan sesuai dengan sumber yang telah ada seperti jurnal, buku, e-book, dan situs web yang dapat dipertanggung jawabkan. Algoritme yang digunakan untuk menunjang penelitian ini adalah regresi linier dan dioptimasi dengan algoritme genetika.
3.2. Analisis Kebutuhan
Analisis kebutuhan dilakukan untuk menunjang penelitian. Dari analisis kebutuhan ini diharapkan dapat membantu pengaplikasian dari algortima yang telah dipilih untuk menyelesaikan masalah yang ada.
3.3. Perancangan Sistem
Bertujuan untuk memudahkan proses implementasi dan pengujian. Pada penelitian ini, perancangan dilakukan dengan merancangan antarmuka dan perancangan pengujian yang akan dilakukan.
3.4. Implementasi
Implementasi merupakan kegiatan membangun sistem informasi dengan mengacu kepada perancangan sistem informasi. Fase-fase pada implementasi, antara lain pembuatan user interface dengan menggunakan software
netbeans dan bahasa pemrograman Java serta pembangunan sistem basis data menggunakan DBMS MySQL pada server localhost (XAMPP) yang bertujuan untuk mempermudah dalam pengolahan data.
3.5. Pengujian Sistem
Pengujian bertujuan untuk mengetahui hasil dari kerja sistem berdasarkan data yang digunakan untuk menguji. Tahap pertama yang dilakukan pada pengujian yaitu menguji parameter yang digunakan untuk optimasi. Selanjutnya, dilakukan pengujian hasil metode yang digunakan dan dibandingkan dengan hasil sebelum di optimasi.
3.6. Kesimpulan
Kesimpulan dilakukan setelah semua tahap sebelumnya selesai. Isi dari kesimpulan merupakan jawaban dari pertanyaan yang ada pada subbab rumusan masalah. Selain itu, kesimpulan berisi saran untuk pengembang supaya menghasilkan penelitian yang lebih baik.
4. ALUR PENYELESAIAN MASALAH
MENGGUNAKAN ALGORITME GENETIKA
4.1. Representasi Kromosom
penelitian ini menggunakan kromosom dengan representasi pengkodean riil (real code). Pengkodean riil bisa mengatasi kelemahan pada algoritme genetika dengan menggunakan pengkodean biner untuk optimasi fungsi. Kromosom yang digunakan dibangkitkan secara acak dengan interval yang berbeda pada setiap gen. Lalu untuk menghitung nilai error
menggunakan persamaan 1 dan menghitung
fitness pada persamaan 2.
Tabel 2. Representasi Kromosom
Proses crossover menggunakan metode
extended intermediate crossover dengan
memilih dua parent secara acak dari populasi. Penggunaan metode extended intermediate
crossover bertujuan untuk menghasilkan
offspring yang bervariasi dari kombinasi nilai kedua parent. Dari dua parent itu akan menghasilkan offspring sebanyak dua.
Crossover rate (Cr) yang digunakan yaitu 0,4. Jika popSize =5 maka akan menghasilkan
offspring sebanyak 2. Jumlah offspring
dihasilkan dari Cr x popSize. Seperti yang sudah dijelaskan di atas dari dua parent yang dipilih secara acak akan menghasilkan dua offspring. Jika offspring ganjil, maka pada crossover yang terakhir hanya akan mengambil satu offspring dari dua induk. Nilai α pada kolom pertama
digunakan untuk menghitung semua individu hanya pada kolom pertama. Perhitungan dari proses crossover:
C1 dan C2 pada kolom 1:
Proses mutasi menggunakan metode
random mutation dengan memilih satu individu
induk secara acak dari populasi. Dari satu individu yang terpilih akan menghasilkan satu
offspring. Pada proses mutasi ini menentukan
mutation rate (mr) yaitu 0,2 maka offspring yang dihasilkan sebanyak 0,2 x 5 = 1. Individu yang terpilih secara acak akan mengalami mutasi pada setiap gen yang terpilih secara acak juga. Sebelum masuk pada perhitungan menentukan maksimum dan mininimum pada rentang kromosom yang telah dibuat digunakan sebagai minimum = -100 dan maksimum = 100.
Dimana :
r = 0,021
Perhitungan dari proses mutasi: x1 = x1 + r (max – min)
= 1,982 + 0,021 (100 – (-100)) = 6,182
4.4.Evaluasi dan Seleksi
Pada tahap evaluasi dilakukan proses penghitungan fitness pada setiap kromosom (Mahmudy, 2013). Proses evaluasi meliputi induk serta offspring yang terbentuk dari proses reproduksi. Untuk kromosom yang terpilih sebagai generasi selanjutnya yaitu kromosom yang mempunyai nilai fitness lebih baik, semakin besar nilai fitness yang dihasilkan maka semakin baik pula kromosom tersebut untuk masuk pada generasi selanjutnya (Mahmudy, 2013).
Pada proses seleksi bertujuan untuk menghasilkan individu yang akan bertahan untuk lolos pada generasi selanjutnya. Proses seleksi menggunakan elitism selection dimana dilakukan dengan cara mengambil individu dengan nilai fitness terbaik pada semua individu induk dan offspring untuk masuk pada generasi selanjutnya. Individu yang terambil sebanyak nilai popSize yang telah ditentukan sebelumnya.
5. HASIL DAN PEMBAHASAN
5.1. Hasil dan Analisis Pengujian Ukuran Populasi
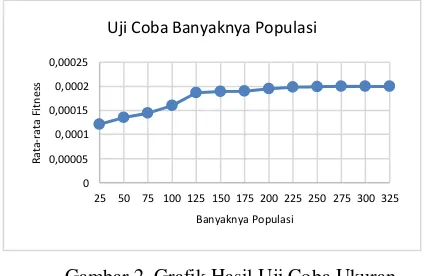
Pengujian yang pertama dilakukan yaitu menguji ukuran populasi untuk menghasilkan ukuran yang paling optimal untuk menghasilkan persamaan regresi linier. Pengujian dilakukan dengan ukuran dari kelipatan 25. Setiap ukuran populasi diuji sebanyak 10 kali percobaan, sehingga didapatkan nilai rata-rata fitness yang paling optimal. Hasil dari percobaan yang telah dilakukan ditunjukkan pada Gambar 2.
Gambar 2. Grafik Hasil Uji Coba Ukuran Populasi
Grafik pada Gambar 2 dapat dilihat bahwa semakin banyak populasi yang digunakan maka akan menghasilkan nilai fitness yang cenderung mengalami kenaikan. Pada grafik ditunjukkan bahwa nilai fitness terendah yaitu populasi 25,
itu disebabkan karena daerah eksplorasi terlalu sempet dan optimasi yang dihasilkan kurang baik. Namun dilihat dari grafik pada populasi sebanyak 125 hingga 250 tidak mengalami kenaikan yang signifikan, hal seperti itu juga terjadi pada penelitian Saputro dengan kasus optimasi penggunaan lahan pertanian(Saputro, et al., 2015). Sehingga pada kasus ini didapatkan populasi yang dengan hasil konvergen pada populasi 300.
5.2.Hasil dan Analisis Pengujian Kombinasi Cr dan Mr
Pengujian dilakukan pada kombinasi nilai
crossover rate dan mutation rate bertujuan untuk mendapatkan kombinasi yang paling tepat supaya dapat digunakan pada masalah ini. Dari masing-masing Cr dan Mr menggunakan metode
extended intermediate crossover dan random
mutation. Setiap kombinasi dari crossover rate
dan mutation rate dilakukan pengujian sebanyak 10 kali percobaan. Pada masalah ini menghasilkan nilai fitness yang tertinggi pada kombinasi cr dan mr yaitu 0,6 dan 0,4 dengan nilai fitness sebesar 7,87x10-4.
Hasil percobaan yang dilakukan ditunjukkan pada Gambar 3.
Gambar 3. Grafik Hasil Uji Coba Kombinasi
Crossover rate dan Mutation rate
Grafik pada Gambar 3 menjelaskan bahwa terdapat nilai fitness yang berbeda pada setiap kombinasi nilai Cr dan Mr. Kombinasi yang tepat dapat menghasilkan solusi yang optimal karena terjadi eksplorasi dan eksplotasi yang seimbang. Jika nilai crossover rate yang dihasilkan lebih rendah sehingga algoritme genetika bergantung pada proses mutasi. Sebaliknya, jika nilai mutasi lebih rendah maka algoritme genetika bergantung pada proses
crossover (Mahmudy, 2013).
5.3. Hasil dan Analisis Pengujian Banyaknya Generasi
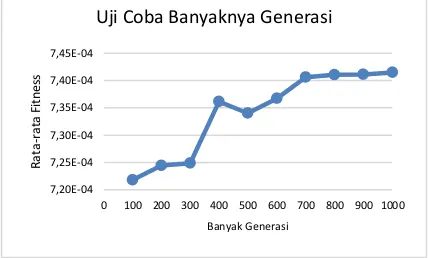
Pegujian pada ukuran banyaknya generasi bertujuan untuk mendapatkan ukuran generasi yang paling optimal. Ukuran generasi yang digunakan pada uji coba yaitu kelipat dari 100 yang dimulai dari 100 hingga 1000. Setiap ukuran generasi dilakukan percobaan sebanyak 10 kali. Hasil percobaan yang dilakukan ditunjukkan pada Gambar 4.
Gambar 4. Grafik Hasil Uji Coba Banyaknya Generasi
Grafik pada Gambar 4 menunjukkan bahwa semakin banyak jumlah generasi mempengaruhi nilai fitness yang dihasilkan. Pada Gambar 6.3 menunjukkan bahwa jumlah generasi 100 menghasilkan nilai fitness paling rendah yaitu sebesar 7,22x10-4. Sedangankan, generasi yang
optimal yaitu pada jumlah generasi 700 dengan nilai fitness sebanyak 7,41x10-4, karena setelah
generasi 700 tidak terdapat kenaikan yang signifikan. Kondisi tersebut dibilang konvergensi, dimana generasi selanjutnya akan menghasilkan nilai yang tidak terpaut jauh sehingga sulit untuk menghasilkan kromosom yang lebih (Mahmudy, 2013). Pada grafik dilihat bahwa semakin banyak jumlah generasi maka nilai fitness juga mengalami kenaikan yang cukup signifikan. Namun, pada titik tertentu pada jumlah generasi nilai fitness yang dihasilkan mengalami kenaikan yang hanya sedikit bahkan tidak terlihat.
5.4. Analisa Perbandingan Hasil Regresi Dengan Algoritme Genetika
Pada pengujian yang terakhir ini yaitu membandingkan hasil dari perhitungan regresi linier dengan algoritme genetika untuk memprediksi jumlah kecelakaan sepeda motor. Hasil dari pengujian sebelumnya dijadikan parameter yaitu hasil uji coba populasi terbaik
dari uji coba banyaknya generasi yaitu 700. Dari hasil sistem dilakukan perbandingan dengan hasil dari perhitungan manual dengan regresi linier berganda pada excel manual. Data sampel yang digunakan untuk perbandingan sebanyak 15 data dari keseluruhan data.
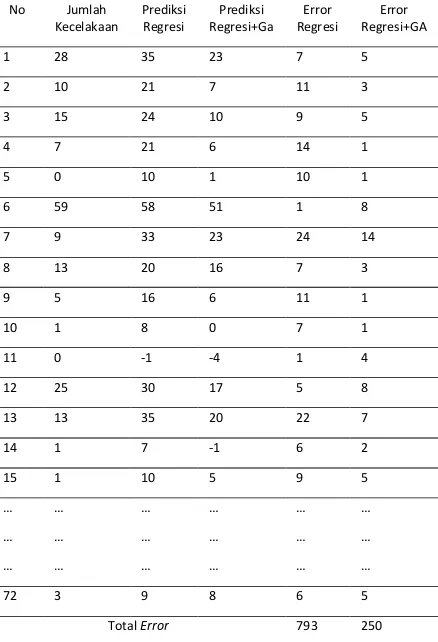
Dari kedua persamaan menghasilkan nilai error yang ditunjukkan pada Tabel 3.
Tabel 3. Hasil Perbandingan Regresi dengan Regresi+GA
Berdasarkan Tabel 3 menunjukkan hasil perbandingan nilai error pada regresi dengan persentase sebanyak 1,5% pada error regresi dan sebesar 0,5% pada error regresi yang telah dioptimasi dengan algoritme genetika.
6. KESIMPULAN
Kesimpulan yang dihasilkan dari penelitian yang telah dilakukan mengenai optimasi persamaan regresi linier berganda untuk prediksi jumlah kecelakaan sepeda motor dengan algoritme genetika dapat dijelaskkan sebagai berikut:
1. Algoritme genetika menggunakan panjang kromosom 10 gen untuk menyelesaikan masalah ini, kromosom tersebut berisi gen yang nantinya akan digunakan untuk persamaan. Gen pertama sebagai koefisien dan yang kesembilan selanjutnya sebagai variabel.
2. Pada proses algoritme genetika menggunakan parameter yang dapat mempengaruhi hasil optimasi. Parameter yang digunakan tidak selalu menghasilkan yang baik. Pada penelitian ini mendapatkan hasil ukuran populasi sebanyak 125 popSize dengan rata-rata nilai fitness 1,87x10-4, hasil
dari kombinasi nilai Cr dan Mr yaitu 0,6:0,4 dengan rata-rata nilai fitness
7,87x10-4, dan banyaknya generasi 700
dengan rata-rata nilai fitness 7,41x10-4.
Proses reproduksi pada crossover
menggunakan metode extended
intermediate dan mutasi menggunakan
metode random mutation. Sedangkan, proses seleksi menggunakan metode
elitism.
3. Persamaan yang dihasilkan dari sistem algoritme genetika ini menunjukkan hasil yang lebih bagus dari pada
persamaan regresi, dengan
menunjukkan nilai error yang lebih rendah yaitu 0,5% dibandingkan dengan regresi yang menghasilkan nilai error
sebesar 1,5%.
7. DAFTAR PUSTAKA
Azkiya, F., 2015. Pemodelan Persamaan
Regresi Linier Berganda Dalam
Memprediksi Berat Badan Ideal
Menggunakan Algoritma Genetika, Malang:
Universitas Brawijaya.
BPS, 2014. Surabaya Dalam Angka 2014
(Surabaya in Figures 2014). Surabaya:
Badan Pusat Statistik Kota Suarabaya.
Fajar, M. S., 2015. Analisis Kecelakaan Lalu Lintans Jalan Raya Di Kota Semarang Menggunakan Metode K-Means Clustering,
Semarang: Universitas Negeri Semarang.
Harahap, G., 1995. Masalah Lalu Lintas dan
Pengembangan Jalan (DPU). Bandung: s.n.
Exponential Smoothing Berbasis Ordered Weighted Aggregation. Jurnal Ilmia NERO,
Volume 1.
Mahmudy, W. F., 2013. Algoritma Evolusi.
Malang: Program Teknologi Informasi dan Ilmu Komputer. Universitas Brawijaya.
Mahmudy, W. F., 2015. Dasar-dasar Algoritma
Evolusi. Malang: Program Teknologi
Informasi dan Ilmu Komputer (PTIIK) Universitas Brawijaya.
Margi, K. & Pendawa, S., 2015. Analisa dan Penerapan Metode Single Exponential Smoothing untuk Prediksi Penjualan Pada Periode Tertentu. Jakarta, s.n.
Michalewicz, Z., 2013. Genetic Algorithms +
Data Structure = Evolution Program. USA:
Spring Science & Business Media.
Permatasari, A. I., 2015. Pemodelan Regresi Linear Dalam Konsumsi KWH Listrik Di
Kota Batu Menggunakan Algoritma
Genetika, Malang: Universitas Brawijaya.
Saputro, H. A., Mahmudy, W. F. & Dewi, C., 2015. Implementasi Algoritma Genetika Untuk Optimasi Penggunaan Lahan Pertanian. Doro: Repository Jurnal Mahasiswa PTIIK Univeristas Brawijaya,
Volume 12.
Statistika, B. P., 2014. Jumlah Kecelakaan, Koban Mati, Luka Berat, Luka Ringan, dan Kerugian Materi yang Diderita Tahun
1992-2013. [Online]
[Accessed 5 Mei 2017].
Undang-Undang, 2009. Undang-Undang Republik Indonesia Nomor 22 Tahun 2009 Tentang Lalu Lintas dan Angkutan Jalan.
Pemerintah Republik Indonesia: s.n.
Zukhri, Z., 2014. Algoritma Genetika Metode Komputasi untuk Menyelesaikan Masalah