Fakultas Ilmu Komputer
Universitas Brawijaya
2909
Analisis Sentimen
Review
Barang Berbahasa Indonesia Dengan Metode
Support Vector Machine
Dan
Query Expansion
Dimas Joko Haryanto1, Lailil Muflikhah2, Mochammad Ali Fauzi3
Program Studi Teknik Informatika, Fakultas Ilmu Komputer, Universitas Brawijaya Email: 1[email protected], 2[email protected], 3[email protected]
Abstrak
Berbelanja secara online sekarang merupakan kegiatan umum yang terjadi pada masyarakat. Berkembangnya jaman membuat seseorang memilih untuk belanja secara online daripada harus melakukan perjalanan ke toko untuk mendapatkan barang yang dibutuhkan. Sebuah review barang yang terdapat pada setiap barang di sebuah toko online dapat berguna untuk melihat bagaimana umpan balik pembeli sebelumnya melalui sebuah komentar. Komentar yang diberikan terdiri dari komentar positif atau komentar negatif. Untuk mengatasi masalah tersebut maka digunakan metode analisis sentimen komentar pada review barang berbahasa Indonesia menggunakan metode SupportVectorMachine dan QueryExpansion. Dalam penelitian ini menggunakan 400 data komentar yang terbagi menjadi dua yaitu positif dan negatif. Adapun metode yang digunakan adalah metode Support Vector Machine kerne Polynomial berderajat dua dengan Query Expansion. Query Expansion digunakan untuk memperluas kata pada data uji yang memiliki sinonim yang tidak terdapat pada data latih. Hasil pengujian akhir menghasilkan rata-rata akurasi sebesar 96,25% dengan parameter nilai learning rate = 0,001, nilai lambda = 0,1, nilai complexity = 0,01 dan iterasi maksimal adalah 50. Berdasarkan hasil pengujian, diperoleh akurasi metode Support Vector Machine dan QueryExpansion sebesar 96,25% dan akurasi menggunakan metode Support Vector Machine tanpa Query Expansion sebesar 94,75%.
Kata kunci: SVM, Query Expansion, Analisis Sentimen, Komentar
Abstract
Shopping an item in online store is a common activity happening to the community now. The rise of time makes someone chooses to shop online rather than having to travel to the store to get what they need. Reviews of each items in an online store can be useful to see how the buyer's previous feedback through a comment. The comments categorized as positive comments or negative comments. Therefore, to overcome the problem then used sentiment analysis reviews of items using Support Vector Machine and Query Expansion method. This research uses 400 data comments that is divided into two comment, that is positive and negative. The method used is Support Vector Macine polynomial kernel with degree two and Query Expansion. Query Expansion is used to expand a word that has synonyms that are not contained in the training data. The final test result yields an average of accuracy is 96,25% with parameter value of learning rate = 0,001, value of lambda = 0,1, value of complexity = 0,01 and maximum iteration is 50. Accuracy of Support Vector Machine and Query Expansion method is better than just using Support Vector Machine method which only gets 94,75% of accuracy.
Keywords: SVM, Query Expansion, Sentiment Analysis, Comment
1. PENDAHULUAN
Kebutuhan masyarakat semakin meningkat seiring dengan mudahnya pembelian barang melalui internet. Pembelian barang sekarang dapat dilakukan mulai dari rumah, kantor atau bahkan tempat alam bebas tanpa perlu harus menemui sang penjual. Review barang yang
online dan kecepatan pengiriman. Pengguna belanja online sering menggunakan komentar dari pengguna sebelumnya ketika mereka akan melakukan pembelian barang (Chen, 2012). Oleh karena itu, pengelompokan review barang dari konsumen dipengaruhi oleh emosi (sentimen) yang dikelompokkan atau diklasifikasikan untuk menentukan kepolarisasiannya yaitu positif atau negatif (Indriati, 2016).
Analisis sentimen mempelajari cara pandang, tingkah laku dan perasaan atau emosi seseorang terhadap sebuah individu, masalah, aktifitas, subjek (Basari, 2013). Analisis sentimen digunakan untuk menganalisis review sebuah barang dari website kemudian mengklasifikasikan komentar tersebut kedalam sentimen positif atau negatif. Teknik klasifikasi yang digunakan pada penelitian-penelitian sebelumnya untuk analisis sentimen adalah Naïve Bayes, Support Vector Machine, dan K-Nearest Neighbor. Beberapa penelitian sebelumnya tentang analisis sentimen pada sebuah review online salah satunya analisis sentimen pada review aplikasi mobile menggunakan metode neighbor weighted k-nearest neighbor (NWKNN) (Indriati, 2016), penelitian tersebut menggunakan NWKNN yang merupakan pengembangan K-Nearest Neighbor dengan menerapkan prinsip pembobotan. Hasil uji dari penelitian tersebut yaitu metode NWKNN mampu melakukan klasifikasi dokumen review aplikasi mobile dengan rata-rata nilai f-measure terbaik sebesar 0.9 pada saat nilai k=20, sementara pada data tidak seimbang diperoleh bahwa nilai k=45 menghasilkan rata-rata nilai f-measure sebesar 0.797. Kedua pengujian tersebut dilakukan pada data latih dan data uji dengan perbandingan 80% dan 20%.
Pada penelitian tentang analisis sentimen tingkat kepuasan pengguna penyedia layanan telekomunikasi seluler Indonesia pada Twitter dengan metode Support Vector Machine dan Lexicon Based Features, peneliti sebelumnya melakukan analisis sentimen tingkat kepuasan masyarakat menggunakan data Twitter mengenai penyedia layanan telekomunikasi seluler. Algoritme yang digunakan pada penelitian tersebut adalah Support Vector Machine Dan Lexicon Based Features dengan menggunakan kernel polynomial berderajat 2 dengan nilai konstanta learning rate 0.0001 dan iterasi maksimum = 50. Data yang digunakan sebanyak 300 data dengan perbandingan 70%
untuk data latih dan 30% untuk data uji. Akurasi yang didapatkan dengan menggunakan metode Support Vector Machine dan Lexicon Based Features sebesar 79%, sedangkan apabila tidak menggunakan metode Lexicon Based Features akurasi yang didapatkan sebesar 84% (Rofiqoh, 2017).
Pada penelitan tentang komparasi teknik klasifikasi teks mining pada analisis sentimen, peneliti sebelumnya menggunakan 3 metode sebagai metode perbandingan pada analisis sentimen yaitu Support Vector Machine, Naïve Bayesian Classification, dan K-Nearest Neighbor. Pada penelitian tersebut digunakan 2 data yaitu data review film dan data Twitter. Data review film yang digunakan berjumlah 1000 data sentimen positif dan 1000 data sentimen negatif. Sementara itu, data Twitter berjumlah 1200 data kicauan yang terdiri dari 600 kelas negatif dan positif. Hasil akhir yang didapat pada data review film yaitu nilai akurasi antara Support Vector Machine dan Naïve Bayes Classification memiliki nilai yang sama yaitu 78.55%, sedangkan K-Nearest Neighbor hanya mendapat nilai 56.7%. Hasil akhir yang didapat pada data Twitter yaitu nilai akurasi dari Support Vector Machine lebih baik dari 2 metode yang lain yaitu sebesar 72%, Naïve Bayesian Classification sebesar 67.33% dan K-Nearest Neighbor sebesar 56.83%. Kesimpulan pada penelitian tersebut menunjukkan bahwa metode Support Vector Machine lebih unggul daripada Naïve Bayesian Classification, sedangkan untuk K-Nearest Neighbor memperoleh hasil jauh dibawah Support Vector Machine ataupun Naïve Bayesian Classification (Ipmawati, 2017).
akurasi yang didapatkan tanpa menerapkan Query Expansion hanya 95% (Firmansyah, 2016).
Analisis sentimen membantu seorang penjual untuk mengevaluasi pendapat dan tingkah laku dari klien terhadap barang mereka, sehingga penjual tersebut mendapatkan review barang mereka secara langsung dari klien dengan menggunakan media sosial seperti Twitteratau komentar pada sebuah toko online. Oleh karena itu, dibutuhkan analisis sentimen untuk menganalisis pandangan seseorang terhadap sebuah barang sehingga bisa meningkatkan daya guna serta penjualan barang tersebut dengan mengetahui kelemahan barang dari sudut pengguna. Pada penelitian ini, hasil akhir yang akan dihasilkan adalah tingkat akurasi yang dicapai dalam melakukan analisis sentimen dengan menggunakan Support Vector Machine dan Query Expansion.
2. DASAR TEORI
2.1 Analisis Sentimen
Analisis sentimen mempelajari pandangan individu, evaluasi, tingkah laku dan perasaan terhadap orang, individu, masalah, aktivitas dan subjek (Basari, 2013). Tujuan dari sentimen analisis adalah memutuskan sikap atau pendapat dari seseorang terhadap suatu topik atau target. Analisis sentimen dapat digunakan untuk menentukan nilai kesukaan atau ketidaksukaan seseorang terhadap suatu barang. Nilai yang sering digunakan pada sentimen analisis yaitu positif dan negatif. Nilai ini dapat digunakan untuk dijadikan parameter dalam pengambilan keputusan.
2.2 Text Mining
Text mining bertujuan untuk menemukan pola yang tersembunyi pada sumber tertentu agar dapat digunakan untuk suatu tujuan (Indriati, 2016). Untuk melakukan analisis pembuat keputusan, maka dibutuhkan data tidak terstruktur yang berjumlah besar dalam bentuk dokumen. Text mining bukanlah sebuah fungsi, akan tetapi kumpulan dari berbagai macam fungsi yang dikombinasikan dan disebut fungsi text mining. Fungsi utama dari text mining meliputi Searching, Information Extraction, Categorization, Summarization, Prioritization, Clustering, Information Monitor dan Question & answers (Mustafa, 2009).
Text mining merupakan bagian dari data
mining, akan tetapi tahapan proses pada text mining lebih banyak dibanding tahapan proses pada data mining, karena data teks memiliki data yang tidak terstruktur sehingga perlu dilakukan beberapa tahap yang pada intinya mengubah data menjadi lebih terstruktur.
2.3 Support Vector Machine
Metode Support Vector Machine (SVM) adalah metode klasifikasi linier dengan menemukan hyperplane terbaik yang berfungsi sebagai pemisah dua buah kelas pada inputspace (Saifinnuha, 2015). Prinsip dasar dari SVM adalah pengklasifikasi linear, kemudian dikembangkan menjadi pengklasifikasi non-linear dengan memasukkan kernel trik pada ruang dimensi tinggi.
Pada umumnya, masalah yang ada di dunia nyata mempunyai bentuk non-linearly separable, sehingga kedua class tidak dapat dipisahkan oleh hyperplane secara sempurna. Maka dari itu, diperlukan modifikasi SVM dengan memasukkan fungsi kernel. Konsep dari SVM non-linear adalah mengubah data x yang dipetakan oleh fungsi 𝛷(𝑥)ke ruang vektor yang memiliki dimensi lebih tinggi. Pemetaan ini bertujuan untuk merepresentasikan data pada ruang vektor baru.
Proses pembelajaran pada SVM saat menemukan support vector hanya bergantung dari dot product dari data yang sudah ditransformasikan pada ruang baru. Nilai dot product dapat dihitung tanpa mengetahui proses transformasi data Φ. Fungsi kernel memberikan kemudahan dalam proses pembelajaran SVM untuk menentukan support vector (Nugroho, 2003).
Fungsi kernel dapat dirumuskan pada Persamaan 1.
𝐾(𝑥𝑖. 𝑥𝑗) = Φ(𝑥𝑖). Φ(𝑥𝑗)
(1)
Tabel 1. Fungsi kernel Nama Kernel Fungsi
Polynomial 𝐾(𝑋𝑖⋅ 𝑋𝑗) = (𝑥𝑖. 𝑥𝑗+ 1)𝑃 Gaussian RBF
𝐾(𝑋𝑖⋅ 𝑋𝑗) = exp (− (‖𝑋𝑖− 𝑋𝑗‖ 2
2𝜎2 ))
Sigmoid 𝐾(𝑋𝑖⋅ 𝑋𝑗) = tanh(𝛼𝑥𝑖. 𝑥𝑗+ 𝛽
2.4 Metode Sequential Support Vector Machine
mempercepat proses iterasi daripada menggunakan solusi konvensional. Langkah-langkah dalam melakukan metode sequential sebagai berikut:
1. Melakukan inisialisasi terhadap parameter yang akan digunakan yaitu λ (lambda), γ (learning rate), C (complexity), ε (epsilon) dan iterasi maksimum.
2. Inisialisasi nilai αi = 0, kemudian hitung matriks dengan Persamaan 2.
𝐷ⅈ𝑗 = 𝑦𝑖𝑦𝑗(𝐾(𝑥1, 𝑥𝑗) + 𝜆2)
(2)
3. Menghitung Persamaan (3), (4), dan (5) untuk memperbarui nilai E dan α. a. 𝐸𝑖= ∑ 𝛼𝑛𝑖 𝑖𝐷𝑖𝑗
(3)
b. 𝛿𝛼𝑖= min{max[𝛾(1 − 𝐸𝑖), −𝛼𝑖] , 𝐶 − 𝛼𝑖}
(4)
c. 𝛼𝑖= 𝛼𝑖+ 𝛿𝛼𝑖(5)
4. Melakukan langkah 3 hingga iterasimaksimum atau Max(|δα|) < ε.
Setelah proses diatas selesai, maka akan didapatkan α dan support vector. Tahap selanjutnya adalah menghitung nilai bias b dengan Persamaan 6.
𝑏 = −12(∑ 𝛼𝑛𝑖=0 𝑖𝑦𝑖𝐾(𝑥𝑖, 𝑥−) + ∑ 𝛼𝑛𝑖=0 𝑖𝑦𝑖𝐾(𝑥𝑖, 𝑥+)) (6) Analisis sentimen dapat dihitung dengan menggunakan Persamaan 7.
𝑓(𝑥) = ∑ 𝛼𝑛𝑖=0 𝑖𝑦𝑖𝐾(𝑥, 𝑥𝑖) + 𝑏 (7)
2.5 Query Expansion
Metode Query Expansion adalah metode membantu mengatasi masalah ketidakcocokan token dengan tambahan term yang relevan. Metode ini telah diterapkan secara luas untuk meningkatkan efisiensi sistem temu kembali (Rivas, 2014). Query Expansion menggambarkan seperangkat teknik untuk memodifikasi kueri agar memenuhi informasi yang dibutuhkan (Selberg, 1997).
Query Expansion digunakan untuk memperluas kata yang tidak terdapat pada data latih, sehingga kata di data uji yang tidak muncul di data latih dapat dilakukan perluasan kata dengan menggunakan data sinonim. Pembentukan data sinonim yang akan digunakan pada Query Expansion dilakukan secara online dengan menggunakan API kateglo. Kateglo adalah aplikasi terbuka yang menyediakan kamus, tesaurus dan glosarium bahasa Indonesia. Sistem akan melakukan akses terhadap Kateglo dengan menggunakan API Kateglo, kemudian hasil yang didapatkan berupa JSON kata tersebut yang memuat definisi, sinonim, antonim, terjemahan, kata turunan, dan gabungan kata. Hasil yang akan diambil hanya
bagian daftar sinonim. Daftar sinonim dari kata tersebut akan disimpan dalam format teks dan digabungkan dengan daftar sinonim dari kata yang lain.
3 METODOLOGI PENELITIAN
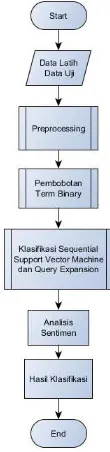
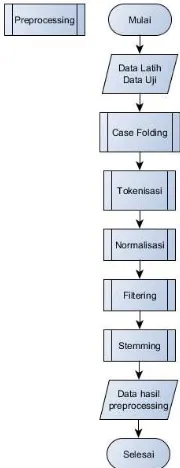
Terdapat beberapa langkah dalam alur sistem ini, langkah awal yaitu memasukkan data latih. Data latih tersebut kemudian dilakukan preprocessing. Preprocessing adalah tahap awal teknik text mining yang digunakan untuk membuat data yang terstruktur dan siap untuk diproses. Data mentah yang digunakan biasanya merupakan data yang tidak terstruktur. Tahapan dalam teknik preprocessing adalah case folding, tokenisasi, normalisasi, filtering dan stemming. Proses stemming akan menggunakan library JSastrawi. Hasil dari preprocessing tersebut akan dilakukan klasifikasi dengan Sequential Support Vector Machine. Nilai bias yang didapat pada proses ini akan digunakan untuk analisis sentimen.
Pada Gambar 1 dilakukan input data latih dan data uji, kemudian dilakukan preprocessing. Pembobotan yang digunakan yaitu pembobotan term binary dimana token berinilai 1 apabila ada dan 0 apabila tidak ada. Proses analisis sentimen akan menentukan data uji yang dimasukkan tergolong positif atau negatif. Pembobotan term binary pada data uji akan mengalami tambahan proses yaitu Query Expansion, dimana Query Expansion akan memperluas pencarian token dengan bantuan data sinonim yang telah dikumpulkan dari API Kateglo.
Data yang digunakan berjumlah 400 data, dimana 200 data adalah komentar positif dan 200 data adalah komentar negatif. Data komentar tersebut didapatkan dari situs tokopedia.com kemudian disalin ke sebuah file .txt. Apabila nilai hasil perhitungan analisis sentimen bernilai lebih dari 0, maka data uji tersebut akan digolongkan menjadi komentar positif, jika nilai hasil perhitungan analisis sentimen bernilai kurang dari 0, maka data uji tersebut akan digolongan menjadi komentar negatif.
4 PENGUJIAN DAN ANALISIS
Pada penelitian ini akan dilakukan pengujian dan anilisis terhadap hasil dari analisis sentimen review barang berbahasa Indonesia menggunakan metode Support Vector Machine dan Query Expansion. Pengujian yang dilakukan pada penelitian ini yaitu pengujian terhadap nilai parameter γ (learning rate), λ (lambda), C (complexity), ε (epsilon) dan iterasi maksimal, serta pengujian perbandingan analisis sentimen dengan Query Expansion dan tanpa Query Expansion. Setiap pengujian dilakukan sebanyak 10 kali dengan menggunakan 10-fold cross validation
4.1 Pengujian Nilai Parameter γ (learning rate)
Pengujian nilai parameter γ (learning rate) dilakukan untuk melihat nilai learning rate mana yang terbaik. Pengujian dilakukan pada nilai
Gambar 2 Analisis nilai parameter learning rate
learning rate = 0,0001, 0,001, 0,01, 0,1, 1, 10, 20. Kernel yang digunakan yaitu polynomial berderajat dua, λ (lambda) = 0,5, C (complexity) = 0,01, ε (epsilon) = 0,00001 dan iterasi = 50. Gambar 3 menunjukkan hasil pengujian parameter learning rate.
Berdasarkan Gambar 3 didapatkan bahwa pengaruh parameter γ (learning rate) pada proses training menghasilkan akurasi terbaik pada nilai γ (learning rate) sebesar 0.001 dan pengujian menggunakan nilai γ (learning rate) = 0.1 membuat akurasi yang didapatkan mulai konvergen. Penurunan akurasi terjadi pada saat nilai γ (learning rate) terlalu besar. Hal ini akan berpengaruh terhadap kecepatan proses learning. Nilai learning rate digunakan untuk perhitungan δα, dimana δα digunakan untuk perhitungan kondisi berhenti iterasi. Nilai δα yang semakin kecil akan menyebabkan nilai Max(|δα|) bernilai < ε. Apabila nilai Max(|δα|) berada dibawah epsilon, maka iterasi sudah berhenti karena nilai δα telah konvergen. Paramater γ (learning rate) yang diinisialisasi dengan tepat dapat meningkatkan akurasi dan mempercepat proses learning.
4.2 Pengujian Nilai Parameter λ (lambda)
Pengujian nilai parameter lambda dilakukan untuk mendapatkan nilai lambda yang menghasilkan akurasi terbaik. Pengujian ini akan menggunakan kernel polynomial berderajat dua, nilai C (complexity) = 0,01, ε (epsilon) = 0,00001 dan iterasi = 50, sedangkan nilai parameter learning rate didapat dari pengujian sebelumnya yaitu 0,001. Nilai lambda yang akan diujikan yaitu 0,1, 0,3, 0,5, 0,7, 0,9, 1, 2, 3, dan 4.
0,00% 20,00% 40,00% 60,00% 80,00% 100,00% 120,00%
Aku
ra
si
Learning Rate
Learning Rate
Gambar 4 Analisis nilai parameter lambda
Berdasarkan Gambar 4 didapatkan bahwa parameter λ (lambda) berpengaruh terhadap hasil akurasi. Hal ini dapat terlihat pada saat λ (lambda) = 0,1 sampai dengan 0,5 menghasilkan akurasi cukup tinggi, kemudian pada saat nilai λ (lambda) = 0,7 mulai terjadi penurunan akurasi hingga λ (lambda) = 2. Kemudian akurasi mengalami peningkatan pada saat λ (lambda) = 3. Nilai λ (lambda) = 0,1 merupakan hasil terbaik dengan akurasi sebesar 96%. Nilai λ (lambda) yang terlalu besar akan mengakibatkan akurasi menjadi rendah. Hal ini terbukti pada saat pengujian menggunakan λ (lambda) = 50 mengakibatkan akurasi yang didapatkan hanya 63,75%. Nilai λ (lambda) yang terlalu besar akan berpengaruh pada saat perhitungan matriks Hessian. Perhitungan matriks Hessian akan menjadi lebih lambat karena nilai λ (lambda) yang besar akan mengakibatkan kecepatan untuk mencapai konvergensi menjadi lebih lambat dan ketidakstabilan pada proses learning (Vijayakumar, 1999).
4.3 Pengujian Nilai Parameter C (complexity)
Pengujian nilai parameter C (complexity) dilakukan untuk mendapatkan nilai C (complexity) yang menghasilkan akurasi terbaik. Nilai complexity yang akan diujikan yaitu 0,0001, 0,001, 0,01, 0,1, 1, 10, dan 20. Parameter yang akan digunakan yaitu γ (learning rate) = 0,001, λ (lambda) = 0,1, ε (epsilon) = 0,00001 dan iterasi = 50.
Gambar 5 Analisis nilai parameter C
Berdasarkan Gambar 5 didapatkan bahwa pengaruh parameter C (complexity) pada proses training berpengaruh terhadap akurasi. Nilai C (complexity) yang terlalu kecil yaitu 0,0001 menyebabkan akurasi yang didapatkan rendah sebesar 59,25% dan mulai meningkat saat nilai C (complexity) semakin besar. Akurasi terbaik didapatkan saat nilai C (complexity) = 0,01 sebesar 96,00%. Hal ini disebabkan karena pengaruh nilai C (complexity) pada perhitungan
δα. δα digunakan untuk mencari nilai α terbaru yang akan ditambahkan dengan nilai α sebelumnya. Nilai δα juga berpengaruh terhadap pencarian support vector. Data support vector yang didapatkan akan berpengaruh terhadap nilai bias b dan nilai bias b akan berpengaruh pada saat proses klasifikasi dokumen.
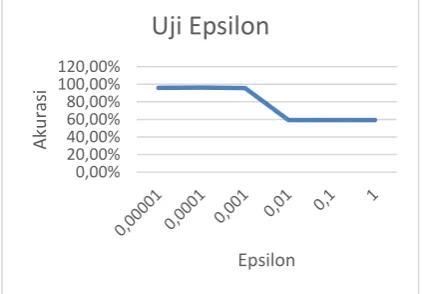
4.4 Pengujian Nilai Parameter ε (epsilon)
Pengujian nilai parameter ε (epsilon) dilakukan untuk mendapatkan nilai ε (epsilon) yang menghasilkan akurasi terbaik. Nilai ε (epsilon) yang akan diujikan yaitu 0,00001, 0,0001, 0,001, 0,01, 0,1, dan 1. Parameter yang akan digunakan yaitu γ (learning rate) = 0,001, λ (lambda) = 0,1, C (complexity) = 0,01 dan iterasi = 50.
Gambar 6 Analisis nilai parameter epsilon
0,00% 20,00% 40,00% 60,00% 80,00% 100,00% 120,00%
0,1 0,3 0,5 0,7 0,9 1 2 3 4
Aku
ra
si
Lambda
Uji Lambda
0,00% 20,00% 40,00% 60,00% 80,00% 100,00% 120,00%
Aku
ra
si
C
Uji C
0,00% 20,00% 40,00% 60,00% 80,00% 100,00% 120,00%
Aku
ra
si
Berdasarkan Gambar 6 didapatkan bahwa nilai ε (epsilon) berpengaruh pada hasil akurasi yang didapatkan. Akurasi terbaik didapatkan saat nilai ε (epsilon) = 0,0001 sebesar 96,25%, kemudian menurun pada saat nilai ε (epsilon) = 0,001 sampai dengan 1. Hal ini karena ε (epsilon) digunakan untuk melihat perubahan nilai α. Apabila max(|δα) < ε, maka perubahan nilai α yang terjadi tidak terlalu signifikan. Akan tetapi, jika nilai ε (epsilon) terlalu besar akan mengakibatkan akurasi rendah karena terjadi konvergensi dini yang berarti iterasi akan berhenti pada saat nilai α yang didapatkan belum optimal.
4.5 Pengujian Nilai Parameter Iterasi
Pengujian nilai parameter iterasi dilakukan untuk mendapatkan nilai iterasi yang menghasilkan akurasi terbaik. Pada pengujian ini, parameter yang akan digunakan adalah parameter dari pengujian sebelumnya yaitu γ (learning rate) = 0,001, λ (lambda) = 0,1, ε (epsilon) = 0,0001, dan C (complexity) = 0,01. Kernel yang akan digunakan yaitu kernel berderajat dua.
Berdasarkan Gambar 7 didapatkan bahwa pengaruh parameter iterasi pada proses learning menghasilkan akurasi yang cenderung stabil. Akurasi terbaik didapatkan pada saat iterasi bernilai 50 sebesar 96,25%. Akurasi yang tinggi disebabkan karena iterasi maksimal memberikan waktu untuk dapat mencapai nilai α yang konvergen dengan dilihat dari perubahan nilai α dan akurasi yang rendah terjadi karena nilai α yang didapat belum mencapai konvergen, sehingga nilai α yang didapatkan belum optimal. Nilai iterasi yang kecil akan menyebabkan semakin sedikit nilai α yang bisa dijadikan support vektor.
Gambar 7 Analisis nilai parameter iterasi
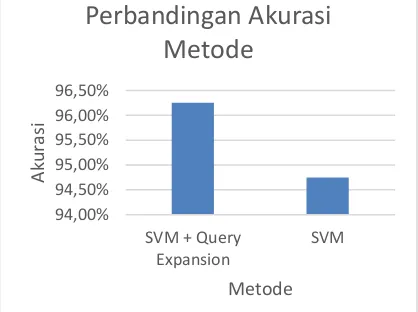
4.6 Perbandigan Akurasi
Query
Expansion
Berdasarkan Gambar 8, didapatkan bahwa terjadi peningkatan akurasi antara metode Support Vector Machine yang menggunakan Query Expansion dibandingkan dengan metode Support Vector Machine yang tidak menggunakan Query Expansion sebesar 1,5%. Pada penggunaan metode Support Vector Machine dan Query Expansion akurasi yang didapatkan sebesar 96,25%, sedangkan pada saat menggunakan metode Support Vector Machine tanpa Query Expansion akurasi yang didapatkan sebesar 94,75%. Hal ini dikarenakan pada pengujian dengan menggunakan Support Vector Machine dan Query Expansion, metode Query Expansion memperluas kata yang terdapat pada data uji dengan menggunakan data sinonim kata yang telah dikumpulkan sebelumnya. Token yang memiliki makna mirip berdasarkan pada data sinonim akan bernilai 1, sehingga token dianggap muncul pada dokumen latih tersebut. Pada pengujian dengan menggunakan Support Vector Machine tanpa menggunakan Query Expansion, hasil yang didapatkan lebih rendah karena terdapat beberapa kata pada data uji yang memiliki makna hampir mirip pada data latih, tetapi tidak dapat dianggap muncul karena penulisan kata yang berbeda, sehingga hasil akurasi menjadi lebih rendah dibandingkan metode Support Vector Machine dengan menggunakan Query Expansion. Perbedaan akurasi yang kecil disebabkan karena data sinonim yang digunakan adalah data dalam bentuk file teks, sehingga metode Query Expansion tetap dapat digunakan apabila sistem tersebut tidak terhubung pada jaringan internet.
Gambar 8 Perbandingan akurasi SVM+QE dan SVM
95,80% 95,90% 96,00% 96,10% 96,20% 96,30%
25 50 75 100 250 500
Aku
ras
i
Iterasi
Uji Iterasi
94,00% 94,50% 95,00% 95,50% 96,00% 96,50%
SVM + Query Expansion
SVM
Aku
ra
si
Metode
Perbandingan Akurasi
5 KESIMPULAN
Metode Support Vector Machine yang diterapkan yaitu Sequential Training SVM dengan tambahan metode Query Expansion dapat diterapkan pada analisis sentimen review barang berbahasa Indonesia. Data yang digunakan yaitu 200 data komentar positif dan 200 data komentar negatif. Data tersebut akan dilakukan preprocessing yaitu case folding, tokenisasi, normalisasi, filtering, dan stemming. Pembobotan token yang digunakan yaitu term binary. Query Expansion digunakan pada saat perhitungan bobot pada data uji. Query Expansion digunakan untuk mendapatkan hasil yang lebih bagus dalam klasifikasi review barang berbahasa Indonesia dengan menggunakan daftar sinonim kata. Parameter terbaik didapatkan pada nilai γ (learning rate) = 0.001, nilai λ (lambda) = 0.1, nilai C (complexity) = 0.01, nilai ε (epsilon) = 0.0001, dan nilai iterasi = 50. Akurasi yang diperoleh dengan menggunakan metode Support Vector Machine dan Query Expansion sebesar 96.25%, sedangkan akurasi yang diperoleh dengan menggunakan metode Support Vector Machine tanpa Query Expansion sebesar 94.75%.
6 DAFTAR PUSTAKA
Basari, A.S.H., Hussin, B., Ananta, I.G.P., Zeniarja, J. 2013. Opinion Mining of Movie Review using Hybrid Method of Support Vector Machine and Particle Swarm Optimization. Procedia Engineering 53 (2013) 453 – 462. Malaysia.
Chen, H., 2012. The Impact of Comments and Recommendation System on Online Shopper Buying Behaviour. Journal of Networks. Beijing.
Firmansyah, R.F.N., Fauzi, M.A., Afirianto, T., 2016. Sentiment Analysis pada Review Aplikasi Mobile Menggunakan Metode Naïve Bayes dan Query Expansion. FILKOM Universitas Brawijaya. Malang
Indriati, Ridok, A. 2016. Sentiment analysis For Review Mobile Applications Using Neighbor Method Weighted K-Nearest Neighbor (NWKNN). Journal of Environmental Engineering & Sustainable Technology. Malang. Ipmawati, J., Kusrini, Luthfi, E.T. 2017.
Komparasi Teknik Klasifikasi Teks
Mining Pada Analisis Sentimen. Indonesian Journal on Networking and Security. Yogyakarta.
Mustafa, A., Akbar, A., Sultas, A., 2009. Knowledge Discovery using Text
Mining: A Programmable
Implementation on Information Extraction and Categorization. International Journal of Multimedia and Ubiquitous Engineering. Pakistan. Nugroho, A.S., Witarto, A.B., Handoko, D.,
2003. Application of Support Vector Machine in Bioinformatics. Proceeding of Indonesian Scientific Meeting in Central Japan. Japan.
Rivas, A.R., Iglesias, E.I., Borrajo, L., 2014. Study of Query Expansion Techniques and Their Application in the Biomedical Information Retrieval. Hindawi Publishing Corporation the Scientific World Journal. Spanyol.
Rofiqoh, U., Perdana, S.P., Fauzi, M.A., 2017. Analisis Sentimen Tingkat Kepuasan Pengguna Penyedia Layanan Telekomunikasi Seluler Indonesia Pada Twitter Dengan Metode Support Vector Machine dan Lexicon Based Features. Jurnal Pengembangan Teknologi Informasi dan Ilmu Komputer. Malang. Saifinnuha, A.Z., 2015. Penerapan Sentimen
Analisis pada Twitter Berbahasa Indonesia untuk Mendapatkan Rating Program Televisi Menggunakan Metode Support Vecotr Machine. S1. Universitas Brawijaya.
Selberg, E.W., 1997. Information Retrieval Advances using Relevance Feedback. Department of Computer Science and Engineering University of Washington. Seattle