EKSTRAKSI INFORMASI UTAMA HALAMAN
WEB
BERITA
MENGGUNAKAN METODE
HYBRID
Septian Devid F.1, Yanuar Firdaus A. W.2, Z. K. Abdurahman Baizal3
1,2
Fakultas Informatika, Institut Teknologi Telkom 3Program Studi Ilmu Komputasi, Institut Teknologi Telkom
1[email protected], 2[email protected], 3[email protected]
Abstrak
Web di internet telah menjadi repository data yang luar biasa besarnya. Telah banyak upaya yang dilakukan untuk menyediakan akses yang efisien terhadap informasi yang relevan di dalam repository data yang sangat besar ini. Salah satu cara untuk menyediakan akses yang efisien ini adalah dengan cara web news content extraction yang memiliki fokus utama mengambil informasi dalam web berita. Pada penelitian ini diimplementasikan metode hybrid untuk mengekstrak informasi utama pada halaman web berita. Teknik ini berusaha mengambil keuntungan dari teknik sequence matching dan tree matching. Struktur data yang digunakan adalah TSReC, yang merupakan salah satu representasi tag sequence yang sesuai untuk kedua teknik sequence matching dan tree matching. Tahap analisis dan pengujian memberikan hasil bahwa metode hybrid yang dibangun terbukti bisa mendapatkan news content pada halaman web berita meskipun pada beberapa dataset masih terdapat noise.
Kata Kunci: web news content extraction, sequence matching, tree matching, TSReC, metode hybrid
Abstract
Web on the internet has become an enormous repository of data. Many efforts to provide efficient access to the relevant information in the very large of data repository. One method to provide efficient access is by web news content extraction with primary focus to take the information in the web news. In this research implemented a method to extract key information on news web pages by using the Hybrid method. This technique is trying to take advantage of the sequence matching techniques and tree matching. The data structure used is TSReC, a variant of tag sequences representation suitable for both sequences matching techniques and tree matching. From analysis and test results stage shown that that Hybrid method is built proved to can get news content on news web pages, although in some datasets, there are still noise.
Keywords: web news content extraction, sequence matching, tree matching, TSReC, hybrid method
1. Pendahuluan
Sejak lahirnya internet, informasi dalam web berkembang secara pesat. Masyarakat yang sebelumnya menggunakan media konvensional sebagai sarana publikasi informasi seperti surat kabar, majalah, tabloid, pamflet, dan sebagainya, mulai beralih memanfaatkan internet karena dirasa lebih efisien dalam mempublikasikan informasi yang mereka hasilkan ataupun untuk mencari informasi yang mereka kehendaki. Akibatnya, informasi yang beredar di internet terus meningkat secara eksponensial.
Informasi yang ditampilkan dalam internet biasanya berupa halaman web yang berformat HTML. Dalam suatu halaman web terdapat berbagai macam informasi yang dapat ditampilkan, walaupun sebenarnya hanya sebagian kecil dari halaman tersebut inti informasi yang ingin disampaikan. Ada berbagai informasi tambahan dari suatu halaman web yang tidak ada hubungannya dengan konten utama dari web tersebut yang disebut dengan noise. Informasi tambahan tersebut diantaranya adalah panel navigasi, event, rela ted links, copyright, sinopsis suatu berita, berbagai macam iklan, dan
lain-lain yang secara keseluruhan bertujuan untuk mempermudah pengguna dalam mengakses informasi dalam halaman web tersebut.
Saat ini para pengguna internet yang akan mengakses informasi lebih dimudahkan dengan adanya layanan mesin pencari yang beragam jenisnya, salah satunya adalah mesin pencari berita yang memiliki fokus utama pada halaman web berita. Dalam sistem mesin pencari ada yang dinamakan dengan proses indexing yang berfungsi untuk untuk mengoptimalkan kecepatan dan kinerja dalam menemukan dokumen yang relevan untuk permintaan pencarian. Tanpa index, mesin pencari akan memeriksa setiap dokumen dalam koleksi dokumen, yang akan memerlukan banyak waktu dan daya komputasi. Secara logika hasil dari suatu query dari mesin pencari akan lebih baik jika proses indexing dilakukan dengan content indexing saja dari suatu halaman website. Oleh sebab itu, diperlukan suatu proses yang dapat memisahkan content utama halaman web dari noise, proses ini disebut dengan ekstraksi web yang menjadi fokus utama dalam penelitian ini.
Wide Web Consortium), hal ini dapat dilihat dari hasil validasi menggunakan markup validator [11]. Masih banyak halaman web memiliki struktur tag yang belum valid. Oleh sebab itu, nantinya sistem ekstraksi web yang dibangun akan diujikan pada dua jenis dataset yaitu mentah dan valid untuk mengetahui pengaruhnya pada performansi sistem. Adapun dalam penelitian ini metode ekstraksi web yang digunakan untuk mengambil informasi utama dari halaman web berita adalah dengan metode hybrid yang merupakan kombinasi atau penggabungan dari konsep tree dan konsep tag sequence.
Tujuan penelitian ini adalah untuk melakukan implementasi ekstraksi informasi utama halaman web berita dengan menggunakan metode hybrid serta melakukan analisis pengaruh penggunaan jumlah dataset yang digunakan dengan kinerja yang ditunjukkan. Selain itu juga akan dilakukan analisis dari perbedaan kinerja dataset mentah dengan dataset yang telah divalidasi dengan validator W3C berdasarkan parameter uji.
Sistematika penulisan hasil penelitian ini meliputi pendahuluan, dasar teori, implementasi, pengujian, dan kesimpulan. Dasar teori yang membahas teori dan teknik yang berkaitan dengan algoritma yang digunakan dalam penelitian ini, sedangkan implementasi meliputi meliputi proses desain template untuk pengenalan pola halaman web berita, melakukan sequence dan tree matching. Bagian pengujian berisi hasil pengujian dan analisis performansi berdasarkan data set yang digunakan. Bagian terakhir yaitu kesimpulan menyatakan resume akhir dari hasil pengujian dan analisis yang telah dilakukan.
2. Web Mining
Web mining dapat dibagi menjadi tiga kategori utama, yaitu content mining, usage mining, dan structure mining
.
Web content mining yaitu merupakan aplikasi untuk menggali, mengekstrak, dan menggabungkan data, informasi dan pengetahuan yang bermanfaat dari isi halaman web [8]. Data web content terdiri dari:a. unstructured data (teks bebas),
b. semi structured data (dokumen HTML), dan c. more structured data (data pada tabel, DB yang
dihasilkan halaman HTML).
Pada penelitian ini memfokuskan kepada web content mining. Web content mining terkadang disebut juga web text mining karena isi teks lebih sering digunakan sebagai penelitian. Teknologi yang biasanya digunakan web content mining adalah NLP dan IR [5,9], tetapi pada penelitian ini memfokuskan kepada IR. Kegunaan web content mining pada World Wide Web antara lain menemukan informasi yang relevan dan menciptakan pengetahuan dari informasi yang ada, sehingga informasi dalam jumlah yang banyak di situs web tetapi mudah untuk
mengaksesnya. Informasi tersebut berupa semi-structured dengan kode HTML, yang mana biasanya halaman web berisi campuran informasi seperti isi utama, iklan, panel navigasi, copyright notice, logo, dan lain-lain.
3. Konsep Metode Hybrid
Metode yang digunakan dalam penelitian ini mencoba untuk mengkombinasikan keuntungan dari teknik berbasis tag sequence dan tree, sehingga disebut sebagai solusi metode hybrid yang diharapkan lebih efisien dan efektif. Gambaran umum dari teknik ini adalah:
a. Menggunakan struktur data representasi halaman web yang diberi nama TSREC (Tag Sequence with Region Code) [7], yang dapat menyimpan informasi struktur pohon yang dibutuhkan. Representasi ini dibangun dari satu kali penindaian HTML dan prose pengkodean region code, sangat cocok sekali untuk tag sequence based dan tree based extraction.
b. Menggunakan algoritma yang efektif berdasarkan TSReC yang berisi dua prosedur yaitu Sequence Matching dan Tree Matching[7]. Prosedur pertama dapat mendeteksi dan menghilangkan bagian yang identik dari halaman web berita, seperti navigation bars, copyright notes. Prosedur yang kedua dapat melakukan matching dan menghilangkan struktur yang sama dari web news pages, seperti advertisement dan activities. Sebagai hasilnya, algoritma ini bisa membedakan web news content dari bagian yang lainnya.
3.1 Definisi Template
Template adalah merupakan halaman web yang belum lengkap yang dijadikan dasar dan dapat di-generate menjadi halaman web yang lengkap dengan mengisi reserved field dengan nilai tertentu (Gambar 1). Template biasanya terdiri atas common part, regular part, dan content part [7]:
a. Common part merupakan reserved teks yang tidak dapat diganti
b. Regular part merupakan reserved rigid structure yang berisi field yang belum terisi yang disiapkan untuk diisi dengan nilai tertentu. c. Content part merupakan reserved area yang
dapat diisi dengan html fragment yang acak/random.
3.2 Tag Sequence with Region Code (TSReC)
Ide dasar dari tag sequence region code adalah memperluas fungsionalitas dari teknik tag sequence yang telah ada dengan menambahkan informasi struktural. Informasi struktural ini mengadopsi konsep region code pada XML processing[6] yang telah terbukti merupakan cara yang ideal menambahkan informasi struktural pada penyimpanan berbasis element. Dengan region code ini, semua relasi struktural seperti parent-child, ascent-decedent dan sibling dapat disimpan.
Algoritma buildTSReC(w) /* w merupakan input 04 int count, level, parent
05 while t = readNextTerm(w) do
Algoritma 1. Build TSReC [7]
Definisi TSReC adalah sequence dari tag-tag element HTML yang memiliki struktur sebagai berikut [7]:
TS = < N,RCb,RCe,RCp,RCl,C>
dengan:
a. N merupakan nama dari TS, biasanya memiliki nama yang sama dengan tag HTML-nya. b. RCb, RCe, RCp, dan RCl adalah region code,
yang equivalent dengan tag begin, tag end, parent, dan level.
c. C merupakan content dari TS, yang bisa saja berisi inner HTML dan teks, ataupun kosong.
TSReC dapat dengan mudah dibangun dengan satu kali scan Web page. Algoritma untuk membangun TSReC merupakan modifikasi dari algoritma konvensional untuk membangun tag tree. Algoritma 1 menunjukkan algoritma untuk membangun TSReC
3.3 Sequence Matching untuk Common Part
Tujuan dari sequence matching adalah untuk mencari common part dari halaman web yang akan diekstrak. Untuk melakukan proses ini, metode hybrid mencoba untuk mengadopsi teknik penghitungan string edit distance atau biasa juga disebut Levenshtein Distance[4]. Operasi yang dilakukan dalam string edit distance di antaranya adalah insert, delete dan substitute[1]. Maksud dari edit distance ini sendiri adalah menghitung jumlah minimum dari operasi insert, delete dan substitution yang dilakukan untuk mengganti string S1 menjadi S2 [2]. Sebagai contoh, edit distance antara “kitten”
dan “sitting” adalah 3, nilai tersebut berasal dari 3
operasi yang dilakukan, yaitu:
a. kitten → sitten (substitution 's' untuk 'k') b. sitten → sittin (substitution 'i' untuk 'e') c. sittin → sitting (insert 'g' diakhir string)[4].
Sehingga pemetaannya adalah:
K i t t e N -
S i t t i N g
Algorithm sequenceMatch(t1,t2)
01 int t1size = sizeof(t1) 02 int t2size = sizeof(t2) 03 int M[t1size+1][t2size+1] and content text then
12 match = 0
Algoritma 2, sequence matching ini menggunakan input berupa dua halaman web yang telah direpresentasikan dalam TSReC. Seperti perhitungan konvensional string edit distance, algoritma ini juga menggunakan teknik dynamic programming (baris 03-19). Dynamic programming digunakan karena efisien dalam pencarian solusi optimal untuk problem yang memiliki banyak overlapping sub-problem [10
].
Berbeda dengan string edit distance yang membandingkan karakter di dalam string, algoritma ini membandingkan TS di dalam TSReC (baris 11). Jika kedua TS yang dibandingkan memiliki nama tag dan konten teks yang sama, maka kedua TS tersebut dianggap sama (cocok).3.4 Tree Matching untuk Regular Part
Pada metode hybrid, sebelum proses tree matching, terlebih dahulu dilakukan proses grouping. Tujuan dari proses grouping adalah untuk mencari tag-tag didalam TSReC yang berada dalam satu sub tree.. Metode grouping ini cukup sederhana yaitu dengan mengecek parent dan tree level TS yang sibling. Jika TS yang sibling memiliki parent dan level tree yang sama, maka TS tersebut berada dalam subtree yang sama sehingga dimasukkan dalam group yang sama dengan cara memperluas jangkauan group region. Sebaliknya jika tidak memiliki parent dan level tree yang sama maka group yang baru akan diciptakan..
Hasil dari proses grouping ini berupa sub tree yang kemungkinan regular atau content parts. Sehingga proses selanjutnya yang akan dilakukan adalah proses untuk membedakan regular part dari bagian yang lainnya. Penentuan apakah suatu sub tree di dalam Web page adalah regular part dihitung dengan membandingkannya dengan sub tree di Web page lain yang sharing rigid pattern.
Fungsi lain yang perlu diperhatikan pada algoritma tree matching adalah fungsi compact Group. Fungsi ini didesign untuk menangani field yang berulang pada regular parts. Pada algoritma compactGroup, dilakukan pengecekan apakah node sibling memiliki patten sequence yang sama.
Setelah proses tree matching, sistem telah dapat mengidentifikasi baik common parts (dengan sequence matching) dan regular parts. Maka sisa bagian dari halaman web merupakan bagian content parts yang dibutuhkan. Dengan mengembalikan bagian ini akan didapatkan content halaman berita yang dibutuhkan.
4. Pengukuran Performansi
Dalam penelitian ini ada tiga parameter yang digunakan untuk mengetahui tingkat keberhasilan sistem yang dibangun, yaitu precision, recall, dan F-Measure.
4.1 Precision, Recall, dan F-Measure
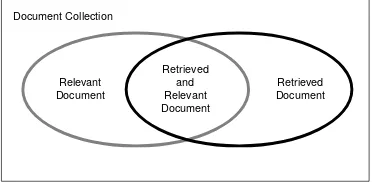
Precision merupakan perbandingan dari pengembalian dokumen yang relevan. Bisa
dikata-kan bahwa precision merupadikata-kan pecahan atau fraction dari dokumen yang didapatkan yang relevan dari informasi yang diinginkan [3].
Precision =
R’: Retrieved Document
Recall merupakan perbandingan dari dokumen relevan yang sudah dikembalikan. Atau bisa dikatakan bahwa recall merupakan fraction dari dokumen yang relevan berdasarkan query atau permintaan yang sukses dijawab atau dikembalikan [3]. Gambar 2 menyajikan illustrasi dari P recision
R’: Retrieved Document
F-Measure didefinisikan sebagai kombinasi dari recall dan precision dengan bobot yang seimbang, rumusan dari F-Measure adalah sebagai berikut [3]:
5. Deskripsi Sistem
Objektivitas yang ingin dicapai dari hasil penelitian ini yakni diharapkan pengguna dapat mengekstrak informasi dari konten beberapa web berita secara otomatis dan mendapatkan nilai akurasi yang dicapai dengan metode hybrid.
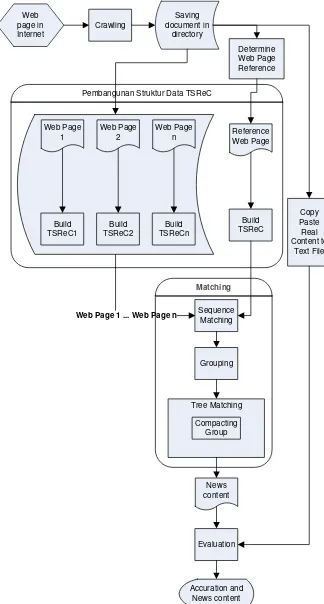
Sistem dibangun menggunakan PHP dengan user interface yang user fiendly sehingga hasil dari sistem akan mudah untuk dioperasikan. Data mentah yang masih dalam bentuk halaman web dan masih mengandung common parts dan regular parts akan diletakkan dalam direktori sesuai nama situs dengan sebelumnya dilakukan proses crawling suatu website dengan menggunakan tools Teleport ataupun secara manual. Setelah dilakukan proses pengekstrakan, content berita yang didapatkan disimpan di database untuk dihitung akurasinya dan selanjutnya disimpan dalam bentuk file txt. Deskripsi sistem ditunjukkan pada Gambar 3.
6. Pengujian dan Analisis
6.1 Skenario Pengujian
Secara garis besar pengujian yang dilakukan dibagi dalam dua tahap. Pada tahap pertama (skenario 1) pengujian dilakukan untuk mengetahui pengaruh jumlah dataset terhadap performansi sistem yang sudah dibangun. Pada tahap kedua (skenario 2,3) dilakukan perbandingan performansi antara dataset mentah dan dataset yang telah di validasi oleh validator W3C.
Adapun rincian skenario pengujian yang dilakukan terhadap sistem ini adalah sebagai berikut: a. Pengujian terhadap pengaruh banyaknya jumlah
dataset yang digunakan terhadap performansi sistem.
b. Pengujian terhadap performansi sistem Web News Content Extraction TSReC yang telah dibangun pada dataset halaman web berita yang masih belum memenuhi standar W3C.
c. Pengujian terhadap performansi sistem Web News Content Extraction TSReC yang telah dibangun pada dataset halaman web berita yang telah divalidasi dengan HTML validator standar W3C.
6.2 Data Uji yang Digunakan
Data uji yang digunakan adalah beberapa halaman web dari berbagai situs berita, dengan 5 kriteria halaman web yang telah memuat content berita secara utuh, bukan cuma headline saja.
Saving
Gambar 3. Deskripsi Sistem
Halaman web yang digunakan sebagai dataset dari berbagai kategori seperti olah raga, politik, budaya, internasional, hiburan dan kategori lainnya (tidak ada ketentuan dalam hal ini). Secara detil website yang digunakan sebagai dataset sejumlah sepuluh website, yaitu:
i. www.pikiran-rakyat.com, dan j. www.vivanews.com
yang masing-masing diambil 51 halaman, dengan komposisi 1 halaman sebagai page reference dan 50 halaman sebagai halaman yang diekstrak. Tidak ada ketentuan khusus dalam penentuan jumlah dataset ini. Jumlah dataset ini diambil dengan pertimbangan untuk mengakomodasi keragaman pola layout dari beragam situs dan untuk mencoba mengetahui adanya perbedaan layout pada beberapa halaman yang berasal dari situs yang sama.
6.3 Analisis Hasil Pengujian
6.3.1 Analisis Pengaruh Jumlah Data terhadap Performansi Sistem
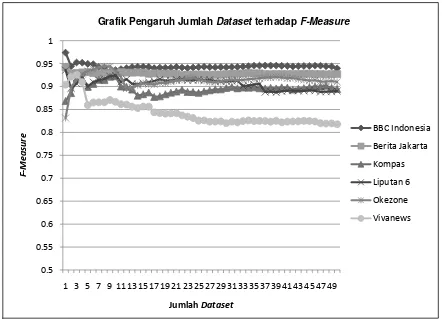
Pengujian ini dilakukan untuk mengetahui keterkaitan antara jumlah da taset yang digunakan dengan performansi yang dihasilkan oleh sistem. Berdasarkan Gambar L-1 dan L-2 pada Lampiran dapat diketahui bahwa pada situs Antara News, Berita Jakarta, BBC Indonesia, Detik, Kompas, Liputan 6, Okezone, dan Viva News jumlah dari dataset yang digunakan tidak terlalu berpengaruh terhadap performansi sistem, hal tersebut terlihat dari grafik yang cenderung stabil walaupun jumlah dataset terus bertambah. Selisih nilai minimum dan maksimum F-Measure dari kedelapan situs tersebut juga sangat kecil, yaitu:
a. Antara News : 0,0763
atau dengan kata lain berapapun jumlah dataset yang digunakan, performansi system akan cenderung stabil.
Untuk dua situs yang tersisa, yaitu Media Indonesia dan Pikiran Rakyat, cenderung tidak memiliki pola tertentu. Pada situs Media Indonesia ketika dataset berjumlah antara 2 sampai 21, nilainya cenderung turun naik dengan angka yang cukup signifikan, tercatat nilai minimum sebesar 0,4457 dan nilai maksimum sebesar 0,7596 sehingga nilai selisihnya yaitu 0,3139. Akan tetapi ketika interval dataset berjumlah 22 keatas performansi yang didapat cenderung stabil dengan selisih nilai minimum dan maksimum sebesar 0,0914.
Sama halnya dengan Media Indonesia, situs Pikiran Rakyat pun memiliki pola yang sama. Interval 2-19 performansi yang ditunjukkan cenderung turun naik dengan nilai yang cukup signifikan dengan nilai minimum 0.0618, nilai maksimum 0,2170 dan selisih sebesar 0,1552. Sedangkan interval 20 – 51 performansi cenderung stabil dengan selisih nilai minimum dan maksimum sebesar 0,0558.
Setelah diperiksa, tidak stabilnya performansi tersebut ternyata terjadi karena walaupun halaman website yang dijadikan dataset saling berhubungan namun terdapat perbedaan yang cukup besar pada layoutnya yaitu pada bagian content part. Sehingga performansi yang ditunjukkan cenderung tidak stabil.
Dari sini dapat diambil kesimpulan bahwa dengan dataset yang cocok dan sesuai dengan metode yang digunakan (seperti pada situs Antara News, Berita Jakarta, BBC Indonesia, Detik, Kompas, Liputan 6, Okezone, dan Viva News), maka pertambahan jumlah dataset tidak akan mempengaruhi performansi sistem.
6.3.2 Analisis Perbandingan Penggunaan Data Mentah dan Valid terhadap Performansi Sistem
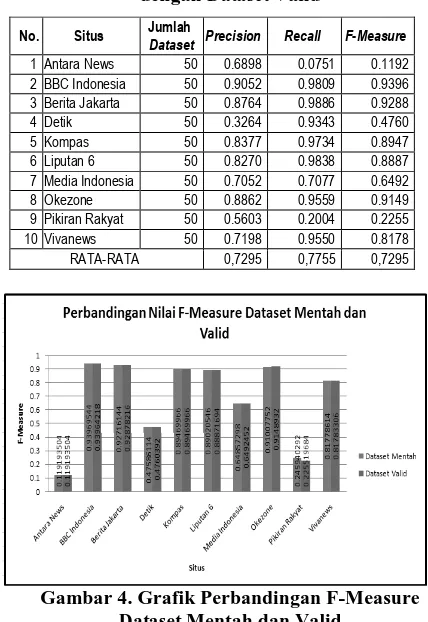
Tabel 1 menyajikan hasil analisis performansi system dengan menggunakan dataset mentah dan valid.
Tabel 1. Hasil Pengukuran Performans Tabel dengan Dataset Mentah
No Situs Jumlah Dataset Precision Recall F -Measure 1 Antara News 50 0,6898 0,0751 0,1192 2 BBC Indonesia 50 0,9053 0,9809 0,9397 3 Berita Jakarta 50 0,8735 0,9886 0,9272
4 Detik 50 0,3270 0,9289 0,4759
5 Kompas 50 0,8377 0,9734 0,8947
6 Liputan 6 50 0,8297 0,9837 0,8902
7 Media Indonesia 50 0,7059 0,7069 0,6486
8 Okezone 50 0,8837 0,9492 0,9101
9 Pikiran Rakyat 50 0,6060 0,2125 0,2459
10 Vivanews 50 0,7197 0,9550 0,8178
RATA-RATA 0,7378 0,7754 0,6869
Tabel 2. Hasil Pengukuran Performansi Tabel dengan Dataset Valid
No. Situs Jumlah Dataset Precision Recall F-Measure 1 Antara News 50 0.6898 0.0751 0.1192 2 BBC Indonesia 50 0.9052 0.9809 0.9396 3 Berita Jakarta 50 0.8764 0.9886 0.9288
4 Detik 50 0.3264 0.9343 0.4760
5 Kompas 50 0.8377 0.9734 0.8947 6 Liputan 6 50 0.8270 0.9838 0.8887 7 Media Indonesia 50 0.7052 0.7077 0.6492 8 Okezone 50 0.8862 0.9559 0.9149 9 Pikiran Rakyat 50 0.5603 0.2004 0.2255 10 Vivanews 50 0.7198 0.9550 0.8178
RATA-RATA 0,7295 0,7755 0,7295
Gambar 4. Grafik Perbandingan F-Measure Dataset Mentah dan Valid
Dari Tabel 1 dan 2 serta Gambar 4 dapat diketahui bahwa, hasil yang diperoleh dari dataset valid cenderung sama dengan dataset mentah, Situs-situs yang mendapatkan nilai tinggi (memiliki kecocokan dengan metode hybrid) pada dataset mentah, juga mendapatkan nilai tinggi pada dataset valid, begitu pula dengan situs-situs yang mendapatkan nilai F-Measure rendah pada dataset mentah juga mendapatkan nilai rendah pada dataset valid, Nilai F-Measure ini bisa sama, karena dalam preprocessing, term-term yang dihilangkan mungkin bukan informasi yang penting dari dataset tersebut.
6.3.3 Analisis Tambahan Peningkatan Performansi
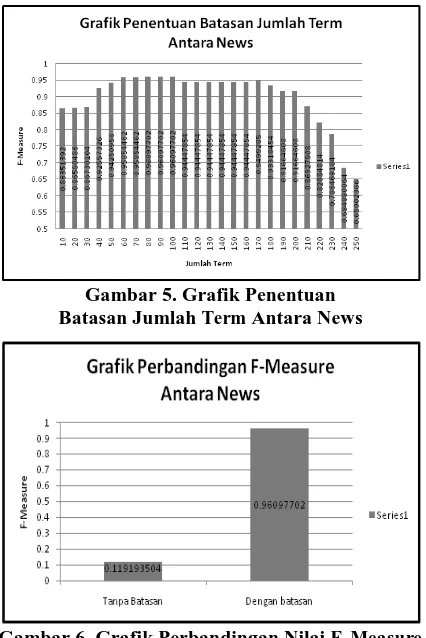
Tujuan dari pengujian ini memperbaiki performansi yang didapatkan oleh situs Antara News dan Pikiran Rakyat, pengujian ini dilakukan dengan cara memberikan batasan jumlah term dari suatu content, sehingga apabila jumlah term suatu group melebihi batas yang telah ditentukan, maka proses compact group akan dibatalkan, Hal ini dapat meminimalisir terjadinya proses kesalahan compact group.
Gambar 5. Grafik Penentuan Batasan Jumlah Term Antara News
Gambar 6. Grafik Perbandingan Nilai F-Measure Dataset Antara News Tanpa Batasan
dan Dengan Batasan Jumlah Term
Gambar 7. Grafik Penentuan Batasan Jumlah Term Pikiran Rakyat
Gambar 8. Grafik Perbandingan Nilai F-Measure Dataset Pikiran Rakyat Tanpa Batasan dan
Dengan Batasan Jumlah Term
Dari Gambar 5 dapat diketahui bahwa performansi sistem di antara interval 10 – 250 memiliki pola naik sampai nilai tertentu dan kemudian turun teratur secara stabil, Nilai performansi tertinggi didapatkan saat batasan jumlah term berada antara interval 80 – 100 yaitu sebesar 0,9610.
Dari Gambar 6 dapat diketahui bahwa nilai F-Measure yang diperoleh tanpa batasan jumlah term sebesar 0,1192 dan nilai F-Measure dengan menggunakan batasan jumlah term sebesar 0,9610. Dari nilai tersebut dapat diperoleh kenaikan performansi yang cukup signifikan sebesar 0,8418.
Sama seperti dataset Antara News, kenaikan performansi dataset Pikiran Rakyat juga cukup signifikan yaitu sebesar 0,7139 yang diperoleh dengan mengambil nilai tertinggi F -Measure yaitu sebesar 0,9598 (Gambar 7 dan 8).
Dari kedua pengujian yang telah dilakukan, dapat disimpulkan penggunaan batasan jumlah term merupakan cara yang cukup efektif untuk menaikkan performansi sistem jika ternyata proses ekstraksi yang dilakukan menghasilkan performansi kurang baik akibat kesalahan proses compact group dalam melaksanakan fungsinya.
7. Kesimpulan dan Saran
7.1 Kesimpulan
Berdasarkan analisis dan pengujian terhadap sistem yang telah dilakukan maka dapat diambil beberapa poin kesimpulan sebagai berikut:
1. Penggunaan jumlah dataset yang berbeda memiliki pengaruh yang bervariasi terhadap performansi parameter precission, recall, dan F-measure yang ditunjukkan, hal ini tergantung dari tingkat similarity page reference dengan page extracted, Semakin similar maka performansi yang ditunjukkan semakin stabil. 2. Penggunaan dataset mentah maupun valid juga
memiliki pengaruh yang bervariasi terhadap performansi precision, recall dan F-measure, tergantung dari proses validasi yang dilakukan oleh validator.
3. Penggunaan batasan term terhadap suatu group (TS yang berada dalam subtree yang sama / sibling ), dapat digunakan sebagai solusi yang sangat efektif untuk meningkatkan performansi sistem jika terjadi kesalahan fungsi proses compact group.
7.2 Saran
Beberapa saran untuk penelitian lebih lanjut, yaitu: 1. Sistem ini akan lebih baik jika
diimplementasikan secara online (misal sebagai plugin browser).
Daftar Pustaka
[1] Bille, Philip, "String Edit Distance and Alignment", Tutorial, 2005.
www.itu.dk/courses/AVA/E2005/StringEditDi stance.pdf, diakses pada 20 Oktober 2009. [2] Dynamic Programming Algorithm for Edit
Distance, http://www.csse.monash.edu.au/ ~lloyd/tildeAlgDS/Dynamic/Edit/ , diakses tanggal 15 Juli 2009.
[3] IR Evaluation, Lecture 9, Lecture Notes of Information Retrieval, Computer Science and Electrical Engineering, University of Maryland,
URL:http://www.cs.umbc.edu/~ian/irF02/lectu res/09Evaluation.pdf
[4] Gonzalo, Navarro, "A guided tour to approximate string matching", ACM
Computing Surveys, 33(1): 31 – 88, 2001. [5] Kosala, Raymond, Hendrik Blockeel, "Web
Mining Research: A Survey", ACM SIGKDD Conference on Knowledge Discovery and Data Mining, July 2000.
[6] Li, Quanzhong, Bongki Moon, "Indexing and Querying XML Data for Regular Path Expressions", In Proceedings of the 27th VLDB Conference, Roma, Italy, 2001.
[7] Li, Y, X. Meng, Q. Li, L. Wang, "Hybrid Method for Automated News Content Extraction from the Web", In Proceedings of 7th Conference on Web Information System Engineering , 327 – 338, 2006.
[8] Liu, Bing, "Web Content Mining", University of Illinois at Chicago, Tutorial, 2005.
http://www.frenchlane.com/WebContent-Mining-4.pdf, diakses tanggal 17 Januari 2009.
[9] Madria, Sanjay Kumar, "Web Mining: A
Bird’s Eye View", University of Missouri-Rolla, Tutorial, 2007.
http://mandolin,cais,ntu,edu,sg/wise2002/web-mining-WISE-30,ppt, diakses tanggal 24 Juli 2009.
[10] McCallum, Andrew, "String Edit Distance (and Intro to Dynamic Programming)", Tutorial, 2006.
www.cs.umass.edu/~mccallum/courses/cl2006 /lect4-stredit.pdf, diakses tanggal 12 Juni 2009 [11] W3C Opensource, "Markup Validation
Lampiran
Gambar L-1. Grafik Pengaruh Jumlah
Dataset
Mentah Terhadap Akurasi Sistem
Gambar L-2. Grafik Pengaruh Jumlah
Dataset
Mentah Terhadap Akurasi Sistem
0.5 0.55 0.6 0.65 0.7 0.75 0.8 0.85 0.9 0.95 1
1 3 5 7 9 11 13 15 17 19 21 23 25 27 29 31 33 35 37 39 41 43 45 47 49
F
-M
e
a
s
u
r
e
Jumlah Dataset
Grafik Pengaruh Jumlah Datasetterhadap F-Measure
BBC Indonesia
Berita Jakarta
Kompas
Liputan 6
Okezone
Vivanews
0 0.1 0.2 0.3 0.4 0.5 0.6 0.7 0.8
1 3 5 7 9 1113151719212325272931333537394143454749
F
-M
e
a
s
u
r
e
Jumlah Dataset
Grafik Pengaruh Jumlah Datasetterhadap F-Measure
Antara News
Detik
Media Indonesia