2011 International Conference
on Asian Language Processing
IALP 2011
Table of Contents
Message from the General Chair...x
Message from the Program Chairs...xi
Message from the Local Organizing Chair...xii
Conference Committees...xiii
Program Committee...xiv
Invited Talks...xvi
Phonology, Morphology, Syntax, and Language Model
A Simplified-Traditional Chinese Character Conversion Model Based on Log-Linear Models ...3Yidong Chen, Xiaodong Shi, and Changle Zhou Improving Chinese Dependency Parsing with Self-Disambiguating Patterns ...7
Likun Qiu, Lei Wu, Kai Zhao, Changjian Hu, and Lingpeng Kong Joint Decoding for Chinese Word Segmentation and POS Tagging Using Character-Based and Word-Based Discriminative Models ...11
Xinxin Li, Xuan Wang, and Lin Yao Natural Language Grammar Induction of Indonesian Language Corpora Using Genetic Algorithm ...15
Arya Tandy Hermawan, Gunawan, and Joan Santoso Error-Driven Adaptive Language Modeling for Chinese Pinyin-to-Character Conversion ...19
Jin Hu Huang and David Powers Theoretical Framework of Mongolian Word Segmentation Specification for Information Processing ...23
Tong Laga and Xiaobing Zhao Research on the Uyghur Information Database for Information Processing ...26
Yusup Ebeydulla, Hesenjan Abliz, and Azragul Yusup Sentence Boundary Detection in Colloquial Arabic Text: A Preliminary Result ...30
Afnan A. Al-Subaihin, Hend S. Al-Khalifa, and AbdulMalik S. Al-Salman A Study of the Classification and Arrangement Rule of Uygur Morphemes for Information Processing ...33
Graph-Based Language Model of Long-Distance Dependency ...37 Faguo Zhou and Xingang Yu
BASRAH: Arabic Verses Meters Identification System ...41 Zainab A. Khalaf, Maytham Alabbas, and Tien-Ping Tan
Semantics
WordNet Editor to Refine Indonesian Language Lexical Database ...47 Gunawan, Jessica Felani Wijoyo, I. Ketut Eddy Purnama, and Mochamad Hariadi
Two Ontological Approaches to Building an Intergrated Semantic Network
for Yami ka-Verbs ...51 Meng-Chien Yang, Si-Wei Huang, and D. Victoria Rau
Issues with the Unergative/Unaccusative Classification of the Intransitive Verbs ...55 Nitesh Surtani, Khushboo Jha, and Soma Paul
A Sentence-Level Semantic Annotated Corpus Based on HNC Theory ...59 Zhiying Liu, Yaohong Jin, and Chuanjiang Miao
An Exploration on the Modes of Word Meaning Extension Based on Metaphorical
and Metonymic Mechanisms ...63 Xiaofang Ouyang
On the Semantic Orientation and Computer Identification of the Chinese Adverb
cai ...67 Lin He and Pengbing Chen
Exploring Both Flat and Structured Features for Number Type Identification
of Chinese Personal Noun Phrases ...71 Jun Lang
Discourse
The Context Imperative Sentences of Modern Chinese ...77 Hao Zhao and Kaihong Yang
Research on Cross-Document Coreference of Chinese Person Name ...81 Ji Ni, Fang Kong, Peifeng Li, and Qiaoming Zhu
Research of Event Pronoun Resolution ...85 Ning Zhang, Fang Kong, and Peifeng Li
Co-reference Resolution in Vietnamese Documents Based on Support Vector
Machines ...89 Duc-Trong Le, Mai-Vu Tran, Tri-Thanh Nguyen, and Quang-Thuy Ha
Research of Noun Phrase Coreference Resolution ...93 Junwei Gao, Fang Kong, Peifeng Li, and Qiaoming Zhu
Discourse Structures of English Exposition ...97 Donghong Liu and Meizhen Liao
Text Understanding and Retrieval
The Comparison of Chinese Spam Filter Based on Generative Model
and Discriminative Model ...107 Yong Han, Yingying Wang, Huafu Ding, and Haoliang Qi
Applying Grapheme, Word, and Syllable Information for Language Identification
in Code Switching Sentences ...111 Yin-Lai Yeong and Tien-Ping Tan
An Integrated Approach Using Conditional Random Fields for Named Entity
Recognition and Person Property Extraction in Vietnamese Text ...115 Hoang-Quynh Le, Mai-Vu Tran, Nhat-Nam Bui, Nguyen-Cuong Phan,
and Quang-Thuy Ha
A Query Reformulation Model Using Markov Graphic Method ...119 Jiali Zuo and Mingwen Wang
Search Results Clustering Based on a Linear Weighting Method of Similarity ...123 Dequan Zheng, Haibo Liu, and Tiejun Zhao
Extracting Pseudo-Labeled Samples for Sentiment Classification Using Emotion
Keywords ...127 Sophia Yat Mei Lee, Daming Dai, Shoushan Li, and Kathleen Ahrens
Imbalanced Sentiment Classification with Multi-strategy Ensemble Learning ...131 Zhongqing Wang, Shoushan Li, Guodong Zhou, Peifeng Li, and Qiaoming Zhu
Formalization and Rules for Recognition of Satirical Irony ...135 Lingpeng Kong and Likun Qiu
Summarization
An Automatic Linguistics Approach for Persian Document Summarization ...141 Hossein Kamyar, Mohsen Kahani, Mohsen Kamyar, and Asef Poormasoomi
Context-Based Persian Multi-document Summarization (Global View) ...145 Asef Poormasoomi, Mohsen Kahani, Saeed Varasteh Yazdi, and Hossein Kamyar
Centroid Integer Selection Model—A High Efficiency Method on Dynamic
Multi-document Summarization ...150 Meiling Liu, Dequan Zheng, Tiejun Zhao, and Yang Yu
Corpus Based Extractive Document Summarization for Indic Script ...154 P. Vijayapal Reddy, B. Vishnu Vardhan, and A. Govardhan
Research on Multi-document Summarization Model Based on Dynamic
Manifold-Ranking ...158 Meiling Liu, Honge Ren, Dequan Zheng, and Tiejun Zhao
Machine Translation
Improving Bilingual Lexicon Construction from Chinese-English Comparable
Corpora via Dependency Relationship Mapping ...169 Hua Xu, Dandan Liu, Longhua Qian, and Guodong Zhou
A Rule-Based Source-Side Reordering on Phrase Structure Subtrees ...173 Fangli Liang, Lei Chen, Miao Li, and Nasun-urtu
Automatic Acquisition of Chinese-Tibetan Multi-word Equivalent Pair
from Bilingual Corpora ...177 Minghua Nuo, Huidan Liu, Longlong Ma, Jian Wu, and Zhiming Ding
Character-Level System Combination: An Empirical Study for English-to-Chinese
Spoken Language Translation ...181 Jinhua Du
Mining Parallel Data from Comparable Corpora via Triangulation ...185 Thi-Ngoc-Diep Do, Eric Castelli, and Laurent Besacier
Using Rich Linguistic and Contextual Information for Tree-Based Statistical
Machine Translation ...189 Bui Thanh Hung, Nguyen Le Minh, and Akira Shimazu
Research on Element Sub-sentence in Chinese-English Patent Machine Translation ...193 Zhiying Liu, Yaohong Jin, and Yuhuan Chi
Lexical Word Similarity for Re-ranking in Vietnamese-English Named Entity Back
Transliteration ...197 Thi Hoang Diem Le and Ai Ti Aw
The Chinese-English Bilingual Sentence Alignment Based on Length ...201 Huafu Ding, Lili Quan, and Haoliang Qi
Optimal Translation Boundaries for BTG-Based Decoding ...205 Xiangyu Duan and Min Zhang
Spoken Language Processing
Acoustic Space in Motor Disorders of Speech: Two Case Studies ...211 Vaishna Narang, Deepshikha Misra, and Garima Dalal
Adopting Malay Syllable Structure for Syllable Based Speech Synthesizer for Iban
and Bidayuh Languages ...216 Sarah F. S. Juan, Vyonne Edwin, Chai Yeen Cheong, Jun Choi Lee, and Alvin W. Yeo
How Vietnamese Attitudes can be Recognized and Confused: Cross-Cultural
Perception and Speech Prosody Analysis ...220 Dang-Khoa Mac, Eric Castelli, Véronique Aubergé, and Albert Rilliard
Non-native Accent Pronunciation Modeling in Automatic Speech Recognition ...224 Basem H.A. Ahmed and Tien-Ping Tan
An In-car Chinese Noise Corpus for Speech Recognition ...228 Jue Hou, Yi Liu, Chao Zhang, and Shilei Huang
Development of Acoustic Space in 3 to 5 Years Old Hindi Speaking Children ...236 Vaishna Narang, Garima Dalal, and Deepshikha Misra
Design of a Query-by-Humming System for Hindi Songs Using DDTW Based
Approach ...240 Prakhar K. Jain, Robin Jain, Hemant A. Patil, and T.K. Basu
Linear Regression for Prosody Prediction via Convex Optimization ...244 Ling Cen, Minghui Dong, and Paul Chan
Analyzing the Relationship between Formants and Pitch for Singing Voice ...248 Hwee Teng Tan and Minghui Dong
Linguistic Resources and Tools
Using HTML Tags to Improve Parallel Resources Extraction ...255 Yanhui Feng, Yu Hong, Wei Tang, Jianmin Yao, and Qiaoming Zhu
Automatic Labeling and Phonetic Assessment for an Unknown Asian Language:
The Case of the “Mo Piu” North Vietnamese Minority (early results) ...260 Geneviève Caelen-Haumont, Sethserey Sam, and Eric Castelli
Automatic Construction of Chinese-Mongolian Parallel Corpora from the Web
Based on the New Heuristic Information ...264 Zede Zhu, Miao Li, Lei Chen, and Shouguo Zheng
Developing Bengali Speech Corpus for Phone Recognizer Using Optimum Text
Selection Technique ...268 Sandipan Mandal, Biswajit Das, Pabitra Mitra, and Anupam Basu
Polarity Shifting: Corpus Construction and Analysis ...272 Xiaoqian Zhang, Shoushan Li, Guodong Zhou, and Hongxia Zhao
Building a Rule-Based Malay Text Segmentation Tool ...276 Bali Ranaivo-Malançon
Language Learning
The Phoneme-Level Articulator Dynamics for Pronunciation Animation ...283 Sheng Li, Lan Wang, and En Qi
The Effect of Arabic Language on Reading English for Arab EFL Learners: An
Eye Tracking Study ...287 Kholod S. Al-Khalifah and Hend S. Al-Khalifa
A Study on Eye Movement of Thai Students Reading Chinese Texts with
or without Marks for Word Boundaries ...291 Yumei Jiao and Peng Yu
Games for Academic Vocabulary Learning through a Virtual Environment ...295 Kiran Pala, Anil Kumar Singh, and Suryakanth V. Gangashetty
Natural Language Grammar Induction of Indonesian Language
Corpora Using Genetic Algorithm
Arya Tandy Hermawan*), Gunawan*,**), Joan Santoso*)
*) Department of Computer Science Sekolah Tinggi Teknik Surabaya
Surabaya, East Java, Indonesia **) Department of Electrical Engineering
Faculty of Industrial Technology Institut Teknologi Sepuluh Nopember
Surabaya, East Java, Indonesia
[email protected], [email protected], [email protected]
Abstract—Grammar Induction is a machine learning process for learning grammar from corpora. This paper will discuss the process of grammar induction for Indonesian language corpora using genetic algorithm. The Grammar production rules will be modeled in the form of chromosomes. The fitness function is used to count how many sentences can be parsed. The data used are Indonesian fairy tales stories such as “Bawang Merah Bawang Putih” and “Malin Kundang”. This paper describes the detailed explanations about the steps of each process carried out for natural language grammar problems.
Keywords-Natural Language Processing; Genetic Algorithm; Indonesian Language; Grammar Induction
I. INTRODUCTION
Grammar induction, also known as grammatical inference, is a process or a machine learning system that aims to produce a set of grammar from the corpus or corpora. The method used in this induction process is genetic algorithm that was developed by John Holland in the 1970's. Many researches have been done in the process of grammar induction using genetic algorithm in [1], [2], [3], and [4]. Research in [1] discusses about development of a CFG induction library, in [3] discusses about structuring a chromosome in CFG Induction using genetic algorithm, and in [4] is about reproduction operator in CFG Induction using genetic algorithm. In previous researches, the induction process is generally done for balanced parentheses and two-symbol palindromes problems in context-free grammar, but it is rarely analyzed in natural language grammar problems. Therefore, this paper will explain how grammar induction process is carried out for natural language grammar problems.
Section 2 describes the flow of the grammar induction process. Section 3 discusses the data used in the process such as corpora selection and preparation. Section 4 discusses the methods used in this paper, such as chromosome structure, crossover method, mutation method, parser, fitness function, and selection method. Section 5 discusses the result of the grammar induction process, section 6 will discuss the conclusion of grammar induction’s result and the last, section 7 suggests for further researches.
II. GRAMMAR INDUCTION PROCESS
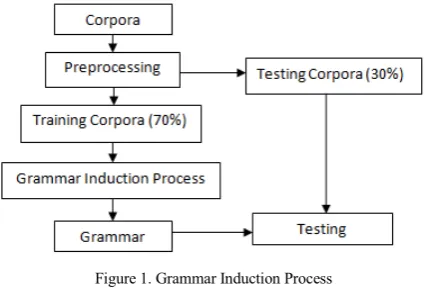
The sequence of grammar induction process is shown in Figure 1. In this induction process, the input data are corpora that will be processed at the preprocessing stage. The data will be divided into training and testing corpora. Next, training data will be used in grammar induction process that will give a grammar as a result. This result will be tested in testing phase.
Figure 1. Grammar Induction Process
III. CORPORA SELECTION AND PREPARATION
Corpora data used in this experiment are the original Indonesian stories such as “Bawang Merah Bawang Putih”, “Malin Kundang”, and a collection of short stories in Kompas of May 2011 and July 2008. The corpora will be divided into one sentence in a row for the POS tagging process. Every word in corpora will be given Indonesian POS tagset [5] using Stanford POS Tagger which is already trained previously.
Corpora data are separated into training and testing data with a distribution of 70 percent training data and 30 percent testing data. The Indonesian POS tagset is considered less effective in the genetic process so that it needs to be reduced. The process of grouping tagset is based on Table 1. Tagset will be used for terminals in the grammar while the number of nonterminal is an input from user. For example, if a corpora contains a sentence as follows:
After being reduced, it will be as follows:
Malin/KB termasuk/KK anak/KB yang/KH cerdas/KS tetapi/KH sedikit/KKT nakal/KS ./.
In that example, the real tagset was converted into reduction tagset based on table 1. NNP Tagset will be converted into KB, VB will be converted into KK, and so on.
This section explains the grammar induction process using genetic algorithm such as how to create a chromosome, the crossover operators and mutation that are used, the parser, the fitness function, and the selection method. The genetic algorithm in this induction process is carried out continuously until the number of generations completed.
A. Chromosome Structure
Chromosome representation used in this induction process is integer representation, whereas chromosome representations in reference [3] is different because it uses binary representation. Each nonterminal and terminal symbol are denoted by integer numbers. All nonterminal symbols are modeled starting from 0 to a certain negative value, while the terminal symbols are modeled starting from 1 to a certain positive integer value. In forming a chromosome, there are some rules to meet for valid chromosomes. There are as follows:
1. The number of nonterminal symbol is determined by the total parameters percentage of the existing terminals. For example the number of terminal is 13 and the parameter is 50% so that the number of terminal will be 6.
2. The terminal symbols that are used must exist in the corpora, otherwise the terminal can not be included in the formation of chromosome. For example, the terminal symbols in the corpus are KB, KS, KK, and “.” so that the input tagset are KB, KS, KK, and “.”. 3. The number of left hand side symbol in the rule is 1
and it is a nonterminal symbol.
4. The maximum number of existing symbols on right hand side of the rule must be defined using a parameter.
5. The number of production rules must be defined so that the length of chromosome can be obtained by multiplying the number of production rules with its length. The length of production rules can be obtained from the addition of total symbols on the left hand side and total symbols on the right hand side.
6. Comparison Ratio between the number of nonterminal and terminal symbols must be determined to make the nonterminal and terminal symbols proportional in the chromosome.
7. Probability for first symbol on the RHS is a nonterminal symbol must be determined. This is due after some observations, most first symbol on the RHS is terminal symbol.
8. The number of symbols on the Right Hand Side for each production rule should vary from 1 to the maximum number of symbols that are distributed uniformly. To create the same length chromosome rule we must add help symbol that is represented by U (Unused) symbol or 99 in integer symbol representation. This is used for filling the empty genes in one block so that all rules in chromosome will have same length.
9. All nonterminal and terminal symbols are distributed uniformly in the chromosome according to comparison ratio between the number of nonterminal and terminal symbols.
With the given constraints, it is expected that the grammar result is valid and able to produce an optimal grammar. Figure 2 shows examples of chromosome structure.
The number of production rules in one chromosome : 10 The number of maximum symbols on right hand side : 3
Percentage of the number of nonterminal obtained from the number of terminal : 0.5
Probability that first symbol on right hand side is nonterminal : 0.2 Comparation ratio between nonterminal and terminal : 0.3 Tagset used in chromosome :
Chromosome :
0 -1 99 99 0 -1 99 99 -1 3 99 99 -1 1 4 0 -1 1 0 99 -1 2 3 3 0 2 2 0 -1 4 99 99 0 3 4 99 0 1 1 99
Chromosome divided into blocks :
0 -1 99 99 | 0 -1 99 99 | -1 3 99 99 | -1 1 4 0 | -1 1 0 99 | -1 2 3 3 | 0 2 2 0 | -1 4 99 99 | 0 3 4 99 | 0 1 1 99
Result of chromosome to be converted from Integer symbol convert to string symbol :
S B U U |S B U U | B KK U U | B KB . S | B KB S U | B KS KK KK | S KS KS S | B . U U | S KK . U | S KB KB U
Grammar :
No. Tagset Chromosome Symbol
1. S 0
In figure 2, the nonterminal symbols are S and B, the terminal symbols are KB (Kata Benda) for noun, KS (Kata Sifat) for adjective, KK (Kata Kerja) for verb, and “.” for end of sentence. Based on chromosome structure that was explained before, it can be concluded that the parameters used in the chromosome structure process are :
1. The Number of production rules in one chromosome.
2. The Number of maximum symbols on right hand side.
3. Percentage of the number of nonterminal obtained from the number of terminal.
4. Probability that first symbol on right hand side is a nonterminal symbol.
5. Comparison ratio between nonterminal and terminal in chromosome.
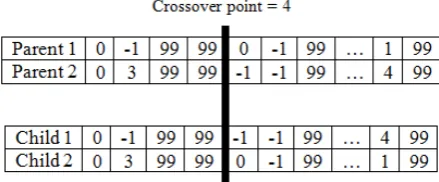
B. Crossover
Crossover operator used in grammar induction process is single point crossover. The process of crossover is generated randomly when the value is smaller than a given crossover probability. Crossover can be done by determining the crossing point and swapping the remaining symbols. The example of crossover operation process can be seen in figure 3.
Figure 3. Crossover Example
C. Mutation
Mutation operator used is uniform mutation method. The mutation generated randomly if the value is smaller than the given mutation probability. Mutation will be done by swapping the nonterminal with terminal symbol, and vice versa. Restriction is given to the mutation if the position of the mutation point is left hand side. In that condition the exchanged symbol is nonterminal symbol only, but if the exchanged symbol is not on the left hand side it can be nonterminal or terminal symbol. The example of mutation process can be seen in figure 4.
Figure 4. Mutation Example
D. Parser
Parser plays an important role in the fitness function. In grammar induction process, the parser used is Earley Parser [6]. This parser is one type of chart parsing. This parser is selected because it can handle left recursion and ambiguity.
This parser is used to determine whether the chromosome or the resulting grammar can parse the sentences in the training corpora or not. Parser will return success or fail result from each sentence parsed in training corpora. In the fitness function, parser will be used to determine how many sentences that can be parsed from the training corpora.
E. Fitness Function
Fitness function is used to assess how well the grammar from the genetic process. Fitness function used is based on how many sentences can be parsed by the chromosome or the grammar of an individual. Fitness function used is as follows:
Where C(X) is the number of sentences that can be parsed by the parser and N(X) is the number of sentences in the corpora.
F. Selection Method
There are various methods used in the selection of genetic algorithm such as roulette wheel, tournament, etc. The method used for selection in grammar induction process is roulette wheel. Roulette wheel is a method which is often used in genetic algorithm. The grammar or chromosome that will be selected is the chromosome or grammar with the highest fitness.
V. TESTING AND RESULT
This section will discuss the result of experiments that have been performed. Experiments carried out at 4 corpora, which are “Bawang Merah Bawang Putih”, the story of “Malin Kundang”, a collection of three short stories in Kompas May 2011 and July 2008. The first experiment uses “Bawang Merah Bawang Putih”, the second uses “Malin Kundang”, and the third experiment uses a collection of three short stories in Kompas May 2011, and the last or fourth experiment uses a collection of three short stories in Kompas July 2008. Parser used in this testing phase is Earley Parser [6]. The result of this process can be seen in Table 3.
An example of the result grammar from grammar induction process can be seen in table 4. Grammar in table 4 is a grammar from Bawang Merah Bawang Putih story. The nonterminal symbols in table 4 are S, B, C, E, D, and E which is generated automatically.
percentage of the number of nonterminal obtained from the number of terminal is 50% and the probability for the first symbol is nonterminal used from 0.2 to 0.3. For the comparison ratio between nonterminal and terminal in chromosome is 0.3. For the crossover probability is 0.6 to 0.9 and the mutation probability is 0.5 to 0.9.
For testing process, we use the grammar from training process and parse the sentences in testing corpora and count how many sentences can be parsed from that grammar. The more sentences can be parsed in testing corpora, the better result of the experiment is gained.
TABLE II. PARAMETER FOR EACH EXPERIMENT
Experiments 1st 2nd 3rd 4th
The number of production rules
in one chromosome 120 120 120 120
The number of maximum symbols
on right hand side 3 3 3 4
Percentage of the number of nonterminal obtained from the number of terminal
50% 50% 50% 50%
Probability that first symbol on right hand side is a nonterminal symbol
0.2 0.3 0.2 0.3
Comparison ratio between nonterminal and terminal in chromosome
0.3 0.3 0.3 0.3
Crossover probability 0.8 0.6 0.8 0.7
Mutation probability 0.9 0.5 0.9 0.5
TABLE III. TESTING RESULT FOR EACH EXPERIMENT
Experiments 1st 2nd 3rd 4th
The number of terminal
symbols 13 11 13 13
The number of nonterminal
symbols 6 5 6 6
The number of sentences
from the training corpora 60 35 167 272
Fitness value 83.37 77.23 97.01 94.85
Testing(how many sentences can be parsed from testing corpora)
Parameters shown in table 2 are used to obtain the best experiment result and the result is shown in table 3. The result shown is quite accurate from the first experiment to the fourth one. Table 4 shows one example of the grammar which is relatively different from Indonesian language grammar but it can be used to parse the document accurately.
VI. CONCLUSION
From this experiment, several things can be concluded, such as tagset reduction plays an important role in the level of grammatical complexity. The reason why tagset needs to be reduced is that the real tagset causes the genetic process ineffective.
The total of production rules in a chromosome is proportional to the number of terminal symbols that are used in the process of grammar induction. In the formation of chromosome, the rule for structuring a chromosome play a vital role for creating a good chromosome. The number of comparison terminal and nonterminal symbols are also important. Parser plays a very important role in the fitness function and testing process.
The result is not common in Indonesian language grammar but it matches to the corpora grammar and the structure is different from grammar that is designed by human manually. This is due to the reduction of the tagset that make the grammar not detailed.
VII. FURTHER RESEARCH
Based on the research that has been done, some things that can be improved to increase accuracy such as the rule of tagset reduction that is used should be examined again so that the result can be better.
ACKNOWLEDGMENT
We would like to thank to all participants who helped and supported us in doing this experiment. We also hope that our experiment can be useful for other NLP experiments. With this method offered, it is expected that, this grammar induction process can be used for other languages. Tagset can be customized with the tagset of the languages to be induced.
REFERENCES
[1] N.S. Choubey, M.U. Kharat and Hari Mohan Pandey, “Developing Genetic Algorithm Library Using Java for CFG Induction”, In
International Journal of Advancement in Technology. 2011.
[2] Bill Keller and Rudi Lutz, “Evolving Stochastic Context-Free Grammars from Examples Using a Minimum Description Length in Principle”, In Workshop on Automata Induction Grammatical
Inference and Language Acquisition, ICML-97.1997.
[3] N.S. Choubey and M.U. Kharat, “Sequential Structuring Element for CFG Induction Using Genetic Algorithm”, In International
Journal of Computer Applications. 2010.
[4] N.S. Choubey and M.U. Kharat, “Reproduction Operator
Evaluation for CFG Induction Using Genetic Algorithm”, In
Journal of Computing. 2010.
[5] Femphy Pisceldo, Mirna Adriani and Ruli Manurung, “Statistical Based Part Of Speech Tagger for Bahasa Indonesia”. In Proceedings of the 3rd International MALINDO Workshop,
Co-located event ACL-IJCNLP 2009. 2009