SKRIPSI
ANALISIS PENJUALAN BARANG LARIS DAN KURANG LARIS
TERHADAP PERCETAKAN AWFA DIGITAL PRINTING
MENGGUNAKAN METODE DECISION TREE DENGAN OPTIMASI
ALGORITMA GENETIKA
Diajukan untuk memenuhi salah satu syarat memperoleh gelar Sarjana Komputer
Disusun Oleh:
Nama : Irham Muzaky
Nim : 311510096
PROGRAM STUDI TEKNIK INFORMATIKA
FAKULTAS TEKNIK
UNIVERSITAS PELITA BANGSA
KABUPATEN BEKASI
HALAMAN PERSETUJUAN
Nama : Irham Muzaky
NIM : 311510096
Fakultas Teknik : Teknik Informatika
Judul Tugas Akhir : Analisis Penjualan Barang Laris Dan Kurang Laris Terhadap Percetakan Awfa Digital Printing Menggunakan Metode Decision Tree dengan Optimasi Algoritma Genetika.
Tugas Akhir ini telah diperiksa dan disetujui, Kabupaten Bekasi, 02 November 2019
Menyetujui :
Dosen Pembimbing I Dosen Pembimbing II
Suherman, M.Kom Adi Rusdi Widya, S.T, M.T
NIDN : 0308086805
NIDN : 0415096901
Mengertahui :
Ka. Prodi Teknik Informatika Dekan Fakultas Teknik Universitas Pelita Bangsa
Aswan S. Sunge, SE., M.Kom Putri Anggun Sari, S.Pt., M.Kom
PERNYATAAN KEASLIAN SKRIPSI
Sebagai mahasiswa Universitas Pelita Bangsa, yang bertanda tangan dibawah ini, saya :
Nama : Irham Muzaky NIM : 311510096
Menyatakan bahwa karya ilmiah saya yang berjudul :
Analisis Penjualan Barang Laris Dan Kurang Laris Terhadap Percetakan Awfa Digitl Printing Menggunakan Metode Decision Tree Dengan Optimasi
Algoritma Genetika.
Merupakan karya asli saya (kecuali cuplikan dan ringkasan yang masing-masing
telahsaya jelaskan sumbernya dan perangkat pendukung seperti laptop dll). Apabila
dikemudian hari, karya saya di sinyalir bukan karya asli saya, yang disertai dengan
bukti-bukti yang cukup, maka saya bersedia untuk dibatalkan gelar saya beserta hak
dan keawajiban yang melekat pada gelar tersebut. Demikian Surat pernyataan ini
sayabuat dengan sebenarnya.
Dibuat di : Bekasi Tanggal 05 November 2019 Yang menyatakan
PERNYATAAN PERSETUJUAN PUBLIKASI KARYA ILMIAH
UNTUK KEPENTINGAN AKADEMIS
Sebagai mahasiswa Universitas Pelita Bangsa, yang bertanda tangan dibawah ini, saya
Nama : Irham Muzaky
NIM : 311510096
Demi mengembangkan ilmu pengetahuan, menyetujui untuk memberikan kepada Universitas Pelita Bangsa Hak Bebas Royalti Non-Eksklusif (Non-Exsclusive Royalti Free Right) atas karya ilmiah saya yang berjudul :
Analisis Penjualan Barang Laris Dan Kurang Laris Terhadap Percetakan Awfa Digitl Printing Menggunakan Metode Decision Tree Dengan Optimasi
Algoritma Genetika.
Beserta perangkat yang diperlukan (bila ada). Dengan Hak Bebas Royalti NonEksklusif ini, Universitas Pelita Bangsa berhak untuk menyimpan data, mengcopy ulang, mempergunakan dan mengelola dalam bentuk database, serta mendistribusikandan menampilkan/mempublikasikan karya ilmiah ini di internet atau media lain untuk kepentingan akademis tanpa ijin dari saya selama tetap mencantumkan saya sebagaipenulis dan pemilik hak cipta. Segala bentuk tuntuan hukum yang timbul ataspelanggaran Hak Cipta karya ilmiah ini menajdu tanggung jawab saya pribadi :
Dibuat di : Bekasi
Tanggal : 05 November 2019 Yang menyatakan
UCAPAN TERIMAKASIH
Segala puji dan syukur penulis panjatkan kepada Tuhan Yang Maha Esa yang
telah melimpahkan kasih dan karunia-Nya sehingga penulis dapat menyelesaikan
penulisan Skripsi ini dengan tepat waktu. Penulisan Laporan Tugas Akhir dengan judul “ANALISIS PENJUALAN BARANG LARIS DAN KURANG LARIS
TERHADAP PERCETAKAN AWFA DIGITL PRINTING MENGGUNAKAN
METODE DECISION TREE DENGAN OPTIMASI ALGORITMA
GENETIKA”, adapunmaksud dari penulisan Skripsi ini untuk memenuhi salah satu
syarat kelulusanFakultas Teknik Jenjang Pendidikan Strata-1 di Universitas Pelita
Bangsa.
Penulis menyadari bahwa penulisan Skripsi ini tidak terlepas dari bimbingan,
bantuan dan dukungan dari berbagai pihak. Untuk itu, pada kesempatan yang
berbahagia ini, penulis mengucapkan terima kasih kepada:
1. Ibu Putri Anggun Sari, SPt., M. Si, Selaku Dekan Fakultas Teknik Universitas Pelita Bangsa.
2. Bapak Aswan S, Sunge. S.E, M.Kom. selaku Ketua Program Studi Teknik Informatika Universitas Pelita Bangsa Cikarang
3. Bapak Suherman, M.Kom. selaku Dosen Pembimbing I Skripsi yang telah banyak memberikan saran dan bimbingan dalam proses penulisan Skripsi ini.
4. Bapak Adi Rusdi Widya, S.T., M.T. Selaku Dosen Pembimbing II Skripsi yang telah banyak memberikan saran dan bimbingan dalam proses penulisan Skripsi ini.
5. Seluruh Dosen Teknik Informatika Universitas Pelita Bangsa
6. Orang tua dan keluarga besar yang selalu memberikan do’a, dukungan dan semangat yang tinggi untuk dapat menyelesaikan penulisan Skripsiini. 7. Teman-teman yang selalu memberikan dorongan dan selalu memberikan
motivasi bagi penulis yang menyelesaikan penulisan Skripsi ini.
8. Seluruh pihak yang belum disebutkan diatas, karena begitu banyak nya bantuan, kesabaran, dan gagasan-gagasan yang diberikan kepada penulis, sehingga penulis Skripsi ini lebih berjalan dengan mudah dan lancar.
Penulis juga menyadari bahwa penulisan Skripsi ini masih terdapat banyak kelemahan dan kekurangannya. Maka dari itu, penulis akan dengan senang hati menerima segala saran dan kritik yang ditunjukan untuk menyempurnakan adanya Skripsi ini. Akhir kata, semoga penulisan Skripsi ini bermanfaat bagi rekan-rekan dansemua pihak yang membutuhkan.
Bekasi, 05 November 2019
ABSTRAK
Data mining adalah proses dimana data dapat dicari dengan pola atau informasi menarik dengan data terpilih digunakan metode-metode tertentu. Masalah yang ditemukan pada penjualan barang yang laris dan kurang laris diperlukannya sebuah metode untuk mengklasifikasi penjualan barang apa saja yang paling laris dan kurang laris. Algoritma C4.5 adalah algoritma yang digunakan untuk membangun decision tree (pengambilan keputusan). Algoritma C.45 salah satu algoritma induksi pohon keputusan. Tujuannya mengoptimasi Algoritma C4.5 Decision Tree dengan Algoritma Genetika. Penggunaan metode Algoritma C4.5 Decision Tree menghasilkan 85,15%, sedangkan hasil setelah dioptimasi menggunakan Algoritma Genetika mencapai 93,09%. demikian hasil optimasi Algoritma C4.5 Decision Tree + Algoritma Genetika dapat meningkatkan nilai akurasi sehingga menghasilkan akurasi yang lebih optimal. Dapat disimpulkan bahwa hasil klasifikasi prediksi penjualan barang laris mencapai 37 setelah di optimasi menjadi 121, sedangkan hasil prediksi kurang laris mencapai 133 setelah di optimasi menjadi 524.
Kata kunci : Algoritma C4.5 Decision Tree, Algoritma Genetika, Analisis, Optimasi.
ABSTRACT
Data mining is the process by which data can be searched for with interesting patterns or information with selected data used by certain methods. Problems found in selling items that are in demand and not selling are needed A method for classifying what is the best-selling and least-selling item is needed. C4.5 algorithm is an algorithm used to build a decision tree (decision preparation). C.45 algorithm is one of the decision tree induction algorithms. The goal is to optimize the C4.5 Decision Tree Algorithm with Genetic Algorithms. The use of the C4.5 Decision Tree Algorithm method yields 85.15%, while the results after being optimized using the Genetic Algorithm reach 93.09%. Thus the results of optimization of the C4.5 Algorithm Decision Tree + Genetic Algorithm can increase the accuracy value resulting in more optimal accuracy. It can be denied from the result of the predicted sales of goods reaching 37 after being optimized to 121, when the prediction results are less than 133 after being optimized to 524.
Keywords : C4.5 Decision Tree Algorithm, Genetic Algorithm, Optimization, Analysis.
DAFTAR ISI
HALAMAN PERSETUJUAN ... i
HALAMAN PENGESAHAN ... ii
PERNYATAAN KEASLIAN SKRIPSI ... iii
PERNYATAAN PERSETUJUAN PUBLIKASI ... iv
UCAPAN TERIMAKASIH ... v
ABSTRAK ... vi
ABSTRACT ... vii
DAFTAR ISI ... ix
DAFTAR TABEL ... xii
DAFTAR GAMBAR ... xiii
BAB I PENDAHULUAN ... 1
1.1. Latar Belakang... 1
1.2. Identifikasi Masalah ... 2
1.3. Rumusan Masalah ... 3
1.4. Batasan Masalah ... 3
1.5. Tujuan dan Manfaat ... 4
1.5.1. Tujuan ... 4
1.6. Metode Pengumpulan Data ... 5 1.7. Sistematika Penulisan ... 6 BAB II ... 7 2.1. Penelitian Terkait ... 8 2.2. Landasan Teori ... 10 2.2.1. Algoritma ... 10
2.2.2. Tahapan Algoritma C4.5 Decision Tree ... 11
2.2.3. Data Mining... 12
1. Pengertitan Data Mining ... 12
2. Fungsi Data Mining ... 13
3. Kategori Dalam Data Mining ... 14
4. Teknik Dalam Data Minig ... 15
5. Proses Tahapan Data Mining ... 16
6. Penerapan Data Mining... 19
2.2.4. Pengertian Decision Tree ... 21
2.2.5. Pengertian Pembentukan Pohon Keputusan Algoritma C4.5 ... 23
2.2.6. Keuntungan Dan Kekurangan Algoritma C4.5 Decision Tree ... 24
2.2.7. Pengertian Optimasi... 25
2.2.8. Pengertian Algoritma Genetika ... 25
2.3. Definisi Data... 27
2.4. Definisi Percetakan ... 27
2.5. Definisi Bagian Percetakan ... 28
BAB III METODE PENELITIAN ... 32
3.1. Objek Penelitian ... 32
3.1.2. Sejarah Perusahaan ... 32
3.2.2. Struktur Organisasi Perusahaan ... 33
3.3.2. Sistem yang Berjalan ... 34
3.2. Metode Penelitian ... 35
3.3. Metode Pengumpulan Data ... 38
3.4. Pengolahan Data Awal ... 39
3.5. Pengelolaan Data Awal ... 40
3.6. Metode Yang Diusulkan ... 45
BAB IV HASIL DAN PEMBAHASAN ... 47
4.1. Hasil Pengujian ... 43
4.1.1. Pengujian Decision Tree ... 47
4.1.2. Pengujian Decision Tree dan Algoritma Genetika ... 54
4.2. Pembahasan Hasil Pengujian... 57
BAB V PENUTUP ... 60
5.1. Kesimpulan... 60
5.2. Saran ... 61
DAFTAR PUSTAKA ...
DAFTAR TABEL
Tabel 3.1. Dataset Penjualan ... 39
Tabel 3.2. Data Awal ... 39
Tabel 3.3. Atribut yang Digunakan ... 40
Tabel 3.4. Menentukan Barang Laris Dan Kurang Laris. ... 41
Tabel 3.5. Pengujian Data ... 41
Tabel 3.6. Model Confusion Matrix ... 44
Tabel 4.1. Data yang Digunakan ... 47
DAFTAR GAMBAR
Gambar 2.1. Tahapan Knowladge Discovery in Database (KDD) ... 17
Gambar 2.2. Model Pohon Keputusan ... 23
Gambar 2.3. Kerangka Berfikir ... 31
Gambar 3.1. Struktur Organisasi Percetakan Awfa Digital Printing ... 33
Gambar 3.2 Sistem yang Berjalan ... 34
Gambar 3.3 Tahapan Penelitian... 36
Gambar 3.4 Ilustrasi Split Validation ... 42
Gambar 3.5. Metode yang Diusulkan ... 46
Gambar 4.1. Import Dataset. ... 48
Gambar 4.2. Tampilan Operator yang Digunakan... 49
Gambar 4.3. Split Validation. ... 50
Gambar 4.4. Decision Tree (Pohon Keputusan) ... 51
Gambar 4.5. Hasil Accuracy Decision Tree ... 53
Gambar 4.6. Model Decision Tree + Algoritma Genetika ... 54
Gambar 4.7. Konfigurasi Operator Generate ... 55
Gambar 4.8. Hasil Accuracy Decision Tree + Algoritma Genetika ... 56
Gambar 4.9. Performance Vector ... 56
Gambar 4.10. Grafik Hasil Pengujian Pred. Laris ... 57
BAB I
PENDAHULUAN
1.1. Latar Belakang
Perkembangan teknologi informasi telah banyak memberikan kontribusi
pada cepatnya pertumbuhan, data yang terkumpul dan disimpan pada jumlah yang
besar. Untuk mendapatkan data yang valid dibutuhkan sebuah metode agar data
yang diolah menjadi informasi berharga dan menjadi informasi yang bermanfaat
untuk mendukung diambilnya sebuah keputusan dalam keperluan pribadi, bisnis,
sains dan teknologi. Suatu teknologi yang bisa mewujudkannya adalah dengan
menggunakan atau memanfaatkan Data mining. Data mining adalah proses dimana
data dapat dicari dengan pola atau informasi menarik dengan data terpilih
digunakan metode-metode tertentu. Salah satu metode yang dipakai ialah metode
Decision tree dan Algoritma Genetika. Dalam usaha penjualan khususnya dibidang
percetakan pastinya mempunyai data-data penjualan yang begitu banyak sehingga
agar dapat memantau data penjualan diperlukannya sebuah metode untuk
mengklasifikasi penjualan barang apa saja yang paling digemari pelanggan dan
yang sedikit digemari. Metodologi yang digunakan dalam mengklasifikasi
penjualan barang ini menggunakan Decision Tree dengan mengoptimasi
menggunakan Algoritma Genetika untuk mengetahui apa saja yang paling sering
dibeli oleh konsumen.
Dengan adanya data mining diharapkan mampu untuk mengolah data-data
data atau informasi yang dibutuhkan dengan demikian bisa menggali informasi
yang berguna mampu mengambil kesimpulan dari permasalahan yang ada pada
masalah penggalian data menjadi sebuah informasi guna dapat membantu atau
mempermudah barang apa saja yang paling sering di beli oleh konsumen.
Proses transaksi penjualan pada percetakan ini memiliki banyak data-data
transaksi yang begitu banyak sehingga menyulitkan untuk mendapatkan informasi
data barang apa saja yang paling laku dan barang apa saja yang kurang diminati.
Tujuan penelitian ini ialah untuk menerapkan teknik data mining dengan
menggunaka metode Decision tree algoritma C4.5 dan Optimasi dengan
menggunakan Algoritma Genetika kasus di percetakan dan diharapkan mampu
memberikan informasi berupa klasifikasi penjualan barang apa saja yang paling
sering diminati oleh konsumen dan barang yang kurang diminati. Sehingga
kedepannya pemilik bisnis ini dapat melakukan analisa barang apa saja yang paling
laku dipasaran.
1.2. Identifikasi Masalah
Dari latar belakang yang telah ditulis, penulis memberikan identifikasi
masalah yang akan dijadikan bahan penelitian sebagai berikut yaitu :
1) Kurang optimalnya hasil informasi yang dihasilkan dari Algoritma C4.5 itu
sendiri. Dan belum adanya suatu tambahan fitur optimasi dalam pengolahan
data agar hasil akurasi yang didapat lebih optimal.
2) Kurangnya informasi dari data penjualan barang laris dan kurang laris di
1.3. Rumusan Masalah
Berdasarkan identifikasi masalah yang telah dipaparkan, maka rumusan
sebagai berikut :
1) Bagaimana mengoptimasi menggunakan metode Descision Tree dengan
Algoritma Genetika sehingga dapa menghasilkan akurasi yang lebih optimal
dalam pengklasifikasian penjualan barang yang laris dan kurang laris?
1.4. Batasan Masalah
Agar masalah yang dibahas tidak menyimpang dari tujuan, maka perlu
dibuat batasan masalah, yaitu :
1) Metode yang digunakan adalah Decision Tree untuk menentukan penjualan
barang yang laris dan kurang laris dengan optimasi algoritma genetika.
2) Data yang digunakan untuk menganalisa adalah data dari percetakan Awfa
Digital Printing.
3) Data yang diambil bersumber dari percetakan Awfa Digital Printing.
1.5. Tujuan dan Manfaat 1.5.1. Tujuan
Sesuai dengan rumusan masalah yang telah diutarakan, maka tujuan
dibuatnya penelitian ini adalah :
1) Digunakannya data mining untuk mengklasifikasi penjualan barang agar
data – data yang jumlahnya banyak dapat diolah menjadi informasi yang
bermanfaat. Dengan menggunakan algoritma C4.5.
2) Meningkatkan efektifitas dan produktifitas dalam mengklasifikasi atau
mencari barang (produk) apa saja yang paling diminati, atau yang kurang
diminati.
3) Mempermudah dan memperlancar cara kerja pegawai dalam pengolahan
data – data penjualan yang lebih efektif dan efisien, sehingga
menghasilkan pengolahan data yang lebih baik dari sebelumnya yang
sedang berjalan saat ini.
1.5.2. Manfaat
Manfaat dari penelitian ini adalah untuk mempermudah dalam mengambil
kepustusan dan mengetahui informasi pembelian produk yang sering dibeli oleh
konsumen dan yang kurang diminati konsumen.
Mempermudah dan memperlancar dalam pengolahan data penjualan yang
lebih efektif dan lebih efisien, sehingga menghasilkan pengolahan data yang lebih
1) Manfaat bagi penulis
Penulis dapat menambah pengetahuan dan pemahaman dalam bidang
kajian data mining khususnya algoritma C4.5. Dan penelitian ini dapat
dijadikan sarana untuk ilmu pengetahuan dan keterampilan yang sudah
di dapatkan selama masa perkuliahan.
2) Manfaat bagi akademik
Dapat menambah literasi ilmiah di perpustakaan serta dapat dijadikan
sebagai acuan ilmu pengetahuan bagi mahasiswa yang sedang
mengembangkan dan mengkaji data mining khusunya menggunakan
algoritma C4.5.
3) Bagi pembaca
Sebagai bahan referensi, masukan, dan tambahan ilmu pengetahuan
khususnya mengenai data mining menggunakan algoritma C4.5 yang
nantinya dapat dikembangkan lagi lebih jauh dari yang sebelumnya.
1.6. Metode Pengumpulan Data
Berikut ini adalah metode pengumpulan data yang diterapkan penulis dalam
melakukan penelitian :
1) Studi Pustaka
Penulis mempelajari materi terkait dan menyusun penelitian ini
2) Sumber Data
Penulis memperoleh data penelitian ini, data yang digunakan
bersumber dari karyawan atau pengurus percetakan Awfa Digital
Printing.
1.7. Sistematika Penulisan
Skripsi ini tersusun dalam lima bagian, yaitu pendahuluan, landasan teori
atau tinjauan pustaka, metode penelitian, hasil dan pembahasan, serta penutup.
Dimana masing – masing penelitian tersebut menghasilkan pembahasan secara
sistematis.
BAB I : PENDAHULUAN
Pada isi bab pertama, pendahuluan membahas tentang latar belakang
penelitian, identifikasi dan batasan masalah, rumusan masalah, maksud dan tujuan
penelitian, manfaat penelitian, metode pengumpulan data dan sistematika
penulisan.
BAB II : TINJAUAN PUSTAKA
Bab dua, landasan teori terbagi ke dalam beberapa sub bab yang didalamnya
mendeskripsikan teori – teori yang didapat dari sumber – sumber yang relevan
untuk dijadikan panduan dalam penyusunan skripsi.
BAB III : METODE PENELITIAN
Bab tiga berisi tentang penjelasan tahap penelitian, objek penelitian, data
BAB IV : HASIL DAN PEMBAHASAN
Bab keempat, penulis menerapkan metode data mining pada data yang telah
diperoleh serta pembahasan dari penelitian yang dilakukan.
BAB V : PENUTUP
Bab ini merupakan bab terakhir yang terdiri dari dua sub bab yakni,
kesimpulan dan saran. Bab ini juga memuat hasil kesimpulan dari penelitian beserta
BAB II
TINJAUAN PUSTAKA
2.1. Penelitian Terkait
Adapun penelitian terkait dengan yang berhubungan dengan skripsi ini yaitu :
Penelitian pertama [2] dalam jurnalnya yang berjudul “Analisa Algoritma
C4.5 Untuk Memprediksi Penjualan Motor Pada Pt. Capella Dinamik Nusantara Cabang Muka Kuning”. Pada penelitian ini, peneliti menggunakan algoritma C4.5
untuk melihat pola prediksi perilaku konsumen membeli motor. Jumlah data yang
sangat banyak sangat sulit untuk dianalisa, analisa digunakan untuk melihat pola
dari data penjualan sehingga dapat menghasilkan prediksi penjualan motor yang
kedepannya berguna untuk pendistribusian sepeda motor dibeberapa wilayah.
Algoritma C4.5 dianggap sebagai algoritma yang mampu membantu dalam
melakukan klasifikasi data yang banyak karena karakteristik dalam bentuk data
yang diklasifikasi dapat diperoleh dengan jelas dan tepat, baik dalam bentuk
struktur pohon keputusan (Decision tree) maupun aturan if-then, sehingga dapat
memudahkan pengguna dalam melakukan penggalian informasi terhadap data yang
bersangkutan. Pada pemilihan atribut juga sangat mempengaruhi dalam pengolahan
Algoritma C4.5 karena keputusan sangat bergantung pada atribut yang dipilih.
Penelitian kedua [3] dengan judul penelitiannya “Metode Decision Tree
Algoritma C.45 Dalam Mengklasifikasi Data Penjualan Bisnis Gerai Makanan
memprediksi untuk menentukan menu makanan yang terjual dengan status
penjualan yang laris dan kurang laris berdasarkan dari menu makanan yang ada.
Dan penelitian ini menggunakan Algoritma C4.5 untuk membuktihan hasil
penelitian dalam mencari menu makanan apa saja yang kurang laris, laris dan sangat
laris pada bisnis gerai makan cepat saji XYZ, menghitung entropy, untuk semua
kasus, menghitung entropy untuk sub kasus (berdasarkan atribut) dan menghitung
gain. Dan hasil yang didapat dari Algoritma C4.5 dihasilkan nilai entropy dan gain
tertinggi ialah 1,501991 terdapat di atribut-atribut menu makanan dalam
menghitung dengan cara manual. Sedangkan hasil yang menggunakan Rapidminer
ialah dari jumlah yang terjual menu makanan (Rice bento = kurang laris, dada =
laris) dengan bobot (weight) masing-masing atribut : Harga (0,738), Jenis Menu
(0,067), Jumlah Terjual (0,156), Status Penjualan (0,040).
Penelitian ketiga [1] penelitian ini yang berjudul “Menentukan
Kemungkinan Masuknya Calon Mahasiswa Baru Pada Sebuah Perguruan Tinggi
Swasta Manggunakan Teknik Klasifikasi Pohon Keputusan Dengan Aplikasi Rapidminer 5.1”. Metode klasifikasi yang digunakan untuk mengambil sebuah
keputusan untuk memperkirakan suatu kasus yaitu data mahasiswa yang lulus dan
gagal, dengan data calon mahasiswa mendaftar membandingkan dengan data
mahasiswa yang sudah di terima menjadi mahasiswa. Dipenelitian ini
menggunakan Rapidminer untuk dilakukan data Cleaning yaitu berupa
penghapusan data yang terduplikasi dan inkonsistensi. Adapun data yang akan diuji
variabel input yang digunakan antara lain gelombang, pekerjaan orangtua, asal
dari hasil data cleaning ini tersisa data sebanyak 513 orang untuk data tahun 2009,
730 orang untuk data tahun 2010, dan .sebanyak 730 orang untuk data tahun 2011.
Pengujian dengan menggunakan rapidminer menghasilkan data yang telah diolah
ialah 2011 sebanyak 744 orang, 905 orang, dan 883 orang. Dari data yang sudah
didapat ternyata masih banyak terdapat duplikasi data, inkonsistensi data berupa
field yang kosong dan kesalahan cetak (tipografi).
2.2. Landasan Teori
Di dalam landasan teori, penulis menyertakan referensi jurnal dan buku
untuk mendukung teori dalam penelitian ini.
2.2.1. Algoritma
Algoritma C4.5. merupakan kelompok algoritma pohon keputusan (decision
tree). Algoritma ini mempunyai input berupa training samples dan samples.
Training samples berupa data contoh yang akan digunakan untuk membangun
sebuah tree yang telah diuji kebenaranya. Sedangkan samples merupakan field-field
data yang nantinya akan kita gunakan sebagai parameter dalam melakukan
klasifikasi data [3].
Algoritma C4.5 adalah algoritma yang digunakan untuk membangun
decision tree (pengambilan keputusan). Algoritma C.45 salah satu algoritma
induksi pohon keputusan yaitu ID3 (Iterative Dichotomiser 3). ID3 dikembangkan
oleh J. Ross Quinlan. Dalam prosedur algoritma ID3, input berupa sampel training,
label training dan atribut. Algoritma C4.5 merupakan pengembangan dari ID3.
adalah sebagai antara lain bisa mengatasi missing value, bisa mengatasi
continu data, dan pruning [6]
2.2.2. Tahapan Algoritma C4.5 Decision Tree
[12] Algoritma decision tree digunakan untuk membangun sebuah pohon
keputusan yang mudah dimengerti, fleksibel, dan menarik karena dapat
divisualisasikan dalam bentuk gambar. Pohon keputusan adalah salah satu metode
klasifikasi yang paling populer karena mudah untuk diinterpretasi oleh manusia.
Pohon keputusan adalah model prediksi menggunakan struktur pohon atau struktur
berhirarki. Konsep dari pohon keputusan adalah mengubah data menjadi pohon
keputusan dan aturan-aturan keputusan.
Ada beberapa tahap dalam membuat sebuah pohon keputusan dengan
algoritma C4.5 yaitu:
a) Mempersiapkan data training, dapat diambil dari data histori yang
pernah terjadi sebelumnya dan sudah dikelompokan dalam kelas-kelas
tertentu.
b) Menentukan akar dari pohon dengan menghitung nilai gain yang
tertinggi dari masing-masing atribut atau berdasarkan nilai index
entropy terendah. Sebelumnya dihitung terlebih dahulu nilai index
c) Hitung nilai gain dengan rumus:
d) Untuk menghitung gain ratio perlu diketahui suatu term baru yang
disebut Split Information dengan rumus:
e) Selanjutnya menghitung gain ratio
f) Ulangi langkah ke-2 hingga semua record terpartisi Proses partisi
pohon keputusan akan berhenti disaat:
1) Semua tupel dalam record dalam simpul m mendapat kelas yang sama
2) Tidak ada atribut dalam record yang dipartisi lagi
3) Tidak ada record didalam cabang yang kosong.
2.2.3. Data Mining
1. Pengertian Data Mining
Data mining mengacu pada proses pencarian informasi yang belum
diketahui sebelumnya dari rangkaian sekumpulan data yang besar [2].
Pada prosesnya data mining akan mengekstrak informasi yang akan
diolah dengan cara menganalisis adanya pola-pola ataupun hubungan
Definisi lain data mining adalah serangkaian proses yang
memperkerjakan satu atau lebih teknik pengolahan komputer untuk
menganalisis dan mengekstrak data secara otomatis atau serangkaian proses
untuk menggali nilai tambah dari suatu kumpulan data yang selama ini tidak
diketahui secara manual [2].
Data mining, sering juga disebut sebagai knowledge discovery in
database (KDD) adalah kegiatan yang meliputi pengumpulan, pemakaian data,
historis untuk menemukan keteraturan, pola atau hubungan dalam set data
berukuran besar [14].
2. Fungsi Data Mining
Fungsi-fungsi yang diterapkannya dalam data mining [17] :
1) Assosiation, adalah proses untuk menemukan aturan asosiasi antara
suatu kombinasi item dalam suatu waktu.
2) Sequence, proses untuk menemukan aturan asosiasi antara suatu
kombinasi item dalam suatu waktu dan diterapkan lebih dari satu
periode.
3) Clustering, adalah proses pengelompokan sejumlah data/obyek ke
dalam kelompok data sehingga setiap kelompok berisi data yang
mirip.
4) Classification, proses penemuan model atau fungsi yang
tujuan untuk dapat memperkirakan kelas dari suatu objek yang
labelnya tidak diketahui.
5) Regression, adalah proses pemetaan data dalam suatu prediksi.
6) Forecasting, adalah proses pengestimasian nilai prediksi berdasarkan
pola - pola di dalam sekumpulan data.
7) Solution, adalah proses penemuan akar masalah dan problem solving
dari persoalan bisnis yang di hadapi atau paling tidak sebagai
informasi dalam pengambilan keputusan.
3. Kategori dalam Data Mining
Berikut kategori dalam data mining [17] :
1) Prediktif Tujuan dari tugas prediktif adalah untuk memprediksi nilai
dan atributtertentu berdasarkan pada nilai atribut – atribut lain. Atribut
yang 10 diprediksi umumnya dikenal sebagai target atau variabel tak
bebas, sedangkan atribut – atribut yang digunakan untuk membuat
prediksidikenal sebagai explanatory atau variabel bebas.
2) DeskriptifTujuan dari deskriptif adalah untuk menurunkan pola – pola
(korelasi, trend, cluster, teritori, dan anomaly) yang meringkas
hubungan yangpokok dalam data. Tugas data mining deskriptif sering
merupakan penyelidikan dan seringkali memerlukan teknik post –
4. Teknik dalam Data Mining
Teknik yang digunakan dalam data mining erat kaitanya dengan “penemuan” (discovery) dan “pembelajaran” (learning) yang terbagi dalam
tiga metode utama pembelajaran yaitu [17]
1) Supervised Learning adalah teknik yang paling banyak digunakan.
Teknik ini sama dengan “programing by example”. Teknik ini
melibatkan fase pelatihan dimana data pelatihan historis yang karakter – karakternya dipetakan ke hasil – hasil yang telah diketahui diolah
dalam algoritma data mining. Proses ini melatih algoritma untuk
mengenali variabel – variabel dan nilai – nilai kunci yang nantinya akan
digunakan sebagai dasar dalam perkiraan – perkiraan ketika di berikan
data baru.
2) Unsupervised Learning
Teknik pembelajaran ini tidak melibatkan fase pelatihan seperti yang
terdapat pada supervised learning. Teknik ini bergantung pada
penggunaan algoritma yang mendeteksi semua pola, seperti
associations dan sequences, yang muncul dari kriteria penting yang
spesifik dalam data masukan. Pendekatan ini mengarah pada
pembuatan banyak aturan (rules) yang mengkarakterisasikan penemuan
associations, clusters, dan segments. Aturan – aturan ini kemudian
3) Reinforcement Learning
Teknik pembelajaran ini jarang digunakan dibandingkan dengan dua
teknik lainya, namun memiliki peranan – peranan yang terus
dioptimalkan dari waktu ke waktu memiliki control adaptif. Teknik ini sangat menyerupai kehidupan nyata yaitu seperti “on – job training”,
dimana seorang pekerja diberikan sekumpulan tugas yang
membutuhkan keputusan – keputusan. Pada beberapa titik waktu kelak
diberikan penilaian atas performace pekerja tersebut kemudian pekerja
diminta mengevaluasi keputusan – keputusan yang telah dibuatnya
sehubungan dengan hasil performace pekerja tersebut. Reinformace
learning sangat tepat digunakan untuk menyelesaikan masalah –
masalah yang sulit bergantung pada waktu.
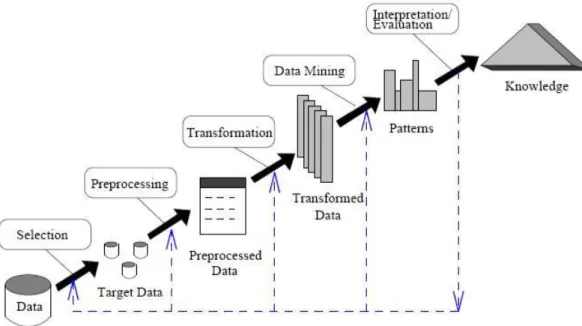
5. Proses Tahapan Data Mining
Menurut [17] data mining merupakan salah satu dari rangkaian
Knowledge Discovery Database (KDD). KDD berhubungan dengan teknik
integrasi dan penemuan proses tersebut memiliki tahap sebagai berikut.
1) Pembersihan data (untuk membuang data yang tidak konsisten dan
noise).
2) Integrase data (penggabungan data dari beberapa sumber).
3) Transformasi data (data diubah menjadi bentuk yang sesuai untuk di
mining). Aplikasi teknik data mining, proses ekstrasi pola dari data yang
4) Evaluasi pola yang ditemukan (proses interprestasi pola menjadi
pengetahuan yang dapat digunakan untuk mendukung pengambilan
keputusan).
5) Presentasi pengetahuan (dengan teknik visualisasi).
Gambar 2.1 Tahapan Knowledge Discovery in Database (KDD)
Tahap ini merupakan bagian dari proses pencarian pengetahuan yang
mencakup pemeriksaan apakah pola atau informasi yang ditemukan
bertentangan dengan fakta atau hipotesa yang ada sebelumnya. Langkah
terakhir KDD adalah mempresentasikan pengetahuan dalam bentuk yang
mudah dipahami pengguna.
1. Data selection
Pemilihan (seleksi) data dari sekumpulan data operasional perlu
hasil seleksi yang digunakan untuk proses data mining, disimpan dalam suatu
berkas, terpisah dari basis data operasional.
2. Pre-processing / cleaning
Sebelum proses data mining dapat dilaksanakan, perlu dilakukan proses
cleaning pada data yang menjadi fokus KDD. Proses cleaning mencakup
antara lain membuang duplikasi data, memeriksa data yang inkonsisten, dan
memperbaiki kesalahan pada data.
3. Transformation
Coding adalah proses transformasi pada data yang telah dipilih,
sehingga data tersebut sesuai untuk proses data mining. Proses coding dalam
KDD merupakan proses kreatif dan sangat tergantung pada jenis atau pola
informasi yang akan dicari dalam basis data.
4. Data mining
Data mining adalah proses mencari pola atau informasi menarik dalam
data terpilih dengan menggunakan teknik atau metode tertentu. Teknik,
metode, atau algoritma dalam data mining sangat bervariasi. Pemilihan
metode atau algoritma yang tepat sangat bergantung pada tujuan dan proses
KDD secara keseluruhan.
5. Interpretation / evalution
Pola informasi yang dihasilkan dari proses data mining perlu
berkepentingan. Tahap ini merupakan bagian dari proses KDD yang disebut
interpretation. Tahap ini mencakup pemeriksaan apakah pola atau informasi
yang ditemukan bertentangan dengan fakta atau hipotesis yang ada
sebelumnya.
6. Penerapan Data Mining
A. Analisa Pasar & Manajemen.
Sumber data yang digunakan seperti transaksi kartu kredit, kartu
anggota club tertentu, kupon diskon, keluhan pembeli, ditambah
dengan studi tentang gaya hidup public. Beberapa solusi yang dapat di
selesaikan dengan data mining antara lain [17] :
1) Menembak target pasar
Data mining dapat melakukan pengelompokkan (clustering) dari
model – model pembeli dan melakukan klasifikasi terhadap setiap
pembeli sesuai dengan karakteristik yang diingikan seperti
kedudukan yang sama, tingkat penghasilan yang sama, kebiasaan
membeli dan karakteristik lainya.
2) Melihat pola beli pemakai dari waktu ke waktu
Data mining dapat digunakan untuk melihat pola beli dari waktu
ke waktu. Sebagai contoh: ketika seseorang menikah, bisa saja
dia kemudian memutuskan untuk pindah dari single account ke
3) Cross Market Analysis
Kita dapat memanfaatkan untuk melihat hubungan antara
penjualan satu produk dengan yang lainya.
4) Profil Customer
Data mining dapat melihat profile customer sehingga dapat
mengetahui kelompok customer tertentu suka membeli produk
apa saja.
5) Identifikasi Kebutuhan Customer
Dapat mengidentifikasi produk apa saja yang terbaik untuk tiap
kelompok customer dari faktor apa saja yang dapat menarik
konsumen baru.
6) Menilai loyalitas Customer
7) Informasi Summary
Dapat digunakan untuk membuat laporan summary yang bersifat
multi dimensi dan dilengkapi dengan informasi statistic lainya
B. Analisa Perusahaan dan Manajemen Resiko.
1) Perencanaan Keuangan dan Analisa Aset
Data mining dapat membantu melakukan analisis dan prediksi
cash flow serta dapat melakukan contingent claim analysis untuk
mengetahui asset. Selain itu dapat menggunakan untuk analisis
2) Perencanaan Sumber Daya
Dengan melihat ringkasan informasi serta pola pembelanjaan dan
pemalsuan dari masing – masing resource. Maka dapat
memanfaatkan untuk resource planning.
3) Persaingan
Data mining membantu memonitor pesaing – pesaing dengan
melihat market direction mereka. Data mining juga dapat
melakukan pengelompokan customer dan dapat memberikan
variasi harga untuk masing – masing grup.
4) Telekomunikasi
Data mining melihat jutaan transaksi yang masuk, dan melihat
transaksi manakah yang harus ditangani secara manual. Tujuanya
adalah untuk menambah layanan otomatis.
2.2.4. Pengertian Decision Tree
Pohon keputusan adalah metode klasifikasi dan prediksi yang sudah terbukti
dalam mengambil keputusan. Metode ini bertujuan untuk mengubah fakta menjadi
pohon keputusan yang merepresentasikan aturan yang dapat mudah dimengerti
dengan bahasa alami. Proses dari pohon keputusan ini dimulai dari node akar
hingga node daun yang dilakukan secara rekursif dimana setiap percabangan
Algoritma Decision tree dibangun untuk sebuah pohon keputusan agar
mudah mengerti dan dapat dipahami karena dapat divisualisasikan dalam bentuk
gambar pohon keputusan, yaitu decision tree [12].
Decision tree dalam algoritma C4.5 merupakan salah satu metode
pengambil keputusan yang menggunakan Decision tree (Pohon Keputusan) dimana
setiap node mempresentasikan atribut, dimana cabang pohon keputusan
merepresentasikan nilai dari atribut tersebut [21]
Menurut [1] bahwa sebuah pohon keputusan adalah sebuah struktur yang
dapat digunakan untuk membagi kumpulan data yang besar menjadi
himpunan-himpunan record yang lebih kecil dengan menerapkan serangkaian aturan
keputusan. Dengan masing-masing rangkaian pembagian tersebut, anggota
himpunan hasil menjadi mirip satu dengan yang lainnya. Sebuah pohon keputusan
mungkin dibangun dengan cara seksama secara manual atau dapat tumbuh secara
otomatis dengan menerapkan salah satu atau beberapa algoritma pohon keputusan
untuk memodelkan himpunan data yang terklasifikasi.
Data dalam pohon keputusan biasanya dinyatakan dalam bentuk tabel
dengan atribut dan record. Atribut menyatakan suatu parameter yang dibuat sebagai
kriteria dalam pembentukan pohon. Proses pada pohon keputusan adalah mengubah
bentuk data dalam tabel menjadi model pohon dan mengubah bentuk pohon
2.2.5. Pengertian Pembentukan Pohon Keputusan Algoritma C4.5
Pohon keputusan adalah model prediksi menggunakan struktur pohon atau
struktur berhirarki.
Contoh dari pohon keputusan dapat dilihat di Gambar 2.2 berikut ini.
Gambar 2.2 Model Pohon Keputusan..
Disini setiap percabangan menyatakan kondisi yang harus dipenuhi dan tiap
ujung pohon menyatakan kelas data. Contoh di Gambar adalah identifikasi pembeli
komputer,dari pohon keputusan tersebut diketahui bahwa salah satu kelompok yang
potensial membeli komputer adalah orang yang berusia di bawah 30 tahun dan juga
pelajar. Setelah sebuah pohon keputusan dibangun maka dapat digunakan untuk
mengklasifikasikan record yang belum ada kelasnya. Dimulai dari node root,
menggunakan tes terhadap atribut dari record yang belum ada kelasnya tersebut
lalu mengikuti cabang yang sesuai dengan hasil dari tes tersebut,yang akan
membawa kepada internal node (node yang memiliki satu cabang masuk dan dua
atau lebih cabang yang keluar), dengan cara harus melakukan tes lagi terhadap
Record yang kelasnya tidak diketahui kemudian diberikan kelas yang sesuai
dengan kelas yang ada pada node daun. Pada pohon keputusan setiap simpul daun
menandai label kelas. Proses dalam pohon keputusan yaitu mengubah bentuk data
(tabel) menjadi model pohon (tree) kemudian mengubah model pohon tersebut
menjadi aturan (rule).
2.2.6. Keuntungan dan Kekurangan Algoritma C4.5 Decision Tree
Menurut [22] Algoritma C4.5 Decision tree memiliki keuntungan sebagai
berikut :
1) Mudah dimengerti dan dapat dipahami.
2) Memiliki nilai meski hanya dengan data sedikit.
3) Dapat digabungkan dengan teknik keputusan lainnya.
4) Dapat membentangkan semua permasalahan agar dapat diklasifikasikan.
5) Berfungsi menganalisa dalam mengambil keputusan mengenai
kemungkinan dari alternatif.
6) Dapat bekerja dalam mengukur hasil nilai dalam mencapai keputusan.
7) Membantu dalam membuat keputusan yang terbaik dari sumber
informasi yang ada.
Kekurangan metode Algoritma C4.5 adalah [17]:
1) Terjadi overlap terutama ketika kelas – kelas dan kriteria yang
digunakan jumlahnya sangat banyak. Hal tersebut juga dapat
menyebabkan meningkatnya waktu pengambilan keputusan dan
2) Pengakumulasian jumlah eror dari setiap tingkat dalam sebuah
keputusan yang besar.
3) Kesulitan dalam mendesain pohon keputusan yang optimal.
4) Hasil kualitas yang didapatkan dari metode pohon keputusan sangat
bergantung pada bagaimana pohon tersebut didesain.
2.2.7. Pengertian Optimasi
Menurut [18] Optimasi adalah suatu usaha atau kegiatan untuk
mendapatkan hasil terbaik dengan persyaratan yang diberikan. Menggunakan
metode optimasi pada salah satu dari dua algoritma pembelajaran bertujuan untuk
memberikan perbedaan hasil yang diperoleh. Mayoritas algoritma optimasi yang
digunakan untuk memecahkan masalah teknik adalah dengan menggunakan metode
Conjugate Gradient.
2.2.8. Pengertian Algoritma Genetika
Algoritma genetika (GA) merupakan salah satu metode data mining yang
efektif digunakan untuk pengenalan pola dan solusi masalah optimasi. Algoritma
genetika biasa digunakan untuk proses optimasi dan pencarian pola yang
menggunakan prinsip kerja seperti proses seleksi alam. Algoritma ini memiliki
konsep menyerupai proses seleksi alam dimana yang terkuat akan menjadi
pemenang, pemenang terbaik merupakan hasil yang optimal dari proses genetika
yang disebut fitness. Tahap penyelesaian yang didapatkan dari algoritma ini dapat
didipat dari setiap solusi dan setiap individu bergantung pada nilai kromosom dan
dievaluasi oleh fungsi fitness [18].
Algoritma genetika sendiri memiliki sebuah aturan populasi masing-
masing mewakili sebuah solusi untuk suatu masalah. Algoritma genetik muncul
disaat yangtepat ketika suatu masalah tersebut memerlukan optimasi sehubungan
dengan komputasi. Paradigma ini dapat diterapkan untuk memecahkan masalah
pada data mining. Tujuannya adalah untuk mengurangi error dalam
pengklasifikasian tranningset. Ide utama algoritama genetik adalah mengumpulkan
populasi yang merupakan solusi untuk suatu masalah, dan mencoba untuk
menghasilkan solusi yang lebih baik dari sebelumnya. Algoritma genetika beoperasi
melalui siklus sederhana yang terdiri dari empat tahapan sebagai berikut: insialisasi, seleksi, crossover dan mutasi [20].
Algoritma genetika memainkan peran penting dalam teknologi data mining,
yang diputuskan berdasarkan adanya karakteristik dan keunggulan
tersendiri,terutama dalamaspek berikut:
1. Algoritma genetika dapat menetapkan parameter yang langsung
beroperasi untuk mengatur dataset, antrian, matrik, grafik dan struktur
lainnya.
2. Memiliki kinerja pencarian yang lebih baik; mengurangi resiko solusi
optimalparsial. Pada saat yang sama, algoritma genetika itu sendiri juga
sangat mudahuntuk bekerja secara parallel.
4. Algoritma genetika dapat memandu arah pencarian. Algoritma genetika
memiliki tiga operator genetik utama yaitu crossover (prosespenukaran
kromosom), mutasi (proses penggantian salah satu solusi untuk
meningkatkan keragaman populasi), seleksi (penggunaan solusi dengan
nilai fitnessyang tinggi untuk lulus ke generasi berikutnya) [3].
2.3. Definisi Data
Data adalah fakta yang dapat digunakan sebagai input dalam menghasilkan
informasi. Data dapat berupa bahan untuk diskusi, pengambilan keputusan,
perhitungan atau pengukuran. Saat ini, data tidak hanya dalam bentuk kumpulan
huruf-huruf dalam bentuk kata atau kalimat, tetapi juga dapat dalam bentuk suara,
gambar diam dan bergerak, baik dalam bentuk dua maupun tiga dimensi [13]
Data merupakan bahan ‘mentah’. Sebagai bahan mentah, data merupakan
input yang setelah diolah berubah bentuknya menjadi output yang disebut informasi
[13].
2.4. Definisi Percetakan
Menurut [5], cetak digital adalah semua teknologi reproduksi yang
menerima data elektronik dan menggunakan titik (dot) untuk replikasi. Semua
mesin cetak yang memanfaatkan komputer sebagai sumber data dan proses cetak
memanfaat prinsip titik; dimana gambar atau image pada material
(kertas, plastik, tekstil, dll) tersusun dari kumpulan titik-titik.
Oleh karena itu, menurut [4] pengertian digital printing dapat digolongkan
2.5. Definisi Bagian Percetakan
Berikut adalah bagian yang ada di percetakan Awfa Digital Printing yaitu:
1. Bagian manajemen keuangan
Menurut [11] merupakan ilmu dan seni dalam mengelola uang yang
mempengaruhi kehidupan setiap orang dan setipa organisasi. Keuangan
berhubungan dengan proses, lembaga, pasar, dan instrumen yang terlibat
dalam transfer uang dimana diantara individu maupun antar bisnis dan
pemerintah.
2. Bagian manajemen operasional
Menurut [8] Manajemen operasional adalah suatu sert aktivitas yang
menciptakan nilai berupa barang dan jasa dengan melakukan
transformasi masukan menjadi keluaran.
A. Bagian Desain Grafis
[15] memaparkan beberapa pendapat tokoh akan pengertian desain grafis
sebagai berikut:
1) Menurut Suyanto desain grafis didefinisikan sebagai aplikasi dari
keterampilan seni dan komunikasi untuk kebutuhan bisnis dan
industri. Aplikasi-aplikasi ini dapat meliputi periklanan dan
penjualan produk, menciptakan identitas visual untuk institusi,
produk dan perusahaan, dan lingkungan grafis; desain informasi;
2) Sedangkan Jessica Helfand dalam situs aiga.com mendefinisikan
desain grafis sebagai kombinasi kompleks kata-kata dan gambar,
angka-angka dan grafik, foto-foto dan ilustrasi yang membutuhkan
pemikiran khusus dari seorang individu yang bisa menggabungkan
elemen-eleman ini, sehingga mereka dapat menghasilkan sesuatu
yang khusus, sangat berguna,mengejutkan atau subversif atau
sesuatu yang mudah diingat.
3) Menurut Danton Sihombing desain grafis mempekerjakan berbagai
elemen seperti marka, simbol, uraian verbal yang divisualisasikan
lewat tipografi dan gambar baik dengan teknik fotografi ataupun
ilustrasi. Elemen-elemen tersebut diterapkan dalam dua fungsi,
sebagai perangkat visual dan perangkat komunikasi.
4) Warren dalam Suyanto memaknai desain grafis sebagai suatu
terjemahan dari ide dan tempat ke dalam beberapa jenis urutan
yang struktural dan visual.
5) Sedangkan Blanchard mendefinisikan desain grafis sebagai suatu
seni komunikatif yang berhubungan dengan industri, seni dan
proses dalam menghasilkan gambaran visual pada segala
permukaan.
6) Demikian halnya senada dengan definisi yang dipaparkan Henricus
Kusbiantoro bahwa desain adalah kompromi antara seni dan bisnis.
visual, namun sekaligus tidak kehilangan karakter dan keunikan
dari segi eksekusi visual baik konsep maupun visual teknis.
2.6. Kerangka Pemikiran
Dalam penelitian ini perlu adanya kerangka pemikiran yang digunakan
untuk sebagai landasan serta pedoman agar penelitian ini berjalan sesuai dengan
alur yangdirencanakan. Permasalahan pada penelitian ini adalah belum adanya
metode yangdapat digunakan untuk mengoptimasi data penjualan barang yang
laris dan kurang laris.
Metode yang digunakan pada penelitian ini adalah algoritma C4.5
Decision tree dan jugaalgoritma genetika untuk dilakukan pengujian. Pengujian
dari metode yang telah diterapkan menggunakan cara Confusion Matrix dan
Accuracy Performance Vector (Performance). Untuk tool yangdigunakan untuk
melakukan pengujian metode adalah aplikasi RapidMiner. Adapun kerangka
BAB III
METODE PENELITIAN
3.1. Objek Penelitian
Objek penelitian ini ialah untuk menerapkan teknik data mining pada kasus
di percetakan dan diharapkan mampu memberikan informasi berupa klasifikasi
penjualan barang apa saja yang diminati oleh konsumen dan barang yang kurang
diminati. Sehingga kedepannya pemilik bisnis ini dapat melakukan analisa barang
apa saja yang laku dipasaran.
3.1.1. Sejarah Perusahaan
Percetakan awfa digital printing adalah bentuk usaha yang bergerak di
bidang advertising, dimana ruanglingkup usahanya meliputi cetak banner,
undangan, kartu nama, supplier atk, dan lain-lain. Usaha tersebut berlokasi di jalan
kavling pulo no 5 rt/rw Ds. Sukaraya Kec. Karang Bahagia Kab. Bekasi. Usaha
tersebut berdiri pada tanggal 23 agustus 2017. Usaha ini didirikan karena minimnya
pelayanan percetakan di daerah sekitar, sehingga dapat membantu kebutuhan
3.2.1. Struktur Organisasi Perusahaan
Berikut Struktur Organisasi pada Percetakan Awfa Digital Printing
Gambar 3.1 Struktur Organisasi Percetakan Awfa Digital Printing. Adapun Pembagian bidang pekerjaan (Job Desk) yang berjalan di Percetakan Awfa Digital Printing adalah sebagai berikut :
1. Pemilik
Adapun tugas dan kewenangan seorang Pemilik adalah sebagai berikut :
a. Menentukan kebijakan berkaitan pengembangan percetakan.
b. Memeriksa semua laporan mengenai perkembangan percetakan.
c. Mengawasi kinerja seluruh pegawai dan jajaran.
2. Bagian Keuangan
a. Menghitung / Mengelola keuangan penjualan.
b. Membuat laporan.
c. Memeriksa setiap laporan.
3. Bagian Operasional Operator Cetak
a. Mengelola operasional mesin percetakan.
4. Bagian Operasional Desain.
a. Membuat desain yang dipesan konsumen.
Pemilik
Bagian Keuangan
Bagian Desain
Bagian Operasional
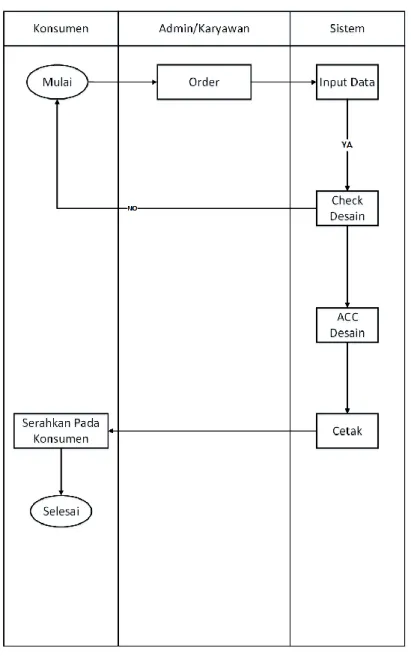
3.3.1. Sistem yang Berjalan
Berikut ini adalah mekanisme system yang berjalan pada percetakan :
Gambar 3.2 Sistem yang Berjalan.
Berikut ini adalah penjelasan dari Sistem yang Berjalan pada Percetakan
Awfa Digital Printing pada digambar gambar tersebut:
2. Admin login terlebih dahulu untuk mencatat pesanan desain dari
konsumen. Pada saat ini admin tidak lagi menggunakan alat tulis
melainkan sudah mengoperasionalkan komputer yang sudah ada
aplikasi untuk memproses, dan akan di berikan ke desainer untuk di
buatkan desain sesuai keinginan konsumen.
3. Desainer membuat desain sesuai dengan permintaan, setelah desain
dibuat akan di perlihatkan kepada konsumen apakah desain yang di
maksud sesuai, jika dirasa tidak sesuai maka akan didesain kembali
sampai konsumen merasa bahwa pesanan yang di pesannya cukup. Jika
sudah disetujui maka tahap selanjutnya file desain tersebut akan di
berikan ke karyawan/ admin yang nantinya akan di cetak mejadi hasil
jadi.
4. Setelah dicetak desain akan diberikan kepada konsumen dengan hasil
yang sudah di finishing (rapih).
5. Dan setelah desain diterima oleh konsumen maka konsumen akan
melakukan transaski (membayar) pesanan yang telah ia pesan.
3.2. Metode Penelitian
Pada penelitian ini, data yang digunakan adalah data penjualan. Data ini
akan diolah menggunakan beberapa metode data miningsehingga diperoleh metode
yang dapat digunakan sebagai rules dalam memprediksipenjualan barang yang laris
dan kurang laris. Dalam penelitian ini akan dilakukan beberapa langkah-langkah
Gambar 3.3 Tahapan Penelitian. 1. Pengumpulan Data
Pada bagian pengumpulan data dijelaskan dari mana data dalam
penelitian ini didapatkan, meliputi data kuantitatif dan data kualitatif. Data
kuantitatif yang diperoleh dari sumber perusahaan Percetakan untuk
keperluan penelitian, sedangkan data kualitatif berisi tentang data yang
dihasilkan dari penelitian.
2. Pengolahan Awal Data
Pengelompokan awal data menjelaskan tentang tahapan awal data
mining. Pengolahan awal data meliputi proses input data ke format yang
3. Metode yang Diusulkan
Metode yang Diusulkan menjelaskan tentang metode yang diusulkan
untuk mengoptimasi klasifikasi penjualan barang yang laris dan kurang
laris. Penjelasan ini meliputi pengaturan dan pemilihan dari atribut-atribut
yang digunakan sebagai parameter dan arsitektur melalui uji coba.
4. Eksperimen dan Pengujian Metode
Pada bagian Eksperimen dan Pengujian Metode menjelaskan tentang
langkah-langkah eksperimen meliputi cara pemilihan arsitektur yang tepat
dari model atau metode yang diusulkan sehingga didapatkan hasil yang
dapat membuktikan bahwa metode yang digunakan adalah tepat.
5. Evaluasi dan Validasi Hasil
Pada bagian Evaluasi dan Validasi Hasil dijelaskan tentang evaluasi dan
validasi hasil penerapan metode pada penelitian yang dilakukan. Penjelasan
mengenai hal ini akan dijelaskan pada selanjutnya yaitu BAB IV.
3.3. Metode Pengumpulan Data
Dalam metode pengumpulan data terdapat 2 metode yaitu pengumpulan
data Kuantittif dan kualitatif. Data kuantitatif adalah data yang didapat langsung
dari sumbernya sedangkan data sekunder adalah data yang diperoleh secara tidak
Adapun jenis data yang digunakan dalam penelitian ini adalah sebagai
berikut:
1) Data kuantitatif, yaitu data yang diperoleh dari sumber perusahaan
Percetakan Awfa Digital Printing berupa dataset transaksi penjualan.
2) Data kualitatif, yaitu data yang diperoleh dari sumber penelitian untuk
mengumpulkan informasi baik secara tulisan maupun lisan. Penulis juga
mengumpulkan referensi-referensi literatur jurnal dan buku yang berkaitan
dengan algoritma C4.5 Decision Tree dan Algoritma Genetika,
menggunakan Rapidminer untuk mengolah dataset penjualan menjadi
bentuk informasi guna untuk melihat hasil penjualan laris dan kurang laris.
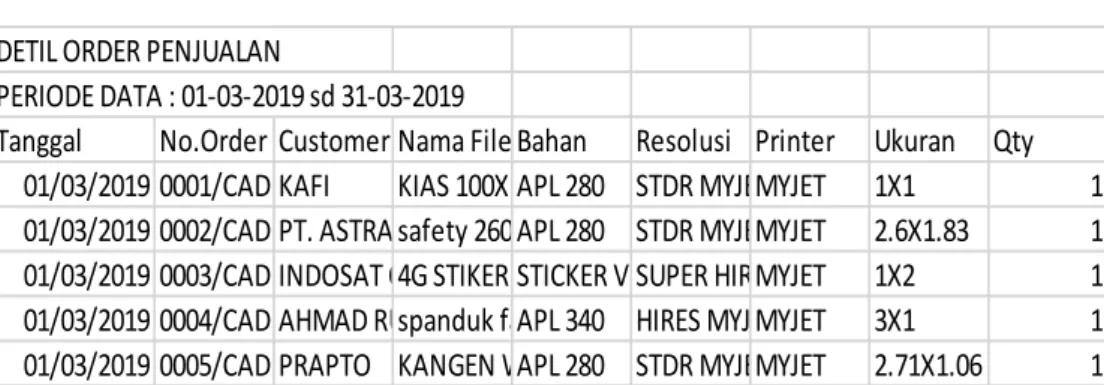
Berikut adalah daset yang bersumber dari percetakan.
Table 3.1 Dataset Penjualan.
DETIL ORDER PENJUALAN
PERIODE DATA : 01-03-2019 sd 31-03-2019
Tanggal No.Order Customer Nama File Bahan Resolusi Printer Ukuran Qty 01/03/2019 0001/CADP/III/19 KAFI KIAS 100X100CM APL 280 STDR MYJET MYJET 1X1 1 01/03/2019 0002/CADP/III/19 PT. ASTRA DAIHATSU MOTOR safety 260x183 cm APL 280 STDR MYJET MYJET 2.6X1.83 1 01/03/2019 0003/CADP/III/19 INDOSAT OOREDOO 4G STIKER 1X2M STICKER VINYL SUPER HIRES MYJET MYJET 1X2 1 01/03/2019 0004/CADP/III/19 AHMAD RUSBIANTO spanduk family gathering 1x3m APL 340 HIRES MYJET MYJET 3X1 1 01/03/2019 0005/CADP/III/19 PRAPTO KANGEN WATER 271x106cm APL 280 STDR MYJET MYJET 2.71X1.06 1
3.4. Pengolahan Data Awal
Pada tahap pemilihan data ini, data yang digunakan merupakan data yang
akan dilakukan test atau uji coba dengan cara memilih data yang hannya diperlukan
yaitu: dataset transaksi penjualan perbulan, Periode Data : 01-03-2019 sd
nama file, bahan yang digunakan, resolusi, printer, ukuran, Qty, harga satuan, total
harga, penerima, kasir, jam invoice. Namun data yang akan digunakan: nama bahan,
qty (jumlah), harga satuan, total harga, dan keterangan.
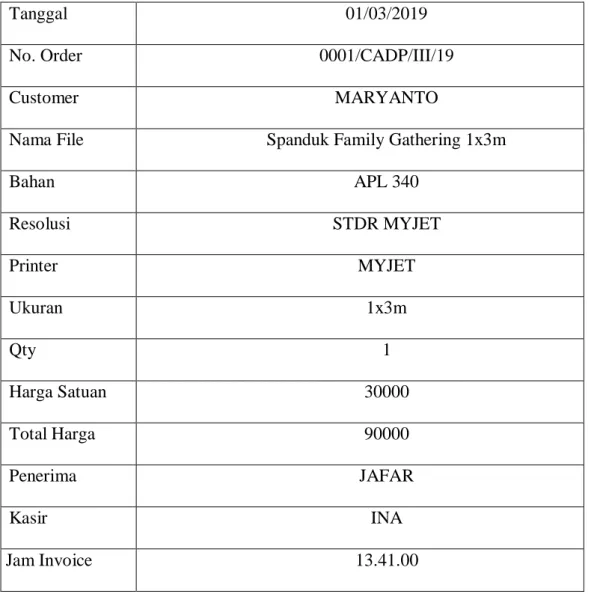
Tabel 3.2 Data Awal.
Tanggal 01/03/2019
No. Order 0001/CADP/III/19
Customer MARYANTO
Nama File Spanduk Family Gathering 1x3m
Bahan APL 340 Resolusi STDR MYJET Printer MYJET Ukuran 1x3m Qty 1 Harga Satuan 30000 Total Harga 90000 Penerima JAFAR Kasir INA Jam Invoice 13.41.00
3.5. Pengelolaan Data Awal
Pada dataset penjualan sebelum diolah maka harus dilakukan proses
karena tidak semua data awal yang di masukan pada tahap proses mining bias diolah
semua, hanya beberapa bagian atribut saja, seperti pada gambar berikut ini :
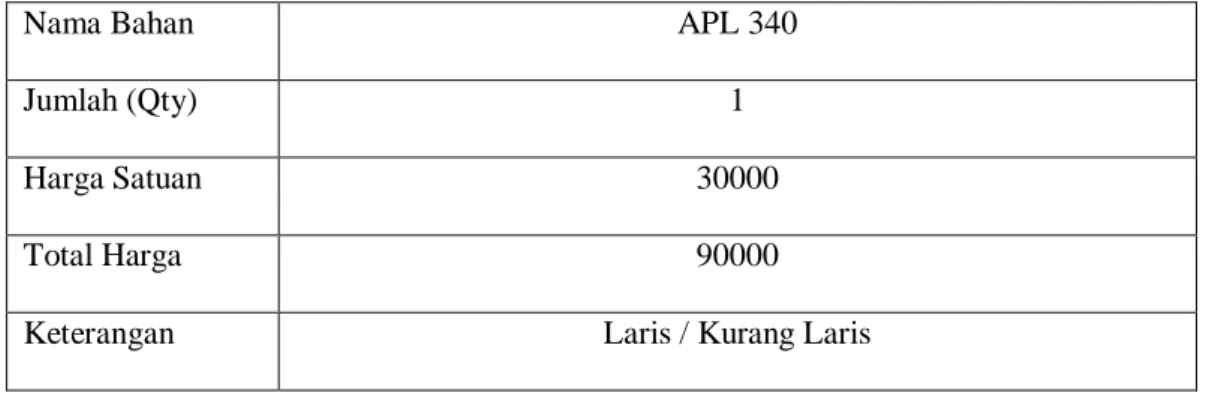
Tabel 3.3 Atribut yang Digunakan.
Nama Bahan APL 340
Jumlah (Qty) 1
Harga Satuan 30000
Total Harga 90000
Keterangan Laris / Kurang Laris
Data yang digunakan dalam penelitian ini hanya di ambil sebanyak 5 atribut,
karena hanya data yang berpengaruh dalam proses memining saja yang digunakan
(Berpengaruh). Agar sesuai diproses kedalam Rapidminer.
Tabel 3.4 Menentukan Barang Laris Dan Kurang Laris.
Sumber : Percetakan Awfa Digital Printing.
Ketentuan Jumlah Barang Keterangan
> 5 Laris
≤ 5 Kurang Laris
Selain itu juga penulis memberikan keterangan yang bersumber dari tempat
data tersebut di ambil yaitu di percetakan Awfa Digital Printing, batas barang apakah barang tersebut apabila kurang dari batas yang ditentukan maka “Tidak
Laris”, apabila barang yang ditentukan lebih besar maka barang tersebut “Laris”.
Tabel 3.5 Pengujian Data.
Jumlah Data 1000 100%
Data Traning 800 80%
Data Testing 200 20%
Data yang akan disiapkan untuk klasifikasi dibagi menjadi dua seperti pada
Tabel 3.5, data training (80%) dan data testing (20%). Pembagian data menjadi data training dan data testing menggunakan tools Split Validation. Split Validation
adalah teknik validasi yang membagi data menjadi dua bagian secara acak, sebagian
sebagai data training dan sebagian lainnya sebagai data testing. Dengan
menggunakan split validation akan dilakukan percobaan training berdasarkan split
ratio yang telah ditentukan sebelumnya, untuk kemudian sisa dari split ratio data
training akan dianggap sebagai data testing. Data training adalah data yang akan
dipakai dalam melakukan pembelajaran sedangkan data testing adalah data yang
belum pernah dipakai sebagai pembelajaran dan akan berfungsi sebagai data
pengujian kebenaran atau keakurasian hasil pembelajaran [19]. Berikut adalah
Gambar 3.4 Ilustrasi Split Validation.
Split Validation adalah teknik validasi yang membagi data menjadi dua
bagian secara acak, sebagian sebagai data training dan sebagian lainnya sebagai
data testing. Dengan menggunakan Split Validation akan dilakukan percobaan
training berdasarkan split ratio yang telah ditentukan sebelumnya, untuk kemudian
sisa dari split ratio data training akan dianggap sebagai data testing. Data training
adalah data yang akan dipakai dalam melakukan pembelajaran sedangkan data
testing adalah data yang belum pernah dipakai sebagai pembelajaran dan akan
berfungsi sebagai data pengujian kebenaran atau keakurasian hasil pembelajaran
1. Choosing the appropriate Data Mining task
Pada tahap ini memilih jenis data mining yang digunakan. Pada
penelitian untuk prediksi penjualan barang laris dan kurang laris maka dipilih
jenis data mining yang akandigunakan adalah klasifikasi.
2. Choosing the Data Mining Algorithm
Setelah pemilihan jenis data mining yang akan digunakan yaitu
klasifikasi, maka selanjutnya menentukan algoritma klasifikasi yang akan
digunakan yaituAlgoritma C4.5 setelah itu dioptimasi dengan menggunakan
algoritma genetika.
3. Employing the Data Mining Algorithm
Tahap ini dilakukan untuk pengolahan data dengan algoritma yang telah
dipilih untuk mendapatkan algoritma terbaik dengan tingkat akurasi yang
tinggidalam klasifikasi prediksi penjualan barang yang laris dan kurang laris.
4. Evaluation
Dalam tahap ini dilakukan evaluasi dan menafsirkan pola yang
didapatkan dari hasil algoritma yang dipakai untuk mengetahui aturan,
kehandalan, dan lain - lain. Evaluasi dilakukan dengan menerapkan pola yang
didapat dari proses sebelumnya terhadap data testing yang disediakan.
Evaluasi dilakukan dengan confusion matrix dan accuracy performance
vector. Hasil dari confusion matrix akan digunakanuntuk menampilkan hasil
Accuracy, Precision, dan Recall. Accuracy merupakanpresentase antara nilai
keberhasilan algoritma yang digunakan. Precision merupakan nilai akurasi
dengan class yang telah diprediksi [1]. Berikut adalah tabel confusionmatrix:
Tabel 3.6 Model Confusion Matrix. Classification Predicted class
Class = Yes Class = No
Class = Yes a (true positive-TP) b (false negative-FN)
Class = No c (false positive-FP) d (true negative-TN)
Rumus untuk menghitung tingkat akurasi pada
matrik adalah : Accuracy = 𝑇𝑃+𝑇𝑁 𝑇𝑃+𝐹𝑃+𝑇𝑁+𝐹𝑁 = 𝐴+𝐷 𝐴+𝐵+𝐶+𝐷 Keterangan :
a : jika nilai prediksi positif dan kelas sebenarnya positif
b : jika nilai prediksi negatif dan kelas sebenarnya positif
c : jika nilai prediksi positif dan kelas sebenarnya negatif
d : jika nilai prediksi negatif dan kelas sebenarnya negatif
Berikut adalah rumus untuk menghitung Accuracy :
Accuracy = 𝐴+𝐷
𝑎+𝑏+𝑐+𝑑
Berikut adalah rumus untuk menghitung Recall :
Recall = 𝑎
𝑎+𝑐
Precision = 𝑎
𝑎+𝑏
5. Using the discovered knowledge
Pada tahap ini menggunakan pengetahuan yang diperoleh dari proses
data mining untuk penerapan pada aplikasi atau lainnya. Pengetahuan
klasifikasi dataset diterapkan pada data baru untuk membuat klasifikasi
penjualan barang yang laris dan kurang laris.
3.6. Metode yang Diusulkan
Dalam penelitian ini melalui tahapan dilakukannya uji coba menggunakan
metode algoritma C4.5 dan Optimasi GA (Genetic Algorithm). Data dianalisa
dengan menggunakan algoritma sesuai dengan metode yang telah di rencanakan,
setelah itu membandingkan metode dengan optimasi GA (Genetic Algorithm)
untuk melihat perbandingan tertinggi timgkat akurasi. Pada tahapan uji coba ini
akan dilakukan beberapa langkah atau tahapan pengujiandata yaitu seperti berikut:
Dari gambar metode yang diusulkan akan mendapat dan mengetahui hasil
yang didapatkan oleh algoritma C4.5, kemudian pada hasil tersebut akan
ditambahkan algoritma genetika sebagai optimasi yang digunakan untuk
meningkatkan hasil dari algoritma C4.5. Padatahap akhir hasil dari keduanya akan
dibandingkan sehingga akan diketahui hasil dari uji coba seberapa efektifnya
BAB IV
HASIL PENGUJIAN DAN PEMBAHASAN
4.1. Hasil Pengujian
Hasil penelitian pengujian untuk mengetahui hasil dari suatu proses
penelitian. Berikut adalah beberapa hasil pengujianyang telah dilakukan :
4.1.1. Pengujian Decision Tree
Tahapan awal yang dilakukan dalam penelitian ini yaitu mempersiapkan
dataset penjualan barang yang didapatkan dari sumber yaitu percetakan awfa digital
printing. Data yang diambil adalah dataset penjualan barang yang merupakan data
yang berjumlah 1000 data danmemiliki 5 atribut.
Tabel 4.1 Data yang Digunakan.
Nama Bahan Jumlah Harga Satuan Total Harga Keterangan
APL 280 5 9000 45000 Laris
APL 340 3 30000 90000 Laris
AP 150 2 2500 5000 Kurang Laris
APL 440 1 40000 40000 Laris
APL 280 7 9000 63000 Kurang Laris
AP 150 10 2500 25000 Laris
APL 440 5 40000 200000 Kurang Laris
APL 440 2 40000 80000 Kurang Laris
APL 340 12 30000 360000 Laris
Pada Tabel 4.1 data awal yaitu “Data yang Digunakan” dataset uji coba,
harus dikelola terlebih dahulu karena peneliti menganggap ada data yang tidak
tersebut antara lain yang didalamnya terdapat atribut seperti : tanggal, no order,
nama customer, nama file, bahan yang digunakan, resolusi, printer, ukuran, Qty,
harga satuan, total harga, penerima, kasir, jam invoice. Namun data yang akan
digunakan hanya atribut: nama bahan, qty (jumlah), harga satuan, total harga, dan
keterangan. pengujian menggunakan operator yang terdapat pada aplikasi
RapidMiner. Setelah data dianggap sudah cukup maka tahap selanjutnya adalah
pengujian pada aplikasi RapidMiner. Pengujian ini menggunakan Aplikasi
RapidMiner 9.3.Adapun operators yang digunakan yaitu sebagai berikut :
Pertama peneliti menggunakan operators Read Excel yang digunakan untuk
melakukan import dataset dengan cara pilih Import Configuration Wizard lalu pilih
data yang akan dikelola dan pilih atribut yang akan melalui tahapan proses
pengolahan data, maka akantampil hasil seperti berikut :
Gambar 4.1 Import Dataset.
Pada gambar tersebut menampilkan isi dari dataset yang akan diolah. Lalu pilih “finish” untuk ke tahap selanjutnya.
Gambar 4.2 Tampilan Operator yang Digunakan.
Penggunaan Tool Examples berfungsi untuk mengisi data, atau atribut yang
missing data (data yang tidak terisi) lalu pilih atribut yang datanya tidak terisi lalu “Ok”. Maka jika menggunakan Tools ini data akan terisi diambil nilai rata-rata
secara otomatis pada Rapidminer. Penggunaan operator ini juga, jika data yang
dimasukan ada kesalahan atau terjadi Human error pada saat data awal yang
sebelumnya diolah agar dapat di proses oleh Aplikasi Rapidminer.
Set Role menentukan parameter atribut yang akan dijadikan hasil dari bentuk pohon keputusan. Setelah itu klik “Set Role”, maka akan muncul tampilan dipojok
atas kanan, pilih “Atribut Name”. Atribut yang dipilih adalah atribut “Keterangan”,