3.1 Jenis Penelitian
Jenis penelitian yang digunakan dalam penelitian ini adalah penelitian kuantitatif kausal, yaitu tipe research konklusif yang bertujuan untuk menentukan hubungan sebab akibat (hubungan kausal) dari suatu fenomena (Tjiptono, Santoso, 2001, p.48). Dalam kasus ini yaitu menyelidiki pengaruh perilaku konsumen terhadap keputusan pembelian dengan adanya promosi harga ”50%
Discount”.
3.2 Populasi dan Sampel 3.2.1 Populasi
Populasi merupakan sekumpulan orang atau obyek yang memiliki kesamaan dalam satu atau beberapa hal dan yang membentuk masalah pokok dalam suatu research khusus (Tjiptono, Santoso, 2001, p.79). Populasi dalam penelitian ini mencakup semua konsumen restoran yang berdomisili di Surabaya.
Karena demikian luasnya populasi yang diteliti menyebabkan penelitian ini hanya mengambil beberapa unit sampel dari populasi yang ditentukan untuk mewakili populasi tersebut.
3.2.2 Sampel
Sampel adalah sebagian individu dari populasi yang diteliti yang dipandang dapat menggambarkan secara representatif mengenai keadaan populasi (Arikunto, 2002, p.109). Penelitian ini ditujukan untuk memahami konsumen secara utuh, karena itu tidak menggunakan sampling frame. Teknik yang digunakan adalah non probability dengan cara judgmental sampling. Berdasarkan pendapat Solimun (2005, p.57) menyatakan ”...besar sampel yang disarankan adalah 100 sampel. Untuk mengantisipasi kuesioner- kuesioner yang tidak valid maka peneliti menetapkan jumlah sampel sebanyak seratus empat puluh responden yang paling mudah dicapai, terutama sampel yang hadir pada saat penelitian dilaksanakan. Dimana sebanyak 109 (seratus sembilan) kuesioner valid
dan sebanyak 31(tiga puluh satu) kuesioner tidak valid, namun data yang digunakan hanya sebanyak 100 (seratus).
Judgmental sampling yaitu penyeleksian populasi mengenai siapa yang menjadi target sampel untuk mendapatkan informasi yang akurat (Maholtra, 1997, p.306). Judgmental sampling dilakukan dengan membagikan kuesioner kepada para pelajar, ataupun anggota dari organisasi–organisasi sosial yang lain.
Selanjutnya, peneliti juga akan membagikan kuesioner kepada sampel-sampel yang dijumpai baik di jalan jalan, maupun di restoran-restoran ”50% Discount”.
Karakteristik sampel untuk penelitian ini adalah konsumen yang pernah mencoba promosi ”50% Discount” yang berdomisili di Surabaya, dan berusia 17 tahun ke atas.
3.3 Jenis dan Sumber Data 1.3.1 Data Primer
Data primer diperoleh dari seluruh masyarakat Surabaya sebagai konsumen yang pernah mencoba promosi harga ”50% Discount”. Data-data didapatkan melalui penyebaran kuesioner saat survei lapangan. Data primer yang didapat mencakup faktor-faktor sosial, personal, psikologikal dan culture dari perilaku konsumen yang mempengaruhi proses pengambilan keputusan pembelian, dihadapkan dengan fenomena promosi ”50% Discount”.
1.3.2 Data sekunder
Diperoleh dari buku penuntun yang sudah diterbitkan, seperti majalah, jurnal, literatur perpustakaan, dan diktat-diktat perkuliahan.
3.4 Metode dan Prosedur Pengumpulan Data 3.4.1 Kuesioner
Dalam penelitian ini, peneliti menggunakan teknik pengumpulan data dengan metode survei lapangan melalui penyebaran kuesioner. Prosedur pengumpulan data dalam penelitian ini adalah sebagai berikut:
1. Membagikan kuesioner kepada responden yang sesuai dengan standar karakteristik yang diperlukan.
2. Kuesioner yang telah diisi oleh responden dikumpulkan, disortir, dan diberi skor.
Kuesioner yang akan dibagikan terdiri dari 2 bagian, yaitu latar belakang responden, dan faktor-faktor perilaku konsumen. Kuesioner yang akan dibagikan tersebut merupakan kuesioner yang bersifat tertutup dengan menggunakan, Likert Scale Method, dimana jawaban responden telah dibatasi dengan menyediakan alternatif jawaban yaitu:
• Sangat tidak setuju diberi skor 1
• Tidak setuju diberi skor 2
• Netral cenderung tidak setuju diberi skor 3
• Netral cenderung setuju diberi skor 4
• Setuju diberi skor 5
• Sangat setuju diberi skor 6
Sebelum penulis membagikan kuesioner kepada 140 responden, penulis terlebih dahulu melakukan pre-sampling dimana penulis membagikan kuesioner kepada 10 responden sebagai percobaan kuesioner. Hal ini dimaksudkan untuk menyempurnakan kuesioner yang akan dibagikan. Setelah dilakukan pre- sampling kuesioner dibagikan pada tanggal 20 Febuari sampai 4 maret 2008 di mal-mal (Tunjungan Plaza, Galaxy Mall, Supermall ), Universitas Kristen Petra, Sinar Jemursari, dan G Walk .
3.4.2 Kajian pustaka
Didapat dengan cara melakukan riset, melalui membaca buku-buku teori pendukung, artikel-artikel dari berbagai surat kabar, dan media cetak yang berhubungan dengan penelitian.
3.5 Variabel dan Definisi Operasional Variabel
Dalam penelitian ini yang menjadi variabel independen adalah faktor- faktor perilaku konsumen. Sedangkan variabel dependennya adalah proses pengambilan keputusan pembelian konsumen. Berikut adalah definisi operasional dari variabel independen dan dependen yang sudah diidentifikasikan sebelumnya supaya variabel tersebut dapat diukur dan digunakan dalam penelitian ini:
1. Social (X1):
a. Group (X1.1)
Kelompok dimana orang tersebut berada yang mempunyai pengaruh langsung, primary groups (keluarga, teman, tetangga, dan rekan kerja) dan secondary groups yang lebih formal dan memiliki interaksi rutin yang sedikit (kelompok keagamaan, perkumpulan profesional dan serikat dagang).
• Membeli makanan di restoran “50 % Discount” karena diajak teman.
• Membeli makanan di restoran “50 % Discount” karena pengaruh teman.
b. Family (X1.2)
Keluarga memberikan pengaruh yang besar dalam perilaku pembelian.
Para pelaku pasar telah memeriksa peran dan pengaruh suami, istri, dan anak dalam pembelian produk dan servis yang berbeda.
• Membeli makanan di restoran “50 % Discount” diajak keluarga.
• Membeli makanan di restoran “50 % Discount” karena pengaruh orang tua.
• Membeli makanan di restoran “50 % Discount” karena pengaruh saudara.
Penulis tidak memasukkan faktor roles dan status karena tidak ada peran ataupun status yang dapat ditunjukkan kepada masyarakat dengan membeli produk ”50 % discount”.
2. Personal (X2),
a. Economic situation (X2.1)
Situasi ekonomi seseorang amat sangat mempengaruhi pemilihan produk dan keputusan pembelian pada suatu produk tertentu. Selama masa resesi para pelaku pasar perlu untuk mengamati keadaan pasar serta konsumen. Konsumen mengurangi konsumsi di restoran, hiburan, dan liburan, keadaan demikian membuat para pelaku pasar berlomba-lomba mengadakan promosi (50%
Discount) untuk kembali menaikkan daya konsumsi masyarakat.
• Membeli makanan di restoran “50 % Discount” karena dianggap lebih murah.
• Membeli makanan di restoran “50 % Discount” karena sesuai dengan anggaran yang ada.
• Membeli makanan di restoran “50 % Discount” karena dapat menghemat pengeluaran bulanan.
b. Life style (X2.2)
Gaya hidup menggambarkan keseluruhan seseorang dalam berinteraksi dengan lingkungan sekitarnya. Orang-orang yang datang dari kebudayaan, kelas sosial, dan pekerjaan yang sama mungkin saja mempunyai gaya hidup yang berbeda. Para pelaku pasar mencari hubungan antara produknya dengan konsumennya
• Memilih makan di restoran dengan “50 % discount” pada saat waktu luang.
• Memilih makan di restoran dengan “50 % discount” dibanding dengan bidang usaha lain yang juga mengadakan program yang sama di saat yang sama.
c. Personality dan Self Concept (X2.3)
Personality dapat diartikan sebagai karakteristik psikologi yang berasal dari dalam diri yang mempengaruhi dan menentukan bagaimana seseorang merespon kepada lingkungannya. Orang yang menganggap dirinya sebagai orang dari kalangan kelas atas akan memilih makan di restoran berkelas.
• Pendapat pribadi sangat berpengaruh terhadap keputusan yang diambil orang lain.
• Mempertimbangkan hal-hal mendetail dalam mengambil keputusan.
• Tidak mudah dipengaruhi oleh orang lain dalam mengambil keputusan.
• Suka bersosialisasi.
• Cenderung melakukan segala sesuatu secara individu.
d. Occupation (X2.5)
Pekerjaan seseorang mempengaruhi barang dan jasa yang dibeli. Pekerja konstruksi sering membeli makan siang dari catering yang datang ke tempat kerja, bussines eksekutif akan membeli makan siang dari full service restoran, sedangkan pekerja kantor membawa makan siangmya dari rumah atau membeli dari restoran cepat saji terdekat.
• Sering makan di restoran “50 % discount” pada saat jam makan siang.
3. Psychological (X3):
a. Motivation (X3.1)
Berdasarkan teori Maslow, seseorang dikendalikan oleh suatu kebutuhan pada suatu waktu. Kebutuhan manusia diatur menurut sebuah hierarki, dari yang paling mendesak sampai paling tidak mendesak ( kebutuhan psikologikal, keamanan, sosial, harga diri, pengaktualisasian diri). Kebutuhan manusia yang paling mendasar adalah kebutuhan untuk makan.
• Membeli makanan di restoran “50 % discount” karena lapar.
• Membeli makanan di restoran “50 % Discount” karena dengan harga murah prestige tetap terjaga.
b. Perception (X3.2)
Orang dapat membentuk berbagai macam persepsi yang berbeda dari rangsangan yang sama. Tindakan seseorang itu dipengaruhi oleh persepsinya akan situasi. Dengan adanya stimulus “50 % discount”, akan mempengaruhi persepsi dan respon seseorang dalam memilih produk yang dibeli.
• Membeli produk “50 % discount” karena mendapatkan porsi yang lebih banyak.
• Dengan adanya promosi “50 % discount” yang diadakan apakah anda menganggap image restoran menjadi jelek.
c. Learning (X3.3)
Pembelajaran adalah suatu proses, yang selalu berkembang dan berubah sebagai hasil dari informasi terbaru yang diterima (didapatkan dari membaca, diskusi, observasi, berpikir). Konsumen restoran mengalami pembelajaran melalui banyaknya iklan, spanduk “50 % discount”, dan melalui pengamatan akan pengalaman orang lain yang telah mencoba makanan “50 % discount”.
• Membeli produk karena terus menerus diiklankan.
• Membeli produk karena banyaknya konsumen lain yang membeli.
d. Beliefs and Attitudes (X3.4)
Beliefs adalah pemikiran deskriptif bahwa seseorang mempercayai sesuatu. Beliefs dapat didasarkan pada pengetahuan asli, opini, dan iman.
Sedangkan attitudes adalah evaluasi, perasaan suka atau tidak suka, dan kecenderungan yang relatif konsisten dari seseorang pada sebuah obyek atau ide.
• Makan di restoran “50% discount” karena percaya dengan adanya diskon harga menjadi murah.
• Lebih menyukai makan di restoran “50% discount” karena harga yang murah.
4. Culture ( X4) a. Culture (X4.1)
Nilai-nilai dasar, persepsi, keinginan, dan perilaku yang dipelajari seseorang melalui keluarga dan lembaga penting lainnya
• Terbiasa meluangkan waktu untuk makan di luar bersama keluarga.
• Memilih makan di restoran “50% discount” karena praktis.
b. Social class (X4.2)
Pengelompokkan individu berdasarkan kesamaan nilai, minat, dan perilaku. Kelompok sosial tidak hanya ditentukan oleh satu faktor saja misalnya pendapatan, tetapi ditentukan juga oleh pekerjaan, pendidikan, kekayaan, dan lainnya
• Pendapatan yang diterima lebih dari cukup untuk memenuhi kebutuhan sehari-hari.
c. Subculture (X4.3)
Sekelompok orang yang berbagi sistem nilai berdasarkan persamaan pengalaman hidup dan keadaan, seperti kebangsaan, agama, dan daerah.
• Budaya masyarakat indonesia ( contohnya “ belum makan jika belum makan nasi” ) turut mempengaruhi pilihan makan di restoran “50%
discount” . 5. Purchase (Y)
a. Fully Planned Purchase (Y1)
Produk dan merek sudah dipilih sebelumnya, terjadi ketika keterlibatan dengan produk tinggi (barang otomotif) namun bisa juga terjadi dengan keterlibatan pembelian yang rendah (kebutuhan rumah tangga). Planned purchase dapat dialihkan dengan taktik marketing misalnya pengurangan harga, kupon, atau aktivitas promosi lainnya.
• Makan di restoran “50% discount” untuk merayakan event-event tertentu (misalnya ulang tahun).
b. Partially Planned Purchase ( Y2)
Bermaksud untuk membeli produk yang sudah ada tetapi pemilihan merek ditunda sampai saat pembelajaran. Keputusan akhir dapat dipengaruhi oleh discount harga, atau display produk.
• Memutuskan untuk beralih makan di restoran “50% discount” karena tertarik dengan promosi yang ditawarkan.
• Memutuskan makan di restoran “50% discount” yang lain karena lebih menyukai jenis makanan yang ditawarkan.
c. Unplanned Purchase (Y3)
Produk dan merek dipilih di tempat pembelian. Konsumen sering memanfaatkan katalog dan produk pajangan sebagai pengganti daftar belanja.
• Memutuskan makan di restoran “50% discount” setelah melihat spanduk yang dipasang diluar restoran.
3.6 Teknik Analisa Data
Setelah data-data terkumpul akan dilakukan pengujian validitas dan reliabilitas agar hasil kesimpulan penelitian akurat. Pengujian validitas dan reliabilitas dilakukan untuk setiap faktor atau variabel yang ada dalam kuesioner, bila dalam sebuah kuesioner terdapat enam faktor maka pengujian validitas dan reliabilitas harus dilakukan enam kali. Apabila hasil dari pengujian tersebut tidak valid dan reliabel maka pengujian validitas dan reliabilitas ini diulang dengan mengeluarkan pertanyaan yang sama dan menggunakan prosedur yang sama sampai hasil dari pengujian tersebut valid dan reliabel.
3.6.1 Uji Validitas
Uji validitas digunakan untuk mengukur sah atau valid tidaknya suatu kuesioner. Suatu kuesioner dapat dikatakan valid jika pertanyaan pada kuesioner mampu untuk mengungkapkan sesuatu yang akan diukur oleh kuesioner tersebut (Ghozali, 2002, p.135). Uji validitas dapat dilakukan dengan menghitung korelasi
secara parsial dari masing-masing kuesioner dengan total skor variabel yang diteliti. Jika hasil korelasi tersebut menunjukkan signifikansi 5%, maka item-item pertanyaan tersebut dikatakan valid dan dapat digunakan untuk analisis selanjutnya
Langkah-langkah dalam pengujian validitas tersebut adalah sebagai berikut:
a. Mendefinisikan secara operasional konsep yang akan diukur.
b. Melakukan uji coba skala pengukuran pada sejumlah responden. Responden diminta untuk menyatakan apakah responden setuju atau tidak setuju dengan masing-masing pertanyaan.
c. Mempersiapkan tabel tabulasi.
d. Menghitung korelasi masing-masing pertanyaan dengan skor total menggunakan rumus sebagai berikut:
n( ∑XiY )-( ∑Xi ) ( ∑Y ) (3.1) r =
√[ ∑Xr2 – ( ∑Xi )2 ] x √ [ n∑Y2 – ( ∑Y )2 ] Dimana :
r = koefisien korelasi Xi = skor pernyataan ke-i
Y = skor total dari item pernyataan n = jumlah responden
e. Membandingkan hasil perhitungan dengan angka kritis tabel korelasi nilai r dengan nilai signifikan sebesar 5%
• Korelasi dianggap valid jika tingkat signifikansi korelasi tersebut dibawah 0,05.
• Korelasi dianggap tidak valid jika tingkat signifikansi korelasi tersebut melebihi 0,05 (Arikunto, 1992, p.109).
3.6.2 Uji Reliabilitas
Menururt Simamora, reliabilitas adalah tingkat keandalan kuesioner.
Kuesioner yang reliabel adalah kuesioner yang apabila dicobakan secara berulang kepada kelompok yang sama akan menghasilkan data yang sama. Reliabilitas
menunjukkan konsistensi dan stabilitas dari suatu skor (skala pengukuran) (Simamora, 2002, p.63).
Langkah-langkah mengukur reliabilitas dari kuesioner adalah sebagai berikut:
a. Menyajikan alat pengukur kepada sejumlah responden lalu dihitung validitas item-item yang akan diukur. Item-item yang valid dikumpulkan menjadi satu, yang tidak valid tidak dipakai.
b. Membagi item-item yang valid tersebut menjadi dua belahan.
c. Skor untuk masing-masing item pada tiap belahan dijumlahkan.
d. Mengkorelasikan skor total belahan pertama dengan skor belahan kedua dengan menggunakan rumus :
2 ( ru ) (3.2) Rtot =
1 + ru
Dimana :
Rtot = angka reliabilitas keseluruhan item
ru = angka korelasi belahan pertama dan kedua
e. Membandingkan hasil perhitungan dengan angka kritis tabel korelasi nilai r untuk menentukan korelasi yang signifikan. Suatu kuesioner dapat dikatakan reliabel atau handal jika kuesioner dalam satu variabel memiliki jawaban konsisten dari waktu ke waktu, dengan syarat nilai dari uji reliabilitas dapat menunjukkan nilai alpha > 0,6 (Ghozali, 2002, p.132).
Setelah data-data yang diperlukan diperoleh, dilakukan proses pemilahan data. Pemilahan data akan membantu dalam mengetahui kesalahan-kesalahan yang terjadi, sekaligus juga memastikan bahwa data yang diperoleh sesuai dengan standar kualitas minimum yang ditetapkan. Dengan begini data-data yang diterima dapat dijamin keakuratannya.
Teknik analisa data yang dipakai adalah:
1. Analisa deskriptif
• Meliputi analisa frekuensi untuk melihat latar belakang responden dilihat dari gender, tempat tinggal, kebiasaan konsumsi, status, pendapatan dan frekuensi berkunjung.
• Untuk melihat rata-rata dan standar deviasi dari masing-masing indikator variabel perilaku dan keputusan pembelian konsumen.
2. Model persamaan struktural (SEM)
Penelitian ini bertujuan menguji dan menganalisis hubungan kausal antara variabel independen dan dependen, sekaligus memeriksa validitas dan reliabilitas instrumen penelitian secara keseluruhan. Oleh karena itu digunakan teknik analisis Structural Equation Modeling (SEM) dengan menggunakan paket program AMOS (Analysis of Moment Structure) versi 4.0. SEM merupakan sekumpulan teknik-teknik yang memungkinkan pengujian beberapa variabel dependen dengan beberapa variabel independen secara simultan. Ghozali (2005, p.7) mengungkapkan bahwa SEM memungkinkan untuk dapat menjawab pertanyaan penelitian yang bersifat regresif maupun dimensional yaitu mengukur dimensi-dimensi dari sebuah konsep. Pada saat seorang peneliti menghadapi pertanyaan penelitian berupa identifikasi dimensi-dimensi sebuah konsep atau konstruk dan pada saat yang sama ingin mengukur pengaruh atau derajat hubungan antar faktor yang telah diidentifikasi dimensi-dimensinya, maka SEM akan memungkinkan untuk melaksanakannya. SEM juga merupakan pendekatan terintegrasi antara analisis faktor, model struktural dan analisis jalur (Solimun, 2002, p.65).
Penggunaan SEM memungkinkan peneliti untuk menguji hubungan antara variabel yang kompleks untuk memperoleh gambaran menyeluruh mengenai keseluruhan model. SEM dapat menguji secara bersama-sama (Ghozali , 2005, p.3):
1. Model struktural hubungan antara konstruk independen dan dependen
2. Model measurement hubungan (nilai loading) antara indikator dengan konstruk Digabungkannya pengujian model struktural dan pengukuran tersebut memungkinkan peneliti untuk:
1. Menguji kesalahan pengukuran (measurement error) sebagai bagian yang tidak terpisahkan dari SEM.
2. Melakukan analisis faktor persamaan dengan pengujian hipotesis.
3.6.3 Pengujian Hipotesis
Penelitian ini merupakan penelitian atas lima variabel yakni faktor sosial, faktor personal, faktor kultural, faktor psikologikal, keputusan pembelian. Dalam pengujian hipotesis yang diajukan, data yang diperoleh selanjutnya diolah sesuai dengan kebutuhan analisis. Untuk kepentingan pembahasan, data diolah dan dipaparkan berdasarkan prinsip-prinsip statistik deskriptif, sedangkan untuk kepentingan analisis dan pengujian hipotesis digunakan statistik inferensial.
Untuk menguji hipotesis digunakan analisis multivariat dengan Structural Equation Modeling (SEM) dengan menggunakan program AMOS 4.0. Pengujian apakah hipotesis yang diajukan dapat diterima dilakukan dengan jalan membandingkan nilai probabilitas (p) dengan taraf signifikan α yang ditentukan sebesar 0,05. Apabila nilai probabilitas (p) lebih kecil dari nilai α (0,05), maka hipotesis tersebut dapat diterima. Begitu pula sebaliknya, jika nilai probabilitas (p) lebih besar dari nilai α (0,05), maka hipotesis tersebut tidak diterima. Namun, sebelum dilakukan pengujian hipotesis, maka terlebih dahulu dilakukan analysis factor comfirmatory guna melihat dimensi-dimensi yang dapat digunakan untuk membentuk faktor atau konstruk.
3.6.4 Pengujian Hipotesis Penelitian a. Social (X1)
Variabel yang digunakan sebagai indikator Social (X1) adalah group (X1.1), family (X1.2),
Gambar 3.1.Tabel indikator dan variabel latent untuk faktor social.
Group (X1.1)
Family (X1.2)
Social (X1)
b. Personal (X2)
Variabel Personal (X2) menggunakan lima indikator yakni economic (X2.1), lifestlye (X2.2), personality dan self concept (X2.3), Occupation (X2.4)
Gambar 3.2 Tabel indikator dan variabel latent untuk faktor personal.
c. Psychological (X3)
Variabel yang digunakan dalam faktor psychological (X3) adalah motivation (X3.1), perception (X3.2), learning (X3.3), belief and attitude (X3.4)
Gambar 3.3 Tabel indikator dan variabel latent untuk faktor psychological.
d. Culture (X4)
Terdapat tiga variabel yang dalam faktor kultur (X4) adalah social class (X4.1), subculture (X4.2), culture (X4.3)
Personality dan Self Concept (X2.3) Economic (X2.1)
Lifestyle (X2.2)
Occupation (X2.4)
Personal (X2)
Perception(X3.2)
Learning (X3.3)
Belief and Attitude (X3.4) Motivation (X3.1)
Psychological (X3)
Gambar 3.4 Tabel indikator dan variabel latent untuk faktor culture.
e. Purchase (Y)
Terdapat tiga variabel yang dalam keputusan pembelian yaitu fully planned purchase (Y1), partially planned purchase ( Y2), dan unplanned purchase (Y3)
Gambar 3.5 Tabel indikator dan variabel latent untuk keputusan pembelian.
Pengujian apakah variabel-variabel ini dapat digunakan untuk membentuk faktor atau konstruk dilakukan dengan jalan melihat nilai probabilitas (p) dari nilai koefisien lambda (λ). Jika nilai probabilitas (p) koefisien lambda lebih kecil dari nilai α (0,05), maka indikator atau dimensi tersebut dapat digunakan untuk membentuk faktor atau konstruk. Begitu pula sebaliknya, jika nilai probabilitas (p) koefisien lambda lebih besar dari nilai α (0,05), maka indikator atau dimensi tersebut tidak dapat digunakan untuk membentuk faktor atau konstruk.
Subculture (X4.2) Culture(X4)
Social Class (X4.1)
Culture (X4.3)
Partially Planned Purchase (Y2) Purchase (Y)
Unplanned Purchase (Y3) Fully Planned Purchase (Y1)
3.6.5 Analisis SEM
Teknik SEM memungkinkan seorang peneliti menguji beberapa variabel dependen sekaligus, dengan beberapa variabel independen. Adapun tujuh langkah-langkah untuk melakukan pemodelan SEM adalah:
a. Pengembangan model berbasis konsep dan teori
Model persamaan struktural didasarkan pada hubungan kausalitas, dimana perubahan satu variabel diasumsikan akan berakibat pada perubahan variabel lainnya. Kuatnya hubungan kausalitas antara dua variabel yang diasumsikan oleh peneliti bukan terletak pada metode analisis yang dipilih, tetapi terletak pada justifikasi secara teoritis untuk mendukung analisis.
b. Mengkonstruksi diagram jalur
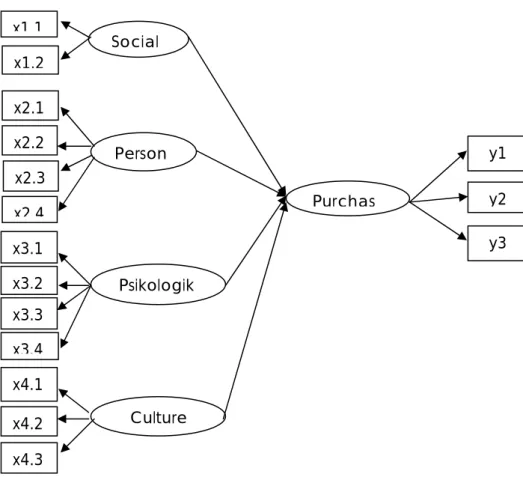
Setelah menyusun model berbasis teori, langkah selanjutnya adalah menerjemahkan model tersebut ke dalam diagram jalur (path diagram) agar dapat diestimasikan dengan menggunakan program AMOS 4. Dalam model structural dikenal dua variabel, yaitu variabel eksogen dan endogen. Sedangkan untuk persamaan-persamaan struktural (structural equations) yang dirumuskan untuk menyatakan hubungan kausalitas antar berbagai konstruk. Dimana persamaan tersebut pada dasarnya dibangun dengan pedoman sebagai berikut: variabel endogen (terikat) = variabel eksogen + variabel endogen + error. Variabel eksogen adalah variabel yang nilainya ditentukan di luar model, seperti variabel bebas dan variabel instrumen (juga disebut predetermined variables). Sedangkan variabel endogen adalah variabel yang nilainya ditentukan berdasarkan model, seperti variabel tidak bebas. Diagram jalur untuk penelitian ini adalah
Gambar 3.6 Model diagram jalur
c. Menerjemahkan diagram jalur ke dalam persamaan
Persamaan yang dihasilkan pada penelitian ini adalah persamaan model struktural (structural model), karena tujuan penelitian ini adalah ingin mengetahui hubungan kausalitas antar variabel yang diteliti.
d. Memilih matriks dan teknik estimasi
Setelah model dispesifikasikan secara lengkap, langkah berikutnya adalah memilih jenis input (kovarians dan korelasi). Matriks input yang dipilih dalam penelitian ini adalah matriks covarians. Alasan memilih input data matriks covarians adalah karena matriks covarians memiliki keunggulan dalam menyajikan perbandingan yang valid antara populasi yang berbeda atau sampel yang berbeda. Selain itu matriks covarians lebih sesuai untuk memvalidasi hubungan kausal.
Purchas
Psikologik
Culture Person Social x1 1
x1.2 x2.1
x2 4 x2.3 x2.2
y3 y2 y1
x3.2 x3.1
x4.1 x4.2 x4.3 x3.4 x3.3
Setelah memilih matriks input, maka AMOS akan melakukan estimasi coefisien path. Dalam melakukan estimasi model, ukuran sampel memegang peranan yang cukup penting. Dalam program AMOS 4 teknik-teknik estimasi yang tersedia adalah: (a) Maximum Likelihood Estimation (ML), (b) Generalized Least Square Estimation (GLS), (c) Unweighted Least Square Estimation (ULS), (d) Scale Free Least Square Estimation (SLS), dan (e) Symtotically Distribution- free Estimation (ADF). Selanjutnya memilih teknik analisis dengan mempertimbangkan ukuran sampel:
• Bila ukuran sampel adalah kecil (100-200) dan asumsi normalitas dipenuhi, gunakan ML, ULS dan SLS, biasanya tidak menghasilkan uji χ2, karena itu tidak menarik perhatian peneliti.
• Bila asumsi normalitas dipenuhi dan ukuran sample sampai dengan antara 200-500 gunakan ML dan GLS. Bila ukuran sample kurang dari 500, hasil GLS cukup baik.
• ADF, bila asumsi normalitas kurang dipenuhi dan ukuran sample lebih dari 2500.
Metode yang digunakan dalam penelitian ini adalah Maximum Likelihood (ML).
Metode ini dipilih mengingat ukuran sample adalah antara 100-200.
e. Menilai masalah identifikasi
Masalah identifikasi merupakan masalah ketidakmampuan dari model yang dikembangkan untuk menghasilkan estimasi yang unik. Masalah identifikasi dapat muncul melalui gejala sebagai berikut:
1. Standard error untuk satu sampai beberapa koefisien sangat besar.
2. Program tidak mampu menghasilkan matriks informasi yang seharusnya disajikan.
3. Munculnya angka-angka aneh, seperti varians error yang negatif.
4. Munculnya angka korelasi yang sangat tinggi antar koefisien estimasi yang diperoleh (> 0,9).
Jika diketahui ada problem identifikasi maka ada tiga hal yang harus dilihat : 1. Besarnya jumlah koefisien yang diestimasi relatif terhadap jumlah kovarian
atau korelasi, yang diindikasikan dengan nilai degree of freedom yang kecil.
2. Digunakan pengaruh timbal balik atau resiprokal antar konstruk.
3. Kegagalan dalam menetapkan nilai tetap pada skala konstruk.
f. Evaluasi kriteria goodness of fit
Dalam langkah ini yang pertama harus dilakukan adalah memenuhi asumsi-asumsi SEM. Adapun asumsi-asumsi SEM yang harus dipenuhi adalah sebagai berikut:
1. Ukuran Sampel
Ukuran sampel yang harus dipenuhi dalam pemodelan SEM adalah minimum berjumlah 100, selanjutnya menggunakan perbandingan 5 observasi untuk setiap parameter yang diestimasi. Oleh karena itu, bila mengembangkan model dengan 20 parameter maka minimum digunakan 100 sampel.
2. Normalitas dan Linieritas
Sebaran data harus dianalisis untuk melihat apakah asumsi normalitas terpenuhi sehingga data dapat diolah lebih lanjut dengan pemodelan SEM. Normalitas dapat diuji dengan melihat gambar histogram data atau dapat diuji dengan model statistik. Uji normalitas dilakukan dengan menggunakan uji skewness yang menunjukkan bahwa hampir seluruh variabel normal pada tingkat signifikansi 0,01 (1%). Hal ini terlihat pada nilai CR dari skewness yang berada di bawah ± 2,58. Nilai mutivariat pada uji normalitas adalah koefisien kurtosis multivariate, apabila hasil yang diperoleh masih di bawah nilai batas ± 2,58, ini berarti bahwa ada data yang digunakan berdistribusi multivariat normal.
3. Angka Ekstrim (Outliers)
Outliers adalah observasi yang muncul dengan nilai-nilai ekstrim baik secara univariat maupun multivariat yaitu yang muncul karena kombinasi karakteristik unik yang dimilikinya dan terlihat sangat jauh berbeda dari observasi-observasi lainnya. Outlier muncul dengan 4 (empat) kategori, yakni:
a) Outlier muncul karena kesalahan prosedur seperti kesalahan dalam memasukkan data atau kesalahan dalam mengkoding data.
b) Outlier muncul karena keadaan benar-benar khusus yang memungkinkan profil data menjadi lain, tetapi peneliti mempunyai penjelasan mengenai apa yang menyebabkan munculnya nilai ekstrim tersebut.
c) Outlier muncul karena adanya sesuatu alasan tetapi peneliti tidak dapat mengetahui apa penyebab munculnya nilai ekstrim tersebut.
d) Outlier munculnya dalam rentang nilai yang ada, tetapi bila dikombinasikan dengan variabel lain, kombinasinya menjadi tidak lazim atau sangat ekstrim. Inilah yang disebut multivariat outlier.
4. Multikolinealitas (Multicollinearity)
Multicollinearity adalah suatu kondisi, dimana terdapat hubungan korelasi yang tinggi antar sebagian atau seluruh variabel independen dalam suatu regresi berganda. Multicollinearity dapat dideteksi dari determinan matriks kovarians. Nilai determinan matriks kovarian yang sangat kecil memberi indikasi adanya problem multicollinearity. Selanjutnya, setelah asumsi-asumsi SEM terpenuhi maka dilakukan kelayakan model. Untuk menguji kelayakan model yang dikembangkan dalam model persamaan struktural ini, maka akan digunakan beberapa indeks kelayakan model.
AMOS juga digunakan untuk mengidentifikasikan model yang diajukan memenuhi kriteria model persamaan struktural yang baik. Adapun kriteria tersebut adalah:
1. Derajat kebebasan (Degree of Freedom) harus positif 2. χ2 (chi square statistic) dan probabilitas
Alat uji fundamental untuk mengukur overall fit adalah likelihood ratio chi square statistic. Model dikategorikan baik harus mempunyai chi square = 0 berarti tidak ada perbedaan. Tingkat signifikan penerimaan yang direkomendasikan adalah apabila nilai probabilitas (p) lebih besar dari tingkat signifikasi (α) (Hair et al., 1998, p389) yang berarti matriks input sebenarnya dengan matriks input yang diprediksi tidak berbeda secara statistik ( Ghozali, 2005, pp19-23).
3. CMIN/DF (Normed Chi Square)
CMIN/DF adalah ukuran yang diperoleh dari nilai chi-square dibagi dengan degree of freedom. Menurut Hair et al. (1998, p.340) nilai yang
direkomendasikan untuk menerima kesesuian sebuah model adalah nilai CMIN/DF yang lebih kecil atau sama dengan 2,0 atau 3,0.
4. Goodness of fit Index (GFI)
Digunakan untuk menghitung proporsi tertimbang dari varians dalam matriks kovarians sampel yang dijelaskan oleh matriks kovarians populasi yang terestimasikan. Indeks ini mencerminkan tingkat kesesuaian model secara keseluruhan yang dihitung dari residual kuadrat model yang diprediksi dibandingkan dengan data yang sebenarnya. Nilai Goodness of Fit Index biasanya dari 0 sampai 1. Semakin besar jumlah sampel penelitian maka nilai GFI akan semakin besar. Nilai yang lebih baik mendekati 1 mengindikasikan model yang diuji memiliki kesesuaian yang baik (Hair et al., 1998, p.387) . 5. Adjusted GFI (AGFI)
Menyatakan bahwa GFI adalah analog dari R2 (R square) dalam regresi berganda. Fit Index dapat diadjust terhadap degree of freedom yang tersedia untuk menguji diterima tidaknya model. Tingkat penerimaan yang direkomendasikan adalah bila mempunyai nilai sama atau lebih besar dari 0,9.
6. Tuker-Lewis Index (TLI)
TLI adalah sebuah alternatif incremental fit index yang membandingkan sebuah model yang diuji terhadap sebuah baseline model.
Nilai yang direkomendasikan sebagai acuan untuk diterimanya sebuah model adalah lebih besar atau sama dengan 0,9 dan nilai yang mendekati 1 menunjukkan a very good fit. TLI merupakan index fit yang kurang dipengaruhi oleh ukuran sampel.
7. CFI (Comparative Fit Index)
CFI juga dikenal sebagai Bentler Comparative Index. CFI merupakan indeks kesesuaian incremental yang juga membandingkan model yang diuji dengan null model. Indeks ini dikatakan baik untuk mengukur kesesuaian sebuah model karena tidak dipengaruhi oleh ukuran sampel (Hair et al., 1998, p.289). Indeks yang mengindikasikan bahwa model yang diuji memiliki kesesuian yang baik adalah apabila CFI lebih besar dari 0,90.
8. RMSEA (Root Mean Square Error of Approximation)
Nilai RMSEA menunjukkan goodness of fit yang diharapkan bila model diestimasikan dalam populasi. Nilai RMSEA yang lebih kecil atau sama dengan 0,08 merupakan indeks untuk dapat diterimanya model yang menunjukkan sebuah close fit dari model itu didasarkan degree of freedom.
RMSEA merupakan indeks pengukuran yang tidak dipengaruhi oleh besarnya sampel sehingga biasanya indeks ini digunakan untuk mengukur fit model pada jumlah sampel besar.
Pengujian hipotesis dilakukan dengan menguji signifikansi regresi berdasarkan uji F pada α = 0,05 pada masing-masing koefisien persamaan, baik secara langsung maupun secara parsial. Setelah dilakukan pengujian terhadap asumsi dasar SEM dan terhadap uji kesesuaian dan uji statistik, langkah berikutnya adalah melakukan modifikasi terhadap model yang tidak memenuhi syarat pengujian yang telah dilakukan. Setelah model diestimasi, residualnya haruslah kecil atau mendekati nol dan distribusi frekuensi dari kovarians residual harus bersifat simetrik (Hair et al., 1998, p.388) memberikan sebuah pedoman untuk mempertimbangkan perlu tidaknya modifikasi terhadap sebuah model, yaitu dengan melihat sejumlah residual yang dihasilkan oleh model. Bila jumlah residual lebih besar dari 5% dari semua residual kovarians yang dihasilkan oleh model, maka modifikasi perlu dipertimbangkan. Bila ditemukan nilai residual yang dihasilkan oleh model cukup besar (>2,58), maka cara lain dalam memodifikasi adalah dengan mempertimbangkan untuk menambah jalur baru terhadap model yang diestimasi. Nilai residual lebih besar atau sama dengan 2,58 diinterpretasikan sebagai signifikan secara statistik pada tingkat 5% dan residual yang signifikan ini menunjukkan adanya prediction error yang substansial untuk sepasang indikator.
g. Interpretasi dan modifikasi model
Bilamana model cukup baik maka langkah berikutnya dalam SEM adalah melakukan interpretasi, bilamana belum baik, maka perlu diadakan modifikasi.
Beberapa program komputer seperti lisrel dan amos dilengkapi dengan model modifikasi. Sebuah nilai indeks modifikasi menunjukkan bilamana model tersebut
dimodifikasi maka nilai khi kuadrat (χ2) akan turun sebesar nilai indeks tersebut.
Pada tahap akhir SEM adalah melakukan interpretasi terhadap hasil analisis.
Untuk itu, SEM menyediakan dua buah informasi, pertama setara dengan model struktural dan kedua sama dengan analisis path. (Solimun, 2005).