xii
APLIKASI ALGORITMA CONJUGATE GRADIE NT
PADA JARINGAN SYARAF TIRUAN
PE RAMBATAN BALIK
Abstrak
Jaringan syaraf lapis jamak telah berhasil diaplikasikan ke berbagai
permasalahan. Algoritma penurunan tercuram (steepest descent) merupakan algoritma yang popular digunakan sebagai algoritma pembelajaran pada jaringan syaraf
perambatan balik yang kemudian disebut sebagai algoritma perambatan balik standar.
Algoritma ini menghasilkan kekonvergenan yang lambat dan sangat tergantung pada
parameter pesat belajarnya.
Penelitian ini bertujuan untuk memperbaiki unjuk kerja kecepatan konvergen
pada algoritma perambatan balik standar. Algoritma conjugate gradient yang merupakan algoritma iteratif yang handal untuk menyelesaikan persamaan linear simultan skala
besar dapat juga digunakan untuk mengoptimalkan algoritma belajar pada jaringan
perambatan balik.
Pengujian dilakukan dengan membuat program dengan bahasa C+ + untuk
masing-masing algoritma dengan compiler Borland C+ + versi 5.02 dan kemudian
mengaplikasikan masing-masing program pada beberapa kasus. Dan dari situ bisa
xiii
THE APPLICATION OF
CONJUGATE GRADIE NT ALGORITHM
FOR BACKPROPAGATION NE URAL NE TWORK
Abstract
Multilayer neural network has been succesfully applied to many problems.
Steepest descent is a popular learning algorith for backpropagation neural network,
called standard backpropagation algorithm. This algorithm converges very slowly
and depend on learning rate parameter.
The goal of this research is to overcome these problems. Conjugate gradient
which is the most popular iterative algorithm for solving large system of linear
equations. This algorithm can be used to optimize backpropagation learning
algorithm.
The program in C+ + language with Borland C+ + version 5.02 is made for
analyze the performance of standar backpropagation and conjugate gradient
APLIKASI ALGORITM A
CO NJUGATE GRADIENT
PADA JARINGAN SYARAF TIRUAN
PERAM BATAN BALIK
Tesis
Program Studi Teknik Elektro Jurusan Ilmu-ilmu Teknik
disusun oleh :
W iwien W idyastuti 18475/I-1/1820/02
PROGRA M PA SCA SA RJA NA
UNIVERSITA S GA DJA H MA DA
vi
DAF TAR ISI
HALAMAN JUDUL………. i
HALAMAN PE NGE SAHAN………... ii
HALAMAN PE RNYATAAN………... iii
PRAKATA……… iv
DAFTAR ISI………. vi
DAFTAR TABE L………. ix
DAFTAR GAMBAR………. x
ABSTRAK………. xii
I. PE NGANTAR……….… 1
A. Latar Belakang………. 1
B. Perumusan Masalah………. 2
C. Batasan Masalah………... 3
D. Keaslian Penelitian……….. 3
E . Tujuan Penelitian………. 4
F. Hipotesis……….. 4
G. Cara Penelitian……… 4
II. TINJAUAN PUSTAKA………. 6
A. Tinjauan Pustaka……….. 6
vii
1. Metode Steepest Descent (Penurunan Tercuram)………….…... 7
2. Metode Conjugate Gradient………... 10
3. Jaringan Perambatan Balik (Back propagation)………... 14
3.1. Algoritma Perambatan Balik………. 17
3.2. Fungsi Aktivasi………. 21
3.3. Memilih Bobot dan Prasikap Awal……… 23
3.4. Lama Pelatihan………. 24
3.5. Jumlah Pasangan Pelatihan………... 25
3.6. Representasi Data………. 25
3.7. Jumlah Lapisan Tersembunyi……… 26
3.8. Indeks Unjuk Kerja (Performance Index)……….. 26
4. Jaringan Perambatan Balik dengan Conjugate Gradient……….. 28
III. CARA PE NE LITIAN……….. 30
A. Bahan Penelitian……….. 30
B. Alat Penelitian……….. 30
C. Jalannya Penelitian………... 31
D. Kesulitan-Kesulitan………. 49
IV. HASIL PE NE LITIAN DAN PE MBAHASAN………. 50
A. Hasil Uji Coba Masalah Pengenalan Gerbang AND……… 52
B. Hasil Uji Coba Masalah Pengenalan Gerbang XOR………. 55
viii
D. Pembahasan Umum……… 62
V. KE SIMPULAN………... 68
A. Kesimpulan………. 69
B. Saran……… 69
DAF TAR PUSTAKA………... 71
LAMPIRAN
ix
DAF TAR TABE L
No. Nama Tabel Halaman
Tabel 4.1. Pola gerbang AND………. 50
Tabel 4.2. Pola gerbang XOR……….…. 50
Tabel 4.3. Pola Bilangan……….…. 51
Tabel 4.4. Hasil uji coba gerbang AND………... 52
Tabel 4.5. Hasil uji coba gerbang XOR………... 56
Tabel 4.6. Hasil uji coba masalah pengenalan bilangan……… 59
x
DAF TAR GAMBAR
No. Nama Tabel Halaman
Gambar 2.1. Jaringan syaraf perambatan balik dengan 1 lapisan
tersembunyi ………... 15
Gambar 2.2. Jaringan tiga lapis .……….…. 16
Gambar 2.3. Fungsi sigmoid biner, dengan rentang nilai (0,1) ……… 22
Gambar 2.4. Fungsi sigmoid bipolar, dengan rentang nilai (-1,1) ………… 22
Gambar 3.1. Lokasi Selang ………..………... 34
Gambar 3.2. Selang tidak dikurangi ……… 35
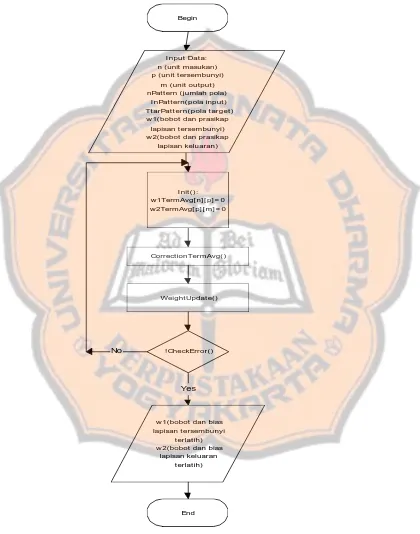
Gambar 3.3. Diagram alir program pelatihan jaringan perambatan balik
standar …….……….. 41
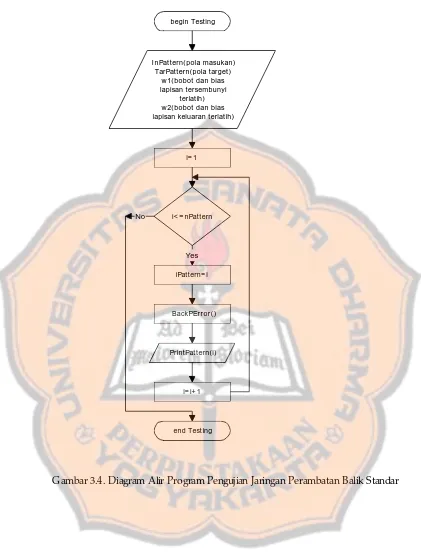
Gambar 3.4. Diagram alir program pengujian jaringan perambatan balik
standar ………... 44
Gambar 3.5. Diagram alir program pelatihan jaringan perambatan dengan
conjugate gradient ………... 45
Gambar 3.6. Diagram alir program pengujian jaringan perambatan balik
dengan conjugate gradient ………... 48 Gambar 4.1. Hasil masalah gerbang AND dengan BPS pesat belajar 0,5…. 53
Gambar 4.2. Hasil masalah gerbang AND dengan BPS pesat belajar 0,1…. 53
Gambar 4.3. Hasil masalah gerbang AND dengan BPS pesat belajar 0,05... 54
Gambar 4.4. Hasil masalah gerbang AND dengan BPCG ……….. 54
xi
Gambar 4.6. Hasil masalah gerbang XOR dengan BPS pesat belajar 0,1…. 57
Gambar 4.7. Hasil masalah gerbang XOR dengan BPS pesat belajar 0,05... 57
Gambar 4.8. Hasil masalah gerbang XOR dengan BPCG ………..…. 58
Gambar 4.9. Grafik hubungan antara waktu dan unit tersembunyi BPS…... 60
Gambar 4.10. Grafik hubungan antara waktu dan unit tersembunyi BPCG... 61
Gambar 4.11. Grafik hubungan antara waktu dan unit tersembunyi BPS dan BPCG ……… 61
Gambar 4.12. Kompleksitas waktu algoritma penurunan tercuram dan conjugate gradient ………... 63
Gambar 4.13. Gambar 3 dimensi dari F(x) ………... 64
Gambar 4.14. Gambar kontur dari F(x) ……… 65
Gambar 4.15. Gambar lintasan dengan penurunan tercuram dengan ukuran langkah sangat kecil ………... 65
Gambar 4.16. Gambar lintasan dengan penurunan tercuram ukuran langkah 0,12 ………... 66
Gambar 4.17. Gambar lintasan dengan conjugate gradient ……… 66
Gambar 4.18. Grafik penurunan galat tiap iterasi……….. 68
xii
APLIKASI ALGORITMA CONJUGATE GRADIE NT
PADA JARINGAN SYARAF TIRUAN
PE RAMBATAN BALIK
Abstrak
Jaringan syaraf lapis jamak telah berhasil diaplikasikan ke berbagai
permasalahan. Algoritma penurunan tercuram (steepest descent) merupakan algoritma yang popular digunakan sebagai algoritma pembelajaran pada jaringan syaraf
perambatan balik yang kemudian disebut sebagai algoritma perambatan balik standar.
Algoritma ini menghasilkan kekonvergenan yang lambat dan sangat tergantung pada
parameter pesat belajarnya.
Penelitian ini bertujuan untuk memperbaiki unjuk kerja kecepatan konvergen
pada algoritma perambatan balik standar. Algoritma conjugate gradient yang merupakan algoritma iteratif yang handal untuk menyelesaikan persamaan linear simultan skala
besar dapat juga digunakan untuk mengoptimalkan algoritma belajar pada jaringan
perambatan balik.
Pengujian dilakukan dengan membuat program dengan bahasa C+ + untuk
masing-masing algoritma dengan compiler Borland C+ + versi 5.02 dan kemudian
mengaplikasikan masing-masing program pada beberapa kasus. Dan dari situ bisa
xiii
THE APPLICATION OF
CONJUGATE GRADIE NT ALGORITHM
FOR BACKPROPAGATION NE URAL NE TWORK
Abstract
Multilayer neural network has been succesfully applied to many problems.
Steepest descent is a popular learning algorith for backpropagation neural network,
called standard backpropagation algorithm. This algorithm converges very slowly
and depend on learning rate parameter.
The goal of this research is to overcome these problems. Conjugate gradient
which is the most popular iterative algorithm for solving large system of linear
equations. This algorithm can be used to optimize backpropagation learning
algorithm.
The program in C+ + language with Borland C+ + version 5.02 is made for
analyze the performance of standar backpropagation and conjugate gradient
1
I.
PE NGANTAR
A. Latar Belakang
Suatu jaringan syaraf tiruan merupakan sistem pemrosesan informasi yang
mempunyai karakteristik kinerja yang mirip dengan jaringan syaraf biologis (Fausett,
Laurence. 1994). Pendekatan jaringan syaraf tiruan menerapkan prinsip-prinsip
komputasi dan organisasional yang berasal dari studi neurobiologi.
Sejalan dengan perkembangan komputer modern yang sangat pesat dengan
kemampuan komputasi yang semakin tinggi, semakin memungkinkan untuk
membuat simulasi pemrosesan pada syaraf. Teknologi yang semakin canggih
sekarang ini telah memungkinkan untuk memproduksi perangkat keras khusus untuk
jaringan syaraf. Kemajuan di bidang komputasi juga membuat studi tentang jaringan
syaraf semakin mudah dilakukan.
Jaringan syaraf tiruan dapat diaplikasikan ke berbagai bidang, misalnya untuk
prediksi atau ramalan cuaca, prediksi harga saham, klasifikasi, asosiasi data,
konseptualisasi data dan penapisan data.
Jaringan syaraf tiruan didasari oleh model matematika dari pengolahan
informasi dan mempunyai cara untuk menyatakan hubungan dari data atau informasi
tersebut. Metode-metode numerik dan kemampuan komputer baik perangkat lunak
maupun perangkat keras merupakan hal penting dalam jaringan syaraf tiruan
Keberhasilan sebuah jaringan syaraf tiruan tentu saja juga sangat bergantung
dari metode yang digunakan. Pemilihan metode yang efisien merupakan salah satu
elemen penting akan keberhasilan suatu jaringan.
Jaringan syaraf tiruan perambatan balik (back propagation) telah berhasil diaplikasikan untuk berbagai permasalahan. Jaringan perambatan balik standar
mengadopsi algoritma penurunan tercuram (steepest descent) sebagai algoritma belajarnya. Jaringan perambatan balik standar sangat sensitif pada parameter pesat
belajar. Pemilihan pesat belajar yang tidak tepat bisa mengakibatkan jaringan belajar
dengan sangat lambat bahkan gagal mencapai target yang diinginkan.
Algoritma conjugate gradient merupakan salah satu metode komputasi yang handal dalam menyelesaikan persamaan linear secara iteratif. Algoritma ini kemudian
secara luas dikembangkan dan dapat digunakan juga sebagai algoritma untuk
menyelesaikan persamaan nonlinear. Fungsi kesalahan yang diminimalkan pada
jaringan perambatan balik seringkali berupa persamaan nonlinear. Oleh karena itu
algoritma conjugate gradient dapat digunakan sebagai algoritma untuk memperbaiki kekurangan pada jaringan syaraf tiruan perambatan balik yang standar.
B. Perumusan Masalah
Metode standar dari jaringan perambatan balik mengadopsi teknik penurunan
tercuram sebagai algoritma pelatihan. Sifat algoritma ini sangat sensitif pada
pemilihan parameter pesat belajar. Selain itu, bobot selalu dimodifikasi dalam arah
negatif dari gradien. Pesat belajr yang terlalu besar dapat mengakibatkan
ketidakstabilan yang berarti pelatihan gagal mencapai target yang diharapkan. Pesat
Sedangkan pesat belajar yang ditentukan tiap iterasi akan menghasilkan gerakan sigsag
dan berakibat pelatihan berjalan dengan lambat, sehingga iterasi yang dibutuhkan
sangat banyak dan tentu saja waktu yang dibutuhkan juga bertambah panjang.
Berdasarkan hal tersebut di atas maka peneliti akan mengaplikasikan
algoritma conjugate gradient nonlinear tersebut pada jaringan syaraf tiruan perambatan balik agar kinerja jaringan lebih baik.
C. Batasan Masalah
Untuk menghindari meluasnya masalah yang akan diteliti, lingkup
permasalahan terbatas pada pembuatan program aplikasi algoritma conjugate gradient pada jaringan syaraf tiruan perambatan balik dan program aplikasi jaringan syaraf
tiruan perambatan balik standar yang mengadopsi metode penurunan tercuram.
Kemudian hasil dari kedua algoritma di atas akan dibandingkan kinerjanya yaitu
tentang banyaknya iterasi, waktu yang diperlukan serta keberhasilannya dalam
mencapai target. Masalah yang akan digunakan untuk perbandingan adalah masalah
yang sudah diketahui fungsi kesalahannya.
D. Keaslian Penelitian
Berbagai penelitian tentang algoritma conjugate gradient dan jaringan syaraf tiruan telah dilakukan. Keaslian penelitian atau perbedaan dari penelitian yang sudah
dilakukan terletak pada :
1. Masalah-masalah yang akan digunakan untuk mengaplikasikan algoritma.
3. Program yang akan penulis buat dengan bahasa pemrograman C+ + .
E . Tujuan Penelitian
Tujuan dilakukannya penelitian ini adalah :
1. Untuk mempelajari, memahami algoritma conjugate gradient khususnya yang digunakan untuk menyelesaikan masalah nonlinear.
2. Dapat dibuat program simulasi jaringan syaraf tiruan menggunakan algoritma
pelatihan perambatan balik dengan conjugate gradient dan algoritma pelatihan perambatan balik standar.
3. Membandingkan kedua algoritma pelatihan tersebut di atas.
F . Hipotesis
Berdasarkan penelitian diharapkan algoritma conjugate gradient dapat digunakan sebagai teknik optimisasi pada jaringan syaraf perambatan balik yang menghasilkan
kinerja yang lebih baik dari pada jaringan syaraf perambatan balik yang standar.
G. Cara Penelitian
Tahap-tahap yang akan dilakukan dalam penelitian ini adalah sebagai berikut :
1. Studi pustaka
Pada tahap ini akan dipelajari berbagai literatur yang berhubungan dengan
2. Pembuatan program
Setelah melakukan studi pustaka, maka segera dapat dilakukan pembuatan
program. Bahasa pemrograman yang akan digunakan adalah bahasa C+ + .
Program yang dibuat ada 2 macam yaitu program jaringan syaraf perambatan
balik dengan metode conjugate gradient dan program jaringan syaraf perambatan balik standar.
3. Pencarian masalah
Pencarian masalahan dilakukan dengan melakukan pemilihan terhadap
masalah-masalah yang telah ada yang sekiranya dapat mewakili permasalah-masalahan umum
yang sering dijumpai.
4. Aplikasi program
Setelah program selesai dan telah diperiksa kebenarannya, maka segera dapat
digunakan untuk mengaplikasikan berbagai masalah jaringan syaraf tiruan yang
hasilnya akan digunakan untuk menganalisis unjuk kerja dari masing-masing
metode.
5. Analisis
Setelah program diaplikasikan untuk berbagai masalah, maka hasil yang
diperoleh tersebut dianalisis untuk mengetahui unjuk kerja dari masing-masing
metode. Unjuk kerja yang akan dibahas di sini adalah mengenai unjuk kerja
kekonvergenan, banyaknya iterasi yang dibutuhkan dan waktu yang diperlukan
6
II. TINJAUAN PUSTAKA
A. Tinjauan Pustaka
Hestenes dan E duard Stiefel pada tahun 1952 pertama kali menemukan
metode conjugate gradient yang digunakan untuk menyelesaikan sistem persamaan linear. Dari sini muncul penelitian-penelitian tentang conjugate gradient yang membicarakan berbagai aspek.
Fletcher dan Reeves, 1964 menggunakan metode conjugate gradient untuk minimisasi fungsi.
Kemudian pada tahun 1993, Jianming Jin menulis buku tentang
metode-metode Finite E lement yang digunakan untuk menyelesaikan masalah-masalah
elektromagnetik. Berbagai macam metode dipaparkan oleh Jianming, termasuk di
dalamnya adalah metode conjugate gradient.
Arioli, pada tahun 2001, meneliti tentang kriteria penghentian pada algoritma
conjugate gradient dalam kerangka metode Finite E lemen.
Penelitian lain dilakukan oleh Zdenek Strakos dan Petr Tichy, pada tahun
2002. Mereka meneliti tentang perkiraan galat dalam metode Conjugate gradient Method dan mengapa hal tersebut dapat dilakukan dalam perhitungan finite presisi.
Sedangkan penelitian dan buku tentang jaringan syaraf tiruan antara lain buku
tentang dasar-dasar dari jaringan syaraf ditulis oleh Laurene Fausett pada tahun 1994.
Buku ini berisi tentang arsitektur, algoritma dan aplikasi dari jaringan syaraf termasuk
Kemudian pada tahun 1997 , Jyh-Shing Roger Jang, Chuen-Tsai Sun, E iji
Mizutani menulis buku tentang jaringan syaraf kabur (neuro-fuzzy) dan komputasinya. Buku ini menjelaskan metode-metode komputasi yang dapat digunakan untuk
memecahkan persoalan pada jaringan syaraf kabur antara lain metode penurunan
tercuram dan metode conjugate gradient. Tetapi metode-metode tersebut dijelaskan secara terpisah dari jaringan syaraf kabur.
Tahun 1999, Martin T. Hagan, Howard B. Demuth dan Mark Beale dalam
bukunya menuliskan jaringan perambatan balik dengan optimisasi menggunakan
algoritma conjugate gradient. Algoritma pencarian garis yang digunakan untuk optimisasinya adalah algoritma golden section search.
Berhubungan dengan penelitian sebelumnya tentang aplikasi metode conjugate gradient pada berbagai masalah maka peneliti juga akan mengaplikasikannya pada masalah jaringan saraf dalam hal ini adalah jaringan perambatan balik.
B. Landasan Teori
1. Metode Steepest Descent (Penurunan Tercuram)
Metode penurunan tercuram merupakan salah satu metode yang digunakan untuk
optimisasi. Pada algoritma pelatihan jaringan syaraf, penurunan tercuram digunakan
untuk untuk mengoptimalkan performance index F(x). Arti mengoptimalkan di sini adalah mencari nilai x yang meminimalkan F(x). Penurunan tercuram adalah metode iteratif yang memulai taksiran x dengan taksiran awal x0 dan kemudian tiap iterasinya akan memperbaiki taksiran dengan persamaan yang berbentuk:
k k k
k
x
p
atau
(
k k)
k kk
x
x
p
x
=
−
=
α
∆
+1 (2.2)dengan vektor pk adalah search direction (arah pencarian) dan
α
k adalah learning rate(pesat belajar) yang merupakan skalar positif. Pesat belajar menentukan panjang
langkah pada tiap pencarian.
Pada tiap iterasi diharapkan fungsi selalu menurun, atau dengan kata lain :
( ) ( )
x
kF
x
kF
+1<
(2.3)Kemudian arah pk dapat dipilih dengan memakai ekspansi deret Taylor urutan pertama sebagai berikut :
( )
(
)
( )
kT k k k
k
k
F
x
x
F
x
g
x
x
F
+1=
+
∆
≈
+
∆
(2.4)dengan gk adalah gradien pada taksiran lama xk:
( )
x xkk
F
x
g
≡
∇
= (2.5)Agar
F
( ) ( )
x
k+1<
F
x
k , maka suku ke-dua dari persamaan di sebelah kanan harusnegatif:
0
<
=
∆
kT k k k T
k
x
g
p
g
α
(2.6)α
k dipilih bilangan yang kecil tapi lebih besar dari nol , artinya :0
<
k T k
p
g
(2.7)Semua vektor pk yang memenuhi persamaan di atas disebut arah penurunan. Fungsi akan turun jika dilakukan langkah yang cukup kecil pada arah ini. Sedangkan yang
dimaksud dengan arah penurunan tercuram adalah arah yang akan mengakibatkan
fungsi turun paling cepat. Hal ini terjadi jika k T k
p
g
paling negatif. Ini akan terjadik
k
g
p
=
−
(2.8)Dengan menggunakan persamaan(2.8) pada persamaan(2.1) diperoleh metode
penurunan tercuram sebagai berikut :
k k k
k
x
g
x
+1=
−
α
(2.9)Pada penurunan tercuram ada 2 metode yang umum digunakan untuk
menentukan pesat belajar
α
k. Cara pertama adalah meminimalkan F(x) terhadapα
kpada tiap iterasi. Dengan kata lain, memilih
α
k yang meminimalkan :(
x
k kp
k)
F
+
α
(2.10)Untuk fungsi kuadratis, dapat disusun minimisasi linear secara analitis. Jika fungsi
kuadratis adalah sebagai berikut :
c
x
b
Ax
x
x
F
=
T+
T+
2
1
)
(
(2.11)Maka turunan dari fungsi(2.10) terhadap
α
k untuk fungsi kuadratis F(x) adalah :(
)
( )
( )
x x kT k k k x x T k k k k
p
x
F
p
p
x
F
p
x
F
d
d
k k = =+
∇
∇
=
+
α
α
2α
(2.12)Jika turunan tersebut disamakan dengan nol, maka
α
k diperoleh :( )
( )
k kT k k T k k x x T k k x x T k
p
A
p
p
g
p
x
F
p
p
x
F
kk
=
−
∇
∇
−
=
= = 2α
(2.13)dengan Ak adalah matriks Hessian yang dievaluasi pada xk :
( )
k x x
k
F
x
A
=
∇
≡
2Cara kedua adalah dengan memilih suatu nilai tertentu untuk
α
k, misalnyaα
k= 0,02 atau menggunakan variabel yang sudah ditentukan sebelumnya, misalnyaα
k= 1/k.2. Metode Conjugate Gradient
Metode conjugate gradient dikembangkan oleh E .Stiefel dan M.R. Hestenes. Pertama kali metode ini digunakan sebagai metode untuk menyelesaikan persamaan
linear atau persamaan matriks secara iteratif. Conjugate gradient merupakan metode efektif untuk sistem persamaan linear dengan ukuran besar, yaitu :
A x= b (2.15)
Dengan x adalah vektor yang tidak diketahui, b adalah vektor yang sudah diketahui dan A adalah matriks simetris, definit positif yang telah diketahui. Matriks A adalah definit positif jika untuk tiap vektor x yang tidak nol :
0
>
Ax
x
T (2.16)Jika terdapat suatu fungsi kuadratis :
c
x
b
Ax
x
x
F
=
T−
T+
2
1
)
(
(2.17)dengan A adalah matriks, x dan b adalah vektor dan c adalah skalar konstan. Jika A adalah matriks simetris dan definit positif maka F(x) dapat diminimisasi dengan menggunakan penyelesaian dari A x= b.
∂
∂
∂
∂
∂
∂
=
)
(
...
)
(
)
(
)
(
'
2 1x
F
x
x
F
x
x
F
x
x
F
n (2.18)dengan menggunakan persamaan (2.18) pada persamaan (2.17), diperoleh :
b
Ax
x
A
x
F
=
T+
−
2
1
2
1
)
(
'
(2.19)Jika A adalah matriks simetris maka persamaan (2.18) menjadi :
b
Ax
x
F
'
(
)
=
−
(2.20)Karena A adalah definit positif, maka bentuk permukaan fungsi kuadratik F(x) adalah seperti mangkuk, yang berarti titik minimum dari fungsi terletak di dasar mangkuk
yang mempunyai gradien nol. Sehingga dengan membuat gradien sama dengan nol,
persamaan (2.20) menjadi suatu sistem persamaan linear yang akan dipecahkan
sebagai berikut :
b
Ax
=
(2.21)Dari sini terlihat bahwa penyelesaian dari A x= b adalah merupakan titik minimum dari F(x). Jika A adalah matriks simetris yang definit positif, A x= b dapat diselesaikan dengan mencari nilai x yang meminimalkan F(x).
Metode conjugate gradient dapat juga digunakan untuk menyelesaikan suatu sistem persamaan linear walaupun A bukan matriks simetris, bukan definit positif, bahkan jika A bukan matriks bujur sangkar. Caranya adalah dengan mengalikan A dengan transposenya :
b
A
Ax
A
T=
TUntuk mencari titik minimum pada fungsi kuadratis seperti pada persamaan
(2.11), sekumpulan vektor {pk} akan mutually conjugate dengan matriks Hessian A yang definit positif jika dan hanya jika :
j
k
untuk
0
≠
=
j T kAp
p
(2.23)Salah satu himpunan vektor conjugate adalah eigenvector dari A. Jika
{
λ
1,
λ
2,...,
λ
n}
adalah eigenvalues dari matriks Hessian A dan{
z
1,
z
2,...,
z
n}
adalaheigenvector-nya, maka untuk melihat bahwa eigenvector-nya conjugate, adalah dengan mengganti pk pada persamaan di atas dengan zk sebagai berikut :
j
k
untuk
0
≠
=
=
j T k j j Tk
Az
z
z
z
λ
(2.24)persamaan terakhir bisa demikian karena eigenvek tor dari matriks simetris adalah mutually orthogonal.
Dari situ bisa dilihat bahwa fungsi kuadratis dapat diminimisasi secara tepat
dengan menggunakan arah pencarian sepanjang eigencector matrik Hessian, sebab eigenvector merupakan sumbu utama dari kontur fungsi. Tetapi mencari eigenvector secara praktek tidak mudah dilakukan karena untuk mencari eigenvector terlebih dulu harus mencari matrik Hessian. Oleh karena itu dicari cara agar penghitungan turunan
ke-2 tidak diperlukan.
Pada fungsi kuadratis seperti pada (2.11) :
b
Ax
x
F
x
F
=
=
+
∇
(
)
'
(
)
(2.25)A
x
F
=
∇
2(
)
(2.26)
dengan menggunakan persamaan tersebut, dapat diketahui perubahan gradien pada
iterasi k+ 1, yaitu :
(
k) (
k)
kk k
k
g
g
Ax
b
Ax
b
A
x
g
=
−
=
+
−
+
=
∆
kemudian dari persamaan (2.2) :
(
k k)
k kk
x
x
p
x
=
−
=
α
∆
+1 (2.28)dan
α
k dipilih untuk meminimalkan F(x) pada arah pkKondisi konjugasi dapat dituliskan kembali :
j
k
dengan
0
≠
=
∆
=
∆
=
j T k j T k j T kk
p
Ap
x
Ap
g
p
α
(2.29)Arah pencarian akan conjugate jika ortogonal dengan perubahan gradien. Arah pencarian pertama (p0) ditentukan sembarang dan p1 adalah vektor yang ortogonal terhadap
∆
g0. Secara umum untuk memulai pencarian digunakan arah dari metodepenurunan tercuram :
0
0
g
p
=
−
(2.30)Kemudian, pada tiap iterasi, vektor pk dipilih vektor yang ortogonal terhadap
{
∆
g
0,
∆
g
1,...,
∆
g
k−1}
. Prosedur ini mirip dengan ortogonalisasi Gram-Schmidt, yangdisederhanakan untuk iterasi menjadi :
1
−
+
−
=
k k kk
g
p
p
β
(2.31)Skalar
β
k dapat dipilih dari beberapa metode yang memberikan hasil yang sama untukfungsi kuadratis. Pertama adalah menurut Hestenes dan Steifel :
1 1 1 − − −
∆
∆
=
k T k k T k kp
g
g
g
β
(2.32)Kedua , menurut Fletcher dan Reeves :
1 1 − −
=
k T k k T k kg
g
g
g
β
(2.33)1 1 1 − − −
∆
=
k T k k T k kg
g
g
g
β
(2.34)Secara ringkas, metode conjugate gradient terdiri dari langkah-langkah sebagai berikut : 1. Pilih arah pencarian awal yang merupakan negatif dari gradien seperti
persamaan(2.30) :
0
0
g
p
=
−
2. Lakukan langkah seperti persamaan (2.28):
(
k k)
k kk
x
x
p
x
=
−
=
α
∆
+1dengan
α
k dipilih untuk meminimalkan fungsi sepanjang arah pencarian. Untukfungsi kuadratis dapat digunakan persamaan (2.13) :
( )
( )
k kT k k T k k x x T k k x x T k
p
A
p
p
g
p
x
F
p
p
x
F
kk
=
−
∇
∇
−
=
= = 2α
Sedangkan untuk fungsi non-linear lainnya dapat menggunakan teknik-teknik
minimisasi linear yang umum dipakai.
3. Pilih arah pencarian selanjutnya menggunakan persamaan (2.31) :
1
−
+
−
=
k k kk
g
p
p
β
dengan
β
k dapat dihitung dengan salah satu dari persamaan (2.32), persamaan(2.33), atau persamaan(2.34).
3. Jaringan Perambatan Balik (Backpropagation)
jaringan agar mampu menanggapi secara benar pola-pola masukan yang digunakan
saat pelatihan (mengingat) dan mampu memberikan tanggapan yang baik untuk
pola-pola yang mirip tetapi tidak sama dengan pola-pola-pola-pola pelatihan (generalisasi).
Pelatihan jaringan dengan perambatan balik meliputi tiga tahap, pertama
adalah tahap maju (feedforward) untuk input pola pelatihan, kedua adalah perhitungan dan perambatan balik (back propagation) dari galat yang bersangkutan dan yang terakhir adalah penyesuaian bobot. Setelah pelatihan, aplikasi jaringan hanya meliputi
komputasi dari tahap maju.
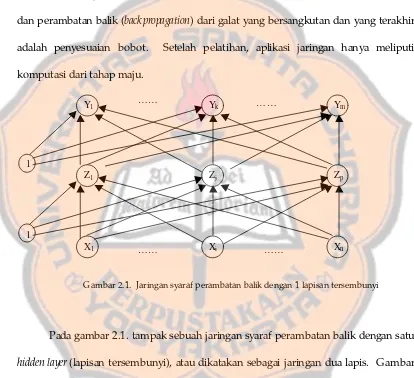
Gambar 2.1. Jaringan syaraf perambatan balik dengan 1 lapisan tersembunyi
Pada gambar 2.1. tampak sebuah jaringan syaraf perambatan balik dengan satu
hidden layer (lapisan tersembunyi), atau dikatakan sebagai jaringan dua lapis. Gambar 2.2. adalah cara lain untuk mengilustrasikan multilayer network (jaringan lapis jamak), dalam gambar 2.2 menunjukkan diagram dari jaringan tiga lapis. Secara sederhana,
jaringan lapis jamak adalah jaringan perceptron yang bertingkat. Keluaran dari
jaringan pertama merupakan masukan jaringan kedua, dan keluaran jaringan kedua
merupakan masukan jaringan ketiga. Tiap lapis dapat memiliki jumlah neuron yang
Y1 Yk Ym
1
Z1
X1 Xi Xn
Zj Zp
1
……
……
……
berbeda, bahkan dapat juga memiliki transfer function/ activation function (fungsi aktivasi) yang berbeda pula.
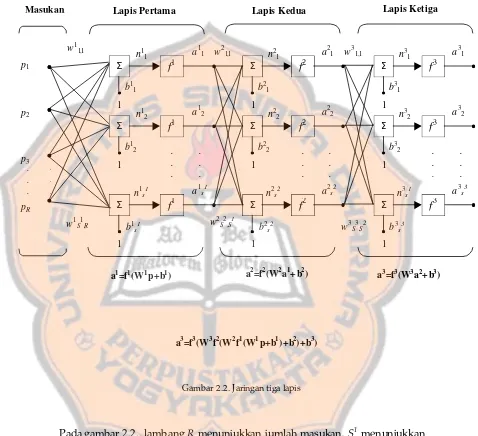
Gambar 2.2. Jaringan tiga lapis
Pada gambar 2.2., lambang R menunjukkan jumlah masukan, S1
menunjukkan
jumlah neuron pada lapis pertama, S2 adalah jumlah neuron pada lapis kedua dan S3 menunjukkan jumlah neuron pada lapis ketiga.
Pada jaringan lapis jamak, lapisan yang keluarannya merupakan keluaran dari
jaringan disebut dengan output layer (lapisan keluaran), pada gambar 2.2. adalah lapis .
. .
Σ
f
1n11 a 1
1
b11
1
Σ
f
1n12 a 1
2
b12
1
Σ
f
1a1s1
1 n1s1
b1s1
. . . . . . . . .
Σ
f
2n21 a 2
1
b21
1
Σ
f
2n22 a 2
2
b22
1
Σ
f
2a2s2
1 n2s2
b2s2
. . . . . .
Σ
f
3n31 a 3
1
b31
1
Σ
f
3n32 a 3
2
b32
1
Σ
f
3a3s3
1 n3s1
b3s3
. . . . . .
w11,1 w3
1,1
w21,1
p1
p2
p3
pR
w1S1,R w
2
S2,S1 w3
S3,S2
Masukan Lapis Pertama Lapis Kedua Lapis Ketiga
a1=f1(W1p+b1) a2=f2(W2a1+b2) a3=f3(W3a2+b3)
ketiga. Sedangkan lapisan yang lain (lapis pertama dan kedua) disebut sebagai lapisan
tersembunyi.
3.1. Algoritma Perambatan Balik
Seperti yang dijelaskan di awal, bahwa pelatihan jaringan dengan perambatan
balik meliputi tiga tahap yaitu meneruskan (feedforward) pola-pola masukan pelatihan, merambatkan balik galat yang bersesuaian dan penyesuaian bobot.
Pada saat meneruskan pola masukan, berdasarkan gambar 2.1. tiap unit
masukan (Xi) menerima sinyal masukan dan meneruskan ke unit-unit pada lapisan tersembunyi Z1,… .,Zp. Kemudian tiap unit tersembunyi menghitung aktivasinya dan mengirimkan sinyal tersebut (zj) ke tiap unit keluaran. Tiap unit keluaran (Yk) menghitung aktivasinya (yk) agar menghasilkan tanggapan jaringan untuk pola masukan yang diberikan.
Pada saat pelatihan, tiap unit keluaran membandingkan aktivasi yk dengan nilai target tk untuk menentukan galat untuk suatu pola pada unit tersebut. Berdasarkan galat ini, faktor
δ
k (k= 1,… ,m) dapat dihitung. Faktorδ
k digunakan untukmendistribusikan galat pada unit keluaran Yk kembali ke semua unit di lapis sebelumnya (lapis tersembunyi yang terhubung ke Yk). Faktor
δ
k nantinya jugadigunakan untuk menyesuaikan bobot antara keluaran dan lapis tersembunyi.
Dengan cara yang sama, faktor
δ
j(j= 1,….,p) dihitung dari tiap unit tersembunyi Zj.Galat tidak perlu dirambatkan balik ke lapisan masukan, tetapi faktor
δ
j tetapSetelah semua faktor
δ
ditentukan, bobot untuk semua lapisan dapatdisesuaikan secara bersamaan. Penyesuaian bobot wjk (dari unit tersembunyi Zjke unit keluaran Yk) dilakukan berdasarkan faktor
δ
jdan aktivasi xidari unit masukan.Lambang-lambang yang digunakan dalam algoritma pelatihan pada jaringan
perambatan balik adalah sebagai berikut :
x Vektor masukan pelatihan :
x= (x1, … , xi,… ,xn) t vektor keluaran target
t= (t1,… ,tk,… ,tm)
δ
k Bagian dari koreksi galat dari penyesuaian bobot wjk yang berhubungandengan galat pada unit keluaran Yk, juga merupakan informasi tentang galat pada unit Yk yang dirambatkan balik ke unit tersembunyi yang berhubungan dengan unit Yk.
δ
j Bagian dari koreksi galat dari penyesuaian bobot vij yang berhubungandengan perambatan balik informasi galat dari lapisan keluaran ke unit
tersembunyi Zj
α
Pesat belajarXi Unit masukan ke-i :
Untuk sebuah unit masukan, sinyal masukan dan sinyal keluarannya sama,
yaitu xi.
Net input pada Zj dilambangkan dengan Z_inj :
=
+
∑
i ij i j
j
v
x
v
in
z
_
0Sinyal keluaran (aktivasi) dari Zjdilambangkan dengan zj: zj=f(z_inj).
w0k Prasikap pada unit keluaran k Yk Unit keluaran k :
Net input pada Yk dilambangkan dengan y_ink :
=
+
∑
j jk j k
k
w
z
w
in
y
_
0Sinyal keluaran (aktivasi) dari Yk dilambangkan dengan yk : yk=f(y_ink)
Sedangkan algoritma pelatihannya adalah sebagai berikut :
Langkah 0 Berikan bobot awal (dengan nilai acak yang kecil)
Langkah 1 Selama kondisi berhenti belum memenuhi, kerjakan langkah
2-9.
Langkah 2 Untuk tiap pasangan pola pelatihan, lakukan langkah 3-8
Tahap Maju
Langkah 3 Tiap unit masukan (Xi, i=1,….,n) menerima sinyal input xi
dan mengirimkan sinyal tersebut ke semua unit pada
lapisan berikutnya (unit tersembunyi).
Langkah 4 Tiap unit tersembunyi (Zj, j=1,..,p) menjumlah sinyal
input terbobot :
∑
=
+
=
ni ij i j
j
v
x
v
in
z
Kemudian aplikasikan fungsi aktivasinya untuk menghitung
sinyal keluaran :
z
j=
f
(
z
_
in
j)
Dan mengirimkan sinyal ini ke semua unit pada lapisan di
atasnya (unit keluaran).
Langkah 5 Tiap unit keluaran (Yk, k=1,…,m) menjumlahkan sinyal
masukan terbobot :
∑
=
+
=
pj
jk j k
k
w
z
w
in
y
1 0
_
Dan aplikasikan fungsi aktivasinya untuk menghitung
sinyal output
y
k=
f
(
y
_
in
k)
Tahap Perambatan balik dari galat
Langkah 6 Tiap unit keluaran (Yk, k=1,…,m) menerima pola target
yang sesuai dengan pola masukan pelatihan, hitung
informasi galat :
δ
k=
(
t
k−
y
k) (
f
'y
_
in
k)
Hitung koreksi bobot (yang akan digunakan untuk
penyesuaian bobot) :
∆
w
jk=
αδ
kz
jHitung koreksi prasikap (yang akan digunakan untuk
penyesuaian prasikap) :
∆
w
0k=
αδ
kKirimkan δk ke unit pada lapisan sebelumnya.
Langkah 7 Tiap unit tersembunyi (Zj, j=1,….,p) menjumlahkan delta
∑
=
=
mk
jk k
j
w
in
1
_
δ
δ
Kalikan dengan turunan dari fungsi aktivasinya untuk
menghitung informasi galat :
δ =
jδ
_
in
jf
'(
z
_
in
j)
Hitung koreksi bobot (yang akan digunakan untuk
penyesuaian vij) :
∆
v
ij=
αδ
jx
iHitung koreksi prasikap (untuk penyesuaian v0j) :
∆
v
0j=
αδ
jPenyesuaian Bobot dan Prasikap
Langkah 8 Tiap unit keluaran (Yk, k=1,…,m) menyesuaikan prasikap
dan bobotnya (j=0,…,p) :
w
jk(
baru
)
=
w
jk(
lama
)
+
∆
w
jkTiap unit tersembunyi (Zj, j=1,…,p) menyesuaikan prasikap
dan bobotnya (I=0,…,n) :
v
ij(
baru
)
=
v
ij(
lama
)
+
∆
v
ijLangkah 9 Pengetesan kondisi berhenti.
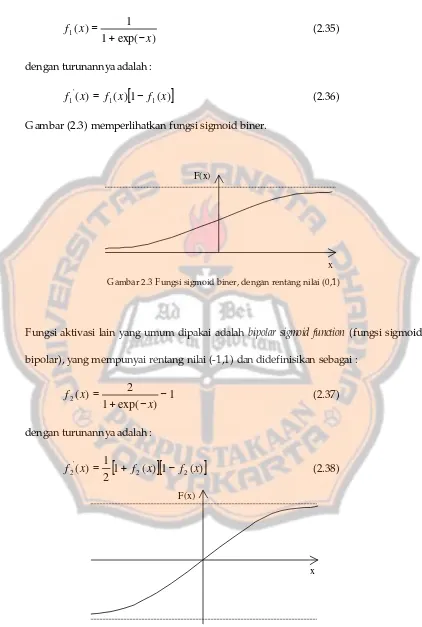
3.2. F ungsi Aktivasi
Fungsi aktivasi untuk jaringan perambatan balik harus mempunyai
)
exp(
1
1
)
(
1x
x
f
−
+
=
(2.35)dengan turunannya adalah :
[
1
(
)
]
)
(
)
(
1 1'
1
x
f
x
f
x
f
=
−
(2.36)Gambar (2.3) memperlihatkan fungsi sigmoid biner.
Gambar 2.3 Fungsi sigmoid biner, dengan rentang nilai (0,1)
Fungsi aktivasi lain yang umum dipakai adalah bipolar sigmoid function (fungsi sigmoid bipolar), yang mempunyai rentang nilai (-1,1) dan didefinisikan sebagai :
1
)
exp(
1
2
)
(
2
=
+
−
−
x
x
f
(2.37)dengan turunannya adalah :
[
1
(
)
][
1
(
)
]
2
1
)
(
2 2'
2
x
f
x
f
x
f
=
+
−
(2.38)Gambar 2.4 Fungsi sigmoid bipolar, dengan rentang nilai (-1,1)
x F(x)
Gambar 2.4. memperlihatkan fungsi sigmoid bipolar.
3.3. Memilih Bobot dan Prasikap Awal
Ada beberapa cara untuk menentukan inisialisasi bobot dan prasikap. Pilihan
pertama adalah dengan inisialisasi acak (random initialization). Pilihan bobot awal akan mempengaruhi suatu jaringan apakah akan mencapai minimum global atau hanya
mencapai minimum lokal dari galat, dan juga berpengaruh pada kecepatan menuju
konvergen. Penyesuaian bobot antara dua unit tergantung pada turunan pada fungsi
aktivasi di unit atas dan fungsi aktivasi di unit bawah. Karena hal tersebut, maka
sangat penting untuk menghindari suatu bobot awal yang akan menyebabkan aktivasi
dan turunan dari aktivasi sama dengan nol. Nilai bobot awal harus tidak terlalu besar
sehingga sinyal masukan awal pada tiap unit tersembunyi tidak berada di daerah di
mana turunan dari fungsi sigmoid mempunyai nilai yang sangat kecil ( daerah
saturasi/jenuh). Sebaliknya, jika bobot awal terlalu kecil, net input pada unit tersembunyi atau unit keluaran akan dekat ke nol yang juga akan menyebabkan
pembelajaran berjalan dengan lambat.
Prosedur yang umum untuk inisialisasi bobot dan prasikap adalah nilai acak
antara -0,5 dan 0,5 (atau antara -1 dan 1 atau selang tertentu yang sesuai). Nilai
tersebut boleh positif atau negatif karena bobot akhir setelah pelatihan juga bisa
keduanya.
Cara inisialisasi lain adalah inisialisasi yang dikembangkan oleh Nguyen dan
Widrow (1990). Pendekatan dari cara ini berdasar pada analisis geometri dari
ke unit keluaran (dan prasikap pada unit keluaran) diinisialisasi secara acak dengan
nilai antara -0,5 dan 0,5 seperti pada kasus secara umum.
Inisialisasi bobot dari unit masukan ke unit tersembunyi dirancang untuk
meningkatkan kemampuan belajar dari unit tersembunyi.
Prosedur inisialisasi bobot menurut Nguyen dan Widrow adalah sebagai berikut :
Langkah 1 Hitung faktor skala :
β
=
0
,
7
(
p
)
1n=
0
,
7
np
dengan n adalah jumlah unit masukan dan p adalah
jumlah unit tersembunyi.
Langkah 2 Untuk tiap unit tersembunyi (j=1,….,p) :
Inisialisasikan vektor bobot (dari unit masukan) :
vij(lama)=nilai acak antara -0,5 dan 0,5 (atau
antara -γ dan γ)
Hitung :
v
j(
lama
)
=
v
1j(
lama
)
2+
v
2j(
lama
)
2+
...
+
v
nj(
lama
)
2Inisialisasikan kembali bobot :
)
(
)
(
lama
v
lama
v
v
j ij ij
β
=
Tentukan prasikap :
v0j= nilai acak antara -β dan β.
3.4. Lama Pelatihan
Tujuan dari jaringan perambatan balik adalah untuk mencapai keseimbangan
antara tanggapan yang benar untuk pola pelatihan dan tanggapan yang baik untuk
tujuan tersebut maka jaringan tidak perlu melanjutkan pelatihan sampai total galat
kuadrat benar-benar mencapai minimum. Hecht dan Nielsen (1990) menyarankan
untuk menggunakan dua kelompok data selama pelatihan. Satu kelompok pola
pelatihan dan satu kelompok pola untuk pengecekan pelatihan. Pada selang selama
pelatihan, galat dihitung menggunakan pola pengecekan untuk pelatihan. Pada saat
galat untuk pola pengecekan pelatihan menurun, pelatihan dilanjutkan. Ketika galat
mulai meningkat, jaringan mulai mengingat pola pelatihan secara spesifik yang artinya
kemampuan generalisasinya mulai menghilang. Pada titik ini, pelatihan dihentikan.
3.5. Jumlah Pasangan Pelatihan
Menurut Baum dan Haussler (1989), jika tersedia pola pelatihan yang cukup,
jaringan akan dapat menggeneralisasi sesuai yang diinginkan. Pola pelatihan yang
cukup ditentukan dengan kondisi sebagai berikut :
e
W
P
e
P
W
=
=
atau
,
(2.39)dengan W adalah jumlah bobot yang dilatih, P adalah jumlah pola pelatihan yang tersedia dan e adalah ketepatan klasifikasi yang diharapkan.
Jika jaringan dilatih untuk mengklasifikasi 1-(e/2) bagian dari pola pelatihan secara benar, dengan 0<e< 1/8, maka jaringan akan mengklasifikasikan 1-e dari pola pengetesan secara benar pula.
3.6. Representasi Data
Pada banyak kasus, vektor masukan dan vektor keluaran mempunyai
penyesuaian bobot adalah aktivasi dari unit sebelumnya, maka unit yang aktivasinya
nol tidak akan belajar. Untuk itu disarankan bahwa pembelajaran dapat ditingkatkan
jika masukan dinyatakan dalam bentuk bipolar dan fungsi sigmoid bipolar digunakan
sebagai fungsi aktivasi.
3.7. Jumlah Lapisan Tersembunyi
Hasil teoritis (Fausett, 1994) menunjukkan bahwa satu lapisan tersembunyi
cukup efisien untuk jaringan perambatan balik untuk mengaproksimasi pemetaan
kontinyu dari pola masukan ke pola keluaran untuk sembarang derajat akurasi.
Walau demikian, dua lapisan tersembunyi akan membuat pelatihan lebih mudah
untuk situasi tertentu.
3.8. Indeks Unjuk Kerja (Performance Indeks)
Indeks unjuk kerja adalah ukuran kuantitatif dari unjuk kerja jaringan. Angka
indeks unjuk kerja kecil menunjukkan unjuk kerja jaringan yang baik, sedangkan
indeks unjuk kerja besar menunjukkan unjuk kerja jaringan yang buruk.
Algoritma perambatan balik untuk jaringan lapis jamak merupakan
generalisasi dari algoritma L MS (L east Mean Square), kedua algoritma tersebut menggunakan indeks unjuk kerja yang sama yaitu galat rata-rata kuadrat (mean square error). Algoritma diberikan dengan sekumpulan pola pelatihan :
{
p
1,
t
1} {
,
p
2,
t
2} {
,....,
p
k,
t
k}
(2.40)dengan pk adalah masukan jaringan dan tk adalah target keluaran yang diharapkan. Pada setiap masukan yang diaplikasikan ke jaringan, keluaran jaringan dibandingkan
meminimalkan galat rata-rata kuadrat. Galat yang merupakan fungsi bobot yang akan
diminimalkan adalah sebagai berikut :
(
)
∑
−
=
k k ky
t
E
0
.
5
2 (2.41)Dengan aturan rantai, diperoleh gradien dari galat pada lapisan keluaran sebagai
berikut :
(
)
(
)
[
]
[
]
(
)
[
]
(
)
_
'
_
_
5
0
5
.
0
2 2 J K K K K JK K K K K JK k k k JK JKz
in
y
f
y
t
in
y
f
w
y
t
in
y
f
t
.
w
y
t
w
w
E
−
−
=
∂
∂
−
−
=
−
∂
∂
=
−
∂
∂
=
∂
∂
∑
(2.42)Kemudian, informasi error
δ
K didefinisikan :[
K K]
(
K)
K
=
t
−
y
f
'
y
_
in
δ
(2.43)Dengan cara yang sama, dapat dicari gradien pada lapisan tersembunyi sebagai
berikut :
[
]
[
]
(
)
(
)
[ ]
I k J Jk k k J IJ Jk k k k IJ k k k IJ k k k k k IJ k k IJx
in
z
f
w
z
v
w
in
y
v
in
y
v
in
y
f
y
t
y
v
y
t
v
E
∑
∑
∑
∑
∑
−
=
∂
∂
−
=
∂
∂
−
=
∂
∂
−
−
=
∂
∂
−
−
=
∂
∂
_
'
_
_
_
'
δ
δ
δ
(2.44)(
J)
k
JK k
J
=
∑
δ
w
f
'
z
_
in
δ
(2.45)4. Jaringan Perambatan Balik dengan algoritma Conjugate Gradient
Algoritma dasar dari perambatan balik biasanya berjalan lambat untuk
kebanyakan aplikasi. Berbagai variasi dari perambatan balik telah dikembangkan
untuk meningkatkan kecepatan dari proses pelatihan. Di antaranya adalah dengan
penggunaan momentum, variasi pesat belajar dan penggunaan algoritma optimisasi
numerik yang umum, salah satunya adalah algoritma conjugate gradient yang akan dipakai dalam penelitian ini.
Algoritma conjugate gradient seperti dijelaskan di sub bab II.B.2 tidak dapat
digunakan secara langsung pada masalah-masalah pelatihan jaringan syaraf, karena
pada jaringan syaraf indeks unjuk kerjanya tidak selalu berbentuk fungsi kuadratis.
Oleh karena itu perlu sedikit modifikasi, pertama adalah bahwa persamaan (2.13)
pada algoritma langkah 2 tidak dapat digunakan. Untuk itu diperlukan line search (metode pencarian garis) yang umum, misalnya metode Golden Section Search.
Modifikasi kedua adalah algoritma harus di-reset setelah sejumlah iterasi tertentu. Ada banyak prosedur yang disarankan, tetapi metode paling sederhana adalah dengan
me-reset arah pencarian pada arah pencarian dari metode penurunan tercuram (negatif dari gradien) setelah n iterasi (Scales, 1985).
Menurut Hagan, Demuth dan Beale (1999) aplikasi algoritma conjugate gradient
pada jaringan perambatan balik adalah sebagai berikut :
1. Algoritma perambatan balik digunakan untuk menghitung gradien (
δ
k danδ
j2. Algoritma conjugate gradient digunakan untuk menentukan penyesuaian bobot
(mencari
α
pada langkah 6 dan langkah 7 serta penyesuaian bobot dan prasikappada langkah 8 ).
30
III. CARA PE NE LITIAN
Bagian ini akan menjelaskan tentang bahan dan alat yang digunakan dalam
penelitian, jalannya penelitian serta kesulitan-kesulitan yang timbul selama penelitian.
A.
Bahan Penelitian
Bahan penelitian yang dimaksud di sini adalah data yang dipakai dalam
penelitian. Permasalahan-permasalahan yang digunakan diperoleh dari
literatur-literatur seperti yang tertulis pada daftar pustaka sebagai berikut :
1. Masalah pengenalan gerbang AND
2. Masalah pengenalan gerbang exclusive-OR (XOR)
3. Masalah pengenalan pola bilangan 1 sampai dengan 0
Pola bilangan dinyatakan dalam larik 7x5 sebagai berikut :
--#--
-###-
-###-
----#
#####
-##--
#---#
#---#
---##
#---#--
----#
----#
--#-#
#---#--
---#-
--##-
-#--#
####---#--
--#--
----#
#####
----#
--#--
-#---
#---#
----#
----#
-###-
#####
-###-
----#
-###-B.
Alat Penelitian
Alat penelitian yang digunakan berupa perangkat lunak (software) dan perangkat keras (hardware) komputer sebagai berikut :
1. Perangkat lunak komputer
Bahasa pemrograman yang dipakai adalah bahasa C+ + menggunakan compiler
Borland C+ + versi 5.02.
2. Perangkat keras komputer
Perangkat keras yang digunakan selama penelitian adalah satu unit notebook IBM
ThinkPad 390E Pentium II 300MHz, memory 64 MB.
C.
Jalannya Penelitian
Jalannya penelitian dimulai dengan mempelajari berbagai literatur tentang
algoritma conjugate gradient, algoritma penurunan tercuram, serta jaringan syaraf perambatan balik yang merupakan dasar dari seluruh penelitian.
1. Pembuatan Program
Setelah melakukan studi pustaka, tahap selanjutnya adalah pembuatan
program. Persiapan pertama dalam pembuatan program adalah pembuatan pseudo-code(algoritma) dari kedua algoritma pelatihan yang akan dibuat programnya yaitu algoritma pelatihan perambatan balik standar dan algoritma pelatihan perambatan
a. Perambatan Balik Standar
Penelitian ini akan membandingkan unjuk kerja dari kedua algoritma tersebut.
Karena algoritma perambatan balik dengan conjugate gradient merupakan algoritma pelatihan dengan model batch, maka algoritma pelatihan perambatan balik standar dibuat juga dengan model batch. Sehingga algoritma perambatan balik standar pada dasar teori yang dibuat dengan pelatihan per pola harus dimodifikasi terlebih dulu
sehingga sesuai dengan model batch.
Pengetesan kondisi berhenti pada langkah 10 dilakukan dengan menghitung
rata-rata galat. Galat tiap pasangan pelatihan (Fausset,1994) dihitung dengan rumus :
[
]
∑
−
=
k
k
k
y
t
E
0
.
5
2 (3.1)Bila dinyatakan sebagai fungsi galat, menjadi :
( )
=
∑
[
−
( )
]
k
k
k
y
w
t
w
F
0
.
5
2 (3.2)Maka galat untuk keseluruhan pola dihitung dengan rata-rata galat sebagai berikut :
[
]
∑∑
−
=
n k
n k
k
y
t
N
E
0
.
5
2 (3.4)dengan N adalah jumlah pola pelatihan. Fungsi galatnya :
( )
=
∑∑
[
−
( )
]
n k
n k
k
y
w
t
N
w
F
0
.
5
2 (3.5)b. Perambatan Balik dengan Conjugate Gradient
conjugate gradient. Kedua algoritma tersebut digabung dan disusun kembali sehingga menjadi algoritma pelatihan yang baru yang disebut dengan algoritma pelatihan
perambatan balik dengan conjugate gradient.
Menurut Hagan, Demuth dan Beale (1999), karena permasalahan-permasalahan
dalam jaringan syaraf biasanya mempunyai fungsi galat atau indeks unjuk kerja yang
tidak kuadratis maka algoritma conjugate gradient seperti pada dasar teori tidak dapat diaplikasikan secara langsung. Algoritma tersebut harus disesuaikan sehingga dapat
digunakan untuk memecahkan masalah yang tidak linear dengan permukaan yang
tidak kuadratis.
Fungsi galat pada persamaan 3.5 tampak seperti persamaan kuadratis tetapi
karena yk(w) pada penelitian menggunakan fungsi aktivasi sigmoid bipolar maka
fungsi galat menjadi tidak kuadratis.
Selain itu algoritma conjugate gradient untuk pemecahan masalah tidak kuadratis membutuhkan metode pencarian linear (linear search ) yang umum untuk mencari letak minimum dari fungsi pada suatu arah tertentu. Pencarian ini terdiri dari 2 langkah
yaitu lokasi selang (interval location) dan pengurangan selang (interval reduction). Tujuan dari langkah lokasi selang adalah menemukan selang awal yang mengandung
minimum lokal. Kemudian langkah pengurangan selang akan
mengurangi/memperkecil ukuran selang awal tersebut sampai dengan toleransi
ketelitian yang diinginkan.
Prosedur dari langkah lokasi selang ditunjukkan pada gambar 3.1. Dimulai
dengan mengevaluasi fungsi galat pada titik awal, yang dilambangkan dengan a1 pada
gambar 3.1. Titik ini merupakan nilai bobot dan prasikap jaringan saat itu. Dengan
Langkah selanjutnya adalah mengevaluasi galat pada titik kedua, dalam
gambar 3.1. dilambangkan dengan b1, yang berjarak
ε
dari titik awal, sepanjang arahpencarian pertama p0. Dengan kata lain, dievaluasi nilai :
(
x
0p
0)
F
+
ε
Kemudian dilanjutkan dengan mengevalusai fungsi galat pada titik baru bi, yang secara berurutan mempunyai jarak titik dua kali lipat dari sebelumnya. Proses
ini berhenti saat fungsi galat meningkat antara dua evaluasi yang berturutan. Pada
gambar 3.1. dilambangan dengan b3 ke b4. Pada titik ini , diketahui bahwa titik
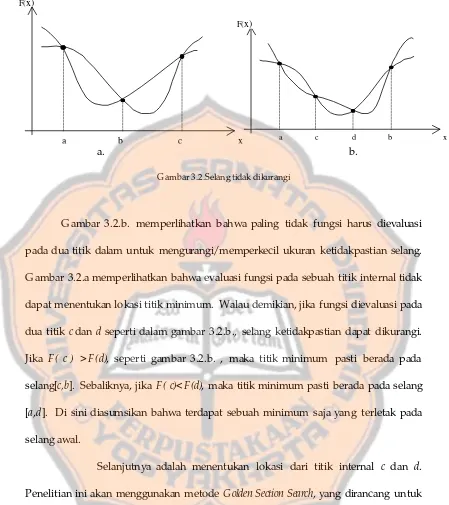
minimum berada antara titik a5 dan b5. Sehingga tidak diperlukan lagi untuk memperlebar selang , karena titik minimum kemungkinan berada pada selang [a4,b4] atau selang [a3,b3]. Kedua kemungkinan ini ditunjukkan pada gambar 3.2.a.
Gambar 3.1. Lokasi Selang
Setelah diperoleh selang yang mengandung titik minimum, langkah
selanjutnya pada pencarian linear adalah pengurangan selang. Pada langkah ini, fungsi
pada titik-titik internal selang [a5,b5] yang merupakan hasil dari langkah lokasi selang
akan dievaluasi.
a1 b1
a2 b2
a3 b3
a4 b4
b5
a5
ε
2ε
4ε
8ε
a. b.
Gambar 3.2.Selang tidak dikurangi
Gambar 3.2.b. memperlihatkan bahwa paling tidak fungsi harus dievaluasi
pada dua titik dalam untuk mengurangi/memperkecil ukuran ketidakpastian selang.
Gambar 3.2.a memperlihatkan bahwa evaluasi fungsi pada sebuah titik internal tidak
dapat menentukan lokasi titik minimum. Walau demikian, jika fungsi dievaluasi pada
dua titik c dan d seperti dalam gambar 3.2.b., selang ketidakpastian dapat dikurangi. Jika F( c ) >F(d), seperti gambar 3.2.b. , maka titik minimum pasti berada pada selang[c,b]. Sebaliknya, jika F( c)< F(d), maka titik minimum pasti berada pada selang [a,d]. Di sini diasumsikan bahwa terdapat sebuah minimum saja yang terletak pada selang awal.
Selanjutnya adalah menentukan lokasi dari titik internal c dan d. Penelitian ini akan menggunakan metode Golden Section Search, yang dirancang untuk mengurangi banyaknya fungsi yang dievaluasi. Pada tiap iterasi, dibutuhkan satu
evaluasi fungsi baru. Pada kasus pada gambar 3.2.b., titik a akan dibuang dan titik c akan menjadi titik luar. Kemudian titik c baru diletakkan antara titik c lama dan titik d. Golden section search akan meletakkan titik baru sehingga selang dari ketidakpastian akan berkurang secepat mungkin.
F(x)
x
a b c
F(x)
x
Algoritma Golden Section Search : τ=0,618
Tentukan :
(
)(
)
( )
(
)(
1 1)
( )
1 1 1 1 1 1 1 1,
1
,
1
d
F
F
a
b
b
d
c
F
F
a
b
a
c
d c=
−
−
−
=
=
−
−
+
=
τ
τ
Untuk k=1,2,….kerjakan :
Jika Fc<Fd, kerjakan :
Tentukan :
(
)(
)
( )
11 1 1 1 1 1 1
;
1
;
;
+ + + + + + + +=
=
−
−
+
=
=
=
=
k c c d k k k k k k k k k kc
F
F
F
F
a
b
a
c
c
d
d
b
a
a
τ
jika tidak, kerjakan :
Tentukan :
(
)(
)
( )
11 1 1 1 1 1 1
;
1
;
;
+ + + + + + + +=
=
−
−
+
=
=
=
=
k d d c k k k k k k k k k kd
F
F
F
F
a
b
b
d
d
c
b
b
c
a
τ
selesaiselesai sampai
b
k+1−
a
k+1<
tol
, dengan tol adalah toleransi ketelitian yang dikehendaki.Satu hal lagi yang perlu dimodifikasi pada algoritma conjugate gradient agar dapat diaplikasikan ke pelatihan jaringan syaraf. Untuk fungsi kuadratis, algoritma
akan konvergen ke titik minimum pada jumlah iterasi tidak lebih dari n iterasi, dengan n adalah jumlah parameter yang dioptimasi (Hagan, Demuth, Beale, 1999). Tetapi pada kenyataannya fungsi galat untuk jaringan lapis jamak bukan merupakan fungsi
Pengembangan algoritma conjugate gradient tidak menunjukkan arah pencarian mana yang digunakan setelah satu siklus n iterasi lengkap. Metode paling sederhana yang digunakan pada penelitian ini adalah me-reset arah pencarian ke arah pencarian dari penurunan tercuram (negatif dari gradien) setelah n iterasi (Scales, 1985).
Berdasarkan modifikasi-modifikasi di atas, disusun algoritma perambatan
balik dengan conjugate gradient sebagai berikut :
Langkah 0 Berikan bobot awal (dengan nilai acak yang kecil)
Langkah 1 Selama kondisi berhenti belum memenuhi, kerjakan langkah
2-13.
Langkah 2 Untuk tiap pasangan pola pelatihan, lakukan langkah 3-7.
Lakukan untuk seluruh pola(pola ke-1,…., pola ke-N
dengan N adalah jumlah keseluruhan pola).
Tahap Maju
Langkah 3 Tiap unit masukan (Xi, i=1,….,n) menerima sinyal input
xi dan mengirimkan sinyal tersebut ke semua unit pada
lapisan berikutnya (unit tersembunyi).
Langkah 4 Tiap unit tersembunyi (Zj, j=1,..,p) menjumlah sinyal
input terbobot :
∑
=
+
=
ni ij i j
j
v
x
v
in
z
1 0
_
Kemudian aplikasikan fungsi aktivasinya untuk menghitung
sinyal keluaran :
z
j=
f
(
z
_
in
j)
Dan mengirimkan sinyal ini ke semua unit pada lapisan di
atasnya (unit keluaran).
masukan terbobot :
∑
=
+
=
pj
jk j k
k
w
z
w
in
y
1 0
_
Dan aplikasikan fungsi aktivasinya untuk menghitung
sinyal output :
y
k=
f
(
y
_
in
k)
Tahap Perambatan balik dari galat
Langkah 6 Tiap unit keluaran (Yk, k=1,…,m) menerima pola target
yang sesuai dengan pola masukan pelatihan, hitung
informasi galat :
δ
k=
(
t
k−
y
k) (
f
'y
_
in
k)
Hitung gradien pada lapisan output (k=1,…,m dan
j=0,…,p):
G
2
jk=
−
δ
kz
jKirimkan δk ke unit pada lapisan sebelumnya.
Langkah 7 Tiap unit tersembunyi (Zj, j=1,….,p) menjumlahkan delta
masukannya (dari unit pada lapisan berikutnya),
∑
=
=
mk
jk k
j
w
in
1
_
δ
δ
Kalikan dengan turunan dari fungsi aktivasinya untuk
menghitung informasi galat :
δ =
jδ
_
in
jf
'(
z
_
in
j)
Hitung gradien pada lapisan tersembunyi (j=1,…,p dan
i=0,…,n):
G
1
ij=
−
δ
jx
igradien (j=0,…,p):
(
)
N
polaN
G
pola
G
rata
rata
G
2
jk−
=
2
jk(
1
)
+
....
+
2
jk(
)
Tiap unit tersembunyi (Zj, j