ISSN 0973-4562 Volume 10, Number 5 (2015) pp. 11763-11776 © Research India Publications
http://www.ripublication.com
Decoding Approach With Unsupervised Learning of Two
Motion Fields For Improving Wyner-Ziv Coding of Video
I Made Oka Widyantara
Telecommunication System Lab., Department of Electrical Engineering, Udayana University
Kampus Bukit Jimbaran, Badung, Ba li, Indonesia, 80361 + 62-0361-701533, [email protected]
Abstract
Wyner-Ziv video coding (WZVC) is a video coding paradigm allows exploiting the source statistic, partially or totally, at the decoder to reduce the computational burden at the encoder. Side information (SI) generation is a key function in the WZVC decoder, and plays an important role in determining the performance of the codec. In this context, this paper proposes decoding approach with unsupervised learning of two motion fields to improve the accuracy of generation of soft SI on WZVC codec. The method used in this paper is based on the generalization of Expectation-Maximization (EM) algorithm, in which the learning process of motion fields used the Low-Density Parity-Check (LDPC) decoder soft output values and two frames previously decoded as initial SI. In this method, the decoder always updated the accuracy of soft SI by renewing two motion fields iteratively. The goal is to minimize the transmission of the bits required by the decoder to estimate frame WZ. The experimental results show that the proposed codec WZVC could improve performance rate-distortion (RD) and lower the bit transmission compared to the existing WZVC.
Keywords: Wyner-Ziv Video Coding, Unsupervised learning, EM Algorithm, Side Information, LDPC
Introduction
WZVC was developed based on Information theories; they are Slepian-Wolf theorem [1] and Wyner-Ziv [2]. The Slepian-Wolf (SW) theorem for lossless compression states that it is possible to encode correlated sources independently and decode them jointly, while achieving the same rate bounds which can be attained in the case of joint encoding and decoding. The Wyner-Ziv (WZ) theorem extends the SW one to the case of lossy compression when SI available at decoder. By using both of them, the WZVC decoders are responsible for exploiting all (or most off) the source statistics and, therefore, to achieve efficient compression.
The general scheme of WZVC classifies video frames into Key frame and WZ frame. The Key frame is encoded using conventional video coding; therefore, the WZ frame is encoded by channel coding principles, and is decoded by the SI of frames that were decoded earlier. With this scheme, the complexity of the encoder can be reduced but the decoder takes an additional burden to generate SI and Frame WZ decoding.
To form WZ decoding, the decoder must perform SI generation process. The quality of SI becomes an important indicator in the decoding process, because the quality of the SI determines the upper limit of WZVC performance. SI can be generated by motion compensated temporal interpolation/extrapolation (MCTI/E) method, based on the previously encoded frame. In the motion estimation at the decoder, the decoder does not have access to the current frame. This limits the accuracy of the estimated motion vectors, so more bitrates are needed to reconstruct the current frame. The difference in bitrate is stated to be the loss of video coding [3]. Several technical approaches of motion estimation for generating SI at the decoder are described and their performances are compared by [4]. A common approach is transform domain motion extrapolation/interpolation. For example, the first set of motion extrapolation forms forward motion estimation from F(t-2) to F(t-1), then for blocks in F(t), the motion vector of the co-located block in F(t-1) is used to obtain correspondence compensated in F(t-1) frame. Without finding any information about the current frame, the motion interpolation or extrapolation generally assumes that the objects are moving at a constant speed so the motion vector already estimated reflects the actual motion of the reference frame. This is a simple assumption and does not correspond to the actual characteristics. As a result, the estimated SI does not match the current frame.
estimation based on the partially decoded frame will be worse than the initial SI. Conversely, if the BER is low, the increase in RD performance becomes very small. The second category is the SI generator techniques with motion learning techniques, in which the generation of soft SI is performed by: (i) renewing the motion field using a value-based LDPC decoder soft estimate of the EM algorithm [14], and (ii) using the bands of transform that have been decoded [15,16]. Both of these approaches use statistical information sources available during the decoding process to iteratively improve the motion field. This approach can improve the RD performance codec WZVC especially for the larger GOP measure, which is an unusual thing in WZVC.
Specifically, the codec decoder WZVC-EM proposed by [14] using only the bit stream of a WZ frame (the LDPC decoder soft output values) to study the motion vectors with reference to one previous frame of reconstruction. Motion vectors relate the correlation in the sequence of video frames, and become the unknown variables in the decoder WZVC. Based only on the reconstruction of the previous frame as a reference frame, unsupervised learning of one motion field of WZVC-EM codec performance is limited by the quality of the SI frame. In the video sources that have much temporal correlation, statistical information of current frame can be very much different from the previous frame. Thus, the use of inaccurate information in the estimation of current frame can degrade the performance of the WZVC-EM codec. The use of more frames as a reference frame already available at the decoder can be used as a solution to improve the accuracy of the soft SI generation.
In this paper, by using the framework [14] a new design where WZVC codec decoder iteratively learning of unknown motion fields between the WZ frames and multiple SI frames is proposed, where it should based on the generalization of the EM algorithm [17]. Motion field compensated version of the multiple SI is used to generate high-quality soft SI. The goal is to improve the efficiency of RD in frame WZ coding.
This paper is organized as follows: section 2 describes unsupervised learning of multiple motion fields based on generalization of EM algorithm. Section 3 describes the details of the proposed modifications WZVC codec. Section 4 describes the analysis of the performance of the RD experiment which has been done. Finally, section 5 is the conclusion of this paper.
Generalized Em-Based Unsupervised Learning of Motion Field
In Figure 1, the current WZ frame (X) associated to multiple reference frames Ŷk
through multiple motion fields Mk, where k = 1,…., K. WZ frame (X) is encoded into
the syndrome bits (S) with LDPC encoder and subsequent the syndrome bits (S) is gradually transmitted to the decoder through the feedback channel. In the decoder, a scheme of unsupervised learning base on generalization of EM algorithm was made to learning of multiple motion fields (Mk) iteratively. When Mk can be estimated
accurately, then the decoder can save the transmission bitrate to decode the WZ frame. Generalisation of the EM algorithm to learn of Mk, can be explained as
Model
Based on reference [14], model of the decoder's posteriori probability distribution of the source X based on the soft estimate decoder LDPC () parameter is as follows:
,
{X} {X, } . . ,
app
i j
P P
i j X i j (1)in which θ(i,j,) = Papp{X(i,j) = } is related to the soft estimate of X(i,j) with
luminance value {0,..,2d– 1}.
Decoder intends to calculate the posteriori probability distribution of Mk, as
follows:
{M } | , ;
, | ;
app k k k
k k k
p P M Y S
P M P Y S M
(2)
with the second step of Bayes. This form affirms a form of EM iterative solution.
Figure 1: Scheme of unsupervised learning of motion fields through EM algorithm
E-step Algorithm
E-step updated to the estimated distribution on multiple motion fields (Mk) with
reference to the parameter of the soft estimate decoder LDPC (θ), in which θ is used to help the motion estimation in order to improve a posteriori probability on Mk.
When the Mk estimation is done by the block-by-block motion vectors M(u,v), then
every block of θ(t-1) is compared to the collocated block of in each Yk, as well as all
those in a fixed motion search range around it. At iteration t, for a block of θ(u,v)( t-1) with top left pixel located at (u,v), the distribution on the shift M(u,v) becomes updated
as below and normalized:
( , )
( ) ( 1) ( 1)
( , )k : ( , )k ( , )k u vk | ( , )k; ( , )
t t t
app u v app u v u v M u v u v
P M P M P Y M
(3)
( , ) 1,...,
k
u v M
M m m k1, 2,....,K
where m1,...,mM is the range of configuration of M(u,v)k with nonzero probability,
Ŷ(u,v)k + M(u,v)k is n n blocks of Ŷk with the upper left pixel position which is placed on
LDPC Encoder
LDPC Decoder (M-step)
Generate soft SI
Block-based motion estimator
(E-step) Reconstruction
X S θ
Ŷ
Motion field interpolation Rate control
P{Mu,v}
P{Mi.j}
Probability model
{(u,v)+ M(u,v)}, and P{Ŷ(u,v)k+ M(u,v)k|M(u,v)k;θ( t-1)
(u,v)} is the probability of observing
Ŷ(u,v)k+ M(u,v)k generated through M(u,v)k of X(u,v) which is parameterized by θ(u,v) (t-1). All the distributions on M(u,v)k are normalized; therefore, the summation becomes one.
Probability models iteratively updates the soft SI by blending information from the pixels Ŷkcorresponding to the motion field distribution that already repaired. This
procedure includes two stages: (i) motion field interpolation to improve the resolution of the estimated motion field on a pixel-by-pixel (M(i,j)k,), and (ii) generation of soft side information ( ). M(i,j)k is made by interpolating block-based motion field M(u,v)k
which has been repaired. In this paper, we propose a Lanczos interpolation technique to improve the M(u, v)k into pixel resolution, which can reduce the complexity of
decoding codec WZVC [18]. Lanczos interpolation
This is based on the function of the 3-lobed Lanczos window as interpolation function [19]. For a point (xD,yD) on the distribution of pixel-based motion field M(i,j)(xD,yD),
the interpolation algorithm using the distribution of block-based motion field M(u,v)(xS,yS) in 36 blocks of the nearest neighbours of the point (xS,yS) is as follows:
0 1 0 2 0
3 0 4 0 5 0
0 1 0 2 0
3 0 4 0 5 0
int( ) 2; 1; 2;
3; 4; 5;
int(y ) 2; 1; 2;
3; 4; 5;
s s s s s s
s s s s s s
s s s s s s
s s s s s s
x x x x x x
x x x x x x
y y y y y
y y y y y y
(4)
where (xD,yD) are the coordinates of the pixel-based motion field M(i,j)(xD,yD), and
(xS,yS) are the coordinates calculated from the position of M(u,v)(xS,yS) which are
mapped to (xD,yD).
First, the probability distribution of M(u,v)(xS,yS) is interpolated along the x-axis to
generate 6 intermediate value distribution of motion field I(u,v)(xS,yS)k,, where k = 0, ..,
5.
5
( , ) (u,v)
0
(x , y ) , , 0 5
u v s s k i app si sk
i
I a P M x y k
(5)Then, the probability distribution of M(i,j)(xD,yD) is calculated by interpolating the
intermediate values along the y-axis distribution:
5
( , ) ,
0
, (x , y )
app i j D D k u v s s k k
P M x y b I
(6)ai and bk are the coefficients which are expressed as:
i s si
k s si
a L x x
b L y y
(7)
sin ( ). ( ) sin( ) sin( 3), 0 | | 3 3
0 , 3 | |
L x c x Lanczos x
x x
x
x x
x
(8)
Soft SI generator
Soft SI generator are summing the estimation of each Ŷk block after being weighted by Papp{Mi,j(xD,yD)}. Since there are as many as Ŷk which have to be weighted, then
soft SI generator selectively blends the aggregate in order to contribute to the improvement of . In general, the probability that blended SI has a value of in pixel (i, j) is:
1
( ) ( )
( , ) ( , )
1
, , , | ,
M
k k
m K
t t
app i j i j k
k m m
i j P M m P X i j M m Y
1
( )
( , ) ,
1
, M
k k
m K
t
app i j Z k m k m m
P M m p Y i j
(9) where PZk(z) is the probability mass function (pmf) of k as independent additive
noise Z. Ŷk,m is the reconstruction of the k frame which is compensated through m
motion configurations.
Equation (9) shows that the sum of the weights includes the whole shift version of
Ŷk.. When the entire distribution of M(i,j)k is obtained, the blending operation allows all
candidates of the partial shift to contribute to soft SI, (i, j) Block candidates model
In a block-based estimation, a block model candidate of [20] is applied to the model of the relationship of WZ frame with SI. In the context of the symbol-based encoding, each block in WZ frame (which is parameterized by θ) consists of 2m level, which is distributed simultaneously over {0,1,2,...,2m-1}. Each block of soft estimate decoder LDPC (θu,v) is paired with M block candidate of each reference frame Ŷ(u,v)k + M(u,v)k.
Statistical dependence between θ and Ŷ(u,v)k + M(u,v)k is through the vector M(u,v)k =
(m1, m2,.., mM), respectively Laplacian distributed. When Mu,v = mi is known, then the
candidate block Ŷ(u,v)k[i,mi] are statistically dependent on block x[i] (which is
parameterized by θ) in accordance with:
Yˆ( , )u v k
i m, i x i n i modulo 2m (10) in which the random vector n[i] has the same independent symbols as l{0,1,2,..,2m-1}, with probability l. The symbol of all the other candidates, Ŷ(u,v)k[i,j
mi] in this block is distributed at the same time through{0,1,2,., 2m-1} and
independent on x[i].
0 1 ... 2m 1
l l
(11)
where,
2
1 2
2 2
exp , jika 0 l 2
2
(2 )
exp , jika 0 l 2
2
m
l m
m
l
l
(12)
M-step Algorithm
In the M-step, soft estimate decoder LDPC (θ) is updated by LDPC decoder using soft SI ( ) that has been generated with Equation (9), based on the joint bitplane LDPC decoding method which is detailed in [14]. At iteration t, the value of θ is calculated by:
( )
( )
( ) 1 1 ( )
1 01
, , : ( , , ) g 1 g
d
t t t t
g g
g
i j i j
(13)where g denote the gth in Gray mapping of luminance value and 1[.] denote
indicator function. M-step also generates a hard estimate of for frame WZ by by
taking one most probable value for each pixel according to θ.
(i,j) = argmax θ(i,j, ) (14)
By iterating through the M-step and the E-step, the LDPC decoder requests more syndrome bits if the estimates is not convergent. The algorithm terminates when the hard estimate of yields syndrome which is identical to S.
Decoding Approach With Unsupervised Learning of Two Motion
Fields
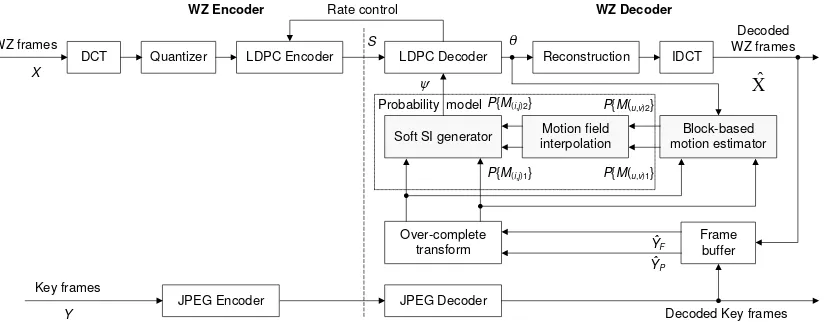
Based on the scheme of EM generalization-based unsupervised learning of multiple motion fields, the existing WZVC-EM codes are extended [14], from the decoding with unsupervised learning of the one motion field into two motion fields. The proposed transform domain WZVC codec architecture can be seen in Figure 2, works as follows:
1. Input video sequence is divided into key frame (X) and WZ frame (Y), each is encoded using intra JPEG and Wyner-Ziv. The 8 x 8 block-based Discrete Cosine Transform (DCT) is applied to each WZ frame (Y) by the Wyner-Ziv coding - and then quantize the transform coefficients into indices. The encoder communicates these indices to the decoder using rate-adaptive LDPC through the feedback channel.
2. The decoder makes soft SI ( ) for each key frame (X) by applying the method of motion compensated frame SI interpolation, using the past (Ŷp) and future
categorize the past and future decoded frames, we use the hierarchical coding structure as proposed in [21], which means that the GOP size is greater than 2, the entire decoded X is used to decode the remaining frames in the GOP. 3. Then, 8 8 DCT is applied to Ŷp and ŶF to transform the 8 8 blocks on
entire pixel shift which are then quantized into indices. In this way, indices of each motion candidate, Ŷp and ŶF, available in the motion estimator to be
compared with the LDPC decoder soft estimate (θ), that is coefficient of the index of X, and which is available in soft SI generator on probability models for blended soft SI .
Figure 2: Domain transform WZVC codec architecture with unsupervised learning two motion fields
4. Each block-based motion estimator updates the a posteriori probability distribution of block-based motion field Papp{M(u,v)k} that is
Papp{M(u,v)1}between θ with Ŷp and Papp{M(u,v)2} between θ and ŶF using
Equation (3).
5. Lanczos interpolation upsample the Papp{M(u,v)1}and Papp{M(u,v)2} to the a
posteriori probability distribution of pixel-basis motion field Papp{M(i,j)1} and
Papp{M(i,j)2}.
6. Furthermore, the soft SI generator selectively chooses the best content of the
Ŷp and ŶF which are matched with X using Equation (9), with k = 1, 2.
Experiments
Test Conditions
The results of testing presented in this paper were obtained through the same mechanism as in [14]. For the motion estimator and the probability models, the motion search range is set to ± 5 each pixel horizontally and vertically. In the EM algorithm in the decoder, the initial value of the Laplacian noise variance Z1 and Z2
DCT Quantizer LDPC Encoder LDPC Decoder
Soft SI generator
Decoded WZ frames
WZ frames S
Rate control
WZ Encoder WZ Decoder
Xˆ
Block-based motion estimator Reconstruction IDCT
Over-complete transform
JPEG Encoder JPEG Decoder
Decoded Key frames
θ
Motion field interpolation
ŶP
P{M(u,v)1}
P{M(i,j)1}
Frame buffer Probability modelP{M(i,j)2} P{M(u,v)2}
ŶF
X
are the same as in [14] and the initial distribution of both of the motion fields, M(u,v)1
and M(u,v)2 experimentally selected, such as:
2 3 , 4( ) 3 1
( , ) 4 80 , 2
1 80
, (0, 0)
(0, ), ( , 0)
, k
u v t
app u v u v
if M
P M if M
otherwise (15)
The RD performance is measured at four points, associated with the four JPEG quantization scale factors of 0.5, 1, 2 and 4 [22]. As the WZVC codec performance analysis in general, the luminance component of each frame is used to calculate the bitrate and the peak-to-peak signal to noise ratio (PSNR).
RD Performance Evaluation
Proposed WZVC codec versus was existing WZVC codec
Figure 3 shows that the performance of the proposed WZVC codec is consistently better than the existing WZVC codec. For GOP size 2, 4 and 8, the RD gain respectively increase by 0.33 dB, 0.24 dB, 0.1 dB for Foreman and 0.25 dB, 0.3 dB, 0.2 dB for Carphone. This shows that selectively blending two probabilities a pixel-based motion fields to shift two SI frames (ŶP and ŶF), can improve the accuracy of
soft SI and lower transmission bitrate to estimate frame WZ.
28 29 30 31 32 33 34 35 36
150 250 350 450 550 650
PSN R (d B ) Rates (Kbps)
Foreman, GOP = 2
Motion learning Proposed method Motion oracle No compensation JPEG 29 30 31 32 33 34 35 36 37 38
100 200 300 400 500
PSN R (d B ) Rates (Kbps)
Carphone, GOP = 2
Motion learning Proposed method Motion oracle No compensation JPEG 28 29 30 31 32 33 34 35 36
100 200 300 400 500 600
PSN R (d B ) Rates (Kbps)
Foreman, GOP = 4
Motion learning Proposed method Motion oracle No compensation JPEG 29 30 31 32 33 34 35 36 37 38
100 200 300 400 500
PSN R (d B ) Rates (Kbps)
Carphone, GOP = 4
(a) (b)
Figure 3: RD performance at GOP = 2, 4 and 8, respectively for: (a) Foreman video sequence, and (b) Carphone video sequence
Proposed WZVC codec versus alternative WZVC codecs
Figure 3 also shows the RD performance comparison between the WZVC codec and that has proposed and the alternative WZVC codec. Alternative codec uses decoding with motion oracle and no motion compensation [14]. Comparison with JPEG is also conducted to provide a comparison of the performance of RD with conventional coding standards. It was observed that the proposed WZVC codec produces better RD performance compared to the motion oracle decoding, especially for Carphone video sequence, reaching 0.3 dB at GOP size 8. This can be estimated that although the motion oracle able to provide information about the motion in the motion estimator, but the motion information provided was calculated with motion compensation temporal interpolation (MCTI) in the encoder. So that, the motion information is not true motion. When the temporal distance increases, the accuracy of the motion of motion oracle is also declined.
Quality and Bitrate Temporal Evaluation
Figure 4 shows the comparison of the temporal with existing WZVC codec in PSNR form and the total number of bits required for each WZ frame, using GOP size 4 and JPEG quantization scale factor of 0.5 for Foreman and Carphone sequences. In general, both WZVC codec produce the same video reconstruction (PSNR) but it is different in regard to the rate required to estimate WZ frame. For Foreman, the proposed WZVC codec consumes more bits in the middle of each frame in the GOP structure, such as frame 18 that is between frame 16 and 20. However, as a whole, our proposed method can lower the bitrate transmission respectively by 4.32% per frame for Foreman and 5.46% per frame for Carphone.
28 29 30 31 32 33 34 35 36
100 200 300 400 500 600
PSN
R
(d
B
)
Rates (Kbps)
Foreman, GOP = 8
Motion learning Proposed method Motion oracle No compensation JPEG
29 30 31 32 33 34 35 36 37 38
50 150 250 350 450 550
PSN
R
(d
B
)
Rates (Kbps)
Carphone, GOP = 8
(a) (b)
Figure 4: Bitrate and quality temporal evaluation on GOP size 4, and Qf = 0.5: (a) Foreman video sequence, (b) Carphone video sequence
Decoding Complexity Evaluation
Encoding complexity is measured only from the decoder, because the codec scheme is identical from the encoder side. Decoding complexity measurement is expressed as the average of the EM iteration time per quadrant WZ Frame required by the decoder to fulfil syndrome condition.
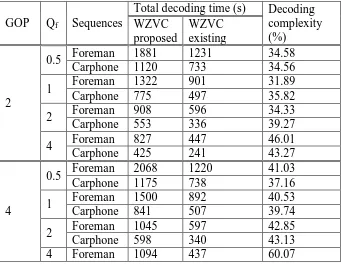
Table 1: Analysis of complexity for Foreman and Carphone sequences using Qf = 0.5, 1, 2, and 4 on the GOP 2, 4 and 8
GOP Qf Sequences
Total decoding time (s) Decoding complexity (%) WZVC proposed WZVC existing 2
0.5 Foreman 1881 1231 34.58
Carphone 1120 733 34.56
1 Foreman 1322 901 31.89
Carphone 775 497 35.82
2 Foreman 908 596 34.33
Carphone 553 336 39.27
4 Foreman 827 447 46.01
Carphone 425 241 43.27
4
0.5 Foreman 2068 1220 41.03
Carphone 1175 738 37.16
1 Foreman 1500 892 40.53
Carphone 841 507 39.74
2 Foreman 1045 597 42.85
Carphone 598 340 43.13
4 Foreman 1094 437 60.07
10 15 20 25 30 35 40 45
0 4 8 12 16 20 24 28 32 36 40 44 48 52 56 60 64 68 72 76 80 84 88 92 96
B it p e r fr m a e ( K b it ) Frame number Foreman. GOP 4, Qf = 0.5
Existing WZVC WZ frames Proposed WZVC WZ frames Key frame (JPEG)
5 10 15 20 25 30 35 40
0 4 8 12 16 20 24 28 32 36 40 44 48 52 56 60 64 68 72 76 80 84 88 92 96
B it p e r fr m a e ( K b it ) Frame number Carphone, GOP4, Qf = 0.5
Existing WZVC WZ frames Proposed WZVC WZ frames Key frame (JPEG)
31 33 35 37
0 4 8 12 16 20 24 28 32 36 40 44 48 52 56 60 64 68 72 76 80 84 88 92 96
P S N R ( d B ) Frame number
Existing WZVC WZ frames Proposed WZVC WZ frames Key frame (JPEG)
32 34 36 38 40
0 4 8 12 16 20 24 28 32 36 40 44 48 52 56 60 64 68 72 76 80 84 88 92 96
P S N R ( d B ) Frame number
Carphone 434 226 47.98
8
0.5 Foreman 2678 1228 54.15
Carphone 1182 711 39.85
1 Foreman 1607 904 43.78
Carphone 842 488 42.08
2 Foreman 1124 610 45.67
Carphone 842 488 42.08
4 Foreman 893 433 51.50
Carphone 430 213 50.47
Table 1 shows a comparison between the decoding complexity of the proposed WZVC codec with the existing WZVC codec, respectively for Foreman and Carphone video sequence. Based on the table, then the decoding complexity can be analyzed as follows:
Proposed WZVC decoder is 1.8 times more complex in average than the existing WZVC decoder. Generation two motion fields in proposed WZVC codec has improved the overall decoding complexity. In some literature, efforts to improve the RD performance of WZVC codec also produces an increase in the complexity of decoding up to 1.3 times and 12% (on a different method) [13] [16].
The complexity of the proposed decoding WZVC tends to increase the size of the accretion GOP. This increase also occurred on the quantization scale factor. The greater the temporal distance of SI frames in the GOP structure, the more difficult the two motion fields estimation will be. In addition, the larger the quantization scale factor, the lower the quality of the SI frame (decoded JPEG) will be. In these conditions, the decoder requires more number of iterations of EM to produce convergence syndrome in LDPC decoder. This leads to the consumption of time in EM iteration becomes more.
Conclusion
This paper describes a WZVC codec that learning two motion fields in unsupervised mode in the decoder. Proposed decoder with unsupervised learning of two field motions generalize the framework of statistical estimation of the one motion field decoder, based on a generalization of the EM algorithm. The proposed method can improve the RD performance and bitrate saving compared with existing WZVC codec.
Refrences
[2]. Wyner, A.D., and Ziv, J., 1976, „The Rate-Distortion function for source coding with side information at the decoder,” IEEE Transaction. Information Theory, Vol. 22, pp. 1-10.
[3]. Li, Z., Liu, L., and Delp, E.J., 2007, “Rate Distortion Analysis of Motion Side Estimation in Wyner–Ziv Video Coding,” IEEE Transaction Image Processing, 16(1), pp. 98–113.
[4]. Brites, C. ., Ascenso, J., and Pereira, F., 2013, ”Side Information Creation of Efficient Wyner-Ziv video Coding: Classifying and Reviewing,” Signal Processing : Image Communication, 28, pp. 689-726.
[5]. Ascenso, J., Brites, C., and Pereira, F., 2005, “Motion compensated refinement for low complexity pixel based distributed video coding,” Proc. IEEE International Conference on Advanced Video and Signal Based Surveillance (AVSS), pp. 593–598.
[6]. Artigas, X., and Torres, L., 2005, “Iterative generation of motion compensated side information for distributed video coding”, Proc. IEEE International Conference on Image Processing (ICIP), Vol. 1, pp. 833–836. [7]. Adikari, A.B.B., Fernando, W.A.C., Arachchi, H.K., and Weerakkody, W.A.R.J., 2006, “Sequential motion estimation using luminance and chrominance information for distributed video coding of Wyner–Ziv frames,” IEE Electronics Letters, 42(7), pp. 398-399.
[8]. Weerakkody, W.A.R.J., Fernando, W.A.C., Martinez, J., Cuenca, P., and Quiles, F., 2007, ”An iterative refinement technique for side information generation in DVC,” Proc. IEEE International Conference on Multimedia and Expo (ICME), Beijing, China.
[9]. Ye, S., Ouaret, M., Dufaux, F., and Ebrahimi, T., 2008, ”Improved side information generation with iterative decoding and frame interpolation for distributed video coding,” Proc. IEEE International Conference on Image Processing (ICIP), San Diego, CA, USA.
[10]. Bandem, M.B., Mrak, M., and Fernando, W.A.C., 2008, ”Side Information Refinement Using Motion Estimation in DC Domain for Transform-based Distributed Video Coding,” IET Electronic Letter, 44(16), pp. 965-066. [11]. Bandem, M.B., Fernando, W.A.C., Martinez, J., and Cuenca, P., 2009,
”An Iterative Side Information refinement Technique for Transform Domain Distributed Video Coding,” Proc. IEEE International Conference on Multimedia and Expo (ICME), New York City, NY, USA.
[12]. Martins, R., Brites, C., Ascenso, J., and Pereira, F., 2009, “Refining Side Information for Improved Transform Domain Wyner–Ziv Video Coding,” IEEE Transactionson Circuitsand Systems for Video Technology, 19(9), pp.1327–1341.
[14]. Varodayan, D., Chen, D., Flierl, M., and Girod, B., 2008, “Wyner-Ziv Coding of Video With Unsupervised Motion Vector Learning,” EURASIP Signal Processing: Image Communication Journal, Special Issue on Distributed Video Coding, Vol.23, pp. 369-378.
[15]. Martins, R., Brites, C., Ascenso, J., and Pereira, F., 2010, “Statistical Motion Learning for Improved Transform Domain Wyner-Ziv Video Coding”, IET Image Processing, Vol. 4, pp. 28-41.
[16]. Brites, C., Ascenso, J., and Pereira, F., 2012, “Learning Based Decoding Approach for Improved Wyner–Ziv Video Coding“, Proc. The Picture Coding Symposium (PCS), Krakow, Poland.
[17]. Chen, D., Varodayan, D., Flierl, M., and Girod, B., 2008, “Wyner-Ziv Coding of Multiview Images With Unsupervised Learning of Two Disparities”, Proc. IEEE International Conference on Multimedia and Expo (ICME), pp. 629-632.
[18]. Widyantara, I M.O., Wirawan, and Hendrantoro, G., 2012, ”Reducing Decoding Complexity by Improving Motion Filed Using Bicubic and Lanczos Interpolation Techniques in Wyner-Ziv Video Coding”, KSII Transactions on Internet and Information System, 9(6), pp. 2351-2369. [19]. Intel, 2009, ”Intel Integrated Performance Primitives for Intel®
Architecture, Reference manual, Vol. 2: Image and video processing”. [20]. Varodayan, D.P., 2010, ”Adaptive Distributed Source Coding”, Ph.D.
thesis, Department of Electrical Engineering, Stanford University.
[21]. Aaron, A.M., Zhang, R., and Girod, B., 2002, “Wyner-Ziv coding of motion video”, Proc. Asilomar Conference on Signals, System and Computer, pp. 240-244.