KLASIFIKASI DATA
R Denny Prasetyadi Utomo¹, Retno Novi Dayawati², Kemas Rahmat Saleh Wiharja³
¹Teknik Informatika, Fakultas Teknik Informatika, Universitas Telkom
Abstrak
Data Mining merupakan solusi yang mampu menemukan pola dan aturan (rule) dari sekumpulan data yang besar. Dari aspek bisnis, data mining mempunyai kandungan informasi yang potensial. Data mining mampu menemukan informasi yang tersembunyi.
C&RT (Classification and Regression Trees) merupakan salah satu metode atau algoritma dari salah satu teknik eksplorasi data yaitu teknik pohon keputusan atau disebut juga decision tree. Decision tree merupakan salah satu metode klasifikasi yang menarik karena mudah
diinterpretasikan oleh manusia, dapat dibentuk relatif cepat dibanding metode lain, dan memiliki akurasi yang baik pada hasil klasifikasinya.
C&RT memiliki waktu Pembentukan Tree yang relatif lebih Lama dibandingkan dengan metode klasifikasi menggunakan decision tree yang lainnya. Karena akurasi dari C&RT yang baik dalam klasifikasi data, pada Tugas Akhir ini dilakukan penelitian untuk mengoptimasi pembentukan tree pada C&RT. Optimasi dilakukan dengan cara sampling data latih untuk mempercepat split pada pembentukan tree.
Kata Kunci : data mining, klasifikasi, decision tree, C&RT
Abstract
Data Mining is a solution that can find patern and rule from large data. From bussiness aspect, data mining have a potential information. Data mining can discover hidden information. C&RT (Classification and Regression Tree) is a method or algorithm from one of the data exploration technique that is decision tree. Decision tree is a interesting classification method because easy to understand by people, constructed more fast, and have good accuration on the classification result.
If it compared with other classification method, C&RT is need long time in tree construction. Because the accuration of C&RT is good for data classification, on this final poject will do a research to optimize tree construction on C&RT. Sampling the data is used to accelerate splitting root of tree in tree construction.
1.
Pendahuluan
1.1
Latar belakang
Perkembangan jumlah data dalam sektor industri semakin lama semakin bertambah besar. Dimana banyak perusahaan atau organisasi telah mengumpulkan data sekian tahun lamanya (data pembelian, data penjualan, data nasabah, data transaksi dsb.). Hampir semua data tersebut dimasukkan dengan menggunakan aplikasi komputer yang digunakan untuk menangani transaksi sehari-hari yang kebanyakan adalah OLTP (On Line Transaction Processing). Setelah berjalan beberapa tahun kemudian muncul pertanyaan, akan kita apakan data tersebut? Haruskah kita buang? Dapatkah data history tersebut kita manfaatkan?
Data mining merupakan solusi yang mampu menemukan pola dan aturan (rule) dari sekumpulan data yang besar. Dari aspek bisnis, data mining
mempunyai kandungan informasi yang potensial. Data mining mampu menemukan informasi yang tersembunyi.
Salah satu task data mining adalah teknik klasifikasi. Klasifikasi merupakan suatu proses untuk menemukan sekumpulan model (fungsi) yang menggambarkan dan membedakan kelas-kelas atau konsep data yang bertujuan untuk memudahkan penggunaan model dalam memprediksi kelas-kelas objek, dimana label-label kelas tidak diketahui sebelumnya.
C&RT (Classification and Regression Trees) merupakan salah satu metode atau algoritma dari salah satu teknik eksplorasi data yaitu teknik pohon keputusan atau disebut juga decision tree. Decision tree merupakan salah satu metode klasifikasi yang menarik karena mudah diinterpretasikan oleh manusia, dapat dibentuk relatif cepat dibanding metode lain, dan memiliki akurasi yang baik pada hasil klasifikasinya. Pembentukan pohon pada algoritma C&RT dilakukan dengan cara memecahkan subset dari data set menggunakan semua variabel prediktor untuk menciptakan dua node anak secara berulang-ulang. Algoritma ini mampu melakukan klasifikasi pada data yang bertipe categorical maupun continuous.
Pada tugas akhir ini akan dilakukan optimasi pembentukan tree pada algoritma C&RT dengan cara melakukan sampling pada data training. Optimasi ini dilakukan untuk memperbaiki performansinya. Setelah itu akan dilakukan analisis terhadap hasil optimasi algoritma tersebut.
1.2
Perumusan masalah
Dengan mengacu pada latar belakang masalah diatas, maka permasalahan yang akan dibahas dan diteliti adalah :
1. Bagaimana cara kerja untuk mengoptimasi pembentukan decision tree
pada C&RT dalam klasifikasi data.
2. Bagaimana menerapkan optimasi pembentukan decision tree pada C&RT dalam klasifikasi data.
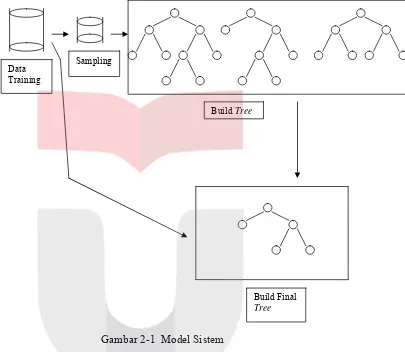
5. model sistem yang digunakan pada Tugas Akhir ini sebagai berikut:
Gambar 2-1 Model Sistem
Berdasarkan gambar diatas, langkah pertama yaitu mengambil sampling dari data training, kemudian dibangun tree untuk klasifikasi dengan menggunakan algoritma C&RT. Setelah itu dibentuk Final Tree dengan cara mengiriskan semua tree yang terbentuk pada langkah sebelumnya dan juga mengacu pada data training yang ada.
Batasan masalah untuk Tugas Akhir ini adalah sebagai berikut : 1. Data yang digunakan adalah data kategorik (bukan numerik). 2. Data yang digunakan merupakan data UCI.
3. Tidak menangani preprocessing.
1.3
Tujuan
Berdasarkan rumusan masalah di atas, maka tujuan dari tugas akhir ini adalah:
1. menghasikan perangkat lunak untuk mengoptimasi pembentukan
decision tree pada C&RT.
Data Training
2. Menganalisis performansi algoritma C&RT yang telah dilakukan optimasi.
Hipotesa Awal : waktu yang dibutuhkan untuk pembentukan tree pada hasil optimasi lebih cepat dibandingkan dengan algoritma C&RT yang tidak dilakukan optimasi.
1.4
Metodologi penyelesaian masalah
Metode yang digunakan dalam penyelesaian tugas akhir ini adalah menggunakan metode studi pustaka atau studi literatur dan analisis dengan langkah kerja sebagai berikut :
1. Studi Literatur :
a. Pencarian referensi, mencari referensi dan sumber-sumber lain yang layak yang berhubungan dengan data mining, decision tree, C&RT. b. Pendalaman materi, mempelajari dan memahami materi yang
berhubungan dengan tugas akhir.
2. Mempelajari konsep dari decision tree yang akan digunakan dalam implementasi perangkat lunak.
3. Melakukan analisis klasifikasi pada data mining dalam perancangan perangkat lunak
4. Melakukan implementasi perancangan perangkat lunak
5. Melakukan pengujian perangkat lunak dengan memasukkan data serta mencatat hasil keluaran program.
PENUTUP
5.1
KESIMPULAN
5.1.1 Sehubungan Dengan Hasil Penelitian
1. Penggunaan algoritma BOAT mampu meningkatkan performansi waktu pada saat proses klasifikasi menggunakan metode C&RT tanpa mengurangi akurasinya.
2. Nilai bagsize (prosentase ukuran sampling) yang efektif meningkatkan performansi metode C&RT adalah ≤ 12 % dan numbag ( banyaknya sampling yang digunakan) yang paling baik adalah 2
3. Menurut hasil percobaan yang dilakukan terhadap 5 data yang digunakan, optimasi C&RT dapat mempercepat waktu pembentukan tree sebesar 74.5% dan memiliki rata-rata hasil optimasi C&RT terbesar lebih cepat 47.24 % dibandingkan dengan C&RT normal dalam pembentukan tree.
5.2
SARAN
Daftar Pustaka
[1] A.C.Davison and D.V.Hinkley. Bootstrap Methods and their Application.
Cambridge Series in Statisticaland Probabilistic Mathematics. Cambridge University Press, 1997.
[2] Alwi, Hasan, et al. 2003. Tata Bahasa Buku Bahasa Indonesia. Edisi Ketiga. Jakarta: Balai Pustaka.Alwi, Hasan, et al. 2003. Tata Bahasa Buku Bahasa Indonesia. Edisi Ketiga. Jakarta: Balai Pustaka.
[3] Andrea Tettamanzi and Marco Tomassini. Soft Computing. Springer 2001.
[4] Breiman, L., Friedman, J. H., Olshen, R. A., & Stone, C. J. (1984).
Classification and Regression Trees. Wadsworth International
Group,Belmont,California.
[5] F. Olken. Random Sampling from Databases. PhD thesis, University of California at Berkeley, 1993.
[6] Jiawei Han and Micheline Kamber. Data Mining : Concepts and Techniques. Intelligent Database Systems Research Lab, School of Computing Science, Simon Fraser University.
[7] Johannes Gehrke, Venkatesh Ganti, Raghun Ramakrishnan and Wei-Yin
Loh. BOAT-Optimistic Decision Tree Construction. Departement of
Computer Science and Departement of Statistics, University of Wisconsin-Madison.
[8] Johannes Gehrke, Venkatesh Ganti and Raghun Ramakrishnan. Rain
Forest-A Framework for Fast Decision Tree Construction of Large
Dataset. Departement of Computer Science and Departement of Statistics, University of Wisconsin-Madison.
[9] J.Ross Quinlan. Induction of decision trees. Machine Learning, 1:81 – 106,1986.
[10] Kusumadewi, Sri. Artificial Intellegence (Teknik dan Aplikasi. edisi pertama). Graha Ilmu. Jogjakarta. 2003.[hal. 279-331]