BAB IV
METODE PENELITIAN. A. Jenis Penelitian
Menurut Paradigmanya, Penelitian Ini Termasuk Penelitian Kuantitatif Inferensial, Yaitu Menekankan Analisisnya Pada Data-data Angka (numerikal ) Yang Diolah Dengan Metode Statistik Dan Membentuk Kesimpulan Hasil Penelitian Pada Suatu Probabilitas Kesalahan Penolakan Hipotesis Nihil. Dengan Metoda Kuantitatif Dapat Diperoleh Signifikansi Perbedaan Atau Hubungan Antar Variabel Yang Diteliti. Umumnya Penelitian Kuantitatif Merupakan Penelitian Dengan Menggunakan Jumlah Sampel Besar.
Metode kuantitatif bisa diartikan sebagai suatu metode penelitian yang dilandaskan pada filsafat positivism, yang digunakan guna meneliti populasi atau sampel tertentu, dimana pengumpulan data menggunakan instrument penelitian dan analisis data bersifat statistik (kuantitatif) dengan tujuan menguji hipotesis yang telah ditetapkan (Sugiyono, 2012:11). Kemudian menurut Robert Donmoyer, (dalam Given, 2008 : 713), penelitian kuantitatif adalah pendekatan terhadap kajian empiris guna mengumpulkan, menganalisa, serta menampilkan data dalam bentuk angka (numerik) daripada naratif.
Penelitian kuantitatif inferensial menekankan analisanya pada data numerik dan diolah dengan metode statistik dan melakukan analisis hubungan antar variabel dengan pengujian hipotesis (Badriah, 2006:16). Dengan demikian, kesimpulan pada penelitian kuantitatif inferensial melebihi sajian data kuantitatif
dan kesimpulannya adakalanya bersifat umum.
B. Definisi, Operasionalisasi, dan Pengukuran variabel
variabel Penelitian dalam penelitian ini terdiri dari variabel terikat dan variabel bebas. Sugiyono (2008:40) mendefinisikan variabel terikat sebagai variabel yang dipengaruhi atau menjadi akibat, karena adanya variabel bebas (bebas). variabel terikat sering disebut variabel output, kriteria, konsekuen. Dalam bahasa Indonesia disebut variabel terikat. Variabel terikat (dependen variabel) adalah variabel yang memberikan reaksi atau respon jika dihubungkan dengan variabel bebas, biasa dinotasikan dengan Y. Dalam penelitian ini variabel terikatnya adalah kesulitan keuangan, dimana kategori Perusahaaan yang mengalami kesulitan keuangan dalam penelitian ini adalah sebagai berikut;
1. Perusahaan yang selama dua tahun berturut-turut tidak membagikan deviden yaitu pada tahun 2011 dan 2012. (Lusiana & Kristijati, 2003) dan 2. Perusahaan yang selama 2 tahun berturut-turut memiliki laba bersih negatif
yaitu pada tahun 2011 dan 2012. (Lusiana & Kristijati, 2003).
Sebagai kontrol juga dipilih perusahaan yang sehat pada tahun 2011-2012. Data laporan keuangan 2011-2012 digunakan sebagai pedoman penentuan apakah suatu perusahaan mengalami kesulitan keuangan atau tidak. Sedangkan data laporan keuangan tahun 2008-2010 adalah merupakan data yang akan diolah. Berdasarkan kriteria di atas, diperoleh sample sebanyak 160 perusahaan manufaktur.
Sedangkan variabel bebas menurut Sugiyono (2008 : 39) merupakan variabel yang menjadi sebab perubahannya atau timbulnya variabel terikat. Variabel ini sering disebut sebagai Variabel Stimulus, prediktor, Antecedent, Variabel Pengaruh, Variabel Perlakuan, Kausa, Treatment, Risiko, atau variabel Bebas. Dinamakan sebagai Variabel Bebas karena bebas dalam mempengaruhi variabel lain.
Operasionalisasi variabel dibutuhkan dalam menentukan indikator, jenis, serta skala dari variabel-variabel yang diteliti dalam suatu penelitian, sehingga pengujian hipotesis dengan statistik dapat dilakukan dengan benar.
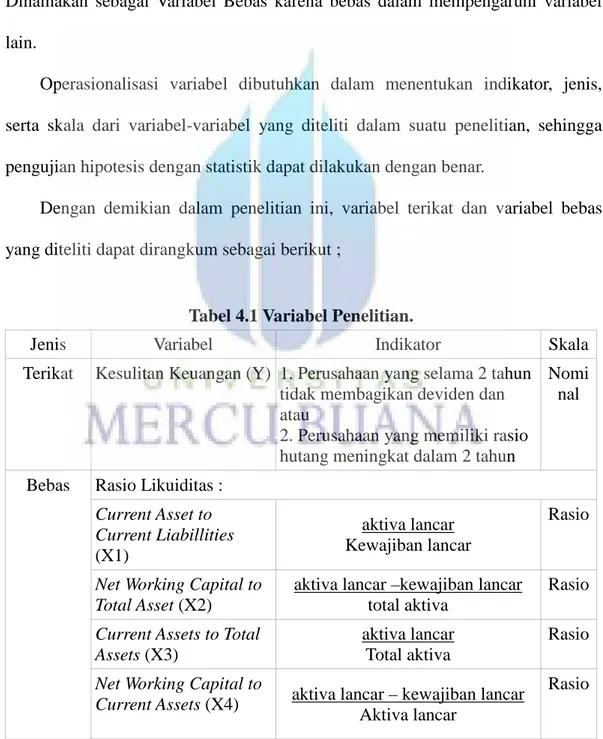
Dengan demikian dalam penelitian ini, variabel terikat dan variabel bebas yang diteliti dapat dirangkum sebagai berikut ;
Tabel 4.1 Variabel Penelitian.
Jenis Variabel Indikator Skala
Terikat Kesulitan Keuangan (Y) 1. Perusahaan yang selama 2 tahun tidak membagikan deviden dan atau
2. Perusahaan yang memiliki rasio hutang meningkat dalam 2 tahun
Nomi nal
Bebas Rasio Likuiditas : Current Asset to Current Liabillities (X1) aktiva lancar Kewajiban lancar Rasio
Net Working Capital to Total Asset (X2)
aktiva lancar –kewajiban lancar total aktiva
Rasio Current Assets to Total
Assets (X3)
aktiva lancar Total aktiva
Rasio Net Working Capital to
Current Assets (X4) aktiva lancar – kewajiban lancar Aktiva lancar
Bebas Rasio Solvabilitas : Total Debt to Equity (X5) Total Kewajiban Total Modal Rasio Long-term Debt to Equity (X6)
Kewajiban jangka panjang Total modal
Rasio Equity to Total Aktiva
(X7)
Total Modal Total Aktiva
Rasio Long Term Debt to
Total Assets (X8)
Kewajiban jangka panjang Total Aktiva
Rasio Hutang Lancar terhadap
Total Aktiva (X9)
Kewajiban lancar Total Aktiva
Rasio Bebas Rasio Profitabilitas :
Net Profit to Total Asset (X10)
Laba operasi Total Aktiva
Rasio Net Profit to Equity
(X11) Laba bersih Total modal Rasio Operating Profit Margin (X12) Laba Bersih Penjualan Rasio EBIT to Sales (X13) Laba operasi
Penjualan
Rasio EBIT to Total Assets
(X14)
Laba operasi Total aktiva
Rasio Bebas Rasio Aktivitas :
Sales to Total Assets (X15)
Penjualan Total Aktiva
Rasio Sales to Current Assets
(X16) Penjualan Aktiva lancar Rasio Working Capital Turnover (X17) Penjualan
Aktiva lancar – kewajiban lancar
Rasio Bebas Retained Earning to
Total Assets (X18)
Laba ditahan Total Aktiva
Rasio Bebas Company Size (X19) Log (total aktiva) Rasio Bebas Market value of Equity
to Book Value of Debt (X20)
((Lembar saham beredar) x (harga saham akhir tahun))/Total
kewajiban
C. Populasi, Sampel Dan Data.
Banyak ahli mendefinisikan populasi, diantaranya adalah menurut Sugiyono ( 2011:117-118) “Populasi adalah wilayah generalisasi yang terdiri atas: obyek/subyek yang mempuyai kualitas dan karakteristik tertentu yang ditetapkan oleh peneliti untuk dipelajari dan kemudian ditarik kesimpulannya”. Jadi populasi bukan hanya orang, tetapi juga obyek dan benda-benda alam yang lain. Populasi bukan sekedar jumlah yang ada pada obyek/subyek yang dipelajari, tetapi meliputi seluruh karakteristik atau sifat yang dimiliki oleh subyek atau obyek itu. Selain itu, Bugin (2011 : 111) mendifiniskan populasi penelitian sebagai “Keseluruhan (universum) dari objek penelitian yang dapat berupa manusia, hewan, tumbuh-tumbuhan, udara, gejala, nilai, peristiwa, sikap hidup, dan sebagainya, sehingga objek-objek ini dapat menjadi sumber data penelitian.” Populasi dalam penelitian ini adalah Perusahaan Manufaktur go public yang terdaftar di Bursa Efek Indonesia (BEI) pada periode 2008-2012.
Kemudian sampel dapat didefinisikan sebagai sebagian dari populasi (Sugiyono, 2010 : 215). Dalam penelitian ini, teknik pengambilan sampel yang digunakan adalah metode purposive sampling. Metode ini merupakan teknik penentuan sampel dengan pertimbangan tertentu (Sugiyono, 2012 : 68). Purposive sampling dilakukan dengan cara mengambil subjek bukan diataskan strata, random, atau daerah tetapi didasarkan atas adanya tujuan tertentu. Teknik ini biasanya dilakaukan karena adanya pertimbangan, misalnya alasan keterbatasan waktu, tenaga, dan dana sehingga tidak mengambil sampel yang besar dan jauh
(Arikunto, 2010 : 183). Adapun kriteria penentuan sample pada penelitian ini adalah berikut ;
1. Perusahaan manufaktur yang terdaftar di BEI dan mempublikasikan laporan keuangan selama periode 2008-2012.
2. Perusahaan manufaktur memiliki data laporan keuangan lengkap periode 2008-2012, terutama untuk variabel-variabel laporan keuangan yang digunakan dalam menghitung rasio-rasio keuangan dalam penelitian ini.
Jumlah perusahaan manufaktur yang terdaftar di BEI periode 2008-2012 sebanyak 166 perusahaan. Selama periode penelitian, perusahaan manufaktur yang memenuhi kriteria penentuan sampel sebanyak 160 perusahaan. Kemudian dari sampel tersebut diklasifikasikan sebanyak 15 perusahaan menagalami kesulitan keuangan dan 145 perusahaan tidak mengalami kesulitan keuangan.
Data dalam penelitian ini dibagi menjadi dua, dimana tahun 2012 dan 2011 menjadi ukuran perusahaan yang mengalami kesulitan keuangan, sedang tahun 2008-2010 menjadi model prediksi untuk 1-3 tahun sebelum kesulitan keuangan.
Data yang terkumpul dan digunakan dalam penelitian ini adalah data sekunder, yang merupakan sumber data yang tidak langsung memberikan data kepada pengumpul data. (Sugiyono, 2010 : 137). Sumber data pada penulisan berasal dari berbagai sumber jurnal, buku serta penelitian sebelumnya yang mendukung penulisan ini. Sementara sumber data yang digunakan dan diolah dalam analisis penulisan ini diambil dari buku Indonesian Capital Market Dictionary (ICMD) tahun 2008 sampai dengan tahun 2011, serta dari situs web
resmi Bursa Efek Indonesia www.idx.co.id.
Data sekunder menurut Sugiyono (2010:137), adalah ”Sumber data yang tidak langsung memberikan data kepada pengumpul data, misalnya lewat orang lain atau lewat dokumen”.
Data sekunder biasanya disajikan dalam bentuk diagram-diagram, tabel-tabel, data-data, atau topik suatu penelitian. Dalam penelitan ini, data yang diperoleh merupakan data yang memiliki hubungan langsung dengan penelitian dan bersumber dari Bursa Efek Indonesia, serta data-data lain yang diperlukan dari penelitian ini yang juga diperoleh dari hasil pencarian di internet baik mengenai jurnal, artikel, serta hasil dari penelitian-penelitan sebelumnya yang dapat digunakan sebagai perbandingan oleh penulis.
D. Teknik Pengumpulan Data
Data adalah sekumpulan informasi yang diperlukan untuk pengambilan keputusan (Kuncoro, 2002). Sedangkan Teknik pengumpulan data adalah mengamati variabel yang akan diteliti dengan metode wawancara; tes; observasi; kuosioner; dan sebagainya (Arikuntoro, 2002 : 207). Nazir Moh dalam bukunya yang berjudul Metode Penelitian mengklasifikasikan teknik pengumpulan data menjadi penelitian kepustakaan dan penelitian lapangan.
Penelitian Kepustakaan Library Research, merupakan pengumpulan data dengan cara mempelajari, mengkaji dan memahami sumber-sumber data yang ada pada beberapa buku yang terkait dalam penelitian. Kemudian penelitian
lapangan/Field Research, yaitu penelitian yang dilakukan dengan cara mendatangi langsung tempat yang menjadi objek penelitian, baik dengan cara wawancara atau pengamatan.
Dalam mengumpulkan data, peneliti melakukan penelitian lapangan dengan mengunjungi situs web resmi Bursa Efek Indonesia www.idx.co.id. Kemudian penulis juga melakukan penelitian kepustakaan dengan cara mengumpilkan data dengan memanfaatkan sumber perpustakaan untuk memperoleh data penelitian. Sehingga dapat disimpulkan, berdasarkan studi kepustakaan tersebut menggunakan literatur-literatur atau buku-buku yang relevan dengan permasalahan yang akan dibahas. (Zed 2008: 1).
E. Metode Analisis
Teknik analisis dalam tulisan ini menggunakan metode pengujian analisis diskriminan dan metode pengujian hipotesis kausal dengan menggunakan regres logistik (Logistic Regresion) sebagai alternatif jika asumsi dasar pada analisis diskriminan tidak terpenuhi.
Analisis Diskriminan merupakan suatu teknik analisa Statistika dependensi yang berguna untuk mengklasifikasikan objek beberapa kelompok. Pengelompokan dengan analisis diskriminan terjadi karena adanya pengaruh satu atau lebih variabel lain yang merupakan variabel independen. Kombinasi linier antara variabel-variabel akan membentuk suatu fungsi diskriminan (Tatham et al.,1998).
Model analisis diskriminan adalah sebuah persamaan yang menunjukkan suatu kombinasi linier dari berbagai variabel independen, dimana model dalam penelitian ini adalah berikut :
D = b0 + b1 X1 + b2 X2 + b3 X3 + ... + bk Xk Dimana:
D = skor diskriminan
B = koefisien diskriminasi atau bobot X1-Xk = variabel bebas (rasio – rasio keuangan)
Dalam analisis diskriminan, asumsi yang harus dipenuhi adalah :
1. Variabel independen harus berdistribusi normal (Multivariate normality). Jika data tidak berdistribusi normal, akan menimbulkan masalah ketepatan fungsi (model) diskriminan. Regresi logistic (logistic regression) bisa menjadi metode alternatif jika terdapat data tidak berdistribusi normal. 2. Variabel independen memiliki matriks kovarians yang relatif sama.
3. Tidak ada korelasi antar variabel independen. Jika ada korelasi yang kuat antara variabel independen, maka terjadi multikolinearitas.
4. Tidak ada data yang sangat ekstrim (outlier) pada variabel bebas. Jika terdapat data outlier dapat berakibat pada berkurangnya ketepatan klasifikasi fungsi diskriminan.
Untuk menguji normalitas data, digunakan beberapa pengujian normalitas, diantranya adalah berikut ini ;
1. Shapiro-Wilk test merupakan uji yang paling direkomendasikan oleh banyak ahli karena paling bagus dalam mendeteksi normalitas. Uji ini dikemukakan oleh Shapiro dan Wilk pada. Kelebihan dari uji ini adalah sangat efektif digunakan pada sampel sebanyak 7 s/d 50 responden, di mana uji yang lain tidak reliable pada jumlah sampel yang kecil. Namun Kelemahan dari uji ini adalah hanya efektif digunakan pada sampel kurang dari 2000. Apabila lebih dari 2000 sudah tidak reliable lagi.
2. Skewness-Kurtosis Test diperkenalkan Oleh D'Agostino dan Belanger pada tahun 1990. Bisa dikatakan uji ini merupakan uji yang paling reliable diantara yang lain, sebab akan tetap mendeteksi ketidak-normalan pada jumlah sampel berapapun, baik jumlah kecil maupun besar.
3. Kolmogorov-Smirnov test (K-S test) merupakan pengujian statistik non-parametric yang paling mendasar dan paling banyak digunakan, pertama kali diperkenalkan dalam makalahnya Andrey Nikolaevich Kolmogorov pada pada tahun 1933 yang kemudian ditabulasikan oleh Nikolai Vasilyevich Smirnov pada tahun 1948. Konsep dasar dari uji normalitas Kolmogorov-Smirnov adalah dengan membandingkan distribusi data yang akan diuji normalitasnya dengan distribusi normal baku. Distribusi normal baku adalah data yang telah ditransformasikan ke dalam bentuk Z-Score dan diasumsikan normal. Jadi uji Kolmogorov-Smirnov merupakan uji beda antara data yang diuji normalitasnya dengan data normal baku. Seperti pada uji beda biasa, apabila signifikansi di bawah 0,05 berarti
terdapat perbedaan yang signifikan, dan jika signifikansi di atas 0,05 maka tidak terjadi perbedaan yang signifikan. Penerapan uji Kolmogorov-Smirnov adalah bahwa jika signifikansi di bawah 0,05 berarti data yang akan diuji mempunyai perbedaan yang signifikan dengan data normal baku, berarti data tersebut tidak normal.
Pengujian normalitas data dengan ketiga cara di atas dilihat dengan cara melihat nilai Prob>Chi2, apabila nilainya > 0,05 maka berdistribusi normal. Namun jika distribusi data masih tidak normal, akan dilakukan transformasi data baik dengan cubic; square; identity; square root; log; 1/(square root); inverse; 1/square atau 1/cubic, yang dapat dilakukan dengan dengan aplikasi STATA.
Apabila setelah data ditransformasi namun masih tidak berdistribusi normal, maka seperti dikatakan di atas, bahwa jika asumsi dasar analisis diskriminan tidak terpenuhi (normalitas data), maka dapat dilgunakan metode regresi logistik. Sebagai alternatif, Analisis regresi logistik digunakan untuk menjelaskan hubungan antara variabel respon yang berupa data dikotomik/biner dengan variabel bebas yang berupa data berskala interval dan atau kategorik (Hosmer dan Lemeshow, 1989). Variabel dikotomik atau biner adalah variabel yang hanya mempunyai dua kategori saja, yaitu kategori yang menyatakan terjadi (Y=1) dan kategori yang menyatakan kejadian tidak terjadi (Y=0).
Regresi Logistik merupakan metode analisis statistik yang menggambarkan hubungan antara variabel bebas yang memiliki dua kategori atau lebih dengan satu
atau beberapa variabel tidak bebas. Regresi Logistik cocok digunakan untuk penelitian dimana variabel bebasnya bersifat kategori, (baik nominal maupun non metrik) dengan variabel tidak bebasnya dapat berupa kombinasi antara metrik dan non-metrik (Ghozali 2005:9).
Regresi logistik sebenarnya sama dengan analisis regresi berganda, hanya saja pada regresi logistik variabel terikatnya berupa variabel dummy (0 dan 1). Model regresi logistik menggunakan transformasi logit, dimana pada model ini, yang diregresikan adalah peluang variabel respon sama dengan 1. Model umum regresi logistik biner adalah berikut ;
P(Y=1) =π (x)=
exp β0 + β1χ1 + ….. + βpχp 1 + exp β0 + β1χ1 + ….. + βpχp
Dimana π (x) adalah peluang kejadian sukses dengan nilai probabilitas 0≤π(x)≤1 dan βj adalah nilai parameter dengan j = 1,2,...,p. π(x) merupakan fungsi yang non linear, sehingga perlu dilakukan transformasi ke dalam bentuk logit untuk memperoleh fungsi yang linear agar dapat dilihat hubungan antara variabel bebas dan variabel tidak bebas. Dengan melakukan transformasi dari logit π(x), maka didapat persamaan yang lebih sederhana, yaitu:
g(x) = In
π (x)
= (β0 + β1χ1 + ….. + βpχp
mengetahui kekuatan rasio keuangan terhadap penentuan prediksi kesulitan keuangan. Model regresi logistik yang digunakan adalah berikut :
Ln = Pt
=
(β0+ β1 Likuiditas + β2 Solvabilitas + β3 Profitabilitas +
β4 Aktivitas + β5 Laba ditahan pada total Aset +
β6 Ukuran Perusahaan+ β7 Pnilai Pasar Saham pada Nilai
Buku Hutang) 1-pt
Dimana :
Pt/ 1-pt = Probabilitas Perusahaan mengalami kesulitan keuangan t tahun sebelum β0 = Konstata
βn = Koefisien regresi variabel bebas
χ1 - χn = variabel bebas (rasio – rasio keuangan)
Pengujian hipotesis dilakukan dengan menguji rasio keuangan secara per tahun sebelum kesulitan keuangan, yaitu ;
1. Pengujian satu (1) tahun sebelum kesulitan keuangan, 2. Pengujian dua (2) tahun sebelum kesulitan keuangan, 3. Pengujian tiga (3) tahun sebelum kesulitan keuangan,
Apabila dari beberapa variabel bebas ada yang berskala nominal atau ordinal, maka variabel tersebut tidak tepat jika dimasukkan dalam model logit karena angka-angka yang digunakan untuk menyatakan tingkatan tersebut hanya sebagai identifikasi dan tidak mempunyai nilai numerik.
a) Regresi logistik tidak mengasumsikan hubungan linear antar variabel terikat dan independent
b) variabel terikat harus bersifat dikotomi (2 variabel)
c) variabel bebas tidak harus memiliki keragaman yang sama antar kelompok variabel
d) Kategori dalam variabel bebas harus terpisah satu sama lain atau bersifat eksklusif
e) Sampel yang diperlukan dalam jumlah relatif besar, minimum dibutuhkan hingga 50 sampel data untuk sebuah variabel prediktor (bebas).
Dalam penelitian ini, analisis data dilakukan dengan regresi logistik. Menurut Ghozali (2001:225), “Regresi logistik digunakan untuk menguji apakah probabilitas terjadinya variabel terikat dapat diprediksi dengan variabel bebasnya”. Teknik analisis regresi logistik tidak memerlukan asumsi normalitas data pada variabel bebasnya (Ghozali, 2001:225), serta mengabaikan heteroskedastisitas (Gujarati, 2003:597).
1. Pendekatan Maximum Likelihood
Regresi logistik membentuk persamaan atau fungsi dengan pendekatan maximum likelihood, yang memaksimalkan peluang pengklasifikasian objek yang diamati menjadi kategori yang sesuai kemudian mengubahnya menjadi koefisien regresi yang sederhana. Dua nilai yang biasa digunakan sebagai variabel terikat yang diprediksi adalah 0 dan 1 (1=berhasil, 0=gagal).
Untuk mengetahui pengaruh variabel bebas terhadap variabel tidak bebas secara bersama-sama (overall) di dalam model, dapat menggunakan Uji Likelihood rasio. Uji statistik yang digunakan adalah berikut ;
G2 = -2In
Lo
Lp
Dimana ; Lo = Maksimum Likelihood dari model reduksi (Reduced Model) atau model yang terdiri dari konstanta saja
Lp = Maksimum Likelihood dari model penuh (Full Model) atau dengan semua variabel bebas.
Statistik ini mengikuti distribusi Khi-kuadrat dengan derajad bebas p sehingga hipotesis ditolak jika p-value < α, yang berarti variabel bebas X secara bersama-sama mempengaruhi variabel tak bebas Y. Dimana Hipotesisnya adalah sebagai berikut:
a) Ho: β1 = β2 =....= βp = 0 (tidak ada pengaruh veriabel bebas secara simultan terhadap variabel tak bebas)
b) H1: minimal ada satu βj ≠ 0 (ada pengaruh paling sedikit satu veriabel bebas terhadap variabel tak bebas)
Likelihood berarti juga peluang atau probabilitas untuk hipotesis tertentu. Pada regresi logistik dengan nilai Y antara 0 dan 1, pendekatan linear tidak bisa kita gunakan. Oleh karena itu metode maximum likelihood sangat berguna dalam menentukan kecocokan model yang tepat bagi persamaan yang kita miliki.
2. Rasio Peluang (Odds ratio)
Regresi Logistik juga menghasilkan rasio peluang (odds ratio) terkait dengan nilai setiap prediktor. Odds rasio adalah ukuran risiko atau kecenderungan untuk mengalami suatu kejadian ‘terjadi‘ antara satu kategori dengan kategori lainnya, yang mana didefinisikan sebagai rasio dari odds untuk xj = 1 terhadap xj = 0. Odds ratio menyatakan risiko atau kecenderungan pengaruh observasi untuk xj = 1 adalah berapa kali lipat jika dibandingkan dengan observasi dengan xj = 0. Peluang (odds) dari suatu kejadian dapat diartikan sebagai probabilitas hasil yang muncul yang dibagi dengan probabilitas suatu kejadian 'tidak terjadi'. Dengan demikian secara umum, rasio peluang (odds ratio) merupakan sekumpulan peluang yang dibagi dengan peluang lainnya. Rasio peluang bagi prediktor diartikan sebagai jumlah relatif dimana hasil peluang meningkat (rasio peluang > 1) atau menurun (rasio peluang < 1) ketika nilai variabel prediktor meningkat sebesar 1 unit. Odds ratio dilambangkan dengan θ, didefinisikan sebagai perbandingan dua nilai odds xj = 1 dan xj = 0, dimana dapat dirumuskan sebagai berikut :
Θ =
( π(1)/(1- π(1)) ( π(0)/(1- π(0))
Seperti dikatakan sebelumnya, Regresi logisitk tidak memerlukan asumsi sebaran data normal (normalitas), heteroskedatisitas, dan autokorelasi, hal ini
dikarenakan variabel terikat pada regresi logistik berupa variabel dummy/kategori (0 dan 1), sehingga residualnya tidak memerlukan ketiga pengujian tersebut. Karena masih melibatkan variabel-variabel bebas, maka masih diperlukan untuk dilakukan pengujian multikolinearitas. Pada Regresi logisitk, pengujian multikolinearitas dapat menggunakan goodness of fit test, yang kemudian dilanjutkan dengan pengujian hipotesis (uji X2) untuk melihat variabel – variabel bebas mana saja yang berpengaruh signifikan, sehingga dapat tetap digunakan dalam penelitian, dimana kemudian, di antara variabel – variabel bebas yang signifikan tersebut, dapat dibentuk suatu matrix korelasi, dan apabila tidak terdapat variabel bebas yang saling memiliki korelasi tinggi, maka dapat dikatakan bahwa tidak terdapat gangguan multikolinearitas pada model penelitian (David W. Hosmer, 2011).
3. Uji Kelayakan Model Regresi (Goodness of Fit Test)
Dalam menguji kelayakan model regresi logistik, dapat dilihat dari nilai Chi-square dari hasil uji Homser dan Lemeshow Goodness of Fit Test. Goodness of Fit Test adalah kebaikan fit suatu parameter yang telah diestimasi pada regresi logistik, dimana pengukuran Goodness of Fit Test memberikan keseluruhan indikasi fit dari model. (Hosmer dan Lemeshow 1989, p.136).
Dasar pengambilan keputusan dari uji Hosmer dan Lemeshow Goodness of Fit Test dapat dilihat dari nilai Chi-square p-value. Jika p-value > 0,05 maka model yang di estimasikan fit dengan data, sementara bila p-value < 0,05 maka
model yang diestimasikan tidak fit dengan data.
Dalam menguji keseluruhan model regersi logistik (overall model fit) dilakukan dengan membandingkan nilai antara -2 Log Likelihood pada awal (Block Number = 0) dengan nilai -2 Log Likelihood pada akhir (Block Number = 1). Adanya pengurangan nilai antara -2 Log Likelihood awal dengan nilai -2 Log Likelihood pada langkah berikutnya menunjukkan bahwa model yang dihipotesiskan fit dengan data (Ghozali, 2001). Dengan kata lain jika terjadi penurunan nilai -2 Log Likelihood mengindikasikan bahwa model regresi tersebut adalah model regresi yang baik.Dalam menguji Model regresi logistik dipperlukan pengujian koefisian regresi yang bertujuan untuk mendefinisikan variabel bebas yang secara signifikan mempengaruhi variabel tidak bebas.