Dalam bab ini akan diberikan contoh-contoh dan studi kasus, untuk menjelaskan funsgi dan perintah-perintah R yang digunakan. Bagian contoh kasus dasar
merupakan studi kasus yang menggunakan perintah penulisan kode R yang sederhana, sedangkan untuk bagian kasus lanjut adalah studi kasus yang menggunakan perintah penulisan kode R yang lebih kompleks.
A. Contoh kasus dasar
A.1. Rerata (mean), variansi dan standar deviasi
Sebagai contoh, data mengenai banyaknya mobil merek X (dalam satuan ribu) yang terjual di Indonesia pada periode tahun 1990 sampai 1999. yakni
74 122 235 111 292 111 211 133 156 7
selanjutnya, kita ingin menghitung mean, variansi dan standar deviasi data tersebut. Berikut adalah penulisan perintah R
> mobilx = c(74, 122, 235, 111, 292, 111, 211, 133, 156, 79) > mean(mobilx) [1] 152.4 > var(mobilx) [1] 5113.378 > std(mobilx)
Error: couldn't find function "std"
> sqrt(var(mobilx)) [1] 71.50789
> sqrt(sum((mobilx - mean(mobilx))^2/(length(mobilx )-1))) [1] 71.50789
Contoh & Studi Kasus R
BAB
VI
Pada proses penghitungan nilai standar deviasi (std), tertulis pesan error, dimana tidak dikenali fungsi/perintah std, namun error tersebut dapat kita tangani, mengingat standar deviasi adalah kuadrat variansi sehingga baris terakhir merupakan rumus/fungsi menghitung standar deviasi dari data mobil X yang ada. Dimana rumus matematis standar deviasi adalah:
SD(X) =
∑
= − − n i i x x n 1 2 ) ( 1 1R juga menyediakan fungsi untuk mengitung standar deviasi untuk data yang sederhana yaitu:
> std = function(x) sqrt(var(x)) > std(variabel random)
A.2. Data univariat
Data dibagi menjadi tiga jenis utama, yaitu: kategori, diskrit dan kontinu. Data kategori
Contoh, suatu survey yang menanyakan responden apakah mereka merokok atau tidak. Datanya adalah:
Yes, No, No, Yes, Yes
Penulisan data tersebut dalam R adalah sebagai berikut: > x=c("Yes","No","No","Yes","Yes")
dan dengan menggunakan perintah table(x)akan membentuk tabel frekuensi data kategorik:
> table(x)
> x
No Yes 2 3
Data kategori biasa digunakan untuk mengklasifikasikan data ke dalam bentuk levelisasi atau faktor. Sebagai contoh, data perokok bisa merupakan bagian dari survey mengenai kesehatan pelajar. R akan secara otomatis mengenali suatu faktor atau tidak. Untuk membuat faktor digunakan perintah factor atau as.factor . Misalkan contoh berikut:
> x=c("Yes","No","No","Yes","Yes")
> x # mencetak nilai X [1] "Yes" "No" "No" "Yes" "Yes"
> factor(x) # mencetak nilai dalam factor(x) [1] Yes No No Yes Yes
Levels: No Yes # notice levels are printed.
A.3. Diagram batang (Bar chart)
Diagram batang (bar chart) menggambarkan suatu bagian data baik proporsinya maupun frekuensinya.
Contoh: Suatu survey pada suatu kelompok yang terdiri dari 25 orang mendata tentang tingkat kesukaan terhadap suatu produk sabun cuci. Kategorinya adalah (1) untuk merek A, (2) untuk merek B, (3) untuk merek C dan (4) untuk merek D. Data hasil survey adalah sebagai berikut:
3 4 1 1 3 4 3 3 1 3 2 1 2 1 2 3 2 3 1 1 1 1 4 3 1
Data tersebut akan dibuat bar chart untuk proporsi dan frekuensi berdasarkan kategori. Pertama, kita menggunakan fungsi scan() untuk menuliskan dan membaca data tersebut:
> sabun = scan()
1: 3 4 1 1 3 4 3 3 1 3 2 1 2 1 2 3 2 3 1 1 1 1 4 3 1 26:
Read 25 items
> barplot(sabun) # masih salah
> barplot(table(sabun)) # Benar, gunakan summarized data. > barplot(table(sabun)/length(sabun)) # dibagi dengan n untuk
proporsi dan barplotnya berturut-turut sesuai dengan penulisan R di atas:
Gambar 6.2: Barplot 2 data sabun [ > barplot(table(sabun) ]
Gambar 6.3: Barplot 3 data sabun
A.4. Pie chart
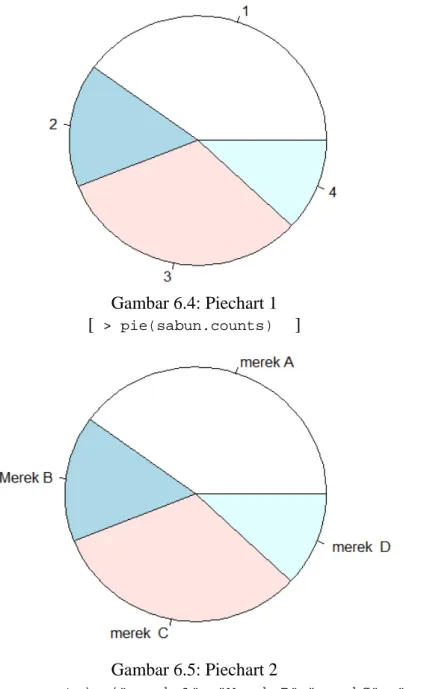
Dengan menggunakan data yang sama seperti sebelumnya (data sabun) akan kita bentuk grafik pie chart, dengan perintah penulisan R sebagai berikut:
> sabun.counts = table(sabun) # menyimpan hasil table > pie(sabun.counts) # pie pertama
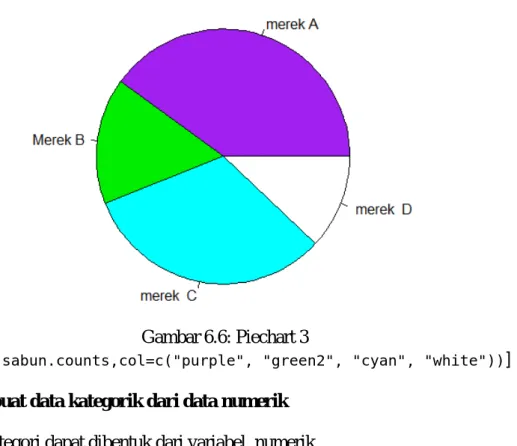
> names(sabun.counts) = c("merek A ", "merek B","merek C", "merek D") # memberi nama
> pie(sabun.counts) # mencetak nama
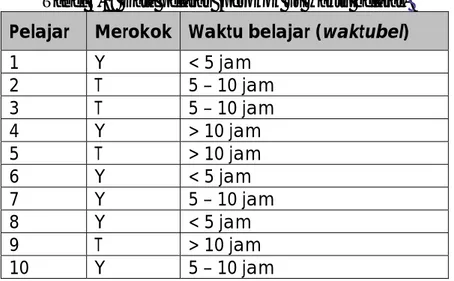
> pie(sabun.counts, col = c("purple","green2", "cyan", "white")) # memberikan warna
Grafik pie-chart dari masing-masing perintah tersebut adalah sebagai berikut:
Gambar 6.4: Piechart 1
[ > pie(sabun.counts) ]
Gambar 6.5: Piechart 2
Gambar 6.6: Piechart 3
[ > pie(sabun.counts,col=c("purple", "green2", "cyan", "white"))] A.5. Membuat data kategorik dari data numerik
Variabel kategori dapat dibentuk dari variabel numerik.
Sebagai contoh, suatu gaji dapat dikategorikan dalam 0 – 1 juta, 1 – 5 juta, lebih dari 5 juta. Untuk membuat kategori tersebut, R menyediakan fungsi cut() dan fungsi table() . Misalkan daftar gaji adalah sebagai berikut:
12 0.4 5 2 50 8 3 1 4 0.25 dan akan dibagi menjadi kategori [0,1],[1,5],[5,50]
Untuk menggunakan perintah cut, kita memerlukan cut point (titik potong). Dalam kasus ini 0, 1, 5, dan 50 (= max(gaji)). Berikut adalah penulisan sintaknya:
> gaji = c(12, .4, 5, 2, 50, 8, 3, 1, 4, .25) # memasukkan data > kat = cut(gaji,breaks=c(0,1,5,max(gaji))) # menentukan breaks > kat # menampilkan nilai
[1] (5,50] (0,1] (1,5] (1,5] (5,50] (5,50] (1,5] (0,1] (1,5] (0,1] Levels: (0,1] (1,5] (5,50] > table(kat) # pengelompokkan kat (0,1] (1,5] (5,50] 3 4 3
> levels(gaji) = c("miskin","kaya","sangat kaya") # mengganti label > table(gaji)
> gaji
miskin kaya sangat kaya 3 4 3
Catatan: Fungsi cut() dapat digunakan untuk menjawab pertanyaan “ pada interval yang mana suatu bilangan/data termasuk”, dimana outputnya adalah interval (sebagai suatu faktor). Dengan demikian perlu menggunakan fungsi table() untuk mensumarize hasil dari fungsi cut
B. Contoh kasus lanjut B.1. Distribusi binomial
Misalkan untuk 500 sampel berdistribusi binomial dari 20 kali percobaan, dengan probabilitas sukses sebesar 40%.
Pertama-tama anda menggunakan metode rbinom dan melihat summarynya dengan fungsi summary():
> x <- rbinom(500,20,.4) > summary(x)
Min. 1st Qu. Median Mean 3d Qu. Max. 3.000 6.000 8.000 8.066 10.000 14.000
B.2. Matrik dan Aljabar Linear
R dapat juga digunakan untuk menghitung operasi pada matriks dan memecahkan solusi perkalian matriks. Misalkan kita mempunyai elemen matriks M: 35,14,11,1,4,11,3,0,12,9,38,4,2,5,12,2. > M <- c(35,14,11,1,4,11,3,0,12,9,38,4,2,5,12,2) # dalam bentuk matrik baris > M [1] 35 14 11 1 4 11 3 0 12 9 38 4 2 5 12 2 > dim(M) NULL
Pada penulisan di atas, M tidak mempunyai dimensi, untuk itu kita perlu menambahkan dengan metode dim:
> dim(M) <- c(4, 4) > M [,1] [,2] [,3] [,4] [1,] 35 4 12 2 [2,] 14 11 9 5 [3,] 11 3 38 12 [4,] 1 0 4 2 > dim(M) [1] 4 4
Sedangkan untuk mendapatkan transpose matriks M, dapat dituliskan perintah: > Mt <- t(M)
[,1] [,2] [,3] [,4] [1,] 35 14 11 1 [2,] 4 11 3 0 [3,] 12 9 38 4 [4,] 2 5 12 2
Untuk mendapatkan perkalian matriks, dua penulisan/statement akan menghasilkan masing-masing nilai yang berbeda:
> M*M [,1] [,2] [,3] [,4] [1,] 1225 16 144 4 [2,] 196 121 81 25 [3,] 121 9 1444 144 [4,] 1 0 16 4 > M%*%M [,1] [,2] [,3] [,4] [1,] 1415 220 920 238 [2,] 748 204 629 201 [3,] 857 191 1651 517 [4,] 81 16 172 54
Untuk mencari solusi dari matrik M , kita memerlukan fungsi solve() dengan penulisan sebagai berikut:
> solve(M) [,1] [,2] [,3] [,4] [1,] 0.034811530 -0.007095344 -0.02039911 0.1053215 [2,] -0.036807095 0.096674058 0.02793792 -0.3725055 [3,] -0.004545455 -0.018181818 0.07272727 -0.3863636 [4,] -0.008314856 0.039911308 -0.13525499 1.2200665 > solve(M)%*%M [,1] [,2] [,3] [,4] [1,] 1.000000e+00 -1.734723e-17 1.665335e-16 8.326673e-17 [2,] 1.665335e-16 1.000000e+00 0.000000e+00 0.000000e+00 [3,] -2.220446e-16 -2.775558e-17 1.000000e+00 -2.220446e-16 [4,] 2.220446e-16 5.551115e-17 8.881784e-16 1.000000e+00
Untuk memecahkan persamaan linear, misal untuk matrik A dan vector kolom B sedemikian hingga, b = Ax, adalah:
> b <- c(1, 2, 3, 4) > (x <- solve(M, b))
[1] 0.3807095 -1.2496674 -1.3681818 4.5460089
menghasilkan nilai dengan x1 = 0.3807095, x2 = -1.2496674, x3 = -1.3681818, x4 =
B.3. Bekerja dengan data kategori bivariate
Perintah table akan menyimpulkan (summarize)data bivariate dengan cara yang sama pada data univariat.
Misalkan survey pada pelajar mengenai apakah pelajar yang merokok, lebih sedikit belajarnya. Datanya sebagai berikut:
Tabel 6.1: Data pelajar (perokok vs waktu belajar)
Pelajar Merokok Waktu belajar (waktubel)
1 Y < 5 jam 2 T 5 – 10 jam 3 T 5 – 10 jam 4 Y > 10 jam 5 T > 10 jam 6 Y < 5 jam 7 Y 5 – 10 jam 8 Y < 5 jam 9 T > 10 jam 10 Y 5 – 10 jam
Untuk menulis data Tabel 6.1 di atas, kita buat menjadi dua vektor, kemudian gunakan fungsi table.Penulisannya adalah:
> merokok = c("Y", "T", "T", "Y", "T", "Y", "Y", "Y", "T","Y") > waktubel = c(1,2,2,3,3,1,2,1,3,2) > table(merokok,waktubel) waktubel merokok 1 2 3 T 0 2 2 Y 3 2 1
Dari hasil R di atas, sepertinya terlihat adanya suatu hubungan.
Langkah yang cukup baik jika kita mempunyai total margin dan proporsi data.
Sebagai contoh, berapa proporsi perokok yang belajar selama 5 jam atau kurang dari 5 jam?
Kita dapat menghitungnya secara manual dari 3/(3+2+1) = ½., namun bagaimana menulisnya di R?. Fungsi yang digunakan untuk menghitung proporsinya adalah prop.table. Berikut penulisan lengkap di R:
> tmp=table(merokok,waktubel) # menyimpan data ke table > old.digits = options("digits") # menyimpan bilangan digit > options(digits=3) # mencetak 3 posisi desiman
> prop.table(tmp,1) # jumlah setiap baris sama dengan 1 waktubel
merokok 1 2 3 T 0.000 0.500 0.500 Y 0.500 0.333 0.167
> prop.table(tmp,2) # jumlah setiap kolom sama dengan 1 waktubel merokok 1 2 3 T 0.000 0.500 0.667 Y 1.000 0.500 0.333 > prop.table(tmp) waktubel merokok 1 2 3 T 0.0 0.2 0.2 Y 0.3 0.2 0.1
> options(digits=old.digits) # restore the number of digits
B.4. Bekerja dengan data bivariate: data kategorik vs data numerik
Misalkan anda mempunyai data numerik untuk suatu kategori. Sebagai contoh, untuk data pengujian efek suatu obat, yang terdiri dari dua kelompok, kelompok kendali dan kelompok eksperimen, seperti berikut:
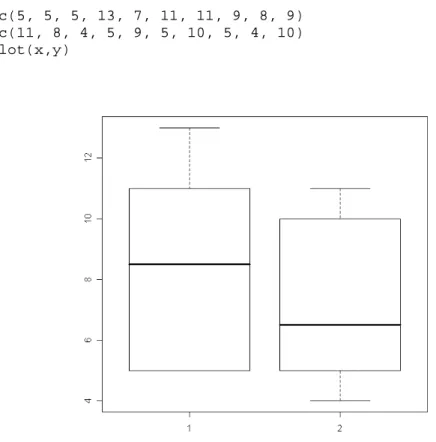
eksperimen: 5 5 5 13 7 11 11 9 8 9 kendali: 11 8 4 5 9 5 10 5 4 10
Pertanyaannya adalah, bagaimana cara untuk menampilkan kedua kelompok tersebut bersamaan. Pertanyaan tersebut dapat terjawab dengan menggunakan perintah boxplot. Penulisan dalam R adalah sebagai berikut:
> x = c(5, 5, 5, 13, 7, 11, 11, 9, 8, 9) > y = c(11, 8, 4, 5, 9, 5, 10, 5, 4, 10) > boxplot(x,y)
Dari perbandingan boxplot di atas, terlihat variabel y (kelompok kendali, dengan label 2) sepertinya lebih kecil dibanding variabel x (kelompok eksperimen, dengan label 1).
Soal Latihan Bab VI
1. Buatlah histogram dan barplot untuk dataset yang built-in di R, yakni dataset
Titanic, USAccDeaths, dan USArrest. Data manakah yang skew? Dan data mana yang mempunyai outlier, dan data manakah yang simetris?
2. Anggap, diketahui jumlah kegagalan tipe O dalam penerbangan pertama pesawat ruang angkasa Challenger yakni:
0 1 0 NA 0 0 0 0 0 1 1 1 0 0 3 0 0 0 0 0 2 0 1
(NA berarti not available(missing value): yakni peralatannya rusak) . Buatlah tabel untuk kategori yang mungkin, Carilah nilai mean. (Sebelumnya anda harus mencoba perintah mean(x, na.rm=TRUE) untuk menghindari nilai NA, atau lihat pembahasan mengenai x[!is.na(x) pada manual R.)
3. Misalkan, pada suatu sekolah akan dilakukan evaluasi belajar siswa oleh guru dengan skala Leichert 1-5. Anggap diketahui jawaban untuk 3 pertanyaan (Tanya) pertama ditunjukkan pada tabel berikut
Masukkan data untuk Tanya1 dan Tanya2 menggunakan c(), scan(), read.table atau data.entry()
a. Buatlah tabel hasil Tanya1 dan Tanya1 secara terpisah b. Buatlah tabel kontingensi Tanya1 dan Tanya2
c. Buatlah barplot Tanya2 dan Tanya3
Siswa Tanya 1 Tanya 2 Tanya 3 1 3 5 1 2 3 2 3 3 3 5 1 4 4 5 1 5 3 2 1 6 4 2 3 7 3 5 1 8 4 5 1 9 3 4 1 10 4 2 1
4. Data mammals yang terintegrasi (built-in) dalam R terdiri dari variabel body weight vs. brain weight. Gunakan perintah cor untuk mendapatkan koefisien korelasi Pearson-Spearman. Apakah kedua variabel tersebut similar? Buatlah plot data menggunakan perintah plot , dan lihatlah apakah kedua variabel tersebut terlihat similar?. Jika anda tidak yakin dan terjawab dengan plot tersebut, maka lakukan plot logaritma (log) setiap variabel dan perhatikan apakah sudah terjadi perbedaan!
5. Data ToothGrowth yang built-in dalam R adalah hasil studi yang mengukur pertumbuhan gigi sebagai suatu fungsi dari jumlah konsumsi Vitamin C. Sumber Vitamin C berasal dari jus jeruk (orange juice) atau suplemen vitamin (vitamin supplement). Scatterplot dari variabel dosage vs length adalah sebagai berikut:
> data(“ToothGrowth”) > attach(ToothGrowth)
> plot(len ~ dose, pch=as.numeric(aupp)) ## klik mouse untuk menambahkan legend
> tmp = levels(aupp) # menyimpan untuk sementara > legend(locator(1), legend=tmp, pch=1:length(tmp)) > detach(ToothGrowth)
Dari plot yang dihasilkan, apakah yang dapat anda simpulkan dari kedua variabel tersebut?
![Gambar 6.2: Barplot 2 data sabun [ > barplot(table(sabun) ]](https://thumb-ap.123doks.com/thumbv2/123dok/2509309.2768508/4.892.256.662.128.1060/gambar-barplot-data-sabun-gt-barplot-table-sabun.webp)