BAB II
HIDDEN MARKOV MODEL
2.1. Pendahuluan
Proses Stokastik dapat dipandang sebagai suatu barisan peubah acak { ,X t Tt ∈ } dengan T adalah parameter indeks dan X menyatakan keadaan pada saat t t. Himpunan dari semua nilai state X yang mungkin dinamakan ruang keadaan dan t biasa ditulis ΩXt. Pada umumnya T adalah bilangan bulat, di mana pada nilai negatif adlah pengamatan yang lalu. Di sini akan diambil T adalah himpunan bilangan bulat non negatif, karena kasus data yang diamati bukan berdasarkan waktu tapi lokasi.
Selanjutnya, proses stokastik { ,X t Tt ∈ } disebut suatu proses Markov jika untuk t T∈ berlaku
1 0 0 1 1 1 1 1 1 1
( t , , , t t ) ( t t t )
P X + = j X =i X =i K X − =i− =P X + = j X − =i− (2.1) , dengan i i0 1, , ,K it−1, ,i j∈ΩXt dan P X( t+1= j Xt = menyatakan peluang bersyarat i)
suatu keadaan Xt+1 jika diberikan keadaan X , artinya peluang suatu proses berada di t
keadaan j pada waktu t+1 hanya bergantung pada proses yang berada di keadaan i pada waktu t. Proses Markov secara umum sudah dipaparkan dengan jelas oleh Karlin dan Taylor (1975), Gillespie (1992), dan Rogers dan William (1994).
Rantai Markov adalah suatu proses Markov dengan ruang keadaan yang bernilai diskrit. Rantai markov dengan parameter diskrit adalah proses markov yang memiliki ruang keadaan diskrit dengan parameter T =(1, 2, , )K n . Teori lebih dalam tentang rantai Markov bisa dipelajari pada Ross (1996)
Dalam praktek, realisasi dari rantai Markov umumnya tidak dapat diobservasi secara langsung, karena itu disebut model Markov tersembunyi. State pada model ini terbagi menjadi 2, yaitu observasi state dan state tersembunyi, sehingga model ini disebut juga model bivariat. Contoh dalam bioinformatika, jika diberikan barisan DNA, ACCAATGGATAGAC..., maka barisan DNA tersebut merupakan observasi state, dan hidden statenya bisa bermacam-macam, tergantung dari informasi apa yang ingin diperoleh. Seperti pada kasus Hongki (2004), unsur penjajaran DNA bisa
yang terobservasi tersebut berasal dari keadaan yang cocok, sisipan, atau hapusan. Contoh lain dalam bioinformatika yang bisa dijadikan sebagai keadaan yang tersembunyi adalah {intron, ekson, UTR} dan {coding region, non-coding region} untuk MMT orde-1. Untuk analisis struktur orde-2, yang tersembunyi adalah {CpG-island, non-island} dan {α-helix, β-sheet, loop}.
2.2. Definisi MMT
Model MMT merupakan 5-tuple (5 pasangan di mana masing-masing anggota bisa berupa himpunan atau ukuran) sebagai berikut:
1) Banyaknya elemen state yang tidak terobservasi (tersembunyi) pada model, N. Dianggap X sebagai keadaan yang terjadi pada saat t. Sebagai contoh, perhatikan t kasus di atas. Di sini N = 3, karena terdapat keadaan cocok, sisipan, dan hapusan. Untuk kasus ini bisa ditulis X = i, i = 1 (cocok), 2 (sisipan), dan 3 (hapusan). N t
dapat berupa konstanta ataupun variabel acak. Hal ini sangat bergantung pada si pengamat. Dalam pembahasan di sini N adalah suatu konstanta.
2) Matrikas peluang transisiA={ }aij dimana aij adalah elemen dari A yang merupakan peluang bersyarat dari keadaan pada saat t+1, jika diketahui keadaan X pada saat t, atau aij =P X( t+1 = j Xt =i) ;1≤i j N, ≤ . Karena itu A berukuran NxN. Perlu diingat bahwa aij ≥0 untuk setiap 1≤ ,i j N≤ dan
1 1 N ij j a = =
∑
untuksetiap 1≤ ≤i N, artinya jumlah elemen setiap baris adalah 1.
Untuk kasus barisan DNA dengan keadaan seperti pada 1), akan ada matriks
transisi A ukuran 3x3, 11 12 13 21 22 23 31 32 33 1 2 3 a a a A a a a a a a ⎛ ⎞ ⎜ ⎟ = ⎜ ⎟ ⎜ ⎟ ⎝ ⎠ .
3) Banyaknya elemen keadaan yang terobservasi, M. M umumnya tetap, ditentukan si pengamat, tetapi M juga bisa dimisalkan variabel acak. Misalkan variabel acak untuk keadaan ini adalah K, k =1,2,...,M. Untuk kasus barisan DNA, banyaknya elemen hanya 4, masing-masing A, C, G, dan T, sehingga k = 1,2,3,4. Yang menjadi permasalahan di sini adalah realisasi dari 4 elemen tersebut sepanjang T
4) Distribusi peluang observasi pada saat t berada pada state i (disebut juga peluang emisi), dan dinotasikan B ={bi(k)}, dimana
( ) ( ) ,1 ,1
k
i i t t
b =b k =P O =k X =i ≤ ≤i N ≤ ≤k M , dan K adalah observasi pada waktu ke-t berada (bernilai) k. jadi B berukuran NxM, dan seperti di matriks transisi A, jumlah elemen setiap baris adalah 1. Secara teoritis, realisasi Ot biasa
ditulis Ot = vk, 1≤vk≤M. Hal ini dikarenakan untuk masing-masing k, vk
mempunyai nilai realisasi yang berbeda.
5) State awal π0 ={ ( )}π0 i dimana π0( )i =P X( 0 =i) ,1≤ ≤i N . Untuk kasus di atas,
0(1) match, (2)0 insertion, dan (3)0 deletion
π = π = π = .
Istilah tuple di atas berkaitan dengan himpunan dan ukuran. Di sini himpunannya diwakili oleh variabel acak. Dari definisi di atas, cukup jelas bahwa dari nilai 5-tuple (N, M, A, B, dan π ), terdapat 3 komponen adalah ukuran (probabilitas), 0 yaitu A, B, dan π . Akibatnya MMT lebih dikenal dengan notasi 0 λ=( , , )A B π0 dengan A berukuran NxN dan B berukuran MxN.
Berikut adalah ilustrasi gambar untuk model MMT
2.3. Masalah Utama dalam MMT
Secara garis besar ada 3 masalah utama yang harus diselesaikan ketika seorang peneliti menerapkan MMT di dunia nyata. Tetapi sebelumnya, perlu dipahami dengan baik 2 istilah, yaitu:
1. Orde dari suatu rantai Markov, misal rantai Markov orde-1.
Di sini, pada waktu sembarang t, peluang kejadian pada satu waktu berikutnya hanya bergantung pada waktu sekarang. Lihat penjelasan untuk
O1 X1 X2 O2 X3
…
XT OT…
O3persamaan (2.1). Sedangkan dalam rantai Markov orde-2, keadaan yang tersembunyi memiliki syarat di dua waktu sebelumnya.
2. Independensi/Kebebasan
Distribusi peluang dari suatu barisan observasi O=
{
O O1, 2,...,OT}
pada suatu waktu t hanya bergantung pada barisan keadaan X ={
X X1, 2,...,XT}
pada waktu yang sama. Dari asumsi ini, dapat didefinisikan bahwa:0 , , 1 ( , A B ) T ( t t, ) t P O X λ π P O X λ = =
∏
(2.2) Bukti:(
)
(
) (
)
(
) (
)
(
)
(
)
1 1 1 1 1 1 1 1 2 2 1 1 1 1 1 1 2 2 1 1 3 3 1 1 1 1 1 1 ( , ) , | , , , ,| , , , , | , , , ,| , , , | , , , , | , , , ,| , , , ,| T T T T T T T T T T T T T T T T T T T T T T P O X P O o O o X x X x P O o X x X x P O o O o X x X x P O o X x X x P O o X x X x P O o O o X x X x P O o X x X x P O o λ λ λ λ λ λ λ λ = = = = = = = = = = = = = = = = = = = = = = = = = = = = = = K K K K K K K K K L K K(
)
(
1 1 1 1)
(
)
1 1 1 , , , ,| , ,| , ( , ) ( ) T T T T T T T t t t X x X x P O o X x P O o X x P O X terbukti λ λ λ λ = = = = = = = = =∏
K KPersamaan (2.2) sangat berguna dalam MMT, karena semua algoritma yang digunakan untuk membangun MMT memakai sifat ini. Hal ini dikarenakan di dalam persamaan tersebut kita menghitung peluang barisan observasi diketahui model, dan karena dalam MMT melibatkan keadaan tersembunyi, maka penentuan peluangnya juga bersyarat terhadap keadaan tersembunyi tersebut.
Selanjutnya, berikut ini adalah tiga masalah utama yang harus diselesaikan dalam membangun MMT, yaitu:
1. Diberikan barisan observasi O o o= 1 2K dan model oT λ =( , , )A B π0 . Bagaimana menghitung P
(
O|λ)
, yaitu peluang observasi jika diberikan model. Pertanyaan ini sangat berguna jika kita bermaksud untuk memilih salah satu yang terbaik yang sesuai dengan barisan observasinya di antara beberapa model yang ada.2. Diberikan barisan observasi O o o= 1 2K dan model oT λ =( , , )A B π0 . Bagaimana menentukan barisan state X =x x1 2K yang optimal. Kesulitannya adalah xT bagaimana kriteria barisan state dikatakan barisan yang optimal.
3. Bagaimana menyesuaikan model parameter λ=( , , )A Bπ0 untuk memaksimalkan
(
O|λ)
P . Dengan kata lain, bagaimana mengestimasi parameter λ=( , , )A Bπ0 . Dengan melihat kasus pada barisan DNA, misal terdapat barisan protein ACAATG, maka masalah yang pertama adalah menghitung peluang terjadinya sususan barisan DNA terobservasi, bersyarat λ ditetapkan/diketahui atau
( )
P ACAATGλ . Masalah yang kedua adalah mencari barisan keadaan tersembunyi yang optimal yang elemen barisannya terdiri atas cocok, sisipan, dan hapusan dari barisan observasi yang diberikan.
Masalah pertama dapat diselesaikan dengan menggunakan algoritma maju mundur dan masalah yang kedua dapat diselesaikan dengan menggunakan algoritma Viterbi. Sedangkan untuk masalah yang terakhir, algoritma Baum-Welch dapat digunakan untuk mencari solusinya.
2.4. Algoritma Maju Mundur
Algoritma ini adalah proses iterasi yang didasarkan pada perhitungan peluang bersyarat melalui sifat-sifat pada peluang. Dengan menggunakan definisi peluang bersyarat, sudah bisa dihitung P
(
O|λ)
, tetapi operasi perhitungan yang dibutuhkan akan bertambah banyak, naik secara eksponensial, seiring dengan bertambah panjangnya barisan observasinya. Untuk menghitung P(
O|λ)
diperlukan 2 .T NT kalioperasi, dengan T
N adalah kemungkinan keadaan tersembunyi yang terjadi, jika barisan observasi adalah sepanjang T dan state sebanyak N.
Ambil kasus N=3 dan M=2, dimana keadaan tersembunyinya adalah cocok (1), sisipan (2), dan hapusan (3) dan barisan DNA berukuran 2, yaitu observasi AG. Untuk kemudahan penulisan, misalkan A = 1 dan G = 3 dan ambil,
0 0.7 0.1 0.2 0.6 0.3 0.1 0.4 0.2 0.4 A ⎛ ⎞ ⎜ ⎟ = ⎜ ⎟ ⎜ ⎟ ⎝ ⎠ , 0 0.6 0.2 0.1 0.1 0.2 0.4 0.3 0.1 0.1 0.1 0.5 0.3 B ⎛ ⎞ ⎜ ⎟ = ⎜ ⎟ ⎜ ⎟ ⎝ ⎠ , dan 0 0.5 0.3 0.2 π ⎛ ⎞ ⎜ ⎟ = ⎜ ⎟ ⎜ ⎟ ⎝ ⎠
Berdasarkan barisan observasi dan keadaan tersembunyi di atas, terlihat bahwa terdapat 9 kemungkinan yang terjadi untuk menghitung P O( 1=1,O2 =3λ0):
1) P O
(
1=1,O2 =3 dan X1 =1,X2 =1λ)
= P O(
2 =3,X2 =1O1=1,X1=1,λ)
.P O(
1=1,X1=1,λ)
= ⎣⎡P O( 2 =3 X2 =1, ). (λ P X2 =1 X1 =1, ) .λ ⎦⎤ P O(
1 =1X1=1,λ)
. (P X1=1, )λ = (0.1) . (0.7) . (0.6) . (0.5) = 0.021 2) P O(
1=1,O2 =3 dan X1 =1,X2 =2λ)
= P O(
2 =3,X2 =2O1 =1,X1=1,λ)
.P O(
1 =1,X1=1,λ)
= ⎣⎡P O( 2 =3 X2 =2, ). (λ P X2 =2 X1=1, ) .λ ⎦⎤ P O(
1=1X1 =1,λ)
. (P X1=1, )λ = (0.3) . (0.1) . (0.6) . (0.5) = 0.009 3) P O(
1=1,O2 =3 dan X1 =1,X2 =3λ)
= (0.5) . (0.2) . (0.6) . (0.5) = 0.030 4) P O(
1=1,O2 =3 dan X1 =2,X2 =1λ)
= (0.1) . (0.6) . (0.2) . (0.3) = 0.0036 5) P O(
1=1,O2 =3 dan X1 =2,X2 =2λ)
= (0.3) . (0.3) . (0.2) . (0.3) = 0.0054 6) P O(
1=1,O2 =3 dan X1 =2,X2 =3λ)
= (0.5) . (0.1) . (0.2) . (0.3) = 0.003 7) P O(
1=1,O2 =3 dan X1 =3,X2 =1λ)
= (0.1) . (0.4) . (0.1) . (0.2) = 0.0008 8) P O(
1=1,O2 =3 dan X1 =3,X2 =2λ)
= (0.3) . (0.2) . (0.1) . (0.2) = 0.0012 9) P O(
1=1,O2 =3 dan X1 =3,X2 =3λ)
= (0.5) . (0.4) . (0.1) . (0.2) = 0.004Berdasarkan 9 nilai di atas, bisa dihitung saat ini dan besok sesuai bersyarat λ atauP O( 1=1,O2 =3 )λ dengan cara menjumlahkan 9 nilai di atas,
1 2 ( 1, 3 ) P O = O = λ =
(
1 2 1 2)
, 1, 3 dan , ,1 , 3 i j P O = O = X =i X = j λ ≤i j≤∑
= 0.021 + 0.009 + 0.030 + 0.0036 + 0.0054 + 0.003 + 0.0008 + 0.0012 + 0.004 = 0.078Perhatikan pada 1), 4), 7), 8), dan 9), terlihat bahwa peluangnya sangat kecil. Hal ini wajar karena peluang emisinya sebesar 0.1, lebih kecil dibanding yang lain. Kesimpulannya, jika nilai elemen matriks emisi sangat kecil, maka peluang yang dihasilkan juga kecil. Hal ini juga berlaku untuk matriks transisi, seperti yang ditunjukkan oleh 2) dan 6), hanya tidak sekecil 7) karena di 2) dan 6) peluang pada matriks emisi dan peluang awalnya masih cukup besar.
Pada dasarnya kita bisa memperluas perumusan ini untuk barisan observasi T dengan mengambil jumlah dari peluang masing-masing kemungkinan yang terjadi. Untuk lebih jelasnya lihat persamaan (2.3) di bawah ini:
1 ( ,..., ) ( ) ( , ) N X X X P O λ P O X λ = =
∑
(2.3)Pada kasus di atas bisa terlihat bahwa kita butuh setidaknya 2 .T NT= 2.2.32 =
36 kali operasi. Hal ini bisa dilihat dari ke-9 nilai, untuk setiap kejadian yang mungkin membutuhkan 4 kali operasi.
Terlihat metode di atas tidak efisien, jadi diperlukan suatu metode baru yang dapat mereduksi operasi perhitunganP
(
O|λ)
. Kemudian diperkenalkan algoritma maju dan mundur. Algoritma ini menyimpan nilai yang terhitung pada iterasi yang sebelumya, sehingga paling banyak butuh N T2 operasi. Perbedaannya mungkin tidakakan terlalu berbeda secara signifikan dengan metode sebelumnya untuk kasus di atas, karena panjang barisan observasinya hanya 2. Akan tetapi algoritma ini akan sangat berguna dan efisien ketika panjang barisan observasinya cukup besar. Umumnya, T jauh lebih besar dari N, jadi pengurangan ini sangat membantu pemakai MMT.
Di bawah ini dapat dipelajari algoritma maju. Definisikan ( )αt i sebagai variabel maju dimana
(
1 2)
( ) ,
t i P O O O Xt t i
α = K = λ (2.4)
dengan kata lain, ( )αt i menyatakan total peluang observasi berakhir di state X pada i saat t dimana t =1, 2,...,T jika diberikan barisan observasi O O O . Secara umum, 1 2... t algoritma maju ini memuat 3 kegiatan (Rabiner 1989):
1. Inisialisasi
( )
( ) ( )
1 i 0 i b Oi 1 α =π untuk i= K1, ,N (2.5) 2. Induksi( )
( )
(
1)
1 1 + = + ⎪⎭ ⎪ ⎬ ⎫ ⎪⎩ ⎪ ⎨ ⎧ =∑
N j t i ij t t j α i a b O α untuk j= K1, ,N dan t=1, ,KT−1 (2.6) 3. Terminasi(
)
∑
( )
= = N i T i | O P 1 α λ (2.7)Pada tahap inisialisasi (t=1), peluang berada di state ke i tidak lain adalah peluang awalnya, π0( )i , sehingga berdasarkan (2.4) dengan t=1 diperoleh (2.5),
(
)
(
) (
)
(
)
(
)
( )
1 1 1 1 1 1 0 1 1 0 1 1 0 1 ( ) , | , , ( ) | , , karena ( ) | , ( ) i i i i i i i P O X x P O X x P X x i P O X x i P O X x i b O α λ λ λ π λ π λ π = = = = = = = = = = untuk i=1 K,2, ,NPada tahap induksi, akan dihitung nilai α pada saat t>1, pembuktiannya dilakukan dengan memanfatkan 2 asumsi MMT,
( )
(
)
(
)
(
)
(
)
1 1 2 1 1 1 2 1 1 1 1 2 1 1 1 1 1 2 1 1 1 , ,..., , , | , ,..., , | , ( | ) , ,..., | , ( | , ) ( | ) , ,..., , | ( | , ) t t t t t t t t t t t t t t t t t j P O O O O X j P O O O O X j P X j P O O O X j P O X j P X j P O O O X j P O X j α λ λ λ λ λ λ λ λ + + + + + + + + + + + + + = = = = = = = = = = = =(
)
(
)
(
)
1 2 1 1 1 2 1 1 1 1 2 1 1 2 1 1 1 2 , ,..., , | ( ) , ,..., , , ( ) , ,..., , ( | , ,..., , , ) ( ) , ,.. t t j t N t t t j t i N t t t t t j t i P O O O X j b O P O O O X i X j λ b O P O O O X i λ P X j O O O X i λ b O P O O λ + + + + = + + = = = ⎡ ⎤ =⎢ = = ⎥ ⎣ ⎦ ⎡ ⎤ =⎢ = = = ⎥ ⎣ ⎦ =∑
∑
(
)
1 1 1 1 1 ., , ( | , ) ( ) ( ) ( ) N t t t t j t i N t ij j t i O X i λ P X j X i λ b O i a b O α + + = + = ⎡ = = = ⎤ ⎢ ⎥ ⎣ ⎦ ⎡ ⎤ = ⎢⎣ ⎥⎦∑
∑
dengan j= K1, ,N dan t=1, ,KT−1Sebagai contoh, misalkan hanya ada 2 observasi (t=2), maka untuk menghitungα2
( )
j , bisa dilihat langkah-langkahnya sebagai berikut:α2
( )
j =P O O X(
1 2, 2 = j λ)
(
) (
)
(
)
1 2 1 2 1 2 1 2 1 2 1 2 , 1, , 2, , , P O O X X j P O O X X j P O O X N X j λ λ λ = = = + = = + + = = K(
1 2 1 2)
1 , , N i P O O X i X jλ = =∑
= =(
1 2 1 2) (
1 2)
1 | , , , , N i P O O X i X j λ P X i X j λ = =∑
= = = =(
1 2 1 2) (
2 1) (
1)
1 | , , | , , N i P O O X i X j λ P X j X i λ P X i λ = =∑
= = = = =( )
(
)
0 1 2 1 2 1 | , , N ij i i a P O O X i X j π λ = =∑
= =( )
( ) ( )
0 1 2 1 N ij i j i i a b O b O π = =∑
( )
( )
∑
= = N i j ijb O a i 1 2 1 α( )
( )
⎪⎭ ⎪ ⎬ ⎫ ⎪⎩ ⎪ ⎨ ⎧ =∑
= N i ij j O i a b 1 1 2 αJadi dengan induktif dapat ditulis secara umum sebagai berikut
( )
( )
( )
1 1 1 + = + =⎩⎨⎧∑ ⎭⎬⎫ j t N i t ij t j α i a b O α untuk j= K1, ,N dan t=1, ,K T−1 (2.8) Maka(
)
=∑( )
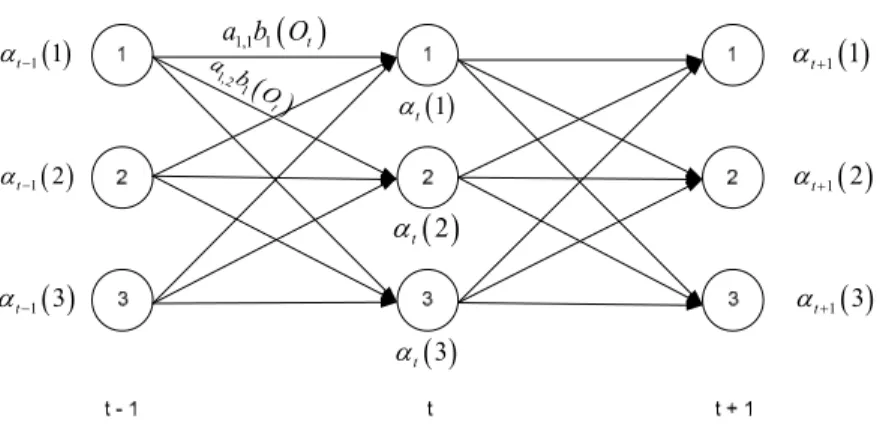
= N i T i O P 1 |λ α (2.9)Maksud dari (2.9) adalah menjumlahkan semua peluang gabungan dari observasi dan keadaan tersembunyi bersyarat model sehingga diperoleh peluang marjinal dari observasi tersebut. Sebagai ilustrasi dari algoritma maju, perhatikan gambar berikut,
( ) 1 1 t α− ( ) 1 2 t α− ( ) 1 3 t α− ( )3 t α ( )2 t α ( )1 t α ( ) 1 1 t α+ ( ) 1 2 t α+ ( ) 1 3 t α+ ( ) 1,1 1 t a b O ( ) 1,2 1 t a b O
Gambar 2. Ilustrasi Algoritma maju
Sebagai contoh, ambil kasus pada metode sebelumnya (9 nilai peluang) yang hasilnya selanjutnya dibandingkan. Akan dihitung P O( 1=1,O2 =3 )λ dari suatu barisan observasi AG. Perhatikan kembali matriks matriks transisi, matriks emisi, dan nilai awal pada hal. 15,
Pada tahap inisialisasi, tentu ada 3 buah α , masing-masing untuk cocok, sisipan, dan hapusan,
( )
( ) ( )
1 1 1 b1 1 α =π = (0.5) . (0.6) = 0.3( )
( ) ( )
1 2 2 b2 1 α =π = (0.3) . (0.2) = 0.06( )
( ) ( )
1 3 3 b3 1 α =π = (0.2) . (0.1) = 0.02Selanjutnya, pada tahap induksi akan dihitung α2
( )
j dengan 1≤ ≤j 3.( )
2 1 α = 3 1( )
1 1(
2)
1 3 i i i a b O α = ⎧ ⎫ = ⎨ ⎬ ⎩∑
⎭ ={
(0.3) . (0.7) + (0.06) . (0.6) + (0.02) . (0.4) . (0.1)}
= 0.0254( )
2 2 α = 3 1( )
2 2(
2)
1 3 i i i a b O α = ⎧ ⎫ = ⎨ ⎬ ⎩∑
⎭ ={
(0.3) . (0.1) + (0.06) . (0.3) + (0.02) . (0.2) . (0.3)}
= 0.0156( )
2 3 α = 3 1( )
3 3(
2)
1 3 i i i a b O α = ⎧ ⎫ = ⎨ ⎬ ⎩∑
⎭ ={
(0.3) . (0.2) + (0.06) . (0.1) + (0.02) . (0.4) . (0.5)}
= 0.037Terakhir adalah tahap terminasi dengan cara menghitung P O( 1=1,O2 =3 )λ dengan menjumlahkan α2
( )
j dengan 1≤ ≤j 3, 1 2 ( 1, 3 ) P O = O = λ = 3 2( )
1 i i α =∑
= 0.0254 + 0.0156 + 0.037 = 0.078Berdasarkan contoh ini, terlihat dua metode memiliki hasil yang sama, namun banyaknya operasi perhitungan tidak sama. Terlihat bahwa algoritma maju lebih efisien daripada metode definisi peluang bersyarat. Selanjutnya, akan dibahas metode mundur beserta contohnya di kasus yang sama. Hal ini dilakukan untuk mengetahui apakah metode maju dan mundur menghasilkan peluang yang sama. Di bawah ini adalah metode mundur.
Algoritma ini langkahnya serupa dengan algoritma maju. Di sini inisialisasi didasarkan pada seluruh observasi yang ada, jadi algoritma ini mengganti O O1 2K Ot pada persamaan (2.4) dengan O Ot+1 t+2KOT. Di sini pemakai berpikir seperti akan menaksir ke depan. Pandang variabel mundur,
( ) (
λ)
βt i =P Ot+1Ot+2KOT |Xt =i, (2.10)
Algoritma mundur selengkapnya dapat dilihat di bawah ini: 1. Inisialisasi
( )
i =1 T β , untuk i=1,K,N (2.11) 2. Induksi βt( )
i 1 1 1 ( ) ( ) N j t t ij j b O+ β+ j a = =∑
, untuk t =T−1,T −2,K,1, i=1,K,N (2.12) 3. Terminasi
(
)
0 1( )
1 | N i(1) ( ) i P O λ b π i β i = =∑
(2.13)Pada tahap inisialisasi, diambil βT
( )
i =1 karena i adalah state final, dan bernilai nol untuk i yang lain. Untuk tahap induksi, pembuktiannya mirip dengan algoritma maju. Untuk lebih jelasnya, langkah-langkah pembuktiannya bisa dilihat di bawah ini:( )
(
)
(
)
(
) (
)
(
)
1 2 1 2 1 1 1 2 1 2 1 1 1 1 2 1 1 , ,..., , , ,..., , , ,..., , , , ,..., , , , ,..., t t t T t N t t T t t j N t t T t t t T t t j N t t t T t j i P O O O X i P O O O X j X i P O O O X j X i P O O X j X i P O X j P O O X j β λ λ λ λ λ + + + + + = + + + + + = + + + + = = = = = = = = = = = = = =∑
∑
∑
(
) (
)
(
) (
) (
)
(
)
(
)
1 1 1 2 1 1 1 1 1 1 1 1 1 1 1 , , , , ,..., , , , ( ) , ( ) ( ) t t t N t t t T t t t j N t t t t t j N j t t ij j X i P X j X i P O X j P O O X j P X j X i P O X j j P X j X i b O j a λ λ λ λ λ λ β λ β + + + + + + = + + + + = + + = = = = = = = = = = = = = =∑
∑
∑
untuk 1t=T −1,T−2,K, , i=1,K,NSebagai contoh, kita ambil kasus yang sama dengan kasus pada algoritma maju untuk menghitung P O( 1=1,O2 =3 )λ . Pada tahap inisialisasi, β2
( )
i = untuk i 1 = 1, 2, 3. Selanjutnya, di tahap induksi akan dihitung β1( )
i dengan i = 1, 2, 3,( )
1 1 β = 3 1 2 1 (3) ( ) j j j a b β j =∑
= (0.7) . (0.1) . 1 + (0.1) . (0.3) . 1 + (0.2) . (0.5) . 1 = 0.2( )
1 2 β = 3 2 2 1 (3) ( ) j j j a b β j =∑
= (0.6) . (0.1) . 1 + (0.3) . (0.3) . 1 + (0.1) . (0.5) . 1 = 0.2( )
1 3 β = 3 3 2 1 (3) ( ) j j j a b β j =∑
= (0.4) . (0.1) . 1 + (0.2) . (0.3) . 1 + (0.4) . (0.5) . 1 = 0.3Untuk memulai induksi, dibandingkan dengan algoritma maju di mana proporsi α didominasi oleh keadaan cocok dan hapusan, di sini proporsiβ untuk masing-masing keadaan hampir sama. Jadi pada λ yang sama tidak ada keterkaitan nilai awal α1 dan β1.
Pada tahap terminasi, akan dihitung P O( 1=1,O2 =3 )λ dengan P O( 1=1,O2 =3 )λ = 3 1 1 (1) ( ) i i i b π β i =
∑
= (0.6) . (0.5) . (0.2) + (0.2) . (0.3) . (0.2) + (0.1) . (0.2) . (0.3) = 0.06 + 0.012 + 0.006 = 0.078Berdasarkan contoh kasus di atas, terlihat bahwa perhitungan melalui algoritma maju dan mundur akan menghasilkan nilai peluang yang sama. Tapi kesimpulan ini tidak selalu benar. Jika elemen-elemen peluang transisi dan emisi berupa bilangan rasional, seperti contoh di atas, maka algoritma maju dan mundur akan memberikan hasil yang sama. Sebaliknya, jika matriks tersebut mengandung satu atau lebih bilangan irasional, maka metode maju dan mundur akan memberikan hasil yang berbeda. Dengan kata lain, jika peluang transisi dan emisi ditaksir dari frekuensi relatif, metode maju dan mundur yang dihasilkan sering kali berbeda.
Variabel mundur bisa juga dikombinasikan dengan variabel maju untuk menghitung P O
( )
λ seperti yang tampak di bawah ini:(
1,..., T, t)
P O O X =i λ = P O
(
1,...,O XT t =i,λ)
P X( t =i, )λ= P O
(
1,...,O Xt t =i,λ) (
P Ot+1,...,O XT t =i,λ)
P X( t =i, )λ= αt( ) ( )i βt i (2.14)
( )
1 ( ) ( ) N t t i P Oλ α i β i = =∑
(2.15) 2.5. Algoritma ViterbiSetelah mempelajari algoritma maju dan mundur untuk menghitung P O
( )
λ ,akan dilanjutkan untuk menyelesaikan masalah kedua dalam membangun MMT, yaitu jika diberikan barisan observasi O o o= 1 2K dan model oT λ=
(
A,B,π)
, bagaimana menentukan barisan hidden state X =x x1 2K yang optimal. Salah satu metode yang xT sering digunakan adalah dengan algoritma Viterbi.Definisikan,
( )
(
)
1, 2, , 1 1 2 1 2 1 max , , t t i X X X P O O O X Xt Xt Xt i δ λ − − = = K K L (2.16)Berikut ini adalah algoritma lengkap untuk Viterbi: 1. Inisialisasi
( )
( )
1 i 0( )i b Oi 1 δ =π , 1≤i≤N (2.17)( )
0 1 i = ψ (2.18) 2. Induksi{
1}
1 ( ) ( ) max ( ) t j b Oj t i N aij t i δ δ− ≤ ≤ = , 2≤t ≤T dan (2.19)( )
{
1( )
}
1 arg max t ij t i N j a i ψ δ− ≤ ≤ = , 2≤t ≤T dan 1≤ j≤N (2.20) 3. Terminasi( )
{
i}
max P T N i * δ ≤ ≤ = 1 (2.21)( )
{
i}
max arg q T N i * T δ ≤ ≤ = 1 (2.22) 4. Penjajagan Mundur( )
* t t * t q q =ψ +1 +1 , 1t =T−1,T−2,L, (2.23) Pada tahap inisialisasi (t = 1),( )
(
)
1 i P X1 i O, 1 δ = =(
1| 1) (
1)
P O X i P X i = = =( )
1 0( ) i b O π i =Pada tahap induksi, ( ) t j δ =
(
)
1, 2, , 1 1 1 1 max , , t t t t X X X− P O O X X − X jλ = K K L =(
)
(
)
{
}
1, 2, , 1 1 1 1 1 1 1 1 1 max , , , , , , t t t t t t t t X X X− P O O O− X X− X j λ P O O− X X − X j λ = = K K L K L ={
(
)
(
)
}
1, 2, , 1 1 1 1 1 max , , , , t t t t t t X X X− P O X j λ P O O− X X− X j λ = = K K L =(
)
{
(
)
}
1, 2, , 21 1 1 1 2 1 , max max , , , , t t t X X X i N t t t t P O X j λ P O O X X X i X j λ − ≤ ≤ − − − = = = K K L ={
(
)
(
)
}
1, 2, , 21 1 1 1 1 2 1 ( ) max max , , , t j t X X X i N t t t t t b O P X j X i P O O X X X i λ − ≤ ≤ − − − − = = = K K L ={
(
)
(
)
}
1 2 2 1 1 1 1 2 1 1 , , , ( ) max max , , , t j t i N t t X X X t t t b O P X j X i P O O X X X i λ − − − − − ≤ ≤ = = K K L = ={
(
1)
1}
1 ( ) max ( ) j t i N t t t b O P X j X− i δ− i ≤ ≤ = = ={
1}
1 ( ) max ( ) j t i N ij t b O a δ− i ≤ ≤Sebagai contoh, ambil kasus untuk barisan protein dengan observasi AG sama seperti pada kasus-kasus sebelumnya. Berdasarkan algoritma Viterbi, diperoleh:
1. Inisialisasi
( )
1 1 δ = π0(1)b1( )
1 = (0.5) . (0.6) = 0.3( )
1 2 δ = π0(2)b2( )
1 = (0.3) . (0.2) = 0.06( )
1 3 δ = π0(3)b3( )
1 = (0.2) . (0.1) = 0.02 2. Induksi 2(1) δ = 1{
1 1}
1 3 (3) max i ( ) i b a δ i ≤ ≤ = (0.1) . max{(0.7) . (0.3),(0.6) . (0.06),(0.4) . (0.02)} = (0.1) . (0.7) . (0.3) = 0.0212(2) δ = 2
{
2 1}
1 3 (3) max i ( ) i b a δ i ≤ ≤ = (0.3) . max{(0.1) . (0.3),(0.3) . (0.06),(0.2) . (0.02)} = (0.3) . (0.1) . (0.3) = 0.009 2(2) ψ = 1 2(3) δ = 3{
3 1}
1 3 (3) max i ( ) i b a δ i ≤ ≤ = (0.5) . max{(0.2) . (0.3),(0.1) . (0.06),(0.4) . (0.02)} = (0.5) . (0.2) . (0.3) = 0.03 2(3) ψ = 1 3. Terminasi P = *{
( )
}
2 1 3 max i δ i ≤ ≤ = max{
δ2( ) ( ) ( )
1 ,δ2 2 ,δ2 3}
= max{0.021, 0.009, 0.03} = 0.03 * 2 q ={
2( )
}
1 3 arg max i i δ ≤ ≤ = 3 4. Penjajagan Mundur * 1 q =( )
* 2 q2 ψ = ψ2( )
3 = 1Berdasarkan hasil algoritma Viterbi di atas, dapat disimpulkan bahwa barisan hidden state yang optimal adalah x1=cocok dan x3 =hapusan.
2.6. Algoritma Baum-Welch
Untuk mengatasi masalah ketiga dalam MMT, biasanya digunakan algoritma Baum-Welch. Algoritma Baum-Welch digunakan untuk mengestimasi 3 parameter MMT sehingga terbentuk model baru λˆ ˆ ˆ ˆ( , , )A Bπ di mana P O( λˆ)≥P O( λ). Prosedur ini diulang terus menerus sampai proses konvergen. Permasalahan yang muncul adalah bagaimana menentukan nilai awal π0 agar barisan taksiran tersebut konvergen dengan cepat, sehingga iterasi yang dilakukan efisien. Pemilihan nilai awal
ini perlu dilakukan dengan hati-hati, karena hasil dari taksiran parameter MMT sangat dipengaruhi oleh nilai awal ini.
Algoritma Baum-Welch merupakan kasus khusus dari algoritma EM (Ekspektasi Maksimum). Algoritma EM merupakan algoritma yang dipakai untuk mempelajari model-model probabilistik dalam suatu kasus yang melibatkan keadaan yang tersembunyi (Rabiner 1989). Lebih khusus, algoritma ini merupakan prosedur iteratif untuk menghitung penaksir Maksimum-likelihood, L
( )
λ , yang diterapkan pada data tidak lengkap. Algoritma EM memiliki 2 prosedur berurutan yang dilakukan secara berulang secara terpadu. 2 prosedur tersebut adalah:1. E-step : menentukan ekspektasi bersyarat E
[
logP(
O,X |λ)
]
2. M-step : memaksimumkan ekspektasi bersyarat tersebut terhadap λ
Dalam kasus MMT, data lengkap adalah informasi mengenai keadaan Xt sama
baiknya dengan observasi Ot untuk setiap t. Jadi data tidak lengkapnya adalah hanya
observasi Ot itu sendiri. Fungsi likelihood dari data tak lengkap adalah P
(
O|λ)
danfungsi likelihood dari data lengkap adalah P
(
O, X |λ)
. Pada E-step, data yang “hilang/tersembunyi” ditaksir melalui data yang terobservasi dan estimasi parameter model. Peluangnya di-log-kan untuk mempermudah perhitungan (G. F. Larrahondo, S. Bridges, Eric A. H., 2005). Untuk peluang yang sangat kecil, kekonvergenan akan lebih cepat tercapai dan membutuhkan batas ambang yang juga sangat kecil. Untuk menghindari hal-hal ini, maka peluang perlu di-log-kan. Dengan kata lain, dalam algoritma EM, yang akan diestimasi adalah(
)
[
logPO,X |λ]
E (2.24)
Berdasarkan definisi ekspektasi, persamaan (2.24) dapat ditulis sebagai berikut,
(
| , 0)
log(
(
, |)
)
x
P X O λ P O x λ
∑
(2.25)dengan λ0 merupakan taksiran awal dari parameter λ . Berdasarkan asumsi kebebasan bersyarat, maka diperoleh
(
)
0 1( )
1 , | t t t T x x x t t P O X λ π a − b O = =∏
(2.26)(
)
(
)
(
)
(
)
( )
1 0 0 0 0 1 0 1 , , | log , | log , | log t t t T x x x x t T x t x t Q P O x P O x a P O x b O λ λ λ π λ λ − = = ⎛ ⎞ = + ⎜ ⎟ ⎝ ⎠ ⎛ ⎞ + ⎜ ⎟ ⎝ ⎠∑
∑
∑
∑
∑
(2.27)Selanjutnya perhatikan bagian pertama pada persamaan (2.27),
(
0)
0(
0 0)
0 1 , | log N , | log ( ) x i P O x λ π P O X i λ π i = = =∑
∑
(2.28)dengan menggunakan multiplier Langrange dengan syarat bahwa 0
1 ( ) 1 N i i π = =
∑
, diperoleh(
0 0)
0 0 1 1 0 , | log ( ) ( ) 1 0 ( ) N N i i P O X i i i i λ π η π π = = ⎛ ⎞ ∂ = + ⎛ − ⎞ = ⎜ ⎜ ⎟⎟ ∂ ⎝∑
⎝∑
⎠⎠ maka(
0 0)
0 , | 0 ( ) P O X i i λ η π = + =(
0 0)
0 , | ( )i P O X i λ π η = = − (2.29)(
0 0)
0 1 1 , | ( ) N N i i P O X i i λ π η = = = = −∑
∑
(
0 0)
1 1 1 N , | i P O X i λ η = = −∑
=(
0 0)
1 , | N i P O X i η λ = = −∑
= (2.30) sedangkan,(
)
(
) (
)
(
0)
1 0 0 0 0 1 0 0 | , | , | , λ λ λ λ O P i X P i X O P i X O P N i N i = = = = = ∑ = ∑ =dari persamaan (2.29) dan (2.30) maka diperoleh,
(
)
(
)
(
)
0 0 0 0 0 0 , | , | ( ) | P O X i P O X i i P O λ λ π η λ = = = − = (2.31)Berikutnya adalah untuk bagian kedua dari persamaan (2.27) adalah
(
)
⎟ ⎠ ⎞ ⎜ ⎝ ⎛ ∑ = ∑ T − t x x xP O,x|λ0 1loga t 1 t (2.32)Dengan menggunakan multiplier Langrange dengan syarat 1
1 =
∑ =
N
(
0)
1 1 1 , | T log x xt t N ij 1 0 x t j ij P O x a a a λ − η = = ⎛ ⎛ ⎞⎞ ∂ ⎛ ⎞+ − = ⎜ ⎜ ⎟ ⎜ ⎟⎟ ⎜ ⎟ ∂ ⎝∑
⎝∑
⎠ ⎝∑
⎠⎠ maka(
1 0)
1 1 1 1 1 , , | log t t 1 0 N N T N t t x x ij i j t j ij P O X i X j a a a − λ − η = = = = ⎛ ⎛ ⎞⎞ ∂ = = ⎛ ⎞+ − = ⎜ ⎜ ⎟ ⎜ ⎟⎟ ⎜ ⎟ ∂ ⎝∑∑
⎝∑
⎠ ⎝∑
⎠⎠(
1 0)
1 1 1 1 log , , | 1 0 N N T N ij t t ij i j t j ij a P O X i X j a a = = = − λ η = ⎛ ⎛ ⎞⎞ ∂ = = + − = ⎜ ⎜ ⎟⎟ ⎜ ⎟ ∂ ⎝∑∑∑
⎝∑
⎠⎠(
1 0)
1 , , | 0 T t t t ij P O X i X j a λ η − = = = + =∑
atau(
1 0)
1 , , | T t t t ij P O X i X j a λ η − = = == −
∑
, terlihat bahwa aij masih bergatung pada η , untuk itu dicari nilai η dengan menjumlahkan aij untuk semua j, diperoleh(
1 0)
1 1 1 , , | T t t N N t ij j j P O X i X j a λ η − = = = = = = −∑
∑
∑
atau(
1 0)
1 1 , , | N T t t j t P O X i X j η − λ = = = −∑∑
= = , mengingat(
, t 1 , t | 0)
(
, t 1 | t , 0) (
t , 0)
P O X− =i X = j λ =P O X− =i X = j λ P X = j λ , maka(
1 0) (
0)
1 1 , | , , T N t t t t j P O X i X j P X j η − λ λ = = = −∑∑
= = = atau(
1 0)
1 , | T t t P O X i η − λ = = −∑
=Selanjutnya η disubtitusi ke aij di atas, sehingga diperoleh
(
)
(
)
∑ ∑ = − = − = = = = T t t T t t t ij i X O P j X i X O P a 1 1 0 1 1 0 | , | , , λ λ (2.33) Selanjutnya, perhatikan bagian ketiga pada persamaan (2.27), yaitu(
)
( )
∑ ∑ ⎟ ⎠ ⎞ ⎜ ⎝ ⎛ = x T t bx ot x O P t 1 0 log | , λ( )
(
0)
( )
( )
1 1 1 , | log 1 0 N T K t i t i i t j i P O X i b o b j b j = λ = η = ⎛ ⎛ ⎞⎞ ∂ = ⎛ ⎞+ − = ⎜ ⎜ ⎟ ⎜ ⎟⎟ ⎜ ⎟ ∂ ⎝∑
⎝∑
⎠ ⎝∑
⎠⎠ atau( )
( ) (
0)
( )
1 1 1 1 log , | 1 0 N N T K i t j i j i t j i b j P O X i b j b j = = = λ δ η = ⎛ ⎛ ⎞⎞ ∂ = + − = ⎜ ⎜ ⎟⎟ ⎜ ⎟ ∂ ⎝∑∑∑
⎝∑
⎠⎠ dengan ⎩ ⎨ ⎧ = = lainnya j ot j , 0 , 1 δSetelah diturunkan diperoleh,
(
)
( )
0 1 1 , | 0 N T t j i t i P O X i b j λ δ η = = = + =∑∑
atau( )
1 1(
0)
, | N T t j i t i P O X i b j λ δ η = = = = −∑∑
(2.34)( )
1 1(
0)
1 1 , | N T t j K K i t i j j P O X i b j λ δ η = = = = = = −∑∑
∑
∑
(
0)
(
0)
1 1 1 1 1 , | , | K N T N T t j t j i t i t P O X i P O X i η λ δ λ = = = = = = −∑∑∑
= =∑∑
=dengan mensubstitusikan η pada persamaan (2.34), diperoleh,
( )
(
)
(
)
(
)
(
)
∑ ∑ ∑ ∑ ∑ ∑ = = = = = = = = = = = = T t t T t t j N i T t t N i T t t j i i X O P i X O P i X O P i X O P j b 1 0 1 0 1 1 0 1 1 0 | , | , | , | , λ δ λ λ δ λ (2.35)Algoritma Baum-Welch juga dikenal sebagai algoritma Maju-Mundur dengan variabel maju dan mundur adalah sebagai berikut:
(
)
( )
(
11 22)
( ) , , | t t t t t t T t i P O O O X i i P O O O X i α λ β + + λ ⎧ = = ⎪ ⎨ = = ⎪⎩ K K (2.36)Kemudian didefinisikan variabel baru
(
1)
( , ) , ,
t i j P Xt i Xt j O
ξ = = + = λ (2.37)
Dengan menggunakan definisi peluang bersyarat dan aturan Bayes, maka persamaan (2.37) berubah menjadi
( , ) t i j ξ = P X
(
t =i X, t+1= j O,λ)
=(
)
( )
1 , , t t P X i X j O P O λ λ + = = =(
) (
) (
)
(
)
( )
1 2 t, t t 1 t t 1 t 1 t 2 T, t 1 | P O O O X i P X j X i P O X j P O O X j P O λ λ λ + + + + + = = = = = K K =( )
1 1 ( ) ( ) ( ) t i a b Oij j t t j P O α β λ + + (2.38) dengan P O( )
λ = 1 ( ) ( ) N t t i i i α β =∑
= 1 1 1 1 1 ( ) ( ) ( ) N N t ij j t t i j i a b O j α β − + + = =∑∑
.Dari ( , )ξt i j yang diketahui, bisa dihitung peluang berada di state i pada saat t, ( )γt i , dengan menjumlahkan atas j,
γt( )i = 1 ( , ) N t j i j ξ =
∑
(2.39)Dihitung ekspektasi banyaknya transisi dari state i ke state j, sebut saja dengan ( , )i j
τ , dengan menjumlahkan atas t, 1 ( , ) T t( , ) t i j i j τ ξ = =
∑
(2.40)Kemudian dihitung ekspektasi banyaknya yang berpindah dari state i, tulis dengan ( )i
τ , dengan menjumlahkan atas t dari 1 sampai T,
1 1 1 ( ) T t( ) T N t( , ) t t j i i i j τ γ ξ = = = =
∑
=∑∑
(2.41)Dengan menghubungkan antara persamaan (2.31) dengan (2.39), maka ˆπi bisa berbentuk: πˆ ( )0 i =
(
)
(
0 0)
0 , | | P O X i P O λ λ = = P X(
0 =i O,λ0)
= 1(
0 1)
1 , , N j P X i X j O λ − = = =∑
= 1 0 1 ( , ) N j i j ξ − =
∑
= γ0( )i (2.42)Kemudian ˆA a= ˆij bisa juga diubah dalam bentuk lain dengan menghubungkan persamaan (2.33), (2.40), dan (2.41): aˆij =
(
)
(
)
1 1 1 1 , , | , | T t t t T t t P O X i X j P O X i λ λ − = − = = = =∑
∑
=(
)
(
)
1 1 0 1 0 , , | , | T t t t T t t P O X i X j P O X i λ λ − + = − = = = =∑
∑
=(
)
(
)
1 1 0 1 0 0 , | , ( ) | , ( ) T t t t T t t P X i X j O P O P X i O P O λ λ λ λ − + = − = = = =∑
∑
=(
)
(
)
1 1 0 1 0 0 , | , | , T t t t T t t P X i X j O P X i O λ λ − + = − = = = =∑
∑
= ( , ) ( ) i j i τ τ (2.43)Terakhir, B b jˆ = ˆi( ) bisa ditulis dalam bentuk yang lebih sederhana dengan melihat persamaan (2.35), (2.39), dan (2.41): ˆ ( )b j = i
(
)
(
)
1 1 , | , | T t j t T t t P O X i P O X i λ δ λ = = = =∑
∑
=(
)
(
)
1 1 | , | , T t j t T t t P X i O P X i O λ δ λ = = = =∑
∑
= 1, 1 ( ) ( ) t T t t O j T t t j j γ γ = = =
∑
∑
(2.44)Sebagai contoh, kita tinjau kembali kasus barisan protein AG yang pernah dibahas pada bagian-bagian sebelumnya,
1 ˆ (1,1) ξ = 1(1) 11 1(3) (1)2 ( ) a b P O α β λ = (0.3) . (0.7) . (0.1) . (1) 0.078 = 0.269 1 ˆ (1,2) ξ = 1(1) 12 2(3) (2)2 ( ) a b P O α β λ = (0.3) . (0.1) . (0.3) . (1) 0.078 = 0.115 1 ˆ (1,3) ξ = 1(1) 13 3(3) (3)2 ( ) a b P O α β λ = (0.3) . (0.2) . (0.5) . (1) 0.078 = 0.385 1 ˆ (2,1) ξ = 1(2) 21 1(3) (1)2 ( ) a b P O α β λ = (0.06) . (0.6) . (0.1) . (1) 0.078 = 0.046
sama seperti di atas, dan berturut-turut diperoleh ξˆ (2,2) 0.0691 = , ξˆ (2,3) 0.0391 = ,
1 ˆ (3,1) 0.011 ξ = , ξˆ (3,2) 0.0151 = , dan ξˆ (3,3) 0.0511 = . 1 ˆ (1) γ = 3 1 0 ˆ (1, ) j j ξ =
∑
= 0.269 + 0.115 + 0.385 = 0.769 1 ˆ (2) γ = 3 1 0 ˆ (2, ) j j ξ =∑
= 0.046 + 0.069 + 0.039 = 0.154 1 ˆ (3) γ = 3 1 0 ˆ (3, ) j j ξ =∑
= 0.011 + 0.015 + 0.051 = 0.077 Karena hanya ada 2 observasi, maka 2 1 11 ˆ ˆ ˆ(1) t(1) (1) t τ − γ γ = =
∑
= = 0.769, τˆ(2)=γˆ1(2)= 0.154, dan τˆ(3)=γˆ1(3) = 0.077. Nilai τˆ( , )i j = ξˆ ( , )1 i j untuk 1≤i j, ≤3.Dari hasil perhitungan di atas, dapat kita estimasi 3 parameter MMT,
1 0 1 1 ˆ (1) 0.769 ˆ ˆ ( ) (2) 0.154 ˆ (3) 0.077 i γ π γ γ ⎛ ⎞ ⎛ ⎞ ⎜ ⎟ ⎜ ⎟ =⎜ ⎟ ⎜= ⎟ ⎜ ⎟ ⎜ ⎟ ⎝ ⎠ ⎝ ⎠
ˆ(1,1) ˆ(1, 2) ˆ(1,3) 0.269 0.115 0.385 ˆ(1) ˆ(1) ˆ(1) 0.769 0.769 0.769 ˆ(2,1) ˆ(2, 2) ˆ(2,3) 0.046 0.069 0.039 ˆ ˆ(2) ˆ(2) ˆ(2) 0.154 0.154 0.154 0.011 ˆ(3,1) ˆ(3, 2) ˆ(3,3) 0 ˆ(3) ˆ(3) ˆ(3) ij a τ τ τ τ τ τ τ τ τ τ τ τ τ τ τ τ τ τ ⎛ ⎞ ⎜ ⎟ ⎜ ⎟ ⎜ ⎟ =⎜ ⎟= ⎜ ⎟ ⎜ ⎟ ⎜ ⎟ ⎜ ⎟ ⎝ ⎠ 0.35 0.15 0.5 0.3 0.45 0.25 0.14 0.2 0.66 0.015 0.051 .077 0.077 0.077 ⎛ ⎞ ⎜ ⎟ ⎛ ⎞ ⎜ ⎟ ⎜ ⎟ ⎜ ⎟ = ⎜ ⎟ ⎜ ⎟ ⎜ ⎟ ⎜ ⎟ ⎝ ⎠ ⎜ ⎟ ⎜ ⎟ ⎝ ⎠ ˆ ij b = 1 1 1 1 1 1 1, 1 1, 2 1, 3 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1, 1 1, 2 1, 3 1 1 1 1 1 1 1 1 1 1 1 1 1, 1 1, 1 1 1 ˆ(1) ˆ(1) ˆ(1) ˆ(1) ˆ (1) ˆ(1) ˆ (2) ˆ(2) ˆ(2) ˆ(2) ˆ(2) ˆ(2) ˆ(3) ˆ(3) ˆ (3) t t t t t t t t O t O t O t t t t O t O t O t t t t O t O t γ γ γ γ γ γ γ γ γ γ γ γ γ γ γ = = = = = = = = = = = = = = = = = = = = = =
∑
∑
∑
∑
∑
∑
∑
∑
∑
∑
∑
∑
∑
∑
1 1 1, 4 1 1 1 1 1 1, 4 1 1 1 1 1 1 1 1 2 1, 3 1, 4 1 1 1 1 1 1 1 1 1 ˆ (1) ˆ (1) ˆ(2) 1 0 0 0 1 0 0 0 ˆ (2) 1 0 0 0 ˆ(3) ˆ (3) ˆ(3) ˆ(3) ˆ(3) t t t t t t O t t O t t O t O t t t γ γ γ γ γ γ γ γ γ = = = = = = = = = = = = = = ⎛ ⎞ ⎜ ⎟ ⎜ ⎟ ⎜ ⎟ ⎜ ⎟ ⎜ ⎟ ⎜ ⎟ ⎛ ⎞ ⎜ ⎟ ⎜ ⎟ ⎜ ⎟ = ⎜ ⎟ ⎜ ⎟ ⎜ ⎟ ⎜ ⎟ ⎝ ⎠ ⎜ ⎟ ⎜ ⎟ ⎜ ⎟ ⎜ ⎟ ⎜ ⎟ ⎜ ⎟ ⎜ ⎟ ⎝ ⎠∑
∑
∑
∑
∑
∑
∑
∑
∑
∑
Dari estimator yang dihasilkan, maka diperoleh model λˆ ˆ ˆ ˆ( , ,A Bπ0). Dengan bentuk B bˆ = seperti di atas, maka sudah bisa dipastikan bahwa ˆij P O
( )
λˆ =1 dan ini jauh lebih besar dibandingkan dengan P O( )
λ =0.078.Contoh di atas merupakan contoh yang tidak bagus, karena hanya melibatkan dua obervasi, akibatnya estimator yang dihasilkan, terutama matriks peluang emisi, akan memiliki elemen matriks yang isinya 0 dan 1. Dengan demikian maka nilai peluang observasinya akan bernilai 1, sehingga tidak perlu ada iterasi lagi.