3.1 Desain Penelitian
Jenis desain penelitian yang saya gunakan di dalam penelitian ini ialah jenis deskriptif Dengan penelitian asosoatif ini dapat diketahui pengaruh variabel independen terhadap variabel dependen dan bagaimana tingkat ketergantungan antara kedua variabel tersebut
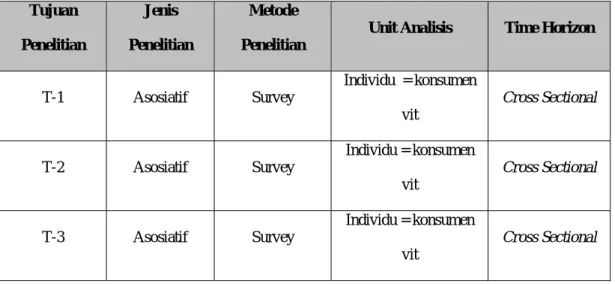
Tabel : 3.1 penjelasan tentang desain penelitian Berikut adalah penjelasan mengenai tentang desain penelitian : Tujuan Penelitian Jenis Penelitian Metode Penelitian
Unit Analisis Time Horizon
T-1 Asosiatif Survey Individu = konsumen vit Cross Sectional T-2 Asosiatif Survey Individu = konsumen vit Cross Sectional T-3 Asosiatif Survey Individu = konsumen vit Cross Sectional Keterangan :
1. Tujuan pertama : Untuk mengetahui pengaruh karakteristik kategori produk merek terhadap keputusan perpindahan merek
2. Tujuan Kedua : untuk mengetahui pengaruh kebutuhan variasi produk merek terhadap keputusan perpindahan merek
3. Tujuan ketiga : untuk mengetahui pengaruh mana yang dominan terhadap keputusan perpindahan merek
3.2 Operasionalisasi Variabel Penelitian
Menurut Sugiyono (2007, p32), variabel adalah suatu atribut atau sifat atau nilai dari orang, obyek atau kegiatan yang mempunyai variasi tertentu yang ditetapkan oleh peneliti untuk dipelajari dan ditarik kesimpulannya.
Skala yang digunakan adalah skala likert. Menurut Sugiyono (2007, p86) skala likert digunakan untuk mengukur sikap, pendapat, dan persepsi seseorang atau sekelompok orang tentang fenomena sosial. Skala likert ini berhubungan dengan pernyataan tentang sikap seseorang terhadap sesuatu, misalnya setuju-tidak setuju, senang-tidak senang dan baik-tidak baik
Variabel merupakan gejala yang menjadi fokus penelitian untuk diamati. Dalam penelitian ini terdapat dua variabel yaitu variabel bebas (independen) dan variabel terikat (dependen). Variabel bebas adalah unit atau ukuran yang diubah dalam suatu pengamatan, sedangkan variabel terikat menjadi hal yang diperhatikan dalam suatu pengamatan. Skala yang digunakan adalah skala Likert karena dengan skala ini variabel yang akan diukur dijabarkan menjadi dimensi, dimensi dijabarkan menjadi sub variabel, kemudian sub variabel dijabarkan lagi menjadi indikator-indikator yang dapat diukur.
Definisi operasional variabel bertujuan untuk menjelaskan makna variabel yang sedang diteliti. Memberikan pengertian tentang definisi operasional adalah unsur penelitian yang memberitahukan bagaimana cara mengukur suatu variabel, dengan kata lain definisi operasional adalah semacam petunjuk pelaksanaan bagaimana caranya mengukur suatu variabel.
Adapun definisi operasional variabel penelitian ini terdiri atas:
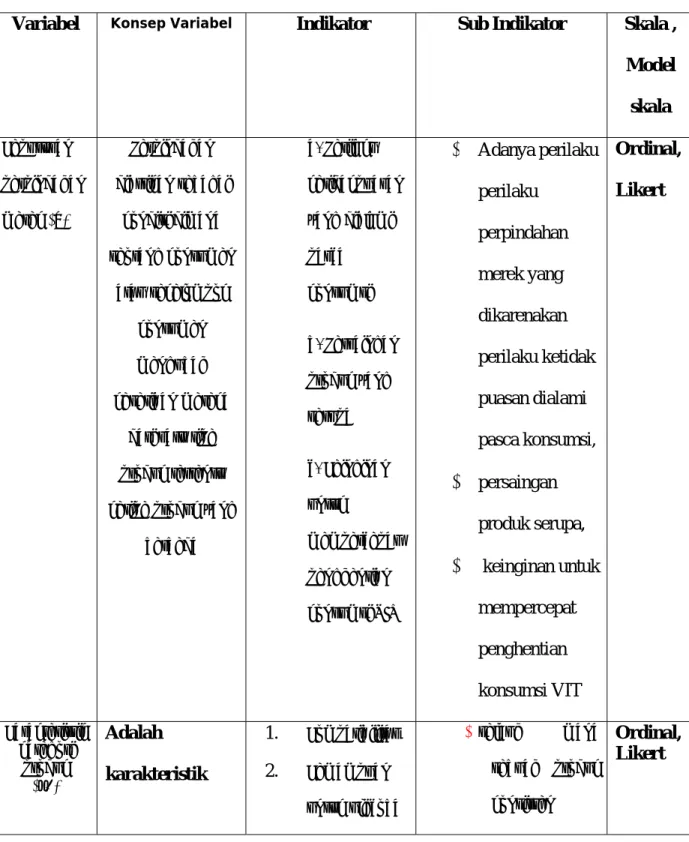
Tabel : 3.2 Operasional variabel penelitian
Variabel
Konsep VariabelIndikator
Sub Indikator
Skala ,
Model
skala
Keputusan perpindahan merek (Y) Perpindahan diartikan sebagai kondisi dimana seorang konsumen atau sekelompok konsumen mengubah kesetiaan merekadari satu tipe produk tertentu ketipe produk yang
berbeda a. Perilaku ketidakpuasan yang dialami pasca konsumsi b. Persaingan produk yang serupa c. Keinginan untuk mempercepat penghentian konsumsi VIT
• Adanya perilaku
perilaku
perpindahan
merek yang
dikarenakan
perilaku ketidak
puasan dialami
pasca konsumsi,
• persaingan
produk serupa,
• keinginan untuk
mempercepat
penghentian
konsumsi VIT
Ordinal,
Likert
Karakteristik kategori produk (x1)Adalah
karakteristik
1.
Kompatibilitas2.
Kemampuan untuk uji coba• sejauh mana sebuah produk konsisten
Ordinal,
Likert
berdasarkan
golongan produk
yang
membedakan
masing – masing
konsumen dalam
mencari variasi
melalui
keterlibatan,
3.
Kemampuan untuk diteliti4.
Kecepatan5.
Kesederhanaan6.
Manfaat relative7.
Simbolisme produk8.
Strategi pemasaran dengan afeksi, kognisi, dan perilaku konsumen saat ini, • sejauh mana suatu produk dapat diuji, • sejauh mana produk atau dampak yang dihasilkan produk, • seberapa cepat manfaat suatu produk dipahami oleh konsumen, • sejauh mana suatu produk memiliki keunggulan bersaing yang bertahan atas kelas produk,bentuk produk, dan merek lainnya,
• apakah makna suatu produk atau merek bagi konsumen, • penyebab keberhasilan atau kegagalan produk dan merek. Kebutuhan mencari variasi (x2) merupakan suatu sikap konsumen yang ingin mencoba merek lain dan memuaskan rasa penasarannya terhadap merek lain serta diasosiasikan sebagai keinginan untuk berganti kebiasaan a. Adanya rasa bosan terhadap merek air minum VIT
b. Banyaknya merek air mineral
c. Tidak khawatir dalam mencoba merek yang berbeda.
• Konsumen melakukan pembelian secara spontan • bertujuan mencoba merek baru dari suatu produk
Ordinal,
Likert
Data yang dihasilkan dari penyebaran angket adalah berskala pengukuran ordinal, mengingat angket yang disebarkan menggunakan skala Likert dengan kisaran 1-5 dari alternatif-alternatif jawaban yang disediakan. Penggunaan skala ordinal tidak memungkinkan untuk memperoleh nilai mutlak (absolut) dari objek yang diteliti, tetapi hanya kecenderungan. Angket yang merupakan alat ukur dalam penelitian ini perlu diuji validitas dan reliabilitasnya. Riduwan & Engkos (2007, p20) mengemukakan bahwa skala likert digunakan untuk mengukur sikap, pendapat dan persepsi seseorang atau sekelompok orang tentang kejadian atau gejala sosial.
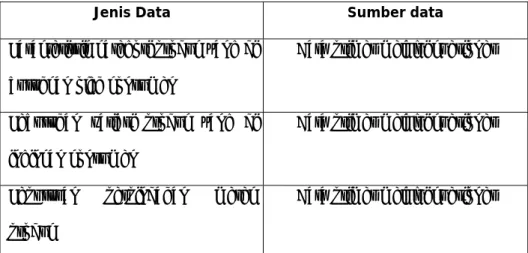
3.3 Jenis dan sumber data
Jenis data yang digunakan adalah data kualitatif yang di peroreh melalui instrument kuesioner.Peneliti menggunakan 2 macam sumber data yaitu sumber data primer dan sumber data sekunder.
1. Sumber data primer adalah data yang di kumpulkan secara langsung dari responden yakni konsumen VIT
2. Sumber data sekunder di lakukan dengan menggunakan studi literatur, baik melalui buku-buku pendukung,majalah ,jurnal ilmiah, laporan umum yang dipublikasikan.
Tabel : 3.3 sumber dan jenis data
Jenis Data Sumber data
Karakteristik kategori produk yang di butuhkan oleh konsumen
Data primer melalui kuesioner
Kebutuhan variasi produk yang di inginkan konsumen
Data primer melalui kuesioner
Keputusan perpindahan merek produk
3.4 Teknik pengumpulan data
Teknik pengumpulan data yang dilakukan di dalam penelitian ini menggunakan data primer (yaitu didapatkan secara langsung di lapangan) serta data sekunder. Dalam mengumpulkan data-data tersebut, penulis mengumpulkan data primer melalui metode wawancara dan kuesioner, sedangkan data sekunder diperoleh melalui studi kepustakaan.
Untuk menguatkan paradigma yang diteliti, maka dilakukan studi kepustakaan. Studi kepustakaan meliputi pengumpulan teori dari buku-buku karangan ahli ekonomi, jurnal-jurnal, situs-situs relevan dan artikel-artikel yang mendukung. Studi kepustakaan dilakukan di perpustakaan Universitas Bina Nusantara
Teknik pengumpulan data yang di lakukan adalah :
Kuesioner, berisi serangkaian pertanyaan yang di sebarkan kepada responden . Kuesioner dalam penelitian ini di buat dengan skala ordinal dengan pemberian bobot seperti berikut: Sangat Setuju (SS) = 5 Setuju (S) = 4 Ragu – Ragu =3 Kurang Setuju =2 Tidak Setuju =1
3.5 Teknik pengambilan sample
Teknik sampling adalah bagian dari metodologi statistika yang berhubungan dengan pengambilan sebagian dari populasi. “sampel adalah bagian dari populasi”. Jika sampling dilakukan dengan metode yang tepat, analisa statistik dari suatu
sampel dapat digunakan untuk menggeneralisasikan keseluruhan populasi. Metode sampling banyak menggunakan teori probabilitas dan teori statistika.
Tahapan sampling antara lain:
¾ Mendefinisikan populasi yang hendak diamati
¾ Menentukan kerangka sampel, yakni kumpulan semua item atau peristiwa yang mungkin
¾ Menentukan metode sampling yang tepat
¾ Melakukan pengambilan sampel (pengumpulan data) ¾ Melakukan pengecekan ulang proses sampling
Probability sampling adalah teknik sampling yang memberikan peluang/kesempatan yang sama bagi setiap unsur (anggota) populasi untuk dipilih menjadi anggota sampel. Teknik ini meliputi :
a. Teknik Sampling Random Sederhana (Simple Random Sampling)
Sampel acak sederhana adalah sebuah sampel yang diambil sedemikian rupa sehingga setiap unit penelitian atau satuan elementer dari populasi mempunyai kesempatan yang sama untuk dipilih sebagai sampel.
b. Teknik Sampling Random Sistematik (Systematic Random Sampling)
Apabila ukuran populasinya sangat besar, hingga tidak memungkinkan dilakukan pemilihan sampel dengan cara pengundian, maka teknik sampling random sederhana tidaklah tepat untuk digunakan. Dalam keadaan populasi yang demikian, gunakanlah teknik sampling random sistematik. Persyaratan yang harus dipenuhi agar teknik sampling ini dapat digunakan, sama dengan persyaratan untuk sampel random sederhana, yakni tersedianya kerangka sampling (ukuran populasinya diketahui
dengan pasti), dan populasinya mempunyai pola beraturan yang memungkinkan untuk diberikan nomor urut serta bersifat homogen.
c. Teknik Sampling Random Berstrata (Stratified Random Sampling)
Teknik sampling ini digunakan apabila populasinya tidak homogen (heterogen). Makin heterogen suatu populasi, makin besar pula perbedaan sifat-sifat antara lapisan tersebut. Padahal, sebagaimana telah diungkapkan di atas, presisi dan tingkat kerepresentatifan sampel yang diambil dari suatu populasi antara lain dipengaruhi oleh derajat keseragaman (tingkat homogenitas) populasi yang bersangkutan. Untuk dapat menggambarkan secara tepat tentang sifat-sifat populasi yang heterogen, maka populasi yang bersangkutan harus dibagi-bagi kedalam lapisan-lapisan (strata) yang seragam atau homogen, dan dari setiap strata dapat diambil sampel secara random (acak).
Untuk dapat menggunakan teknik sampling random strata, ada beberapa syarat yang harus dipenuhi, antara lain :
1. Harus ada kriteria yang jelas yang akan dipergunakan sebagai dasar untuk menstratifikasi populasi ke dalam lapisan-lapisan. Secara teoritis, yang dapat dijadikan kriteria untuk pembagian strata itu ialah variabel-variabel yang akan diteliti atau variabel-variabel yang menurut peneliti mempunyai hubungan yang erat dengan variabel-variabel yang hendak diteliti itu.
2. Harus ada data pendahuluan dari populasi mengenai kriteria yang dipergunakan untuk menstratifikasi.
3. Jumlah satuan elementer dari setiap strata (ukuran setiap subpopulasi) harus diketahui dengan pasti. Hal ini diperlukan agar peneliti dapat membuat kerangka sampling untuk setiap subpopulasi atau strata yang akan dijadikan sumber dalam
menentukan sampel atau responden. Untuk menentukan sampel sasaran atau responden masih perlu dilanjutkan dengan menggunakan teknik sampling random sederhana atau teknik sampling random sistematik, setelah sebelumnya dibuatkan kerangka sampling untuk setiap subpopulasinya.
Sampel strata terdiri dari dua macam, yakni sampel strata proporsional dan sampel strata disproporsional. Teknik sampling random strata proporsional digunakan apabila proporsi ukuran subpopulasi atau jumlah satuan elementer dalam setiap strata relatif seimbang atau relatif sama besar.
Penggunaan Teknik Sampling Random Strata Proporsional agak kurang tepat jika proporsi ukuran subpopulasinya (jumlah satuan elementer pada strata) tidak seimbang, ada yang jumlahnya besar ada pula yang jumlahnya kecil, sehingga kalau digunakan teknik sampling strata proporsional dapat kejadian ukuran subpopulasinya sama dengan ukuran sampelnya. Padahal, jika ukuran sampelnya sama dengan ukuran populasinya (total sampling atau sensus) maka data yang diperoleh dari sampel tersebut tidak bisa diolah atau dianalisis dengan menggunakan analisis statistik inferensial. Oleh karena itu, dalam keadaan populasi yang demikian, digunakanlah Teknik Sampling Random Strata Disproporsional.
d. Teknik Sampling Random Klaster (Cluster Random Sampling)
Teknik ini digunakan apabila ukuran populasinya tidak diketahui dengan pasti, sehingga tidak memungkinkan untuk dibuatkan kerangka samplingnya, dan keberadaannya tersebar secara geografis atau terhimpun dalam klaster-klaster yang berbeda-beda.
Sedangkan non probability sampling adalah teknik yang tidak memberikan peluang/kesempatan sama bagi setiap unsur atau anggota populasi untuk dipilih menjadi sampel. Teknik ini terdiri dari :
a. Sampling Kuota
Sampling kuota adalah teknik untuk menentukan sampel secara bebas dari populasi yang mempunyai ciri-ciri tertentu sampai jumlah (kuota) yang diinginkan.
b. Sampling Aksidental
Sampling aksidental adalah teknik penentuan sampel berdasarkan kebetulan, yaitu siapa saja yang kebetulan bertemu dengan peneliti dapat digunakan sebagai sampel, bila dipandang orang yang kebetulan ditemui itu cocok sebagai sumber data.
c. Judgement Sampling
Cara pengambilan sampel, yang bersedia dipilih berdasarkan tujuan. Dipilih berdasarkan unit analisis seorang ahli
d. Purposive Sampling
Purposive sampling adalah teknik penentuan sampel untuk tujuan tertentu saja. Misalnya pada penelitian tentang disiplin pegawai, maka sampel yang dipilih adalah orang yang ahli dalam bidang kepegawaian saja.
Sampling jenuh adalah teknik penentuan sampel bila semua anggota populasi digunakan sebagai sampel. Hal ini sering dilakukan bila jumlah populasi relatif kecil.
f. Snowball Sampling
Snowball sampling adalah teknik penentuan sampel yang mula-mula jumlahnya kecil, kemudian sampel ini disuruh memilih teman-temannya untuk dijadikan sampel. Begitu seterusnya, sehingga jumlah sampel semakin banyak.
Populasi dalam penelitian ini adalah konsumen VIT yang beralih kemerek lain di wilayah Jakarta Barat. Karena jumlah populasi yang besar jumlahnya laki-laki : 1.162.379 perempuan: 1.116.446 jumlah keseluruhan : 2.278.825 , maka dirasakan perlu untuk mengambil sampel yang menunjukkan karakteristik dari populasi .
Teknik pengambilan sampel menurut rumus dari Taro Yamane atau Slovin (dalam Riduwan, 2007:49) ialah sebagai berikut :
N n =
N.d2 + 1
Dimana :
n = Jumlah sampel
N = Jumlah Populasi = 2.278.825 responden
Berdasarkan rumus tersebut diperoleh jumlah sampel sebesar 99,99% = 99 responden, dibulatkan menjadi 100 responden. Teknik pengambilan sample yang di gunakan adalah probality sampling teknik pengambilan sample yang memberikan peluang yang sama bagi setiap unsur populasi untuk dipilih menjadi anggota sample dengan menggunakan sample random sampling, yaitu pengambilan sampling anggota populasi yang dilakukan secara acak tanpa memperhatikan strata yang vada di dalam populasi. . Teknik ini terdiri sampling sistematis, sampling kuota, sampling aksidental, sampling purposive, sampling jenuh dan snowball sampling.
Populasi dalam penelitian ini adalah konsumen Jakarta Barat yang pernah mengkonsumsi produk Vit. Karena jumlah populasi yang besar, maka dirasakan perlu untuk mengambil sampel yang menunjukkan karakteristik dari populasi. Target populasi dalam penelitian ini adalah konsumen produk VIT yang berada di wilayah Jakarta barat. Penelitian mengambil sample 100 orang responden .
3.6 Teknik Pengolahan data
Data yang diperoleh akan diolah dengan menggunakan SPSS (Statistical Program For Social Science) versi 16 untuk Windows. Namun sebelum dianalisis, bobot dari setiap jawaban kuesioner akan diuji validitas dan reliablilitasnya untuk mengetahui apakah isi kuesioner sesuai dengan sasaran yang ingin dicapai.
` `3.6.1 Skala Likert
Untuk mengukur pernyataan mengenai kompensasi dan lingkungan kerja terhadap kinerja karyawan, maka setiap jawaban diberi nilai (skor). Dimana dalam pemberian nilai digunakan Skala Likert. Skala Likert digunakan untuk mengukur sikap, pendapat dan persepsi seseorang atau kelompok tentang suatu kejadian atau gejala sosial. Dalam penelitian ini, peneliti telah menetapkan variabel-variabel secara spesifik.
Untuk menghindari adanya jawaban netral, maka penulis akan menggunakan hanya 5 (lima) pilihan jawaban. Hal ini dilakukan agar data yang diperoleh lebih akurat. Setiap jawaban dihubungkan dengan bentuk pernyataan atau dukungan sikap yang diungkapkan dengan nilai (skor) jawaban sebagai berikut :
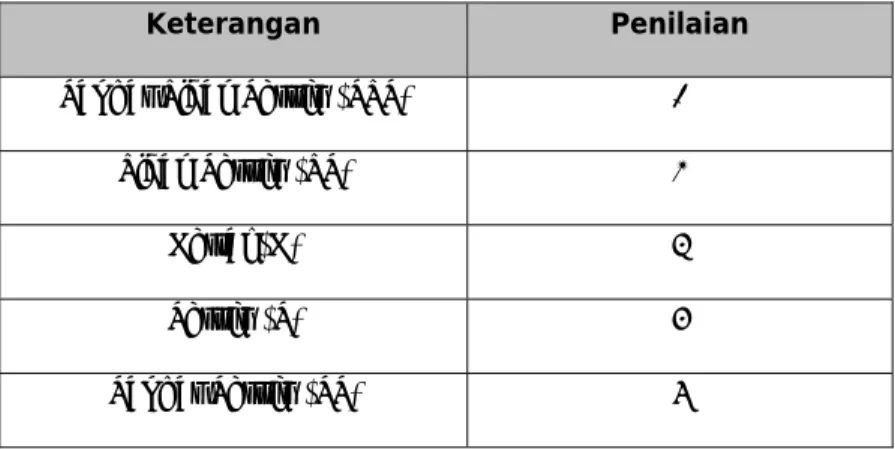
Tabel 3.4 Bobot dan Kategori Pengukuran Data
Keterangan Penilaian
Sangat Tidak Setuju (STS) 1
Tidak Setuju (TS) 2
Netral (N) 3
Setuju (S) 4
Sangat Setuju (SS) 5
Sumber Data : Penulis
3.6.2 Transformasi Data Melalui Method of Successive Interval (MSI) Skala pengukuran dari data penelitian ini adalah ordinal. Untuk data yang mempunyai skala ordinal dengan menggunakan skala Likert, dengan bobot nilai 5,4,3,2,1 atau pengukuran sikap dengan kisaran positif sampai dengan negatif, perlu ditransformasi menjadi skala interval dengan “Method of Successive Interval” (Riduwan, 2007:30). Hal ini dilakukan untuk memenuhi sebagian dari syarat analisis parametrik.
Adapun langkah-langkahnya sebagai berikut:
a) Pertama, perhatikan setiap butir jawaban responden dari angket yang disebarkan
b) Pada setiap butir ditentukan berapa orang yang mendapat skor 1, 2, 3, 4 , dan 5 yang disebut sebagai frekuensi
c) Setiap frekuensi dibagi dengan banyaknya responden dan hasilnya akan disebut sebagai proporsi
d) Tentukan nilai proporsi kumulatif dengan jalan menjumlahkan nilai proporsi secara berurutan per kolom skor
e) Gunakan Tabel Distribusi Normal, hitung nilai Z untuk setiap proporsi kumulatif yang diperoleh
f) Tentukan nilai tinggi densitas untuk setiap nilai Z yang diperoleh (dengan menggunakan tabel Tinggi Densitas)
g) Menghitung nilai skala dengan rumus Method of Successive Interval Nilai Skala (NS) =
Density at Lower Limit - Density at Upper Limit Area Below Upper Limit - Area Below Lower Limit
f) Menentukan nilai transformasi (nilai untuk skala interval) dengan menggunakan rumus : Y = NS + [ 1 + |NS min | ]
Untuk mempermudah proses transformasi, peneliti menggunakan software MSI (Microsoft Office Excel Add-In – STAT97).
3.6.3 Uji Validitas
Uji validitas merupakan kegiatan yang dilakukan untuk menunjukkan sejauh mana alat ukur sesuai dengan apa yang hendak diukur. Menurut Riduwan (2004 : 109-110), validitas adalah suatu ukuran yang menunjukkan tingkat keandalan atau kesahihan suatu alat ukur. Data yang kami kumpulkan dalam penelitian ini harus valid. Maksudnya, data yang kami kumpulkan ini harus benar-benar sesuai atau
menjawab sesuatu yang ingin dicapai dari penelitian ini. Pengujian validitas dilakukan untuk mengetahui apakah alat pengumpul data yang digunakan benar-benar mengukur indikator variabel yang diteliti. Instrumen dikategorikan valid apabila instrumen yang digunakan mampu mengukur apa yang diinginkan, dan dapat mengungkapkan data dari variabel yang diteliti secara tepat.
Untuk menguji validitas, terlebih dahulu dicari harga korelasi antara bagian-bagian dari alat ukur dengan skor total yang merupakan jumlah tiap skor butir. Untuk menghitung validitas alat ukur, digunakan Pearson Product Moment, dengan rumus :
r hitung = n (∑ Xi Yi) – (∑Xi) . (∑Yi) √ { n .∑Xi 2 – (∑Xi) 2} . {n. ∑Yi2 – (∑Yi) 2}
Dimana:
r hitung = koefisien korelasi ∑Xi = jumlah skor item
∑Yi = jumlah skor total (seluruh item) N = jumlah responden
Dasar pengambilan keputusan adalah:
- Jika r hitung positif, serta r hitung > r table, maka butir atau variable tersebut valid
- Jika r hitung tidak positif, serta r hitung < r table, maka butir atau variable tersebut tidak valid
- Jika r hitung > r table, tapi bertanda negative, maka butir atau variable tersebut tidak valid
√ 1- r 2
Dimana:
t = nilai t hitung
r = koefisien korelasi r hitung n = jumlah responden
Distribusi (table t) untuk α = 0.05 dan derajat kebebasan (dk = n-2) Kaidah keputusan : Jika t hitung > t table, berarti valid sebaliknya
T hitung < t table, berarti tidak valid
Jika instrument itu valid, maka dilihat criteria penafsiran mengenai indeks korelasinya ® sebagai berikut (Riduwan & Engkos), 217, 2007) :
- Antara 0,800 – 1,000 : sangat tinggi - Antara 0,600-0,799: tinggi
- Antara 0,400 – 0,599 : cukup tinggi - Antara 0,200-0,399 : rendah
- Antara 0,000 – 0, 199: sangat rendah (tidak valid)
3.6.4 Uji Reliabilitas
Uji reliabilitas merupakan salah satu atau cirri karakter utama instrument pengukuran yang baik, karena pengukuran yang memiliki reliabilitas tinggi yaitu pengukuran yang mampu memberikan hasil ukur yang terpercaya atau reliabel. Maksudnya, data yang kami kumpulkan dan olah itu harus dapat dipercaya kebenarannya dan mampu diandalkan oleh pihak pengguna informasi hasil riset pemasaran ini. Reliabilitas dapat diartikan sebagai accuracy (ketepatan). Dalam hal ini kita mempersoalkan apakah skor responden yang kita peroleh dengan instrumen
yang kita gunakan benar-benar merupakan skor yang sebenarnya dari responden tersebut di dalam hal karakteristik yang kita ukur. Reliabilitas lebih mudah dimengerti dengan memperhatikan tiga kriteria dari suatu alat ukur, yaitu : kemantapan, ketepatan dan homogenitas. Pengujian reliabilitas dilakukan untuk menilai konsistensi dan stabilitas instrument penelitian dengan menggunakan koefisien Cronbach Alpha. Instrumen dianggap reliable jika Cronbach Alpha > 0.6. Perkiraan Cronbach Alpha juga menunjukkan pada kita bagaimana tingginya butir-butir dalam kuesioner berkorelasi atau berinteraksi.Langkah-langkah mencari nilai reliabilitas dengan metode Cronbach Alpha ialah sebagai berikut:
1. Menghitung varians skor tiap-tiap item 2. Menjumlahkan varians semua item 3. Menghitung varians total
4. Masukkan nilai Alpha
Setelah semua butir-butir pernyataan dalam suatu variable dinyatakan valid, maka selanjutnya dilakukan uji reliabilitas. Dasar pengambilan keputusannya adalah sebagai berikut (Santoso, 2000, p250):
-Jika r Alpha positif dan r Alpha > r table, maka butir atau variable tersebut reliable -Jika r Alpha positif dan r Alpha < r table, maka butir atau variable tersebut tidak reliable
- Jika r Alpha > r table tapi bertanda negative, maka butir atau variable tersebut tidak reliabel
3.6.5 Uji Normalitas
mengukur data berskala ordinal, interval ataupun rasio. Distribusi sampling bisa memiliki distribusi normal atau tidak normal. Secara teoritis, semakin besar ukuran sampel, maka data akan mendekati normal. Uji Normalitas distribusi akan banyak digunakan dalam statistik inferensi untuk menentukan metode pengolahan data. Uji normalisasi distribusi data dari sampel yang dikumpulkan di dalam penelitian ini akan dilakukan dengan menggunakan SPSS.
Jika data berdistribusi normal, maka bisa dilakukan analisis statistik parametrik, namun jika data berdistribusi tidak normal, maka dilakukan analisis statistik nonparametrik. Dalam pembahasan ini akan dilakukan uji One Sample Kolmogorov-Smirnov dengan menggunakan taraf signifikansi 0.05 .
Kriteria pengujian:
a. Angka signifikansi Uji Kolmogorov-Smirnov Sig ≥ 0.05, maka data berdistribusi normal
b. Angka signifikansi Uji Kolmogorov-Smirnov Sig < 0.05, maka data berdistribusi tidak normal
Menurut Singgih Santoso (2007, p152-155), dalam melakukan kegiatan statistik inferensi, ada dua hal yang harus diuji terlebih dahulu :
a. Apakah beberapa sampel yang telah diambil berasal dari populasi yang sama (populasi data berdistribusi normal)?
b. Apakah sampel-sampel tersebut mempunyai varians yang sama? Dengan kata lain, uji normalitas data dan uji varians adalah hal yang lazim sebelum sebuah metode statistik diterapkan. Uji normalitas dan kesamaan varians sebuah sampel data dilakukan dengan bantuan alat uji SHAPIRO-WILK,LILLIEFORS atau KOLMOGOROV-SMIRNOV, serta gambar NORMAL PROBABILITY PLOTS.
Manurut Singgih Santoso (2007, p154), dalam menjelaskan output test of normality, ada pedoman pengambilan keputusan :
1. Nilai Sig. atau signifikan atau nilai probabilitas < 0.05, distribusi adalah tidak normal.
2. Nilai Sig. atau signifikan atau nilai probabilitas < 0.05, distribusi adalah normal.
Dengan menjelaskan menjelaskan output test of homogenity of varians, ada pedoman pengambilan keputusan :
1. Nilai Sig. atau signifikan atau nilai probabilitas < 0.05, data berasal dari populasi-populasi yang mempunyai varians tidak sama.
2. Nilai Sig. atau signifikan atau nilai probabilitas < 0.05, data berasal dari populasi-populasi yang mempunyai varians sama.
Selain itu, pada gambar Q-Q Plot terlihat ada garis lurus dari kiri ke kanan atas. Garis itu berasal dari nilai z. Jika suatu distribusi data normal, maka data akan tersebar di sekeliling garis.
Menurut Uyanto (2006, p35-36) asumsi normalitas merupakan prasyarat dari prosedur statistik inferensial. Ada beberaoa cara untuk mengeksplorasi asumsi normalitas ini antara lain: Uji normalitas Shapiro-Wilk dan uji normalitas Lilliefors (Kolmogorov-Smirnov). Dalam penelitian ini, uji normalitas yang digunakan adalah uji normalitas Lilliefors (Kolmogorov-Smirnov). Uji normalitas ini terdapat dalam prosedur SPSS Explore, selain itu juga akan ditampilkan secara garis normal probability plot dan detrended normal plot.
3.6.5.1 Normal Probability Plot
berasal dari populasi yang terdistribusi normal, maka titik-titik data akan terletak kurang lebih dalam suatu garis lurus.
3.6.5.2 Deterended Normal Plot
Dalam Deterended Normal Plot yang digambarkan adalah simpangan dari nilai data terhadap garis lurus. Jika sampel data berasal dari populasi yang terdistribusi normal, maka titik-titik nilai data akan membentuk pola tertentu dan akan terkumpul di sekitar garis mendatar yang melalui titik nol.
Bentuk hipotesis untuk uji normalitas ádalah sebagai berikut : Ho : data berasal dari populasi yang berdistribusi normal. Ha : data tidak berasal dari populasi yang berdistribusi normal
i. Dalam pengujian hipótesis, kriteria untuk menolak atau tidak menolak Ho berdasarkan P-value hádala sebagai berikut :
Jika P-value < α , maka Ho ditolak Jika P-value ≥ α , maka Ho diterima
ii. Dalam program SPSS digunakan istilah Significance (yang disingkat Sig.) untuk P-value, dengan kata lain P-value = Sig.
3.6.6 Korelasi
3.6.6.1 Pengertian Kolerasi
Korelasi adalah hubungan antara variabel-variabel yang diminati, apakah sampel yang ada menyediakan bukti cukup bahwa ada kaitan antara variabel-variabel dalam populasi asal sampel, jika ada hubungan maka seberapa kuat hubungan antara variabel-variabel yang di uji. Keeratan hubungan tersebut disebut juga koefisien atau koefisien korelasi. Perlu dicatat bahwa dalam korelasi itu kita belum menentukan dengan pasti variabel independent dan dependentnya seperti
yang kita lakukan dalam analisis regresi. Nilai koefisien korelasi (r) yaitu -1 ≤ r ≤ 1, yang dapat diartikan sebagai berikut :
• Jika nilai r mendekati 1, maka memiliki hubungan antar variabel yang sangat kuat dan positif.
• Jika nilai r mendekati -1, maka memiliki hubungan antar variabel yang sangat kuat dan negatif.
• Jika nilai r mendekati -1, maka memiliki hubungan antar variabel yang sangat lemah bahkan tidak mempunyai hubungan antar variabel yang diteliti.
Koefisien korelasi positif artinya jika nilai X atau variabel bebas meningkat, maka nilai Y atau variabel terikat juga akan meningkat. Koefisien korelasi negatif artinya jika nilai X atau variabel bebas meningkat, maka nilai Y atau variabel terikat menurun atau sebaliknya. Interpretasi Koefisien Korelasi Nilai r :
3.6.6.2 Korelasi Pearson
Menurut pendapat Riduwan dan Kuncoro (2007, p61-62), Korelasi Pearson Product Moment (PPM) digunakan untuk mengetahui derajat hubungan antara variabel bebas (independent) denga variabel terikat (dependent).
Rumus yang digunakan Korelasi PPM (sederhana) : rxy = n(∑XY) – (∑X)(∑Y)
√ {n.∑X2 – (∑X)2} {n.∑Y2 – (∑Y)2}
Interval Koefisien Tingkat Hubungan 0.80 – 1.000 Sangat Kuat 0.60 – 0.799 Kuat 0.40 – 0.599 Cukup Kuat 0.20 – 0.399 Rendah 0.00 – 0.199 Sangat Rendah Sumber : Riduwan (2005, p136)
Besar kecilnya sumbangan variabel X terhadap Y dapat ditentukan dengan rumus koefisien determinan sebagai berikut :
KP = r2 x 100%
Dimana : KP = Nilai Koefisien Determinan r = Nilai Koefisien Korelasi
Berdasarkan pendapat Riduwan dan Kuncoro (2007, p62), pengujian signifikansi yang berfungsi apabila peneliti ingin mencari makna generalisasi dari hubungan variabel X terhadap Y, maka hasil korelasi PPM tersebut diuji dengan Uji Signifikasi sebagai berikut :
Hipotesis :
Ho : Tidak ada hubungan yang signifikan antara variabe x dengan variabel Y Ha : Ada hubungan yang signifikan antara variabe x dengan variabel Y Dasar Pengambilan Keputusan :
¾ Jika nilai probabilitas 0.05 lebih kecil atau sama dengan nilai probabilitas sig atau [0.05 ≤ Sig], maka Ho diterima dan Ha ditolak, artinya tidak signifikan.
¾ Jika nilai probabilitas 0.05 lebih besar atau sama dengan nilai probabilitas sig atau [0.05 ≥ Sig], maka Ho ditolak dan Ha diterima, artinya signifikan.
Berfungsi untuk mencari besarnya hubungan antara dua variabel bebas (X) atau lebih secara simultan (bersama-sama) dengan variabel terikat (Y). Rumus Korelasi Ganda sebagai berikut:
Rx1x2y = r2X1Y + r2X2Y – 2(rX1Y) (rX2Y) (rX1X2)
1 – r2X1X2
Selanjutnya untuk mengetahui signifikasi Korelasi Ganda bandingkan antara probabilitas 0,05 dengan probabilitas Sig sebagai berikut :
Hipotesis :
Ho : Tidak ada hubungan yang signifikan antara variabel X1 dan X2 dengan variabel Y
Ho : Ada hubungan yang signifikan antara variabel X1 dan X2 dengan variabel Y
3.6.7 Uji Asumsi Klasik 3.6.7.1 Uji Normalitas
Ada cara lain untuk menentukan data berdistribusi normal atau tidak dengan menggunakan rasio skewness dan rasio kurtosis. Rasio skewness dan rasio kurtosis dapat dijadikan petunjuk apakah suatu data berdistri busi normal atau tidak. Rasio skewness adalah nilai skewness dibagi dengan standart nilai error skewness, sedang rasio kurtosis adalah nilai kurtosis dibagi dengan standart nilai error kurtosis. Bila rasio kurtosis dan skewness berada diantara - 2 hingga + 2, maka distribusi data adalah normal. (santoso 200, p53).
Uji Multikolinieritas merupaka uji yang ditunjukan untuk menguji apakah model regresi ditemukan adanya korelasi antar variable bebas (variable independent). Model uji regresi yang baik sebaiknya tidak terjadi multikolinieritas. Untuk mendeteksi ada ataau tidaknya multikolinieritas, yaitu dengan :
1. Dengan melihat Nilai VIF (Variance Inflation Factor). Menurut Santosos (2001), pada umumnya jika VIF lebih besar dari 5 maka variable tersebut mempunyai persoalan multikolinieritas dengan variable bebas lainnya.
2. Dengan membandingakan nilai koefisien determinasi indivisual (r²) dengan nilai determinasi secara serentak (R²).
3. Dengan melihat nilai Eigenvalue dan condition index, Apabila satu atau lebih variable bebas yang mendekati nol memberikan petunjuk adanya multikolinieritas.
4. Menganalisi korelasi antar variable bebas. Jika terjadi korelasi cukup tinggi (diatas 0,90) maka hal ini merupakan indikasi adanya multikolinieritas.
3.6.7.3 Uji Heterokedatisitas
Uji heteroskedastisitas bertujuan menguji apakah dalam model regresi terjadi ketidaksamaan veriance dari residual satu pengamatan ke pengamatan yang lain. Jika variance tetap maka disebut homoskedastisitas dan jika berbeda maka terjadi problem heteroskedastisitas. Model regresi yang baik yaitu homoskesdatisitas atau tidak terjadi heteroskedastisitas.
Salah satu cara untuk mendeteksi ada tidaknya heteroskedastisitas yaitu melihat scatter plot (nilai prediksi dependen ZPRED dengan residual SRESID). Cara menganalisis :
• Dengan melihat apakah titik-titik memiliki pla tertentu yang teratur seperti bergelombang, melebar kemudian menyempit, jika terjadi maka mengindikasikan terdapat heteroskedastisitas.
• Jika tidak terdapat pola tertentu yang jelas, serta titik-titik menyebar diatas dan dibawah angka 0 pada sumbu Y maka mengindikasikan tidak terjadi heteroskedastisitas.
3.6.7.4 Uji Autokorelasi
Uji autokorelasi bertujuan menguji apakah model regresi linier ada korelasi antara kesalahan pengganggu pada periode t dengan kesalahan pengganggu pada periode sebelumnya (t-1). Jika terjadi korelasi maka dinamakan ada problem autokorelasi. Model regresi yang baik adalh model regresi yang bebas autokorelasi. Salah satu cara untuk mendeteksi gejala autokorelasi yaitu uji Durbin Watson (DW test).
Uji Durbin Watson hanya digunakan untuk autokorelasi tingkat satu (first autocorrelation) dan mensyaratkan adanya intercept (konstanta) dalam model regresi dan tidak ada variable lagi diantara variable bebas.
Pengambilan keputusan dalam uji Durbin Watson adalah : 1. Menentukan Hipotesis
H0 : tidak ada autokorelasi H1 : ada aotukorelasi
2. Menentukan nilai α dengan d table (n,k) terdii atas dl dan du 3. Menentukan criteria pengujian
• Tidak terjasi aotokorelasi jika (4-dl) < dw < dl
• Terjadi autokorelasi negative jika dw > (4-dl), koefisien korelasinya lebih kecil dari nol
• Jika dw terletak antara (4-du) dan (4-dl) maka hasilnya tidak dapat disimpulkan
• Jka n < 15
3.6.8 Regresi Linear Berganda
Menurut Riduwan dan Engkos Achmad Kuncoro (2001, p83) Regresi adalah suatu proses memperkirakan secara sistematis tentang apa yang paling mungkin terjadi di masa yang akan datang berdasarkan informasi masa lalu dan sekarang yang dimiliki agar kesalahannya dapat diperkecil.
Regresi linear berganda (Multiple Regression) adalah regresi dimana terdapat lebih dari satu variabel bebas. Analisis regresi berganda digunakan dalam penelitian ini karena regresi berfungsi untuk meramalkan variabel terikat (Y) apabila variabel bebas (X) diketahui. Analisis ini digunakan bila peneliti bermaksud meramalkan bagaimana keadaan (naik turunnya) variabel terikat bila dua atau lebih variabel bebas sebagai faktor prediktor dimanipulasi (dinaik turunkan nilainya). Analisis regresi berganda dilakukan bila jumlah variabel bebasnya minimal dua. Persamaan regresi berganda adalah :
Y = a + b1X1 + b2X2 +....+ bnXn + e
Y = variabel terkait a = konstanta b1, b2 = koefisien regresi
X1, X2 = variabel bebas
Rancangan Uji Hipotesis
Rancangan Uji Hipotesis menggunakan tingkat kepercayaan 95%, dimana tingkat presisi (α) = 5% = 0,05.
Dasar pengamilan keputsan :
(1) Jika nilai probabilitas 0,05 lebih kecil atau sama dengan nilai probabilitas Sig atau [0,05 ≤ Sig], maka Ho diterima dan Ha ditolak, artinya tidak signifikan.
(2) Jika nilai probabilitas 0,05 lebih besar atau sama dengan nilai probabilitas Sig atau [0,05 ≥ Sig], maka Ho ditolak dan Ha diterima, artinya signifikan.
Variabel :
X1 = Karakteristik kategori produk X2 = kebutuhan mencari variasi Y = keputusan perpindahan merek
Hipotesis T 1 Untuk mengetahui pengaruh antara Karakteristik kategori produk terhadap keputusan perpindahan merek
¾ Ho = Tidak ada pengaruh yang signifikan antara karakteristik kategori produk
terhadap Keputusan perpindahan merek
¾ Ha = Ada pengaruh yang signifikan antara karakteristik kategori produk terhadap
Keputusan perpindahan merek
HipotesisT - 2 Untuk mengetahui pengaruh antara kebutuhan mencari variasi produk terhadap Keputusan perpindahan merek
¾ Ho = Tidak ada pengaruh yang signifikan antara kebutuhan mencari variasi produk
¾ Ha = Ada pengaruh yang signifikan antara kebutuhan mencari variasi produk
terhadap Keputusan perpindahan merek
Hipotesis T - 3 Untuk mengetahui pengaruh antara karakteristik kategori produk dan kebutuhan mencari variasi produk terhadap keputusan perpindahan merek
¾ Ho = Tidak ada pengaruh yang signifikan antara karakteristik kategori produk dan
kebutuhan mencari variasi produk terhadap keputusan perpindahan merek
¾ Ha = Ada pengaruh yang signifikan antara karakteristik kategori produk dan
kebutuhan mencari variasi produk terhadap keputusan perpindahan merek
3.7 Rancangan Implikasi Hasil Penelitian
Rancangan implikasi hasil penelitian ini yaitu setelah data yang terkumpul baik melalui data primer yang dilakukan dengan kuesioner dan data sekuner yang diproleh dari perusahaan, data tersebut kemudian dilakukan analisis hubungan antara karakteristik kategori produk dan kebutuhan mencari variasi produk terhadap keputusan perpindahan merek, dan dilakukan analisis pengaruh antara karakteristik kategori produk dan kebutuhan mencari variasi produk terhadap keputusan perpindahan merek.
Dari analisis di atas, apabila terdapat pengaruh dan hubungan yang kuat antara karakteristik kategori produk dan kebutuhan mencari variasi produk terhadap keputusan perpindahan merek. Jika dilhat dari karakteristik kategori produk meningkat/ tinggi, apabila karakteristik kategori produk meningkat baik maka akan semakin besar kemungkinan untuk berpindah merek keproduk lain.