Penentuan Ukuran Sampel Survei Pilkada Jawa Barat Melalui Highest
Posterior Density Dengan Pendekatan Bayes
Neneng Sunengsih
1, Achmad Zanbar S
2, dan Resa S. Pontoh
31Jurusan Statistika Universitas Padjajaran
e-mail: [email protected]
2 Jurusan Statistika Universitas Padjajaran
e-mail: [email protected]
3 Jurusan Statistika Universitas Padjajaran
Abstrak. Penentuan ukuran sampel dengan tingkat presisi yang tinggi menjadi sangat penting dalam suatu polling. Metode frequentist biasa dilakukan dalam menentukan ukuran sampel karena hanya memerlukan asumsi kenormalan, ukuran populasi, proporsi sukses, dan tingkat error yang diinginkan. Metode Bayes memberikan alternatif lain dalam penentuan ukuran sampel polling dengan memperhitungan persentase dukungan masing-masing partai terhadap setiap calon kandidat. Selain itu melalui selang Highest Posterior Density (HPD) dapat dihindari ketergantungan rumusan ukuran sampel pada pendekatan distribusi normal, sehingga ketidakefisienan selang dapat direduksi sekecil mungkin. Diketahui bahwa total pemilih PILKADA JABAR tahun 2008 adalah 27.933.259 jiwa yang tersebar di 63.031 TPS. Untuk nilai error 5% diperoleh nilai ukuran sampel melalui metode frequentist adalah 439 TPS dengan total pemilih 175.728 jiwa dan nilai presisi 1%. Sedangkan melalui HDP melalui pendekatan metode Bayes diperoleh ukuran sampel 443 TPS dengan total pemilih 177.200 dan nilai presisi 0,16%.
Kata kunci: Metode frequentist, metode Bayes, Highest Posterior Density (HPD)
1. Pendahuluan
Pemilihan Gubernur Jawa Barat merupakan implementasi dari UU No 12 tahun 2008 dan Peraturan Pemerintah Republik Indonesia No 6 tahun 2005 tentang Pemilihan Kepala Daerah (Pilkada). Hasil Pilkada sangat dinantikan oleh masyarakat yang berharap untuk segera mengetahui persentase perolehan suara dari masing-masing kandidat. Saat ini, masyarakat tidak perlu menunggu terlalu lama untuk mengetahui prediksi perolehan suara dari para kandidat. Hal ini dikarenakan berkembangnya informasi yang dikeluarkan oleh beberapa lembaga survey melakukan proses perhitungan cepat (Quick Count).
Lembaga survey yang melakukan perhitungan cepat dalam Pilgub Jabar menggunakan Stratified Cluster Sampling. Strata dibentuk berdasarkan kabupaten atau kota sebanyak 26 stratum. Dengan demikian, semua kabupaten dan kota di Jawa Barat akan terpilih. Selanjutnya dalam masing–masing strata akan dibentuk klaster yang terdiri atas kelurahan atau desa; hal ini bertujuan agar dari setiap kelurahan dan desa terpilih dapat dipilih sebuah TPS secara proporsional yang akan mewakili kabupaten dan kota.
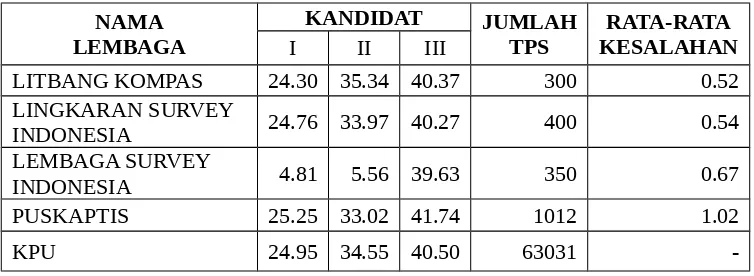
Tabel 1. Nama Lembaga Penyelenggara Quick Count Berikut Ukuran
Sampel dan Hasil Prediksinya
NAMA LEMBAGA
KANDIDAT JUMLAH
TPS KESALAHANRATA-RATA
I II III
LITBANG KOMPAS 24.30 35.34 40.37 300 0.52
LINGKARAN SURVEY
INDONESIA 24.76 33.97 40.27 400 0.54
LEMBAGA SURVEY
INDONESIA 4.81 5.56 39.63 350 0.67
PUSKAPTIS 25.25 33.02 41.74 1012 1.02
KPU 24.95 34.55 40.50 63031
-Sumber : Harian Kompas tanggal 23 April 2008
Beberapa jenis kesalahan yang sering terjadi dalam suatu survey adalah Sampling Error dan Non-sampling Error yang besarnya diukur oleh Margin of Error (MoE). Faktor kesalahan lainnya yang perlu diperhatikan pula adalah Coverage Error, Measurement Error dan Non-response Error.
Coverage Error adalah kesalahan yang berkaitan dengan ketidakmampuan menjangkau sebagian populasi; misalnya di gunung, Rumah Sakit, dan Penjara. Measurement Error adalah kesalahan yang terjadi jika tidak mengukur yang seharusnya diukur; misalnya kesalahan program komputer, pamakaian istilah yang kurang tepat, pengurutan pertanyaan, kesalahan pewawancara, dan waktu wawancara. Non-response Error adalah kesalahan akibat tidak berhasil melakukan wawancara (memperoleh data); kesalahan jenis ini belum dapat diukur.
Ukuran sampel yang biasa digunakan dalam Quick Count menurut Melissa Estok (2000) adalah
2 2
1
(1
)
(1
)
p
p
n
d
p
p
Z
N
(1)Dalam hal ini, n menyatakan ukuran sampel,
p
menyatakan proporsi populasi, N menyatakan ukuran populasi,d menyatakan Margin of Error atau Bound of Error dan1
Z
menyatakan nilai tabel distribusi normal standar. Penentuan ukuran sampel melalui Persamaan (1) diperoleh dengan menentukan nilaip
oleh peneliti berdasarkan asumsi populasinya homogen atau heterogen. Menurut Maria Estok (2000), jika salah satu kandidat mendapat dukungan 80% maka populasi dikatakan homogen, selain itu dinyatakan heterogen.Banyaknya TPS yang diambil sebagai sampel di Persamaan (1) ditentukanoleh Margin of Error yang nilainya ditetapkan oleh pendugaan parameter distribusi proporsi binom. Selanjutnya, yang menjadi perhatian di sini adalah kandidat peserta pilkada bisa lebih dari dua pasang. Artinya proporsi yang diduga akan sebanyak kandidat tersebut atau dengan kata lain distribusi dari proporsi menjadi multinom.
dimanfaatkan sebagai informasi awal (prior knowlege) dalam penentuan ukuran sampel melalui pendekatan analisis Bayes.
2. Penentuan Ukuran Sampel Secara Frequentist
Penentuan ukuran sampel merupakan sebuah pertanyaan penting sebelum suatu survey dilakukan karena akan menentukan kualitas dan presisi dalam penaksiran parameter atau power dari pengujian hipotesis. Banyak cara yang dapat dilakukan dalam menentukan ukuran sampel; secara umum dapat dikelompokkan menjadi dua yaitu Non-bayesian (cara klasik atau frequentist) dan Bayesian.
Dalam penelitian ini, ukuran sampel akan ditentukan berdasarkan konsep selang kepercayaan sehingga perbedaan antara cara frequentist dan Bayesian dapat terlihat lebih jelas khususnya berdasarkan prosedur dan kriteria dari penentuan ukuran sampel tersebut.
Dalam konsep frequentist, peluang digunakan jika interpretasi mengenai parameter didasarkan pada eksperimen yang diulang beberapa kali. Sedangkan untuk konsep Bayesian, peluang digunakan sebagai ukuran kepercayaan tentang nilai dari parameter yang tidak diketahui. Selang Bayesian mencakup proporsi
(1
)
100% distribusi posterior dari parameter tersebut tanpa mensyaratkan pengulangan dengan ukuran sampel yang sama (Harold.1974).Ukuran sampel untuk proporsi binom menurut Cochran yang melibatkan finite population correction adalah:
2 2 2 2 1 1 1 1 1 � � � � � � z d n z N d Bentuk tersebut selanjutnya oleh Adcock (1987) disederhanakan menjadi :
21 , 21
n
d
�
(2)Menurut Goodman [3] dengan pendekatan selang kepercayan untuk sampel besar, dapat dibentuk :
i
i i
� �
sehingga agar ukuran sampel dapat ditentukan maka presisi untuk tiap parameter dari populasi multinom harus ditetapkan yaitu sebesar
d
i untuk setiap kategori atau :
2
/k i 1 i
l i i di
n
dan 2/k i
1 i
l i n i di
Selanjutnya dapat diselesaikan dan diperoleh :
2 1 , /
2 1 i i k i i n d
(3)
Prosedur umum dalam penentuan ukuran sampel untuk penaksiran proporsi multinom dengan tingkat keyakinan simultan tertentu
dan setengah lebar selang kepercayaan
1, 2...,
i
i
�
�
untuk suatu nilai yang mungkin dari vektor parameter
1, , ...,
2 3
k
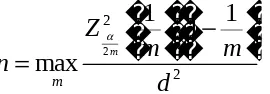
. Berdasarkan prosedur di atas, maka diperoleh formula :2 2 2
1
1
1
max
m mZ
m
m
n
d
� ��
� ��
�
�
� ��
�
(4)Persamaan (4) digunakan jika prior knowledge tidak tersedia dan diambil nilai
1 2 3
...
d
d
d
d
. Nilaim
yang memaksimumkan Persamaan (4) bergantung pada
dand
, Thompson sudah membuat tabel 2 yang menyatakan ukuran sampel untuk selang taksiran simultan dari parameter populasi multinom berdasarkan nilai ddan
.Tabel 2. Nilai
nd
2 danm
untuk Berbagai Alpha dalam Penaksiran Parameter dari Populasi Multinom Secara Simultan
0.001 0.005 0.01 0.02 0.025 0.05 0.10 0.202
nd
3.02892 2.28514 1.96986 1.65872 1.55963 1.27359 1.00635 0.74739m
2 2 2 2 2 3 3 3Tabel 2. dicuplik dari Thompson (1987) yang memuat nilai 2
nd
sehingga besarnya ukuran sampel ditentukan tidak berdasarkan banyaknya kelas dalam populasi, sementara itu besaranm
menunjukkan banyaknya parameter yang tidak nol yang diantaranya terdapat nilai worst case untuk alpha tertentu. Cara ini kurang praktis, karena memerlukan bantuan tabel.Jeffrey [5] memodifikasi metode Tortora dan metode Thompson , sehingga diperoleh formula sebagai berikut :
/ 2
2
2
1 2 2 2
2
1
2
1
4
1
1
2
i
i i i i i i i
i
Z
n
d
d
d
�
�
�
�
�
�
�
(2.11)Apabila tidak ada informasi sebelumnya mengenai nilai
i, maka diambil
i = 0.5 untukbeberapa i, sehingga n ditentukan berdasarkan :
/ 2 / 2 2 2 2
0.25
i i iZ
n
Z
d
�
(5)Penentuan ukuran sampel melalui metode frequentist akan selalu dapat diperoleh. Lain halnya jika digunakan metode Bayes; metode ini bisa mengundang perdebatan dalam tahapan penentuan distribusi prior dan distribusi posteriornya. Demikian juga dalam penggunaan presisinya, metode Bayes tidak seluas metode klasik (Pham-Ghia,1992).
Menurut Joseph (1995), sebenarnya metode Bayes memberikan sumbangan alternatif yang atraktif untuk formula frequentist, misalnya melalui selang Highest Posterior Density (HPD) dapat dihindari ketergantungan pada pendekatan distribusi normal.
Dengan demikian ketidakefisienan selang yang mempunyai dua ekor yang sama dapat dikurangi. Perhitungan metode Bayes bukan berarti tanpa tantangan, karena melalui metode Bayes masalah hitungan yang rumit dan pemilihan kriteria yang harus beralasan berdasarkan pada banyak literatur.
Seperti halnya penentuan ukuran sampel secara frequentist, maka pada pendekatan Bayes pun ukuran sampel ditentukan berdasarkan konsep selang kepercayaan akan tetapi inferensi Bayesian menyatakannya dalam peluang subjektif sebagai ukuran kepercayaan tentang nilai dari parameter yang tidak diketahui kemudian digunakan untuk membentuk distribusi posterior.
Suatu cara lain untuk meringkas ketidakpastian posterior adalah dengan menghitung daerah dari Highest Posterior Density (HPD), yaitu daerah yang berisi
100 1
%
dari peluang posterior di mana densitas yang berada dalam daerah tersebut tidak pernah lebih sempit dibandingkan dengan yang berada di luarnya (Box.Tiao, 1973).Ukuran sampel n yang akan ditentukan dalam tesis ini akan digunakan untuk menaksir parameter proporsi
, maka
merupakan variabel acak yang distribusinya dinyatakan dengan( )
P H
= f
sebagai distribusi peluang prior, selanjutnyaP D H
( | )
=f x
|
: likelihood dari data atau dapat disebut juga dengan distribusi sampling, kemudianP D
( )
=
|
f x
f x
f
d
�
: distribusi peluang marginal dari sampel dalam
(ruangparameter
) yang tidak bergantung pada observasi sebelumnya, sedangkanP H D
( | )
=
| ,
f
x n
: distribusi peluang posterior untuk parameter
yang bergantung pada data x dan n. Dalam analisis Bayesian untuk menaksir sebuah parameter , dalam hal ini adalah proporsi, sebagai pengganti loss function digunakan HPD credible interval yaitu selang dimana length (l) akan mencerminkan presisi, sehingga analisisnya tidak menggunakan full Bayesian formula .Selanjutnya jika informasi awal tidak tersedia, maka penentuan ukuran sampel dapat memilih worst scenario yang menawarkan nilai maksimum dan nilai minimum dari kriteria Bayesian, rata-rata atau rata-rata peluang cakupan. Dari banyak pilihan kriteria ternyata hanya worst scenario yang memberikan jaminan tercapainya presisi yang diinginkan, karena secara umum ukuran sampel yang dihasilkan selalu lebih besar. Sebagai ukuran dari error estimasi yang mengindikasikan akurasi dari penaksiran, umumnya Bayesian menggunakan varians posterior dari taksiran (Joseph, 1995).
lebar interval (l) dan Tolerance Region R yang simetris untuk HPD sehingga diperoleh formula ukuran sampel minimum.
Ukuran sampel untuk proporsi binom ditentukan berdasarkan kriteria ACC eksak yang tidak mudah dikerjakan secara manual, istilah eksak di sini diartikan bahwa satu-satunya sumber error adalah dari computer error (Joseph,1995). Agar penyelesaiannya lebih sederhana, jika n cukup besar maka Adcock (1987) menggunakan pendekatan pada distribusi normal untuk distribusi posteriornya dan akhirnya diperoleh formula ACC yang konservatif sebagai berikut :
2 1 ,
2
1 0.25
n
d
�
(6)penentuan ukuran sampel bergantung pada R(X) yang dipilih. Untuk kasus proporsi multinom, parameter yang ditaksir berupa vektor, selang taksirannya akan berbentuk matriks dan R(X) dipilih Ellipsoida (merupakan proyeksi bola pada bidang datar yang merepresentasikan varians kovarians dari estimator ).
Menurut Wilks(1962) volume ellipsoida mengikuti distribusi chi-kuadrat , sehingga berdasarkan kriteria volume minimum ellipsoida dihasilkan formula ukuran sampel :
2 1 , 2
1
kn
d
�
(7)4. Penentuan Ukuran Sampel Pemilihan Gubernur Jawa Barat
Menurut KPU Jabar, penduduk Jawa Barat yang mempunyai hak pilih adalah sebanyak 27.933.259 orang yang didistribusikan ke dalam 63.031 TPS yang tersebar di 605 kecamatan dari 26 kota/kabupaten, sehingga rata-rata jumlah pemilih per TPS adalah sekitar 400 pemilih.Ukuran sampel yang diperoleh dengan cara frequentist dan Bayesian berupa banyaknya pemilih kemudian dibagi oleh rata-rata banyaknya pemilih per TPS, sehingga satuan terakhir berupa banyaknya TPS terpilih.
Sumber : Harian Kompas, 21 Juli 2008
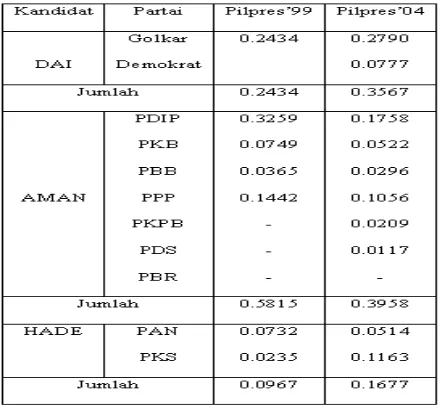
Dalam Pilgub Jabar terdapat tiga pasang kandidat, sehingga banyaknya kategori adalah tiga (k=3), jumlah ini ditentukan ketika golput diabaikan, akan tetapi jika golput dipertimbangkan sebagai suatu pilihan maka banyaknya kategori menjadi empat (k=4). Kandidat pertama diusung oleh dua partai, kandidat kedua diusung tujuh partai dan kandidat ketiga diusung oleh dua partai. Untuk mengetahui peta kekuatan dari ketiga kandidat tersebut, maka pada Tabel 3 disajikan perolehan suara dari partai-partai di atas ketika bertarung dalam pemilu legislatif tahun 1999 dan 2004 di Jawa Barat .
Tabel 4. Perolehan Suara Partai Dalam Pemilu Legislatif Berdasarkan HPD dengan pendekatan Bayes
5. Kesimpulan
Formulasi Bayesian untuk proporsi yang berdistribusi multinom dapat dipilih sebagai alternatif penentuan ukuran sampel dalam pilkada yang menggunakan desain Simple Random Sampling, karena dapat mengakomodasi peta kekuatan setiap kandidat pada pilkada sebelumnya sebagai informasi awal, sehingga tidak perlu survey pendahuluan untuk membuat estimasi bagi parameter proporsinya, akan tetapi apabila populasinya heterogen, maka harus disesuaikan dengan desain samplingnya sehingga variabilitas populasi tercermin dalam TPS terpilih.
Ukuran sampel yang ditawarkan dengan pendekatan Bayes di atas sebaiknya dibandingkan dengan ukuran sampel secara frequentist, agar terlihat konsep mana yang dapat menghasilkan selang kepercayaan yang lebih sempit.
Daftar Pustaka
[1]. Box.Tiao (1973), Bayesian Inference in Statistical Analysis, Addison-Wesley Publishing Company.
[2]. Harold J.Larson (1974), Introduction to Probability Theory and Statistical Inference (2nd ed), Wiley International Edition , 343-347.
[3]. Melissa Estok, Neil Neville and Glenn Cowan (2000), The Quick Count and Election Observation .
[4]. Adcock,C.J(1987),A Bayesian Approach to calculating sample size for multinomial sampling, The Statistician ,vol 36, pp.155 – 159.
[5]. Lawrence Joseph David B. Wolfson and Roxane du Berger (1995), Sample Size Calculation for Binomial Proportions via Highest Posterior Density Intervals, The Statistician vol 44, pp 143-154.
[6]. Pham-Gia, T. And Turkkan, N (1992) Sample Size Determination in Bayesian Analysis.Statistician, Vol.41, pp. 389-397