Kemajuan zaman dan meningkatnya kehidupan modern berbanding lurus dengan mobilitas kehidupan masyarakat. Padatnya aktifitas memicu terjadinya kehidupan sedenter (kurang olahraga) dan pola makan yang kurang terkontrol yang berakibat Diabetes Melitus. Mengidap diabetes dalam jangka panjang mengakibatkan komplikasi vaskular. Mikroangiopati merupakan lesi spesifik diabetes yang menyerang kapiler dan arteriola retina (retinopati diabetik), (Price & Wilson, 2006). Perkembangan kapiler dan arteriola tersebut dapat digunakan untuk mendeteksi dini retinopati diabetik. Oleh karena itu dilakukan penelitian untuk klasifikasi guna mendeteksi retinopati diabetik lebih dini.
Data yang digunakan berasal dari situs MESSIDOR (Methods to evaluate segmentation and indexing techniques in the field of retinal ophthalmology). Jumlah data yang digunakan
sebanyak 100 data citra berwarna. Sebelum dilakukan tahap klasifikasi dilakukan beberapa tahapan berupa preprocessing terdiri dari pemisahan kanal, penajaman kontras, binerisasi, dan cropping. Proses dilanjutkan dengan ekstraksi fitur dengan parameter sigma, thetha, dan F. Langkah berikutnya adalah mereduksi dimensi dengan PCA.
ABSTRACT
The progress of times and the increase of modern life had immediate effects to the mobility of people's lives. The density of activity trigger a sedentary life (lack of exercise) and poorly controlled eating habit cause long-term risk such as diabetes mellitus. Long run diabetes lead to vascular complications. Microangiopathy is a specific lesion of diabetic that attack capillaries and arterioles of the retina (diabetic retinopathy), (Price & Wilson, 2006). This paper focuses on the classification to detect diabetic retinopathy.
The data to be used came from MESSIDOR site (Methods to evaluate segmentation and indexing techniques in the field of retinal ophthalmology). The number of data is 100 colored image data. Before classification stage was done, some preprocessing stages consist of the separation of channels, sharpening contrast, binaryzation, and cropping are performed. The process was followed by feature extraction with parameter sigma, thetha, and F. The next step reducing the dimensions with PCA.
Classification was used is Support Vector Machine by making changes to the kernel function to get the best accuracy value. The results of classification show the best accuration using 3-Order Polynomial Kernel is 99%, while the lowest accuration in the Sequential Minimal Optimization Method kernel is 45%.
KLASIFIKASI POLA MIKROVASKULER RETINA UNTUK DETEKSI DINI RETINOPATI DIABETIK MENGGUNAKAN SUPPORT VECTOR
MACHINE SKRIPSI
Diajukan untuk Memenuhi Salah Satu Syarat Memperoleh Gelar Sarjana Komputer
Program Studi Teknik Informatika
Disusun Oleh : Renny Nita Hernawati
10 5314 104
PROGRAM STUDI TEKNIK INFORMATIKA
JURUSAN TEKNIK INFORMATIKA
FAKULTAS SAINS DAN TEKNOLOGI
UNIVERSITAS SANATA DHARMA
YOGYAKARTA
PATTERN CLASSIFICATION OF RETINAL MICROVASKULER TO EARLY DETECTION OF RETINOPHATY DIABETIC USING SUPPORT
VECTOR MACHINE A Thesis
Presented as Partial Fulfillment of the Requirements to Obtain Sarjana Komputer Degree
in Informatics Enggineering Study Program
By :
Renny Nita Hernawati 10 5314 104
INFORMATICS ENGGINEERING STUDY PROGRAM
DEPARTMENT OF INFORMATICS ENGINEERING
FACULTY OF SCIENCE AND TECHNOLOGY
SANATA DHARMA UNIVERSITY
YOGYAKARTA
2015
HALAMAN PENGESAHAN
Saya menyatakan dengan sesungguhnya, bahwa skripsi yang saya tulis ini tidak memuat karya atau bagian karya orang lain, kecuali yang telah disebutkan dalam kutipan daftar pustaka, sebagaimana layaknya sebuah karya ilmiah.
Yogyakarta, 31 Agustus 2015 Penulis,
HALAMAN MOTTO
“ If A equals success, then the formula is :
A=X+Y+Z
.
X
is work,
Y
is play.
Z
is keep your mouth shut.”
–
Einstein
I can do all things through Christ who strengthens me.
-
Philippians 4:13LEMBAR PERNYATAAN PERSETUJUAN
PUBLIKASI KARYA ILMIAH UNTUK KEPENTINGAN AKADEMIS
Yang bertanda tangan di bawah ini, saya mahasiswa Universitas Sanata Dharma : Nama : Renny Nita Hernawati
NIM : 105314104
Demi pengembangan ilmu pengetahuan , saya memberikan kepada Perpustakaan Universitas Sanata Dharma karya ilmiah saya yang berjudul :
KLASIFIKASI POLA MIKROVASKULER RETINA UNTUK DETEKSI DINI RETINOPATI DIABETIK MENGGUNAKAN SUPPORT VECTOR
MACHINE
beserta perangkat yang diperlukan (bila ada). Dengan demikian saya memberikan kepada Perpustakaan Universitas Sanata Dharma hak untuk menyimpan, me- ngalihkan dalam bentuk media lain, mengelolanya dalam bentuk pangkalan data, mendistribusikan secara terbatas, dan mempublikasikannya di Internet atau media lain untuk kepentingan akademis tanpa perlu meminta ijin dari saya maupun memberikan royalti kepada saya selama tetap mencantumkan nama saya sebagai penulis.
Demikian pernyataan ini yang saya buat dengan sebenarnya. Dibuat di Yogyakarta
Pada tanggal : 31 Agustus 2015 Yang menyatakan
ABSTRAK
Kemajuan zaman dan meningkatnya kehidupan modern berbanding lurus dengan mobilitas kehidupan masyarakat. Padatnya aktifitas memicu terjadinya kehidupan sedenter (kurang olahraga) dan pola makan yang kurang terkontrol yang berakibat Diabetes Melitus. Mengidap diabetes dalam jangka panjang mengakibatkan komplikasi vaskular. Mikroangiopati merupakan lesi spesifik diabetes yang menyerang kapiler dan arteriola retina (retinopati diabetik), (Price & Wilson, 2006). Perkembangan kapiler dan arteriola tersebut dapat digunakan untuk mendeteksi dini retinopati diabetik. Oleh karena itu dilakukan penelitian untuk klasifikasi guna mendeteksi retinopati diabetik lebih dini.
Data yang digunakan berasal dari situs MESSIDOR (Methods to evaluate segmentation and indexing techniques in the field of retinal ophthalmology).
Jumlah data yang digunakan sebanyak 100 data citra berwarna. Sebelum dilakukan tahap klasifikasi dilakukan beberapa tahapan berupa preprocessing terdiri dari pemisahan kanal, penajaman kontras, binerisasi, dan cropping. Proses dilanjutkan dengan ekstraksi fitur dengan parameter sigma, thetha, dan F. Langkah berikutnya adalah mereduksi dimensi dengan PCA.
Percobaan proses klasifikasi dengan Support Vector Machine dilakukan dengan melakukan perubahan pada fungsi kernel. Hasil klasifikasi menunjukkan nilai akurasi terbaik menggunakan kernel Polynomial orde 3 senilai 99%, sedangkan nilai akurasi terendah pada kernel Sequential Minimal Optimization Method sebesar 45%.
The progress of times and the increase of modern life had immediate effects to the mobility of people's lives. The density of activity trigger a sedentary life (lack of exercise) and poorly controlled eating habit cause long-term risk such as diabetes mellitus. Long run diabetes lead to vascular complications. Microangiopathy is a specific lesion of diabetic that attack capillaries and arterioles of the retina (diabetic retinopathy), (Price & Wilson, 2006). This paper focuses on the classification to detect diabetic retinopathy.
The data to be used came from MESSIDOR site (Methods to evaluate segmentation and indexing techniques in the field of retinal ophthalmology). The number of data is 100 colored image data. Before classification stage was done, some preprocessing stages consist of the separation of channels, sharpening contrast, binaryzation, and cropping are performed. The process was followed by feature extraction with parameter sigma, thetha, and F. The next step reducing the dimensions with PCA.
KATA PENGANTAR
Puji syukur penulis panjatkan kepada Tuhan Yesus Kristus yang telah memberikan rahmat dan karunia yang berlimpah sehingga penulis dapat menyelesaikan tugas akhir dengan baik.
Penulis menyadari bahwa pada saat penyusunan tugas akhir ini penulis mendapatkan banyak bantuan dari berbagai pihak, baik berupa dukungan, perhatian, kritik dan saran yang sangat penulis butuhkan. Pada kesempatan ini penulis akan menyampaikan ucapan terima kasih kepada:
1. Tuhan Yesus Kristus yang senantiasa mencurahkan kasih karunianya serta memberikan bimbingan dan berkat dalam setiap hal.
2. Dr. Cyprianus Kuntoro Adi, SJ., M.A., M.Cs selaku dosen pembimbing tugas akhir yang telah dengan sabar dan penuh perhatian membimbing saya dalam penyusunan tugas akhir. Terima kasih atas motivasi yang selalu diberikan untuk mendorong saya.
3. Ibu Dr. Anastasia Rita Widiarti M.Kom dan bapak Robertus Adi Nugroho S.T., M.Eng. selaku dosen penguji tugas akhir yang telah memberikan kritik dan saran yang berguna dalam tugas akhir ini.
4. Kedua orang tua tercinta Bapak Paryono dan Ibu Ukin suhari yang selalu mendoakan, memotivasi, dan memberikan dukungan moral maupun dukungan financial kepada penulis, sehingga penulis dapat menyelesaikan tugas akhir ini.
5. Kakakku Henny Dian Puntorini yang selalu mendukung, mendoakan, memotivasi, dan selalu mengingatkanku untuk tidak pernah berputus asa dalam penyusunan tugas akhir ini.
6. Sahabat-sahabatku Amel, Novi, Andhini, Ria, Maria, Sepen, Stella, Vyta, Dita, Tommy, Tedy, Theo, Ardy, Doni, Yoga, Ougi, Edo, Karl, Fafe yang berjuang bersama dalam penyusunan tugas akhir dan atas canda tawa yang selalu ada mewarnai hari-hari penyusunan tugas akhir ini.
7. Romo Poldo, Audris Evan Utomo, dan festi tempat berbagi dan belajar bersama
8. Aryo Seno pacar, partner, sekaligus sahabat terbaik yang senantiasa memberikan dukungan serta tempat berkeluh kesah.
9. Teman-teman TI angkatan 2010 Sanata Dharma terimakasih atas semangat dan perjuangan bersama yang selalu kalian berikan kepada satu sama lain. 10. Terima kasih kepada semua pihak yang tidak dapat penulis sebutkan satu per
satu yang telah mendukung penyelesaian tugas akhir ini secara langsung atau tidak langsung.
Penulis menyadari adanya kekurangan dalam penulisan laporan tugas akhir ini. Saran dan kritik sangat penulis harapkan untuk perbaikan yang akan datang. Akhir kata, penulis berharap tulisan ini berguna bagi perkembangan ilmu pengetahuan dan pengguna.
Yogyakarta, 31 Agustus 2015
DAFTAR ISI
HALAMAN JUDUL ... i
HALAMAN PERSETUJUAN ... iii
HALAMAN PENGESAHAN ... iv
PERNYATAAN KEASLIAN KARYA ... v
HALAMAN MOTTO ... vi
LEMBAR PERNYATAAN PERSETUJUAN ... vii
ABSTRAK ... xiii
KATA PENGANTAR ... x
DAFTAR ISI ... xii
DAFTAR GAMBAR ... xiv
DAFTAR TABEL ...xv
BAB I ... 1
PENDAHULUAN ... 1
10.1 Latar Belakang Masalah ... 1
10.2 Rumusan Masalah ... 3
10.3 Tujuan Penelitian ... 4
10.4 Batasan Masalah ... 4
10.5 Luaran penelitian... 4
10.6 Metodologi penelitian ... 5
10.7 Sistematika Penelitian ... 6
BAB II ... 7
LANDASAN TEORI ... 7
2.1.Retinopati Diabetik ... 7
2.2.Pengolahan Citra Digital ... 13
2.3Pengenalan Pola ... 14
2.3.1.Ekstraksi fitur ... 15
BAB III... 22
METODOLOGI PENELITIAN ... 22
3.1.Data ... 22
3.2.Metodologi Penelitan ... 23
3.3.Metode Preprocessing ... 25
3.3.Metode Ekstraksi Fitur dengan Menggunakan Filter Gabor 2D ... 25
BAB IV ... 30
IMPLEMENTASI DAN ANALISA SISTEM ... 30
4.1. User Interface ... 30
4.2. Analisis Hasil ... 33
4.2.1 Preprocessing ... 33
4.2.2 Filter Gabor 2D ... 36
4.2.3 Support Vector Machine ... 38
BAB V ... 52
KESIMPULAN DAN SARAN ... 52
5.1 Kesimpulan ... 52
5.2 Saran ... 53
DAFTAR PUSTAKA ... 54
LAMPIRAN I : DATA TRAINING ... 56
DAFTAR GAMBAR
Gambar 2.1 Mekanisme Pengenalan Pola………. 15
Gambar 3. 1 Citra digital retina grade0, grade 1, grade 2, grade 3…………. 23
Gambar 3. 2 Diagram Blok Keseluruhan Sistem……… 24
Gambar 3. 3 Diagram Blok Preproses……… 25
Gambar 3. 4 Citra Kanal merah, hijau, biru……… 26
Gambar 3. 5 Citra biner dan Negasi……… 28
Gambar 4. 1 User interface Halaman utama………... 34
Gambar 4. 2 Halaman Preprocessing……….. 34
Gambar 4. 3 Halaman Hasil Preprocessing……… 35
Gambar 4. 4 Halaman Hasil Klasifikasi………. 36
Gambar 4. 5 Tampilan Uji Tunggal……… 36
Gambar 4. 6 Grafik Akurasi menggunakan PCA dan tanpa PCA………….. 44
Tabel 4. 7 Confussion Matrix kernel Polynomial menggunakan PCA……... 44
Tabel 4. 8 Confussion Matrix Kernel Sequential Minimal Optimization
dengan PCA………
45
DAFTAR TABEL
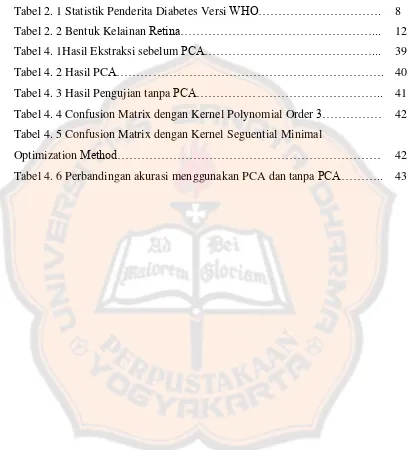
Tabel 2. 1 Statistik Penderita Diabetes Versi WHO………. 8
Tabel 2. 2 Bentuk Kelainan Retina………... 12
Tabel 4. 1Hasil Ekstraksi sebelum PCA………... 39
Tabel 4. 2 Hasil PCA………. 40
Tabel 4. 3 Hasil Pengujian tanpa PCA……….. 41
Tabel 4. 4 Confusion Matrix dengan Kernel Polynomial Order 3……… 42
Tabel 4. 5 Confusion Matrix dengan Kernel Seguential Minimal Optimization Method……… 42
BAB I
PENDAHULUAN
1.1Latar Belakang Masalah
Kemajuan zaman dan meningkatnya kehidupan modern berbanding lurus dengan mobilitas kehidupan masyarakat. Dampaknya masyarakat
cenderung menyukai hal yang berbau praktis dan cepat. Padatnya aktifitas juga semakin memicu terjadinya kehidupan sedenter (kurang olahraga) dan pola makan yang kurang terkontrol. Pada umumnya masyarakat Indonesia
menyukai panganan pokok berupa nasi. Berbeda dengan cara konsumsi di negara lain yang melakukan variasi makanan pokok. Padahal makanan pokok
berupa nasi dikenal sebagai makanan yang tinggi karbohidrat. Akibatnya masyarakat Indonesia lebih rentan terserang penyakit berbahaya Diabetes Melitus.
Diabetes melitus adalah gangguan metabolisme yang secara genetis dan klinis termasuk heterogen dengan manifestasi berupa hilangnya toleransi karbohidrat (Price, 2006). Diabetes sendiri merupakan salah satu ancaman
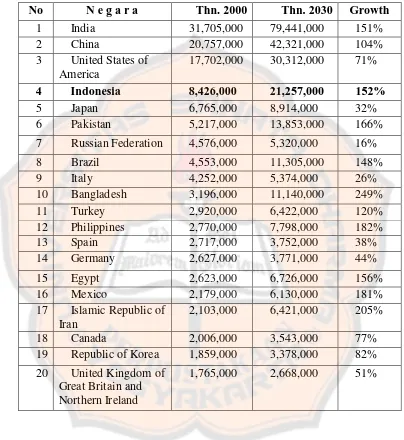
bagi kesehatan umat manusia di abad 21. Menurut World Health Organization (WHO) Indonesia berada di urutan keempat Negara dengan jumlah
penyandang Diabetes Melitus terbanyak. Jumlah penderitanya diprediksi akan semakin meningkat hingga mencapai angka 21,3 juta pada tahun 2030 (Sitompul,2008).
Mengidap Diabetes dalam jangka waktu lama beresiko terhadap berbagai kelainan lain baik pada penderita diabetes tipe 1 maupun 2, yaitu
hipoglikemia, ketoasidasis, dan komplikasi. Hipoglikemia merupakan dampak Diabetes dimana penderitanya mengalami kadar gula dalam darah sangat rendah atau di bawah normal. Ketoasidasis terjadi ketika glukosa dalam darah
tidak dapat diolah dengan baik oleh tubuh, sehingga tubuh menggunakan lemak dan protein dalam proses pembakaran energi. Dampak lain yang cukup
berbahaya merupakan komplikasi, gejalanya akan nampak berupa serangan jantung, stroke, kebutaan, penyakit ginjal dan luka yang sulit disembuhkan
hingga diperlukan adanya amputasi.
Komplikasi vaskular jangka panjang dari diabetes melibatkan pembuluh-pembuluh kecil berupa mikroangiopati dan pembuluh sedang besar makroangiopati. Mikroangiopati merupakan lesi spesifik diabetes yang
menyerang kapiler dan arteriola retina (retinopati diabetik), glomerulus ginjal (neuropati diabetik), dan saraf-saraf perifer (neuropati diabetik) serta otot-otot
dan kulit. (Price, 2006)
Kebutaan yang terjadi pada penderita diabetes disebabkan oleh retinopati diabetik. Penyebabnya bukan hanya lamanya seseorang menderita
diabetes, faktor lain yang memicu berupa pubertas,kehamilan, dan hiperglikemia. Jika pada hipoglikemia penderitanya mengalami kadar gula rendah hal sebaliknya terjadi pada penderita hiperglikemia. Hiperglikemia
3
Hal inilah yang menimbulkan kebutaan hingga menurunkan produktifitas seseorang, lebih jauh lagi akan menjadi beban bagi lingkungan.
Permasalahan retinopati dan menurunnya produktivitas dapat diminimalisir dengan pendeteksian dini yang dapat dilakukan oleh dokter
umum. Dokter umum memiliki peranan penting dalam deteksi dini retinopati. Dengan melakukan prosedur penatalaksanaan awal kemudian dilanjutkan
dengan menentukan kasus rujukan ke dokter spesialis mata.
Berdasarkan latar belakang tersebut diatas, untuk mendukung kerja peranan dokter umum diperlukan suatu sistem deteksi dengan menggunakan
model komputasi. Dengan adanya hal tersebut resiko terjadinya retinopati dapat diminimalisir. Oleh karena itu peneliti akan membangun suatu sistem kecerdasan buatan yang mampu mendeteksi tingkat resiko retinopati diabetik
berdasarkan hasil citra digital dari kamera fundus dengan menampilkan hasil yang sudah diklasifikasikan untuk membantu pengambilan keputusan dan
diagnosis kelanjutan yang akan dilakukan oleh dokter umum.
1.2Rumusan Masalah
Berdasarkan latar belakang yang telah dijelaskan sebelumnya peneliti
merumuskan permasalahan yakni,
1. Apakah metode Support Vector Machine dapat digunakan
untuk mengklasifikasikan citra digital retina berwarna untuk deteksi retinopati diabetik?
2. Berapakah nilai akurasi yang dihasilkan?
1.3Tujuan Penelitian
Tujuan dari dilakukannya penelitian ini untuk melakukan klasifikasi pola
mikrovaskuler pada suatu citra digital retina untuk mendeteksi retinopati diabetik dengan tepat.
1.4Batasan Masalah
Mengingat cakupan permasalahan yang akan diteliti begitu luas, maka
peneliti melakukan pembatasan permasalahan yang akan dibahas, meliputi :
1. Citra digital retina yang akan diuji adalah citra digital retina yang berasal dari database MESSIDOR.
2. Menggunakan inputan citra digital berwarna retina bertipe .tiff
3. Citra inputan mengalami proses preprocessing dengan menggunakan fungsi yang disediakan library MATLAB.
4. Proses ekstraksi ciri dengan menggunakan filter Gabor 2D.
5. Pengklasifikasian didasarkan pada hasil diagnosa medis yang menunjukkan jumlah mikroaneurisma, hemorrhages, dan neovaskularisasi.
1.5Luaran penelitian
Suatu sistem cerdas yang mampu menerima masukan berupa citra digital
5
1.6Metodologi penelitian
Manfaat dan kegunaan dari dilakukannya penelitian ini antara lain :
1. Metode Studi literatur
Studi literatur berfungsi untuk mencari dan mengumpulkan beragam
literatur yang berkaitan dengan penelitian. Metode ini dilakukan dengan mengumpulkan berbagai informasi tentang retinopati diabetik, citra digital, ekstraksi fitur, dan Support Vector Machine melalui internet, jurnal, dan
media informasi lainnya.
2. Pengumpulan Data
Tahap ini dilakukan dengan mencari dan mengumpulkan data yang didapat
dari database MESSIDOR.
3. Perancangan
Tahap perancangan merupakan tahap untuk merancang jalannya penelitian
baik dari preprocessing hingga didapatkan hasil klasifikasi.
4. Implementasi dan pengujian
Implementasi merupakan tahap merealisasikan rancangan yang telah
dibuat untuk menghasilkan luaran berupa hasil klasifikasi menggunakan SVM. Sedangkan pengujian merupakan tahap untuk menguji seberapa tinggi tingkat akurasi yang dihasilkan.
5. Evaluasi
Menganalisa hasil implementasi dan membuat kesimpulan yang
didasarkan pada hasil yang telah dikerjakan.
1.7Sistematika Penelitian BAB I PENDAHULUAN
Berisi latar belakang, rumusan masalah, tujuan, batasan masalah, metodologi penelitian, dan sistematika penulisan.
BAB II LANDASAN TEORI
Berisi landasan teori yang dipakai untuk pembahasan tugas akhir.
BAB III ANALISA DAN PERANCANGAN SISTEM
Bab ini berisi dan gambaran umum mengenai perancangan sistem yang akan
dibangun, yaitu sebuah perangkat lunak yang dapat mengenali citra masukan dan menghasilkan luaran berupa informasi yang sudah diklasifikasikan
BAB IV IMPLEMENTASI SISTEM
Berisi implementasi sistem menggunakan metode Support Vector Machine.
BAB V ANALISA HASIL DAN PEMBAHASAN
Bab ini berisi analisa hasil dan pembahasan mengenai pengenalan dan
pengujian citra retina.
BAB VI KESIMPULAN DAN SARAN
Bab ini berisi kesimpulan dan saran yang diperoleh dari pembuatan tugas
BAB II
LANDASAN TEORI
Bab ini menjelaskan tentang teori-teori yang digunakan, yaitu tentang retinopati diabetik, pengolahan citra digital, ekstraksi fitur, dan klasifikasi
berdasarkan Support Vector Machine.
2.1. Retinopati Diabetik
Diabetes melitus adalah gangguan metabolisme yang secara genetis dan klinis
termasuk heterogen dengan manifestasi berupa hilangnya toleransi karbohidrat. Jika berkembang secara klinis, maka diabetes melitus ditandai dengan hiperglikemia puasa dan postpradial, aterosklerotik, dan penyakit vaskular
mikroangiopati, dan neuropati. Pasien dengan kelainan toleransi glukosa ringan (gangguan glukosa puasa dan gangguan toleransi glukosa) dapat tetap berisiko
mengalami komplikasi metabolik diabetes. (Price, 2006)
Berdasarkan hasil statistik dari berbagai sumber penderita diabetes selalu mengalami peningkatan dari tahun ke tahun. Tabel 2.1 menunjukan statistik
penderita diabetes versi WHO. Pada tabel 2.1 ditunjukan jumlah penderita pada tahun 2000 dan prediksi jumlah penderita pada tahun 2030 yang disertai dengan persentase pertumbuhan penderita diabetes. Indonesia berada pada urutan keempat
dari penderita diabetes terbanyak didunia.
Tabel 2. 1 Statistik Penderita Diabetes Versi WHO
17,702,000 30,312,000 71%
4 Indonesia 8,426,000 21,257,000 152%
5 Japan 6,765,000 8,914,000 32%
6 Pakistan 5,217,000 13,853,000 166% 7 Russian Federation 4,576,000 5,320,000 16% 8 Brazil 4,553,000 11,305,000 148%
9 Italy 4,252,000 5,374,000 26%
10 Bangladesh 3,196,000 11,140,000 249% 11 Turkey 2,920,000 6,422,000 120% 12 Philippines 2,770,000 7,798,000 182%
13 Spain 2,717,000 3,752,000 38%
14 Germany 2,627,000 3,771,000 44% 15 Egypt 2,623,000 6,726,000 156% 16 Mexico 2,179,000 6,130,000 181% 17 Islamic Republic of
Iran
Diabetes melitus hiperglikemia kronik menimbulkan kerusakan jangka panjang berupa disfungsi atau kerusakan beberapa organ, terutama mata, ginjal,
9
Komplikasi metabolik diabetes disebabkan oleh perubahan yang relatif akut dari konsentrasi glukosa plasma. Sedangkan komplikasi vaskular jangka panjang
dari diabetes melibatkan pembuluh-pembuluh kecil mikroangeropati dan pembuluh-pembuluh sedang dan besar makroangiopati. Mikroangiopati merupakan lesi spesifik diabetes yang menyerang kapiler dan arteriola retina
(retinopati diabetik) dan saraf-saraf perifer (neuripati diabetik) dan saraf-saraf perifer (neuropati diabetik), otot-otot serta kulit. Dipandang dari sudut histokimia,
lesi-lesi ini ditandai dengan peningkatan penimbunan glikoprotein. Selain itu, karena senyawanya kimia dari membran dasar dapat berasal dari glukosa, maka
hiperglikemia menyebabkan bertambahnya kecepatan pembentukan sel-sel membran dasar.
Perkembangan retinopati berkaitan dengan hiperglikemia yang diawali oleh keberadaan mikroaneurisma yaitu pelebaran sakular yang kecil dari arteriola
retina. Hal ini yang menyebabkan terjadinya neovaskularisasi dan jaringan parut yang dapat menumbulkan kebutaan dan disebut dengan retinopati.
Retinopati diabetik terjadi sebagai akibat dari lamanya menderita Diabetes Melitus. Patofisiologi pada retinopati diabetik melibatkan lima proses yang terjadi yaitu (Price, 2006) :
1. Pembentukan mikroaneurisma
2. Peningkatan permeabilitas pembuluh darah 3. Penyumbatan pembuluh darah
4. Proliferasi pembuluh darah baru (neovaskular) dan jaringan fibrosa di retina 5. Kontraksi dari jaringan fibrosis kapiler dan jaringan vitreus.
Penyumbatan dan kebocoran yang terjadi pada beberapa pembuluh darah merupakan penyebab terjadinya kebutaan. Tingkat kebocoran yang terjadi
mendasarkan jenis retinopati itu sendiri.
Klasifikasi retinopati Diabetes pada umumnya didasarkan pada beratnya perubahan mikrovaskular retina dan ada tidak adanya pembentukan pembuluh
darah baru di retina. Early Treatment Diabetic Retinopathy Study Research Group (ETDRS) membagi retinopati diabetik atas nonproliferatif dan proliferatif. (W.Sudoyo, dkk, 2009)
Klasifikasi Retinopati Diabetik Menurut ETDRS tersebut sebagai berikut :
Retinopati diabetik nonproliferatif
Retinopati nonproliferatif minimal: terdapat ≥ 1 tanda berupa dilatasi vena, mikroaneurisma, perdarahan intraretina yang kecil atau eksudat keras.
1. Retinopati nonproliferatif ringan sampai sedang: terdapat ≥ 1 tanda berupa dilatasi vena derajat ringan, perdarahan, eksudat keras, eksudat lunak atau
IRMA.
2. Retinopati nonproliferatif berat: terdapat ≥ tanda berupa perdarahan dan mikroaneurisma pada 4 kuadran retina, dilatasi vena pada 2 kuadran, atau
IRMA pada 1 kuadran
11
Retinopati diabetik proliferatif
1. Retinopati proliferatif ringan (tanpa resiko tinggi): bila ditemukan minimal adanya neovaskular pada diskus (NVD) yang mencangkup < ¼ dari daerah diskus tanpa disertai perdarahan preretina atau vitreus; atau neovaskular di
mana saja di retina (NVE) tanpa disertai perdarahan preretina atau vitreus.
2. Retinopati proliferatif resiko tinggi; apabila ditemukan 3 atau 4 dari factor resiko sebagai berikut,
3. ditemukan pembuluh darah baru di mana saja di retina,
4. ditemukan pembuluh darah baru pada atau dekat diskus optikus,
5. pembuluh darah baru yang tergolong sedang atau berat yang mencangkup < ¼ daerah diskus,
6. perdarahan vitreus adanya pembuluh darah baru yang jelas pada diskus optikus atau setiap adanya pembuluh darah baru yang disertai perdarahan, merupakan dua gambaran yang paling sering ditemukan pada retinopati
proliferatif dengan resiko tinggi.
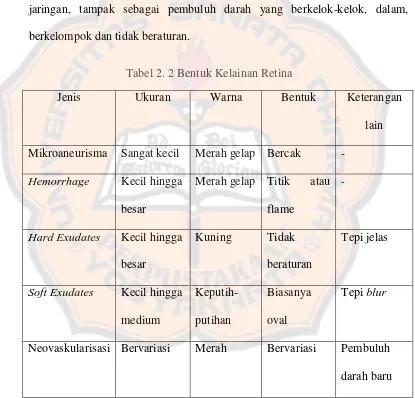
Kelainan pada retina yang dapat terjadi akibat retinopati diabetik diantaranya (Kuivalainen, 2005) :
1. Mikroaneurisma merupakan penonjolan dinding kapiler terutama daerah vena dengan bentuk berupa bintik merah kecil yang terletak dekat pembuluh darah.
2. Hemorrhages biasanya tampak pada dinding kapiler dan terlihat bercak darah keluar dari pembuluh darah, terlihat berwarna merah gelap, lebih besar dari
mikroaneurisma.
3. Hard exudates merupakan infiltrasi lipid ke dalam retina. Gambarannya khusus yaitu tidak beraturan dan kekuning-kuningan.
4. Soft exudates sering disebut cotton wool patches merupakan iskemia retina, terlihat bercak berwarna kuning bersifat difus dan berwarna putih.
5. Neovaskularisasi atau pembuluh darah baru biasanya terletak di permukaan jaringan, tampak sebagai pembuluh darah yang berkelok-kelok, dalam,
berkelompok dan tidak beraturan.
Tabel 2. 2 Bentuk Kelainan Retina
Jenis Ukuran Warna Bentuk Keterangan lain
Mikroaneurisma Sangat kecil Merah gelap Bercak -
Hemorrhage Kecil hingga
besar
Merah gelap Titik atau
flame
-
Hard Exudates Kecil hingga
besar
Kuning Tidak
beraturan
Tepi jelas
Soft Exudates Kecil hingga medium
Neovaskularisasi Bervariasi Merah Bervariasi Pembuluh
darah baru
Hasil diagnosa medis setiap citra dapat menunjukkan tingkat retinopati diabetik (Setiawan, 2012):
13
1 : (0 < μA <= 5) AND (H = 0)
2 : ((5 < μA < 15) OR (0 < H < 5)) AND (NV = 0)
3 : (μA >= 15) OR (H >=5) OR (NV = 1)
μA adalah jumlah mikroaneurisma, H adalah jumlah hemorrhages, NV = 1 artinya
terdapat neovaskularisasi, NV = 0 artinya tidak terdapat neovaskularisasi.
2.2. Pengolahan Citra Digital
Secara umum, istilah pengolahan citra digital menyatakan “pemrosesan
gambar berdimensi-dua melalui computer digital”. Menurut Efford, pengolahan
citra adalah istilah umum untuk berbagai teknik yang keberadaannya untuk memanipulasi dan memodifikasi citra dengan berbagai cara. (Abdul Kadir, 2013)
Suatu citra dapat didefinisikan sebagai fungsi y f(x,y) berukuran M baris
dan N kolom, dengan x dan y adalah koordinat spasial, dan amplitude f di titik koorditat (x,y) dinamakan intensitas atau tingkat keabuan dari citra pada titik tersebut. Apabila nilai x,y dan nilai amplitude f secara keseluruhan berhingga
(finite) dan bernilai diskrit maka dapat dikatakan bahwa citra tersebut adalah citra (Putra, 2010).
Pada pengenalan pola, pengolahan citra antara lain berperan memisahkan objek dari latar belakang secara otomatis. Selanjutnya objek akan diproses oleh pengklasifikasi pola.
Seringkali dijumpai citra yang memiliki kualitas rendah akibat kekurangan sinar ketika dibidik. Dengan menggunakan pengolahan citra, citra seperti itu dapat diperbaiki melalui peningkatan kecerahan dan kontras. Pada penelitian ini
dilakukan penajaman dengan kontras dengan CLAHE (Contras Limited Adaptive
Histogram Equalization). CLAHE dapat digunakan sebagai alternative pengganti
ekualisasi histogram. Ekualisasi histogram bekerja pad seluruh citra, sedangkan
CLAHE beroperasi pada daerah kecil di citra yang disebut blok. Setiap blok ditingkatkan nilai kontrasnya, sehingga histogram dari wilayah sekitar cocok untuk histogram tertentu. Setelah melakukan pemerataan, CLAHE
menggabungkan blok tetangga menggunakan interpolasi biner untuk menghilangkan batas-batas artifisial. CLAHE juga dapat dilakukan untuk
menghindari derau yang ada pada citra dengan membatasi daerah homogen. (Setiawan, 2012) .
2.3Pengenalan Pola
Pengenalan pola (pattern recognition) adalah suatu ilmu untuk
mengklasifikasikan atau menggambarkan sesuatu berdasarkan pengukuran kuantitatif fitur (ciri) atau sifat utama dari suatu obyek. Pola sendiri adalah suatu entitas yang terdefinisi dan dapat diidentifikasikan serta diberi nama. Pola bisa
merupakan kumpulan hasil pengukuran atau pemantauan dan bisa merupakan kumpulan hasil pengukuran atau pemantauan dan bisa dinyatakan dalam notasi
vektor atau matriks (Putra, 2010)
Pada dasarnya pengenalan pola terdiri dari beberapa mekanisme utama yang tergantung dari pendekatan yang dilakukan. Beberapa kasus data yang sudah
15
Gambar 2.1Mekanisme Pengenalan Pola
Pra pengolahan berfungsi mempersiapkan data citra digital retina agar
dapat menghasilkan ciri yang lebih baik pada tahap berikutnya. Pada tahap ini dilakukan proses grayscaling, penajaman kontras, dan cropping yang bertujuan untuk menonjolkan ciri dan mengurangi dimensi data.
Pencari dan seleksi fitur merupakan langkah untuk menemukan karakteristik pembeda yang mewakili sifat utama pada citra digital retina sekaligus mengurangi dimensi menjadi sekumpulan bilangan yang lebih sedikit
namun representatif.
Klasifikasi berfungsi mengelompokan hasil ekstraksi fitur ke dalam kelas yang sesuai dengan menggunakan pemisah kelas.
2.3.1. Ekstraksi fitur
Ekstraksi fitur merupakan langkah awal dalam melakukan klasifikasi dan interpretasi citra. Proses ini berkaitan dengan kuantisasi karakteristik citra ke
dalam sekelompok nilai ciri yang sesuai. Secara umum metode ekstraksi fitur dikelompokkan menjadi empat bagian (Putra, 2010) yaitu :
1. Berdasarkan bentuk atau topologi
2. Berdasarkan sifat-sifat permukaan atau tekstur 3. Berdasarkan struktur geometri
4. Berdasarkan warna
Fitur menurut D.G. Kendall (M.B Stegman, 2002) dinyatakan dengan susunan bilangan yang dapat dipakai untuk mengidentifikasi objek.
Fitur-fitur suatu objek mempunyai peran penting untuk berbagai aplikasi berikut :
1. Pencarian citra : fitur dipakai untuk mencari objek-objek tertentu yang berada
di dalam database.
2. Penyederhanaan dan hampiran bentuk : bentuk objek dapat dinyatakan dengan representasi yang lebih ringkas
3. Pengenalan dan klasifikasi: sejumlah fitur dipakai untuk menentukan jenis objek.
Untuk kepentingan aplikasi yang telah disebutkan, fitur hendaknya efisen.
Fitur yang efisien perlu memenuhi sifat-sifat penting berikut : (Mingqiang, Kidiyo, & Joseph, 2008) :
1. Teridentifikasi : fitur berupa nilai yang dapat digunakan untuk membedakan antara suatu objek dengan objek lain. Jika kedua fitur
tersebut didampingkan, dapat ditemukan perbedaan hakiki.
2. Tidak dipengaruhi oleh translas, rotasi, dan penyekalan. Dua objek sama tetapi berbeda dalam lokasi, arah pemutaran, dan ukuran tetap dideteksi
sama.
17
5. Tidak bergantung pada tumpang tindih
6. Tidak bergantung secara statis : dua fitur harus tidak bergantung satu
dengan yang lain secara statistik.
2.3.1.1 Filter Gabor 2D
Metode Filter Gabor 2D mampu menghubungkan representasi tekstur dan
detektor citra yang optimal. Fungsi fabor Filter 2D juga mampu meminimalisasi ciri yang tidak penting dalam citra. (Mandasari, dkk, 2012)
Filter Gabor 2D diperoleh dari sebuah fungsi Gaussian yang dimodulasi
menggunakan variasi frekuensi ditunjukkan dengan
Fungsi Gaussian 2-D ditunjukkan dengan persamaan :
(2.1)
Dengan nilai dan nilai . x
dan y merupakan nilai koordinat piksel dalam citra, f merupakan frekuensi
gelombang sinusoidal, merupakan kontrol terhadap orientasi dari sebuah
fungsi Filter Gabor 2D, dan σ merupakan standar deviasi dimana .
Fungsi kompleks filter Gabor 2D ditunjukkan dengan persamaan :
(2.2)
Real
(2.3)
Imaginer
(2.4)
2.3.1.2 Principal Component Analysis
Analisis komponen utama atau Pincipal Component Analysis adalah salah satu cara mengidentifikasi pola dalam data dan mengekspresikannya sedemikian rupa sehingga dapat terlihat persamaan dan perbedaannya. Pola ini
berguna untuk mengkompresi data, yaitu mengurangi ukuran atau dimensi data tanpa kehilangan banyak informasi yang terkandung.
Principal Component Analysis (PCA) melakukan/ transformasi set data
dari dimensi lama ke dimensi baru (yang relatif berdimensi lebih rendah) dengan memanfaatkan teknik dalam aljabar linear, tanpa memerlukan masukan parameter tertentu dalam memberikan hasil pemetaan. Tujuan dari
PCA yaitu meminimalkan redundansi yang diukur oleh nilai jarak dari kovarian dan memaksimalkan nilai keluaran pemetaan, diukur dengan varian.
Jika data dalam dimensi asli sulit untuk dipresentasikan melalui grafik, maka data tersebut disederhanakan menggunakan data set yang dipresentasikan melalui rumus. Misalkan mempunyai data set yang sudah
decentering dengan kovarian
(2.5)
19
(2.6)
atau
(2.7)
Persamaan di atas bisa diselesaikan untukmencari nilai dengan menyelesaikan
(2.8)
Untuk eigenvalue dan eigenvector dengan solusi
adalah eigenvector dan adalah eigenvalue yang terletak dalam span
(Santoso, 2007)
2.3.1.3 Support Vector Machine
Support Vector Machine (SVM) dikembangkan oleh Boser, Guyon,
Vapnik. Pertama kali dipresentasikan pada tahun 1992 di Annual Workshop on Computational Learning Theory. SVM merupakan metode yang berusaha menemukan hyperplane terbaik pada input space. Prinsip dasar SVM adalah
pengklasifikasi linier, dan selanjutnya dikembangkan agar dapat bekerja pada permasalahan nonlinier dengan memasukkan konsep kernel trick pada ruang
kerja berdimensi tinggi. (Nugroho dkk, 2003).
Hyperplane (batas keputusan) pemisah terbaik antara kedua kelas dapat ditemukan dengan mengukur margin dan mencari titik maksimalnya. Margin
adalah jarak antara hyperplane tersebut dengan data terdekat dari masing- masing kelas. Data yang paling dekat ini disebut sebagai support vector.
Usaha untuk mencari lokasi hyperplane merupakan inti dari proses pelatihan pada SVM. Data latih yang tersedia dinyatakan oleh (xi, yi)
dengan i = 1, 2, …, N, dan xi = xi1, xi2, … xiq)T sebagai atribut (fitur) set
untuk data latih yang ke-i, Untuk yi ϵ {-1,+1} menyatakan label kelas. Diasumsikan terpisah oleh hyperplane klasifikasi linear SVM, yang
dinotasikan :
(2.9)
w dan b adalah parameter model. Secara teknis SVM bertujuan
menentukan variabel w dan b sehingga data pelatihan dideskripsikan sebagai :
(2.10)
(2.11)
Agar SVM dapat bekerja pada permasalahan non-linear, perlu proses
pemetaan dengan menggunakan perhitungan dot-product dua buah data pada ruang fitur baru untuk memetakan data ke dimensi yang lebih tinggi. Teknik
komputasi ini disebut dengan kernel trick, yaitu menghitung dot-product dua buah vector di ruang dimensi baru dengan menggunakan komponen kedua buah vector tersebut di ruang dimensi asal sebagai berikut:
21
Dan untuk prediksi pada set data dengan dimensi fitur yang baru diformulasikan :
(2.13)
N adalah jumlah data yang menjadi support vector, xi adalah support
vector, dan z adalah data uji yang akan dilakukan prediksi.
BAB III
METODOLOGI PENELITIAN
Bab Analisa dan Perancangan Sistem merupakan bab yang berisi
penjelasan mengenai gambaran proses yang akan dilalui beserta cara kerja yang akan digunakan dalam penelitian.
3.1.Data
Data yang digunakan untuk penelitian merupakan data yang dimiliki oleh MESSIDOR (Methods to evaluate segmentation and indexing techniques in the field of retinal ophthalmology). MESSIDOR adalah program penelitian Techno
Vision yang didanai oleh Kementrian Riset dan Pertahanan Perancis pada tahun 2004.
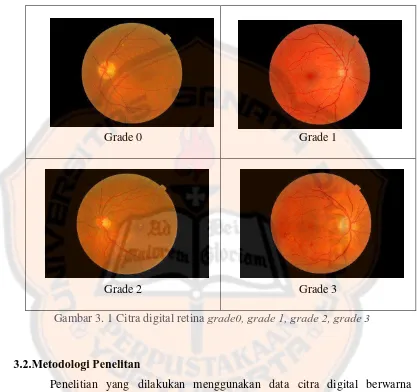
Data MESSIDOR yang digunakan berupa data citra digital retina berekstensi .tiff . Data yang digunakan berjumlah 100 data citra yang terdiri dari 25 data mata normal, 25 data grade 1, 25 data grade 2, dan 25 data grade 3.
Penampakan data citra yang digunakan dapat dilihat pada halaman lampiran.
Data citra yang digunakan mengandung informasi utnuk menentukan tingkat keparahan retinopati diabetik yang diderita. Informasi tersebut ditunjukan
23
Contoh citra retina sehat dan yang terjangkit retinopati diabetik ditunjukkan pada gambar 3.1
Grade 0 Grade 1
Grade 2 Grade 3
Gambar 3. 1 Citra digital retina grade0, grade 1, grade 2, grade 3
3.2.Metodologi Penelitan
Penelitian yang dilakukan menggunakan data citra digital berwarna
sebagai masukkan. Karakter yang akan dikenali pada citra tersebut berupa beratnya perubahan mikrovaskular retina dan ada tidaknya pembetukan pembuluh
darah baru.
Input yang diproses dengan menggunakan ekstensi .tiff dengan ukuran asli 2240x1488 pixel berupa citra digital berwarna retina. Data cita masukkan
akan melalui preprocessing yang terdiri dari beberapa langkah. Langkah untuk melakukan preprocessing diawali dengan memisahkan kanal yang terdiri dari
kanal merah, hijau, dan biru. Hasil dari kanal hijau yang digunakan pada penelitian. Citra kanal hijau kemudian mengalami penajaman kontras untuk
menonjolkan informasi di dalamnya. Hasil dari penajaman kontras dikenai proses binerisasi kemudian dinegasikan. Untuk semakin meminimalkan ukuran dilakukan proses cropping. Gambaran dari keseluruhan sistem yang dibuat
ditunjukkan pada gambar 3.2 berupa diagram blok keseluruhan sistem.
Gambar 3. 2 Diagram Blok Keseluruhan Sistem
25
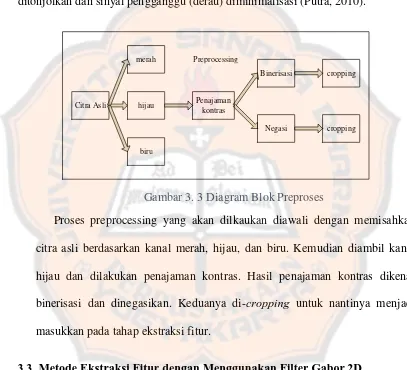
3.3.Metode Preprocessing
Proses preprocessing diperlukan dalam pengolahan suatu citra digital berwarna. Fungsinya untuk memperbaiki kualitas suatu citra dan mengolah
informasi di dalamnya untuk proses berikutnya. Pada tahap ini sinyal informasi ditonjolkan dan sinyal pengganggu (derau) diminimalisasi (Putra, 2010).
Gambar 3. 3 Diagram Blok Preproses
Proses preprocessing yang akan dilkaukan diawali dengan memisahkan citra asli berdasarkan kanal merah, hijau, dan biru. Kemudian diambil kanal
hijau dan dilakukan penajaman kontras. Hasil penajaman kontras dikenai binerisasi dan dinegasikan. Keduanya di-cropping untuk nantinya menjadi
masukkan pada tahap ekstraksi fitur.
3.3. Metode Ekstraksi Fitur dengan Menggunakan Filter Gabor 2D
Metode ekstraksi fitur dengan menggunakan Filter Gabor digunakan karena mampu mengenali karakteristik pada sistem visual manusia. Cara untuk
mendapatkan nilai fitur yang terbaik pada Filter Gabor dengan mengubah nilai parameternya. Parameter yang dimiliki oleh filter Gabor antara lain frekuensi filter, sudut orientasi, lebar pita frekuensi, lebar pita angular, standar deviasi, dan
merah Preprocessing
hijau
biru
Binerisasi cropping
Citra Asli Penajaman kontras
Negasi cropping
Algoritma untuk melakukan ekstraksi fitur menggunakan Gabor Filter berupa : 1. Menentukan nilai sigma,theta, dan F
2. Ambil data berupa citra digital berwarna retina, kemudian data tersebut dibagi dua untuk digunakan sebagai data training dan data testing
3. Melakukan multiple Gabor Transforms dengan perngubahan parameter
ke data training, dan menggunakan perubahan gambar sebagai fitur.
4. Menambahkan Gabor Linear Modeling ke data training.
5. Setelah menghasilkan GLM dari data training, kita akan menguji
seberapa baik Gabor dengan penambahan GLM dalam menghasilkan fitur pada testing
6. Seteleh mendapatkan nilai output dari GLM menggunakan ekstraksi
fitur dari testing image, didapatkan hasil seberapa baik pendeteksi dapat menunjukan lokasi kelainan.
3.4.Metode Klasifikasi Menggunakan Support Vector Machine
Untuk dapat menggunakan PCA dengan tepat digunakan algoritma berikut :
1. Matriks X adalah hasil pengurangan rata-rata dari setiap dimensi data pada
matriks data.
2. Matriks Cx adalah covariance matrix dari matriks X. 3. Hitung eigenvector dan eigenvalue dari Cx .
4. Pilih component dan bentuk vector feature dan principal component dari
eigenvector yang memiliki eigenvalue paling besar diambil.
27
Algoritma untuk melakukan klasifikasi menggunakan SVM adalah sebagai
berikut :
1. Tentukan H dimana
Hij = yiyjxi.xj (3.1)
2. Cari α sehingga
(3.2)
3. Menjadi maksimal, dengan syarat :
(3.3) 4. Hitung
(3.4)
5. Tentukan seluruh support vector S dengan mencari indexnya dimana αi ≥ 0
6. Hitung
(3.5)
7. Tiap titik baru x’ dapat terklarifikasi dengan memeriksa
(3.6)
Fungsi kernel yang biasa digunakan dalam literature SVM :
1. Linear
(3.7)
2. Polynomial
(3.8)
3. Gaussian RBF
(3.9)
4. Sigmoid(tangen hiperbolik)
(3.10)
Klasifikasi non-linear
1. Lakukan pemetaan data ke dimensi lebih tinggi dengan kernel yang dipilih
2. Tentukan H dimana
(3.11)
3. Cari α sehingga
(3.12)
Menjadi maksimal, dengan syarat :
(3.13)
4. Hitung
(3.14)
5. Tentukkan seluruh support vector S dengan mencari indexnya dimana
6. Hitung
(3.15)
7. Tiap titik baru x’ dapat terklasifikasi dengan memeriksa
29
(3.16)
3.5.Evaluasi hasil
Pada K-Fold cross validation dataset yang utuh dipecah secara random menjadi k subset dengan size yang hampir sama dan saling eksklusif satu sama
lain. Model pada klasifikasi di latih dan diuji sebanyak k kali. Setiap proses pelatihan semua dilatih pada semua fold kecuali hanya sat fold yang digunakan untuk proses pengujian. Penilaian cross-validation terhadap akurasi model secara
keseluruhan dihitung dengan mengambil rerata dari semua hasil akurasi individu
‘k’, seperti yang ditunjukkan dengan persaman berikut:
(3.17)
Keterangan :
Σ data benar = jumlah angka pada diagonal matriks
Σ seluruh data = keseluruhan data yang digunakan untuk pengujian
BAB IV
IMPLEMENTASI DAN ANALISA SISTEM
Bab implementasi dan analisa sistem merupakan bab yang menjelaskan implementasi yang telah dipaparkan pada bagian metodologi. Berupa
preprocessing, ekstraksi fitur, klasifikasi menggunakan metode Support Vector
Machine, hingga mendapatkan nilai akurasi menggunakan confusion matrix.
4.1. User Interface
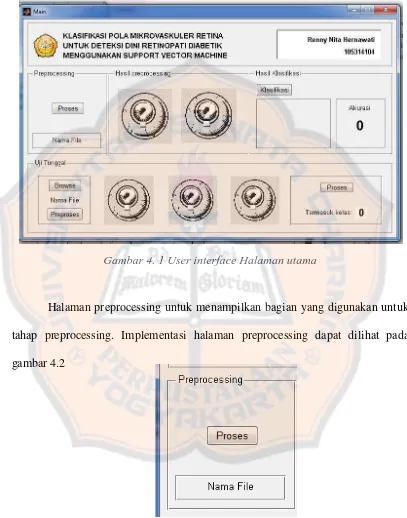
Untuk mempermudahkan dalam melakukan klasifikasi pada penelitian ini dibuat suatu user interface. User interface ini dibuat untuk membantu dalam
preproses, ekstraksi fitur hingga mendapatkan hasil klasifikasi beserta akurasinya. Halaman utama ditunjukkan pada gambar 4.1 . Pada halaman utama terdiri dari
beberapa bagian menu, untuk preprocessing dan klasifikasi, serta halaman untuk melakukan pengujian dengan data tunggal.
31
Gambar 4. 1 User interface Halaman utama
Halaman preprocessing untuk menampilkan bagian yang digunakan untuk tahap preprocessing. Implementasi halaman preprocessing dapat dilihat pada gambar 4.2
Gambar 4. 2 Halaman Preprocessing
Halaman Hasil preprocesising merupakan halaman yang menunjukan data citra yang sedang mengalami proses preprocessing, data citra yang ditampilkan pada halaman tersebut akan berubah-ubah sesuai dengan data yang sedang
diproses.
Gambar 4. 3 Halaman Hasil Preprocessing
Halaman hasil klasifikasi merupakan halaman yang menunjukan hasil
klasifikasi seluruh dataset yang berjumlah 100 data citra. Pada panel ini ditunjukkan jumlah data yang diklasifikasikan pada kelas yang benar melalui
33
Gambar 4. 4 Halaman Hasil Klasifikasi
Gambar 4.5 merupakan panel untuk melakukan uji tunggal. Pada panel ini masukan berupa citra tunggal yang akan mengalami preproses dan ekstraksi fitur
seperti pada proses klasifikasi yang dilakukan pada dataset. Perbedaan pada uji tunggal citra masukan dideteksi satu per satu dan data yang dimasukan bukan
berasal dari dataset yang digunakan untuk training.
Gambar 4. 5 Tampilan Uji Tunggal
4.2.Analisis Hasil
4.2.1 Preprocessing
Tahap preprocessing merupakan tahapan awal sebelum dilakukan ekstraksi
fitur dan klasifikasi. Proses preprocessing berjalan jika button proses diklik kemudian semua data yang dimiliki akan dilooping satu per satu.
Data yang ada tersimpan dalam folder dataFoto, untuk membaca folder tersebut digunakan fungsi strcat, dan untuk melakukan looping nilai i diset
untuk folder yang menunjukkan kelas yang dimiliki sejumlah 4, di dalam folder tersebut terdapat data citra yang masing-masing berjumlah 25 citra, untuk meloopingnya digunakan j. proses looping yang terjadi ditunjukkan pada potongan source code berikut
Kode Program 4. 1 looping dataFoto
Citra masukkan yang digunakan berupa citra digital berwarna retina..
Preprocessing diawali dengan melakukan pemisahan kanal warna. Komponen kanal pada suatu citra berwarna terdiri dari tiga unsur, yaitu merah, hijau, dan biru. Pemisahan kanal tersebut dilakukan dengan menggunakan
red=data(:,:,1) untuk mendapatkan kanal merah, green=data(:,:,2) kanal
hijau, dan blue=data(:,:,3)kanal biru. Selanjutnya dilakukan perbaikan kontras
dengan CLAHE untuk mendapatkan citra dengan tingkat kontras yang sesuai sehingga detail pembuluh darah pada citra nampak jelas. CLAHE memperbaiki kontras citra secara adaptif dengan ukuran window tertentu sehingga kontras keseluruhan citra optimal dapat tercapai. (Mandasari, dkk, 2012) Matlab memiliki
fungsi CLAHE berupa adapthisteq. Lakukan penajaman kontras tersebut pada semua kanal warna ad_red=adapthisteq (red);, ad_green=adapthisteq
(green);dan ad_blue=adapthisteq (blue);. Contoh perubahan pada citra
for i=1:4
folder=strcat('dataFoto\GRADE',num2str(n),'\');
for j=1:25
file = strcat(folder,'grade',num2str(n),'
35
yang telah mengalami pemisahan kanal dan penajaman kontras ditunjukan pada gambar
Gambar 3. 4 Citra Kanal merah, hijau, biru
Tidak semua kanal citra mampu menunjukkan informasi yang maksimal. Untuk segmentasi mikroaneurisma kanal citra yang diambil adalah kanal hijau,
karena pada kanal ini mikroaneurisma dan pembuluh darah akan terlihat gelap dan jelas jika dibanding yang lain (Zahara, dkk, 2011).
Selanjutnya dilakukan proses binerisasi pada citra kanal hijau untuk
masukkan pada Filter Gabor. Mengubah citra kanal hijau menjadi citra biner dilakukan dengan menggunakan fungsi binerisasi yang dimiliki oleh matlab g =
im2bw(Gambar2). im2bw memiliki fungsi mengubah image ke dalam bentuk
biner.
Mengingat ukuran citra yang diolah tinggi perlu dilakukan pemisahan pada
bagian data yang memberikan informasi dengan background. Cara ini dilakukan dengan menemukan titik tengah pada citra menggunakan center = [lebar/2
tinggi/2]; yang selanjutnya digunakan untuk memisahkan daerah digunakan
menggunakan rumus luas lingkaran pada code program 3.2.
Merah Hijau Biru
Kode Program 3. 1 Cropping
Citra biner yang sudah melakukan proses binerisasi dan cropping
diinverskan dengan menggunakan tanda ~ sehingga neg=~g; untuk dijadikan masukkan pada tahap Filter Gabor 2D. Bentuk citra yang telah mengalami preprocessing dan akan digunakan ditunjukan pada gambar 3.5 Citra yang dibinerisasi dinamakan biner, dan citra hasil invers nya dinamakan negasi.
Biner Negasi
Gambar 3. 5 Citra biner dan Negasi
4.2.2 Filter Gabor 2D
Proses ekstraksi dengan menggunakan filter Gabor 2D dimulai dengan menentukan nilai sigma, theta, dan F. Masukkan untuk filter gabor 2D berupa
[lebar tinggi]=size(g); center = [lebar/2 tinggi/2]; jari = min(center);
for a=1:lebar
for b=1:tinggi
jarak = sqrt((a - center(1)) .^ 2 + (b - center(2)) .^ 2);
if jarak > jari
g(a, b) = 255;
37
citra biner dan citra yang dinegasikan. Awali proses dengan menentukan training image dan testing image. Masukkan yang digunakan untuk melakukan training
dan testing ini merupakan data biner dan negasi hasil dari preprocessing
Untuk melakukan ektraksi fitur pada training image inisialisasikan parameter untuk melakukan multiple Gabor transform seperti yang ditunjukkan
pada code program 4.2
Kode Program 4. 2 Inisialisasi parameter Gabor Transform
Parameter yang diinisialisasikan pada code program 4.2 berguna untuk
melakukan multiple gabor transform yang selanjutnya ditambahkan Gabor Linear Model untuk mendapatkan feature. Penambahan Gabor Linear Model dilakukan
dengan menggunakan fungsi glmfit yang dimiliki Matlab.
Kode Program 4. 3 Penambahan glm
Nilai hasil ekstraksi disimpan dan dilakukan proses transpose. Transpose
matriks dilakukan dengan memberikan tanda petik (‘) pada nilai yang akan
ditranspos. Transpose matrik merupakan merubah baris menjadi kolom, atau kolom jadi baris. Transpose matriks yang terjadi disini merupakan perubahan
% initialize parameters for Gabor transforms
filter_size = 50.*scale;
filter_size_halfed = round((filter_size)/2); Fs = 0.1:0.1:0.4;
sigmas = [2:2:2].*scale; thetas=pi/12:pi/12:pi-pi/12;
% reshape feature array
szG = size(features);
features = reshape(features,[prod(szG(1:2)),prod(szG(3:end))]);
% fit GLM with the features and the location of the vessels
b = glmfit(features,trainingAns(:),'normal');
% see the output of the model based on the training features
CTrain = glmval(b,features,'logit');
CTrain = reshape(CTrain,szG(1:2));
kolom menjadi baris. Tujuan dilakukannya transpose untuk memudahkan pembacaan data pada saat melakukan klasifikasi.
Kode Program 4. 4 Transpose hasil ekstraksi
Hasil dari preprocessing dan ekstraksi ditunjukkan pada tabel 4.1. Pada
tabel tersebut terdapat 100 data dengan dimensi data masing-masing 122. Baris pertama tidak termasuk data hasil ekstraksi. Baris pertama menunjukkan label
yang dimiliki data tersebut. Label ini akan berguna ketika melakukan proses klasifikasi, yang gunanya mencocokan data tersebut berada di kelas mana.
4.2.3 Support Vector Machine
Pengujian dilakukan dengan cara mengubah-ubah fungsi kernel pada
SVM pada proses training. Tujuan dilakukannya proses tersebut untuk menemukan fungsi kernel terbaik agar menghasilkan nilai akurasi yang tinggi.
Untuk melakukan klasifikasi ambil dataset hasil preprocessing dan ekstraksi fitur yang disimpan dalam bentuk matrik dengan menggunakan fungsi load matlab yang dilanjutkan dengan nama file berupa hasilPreprocessing.mat.
Kode Program 4. 5 Option PCA
Untuk melakukan klasifikasi dengan data yang di pca isi nilai option pada kelas svm dengan nilai 1, untuk melakukan klasifikasi tanpa
menambahkan PCA nilai option diisi dengan nilai 0. Dataset hasil ekstrasi [b]=ekstraksi( Img,bwImg);
b=b';
bHasil=[bHasil;b];
if option == 1
[ att, ~ ] = pca( att, pc);
save ('dataPCA.mat','att');
39
%melakukan prediksi
for i=1:m
prediksi(1) = svmclassify(SVMStruct_1,data_latih(i,:)); tanpa mengunakan PCA ditunjukkan pada tabel 4.1, sedangkan dataset yang dikenai PCA ditunjukkan pada tabel 4.2.
Tabel 4. 1Hasil Ekstraksi sebelum PCA
Tabel 4. 2 Hasil PCA
Dataset yang baik yang menggunakan PCA atau tidak akan dicocokan dengan prediksi klasifikasi yang dibuat pada kelas svm. Pencocokan ini
digunakan untuk menentukan data tersebut berada di kelas mana. Source code untuk melakukan prediksi ditunjukkan pada kode program 4.6.
kelas_1 = [1 1 1 1]; kelas_2 = [0 0 1 1]; kelas_3 = [0 1 0 1]; kelas_4 = [0 1 1 0];
Code Program 4. 6 Menentukan Prediksi SVM
Data yang telah diklasifikasi dan dilakukan prediksi, akan dihitung nilai akurasinya. Untuk menghitung nilai akurasi dilakukan dengan membagi jumlah data benar dengan jumlah seluruh data yang kemudian hasilnya
dikalikan dengan 100 untuk mendapatkan nilai persentase. Pada penelitian ini dilakukan dengan membentuk confusionmatrik menggunakan fungsi confusionmat membandingkan kelas latih dengan kelas uji hasil. Untuk
mendapatkan nilai prosentase akurasi dilakukan dengan menjumlahkan diagonal hasil prediksi sebagai jumlah data benar dan dibagi dengan jumlah
hasil prediksi sebagai jumlah data keseluruhan. Hasil pembagian keduanya dikali dengan 100 untuk mendapatkan nilai persentase.
Code Program 4. 7 Hitung Akurasi
prediksi(2) =
svmclassify(SVMStruct_2,data_latih(i,:)); prediksi(3)
= svmclassify(SVMStruct_3,data_latih(i,:));
prediksi(4) = svmclassify(SVMStruct_4,data_latih(i,:));
jarak(1) = sum(xor(prediksi, kelas_1)); jarak(2) = sum(xor(prediksi, kelas_2)); jarak(3) = sum(xor(prediksi, kelas_3)); jarak(4) = sum(xor(prediksi, kelas_4));
[a, idx_kelas] = min(jarak); kelas_uji_hasil(i) = idx_kelas;
end
[kelas_latih, kelas_uji_hasil]= svm( data,pc,option);
hasil_prediksi = confusionmat(kelas_latih, kelas_uji_hasil); akurasi=(sum(diag(hasil_prediksi))/sum(hasil_prediksi(:)))*100;
assignin('base','hasil_prediksi',hasil_prediksi);
41
Percobaan untuk mendapatkan nilai akurasi terbaik yang dilakukan menggunakan 2 cara seperti yang sudah dijelaskan sebelumnya, yakni dengan
melakukan perubahan pada fungsi kernel dan masukan dataset tanpa PCA dan masukkan yang dikenai PCA. Pada saat percobaan dataset yang dimasukan tidak sekaligus dua dataset PCA dan tanpa PCA, melainkan salah satu jenis dengan
salah satu kernel. Kemudian dilakukan perhitungan akurasi, untuk menentukan yang paling optimal dan digunakan.
Menghitung nilai akurasi dilakukan dengan menjumlahkan diagonal
pada confusion matrix sebagai jumlah data benar. Kemudian dibagi total seluruh data yang dimiliki dan dikali 100. Percobaan pertama dilakukan dengan
menggunakan Kernel Polynomial orde 2 seperti yang ditunjukkan pada tabel
Tabel 4. 3 Confusion Matrix Kernel Polynomial orde 2 tanpa PCA
Grade0 Grade1 Grade2 Grade3
Grade0 24 1 0 0
Grade1 12 11 0 2
Grade2 23 0 0 2
Grade3 16 2 0 7
Hasil dari percobaan menggunakan Kernel Polynomial orde 2 didapatkan 24 data benar terklasifikasi pada grade 0, 11 data terklasifikasi benar
pada grade 1, tidak ada data yang terklasifikasi benar pada grade 2, dan 7 data yang terkalsifikasi benar pada grade 3. Nilai akurasi didapatkan dengan menjumlahkan nilai 24, 11, 0, dan 7 dikalikan dengan jumlah data yang dimiliki
sejumlah 100 dan dikalikan 100 untuk mendapatkan persentase. Hasilnya Kernel
Polynomial orde 2 menghasilkan nilai akurasi sebesar 42%. Hal yang sama dilakukan pada kernel lain
Tabel 4. 4 Confusion Matrix Kernel Polynomial Order 3 tanpa PCA
Grade0 Grade1 Grade2 Grade3
Grade0 23 2 0 0
Grade1 12 11 0 2
Grade2 20 0 1 4
Grade3 13 2 0 10
Dari 100 data yang diujikan pada Kernel Polynomial Order 3 yang
ditunjukkan pada tabel 4.4 didapatkan 45 data terdeteksi dengan benar terdiri dari 23 data pada grade 0, 11 data grade 1, 1 data grade 2, dan 10 data grade
3. Nilai akurasi yang diperoleh sebesar 45%.
Tabel 4. 5 Confusion Matrix Kernel Linear tanpa PCA
Grade0 Grade1 Grade2 Grade3
Grade0 25 0 0 0
Grade1 18 5 0 2
Grade2 23 0 0 2
Grade3 19 0 0 6
Tabel 4.5 menunjukkan hasil Confusion Matrix Kernel Linear tanpa PCA didapatkan 36 data terdeteksi dengan benar terdiri dari 25 data pada grade 0, 5
43
Tabel 4. 6 Confusion Matrix Kernel Quadratic tanpa PCA
Grade0 Grade1 Grade2 Grade3
Grade0 24 1 0 0
Grade1 12 11 0 2
Grade2 23 0 0 2
Grade3 16 2 0 7
Tabel 4.6 menunjukkan hasil Confusion Matrix Kernel Linear tanpa PCA didapatkan 42 data terdeteksi dengan benar terdiri dari 24 data pada
grade 0, 11 data grade 1, tidak ada data terdeteksi benar pada data grade 2, dan 7 data grade 3. Nilai akurasi yang diperoleh sebesar 42%.
Tabel 4. 7 Confusion Matrix Kernel RBF tanpa PCA
Grade0 Grade1 Grade2 Grade3
Grade0 25 0 0 0
Grade1 18 5 0 2
Grade2 23 0 0 2
Grade3 19 2 0 6
Tabel 4.7 menunjukkan hasil Confusion Matrix Kernel RBF tanpa PCA
didapatkan 36 data terdeteksi dengan benar terdiri dari 25 data pada grade 0, 5 data grade 1, tidak ada data terdeteksi benar pada data grade 2, dan 6 data
grade 3. Nilai akurasi yang diperoleh sebesar 36%.
Tabel 4. 8 Confusion Matrix Kernel Least Square Method tanpa PCA
Grade0 Grade1 Grade2 Grade3
Grade0 25 0 0 0
Grade1 18 5 0 2
Grade2 23 0 0 2
Grade3 19 0 0 6
Tabel 4.8 menunjukkan hasil Confusion Matrix Kernel Least Square Method tanpa PCA didapatkan 36 data terdeteksi dengan benar terdiri dari 25
data pada grade 0, 5 data grade 1, tidak ada data terdeteksi benar pada data grade 2, dan 6 data grade 3. Nilai akurasi yang diperoleh sebesar 36%.
Tabel 4. 9 Confusion Matrix Kernel Quadratic Programming Method tanpa PCA
Grade0 Grade1 Grade2 Grade3
Grade0 25 0 0 0
Grade1 18 5 0 2
Grade2 23 0 0 2
Grade3 19 0 0 6
Tabel 4.9 menunjukkan hasil Confusion Matrix Kernel Quadratic
Programming Method tanpa PCA didapatkan 36 data terdeteksi dengan benar terdiri dari 25 data pada grade 0, 5 data grade 1, tidak ada data terdeteksi
45
Tabel 4. 10 Confusion Matrix Kernel Seguential Minimal Optimization Method
tanpa PCA
Grade0 Grade1 Grade2 Grade3
Grade0 25 0 0 0
Grade1 18 5 0 2
Grade2 23 0 0 2
Grade3 19 0 0 6
Tabel 4.10 menunjukkan hasil kernel Sequential Minimal Optimization Method sebesar 30%. Pada pengujian 100 data 30 data yang terdeteksi dengan
benar, terdiri dari 25 data grade 0, 5 data grade 1, dan 6 data grade 3.
Setelah seluruh kernel dicoba tanpa melakukan PCA didapat nilai akurasi yang paling tinggi pada Kernel Polynomial orde 3 sebesar 45%, sedangkan nilai akurasi yang paling rendah pada saat menggunakan kernel
Sequential Minimal Optimization sebesar 30%. Percobaan selanjutnya ditambahkan PCA pada dataset, untuk membandingkan apakah nilai akurasi
akan meningkat atau tidak.
Tabel 4. 11 Confussion Matrix kernel Polynomial orde 2 menggunakan PCA
Grade0 Grade1 Grade2 Grade3
Grade0 25 0 0 0
Grade1 2 22 1 0
Grade2 7 0 18 0
Grade3 8 2 1 16
Percobaan menggunakan Kernel Polynomial orde 2 menggunakan PCA yang ditunjukkan pada tabel 4.11 menghasilkan 25 data terklasifikasikan
secara benar pada grade 0, 22 data benar pada grade 1, 18 data benar
terklasifikasikan pada grade 2, dan 16 data terklasifikasikan benar pada grade
3. Nilai akurasinya sebesar 82%.
Tabel 4. 12 Confussion Matrix kernel Polynomial orde 3 menggunakan PCA
Grade0 Grade1 Grade2 Grade3
Grade0 25 0 0 0
Grade1 0 25 0 0
Grade2 0 0 25 0
Grade3 1 0 0 24
Tabel 4.12 menunjukkan hasil kernel Polynomial orde 3 sebesar 99%. Pada pengujian 100 data 30 data yang terdeteksi dengan benar, terdiri dari 25
data grade 0, 5 data grade 1, dan 6 data grade 3.
Tabel 4. 13 Confussion Matrix kernel Linear menggunakan PCA
Grade0 Grade1 Grade2 Grade3
Grade0 25 0 0 0
Grade1 6 19 0 0
Grade2 23 0 1 1
Grade3 20 0 2 3
Tabel 4.13 menunjukkan hasil Kernel Linear menggunakan PCA yang ditunjukkan menghasilkan 25 data terklasifikasikan secara benar pada grade 0,
47
Tabel 4. 14 Confussion Matrix kernel Quadratic menggunakan PCA
Grade0 Grade1 Grade2 Grade3
Grade0 25 0 0 0
Grade1 2 22 1 0
Grade2 7 0 18 0
Grade3 8 0 1 16
Tabel 4.14 menunjukkan hasil Kernel Quadratic menggunakan PCA yang menghasilkan 25 data terklasifikasikan secara benar pada grade 0, 22 data
benar pada grade 1, 18 data benar terklasifikasikan pada grade 2, dan 16 data terklasifikasikan benar pada grade 3. Nilai akurasinya sebesar 81%
Tabel 4. 15 Confussion Matrix kernel RBF menggunakan PCA
Grade0 Grade1 Grade2 Grade3
Grade0 25 2 0 0
Grade1 6 19 0 2
Grade2 23 0 1 1
Grade3 20 2 2 3
Tabel 4.15 menunjukkan hasil Kernel RBF menggunakan PCA yang menghasilkan 25 data terklasifikasikan secara benar pada grade 0, 19 data
benar pada grade 1, 1 data benar terklasifikasikan pada grade 2, dan 3 data terklasifikasikan benar pada grade 3. Nilai akurasinya sebesar 47%
Tabel 4. 16 Confussion Matrix kernel Least Square Method menggunakan PCA
Grade0 Grade1 Grade2 Grade3
Grade0 25 0 0 0
Grade1 6 19 0 0
Grade2 25 0 0 0
Grade3 22 0 1 2
Tabel 4.16 menunjukkan hasil Kernel Least Square Method menggunakan PCA yang menghasilkan 25 data terklasifikasikan secara benar pada grade 0, 19 data benar pada grade 1, tidak ada data benar terklasifikasikan pada grade
2, dan 2 data terklasifikasikan benar pada grade 3. Nilai akurasinya sebesar 46%
Tabel 4. 17 Confussion Matrix kernel Quadratic Programming Method
menggunakan PCA
Grade0 Grade1 Grade2 Grade3
Grade0 25 2 0 0
Grade1 6 19 0 2
Grade2 23 0 1 1
Grade3 20 0 2 3
Tabel 4.17 menunjukkan hasil Kernel Least Square Method menggunakan PCA yang menghasilkan 25 data terklasifikasikan secara benar pada grade 0,
49
Tabel 4. 18 Confussion Matrix Kernel Sequential Minimal Optimization dengan PCA
Grade0 Grade1 Grade2 Grade3
Grade0 25 0 0 0
Grade1 6 19 0 0
Grade2 25 0 0 0
Grade3 24 0 0 1
Tabel 4.17 menunjukkan hasil Kernel Sequential Minimal Optimization menggunakan PCA yang menghasilkan 25 data terklasifikasikan secara benar
pada grade 0, 19 data benar pada grade 1, tidak ada data benar terklasifikasikan pada grade 2, dan 3 data terklasifikasikan benar pada grade
3. Nilai akurasinya sebesar 45%. Tabel 4. 19 Perbandingan akurasi
menggunakan PCA dan tanpa PCA
Berdasarkan hasil pengujian yang telah dilakukan, didapatkan kesimpulan bahwa klasifikasi dengan menggunakan pereduksi dimensi data PCA menghasilkan nilai yang lebih tinggi. Pada saat tanpa menggunakna PCA
nilai akurasi paling tinggi ketika menggunakan Kernel Polynomial Order 3 sebesar 45%, sedangkan nilai paling rendah pada Kernel Sequential Minimal
Optimization Method sebesar 30%. Pada saat ditambahkan PCA nilai akurasi
meningkat dan hasil akurasi paling tinggi pada saat menggunakan Kernel
Polynomial Order 3 sebesar 99%, dan nilai akurasi paling rendah saat menggunakan Kernel Sequential Minimal Optimization Method sebesar 45%.