KLASIFIKASI DOKUMEN TEKS MENGGUNAKAN
METODE
SUPPORT VECTOR MACHINE
DENGAN
PEMILIHAN FITUR
CHI-SQUARE
ARINI DARIBTI PUTRI
DEPARTEMEN ILMU KOMPUTER
FAKULTAS MATEMATIKA DAN ILMU PENGETAHUAN ALAM INSTITUT PERTANIAN BOGOR
PERNYATAAN MENGENAI SKRIPSI DAN
SUMBER INFORMASI SERTA PELIMPAHAN HAK CIPTA
Dengan ini saya menyatakan bahwa skripsi berjudul Klasifikasi Dokumen Teks Menggunakan Metode Support Vector Machine dengan Pemilihan Fitur Chi-Square adalah benar karya saya dengan arahan dari komisi pembimbing dan belum diajukan dalam bentuk apa pun kepada perguruan tinggi mana pun. Sumber informasi yang berasal atau dikutip dari karya yang diterbitkan maupun tidak diterbitkan dari penulis lain telah disebutkan dalam teks dan dicantumkan dalam daftar pustaka di bagian akhir skripsi ini.
Dengan ini saya melimpahkan hak cipta dari karya tulis saya kepada Institut Pertanian Bogor.
Bogor, Juni 2013
Arini Daribti Putri
ABSTRAK
ARINI DARIBTI PUTRI. Klasifikasi Dokumen Teks Menggunakan Metode
Support Vector Machine dengan Pemilihan Fitur Chi-Square. Dibimbing oleh JULIO ADISANTOSO.
Peningkatan jumlah dokumen membuat masyarakat semakin sulit memperoleh informasi sesuai dengan apa yang diinginkan. Masalah ini memerlukan teknik pengolahan teks yang mengorganisasikan dokumen sesuai dengan ketegorinya. Salah satunya adalah klasifikasi teks. Klasifikasi teks dapat mengorganisasikan dokumen sesuai dengan ketegori yang telah ditentukan sebelumnya secara otomatis. Salah satu metode klasifikasi ruang vektor teks yang populer ialah support vector machine (SVM) yang berusaha mencari bidang pemisah terbaik pada input space. Algoritme ini merupakan algoritme klasifikasi terbaik dibandingkan dengan metode klasifikasi ruang vektor lainnya, yaitu
Rocchio, k-nearest neighbor (KNN) dan decision tree. Penelitian ini bertujuan menerapkan dan mengevaluasi metode SVM yang dapat meningkatkan kinerja fungsi klasifikasi dokumen serta mengukur akurasi algoritme SVM dalam proses komputasi. Hasil akhir menunjukkan bahwa kernel linear dan kernel polinomial pada pengujian SVM menghasilkan nilai akurasi yang sama, yaitu 96.3504% dan pengujian kernel RBF menghasilkan akurasi sebesar 95.6204% untuk klasifikasi dokumen teks menggunakan pemilihan fitur ciri chi-squared.
Kata kunci: klasifikasi teks, mesin pembelajaran, support vector machines
ABSTRACT
ARINI DARIBTI PUTRI. Text Document Classification Using Support Vector Machine Method with Chi-Square Feature Selection. Supervised by JULIO ADISANTOSO.
Increasing number of documents makes people more difficult to obtain the information which they desired. This problem requires text processing techniques to organize the documents in accordance with the categories. One of which is text classification. Text classification can organize document in accordance with predefined categories automatically (supervised machine learning). One popular method of text classification is support vector machines (SVM) that tries to find the best hyperplane in the input space. This algorithm is the best classification algorithm compared with other vector space classification method, namely Rocchio, k-nearest neighbor (KNN) and decision tree. This research measures the suitability of SVM for text classification and to prove whether the SVM is able to classify the documents in a linear separable manner. The final result shows that linear kernel and polynomial kernel in the SVM test produce the same accuracy value of 96.3504% and testing the RBF kernel produces accuracy of 95.6204% for classification of text documents using chi-squared feature selection.
Skripsi
sebagai salah satu syarat untuk memperoleh gelar Sarjana Komputer
pada
Departemen Ilmu Komputer
KLASIFIKASI DOKUMEN TEKS MENGGUNAKAN
METODE
SUPPORT VECTOR MACHINE
DENGAN
PEMILIHAN FITUR
CHI-SQUARE
ARINI DARIBTI PUTRI
DEPARTEMEN ILMU KOMPUTER
FAKULTAS MATEMATIKA DAN ILMU PENGETAHUAN INSTITUT PERTANIAN BOGOR
Judul Skripsi : Klasifikasi Dokumen Teks Menggunakan Metode Support Vector Machine dengan Pemilihan Fitur Chi-Square.
Nama : Arini Daribti Putri NIM : G64090087
Disetujui oleh
Ir Julio Adisantoso, MKom Pembimbing I
Diketahui oleh
Dr Ir Agus Buono, MSi MKom Ketua Departemen
PRAKATA
Puji dan syukur penulis panjatkan kepada Allah subhanahu wa ta’ala atas segala karunia-Nya sehingga sehingga penulis dapat menyelesaikan tugas akhir dengan judul Klasifikasi Dokumen Teks Menggunakan Metode Support Vector Machine dengan Pemilihan Fitur Chi-Square.
Penulis juga menyampaikan terima kasih kepada pihak-pihak yang telah membantu dalam penyelesaian tugas akhir ini, yaitu:
1. Ayahanda Ibrahim, Ibunda Nuriyanti, serta keluarga besar penulis (Hendra Rianda, Rindu, dan Riski Ramadhanif) yang selalu memberikan doa, nasihat, semangat, dan kasih sayang yang luar biasa kepada penulis.
2. Bapak Ir. Julio Adisantoso, M.Kom selaku dosen pembimbing tugas akhir yang memberikan bimbingan, ide, dukungan, semangat serta kesabaran dalam pengerjaan tugas akhir ini.
3. Bapak Ahmad Ridha dan Bapak Musthafa selaku dosen penguji yang telah memberi masukan dan saran pada tugas akhir penulis.
4. Kak Wido dan Sapariansyah atas kerjasamanya dalam menyelesaikan tugas akhir ini.
5. Rekan satu bimbingan Damayanti Elizabeth, Rahmatika Dewi, Fitria Rahmadina, Achmad Mansur Z, Tedy Saputra, dan Edo Apriyadi. Terima kasih atas bantuan, kebersamaan dan semangatnya dalam menyelesaikan tugas akhir ini.
6. Mellisa, Sasa, Haikal, Vony, Galih, Dola, Julian, Kak Zhia, Dhila. Terima kasih atas semangat dan dukungannya yang telah diberikan kepada penulis. Semoga kita bisa berjumpa kembali kelak sebagai orang-orang sukses. 7. Seluruh keluarga besar IKPMR yang terus menyebarkan energi positif dan
memberikan semangat kepada penulis selama melaksanakan tugas akhir ini. 8. Seluruh keluarga besar KRIBONDING, KOST HARMONI 2 yang selalu
bersedia mendengarkan keluh kesah, dan memberikan semangat kepada penulis selama melaksanakan tugas akhir ini.
9. Seluruh rekan-rekan Ilmu Komputer angkatan 46 atas segala kebersamaan, bantuan, canda tawa, dan kenangan indah serta semangat bagi penulis slama masa studi. Semoga kita semua bisa berjumpa kembali kelak sebagai orang-orang sukses.
Bogor, Juni 2013
DAFTAR ISI
DAFTAR TABEL vi
DAFTAR GAMBAR vi
DAFTAR LAMPIRAN vi
PENDAHULUAN 1
Latar Belakang 1
Perumusan Masalah 2
Tujuan Penelitian 2
Manfaat Penelitian 2
Ruang Lingkup Penelitian 2
METODE 3
Gambaran Umum Sistem 3
Data Penelitian 3
Praproses 4
Pemilihan Fitur Ciri 4
Pembobotan Kata 6
Klasifikasi Dokumen 6
Pengujian 9
Lingkungan pengembangan sistem 9
HASIL DAN PEMBAHASAN 10
Pengumpulan Dokumen 10
Praproses 10
Pemilihan Fitur Ciri dan Pembobotan Kata 10
Klasifikasi Dokumen 11
Pengujian 13
SIMPULAN DAN SARAN 15
Simpulan 15
Saran 15
DAFTAR PUSTAKA 15
DAFTAR TABEL
1 Tabel kontingensi antara kata terhadap kelas 5
2 Nilai kritis � untuk taraf nyata α 6
3 Confusion matrix untuk klasifikasi biner 9
4 Deskripsi dokumen uji (.xml) 10
5 Hasil tahap pemilihan fitur ciri dengan taraf nyata 0.01 11
6 Matriks dimensi M × N klasifikasi 12
7 Hasil akurasi parameter terbaik pada pemodelan setiap kernel 13 8 Confusion matrix SVM dengan data 137 × 6802 14 9 Confusion matrix SVM dengan data 137 × 1309 14
DAFTAR GAMBAR
1 Tahap penelitian 3
2 SVM berusaha menemukan bidang pemisah terbaik (Manning
et al. 2008) 7
3 Transformasi klasifikasi dua dimensi ke dalam ruang fitur tiga
dimensi (Gijsberts 2007) 8
DAFTAR LAMPIRAN
1 Hasil pengujian setiap kernel 17
PENDAHULUAN
Latar Belakang
Perkembangan teknologi informasi yang melibatkan banyak dokumen semakin meningkat. Penyimpanan dokumen yang berisi tentang segala sumber informasi dari penyedia sumber informasi tersebut tersebar di berbagai lokasi. Penyebaran informasi tersebut banyak dilakukan dengan menggunakan media berupa halaman web. Menurut riset dari Hearst (2003), ukuran data di media Internet tahun 2002 mencapai 532897 Terabytes dengan sekitar 41.7%-nya adalah teks. Berdasarkan Netcraft Web Server Survey, jumlah halaman yang aktif pada Mei 2008 adalah 168 milyar situs web. Volume yang besar membuat masyarakat semakin sulit memperoleh informasi sesuai dengan yang diinginkan. Untuk itu, diperlukan teknik pengolahan teks yang mengorganisasikan dokumen sesuai dengan ketegorinya, sehingga informasi yang tersedia dapat terorganisasi dengan baik dan mudah diakses sesuai dengan kebutuhan pengguna. Salah satu metode yang dapat digunakan adalah klasifikasi dokumen. Klasifikasi dokumen adalah proses menggolongkan suatu dokumen ke dalam suatu kategori tertentu (Manning
et al. 2008).
Klasifikasi termasuk teknik pembelajaran mesin atau biasa disebut supervised learning. Menurut Manning et al. (2008), supervised learning adalah proses pembelajaran mengenai ciri dari tiap-tiap kategori yang ada. Teknik ini membangun sebuah classifier yang mempelajari ciri tiap kategori berdasarkan dokumen latih yang dimiliki. Beberapa metode klasifikasi yang dapat digunakan dalam proses pembelajaran, yaitu multinomial naive bayes, multivariate Bernoulli model,
Rocchio classification, k-Nearest Neighbor (KNN), dan support vector machine
(SVM).
Peningkatan dokumen akan mempengaruhi kinerja klasifikasi yang menyebabkan kerja sistem classifier akan semakin berat. Hal tersebut dikarenakan sistem klasifikasi mengambil isi dari uraian setiap dokumen. Salah satu cara untuk meningkatkan kinerja dari sistem klasifikasi dengan menerapkan teknik pemilihan fitur dokumen. Pemilihan fitur merupakan suatu metode yang bertujuan untuk mengurangi jumlah kata yang digunakan untuk menjadi penciri dan meningkatkan akurasi hasil klasifikasi. Ada beberapa teknik yang digunakan untuk melakukan pemilihan fitur dokumen antara lain document frequency thresholding (DF),
information gain (IG), mutual information (MI), term strength (TS) dan chi-square testing (� ) (Yang et al. 2003).Penelitian klasifikasi teks menggunakan pemilihan fitur ciri yang telah dilakukan sebelumnya, antara lain Herawan (2011) menggunakan metode naive bayes dengan ekstraksi ciri chi-square dan Saputra (2012) menggunakan metode semantic smoothing dengan ekstraksi ciri chi-square. Akurasi yang diperoleh dari penelitian dengan menggunakan naive Bayes adalah 93.26% dan semantic smoothing adalah 95.55%. Hal ini membuktikan bahwa kedua penelitian tersebut dapat digunakan untuk melakukan klasifikasi dokumen teks. Namun metode ini cocok untuk dokumen yang relatif pendek.
2
sehingga masalah klasifikasi non-linear dapat diselesaikan dengan cara meningkatkan dimensi ruangnya (Pilászy 2005). Pada metode SVM terdapat fungsi kernel yang memetakan data ke ruang vektor yang berdimensi lebih tinggi sehingga kelas dapat dipisahkan secara linear oleh sebuah bidang pemisah. Dengan demikian metode ini diharapkan dapat menghasilkan kinerja klasifikasi lebih baik dan lebih efisien.
Perumusan Masalah
Perumusan masalah pada penelitian ini adalah: 1 Apakah SVM mampu mengkategorikan dokumen teks?
2 Seberapa besar akurasi yang dihasilkan dari SVM dalam mengklasifikasikan dokumen dengan menggunakan pemilihan fitur chi-square?
3 Apa pengaruh pemilihan fitur chi-square terhadap klasifikasi SVM?
Tujuan Penelitian
Tujuan penelitian ini adalah menerapkan dan mengevaluasi metode SVM menggunakan pemilihan fitur chi-square yang dapat meningkatkan kinerja fungsi klasifikasi dokumen teks serta mengukur akurasi algoritme SVM dengan melihat pengaruh pemilihan fitur chi-square dalam proses komputasi.
Manfaat Penelitian
Penelitian ini diharapkan dapat menambah metode klasifikasi dokumen dan membantu dalam mengorganisasikan dokumen secara cepat, efisien, dan memiliki kinerja sangat baik.
Ruang Lingkup Penelitian
Ruang lingkup penelitian ini meliputi:
1 Dokumen yang digunakan adalah dokumen berbahasa Indonesia berisi tentang pertanian berjumlah 457 dokumen dalam format XML.
2 Koleksi dokumen dibagi menjadi dua kelas yaitu kelas tanaman obat dan kelas hortikultura.
3 Penelitian difokuskan kepada klasifikasi dokumen dengan menggunakan metode klasifikasi SVM.
4 Pemodelan dan pengujian SVM menggunakan Matlab R2008b dengan menggunakan Library for Support Vector Machine (LIBSVM).
3
METODE
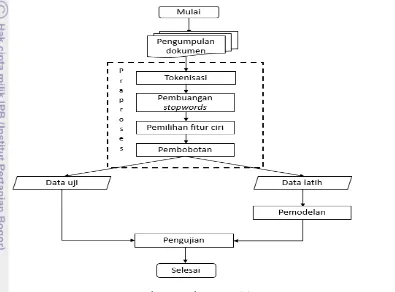
Gambaran Umum Sistem
Alur dari penelitian secara garis besar ditunjukkan pada Gambar 1. Beberapa tahap dari sistem yaitu pengumpulan dokumen, praproses, pembagian data, pemodelan dan pengujian hasil klasifikasi.
Pada penelitian ini, data yang diproses merupakan koleksi dokumen yang dibagi menjadi dua kategori yaitu data latih dan data uji. Kedua kategori data tersebut akan digunakan pada tahapan praproses yang terdiri atas tokenisasi,
stopword, pemilihan fitur ciri, dan pembobotan.
Tahap selanjutnya adalah pemodelan dengan menggunakan metode klasifikasi SVM pada data latih dan hasilnya digunakan sebagai dasar pembuatan model SVM. Setelah itu dilakukan pengujian model klasifikasi terhadap dokumen uji yang sudah diketahui kelasnya dan dilakukan proses perhitungan hasil klasifikasi.
Data Penelitian
Data penelitian yang digunakan merupakan penggabungan hasil koleksi dokumen tumbuhan obat dan dokumen hortikultura yang berasal dari Laboratorium Temu Kembali Informasi IPB yang sudah pernah digunakan pada penelitian Herawan (2011) dan Sari (2012).
4
Koleksi dokumen yang digunakan sebanyak 457 dokumen dibagi menjadi 70% dokumen latih (320 dokumen) dan 30% dokumen uji (137 dokumen). Data latih digunakan sebagai input pelatihan pengklasifikasi SVM dan data uji digunakan untuk menguji model hasil pelatihan SVM.
Data ini merupakan dokumen berbahasa Indonesia dengan format XML. Kusnawi (2010) menyatakan bahwa XML merupakan bahasa markup yang dirancang untuk penyampaian informasi melalui website dan juga dapat digunakan untuk pertukaran informasi antar sistem database.
Praproses
Tahapan awal dalam proses klasifikasi setelah dokumen tersedia adalah praproses. Tahap pertama yang dilakukan saat praproses adalah tokenisasi, yaitu proses pemisahan kata dari dokumen dengan menggunakan karakter spasi sebagai tanda pemisahnya (Wibowo 2010). Proses ini diawali dari mengambil isi dokumen dengan tabel corpus, selanjutnya dilakukan proses pembacaan seluruh karakter yang terdapat pada dokumen, baik karakter huruf, angka, tanda baca dan karakter yang tidak terlihat.Dengan demikian, tokenisasi membagiteks input menjadi unit-unit kecil yang dapat berupa suatu kata atau angka.
Tahap kedua yaitu membuang daftar kata yang tidak bermakna yang biasa disebut stopword. Kata yang tercantum dalam daftar koleksi dokumen dibuang dan tidak ikut diproses pada tahap selanjutnya. Kata-kata yang termasuk dalam
stopwords pada umumnya merupakan kata-kata yang sering muncul di setiap dokumen sehingga kata tersebut tidak dapat digunakan sebagai penciri suatu dokumen (Herawan 2011). Proses ini bertujuan mengekstrak kata yang tidak penting dari dokumen.
Pemilihan Fitur Ciri
Pemilihan fitur merupakan suatu proses memilih subset dari setiap kata unik yang ada di dalam himpunan dokumen latih yang akan digunakan sebagai fitur di dalam klasifikasi dokumen (Manning et al. 2008).Menurut Manning et al. (2008), pemilihan fitur memiliki dua tujuan, yaitu mengurangi jumlah kata yang digunakan dan meningkatkan akurasi hasil klasifikasi.Ada beberapa metode pemilihan fitur yang baik untuk proses klasifikasi dokumen, yaitu pemilihan fitur berbasis frekuensi, information gain, dan chi-square (� ).
Pada penelitian ini, pemilihan fitur dilakukan dengan metode chi-square. Chi-square merupakan pengujian hipotesis mengenai perbandingan antara frekuensi contoh yang benar-benar terjadi dengan frekuensi harapan yang didasarkan atas hipotesis tertentu pada setiap kasus atau data (Herawan 2011). Perhitungan nilai
chi-square yang digunakan untuk melakukan pengujian perbedaan antara pola frekuensi observasi (��) dengan frekuensi harapan (��) menggunakan formula :
5
e
i=
∑fk × ∑T∑fbΣfkadalah jumlah frekuensi pada kolom, Σfb adalah jumlah frekuensi pada baris dan ΣT = jumlah keseluruhan baris atau kolom.Berdasarkan nilai chi-square pada Persamaan 1 dapat diambil suatu keputusan statistik apakah terjadi perbedaan antara pola frekuensi observasi dengan frekuensi harapan. Hipotesis nol (H0)
diterima jika nilai � < nilai kritis pada derajat bebas dan taraf nyata tertentu. Hipotesis nol (H0) ditolak jika nilai � > nilai kritis pada derajat bebas dan taraf
nyata tertentu.
Pada penelitian ini, chi-square (� ) mengukur derajat bebas tiap kata penciri
t dengan kelas c agar dapat dibandingkan dengan sebaran � (Mesleh 2007). Chi-square menguji hubungan atau pengaruh dua variabel dan mengukur keterkaitan antara variabel satu dengan lainnya.
Penghitungan nilai chi-square pada setiap kata t yang muncul pada setiap kelas c dapat dibantu dengan menggunakan tabel kontingensi (Tabel 1). Nilai yang terdapat pada tabel kontingensi merupakan nilai frekuensi observasi dari suatu kata terhadap kelas.
Penghitungan nilai chi-square berdasarkan Tabel 1 pada Persamaan 1 dapat disederhanakan menjadi:
� t,c =(A+C)(B+DN(AD)(-A+BCB)2)(C+D)
dengan t merupakan kata yang sedang diujikan terhadap suatu kelas c, N merupakan jumlah dokumen latih, A merupakan banyaknya dokumen pada kelas c yang memuat kata t, B merupakan banyaknya dokumen yang tidak berada di c namun memuat kata t, C merupakan banyaknya dokumen yang berada di kelas c namun tidak memiliki kata t di dalamnya, serta D merupakan banyaknya dokumen yang bukan merupakan dokumen kelas c dan tidak memuat kata t.
Pengambilan keputusan dilakukan berdasarkan nilai � dari masing-masing kata. Kata yang memiliki nilai � di atas nilai kritis pada taraf nyata α adalah kata yang akan dipilih sebagai penciri dokumen. Kata yang dipilih sebagai penciri merupakan katayang memiliki pengaruh terhadap kelas c. Nilai kritis � untuk taraf nyata α ditunjukkan pada Tabel 2.
Tabel 1 Tabel kontingensi antara kata terhadap kelas
Kata
Kelas
1 0
1 A B
6
Penelitian ini menggunakan satu taraf nyata α yaitu 0.01 yang diartikan bahwa kriteria kata yang dipilih sebagai penciri dokumen adalah kata yang memiliki nilai χ2 lebih besar atau sama dengan 6.63. Hasil pemilihan fitur ini akan dilakukan pembobotan dan kata-kata yang dipilih sebagai penciri tersebut akan digunakan sebagai data masukan untuk klasifikasi.
Pembobotan Kata
Proses pembobotan dari suatu kata yang terpilih dengan menggabungkan aspek lokal dan global pada setiap term, yaitu menghitung termfrequency (tf) dari setiap dokumen yang ada di koleksi dokumen dikalikan dengan bobot global
inverse document frequency (idf) pada setiap term. tft,d ×idf
di manatf adalah jumlah kemunculan setiap term t dalam sebuah dokumen d dan dinotasikan dengan tft,d sedangkan idf dari sebuah term t adalah kemunculan term
t pada keseluruhan dokumen disebut juga pembobotan global yaitu:
idf=logdfN t
dengan N adalah banyaknya dokumen dan dft adalah jumlah dokumen yang mengandung term t. Hasil dari pembobotan ini selanjutnya digunakan pada tahap klasifikasi dokumen.
Klasifikasi Dokumen
Klasifikasi dibedakan menjadi dua jenis yaitu klasifikasi berbasis peluang dan klasifikasi ruang vektor. Manning et al. (2008) menyatakan ada beberapa algoritme yang dapat dilakukan untuk melakukan klasifikasi dokumen berbasis vektor yaitu
Rocchio, KNN, decision tree (DT) dan SVM.
Chenometh et al. (2009) merangkum perbandingan antara empat klasifikasi berbasis ruang vektor yang sering digunakan dalam kategori teks yaitu Rocchio, KNN, DT, dan SVM. Chenometh et al. (2009) menyatakan bahwa SVMmerupakan algoritme klasifikasi terbaik dibandingkan dengan lainnya, meskipun sangat mudah terjadi error dalam data training. Sedangkan Kaiser et al. (2005) menyatakan teknik-teknik tersebut berbeda dalam mekanisme pembelajaran dan representasi
7 model yang dipelajari. KNN dan SVM merupakan algoritme yang memberikan hasil klasifikasi terbaik dengan presisi di atas 85%.
Hasil data latih dari semua tahap praproses terdiri atas beberapa dokumen berupa vektor dari frekuensi kemunculan fitur yang digunakan pada sistem klasifikasi untuk mengkategorikan dokumen. Metode klasifikasi yang digunakan adalah SVM yang berusaha mencari bidang pemisah terbaik pada input space
(Pilászy 2005). Bidang pemisah terbaik ialah bidang pemisah yang menghasilkan nilai margin terbesar dan berada di tengah-tengah antara dua set objek dari dua kelas (Gambar 2). Nilai margin merupakan jarak antara bidang pemisah dengan elemen terluar dari kedua kelas. Dalam hal ini fungsi pemisah yang dicari adalah fungsi linear sebagai berikut:
f(x) = sign (wTxi +b = 0)
dengan w adalah bobot yang merepresentasikan posisi hyperplane pada bidang normal, x adalah vektor data masukan, dan b adalah bias yang merepresentasikan posisi bidang relatif terhadap pusat koordinat.
Selanjutnya data dikelompokkan dengan menggunakan fungsi pemisah yang sudah ditemukan, di mana untuk menentukan kelasnya w.xi + b = +1 adalah bidang
pemisah pendukung dari kelas +1 dan w.xi + b = −1 adalah bidang pemisah
pendukung dari kelas −1.
Secara matematika, mencari bidang pemisah terbaik ekuivalen dengan memaksimalkan margin antara dua kelas yang dihitung dengan formula ∥w∥2 2 . Memaksimalkan margin antara kedua kelas sama dengan meminimumkan fungsi tujuan ∥w∥2 dengan memperhatikan pembatas yi w∙xi+b ≥ 1 di mana xi adalah data input dan yiadalah keluaran dari data xi.
Selanjutnya, masalah klasifikasi diformulasikan ke dalam quadratic programming (QP) problem yang dapat diselesaikan dengan Lagrange multiplier:
8
� �, �, � = ∥w∥2− ∑��= αi yi(w. xi+ b– 1)
dengan ∝iadalah Lagrange multiplier yang berkorespondensi dengan xi.
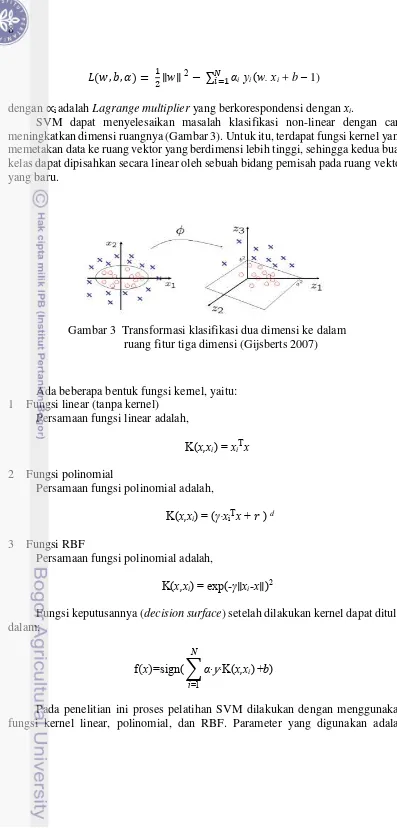
SVM dapat menyelesaikan masalah klasifikasi non-linear dengan cara meningkatkan dimensi ruangnya (Gambar 3). Untuk itu, terdapat fungsi kernel yang memetakan data ke ruang vektor yang berdimensi lebih tinggi, sehingga kedua buah kelas dapat dipisahkan secara linear oleh sebuah bidang pemisah pada ruang vektor yang baru.
Ada beberapa bentuk fungsi kernel, yaitu: 1 Fungsi linear (tanpa kernel)
Persamaan fungsi linear adalah,
K(x,xi) = xiTx
2 Fungsi polinomial
Persamaan fungsi polinomial adalah,
K(x,xi) = (γ∙xiTx + � )d
3 Fungsi RBF
Persamaan fungsi polinomial adalah,
K(x,xi)= exp(-γ∥xi-x∥)2
Fungsi keputusannya (decision surface) setelah dilakukan kernel dapat ditulis dalam:
f x =sign(∑α∙y∙K(x,xi) N
i=1
+b)
Pada penelitian ini proses pelatihan SVM dilakukan dengan menggunakan fungsi kernel linear, polinomial, dan RBF. Parameter yang digunakan adalah
9 parameter terbaik dari hasil proses cross-validation dengan nilai fold ialah 5. Penelitian ini menggunakan LIBSVM.
Setelah didapatkan hasil klasifikasi tiap kelas dari dokumen latih berdasarkan klasifikasi SVM, maka proses selanjutnya dilakukan pengujian metode SVM dari dokumen uji terhadap dokumen latih.
Pengujian
Pengujian hasil klasifikasi dokumen dilakukan untuk mengetahui tingkat keakurasian klasifikasi SVM. Pengujian dilakukan pada hasil kelas untuk data uji terhadap data latih. Pengujian penelitian ini menggunakan metode confusion matrix
dan perhitungan tingkat akurasi.
Confusion matrix merupakan sebuah tabel yang terdiri atas banyaknya baris data uji yang diprediksi benar dan salah oleh model klasifikasi, yang digunakan untuk menentukan kinerja suatu model klasifikasi (Tan et al. 2006). Pengujian dilakukan untuk mendapatkan tingkat akurasi hasil prediksi yang berupa jumlah
true positive, true negative, false positive, dan false negative pada Tabel 3.
Perhitungan akurasi dinyatakan dalam persamaan berikut :
Akurasi= F11+F10+F01+F00 F11+F00
Lingkungan pengembangan sistem
Penelitian ini menggunakan perangkat lunak dan perangkat keras dengan spesifikasi adalah sebagai berikut:
1 Perangkat lunak:
Sistem operasi Microsoft Windows 8
Notepad++ sebagai code editor Matlab R2008b
Java dan PHP MySQL sebagai bahasa pemrograman pada praproses
Microsoft Office 2013 sebagai aplikasi yang digunakan untuk melakukan perhitungan dalam evaluasi sistem
Tabel 3 Confusion matrix untuk klasifikasi biner
Actual Class Predicted class
1 0
1 F11 F10
10
2 Perangkat keras:
Intel Pentium Core i3 @3.0 Ghz
Memori 2990MB RAM
Harddisk dengan kapasitas sisa 300GB
Monitor resolusi 1366 × 768 pixel Mouse dan keyboard
HASIL DAN PEMBAHASAN
Pengumpulan Dokumen
Dokumen yang digunakan terdiri atas 457 dokumen untuk masing-masing kelas, yaitu kelas tanaman obat dan kelas hortikultura.
Keseluruhan kelas yang berjumlah 457 terbagi menjadi 320 dokumen latih dan 137 dokumen uji. Deskripsi dokumen uji yang digunakan dapat dilihat pada Tabel 4.
Adapun dokumen dikelompokkan ke dalam tag sebagai berikut:
<dok></dok>, tag ini mewakili keseluruhan dokumen dan melingkupi tag-tag
lain yang lebih spesifik.
<id></id>, tag ini menunjukkan ID dari dokumen.
<content></content>, menunjukkan isi atau informasi dari dokumen.
Praproses
Pengindeksan keseluruhan dokumen yang dilakukan pada tahap tokenisasi dan pembuangan stopword menghasilkan 12182 kata di mana 6802 kata yang berupa kata unik yang ditemui di setiap dokumen dalam keseluruhan dokumen latih.
Pemilihan Fitur Ciri dan Pembobotan Kata
Hasil keluaran dari tahap praproses berupa vektor kata unik dan selanjutnya dilakukan pembobotan tf-idf pada setiap term. Hasil kata tersebut menghasilkan matriks yang digunakan untuk tahap klasifikasi di mana ukuran matriks untuk data latih sebanyak 320 × 6802 dan ukuran matriks untuk data uji sebanyak 137 × 6802. Vektor tersebut diproses pada tahap pemilihan fitur ciri. Metode yang digunakan pada pemilihan fitur ciri ini yaitu chi-square. Pada metode chi-square
Tabel 4 Deskripsi dokumen uji (.xml)
Dokumen bytes
Ukuran rata-rata dokumen 1790
Ukuran seluruh dokumen 817849
Ukuran dokumen terbesar 13581
11 diperlukan taraf nyata α yang merupakan kesalahan yang dibuat pada waktu menguji hipotesis, menolak H0 padahal H0 benar. Taraf nyata α yang digunakan
yaitu 0.01 agar peluang kesalahan sebesar 1%. Pemilihan nilai taraf nyata 0.01 berdasarkan riset penelitian Saputra (2012) yang menyatakan kinerja klasifikasi pada taraf nyata 0.01 lebih baik daripada taraf nyata 0.05 karena pada taraf nyata 0.01 menghasilkan himpunan kata penciri lebih sedikit.
Berdasarkan teori terpenuhinya hipotesis, taraf nyata 0.01 dapat diartikan bahwa kriteria kata yang dipilih adalah kata yang memiliki nilai χ2 di atas 6.63.
Hasil dari tahapan pemilihan fitur ciri adalah 1233 kata unik pada kelas tanaman obat dan 337 kata unik pada kelas hortikultura (Tabel 5). Kumpulan kata yang dihasilkan pada tahapan pemilihan fitur inilah yang kemudian hanya akan diolah pada sistem klasifikasi.
Kata “achantaceae, gelsemium” merupakan salah satu contoh kata yang hanya terdapat pada kelas tanaman obat. Kata “budidaya, lingkungan” merupakan salah satu contoh kata yang hanya terdapat pada kelas hortikultura. Ada beberapa kata yang sama, seperti kata “zat, tropis, petani” terdapat pada kelas tanaman obat dan hortikultura.
Setelah didapatkan hasil pemilihan fitur, kata-kata yang terpilih oleh chi-square akan menjadi penciri suatu kelas. Kemudian, untuk semua term pada masing-masing dokumen dihitung bobotnya sehingga dapat digunakan dalam proses klasifikasi.
Klasifikasi Dokumen
Seluruh hasil data praproses dengan menggunakan pembobotan idf dan pemilihan fitur ciri chi-square merupakan matriks yang digunakan sebagai data latih dan data uji. Pada tahap praproses dengan menggunakan pembobotan idf menghasilkan ukuran matriks data latih sebanyak 320 × 6802, menunjukkan 320 baris matriks yang menjelaskan tentang banyaknya dokumen dan 6802 kolom yang menjelaskan kata unik hasil pembuangan stopword yang akan digunakan. Pada data uji terdapat matriks sebanyak 137 × 6802 yang menunjukkan 137 baris (banyaknya dokumen) dan 6802 kolom (kata unik yang digunakan). Sedangkan proses pemilihan fitur ciri chi-square memiliki ukuran matriks data latih sebanyak 320 × 1309 menunjukkan 320 baris matriks yang menjelaskan tentang banyaknya dokumen dan 1309 kolom yang menjelaskan kata unik yang akan digunakan. Pada data uji terdapat matriks sebanyak 137 × 1309 yang menunjukkan 137 baris (banyaknya dokumen) dan 1309 kolom (kata unik yang digunakan). Matriks yang akan diolah untuk klasifikasi terdapat pada Tabel 6.
Tabel 5 Hasil tahap pemilihan fitur ciri dengan taraf nyata 0.01
No Kelas Jumlah kata unik
1 Tanaman obat 1233
12 polynomial dan kernel RBF sehingga untuk mengklasifikasikan data yang tidak dapat dipisahkan secara linear, formula SVM mentransformasikan data ke dalam dimensi ruang fitur dengan menggunakan fungsi kernel. Proses pelatihan dan pengujian ini bertujuan membangun model klasifikasi dan menghitung tingkat akurasi SVM dalam memprediksi data uji. Proses pemodelan dapat dilihat pada Lampiran 1.
Pelatihan SVM membutuhkan parameter sesuai dengan kernelnya. Untuk mengoptimalkan parameter maka dilakukan proses grid search pada saat pelatihan.
Grid search dijalankan menggunakan k-fold cross validation. Nilai k-fold yang digunakan pada penelitian ini yaitu sebesar 5-fold. Setiap proses pelatihan SVM yang menggunakan fungsi kernel diperlukan parameter terbaik untuk mendapatkan akurasi yang terbaik jika mencapai rataan nilai tertinggi. Namun pada penelitian ini didapatkan rataan nilai hampir sama di setiap iterasi pemodelan sehingga pengambilan parameter dilakukan pada nilai akurasi tertinggi pertama. Untuk melihat pengaruh pemilihan parameter maka pelatihan dicoba dengan menggunakan kernel RBF. Hasil grid_search dapat dilihat pada Lampiran 2.
Pada pelatihan SVM yang menggunakan fungsi kernel linear diperlukan parameter c (cost) dan kemudian akan dicari parameter terbaik yang akan digunakan pada tahap pengujian. Pada penelitian ini dihasilkannya nilai parameter terbaik sebesar 99.6875% di setiap proses cross-validation. Tetapi hanya akan diambil satu nilai parameter terbaik untuk pengujian. Ini disebabkan karena parameter c pada kernel linear tidak mempengaruhi akurasi cross-validation pada saat training dan fungsi kernel linear tidak memiliki pengaruh terhadap pemetaan data ke ruang vektor yang lebih tinggi. Pada fungsi kernel polinomial diperlukan parameter c (cost), γ (gamma), d (degree) dan r (coef0) yang akan dicari parameter terbaik digunakan pada tahap pengujian. Pada fungsi kernel RBF diperlukan parameter c (cost), γ (gamma) kemudian akan dicari parameter terbaik yang akan digunakan pada tahap pengujian.
Pemilihan parameter terbaik untuk kedua data latih dapat dilihat pada Tabel 7. Pemilihan parameter terbaik untuk kernel linear dengan metode 5-fold cross-validation dilakukanpada rentang 2-5 ≤ c ≤ 215 dengan hasilakurasi 99.6875%. Pemilihan parameter terbaik untuk kernel polinomial dengan metode 5- fold cross-validation menghasilkan parameter c pada rentang 2-5 ≤ c ≤ 215, parameter γ (gamma) pada rentang 2-15≤ γ≤ 23, parameter d (degree) pada rentang 1 ≤ d≤ 4,
dan parameter r (coef0) pada rentang 0 ≤ x ≤ 4 dengan akurasi cross-validation
sebesar 99.6875%. Pada penggunaan kernel RBF dengan metode 5-fold cross-validation menghasilkan parameter terbaik untuk c (cost) pada rentang 2-5≤ c≤ 215
13
Pengujian
Pengujian dilakukan terhadap ketiga model kernel SVM dengan menggunakan ukuran data sebanyak 137 × 6802 dan 137 × 1309. Pengujian data tersebut menggunakan parameter model klasifikasi terbaik untuk menentukan hasil klasifikasi akhir. Perhitungan hasil klasifikasi SVM untuk kelas a (tanaman obat) dan kelas b (hortikultura) berupa confusion matrix.
Perhitungan akurasi untuk ukuran data 137 × 6802 menggunakan confusion matrix di mana total jumlah data yang benar dibagi dengan total keseluruhan data uji dapat dilihat pada Tabel 8. Hasil perhitungan akurasi dengan kernel linear pada kelas a yang benar adalah 0 dan untuk jumlah dokumen yang salah berjumlah 39, sedangkan pada kelas b jumlah dokumen yang benar adalah 97 dan untuk jumlah dokumen yang salah berjumlah 0. Hasil perhitungan akurasi untuk kernel polinomial pada kelas a yang benar adalah 0 dan untuk jumlah dokumen yang salah berjumlah 39, sedangkan pada kelas b jumlah dokumen yang benar adalah 97 dan untuk jumlah dokumen yang salah berjumlah 0. Hasil perhitungan akurasi untuk kernel RBF pada kelas a yang benar adalah 4 dan untuk jumlah dokumen yang salah berjumlah 36, sedangkan pada kelas b jumlah dokumen yang benar adalah 97 dan untuk jumlah dokumen yang salah berjumlah 0.
Perhitungan akurasi untuk ukuran data 137 × 1309 menggunakan confusion matrix di mana total jumlah data yang benar dibagi dengan total keseluruhan data uji dapat dilihat pada Tabel 9. Hasil perhitungan akurasi dengan kernel linear pada kelas a yang benar adalah 35 dan untuk jumlah dokumen yang salah berjumlah 4, sedangkan pada kelas b jumlah dokumen yang benar adalah 97 dan untuk jumlah dokumen yang salah berjumlah 0. Hasil perhitungan akurasi untuk kernel polinomial pada kelas a yang benar adalah 35 dan untuk jumlah dokumen yang salah berjumlah 4, sedangkan pada kelas b jumlah dokumen yang benar adalah 97 dan untuk jumlah dokumen yang salah berjumlah 0. Hasil perhitungan akurasi untuk kernel RBF pada kelas a yang benar adalah 35 dan untuk jumlah dokumen yang salah berjumlah 4, sedangkan pada kelas b jumlah dokumen yang benar adalah 97 dan untuk jumlah dokumen yang salah berjumlah 1.
Tabel 7 Hasil akurasi parameter terbaik pada pemodelan setiap kernel
14
Pada ukuran matriks data uji sebesar 137 × 6802 yang diperoleh dari pemilihan bobot idf, nilai akurasi untuk kernel linear, kernel polinomial dan kernel RBF masing-masing menghasilkan 70.80%, 70.80% dan 73.72%. Sedangkan pada ukuran matriks data uji sebesar 137 × 1309 yaitu data uji dengan pemilihan fitur
chi-square, setiap kernel pada metode klasifikasi SVM memiliki hasil akurasi yang baik, di mana kernel linear, kernel polinomial dan kernel RBF masing-masing menghasilkan 96.35%, 96.35% dan 95.62%.
Dari hasil akurasi yang didapatkan dengan membandingkan hasil akurasi data menggunakan pemilihan fitur chi-square dan menggunakan pemilihan berdasarkan pembobotan idf, diperoleh data yang sangat berbeda di mana hasil akurasi dengan menggunakan chi-square lebih baik daripada menggunakan pemilihan berdasarkan bobot idf. Hal ini menunjukkan bahwa pemilihan fitur chi-square terhadap metode SVM dengan menggunakan ketiga kernel tersebut mampu mengklasifikasi dokumen teks dengan dua kelas sesuai dengan teori SVM yang dikembangkan untuk masalah klasifikasi dengan dua kelas. Ini dikarenakan pemilihan fitur chi-square membantu dan memiliki pengaruh dalam memisahkan data secara linear sehingga data yang diklasifikasikan dengan menggunakan SVM dapat dipisahkan lebih linear. Dengan akurasi ketiga kernel dapat dibuktikan bahwa SVM dengan menggunakan pemilihan fitur chi-square memiliki akurasi yang lebih baik dibandingkan dengan metode klasifikasi dan pemilihan fitur chi-square pada riset
15 sebelumnya, seperti riset Herawan (2011) dengan akurasi 93.26% dan Saputra (2012) dengan akurasi 95.55%.
SIMPULAN DAN SARAN
Simpulan
Hasil penelitian menunjukkan bahwa pemilihan fitur chi-square terhadap SVM memberikan hasil akurasi yang baik untuk klasifikasi dokumen teks dengan dua kelas. Pada pengujian ukuran data matriks (137 × 1309) terhadap metode SVM dengan menggunakan kernel linear dan polinomial dihasilkan nilai akurasi sama baik, yaitu 96.35% dan pada kernel RBF dihasilkan akurasi sebesar 95.62%. Dari percobaan yang telah dilakukan, klasifikasi dapat berjalan baik pada data latih sebesar 320 dokumen. Ini dibuktikan dengan akurasi cross-validation sebesar 99.69% pada saat pemodelan SVM. Dengan demikian, pemilihan fitur chi-square
membantu klasifikasi SVM dalam mengorganisasikan dokumen secara cepat, efisien, dan dapat meningkatkan kinerja sistem klasifikasi.
Saran
Penelitian ini masih memiliki banyak kekurangan yang memerlukan pengembangan lebih lanjut. Berdasarkan penelitian, pengujian ini dilakukan pada data yang jumlahnya relatif sedikit dan belum dapat dikatakan valid jika dibandingkan dengan metode lain. SVM diharapkan mampu diujicobakan pada penelitian dengan data skala besar dan multikelas sehingga hasil akurasi pada penelitian selanjutnya tidak diragukan validitasnya.
DAFTAR PUSTAKA
Chenometh, Megan, Song, Min. 2009. Text categorization. Di dalam:
Encyclopedia of Data Warehouse & Data Mining. hlm 1936-1941.
Gijsberts A. 2007. Evolutionary optimization of kernel[tesis]. Delft (NL): Delft [Internet]. Tersedia pada: http://ieg.ifs.tuwien.ac.at. [diunduh 2012 Des 13]. Kusnawi. 2010. Teknik document object model (DOM) untuk manipulasi
dokumen XML. J Dasi. hlm 1.
Manning CD, Raghavan P, Schütze H. 2008. An Introduction to Information Retrieval. Cambridge (GB): Cambridge Univ Pr.
16
Netcraft. 1995. How many active sites are there?. Tersedia pada: http://news.netcraft.com/active-sites/. [diakses pada 2012 Des 13].
Pilászy I. 2005. Text categorization and support vector machines. Di dalam:
The Proceedings of the 6th International Symposium of Hungarian Researchers on Computational Intelligence, 2005.
Sari PD. 2012. Metode pembobotan kata berbasis sebaran untuk temu kembali informasi dokumen Bahasa Indonesia [skripsi]. Bogor (ID): Institut Pertanian Bogor.
Saputra. 2012. Klasifikasi dokumen Bahasa Indonesia menggunakan semantic smoothing dengan ekstraksi ciri chi-square [skripsi]. Bogor (ID): Institut Pertanian Bogor.
Tan P, Steinbach M, Kumar V. 2006. Introduction to Data Mining. Minneapolis (US): Addison Wesley.
Yang Y, Pedersen J. 1997. A Comparative Study on Feature Selection in Text Categorization. International Conference on Machine Learning 1997.
17
Lampiran 1 Instruksi SVM Matlab 1 Kernel linear
[label_vector, instance_matrix] = libsvmread ('datatrainlibsvm.
train');
Accuracy = 96.3504% (132/137) (classification)
2 Kernel polinomial
18
Lampiran 1 Lanjutan 3 Kernel RBF
datatrain = csvread('training.csv');
labels = datatrain(:,1);
features = datatrain(:,2:end); features_sparse = sparse(features);
libsvmwrite('datatrainlibsvm.train', labels, features_sparse);
[label_vector,instance_matrix]=libsvmread('datatrainlibsvm.train')
;
test_grid_rbf(label_vector,instance_matrix); %parameter kernel
[training_label_vector,training_instance_matrix]=libsvmread('data
trainlibsvm.train');
datatest = csvread('testing.csv');
labels = datatest(:,1);
features = datatest(:,2:end);
features_sparse = sparse(features);
libsvmwrite('datatestlibsvm.test', labels, features_sparse);
[testing_label_vector,testing_instance_matrix]=libsvmread('datates
tlibsvm.test');
model2 =svmtrain(training_label_vector,training_instance_matrix,
'-t 2 -c 1 -g 0.000244141');
[predict_label2, accuracy2, dec_values2] = svmpredict
(testing_label_vector, testing_instance_matrix,model2);
19
Lampiran 2 Hasil grid search pada kernel RBF
Cost Gamma
2-15 2-14 2-13 2-12 2-11 2-10
2-5 70.94% 70.94% 70.94% 71.88% 70.94% 70.94%
2-4 70.94% 75.63% 82.81% 86.88% 90.63% 88.75% 2-3 76.25% 82.50% 86.56% 90.63% 93.13% 93.44% 2-2 82.19% 85.63% 89.69% 92.81% 95.63% 95.63% 2-1 85.31% 89.69% 92.81% 97.50% 98.75% 97.81%
20 89.06% 92.81% 97.81% 99.69% 99.69% 98.44% 21 92.50% 97.50% 99.69% 99.69% 99.69% 98.44% 22 97.19% 99.69% 99.69% 99.69% 99.69% 98.44% 23 99.69% 99.69% 99.69% 99.69% 99.69% 98.44% 24 99.69% 99.69% 99.69% 99.69% 99.69% 98.44% 25 99.69% 99.69% 99.69% 99.69% 99.69% 98.44%
26 99.69% 99.69% 99.69% 99.69% 99.69% 98.44% 27 99.69% 99.69% 99.69% 99.69% 99.69% 98.44% 28 99.69% 99.69% 99.69% 99.69% 99.69% 98.44% 29 99.69% 99.69% 99.69% 99.69% 99.69% 98.44%
210 99.69% 99.69% 99.69% 99.69% 99.69% 98.44%
20
Lampiran 2 Lanjutan
Cost Gamma
2-9 2-8 2-7 2-6 2-5 2-4
2-5 70,94% 70,94% 70,94% 70,94% 70,94% 70,94% 2-4 70,94% 70,94% 70,94% 70,94% 70,94% 70,94%
2-3 73,75% 70,94% 70,94% 70,94% 70,94% 70,94% 2-2 91,56% 70,94% 70,94% 70,94% 70,94% 70,94%
2-1 94,38% 75,31% 70,94% 70,94% 70,94% 70,94%
20 96,25% 92,81% 72,81% 70,94% 70,94% 70,94%
21 93,13% 72,81% 70,94% 70,94% 70,94% 70,94%
22 96,88% 93,13% 72,81% 70,94% 70,94% 70,94%
23 96,88% 93,13% 72,81% 70,94% 70,94% 70,94%
24 96,88% 93,13% 72,81% 70,94% 70,94% 70,94%
25 96,88% 93,13% 72,81% 70,94% 70,94% 70,94%
26 96,88% 93,13% 72,81% 70,94% 70,94% 70,94%
27 96,88% 93,13% 72,81% 70,94% 70,94% 70,94%
28 96,88% 93,13% 72,81% 70,94% 70,94% 70,94%
29 96,88% 93,13% 72,81% 70,94% 70,94% 70,94%
210 96,88% 93,13% 72,81% 70,94% 70,94% 70,94% 211 96,88% 93,13% 72,81% 70,94% 70,94% 70,94% 212 96,88% 93,13% 72,81% 70,94% 70,94% 70,94% 213 96,88% 93,13% 72,81% 70,94% 70,94% 70,94% 214 96,88% 93,13% 72,81% 70,94% 70,94% 70,94%
21
Lampiran 2 Lanjutan
Cost Gamma
2-3 2-2 2-1 2-0 21 22 23
2-5 70,94% 70,94% 70,94% 70,94% 70,94% 70,94% 70,94% 2-4
70,94% 70,94% 70,94% 70,94% 70,94% 70,94% 70,94% 2-3 70,94% 70,94% 70,94% 70,94% 70,94% 70,94% 70,94% 2-2 70,94% 70,94% 70,94% 70,94% 70,94% 70,94% 70,94% 2-1 70,94% 70,94% 70,94% 70,94% 70,94% 70,94% 70,94% 20 70,94% 70,94% 70,94% 70,94% 70,94% 70,94% 70,94% 21
70,94% 70,94% 70,94% 70,94% 70,94% 70,94% 70,94% 22 70,94% 70,94% 70,94% 70,94% 70,94% 70,94% 70,94% 23 70,94% 70,94% 70,94% 70,94% 70,94% 70,94% 70,94% 24 70,94% 70,94% 70,94% 70,94% 70,94% 70,94% 70,94% 25 70,94% 70,94% 70,94% 70,94% 70,94% 70,94% 70,94% 26
70,94% 70,94% 70,94% 70,94% 70,94% 70,94% 70,94% 27
70,94% 70,94% 70,94% 70,94% 70,94% 70,94% 70,94% 28 70,94% 70,94% 70,94% 70,94% 70,94% 70,94% 70,94% 29 70,94% 70,94% 70,94% 70,94% 70,94% 70,94% 70,94% 210 70,94% 70,94% 70,94% 70,94% 70,94% 70,94% 70,94% 211
22
RIWAYAT HIDUP
Penulis dilahirkan di Pekanbaru pada tanggal 30 Agustus 1991. Penulis merupakan anak kedua dari pasangan Ibrahim dan Nuriyanti. Pada tahun 2008, penulis menamatkan pendidikan di SMA Negeri 8 Pekanbaru. Penulis berkesempatan melanjutkan studi di Institut Pertanian Bogor melalui jalur Beasiswa Unggul Daerah (BUD) di Depertemen Ilmu Komputer, Fakultas Matematika dan Ilmu Pengetahuan Alam.
Penulis aktif di berbagai organisasi kemahasiswaan seperti Himpunan Mahasiswa Riau Bogor dan anggota berbagai kegiatan seperti OMI (2010), IT Today (2011). Penulis juga menjadi asisten praktikum pada Mata Kuliah Metode Kuantitatif (2012-2013). Selama awal kuliah penulis juga pernah menjadi staf pengajar di Lembaga Bimbingan Belajar NIC Bogor. Selain itu, penulis melaksanakan kegiatan Praktik Kerja Lapangan di divisi software development PT Inti Komunikasi Selaras Jakarta Selatan pada tahun 2012.