DAFTAR PUSTAKA
Arica N. & Yarman-Vural. 2001. An Overview of Character Recognition Focused on Off-line Handwriting. IEEE Transactions on Systems, Man and Cybernetics, Part C: Applications and Review. 31(2): 216-233.
Entisari,Rokhani. 2009. Pengenalan Pola Huruf Tulisan Tangan Menggunakan Jaringan Saraf Tiruann Dengan Algoritma Backpropagation.Skripsi, Universitas Negeri Yogyakarta.
Fachrurrazi,Sayed.201.Penggunaan Metode SVM Untuk Mengklasifikasi dan Memprediksi Angkutan Udara Jenis Penerbangan Domestik dan Penerbangan Internasional di Banda Aceh. Tesis.Universitas Sumatra Utara.
Khairunnisa. 2012. Pengenalan Tulisan Tangan Latin Bersambung Menggunkan Jaringan Saraf Tiruan Propagasi Balik. Skripsi. Universitas Sumatera Utara.
Krisantus.2007.Penerapan Teknik Support Vector Machine untuk Pendeteksian Intrusi pada Jaringan.Skripsi. Institut Teknologi Bandung.
Liu, J.G., Mason, P.J. 2009. Essential Image Processing and GIS for Remote Sensing. Oxford: Wiley-Blackwell.
Minartiningtyas, B.A. 2010. Artikel Teknik Informatika-Operasi Cropping, (Online), (http://informatika.web.id/operasi-cropping.htm. diakses 27 Desember 2015)
Mulia,Isnan. 2012. Pengenalan Aksara Sunda Menggunakan Ekstraksi Zoning dan Klasifikasi Support Vector Machine. Skripsi.Institut Pertanian Bogor.
Nasution, Rian H. Pengenalan Kata Tulisan Tangan Huruf Korea Menggunakan Jaringan Saraf Tiruan Propagasi Balik. Skripsi. Universitas Sumatera Utara.
Osuna EE, Freund R, Girosi F. 1997. Support Vector Machines: Training and Applications. AI Memo 1602, Massachusetts Institute of Technology.
56
for Handwritten Alphabets Recognition System Using Neural Network. International Journal of Computer Science & Information Technology (IJCSIT) 3(1): 27-38.
Putra, Nanda. 2012. Peningkatan Nilai Fitur Jaringan Propagasi Balik Pada Pengenalan Angka Tulisan Tangan Menggunakan Metode Zoning dan Diagonal Based Feature Extraction.Skripsi. Universitas Sumatera Utara.
Rajashekararadhya SV, Ranjan PV. 2008. Efficient zone based feature extraction algorithm for handwritten numeral recognition of four popular South Indian scripts. Journal of Theoretical and Applied Information Technology.
Santoso, B., 2007, Data Mining : “Data Mining Teknik Pemanfaatan Data Untuk Keperluan Bisnis”. Teori dan Aplikasi. Graha Ilmu Yogyakarta.
Sharma, O. P, Ghose, M. K. dan Shah, K. B. 2012. An Improved Zone Based Hybrid Feature Extraction Model for Handwritten Alphabets Recognition Using Euler Number. International Journal of Soft Computing and Engineering (IJSCE). 2(2): 504-508.
Sutoyo. T. et al. 2009. Teori Pengolahan Citra Digital. Yogyakarta: Penerbit ANDI. Tacbir, Hendro P., Agus,K., & Dila, F.2010. Pengenalan Pola Huruf Arab
menggunakan Jaringan Syaraf Tiruan dengan Metode Backpropagation..
Tazmania,G.2010. Binary Image, (Online),
(https://gentazmania.wordpress.com/tag/java/page/2/. diakses 27 Desember 2015)
Theodoridis S, Koutroumbas K. 2008. Pattern Recognition. Ed ke-4. Burlington (US) : Academic Press.
Trier OD, Jain Ak, Taxt T.1996.Feature extraction methods for character recognition – a survey. Pattern Recognition 4(29) : 641-662.
BAB 3
ANALISIS DAN PERANCANGAN
Bab ini membahas tentang implementasi metode klasifikasi SVM dalam pengenalan pola huruf hijaiyah. Bab ini juga membahas tentang data yang digunakan, pre-processing dan feature extraction yang dilakukan terhadap setiap data.
3.1 Arsitektur Umum
22
Gambar 3.1 Arsitektur umum dari metode yang diajukan
Data Latih Data Uji
Pelatihan SVM
k-fold Cross-validation
Pengujian SVM
Hasil identifikasi (persentasi akurasi pola yang dikenali) Pembentukan Citra biner (thresholding)
Pemotongan (cropping) citra
Normalisasi Resolusi citra (normalization)
Pengurusan objek citra (thinning)
Image Centroid and Zone
Zone Centroid Zone Pre-processing
Ekstraksi Ciri
Klasifikasi
3.2 Akuisisi Data
Data sampel yang digunakan dalam penelitian ini adalah citra huruf hijaiyah tulisan tangan yang dibubuhkan pada kertas putih menggunakan dengan tinta pena warna hitam. Setelah pengambilan data, data tersebut di scan dan disimpan dalam file .bmp. Data sampel dikumpulkan sebanyak 240 pola tulisan tangan berbentuk huruf hijaiyah dari 10 orang, yang setiap orangnya terdiri dari 7 pola huruf hijaiyah. Setiap huruf tulisan tangan disimpan pada file citra yang berbeda. Setiap citra disimpan dengan ukuran awal 700x700 piksel , yang nanti akan diolah kembali menjadi ukuran 70x70.
Total seluruh data sampel adalah 240 pola huruf hijaiyah tulisan tangan. Dari total data tersebut, dibagi penggunaannya untuk data pelatihan (training) dan data pengujian (testing). Banyaknya data training adalah 210 huruf hijaiyah tulisan tangan dan data testing sebanyak 30 huruf hijaiyah tulisan tangan. Data sampel yang digunakan pada penelitian ini dapat dilihat pada lampiran A.
3.3 Pre-processing
Tahapan proses pengolahan citra dapat dilihat pada gambar 3.2.
Gambar 3.2 Tahapan pre-processing
Pengolahan citra dimulai dengan mengubah citra kedalam citra biner dengan proses thresholding , tahap selanjutnya adalah pemotongan (cropping) disertai dengan normalisasi citra menjadi ukuran yang seragam yaitu ukuran 70x70 piksel. Citra yang telah dinormalisasi kemudian akan masuk ketahapan pengurusan objek (thinning)
Pembentukan Citra biner (thresholding)
Pemotongan (cropping) citra
Normalisasi Resolusi citra (normalization)
24
untuk mendapatkan kerangka dari objek huruf. Citra hasil thinning yang kemudian digunakan untuk tahap ekstraksi fitur.
3.3.1. Pembentukan Citra Biner (Threshold)
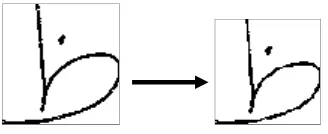
Pada tahap ini citra huruf hijaiyah akan diubah menjadi citra biner ,dimana citra biner merupakan citra yang hanya memiliki dua nilai warna, yaitu 0 (hitam) dan 254 (putih). Nilai threshold yang ditentukan akan menjadi batasan. Pada penelitian ini nilai threshold yang digunakan adalah 127. Nilai yang lebih kecil dari threshold diubah menjadi nilai 0 dan nilai yang lebih besar dari threshold diubah menjadi 255. Pada gambar 3.3 merupakan contoh citra huruf hijaiyah hasil thresholding.
Gambar 3.3 Citra hasil thresholding
3.3.2. Pemotongan Citra (Cropping)
Pemrosesan citra selanjutnya adalah pemotongan citra (crop) dengan menghilangkan area putih yang tidak berisi objek huruf. Citra hasil threshold dipotong sesuai dengan batasan objek huruf tulisan tangan yaitu pemotongan secara horizontal dan pemotongan secara vertikal .Hal ini dilakukan untuk membantu proses pengurusan objek (thinning).
Proses pemotongan citra secara vertikal hampir sama dengan pemotongan horizontal hanya saja pemotongan citra secara vertikal dimulai dengan menghitung putih pada setiap baris yang dimiliki oleh citra. Penentuan bagian awal pemotongan dengan cara memeriksa baris pada bagian atas citra. Baris pertama yang memiliki piksel warna putih kurang dari 90 % akan dijadikan awal pemotongan dan untuk bagian akhir pemotongan diperiksa pada baris dimulai dari bagian bawah citra dengan batasan nilai yang sama. Citra biner yang dipotong dapat dilihat pada gambar 3.4.
Gambar 3.4 Citra hasil cropping 3.3.3. Normalisasi Resolusi Citra (Normalization)
Citra yang telah di crop memiliki ukuran yang berbeda-beda sehingga belum bisa digunakan sebagai inputan standart untu di ekstraksi. Sebagai contoh ukuran citra huruf dzo hasil pemotongan pada tahap sebelumnya adalah 78x80. Citra tersebut akan melalui tahapan normalisasi resolusi (normalization) terlebih dahulu dengan menggunakan ukuran citra 70x70 pixel. Citra hasil normalisasi dapat dilihat pada Gambar 3.5.
Gambar 3.5 Citra hasil normalisasi
3.3.4. Pengurusan Objek Citra (Thinning)
26
Melalui proses pengurusan ini akan didpat kerangka dari objek tuisan tangan huruf hijaiyah. Peneliti menggunakan algortima Zhang-Shuen untuk proses thinning citra. Algoritma Zhang-Shuen ini menggunakan metode parealel dimana nilai baru bagi tiap-tiap piksel dihasilkan dari nilai piksel pada iterasi sebelumnya. Tahapan dari proses ini dapat dilihat pada sub bab 2.3.4 mengenai thinning . Citra hasil thinning merupakan hasil akhir dari tahapan pre-processing citra dan citra ini dapat digunakan pada tahap ekstraksi fitur. Hasil pengurusan objek citra dapat dilihat pada gambar 3.6.
Gambar 3.6 Citra hasil thinning 3.4 Ekstraksi Ciri (Feature Extraction)
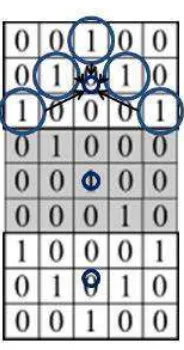
Setelah citra hasil thinning didapat, tahap selanjutnya adalah tahapan ekstraksi ciri, pada penelitian ini penulis menggunakan metode ekstraksi ciri zonning. Metode ini memiliki beberapa variasi algoritma, dan pada penelitian ini menggunakan variasi algoritma Image Centroid and Zone (ICZ) , dan Zone Centroid and Zone (ZCZ) . Gambar 3.7 merupakan citra ilustrasi huruf “S” berukuran 5x9 pixel yang akan melalui tahap ekstraksi ciri menggunakan algoritma ICZ dan algoritma ZCZ .
Dengan menggunakan algoritma Image Centroid and Zone, pertama yang harus dihitung adalah centroid (pusat) dari citra. Centroid dari citra dinyatakan dengan nilai koordinat titik ( , ). Cara menghitung centroid citra yaitu pada persamaan 3.1
...(3.1)
Dengan f(x,y) adalah nilai piksel dari citra pada posisi tertentu. Hasil perhitungan yaitu nilai = 3 dan = 5 sehingga didapatkan nilai centroid citra yaitu (3,5). Setelah nilai centroid didapat, selanjutnya citra dibagi menjadi n zona yang sama, misalkan menjadi 3 zona, yaitu zona atas, zona tengah dan zona bawah, dengan masing-masing zona berukuran 5x3 pixel Kemudian, dihitung jarak antara centroid dan setiap piksel yang ada dalam zona, dalam hal ini piksel yang digunakan adalah piksel non-background. Jarak tersebut dapat diperoleh menggunakan rumus jarak Euclid sebagai berikut :
Jarak = √ − + − ... (3.2)
Gambar 3.8 Perhitungan jarak pikel non-background dengan image centroid zona 1
28
Setelah hasil jarak centroid-pixel untuk masing-masing pixel didapat, selanjutnya hitung rata-rata jarak dengan persamaan :
.... (3.3)
Hasil jarak rata-rata centroid-pixel untuk zona 1 adalah 3,196. Dengan cara yang sama, jarak centroid-pixel dihitung untuk setiap pixel pada zona 2 (tengah) dan 3 (bawah), kemudian dihitung rata-ratanya sehingga jarak rata-rata centroid-pixel yang didapat untuk zona 2 dan 3 berturut-turut ialah 0,94 dan 3,196.
Ekstraksi ciri dengan menggunakan algoritma Zone Centroid and Zone, pertama sekali citra akan langsung dibagi menjadi n zona yang sama, sama hal nya dengan ICZ , maka zona dibagi menjadi 3 zona yaitu zona atas , zona tengah , dan zona bawah. Kemudian zone centroid masing-masing zona dihitung dengan menggunakan persamaan 3.1 . Didapatlah hasil perhitungan zone centroid sebagai berikut :
Zona 1 (atas) : = 3 , = 2.2 Zona 2 (tengah) : = 3 , = 5 Zona 3 (bawah) : = 3 , = 7.8
Gambar 3.9 Perhitungan jarak pikel non-background dengan image centroid zona 1
Untuk zona 1 (atas), perhitungan jarak yang di visualisasikan pada gambar 3.9 dilakukan perhitungan sebagai berikut :
(1,3) Jarak = √ − + − . = 2.15
(2,2) Jarak = √ − + − . = 1.02
(3,1) Jarak = √ − + − . = 1.2
(4,2) Jarak = √ − + − . = 1.02
(5,3) Jarak = √ − + − . = 2.15
Setelah hasil jarak centroid-pixel untuk masing-masing pixel non-background pada zona 1 didapat, selanjutnya hitung rata-rata jarak dengan persamaan 3.3. Hasil perhitungan rata-rata jarak di dapat untuk setiap piksel zona 2 (tengah) dan zona 3 (bawah) berturut-turut ialah 0.94 dan 1.508
Dengan demikian, ketiga nilai dari masing-masing algoritma ini tersimpan dalam format .data yang kemudian akan digunakan dalam pelatihan dan/atau pengujian Support Vector Machine (SVM).
30
Nilai fitur yang didapat dari setiap ekstraksi ciri menggunakan ICZ dan ZCZ selanjutnya akan digunakan dalam proses klasifikasi menggunakan Support Vector Machine (SVM). Proses klasifikasi SVM ini dilakukan dengan cara membandingkan data latih dan data uji. Sebelum proses klasifikasi dilakukan semua data latih divalidasi terlebih dahulu menggunakan cross validation , nilai k yang digunakan pada penelitian ini adalah 10.
Setelah semua data pelatihan di validasi, proses pencarian hyperplane dapat dilakukan dengan mencari nilai margin antara dua set obyek dari kelas yang berbeda berdasarkan parameter bobot (w) dan bias (b) dengan memaksimumkan nilai margin yaitu
|�|
.
Adapun proses untuk klasifikasi data pengujian adalah sebagai berikut :1. Masukkan data pelatihan pertama dan jumlah zona.
2. Menentukan parameter (w) dan bias (b). Nilai w dan b dapat dihitung dari ciri citra yang sudah ditentukan ditahap sebelumnya menggunakan persamaan . + � dimana � = , , , … , �.
3. Hitung jarak antara dua set obyek dari kelas yang berbeda menggunakan persamaan 2.12.
4. Mengambil data yang akan diklasifikasikan dari data pelatihan yang memiliki nilai constrain > 0 (support vector) menggunakan persamaan 2.13.
5. Memberi label prediksi class value .
6. Ulangi langkah 2 hingga 5 untuk semua data pelatihan.
7. Hitung prediksi yang benar dan prediksi yang salah dari data pengujian . 8. Hitung tingkat akurasi keseluruhan pengujian.
3.5.1 Nilai fungsi klasifikasi
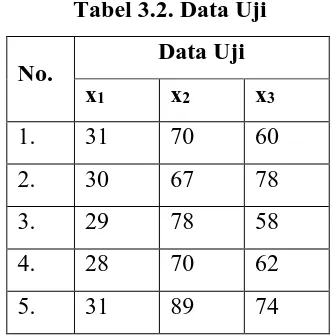
Penentuan klasifikasi dapat ditentukan dengan menentukan nilai bobot dan fitur ciri pada setiap kasus. Pada kasus pengenalan pola ini peneliti akan menggunakan 2 kelas yaitu kelas +1 dan -1 dan 5 data hasil nilai fitur seperti pada Tabel 3.2 .
Untuk mendapatkan fungsi klasifikasi akan diuji menggunakan 5 huruf hijaiyah sebagai data uji seperti pada Tabel 3.2.
Kasus x1 x2 x3 Kelas (y)
Langkah-langkah yang dilakukan dalam menentukan fungsi klasifikasi(hyperplane) dari contoh kasus diatas adalah :
Penentuan variabel bobot dari fitur ciri kasus.
Terdapat tiga fitur ciri pada tabel 3.1 yaitu x1, x2 , x3 sehingga w (bobot) akan memiliki 3 fitur yaitu w1, w2, dan w3.
Optimasi masalah dengan meminimal kan nilai sebagai berikut : min ( + + C (t1 + t2 + t3 + t4)
Dengan syarat sebagai berikut : yi (w.xi + b) ≥ 1 i = 1, 2, 3, …, N
Nilai kelas (y) dan fitur x1, x2 ,dan x3 dimasukkan kedalam persamaan yi (w.xi + b) ≥ 1 i = 1, 2, 3, …, N.
Sehingga didapat beberapa persamaan yaitu :
32
Setelah nilai bobot w1, w3 dan nilai bias (b) di dapat untuk mendapatkan nilai bobot w2 didapat dengan mensubstitusikan ke persamaan (1) seperti berikut : -Substitusi ke Persamaan (1)
(w1 - w2 + w3 + b) ≥ 1 (1- w2 + 1 + 0 – 1) = 0
Maka, w2 = 1
Maka hasil dari penjumlahan beberapa persamaan didapat nilai bobot (w) dan nilai bias (b) untuk 3 kelas dan 4 data adalah
w1 = 1 , w2 = 1 , w3 = 1, dan b = 0.
Langkah berikutnya adalah menentukan fungsi klasifikasi(hyperplane) dengan persamaan berikut :
w1 = 1
Untuk mendapatkan fungsi klasifikasi dan mengetahui setiap kelas dari data yang ada, data uji harus diberikan pada kasus. Tabel 3.3 menunjukkan data uji yang diberikan pada kasus ini merupakan nilai fitur dari huruf ain pada data uji.
Fungsi klasifikasi didapat dengan menggunakan persamaan
34
Tabel 3.3 Fungsi Klasifikasi
No. Data Uji Fungsi Klasifikasi x1 x2 x3 Kelas = sign(x1+x2+x3) maka nilai klasifikasi yang didapat adalah
sign (31+70+60) = sign(131) ; f(x) > 0 , +1.
Pada perancangan sistem akan dilakukan : 3.6.1. Perancangan antarmuka
Perancangan antarmuka merupakan gambaran umum tentang tampilan yang terdapat pada sistem.
1. Rancangan Tampilan Awal
Gambar 3.10. Rancangan tampilan awal Keterangan :
a. Pada header akan tertera nama dari sistem yang dibangun.
b. Merupakan submenu tahapan proses pengenalan pola huruf hijaiyah dari pre-processing sampai tahap pengujian SVM.
c. Pada content akan menampilkan hasil dari tiap proses sistem.
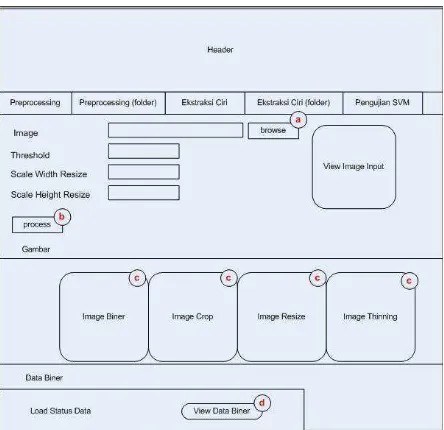
2. Rancangan Tampilan Utama
Pada tampilan utama aplikasi, terdapat beberapa fasilitas (tahapan proses) pengenalan pola dari pemilihan citra huruf, pemrosesan citra, dan hasil klasifikasi citra. Rancangan tampilan utama dapat dilihat sebagai berikut :
36
Keterangan :
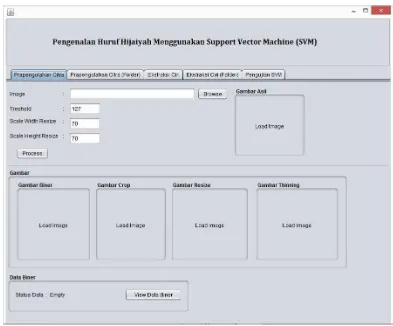
a. Tombol “Browse” memungkinkan user untuk memilih citra huruf hijaiyah pada tempat penyimpanan citra. Setelah citra dipilih, maka citra akan ditampilkan pada bagian “View Image Input”.
b. Tombol “Process” memungkinkan user untuk melakukan proses pre-processing , dengan memasukkan nilai threshold dan ukuran citra yang menjadi batasan pada proses normalisasi. Tahapan pre-processing yaitu threshold, cropping, normalisasi, dan thinning yang hasilnya akan langsung terlihat pada point c. c. Menampilkan citra hasil proses pre-processing yaitu citra biner, citra cropping ,
citra resize serta citra thinning yang nantinya akan di gunakan untuk proses ekstraksi ciri
d. Tombol “View Data Biner” memungkinkan user untuk mengetahui data biner dari citra hasil pre-processing.
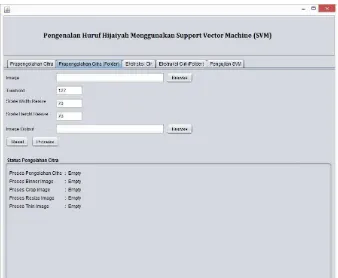
Gambar 3.12. Rancangan tampilan utama – preprocesing(Folder) Keterangan :
a. Tombol “Browse” pada “image” memungkinkan user untuk memilih folder tempat penyimpanan seluruh citra huruf hijaiyah yang akan dikenali.
c. Tombol “Reset” memungkinkan user untuk menghapus seluruh citra hasil pemrosesan.
d. Tombol “Process” memungkinkan user untuk melakukan proses pre-processing seluruh citra yang tersimpan dalam sebuah folder , dengan memasukkan nilai threshold dan ukuran citra yang menjadi batasan pada proses normalisasi.
e. Jumlah citra yang berhasil diolah akan tertera pada status pre-processing.
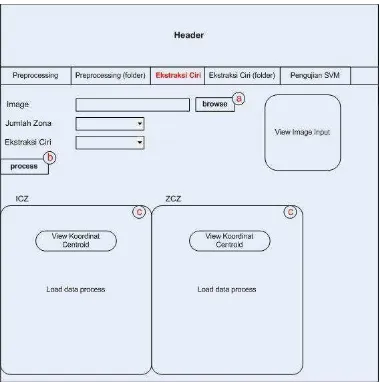
Gambar 3.13. Rancangan tampilan utama – Ekstraksi Ciri
Keterangan :
a. Tombol “Browse” pada “image” memungkinkan user untuk memilih citra huruf hijaiyah hasil dari pre-processing. Citra hasil pre-processing akan ditampilkan pada “View Image Input”.
b. Tombol “Process” memungkinkan user untuk melakukan proses ekstraksi ciri sesuai dengan inputan jumlah zona dan jenis ekstraksi yang akan diproses.
38
Gambar 3.14. Rancangan tampilan utama – Ekstraksi Ciri (Folder) Keterangan Gambar 3.14 :
a. Tombol “Browse” pada “image” memungkinkan user untuk memilih folder tempat penyimpanan seluruh citra huruf hijaiyah hasil pre-processing.
b. Tombol “Process” memungkinkan user untuk melakukan proses ekstraksi ciri sesuai dengan inputan jumlah zona , jenis ekstraksi , serta data mana (training atau testing) yang akan diproses.
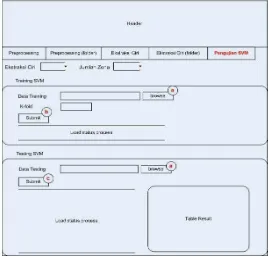
Keterangan :
a. Tombol “Browse” pada “data training” dan “data testing” memungkinkan user untuk memilih folder tempat penyimpanan nilai fitur hasil dari ekstraksi ciri sesua jenis ekstraksi dan jumlah zona yang akan diproses.
b. Tombol “Submit” pada “Training SVM” memungkinkan untuk user melakukan pelatihan SVM serta melakukan validasi sebanyak k yang sudah ditentukan. c. Tombol “ Submit” pada “Testing SVM” memungkinkan untuk user melakukan
BAB 4
IMPLEMENTASI DAN PENGUJIAN SISTEM
Pada bab ini akan membahas hasil yang didapat dari implementasi metode Support Vector Machine (SVM) pada pengenalan tulisan tangan huruf hijaiyah, sesuai dengan
perancangan sistem yang telah dilakukan di Bab 3 serta melakukan pengujian sistem yang telah dibangun.
4.1. Implementasi Sistem
Tahap implementasi sistem merupakan proses pengubahan spesifikasi sistem menjadi sistem yang dapat dijalankan. Pada tahapan ini , metode Support Vector Machine (SVM) akan diimplementasikasn ke dalam sistem menggunakan bahasa pemrograman Java sesuai dengan perancangan yang dilakukan.
4.1.1. Spesifikasi hardware dan software yang digunakan
Spesifikasi perangkat keras (hardware) dan perangkat lunak (software) yang digunakan dalam membangun sistem pencaian association rules ini adalah sebagai berikut.
1. Sistem operasi Microsoft Windows 8.1 Pro
2. Processor Intel(R) Core(TM) i5-5200U CPU @ 2.20GHz 2.19GHz. 3. Memory 4.00GB RAM
4. Kapasitas harddisk 500GB. 5. Netbeans IDE 8.1
6. Notepad ++
4.1.2. Implementasi Perancangan Antarmuka
4.1.2.1. Tampilan utama sistem pre-processing
Tampilan utama sistem ini merupakan tampilan pertama kali muncul ketika sistem dijalankan dan merupakan tampilan untuk tahapan pertama proses pengenalan yaitu pre-processing. Tampilan utama sistem pre-processing dapat dilihat pada Gambar 4.1 dan Gambar 4.2.
Gambar 4.1 Tampilan utama pre-processing
42
Gambar 4.2 Tampilan utama pre-processing (folder)
Tampilan ini merupakan tahap pre-processing dengan memasukkan lokasi folder penyimpanan keseluruhan citra , status pre-processing akan menampilkan jumlah citra yang berhasil diproses dan citra hasil pre-processing akan tersimpan kedalam folder sesuai dengan lokasi output yang telah diinput. Seperti gambar 4.1, nilai threshold dan size untuk proses resizing juga telah ditetapkan pada tampilan ini.
4.1.2.2. Tampilan utama sistem ekstraksi ciri
Tampilan utama sistem ini merupakan tampilan tahapan ekstraksi ciri, dimana citra hasil pre-processing akan di cari nilai fitur untuk memudahkan tahapan pengenalan citra selanjutnya. Tampilan utama ekstraksi ciri setiap citra dapat dilihat pada gambar 4.3 dan gambar 4.4 untuk tampilan utama ekstraksi ciri dimana citra yang ada dalam folder akan diproses secara keseluruhan.
Gambar 4.3 Tampilan utama ekstraksi ciri
Gambar 4.4 Tampilan utama ekstraksi ciri (folder)
44
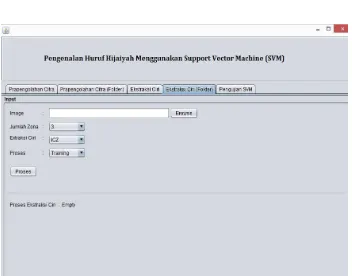
4.1.2.3. Tampilan utama sistem pengujian SVM
Tampilan ini merupakan tampilan tahapan akhir proses pengenalan yaitu tahapan pengujian SVM, nilai fitur setiap citra yang didapat dari proses ekstraksi ciri akan digunakan untuk proses pengenalan huruf tulisan tangan menggunakan metode SVM. Tampilan utama sistem pengujian SVM ini dapat dilihat pada gambar 4.5.
Gambar 4.5 Tampilan utama pengujian SVM 4.1.3. Implementasi data
Data yang dimasukkan ke dalam sistem adalah citra tulisan tangan huruf hijaiyah dari 15 orang.
4.2. Prosedur Operasional
Pada tampilan utama pre-processing, dan tampilan pre-processing(folder) tombol “Browse” yang digunakan untuk memilih citra dan lokasi penyimpanan citra untuk dilakukan tahap pre-processing , berupa binerisasi, cropping, resizing dan thinning. Tampilan “Browse” dipilih dapat dilihat pada Gambar 4.6 dan Gambar 4.7.
Gambar 4.6 Tampilan “Browse” pre-processing
Gambar 4.7 Tampilan “Browse” pre-processing(folder)
Gambar 4.6, citra huruf yang dipilih selanjutnya akan ditampilkan pada panel “input”. Setelah citra huruf ditampilkan, tombol “Process” akan memulai proses pre -processing yang hasilnya akan ditampilkan pada panel “Gambar” seperti yang ditunjukkan pada Gambar 4.8.
46
Gambar 4.8 Tampilan awal aplikasi proses Pre-processing
Pada tampilan utama ekstraksi ciri, dan tampilan ekstraksi ciri(folder) tombol “Browse” yang digunakan untuk memilih citra dan lokasi penyimpanan citra hasil akhir proses pre-processing, yaitu citra thinning untuk dicari nilai fitur setiap citra. Tampilan “Browse” dipilih dapat dilihat pada Gambar 4.9 dan Gambar 4.10.
Gambar 4.10 Tampilan “Browse” ekstraksi ciri(folder)
Citra huruf thinning yang telah dipilih (Gambar 4.9) akan di cari nilai fitur nya berdasarkan zona dan metode ekstraksi ciri yang digunakan. Tombol “Process” akan memulai proses perhitungan sehingga menghasilkan beberapa nilai fitur setiap citra , nilai fitur akan ditampilkan pada panel ICZ dan ZCZ seperti yang ditunjukkan pada Gambar 4.11.
Sedangkan pada tampilan utama ekstraksi ciri(folder), setelah lokasi folder citra pre-processing di inputkan (Gambar 4.10) nilai fitur akan tersimpan sebagai “.data” sesuai lokasi penyimpanan yang telah diinput.
48
Pada tampilan pengujian SVM terdapat 2 tombol “Browse” pada training SVM dan testing SVM, user akan memasukkan lokasi file ekstraksi ciri yang berisi nilai fitur berekstensi “.data “ yang akan dikenali. Hasil pengujian berupa pola prediksi yang ditampilkan langsung dalam bentuk tabel, serta tingkat akurasi pola yang benar. Berikut adalah tampilan “Browse” pengujian SVM .
Gambar 4.12 Tampilan “Browse” pengujian SVM
4.3 Pengujian Sistem
Pengujian dilakukan dengan menggunakan dataset pelatihan dan dataset pengujian yang berekstensi “.data”.Total jenis huruf yang digunakan adalah 7 huruf hijaiyah jumlah data pelatihan terdiri dari 210 data dan data pengujian terdiri dari 30 data. Pada sistem yang dibangun, nilai k yang digunakan adalah 10. Data hasil pengujian dari 7 citra huruf hijaiyah berupa pola prediksi hasil pengujian SVM berdasarkan nilai fitur dari pembagian zona yang dilakukan dan metode ekstraksi yang digunakan. Kemudian dilakukanlah perhitungan akurasi untuk setiap pengujian. Berikut merupakan hasil pengujian citra dengan akurasi terbaik menggunakan metode ekstraksi ciri ZCZ dengan pembagian zona 9 dapat dilihat pada tabel 4.1
Tabel 4.1 Data hasil pengujian
No Nama Citra Actual Output Desired Output
50
Tabel 4.1 Data hasil pengujian(lanjutan)
No Nama Citra Actual Output Desired Output
26 ta_31.bmp ta ta
27 ta_32.bmp ta ta
28 ta_33.bmp ta ta
29 ta_34.bmp ta ta
30 ta_35.bmp ta ta
Untuk hasil akurasi berdasarkan metode ekstraksi ciri dan jumlah zona yang digunakan, nilai akurasi yang dianalisis merupakan rata-rata nilai akurasi dari hasil klasifikasi untuk masing-masing dataset. Hasil akurasi rata-rata berdasarkan metode ekstraksi ciri dan jumlah zona yang digunakan dapat dilihat pada Tabel 4.2
Tabel 4.2 Hasil akurasi rata-rata berdasarkan metode ekstraksi ciri dan jumlah zona yang digunakan
Jumlah Zona Metode Ekstraksi Ciri
(b)
Gambar 4.14 Grafik hasil akurasi pengujian (a) bedasarkan zona (b) berdasarkan metode
ekstraksi yang digunakan
Jika dilihat berdasarkan metode ekstraksi ciri yang digunakan (Gambar 4.14_(b)) dapat dilihat bahwa metode ekstraksi ciri ZCZ menghasilkan akurasi lebih baik daripada metode ekstraksi ICZ untuk setiap pembagian zona yang diuji. Hal ini disebabkan oleh metode ICZ merupakan metode ekstraksi ciri global, yang mengambil ciri dari citra secara keseluruhan. Sementara itu, metode ZCZ merupakan metode ekstraksi ciri lokal, yang mengambil ciri dari citra secara lokal berdasarkan informasi pola lokal sehingga ciri yang diambil lebih mendetail.
Citra input juga sangat mempengaruhi tingkat akurasi, semakin banyak data dilatih maka semakin tinggi tingkat pengenalan objek tersebut. Selain itu , semakin banyak jumlah zona semakin banyak ciri yang diambil dari citra, baik dari ciri global maupun ciri lokal mampu membuat hasil akurasi klasifikasi semakin meningkat. Penelitian ini menggunakan citra huruf hijaiyah yang tidak memiliki varian yang signifikan dikarenakan ketika pada saat pengujian disertakan huruf yang memiliki letak titik diatas maupun dibawah seperti huruf ba , dzal , za, dan gho nilai fitur yang didapat adalah 0 sehingga citra tidak terdefinisi atau tidak dapat diproses.
Pada penelitian ini, hasil akurasi yang didapat mencapai 90% pada pengujian menggunakan metode ekstraksi ciri ZCZ dengan pembagian zona sebanyak 7 dan 9 zona. Hal ini dapat disebabkan oleh jumlah ciri yang diambil dari citra karena jumlah zona mempengaruhi jumlah ciri yang diambil. Semakin banyak jumlah zona, semakin banyak ciri yang diambil dari citra , baik dari ciri global maupun ciri lokal sehingga dapat membuat akurasi hasil pengenalan meningkat.
52
BAB 5
KESIMPULAN DAN SARAN
Bab ini membahas tentang kesimpulan dari metode yang diajukan untuk pengenalan pola huruf hijaiyah pada bagian 5.1, serta pada bagian 5.2 akan dibahas saran-saran untuk pengembangan penelitian selanjutnya.
5.1. Kesimpulan
Kesimpulan yang dapat diambil berdasarkan pengujian sistem pengenalan pola huruf hijaiyah tulisan tangan menggunakan support vector machine adalah sebagai berikut :
1. Penggunaan metode support vector machine mampu mengenali pola huruf hijaiyah tulisan tangan dengan akurasi terbaik untuk metode ekstraksi ciri ZCZ dengan pembagian zona 7 dan 9 buah sebesar 90 %.
2. Berdasarkan pengujian yang dilakukan, citra input huruf hijaiyah memiliki bentuk dasar yang serupa hanya titik yang membedakan setiap citra sehingga mempengaruhi proses pengenalan citra huruf tulisan tangan.
3. Semakin banyak data yang dilatih serta semakin banyak pembagian zona yang dilakukan pada pengujian akan meningkatkan akurasi pengenalan suatu citra.
5.2. Saran
Saran penulis untuk penelitian selanjutnya adalah sebagai berikut :
54
2. Bandingkan akurasi pengenalan huruf hijaiyah secara offline maupun secara online (font hijaiyah).
3. Bandingkan metode klasifikasi Support Vector Machine dengan metode lain pada penelitian yang sama untuk mendapatkan tingkat akurasi pengenalan pola huruf hijaiyah yang lebih baik.
BAB 2
LANDASAN TEORI
Pada bab ini akan dibahas mengenai teori pendukung dan penelitian sebelumnya yang berhubungan dengan metode ekstraksi fitur, serta metode klasifikasi Support Vector Machine dalam pengenalan citra huruf hijaiyah tulisan tangan.
2.1. Citra
Citra merupakan suatu representasi (gambaran), kemiripan, atau imitasi dari suatu objek. Citra sebagai keluaran suatu sistem perekaman data dapat bersifat optik berupa foto, bersifat analog berupa sinyal-sinyal video seperti gambar pada monitor televisi, atau bersifat digital yang dapat langsung disimpan pada suatu media penyimpan (Sutoyo et al, 2009).
Citra digital adalah larik angka-angka secara dua dimensional (Liu and Mason, 2009). Citra digital tersimpan dalam suatu bentuk larik (array) angka digital yang merupakan hasil kuantifikasi dari tingkat kecerahan masing-masing piksel penyusun citra tersebut. Citra digital dapat diklasifikasikan menjadi citra biner, citra keabuan dan citra warna.
2.1.1. Citra biner (binary image)
8
mempermudah proses pengenalan pola, karena pola akan lebih mudah terdeteksi pada citra yang mengandung lebih sedikit warna. Contoh citra biner dan representasi dapat dilihat pada Gambar 2.1 dan Gambar 2.2.
Gambar 2.1 citra huruf T (Sutoyo,2009) Gambar 2.2 representasi citra biner dari huruf T
(Sutoyo,2009) 2.1.2. Citra keabuan (grayscale image)
Citra keabuan yaitu citra yang pixel-nya mempresentasikan derajat keabuan atau intensitas warna putih. Citra grayscale memiliki banyak variasi nuansa abu-abu sehingga berbeda dengan citra hitam-putih seperti terlihat pada Gambar 2.3 dan 2.4. Jumlah bit yang diperlukan untuk tiap piksel menentukan jumlah tingkat keabuan yang tersedia. Tingkat keabuan yang tersedia pada citra grayscale adalah 8 atau 256.
Gambar2.3 citra hitam-putih Gambar 2.4 citra grayscale
2.1.3. Citra warna (color image)
Citra warna merupakan citra yang nilai pixel-nya mempresentasikan warna tertentu berdasarkan jumlah dari bit per-pixel citra yang bersangkutan. Setiap pixel pada citra warna mewakili warna yang merupakan kombinasi dari 3 warna (RGB = Red, Green, Blue). Setiap warna dasar menggunakan penyimpanan 8 bit = 1 byte (nilai maksimum 255 warna) sehingga satu pixel pada citra warna diwakili oleh 3 byte dengan tingkatan warna yang tersedia adalah 256. Jadi untuk tiga warna dasar pada setiap piksel memiliki kombinasi warna sebanyak 4 atau sekitar 16777216. Contoh citra warna ditunjukkan pada Gambar 2.5
Gambar2.5 citra warna (Genta,2010)
2.2. Format Citra Digital
Ada beberapa format citra digital, antara lain: BMP, PNG, JPG, GIF dan sebagainya. Masing-masing format mempunyai perbedaan satu dengan yang lain terutama pada header file. Namun ada beberapa yang mempunyai kesamaan, yaitu penggunaan palette untuk penentuan warna piksel.
2.2.1. Bitmap (.bmp)
Bitmap adalah representasi dari citra grafis yang terdiri dari susunan titik yang
tersimpan di memori komputer. Dikembangkan oleh Microsoft dan nilai setiap titik
diawali oleh satu bit data untuk gambar hitam putih, atau lebih bagi gambar berwarna.
10
Windows. Pada umumnya file bmp tidak di kompresi sehingga memiliki ukuran yang
sangat besar.
2.2.2 GIF
GIF adalah format gambar asli yang dikompres dengan CompuServe. Bitmap dengan
jenis ini mendukung 256 warna dan bitmap ini juga sangat popular dalam internet.
Format GIF hanya dapat menyimpan gambar dalam 8 bit dan hanya mampu
digunakan mode grayscale, bitmap, dan index color.
2.2.3 JPEG
JPEG merupakan skema kompresi file bitmap yang banyak digunakan untuk menyimpan gambar-gambar dengan ukuran lebih kecil. Format citra JPEG ini memiliki karakteristik gambar tersendiri antara lain memiliki ekstensi .jpg atau .jpeg. mampu menanyangkan warna dengan kedalaman 24-bit true color. Umumnya format citra ini digunakan untuk menyimpan gambar-gambar hasil foto.
2.3. Pengolahan Citra
Pengolahan citra merupakan proses memperbaiki kualitas citra, transformasi citra, melakukan pemilihan ciri citra untuk tujuan analisis dan mendapatkan kualitas citra yang lebih baik (Sutoyo, 2009). Tujuan dari pengolahan citra adalah bagaimana mengolah citra sebaik mungkin sehingga dapat memberikan informasi baru yang lebih bermanfaat. Beberapa teknik pengolahan citra yang digunakan adalah sebagai berikut.
2.3.1. Thresholding
Thresholding merupakan suatu proses mengubah citra berderajat keabuan menjadi citra biner atau hitam putih sehingga dapat diketahui daerah mana yang termasuk obyek dan background dari citra secara jelas (Evan, 2010).
diganti dengan 1 (putih), jika nilai piksel pada citra keabuan lebih kecil dari threshold maka nilai piksel akan diganti dengan 0 (hitam). Citra hasil thresholding dapat didefinisikan sebagaimana Persamaan 2.2.
(2.1)
Dimana : g(x,y) = piksel citra hasil binerisasi
f(x,y) = piksel citra asal T = nilai threshold
Adapun citra hasil threshoding seperti pada Gambar 2.6
(a) (b)
Gambar 2.6 (a) citra grayscale , (b) citra threshold.
2.3.2. Cropping
12
Gambar 2.7 proses cropping (Brigida,2010)
2.3.3. Normalisasi
Normalisasi adalah proses mengubah ukuran citra, baik menambah atau mengurangi, menjadi ukuran yang ditentukan tanpa menghilangkan informasi penting dari citra tersebut (Sharma et. al, 2012). Dengan adanya proses normalisasi maka ukuran semua citra yang akan diproses menjadi seragam.
2.3.4. Thinning
Proses thinning (penipisan) merupakan operasi pemrosesan reduksi citra biner
menjadi rangka (skeleton) yang menghampiri garis sumbu objek. Thinning bertujuan
untuk mengurangi bagian yang tidak perlu (redundant) sehingga dihasilkan informasi
yang esensial saja. Pola penipisan harus tetap mempunyai bentuk yang menyerupai
pola asalnya. Proses thinning dapat dilihat pada Gambar 2.8.
(a) (b)
Gambar 2.8 (a) citra huruf A hasil scanning citra
Citra hitam putih yang diambil sebagai masukan, akan ditipiskan terlebih dahulu.
Proses penipisan ini merupakan proses menghilangkan piksel-piksel hitam (mengubah
menjadi piksel putih) pada tepi-tepi pola. Penipisan ini dilakukan dengan mengurangi
ketebalan sebuah objek hingga ke batas minimum yang di perlukan oleh program
sehingga dapat dikenali. Citra hasil penipisan ini akan digunakan sebagai masukan
untuk dibandingkan dengan target yang telah disediakan. Citra hasil dari penipisan
biasanya disebut dengan skeleton.
2.4. Ekstraksi Fitur
Ekstraksi fitur adalah proses pengukuran terhadap data yang telah dinormalisasi untuk membentuk sebuah nilai fitur. Nilai fitur digunakan oleh pengklasifikasi untuk mengenali unit masukan dengan unit target keluaran dan memudahkan pengklasifikasian karena nilai ini mudah untuk dibedakan (Pradeep et. al, 2011). Pada penelitian ini , penulis menggunakan metode ekstraksi zoning.
2.4.1. Ekstraksi Ciri Zoning
14
Gambar 2.9 Pembagian zona pada citra biner (Isnan,2012)
Ada beberapa algoritme untuk metode ekstraksi ciri zoning, di antaranya metode ekstraksi ciri jarak metrik ICZ (image centroid and zone), metode ekstraksi ciri jarak metrik ZCZ (zone centroid and zone). Kedua algoritma tersebut menggunakan citra digital sebagai input dan menghasilkan fitur untuk klasifikasi dan pengenalan sebagai output-nya. Berikut merupakan tahapan dalam proses ekstraksi ciri ICZ, ZCZ .(Rajashekararadhya dan Ranjan 2008).
Algoritme 1: Image Centroid and Zone (ICZ) berdasarkan jarak metrik. Tahapan
1. Hitung centroid dari citra masukan.
2. Bagi citra masukan ke dalam n zona yang sama.
3. Hitung jarak antara centroid citra dengan masing-masing piksel yang ada dalam zona
4. Ulangi langkah ke 3 untuk setiap piksel yang ada di zona. 5. Hitung rata-rata jarak antara titik-titik tersebut.
6. Ulangi langkah-langkah tersebut untuk keseluruhan zona.
7. Hasilnya adalah n fitur yang akan digunakan dalam klasifikasi dan pengenalan .
Zona 1 (atas)
Zona 2 (tengah)
Algoritma 2: Zone Centroid Zone (ZCZ) berdasarkan jarak metrik. 1. Bagi citra masukan ke dalam sejumlah n bagian yang sama . 2. Hitung centroid dari masing-masing zona.
3. Hitung jarak antara centroid masing-masing zona dan piksel yang ada di zona.
4. Ulangi langkah ke 3 untuk seluruh piksel yang ada di zona. 5. Hitung rata-rata jarak antara titik-titik tersebut.
6. Ulangi langkah 3-7 untuk setiap zona secara berurutan.
7. Hasilnya adalah n fitur yang akan digunakan dalam klasifikasi dan pengenalan
2.5. Support Vector Machine (SVM)
Support Vector Machine (SVM) adalah suatu teknik untuk melakukan prediksi, baik
dalam kasus klasifikasi maupun regresi (Santoso, 2007). SVM berada dalam satu
kelas dengan Artificial Neural Network (ANN) dalam hal fungsi dan kondisi
permasalahan yang bisa diselesaikan. Keduanya masuk dalam kelas supervised
16
pemisah terbaik tidak hanya dapat memisahkan data tetapi juga memiliki margin paling besar.
(a) (b)
Gambar 2.10 (a) alternatif bidang pemisah (b) hyperplane terbaik dengan margin (m)
terbesar (Krisantus,2007)
Data yang berada atau terdekat pada bidang pemisah ini disebut support vector. Pada Gambar 2.7 (b) dua kelas dipisahkan oleh sepasang bidang pembatas yang sejajar. Bidang pembatas pertama membatasi kelas pertama (kotak) sedangkan bidang pembatas kedua membatasi kelas kedua (lingkaran), sehingga pattern yang termasuk kelas 1(sampel negatif) memenuhi pertidaksamaan :
. + � − (2.3)
Sedangkan pattern yang termasuk kelas 2 (sampel positif) dapat dirumuskan sebagai pattern yang memenuhi pertidaksamaan :
. + � + (2.4)
Dimana w = normal bidang (parameter bobot) x = label kelas (vektor input)
Kedua kelas dapat terpisah secara sempurna oleh bidang pemisah (classifier/Hyperplane). Hyperplane pemisah terbaik antara kedua kelas dapat ditemukan dengan mengukur margin Hyperplane tersebut dan mencari titik maksimalnya. Margin merupakan jarak antara Hyperplane tersebut dengan pattern terdekat dari masing-masing kelas. Nilai margin (jarak) antara hyperplane (berdasarkan rumus jarak ke titik pusat adalah :
− − − −
�
=
|�| (2.5) Dengan mengalikan b dan w dengan sebuah konstanta, akan menghasilkan nilai margin yang dikalikan dengan konstanta yang sama. SVM menggunakan konsep margin yang didefinisikan sebagai jarak terdekat antara decision boundary dengan sembarang data training, dengan memaksimumkan nilai margin maka akan didapat suatu decision boundary tertentu. Margin terbesar didapat dengan memaksimalkan nilai jarak antara hyperplane dan titik terdekatnya yaitu|�|
.
Maka pencarian hyperplane terbaik dengan nilai margin terbesar dapat dirumuskan menjadi masalah optimasi konstrain yaitu mencari titik minimal persamaan (2.6) dengan memperhatikan constraint persamaan (2.7).min | | (2.6)
. w + b)-1 0 (2.7)
Menggunakan metode lagrange multiplier dapat lebih mudah menyelesaikan permasalahan optimasi konstrain dalam mencari titik minimal dengan menggunakan tambahan konstrain � yang disebut sebagai lagrange multiplier dalam fungsi sebagai berikut :
(2.8)
Keterangan :
� bernilai nol atau positif ( � 0 ).
18
Vektor w sering bernilai besar hingga tak terhingga, tetapi nilai
�
terhingga. Oleh karena itu formula lagrangian Lp (prima problem) diubah kedalam dual problem�� dengan mensubstitusikan persamaan 2.10 ke Lp sehingga diperoleh dual problem �� dengan konstrain yang berbeda.
��
�
= ∑�= � -∑
�= , −� �
(2.11)
Pencarian hyperplane terbaik dapat dirumuskan sebagai berikut :
(2.12)
Dari hasil perhitungan ini diperoleh � > 0 (support vector) , data yang memiliki nilai � yang positif inilah yang berperan pada model decision boundary, sehingga kelas dari data pengujian x dapat ditentukan berdasarkan nilai dari fungsi keputusan:
f ( ) = ∑��= � + � (2.13) Dimana :
= support vector
= data yang akan diklasifikasi ns = jumlah support vector
dalam ruang ciri berdimensi lebih tinggi kemudian diterapkan klasifikasi linear dalam ruang tersebut.
2.5.1 Contoh Kasus
Contoh kasus pertama SVM dengan dua kelas dan empat data pada Tabel 2.1 berikut ini merupakan problem linier yang akan ditentukan fungsi klasifikasi (hyperpalane).
Adapun formulasi masalahnya adalah sebagai berikut :
Tabel 2.1 Contoh kasus nilai fitur dan kelas Kasus X
Langkah-langkah yang dilakukan dalam menentukan fungsi klasifikasi(hyperplane) dari contoh kasus diatas adalah :
Penentuan variabel bobot dari fitur ciri kasus.
Terdapat dua fitur ciri pada tabel 3.1 yaitu x1, x2 sehingga w (bobot) akan memiliki 2 fitur yaitu w1 dan w2 .
Optimasi masalah dengan meminimal kan nilai sebagai berikut : min ( + + C (t1 + t2 + t3 + t4)
20
w1 = 1 , w2 = 1 , b = 1 Jadi persamaan fungsi pemisahnya adalah :
f(x) = x1 + x2 -1
Sehingga semua nilai f(x) < 0 diberi label -1 dan f(x) > 0 diberi laber +1.
2.6. Penelitian Terdahulu
Penelitian tentang pengenalan pola telah dilakukan dengan menggunakan beberapa metode. Variasi metode ekstraksi ciri yang digunakan adalah metode yang diajukan oleh Rajashekararadhya & Ranjan (2008), yaitu Image Centroid and Zone (ICZ), Zone Centroid and Zone (ZCZ), dan gabungan ICZ dan ZCZ. Dalam penelitian ini diperoleh tingkat pengenalan rata-rata karakter angka Kannada, Telugu, Tamil, dan Malayalam yang di tulis tangan diatas 90% dengan melakukan penggabungan metode ekstraksi ciri ICZ dan ZCZ untuk klasifikasi menggunakan JST dan KNN. Tingkat pengenalan menggunakan metode zoning ini juga mencapai 87% dengan menggabungkan metode ekstraksi ciri diagonal based untuk peningkatan nilai fitur jaringan propagasi balik pada pengenalan angka tulisan tangan oleh Nanda (2012).
Support Vector Machine (SVM) merupakan metode klasifikasi yang mencari support vector terbaik yang memisahkan dua buah class dengan margin terbesar. SVM secara konseptual merupakan classifier yang bersifat linier tetapi dapat dimodifikasi dengan menggunakan kernel (fungsi yang memudahkan proses pengklasifikasian data) sehingga dapat menyelesaikan permasalahan yang bersifat tidak linier (non linier). Metode ini telah menyelesaikan kasus pengklasifikasi dan memprediksi angkutan udara jenis penerbangan internasional di Banda Aceh (Sayed,2011) dengan tingkat akurasi model hingga 84,31%.
Tabel 2.2. Penelitian terdahulu
No. Peneliti / Tahun Metode yang digunakan Akurasi
1. Rajashekararadhya & Ranjan (2008) Support Vector Machine
K-Nearet Neighbor 90%
2. Sayed (2011) Support Vector Machine 84,31%
3. Nanda (2012) Zoning dan Diagonal Based
BAB 1
PENDAHULUAN
1.1. Latar Belakang
Pengenalan pola (pattern recognition) merupakan disiplin ilmu yang mengklasifikasikan objek dalam banyak kategori atau kelas. Pengenalan pola juga merupakan bagian penting dalam banyak sistem cerdas yang dibangun untuk membantu dalam pengambilan keputusan (Theodoridis & Koutroumbas 2008).
Optical Character Recognition (OCR) merupakan salah satu bentuk pengenalan pola yang dapat mengenali karakter pada media tertentu, baik yang bersifat online maupun offline. Metode online menerapkan koordinat dua dimensi dari poin-poin penulisan direpresentasikan sebagai fungsi waktu dan urutan setiap garis yang dituliskan juga disimpan secara realtime untuk mengenali kata yang dituliskan (Arica & Yarman, 2001). Metode offline menerapkan konversi secara otomatis tulisan pada sebuah citra menjadi karakter yang dapat diolah oleh komputer dan aplikasi perosesan teks, biasanya metode offline ini dilakukan dengan pengambilan gambar dari scanner, kamera digital ataupun media input digital lainnya dimana image dipreprocessing dengan algoritma tertentu sehingga dikenali sesuai dengan objek yang aslinya.
Penerapan pengenalan pola dapat diterapkan pada berbagai macam bentuk seperti gambar, sidik jari, tanda tangan, huruf dan lain sebagainya. Tujuan dari pengenalan pola ini adalah untuk menterjemahkan karakter yang dikenal manusia agar bisa dikenal oleh sistem komputer. Alur kerja dari OCR terdiri atas 5 tahapan, proses input citra, praproses, segmentasi, ekstraksi ciri, dan klasifikasi serta hasil pengenalan citra. Penelitian ini akan melakukan pengenalan pola pada huruf dengan metode offline. Huruf yang akan dikenali adalah huruf hijaiyah.
2
membedakannya disesuaikan dengan karakteristik dari masing-masing huruf tersebut. Proses klasifikasi dan identifikasi yang paling sederhana dan langsung yaitu dengan menggunakan penglihatan. Hal tersebut yang menjadi ide dasar untuk membuat suatu perangkat komputer agar dapat mendapatkan informasi lebih cepat untuk menghindari ambiguitas pada kata itu sendiri.
Pada kasus pengenalan huruf dan pola sudah pernah dilakukan penelitian oleh Tacbir et. al, (2012) dengan kasus Pengenalan Pola Huruf Arab Menggunakan Jaringan Syaraf Tiruan (JST) dengan Metode Backpropagation. Rosi (2008) “Pengenalan Huruf Alphabet Kapital dengan Menggunakan Ekstraksi Ciri Zoning menggunakan JST Backpropagation ”.
Prapengolahan citra dan ekstraksi fitur merupakan tahapan awal dalam proses pengenalan tulisan tangan. Pemilihan metode ekstraksi fitur yang baik sangat mempengaruhi untuk tercapainya tingkat pengenalan yang tinggi (Jain&Taxt, 1996). Ada beberapa metode ekstraksi fitur yang dapat digunakan yaitu zoning, gabor, momen zernike dan model deformable. Proses ekstraksi fitur dilakukan untuk mendapatkan nilai fitur yang dibutuhkan untuk tahap pengklasifikasian.
Setiap data sampel akan melalui proses prapengolahan citra dan tahap ekstrasi fitur. Ekstraksi fitur dalam pengolahan bertujuan untuk mendapatkan frekuensi kemunculan dari masing-masing pola. Penelitian ini menggunakan ekstraksi fitur zoning. Variasi metode ekstraksi ciri yang digunakan adalah metode yang diajukan oleh Rajashekararadhya & Ranjan (2008), yaitu Image Centroid and Zone (ICZ), Zone Centroid and Zone (ZCZ), dan gabungan ICZ dan ZCZ. Dalam penelitian ini diperoleh tingkat pengenalan rata-rata karakter angka Kannada, Telugu, Tamil, dan Malayalam yang di tulis tangan diatas 90% dengan melakukan penggabungan metode ekstraksi ciri ICZ dan ZCZ untuk klasifikasi menggunakan JST dan KNN. Tingkat pengenalan menggunakan metode zoning ini juga mencapai 87% untuk peningkatan nilai fitur jaringan propagasi balik pada pengenalan angka tulisan tangan Nanda (2012).
Metode ini telah menyelesaikan kasus pengklasifikasi dan memprediksi angkutan udara jenis penerbangan internasional di Banda Aceh (Sayed,2011) dengan tingkat akurasi model hingga 84,31%.
Pada penelitian ini, penulis memilih menggunakan ekstraksi zoning dengan metode Support Vector Machine . Dengan harapan sistem ini mampu beradaptasi terhadap pola citra dan dapat berguna sebagai media pengenalan huruf hijaiyah tulisan tangan.
Berdasarkan latar belakang diatas, penulis mengajukan proposal penelitian terhadap kasus pengenalan huruf dengan judul “IDENTIFIKASI HURUF HIJAIYAH TULISAN TANGAN MENGGUNAKAN SUPPORT VECTOR MACHINE (SVM).
1.2. Rumusan Masalah
Setiap orang memiliki variasi penulisan tangan yang berbeda-beda, terutama pada huruf hijaiyah. Agar tulisan tangan tersebut dapat dikenali secara digital, dibutuhkan sebuah sistem pengenalan pola untuk mengatasi ketidakakuratan makna kata huruf hijaiyah.
1.3. Batasan Masalah
Untuk menghindari penyimpangan dan perluasan yang tidak diperlukan , penulis membuat batasan :
1. Pengenalan pola berdasarkan tulisan tangan huruf hijaiyah dilakukan secara offline. 2. Inputan citra yang telah dipindai dalam format .bitmap (.bmp).
3. Inputan citra yang dikenali adalah huruf hijaiyah (7 huruf). 4. Akuisisi citra diambil dari 10 orang.
1.4. Tujuan Penelitian
4
1.5. Manfaat Penelitian
Manfaat yang dapat diperoleh dari penelitian ini adalah :
1. Sistem diharapkan mampu mengenali pola huruf hijaiyah tulisan sebagai media pembelajaran dengan keluaran yang dihasilkan persentasi tingkat pengenalan data sampel.
2. Penelitian dapat menjadi bahan rujukan untuk pengembangan penelitian lebih lanjut, khususnya di bidang pengenalan pola.
1.6. Metodologi
Terdapat beberapa tahapan dalam penelitian ini untuk menghasilkan suatu sistem yang sesuai dengan yang diharapkan.
1. Studi Literatur
Kegiatan mempelajari dokumentasi literatur dan teori yang berkaitan dengan penelitian. Dalam tahap ini merupakan proses pengumpulan referensi, baik buku, jurnal, tesis, makalah dan sumber-sumber lain termasuk yang diperoleh dari internet sebagai sumber data dan informasi yang berkaitan dengan image processing, ekstraksi ciri, Support Vector Machine dan data tulisan tangan huruf hijaiyah.
2. Analisis Permasalahan
Pada tahap ini dilakukan analisis terhadap studi literatur untuk mendapatkan pemahaman mengenai metode yang akan digunakan, yaitu Support Vector Machine untuk menyelesaikan masalah pengenalan huruf hijaiyah tulisan tangan. 3. Perancangan
Pada tahap ini dilakukan perancangan arsitektur, pengumpulan data, dan perancangan antarmuka. Proses perancangan berdasarkan hasil analisis studi yang telah didapatkan.
4. Implementasi
5. Pengujian
Pada tahap ini dilakukannya pengujian terhadap perangkat lunak yang dibangun, untuk memastikan hasil keakuratan dari sistem yang dibuat sesuai dengan apa yang diharapkan.
6. Dokumentasi dan Penyusunan Laporan
Pada tahap ini dilakukannya penulisan dokumentasi dan laporan mengenai perangkat lunak yang dikembangkan.
1.7. Sistematika Penulisan
Sistematika penulisan dari skripsi ini terdiri dari lima bagian utama sebagai berikut. BAB 1 : PENDAHULUAN
Bab ini berisi latar belakang, rumusan masalah, batasan masalah, tujuan penelitian, manfaat penelitian, metodologi penelitian, dan sistematika penulisan.
BAB 2 : LANDASAN TEORI
Bab ini berisi teori-teori yang digunakan untuk memahami permasalahan yang dibahas pada penelitian ini. Pada bab ini dijelaskan mengenai teori yang berhubungan dengan pengenalan pola, ekstraksi fitur dan Support Vector Machine.
BAB 3 : ANALISIS DAN PERANCANGAN
Bab ini menjabarkan arsitektur umum, pre-processing yang dilakukan, feature extraction, serta analisis dan penerapan metode Support Vector Machine dalam pengenalan huruf hijaiyah tulisan tangan.
BAB 4 : IMPLEMENTASI DAN PENGUJIAN
6
BAB 5 : KESIMPULAN DAN SARAN
ABSTRAK
Huruf hijaiyah memiliki bentuk yang sangat unik dan variatif antara satu dengan yang lainnya, Untuk membedakannya, huruf hijaiyah harus disesuaikan dengan karakteristiknya masing-masing. Pada penelitian ini digunakan Support Vector
Machine untuk mengenali tulisan tangan huruf hijaiyah dari beberapa orang. Sebelum tahap identifikasi dilakukan citra huruf akan mengalami pre-processing , dan ekstraksi ciri menggunakan metode zoning. Metode zoning ini menghitung jumlah piksel aktif (hitam) setiap zona dan melakukan perbandingan terhadap zona yang memiliki jumlah piksel aktif yang paling banyak. Ekstraksi ciri yang digunakan adalah variasi dari metode zoning yaitu Image Centroid and Zone (ICZ) dan Zone Centroid and Zone (ZCZ). Pembagian zona yang digunakan adalah 3,5,7, dan 9 zona. Pada penelitian ini ditunjukkan bahwa metode yang diajukan mampu mengenali tulisan tangan huruf hijaiyah dengan akurasi terbaik menggunakan metode zoning ZCZ dengan pembagian zona 7 dan 9 yaitu 90 %.
vi
PATTERN RECOGNITION ON HIJAIYAH LETTERS USING SUPPORT VECTOR MACHINE (SVM)
ABSTRACT
Hijaiyah letters have very unique shape and varies between one and another. To
differentiate it, hijaiyah letters have to be adapted with their own characteristic. This
research used a support vector machine to recognize the handwriting of hijaiyah letters from some people. Pre-processing, and feature extraction using zoning methode will be done before the identification phase. Zoning method summing every active (black) pixel from each zone and divide value from each zone by a zone with most active pixel. Feature extraction method used is the variations of zoning method that is Image Centroid and Zone (ICZ) and Zone Centroid and Zone (ZCZ). The number of zones used are 3.5 .7, and 9 zones. This research shows that the proposed method is able to identify handwriting of the hijaiyah letters with the best accuracy using Zone Centroid Zone (ZCZ) feature extraction method using 7 and 9 zone is 90%.
PENGENALAN POLA HURUF HIJAIYAH MENGGUNAKAN SUPPORT VECTOR MACHINE (SVM)
SKRIPSI
NADYA AMELIA 101402014
PROGRAM STUDI S1 TEKNOLOGI INFORMASI
FAKULTAS ILMU KOMPUTER DAN TEKNOLOGI INFORMASI UNIVERSITAS SUMATERA UTARA
iii
PENGENALAN POLA HURUF HIJAIYAH MENGGUNAKAN SUPPORT VECTOR MACHINE (SVM)
SKRIPSI
Diajukan untuk melengkapi tugas dan memenuhi syarat memperoleh ijazah Sarjana Teknologi Informasi
NADYA AMELIA 101402014
PROGRAM STUDI S1 TEKNOLOGI INFORMASI
FAKULTAS ILMU KOMPUTER DAN TEKNOLOGI INFORMASI UNIVERSITAS SUMATERA UTARA
PERSETUJUAN
Judul : PENGENALAN POLA HURUF HIJAIYAH
MENGGUNAKAN SUPPORT VECTOR MACHINE (SVM)
Kategori : SKRIPSI
Nama : NADYA AMELIA
Nomor Induk Mahasiswa : 101402014
Program Studi : SARJANA (S1) TEKNOLOGI INFORMASI
Fakultas : ILMU KOMPUTER DAN TEKNOLOGI INFORMASI ..UNIVERSITAS SUMATERA UTARA
Komisi Pembimbing :
Pembimbing 2 Pembimbing 1
Sajadin Sembiring, S.Si., M.Comp.Sc Dr. Erna Budhiarti Nababan, M.IT
NIP. - NIP. -
Diketahui/Disetujui oleh
Program Studi S1 Teknologi Informasi Ketua,
iii
PERNYATAAN
PENGENALAN POLA HURUF HIJAIYAH MENGGUNAKAN SUPPORT VECTOR MACHINE (SVM)
SKRIPSI
Saya mengakui bahwa skripsi ini adalah hasil karya saya sendiri, kecuali beberapa kutipan dan ringkasan yang masing-masing telah disebutkan sumbernya.
Medan, 14 Juni 2016
UCAPAN TERIMA KASIH
Alhamdulillah, puji dan syukur penulis panjatkan kepada Allah SWT yang telah memberikan rahmat, karunia, taufik dan hidayah-Nya, serta segala sesuatu dalam hidup, sehingga penulis dapat menyelesaikan skripsi ini sebagai syarat untuk memperoleh gelar Sarjana Teknologi Informasi, Program Studi (S1)Teknologi Informasi, Fakultas Ilmu Komputer dan Teknologi Informasi.
Ucapan terima kasih penulis sampaikan kepada semua pihak yang telah membantu penulis dalam menyelesaikan skripsi ini baik secara langsung maupun tidak langsung. Pada kesempatan ini penulis ingin mengucapkan terima kasih yang sebesar-besarnya kepada:
1. Keluarga penulis, Ayahanda Munawirman, Ibunda Nofiar, Abang penulis Ferdie Yolandho, dan adik penulis Anisa Khuntum Khaira beserta keluarga besar yang selalu memberikan dukungan, perhatian serta doa kepada penulis sehingga dapat menyelesaikan skripsi ini.
2. Ibu Dr. Erna Budhiarti Nababan, M.IT. selaku Dosen Pembimbing I dan Bapak Sajadin Sembiring,S.Si.,M.Comp.Sc., selaku Dosen Pembimbing II yang telah banyak meluangkan waktunya serta memberikan bimbingan dan dukungan kepada penulis dalam penyusunan dan penulisan skripsi ini.
3. Bapak Dr. Sawaluddin, M.IT selaku Dosen Penguji I dan Bapak Romi Fadillah Rahmat, B.Comp.Sc., M.Sc. selaku Dosen Penguji II yang telah memberikan kritik dan saran yang membangun dalam penyempurnaan skripsi ini.
4. Bapak Muhammad Anggia Muchtar, ST., MM.IT. selaku Ketua Program Studi S1 Teknologi Informasi dan Bapak Mohammad Fadly Syahputra, B.Sc., M.Sc.IT. selaku Sekretaris Program Studi S1 Teknologi Informasi.
5. Seluruh Dosen Program Studi S1 Teknologi Informasi yang telah memberikan ilmu yang bermanfaat bagi penulis dari awal perkuliahan.
6. Teman-teman penulis, Rizki Ramadhan, Maslimona Harimita Ritonga, Sonya L Akbar, Faradilla S, Utami M Dinanti, dan seluruh mahasiswa TI 2010 yang telah memberikan semangat dan menjadi teman diskusi penulis dalam menyelesaikan skripsi ini.
7. Seluruh staf TU (Tata Usaha) serta pegawai di Program Studi S1 Teknologi Informasi
8. Semua pihak yang terlibat langsung ataupun tidak langsung yang tidak dapat penulis ucapkan satu per satu yang telah membantu penyelesaian skripsi ini.
v
ABSTRAK
Huruf hijaiyah memiliki bentuk yang sangat unik dan variatif antara satu dengan yang lainnya, Untuk membedakannya, huruf hijaiyah harus disesuaikan dengan karakteristiknya masing-masing. Pada penelitian ini digunakan Support Vector
Machine untuk mengenali tulisan tangan huruf hijaiyah dari beberapa orang. Sebelum tahap identifikasi dilakukan citra huruf akan mengalami pre-processing , dan ekstraksi ciri menggunakan metode zoning. Metode zoning ini menghitung jumlah piksel aktif (hitam) setiap zona dan melakukan perbandingan terhadap zona yang memiliki jumlah piksel aktif yang paling banyak. Ekstraksi ciri yang digunakan adalah variasi dari metode zoning yaitu Image Centroid and Zone (ICZ) dan Zone Centroid and Zone (ZCZ). Pembagian zona yang digunakan adalah 3,5,7, dan 9 zona. Pada penelitian ini ditunjukkan bahwa metode yang diajukan mampu mengenali tulisan tangan huruf hijaiyah dengan akurasi terbaik menggunakan metode zoning ZCZ dengan pembagian zona 7 dan 9 yaitu 90 %.
PATTERN RECOGNITION ON HIJAIYAH LETTERS USING SUPPORT VECTOR MACHINE (SVM)
ABSTRACT
Hijaiyah letters have very unique shape and varies between one and another. To
differentiate it, hijaiyah letters have to be adapted with their own characteristic. This
research used a support vector machine to recognize the handwriting of hijaiyah letters from some people. Pre-processing, and feature extraction using zoning methode will be done before the identification phase. Zoning method summing every active (black) pixel from each zone and divide value from each zone by a zone with most active pixel. Feature extraction method used is the variations of zoning method that is Image Centroid and Zone (ICZ) and Zone Centroid and Zone (ZCZ). The number of zones used are 3.5 .7, and 9 zones. This research shows that the proposed method is able to identify handwriting of the hijaiyah letters with the best accuracy using Zone Centroid Zone (ZCZ) feature extraction method using 7 and 9 zone is 90%.
vii 2.1.2 Citra keabuan (grayscale image) 8
2.3.2 Cropping 11
2.3.3 Normalisasi 12
2.3.4 Thinning 12
2.4 Ekstraksi Fitur 13
2.4.1 Ekstraksi Ciri Zonning 13
2.5 Support Vector Machine (SVM) 15
2.6 Penelitian Terdahulu 20
BAB 3 ANALISIS DAN PERANCANGAN SISTEM 21
3.1 Arsitektur Umum 21
3.2 Akuisisi Data 23
3.3 Preprocessing 23
3.3.1 Pembentukan citra biner (threshold) 24 3.3.2 Pemotongan citra (cropping) 24 3.3.3 Normalisasi Resolusi Citra (normalization) 25 3.3.4 Pengurusan objek citra (thinning) 25 3.4 Ekstraksi Ciri (Feature Extraction) 26
3.5 Klasifikasi 30
3.6 Perancangan Sistem 34
BAB 4 IMPLEMENTASI DAN PENGUJIAN SISTEM 40
4.1 Implementasi Sistem 40
4.1.1 Spesifikasi software dan hardware yang digunakan 40 4.1.2 Implementasi Perancangan Antarmuka 40 4.1.2.1 Tampilan utama sistem pre-processing 41 4.1.2.2 Tampilan utama sistem ekstraksi ciri 42 4.1.2.3 Tampilan utama sistem pengujian SVM 44
ix
DAFTAR TABEL
Hal. Tabel 2.1 Contoh kasus nilai fitur dan kelas 20
Tabel 2.2 Penelitian terdahulu 21
Tabel 3.1 Nilai fitur dan kelas 33
Tabel 3.2 Data uji 35
Tabel 3.3 Fungsi klasifikasi 36
Tabel 4.1 Data hasil pengujian 49
Tabel 4.2 Data hasil pengujian(lanjutan) 50
DAFTAR GAMBAR
Gambar 3.2 Tahapan pre-processing 23
Gambar 3.3 Citra hasil thresholding 24
Gambar 3.10 Rancangan tampilan awal 35
xi