i
PERANCANGAN SISTEM PENENTUAN KECAKAPAN MENULIS BAHASA INGGRIS SISWA SMP MENGGUNAKAN
ALGORITMA K-MODES CLUSTERING (STUDI KASUS : SMPN 6 DENPASAR)
SKRIPSI
IGM SURYA A. DARMANA NIM. 1208605039
PROGRAM STUDI TEKNIK INFORMATIKA JURUSAN ILMU KOMPUTER
FAKULTAS MATEMATIKA DAN ILMU PENGETAHUAN ALAM UNIVERSITAS UDAYANA
SURAT PERNYATAAN KEASLIAN KARYA ILMIAH
Program Studi : Teknik Informatika
E-mail : [email protected]
Nomor telp/HP : 081236036878
Alamat : Jalan Raya Pemogan Gang BPU Pudak Sari II No. 7
Belum pernah dipublikasikan dalam dokumen skripsi, jurnal nasional maupun internasional atau dalam prosiding manapun, dan tidak sedang atau akan diajukan untuk publikasi di jurnal atau prosiding manapun. Apabila di kemudian hari terbukti terdapat pelanggaran kaidah-kaidah akademik pada karya ilmiah saya, maka saya bersedia menanggung sanksi-sanksi yang dijatuhkan karena kesalahan tersebut, sebagaimana diatur oleh Peraturan Menteri Pendidikan Nasional Nomor 17 Tahun 2010 tentang Pencegahan dan Penanggulangan Plagiat di Perguruan Tinggi.
iii
Judul : Perancangan Sistem Penentuan Kecakapan Menulis Bahasa
Inggris Siswa SMP Menggunakan Algoritma k-Modes Clustering
Nama : IGM Surya A. Darmana
NIM. : 1208605039
Pembimging I : Ida Bagus Gede Dwidasmara, S.Kom., M.Cs. Pembimbing II : I Putu Gede Hendra Suputra, S.Kom., M.Kom.
ABSTRAK
Hal yang paling berat dalam proses belajar mengajar adalah menganalisis hasil evaluasi siswa. Pada penelitian ini penulis jumpai kesulitan yang dihadapi oleh guru-guru Bahasa Inggris pada SMPN 6 Denpasar dalam mengevaluasi hasil tulisan Bahasa Inggris karena terdapat beberapa kriteria yang harus dinilai yaitu, Pengembangan Konten (Content Development), Penyusunan (Organization), Tatabahasa/Struktur Kalimat (Grammar/Structure), Kosakata (Vocabulary), dan Mekanisme Penulisan (Mechanics).
Berdasarkan kasus diatas, dalam penelitian ini dirancang sebuah sistem yang dapat mengelompokkan data siswa berdasarkan atribut kriteria yang harus dinilai dengan metode clustering menggunakan algoritma k-modes yang diperkenalkan pertama kali oleh Huang Z. (1998). Algorima k-modes memperluas algoritma k-Means untuk dapat melakukan proses clustering pada data yang bersifat kategorikal dengan mengganti means dari cluster menggunakan modus.
Dari hasil pengujian yang telah dilakukan, sistem yang dibangun sudah mampu mengelompokkan data siswa berdasarkan atribut kriteria dalam penentuan tingkat kecakapan menulis Bahasa Inggris. Berdasarkan hasil validasi cluster menggunakan silhouette index yang dihasilkan pada k = 4, diperoleh nilai sebesar 0.7519464480837383 menggunakan metode simple matching yang diajukan oleh Huang dengan sedikit penambahan bobot pada kriteria penilaian jika pada saat proses pencocokan terdapat kategori yang tidak sama dan 0.6180349051105538 menggunakan metode perhitungan jarak yang diajukan oleh Zenghyou, dkk. Dimana jika nilai silhouette index semakin mendekati 1 maka masing-masing data sudah di alokasikan dalam kelompok yang tepat.
Kata Kunci : Bahasa Inggris, Kecakapan Menulis, Data Mining, Clustering,
iv
Title : Perancangan Sistem Penentuan Kecakapan Menulis Bahasa
Inggris Siswa SMP Menggunakan Algoritma k-Modes Clustering
Name : IGM Surya A. Darmana
Regisration : 1208605039
First Supervisor : Ida Bagus Gede Dwidasmara, S.Kom., M.Cs. Second Supervisor : I Putu Gede Hendra Suputra, S.Kom., M.Kom.
ABSTRACT
The most difficult thing in the learning process is to analyze the results of student evaluations. In this study the researcher has encountered difficulties faced by teachers of English in SMPN 6 Denpasar in evaluating the English writings because there are several criteria that must be assessed, namely, Content Development, Organization, Grammar / Sentence Structure, Vocabulary, and Writing mechanism (Mechanics).
Based on the above case, the study design a system that can classify student data, based on the attributes of criteria to be assessed by the method of clustering using k-modes algorithm which was first introduced by Huang Z. (1998). K-modes algorithm expands k-Means algorithm to perform clustering process on categorical data by replacing the means of the cluster by using the mode.
From the testing that has been done, the system built has already been able to classify the student data based on attribute criteria in determining the level of English writing proficiency. Based on the results of the cluster validation using the silhouette index generated at k = 4, obtained a value of 0.7519464480837383 using simple matching proposed by Huang with little additional weight on the assessment criteria if at the time of matching process there were categories that are not the same and 0.6180349051105538 using methods of calculation distances proposed by Zenghyou, et al. Where if the silhouette index value is approaching to 1, the respective data is already allocated in the right group.
Keywords : English, Writing Proficiency, Data Mining, Clustering, K-Modes
v
KATA PENGANTAR
Penelitian dengan judul “Perancangan Sistem Penentuan Kecakapan
Menulis Bahasa Inggris Siswa SMP Menggunakan Algoritma K-Modes Clustering”
ini disusun dalam rangkaian kegiatan pelaksanaan Tugas Akhir di Jurusan Ilmu Komputer FMIPA UNUD. Sehubungan dengan telah terselesaikannya penelitian ini, maka diucapkan terimakasih dan penghargaan kepada berbagai pihak yang telah membantu penyusun, antara lain :
1. Bapak Ida Bagus Gede Dwidasmara, S.Kom., M.Cs. selaku Pembimbing I yang telah membimbing dan membantu menyempurnakan penelitian ini. 2. Bapak I Putu Gede Hendra Suputra, S.Kom., M.Kom. selaku Pembimbing
IIyang telah banyak membantu dan meluangkan waktu untuk penelitian ini. 3. Bapak Agus Muliantara, S.Kom., M.Kom. selaku Ketua Jurusan Ilmu
Komputer Fakultas Matematika dan Ilmu Pengetahuan Alam Universitas Udayana yang telah banyak memberikan masukan dan motivasi sehingga memperlancar dalam proses pelaksanaan penelitian ini.
4. Bapak-bapak dan ibu-ibu dosen di Jurusan Ilmu Komputer yang bersedia
meluangkan waktunya untuk memberikan masukan dalam penyempurnaan penelitian ini.
5. Rekan-rekan mahasiswa di Jurusan Ilmu Komputer yang telah memberi dukungan, motivasi, semangat dan kerja sama dalam penelitian ini.
Penulis menyadari bahwa tugas akhir ini masih belum sempurna, untuk itu kritik dan saran yang bermanfaat demi kesempurnaan tugas akhir ini sangat penyusun harapkan.
Bukit Jimbaran, April 2016 Penyusun
vi
DAFTAR ISI
HALAMAN JUDUL ...i
LEMBAR PENGESAHAN TUGAS AKHIR ... ii
ABSTRAK ... iii
DAFTAR LAMPIRAN ... xiii
BAB I PENDAHULUAN ... 1
1.6 Metodologi Penelitian ... 4
1.6.1 Desain Penelitian ... 4
1.6.2 Pengumpulan Data ... 5
1.6.3 Metode Yang Digunakan ... 5
BAB II TINJAUAN PUSTAKA ... 7
2.1 Tinjauan Teoritis ... 7
2.1.1 Analisis Berbasis Cluster ... 7
2.1.2 Clustering Pada Set Data Kategorikal ... 9
2.1.3 Algoritma k-Means ... 10
vii
2.1.5 Metode Inisialisasi Untuk Mencari Centroid Awal pada k-Modes ... 15
2.1.6 Metode Pengembangan Perangkat Lunak Waterfall ... 15
2.1.7 Functional Decomposition Diagram (FDD) ... 16
2.1.8 Data Flow Diagram (DFD) ... 16
2.1.9 Evaluasi Cluster Menggunakan Silhoutte Index ... 18
2.1.10 Strategi Pengujian Perangkat Lunak ... 19
2.2 Tinjauan Empiris ... 20
BAB III ANALISIS DAN PERANCANGAN ... 22
3.1 Analisis Kebutuhan Sistem ... 23
3.1.1 Kebutuhan Fungsional ... 23
3.1.2 Kebutuan Non-Fungsional ... 25
3.2 Functional Decomposition Diagram (FDD) ... 25
3.3 Data Flow Diagram (DFD) ... 29
3.3.1 Context Diagram ... 29
3.3.2 DFD Level-0 Sistem ... 30
3.3.3 DFD Level-1 Manajemen Siswa ... 33
3.3.4 DFD Level-1 Manajemen Kriteria ... 35
3.3.5 DFD Level-1 Manajemen Tugas ... 37
3.3.6 DFD Level-1 Pengelompokan Siswa ... 39
3.4 Diagram Alir Sistem ... 41
3.5 Diagram Alir Algoritma k-Modes ... 44
3.5 Entity Relationship Diagram (ERD) ... 52
3.6 Rancangan Antar Muka Sistem ... 53
3.5 Pengujian dan Evaluasi ... 62
viii
BAB IV HASIL DAN PEMBAHASAN... 64
4.1 Pengumpulan Dataset ... 64
4.2 Lingkungan Implementasi ... 67
4.3 Implementasi Basis Data ... 67
4.5 Implementasi Algoritma k-Modes pada Sistem ... 70
4.5.1 Fungsi Utama ... 70
4.5.2 Fungsi Pemilihan Centroid ... 72
4.5.3 Fungsi Pencocokan Kategori ... 73
4.5.4 Fungsi Perhitungan Total Jarak ... 74
4.5.5 Fungsi Pengelompokkan ... 76
4.5.6 Fungsi Penentuan Centroid Baru ... 77
4.6 Implementasi Antar Muka Sistem ... 79
4.7 Pengujian ... 88
4.7.1 Pengujian Fungsionalitas Sistem (Black Box Testing) ... 88
4.7.2 Evaluasi Cluster dengan Silhoutte Index ... 111
BAB V KESIMPULAN DAN SARAN ... 113
5.1 Kesimpulan ... 113
5.2 Saran ... 114
ix
DAFTAR TABEL
Tabel 2.1 Jenis-jenis Proses Clustering ... 7
Tabel 3.2 Kebutuhan Fungsional Sistem ... 23
Tabel 3.2 Kebutuhan Fungsional Sistem (Lanjutan) ... 24
Tabel 3.3 Penjelasan Proses dan Sub Proses dalam FDD ... 27
Tabel 3.3 Penjelasan Proses dan Sub Proses dalam FDD (Lanjutan) ... 28
Tabel 3.3 Contoh data set penilaian siswa ... 45
Tabel 3.5 Frekuensi Atribut C1 Pada Dataset Kasus ... 48
Tabel 3.6 Contoh Hasil Perhitungan Jarak X2 dengan Q1 ... 49
Tabel 3.7 Contoh Hasil Perhitungan Jarak Xi dengan Qk ... 49
Tabel 3.8 Pembobtan Kategori ... 50
Tabel 3.9 Contoh Hasil Perhitungan Jarak Xi dengan Qk ... 51
Tabel 3.10 Rancangan Tabel Pengujian Black Box ... 63
Tabel 4.1 Kriteria penentuan kecakapan menulis Bahasa Inggris ... 64
Tabel 4.2 Detail Kriteria Pengembangan Konten (C1) ... 64
Tabel 4.3 Detail Kriteria Penyusunan (C2) ... 65
Tabel 4.4 Detail Kriteria Tatabahasa/Struktur Kalimat (C3) ... 65
Tabel 4.5 Detail Kriteria Kosakata (C4) ... 66
Tabel 4.6 Detail Kriteria Mekanisme Penulisan (C5) ... 66
Tabel 4.7 ChecklistKebutuhan ... 89
Tabel 4.8 Pengujian validasi input pada proses login ... 90
Tabel 4.9 Pengujian pemberian hak akses pada proses login ... 90
Tabel 4.10 Pengujian menu dashboard guru ... 91
Tabel 4.11 Pengujian menu dashboard siswa ... 92
Tabel 4.12 Pengujian operasi pencarian dan filter kelas data siswa ... 93
Tabel 4.13 Pengujian operasi penambahan data siswa baru ... 95
Tabel 4.14 Pengujian operasi pembaruan data siswa ... 96
Tabel 4.15 Pengujian operasi penghapusan data siswa ... 97
Tabel 4.16 Pengujian operasi penilaian tugas siswa ... 98
x
Tabel 4.18 Pengujian operasi pembaruan data tugas ... 102
Tabel 4.19 Pengujian operasi penghapusan data tugas ... 104
Tabel 4.20 Pengujian operasi penghapusan data tugas ... 104
Tabel 4.21 Pengujian operasi penambahan data kriteria baru ... 106
Tabel 4.22 Pengujian operasi pembaruan data kriteria ... 107
Tabel 4.23 Pengujian operasi penghapusan data kriteria ... 108
Tabel 4.24 Pengujian operasi pengelompokan data siswa ... 109
Tabel 4.25 Pengujian operasi untuk menampilkan hasil penilaian dan kelompok kepada siswa ... 110
Tabel 4.26 Kode Metode Perhitungan Jarak ... 111
Tabel 4.27 Nilai SI Pada k = 2 ... 111
Tabel 4.28 Nilai SI Pada k = 3 ... 111
Tabel 4.29 Nilai SI Pada k = 4 ... 112
xi
DAFTAR GAMBAR
Gambar 2.1 Klasifikasi Algoritma Clustering untuk Data Kategorikal ... 9
Gambar 2.2 Model Metodologi Waterfall ... 15
Gambar 2.3 Simbol-simbol pada DFD ... 17
Gambar 3.1 Functional Decomposition Diagram Sistem ... 26
Gambar 3.2 Context Diagram Sistem ... 29
Gambar 3.3 DFD Level-0 Sistem ... 30
Gambar 3.4 DFD Level-1 Manajemen Siswa ... 33
Gambar 3.5 DFD Level-1 Manajemen Kriteria ... 35
Gambar 3.6 DFD Level-1 Manajemen Tugas ... 37
Gambar 3.7 DFD Level-1 Pengelompokan Siswa ... 40
Gambar 3.8 Diagram alir sistem (a) ... 41
Gambar 3.9 Diagram alir sistem (b) ... 42
Gambar 3.10 Diagram alir sistem (c) ... 43
Gambar 3.11 Diagram alir algoritma k-Modes ... 44
Gambar 3.12 Diagram alir sub proses pengalokasian setiap dataset ke centroid terdekatnya ... 45
Gambar 3.13 Entity Relationship Diagram Sistem ... 52
Gambar 3.14 Rancangan Antar Muka Tampilan Login... 53
Gambar 3.15 Rancangan Antar Muka Tampilan Dashboard Guru ... 54
Gambar 3.16 Rancangan Antar Muka Tampilan Dashboard Guru ... 55
Gambar 3.17 Rancangan Antar Muka Tampilan Manajemen Siswa ... 56
Gambar 3.18 Rancangan Antar Muka Tampilan Form Tambah Siswa ... 56
Gambar 3.19 Rancangan Antar Muka Tampilan Form Penilaian Siswa ... 57
Gambar 3.20 Rancangan Antar Muka Tampilan Manajemen Kriteria ... 57
Gambar 3.21 Rancangan Antar Muka Tampilan Form Tambah Kriteria ... 58
Gambar 3.22 Rancangan Antar Muka Tampilan Manajemen Tugas ... 59
Gambar 3.23 Rancangan Antar Muka Tampilan FormTambah Tugas ... 59
Gambar 3.24 Rancangan Antar Muka Tampilan Penyetoran Tugas ... 60
xii
Gambar 3.26 Rancangan Antar Muka Tampilan Hasil Pengelompokan Siswa .... 61
Gambar 3.27 Rancangan Antar Muka Tampilan Lihat Nilai Siswa ... 62
Gambar 4.1 Skema Basis Data Sistem ... 67
Gambar 4.2 Implementasi Tampilan Login ... 79
Gambar 4.3 Implementasi Tampilan Dashboard Guru ... 80
Gambar 4.4 Implementasi Tampilan Dashboard Siswa ... 80
Gambar 4.5 Implementasi Tampilan Manajemen Data Siswa ... 81
Gambar 4.6 Implementasi Tampilan Tambah Data Siswa ... 81
Gambar 4.7 Implementasi Tampilan Form Penilaian Siswa ... 82
Gambar 4.8 Implementasi Tampilan Manajemen Kriteria ... 83
Gambar 4.9 Implementasi Tampilan Form Tambah Kriteria ... 83
Gambar 4.10 Implementasi Tampilan Detail Kriteria ... 84
Gambar 4.11 Implementasi Tampilan Manajemen Tugas ... 84
Gambar 4.12 Implementasi Tampilan Form Tambah Tugas ... 85
Gambar 4.13 Implementasi Tampilan Pengumpulan Tugas ... 86
Gambar 4.14 Implementasi Tampilan Form Pengumpulan Tugas ... 86
Gambar 4.15 Implementasi Tampilan Hasil Pengelompokan (a) ... 87
Gambar 4.16 Implementasi Tampilan Hasil Pengelompokan (b) ... 87
Gambar 4.17 Implementasi Tampilan Hasil Pengelompokan (c) ... 88
Tabel 4.26 Kode Metode Perhitungan Jarak ... 111
xiii
DAFTAR LAMPIRAN
Lampiran1
BAB I
PENDAHULUAN
1.1 Latar Belakang
Proses belajar mengajar merupakan serangkaian aktivitas yang terdiri dari persiapan, pelaksanaan, dan evaluasi pembelajaran. Ketiga hal tersebut merupakan rangkaian utuh yang harus dilaksanakan oleh seorang guru. Hal yang paling berat dari ketiga komponen tersebut adalah menganilisis hasil evaluasi siswa. Secara umum masih sangat banyak dijumpai guru-guru yang menganalisis hasil evaluasi siswa secara manual sehingga hal tersebut memerlukan proses yang lama dan hasilnya kurang akurat. Pada penelitian ini penulis jumpai kesulitan yang dihadapi oleh guru-guru Bahasa Inggris pada SMP N 6 Denpasar dalam mengevaluasi hasil tulisan Bahasa Inggris karena terdapat beberapa kriteria yang harus dinilai.
Dalam penenentuan kecakapan menulis Bahasa Inggris Siswa terdapat lima hal penting sebagai kriteria yang akan menjadi alat ukur penilaian kemampuan siswa dalam menulis Bahasa Inggris. Kriteria yang digunakan sebagai pertimbangan dalam penentuan kecakapan menulis Bahasa Inggris siswa yang
dikutip dari Marhaeni (2005) yaitu, Pengembangan Konten (Content Development),
Penyusunan (Organization), Tatabahasa/Struktur Kalimat (Grammar/Structure),
Kosakata (Vocabulary), dan Mekanisme Penulisan (Mechanics).
Dalam penelitian ini, akan dirancang sebuah sistem yang dapat mengelompokkan data siswa berdasarkan atribut kriteria yang akan menjadi alat
ukur penilaian dalam menulis Bahasa Inggris menggunakan teknik clustering.
Clustering merupakan suatu pekerjaan yang memisahkan data ke dalam sejumlah
kelompok (cluster) menurut karakteristiknya masing-masing (Prasetyo, 2014)
dengan tujuan, objek yang ada dalam sebuah kelompok memiliki kesamaan atau terkait satu sama lain dan objek tersebut tidak sama dengan objek yang berada pada kelompok yang lain (Tan P., Steinbach M., Kumar V., 2005). Salah satu algoritma
yang dapat digunakan untuk melakukan proses clustering adalah algoritma
k-Means. Algoritma k-Means merupakan algoritma pengelompokan iteratif yang
2
di mana algoritma k-Means sederhana untuk diimplementasikan dan dijalankan,
realtif cepat, dan mudah beradaptasi (Wu & Kumar, 2009 dalam Prasetyo, 2014).
Algoritma k-Means terkenal akan efisiensinya dalam melakukan proses clustering
pada data set yang besar. Akan tetapi, algoritma ini terbatas pada data yang menggunakan nilai numerik sehingga Huang Z. (1998) memperkenalkan suatu
algoritma yang memperluas algoritma k-Means untuk dapat melakukan proses
clustering pada data yang bersifat kategorik ataupun campuran antara data numerik
dan data kategorikal. Algoritma pertama yang diperkenalkan adalah algoritma
k-Modes, di mana algoritma ini menggunakan pengukuran pencocokan
ketidaksamaan sederhana terhadap objek-objek kategorikal, mengganti means dari cluster menggunakan modus, dan menggunakan sebuah metode berbasis frekuensi
untuk memperbarui modus pada proses clustering untuk meminimalkan fungsi
biaya clustering. Dengan perluasan tersebut, algoritma k-Modes mampu melakukan
proses clustering terhadap data kategorikal seperti layaknya pada algoritma
k-Means. Selain algoritma k-Modes Huang juga memeperkanalkan algoritma
k-Prototype yang mengintegrasikan algoritma k-Means dan k-Modes untuk
melakukan clustering dengan data campuran antara data numerik dan data
kategorikal.
Penelitian ini diharapkan dapat memberikan kemudahan kepada guru Bahasa Inggris khususnya di SMPN 6 Denpasar dalam melakukan proses analisis dan evaluasi terhadap penilaian tingkat kecakapan siswa dan menjadi tolak ukur atau acuan dalam meningkatkan tingkat kecakapan siswa dalam menulis.
1.2 Rumusan Masalah
Sesuai dengan latar belakang yang telah disampaikan di atas, dapat dirumuskan permasalahan dalam penelitian ini yaitu :
a. Bagaimana merancang suatu sistem yang mampu melakukan proses
clustering data siswa berdasarkan atribut kriteria dalam penentuan tingkat kecakapan menulis Bahasa Inggris ?
b. Bagiamana mencari jumlah cluster k yang optimal dalam proses clustering
3
1.3 Batasan Masalah
Adapun batasan masalah dari penelitian ini yaitu:
a. Sistem yang dibangun adalah sistem berbasis web.
b. Siswa dapat menggunakan sistem apabila sudah didaftarkan terlebih dahulu
oleh guru ke dalam sistem.
c. Proses penilaian dilakukan langsung oleh guru melalui sistem.
d. Implementasi yang dibuat dengan ruang lingkup siswa sekolah menengah
pertama kelas VIII pada SMPN 6 Denpasar.
e. Algoritma yang digunakan untuk proses clustering adalah K-Modes dengan
menggunakan atribut yang merupakan data kategorikal.
f. Materi-materi dan soal-soal yang digunakan telah ditentukan sebelumnya
oleh guru.
g. Kriteria utama yang digunakan sebagai pertimbangan dalam penentuan
kecakapan menulis Bahasa Inggris siswa dikutip dari Marhaeni (2005) yang
diberikan oleh guru yaitu, Pengembangan Konten (Content Development),
Penyusunan (Organization), Tatabahasa/Struktur Kalimat
(Grammar/Structure), Kosakata (Vocabulary), dan Mekanisme Penulisan (Mechanics)dengan kategori pada setiap kriteria utama dibagi menjadi lima bagian yaitu, Sangat Rendah, Rendah, Sedang, Tinggi, dan Sangat Tinggi.
1.4 Tujuan Penelitian
4
1.5 Manfaat Penelitian
Adapun manfaat dari penelitian ini adalah dapat membantu para pengajar (guru) dalam mengukur kinerja ataupun kemampuan dan kecakapan dari siswa SMP dalam menulis Bahasa Inggris.
1.6 Metodologi Penelitian
Pada sub bab metodologi penelitian ini akan menjelaskan langkah-langkah yang akan dilalui untuk melakukan perancangan sistem. Adapun sub bab bahasan yang akan dijelaskan adalah desain penelitian, pengumpulan data, pengolahan data awal, dan metode yang digunakan.
1.6.1 Desain Penelitian
Penelitian ini mengambil judul “Perancangan Sistem Penentuan Kecakapan
Menulis Siswa SMP Menggunakan Algoritma K-Modes Clustering”. Desain
penelitian yang digunakan dalam penelitian ini adalah studi kasus. Di mana penelitian dipusatkan pada suatu kasus tertentu dengan menggunakan individu atau kelompok sebagai bahan studinya. Penggunaan penelitian studi kasus ini biasanya difokuskan untuk menggali dan mengumpulkan data yang lebih dalam terhadap objek yang diteliti untuk dapat menjawab permasalahan yang sedang terjadi (Hasibuan, 2007:81). Penilitian ini akan mengambil tempat pada SMPN 6 Denpasar.
5
metode clustering menggunakan algoritma k-Modes yang digunakan untuk melakukan pengelompokan data bersifat kategorikal.
1.6.2 Pengumpulan Data
Setelah tahapan identifikasi masalah dan tujuan telah dilaksanakan, maka tahapan selanjutnya adalah tahap pengumpulan data. Untuk mengetahui data apa saja yang dibutuhkan untuk menyelesaikan permasalahan ini, sebelumnya telah dilakukan studi literatur dan studi lapangan.
Pengumpulan data dilakukan dengan menggunakan metode observasi yaitu metode yang digunakan untuk mengumpulkan data dengan menghubungi pihak SMPN 6 Denpasar untuk mendapatkan data dan melakukan wawancara langsung kepada narasumber yang dalam kasus ini adalah guru Bahasa Inggris yang akan menggunakan sistem.
Jenis data yang digunakan pada penelitian ini dari cara memperolehnya yaitu data primer. Data primer adalah data yang diambil langsung dari objek penelitian atau merupakan data yang berasal dari sumber asli atau pertama. Data primer tersebut harus dicari melalui narasumber atau responden yaitu orang yang dijadikan objek penelitian atau orang yang dijadikan sebagai sarana informasi maupun data (Hasibuan, 2007).
Pada penelitian ini data yang digunakan adalah data dari hasil tulisan siswa untuk soal yang telah diberikan oleh pihak guru yang diperiksa. Soal tersebut mengacu pada kriteria-kriteria yang telah ditentukan pada tahap sebelumnya untuk mengukur kecakapan menulis siswa.
1.6.3 Metode Yang Digunakan
Dalam perancangan Sistem Penentuan Kecakapan Menulis Bahasa Inggris
Siswa SMP, metode yang digunakan adalah metode clustering menggunakan
algoritma k-Modes dan modifikasinya. Metode clustering adalah sebuah teknik
pengelompokan data ke dalam beberapa kelompok sesuai dengan kedekatan atribut
yang dimilikinya sedangkan algoritma yang digunakan adalah algoritma k-Modes
6
7
BAB II
TINJAUAN PUSTAKA
2.1 Tinjauan Teoritis
2.1.1 Analisis Berbasis Cluster
Analisis berbasis cluster merupakan suatu teknik untuk membagi data ke
dalam beberapa kelompok (cluster) yang memiliki arti dan berguna. Jika kelompok
yang memiliki arti adalah tujuannya, maka cluster-cluster harus dapat mengetahui struktur alami dari data. Semakin besar kesamaan (homogenitas) antar objek dalam
suatu cluster dan semakin besar perbedaan antara cluster, maka clustering akan
semakin baik (Tan P., Steinbach M., Kumar V., 2005:487).
Pada proses clustering tidak diperlukan label kelas untuk setiap data yang
diproses karena nantinya label baru bisa diberikan ketika cluster sudah terbentuk.
Karena tidak adanya label kelas maka clustering sering disebut juga pembelajaran
tidak terbimbing (unsupervised learning) (Prasetyo, 2014).
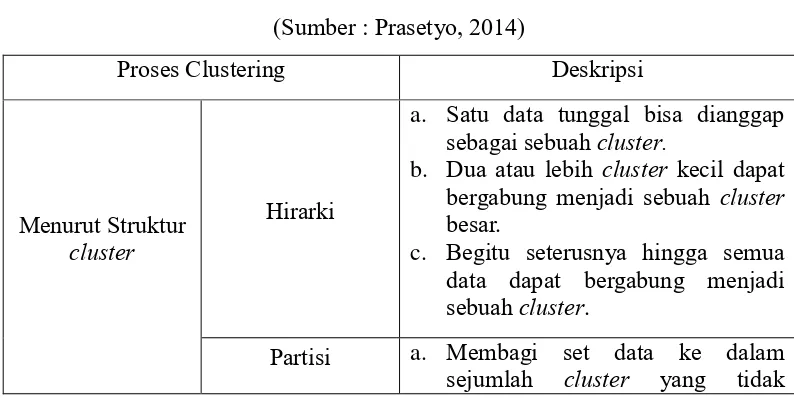
Prasetyo menyatakan bahwa proses clustering dapat dibedakan menjadi tiga
jenis, yaitu dapat dibedakan menurut struktur cluster, keanggotaan data dalam
cluster, dan kekompakan data dalam cluster. Adapun penjabaran dari ketiga jenis
proses clustering tersebut ditunjukkan secara rinci pada Tabel 2.1
Tabel 2.1 Jenis-jenis Proses Clustering
(Sumber : Prasetyo, 2014)
bergabung menjadi sebuah cluster
besar.
c. Begitu seterusnya hingga semua
data dapat bergabung menjadi sebuah cluster.
Partisi a. Membagi set data ke dalam
8
bertumpang-tindih antara satu cluster dengan cluster lain.
b. Setiap data hanya menjadi anggota
satu cluster saja.
Menurut keanggotaan data
dalam cluster
Ekslusif Sebuah data bisa dipastikan hanya menjadi anggota satu cluster dan tidak
menjadi angota di cluster lain.
Tumpang-tindih Membolehkan sebuah data menjadi anggota di lebih dari satu cluster.
Menurut kekompakan data
dalam cluster
Lengkap Jika semua data bisa bergabung, maka
data kompak menjadi satu cluster, jika tidak data dikatakan menyimpang. Parsial
Karena tidak ada label kelas yang digunakan dalam prosesnya, oleh Prasetyo clustering dikatakan sangat cocok untuk melakukan clustering data yang label
kelasnya memang sulit didapatkan pada saat pembangkitan fitur. Pada clustering,
segera setelah cluster terbentuk, maka label kelas untuk setiap data dapat diberikan
dengan cara mengamati keluaran yang dihasilkan oleh proses clustering. Karena
tidak membutuhkan label kelas, kemiripan (similarity) harus didefinisikan
berdasarkan atribut objek, di mana definisi tersebut bergantung pada algoritma clustering yang diterapkan. Algoritma clustering yang “bagus” digunakan tergantung pada penerapan set data yang diproses.
Pada algoritma clustering terdahulu kebanyakan didesain dengan asumsi
bahwa atribut dari data yang diolah merupakan data yang bersifat numerik. Namun, hal tersebut tidak sepenuhnya benar pada kasus-kasus dalam dunia nyata, data bisa didapatkan dari berbagai macam tipe data seperti diskret (kategorikal), temporal, atau structural (Aggarwal, C.C. & Reddy, C.K., 2014: 15-16). Adapun tipe data
yang dapat diteliti dalam analisis berbasis cluster menurut Aggrawal & Reddy
adalah :
a. Clustering pada data kategorikal. b. Clustering pada data teks.
9
e. Clustering pada rangkaian diskret. f. Clustering pada data berbasis jaringan. g. Clustering pada data yang tidak pasti.
2.1.2 Clustering Pada Set Data Kategorikal
Proses clustering pada set data kategorikal membagi N buah objek ke dalam
k buah cluster. Objek o memiliki m buah atribut {o1, o2,…., om}. Atribut oi,
i=1..m, memiliki sebuah domain Di dari data kategorikal atau boolean. Adapun
klasifikasi dari algoritma yang dapat digunakan untuk melakukan proses clustering
pada data kategorikal diperlihatkan pada Gambar 2.1
Gambar 2.1 Klasifikasi Algoritma Clustering untuk Data Kategorikal (Sumber : Aggarwal, C.C. & Reddy, C.K., 2014: 280)
Dalam proses clustering data kategorikal, perhitungan similarity atau jarak antar
data kategorikal tidak seperti pada data numerik yang kontinyu. Salah satu karekteristik dari data kategorikal adalah atribut kategorikal menggunakan nilai diskret yang tidak memiliki susunan yang inheren yang ada pada atribut data numerik. Beberapa teknik dapat digunakan untuk mengukur similaritas pada
10
probabilitas, information-theoritic measures, dan context-based similarity
measures (Aggarwal, C.C. & Reddy, C.K., 2014: 284).
2.1.3 Algoritma k-Means
Secara historis algoritma k-Means menjadi salah satu algoritma yang paling
penting dalam bidang data mining (Wu & Kumar, 2009 pada Prasetyo, 2014:189).
Algoritma k-Means dapat diterapkan pada data yang direpresentasikan dalam
r-dimensi ruang tempat. Algoritma ini mengelompokkan set data r-dimensi, X = {xi |
i=1,…., N }, di mana xi ∈ ℜ yang menyatakan data ke-i sebagai titik data.
Algoritma k-Means mempartisi X ke dalam k cluster, algoritma k-Means
mengelompokkan semua titik data dalam X sehingga setiap titik xi hanya jatuh
dalam satu k partisi. Yang diperhatikan adalah titik berada dalam cluster yang mana,
dilakukan dengan cara memberikan setiap titik sebuah ID cluster. Titik dengan ID
cluster sama berarti berada dalam stu cluster yang sama, sedangkan titik dengan ID cluster yang berbeda berada dalam cluster yang berbeda. Untuk menyatakan hal
ini, biasanya dilakukan dengan vektor keanggotaan cluster m dengan panjang N, di
mana mi bernilai ID cluster titik xi.
Parameter yang harus dimasukkan ketika menggunakan algoritma k- Means
adalah nilai k. Nilai k yang digunakan biasanya didasarkan pada informasi yang
diketahui sebelumnya tentang berapa banyak cluster data yang muncul dalam X,
berapa banyak cluster yang dibutuhkan untuk penerapannya, atau jenis cluster
dicari dengan mengeksplorasi/melakukan percobaan dengan beberapa nilai k.
Beberapa nilai k yang dipilih tidak perlu memahami bagaimana k-means
mempartisi set data x. (Prasetyo, 2014:190)
Dalam k-means, setiap cluster dari k cluster diwakili oleh titik tunggal
dalam ℜ . Set representative cluster dinyatakan C={cj/J=1, ..., k}. Sejumlah k
11
(dissimilarity). Artinya, data-data dengan ketidakmiripan (jarak) yang kecil/dekat
maka lebih besar kemungkinannya untuk bergabung dalam satu cluster. Metrik
yang umum digunakan untuk ketidakmiripannya adalah Euclidean. (Prasetyo,
2014:190)
Prasetyo menyatakan, pada saat data sudah dihitung ketidakmiripan
terhadap setiap centroid, maka selanjutnya dipilih ketidakmiripan yang paling kecil
sebagai cluster yang akan diikuti sebagai relokasi data pada cluster di sebuah
iterasi. Relokasi sebuah data dalam cluster yang diikuti dapat dinyatakan dengan
nilai keanggotaan a yang bernilai 0 atau 1. Nilai 0 jika tidak menjadi anggota sebuah
data cluster, hanya satu yang bernilai 1, sedangkan lainnya 0 seperti dinyatakan
oleh persamaan berikut
= { , arg min{, , }...(6.3.1)
d(xi,cj) menyatakan ketidakmiripan (jarak) dri data ke-i ke cluster cj.
Sementara relokasi centroid untuk mendapatkan titik centroid C didapatkan dengan menghitung rata-rata setiap fitur dari semua data yang tergabung dalam setiap cluster. Rata-rata sebuah fitur dari semua data dalam sebuah cluster dinyatakan oleh persamaan berikut:
C = ∑NK X
= ……… (6.3.2)
Nk adalah jumlah data yang tergabung dalam cluster.
Jika diperhatikan dari langkahnya yang selalu memilih cluster terdekat,
maka sebenarnya K=-Means berusaha untuk meminimalkan fungsi objektif/fungsi biaya non-negatif, seperti dinyatakan oleh persamaan berikut:
= ∑ ∑� ,
=
= ………(6.3.3)
Algoritma clustering dengan k-Means (Prasetyo, 2014:191)
1. Insialisasi: tentukan nilai k sebagai jumlah cluster yang diinginkan dan metric
ketidakmiripan (jarak) yang diinginkan. Jika perlu, tetapkan ambang batas
12
2. Pilih K data dari set data X sebagai centroid.
3. Alokasikan semua data ke centroid terdekat dengan metric jarak yang sudah
ditetapkan (memperbarui cluster ID setiap data).
4. Hitung kembali centroid C berdasarkan data yang mengikuti clusteri
masing-masing.
5. Ulangi langkah 3 dan 4 hingga kondisi konvergen tercapai, yaitu (a) perubahan
fungsi objektif sudah di bawah ambang batas yang diinginkan; atau (b) tidak ada
data yang berindah cluster; atau (c) perubahan posisi centroid sudah di bawah
ambang batas yang ditetapkan.
Algoritma k-means disajikan pada Algoritma k-means mengelompokkan set
data x dalam langkah iterative. Berikut dua langkah utamanya, yaitu (1) penentua
kembali ID cluster dari semua titik data dalam X, da (2) memperbarui representasi
cluster (centroid) berdasarkan titik data dalam setiap cluster.Algoritma bekerja sebagai berikut: Pertama, representasi cluster diinisialisasi dengan memilih k data
daa ℜ secara acak.Selanjutnya, secara iterative melakukan dua langkah berikut
sampai tercapai kondisi konvergen.
Langkah 1:Data assignment. Setiap data ditetapkan ke centroid terdekat dengan
pemecahan hubungan apa adanya. Hasilnya berupa data yang terpartisipasi.
Langkah 2:Relocationof “means”. Setiap representasi cluster direlokasi ke pusat
(center) dengan rata-rata aritmetika dari semua data yang ditetapkan masuk ke dalamnya. Rasionalnya langkah ini didasarkan pada observasi bahwa dalam memberikan set titik, representasi tunggal yang terbaik untuk set tersebut (dalam hal meminimalkan jumlah kuadrat jarak Euclidean diantara setiap titik data dan representative) adalah dari rata-rata dari titik data. Hal ini jugalah yang menyebabkan metode ini
sering disebut dengan cluster mean atau cluster mean atau cluster
centroid, seperti nama yang dimiliki.
Algoritma k-Means mencapai kondisi konvergen ketika pengalokasian kembai titik
data (dan juga lokasi centroid c1) tidak lagi berubah. Proses dari iterasi higga
13
didapatkan. Pada kondisi yang semakin konvergen dapat diamati bahwa nilai fungsi objekti akan semakin menurun.
2.1.4 Algoritma k-Modes
Algoritma k-Means hanya dapat bekerja dengan baik untuk set data yang
tipe data nya numerik (interval atau rasio), namun tidak dapat digunakan untuk fitur
kategorikal (nominal atau ordinal). Untuk menyelesaikan masalah tersebut,
k-Modes melakukan modifikasi pada k-Means sebagai berikut (Prasetyo, 2014) :
1. Menggunakan ukuran pencocokan ketidakmiripan sederhana pada fitur data
bertipe kategorikal.
2. Mengganti mean cluster dengan modus (nilai yang paling sering muncul).
3. Menggunakan metode berbasis frekuensi untuk mencari modus dari
sekumpulan nilai.
Andaikan X dan Y adalah dua data dengan fitur bertipe kategorikal. Ukuran ketidakmiripan di antara X dan Y dapat diukur dengan jumlah ketidakcocokan nilai dari fitur yang berkorespondensi dari dua data. Semakin keil nilai ketidakcocokan, maka semakin mirip dua data tersebut. Metrik seperti ini sering disebut dengan
pencocokan sederhana (simple matching) yang diusulkan oleh Kaufman dan
Rousseeuw (1990) pada Prasetyo, 2014. Formula yang digunakan seperti pada persamaan berikut:
Misalkan X adalah set data yang nilai fiturnya bertipe kategorikal, A1, A2,
...An,maka modus dari X = (X1, X2,…….. Xn) adalah data Q = (q1, q2,…….. qn)
14
, = ∑= , ……… (2.2.4.4)
Untuk persamaan (6.4.4), vector Q merupakan vector yang bukan bagian dari X.
Andaikan , adalah jumlah objek yang dimiliki oleh kategori ke-k pada
atribut Aj dan fr(Aj= |X)= � adalah frekuensi relatif kategori
, dalam X.
Maka fungsi D(X,Q) akan minimal jika fr(Aj=� |X) fr(Aj= |X) untuk qj≠
untuk semua j= 1, ….., r.
Yang perlu ditekankan dalam masalah modus adalah bahwa modus dari set data X tidak bersifat unik. Misalnya modus dari set {[a,b], [a,c], [c,b], [b,c]} bisa didapat [a,b] atau [a,c]. Fungsi objektif yang digunakan dalam K-Modes seperti pada persamaan berikut:
= ∑= ∑= ∑�= , ∈ , , �, ……….(2.2.4.5)
∈ adalah nilai pencocokan seperti pada persamaan (8.15) antara vector dengan
modus cluster yang diikuti, sedangkan , ∈ adalah nilai keanggotaan data
dapat setiap cluster. , ∈ memiliki nilai [0,1] yang didapatkan dari persamaan
w, { ≠ , < , � , = , … , , = , … , ………(2.2.4.6)
k adalah jumlah cluster, sedangkan n adalah jumlah data dalam cluster. Adapun
algoritma k-Modes (Prasetyo, 2014).
1. Pilih k data sebagai inisialisasi centroid (modus), satu untuk setiap cluster.
2. Alokasikan data ke cluster dengan modusnya terdekat menggunakan persamaan
(6.4.1).
3. Perbarui modus (sebagai centroid) dari setiap cluster dengan nilai kategori yang
sering muncul pada setiap cluster.
Ulangi langkah 2 dan 3 selama masih memenuhi syarat: (1) masih ada data yang
berpindah cluster, atau (2) perubahan nilai fungsi objektif masih di bawah ambang
15
2.1.5 Metode Inisialisasi Untuk Mencari Centroid Awal pada k-Modes 2.1.6 Metode Pengembangan Perangkat Lunak Waterfall
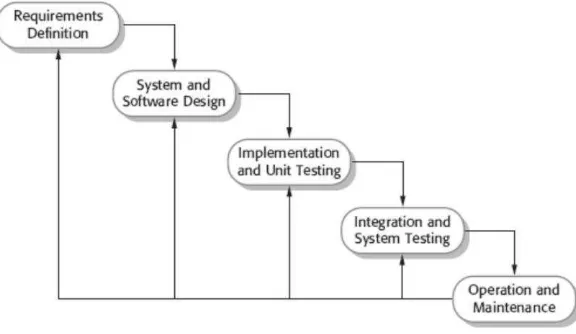
Metode pengembangan perangkat lunak Waterfall merupakan salah satu model proses perangkat lunak yang mengambil kegiatan proses dasar seperti spesifikasi, pengembangan, validasi, dan evolusi. Model ini kemudian merepresentasikannya ke dalam bentuk fase-fase proses yang berbeda seperti analisis dan pendefinisian kebutuhan, perancangan perangkat lunak, implementasi, pengujian unit, integrasi sistem, pengujian sistem, serta operasi dan pemeliharaan (Sommerville, 2003).
Gambar 2.2 Model Metodologi Waterfall
(Sumber : Sommerville, 2003)
Adapun penjelasan tahapan-tahapan dari model waterfall yang ditunjukkan pada gambar 1 menurut Sommerville (2003) adalah sebagai berikut :
1. Analisis dan Penentuan Kebutuhan
Merupakan tahap pengumpulan informasi mengenai kebutuhan sistem yang
didapat dari pengguna (user). Proses ini mendefinisikan secara rinci mengenai fungsi-fungsi, batasan dan tujuan dari perangkat lunak sebagai spesifikasi sistem.
2. Desain Sistem dan Perangkat Lunak
16
representasi antarmuka, dan detail (algoritma) prosedural. Yang dimaksud struktur data adalah representasi dari hubungan logis antara elemen-elemen data individual.
3. Implementasi dan Pengujian
Pada tahap ini, perancangan perangkat lunak direalisasikan sebagai serangkaian program atau unit program. Kemudian proses pengujian melibatkan verifikasi bahwa setiap unit program telah memenuhi kebutuhan yang telah didefinisikan pada tahap pertama.
4. Integrasi dan Uji Coba Sistem
Unit program/program individual diintegrasikan menjadi sebuah kesatuan sistem dan kemudian dilakukan pengujian. Dengan kata lain, pengujian ini ditujukan untuk menguji keterhubungan dari tiap-tiap fungsi perangkat lunak sudah memenuhi kebutuhan. Setelah pengujian sistem selesai dilakukan, perangkat lunak dikirim kepada pelanggan/user.
5. Operasi dan Pemeliharaan Sistem
Tahap ini biasanya memerlukan waktu yang paling lama, di mana sistem diterapkan dan digunakan. Pemeliharaan mencakup proses pengoreksian beberapa kesalahan yang tidak ditemukan pada tahap-tahap sebelumnya ataupun penambahan kebutuhan-kebuthan baru yang diperlukan.
2.1.7 Functional Decomposition Diagram (FDD)
Functional Decomposition Diagram atau disingkat dengan isitlah FDD
merupakan sebuah representasi top-down (disajikan dalam bentuk hirarki) dari
sebuah fungsi atau proses dari suatu sistem (Rosenblatt, 2013:140). Menurut Rosenblatt dengan menggunakan FDD, suatu analis sistem dapat menunjukkan proses bisnis dan memecahnya kembali menjadi beberapa tingkatan fungsi atau proses yang lebih detail yang hampir mirip dengan sebuah struktur organisasi.
2.1.8 Data Flow Diagram (DFD)
17
merupakan level tertinggi dari DFD yang menggambarkan seluruh input ke sistem atau output dari sistem. Diagram konteks akan memberi gambaran tentang keseluruan sistem. Sistem dibatasi oleh boundary (dapat digambarkan dengan garis putus). Dalam diagram konteks hanya ada satu proses. Tidak boleh ada store dalam diagram konteks.
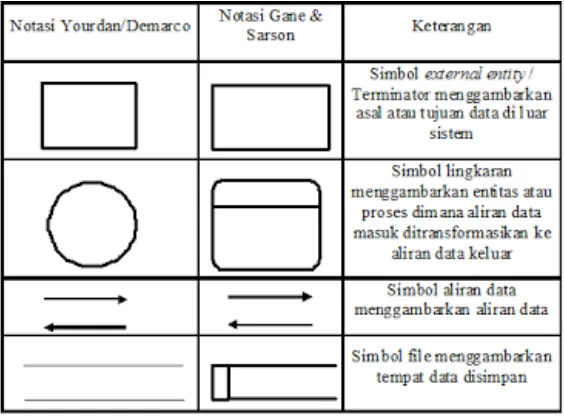
Data Flow Diagram(DFD) adalah suatu diagram yang menggunakan
notasi-notasi untuk menggambarkan arus dari data sistem, yang penggunaannya sangat membantu untuk memahami sistem secara logika, tersruktur dan jelas. DFD merupakan alat bantu dalam menggambarkan atau menjelaskan proses kerja suatu sistem.
DFD sering digunakan untuk menggambarkan suatu sistem yang telah ada atau sistem baru yang akan dikembangkan secara logika tanpa mempertimbangkan lingkungan fisik di mana data tersebut mengalir(misalnya lewat telepon, surat dan sebagainya) atau lingkungan fisik di mana data tersebut akan disimpan (misalnya file kartu, microfiche, hard disk, tape, diskette, dll). DFD merupakan alat yang digunakan pada metodologi pengembangan sistem yang terstruktur (structured analysis and design)
18
2.1.9 Evaluasi Cluster Menggunakan Silhoutte Index
Silhouette Index (SI) dapat digunakan untuk melakukan validasi terhadap
sebuah data, cluster tunggal (satu cluster dari sejumlah cluster), atau bahkan
keseluruhan cluster. Metode ini yang paling banyak digunakan untuk memvalidasi
cluster yang menggabungkan nilai kohesi dan separasi. Untuk menghitung nilai SI
dari sebuah data ke-i, ada 2 komponen yaitu ai dan bi. ai adalah rata-rata jarak data
ke-i terhadap semua data lainnya dalam satu cluster, dan bi didapatkan dengan
menghitung rata-rata jarak data ke-i terhadap semua data dari cluster yang lain tidak
dalam satu cluster dengan data ke-i, kemudian diambil yang terkecil (Tan et al,
2006, Petrovic, 2003 pada Prasetyo, 2014: 283-284).
Berikut formula untuk mnghitung :
= − ∑�= ( , �), = , , … ,
�≠ ………..(6.7.1)
( , �) adalah jarak data ke-i dengan data ke-r dalam satu cluster j, sedangkan
mjadalah jumlah dalam cluster ke-j.
Berikut formula untuk meghitung :
= = ,…,
Nilai ai mengukur seberapa tidak mirip sebuah data dengan cluster yang
diikutinya, nilai yang semakin kecil menandakan semakin tepatnya data tersebut
berada dalam cluster tersebut. Nilai biyang besar menandakan bahwa data tersebut
semakin tepat berada daam cluster tersebut. Nilai SI negative (ai>bi) menandakan
bahwa data tersebut tidak tepat berada dalam cluster tersebut (karena lebih dekat
dengan cluster yang lain). SI bernilai 0 (atau mendekati 0) berarti data tersebut
19
Untuk nilai SI dari sebuah cluster didapatkan dengan menghitung rata-rata nilai SI
semua data yang bergabung dalam cluster tersebut, seperti pada persamaan berikut:
=
j∑ = ……….(6.7.4)
Seentara nilai SI global didapatkan dengan menghitung rata-rata nilai SI dari semua cluster seperti pada persamaan berikut:
= ∑ = ……….(6.7.5)
k adalah jumlah cluster.
2.1.10 Strategi Pengujian Perangkat Lunak
Menurut Everret, G.D. dan McLeod R. strategi pengujian perangkat lunak
dapat di bagi menjadi 4 bagian utama yaitu Static Testing, White Box Testing, Black
Box Testing, dan Performance Testing.
2.1.10.2 Black Box Testing
Black Box Testing atau dikenal sebagai “Behaviour Testing” merupakan suatu metode pengujian yang digunakan untuk menguji executable code dari suatu perangkat lunak terhadap perilakunya. Pendekatan Black Box Testing dapat dilakukan jika sudah ada executable code. Orang-orang yang terlibat dalam Black Box Testing adalah tester, end-user, dan developer. Tester merencanakan keahlian eksekusi pada negative dan positive black box testing. End-user memiliki pengetahuan bagaimana perilaku bisnis yang tepat dan sesuai dengan ekspektasi, dan developer memiliki pengetahuan tentang perilaku bisnis yang di implementasikan pada perangkat lunak.
Tester melakukan black box testing bersama end-user dan developer
20
2.2 Tinjauan Empiris
Pada penelitian ini, peneliti menggunakan beberapa penelitian terkait yang pernah dilakukan oleh peneliti lain sebagai tinjauan studi, yaitu sebagai berikut : 1. Extension to the k-Means Algorithm for Clustering Large Data Sets with
Categorical Values. (Huang, Z. 1998).
Pada penelitian ini, penulis mengembangkan sebuah algoritma baru dari
algoritma k-Means yang digunakan untuk melakukan proses clustering pada
data yang memiliki nilai kategorikal yang diberi istilah k-Modes. Hasil yang
diperoleh dari penelitian ini membuktikan bahwa algoritma k-Modes mampu
melakukan proses clustering pada data set kategorikal yang besar secara efisien.
2. Clustering Categorical Data with k-Modes. (Huang, Z. 2009).
Pada penelitian ini, penulis menjabarkan hasil pengembangan algoritma
k-Modes untuk melakukan proses clustering pada data dengan nilai kategorikal dengan sedikit perubahan pada proses perhitungan ketidaksamaan (dissimilarity) menggunakan fungsi yang didefinisikan oleh Ng, Li, Huang & He, 2007.
3. Attribute Value Weighting in k-Modes Clustering. (Zengyou He, Xiaofei Xu, & Shengchun Deng, 2011).
Pada penelitian ini, penulis mengajukan sebuah metode baru dalam proses
perhitungan ketidaksamaan pada bagian algoritma k-Modes. Metode yang
dikembangan adalah weighted dissimilarity measure menggantikan perhitungan
simple matching pada algoritma k-Modes yang asli. Adapun persamaan yang
digunakan pada metode weighted dissimilarity measure terdapat pada
21
dengan syarat : �( ) = { � | � | ( | ) } Dmiana D adalah set
data yang memiliki m atribut kategorikal. � | adalah frekuensi kemunculan
nilai atribut � pada dataset dan ( | ) adalah frekuensi kemunculan nilai