SISTEM PENENTUAN PENERIMA BANTUAN BEDAH RUMAH DI KABUPATEN SERDANG BEDAGAI MENGGUNAKAN METODE
CLUSTERING K-MEANS DAN VIŠEKRITERIJUMSKO KOMPROMISNO RANGIRANJE (VIKOR)
SKRIPSI
NOVIRA NAILI ULYA SIREGAR 131402108
PROGRAM STUDI TEKNOLOGI INFORMASI
FAKULTAS ILMU KOMPUTER DAN TEKNOLOGI INFORMASI UNIVERSITAS SUMATERA UTARA
MEDAN 2018
SISTEM PENENTUAN PENERIMA BANTUAN BEDAH RUMAH DI KABUPATEN SERDANG BEDAGAI MENGGUNAKAN METODE
CLUSTERING K-MEANS DAN VIŠEKRITERIJUMSKO KOMPROMISNO RANGIRANJE (VIKOR)
SKRIPSI
Diajukan untuk melengkapi tugas dan memenuhi syarat memperoleh ijazah Sarjana Teknologi Informasi
NOVIRA NAILI ULYA SIREGAR 131402108
PROGRAM STUDI TEKNOLOGI INFORMASI
FAKULTAS ILMU KOMPUTER DAN TEKNOLOGI INFORMASI UNIVERSITAS SUMATERA UTARA
MEDAN 2018
PERSETUJUAN
Judul : SISTEM PENENTUAN PENERIMA BANTUAN
BEDAH RUMAH DI KABUPATEN SERDANG BEDAGAI MENGGUNAKAN METODE
CLUSTERING K-MEANS DAN VIŠEKRITERIJUMSKO KOMPROMISNO RANGIRANJE (VIKOR)
Kategori : SKRIPSI
Nama : NOVIRA NAILI ULYA SIREGAR
Nomor Induk Mahasiswa : 131402108
Program Studi : S1 TEKNOLOGI INFORMASI
Fakultas : ILMU KOMPUTER DAN TEKNOLOGI INFORMASI
UNIVERSITAS SUMATERA UTARA
Komisi Pembimbing :
Pembimbing 2 Pembimbing 1
Ulfi Andayani, S.Kom., M.Kom Dr. Syahril Efendi, S.Si., M.IT.
NIP. 19860419 201504 2 004 NIP. 19671110 199602 1 001
Diketahui/disetujui oleh
Program Studi S1 Teknologi Informasi Ketua,
Romi Fadillah Rahmat, B.Comp.Sc., M.Sc NIP. 19860303 201012 1 004
PERNYATAAN
SISTEM PENENTUAN PENERIMA BANTUAN BEDAH RUMAH DI KABUPATEN SERDANG BEDAGAI MENGGUNAKAN METODE
CLUSTERING K-MEANS DAN VIŠEKRITERIJUMSKO KOMPROMISNO RANGIRANJE (VIKOR)
SKRIPSI
Saya mengakui bahwa skripsi ini adalah hasil karya saya sendiri, kecuali beberapa kutipan dan ringkasan yang masing-masing telah disebutkan sumbernya.
Medan, Januari 2018
Novira Naili Ulya Siregar 131402108
UCAPAN TERIMAKASIH
Puji dan syukur kehadirat Allah SWT, karena rahmat dan izin-Nya Penulis dapat menyelesaikan penyusunan skripsi ini, sebagai syarat untuk memperoleh gelar Sarjana Komputer, pada Program Studi S1 Teknologi Informasi Fakultas Ilmu Komputer dan Teknologi Informasi Universitas Sumatera Utara.
Skripsi ini penulis persembahkan kepada kedua orangtua penulis, Ayah Imran Rosidi Siregar dan Ibu Enny Nuryani Nasution. Yang selalu memberikan doa, dukungan dan kasih sayang kepada penulis. Terima kasih penulis ucapkan kepada adik penulis Febri Khairuna Siregar yang selalu memberikan doa dan dukungan semangat dalam pengerjaan skripsi ini.
Penulis menyadari bahwa penelitian ini tidak akan terwujud tanpa bantuan banyak pihak. Dengan kerendahan hati, penulis ingin menyampaikan ucapan terima kasih kepada:
1. Bapak Prof. Dr. Opim Salim Sitompul, M.Sc selaku Dekan Fasilkom-TI Universitas Sumatera Utara.
2. Bapak Romi Fadillah Rahmat, B.Comp.Sc., M.Sc selaku Ketua Program Studi S1 Teknologi Informasi Universitas Sumatera Utara.
3. Bapak Dr. Syahril Efendi, S.Si., M.IT. selaku Dosen Pembimbing I yang telah memberikan bimbingan dan saran kepada penulis.
4. Ibu Ulfi Andayani, S.Kom., M.Kom selaku Dosen Pembimbing II yang telah memberikan bimbingan dan saran kepada penulis.
5. Bapak Dani Gunawan, ST., MT. selaku Dosen Pembanding I yang telah memberikan kritik dan saran dalam penyempurnaan skripsi ini.
6. Bapak Dr. Sawaluddin, M.IT selaku Dosen Pembanding II yang telah memberikan kritik dan saran dalam penyempurnaan skripsi ini.
7. Ompung serta Ocik-ocik yang selalu setia memberikan doa, nasehat dan semangat kepada penulis. Ici dan Faizi selaku adik sepupu yang menghibur penulis.
8. Sahabat tersayang Sukma Yastika Putri, Fauziah Nur Amalia Purba dan Livia Fyoni Kemit yang selalu ada memberikan dukungan semangat.
9. Sahabat POPIWED Deby Aprilia Sihombing, Priyanka S.Kom, Widya Eka Sandri S.Kom dan Junianto yang selalu memberikan dukungan.
10. Sahabat dari SMA yang selalu setia mendengarkan keluh kesah dan memberikan dukungan Kamilah Agita Sari S.Ked, Zakya Radhita Nasution S.Ked, Rizkia Pratiwi S.Ked, Shafura Hanani Nasution S.Ked dan Dinda Talitha S.KG.
11. Teman yang setia menemani selama tugas akhir Jodiaman Tua Marbun S.Kom, Maulidya Rahmah, Devi Novella Siregar dan Tio Febri.
12. Teman-teman seperjuangan yang selalu memberikan dukungan dan motivasi dari TI USU angkatan 2013 dan BPH & Koord KECE HIMATIF periode 2016/2017.
13. Senior Fahrunnisa S.Kom, Rina S.Kom, Wulandari Tarigan S.Kom, Ilhamuddin S.Kom, Ryan Faisal S.Kom, Naniek Matanari S.Kom, dan Handra Akira S.Kom yang memberikan nasehat dan bantuan kepada penulis.
14. Semua pihak-pihak yang telah membantu Penulis secara langsung dan tidak langsung, yang tidak dapat penulis sebutkan satu persatu yang telah membantu penyelesaian skripsi ini.
Semoga Allah SWT melimpahkan nikmat dan karunia kepada semua pihak yang telah memberikan bantuan, perhatian serta dukungan kepada penulis dalam menyelesaikan skripsi ini.
Medan, 25 Januari 2018
Penulis
ABSTRAK
Untuk meningkatkan kesejahteraan masyarakat, Pemerintah membuat suatu program bernama Bantuan Stimulan Perumahan Swadaya (BSPS) atau yang lebih dikenal dengan program bedah rumah. Salah satu implementasinya berada di Kabupaten Serdang Bedagai. Oleh sebab itu dibutuhkan suatu sistem yang mampu mengelompokkan keadaan rumah dari masyarakat miskin lalu dirangkingkan untuk prioritas dalam mendapatkan program bantuan bedah rumah.
Untuk pengelompokkan digunakan metode clustering k-means yang mempunyai beberapa kriteria yaitu jenis lantai, jenis bahan dinding, jenis bahan atap, pengunaan fasilitas buang air besar, jenis kloset, tempat pembuangan akhir tinja, jumlah individu dalam keluarga dan status kesejahteraan. Lalu pada perangkingan digunakan salah satu dari metode multi attribute decision making yaitu VIšekriterijumsko KOmpromisno Rangiranje (VIKOR). Kriteria yang akan digunakan dalam perangkingan adalah sumber air minum, sumber penerangan utama dan bahan bakar untuk masak. Dari hasil pengujian terhadap 1.180 data rumah tangga miskin (RTM) menghasilkan 3 cluster yaitu 538 RTM pada cluster 1, kemudian 593 RTM pada cluster 2 dan 49 RTM pada cluster 3. Untuk penerima bantuan bedah rumah pada tahun pertama akan diberikan kepada 185 RTM, lalu tahun kedua 162 RTM, tahun ketiga 300 RTM, tahun keempat 250 RTM, tahun kelima 150 RTM dan tahun keenam 133 RTM.
Kata kunci: bedah rumah, multi attribute decision making, clustering k-means, VIšekriterijumsko KOmpromisno Rangiranje.
DETERMINATION SYSTEM FOR HOUSE IMPROVEMENT RECIPIENTS IN SERDANG BEDAGAI BY USING CLUSTERING K-MEANS METHOD AND
VIŠEKRITERIJUMSKO KOMPROMISNO RANGIRANJE (VIKOR).
ABSTRACK
To improve the welfare of the community, the Government created a program called Bantuan Stimulan Perumahan Swadaya (BSPS) or better known as house improvement program. One of the implementation is in Kabupaten Serdang Bedagai. Therefore, we need a system capable of grouping the house situation of the poor then ranked to determine the priority in obtaining Program Bedah Rumah. For grouping were done using k-means clustering method consists of several criteria: welfare status, number of individuals in the family, type of floor, type of wall material, type of roof, use of toilet facility, type of toilet, and final disposal place. Then in ranking is used one of the multi-attribute decision making method VIšekriterijumsko KOmpromisno Rangiranje (VIKOR). The criteria were used in ranking are the sources of drinking water, the primary lighting source and the cooking fuel. From the test results of 1,180 poor households (RTM) data produced 3 clusters of 538 RTM in cluster 1, then 593 RTM on cluster 2 and 49 RTM on cluster 3. The house improvement program assistance on the first year will be given to 185 RTM, then second year for 162 RTM, third year for 300 RTM, fourth year for 250 RTM, fifth year for 150 RTM and the last year for 133 RTM.
Keywords: house improvement, multi attribute decision making, clustering k-means, VIšekriterijumsko KOmpromisno Rangiranje.
DAFTAR ISI
Halaman PERSETUJUAN iii PERNYATAAN iv
UCAPAN TERIMA KASIH v
ABSTRAK vii
ABSTRACK viii
DAFTAR ISI ix
DAFTAR TABEL xii
DAFTAR GAMBAR xiv
BAB 1 PENDAHULUAN
1.1 Latar Belakang 1
1.2 Rumusan Masalah 3
1.3 Batasan Masalah 3
1.4 Tujuan Penelitian 4
1.5 Manfaat Penelitian 4
1.6 Metodologi 4
1.7 Sistematika Penulisan 5
BAB 2 LANDASAN TEORI
2.1 Bedah Rumah 7
2.2 Data Mining 8
2.3 Clustering 10
2.4 Algoritma K-Means 10
2.5 Multi Criteria Decision Making (MCDM) 12
2.6 VIšekriterijumsko KOmpromisno Rangiranje (VIKOR) 13
2.7 Penelitian Terdahulu 15
BAB 3 ANALISIS DAN PERANCANGAN
3.1 Data yang Digunakan 18
3.2 Arsitektur Umum 22
3.3 Analisis Clustering K-Means 24
3.3.1 Menentukan Jumlah Cluster 24
3.3.2 Menentukan Pusat Cluster (centroid) 24 3.3.3 Hitung Jarak Data dengan Rumus Euclidean Distance 24 3.3.4 Kelompokkan Data pada Cluster Terdekat 26
3.3.5 Hitung Pusat Cluster Baru 27
3.3.6 Hasil Clustering 31
3.4 Analisis VIKOR 33
3.4.1 Membuat matriks keputusan ternormalisasi 33 3.4.2 Menentukan solusi ideal dan ideal negatif 35
3.4.3 Menghitung Utility Measures 35
3.4.4 Menghitung Indeks VIKOR 37
3.4.5 Perangkingan Alternatif 39
3.4.6 Usulan Solusi Kompromi 39
3.5 Perancangan Sistem 42
3.5.1 Perancangan flowchart 42
3.5.1.1 Flowchart Clustering K-Means 43
3.5.1.2 Flowchart VIKOR 44
3.5.2 Rancangan tampilan antarmuka pengguna 45 BAB 4 IMPLEMENTASI DAN PENGUJIAN
4.1 Implementasi Aplikasi 48
4.1.1 Spesifikasi perangkat keras dan perangkat lunak yang digunakan 48
4.1.2 Implementasi perancangan antarmuka 48
4.1.2.1 Halaman Home 49
4.1.2.2 Halaman Data Umum 49
4.1.2.3 Halaman Parameter 50 4.1.2.4 Halaman Clustering dan VIKOR 51
4.2 Pengujian Sistem 58
BAB 5 KESIMPULAN DAN SARAN
5.1 Kesimpulan 60
5.2 Saran 60
DAFTAR PUSTAKA 62
DAFTAR TABLE
Halaman
Tabel 2.1. Penelitian Terdahulu 16
Tabel 3.1. Jenis Lantai 19
Table 3.2. Jenis Dinding 19
Table 3.3. Jenis Atap 19
Tabel 3.4. Fasilitas Buang Air Besar 20
Table 3.5. Jenis Kloset 20
Table 3.6. Tempat Pembuangan Akhir Tinja 20
Tabel 3.7. Sumber Air Minum 21
Table 3.8. Sumber Penerangan 21
Table 3.9. Bahan Bakar Memasak 22
Tabel 3.10. Pusat Cluster Iterasi 1 26
Table 3.11. Hasil Cluster Iterasi 1 26
Table 3.12. Pusat Cluster Iterasi 2 30
Tabel 3.13. Hasil Cluster Iterasi 2 30
Table 3.14. Hasil Cluster Pertama 31
Table 3.15. Hasil Cluster Kedua 31
Tabel 3.16. Hasil Cluster Ketiga 32
Table 3.17. Data Kriteria Cluster 1 33
Table 3.18. Hasil Normalisasi Matriks 34
Table 3.19. Hasil Si dan Ri 37
Table 3.20. Hasil Qi 38
Table 3.21. Hasil Pengurutan Si, Ri dan Qi 39
Tabel 3.22. Hasil Akhir Perangkingan Cluster Tidak Layak 40 Tabel 3.23. Hasil Akhir Perangkingan Cluster Sedang 41 Tabel 3.24. Hasil Akhir Perangkingan Cluster Hampir Layak 42
DAFTAR GAMBAR
Halaman
Gambar 2.1. Bidang Ilmu Data Mining 8
Gambar 2.2. Tahapan Data Mining 10
Gambar 3.1. Arsitektur Umum 23
Gambar 3.2. Flowchart Clustering K-Means 43
Gambar 3.3. Flowchart VIKOR 44
Gambar 3.4. Rancangan Halaman Home 45
Gambar 3.5. Rancangan Halaman Data Umum 46
Gambar 3.6. Rancangan Halaman Parameter 46
Gambar 3.7. Rancangan Halaman Clustering & VIKOR 47
Gambar 4.1. Halaman Home 49
Gambar 4.2. Halaman Data Umum 49
Gambar 4.3. Halaman Parameter 50
Gambar 4.4. Pusat Cluster Awal 51
Gambar 4.5. Jarak terhadap Cluster 51
Gambar 4.6. Keanggotaan Data 52
Gambar 4.7. Pusat Cluster Baru 52
Gambar 4.8. Iterasi Akhir 53
Gambar 4.9. Hasil Proses K-Means 53
Gambar 4.10. Pilih Cluster 55
Gambar 4.11. Data Kriteria dan Alternatif 55
Gambar 4.12. Data Normalisasi 56
Gambar 4.13. Nilai Si, Ri dan Qi 56
Gambar 4.14. Nilai Si, Ri dan Qi terurut 57
Gambar 4.15. Hasil VIKOR 57
Gambar 4.16. Penerima tahun 2018 58
Gambar 4.17. Jumlah Penerima Bantuan Bedah Rumah 59
BAB 1 PENDAHULUAN
1.1. Latar Belakang
Kemiskinan merupakan salah satu masalah sosial yang ada di Indonesia. Menurut Badan Pusat Statistik (BPS) pada Maret 2016, jumlah penduduk miskin di Indonesia mencapai 28,01 juta orang (10,86%), berkurang sebesar 0,50 juta orang dibandingkan dengan kondisi September 2015 yang sebesar 28,51 juta orang (11,13%).
Untuk mengukur kemiskinan, BPS menggunakan konsep kemampuan memenuhi kebutuhan dasar (basic needs approach). Dengan pendekatan ini, kemiskinan dipandang sebagai ketidakmampuan dari sisi ekonomi untuk memenuhi kebutuhan dasar makanan dan bukan makanan yang diukur dari sisi pengeluaran.
Menurut data BPS, jumlah penduduk di Kabupaten Serdang Bedagai sebanyak 608.691 jiwa yang terdiri dari 305.513 jiwa laki-laki dan 303.178 jiwa perempuan yang tersebar di 243 desa. Dari 17 kecamatan yang ada di Serdang Bedagai terdapat 151.892 penduduk miskin serta 36.061 rumah tangga miskin (RTM). Kecamatan yang paling banyak penduduk miskinnya adalah Kecamatan Perbaungan sebesar 19.075 sedangkan Kecamatan Kotarih mempunyai penduduk miskin terendah sebesar 1.395.
Pemerintah telah melakukan upaya untuk mengurangi jumlah penduduk miskin melalui pemberian bantuan seperti Jaminan Kesehatan Nasional, Kartu Indonesia Sehat, Program Bedah Rumah dan lainnya. Salah satu program penganggulangan kemiskinan yang akan diberikan oleh pemerintah Serdang Bedagai adalah Bantuan Bedah Rumah.
Selain itu, terdapat 21% penduduk di Serdang Bedagai yang tidak mempunyai sanitasi layak.
Untuk prosedur pelaksanaan bantuan bedah rumah, maka rumah tidak layak huni harus mempunyai beberapa kriteria yaitu jenis lantai, jenis dinding, jenis atap,
penggunaan fasilitas buang air besar, jenis kloset, tempat pembuangan akhir tinja, jumlah individu dalam keluarga dan status kesejahteraannya hingga desil ke 4. Status kesejahteraan hingga desil ke 4 ialah 40 % dari jumlah penduduk termiskin. Desil 1 berarti 10 % dari jumlah penduduk miskin.
Dalam pelaksanaan bantuan bedah rumah, dihadapkan dengan keterbatasan anggaran yang ditentukan oleh pemerintah. Karena itu, masyarakat yang dapat diusulkan sebagai penerima bantuan tidak sebanding dengan jumlah masyarakat sasaran yang ada sehingga terjadi bias dalam pengajuan usulan dan verifikasi.
Dari pengamatan masalah diatas, peneliti berkeinginan untuk membangun sistem yang mampu mengklusterkan kriteria bantuan bedah rumah sehingga diperoleh tingkat kelayakan suatu rumah, lalu dilakukan perangkingan untuk menentukan prioritas dalam mendapatkan bantuan bedah rumah. Sehingga penyaluran bantuan bedah rumah ini dilakukan dengan baik dan tepat sasaran agar tidak menimbulkan kerancuan sehingga benar sampai ke rumah tangga miskin yang membutuhkan.
Penelitian dengan menentukan kelompok penerima bantuan bedah rumah sebelumnya telah dilakukan dengan menggunakan clustering k-means pada kecamatan Bahar Utara Jambi dengan kriteria status kesejahteraan, status penguasaan bangunan tempat tinggal, jenis atap, jenis lantai, jenis dinding dan jumlah individu dalam keluarga dan menghasilkan 3 (tiga) cluster (Sarjono, 2016). Selain itu penelitian juga pernah dilakukan untuk merangking penerima bantuan bedah rumah dengan metode pengambil keputusan Multi Attribute Decision Making yaitu Technique for Order Preference by Similarity to Ideal Solution (TOPSIS). Penelitian ini menggunakan 12 kriteria untuk merangkingkan serta metode Entropy yang digunakan untuk menentukan bobot (tingkat kepentingan) awal pada tiap kriteria (Dewi, 2016).
Clustering adalah suatu metode penganalisa data yang merupakan salah satu metode dalam data mining. Tujuan clustering adalah mengelompokan data dengan karakteristik yang sama ke dalam suatu wilayah yang sama berdasarkan ukuran kedekatan (kemiripan).
Pada penelitian ini, penulis mengajukan metode clustering k-means yang telah digunakan pada beberapa penelitian seperti penentuan penerima beasiswa dengan kriteria berupa Indeks Prestasi Kumulatif (IPK), jumlah tanggungan keluarga, dan penghasilan total orang tua yang menghasilkan 3 cluster yaitu menerima, dipertimbangkan, dan tidak berhak menerima beasiswa (Hastuti, 2013). Selain itu
penelitian lain yang dilakukan ialah untuk menilai kedisiplinan siswa di SMPN 21 Medan dengan clustering k-means dan Analytical Hierarchy Process yang menghasilkan 4 cluster yaitu sangat disiplin, disiplin, cukup disiplin dan tidak disiplin (Bancin,2014).
Penggunaan metode MADM digunakan untuk menyeleksi agar mendapatkan alternatif dari sejumlah alternatif. Metode MADM yang akan digunakan adalah VIšekriterijumsko KOmpromisno Rangiranje (VIKOR). VIKOR dapat digunakan untuk menyeleksi lebih dari satu alternatif. Kriteria yang akan digunakan untuk melakukan perangkingan pada penelitian ini adalah sumber air minum, sumber penerangan dan bahan bakar memasak. Penelitian dengan menggunakan metode VIKOR telah dilakukan untuk membantu proses seleksi dan menentukan penerima beasiswa dengan 4 kriteria yaitu indeks prestasi, semester, daya listrik dan jumlah tagihan listrik (Lengkong et al, 2015).
Berdasarkan latar belakang di atas, maka Penulis mengajukan proposal penelitian dengan judul “SISTEM PENENTUAN PENERIMA BANTUAN BEDAH RUMAH DI KABUPATEN SERDANG BEDAGAI MENGGUNAKAN METODE CLUSTERING K-MEANS DAN VIŠEKRITERIJUMSKO KOMPROMISNO RANGIRANJE (VIKOR)”.
1.2. Rumusan Masalah
Permasalahan yang dihadapi adalah penyeleksian rumah tangga miskin masih secara manual dan membutuhkan waktu lama dalam menentukan penerima bantuan bedah rumah yang dilakukan oleh Badan Perencanaan Pembangunan Daerah (Bappeda) Serdang Bedagai sehingga perlu dikembangkan sebuah sistem yang dapat membantu Bappeda untuk menentukan penerima bantuan bedah rumah.
1.3. Batasan Masalah
Pada penelitian ini penulis membuat batasan masalah untuk mencegah meluasnya ruang lingkup permasalahan. Adapun batasan masalah berdasarkan sistem yang akan dibangun, diantaranya yaitu:
1. Data yang akan digunakan adalah data kemiskinan di Kabupaten Serdang Bedagai.
2. Status rumah yang akan menerima bantuan bedah rumah adalah milik sendiri.
3. Kriteria yang akan digunakan untuk mengkluster adalah jenis atap, jenis dinding, jenis lantai, penggunaan fasilitas buang air besar, jenis kloset, tempat pembuangan
akhir tinja, dan jumlah individu dalam keluarga, status kesejahteraan hingga desil ke-4.
4. Kriteria yang digunakan untuk merangkingkan adalah sumber air minum, sumber penerangan utama, dan bahan bakar untuk memasak.
1.4. Tujuan Penelitian
Adapun tujuan dari penelitian ini adalah untuk mengkluster keadaan rumah dari rumah tangga miskin untuk mendapatkan bantuan bedah rumah di Kabupaten Serdang Bedagai sehingga bisa menanggulangi masalah kemiskinan dengan metode clustering k-means dan VIKOR.
1.5. Manfaat Penelitian
Adapun manfaat penelitian ini adalah:
1. Membantu pemerintah untuk menyalurkan bantuan bedah rumah tepat sasaran serta memprioritaskan yang paling membutuhkan
2. Memberi masukan untuk penelitian lain dalam bidang clustering k-means dan Multi Attribute Decision Making VIKOR.
1.6. Metodologi
Beberapa tahapan yang akan dilakukan pada penelitian ini adalah sebagai berikut:
1. Studi Literatur
Pada tahap ini dilakukan proses mengumpulkan bahan referensi mengenai program bedah rumah, multi attribute decision making, clustering k-means, dan VIKOR dari berbagai buku, jurnal, artikel, dan beberapa sumber referensi lainnya.
2. Analisis Permasalahan
Pada tahap ini dilakukan analisis terhadap berbagai referensi yang telah dikumpulkan untuk mendapatkan pemahaman mengenai clustering k-means dan VIKOR untuk menyelesaikan masalah menentukan penerima bantuan bedah rumah di Kabupaten Serdang Bedagai.
3. Perancangan
Pada tahap ini dilakukan perancangan arsitektur yang akan digunakan untuk pengumpulan data dan perancangan antar muka. Proses perancangan dilakukan berdasarkan hasil analisis terhadap studi literatur yang telah didapatkan dan dipahami.
4. Implementasi
Pada tahap ini dilakukan implementasi dari hasil analisis dan perancangan yang telah dilakukan ke dalam pembangunan kode program menggunakan PHP, javascript, dan MySQL.
5. Pengujian
Pada tahap ini dilakukan pengujian terhadap hasil yang didapatkan melalui impelementasi clustering k-means dan VIKOR untuk menentukan penerima bantuan bedah rumah di Serdang Bedagai serta memastikan sistem telah berjalan sesuai dengan yang diharapkan.
6. Penyusunan Laporan
Pada tahap ini dilakukan penyusunan laporan mengenai hasil analisis dan implementasi clustering k-means dan VIKOR untuk menentukan bantuan bedah rumah di Serdang Bedagai.
1.7. Sistematika Penulisan
Sitematika penulisan dari skripsi ini terdiri dari lima bagian utama sebagai berikut:
Bab 1 : Pendahuluan
Bab ini berisi latar belakang, rumusan masalah, batasan masalah, tujuan penelitian, manfaat penelitian, metodologi dan sistematika penulisan.
Bab 2: Landasan Teori
Bab ini berisi teori-teori yang digunakan untuk memahami permasalahan yang dibahas pada penelitian ini. Teori-teori yang berhubungan dengan bedah rumah, data mining, clustering, k-means , multi attribute decision making , VIKOR.
Bab 3: Analisis dan Perancangan
Bab ini berisi tentang analisis dan penerapan clustering k-means untuk pengelompokkan dan VIKOR untuk perangkingan penerima bantuan bedah rumah serta perancangan seperti flowchart dan tampilan.
Bab 4: Implementasi dan Pengujian
Bab ini berisi pembahasan tentang implementasi dari analisis dan perancangan yang telah disusun pada Bab 3. Selain itu, pada bab ini juga dipaparkan hasil dari pengujian sistem yang telah dibangun.
Bab 5: Kesimpulan dan Saran
Bab ini berisi kesimpulan dari seluruh pembahasan pada bab-bab sebelumnya dan saran-saran yang disampaikan untuk pengembangan pada penelitian selanjutnya.
BAB 2
LANDASAN TEORI
2.1. Bedah Rumah
Bedah rumah merupakan salah satu bantuan untuk penanggulangan kemiskinan yang difasilitasi oleh pemerintah. Program Bantuan Stimulan Perumahan Swadaya (BSPS) atau yang lebih dikenal sebagai program bedah rumah menjadi solusi penanganan rumah tidak layak huni (RTLH) di wilayah-wilayah Indonesia.
Rumah tidak layak huni adalah rumah dengan kondisi tak memenuhi persyaratan seperti keselamatan bangunan, kecukupan minimal luas bangunan, dan atau kesehatan penghuni. Berdasarkan data BPS pada 2015, jumlah RTLH sekitar 2,51 juta.
Program bedah rumah bermanfaat agar rumah menjadi layak huni yang memenuhi syarat keselamatan bangunan serta menjadi hunian sehat yang akan memberikan suasana aman dan nyaman bagi penghuninya.
Program ini diprioritaskan bagi masyarakat yang memenuhi kriteria antara lain masuk dalam daftar Rumah Tangga Sasaran (RTS), status tanah yang dimiliki merupakan hak milik sendiri serta rumahnya masuk ke dalam syarat rumah tidak layak huni seperti bahan lantai rumah berupa tanah, bahan atap berupa daun atau rumbia, bahan dinding berupa bambu/kayu/rotan serta tak memiliki akses ke sanitasi layak.
Rumah Tangga Sasaran yang berhak menerima bantuan diambil berdasarkan data by name by address dari Pemutahiran Basis Data Terpadu/ PBDT 2015. Data penerima bantuan berasal dari pendataan yang dilakukan Tim Nasional Percepatan Penanggulangan Kemiskinan (TNP2K).
2.2. Data Mining
Data Mining adalah analisis meninjau sekumpulan data untuk menemukan suatu hubungan yang tidak diduga dan meringkas data secara berbeda dengan sebelumnya yang bermanfaat dan dipahami oleh pemilik data (Larose, 2005).
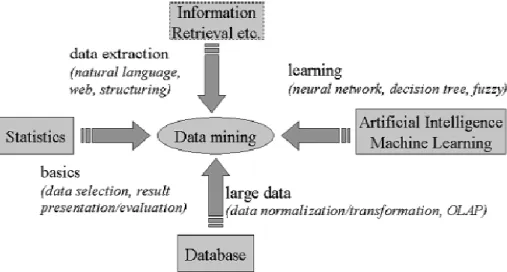
Data Mining mewarisi banyak aspek dan teknik dari berbagai bidang ilmu. Dari Gambar 2.1 menunjukkan bahwa data mining memiliki akar yang panjang dari bidang ilmu seperti kecerdasan buatan (artificial intelligent), machine learning, statistic, database serta information retrieval (Pramudiono, 2006).
Gambar 2.1 Bidang Ilmu Data Mining(Pramudiono, 2006)
Data Mining adalah bagian dari Knowledge Discovery in Database (KDD).
Knowledge Discovery in Database (KDD) adalah keseluruhan proses untuk mencari dan mengidentifikasi pola atau informasi data, dimana pola yang ditemukan bersifat sah, baru, dapat bermanfaat dan dapat dimengerti. Secara garis besar proses KDD terdiri atas beberapa tahap (Fayyad, 1996).
1. Data Selection
Pemilihan (seleksi) data dilakukan dari suatu kumpulan data operasional, sebelum tahap penggalian informasi dalam KDD dimulai proses ini perlu dilakukan. Data hasil seleksi disimpan dalam suatu berkas, terpisah dari basis data operasional.
2. Pre-processing
Proses cleaning perlu dilakukan pada data yang menjadi fokus KDD sebelum proses data mining dapat dilakukan. Proses cleaning melingkupi antara lain membuang data yang memiliki duplikasi, data yang tidak konsisten diperiksa, dan memperbaiki kesalahan pada data, seperti kesalahan cetak (typo), juga dilakukan proses enrichment, yaitu proses “memperkaya” data yang sudah ada dengan data atau informasi lain yang relevan dan diperlukan untuk KDD, seperti data atau informasi eksternal.
3. Transformation
Proses transformasi pada data yang telah dipilih adalah coding, sehingga sesuai untuk proses data mining. Proses coding dalam KDD merupakan proses kreatif dan sangat tergantung pada jenis atau pola informasi yang akan dicari dalam basis data.
4. Data mining
Data mining merupakan proses untuk mencari suatu pola atau informasi yang menarik dalam data yang terpilih dengan teknik atau metode tertentu. Data mining memiliki teknik, metode, atau algoritma dalam sangat bervariasi.
Pemilihan metode dan algoritma yang tepat sangat bergantung pada tujuan dan proses KDD secara keseluruhan.
5. Interpretation/Evalution
Interpretation merupakan proses untuk menampilkan pola informasi yang dihasilkan dari proses data mining oleh pihak yang berkepentingan. Tahap ini meliputi pemeriksaan terhadap pola atau informasi yang ditemukan agar tidak bertentangan dengan fakta atau hipotesis yang ada sebelumnya.
Gambar 2.2 Tahapan Data Mining(Fayyad, 1996)
2.3. Clustering
Clustering adalah metode penganalisaan data untuk menemukan suatu kelompok- kelompok dari sekumpulan objek atau individu yang memiliki karakteristik yang sama.
Clustering merupakan salah satu metode dalam data mining. Di dalam clustering terdapat dua pendekatan. Dua pendekatan utama adalah clustering dengan pendekatan partisi dan clustering dengan pendekatan hirarki (Oliveira et al, 2007). Clustering dengan pendekatan partisi (partition-based clustering) adalah mengelompokkan data dengan memilah-milah data yang dianalisa ke dalam cluster yang ada. Clustering dengan pendekatan hirarki (hierarchical clustering) adalah mengelompokkan data dengan membuat hirarki berupa dendogram yaitu data yang mirip ditempatkan pada hirarki yang berdekatan sedangkan yang tidak diletakkan para hirarki yang berjauhan.
2.4.Algoritma K-Means
K-Means merupakan salah satu metode data clustering non hirarki yang mempartisi data ke dalam cluster sehingga data yang memiliki karakteristik yang sama dikelompokkan ke dalam satu cluster yang sama dan data yang mempunyai karakteristik yang berbeda dikelompokkan ke dalam kelompok lain sehingga data yang berada dalam satu cluster/kelompok memiliki tingkat variasi yang kecil (Agusta, 2007).
Menurut Sarwono (2011), algoritma k-means adalah sebagai berikut:
1. Menentukan k sebagai jumlah cluster yang ingin dibentuk.
2. Membangkitkan nilai random untuk pusat cluster awal (centroid) sebanyak k.
3. Menghitung jarak setiap data input terhadap masing-masing centroid menggunakan rumus jarak Eucledian (Eucledian Distance) hingga ditemukan jarak yang paling dekat dari setiap data dengan centroid.
Berikut adalah persamaan Eucledian Distance:
(𝑥𝑖, 𝜇𝑗) = √(𝑥𝑖 − 𝜇𝑗)2… (2.1) dimana:
𝑥𝑖 : data kriteria
𝜇𝑗 : centroid pada cluster ke-j
4. Mengklasifikasikan setiap data berdasarkan kedekatannya dengan centroid (jarak terkecil).
5. Memperbaharui nilai centroid. Nilai centroid baru diperoleh dari rata-rata cluster yang bersangkutan dengan rumus:
µj (t+1) = 𝑁𝑠𝑗1 ∑𝑗=𝑆𝑗𝑋𝑗… (2.2) dimana:
µj (t+1) : centroid baru pada iterasi ke (t+1) Nsj : banyak data pada cluster Sj
6. Melakukan perulangan dari langkah 2 hingga 5 hingga anggota tiap cluster tidak ada yang berubah.
7. Jika langkah 6 telah terpenuhi, maka nilai pusat cluster (µj) pada iterasi terakhir akan digunakan sebagai parameter untuk menentukan klasifikasi data.
2.5. Multi Criteria Decision Making (MCDM)
Multi criteria decision making (MCDM) merupakan teknik pengambilan keputusan dari beberapa pilihan alternatif yang ada. Di dalam MCDM ini mengandung unsur atribut, obyektif, dan tujuan(Rahardjo et al, 2000).
Atribut menerangkan, memberi ciri kepada suatu obyek. Misalnya tinggi, panjang dan sebagainya.
Obyektif menyatakan arah perbaikan atau kesukaan terhadap atribut, misalnya memaksimalkan umur, meminimalkan harga, dan sebagainya.
Obyektif dapat pula berasal dari attribute yang menjadi suatu obyektif jika pada atribut tersebut diberi arah tertentu.
Tujuan ditentukan terlebih dahulu. Misalnya suatu proyek mempunyai obyektif memaksimumkan profit, maka proyek tersebut mempunyai tujuan mencapai profit 10 juta/bulan.
Kriteria merupakan ukuran, aturan-aturan ataupun standar-standar yang memandu suatu pengambilan keputusan. Pengambilan keputusan dilakukan melalui pemilihan atau memformulasikan atribut-atribut, obyektif-obyektif, maupun tujuan- tujuan yang berbeda, maka atribut, obyektif maupun tujuan dianggap sebagai kriteria.
Kriteria dibangun dari kebutuhan-kebutuhan dasar manusia serta nilai-nilai yang diinginkannya. Ada dua macam kategori dari multi criteria decision making (MCDM), yaitu :
1. Multiple Objective Decision Making (MODM) 2. Multiple Attribute Decision Making (MADM)
Multiple Objective Decision Making (MODM) menyangkut masalah perancangan (design), di mana teknik-teknik matematik optimasi digunakan, untuk jumlah alternatif yang sangat besar (sampai dengan tak berhingga) dan untuk menjawab pertanyaan apa (what) dan berapa banyak (how much).
Multiple Attribute Decision Making (MADM), menyangkut masalah pemilihan, di mana analisa matematis tidak terlalu banyak dibutuhkan atau dapat digunakan untuk pemilihan hanya terhadap sejumlah kecil alternatif saja. Metode Analytical Hierarchy Process (AHP), Simple Additive Weighting Method (SAW), Technique for Order by Similarity to Ideal Solution Method (TOPSIS), VIšekriterijumsko KOmpromisno Rangiranje (VIKOR) merupakan bagian dari teknik MADM.
2.6. VIšekriterijumsko KOmpromisno Rangiranje (VIKOR)
Metode VIšekriterijumsko KOmpromisno Rangiranje (VIKOR) dikembangkan untuk optimasi multikriteria dari sistem yang kompleks. VIKOR digunakan untuk menentukan daftar peringkat, solusi kompromi, dan bobot interval stabilitas. Untuk
kestabilan preferensi solusi kompromi diperoleh dengan initial bobot. Metode VIKOR memiliki kelebihan pada proses pemeringkatan dengan memiliki nilai preferensi untuk pemeringkatan dan dapat mengatasi pemeringkatan banyak alternatif dengan lebih mudah. Serta memperkenalkan indeks berbasis indeks multikriteria pada ukuran khusus
"kedekatan" dengan solusi "ideal" (Opricovic, 1998).
Prosedur perhitungan metode VIKOR menurut (Opricovic & Tzeng, 2004) dan (Zhang, et al., 2016) mengikuti tahap-tahap di bawah ini:
1. Menghitung normalisasi matrik keputusan
Perhitungan normalisasi matrik keputusan terhadap setiap data L𝑖𝑗 mengikuti persamaan:
f
ij=
𝐿𝑖𝑗√∑𝑚𝑖=1𝐿2𝑖𝑗
(2.3)
Dimana 𝑖 merupakan alternatif ke 1,2,3 hingga m, j merupakan alternatif ke 1,2,3 hingga n. 𝑋𝑖𝑗 adalah nilai elemen dari setiap kriteria dan fij merupakan nilai hasil normalisasi. Akan diperoleh matrik 𝐹 yang mengandung keseluruhan nilai elemen hasil normalisasi, ditunjukkan melalui persamaan
F = 𝐴1 𝐴2
⋮ 𝐴𝑚
[
𝐶𝑥1 𝐶𝑥2 𝑥11 𝑥12 𝑥21 𝑥22
… 𝐶𝑥𝑛
… 𝑥1𝑛
… 𝑥2𝑛
⋮ ⋮
𝑥𝑚1 𝑥𝑚1 ⋮ ⋮
… 𝑥𝑚𝑛
]
(2.4)
2. Menentukan solusi ideal dan ideal negatif
Menentukan alternatif dengan nilai tertinggi yang berarti sebagai solusi positif (𝑓𝑗∗). Sedangkan yang mempunyai nilai terendah akan menjadi ideal negatif (𝑓𝑗−). Cara menentukan nilai 𝑓𝑗∗ dan 𝑓𝑗− melalui persamaan:
𝑓𝑗∗ = 𝑚𝑎𝑥𝑖𝑓𝑖𝑗
𝑓𝑗− = 𝑚𝑖𝑛𝑖𝑓𝑖𝑗 (2.5)
3. Menghitung Utility Measures
Untuk mendapatkan nilai 𝑆𝑖 dan 𝑅𝑖, diperlukan nilai bobot kriteria. Bobot kriteria (𝑤𝑗) bertujuan untuk merepresentasikan kepentingan relatif. Nilai 𝑆𝑖 dan 𝑅𝑖 dihitung secara berturut-turut melalui persamaan
Si = ∑ 𝑤𝑗 𝑓𝑗∗ − 𝑓𝑖𝑗
(𝑓𝑗∗ − 𝑓𝑗−)
𝑛𝑗=1 (2.6)
Ri = Maxj [𝑤𝑗 (𝑓𝑗∗ −𝑓𝑖𝑗)
(𝑓𝑗∗ −𝑓𝑗−)] (2.7)
4. Menghitung indeks VIKOR (𝑄𝑖)
Perhitungan indeks VIKOR menggunakan persamaan Qi = 𝑣 [𝑆𝑖 – 𝑆∗
𝑆− − 𝑆∗] + (1 − 𝑣) [𝑅𝑖 – 𝑅∗
𝑅− − 𝑅∗] (2.8) Dengan ketentuan:
S* = Mini(𝑆𝑖) R* = Mini(𝑅𝑖) S- = Maxi(𝑆𝑖) R- = Maxi(𝑅𝑖),
Untuk menghitung nilai VIKOR diperlukan variabel 𝑣 yang dikenal dengan istilah bobot strategis dari mayoritas kriteria, di mana nilai 𝑣 default ditetapkan sebesar 0,5.
5. Melakukan perangkingan alternative dengan nilai 𝑆𝑖, 𝑅𝑖 dan 𝑄𝑖 6. Mengajukan solusi kompromi
Solusi kompromi berupa alternatif (A′) diajukan ketika kondisi C1 dan C2 terpenuhi di mana alternatif A′ merupakan alternatif yang menempati peringkat pertama dalam pemeringkatan nilai VIKOR (𝑄𝑖). Adapun kondisi C1 dan C2 sebagai berikut :
A. Kondisi C1: Acceptable Advantage
Kondisi C1 diterima apabila Q(A2) – Q(A1) ≥ DQ, dengan DQ = 1/(n-1). A1 adalah alternatif urutan pertama dalam perankingan 𝑄𝑖, A2 adalah alternatif urutan kedua dalam perankingan 𝑄𝑖.
B. Kondisi C2: Acceptable Stability
Untuk memenuhi kondisi C2, alternatif A′ harus pula menduduki peringkat pertama dalam pemeringkatan nilai 𝑆𝑖 dan/atau 𝑅𝑖. Apabila kondisi C2 terpenuhi, maka solusi kompromi lain bisa diusulkan, yaitu alternatif A1, A2, … An dimana An ditentukan dari relasi Q(An) – Q(A1) < DQ untuk n yaitu posisi alternatif yang terdekat.
2.7. Penelitian Terdahulu
Beberapa penelitian yang telah dilakukan mengenai bantuan bedah rumah diantaranya dilakukan oleh (Sarjono, 2016) menentukan kelompok prioritas penerima bantuan bedah rumah menggunakan metode clustering k-means. Objek penelitian yang digunakan adalah data penduduk miskin di Kecamatan Bahar Utara Jambi dengan menggunakan 6 kriteria yaitu status kesejahteraan, jenis atap, jenis lantai, jenis dinding, status penguasaan bangunan dan jumlah individu dalam keluarga. Penelitian ini menghasilkan 3 cluster untuk penyeleksian penduduk yang menjadi prioritas utama untuk mendapatkan bantuan bedah rumah.
Penelitian selanjutnya yang dilakukan oleh (Dewi, 2016) yaitu analisis dan perancangan sistem penentuan penerima bantuan bedah rumah Bali Mandara dengan metode entropy dan TOPSIS. Penelitian ini menggunakan 12 kriteria untuk merangking data pemohon bantuan bedah rumah. Pada penelitian ini dihasilkan nama pemohon bantuan bedah rumah yang lebih membutuhkan berdasarkan periode.
Penelitian mengenai implementasi MCDM dengan metode VIKOR yang dilakukan oleh (Lengkong et al., 2015) untuk seleksi penerima beasiswa menggunakan 4 kriteria yaitu indeks prestasi, semester, daya listrik dan jumlah tagihan listrik untuk membantu proses seleksi dan menentukan penerima beasiswa. Hasil penelitian menunjukkan bahwa penggunaan metode VIKOR dapat membantu proses seleksi dan menentukan penerima beasiswa.
Penelitian lainnya mengenai VIKOR sebagai MCDM yang dilakukan oleh (Imanuwelita et al, 2018) yaitu penentuan kelayakan lokasi usaha franchise menggunakan metode AHP dan VIKOR dengan 7 kriteria yaitu jumlah pesaing, infrastruktur tempat usaha, jarak dengan supplier, harga sewa tempat, kepadatan penduduk, ukuran lokasi dan gaji pegawai. Hasil akhir yang diperoleh berupa status kelayakan dari setiap lokasi usaha yang diajukan.
Penelitian selanjutnya yang dilakukan oleh oleh (Fitrah, 2013) yaitu sistem pendukung keputusan dengan metode k-means clustering dan F-AHP dalam penentuan penerima beras raskin. Pada sistem ini untuk menggunakan penghasilan kepala keluarga, jumlah tanggungan kepala keluarga, dan nilai harta beda keluarga sebagai kriteria pengelompokkan. Sedangkan untuk kriteria perangkingan digunakan 4 kriteria yaitu sumber penerangan, pekerjaan kepala keluarga, pendidikan kepala keluarga dan komitmen kepala keluarga. Hasil dari penelitian ini adalah nama para penerima bantuan beras raskin yang didapat dari cluster paling layak.
Penelitian terdahulu yang telah dipaparkan akan diuraikan secara singkat pada Tabel 2.1.
Tabel 2.1. Penelitian Terdahulu
Pada penelitian ini penulis mengimplementasikan metode clustering k-means untuk pengelompokkan dan VIKOR digunakan untuk melakukan perangkingan agar dapat menentukan penerima bantuan bedah rumah.
No .
Peneliti (Tahun)
Judul Penelitian Metode Hasil
1. 1. Sarjono, 2016
Analisa Data Mining untuk Menentukan Kelompok Prioritas Penerima Bantuan Bedah Rumah Menggunakan Metode Clustering K-Means
- Clustering dan - k-means
- 3 cluster untuk mendapatkan bantuan bedah rumah
2. 2. Dewi, 2016
Analisis dan Perancangan Sistem Penentuan Penerima Bantuan Bedah Rumah Bali Mandara dengan Metode Entropy dan Metode Technique For Order Preference By Similarity To Ideal Solution (TOPSIS) Berorientasi
Objek
Entropy dan TOPSIS
Rangking
penerima bantuan bedah rumah
3. 3. Lengkong, et al, 2015
Implementasi Metode VIKOR untuk Seleksi Penerima Beasiswa.
Multi Atributte Decision Making (MADM), Multi Criteria Decision Making
(MCDM) dan VIKOR
Nama penerima bantuan bedah rumah
4. 4. Imanuwelita et al, 2018
Penentuan Kelayakan Lokasi
Usaha Franchise
Menggunakan Metode AHP dan VIKOR
Multi Criteria Decision Making (MCDM),
VIKOR dan
AHP
Status kelayakan dari setiap lokasi yang diajukan
5. 5. Fitrah, 2013
Sistem Pendukung Keputusan Penetuan Penerima Raskin menggunakan metode k-means clustering dan F-AHP.
k-means
clustering, Multi Atributte
Decision Making (MADM) dan F- AHP
Nama penerima bantuan beras raskin dari cluster paling layak
BAB 3
ANALISIS DAN PERANCANGAN
Pada bab ini akan dibahas mengenai analisis dan perancangan sistem. Pada tahap analisis akan dilakukan analisis terhadap algoritma clustering k-means dan VIKOR.
Pada tahap perancangan akan dibahas mengenai flowchart dan tampilan antarmuka pada aplikasi yang akan dibangun.
3.1. Data yang Digunakan
Data yang digunakan dalam penelitian berasal dari data terpadu untuk penangan fakir miskin di Kabupaten Serdang Bedagai. Dari data terpadu tersebut diambil data rumah tidak layak huni dengan status kesejahteraan hingga desil ke 4. Setelah pengumpulan data dilakukan analisis data sesuai dengan kebutuhan sistem. Analisis data dilakukan menggunakan clustering k-means dan VIKOR. Total data yang digunakan 1.180 data rumah tangga miskin.
Dari data tersebut terdapat 11 kriteria yang digunakan dalam penelitian. Dimana 8 kriteria digunakan untuk clustering k-means dan 3 kriteria untuk VIKOR. Adapun 8 kriteria untuk pengelompokkan adalah jenis lantai, jenis dinding, jenis atap, fasilitas buang air besar, jenis kloset, tempat pembuangan akhir tinja, jumlah individu dalam keluarga dan status kesejahteraan hingga desil ke 4. Sedangkan 3 kriteria untuk VIKOR adalah sumber air minum, sumber penerangan dan bahan bakar untuk memasak.
Kriteria jenis lantai digunakan untuk mengetahui rumah tersebut menggunakan lantai jenis apa seperti pada Tabel 3.1 dibawah ini.
Tabel 3.1. Jenis Lantai Kode Keterangan
1 Marmer
2 Keramik
3 Parket/Vinil 4 Ubin/Tegel
5 Kayu/Papan high quality 6 Semen/Bata
7 Bambu
8 Kayu/Papan low quality
9 Tanah
10 Lainnya
Kriteria jenis dinding digunakan untuk mengetahui rumah tersebut menggunakan dinding jenis apa seperti pada Tabel 3.2 dibawah ini.
Tabel 3.2. Jenis Dinding Kode Keterangan
1 Tembok
2 Plester anyaman bambu
3 Kayu
4 Anyaman bambu 5 Batang Kayu
6 Bambu
7 Lainnya
Kriteria jenis atap digunakan untuk mengetahui rumah tersebut menggunakan jenis atap apa seperti pada Tabel 3.3 dibawah ini.
Tabel 3.3. Jenis Atap Kode Keterangan
1 Beton
2 Genteng Keramik 3 Genteng metal
4 Genteng tanah liat
5 Asbes
6 Seng
7 Sirap
8 Bambu
9 Jerami/Ijuk/Rumbia 10 Lainnya
Kriteria fasilitas buang air besar digunakan untuk mengetahui rumah tersebut mempunyai fasilitas buang air besar seperti pada Tabel 3.4 dibawah ini.
Tabel 3.4. Fasilitas Buang Air Besar Kode Keterangan
1 Sendiri
2 Bersama
3 Umum
4 Tidak Ada
Kriteria jenis kloset digunakan untuk mengetahui jenis kloset yang digunakan pada suatu rumah yang dapat dilihat pada Tabel 3.5 dibawah ini.
Tabel 3.5. Jenis Kloset Kode Keterangan
1 Leher Angsa 2 Plengsengan
3 Cemplung
4 Tidak Pakai
Kriteria tempat pembuangan akhir tinja menunjukkan kemana dibuangnya tinja dari suatu rumah seperti pada Tabel 3.6 dibawah ini.
Tabel 3.6. Tempat Pembuangan Akhir Tinja Kode Keterangan
1 Tangki
2 SPAL
3 Lubang Tanah
4 Kolam/Sawah/Sungai 5 Pantai/Tanah Lapang/Kebun
6 Lainnya
Kriteria sumber air minum yang akan dipakai dalam proses perangkingan digunakan untuk mengetahui berasal darimanakah air minum yang digunakan dalam suatu rumah seperti pada Tabel 3.7 dibawah ini.
Tabel 3.7. Sumber Air Minum Kode Keterangan
1 Air kemasan bermerk 2 Air isi ulang
3 Leding meteran 4 Leding eceran 5 Sumur bor/pompa 6 Sumur terlindungi 7 Sumur tak terlindungi 8 Mata air terlindung 9 Mata air tak terlindung 10 Air sungai/danau/waduk 11 Air hujan
12 Lainnya
Kriteria sumber penerangan digunakan untuk mengetahui suatu rumah menggunakan penerangan darimana seperti pada Tabel 3.8 dibawah ini
Tabel 3.8. Sumber Penerangan Kode Keterangan
1 Listrik PLN 2 Listrik non PLN 3 Bukan Listrik
Kriteria bahan bakar memasak digunakan untuk mengetahui bahan bakar apa yang digunakan suatu rumah dalam memasak dapat dilihat pada Tabel 3.9 dibawah ini.
Tabel 3.9. Bahan Bakar Memasak Kode Keterangan
1 Listrik 2 Gas > 3 kg 3 Gas 3 kg
4 Gas kota/biogas 5 Minyak tanah 6 Briket
7 Arang
8 Kayu bakar
9 Tidak memasak di rumah
3.2. Arsitektur Umum
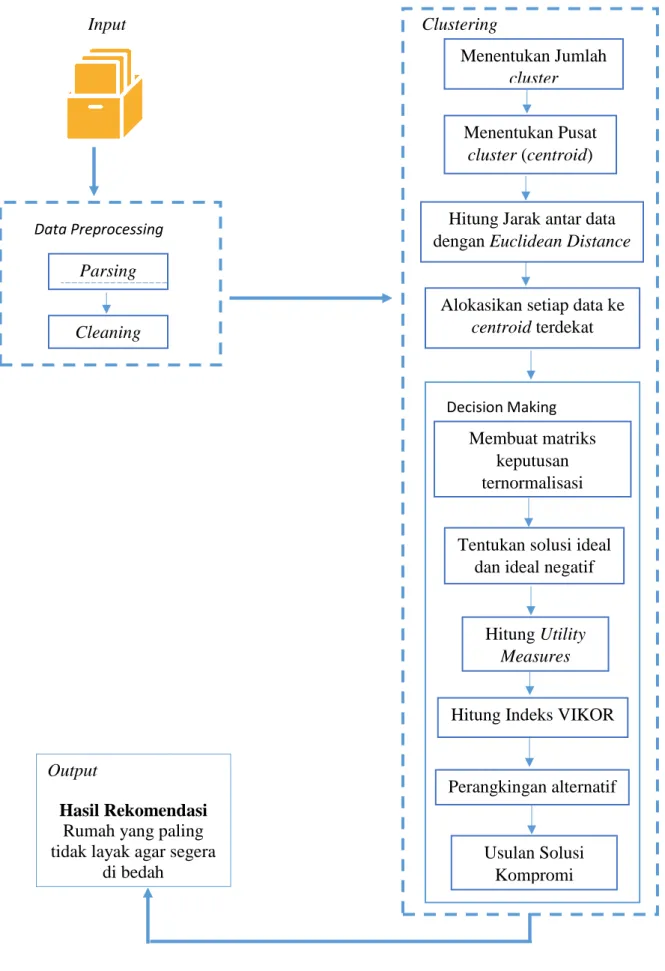
Metode yang diajukan untuk menentukan penerima bantuan bedah rumah terdiri dari beberapa tahapan. Tahapan-tahapan tersebut dimulai dari data preprocessing berupa parsing untuk mendapatkan bagian bagian data yang diinginkan. Lalu cleaning digunakan untuk memeriksa data yang inkonsisten dan kesalahan cetak (tipografi) serta mengisi missing value. Tahapan selanjutnya yaitu clustering, di dalam tahap pengelompokkan ini diawali dengan menentukan jumlah cluster setelah itu tentukan titik pusat cluster (centroid) lalu hitung jarak antar data ke titik pusat cluster dengan persamaan euclidean distance. Kemudian alokasikan data-data tersebut ke cluster terdekat sehingga diketahui di kelompok mana data tersebut berada. Tahap selanjutnya yaitu decision making, dimana data yang telah dikelompokkan akan dirangkingkan.
Dari data tersebut dibuat matriks keputusan berdasarkan kriteria dan alternatif yang dimiliki yang setelah itu dinormalisasikan. Selanjutnya tentukanlah solusi ideal positif dan negatifnya yang diikuti dengan menghitung utility measures. Lalu hitunglah indeks VIKOR berdasarkan nilai utility measures tersebut. Kemudian rangkingkan semua alternatif sehingga didapatilah hasil perangkingan untuk hasil rekomendasi yang berhak menerima bantuan bedah rumah. Adapun tahapan-tahapan diatas dapat dilihat dalam bentuk arsitektur umum pada Gambar 3.1.
Input Clustering
Data Preprocessing
Decision Making
Gambar 3.1 Arsitektur Umum
Menentukan Jumlah cluster
Menentukan Pusat cluster (centroid)
Alokasikan setiap data ke centroid terdekat
Output
Hasil Rekomendasi Rumah yang paling tidak layak agar segera
di bedah Parsing
Cleaning
Hitung Jarak antar data dengan Euclidean Distance
Membuat matriks keputusan ternormalisasi
Hitung Utility Measures Tentukan solusi ideal
dan ideal negatif
Usulan Solusi Kompromi Hitung Indeks VIKOR
Perangkingan alternatif
3.3. Analisis Clustering K-Means
Pada tahap ini dilakukan analisis dengan clustering k-means. Tahapan analisis yang akan dilakukan yaitu:
3.3.1. Menentukan Jumlah Cluster
Tahap awal dalam proses clustering adalah menentukan berapa jumlah cluster yang diinginkan. Pada sistem penentuan penerima bantuan bedah rumah akan digunakan 3 cluster yaitu cluster pertama (C1), cluster kedua (C2) dan cluster ketiga (C3).
3.3.2. Menentukan Pusat Cluster (centroid)
Pada tahap ini ditentukan nilai pusat cluster (centroid) awal secara random dari data yang telah diinputkan. Centroid kriteria 1 jenis lantai, centroid kriteria 2 jenis dinding, centroid kriteria 3 jenis atap, centroid kriteria 4 fasilitas buang air besar, centroid kriteria 5 jenis kloset, centroid kriteria 6 tempat pembuangan akhir tinja, centroid kriteria 7 jumlah anggota rumah tangga, centroid kriteria 8 status kesejahteraan. Maka diperoleh :
C1 = (9; 6; 9; 4; 0; 6; 8; 1) C2 = (4; 3; 4; 2; 2; 3; 5; 2) C3 = (1; 1; 1; 1; 1; 1; 3; 4)
3.3.3. Hitung Jarak Data dengan Euclidean Distance
Kemudian akan dihitung jarak dari setiap data ke setiap pusat cluster yang ada dengan euclidean distance sehingga ditemukan jarak terdekat dari tiap data ke centroid.
Perhitungan dengan euclidean distance dapat digunakan dengan persamaan 3.1 : 𝑑(𝑥𝑖, 𝜇𝑗) = √(𝑥𝑖𝑎 − 𝜇𝑗𝑎)2+ (𝑥𝑖𝑏 − 𝜇𝑗𝑏)2… (3.1) Dengan ketentuan sebagai berikut:
xi : data kriteria
µj : centroid pada cluster ke-j
Jarak data pertama ke pusat cluster pertama
d11=√(6 − 9)2+ (3 − 6)2+ (6 − 9)2+ (4 − 4)2+(0 − 0)2+ ⋯ + (1 − 1)2
= 9.433
Jarak data pertama ke pusat cluster kedua
d12=√(6 − 4)2+ (3 − 3)2+ (6 − 4)2+ (4 − 2)2+(0 − 2)2+ ⋯ + (1 − 2)2
= 7.280
Jarak data pertama ke pusat cluster ketiga
d13=√(6 − 1)2+ (3 − 1)2+ (6 − 1)2+ (4 − 1)2+(0 − 1)2+ ⋯ + (1 − 4)2
= 8.246
Jarak data kedua ke pusat cluster pertama
d21=√(6 − 9)2+ (1 − 6)2+ (6 − 9)2+ (1 − 4)2+(1 − 0)2+ ⋯ + (4 − 1)2
= 10.148
Jarak data kedua ke pusat cluster kedua
d22=√(6 − 4)2+ (1 − 3)2+ (6 − 4)2+ (1 − 2)2+(1 − 2)2+ ⋯ + (4 − 2)2
= 5
Jarak data kedua ke pusat cluster ketiga
d23=√(6 − 1)2+ (1 − 1)2+ (6 − 1)2+ (1 − 1)2+(1 − 1)2+ ⋯ + (4 − 4)2
= 6.480
Jarak data ketiga ke pusat cluster pertama
d31=√(6 − 9)2+ (1 − 6)2+ (6 − 9)2+ (4 − 4)2+(0 − 0)2+ ⋯ + (4 − 1)2
= 8.485
Jarak data ketiga ke pusat cluster kedua
d32=√(6 − 4)2+ (1 − 3)2+ (6 − 4)2+ (4 − 2)2+(0 − 2)2+ ⋯ + (4 − 2)2
= 6
Jarak data ketiga ke pusat cluster ketiga
d33=√(6 − 1)2+ (1 − 1)2+ (6 − 1)2+ (4 − 1)2+(0 − 1)2+ ⋯ + (4 − 4)2
= 7.810
Hasil perhitungan jarak awal pada iterasi-1 dapat dilihat pada Tabel 3.10.
Tabel 3.10. Pusat cluster iterasi 1
Nama Cluster 1 Cluster 2 Cluster 3
Yenemi Br Sitepu 9.433 7.280 8.246
Anto Girsang 10.148 5 6.480
Rasman Purba 8.485 6 7.810
Sayur Sitepu 8.366 4 7.416
….. ….. ….. …..
Syamsudin 10.148 5 6.480
3.3.4. Kelompokkan Data pada Cluster Terdekat
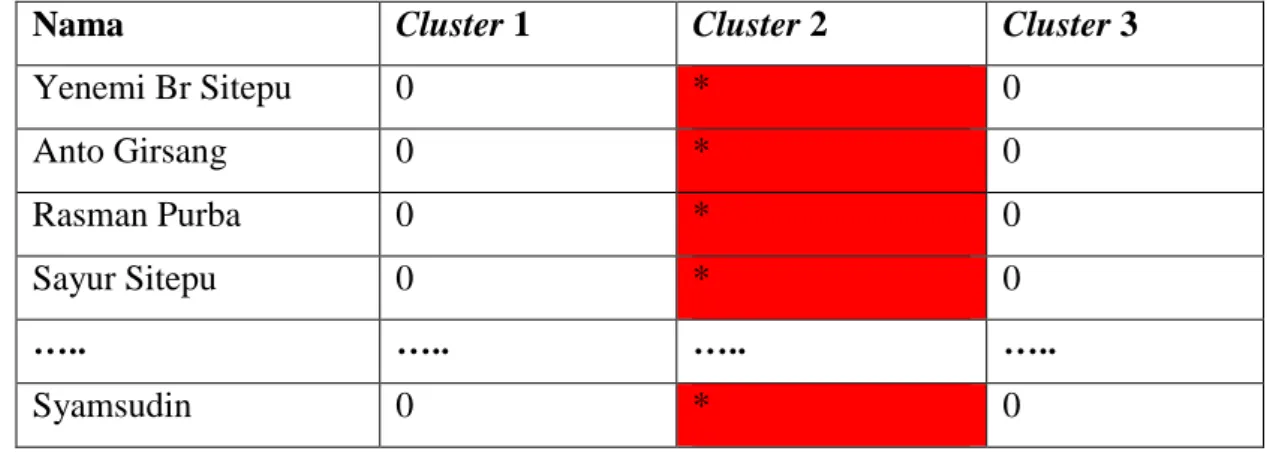
Dari hasil hitungan pada Tabel 3.10, setiap data akan dialokasikan ke suatu cluster berdasarkan jarak terdekat dari pusat clusternya. Pada data pertama diperoleh jarak terdekat dengan pusat cluster kedua, maka data tersebut akan menjadi anggota cluster kedua. Hasil cluster pada iterasi 1 dapat dilihat pada Tabel 3.11:
Tabel 3.11. Hasil cluster iterasi 1
Nama Cluster 1 Cluster 2 Cluster 3
Yenemi Br Sitepu 0 * 0
Anto Girsang 0 * 0
Rasman Purba 0 * 0
Sayur Sitepu 0 * 0
….. ….. ….. …..
Syamsudin 0 * 0
3.3.5. Hitung Pusat Cluster Baru
Menghitung pusat cluster baru dilakukan dengan cara menghitung nilai rata-rata dari masing-masing kriteria seluruh anggota yang menjadi anggota masing-masing cluster. Untuk menghitung pusat cluster baru digunakan persamaan 3.2:
µ=
∑ 𝑥𝑖𝑛𝑖=1
𝑛
(3.2)
Dengan ketentuan:
μ = centroid pada cluster 𝑥𝑖 = objek ke-i
n = banyaknya objek/jumlah objek yang menjadi anggota cluster
a. Pada cluster pertama terdapat 123 data, sehingga perhitungan cluster barunya sebagai berikut
C11= 9+9+9+9+6+..….+9+9+6
123 =931
123 = 7.569 C12= 3+3+3+4+4+..….+4+3+4
123 =449
123 = 3.650 C13= 9+6+9+6+9+..….+9+6+9
123 =987
123 = 8.024 C14= 4+4+4+4+4+..….+4+4+4
123 =465
123 = 3.780 C15= 0+0+0+0+0+..….+0+0+0
123 =22
123 = 0.178 C16= 4+4+4+4+4+..….+4+4+4
123 =507
123 = 4.121 C17= 8+6+5+6+6+..….+5+2+5
123 =558
123 = 4.536 C18= 2+1+1+2+1+..….+3+3+2
123 =320
123 = 2.601
b. Pada cluster kedua terdapat 1042 data, sehinga perhitungan cluster barunya sebagai berikut
C21= 6+6+6+6+6+..….+6+6+6
1042 =6254
1042 = 6.001 C22= 3+1+1+3+3+..….+1+3+1
1042 =2800
1042 = 2.687 C23= 6+6+6+6+6+..….+6+6+6
1042 =6306
1042= 6.051 C24= 4+1+4+1+4+..….+1+1+1
1042 =2412
1042 = 2.314 C25= 0+1+0+1+0+..….+1+1+1
1042 =971
1042 = 0.931
C26= 4+1+4+1+4+..….+1+1+1
1042 =3124
1042 = 2.99 C27= 1+4+4+6+5+..….+5+5+4
1042 =4136
1042 = 3.969 C28= 4+4+4+3+3+..….+4+4+4
1042 =3439
1042 = 3.300
c. Pada cluster ketiga terdapat 15 data, sehinga perhitungan cluster barunya sebagai berikut
C31= 2+2+2+2+2+..….+2+2+2
15 =30
15 = 2 C32= 1+1+1+1+1+..….+1+1+1
15 =15
15 = 1 C33= 6+6+6+6+6+..….+6+6+6
15 =89
15 = 5.933 C34= 1+1+1+1+1+..….+1+1+1
15 =18
15 = 1.2 C35= 1+1+2+1+1+..….+1+1+1
15 =15
15 = 1 C36= 1+1+3+1+1+..….+1+1+1
15 =20
15 = 1.333 C37= 4+3+3+4+5+..….+4+4+4
15 =54
15 = 3.6 C38= 4+4+4+3+4+..….+4+4+4
15 =59
15 = 3.933
Sehingga didapat nilai hasil pusat cluster (centroid) baru adalah C1= (7.569 ; 3.650 ; 8.024 ; 3.780 ; 0,178 ; 4,121 ; 4.536 ; 2.601).
C2= (6.001 ; 2.687 ; 6.051 ; 2.314 ; 0.931; 2.998 ; 3.969; 3.300).
C3= (2 ; 1 ; 5.933 ; 1.2 ; 1 ; 1.333 ; 3.6 ; 3.933).
Setelah itu lakukan iterasi yang kedua dengan tahapan hitung jarak antar data dengan persamaan euclidean distance (3.1) dan diperoleh:
Jarak data pertama ke pusat cluster pertama
d11=√(6 − 7.56)2+ (3 − 3.65)2+ (6 − 8.02)2+ (4 − 3.78)2+. . +(1 − 2.60)2
= 4.641
Jarak data pertama ke pusat cluster kedua
d12=√(6 − 6.001)2+ (3 − 268. )2+ (6 − 6.05)2+ (4 − 2.31)2+. . +(1 − 3.30)2
= 3.757
Jarak data pertama ke pusat cluster ketiga
d13=√(6 − 2)2+ (3 − 1)2+ (6 − 5.933)2+ (4 − 1.2)2+. . +(1 − 3.933)2
= 6.536
Jarak data kedua ke pusat cluster pertama
d21=√(6 − 7.56)2+ (1 − 3.65)2+ (6 − 8.02)2+ (1 − 3.78)2+ ⋯ + (4 − 2.60)2
= 5.829
Jarak data kedua ke pusat cluster kedua
d22=√(6 − 6.001)2+ (1 − 2.68)2+ (6 − 6.05)2+ (1 − 2.31)2+ ⋯ + (4 − 3.3)2
= 3.010
Jarak data kedua ke pusat cluster ketiga
d23=√(6 − 2)2+ (1 − 1)2+ (6 − 5.933)2+ (1 − 1.2)2+ ⋯ + (4 − 3.933)2
= 4.039
Jarak data ketiga ke pusat cluster pertama
d31=√(6 − 7.56)2+ (1 − 3.65)2+ (6 − 8.02)2+ (4 − 3.78)2+ ⋯ + (4 − 2.60)2
= 3.990
Jarak data ketiga ke pusat cluster kedua
d32=√(6 − 6.001)2+ (1 − 2.68)2+ (6 − 6.05)2+ (4 − 2.31)2+ ⋯ + (4 − 3.3)2
= 2.837
Jarak data ketiga ke pusat cluster ketiga
d33=√(6 − 2)2+ (1 − 1)2+ (6 − 5.933)2+ (4 − 1.2)2+ ⋯ + (4 − 3.933)2
= 5.677
Hasil perhitungan diatas dapat dilihat pada Tabel 3.12.
Tabel 3.12. Pusat cluster iterasi 2
Nama Cluster 1 Cluster 2 Cluster 3
Yenemi Br Sitepu 4.641 3.757 6.536
Anto Girsang 5.829 3.010 4.039
Rasman Purba 3.990 2.837 5.667
Sayur Sitepu 5.237 3.168 5.175
….. ….. ….. …..
Syamsudin 5.829 3.010 4.039
Dari Tabel 3.12 di atas, pilihlah cluster yang paling kecil sehingga hasilnya diperoleh seperti pada Tabel 3.13.
Tabel 3.13. Hasil cluster iterasi 2
Nama Cluster 1 Cluster 2 Cluster 3
Yenemi Br Sitepu 0 * 0
Anto Girsang 0 * 0
Rasman Purba 0 * 0
Sayur Sitepu 0 * 0
….. ….. ….. …..
Syamsudin 0 * 0
Pada Tabel 3.13 di atas dapat dibandingkan dengan Tabel 3.11, bahwa posisi cluster masih berubah, maka dilanjutkan dengan iterasi 3. Pada percobaan kali ini, proses akan berhenti pada iterasi ke 6. Adapun titik pusat cluster pada iterasi ke 6 adalah C1= (6.355 ; 2.921 ; 6.421 ; 4 ; 0 ; 4.124 ; 3.680 ; 2.94).
C2= (6.232 ; 2.745 ; 6.128 ; 1.096 ; 1.623 ; 2.212 ; 4.268 ; 3.478).
C3= (2.040 ; 1.306 ; 5.979 ; 1.897 ; 0.918 ; 2.448 ; 4.836 ; 3.489).
3.3.6. Hasil Clustering
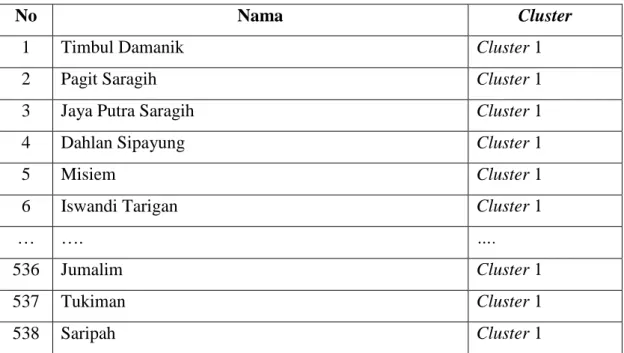
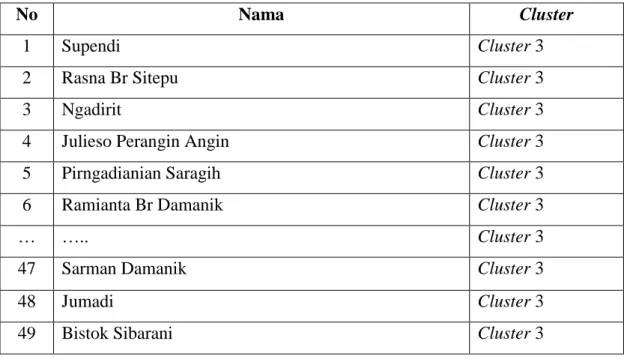
Proses iterasi berakhir pada iterasi ke 6 dan menghasilkan 538 data untuk cluster pertama, 593 data pada cluster kedua dan 49 data pada cluster ketiga yang dapat dilihat di Tabel 3.14, Tabel 3.15 dan Tabel 3.16.
Tabel 3.14. Hasil Cluster Pertama
No Nama Cluster
1 Timbul Damanik Cluster 1
2 Pagit Saragih Cluster 1
3 Jaya Putra Saragih Cluster 1
4 Dahlan Sipayung Cluster 1
5 Misiem Cluster 1
6 Iswandi Tarigan Cluster 1
… …. ….
536 Jumalim Cluster 1
537 Tukiman Cluster 1
538 Saripah Cluster 1
Tabel 3.15. Hasil Cluster Kedua
No Nama Cluster
1 Anto Girsang Cluster 2
2 Sayur Sitepu Cluster 2
3 Lohe Br Manik Cluster 2
4 Mersa Br Simanjuntak Cluster 2
5 Kariono Barus Cluster 2
6 Oslan Sitepu Cluster 2
.. …. …
591 Tumino Cluster 2
592 Sukiman Cluster 2
593 Dewi Sriani Cluster 2
Tabel 3.16. Hasil Cluster Ketiga
No Nama Cluster
1 Supendi Cluster 3
2 Rasna Br Sitepu Cluster 3
3 Ngadirit Cluster 3
4 Julieso Perangin Angin Cluster 3
5 Pirngadianian Saragih Cluster 3
6 Ramianta Br Damanik Cluster 3
… ….. Cluster 3
47 Sarman Damanik Cluster 3
48 Jumadi Cluster 3
49 Bistok Sibarani Cluster 3
Dari hasil pusat cluster didapatkan informasi sebagai berikut:
1. Cluster pertama berisi rumah yang memiliki jenis lantai semen; jenis dinding kayu; jenis atap seng; fasilitas buang air besar tidak ada; jenis kloset tidak ada;
tempat pembuangan akhir tinja di kolam/sawah/sungai; memiliki anggota rumah tangga sebanyak 4 orang; serta status kesejahteraannya berada di desil ke 3.
Keadaan rumah ini dianggap sebagai rumah tidak layak.
2. Cluster kedua berisi rumah yang memiliki jenis lantai semen; jenis dinding kayu; jenis atap seng; fasilitas buang air besar sendiri; jenis kloset plengsengan;
tempat pembuangan akhir tinja di SPAL; memiliki anggota rumah tangga sebanyak 4 orang; serta status kesejahteraannya berada di desil ke 3. Keadaan rumah ini dianggap sebagai rumah sedang sebab telah memiliki fasilitas buang air besar dan tidak terlalu buruk.
3. Cluster ketiga berisi rumah yang memiliki jenis lantai keramik; jenis dinding tembok; jenis atap seng; fasilitas buang air besar bersama ; jenis kloset leher angsa; tempat pembuangan akhir tinja di SPAL; memiliki anggota rumah tangga sebanyak 5 orang; serta status kesejahteraannya berada di desil ke 3. Keadaan rumah ini dianggap sebagai rumah hampir layak.
Oleh karena itu, hasil cluster untuk pengelompokkan keadaaan rumah yang berhak mendapatkan bantuan dikelompokkan menjadi 3 cluster yaitu :