Fakultas Ilmu Komputer
5751
Prediksi Jumlah Produksi Kelapa Sawit Dengan Menggunakan Metode
Extreme Learning Machine
(ELM)
(Studi kasus: PT. Sandabi Indah Lestari Kota Bengkulu)
Ema Agasta1, Imam Cholissodin2, Dian Eka Ratnawati3
Program Studi Teknik Informatika, Fakultas Ilmu Komputer, Universitas Brawijaya Email: 1[email protected], 2[email protected], 3[email protected]
Abstrak
Kelapa sawit merupakan tanaman perkebunan yang menjadi sektor nomor satu di Indonesia. Tanaman ini memiliki biaya dan hasil produksi yang lebih baik dibandingkan tanaman perkebunan lain seperti tebu dan karet. Dalam sebuah perusahaan, hasil produksi kelapa sawit menjadi roda penggerak ekonomi, begitu juga yang terjadi pada PT. Sandabi Indah Lestari. Dalam setiap minggunya perusahaan melakukan perencanaan untuk memprediksi hasil produksi. Perencanaan yang dilakukan terkadang masih memberikan hasil yang kurang optimal. Hal ini disebabkan karena proses perhitungannya yang masih menggunakan analisis manual. Pada penelitian ini akan menggunakan empat fitur prediksi yaitu fitur umur tanan, jumlah pokok/jumlah pohon, luas lahan, dan hasil produksi. Teknik prediksi yang digunakan adalah metode pembelajaran Extreme Learning Machine (ELM). Metode ini memiliki kelebihan pada learning speed dan keakuratan pada hasil prediksi. Proses perhitungan dimulai dari proses normalisasi data, pelatihan sejumlah data latih dan data uji, perhitungan nilai kesalahan prediksi dan menghasilkan nilai akhir. Data yang digunakan adalah data produksi pada periode 2015 – 2017 dengan jumlah data sebanyak 297 data. Dari sejumlah data tersebut akan dibagi menjadi dua data dengan persentase sebesar 80% data pelatihan dan 20% data pengujian. Hasil penelitian didapatkan nilai parameter yang optimal yaitu 13 hidden neuron pada pengujian jumlah neuron dengan nilai Mean Absolute Perscentage (MAPE) sebesar 21,25%, 20,42% pada pengujian fitur data dengan hasil 2 fitur teknikal yang terbaik, dan 20,19% pada pengujian pola dengan hasil akhir berupa pola data 1.
Kata kunci: kelapa sawit, produksi, prediksi,extreme learning machine.
Abstract
Palm oil is a plantation that became the number one sector in Indonesia. This plant has a cost and a better production than other plantation crops such as sugar cane and rubber. In a company, palm oil production becomes the driving force of the economy, as well as what happened to PT. Sandabi Indah Lestari. In every week the company plans to predict the production. Planning done sometimes still give less than optimal results. This is because the calculation process is still using manual analysis. In this research will use four prediction features that are plant age, number of trees, land, and production. The prediction technique used is the learning method of Extreme Learning Machine (ELM). This method has advantages in learning speed and accuracy in predicted results. The calculation process starts from the process of data normalization, training a number of training data and test data, calculation of the prediction error value and produce the final value. The data used is production data in the period 2015 - 2017 with a total of 297 data. From a number of data will be divided into two data with percentage of 80% training data and 20% test data. The result of the research was obtained the optimal parameter value that is 13 hidden neuron in testing the number of neurons with Mean Absolute Perscentage (MAPE) value of 21.25%, 20.42% on the data feature test with the best 2 technical features and 20,19% on testing the pattern with the final result of the data pattern 1.
1. PENDAHULUAN
Sektor tanaman perkebunan di Indonesia banyak didominasi oleh tanaman kelapa sawit, kakao, karet, tebu dan kopi. Dari kelima tanaman ini kelapa sawit yang paling menguntungkan. Menurut kepala BPS Suryamin (2014) yang dipaparkan pada halaman finance.detik.com (2014) menyebutkan bahwa kelapa sawit lebih menguntungkan dibandingkan tebu dan karet dalam hal biaya produksi. Untuk perkebunan kelapa sawit pada satu hektar lahan biaya produksi yang dibutuhkan sebesar 9,7 juta/hektar/tahun dengan nilai produksi mencapai Rp 17 juta/hektar/tahun. Sedangkan untuk satu hektar karet per tahun membutuhkan biaya produksi sebesar Rp. 9,2 juta dengan hasil produksi mencapai Rp 12,97 juta/hektar. Untuk tanaman tebu, dari awal proses penanaman hingga panen membutuhkan biaya produksi Rp 24,2 juta dengan nilai produksi Rp 31 juta. Pada kategori biaya upah pekerja, tanaman karet yang paling tinggi biayanya dengan rincian 31% untuk sawit, 57,09% untuk karet dan 26,21% untuk tebu.
PT. Sandabi Indah Lestari merupakan Perkebunan Besar Swasta (PBS) yang berada di kota Bengkulu. Perusahaan ini melakukan proses penanaman kelapa sawit pada tahun 1999 sampai tahun 2011 dan melakukan tahap produksi ditahun 2004 hingga sekarang. Dalam setiap bulannya perusaahan ini memiliki permasalahan dalam memprediksi hasil produksi kelapa sawit. Hasil produksi yang tidak tepat menjadi penyebab kesalahan dalam pengambilan kebijakan. Selama ini dalam menargetkan hasil produksi, perusahaan melakukan analisis statistik dengan nilai koreksi 5% - 12% pada hasil produksi setiap bulannya. Namun metode ini masih kurang dalam memberikan hasil prediksi yang tepat, karena metode ini menggunakan perhitungan manual dan mempertimbangkan perkiraan dari pengalaman pribadi.
Penelitian yang membahas mengenai produktivitas kelapa sawit dilakukan oleh Yohansyah dan Lubis (2014). Pada penelitian ini Peneliti menggunakan model analisis regresi berganda dengan parameter ukur yang meliputi faktor curah hujan, umur tanam, tenaga kerja panen dan hari hujan. Hasil yang didapatkan menunjukan bahwa parameter tersebut memiliki pengaruh sebesar 79,8% terhadap produktivitas kelapa sawit.
Permasalahan prediksi secara matematis dapat diselesaikan dengan berbagai metode perhtiungan salah satunya adalah metode pembelajaran baru pada bidang keilmuan Jaringan Saraf Tiruan bernama Extreme Learning Machine (ELM). Kelebihan dari metode ELM adalah metode ini mampu menyelesaikan permasalahan data linier dan non linier (Huang, et al., 2012), memberikan waktu komputasi rata – rata lebih baik dibandingkan dengan metode LS-SVM, SVM dan ANN yaitu 0,17 s (Wang, et al., 2016), Hal ini dikarenakan tidak ada perbaikan bobot dan inisialisasi nilai bobot dan bias dilakukan secara random. Selain itu pada persoalan prediksi model ELM memberikan kesalahan error yang lebih kecil dibandingkan dengan ANN dan GP yaitu sebesar 0,0046 (Anicic, et al., 2017).
Berdasarkan uraian tersebut maka Peneliti berkeinginan untuk melakukan sebuah penelitian terkait dengan model pembelajaran ELM dan tanaman kelapa sawit. Data yang akan digunakan adalah data produksi periode tahun 2015 – 2017 dengan parameter umur tanam, luas lahan, jumlah pokok/jumlah pohon dan hasil produksi. Sedangkan pemilihan metode ELM dikarenakan waktu komputasi yang cepat dengan hasil keakuratan prediksi yang baik.
2. METODE USULAN
Dalam proses perhitungan akan menggunakan 9 parameter ukur yaitu umur tanam, luas lahan, jumlah pokok, hasil produksi bulan-1, bulan-2 sampai bulan-5 dan target. Untuk nilai input manual ke sistem, diperlukan masukan nilai seperti jumlah fitur, rasio pembagian data, jenis fungsi aktivasi, dan jumlah neuron pada hidden layer.
Pola data yang digunakan terdiri dari 2 pola. Pola 1 adalah pola data dalam satu bulan terdapat banyak umur tanam. Pola 2 adalah pola data dengan satu umur tanam untuk beberapa bulan dalam satu tahun. Adapun sampel data yang akan digunakan seperti pada Tabel 1.
Tabel 1 Sampel Data Produksi Kelapa Sawit
No
Langkah–langkah perhitungan metode
menerima data masukan berupa data produksi, jumlah fitur, jumlah neuron pada hidden layer, jumlah pembagian data dan jenis fungsi aktivasi. Kemudian sistem melakukan proses normalisasi dari data produksi dan melakukan pembagian data untuk data pelatihan dan data uji. Selanjutnya data dilakukan proses pelatihan yang menghasilkan matriks output weight (𝛽̂)
untuk digunakan pada proses pengujian. Dari proses pengujian akan menghasilkan nilai output layer (𝑦̂). Sistem selanjutnya melakukan denormalisasi data dari nilai hasil pengujian dan melakukan evaluasi hasil. Dengan didapatkannya nilai evaluasi maka proses ELM berhenti. Berikut diagram alir sistem seperti yang ditunjukkan pada Gambar 1.
Gambar 1 Diagram Alir Sistem
2.1 Dataset Penelitian
Data penelitian yang digunakan adalah data produksi PT. Sandabi Indah Lestari pada periode 2015 – 2017. Total data berjumlah 297 dengan parameter utama yaitu umur tanam, luas lahan, jumlah pokok dan hasil panen pada setiap bulan. Data yang dikumpulkan akan dibagi menjadi data latih dan data uji dengan rasio pembagian 80%:20%.
2.2 Extreme Learning Machine (ELM)
Extreme Learning Machine merupakan metode pengembangan Jaringan Saraf Tiruan yang digunakan untuk menyelesaikani permasalahan waktu pembelajaranpada jaringan
feedforward. Metode ini hanya menggunakan satu hidden layer sehingga disebut sebagai
Single Hidden Layer Feedforward Neural Network (SLFNs).
Permasalahan waktu pembelajaran yang lama menurut Huang, Zhu, dan Siew (2006) disebabkan oleh inisialisasi nilai parameter jaringan (input weight dan bias) yang ditentukan secara manual. Berbeda pada metode ELM nilai parameter tersebut diinisialisasikan secara
random sehingga membuat waktu pembelajaran jaringan ELM lebih cepat dibandingkan Support Vector Machine (SVM) dan Backpropogation.
Gambar 2 Arsitektur ELM dengan Bias Sumber: (Yaseen, et al., 2018)
Secara umum arsitektur jaringan ELM digambarkan seperti pada Gambar 2. Dalam metode ELM, proses komputasi dibagi menjadi dua yaitu menggunakan bias atau tanpa bias. Penggunaan bias berfungsi untuk menggeser nilai outputlayer agar tepat dengan target.
Pada proses perhitungan nilai, terdapat penggunaan fungsi aktivasi yang digunakan untuk mengaktifkan atau menonaktifkan neuron, selain itu juga untuk mengarahkan suatu input
menjadi sebuah output tertentu. Terdapat beberapa fungsi aktivasi menurut Srimuang dan Intarasothonchun (2015), salah satunya adalah fungsi sigmoid biner. Berikut persamaan fungsi aktivasi sigmoid biner:
𝐻 = 1 + exp (−𝐻1
𝑖𝑛𝑖𝑡)
Pemilihan fungsi sigmoid biner karena pada penelitian ini digunakan data yang bersifat
non linier. Menurut Julpan, Nababan, dan Zarlis (2015) kelebihan fungsi aktivasi sigmoid biner adalah fungsi ini memiliki keakuratan hasil prediksi yang lebih baik dibandingkan fungsi aktivasi sigmoid bipolar. Selain itu menurut Mahdiyah, Irawan, dan Imah (2015) fungsi aktivasi sigmoid biner termasuk kedalam fungsi aktivasi yang bersifat infinitely differential (tidak terhingga). Hal ini dikarenakan untuk berapapun nilai input weight dan bias yang digunakan matriks 𝐻 selalu menghasilkan nilai output
(Prakoso, Wisesty & Jondri, 2016). Berikut ini akan dibahas mengenai langkah perhitungan dengan metode ELM.
2.2.1 Normalisasi
Tujuan dilakukan normalisasi adalah agar data memiliki kesamaan rentang nilai dengan data yang lain, sehingga hasil yang diharapkan bisa terarah. Metode normalisasi yang digunakan adalah Min-Max Normalization. Dengan menggunakan fungsi aktivasi sigmoid biner, nilai memiliki rentang 0 sampai 1, sehingga dalam proses normalisasi sebaiknya nilai ditransformasikan ke dalam rentang [0,1, 0,9]. Hal ini dikarenakan fungsi sigmoid biner bersifat asimtotik yaitu suatu kondisi yang nilainya pada suatu kurva tertentu tidak pernah mencapai 0 atau 1 (Sukarno, Wirawan, & Adhy, 2015).
𝑥′= 𝑥−𝑚𝑖𝑛
Proses pelatihan ditujukan untuk mengembangkan model pembelajaran jaringan dari ELM. Berikut langkah–langkah pelatihan metode ELM dengan bias menurut (Cholissodin, et al., 2017), (Huang, Zhu, & Siew, 2005):
1) Membuat nilai input weight 𝑤𝑗𝑘 dan nilai bias 𝑏 secara random. Ukuran matriks 𝑏 adalah [1 𝑥 𝑗]
2) Menghitung outputhidden layer(𝐻) dengan fungsi aktivasi sigmoid biner.
𝐻 = 1
3) Menghitung matriks Moore-Penrose Generalized Inverse.
𝐻+= (𝐻𝑇. 𝐻)−1. 𝐻𝑇
Generalized Invers dari matriks 𝐻.
Setelah proses pelatihan data, maka dilanjutkan proses pengujian dengan data uji. Berikut langkah–langkah pengujian metode ELM dengan bias menurut (Cholissodin, et al., 2017), (Huang, Zhu, & Siew, 2005):
1) Mengambil input weight𝑊𝑗𝑘,bias 𝑏dan nilai 𝛽̂ yang didapatkan dari proses pelatihan. 2) Menghitung outputhidden layer(𝐻) dengan
fungsi aktivasi sigmoid biner.
(4)
(5)
(6) (3)
𝐻 = 1
1 +exp(−(𝑥𝑡𝑒𝑠𝑡𝑖𝑛𝑔.𝑤𝑇 +𝑜𝑛𝑒𝑠(𝑁𝑡𝑒𝑠𝑡𝑖𝑛𝑔,1)∗𝑏))
Keterangan:
𝐻 = Matriks keluaran hidden layer. 𝑁𝑡𝑒𝑠𝑡= Banyaknya data uji.
𝑤𝑇 = inputweight tranpose.
𝑜𝑛𝑒𝑠(𝑁𝑡𝑒𝑠𝑡, 1)
=
fungsi matriks denganukuran baris sejumlah data uji pada setiap kolom
𝑥𝑡𝑒𝑠𝑡 = Input datauji
𝑏 = bias
3) Menghitung nilai output layer dengan mengkalikan matriks data uji dan output weight dari hasil pelatihan sesuai pada Persamaan 6.
4) Menghitung nilai evaluasi semua output layer yang sudah didenormalisasi menggunakan MAPE.
2.2.4 Denormalisasi
Denormaliasai data adalah proses untuk mengembalikan nilai prediksi menjadi nilai sebenarnya. Rumus denormalisasi seperti pada Persamaan 8.
𝑥 = 𝑛𝑚𝑎𝑥 − 𝑛𝑚𝑖𝑛 ∗𝑥′− 𝑛𝑚𝑖𝑛 (𝑚𝑎𝑥 − 𝑚𝑖𝑛) + 𝑚𝑖𝑛
Keterangan:
𝑥′ = Nilai data normalisasi.
𝑥 = Nilai data hasil denormalisasi. 𝑚𝑖𝑛 = Nilai minimum pada data set. 𝑚𝑎𝑥 = Nilai maksimum pada data set. 𝑛𝑚𝑎𝑥 = Nilai maksimum baru.
𝑛𝑚𝑖𝑛 = Nilai minimum baru.
2.2.5 Evaluasi
Proses evaluasi hasil menggunakan metode Mean Absolute Precentage Error) (MAPE) dan Mean Absolute Deviation (MAD). Metode MAPE adalah model perhitungan nilai
error dengan cara menghitung selisih antara nilai ramalan dengan nilai aktual yang selanjutnya diabsolutkan dan kemudian dihitung dalam bentuk presentase terhadap data asli (Andini & Auristandi, 2016). Sedangkan proses perhitungan metode MAD dilakukan dengan mencari rata – rata kesalahan prediksi dengan cara menghitung nilai selisih dari nilai prediksi dengan nilai aktual pada sejumlah data. Hasil dari nilai MAPE dalam bentuk presentase, sedangkan hasil nilai MAD dalam bentuk
(ukuran) yang sama dengan data aktual
Dalam menilai kinerja dari suatu model pembelajaran dengan menggunakan metode MAPE, menurut Chang, Wang dan Liu (2007) kinerja suatu model dibagi ke dalam 4 kategori seperti yang ditunjukkan pada Tabel 2.
Tabel 2 Kriteria Nilai MAPE
Nilai MAPE Status
< 10% Sangat bagus
10 - 20% Bagus
20 - 50% Cukup Bagus
>50% Buruk
Persamaan metode MAPE yang digunakan seperti pada Persamaan 9 (Mohammadi, et al., 2015)
𝑀𝐴𝑃𝐸 = 𝑁 ∑ |1 𝑃𝑖,𝑝𝑟𝑒𝑑𝑃− 𝑃𝑖,𝑚𝑒𝑎𝑠
𝑖.𝑚𝑒𝑎𝑠 | × 100 𝑁
𝑖 =1
Perhitungan evaluasi dengan metode MAD mengunakan Persamaan 10 (Heizer & Rander, 2009)
𝑀𝐴𝐷 = ∑ |𝐴𝑘𝑡𝑢𝑎𝑙 − 𝑃𝑒𝑟𝑎𝑚𝑎𝑙𝑎𝑛𝑁 |
𝑁
𝑖 =1
Keterangan:
𝑁 = Jumlah data 𝑃𝑖,𝑝𝑟𝑒𝑑 = Nilai hasil prediksi
𝑃𝑖,𝑚𝑒𝑎𝑠 = Nilai aktual
𝑖 = Indek data
3. HASIL DAN PEMBAHASAN
3.1 Pengujian Jumlah Neuron
Pengujian jumlah neuron dilakukan dengan dua tujuan yaitu untuk mengetahui berapa jumlah neuron yang optimal untuk mendapatkan nilai MAPE terkecil. Tujuan kedua untuk mengetahui pengaruh jumlah neuron
terhadap waktu komputasi.
Jumlah neuron yang diujikan berjumlah 2 sampai jumlah neuron 15. Parameter ukur lain yaitu menggunakan fungsi aktivasi sigmoid biner, rentang input weight dan bias [−1, 1], jumlah fitur 6 yang mana fitur ini terdiri dari 3 data fundamental dan 3 data teknikal. Pemilihan 3 data teknikal berdasarkan pola rotasi kelapa sawit yang rata – rata terjadi selama 3 bulan. Hasil pengujian jumlah neuron pada hidden
(8)
(9)
layer akan ditunjukkan pada Gambar 3 dan Gambar 4.
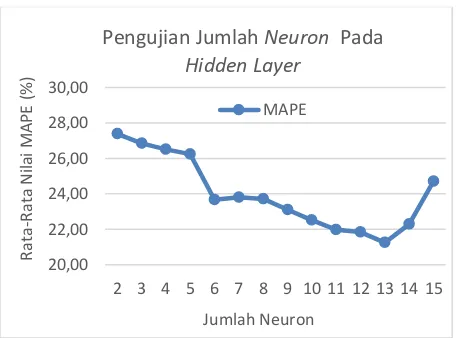
Gambar 3 Grafik Pengujian Neuron
Berdasarkan Gambar 3 yang merupakan hasil pengujian jumlah neuron pada hidden layer
menunjukkan bahwa penggunaan jumlah neuron
yang terlalu besar atau terlalu kecil pada proses pelatihan mengakibatkan hasil MAPE yang tinggi pada hasil data pengujian. Pada Gambar 3
neuron berjumlah 2 dan 3 menghasilkan MAPE yang tinggi. Nilai MAPE juga mulai mengalami kenaikan kembali pada jumlah neuron 14 dan 15.
Berdasarkan hasil tersebut dapat disimpulkan bahwa penggunaan neuron yang banyak membuat penghubung (connector) antara input layer ke output layer yang terbentuk juga semakin banyak, hal ini memungkinkan unit pemrosesan pada sistem pembobotan dalam mengenali data semakin baik. Akan tetapi penggunaan neuron yang terlalu banyak mengakibatkan hasil data uji berbeda jauh dari target. Selain itu hasil nilai MAPE tidak selalu rendah jika menggunakan jumlah hidden neuron
yang semakin banyak.
Menurut Sari (2017) jumlah neuron
yang terlalu besar menyebabkan jaringan tidak bisa menangkap keteraturan pola. Hal ini dikarenakan unit pembobotan yang besar pada
input layer, sehingga hasil output layer sulit mengarah pada pola target. Sedangkan penggunaan jumlah neuron yang terlalu sedikit juga mengakibatkan nilai MAPE besar, ini disebabkan kurangnya proses pembelajaran pola data.
Dalam segi waktu komputasi berdasarkan Gambar 4 menunjukkan bahwa waktu komputasi tercepat terjadi pada penggunaan jumlah neuron 2 dan waktu
komputasi tertinggi terjadi pada jumlah neuron
15. Pada jumlah neuron 3 sampai dengan jumlah
neuron 14 waktu komputasinya tidak mengalami perubahan waktu yang terlalu signifikan atau bisa diartikan bahwa untuk jumlah neuron yang sedikit metode Extreme Learning Machine
memiliki kecepatan waktu komputasi yang stabil.
Gambar 4 Grafik Waktu Komputasi Hasil Pengujian Jumlah Neuron
3.2 Pengujian Jumlah Fitur
Pengujian jumlah fitur ditujukan untuk mengetahui pengaruh dari data teknikal atau pengaruh dari jumlah bulan panen yang digunakan dalam proses pembentukan pola jaringan. Pada pengujian ini menggunakan 5 fitur data teknikal yang terbagi menjadi data teknikal 1, data teknikal 2, 3, 4 dan 5. Maksud dari jumlah data teknikal 1, 2, 3, 4 dan 5 adalah data hasil panen 1 bulan sebelumnya, 2 bulan sebelumnya dan seterusnya. Pengujian dilakukan dengan mengubah nilai data teknikal yang digunakan. Misal menggunakan 3 data fundamental dan 1 data teknikal, 3 data fundamental dan 2 data teknikal dan seterusnya. Penggunaan formasi fitur seperti ini dikarenakan data fundamental kurang memberikan pengaruh dan menyebabkan nilai MAPE tinggi sehingga perlu dilakukan penambahan fitur data teknikal.
Parameter ukur lain yang digunakan dalam pengujian ini adalah menggunakan jumlah neuron pada hidden layer berjumlah 13, fungsi aktivasi sigmoid biner. Hasil pengujian seperti yang ditunjukkan pada Gambar 5. 20,00
Pengujian Jumlah Neuron Pada
Hidden Layer
Pengujian Jumlah NeuronTerhadap
Waktu Komputasi
Gambar 5 Grafik Hasil Pengujian Jumlah Fitur
Berdasarkan Gambar 5 mengenai pengujian jumlah fitur memperlihatkan bahwa banyak sedikitnya jumlah fitur yang digunakan memiliki pengaruh terhadap nilai MAPE. Semakin banyak fitur belum tentu memberikan nilai MAPE yang rendah. Terlihat bahwa dengan jumlah fitur data teknikal 1, 3, 4 dan 5 menghasilkan nilai MAPE yang lebih besar dibandingkan dengan fitur data teknikal berjumlah 2. Rata–rata nilai MAPE terendah terjadi pada fitur data teknikal 2 yaitu sebesar 20,42% dan MAPE tertinggi sebesar 24,51% pada fitur 3.
Dari grafik pengujian pada Gambar 5 kesimpulan yang didapatkan adalah penggunaan data teknikal sangatlah berpengaruh. Penggunaan fitur data teknikal yang terlalu banyak dapat membuat gangguan pada data, hal ini dikarenakan terdapatnya banyak pola data yang berbeda sehingga menyebabkan hasil MAPE yang tinggi. Selain itu dipengaruhi juga oleh fitur data fundamentalnya yang tidak sepenuhnya memberikan pengaruh pada hasil prediksi. Sedangkan fitur data teknikal yang terlalu sedikit membuat hasil prediksi tidak sesuai target karena terbatasnya pola data untuk pembelajaran jaringan. Dari pengujian ini didapatkan kesimpulan bahwa rata–rata nilai MAPE terbaik adalah menggunakan analisis data panen pada bulan kesatu dan kedua dari bulan yang akan dijadikan target prediksi.
3.3 Pengujian Pola Data
Pengujian pola data ditujukan untuk
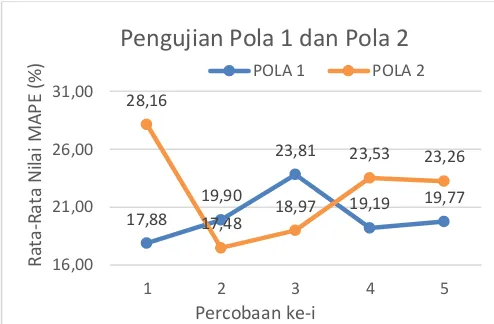
mengetahui kemampuan dari metode ELM dalam mengenali pola suatu data. Pada penelitian ini menggunakan dua jenis pola data. Pola data 1 adalah pola data dengan banyak tahun tanam pada satu bulan sedangkan pola data 2 adalah pola data dengan banyak bulan pada satu tahun tanam saja. Pada proses pengujian menggunakan jumlah neuron 13, fitur data teknikal 2 karena sesuai dengan hasil terbaik pada pengujian fitur dan fungsi aktivasi sigmoid. Hasil pengujian seperti pada Gambar 6.
Gambar 6 Grafik Hasil Pengujian Jenis Pola
Berdasarkan Gambar 6 mengenai hasil pengujian pola data didapatkan hasil bahwa pola 2 memiliki hasil MAPE yang lebih besar dibanding pola 1. Pada pola 1 nilai MAPE terendah sebesar 19,19% dan pola 2 sebesar 17,48%. Sedangkan nilai MAPE tertinggi pola 1 sebesar 23,81% dan pola 2 sebesar 28,16%.
Dari hasil pengujian, pola 2 memiliki nilai MAPE yang lebih besar dari pola 1 itu dikarenakan pada pola 2 terdapat beberapa pola data uji yang tidak dikenali pada data latihnya. Selain itu juga adanya kondisi underfitting pada beberapa data. Kondisi underfitting ini disebabkan karena pada proses pembelajaran (training) pola data, jaringan tidak bisa menangkap hubungan antara sinyal input dengan target hal ini disebabkan oleh kurangnya jumlah
neuron pada hidden layer (Sheela & Deepa, 2013) dan adanya kemungkinan kekuatan unit pembobotan (input weight dan bias) yang terlalu rendah sehingga pola yang ditangkap saat proses pembelajaran terbatas dan menyebabkan hasil yang lebih rendah pada data pelatihannya. Sedangkan pada pola 1 baik pola data latih maupun pola data ujinya memiliki pola yang hampir sama, sehingga hal ini mengakibatkan proses pembelajaran pola 1 lebih baik.
23,16
Pengujian Jumlah Fitur Data Teknikal
MAPE
Pengujian Pola 1 dan Pola 2
4. KESIMPULAN
Metode Extreme Learning Machine
dalam proses komputasinya mampu menghasilkan fitur perhitungan yang optimal. Berdasarkan pengujian yang telah dilakukan didapatkan jumlah hidden neuron yang terbaik berjumlah 13, 2 fitur data teknikal dan pola pembelajaran data adalah pola data 1. Dengan menggunakan fitur tersebut diperoleh rata–rata nilai MAPE sebesar 20,19%.
Dari hasil ketiga pengujian, didapatkan juga kesimpulan lain mengenai waktu komputasi, yaitu waktu yang dibutuhkan untuk melakukan pemrosesan. Dengan menggunakan metode ELM waktu komputasi tercepat yang didapat adalah pada penggunaan jumlah hidden neuron 2, selain itu faktor yang memengaruhi lama tidaknya waktu komputasi adalah jumlah
hidden neuron.
Berdasarkan hasil pengujian maka model prediksi yang digunakan memiliki kinerja yang cukup bagus, karena nilai MAPE berada diantara rentang20 - 50%.
5. DAFTAR PUSTAKA
Andini, T. D. & Auristandi, P., 2016. Peramalan Jumlah Stok Alat Tulis Kantor Di UD Achmad Jaya Menggunakan Metode Double Exponential Smooting. Jurnal Ilmiah Teknologi dan Informasi ASIA (JITIKA), Volume Vol.10, No.1, pp. Engineering, Volume 88, pp. 1-4. Badan Pusat Statistik. 2014. Nilai Produksi dan
Biaya Produksi per Hektar Usaha [Accessed Sunday March 2018].
Chang, P.-C., Wang, Y.-W. & Liu, C.-H., 2007. The Development of a Weighted Evolving Fuzzy Neural Network for PCB Sales Forecasting. Expert Systems with Applications, Volume 32, pp. 88 - 89.
Cholissodin, I. et al., 2017. Optimasi Kandungan
Gizi Susu Kambing Peranakan Etawa (PE) Menggunakan ELM-PSO Di UPT Pembibitan Ternak Dan Hijauan Makanan Ternak Singosari - Malang.
Teknologi Informasi dan Ilmu komputer (JTIIK), Volume 4, No. 1, pp. 31-36. karet [Accessed Sunday March 2018]. Heizer, J. & Rander, B., 2009. Manajemen
Operasi. 9 ed. Jakarta: Terj. Chriswan Sungkono; Salemba Empat.
Huang, G. -B., Zhou, H., Ding, X. & Zhang, R., 2012. Extreme Learning Machine for
Regression and Multiclass
Classification. IEEE Transactions on Systems, Man, and Cybernetics - Part B: Cybernetics , Volume 42.
Huang, G., Zhu, Q. & Siew, C., 2005.
Extreme Learning Machine. Theory and applications. Elsevier science : Neurocomputing, Volume 70, pp. 489-501.
Huang, G. -B., Zhu, Q.-Y. & Siew, C. -K., 2006. Extreme Learning Machine : Theory and Applications. Neurocomputing, Volume 60, pp. 489-501.
Julpan, Nababan, E. B. & Zarlis, M., 2015. Analisis Fungsi Aktivasi Sigmoid Biner Dan Sigmoid Bipolar Dalam Algoritma Backpropogation Pada Prediksi Kemapuan Siswa. Jurnal Teknovasi,
Volume 02, pp. 103 - 116.
Mahdiyah, U., Irawan, M. I. & Imah, E. M.,
2015. Study Comparison
Backpropogation, Support Vector Machine, And Extreme Learning Machine For Bioinformatics Data.
Journal of Computer Science and Information, Volume 8/1, pp. 53 - 59. Mohammadi, K. et al., 2015. Predicting The
Wind Power Density Based Upon Extreme Learning Machine. Energy,
Volume 86, pp. 232-239.
Learning Machine. Journal On Computing, 1(2), pp. 97-116
Sari, V., 2017. Aplikasi Extreme Learning Machine Untuk Peramalan Data Tim Series (STUDI KASUS: SAHAM BANK BRI). THE 5TH URECOL PROCEEDING, pp.1294-1299
Sheela, K. G. & Deepa, S. N., 2013. Review on Methods to Fix Number of Hidden Neurons in Neural Networks..
Mathematical Problems in Engineering,
Volume 2013, p. 11.
Srimuang, W. & Intarasothonchun, S., 2015. Classification Model Of Network Intrusion Using Weighted Extreme Learning Machine. Internasional Joint Conference on Computer Science and Software Engineering (JCSSE), Volume 12.
Sukarno, N. M., Wirawan, P. W. & Adhy, S., 2015. Perancangan dan Implementasi Jaringan Saraf Tiruan Backpropogation untuk Mendiagnosa Penyakit Kulit.
Masyarakat Informatika, Volume 5, Nomor 10.
Wang, B. et al., 2016. Prediction of Fatigue Stress Concentration Factor Using
Extreme Learning Machine.
Computational Materials Science,
Volume 125, pp. 136 - 145. Yaseen, Z. M. et al., 2018. Predicting
Compressive Strength of Lightweight Foamed Concrete Using Extreme Learning Machine Model. Advances in Engineering Software, Volume 115, pp. 112-125.
Yohansyah, W. M. & Lubis, I., 2014. Analisis Produktivitas Kelapa Sawit (Elaeis guineensis Jacq.) di PT. Perdana Inti Sawit Perkasa I, Riau. Bul. Agrohorti,