Fakultas Ilmu Komputer
Universitas Brawijaya
554
Rancang Bangun Aplikasi Deteksi
Spam Twitter
menggunakan Metode
Naive Bayes dan KNN pada Perangkat Bergerak Android
Faisal Aji Prayoga1, Aryo Pinandito2, Rizal Setya Perdana3
Program Studi Teknik Informatika, Fakultas Ilmu Komputer, Universitas Brawijaya Email: 1[email protected], 2[email protected], 3[email protected]
Abstrak
Twitter saat ini adalah salah satu jaringan sosial terkemuka di seluruh dunia berdasarkan jumlah pengguna aktif bulanan setelah Facebook dan Instagram. Orang menggunakan Twitter sebagian besar untuk mengetahui lebih banyak informasi tentang berita terbaru atau mengikuti berita secara umum dengan mengikuti topik yang sedang tren. Seperti Twitter menjadi sumber berita berupa komentar dan balasan untuk berbagi ide terbaru. Oleh karena itu, beberapa aplikasi mobile yang memanfaatkan Twitter API telah dikembangkan untuk memberikan kemudahan dalam menyediakan trending topics kepada penggunanya. Topik tren Twitter menawarkan kesempatan efektif dalam pemasaran sudut pandang bagi pemasar online untuk mempromosikan konten pemasaran mereka. Konten spam di Twitter ternyata mengganggu dan mengganggu pengguna tertentu, sehingga aplikasi mobile untuk menghadirkan konten topik Twitter Twitter yang bebas spam diperlukan. Penelitian ini merancang kerangka aplikasi Android yang memungkinkan pengembang untuk membangun penerapan klasifikasi-klasifikasi spam untuk konten Twitter sebagai perpustakaan aplikasi. Penelitian ini menerapkan dua metode klasifikasi, yaitu Naïve Bayes dan K-Nearest Neighbor, untuk mengidentifikasi spam dalam topik tren Twitter. Metode klasifikasi Naive Bayes dan K-Nearest Neighbor dapat mendeteksi kandungan spam dan ham masing-masing dengan akurasi 82% dan 71%.
Kata Kunci: Spam, Bayes, KNN, Twitter, Android
Abstract
Twitter currently is one of the leading social networks worldwide based on the amount of monthly active users after Facebook and Instagram. People uses Twitter mostly to find out more information about breaking news or keeping up with news in general by following trending topics. As Twitter become a source of news breaks contents in form of comments and replies to share the newest ideas. Therefore, several mobile applications that utilize Twitter API has been developed to provide a convenient way in providing trending topics to their user. Twitter trending topics offers an effective opportunity in marketing point of view for online marketers to promote their marketing contents. Spam contents in Twitter were found to be distracting and annoying for certain users, thus mobile application to deliver spam-free Twitter trending topics contents is needed. This research designs an Android application framework that allow developers to build their own implementation of spam detection classifier for Twitter contents as application library. This research implements two classification methods, i.e. Naive Bayes and Nearest Neighbor, to identify spam in Twitter trending topics. The Naïve Bayes and K-Nearest Neighbor classification methods are able to detect spam and ham contents with 82% and 71% accuracy respectively.
Keywords: Spam, Bayes, KNN, Twitter, Android
1. PENDAHULUAN
Pada masa ini, jejaring sosial telah menjadi salah satu sarana utama masyarakat mendapatkan informasi dan berita. Twitter saat ini merupakan salah satu jejaring sosial
terkini secara khusus. Twitter bukan hanya menjadi penyedia layananan breaking news di jejaring sosial, namun juga mengubah kebiasaan para pengguna jejaring sosial dalam mendapatkan berita dan info terbaru.
Twitter telah memperkenalkan fitur Trending Topics sejak musim panas tahun 2018. Fitur ini memudahkan pengguna untuk mengetahui berita dan atau informasi terbaru di seluruh dunia secara real time. Topik yang muncul akan secara otomatis dihasilkan oleh algoritma milik Twitter, dan disesuaikan dengan lokasi dan daftar akun yang diikuti pengguna tersebut. Twitter sekarang telah menjadi salah satu sumber konten tercepat, dikarenakan berita dan informasi terbaru akan muncul terlebih dahulu di Twitter sebelum muncul di media sosial lain.
Dengan semakin mudah dan terkenalnya media sosial, tidak dapat dipungkiri bahwa konten media sosial menjadi berantakan dan bercampur dengan data yang tidak relevan. Para pelaku pasar yang memakai media sosial, khususnya Twitter, menambahkan kata kunci trending topic pada konten yang mereka tawarkan. Dengan cara ini, mereka dapat mempromosikan konten dagangan mereka ke calon pembeli dengan lebih cepat. Hal ini menyebabkan para pengguna biasa membuang banyak waktu dalam memilih dan memilah informasi atau berita yang mereka inginkan. Konten yang tidak diperlukan namun secara terus menerus muncul dan memberikan dampak negatif ke pengguna secara umum dapat dikategorikan sebagai spam.
Selain menyediakan layanan media sosial melalui website dan aplikasi perangkat bergerak, Twitter juga menyediakan konten-kontennya melalui Application Programming Interface (API). Layanan API tersebut memperbolehkan para pengembang aplikasi mobile, terutama pada platform iOS dan Android, untuk mengintegrasikan aplikasi mereka dengan Twitter. Karena itu, banyak aplikasi penyedia berita yang menggabungkan konten berita dari banyak media sosial menggunakan API.
Terdapat beberapa metode klasifikasi untuk mendeteksi dan mengidentifikasi spam dan konten berbahaya dari keseluruhan konten, seperti metode K-Nearest Neighbor (KNN), Fuzzy K-Means, Extreme Learning Machine (ELM), dan Support Vector Machine (SVM). Adapun metode lain yaitu metode Naive Bayes yang telah dikembangkan untuk memilah konten yang diinginkan dengan spam. Metode-metode
tersebut memiliki akuransi klasifikasi yang bagus. Metode KNN dan Naive Bayes kali ini digunakan untuk memilah konten spam.
Berdasarkan latar belakang yang telah
dipaparkan di atas, “Rancang Bangun Aplikasi
Deteksi Spam Twitter Menggunakan Metode Naive Bayes dan KNN pada Perangkat Bergerak
Android” diangkat sebagai solusi dari permasalahan yang ada. Aplikasi yang akan dihasilkan akan menampilkan konten yang dipilah, konten tepat dan konten spam, kepada pengguna.
2. LANDASAN KEPUSTAKAAN
2.1. Spam
Spam adalah penggunaan perangkat elektronik untuk mengirimkan pesan secara bertubi-tubi tanpa dikehendaki oleh penerimanya. Orang yang melakukan spam disebut spammer. Tindakan spam dikenal dengan nama spamming (Garcia-Molina, 2005). Bentuk spam yang dikenal secara umum meliputi: spam surat elektronik, spam pesan instan, spam mesin pencari informasi web (web search engine spam), spam blog, spam wiki, spam iklan baris, dan spam jejaring sosial. Beberapa contoh lain dari spam yaitu surel berisi iklan, pesan singkat (SMS) pada telepon genggam, berita dalam suatu forum kelompok warta berisi promosi barang yang tidak terkait dengan kegiatan kelompok warta tersebut, berita yang tak berguna dan masuk dalam blog, buku tamu situs web, spam transmisi faks, dan iklan televisi.
Spam dikirimkan oleh pengiklan dengan biaya operasional yang sangat rendah, karena spam tidak memerlukan senarai (mailing list) untuk mencapai para pelanggan-pelanggan yang diinginkan. Karena hambatan masuk yang rendah, maka banyak spammers yang muncul dan jumlah pesan yang tidak diminta menjadi sangat tinggi. Akibatnya, banyak pihak yang dirugikan. Selain pengguna Internet itu sendiri, ISP (Penyelenggara Jasa Internet atau Internet Service Provider), dan masyarakat umum juga merasa tidak nyaman. Spam sering mengganggu dan terkadang menipu penerimanya. Berita spam termasuk dalam kegiatan melanggar hukum dan merupakan perbuatan pidana yang bisa ditindak melalui undang-undang Internet.
2.2. Twitter
mikroblog daring yang memungkinkan penggunanya untuk mengirim dan membaca pesan berbasis teks hingga 140 karakter, yang dikenal dengan sebutan kicauan (tweet). Twitter didirikan pada bulan Maret 2006 oleh Jack Dorsey, dan situs jejaring sosialnya diluncurkan pada bulan Juli. Sejak diluncurkan, Twitter telah menjadi salah satu dari sepuluh situs yang paling sering dikunjungi di Internet, dan dijuluki
dengan "pesan singkat dari Internet”. Di Twitter,
pengguna tak terdaftar hanya bisa membaca kicauan, sedangkan pengguna terdaftar bisa menulis kicauan melalui antarmuka situs web, pesan singkat (SMS), atau melalui berbagai aplikasi untuk perangkat seluler.
Twitter mengalami pertumbuhan yang pesat dan dengan cepat meraih popularitas di seluruh dunia. Hingga bulan Januari 2013, terdapat lebih dari 500 juta pengguna terdaftar di Twitter, 200 juta di antaranya adalah pengguna aktif. Lonjakan penggunaan Twitter umumnya berlangsung saat terjadinya peristiwa-peristiwa populer. Pada awal 2013, pengguna Twitter mengirimkan lebih dari 340 juta kicauan per hari, dan Twitter menangani lebih dari 1.6 miliar permintaan pencarian per hari. Hal ini menyebabkan posisi Twitter naik ke peringkat kedua sebagai situs jejaring sosial yang paling sering dikunjungi di dunia, dari yang sebelumnya menempati peringkat dua puluh dua.
Gambar 1. Pengguna Jejaring Sosial Sumber: Diadaptasi Statista (2017)
Pada tahun 2017 (Statista, 2017), Twitter memiliki 317 juta pengguna aktif, berada di posisi ke 3 jejaring sosial dengan pengguna terbanyak. Pengguna tersebut merupakan pengguna terdaftar.
2.3. Klasifikasi Naive Bayes
Dalam klasifikasi dokumen berbasis teks,
dokumen dapat diklasifikasikan dengan mengevaluasi kata yang terdapat di dalamnya. Naive Bayes adalah salah satu metode yang popular yang dapat digunakan untuk mengklasifikasikan dokumen secara probabilistic. Metode Naive Bayes adalah jenis dari Teori Bayesian dimana kondisi atau kelas yang ada adalah independen dan tidak terikat satu sama lain. Kata yang membentuk sebuah dokumen di kategori tertentu tidak mempengaruhi kategori lain. Oleh karena itu, probabilitas dari dokumen yang diuji akan dihitung masing-masing. Namun, hanya ada kategori di penelitian ini, yaitu spam dan ham (berita yang akurat) (Li, 2015).
Probabilitas dokumen dari kata yang menyusun (W1…W2) memiliki kategori tertentu
(C) dapat dihitung menggunakan persamaan 1. Nilai probabilitas ini juga disebut dengan posterior probabilitas untuk kategori (C).
𝑃(𝐶|𝑊1… 𝑊𝑛) = 𝑃(𝐶)Π𝑖=1𝑛 𝑃(𝑊1|𝐶) (1)
Kemungkinan untuk kata berada kategori tertentu diperoleh dari pembagian antara frekuensi kemunculan kata dalam sebuah dokumen (nk), jumlah kata dalam kategori yang
diamati (nc), dan jumlah variasi kata (n) dari
semua dokumen dalam data pelatihan untuk kategori tertentu seperti pada persamaan 2. Namun, probabilitas prior untuk kategori tertentu diperoleh dari jumlah dokumen (nd)
dalam kategori tertentu dibagi dengan jumlah total dokumen (nt) dari semua kategori dalam
data pelatihan yang diberikan seperti pada persamaan 3.
𝑃(𝑊𝑗|𝐶𝑖) = (1 + 𝑛𝑘)/(𝑛𝑐+ 𝑛) (2)
𝑃(𝐶𝑖) = |𝑛𝑑|/|𝑛𝑡| (3)
Setelah nilai-nilai posterior dari dokumen dievaluasi terhadap setiap kategori telah dihitung, dokumen tersebut diklasifikasikan berdasarkan nilai maksimum-a-posteriori (VMAP) seperti pada persamaan 4. Oleh karena itu, dokumen diklasifikasikan ke dalam kategori yang mana nilai posteriornya paling besar.
𝑣𝑀𝐴𝑃= 𝑎𝑟𝑔𝑚𝑎𝑥 𝑃(𝐶𝑖)Π𝑃(𝑊𝑗|𝐶𝑖) (4)
2.4. Klasifikasi K-Nearest Neighbor
Algoritma k-nearest neighbor (k-NN atau KNN) adalah sebuah metode untuk melakukan klasifikasi terhadap objek berdasarkan data pembelajaran yang jaraknya paling dekat dengan objek tersebut.
1871
600
317 300
217 150
0 500 1000 1500 2000
Facebook Instagram Twitter
Data pembelajaran diproyeksikan ke ruang berdimensi banyak, dimana masing-masing dimensi merepresentasikan fitur dari data. Ruang ini dibagi menjadi bagian-bagian berdasarkan klasifikasi data pembelajaran. Sebuah titik pada ruang ini ditandai kelas c jika kelas c merupakan klasifikasi yang paling banyak ditemui pada k buah tetangga terdekat titk tersebut. Dekat atau jauhnya tetangga biasanya dihitung berdasarkan jarak Euclidean atau jarak Kosinus.
Pada fase pembelajaran, algoritma ini hanya melakukan penyimpanan vektor-vektor fitur dan klasifikasi dari data pembelajaran. Pada fase klasifikasi, fitur-fitur yang sama dihitung untuk data test (yang klasifikasinya tidak diketahui). Jarak dari vektor yang baru ini terhadap seluruh vektor data pembelajaran dihitung, dan sejumlah k buah yang paling dekat diambil. Titik yang baru klasifikasinya diprediksikan termasuk pada klasifikasi terbanyak dari titik-titik tersebut.
Nilai k yang terbaik untuk algoritma ini tergantung pada data; secara umumnya, nilai k yang tinggi akan mengurangi efek noise pada klasifikasi, tetapi membuat batasan antara setiap klasifikasi menjadi lebih kabur. Nilai k yang bagus dapat dipilih dengan optimasi parameter, misalnya dengan menggunakan cross-validation. Kasus khusus di mana klasifikasi diprediksikan berdasarkan data pembelajaran yang paling dekat (dengan kata lain, k = 1) disebut algoritma nearest neighbor.
Ketepatan algoritma KNN ini sangat dipengaruhi oleh ada atau tidaknya fitur-fitur yang tidak relevan, atau jika bobot fitur tersebut tidak setara dengan relevansinya terhadap klasifikasi. Riset terhadap algoritma ini sebagian besar membahas bagaimana memilih dan memberi bobot terhadap fitur, agar performa klasifikasi menjadi lebih baik. Sering kali algoritma KNN ini digabung dengan metode TF-IDF. Nilai TF-IDF sering digunakan sebagai faktor pembobotan dalam pencarian informasi dan mining teks.
Salah satu library deteksi spam yang diimplementasikan di penelitian ini menerapkan metode klasifikasi KNN untuk mengidentifikasi spam dan ham dalam koleksi tweet yang diperoleh dari aplikasi Android. Metode klasifikasi yang diterapkan menggunakan metode TF-IDF untuk menghitung nilai dari
metode TF-IDF berdasarkan frekuensi dalam dokumen (tfij) dan frekuensi dokumen
kebalikannya (idfi) seperti pada persamaan 5.
Frekuensi dokumen kebalikan dari kata i dapat dihitung dari jumlah dokumen untuk kategori k (Nk) dan jumlah dokumen yang mengandung
kata i (dfi) seperti pada persamaan.
𝑎𝑖𝑗𝑘 = 𝑡𝑓𝑖𝑗. 𝑖𝑑𝑓𝑖 (5)
𝑖𝑑𝑓𝑖= log(𝑁𝑘/𝑑𝑓𝑖) (6)
Dengan demikian, nilai berat dokumen j untuk kategori k (wjk) dapat dihitung dengan
menjumlahkan berat kata (aijk) untuk kategori k
yang membentuk dokumen seperti pada persamaan 7.
𝑤𝑗𝑘= ∑𝑛𝑖=1𝑎𝑖𝑗𝑘 (7)
Untuk mengklasifikasikan dokumen, perlu untuk menentukan jarak vektor antara dokumen yang telah dievaluasi dan menentukan jumlah yang diperlukan dokumen dalam koleksi, yaitu nilai K di KNN, yang terdekat dengan dokumen dievaluasi. Vektor jarak antara dua dokumen x dan y dihitung dengan nilai bobot mereka untuk setiap kategori k seperti pada persamaan 8.
𝑐𝑜𝑠(𝑥, 𝑦) = ∑ (𝑤𝑘 𝑥𝑘.𝑤𝑦𝑘) √∑ 𝑤𝑘 𝑥𝑘2 .√∑ 𝑤𝑘 𝑦𝑘2
(8)
3. METODOLOGI
Metodologi menjelaskan langkah-langkah yang akan dilakukan dalam perancangan, implementasi, dan pengujian dari aplikasi perangkat lunak yang akan dikembangkan. Kesimpulan dan saran disertakan sebagai catatan atas aplikasi dan kemungkinan arah pengembangan perangkat lunak selanjutnya. Pada bab ini, hal yang dibicarakan tidak hanya metode, teknik, atau langkah-langkah yang digunakan pada penelitian tetapi juga logika di balik metode, teknik, atau langkah-langkah tersebut sesuai dengan konteks.
Studi Literatur
Studi literatur menjelaskan dasar teori yang digunakan untuk menunjang penulisan skripsi secara khusus. Teori-teori pendukung tersebut meliputi:
1. Spam 2. Twitter
Pengumpulan Data
Data yang dipergunakan dalam penelitian aplikasi mobile Deteksi Spam Twitter Menggunakan Metode Naive Bayes Dan KNN didapatkan dari Twitter API. Sejumlah data akan dipergunakan untu data belajar dan data uji. Adapun data dari riset pustaka, yang dipergunakan untuk menjadi referensi dan acuan untuk menyelesaikan permasalahan yang ada.
Analisis Kebutuhan
Analisis kebutuhan bertujuan untuk mendapatkan semua kebutuhan yang diperlukan dari sistem yang akan dibangun. Analisis kebutuhan dilakukan dengan mengidentifikasi semua kebutuhan (requirements) sistem dan siapa saja yang terlibat di dalamnya. Analisis juga dilakukan untuk mengetahui kondisi lapangan yang ada sehingga dapat diketahui implementasi perangkat lunak yang akan digunakan. Metode analisis yang digunakan adalah Object Oriented Analysis dengan menggunakan bahasa pemodelan UML (Unified Modeling Language). Use case diagram digunakan untuk mendeskripsikan kebutuhan-kebutuhan dan fungsionalitas sistem dari perspektif end-user. Analisis kebutuhan dilakukan dengan mengidentifikasi semua kebutuhan (requirements) perangkat lunak yang kemudian akan dimodelkan dalam use case diagram.
Tahap analisis kebutuhan terdiri atas empat langkah yaitu melakukan penjabaran tentang gambaran umum aplikasi, melakukan proses identifikasi aktor yang terlibat dalam aplikasi, membuat daftar kebutuhan pengguna menggunakan pemodelan diagram use case. Proses analisis kebutuhan ini diawali dengan penjabaran gambaran umum aplikasi, identifikasi aplikasi, penjabaran tentang daftar kebutuhan dan kemudian memodelkannya ke dalam diagram use case. Analisis kebutuhan ini bertujuan untuk menggambarkan kebutuhan-kebutuhan yang harus disediakan oleh sistem agar dapat memenuhi kebutuhan pengguna.
Perancangan Sistem
Perancangan perangkat lunak dilakukan setelah semua kebutuhan perangkat lunak didapatkan melalui tahap analisis kebutuhan. Perancangan perangkat lunak berdasarkan object oriented analysis dan object oriented design yaitu menggunakan pemodelan UML (Unified Modeling Language). Perancangan dimulai dari perancangan alur atau aktifitas yang dilakukan
user secara prosedural yang dimodelkan dalam activity diagram. Selanjutnya, dilakukan perancangan sistem aplikasi dengan mengidentifikasi class, fungsi, dan layout antarmuka pengguna yang dibutuhkan. Kemudian tahap perancangan dilanjutkan dengan perancangan antarmuka pengguna.
Implementasi
Implementasi perangkat lunak mengacu kepada perancangan perangkat lunak. Implementasi perangkat lunak diawali dengan penjabaran spesifikasi lingkungan perancangan perangkat lunak. Selanjutnya dijabarkan mapping class dengan layout saat implementasi perangkat lunak. Implementasi akan dilakukan secara native pada perangkat bergerak berbasis Android.
Pengujian
Pengujian perangkat lunak pada penelitian ini dilakukan agar dapat menunjukkan bahwa perangkat lunak telah mampu bekerja sesuai dengan spesifikasi dari kebutuhan yang telah dianalisa sebelumnya. Strategi pengujian perangkat lunak yang akan digunakan yaitu pengujian unit (unit testing), pengujian validasi (validation testing), dan pengujian kompabilitas pada tahap akhir. Proses pengujian perangkat lunak dimulai dari pengujian unit, kemudian dilanjutkan dengan pengujian validasi, pengujian kompabilitas dan berakhir pada pengujian performa. Pada tahap pengujian unit digunakan metode white-box testing. Kemudian pada tahap pengujian validasi dan kompabilitas digunakan metode black-box testing. Pengujian kompabilitas dilakukan untuk mengetahui bagaimana kompabilitas perangkat lunak ketika berjalan untuk versi Android yang berbeda. Akurasi dan performa metode yang diterapkan pada aplikasi juga dihitung dan diuji. Analisis juga dilakukan untuk mengetahui hasil dari pengujian perangkat lunak sehingga dapat didapatkan kesimpulan dari pengembangan perangkat lunak yang telah dilakukan.
Pengambilan Kesimpulan
lunak lebih lanjut.
4. ANALISIS PERANCANGAN
Tahap perancangan umum sistem menjelaskan mengenai gambar proses kerja sistem secara umum. Lalu pada proses perancangan perangkat lunak memiliki tiga langkah yaitu perancangan arsitektural dan pemodelan activity diagram dari aplikasi.
4.1. Perancangan Umum Sistem
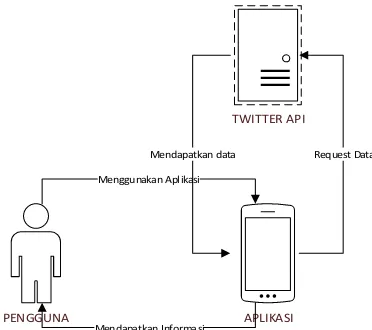
Perancangan umum sistem merupakan tahapan awal dari perancangan perangkat lunak. Perancangan sistem dilakukan untuk merepresentasikan arsitektur sistem yang akan dibuat secara umum. Gambar 2 berikut menunjukkan perancangan umum sistem.
APLIKASI PENGGUNA
TWITTER API
Menggunakan Aplikasi
Mendapatkan Informasi
Mendapatkan data Request Data
Gambar 2. Diagram Blok Perancangan Umum Sistem
4.2. Perancangan Perangkat Lunak
Perancangan aplikasi dilakukan dalam tiga tahap, yaitu perancangan activity diagram, perangcangan arsitektural, dan perancangan antarmuka. Perancangan aplikasi pada skripsi ini menggunakan pendekatan desain berorientasi objek yang direpresentasikan dengan menggunakan UML (Unified Modelling Language).
Diagram aktifitas adalah diagram untuk memodelkan aktifitas antara pengguna dan sistem yang berjalan berdasarkan pada skenario use case. Secara umum, activity diagram dari aplikasi ini ditunjukkan oleh Gambar 3 dibawah.
Mendapatkan
Tweet Training/Persiapan
Memproses Tweet
Mengklasifikasi Menampilkan
Tweet yang dipilah
Gambar 3. Activity Diagram Aplikasi
Perancangan perangkat lunak aplikasi mobile Deteksi Spam Twitter Menggunakan Metode Naive Bayes Dan KNN dibangun menggunakan konsep native mobile application pada perangkat Android. Pada implementasi konsep native application ini, penulis menggunakan Bahasa pemrograman Java dan mengambil data dari Twitter API menggunakan metode OAuth2. Berikut rancangan arsitektur hubungan sistem secara umum yang ditunjukkan diagram framework pada Gambar 4 dibawah ini.
AndroidAppActivity
-classifier: Classifier -classifiedTweet: ClassifiedTweet -tweets: Tweet[] +obtainTweets(): Tweet[] +detectSpam(): void +displayTweets(Tweet[]): void
Classifier
+referenceTweets: Tweet[] +tweets: Tweet[] +prepare(): void +preprocess(): void +classify(Tweet[]): ClassifiedTweet
Preprocessor
+clean(Tweet[]): Tweet[] +tokenize(Tweet[]): Tweet[] +stem(Tweet[]): Tweet[]
ClassifiedTweet
+Spams: Tweet[] +Hams: Tweet[]
Tweet
+screenName: String +contents: String +createTime: DateTime
Gambar 4. Diagram Framework Aplikasi
5. IMPLEMENTASI
5.1. Batasan Implementasi
Pada implementasi perangkat lunak aplikasi mobile Deteksi Spam Twitter Menggunakan Metode Naive Bayes Dan KNN, terdapat batasan-batasan dalam proses yaitu:
smartphone Android menggunakan konsep native.
2. Aplikasi harus dijalankan menggunakan koneksi internet.
3. Komunikasi data antara aplikasi dengan Twitter API mengharuskan pengguna untuk login menggunakan akun Twitter.
4. Klasifikasi Spam dan Ham menggunakan metode Naïve Bayes dan KNN.
5. Pembuatan layout pada user interface aplikasi menggunaka XML bawaan dari Android SDK.
5.2. Implementasi Framework
Aplikasi mobile Deteksi Spam Twitter Menggunakan Metode Naive Bayes Dan KNN ini mempunyai beberapa proses (function) yang terbagi dalam beberapa file java. Pada penulisan skripsi ini hanya dicantumkan algoritma dari beberapa proses saja sehingga tidak semua algoritma function akan dicantumkan. Algoritma proses yang dicantumkan antara lain adalah proses klasifikasi KNN dan Naive Bayes pada sistem yang ditunjukkan oleh Tabel 1 dibawah.
Tabel 1. Implementasi Naive Bayes
package ap.mobile.classification.Base;
import java.util.ArrayList;
public class ClassModel {
public enum Category { (double)(this.wordCountSpam +
this.words.size());
getPosterior(ArrayList<String> words,
Category category) {
double posterior;
switch (category) {
posterior = pSpam(); for(String word: words) {
posterior *=
getPrior(word, Category.SPAM);
}
return posterior;
default:
posterior = pHam();
for(String word: words) {
posterior *=
getPrior(word, Category.HAM);
}
return posterior;
} } }
5.3. Implementasi Antarmuka
Pada implementasi antarmuka aplikasi akan ditampilkan hasil implementasi antarmuka aplikasi mobile Deteksi Spam Twitter Menggunakan Metode Naive Bayes Dan KNN.
Halaman Login adalah halaman awal saat kita membuka aplikasi setelah keluar tampilan halam splash screen. Halaman login terdiri dari logo dan tombol start yang akan menampilkan halaman login Twitter. Gambar 5 adalah gambar implementasi antarmuka halaman login.
Gambar 5. Antarmuka Halaman Login
Halaman trending topics adalah halaman yang muncul setelah pengguna berhasil login. Halaman ini menunjukkan trending topics apa saja yang sedang ada di Indonesia. Gambar 6 adalah gambar implementasi antarmuka halaman trending topics.
Gambar 6. Antarmuka Halaman Trending Topics
Halaman berita adalah halaman yang muncul ketika pengguna memilih salah satu trending topics. Halaman ini menunjukkan berita apa saja, dalam keadaan sudah dipilah sesuai spam dan ham, sesuai trending topics pilihan pengguna. Gambar 7 adalah gambar implementasi antarmuka halaman berita.
Gambar 7. Antarmuka Halaman Berita
6. PENGUJIAN
Proses pengujian dilakukan melaluli 3 tahap yaitu pengujian kompabilitas, pengujian akurasi, dan pengujian waktu proses.
6.1. Pengujian Kompabilitas
Tabel 2. Kasus Uji dan Hasil Pengujian Kompabilitas Android Versi 4.3
Nama Kasus Uji
Pengujian Kompabilitas Android Versi 4.3.
Objek Uji Kebutuhan Non-fungsional.
Tujuan Pengujian
Pengujian dilakukan untuk mengetahui validitas kinerja dari sistem dalam menyediakan fitur-fitur dan antarmuka pengguna.
Prosedur Uji
Membuka setiap halaman sesuai dengan spesifikasi kebutuhan sistem.
Hasil yang diharapkan
Sistem dapat menampilkan fitur-fitur dan antarmuka sesuai implementasi antarmuka sistem.
Hasil yang didapatkan
Sistem dapat menampilkan fitur-fitur dan antarmuka sesuai implementasi antarmuka sistem.
Status
Validitas Valid
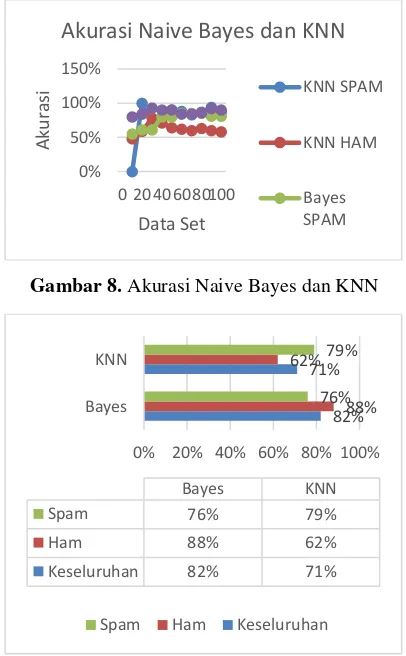
6.2. Pengujian Akurasi
Pengujian akurasi dilakukan dengan menggunakan data set 10 hingga 100 tweet yang kemudian diklasifikasikan dan diuji akurasinya. Hasil yang didapat ditunjukkan pada Gambar 8 dan 9 dibawah ini.
Gambar 8. Akurasi Naive Bayes dan KNN
Gambar 9. Komparasi Akurasi Naive Bayes dan KNN
6.2. Pengujian Waktu Proses
Pengujian waktu proses dilakukan dengan menggunakan data set 10 hingga 100 tweet yang kemudian diklasifikasikan dan diuji waktu prosesnya. Hasil yang didapat ditunjukkan pada Gambar 10, 11, dan 12 dibawah ini.
Gambar 10. Waktu Proses Klasifikasi Naive Bayes
Gambar 11. Waktu Proses Klasifikasi KNN
Gambar 12. Komparasi Waktu Proses Naive Bayes dan KNN
7. KESIMPULAN
Berdasarkan hasil analisa, perancangan, implementasi, dan pengujian yang dilakukan,
0%
Akurasi Naive Bayes dan KNN
KNN SPAM
maka diambil kesimpulan sebagai berikut: 1. Perancangan aplikasi mobile Deteksi
Spam Twitter Menggunakan Metode Naive Bayes Dan KNN telah dibuat sesuai dengan spesifikasi kebutuhan yang telah dianalisa.
2. Aplikasi mobile Deteksi Spam Twitter Menggunakan Metode Naive Bayes Dan KNN yang menggunakan konsep native mobile development sesuai dengan perancangan yang telah dibuat dan dapat digunakan sebagai salah satu media untuk mendapatkan informasi dari Twitter tanpa adanya spam.
3. Pengambilan data pada Twitter API telah berhasil diimplementasikan dengan metode OAuth dan penyampaian data menggunakan Java dan XML.
4. Hasil pengujian kompabilitas pada sistem menunjukkan bahwa sistem dinyatakan kompatibel dengan sistem operasi Android mulai dari veris 4.3. 5. Berdasarkan hasil pengujian akurasi,
metode Naïve Bayes memiliki prosentase akurasi lebih tinggi daripada metode KNN. Metode Naïve Bayes memiliki akurasi 82%, sedangkan metode KNN memiliki akurasi 71%. Hasil ini dikatakan cukup untuk memilah berita antara spam dan ham, sehingga pengguna terbantu dalam mendapatkan informasi yang tepat. 6. Berdasarkan hasil pengujian waktu
proses, metode Naïve Bayes memiliki waktu total yang lebih cepat daripada metode KNN. Pada angka 100 dataset, metode Naïve Bayes memerlukan waktu 1400 ms, sedangakan metode KNn memerlukan 1590 ms.
Saran yang dapat diberikan untuk pengembangan aplikasi mobile Deteksi Spam Twitter Menggunakan Metode Naive Bayes Dan KNN adalah untuk pengembangan lebih lanjut, aplikasi ini dapat dikembangkan dengan metode klasifikasi yang lebih akurat dan lebih baru. Pada pengembangan lebih lanjut perlu ditambahkan pengujian akurasi dan waktu proses dengan data set yang lebih banyak. Perlu dilakukan pengembangan lebih lanjut dengan optimalisasi tampilan pada antar pengguna agar lebih ramah untuk pengguna. Perlu dilakukan pengembangan lebih lanjut agar pengguna tidak perlu melakukan login dengan akun Twitter untuk mendapatkan informasi dan berita. Perlu
dilakukan pengembangan dalam hal library klasifikasi agar bisa digunakan untuk sumber informasi lain, seperti Facebook atau Tumblr. Perlu dilakukan pengembangan untuk beberapa mobile OS lain seperti Windows Phone atau iOS.
DAFTAR PUSTAKA
Arno, C., 2013. Global Social Media Trends in 2013. [online] Search Engine Watch. [Diakses 1 Maret 2017]
Cisco, 2017. Spam Overview. [online] Spam Overview - SenderBase. Tersedia di: <https://www.senderbase.org/static/spa m/> [Diakses 23 Maret 2017]
Coles, S., 2015. How 'Liking' a page on Facebook makes cash for spammers. AOL. [Diakses 1 Maret 2017]
Daniel, L., Domingos, P., 2005. Naive Bayes Models for Probability Estimation. Department of Computer Science and Engineering, University of Washington.
Gandra, S., 2014. Implementation Of Prototype To Detect Spam In YouTube Using The Application TubeKit And Naive Bayes Algorithm. The School of Engineering & Computing Sciences Texas A&M, University-Corpus Christi.
Garcia-Molina, H., 2005. Web spam taxonomy. New York, NY: ACM Press.
Goldberg, M., 2015. The Origins of Spam. New York, NY: ACM Press.
Gottfried, J., 2016. News Use Across Social Media Platforms 2016. [online] PewResearchCenter. Tersedia di: < http://journalism.org/2016/05/26/news - use-across-social-media-platforms-2016 > [Diakses 1 Maret 2017]
Social Computing.
Kelly, R., 2009. Twitter Study: Twitter Study Reveals Interesting Results About Usage. San Antonio, Texas: Pear Analytics.
Li, L., Li, C., 2015. Research and improvement of a spam filter based on Naive Bayes. 7th IEEE International Conference on Intelligent Human-Machine Systems and Cybernetics.
Networked Insights, 2015. How dirty is big data?. [online] Tersedia di: < http://info.networkedinsights.com/Dirty -Data-LP.html > [Diakses 1 Maret 2017]
Rosenstiel, T., Sonderman, J., Loker, K.,
Ivancin, M. & Kjarva, B., 2015. Don’t
Blink or the Story Just Tweeted By You. [online] Don’t Blink or the Story Just Tweeted By You. Tersedia di: < http://biancajgillett.blogspot.co.id > [Diakses 1 Maret 2017]
Schryen, G., 2007. Anti-Spam Measures: Analysis and Design. Heidelberg, Berlin: Springer-Verlag.
Soman, S. J., 2014. Detecting malicious tweets in trending topics using clustering and classification. IEEE International Conference on Recent Trends in Information Technology.
Statista, 2017. Most famous social network sites worldwide as of January 2017, ranked by number of active users (in millions). [online] Tersedia di: < https://www.statista.com/statistics/2720 14/global-social-networks-ranked-by-number-of-users/ > [Diakses 1 Maret 2017]
Trstenjak, B., Mikac, S., Donko, D., 2013. KNN with TF-IDF Based Framework for Text Categorization. 24th DAAAM International Symposium on Intelligent Manufacturing and Automation
Twitter Search Team, 2011. The Engineering
Behind Twitter’s New Search
Experience. Twitter Engineering Blog. Twitter. [Diakses 1 Maret 2017]