TUGAS AKHIR – KI141502
DETEKSI FRAUD MENGGUNAKAN METODE
MODEL MARKOV TERSEMBUNYI PADA PROSES
BISNIS
ANDREAN HUTAMA KOOSASI NRP 5112 100 004
Dosen Pembimbing I
Prof. Drs. Ec. Ir. Riyanarto Sarno, M.Sc., Ph.D Dosen Pembimbing II
Abdul Munif, S.Kom., M.Sc. JURUSAN TEKNIK INFORMATIKA Fakultas Teknologi Informasi
Institut Teknologi Sepuluh Nopember Surabaya 2017
ii
iii
TUGAS AKHIR – KI141502
DETEKSI FRAUD MENGGUNAKAN METODE
MODEL MARKOV TERSEMBUNYI PADA PROSES
BISNIS
ANDREAN HUTAMA KOOSASI NRP 5112 100 004
Dosen Pembimbing I
Prof. Drs. Ec. Ir. Riyanarto Sarno, M.Sc., Ph.D. Dosen Pembimbing II
Abdul Munif, S.Kom., M.Sc. JURUSAN TEKNIK INFORMATIKA Fakultas Teknologi Informasi
Institut Teknologi Sepuluh Nopember Surabaya 2017
iv
v
FINAL PROJECT – KI141502
HIDDEN MARKOV MODEL METHOD FOR
FRAUD DETECTION IN BUSINESS PROCESS
ANDREAN HUTAMA KOOSASI NRP 5112 100 004
Supervisor I
Prof. Drs. Ec. Ir. Riyanarto Sarno, M.Sc., Ph.D. Supervisor II
Abdul Munif, S.Kom., M.Sc. DEPARTMENT OF INFORMATICS Faculty of Information Technology Institut Teknologi Sepuluh Nopember Surabaya 2017
vi
viii
ix
TERSEMBUNYI PADA PROSES BISNIS
Nama : Andrean Hutama Koosasi
NRP : 5112100004
Jurusan : Teknik Informatika – FTIf ITS
Dosen Pembimbing I : Prof. Drs. Ec. Ir. Riyanarto Sarno, M.Sc.,Ph.D. Dosen Pembimbing II : Abdul Munif, S.Kom., M.Sc.
Abstrak
Model Markov Tersembunyi merupakan sebuah metode statistik berdasarkan Model Markov sederhana yang memodelkan sistem serta membaginya dalam dua state, state tersembunyi dan state observasi. Dasar dari pemodelan sistem tersebut ialah Proses Markov, dimana Proses Markov mensyaratkan bahwa suatu proses/aktivitas akan mempengaruhi kondisi proses/aktivitas selanjutnya, namun tidak bergantung pada proses/aktivitas yang telah lampau. Pengaruh yang diberikan dari proses/aktivitas sebelumnya yaitu pengaruh dalam memberikan peluang/probabilitas untuk melakukan prediksi situasi proses/aktivitas selanjutnya. Proses Markov sendiri merupakan pengembangan lebih lanjut dari aturan Bayes dan alur prosesnya merupakan kelanjutan pengembangan dari Bayesian network.
Dalam pengerjaan tugas akhir ini, penulis mengusulkan penggunaan metode Model Markov Tersembunyi untuk menemukan fraud/anomali di dalam sebuah pelaksanaan proses bisnis. Tentang fraud/anomali pada proses bisnis itu sendiri, merupakan hal yang lumrah ditemukan dalam kehidupan sehari-hari. Proses bisnis pada umumnya akan diawali dengan pembentukan/pengesahan prosedur operasional standar (SOP), dilanjutkan dengan beberapa kasus/kejadian yang mengikuti. Dengan penggunaan metode Model Markov Tersembunyi ini, maka pengamatan terhadap elemen penyusun sebuah
x
kasus/kejadian, yakni beberapa aktivitas, akan diperoleh sebuah nilai peluang, yang sekaligus memberikan peringatan akan adanya kecurigaan terhadap kasus/kejadian tersebut sebuah fraud atau tidak.
Hasil eksperimen pembuatan tugas akhir ini menunjukkan bahwa metode yang diusulkan mampu memberikan peringatan berupa penyimpangan nilai peluang kasus dari toleransi yang diberikan, dimana hampir keseluruhan kasus yang mengandung fraud akan memberikan nilai peluang/total peluang yang lebih rendah daripada nilai rata-rata peluang kasus yang normal.
Kata kunci: Business Process, Process, SOP, Standard Operational Procedure, Fraud, Markov Model, Markov Process, Hidden Markov Model, Coupled Hidden Markov Model, Probability
xi
Student Name : Andrean Hutama Koosasi
NRP : 5112100004
Major : Teknik Informatika – FTIf ITS
Supervisor I : Prof. Drs. Ec. Ir. Riyanarto Sarno, M.Sc.,Ph.D. Supervisor II : Abdul Munif, S.Kom., M.Sc.
Abstract
Hidden Markov Model is a known statistic method based on simple Markov Model that simulate a system, and also divide it into two different state, hidden state and observable state. The basic of building system model is Markov Process, which says that a process/activity will affect the next process/ativity after it, but will not affected from past process/activity. What is affected from the previous activity is the probability score of current activity, that usable to predict the next process/activity. Markov Process itself is a continuation from Bayes rules and its process flow derived from Bayesian network concept.
In this undergraduate final project, we suggest the usage of Hidden Markov Model to discover fraud/anomalies in business process. Fraud/anomalies is so common nowadays. A business process usually begin with creating the Standard Operational Procedure (SOP), followed with some case/event that is proper to the standard. By using Hidden Markov Model method, observing sub-elements/components that belong to case/event called some activities will resulting some probability score for each case. This probability score then will be used to warn if there is fraud or not.
The experiment result of this final project shows that suggested method alerts the analyzer about fraud by showing the different probability score than the minimum/maximum score allowed. Almost every fraud case/event will gave lower number than the threshold allowed from the other normal cases/events.
xii
Keywords: Business Process, Process, SOP, Standard Operational Procedure, Fraud, Markov Model, Markov Process, Hidden Markov Model, Coupled Hidden Markov Model, Probability
xiii
Segala puji syukur penulis panjatkan kepada Tuhan Yesus Kristus atas anugerah, karunia, dan kasih setia-Nya, sehingga tugas akhir berjudul “Deteksi Fraud Menggunakan Metode Model Markov Tersembunyi Pada Proses Bisnis” ini dapat diselesaikan sesuai dengan waktu yang telah ditentukan.
Pengerjaan tugas akhir ini menjadi sebuah sarana untuk penulis memperdalam ilmu yang telah didapatkan selama menempuh pendidikan di kampus perjuangan Institut Teknologi Sepuluh Nopember Surabaya, khususnya dalam disiplin ilmu Teknik Informatika. Terselesaikannya buku tugas akhir ini tidak terlepas dari bantuan dan dukungan semua pihak. Pada kesempatan kali ini penulis ingin mengucapkan terima kasih kepada:
1. Kedua orangtua, Papa dan Mama, saudara (adik), dan beserta anggota keluarga lainnya, yang selalu memberikan dukungan penuh untuk menyelesaikan tugas akhir ini.
2. Bapak Prof. Drs. Ec. Ir. Riyanarto Sarno, M.Sc., Ph.D. dan Bapak Abdul Munif, S.Kom., M.Sc. selaku dosen pembimbing yang telah bersedia meluangkan waktu untuk memberikan bimbingan dan petunjuk selama proses pengerjaan tugas akhir ini.
3. Bapak Dr. Agus Zainal Arifin, S.Kom., M.Kom. selaku dosen wali penulis, yang banyak memberikan nasihat mengenai perkuliahan, baik hal yang bersifat akademis maupun non-akademis.
4. Bapak dan Ibu dosen Jurusan Teknik Informatika ITS yang telah banyak memberikan ilmu dan bimbingan yang tidak terkira bagi penulis.
5. Seluruh staf dan karyawan FTIf-ITS yang banyak memberikan kelancaran administrasi akademik kepada penulis.
6. Segenap dosen pengajar pada rumpun mata kuliah (RMK) Manajemen Informasi (MI).
xiv
7. “BRE BRE” – Anton, Ardi, Vicky, Welly, Ryan, Richard, Prasetyo, Felix, dan William yang banyak memberikan hiburan dan masukan sewaktu pengerjaan Tugas Akhir ini berlangsung.
8. Kelly dan Yutika yang banyak memberikan bantuan kepada penulis mengenai topik analisa Tugas Akhir Manajemen Informasi.
9. Rekan-rekan laboratorium dan rumpun mata kuliah (RMK) Manajemen Informasi (MI).
10. Teman-teman seangkatan Teknik Informatika ITS 2012 yang selalu memberikan bantuan dan semangat selama proses pengerjaan Tugas Akhir.
11. Teman-teman SMA dari “Ohana” dan “Ngafe” group chats yang selalu menghibur dan mengusir kejenuhan penulis. 12. Serta semua pihak yang belum penulis sebutkan, namun turut
membantu dalam penyelesaian tugas akhir ini.
Penulis menyadari bahwa tugas akhir ini masih memiliki banyak kekurangan. Penulis mengharapkan kritik dan saran dari pembaca untuk perbaikan kedepannya.
xv
LEMBAR PENGESAHAN ... vii
Abstrak ... ix
Abstract ... xi
KATA PENGANTAR ... xiii
DAFTAR ISI ... xv
DAFTAR GAMBAR ... xix
DAFTAR TABEL ... xxi
DAFTAR KODE SUMBER ... xxiii
BAB I PENDAHULUAN ... 1 1.1 Latar Belakang ... 1 1.2 Rumusan Permasalahan ... 3 1.3 Batasan Permasalahan ... 3 1.4 Tujuan ... 4 1.5 Manfaat ... 4 1.6 Metodologi ... 5 1.7 Sistematika Penulisan ... 6
BAB II DASAR TEORI ... 9
2.1 Fraud ... 9
Skip Sequence ... 9
Skip Decision...10
Wrong Throughput Time ...11
Wrong Resource ...11
Wrong Duty ...11
xvi Wrong Decision... 12 2.2 Teorema Bayes ... 13 2.3 Bayesian Network ... 13 2.4 Algoritma Viterbi ... 14 2.5 Algoritma Forward ... 15 2.6 Algoritma Backward ... 16 2.7 Algoritma Baum-Welch ... 16 2.8 Proses Markov ... 17
2.9 Model Markov Tersembunyi (HMM) ... 18
2.10 Confusion Matrix/Error Matrix ... 19
2.11 Evaluasi Akurasi Metode ... 20
2.12 Evaluasi Recall Metode ... 21
2.13 Evaluasi Specificity Metode ... 21
2.14 Evaluasi Precision Metode ... 21
BAB III METODE PEMECAHAN MASALAH ... 23
3.1 Cakupan Permasalahan... 23
3.2 Pembuatan Model Markov Tersembunyi ... 26
3.3 Pengaturan Posisi Atribut PBF ... 28
3.4 Penyusunan Matriks Probabilitas Antar State ... 30
3.5 Penambahan Kondisi No-atribut ... 32
3.6 Menghitung Probabilitas Total per Kasus ... 33
3.7 Pengukuran Performa Dengan Confusion Matrix ... 34
3.8 Contoh Sederhana Deteksi Fraud ... 35
Pembuatan Model Markov Tersembunyi Berdasarkan Dataset Masukan ... 35
xvii
Deskripsi Umum Sistem ...41
Kebutuhan Fungsional Sistem ...42
Kasus Penggunaan Sistem ...43
4.2 Perancangan Sistem ... 47 BAB V IMPLEMENTASI ... 57 5.1 Lingkungan Implementasi ... 57 Perangkat Keras ...57 Perangkat Lunak ...57 5.2 Implementasi Proses ... 58
Implementasi Pembacaan File Input ...58
Implementasi Pembuatan Matriks Probabilitas Awal 59 Implementasi Pembuatan Matriks Transisi ...60
Implementasi Pembuatan Matriks Emisi ...62
Implementasi Pemrosesan Parameter HMM...64
5.3 Implementasi Antar Muka ... 67
BAB VI PENGUJIAN DAN EVALUASI ... 69
6.1 Lingkungan Uji Coba ... 69
6.2 Data Studi Kasus ... 69
Rincian Data Event Log...69
Adjustment Dengan Label Pakar ...73
Model Persebaran Data ...74
6.3 Pengujian Fungsionalitas ... 74
xviii
Pemrosesan Data Input (Training/Testing) ... 76
Menampilkan File Hasil Prediksi (Training/Testing) 78 6.4 Pengujian Kebenaran Prediksi Data ... 79
6.5 Evaluasi Kualitas Metode ... 80
6.6 Perbandingan Hasil Evaluasi Dengan Evaluasi Metode Sebelumnya ... 81
BAB VII KESIMPULAN DAN SARAN ... 85
7.1 Kesimpulan ... 85 7.2 Saran ... 86 DAFTAR PUSTAKA ... 87 LAMPIRAN A ... 91 LAMPIRAN B... 123 DAFTAR ISTILAH ... 131 BIODATA PENULIS ... 135
xix
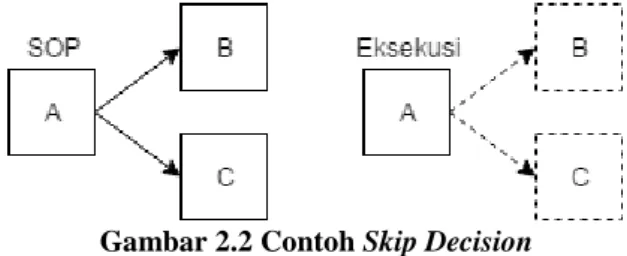
Gambar 2.1 Contoh Skip Sequence ... 10
Gambar 2.2 Contoh Skip Decision ... 10
Gambar 2.3 Contoh Wrong Pattern ... 12
Gambar 2.4 Graf Representasi Contoh Bayesian Network... 14
Gambar 2.5 Diagram Trellis Model Markov Tersembunyi ... 18
Gambar 3.1 Diagram Alur Proses Pengerjaan Tugas Akhir Secara Umum ... 24
Gambar 3.2 Diagram Alur Proses Terinci Model Markov Tersembunyi ... 25
Gambar 3.3 Diagram Trellis Hasil Modifikasi Baum-Welch... 27
Gambar 3.4 Diagram Trellis untuk Probabilitas ... 28
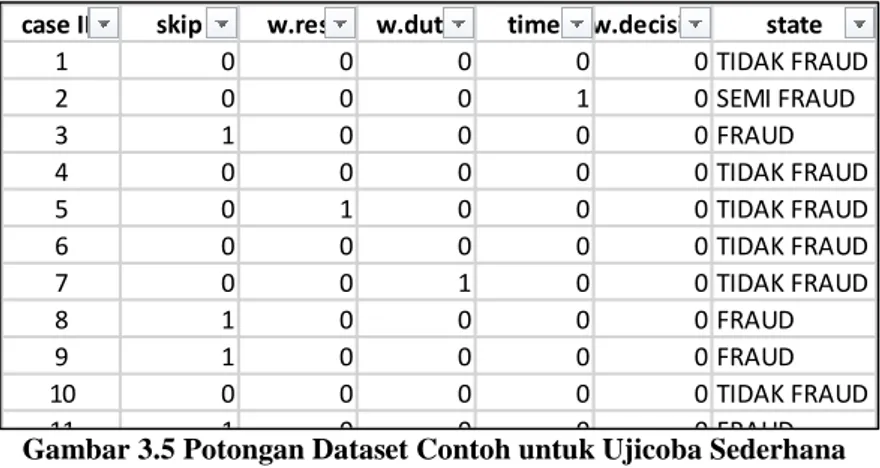
Gambar 3.5 Potongan Dataset Contoh untuk Ujicoba Sederhana36 Gambar 3.6 Potongan Hasil Probabilitas a1 ... 38
Gambar 3.7 Potongan Hasil Probabilitas a2 dan a3 ... 39
Gambar 3.8 Potongan Hasil Probabilitas a4 dan a5 ... 39
Gambar 4.1 Alur Proses Perangkat Lunak ... 42
Gambar 4.2 Diagram Kasus Penggunaan ... 43
Gambar 4.3 Diagram Aktivitas Memproses Data Training ... 45
Gambar 4.4 Diagram Aktivitas Memproses Data Testing ... 47
Gambar 4.5 Antarmuka Utama Perangkat Lunak ... 48
Gambar 4.6 Antarmuka Utama Perangkat Lunak Setelah Proses Training ... 51
Gambar 4.7 Antarmuka Utama Perangkat Lunak Setelah Proses Testing ... 54
Gambar 5.1 Tampilan Antarmuka Utama Perangkat Lunak ... 68
Gambar 6.1 Diagram Workflow SOP Peminjaman Kredit di Bank ... 71
Gambar 6.2 Contoh Atribut Fraud untuk Data Masukan ... 72
Gambar 6.3 Sistem Menampilkan Dialog Pencarian File ... 76
Gambar 6.4 Sistem Menampilkan Evaluasi Kualitas Training ... 77
Gambar 6.5 Sistem Menampilkan Evaluasi Kualitas Testing ... 77
Gambar 6.6 Sistem Menampilkan Data Hasil Prediksi Training 79 Gambar 6.7 Sistem Menampilkan Data Hasil Prediksi Testing .. 79
xx
xxi
Tabel 2.1 Contoh Confusion Matrix Klasifikasi Biner ... 20
Tabel 3.1 Pendapat Pakar Terhadap Atribut PBF ... 28
Tabel 3.2 Pencarian dan Penyetaraan Posisi Atribut ... 29
Tabel 3.3 Pengaturan Atribut PBF Sesuai Kepentingan Pakar ... 30
Tabel 3.4 Matriks Probabilitas Awal (𝜋) ... 30
Tabel 3.5 Matriks Transisi Antar State... 31
Tabel 3.6 Matriks Emisi/Keluaran Atribut ... 32
Tabel 3.7 Matriks Emisi Hasil Penambahan No-atribut ... 32
Tabel 3.8 Confusion Matrix Modifikasi Tiga Kelas ... 35
Tabel 3.9 Matriks Probabilitas Awal ... 36
Tabel 3.10 Matriks Transisi State ... 36
Tabel 3.11 Matriks Emisi State ... 37
Tabel 4.1 Daftar Kebutuhan Fungsional Perangkat Lunak ... 43
Tabel 4.2 Spesifikasi Kasus Penggunaan Memproses Data Training ... 44
Tabel 4.3 Spesifikasi Kasus Penggunaan Memproses Data Testing ... 46
Tabel 4.4 Spesifikasi Elemen pada Antarmuka Utama ... 48
Tabel 4.5 Spesifikasi Elemen Tambahan Proses Training ... 51
Tabel 4.6 Spesifikasi Elemen Tambahan Proses Testing ... 54
Tabel 6.1 Rincian Aktivitas Proses Bisnis ... 72
Tabel 6.2 Frekuensi Persebaran Jenis Data ... 74
Tabel 6.3 Pengujian Memasukkan Data Input ... 74
Tabel 6.4 Pengujian Pemrosesan Data Input ... 76
Tabel 6.5 Pengujian Menampilkan Hasil Prediksi ... 78
Tabel 6.6 Confusion Matrix Data Training ... 80
Tabel 6.7 Confusion Matrix Data Testing ... 80
Tabel 6.8 Evaluasi Kualitas Proses Training ... 80
Tabel 6.9 Evaluasi Kualitas Proses Testing ... 81
Tabel 6.10 Perbandingan False Detection Tiap Metode ... 82
xxii
xxiii
Kode Sumber 5.1 Kode Sumber Pembacaan File Input ... 59 Kode Sumber 5.2 Kode Sumber Matriks Probabilitas Awal ... 60 Kode Sumber 5.3 Kode Sumber Pembuatan Matriks Transisi .... 62 Kode Sumber 5.4 Kode Sumber Pembuatan Matriks Emisi ... 64 Kode Sumber 5.5 Kode Sumber Pemrosesan Parameter HMM .. 67
xxiv
1
1.
BAB I
PENDAHULUAN
Pada bab ini akan dipaparkan mengenai garis besar Tugas Akhir yang meliputi latar belakang, tujuan, rumusan dan batasan permasalahan, metodologi pengerjaan Tugas Akhir, dan sistematika penulisan Tugas Akhir.
1.1
Latar BelakangModel Markov Tersembunyi merupakan sebuah metode untuk merepresentasikan atau menampilkan distribusi probabilitas/kemungkinan berdasarkan sejumlah data observasi yang ada [1]. Model Markov Tersembunyi merupakan metode pengembangan dari Teorema Bayes (Aturan Bayes) dan Proses Markov.
Pada beberapa penelitian dan eksperimen lampau, metode Model Markov Tersembunyi ini telah diimplementasikan dalam beberapa kasus. Contoh penggunaan metode ini secara spesifik ialah pada kasus penggalian fraud (anomali), seperti fraud pada penggunaan kartu kredit [2] dan fraud pada penggunaan internet banking [3]. Kedua contoh implementasi yang disebutkan sebelumnya memanfaatkan nilai probabilitas dari metode Model Markov Tersembunyi ini untuk memprediksi kejadian selanjutnya. penggalian fraud pada kartu kredit memanfaatkan nilai probabilitas untuk menghitung kemungkinan perilaku pemegang kartu kredit yang bisa terjadi [2] dan penggalian fraud pada penggunaan internet banking memetakan profil masing-masing pengguna layanan dengan nilai probabilitas pula [3].
Dengan basis eksperimen fraud yang telah disebutkan, maka pada pengerjaan Tugas Akhir ini penulis mencoba melakukan implementasi penggunaan metode Model Markov Tersembunyi untuk penggalian fraud pada proses bisnis. Proses bisnis merupakan sekumpulan aktivitas bisnis yang saling berkaitan secara logis dan bekerjasama untuk menghasilkan sebuah nilai/tujuan tertentu [4]. Alur kerja proses bisnis ialah sebagai
berikut: pembentukan Prosedur Operasional Standar (Standard Operational Procedure, selanjutnya akan disingkat SOP) sebagai tatanan baku sebuah proses bisnis yang akan dilakukan, akan diikuti dengan beberapa kasus yang menjalankan proses bisnis tersebut, sesuai dengan SOP yang ada. Faktanya, kasus-kasus yang berjalan di lapangan seringkali tidak sesuai/tidak cocok seutuhnya dengan SOP yang telah dibuat. Ketidaksesuaian/ketidakcocokan ini cenderung akan mengarah kepada terbentuknya pelanggaran/fraud. Adapun jenis-jenis fraud yang bisa terjadi cukup beragam, dan akan diuraikan pada bab selanjutnya.
Fraud tidak bisa dihindari, walaupun memiliki peluang kemunculan yang sangat kecil dibandingkan dengan sejumlah besar kasus yang berjalan. Adalah penggalian proses (process mining), sebuah metode tradisional yang cukup terkenal untuk menyelidiki peluang fraud pada event log [5]. Cara kerja penggalian proses secara umum ialah dengan melakukan pencocokan (fitness) antara SOP dengan event log yang berisi beberapa contoh kasus. Dengan mempertimbangkan beberapa hal, seperti tingkat akurasi yang terbilang kurang baik untuk mencari fraud yang spesifik, dan hendak mengembangkan keberagaman metode penggalian fraud, maka penulis mengajukan metode Model Markov Tersembunyi ini sebagai metode alternatif mencari fraud pada event log yang didasarkan dari SOP proses bisnis yang telah ada.
Metode Model Markov Tersembunyi (selanjutnya disebut dengan HMM saja) sendiri ialah metode gabungan dari beberapa algoritma dasar, seperti teorema Bayes, algoritma Viterbi [6], dan algoritma Baum-Welch (Forward-Backward Algorithm) [7]. Teorema Bayes adalah dasar dari sifat ketergantungan prediksi selanjutnya dari kejadian sekarang. Algoritma Viterbi merupakan algoritma yang digunakan untuk menghitung nilai probabilitas kecenderungan tertinggi dari sebuah aktivitas ke aktivitas selanjutnya. Algoritma Baum-Welch merupakan algoritma hybrid (gabungan) yakni dari algoritma Forward dan algoritma
Backward, yang bertugas untuk menghitung semua nilai probabilitas yang mungkin dari satu aktivitas ke aktivitas lainnya.
Tingkat pengukuran kualitas metode ini akan ditentukan dari hasil akurasi (accuracy), positive predictive value (precision) dan true positive rate (recall) [8]. Nilai akurasi didapatkan dari pembagian antara nilai kasus fraud yang ditangkap dengan metode yang diusulkan dengan total kasus fraud yang sesungguhnya. Nilai precision didapatkan dari pembagian antara nilai kasus yang positif terprediksi dengan keseluruhan hasil prediksi positif. Nilai recall didapatkan dari pembagian antara nilai kasus yang positif terprediksi dengan keseluruhan data riil yang positif.
Hasil akhir yang diharapkan menjadi keluaran dari pengerjaan Tugas Akhir ini ialah terdeteksinya fraud dari data contoh yang diberikan, dengan persentase evaluasi yang tinggi. Juga, ditemukannya pola unik/spesifik untuk menentukan fraud dari masing-masing masukan proses bisnis yang spesifik pula.
1.2
Rumusan PermasalahanRumusan masalah yang diangkat dalam Tugas Akhir ini dapat dipaparkan sebagai berikut:
1. Bagaimana cara Model Markov Tersembunyi untuk menemukan fraud yang terdapat pada setiap event log? 2. Bagaimana cara menentukan pembuatan matriks
probabilitas keterkaitan antar atribut?
3. Apakah hasil evaluasi/pengukuran kualitas metode ini mampu menandingi nilai pengukuran kualitas dari metode penelitian sebelumnya?
4. Apa hasil akhir/keluaran yang diharapkan dari perancangan metode ini?
1.3
Batasan PermasalahanPermasalahan yang dibahas dalam Tugas Akhir ini memiliki beberapa batasan, di antaranya sebagai berikut:
1. Lingkungan kerja metode ini menggunakan perangkat lunak Microsoft Office Excel sebagai sarana pemantapan
metode iterasi dan pengembangan perangkat lunak menggunakan bahasa pemrogramman PHP.
2. Masukkan metode ini berupa dataset event log dengan jumlah dan kolom atribut yang telah ditentukan, berikut atribut PBF beserta nilainya pada masing-masing case. 3. Keluaran metode ini berupa data hasil prediksi dengan
thresholding/pemberian nilai toleransi yang ditentukan, dan evaluasi pengukuran kualitas metode ini yakni nilai akurasi, precision, sensitivitas (TPR) dan spesifisitas (TNR).
1.4
TujuanTujuan dari Tugas Akhir ini adalah sebagai berikut:
1. Memunculkan tiga kelas (fraud, semi-fraud, dan tidak-fraud) untuk data hasil prediksi.
2. Membuat dan menyusun matriks probabilitas yang menggambarkan keterkaitan transisi antar state dan antar atribut, yang berbasiskan dataset masukkan.
3. Mengukur nilai evaluasi/pengukuran kualitas metode dan melakukan komparasi dengan nilai evaluasi/pengukuran kualitas metode penggalian proses.
4. Hasil akhir/keluaran berupa rincian data yang berhasil dikelompokkan ke dalam tiga kelas dan nilai hasil evaluasi metode, baik dari proses training maupun testing.
1.5
ManfaatManfaat yang diperoleh setelah pengerjaan Tugas Akhir ini ialah terbentuknya sebuah metode baru yang mampu mendeteksi fraud dan semi-fraud pada setiap proses bisnis berbeda dan bersifat unik, yang menjadi masukan dari metode ini. Dengan bantuan pemanfaatan metode Model Markov Tersembunyi maka kuantitas fraud yang ditemukan diharapkan lebih baik dan tepat dibandingkan metode penggalian proses biasa.
1.6
MetodologiLangkah-langkah yang ditempuh dalam pengerjaan Tugas Akhir ini yaitu:
1. Studi literatur
Dalam pembuatan Tugas Akhir ini telah dipelajari tentang dasar-dasar yang dibutuhkan sebagai penunjang pengerjaan Tugas Akhir ini. Pertama adalah tentang teorema Bayes, kemudian dilanjutkan dengan Bayesian Network, algoritma Viterbi, algoritma Forward, algoritma Backward, algoritma Baum-Welch, Proses Markov, dan Model Markov Tersembunyi. Kemudian adalah menentukan batasan-batasan pengerjaan eksperimen. Selain itu, juga dibantu beberapa literatur lain yang dapat menunjang proses penyelesaian Tugas Akhir ini.
2. Modifikasi metode
Pada tahap ini, penulis menjabarkan cara pemecahan masalah yang terdapat dalam rumusan masalah. Selain itu penulis juga menjabarkan tentang modifikasi yang telah dilakukan pada algoritma sebelumnya sebagai salah satu kontribusi dalam Tugas Akhir ini.
3. Implementasi
Pada tahap ini, dilakukan implementasi dari rancangan metode yang telah dipelajari sebelumnya, yakni pemecahan masalah penentuan fraud pada proses bisnis menggunakan metode Model Markov Tersembunyi dan berikut teorema serta algoritma induk.
4. Pengujian dan evaluasi
Pada tahap ini, dilakukan pengujian hasil implementasi metode dengan menggunakan data uji (data training) yang telah dipersiapkan. Pengujian dan evaluasi ini dilakukan untuk menilai jalannya metode, mengevaluasi fitur utama, mengevaluasi akurasi metode, mencari kesalahan yang dapat terjadi pada saat pengujian,
dan mengadakan perbaikan jika ditemui kekurangan. Tahapan-tahapan dari pengujian adalah sebagai berikut: a. Pemunculan data-data kasus baru dengan disertai
pemunculan fraud yang diketahui (untuk evaluasi kualitas),
b. Penerapan metode (dalam bentuk pola yang dihasilkan dari dataset) dan melakukan perbandingan antara hasil yang diperoleh dengan hasil yang seharusnya dimunculkan.
5. Penyusunan buku Tugas Akhir
Pada tahap ini, dilakukan dokumentasi dan pelaporan dari seluruh konsep, dasar teori, implementasi, proses yang telah dilakukan, dan hasil-hasil yang telah didapatkan selama proses pengerjaan Tugas Akhir.
1.7
Sistematika PenulisanBuku Tugas Akhir ini bertujuan untuk mendapatkan gambaran dari pengerjaan Tugas Akhir ini. Selain itu, diharapkan dapat berguna untuk pembaca yang tertarik untuk melakukan pengembangan lebih lanjut. Secara garis besar, buku Tugas Akhir terdiri atas beberapa bagian seperti berikut ini.
Bab I Pendahuluan
Bab ini berisi latar belakang masalah, tujuan dan manfaat pembuatan Tugas Akhir, permasalahan, batasan masalah, metodologi yang digunakan, dan sistematika penyusunan Tugas Akhir.
Bab II Dasar Teori
Bab ini membahas beberapa teori penunjang yang berhubungan dengan pokok pembahasan dan yang menjadi dasar dari pembuatan Tugas Akhir ini.
Bab III Metode Pemecahan Masalah
Bab ini membahas cara penulis memecahkan masalah yang ada. Penjelasan tentang algoritma yang dikembangkan penulis dan
langkah-langkahnya sehingga dapat memecahkan masalah yang ada.
Bab IV Analisis dan Perancangan Sistem
Bab ini membahas mengenai perancangan perangkat lunak. Perancangan perangkat lunak meliputi perancangan alur, proses dan perancangan antarmuka pada perangkat lunak.
Bab V Implementasi
Bab ini berisi implementasi dari perancangan metode yang berasal dari bab sebelumnya, disertai dengan pembentukan pola/pattern untuk identifikasi fraud/anomali.
Bab VI Pengujian dan Evaluasi
Bab ini membahas pengujian dengan metode pengujian subjektif untuk mengetahui penilaian aspek kegunaan (usability) dari metode ini dan pengujian fungsionalitas yang dibuat dengan memperhatikan keluaran yang dihasilkan serta evaluasi terhadap fitur-fitur perangkat lunak.
Bab VII Kesimpulan
Bab ini berisi kesimpulan dari hasil pengujian serta evaluasi yang dilakukan. Bab ini membahas saran-saran untuk pengembangan sistem lebih lanjut.
Daftar Pustaka
Merupakan daftar referensi yang digunakan untuk pengembangan penyelesaian Tugas Akhir.
9
2.
BAB II
DASAR TEORI
Pada bab ini akan dibahas mengenai teori-teori yang menjadi dasar dari pembuatan Tugas Akhir. Teori-teori tersebut meliputi Fraud, Teorema Bayes, Bayesian Network, Proses Markov, Algoritma Viterbi, Algoritma Forward, Algoritma Backward, Algoritma Baum-Welch, Model Markov Tersembunyi (HMM), Evaluasi Akurasi Model Proses Bisnis, Evaluasi Sensitivitas Model Proses Bisnis, dan Evaluasi Spesifisitas Model Proses Bisnis.
2.1
FraudFraud merupakan anomali/penyimpangan yang merugikan, dan berbagai macam perusahaan dunia telah menganggapnya sebagai masalah yang cukup serius [5]. Dalam kaitannya dengan proses bisnis, maka fraud yang terjadi merupakan pelanggaran pada SOP yang telah disepakati sebelumnya. Adapun jenis-jenis pelanggaran yang dapat terjadi akibat fraud cukup beragam, baik dari segi kelengkapan aktivitas per kasus yang harus dijalani, sampai dengan keabsahan pelaku (resource) yang menangani masing-masing aktivitas.
Pengerjaan Tugas Akhir ini membagi jenis-jenis fraud yang terjadi menurut proses bisnis, sehingga jenis-jenis fraud tersebut dapat dipahami sebagai process-based fraud (PBF) [5]. Berdasarkan dari cara melakukan pelanggaran, maka atribut komponen dari PBF yang dimaksud akan dijelaskan sebagai berikut.
Skip Sequence
Merupakan jenis fraud yang terjadi dengan cara pelaku melompati/melewati aktivitas yang bersifat sequence/sekuens biasa yang menjadi urutan baku pada SOP dari proses bisnis yang dijalankan tersebut [5]. Ilustrasi dari aktivitas sequence beserta pelanggaran skip
sequence seperti ditunjukkan pada Gambar 2.1. Nilai maksimum dari atribut PBF ini ialah sebanyak jumlah maksimum aktivitas berjenis sekuens pada sebuah alur SOP yang ditentukan.
Gambar 2.1 Contoh Skip Sequence
Skip Decision
Merupakan jenis fraud yang terjadi dengan cara pelaku melompati/melewati aktivitas yang bersifat decision/penentuan pengambilan keputusan [5]. Potongan proses yang bersifat decision pada umumnya disimbolkan dengan percabangan aktivitas. Ilustrasi dari aktivitas bersifat decision beserta pelanggaran skip decision seperti ditunjukkan pada Gambar 2.2. Nilai maksimum dari atribut PBF ini ialah sebanyak jumlah maksimum aktivitas berjenis pengambilan keputusan pada alur SOP yang ditentukan.
Wrong Throughput Time
Merupakan jenis fraud yang terjadi dengan cara menyalahi alokasi waktu yang telah ditentukan oleh SOP [9]. Wrong throughput time terbagi kembali berdasarkan jenis pelanggarannya, minimum apabila aktivitas dikerjakan lebih cepat dari alokasi waktu yang ditentukan, serta maximum apabila aktivitas dikerjakan lebih lama dari alokasi waktu yang ditentukan. Nilai maksimum dari atribut PBF ini ialah sebanyak jumlah aktivitas keseluruhan pada alur SOP yang ditentukan.
Wrong Resource
Merupakan jenis fraud yang terjadi apabila sumber daya/resource mengerjakan aktivitas yang tidak dialokasikan untuk diselesaikan oleh sumber daya tersebut menurut SOP [9]. Nilai maksimum dari atribut PBF ini ialah sebanyak jumlah aktivitas (yang menuntun kepada jumlah pelaku sebanyak aktivitas) pada alur SOP yang ditentukan.
Wrong Duty
Merupakan jenis fraud yang terjadi apabila pelaku/resource mengerjakan lebih dari satu aktivitas dalam sebuah kasus [9]. Wrong duty juga bisa terjadi apabila pelaku yang ada mengerjakan aktivitas yang seharusnya diselesaikan oleh pelaku lain yang memiliki tingkat jabatan lebih tinggi untuk melakukan aktivitas tersebut. Nilai maksimum dari atribut PBF ini ialah sebanyak jumlah aktivitas pada alur SOP yang ditentukan.
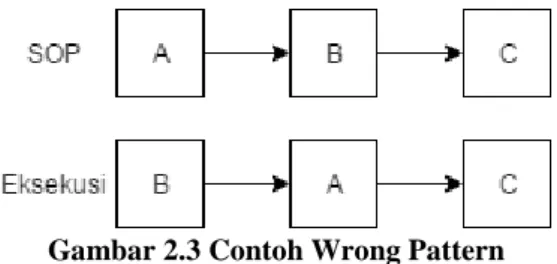
Wrong Pattern
Merupakan jenis fraud yang terjadi dengan cara pelaku menjalankan proses bisnis tidak sesuai dengan urutan aktivitas pada SOP [9]. Berbeda dengan skipped sequence, pada wrong pattern semua aktivitas akan dilalui (tidak ada yang dilalui) namun dengan urutan pengerjaan yang
berbeda dengan ketentuan dari SOP. Ilustrasi pelanggaran wrong pattern seperti ditunjukkan pada Gambar 2.3 berikut. Nilai maksimum dari atribut PBF ini ialah sebanyak jumlah total aktivitas yang ditentukan sebuah alur SOP.
Gambar 2.3 Contoh Wrong Pattern
Wrong Decision
Merupakan jenis fraud yang terjadi dengan cara pelaku mengambil keputusan/decision yang salah [9]. Kesalahan pengambilan keputusan ini kembali lagi dengan pencocokan kriteria dari setiap kasus dengan syarat standar SOP. Nilai maksimum dari atribut PBF ini ialah sama dengan skipped decision, yakni sebanyak jumlah aktivitas berjenis pengambilan keputusan pada alur SOP yang ditentukan.
Jenis-jenis fraud yang telah dijabarkan pada subbab diatas ada yang memiliki turunan, sehingga pada sebuah kasus fraud tidak mutlak bahwa jenis fraud yang ditemui hanya satu jenis saja. Sebagai contoh, wrong duty yang terjadi pada aktivitas bersifat sequence akan menghasilkan fraud berjenis wrong duty sequence, wrong duty pada aktivitas bersifat decision yang menghasilkan wrong duty decision, dan wrong duty pada kombinasi aktivitas bersifat sequence dan decision yang menghasilkan wrong duty combined [9].
2.2
Teorema BayesTeorema Bayes (atau disebut aturan Bayes) menyatakan bahwa probabilitas/peluang atas kejadian di masa mendatang dipengaruhi oleh kejadian yang berlangsung di masa sekarang [10]. Konsep teorema Bayes ini ialah konsep yang mendasari prinsip proses Markov, terutama dalam hal pembentukan matriks probabilitas. Rumusan pernyataan teorema Bayes ditunjukkan pada Persamaan 2.1.
|
* | P A B P B P B A P A (2.1)Penjelasan dari Persamaan 2.1 ialah sebagai berikut. P(B|A) merupakan probabilitas dari aktivitas B diberikan aktivitas A, sehingga sama dengan P(A|B) yang merupakan probabilitas aktivitas A diberikan aktivitas B dikalikan dengan probabilitas keseluruhan terjadinya aktivitas B (P(B)) kemudian dibagi dengan probabilitas keseluruhan terjadinya aktivitas A (P(A)).
2.3
Bayesian NetworkBayesian Network merupakan bentuk graf berarah yang tidak berkesinambungan/tidak memiliki siklus (DAG: Directed Acyclic Graph) [1, 10]. Bayesian Network menggambarkan ketidakterkaitan antar dua atau lebih variabel terpilih. Dalam kaitannya dengan Model Markov Tersembunyi, metode ini merupakan representasi bentuk paling sederhana dari sebuah Bayesian Network dinamis (DBN).
Contoh penerapan Bayesian network ialah sebagai berikut. Diberikan empat buah variabel acak A, B, C, dan D, sehingga dapat dilakukan join probabilitas (joint probability) sederhana seperti pada Persamaan 2.2.
Pada join probabilitas yang terbentuk di Persamaan 2.2, dapat dilakukan faktorisasi sederhana untuk melakukan pemisahan antar variabel acak yang ada, sehingga dapat ditulis seperti Persamaan 2.3 berikut.
P (A,B,C,D) = P(A) P(B) P(C |A) P(D | B,C) (2.3) Diperlukan penyelesaian lebih lanjut untuk menentukan bentuk graf yang sesungguhnya, seperti pada Persamaan 2.4.
( , , , ) ( , | , ) ( , ) P A B C D P A D B C P B C
| | | ,| ,
P A P B P C A P D B C P A P B P C A P D B C dAdD
|
(
| , )
( )
P A P C A P D
C
P
B
C
( | ) ( | , ) P A C P D B C (2.4)Contoh pembentukan graf hasil representasi Persamaan 2.4 seperti ditunjukkan pada Gambar 2.4.
Gambar 2.4 Graf Representasi Contoh Bayesian Network
2.4
Algoritma ViterbiAlgoritma Viterbi merupakan algoritma yang digunakan untuk mencari kejadian selanjutnya/aktivitas selanjutnya dengan melakukan pencarian kejadian/aktivitas yang memiliki nilai total probabilitas tertinggi [6]. Hasil dari pencarian masing-masing
kejadian/aktivitas dengan probabilitas paling mungkin ini kemudian akan membentuk sebuah case/kasus.
Dalam kaitannya dengan Model Markov Tersembunyi, algoritma Viterbi berperan dalam penyelesaian problem decoding. Tugas algoritma ini selaku decoder ialah mencari hidden path terbaik, seperti telah dijabarkan pada definisi sebelumnya [11]. Apabila diketahui sejumlah observasi O = o1, o2, o3, ..., oT dan state objek Q = q1q2q3...qT, maka urutan sekuens Viterbi/Viterbi path dapat dibentuk dengan menggunakan Persamaan 2.5 berikut.
0 1 1 0 1 1 1 2 , ,...
( )
max
( , ,...
, ,
,... ,
| )
t t t t t q q qv j
P q q
q
o o
o q
j
(2.5)Dengan 𝜆 menyatakan bentuk HMM 𝜆 = (A,B). Untuk menghitung nilai probabilitias Viterbi jika diberikan state qj dan waktu t, maka nilai vt(j) dapat dirumuskan sesuai Persamaan 2.6 berikut. 1 1
( )
max
( )
( )
N t t ij j t iv j
v
i a b o
(2.6)Dengan vt-1(i) menyatakan probabilitas Viterbi path sebelumnya, aij menyatakan probabilitas transisi dari state sebelumnya qi menuju state sekarang qj, dan bj(ot) menyatakan kesamaan observasi antar state ot pada state sekarang (j) [11].
2.5
Algoritma ForwardAlgoritma Forward merupakan algoritma yang menghitung probabilitas kemungkinan pada waktu t, diberikan kejadian yang telah lampau [12]. Jika diberikan persamaan HMM 𝜆 = (A,B,𝜋), maka rumusan algoritma Forward untuk menghitung P(O|𝜆) = 𝛼(t,i) ditunjukkan pada Persamaan 2.7 berikut.
1 2 3
( , )
t i
P O O O
(
,
,
,...,
O q
t,
tS
i)
Dengan 𝛼(t,i) menyatakan nilai yang dihasilkan oleh persamaan algoritma Forward pada waktu t dan state ke-i, dan P(O1,O2,O3,...,Ot, qt=Si) menyatakan sejumlah nilai probabilitas dari rangkaian pengamatan O1,O2,O3,...,Ot pada state ke-i dan waktu t.
2.6
Algoritma BackwardAlgoritma Backward merupakan algoritma yang memiliki cara kerja sama dengan algoritma Forward, namun memiliki titik awal (start position) dari akhir proses [12]. Rumusan algoritma Backward untuk menghitung P(O|𝜆) = 𝛽(t,i) ditunjukkan pada Persamaan 2.8 berikut.
1 2
( , )
t i
P O
(
t,
O
t,...,
O
T|
q
tS
i)
(2.8)Dengan 𝛽(t,i) menyatakan nilai yang dihasilkan oleh persamaan algoritma Backward pada waktu t dan state ke-i, dan P(Ot+1,Ot+2,...,OT, qt=Si) menyatakan nilai probabilitas dari rangkaian pengamatan O1,O2,O3,...,Ot pada state ke-i dan waktu t.
2.7
Algoritma Baum-WelchAlgoritma Baum-Welch merupakan algoritma gabungan dari algoritma Forward (𝛼) dan algoritma Backward (𝛽). Algoritma ini digunakan untuk melakukan penggalian terhadap parameter/atribut penyusun metode Model Markov Tersembunyi [7]. Dengan keberadaan observasi yang telah diketahui, algoritma ini bertugas melakukan perhitungan probabilitas maksimal dari sebuah rangkaian proses.
Desain algoritma Baum-Welch memungkinkan untuk memaksimalkan observasi terhadap rangkaian pengamatan P(O1,O2,O3,...,On). Bentuk umum Baum-Welch dapat dilakukan ekspansi sejumlah n sekuens berbeda berisikan m1,m2,m3,...,mn, seperti pada Persamaan 2.9 berikut.
1 1 1 1 1 1 2 3 1 2 2 2 2 2 1 2 3 2 3 3 3 3 3 1 2 3 3 1 2 3 : , , ,..., : , , ,..., : , , ,..., ... : , , ,..., n m m m n n n n n m O O O O O O O O O O O O O O O O O O O O (2.9)
Sedangkan untuk penyelesaian algoritma Baum-Welch dapat dilihat pada Persamaan 2.10 berikut.
1 1 ( , ) ( ) ( 1, ) ( , | , ) : ( | ) kl l t t t t k a b O t l P q k q l O P O
(2.10)Dengan qt menyatakan sekuens pada waktu t, qt+1 menyatakan sekuens pada waktu t+1, O menyatakan observasi yang didasarkan pada k (qt) dan l (qt+1), 𝛼 menyatakan nilai solusi dari algoritma forward, dan 𝛽 menyatakan nilai solusi dari algoritma backward.
2.8
Proses MarkovProses Markov merupakan kumpulan variabel dependen yang tersusun menjadi sebuah proses, yang memenuhi keseluruhan atribut syarat dari properti Markov (Markov properties) [13].
Properti Markov yang dapat dijadikan identifikasi proses Markov ialah bahwa proses Markov memiliki matriks distribusi probabilitas, yakni probabilitas awal (initial probabilitiy) dan probabilitas transisi (transitional probability). Properti Markov yang lain ialah bahwa pada sebuah sekuens (x1,x2,...xn-1), prediksi terhadap nilai selanjutnya (xn) hanya akan bergantung pada nilai sebelumnya saja (xn-1). Oleh karena itu, prediksi nilai selanjutnya tidak bergantung pada kejadian yang telah lampau [13].
2.9
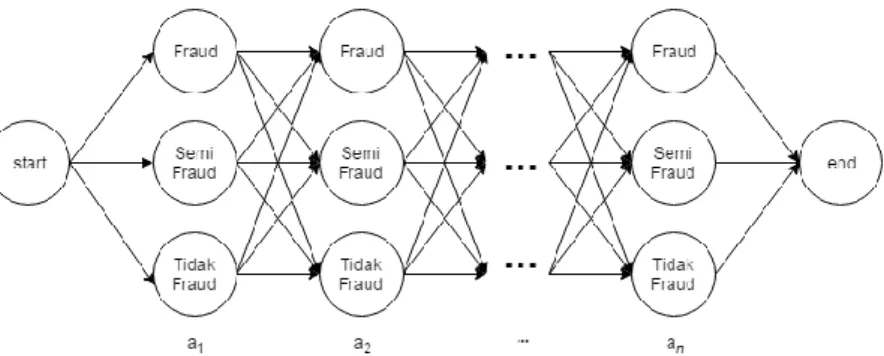
Model Markov Tersembunyi (HMM)Model Markov Tersembunyi merupakan sebuah model stokastik berganda yang memiliki dua tingkat hirarki (state) [2]. Dua buah state yang dimaksud yakni state yang dapat diamati/merupakan objek observasi bagi pengguna (disebut observable state) dan state yang bersifat tersembunyi dari pengguna, dan memerlukan pemecahan dari observasi (disebut hidden state) [3]. Contoh bentuk Model Markov Tersembunyi sederhana yang digambarkan dalam bentuk diagram Trellis ditunjukkan pada Gambar 2.5.
Gambar 2.5 Diagram Trellis Model Markov Tersembunyi
Pada contoh pemetaan HMM seperti Gambar 2.5, Z1,Z2,...,ZN menyatakan observable state/objek pengamatan yang tampak kepada pengamat perilaku, sementara X1,X2,...,XN menyatakan
hidden state/objek tersembunyi, yang biasanya menjadi hasil dari pengamatan terhadap objek yang tampak.
Bentuk lengkap dari persamaan Model Markov Tersembunyi ini seperti dituliskan pada Persamaan 2.11 berikut.
HMM 𝜆 = (A,B,𝜋) (2.11)
Dengan A menyatakan matriks distribusi probabilitas state, B menyatakan matriks distribusi probabilitas observasi, dan 𝜋 menyatakan vektor probabilitas awal (initial probabilities) [2].
Pembentukan vektor probabilitas awal memperhatikan posisi start awal sebuah proses bisnis dimulai pada petri net. Adapun rumusan pembentukan vektor probabilitas awal seperti pada Persamaan 2.12 berikut.
𝜋i = P(q1 = Si) (2.12) Pembentukan matriks distribusi probabilitas state A = [aij] seperti dijelaskan pada Persamaan 2.13 berikut.
aij = (Pqt+1 = Sj | qt = Si) (2.13)
Pembentukan matriks distribusi probabilitas observasi B = [bj(k)] seperti dijelaskan pada Persamaan 2.14 berikut.
bj(k)=P(Vk|Sj) (2.14)
Rangkaian matriks dan vektor penyusun parameter Model Markov Tersembunyi diatas memerlukan sejumlah t sekuens observasi, sehingga O = O1, O2, O3, ..., Ot, dimana Ot merupakan bagian dari V, dan sejumlah R pengamatan atas sekuens observasi tersebut.
2.10
Confusion Matrix/Error MatrixConfusion matrix/error matrix (selanjutnya disebut confusion matrix saja) merupakan matriks pengukuran performa/kualitas sebuah metode, dimana masing-masing kolom pada matriks ini diisikan menurut pengelompokan data pada kelas yang telah ditentukan [14, 15, 16]. Confusion matrix dipilih karena mampu memberikan hasil pengukuran untuk permasalahan dengan kriteria multiclass/memiliki lebih dari dua kelas.
Secara garis besar, confusion matrix membagi kondisi positif dan negatif ke dalam empat macam variabel: True-Positive (TP), Positive (FP), True-Negative (TN), dan False-Negative (FN). Definisi keempat variabel tersebut (dengan menggunakan ilustrasi kondisi positif = fraud) ialah sebagai berikut [17].
1. True-Positive (TP) merupakan kondisi dimana sebuah kasus positif fraud dan berhasil terdeteksi,
2. False-Positive (FP) merupakan kondisi dimana sebuah kasus positif fraud namun tidak terdeteksi sebagai fraud, 3. True-Negative (TN) merupakan kondisi dimana sebuah
kasus negatif fraud dan berhasil tidak terdeteksi, dan 4. False-Negative (FN) merupakan kondisi dimana sebuah
kasus negatif fraud namun terdeteksi sebagai fraud.
Empat variabel kondisi tersebut berlaku untuk klasifikasi bersifat biner. Berdasarkan kondisi diatas, dapat dibentuk sebuah matriks sederhana seperti pada Tabel 2.1 berikut.
Tabel 2.1 Contoh Confusion Matrix Klasifikasi Biner
Prediksi Ya Tidak Fakta Ya True Positive (TP) False Negative (FN)
Tidak False Positive
(FP)
True Negative (TN)
Pada contoh confusion matrix seperti ditunjukkan pada Gambar 3.3, empat variabel dipetakan ke dalam tabel pembagian antara data fakta dengan data hasil prediksi. Penyusunan dengan model semacam ini akan dilanjutkan dengan proses evaluasi metode yang akan dibahas pada subbab berikut, yakni evaluasi akurasi, precision, dan recall metode.
2.11
Evaluasi Akurasi MetodeEvaluasi akurasi metode merupakan pengukuran tingkat kedekatan hasil yang diperoleh dari metode analisa yang digunakan dengan hasil sesungguhnya yang ingin diraih [15, 16]. Rumusan evaluasi akurasi ini seperti pada Persamaan 2.15 berikut.
( ) TruePositive TrueNegative Akurasi ACC Population (2.15)
2.12
Evaluasi Recall MetodeEvaluasi recall metode (True Positive Rate) merupakan pengukuran kondisi positif/benar sesuai dengan fakta, dibandingkan dengan hasil positif/benar yang didapatkan dari penggalian dengan metode analisa [15, 16]. Evaluasi recall merupakan sebutan lain dari (dan selanjutnya disebutkan) evaluasi sensitivity/sensitivitas. Rumusan evaluasi sensitivitas ini seperti pada Persamaan 2.16 berikut.
TruePositive Recall( TPR ) ConditionPositive (2.16)
2.13
Evaluasi Specificity MetodeEvaluasi specificity/spesifisitas metode (True Negative Rate) merupakan pengukuran kondisi negatif/salah sesuai dengan fakta, dibandingkan dengan hasil negatif/salah yang didapatkan dari penggalian dengan metode analisa [15, 16]. Rumusan evaluasi spesifisitas ini seperti pada Persamaan 2.17 berikut.
( ) TrueNegative Specificity TNR ConditionNegative (2.17)
2.14
Evaluasi Precision MetodeEvaluasi precision metode (Positive Prediction Value) merupakan pengukuran perbandingan antara hasil prediksi yang positif sama dengan data awal, dengan keseluruhan hasil prediksi positif [15, 16]. Rumusan evaluasi precision ini seperti pada Persamaan 2.17 berikut. ( ) TruePositive Precision PPV TestConditionPositive (2.18)
23
3.
BAB III
METODE PEMECAHAN MASALAH
Pada bab ini akan dibahas mengenai metodologi pemecahan masalah yang digunakan sebagai dasar solusi dari pembuatan Tugas Akhir. Metodologi tersebut akan menjelaskan tahapan-tahapan yang harus dilalui untuk menghasilkan keluaran hasil dari masukan berupa event log.
3.1
Cakupan PermasalahanPermasalahan utama yang diangkat dalam pengerjaan Tugas Akhir ini ialah bagaimana cara menemukan fraud secara tepat dalam contoh event log yang akan diberikan. Tepat memiliki artian bahwa setelah hasil pengerjaan diberikan, maka evaluasi kualitas yang diberikan harus mampu dipenuhi ketiganya oleh pengerjaan Tugas Akhir ini. Metode Model Markov Tersembunyi akan menjadi komponen sekaligus metode utama dalam pemecahan permasalahan yang diangkat pada pengerjaan Tugas Akhir ini.
Permasalahan pertama dari pengerjaan Tugas Akhir ini ialah menemukan/membuat model event log yang sesuai, untuk memenuhi syarat pembentukan matriks probabilitas algoritma Baum-Welch. Model event log yang diharapkan ialah log dengan jumlah dan kesesuaian atribut yang dibutuhkan. Event log tersebut merupakan dataset awal/masukan bagi metode yang diajukan sebagai pengerjaan Tugas Akhir ini. Dataset yang diharapkan tentunya dataset yang mampu menyediakan nilai probabilitas sesuai dengan jumlah atribut fraud yang ingin diteliti.
Permasalahan kedua dari pengerjaan Tugas Akhir ini ialah menentukan matriks probabilitas untuk memenuhi kriteria pembentukan Model Markov Tersembunyi. Penggunaan algoritma Viterbi dan Welch amat berperan disini. Algoritma Baum-Welch pertama-tama digunakan untuk melakukan estimasi parameter yang belum tersedia, seperti probabilitas transisi antar state, probabilitas output/emisi masing-masing state pada tiap atribut PBF, dan kemudian dilanjutkan dengan algoritma Viterbi
untuk menentukan tatanan hidden path, yang apabila secara utuh digabungkan maka akan menjadi sebuah case baru.
Permasalahan ketiga dari pengerjaan Tugas Akhir ini merupakan pengukuran/evaluasi kemampuan Model Markov Tersembunyi untuk menangani fraud pada proses bisnis. Adapun jenis pengukuran yang diberikan yakni pengukuran akurasi, pengukuran precision, pengukuran sensitivitas (TPR) dan pengukuran spesifisitas (TNR).
Gambar 3.1 Diagram Alur Proses Pengerjaan Tugas Akhir Secara Umum
Diagram alur proses pengerjaan Tugas Akhir ini secara seperti ditunjukkan pada Gambar 3.1. Adapun untuk memulai proses pengerjaan, maka dataset yang diperlukan untuk menjadi masukan ialah dataset berupa event log yang berisi sejumlah kasus, berdasarkan SOP yang dibentuk sebelumnya. Setelah dataset
masukan ditemukan, pada pemrosesan selanjutnya ialah melakukan adjustment/penyesuaian dengan aturan pakar yang telah didefinisikan. Hasil akhir dari pengerjaan Tugas Akhir ini diharapkan berupa pengelompokan tiap case ke dalam kelas yang ditentukan dan evaluasi kualitas metode Model Markov Tersembunyi dari segi akurasi, precision, dan recall. Secara jelas, alur pengerjaan metode yang diusulkan pada pengerjaan tugas akhir ini seperti ditunjukkan pada Gambar 3.2 berikut.
Gambar 3.2 Diagram Alur Proses Terinci Model Markov Tersembunyi
Penjelasan dari alur proses pada Gambar 3.2 ialah sebagai berikut. Proses pengerjaan dimulai dengan input event log yang telah di-generate dari SOP yang ada. Langkah selanjutnya ialah melakukan adjustment/penyesuaian data dengan pendapat pakar yang akan dijelaskan lebih lanjut pada bab pengujian. Hasil dari data yang telah dilakukan penyesuaian ini kemudian akan menjadi input untuk proses estimasi parameter Model Markov Tersembunyi. Proses estimasi ini menggunakan algoritma Baum-Welch. Modifikasi pada algoritma ini menghasilkan output berupa vektor probabilitas awal (𝜋), matriks distribusi probabilitas antar-state (A), dan matriks distribusi probabilitas observasi (B). Dengan menyesuaikan kondisi yang ada, matriks probabilitas observasi kemudian menjadi matriks emisi/luaran yang berisi probabilitas observasi terhadap suatu state.
Hasil output dari estimasi parameter, sebagaimana telah dijelaskan pada paragraf sebelumnya, telah siap digunakan untuk mencari probabilitas antar-state untuk tiap atribut (hingga atribut ke n). Pendefinisian model pengamatan masih merupakan bagian dari pembuatan Model Markov Tersembunyi. Pencarian probabilitas dilakukan dengan cara mengalikan parameter hasil estimasi. Untuk observasi pertama dapat dicari probabilitasnya dengan mengalikan vektor probabilitas awal dan matriks probabilitas state. Observasi setelah observasi pertama dapat dicari dengan mengalikan nilai probabilitas maksimal sebelumnya dengan matriks probabilitas transisi state dan matriks emisi. Pemilihan nilai probabilitas menggunakan prinsip algoritma Viterbi, dimana probabilitas dengan nilai maksimum pada sebuah objek observasi diambil sebagai maximum path oleh Viterbi.
3.2
Pembuatan Model Markov TersembunyiPembuatan event log pertama sangat diperlukan untuk mencocokkan dan melakukan modifikasi terhadap metode iterasi yang digunakan, yaitu Model Markov Tersembunyi yang sesuai. Pemrosesan event log pertama ini menggunakan metode Model Markov Tersembunyi. Pemodelan terhadap bentuk ini memerlukan
dua buah state seperti telah disebutkan sebelumnya, yakni hidden state dan observable state. Oleh karena pengerjaan Tugas Akhir ini merupakan deteksi kecurangan pada proses bisnis, maka penentuan state diambil dari model proses bisnis dataset. Observasi akan diarahkan kepada sekuens atribut pelanggaran per kasus didalam event log, sementara state akan diarahkan kepada state pelanggaran setiap atribut untuk masing-masing kasus (State1,State2,...,Staten).
Untuk melakukan analisa dan perhitungan probabilitas, maka Model Markov Tersembunyi yang digunakan akan dibantu dengan algoritma Baum-Welch yang telah dijelaskan pada Bab 2.7. Diagram trellis yang dibentuk sesuai dengan algoritma Baum-Welch hasil adaptasi/modifikasi terhadap inisialisasi state pada paragraf sebelumnya ditunjukkan pada Gambar 3.2 berikut.
Gambar 3.3 Diagram Trellis Hasil Modifikasi Baum-Welch
Diagram trellis pada Gambar 3.3 berikut merupakan bentuk jadi yang menggambarkan perhitungan akhir nilai probabilitas dari iterasi perkalian metode Model Markov Tersembunyi. Pada Gambar 3.3, posisi hidden state pada rangkaian ialah state per kasus, dan observasi berasal dari atribut PBF.
Gambar 3.4 Diagram Trellis untuk Probabilitas
3.3
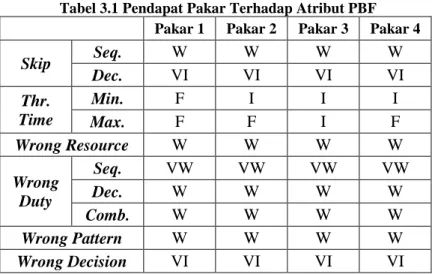
Pengaturan Posisi Atribut PBFPengaturan posisi atribut diperlukan untuk mencari kombinasi observasi antar-atribut yang optimal. Kombinasi observasi yang tepat diperlukan supaya pembentukan matriks transisi antar-state menghasilkan nilai maksimal, yang mempengaruhi pada hasil pengamatan hidden state berdasarkan observasi dari posisi atribut yang telah diatur sebelumnya. Pengaturan atribut ini memperhatikan opini/pendapat pakar seperti pada penelitian sebelumnya [9]. Tabel 3.1 berikut menunjukkan data pendapat pakar terhadap kesepuluh atribut PBF.
Tabel 3.1 Pendapat Pakar Terhadap Atribut PBF Pakar 1 Pakar 2 Pakar 3 Pakar 4
Skip Seq. W W W W Dec. VI VI VI VI Thr. Time Min. F I I I Max. F F I F Wrong Resource W W W W Wrong Duty Seq. VW VW VW VW Dec. W W W W Comb. W W W W Wrong Pattern W W W W Wrong Decision VI VI VI VI
Penjelasan atas atribut pakar pada Tabel 3.1 ialah sebagai berikut: pendapat pakar merupakan nilai linguistik yang dikelompokkan ke dalam 5 (lima) kriteria yakni (diurutkan dari nilai linguistik terendah tertinggi) very weak (VW), weak (W), fair (F), important (I), dan very important (VI).
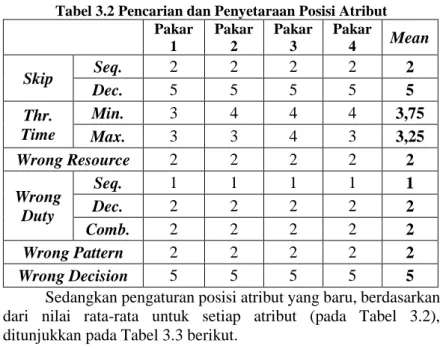
Selanjutnya dilakukan pengaturan ulang terhadap susunan atribut pakar yang akan dijadikan rangkaian observasi terhadap hidden state masing-masing atribut. Pengaturan ulang memperhatikan pendapat hasil rata-rata keempat pakar. Masing-masing kriteria diberikan tanda numerik. Tujuan penggunaan tanda numerik ini ialah untuk kemudahan mengatur ulang urutan atribut, dengan skala 1-5 yang disesuaikan dengan lima tingkat kriteria penilaian secara linguistik. Tabel 3.2 menunjukkan contoh penyetaraan kriteria masing-masing atribut ke dalam bentuk numerik.
Tabel 3.2 Pencarian dan Penyetaraan Posisi Atribut Pakar 1 Pakar 2 Pakar 3 Pakar 4 Mean Skip Seq. 2 2 2 2 2 Dec. 5 5 5 5 5 Thr. Time Min. 3 4 4 4 3,75 Max. 3 3 4 3 3,25 Wrong Resource 2 2 2 2 2 Wrong Duty Seq. 1 1 1 1 1 Dec. 2 2 2 2 2 Comb. 2 2 2 2 2 Wrong Pattern 2 2 2 2 2 Wrong Decision 5 5 5 5 5
Sedangkan pengaturan posisi atribut yang baru, berdasarkan dari nilai rata-rata untuk setiap atribut (pada Tabel 3.2), ditunjukkan pada Tabel 3.3 berikut.
Tabel 3.3 Pengaturan Atribut PBF Sesuai Kepentingan Pakar Atribut 1 Atribut 2 Atribut 3 Atribut 4 Atribut 5
WDutyS SkipSeq WRes WDutyD WDutyC
Atribut 6 Atribut 7 Atribut 8 Atribut 9 Atribut 10
WPattern Tmax Tmin SkipDec WDec
Pada atribut yang memiliki penilaian lebih dari satu macam, misalkan untuk atribut throughput time minimum (Tmin) dan maximum (Tmax), dikarenakan atribut Tmin memiliki pendapat pakar important dengan rasio lebih banyak dibandingkan atribut Tmax yang memiliki rasio pendapat fair lebih banyak, maka hasil pemeringkatan atribut Tmin diletakkan satu posisi lebih penting dibandingkan atribut Tmax.
3.4
Penyusunan Matriks Probabilitas Antar StateMatriks probabilitas dibuat dari pengamatan terhadap event log yang menjadi dataset masukan. Sesuai dengan yang telah dijabarkan pada subbab 3.2 sebelumnya, bahwa penentuan parameter HMM memanfaatkan algoritma Baum-Welch. Setelah melakukan modifikasi pada algoritma tersebut, maka didapatkan observasi berupa sekuens atribut PBF, dan state berupa jenis pelanggaran masing-masing atribut dalam sebuah sekuens.
Setelah mendapatkan nilai-nilai berupa observasi dan state yang dibutuhkan, maka penyusunan matriks bisa dimulai. Tahap pertama ialah melakukan inisialisasi terhadap matriks probabilitas awal (start value). Inisialisasi matriks ini berlangsung untuk semua state, sebagaimana dicontohkan pada Tabel 3.4 berikut. Nilai dari masing-masing inisialisasi awal state diambil dari perbandingan antara frekuensi atribut bernilai state tersebut dengan keseluruhan jumlah kasus dalam dataset.
Tabel 3.4 Matriks Probabilitas Awal (𝜋)
Fraud Semi-Fraud
Tidak-Fraud Start 0,11 0 0,89
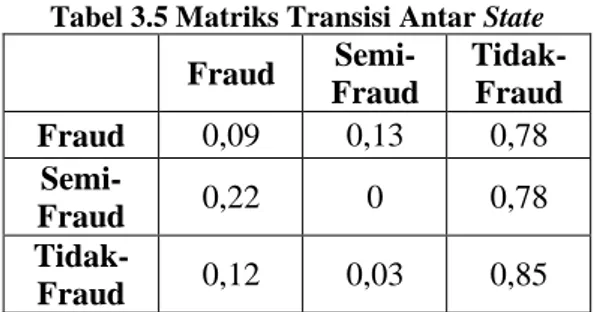
Berikutnya dilakukan inisialisasi matriks transisi antar-state, yang sesuai dengan namanya merupakan matriks berisi nilai probabilitas antara state n dengan state n+1. Contoh bentukan matriks transisi antar state ini dapat dilihat pada Tabel 3.5 berikut.
Tabel 3.5 Matriks Transisi Antar State
Fraud Semi-Fraud Tidak-Fraud Fraud 0,09 0,13 0,78 Semi-Fraud 0,22 0 0,78 Tidak-Fraud 0,12 0,03 0,85
Matriks transisi antar state pada Tabel 3.5 berlaku sebagai distribusi probabilitas state (A). Jenis state pada baris berlaku sebagai state ke-n, sedangkan jenis state pada kolom berlaku sebagai state ke-n+1. Sebagai contoh, untuk mengambil nilai state semi-fraud menuju ke state fraud, maka transisi antar state tersebut bernilai 0,78, dan seterusnya. Matriks ini hanya berlaku untuk transisi dari observasi atribut a1 ke observasi atribut a2, dan sebagainya, sehingga masing-masing transisi memiliki matriks yang berbeda-beda pula.
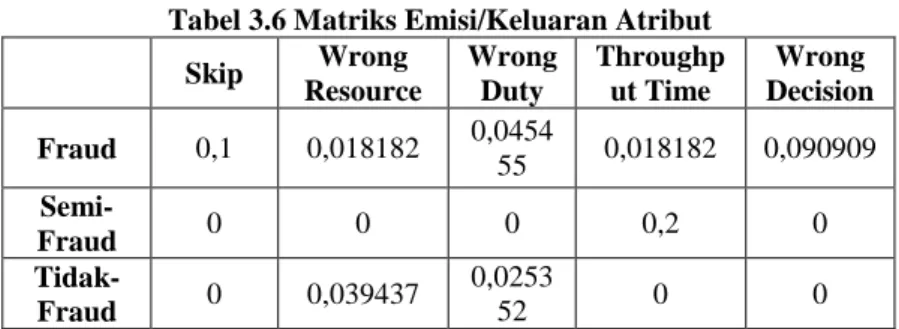
Kemudian, dari jenis-jenis atribut PBF pada event log, dapat dibentuk matriks probabilitas kemunculan suatu atribut pada masing-masing state yang ditentukan. Matriks ini kemudian disebut sebagai matriks probabilitas atribut dan berlaku sebagai nilai emisi/keluaran (emission matrix) pada sebuah state yang diamati. Nilai probabilitas pengisi matriks ini didapatkan dengan cara menjumlahkan frekuensi atribut pada suatu state tertentu dan kemudian dbandingkan dengan jumlah total frekuensi masing-masing atribut PBF pada state tersebut. Contohnya ialah, pada state fraud, frekuensi total atribut wrong decision sebanyak 10. Dimana frekuensi total penjumlahan masing-masing atribut pada state yang sama sebanyak 110. Maka nilai probabilitas atribut tersebut
10
0, 090909
110
. Hasil bentukan matriks emisi/keluaran atributini dapat dilihat pada Tabel 3.6 berikut.
Tabel 3.6 Matriks Emisi/Keluaran Atribut Skip Wrong Resource Wrong Duty Throughp ut Time Wrong Decision Fraud 0,1 0,018182 0,0454 55 0,018182 0,090909 Semi-Fraud 0 0 0 0,2 0 Tidak-Fraud 0 0,039437 0,0253 52 0 0
Pengambilan nilai keluaran ini dirasakan masih belum menggambarkan situasi sesungguhnya frekuensi masing-masing atribut terhadap state yang ada, sebab selain pengambilan probabilitas atribut terjadi, ternyata dijumpai kondisi dimana pada atribut tersebut memiliki nilai tidak lebih dari 0 (tidak terdapat pelanggaran).
3.5
Penambahan Kondisi No-atributSeperti disinggung pada subbab sebelumnya, bahwa frekuensi atribut tidak hanya apabila atribut tersebut terjadi, namun juga apabila atribut tersebut tidak terjadi untuk masing-masing state, seperti ditunjukkan pada Tabel 3.7 berikut.
Tabel 3.7 Matriks Emisi Hasil Penambahan No-atribut
Skip No-skip Wrong Resource No-Wrong Resource Wrong Duty Fraud 0,1 0,1 0,018182 0,181818 0,045455 Semi-fraud 0 0,2 0 0,2 0 Tidak-fraud 0 0,2 0,039437 0,160563 0,025352
No-Wrong Duty Throughp ut Time No-Throughp ut Time Wrong Decision No-Wrong Decision 0,154545 0,018182 0,181818 0,090909 0,109091 0,2 0,2 0 0 0,2 0,174648 0 0,2 0 0,2
Pada Tabel 3.7 pembagian nilai probabilitas masing-masing atribut telah disertai dengan no-atribut, yang menandakan nilai probabilitas apabila atribut tersebut tidak terjadi pada state yang dimaksud.
3.6
Menghitung Probabilitas Total per KasusSetelah pembuatan matriks probabilitas selesai, maka pengerjaan selanjutnya yakni menyelesaikan perhitungan probabilitas antar kasus, yang berasal dari perhitungan probabilitas antar observasi, yang menghasilkan nilai state dari masing-masing observasi tersebut. Cara menghitung probabilitas antar state telah dibangun pada pembahasan sebelumnya yakni bab 3.3 disertai dengan cara menghitung kaitan probabilitas antar atribut dengan state pada bab 3.4. Pengerjaannya memanfaatkan algoritma Baum-Welch. Untuk menghasilkan penggalian probabilitas awal dapat ditentukan dengan rumusan seperti ditulis pada Persamaan 3.1 berikut.
1
( )
t
i*
emit
_
prob
a s( )
(3.1)Dengan
π
i merupakan vektor/matriks probabilitas awal,yang hanya dipakai pada state mula-mula, dan emit_probij merupakan matriks B berisi matriks probabilitas emisi antara observable (atribut) a dengan state s.
Untuk melakukan penggalian nilai probabilitas terhadap elemen sekuens selanjutnya (t+1), maka vektor probabilitas awal
berganti menjadi nilai probabilitas yang dihasilkan dari perhitungan nilai probabilitas awal, sesuai dengan urutan state masing-masing. Nilai probabilitas ini juga mulai memperhitungkan dari seluruh tabel A yang ada. Rumusan untuk menghasilkan nilai probabilitas pada t+1 ini seperti ditulis pada Persamaan 3.2 berikut.
1
( )
t
1(
t
1)*
trans
_
prob
ij*
emit
_
prob
a s( )
(3.2)Dengan α1(t-1) merupakan nilai probabilitas awal, maupun nilai probabilitas sebelumnya (digunakan untuk observable state/atribut setelah atribut awal), trans_probij sebagai matriks A yang berisi nilai probabilitas transisi dari state i ke state j, dan emit_probij merupakan matriks B berisi matriks probabilitas emisi antara observable (atribut) a dengan state s.
3.7
Pengukuran Performa Dengan Confusion MatrixPengukuran performa merupakan proses pemberian nilai atas kinerja dari metode yang telah diusulkan dengan memperhatikan data faktual yang menjadi masukan dan data hasil prediksi metode. Pengukuran performa ini kemudian akan menghasilkan nilai toleransi yang menjadi batas saring bagi data masukan, untuk dapat dikatakan masuk pada kriteria tertentu.
Pada pengerjaan Tugas Akhir ini, pengukuran performa membutuhkan tiga kelas penggolongan data, yakni fraud, semi-fraud, dan tidak-fraud. Untuk sejumlah n kelas, maka ukuran confusion matrix menyesuaikan sebanyak n*n, sehingga untuk tiga kelas akan terdapat 9 buah kolom pada matriks yang akan dibuat. Tabel 3.8 menunjukkan bentukan confusion matrix yang dimaksud.