i
ii
iii
PERNYATAAN KEASLIAN PENELITIAN
Saya yang bertandatangan dibawah ini menyatakan bahwa, skripsi ini merupakan karya saya sendiri (ASLI), dan isi dalam skripsi ini tidak terdapat karya yang pernah diajukan oleh orang lain untuk memperoleh gelar akademis di suatu institusi pendidikan tinggi manapun, dan sepanjang pengetahuan saya juga tidak terdapat karya atau pendapat yang pernah ditulis dan/atau diterbitkan oleh orang lain, kecuali yang secara tertulis diacu dalam naskah ini dan disebutkan dalam daftar pustaka.
Segala sesuatu yang terkait dengan naskah dan karya yang telah dibuat adalah menjadi tanggungjawab saya pribadi.
Bekasi, Oktober 2018
Materai 6.000
Suryana NIM: 311410599
iv
KATA PENGANTAR
Puji syukur penulis panjatkan ke hadiran Allah SWT. yang telah melimpahkan segala rahmat dan hidayah-Nya, sehingga tersusunlah Skripsi yang berjudul “PENERAPAN DATA MINING DALAM MEMPREDIKSI KARYAWAN BERPRESTASI PADA PT. INDOALUMINIUM INTIKARSA INDUSTRI”.
Skripsi tersusun dalam rangka melengkapi salah satu persyaratan dalam rangka menempuh ujian akhir untuk memperoleh gelar Sarjana Komputer (S.Kom.) pada Program Studi Teknik Informatika di Sekolah Tinggi Teknologi Pelita Bangsa.
Penulis sungguh sangat menyadari, bahwa penulisan Skripsi ini tidak akan terwujud tanpa adanya dukungan dan bantuan dari berbagai pihak. Sudah selayaknya, dalam kesempatan ini penulis menghaturkan penghargaan dan ucapan terima kasih yang sebesar-besarnya kepada:
a. Bapak Dr. Ir. Supriyanto, M.P selaku Ketua STT Pelita Bangsa
b. Bapak Aswan Supriyadi Sunge, S.Kom, M.Kom selaku Ketua Program Studi Teknik Informatika STT Pelita Bangsa.
c. Bapak Wahyu Hadikristianto, S.Kom, M.Kom dan Ibu Sifa Fauziah, S.Pd., M.Pd. selaku Pembimbing Utama yang telah banyak memberikan arahan dan bimbingan kepada penulis dalam penyusunan Skripsi ini.
d. Seluruh Dosen STT Pelita Bangsa yang telah membekali penulis dengan wawasan dan ilmu di bidang teknik informatika.
e. Seluruh staf STT Pelita Bangsa yang telah memberikan pelayanan terbaiknya kepada penulis selama perjalanan studi jenjang Strata 1.
f. Rekan-rekan mahasiswa STT Pelita Bangsa, khususnya angkatan 2014, yang telah banyak memberikan inspirasi dan semangat kepada penulis untuk dapat menyelesaikan studi jenjang Strata 1.
g. Calon Istri Serta Keluarga tercinta yang senantiasa mendo’akan dan memberikan semangat dalam perjalanan studi Strata 1 maupun dalam kehidupan penulis.
v
Akhir kata, penulis mohon maaf atas kekeliruan dan kesalahan yang terdapat dalam Skripsi ini dan berharap semoga Skripsi ini dapat memberikan manfaat bagi khasanah pengetahuan Teknologi Informasi di lingkungan STT Pelita Bangsa khususnya dan Indonesia pada umumnya.
Bekasi, Oktober 2018
vi
DAFTAR ISI
PERSETUJUAN ... i
PENGESAHAN ... ii
PERNYATAAN KEASLIAN PENELITIAN ... iii
KATA PENGANTAR ... iv DAFTAR ISI ... vi DAFTAR TABEL ... ix DAFTAR GAMBAR ... x ABSTRACT ... xi ABSTRAK ... xii BAB I PENDAHULUAN ... 1 1.1 Latar Belakang ... 1 1.2 Identifikasi Masalah ... 3 1.3 Rumusan Masalah ... 4 1.4 Batasan Masalah ... 4
1.5 Tujuan dan Manfaat ... 4
1.5.1 Tujuan ... 4
1.5.2 Manfaat ... 5
1.6 Sistematika Penulisan ... 6
vii 2.1 Kajian Pustaka ... 7 2.1.1 Data Mining ... 7 2.1.2 Karyawan ... 20 2.1.3 Algoritma C4.5 ... 23 2.1.4 Rapidminer ... 24 2.2 Penelitian Terdahulu ... 27 2.3 Kerangka Berfikir ... 44
BAB III METODE PENELITIAN... 45
3.1 Objek Penelitian ... 45
3.1.1 Sejarah Perusahaan... 45
3.1.2 Visi dan Misi Perusahaan ... 45
3.1.3 Struktur Organisasi Perusahaan ... 46
3.2 Metode Penelitian ... 46
3.2.1 Pengumpulan Data ... 48
3.3 Metode Yang Diusulkan ... 55
BAB IV HASIL DAN PEMBAHASAN ... 56
4.1 Pengujian dan Validasi Hasil ... 56
4.1.1 Hasil ... 56
4.1.2 Pembahasan Jumlah Kasus, Entropy dan Gain ... 58
BAB V PENUTUP ... 66
viii
5.2 Saran ... 66 DAFTAR PUSTAKA ... 68 LAMPIRAN ... 73
ix
DAFTAR TABEL
Tabel 2.1 Contoh Pekerjaan dan Keluaran Fase CRISP-DM (Rahmayuni, 2014) ... 15
Tabel 2.2 Rangkuman Kajian Penelitian ... 32
Tabel 3.1 Atribut Pada Data Karyawan. ... 51
Tabel 3.2 Atribut Yang Digunakan. ... 53
Tabel 4.1 Kode Atribut Data Training Prediksi Karyawan Berprestasi... 58
Tabel 4.2 Data Training Prediksi Karyawan Berprestasi dan Tidak Berprestasi. ... 59
Tabel 4.3 Perhitungan Entropy dan Gain. ... 61
Tabel 4.4 Rule Hasil Decision Tree. ... 65
x
DAFTAR GAMBAR
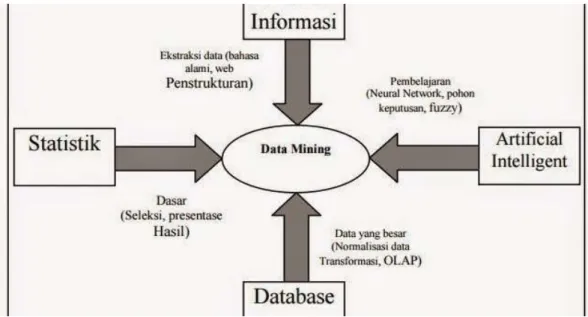
Gambar 2.1 Bidang Ilmu Data Mining ... 8
Gambar 2.2 Proses Data Mining ... 8
Gambar 2.3 Metode Data Mining. ... 10
Gambar 2.4 CRISP-DM . ... 13
Gambar 2.5 Decision Tree. ... 23
Gambar 2.6 Kerangka Berfikir. ... 44
Gambar 3.1 Struktur Organisasi Perusahaan. ... 47
Gambar 3.2 Tahapan Penelitian. ... 48
Gambar 3.3 Data Karyawan ... 50
Gambar 3.4 Langkah Pengujian Metode ... 56
Gambar 4.1 Decision Tree Prediksi Karyawan Berprestasi ... 65
Gambar 4.2 Akurasi Decision Tree Prediksi Karyawan Berprestasi ... 66
xi
ABSTRACT
Achievement employee performance can be achieved if all elements in the company are well integrated, and are able to carry out their roles according to the needs and desires of customers and employees. Therefore, it is necessary to support the existence of competencies to create outstanding employees. The research method used is Decision Tree Learning (DCT). The C4.5 algorithm is part of the DCT, c4.5 algorithm, namely data mining techniques to make poho decisions and will later become a rule. Of the 150 data, all employees obtained will be divided by 80% partition for training data and 20% testing data. Training data is a sample used to build a classifier model, with Rapidminer test equipment. Whereas for processing data using Microsoft Office Excel 2010 program. The results of the study show that (1) Achievement Employees which include special competency and technical competence at PT. Indoaluminium Intikarsa Industri - the average score is included in the high category. (2) The level of accuracy is measured by Confusion Matrix and Receiver Operating Caracteristic (ROC). Evaluation in Confusion Matrix is intended to find the accuracy, precision, and recall data values.
Keywords: Outstanding Employees, Data Mining, C4.5 Algorithm, Confusion Matrix, ROC.
xii ABSTRAK
Kinerja karyawan yang berprestasi dapat dicapai jika seluruh elemen-elemen yang ada dalam perusahaan terintegrasi dengan baik, dan mampu menjalankan peranannya sesuai dengan kebutuhan dan keinginan pelanggan dan karyawan. Oleh sebab itu diperlukan dukungan adanya kompetensi guna menciptakan karyawan berprestasi. Metode penelitian yang digunakan adalah Decision Tree Learning (DCT). Algoritma C4.5 merupakan bagian dari DCT, algoritma c4.5, yakni teknik data mining untuk membuat poho keputusan dan nantinya akan menjadi sebuah rule. Dari 150 data keseluruhan karyawan yang diperoleh akan dibagi partisi 80% untuk data training dan 20% data testing. Data training adalah sampel yang digunakan untuk membangun model classifier, dengan alat uji Rapidminer. Sedangkan untuk pengolahan data menggunakan program Microsoft Office Excel 2010. Hasil penelitian menunjukan bahwa (1) Karyawan Berprestasi yang meliputi koompetensi khusus dan kompetensi teknikal pada PT. Indoaluminium Intikarsa Industri rata – rata skornya termasuk dalam kategori tinggi. (2) Tingkat akurasi diukur dengan Confusion Matrix dan Receiver Operating Caracteristic (ROC). Evaluasi dalam Confusion Matrix ditujukan untuk mencari nilai accuracy, nilai precision, dan nilai recall data.
Kata kunci : Karyawan berprestasi, data mining, algoritma C4.5, Confusion
1
BAB I
PENDAHULUAN
1.1 Latar Belakang
Pemanfaatan teknologi komputer bertujuan sebagai alat bantu dalam mendukung kegiatan operasional suatu bidang usaha untuk memudahkan manusia dalam mendapatkan data atau informasi secara cepat, tepat dan akurat sehingga efektivitas dan efisiensi kerja tercapai. Salah satunya dalam melakukan penilaian prestasi kerja pada perusahaan. Pengembangan dan penelitian terus dilakukan untuk dapat meningkatkan kemajuan teknologi dan ilmu pengetahuan. Perusahaan adalah termasuk pihak yang harus mengembangkan teknologi agar tetap bertahan terhadap persaingan yang semakin ketat serta dapat mengikuti perkembangan kemajuan jaman. Berkembangnya perusahaan juga harus di ikuti oleh meningkatnya kualitas sumber daya manusia yang tergabung didalamnya sehingga semua target perusahaan dapat dicapai bersama-sama. Sumber daya manusia yang berkualitas ditandai dengan kemampuan setiap individu untuk menyelesaikan pekerjaan yang menjadi tanggung jawabnya masing-masing. Perusahaan juga akan memberikan apresiasi terhadap karyawan yang berprestasi agar dapat memacu kinerja karyawan lainnya.
PT. Indoaluminium Intikarsa Industri, sebagai objek penelitian dengan tujuan untuk mengkaji dan mengetahui sejauh mana tingkat penilaian, efektivitas, dan efisiensi kerja untuk menghasilkan prestasi kerja yang optimal. PT. Indoaluminium Intikarsa Industri, yang dikenal sebagai 3I adalah salah satu pabrik
aluminium paling maju dan modern di indonesia yang memasok foil aluminium bekualitas superior untuk kemasan roko, farmasi, dan makanan, insulasi atap, pembukungkus kabel, rumah tangga, dan banyak keperluan lainnya. 3I didirikan pada tahun 1992 dengan parbrik ramah lingkungan yang terletak di cibitung, sektor industri baru Bekasi, Jawa Barat, sekitar 40 km dari Jakarta.
Perusahaan dalam hal memberikan apresiasi tentunya harus melakukan penilaian terhadap kinerja seluruh karyawannya terlebih dahulu. Menilai karyawan bukan hal yang mudah bila jumlah karyawan begitu banyak. Hal ini akan membuat tim penilai menjadi kesulitan mengolah data maupun mendapatkan hasil yang maksimal, apalagi kriteria penilaian yang banyak akan membuat semua data karyawan harus dilihat dengan teliti dan hati-hati. Hasil penilaian dari perusahaan terkadang dinilai tidak obyektif tidak transparannya kriteria-kriteria apa saja yang dilibatkan dalam penilaian karyawan, sehingga muncul anggapan bahwa data dapat dimanipulasi dan hasil dari penilaiannya yang tidak adil. Hal tersebut dapat terjadi karena sulitnya mengambil keputusan dengan kriteria dan data yang begitu besar tanpa adanya otomatisasi penggalian data. Sebagai dampaknya perusahaan tidak akan mendapatkan sumber daya manusia yang kompetitif dikarenakan data dengan kenyataan yang dilapangan sangat berbeda mengenai kinerja karyawan-karyawannya. Salah satu caranya dengan mengembangkan metode penelitian baru yang dapat menambah keakuratan hasil keputusan yaitu penggunaan data mining. Dari pengukuran kinerja ketiga algoritma yang telah dilakukan dengan menggunakan teknik PSO dan berdasarkan jumlah data maka dapat disimpulkan bahwa Algoritma C4.5 memiliki
kemampuan dalam pengambilan keputusan untuk menentukan karyawan teladan yang diterima dan yang ditolak Kajian Komparasi Penerapan Algortma C4.5, Neural Network , Dan Svm Dengan Teknik Pso Untuk Pemilihan Karyawan Teladan PT. Xyz (Rudi Apriyadi Raharjo, 2017). Menimbang dari latar belakang masalah diatas maka penulis mengambil penelitian skripsi ini dengan judul “PENERAPAN DATA MINING DALAM MEMPREDIKSI KARYAWAN BERPRESTASI PADA PT.INDOALUMINIUM INTIKARSA INDUSTRI DENGAN METODE ALGORITMA C4.5”.
1.2 Identifikasi Masalah
Penulis mengumpulkan masalah – masalah dari hasil literatur dan observasi sebagai berikut:
1. Kesulitan dalam melihat tingkat prestasi karyawan secara akurat dan efektif. 2. Karyawan yang dinilai adalah karyawan yang berbeda-beda dalam tugas
tambahannya sehingga membuat berbeda kriteria penilainnya.
3. Adanya beberapa kriteria penilaian yang disebabkan tugas tambahan maka membutuhkan waktu penilaian yang cukup lama.
4. Hasil penilaian dinilai tidak obyektif karena tidak transparannya kriteria dan proses yang digunakan untuk melakukan penilaian karyawan.
5. Masih ada keterbatasan Sumber Daya Manusia dalam proses pengimplementasian tingkat prestasi kerja pada seluruh karyawan PT. Indoaluminium Intikarsa Industri.
1.3 Rumusan Masalah
1. Bagaimana penerapan algoritma C4.5 pada penilaian karyawan berprestasi dan tidak berprestasi pada PT. Indoaluminium Intikarsa Industri?
2. Bagaimana performa algoritma C4.5 pada penilaian karyawan berprestasi dan tidak berprestasi?
1.4 Batasan Masalah
Pembahasan penelitian ini dibatasi agar tidak menyimpang dari apa yang telah dirumuskan, batasan masalah pada penelitian ini sebagai berikut.
1. Belum adanya prediksi dalam melihat tingkat prestasi karyawan yang secara akurat dan efektif.
2. Hasil penilaian dinilai tidak obyektif karena tidak transparannya kriteria dan proses yang digunakan untuk melakukan penilaian karyawan.
3. Hasil Keputusan penilaian karyawan belum dapat dinilai tingkat keakuratannya.
1.5 Tujuan dan Manfaat
1.5.1 Tujuan
1. Untuk mengimplementasikan penilaian kompetensi karyawan dengan menggunakan algoritma C4.5.
2. Untuk mengetahui performa algoritma c4.5 pada penilaian karyawan berprestasi dan tidak berprestasi jika diukur dengan keakuratan hasil prediksi.
1.5.2 Manfaat
Manfaat yang diperoleh dari penelitian ini adalah sebagai berikut: 1. Manfaat Praktis ;
a. Memudahkan pihak PT. Indoaluminium Intikarsa Industri dalam menentukan kebijakan untuk memprediksi karyawan berprestasi secara akurat dan efektif.
b. Menghindari penilaian yang tidak obyektif serta tidak transparan dalam melakukan penilaian terhadap karyawan yang berprestasi maupun tidak berprestasi.
2. Manfaat Teoritis :
Diharapkan dapat memberikan kontribusi bagi penilitian yang berkaitan dengan metode klasifikasi Algoritma C4.5 khusus nya dalam memprediksi karyawan berprestasi atau tidak .
1.6 Sistematika Penulisan
Agar lebih memahami laporan skripsi ini, maka laporan skripsi ini dikelompokkan ke dalam bebrapa sub bab pembahasan dan menggunakan sistematika penyampaian sebagai berikut:
BAB I PENDAHULUAN
Bab ini menjelaskan mengenai uraian secara umum mengenai latar belakang masalah, identifikasi masalah, rumusan dan batasan masalah, tujuan dan manfaat yang ingin dicapai dari penelitian ini serta sistematika penulisan.
BAB II LANDASAN TEORI
Menjelaskan tentang kajian pustaka serta teori yang melandasi penelitian Algoritma C4.5 untuk prediksi karyawan berprestasi.
BAB III METODE PENELITIAN
Menjelaskan tentang metode penelitian dari pengumpulan data eksperimen dengan menguji data yang ada menggunakan Algoritma C4.5 yang memprediksi berprestasi atau tidaknya seorang karyawan.
BAB IV HASIL DAN PEMBAHASAN
Menjelaskan dan menampilkan hasil prediksi dengan menggunakan Algoritma C4.5.
BAB V PENUTUP
7 BAB II
LANDASAN TEORI
2.1 Kajian Pustaka
2.1.1 Data Mining
A. Definisi Data Mining
Data mining adalah serangkaian proses untuk menggali nilai tambah berupa informasi yang selama ini tidak diketahui secara manual dari suatu basis data. Informasi yang dihasilkan diperoleh dengan cara mengekstraksi dan menggali pola yang penting atau menarik dari data yang terdapat pada basis data. Data mining terutama digunakan untuk mencari pengetahuan yang terdapat dalam basis data yang besar sehingga sering disebut Knowledge Discovery Databases (KDD) ( Retno, 2017 : 1 ).
Berdasarkan definisi-definisi yang telah disampaikan, hal penting yang terkait dengan Data Mining adalah:
1. Data Mining merupakan suatu proses otomatis terhadap data yang sudah ada.
2. Data yang akan diproses berupa data yang sangat besar.
3. Tujuan data mining adalah mendapatkan hubungan atau pola yang akan mungkin memberikan indikasi yang bermanfaat.
B. Tahapan Data Mining
Sebagai suatu rangkaian proses, data mining dapat dibagi menjadi beberapa tahap proses yang diilustrasikan pada Gambar 2.2. Tahap-tahap tersebut bersifat interaktif, pemakai terlibat langsung atau dengan perantaraan knowledge base (Ridwan, Suyono, & Sarosa, 2013).
Tahap-tahap data mining adalah sebagai berikut: 1. Pembersihan data (data cleaning)
Pembersihan data merupakan proses menghilang-kan noise dan data yang tidak konsisten atau data tidak relevan.
2. Integrasi Data (data integration)
Integrasi data merupakan penggabungan data dari berbagai database ke dalam satu database baru.
3. Seleksi data (data selection)
Data yang ada pada database sering kali tidak semuanya dipakai, oleh karena itu hanya data yang sesuai untuk dianalisis yang akan diambil dari database.
4. Transformasi data (data transformation)
Data diubah atau digabung ke dalam format yang sesuai untuk diproses dalam data mining.
5. Proses mining
Merupakan suatu proses utama saat metode diterapkan untuk menemukan pengetahuan berharga dan tersembuny dari data.
6. Evaluasi pola (pattern evaluation)
Untuk mengidentifikasi pola-pola menarik ke dalam knowledge based yang ditemukan.
7. Presentasi pengetahuan (knowledge presentation)
Merupakan visualisasi dan penyajian pengetahuan mengenai metode yang digunakan untuk memperoleh pengetahuan yang diperoleh pengguna.
C. Pengelompokan Data Mining
Data mining dibagi menjadi beberapa kelompok berdasarkan tugas yang dapat dilakukan, yaitu :
1. Classification
Suatu teknik dengan melihat pada kelakuan dan atribut dari kelompok yang telah didefinisikan. Teknik ini dapat memberikan klasifikasi pada data baru dengan memanipulasi data yang ada yang telah diklasifikasi dan dengan menggunakan hasilnya untuk memberikan sejumlah aturan. Salah satu
contoh yang mudah dan popular adalah dengan Decision tree yaitu salah satu metode klasifikasi yang paling populer karena mudah untuk diinterpretasi. Decision tree adalah model prediksi menggunakan struktur pohon atau struktur berhirarki.
2. Association
Digunakan untuk mengenali kelakuan dari kejadian-kejadian khusus atau proses dimana hubungan asosiasi muncul pada setiap kejadian. Salah satu contohnya adalah Market Basket Analysis, yaitu salah satu metode asosiasi yang menganalisa kemungkinan pelanggan untuk membeli beberapa item secara bersamaan.
3. Clustering
Digunakan untuk menganalisis pengelompokkan berbeda terhadap data, mirip dengan klasifikasi, namun pengelompokkan belum didefinisikan sebelum dijalankannya tool data mining. Biasanya menggunakan metode neural network atau statistik. Clustering membagi item menjadi kelompok-kelompok berdasarkan yang ditemukan tool data mining.
4. Decision Tree
Pohon keputusan atau yang lebih dikenal dengan istilah Decision Tree ini merupakan implementaasi dari sebuah sistem yang manusia kembangkan dalam mencari dan membuat keputusan untuk masalah-masalah tersebut dengan memperhitungkan berbagai macam faktor yang berkaitan di dalam lingkup masalah tersebut. Dengan pohon keputusan, manusia dapat dengan mudah mengidentifikasi dan melihat hubungan antara faktor-faktor yang mempengaruhi suatu masalah sehingga dengan memperhitungkan faktor-faktor tersebut dapat dihasilkan penyelesaian terbaik untuk masalah tersebut. Pohon keputusan ini juga dapat menganalisa niai resiko dan nilai suatu informasi yang terdapat dalam suatu alternatif pemecahan masalah. Pohon keputusan dalam analisis pemecahan masalah pengambilan keputusan merupakan pemetaan alternatif-alternatif pemecahan masalah
yang dapat diambil dari masalah tersebut. Pohon keputusan juga memperlihatkan faktor-faktor kemungkinan yang dapat mempengaruhi alternatif-alternatif keputusan tersebut, disertai dengan estimasi hasil akhir yang akan didapat bila kita mengambil alternatif keputusan. Secara umum, pohon keputusan adalah suatu gambaran permodelan dari suatu persoalan yang terdiri dari serangkaian keputusan yang mengarah kepada solusi yang dihasilkan. Peranan pohon keputusan sebagai alat bantu dalam mengambil keputusan telah dikembangkan oleh manusia sejak perkembangan teori pohon yang dilandaskan pada teori graf. Seiring dengan perkembangannya, pohon keputusan kini telah banyak dimanfaatkan oleh manusia dalam berbagai macam sistem pengambilan keputusan.
Decision Tree adalah struktur flowchart yang menyerupai tree (pohon), dimana setiap simpul internal menandakan suatu tes pada atribut, setiap cabang mempresentasikan hasil tes, dan simpul daun mempresentasikan kelas atau distribusi kelas. Alur pada decision tree di telusuri dari simpul akar ke simpul daun yang memegang prediksi. (Aprilla Dennis, 2013).
D. Fungsi dan Tugas Data Mining
Data mining menganalisis data menggunakan tool untuk menemukan pola dan aturan dalamhimpunan data. Perangkat lunak bertugas untukmenmukan pola dengan mengidentifikasi aturan dan fitur pada data. Tool data mining diharapkan mampumengenal pola ini dalam data dengan input minimaldari user.
E. Metode Data Mining
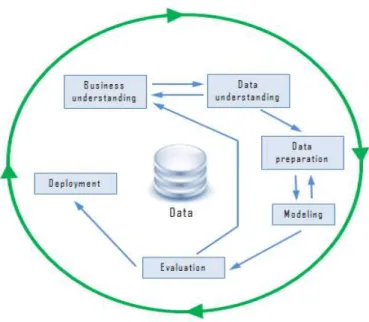
Data mining telah diterapkan di hampir seluruh bidang industri dan pengetahuan. Dengan semakin luasnya penerapan data mining tersebut, terdapat keinginan dari sekelompok analis data mining yang mewakili DaimlerChrysler, SPSS, dan NCR untuk membuat sebuah model proses data mining yang netral terhadap jenis industri, tools, dan aplikasi.
Para analisis tersebut bergabung dan membangun Cross-Industry Standard Process for Data Mining (CRISP-DM) pada tahun 1996. CRISP-DM
menyediakan proses standar pelaksanaan data mining untuk menyelesaikan masalah dalam sebuah bisnis atau penelitian yang dapat digunakan semua orang
Gambar 2.4 CRISP-DM (Sigit Abdillah, 2015)
Berdasarkan CRISP-DM, sebuah proyek data mining merupakan sebuah siklus hidup yang terdiri atas enam fase (Hadi, 2017):
1. Business Understanding
Fase awal ini berfokus pada pemahaman tujuan dan kebutuhan proyek dari perspektif bisnis, kemudian mengubah pengetahuan ini ke dalam definisi masalah dan desain rencana awal data mining untuk mencapai tujuan proyek.
2. Data Understanding
Fase pemahaman data dimulai dengan pengumpulan data awal dan dilanjutkan dengan aktifitas-aktifitas lain untuk mengenal data, mengidentifikasi permasalahan kualitas data, atau untuk mendeteksi subset data yang menarik untuk membentuk hipotesis bagi informasi yang tersembunyi.
Fase periapan data meliputi seluruh aktifitas yang dilakukan untuk membangun dataset akhir (data yang akan digunakan sebagai masukan bagi aplikasi pemodelan) dari data mentah awal. Proses persiapan data biasanya dilakukan berulang kali untuk memastikan kualitas data telah dicapai. Aktifitas persiapan data antara lain pemilihan tabel , record, dan atribut, serta pembersihan dan trasnformasi data.
4. Modeling
Pada fase ini, berbagai jenis teknik pemodelan dipilih dan diaplikasikan serta parameter-parameternya dikalibrasi untuk mendapatkan hasil yang optimal. Biasanya terdapat beberapa teknik juga memiliki kebutuhan akan bentuk data yang spesifik. Oleh karena itu, seringkali proses persiapan data dibutuhkan kembali.
5. Evaluation
Pada tahap ini, model yang tampak memiliki kualitas tinggi dari perspektif analisis data telah dihasilkan. Sebelum dilanjutkan ke tahap penerapan, model yang dihasikan dievaluasi dan di – review tiap langkah pembuatannya untuk memastikan model tersebut telah mencapai tujuan bisnis dengan tepat. Tujuan utamanya adalah untuk menentukan apakah terdapat beberapa permasalahan bisnis yang tidak dicakup dengan baik. Pada akhir fase ini, keputusan mengenai pengaplikasian hasil data mining harus dapat dicapai.
6. Deployment
Pekerjaan yang dilakukan pada fase penerapan ini tergantung pada kebutuhn dan tujuan proyek data mining, dari yang paling sederhana seperti pembuatan laporan, hingga yang paling kompleks seperti pengimplementasian proses data mining ke dalam sistem organisasi.
Panduan CRISP-DM yang dikeluarkan oleh Konsorsium CRIPS-DM memberikan contoh-cotoh pekerjaan yang dapat dilakukan untuk tiap fasenya besera hasil keluaran yang didapatkan (Tabel 2.2). Contoh pekerjaan dan keluaran
ini merupakan contoh secara umum dimana penerapannya tergantung pada jenis industri dn kebutuhan serta tujuan data mining (Rahmayuni, 2014).
Tabel 2.1 Contoh Pekerjaan dan Keluaran Fase CRISP-DM (Rahmayuni, 2014)
F. Jenis Data Mining
Sebagai teknologi umum, data mining dapat diaplikasikan pada semua jenis data selama data tersebut bermakna untuk aplikasi target. Bentuk data yang paling dasar untuk aplikasi pertambangan adalah data database, data warehouse dan data transaksional. Data mining juga dapat diterapkan pada bentuk data lainnya (misalnya, data stream, data pesanan/urutan, grafik atau data jaringan, data spasial, data teks, data multimedia).
Terkadang transformasi data dan konsolidasi dilakukan sebelum proses pemulihan data, terutama dalam kasus pergudangan data. Pengurangan data juga
dapat dilakukan untuk mendapatkan representasi data asli yang lebih kecil tanpa mengorbankan integritasnya(Jiawei, Kamber, Han, Kamber, & Pei, 2012)
1. Data Database
Sistem database, juga disebut sistem manajemen basis data (DBMS) terdiri dari kumpulan data yang saling terkait, dikenl sebagai database, dan satu set program perangkat lunak untuk mengelola dan mengakses data. Program perangkat lunak menyediakan mekanisme untuk mendefinisikan struktur database dan penyimpanan data untuk menentukan dan mengelola akses data bersamaan, bersama, atau terdistribusi dan untuk memastikan konsistensi dan keamanan informasi yang tersimpan meskipun sistem mogok atau upaya akses yang tidak sah.
Database relasional adalah kumpulan tabel, yang masing masing diberi keunikan nama. Setiap tabel terdiri dari sekumpulan atribut (kolom atau kolom) dan biasanya took set besar tupel (catatan atau baris). Setiap tuple dalam tabel relasional mewakili sebuah objek diidentifikasi dengan kunci unik dan dijelaskan oleh seperangkat nilai atribut. Model data semantik, seperti model data entity-relationship (ER), sering dibangun untuk basis data relasional. Model data ER mewakili database sebagai seperangkat entitas dan hubungannya.
Data relasional dapat diakses dengan query database yang ditulis dalam bahasa(mis,SQL) atau dengan bantuan antarmuka pengguna grafis. Permintaan yang diberikan adalah diubah menjadi satu set operasi relasioanal, seperti join, selection, dan projection, dan kemudian dioptimalkan untuk pengolahan yang efisien. Permintaan memungkinkan pengambilan himpunan bagian tertentu dari data. Mialkan pekerjaan anda adalah menganalisis data AllElectronics. Melalui Penggunaan kueri relasional, anda bisa menanyakan hal-hal seperti, “Tunjukan daftar semua item yang ada dijual pada kuartal terakhir”. “Bahasa relasional juga menggunakan fungsi agregat seperti jumlah, avg (rata-rata), hitungan, maks(maksimum), dan min (minimum)”. Menggunakan agregat memungkinkan anada untuk bertanya: “Tunjukan total penjualan bulan terakhir, dikelompokkan
menurut cabang”, atau “Berapa banyak penjualan transaksi terjadi di bulan Desember?” atau “Salesman mana yang paling tinggi penjualan?”
Saat menggali database relasional, kita bisa melangkah lebih jauh dengan mencari tren atau pola data Misalnya, sistem data mining bisa menganalisa data pelanggan untuk mmprediksi risiko kredit pelanggan baru berdasarkan pendapatan, usia, dan kredit sebelumnya informasi. Sistem data mining juga dapat mendeteksi penyimpangan – yaitu, item dengan penjualan yang jauh dari yang diharapkan diabandingkan dengan tahun sebelumnya. Penyimpangan semacam itu kemudian bisa diselidiki lebih lanjut. Misalnya, data miining mungin menemukan yang telah terjadi perubahan kemasan barang atau kenaikan harga yang signifikan. Database relasional adalah salah satu informasi yang paling umum tersedia dan terkaya repositori, dan dengan demikian mereka adalah bentuk data utama dalam studi data mining. (Jiawei, Kamber, Han, Kamber, & Pei, 2012)
2. Data Warehouse
(Jiawei, Kamber, Han , Kamber, & Pei, 2012) Misalkan AllElectronics adalah perusahaan internasional yang sukses dengan cabang di seluruh dunia. Setiap orang memiliki kumpulan database tersendiri. Presiden AllElectronics telah meminta anda untuk memberikan analisis terhadap penjualan per item per jenis barang per cabang untuk kuartal ketiga. Ini adalah tugas yang sulit, terutama karena data yang relevan tersebar di beberapa database yang berada di berbagai lokasi. Jika AllElectronics memiliki data warehouse, tugas ini akan mudah. Sebuah gudang data adalah gudang informasi yang dikumpulkan dari berbagai sumber, disimpan dibawah skema terpadu, dan biasanya berada di satu situs. Gudang data dibangun melalui proses pembrsihan data, integrasi data, transformasi data, pemuatan data, dan penyegaran dta berkla. Untuk memudahkan pengambilan keputusan, data di gudang data diatur sekitar subjek utama (misalnya, pelanggan, item, pemasok, dan aktivitas). Data disimpan untuk memberikan informasi dari perspektif sejarah, seperti dalam 6 sampai 12 bulan terakhir, dan biasanya dirangkum. Misalnya, daripada menyimpan rincian setiap transaksi penjualan, gudang data dapat menyimpan ringkasan transaksi per item
type untuk setiap toko atau, dirangkum ke tingkat yang lebih tinggi, untk setiap toko atau, dirangkum ke tingkat yang lebih tinggi, untuk setiap wilayah penjualan. Sebuah gudang data biasanya dimodelkan oleh struktur data multidimensional, yang disebut data kubus, dimana setiap dimensi sesuai dengan atribut atau sekumpulan atribut dalm skema, dan setiap sel menyimpan nilai dari beberapa ukuran agregat seperti hitungan.
3. Data Transaksional
Secara umum, setiap record dalam database transaksional menangkap transaksi, seperti pembelian pelanggan, pemesanan penerbangan. Transaksi biasanya menyertakan nomor identitas transaksi unit (trans ID) dan daftar item yang membentuk transaksi, seperti barang yang dibeli dalam transaksi. Database transaksional mungkin memiliki tabel tambahan, yanng berisi informasi lain yang terkait dengan transaksi, seperti deskripsi item, informasi tentang wiraniaga atau cabang, dan sebagainya. (Jiawei, Kamber, Han, Kamber, & Pei,2012)
4. Jenis Data Lainnya
Selain data database relasional, data gudang data, dan data transaksi , masih banyak jenis data lain yang memiliki bentuk dan struktur serbaguna dan makna semantik yang agak berbeda. Data semacam itu dapat dilihat pada banyak aplikasi data time-related atau sequence (misalnya catatan sejarah, data bura saham, dan deret waktu dan data urutan bilogis), aliran data (misalnya data surveilans dan sensor video, yang terus menerus ditransmisikan), data spasial (misalnya, peta), data desain teknik (misalnya, desain bangunan, komponen sistem, atau sirkuit terpadu), data hypertext dan multimedia (termasuk teks, gambar, video, dan data audio), grafik dan data jaringan (misalnya, jejaring sosil dan informasi), dan web (gudang inforamsi besar yang didistribusikan secara luas yang tersedia di internet). Aplikasi ini membawa tantangan baru, seperti bagaimana menangani data yang membawa struktur khusus (misalnya, sekuens, pohon, grafik, dan jaringan) dan semantik tertentu (seperti konten pemesanan, gambar, audio dan video, dan konektivitas).
Berbagai jenis pengetahuan bia digali dri jenis data ini,. Disini, kami daftar beberapa. Mengenai data temporal, misalnya, kita bisa menggali data perbankan untuk mengubah tren, yang dapat membantu penjadwalan sesuai dengan volume lalu lintas pelanggan. Data bursa dapat digali untuk mengungkap tren yang dapat membantu anda merencanakan strategi investasi (misalnya, waktu terbaik untuk membeli saham AllElectronics). Kita bisa menambang aliran data jaringan komputer untuk mendeteksi intrusi berdasarkan anomali arus pesan, yng dapat ditemukan dengan penelompokan, kontruksi model arus dinamis atau dengan membandingkan pola yang sering terjadi dengan yang ada pada waktu sebelumnya.
Dengan data spasial, kita bisa mencari pola yang menggambarkan perubahan metropolitan tingkat kemiskinan berdasarkan jarak kota dari jalan raya utama. Hubungan anatara satu set objek spasial dapat diperiksa untuk menemukan himpunan bagian dari objek secara otokorelasi spasial atau terkait. Dengan data test mining, seperti literatur tentang data mining dari sepuluh tahun terkhir, kita dapat mengidentifikasi evaluasi topik hangat dilapangan. Dengan komentar pengguna pertambangan pada produk (yang sering diajukan sebagai pesan teks singkat), kami dapat menilai sentimen pelanggan dan memahamai seberapa baik produk dipeluk oleh pasar. Daro data multimedia, kita bia menggali gambar untuk mengidentifikasi objek dan mengklasifikasikannya dengan menugaskan label semantik atau tag. Dengan mengumpulkan data video game hoki, kita dapat mendetesksi rangakaian video yang sesuai dengan sasaran. Penggalian web dapat membantu kami mempelajari distribusi informasi secara umum, mengkarakterisasi dan mengklasifikasikan halaman web, dan menemukan dinamika web dan asosiasi dan hubungan lainnya diantara halaman web, pengguna, komunitas, dn aktivis berbasis web yang berbeda. Penting untuk diingat bahwa, dalam banyak aplikasi, beberapa jenis data hadir. Misalnya , di penggalian web, sering ada data teks dan data multimedia (misalnya, gambar dan video) dihalaman web, data grafik seperti grafik web, dan data peta pada beberapa situs web. Dalam bioinformatika, urutan genomik, jaringan biologis, dan struktur ruang 3-D genom dapat hidup berdampingan untuk objek biologis tertentu. Penggalian beberapa sumber data data kompleks sering menghasilkan temuan
yang bermanfaat karena peningkatan dan konsolidasi bersama beberapa sumber serupa. Di sisi lain, ini juga menantang karena kesulitan dalam pembersihan data dan integrasi data, serta inteaksi kompleks antara berbagai sumber data tersebut.
Sedangakan data tersebut memerlukan fasilitas yang canggih untuk penyimpanan, pengambilan, dan penyimpanan yang efisien memperbarui, mereka juga menyediakan lahan subur dan menimbulkan tantangan dalam penelitian dan implementasi untuk data mining. Penggalian data pada data semacam itu adalah topik lanjutan. Metode yang terlibat adalah perluasan dari teknik dasar yang disajikan dalam buku ini. (Jiawei, Kamber, Han, Kamber, & Pei, 2012).
2.1.2 Karyawan
A. Definisi Karyawan
Secara umum yang dimaksud dengan karyawan adala orang yang bekerja di suatu perusahaan atau lembaga dan di gaji dengan uang. Atau karyawan dapat diartikan juga sebagai orang yang bertugas sebagai pekerja pada suatu perusahaan atau lembaga untuk melakukan operasional tempat kerjanya dengan balas jasa berupa uang (Wulandari, 2016).
B. Ciri – Ciri Karyawan Baik dan Berkualitas
Karyawan pasti tidak akan pernah lepas dari kinrja, maka setiap pimpinan perusahaan atau lembaga akan selalu melakukan penilaian terhadap kinerja para karyawannya. Adapun sikap dan ciri-ciri karyawan yang baik, diantaranya:
1. Jujur
Mungkin dalam bekerja dimanapun dan menempati posisi apapun sikap yang paling utama harus jujur terhadap pekerjaannya. Karena orang jujur pasti banyak di sukai oleh orang lain dan selalu mendapatkan kepercayaan yang lebih terhadap pekerjaannya.
Bersikap sopan kepada rekan kerja maupun pimpinan dan selalu beretika dalam bekerja merupakan salah satu ciri karyawan yang baik. Karena seorang karyawan yang bersikap seperti ini akan dihargai oleh pimpinan maupun rekan kerja dan memiliki nilai tambah. Karyawan yang baik juga selalu mengikuti kebijakan tempat dia bekerja dan selalu mentaati aturan-aturan tempat kerjanya.
3. Disiplin
Setiap pimpinan atau alasan selalu menyukai karyawan yang disiplinbaik itu dalam melakukan pekerjaan maupun dalam ketepatan waktu. Misalnya datang tepat waktu , istirahat sesuai aturan, tidak menunda pekerjaan dan tidak meninggalkan pekerjaan saat jam kerja berlangsung, karyawan yang seperti itu selalu di sukai pimpinan karena menunjukan bahwa dia disiplin dalam bekerja dan pimpinanpun akan selalu menghargainya.
4. Komunikasi yang baik
Karyawan yang memiliki kemampuan berkomunikasi dengan baik umumnya selalu disukai oleh pimpinan dalam bekerja, baik itu dari cara berkomunikasi secara lisan maupun tulisan. Karena jika cara berkomunikai kurang baik dapat menyebabkan munculnya permasalahan dalam bekerja. 5. Kerja Keras
Salah satu ciri karyawan yang baik adalah selalu bekerja keras, karena cukup sulit untuk mendapatkan karyawan pekerja keras oleh suatu perusahaan. Banyak sekali karyawan yang mengatakan bahwa dirinya adalah seorang pekerja keras padahal kenyataannya tidak.
6. Bekerja Dengan Tim
Dapat bekerja dengan tim merupakan ciri karyawan yang baik, karena setiap perusahaan selalu membutuhkan suatu tim untuk memeahkan suatu permasalahan. Maka sering sekali dibutuhkan karyawan yang dapat bekerja dengan baik dlam sebuah tim.
7. Mampu Beradaptasi dan belajar hal-hal baru
Ciri karyawan yang baik mengetahui bagaimana caranya beradaptasi secara cepat dengan lingkungan kerja maupun pekerjaannya yang baru. Menerima untuk mempelajari hal-hal yang baru dan selalu memberikan yang terbaik dalam setiap pekerjaannya merupakan ciri karyawan yang di sukai dan diperlukan oleh setiap perusahaan atau lembaga.
C. Jenis- Jenis Karyawan
Karyawan pada suatu tempat kerja umumnya dibagi menjadi 2 macam, diantaranya (Mallu,2015) :
1. Karyawan Tetap
Karyawan yang bertugas tetap merupakan karyawan yang mempunyai perjanjian atau kontrak dengan perusahaan atau lembaga tempat dia bekerja dengan jangka waktu yang tidak ditetapkan, dapat dikatakan juga permanen. Umumnya karyawan yang berstatus seperti ini mempunyai hak yang lebih dibandingkan dengan karyawan yang statusnya tidak tetap. Karyawan tetap dapat dikatakan juga karyawan yang aman, maksudnya dia sudah mendapatkan kepastian tentang pekerjaannya jadi tidak memikirkan kapan kontrak kerjanya akan habis, diperpanjang atau tidak, sehingga karyawan tetap hanya tinggal fokus saja kepada pekerjaannya.
2. Karyawan Tidak Tetap
Karyawan yang berstatus tidak tetap merupakan karyawan yang mempunyai perjanjian atau kontrak yang waktunya sudah ditentukan, biasanya karyawan jenis ini di pekerjakan perusahaan atau lembaga hanya ketika dibutuhkan saja. Karyawan tidak tetap umumnya dapat di berhentikan sewaktu-waktu oleh perusahaan atau lembaga tempat dia bekerja saat jasanya tidak dibutuhkan lagi. Karyawan tidak tetap memiliki hak yang cenderung lebih sedikit dibandingkan dengan karyawan tetap. Ciri karyawan yang berstatus tidak tetap misalnya di pekerjakan di pekerjakan oleh perusahaan untuk jangka waktu tertentu, hubungan perusahaan dan
karyawan kontrak tertulis dalam suatu perjanjian kontrak dengan jangka waktu tertentu, dan status karyawan hanya dapat diterapkan untuk pekerjaan tertentu saja.
2.1.3 Algoritma C4.5
Algoritma decision tree digunakan untuk membangun sebuah pohon keputusan yang mudah dimengerti, fleksibel, dan menarik karena dapat divisualisasikan dalam bentuk (Rohman,2013).
Gambar 2.5 Decision Tree (Huda,2010)
Pohon keputusan adalah salah satu metode klasifikasi yang paling populer karena mudah untuk diinterpretasi oleh manusia. Pohon keputusan adalah model prediksi menggunakan struktur berhirarki. Konsep dari pohon keputusan adalah mengubah data menjadi pohon keputusan dan aturan-aturan keputusan.
Ada beberapa tahap dalam membuat sebuah pohon keputusan dengan Algoritma C4.5 yaitu (Ina,2013):
1. Mempersiapkan data trainiing, dapat diambil dari data histori yang pernah terjadi sebelumnya dan sudah dikelompokan dalam kelas-kelas tertentu.
2. Menentukan akar dari pohon dengan menghitung nilai gain yang tertinggi dari masing-masing atribut atau berdasarkan nilai index entropy terendah. Sebelumnya dihitung terlebih dahulu nilai index entropy, dengan rumus:
𝐄𝐧𝐭𝐫𝐨𝐩𝐲(𝐒) = ∑ − 𝑛 𝑖−1 𝑝𝑖 ∗ 𝑙𝑜𝑔2𝑝𝑖 Keterangan : S = Himpunan Kasus n = Jumlah partisi S
p = Proporsi dari Si terhadap S 3. Hitung nilai gain dengan rumus :
𝐺𝑎𝑖𝑛(𝑆, 𝐴) = 𝐸𝑛𝑡𝑟𝑜𝑝𝑦 − ∑ |𝑠𝑖||𝑠𝑖| 𝑛 𝑖=1 ∗ 𝐸𝑛𝑡𝑟𝑜𝑝𝑦(𝑆𝑖) Keterangan : S = Himpunan Kasus A = Atribut
n = Jumlah partisi atribut A
|Si| = Jumlah kasus pada partisi ke –i |S| = Jumlah kasus data dalam s
2.1.4 Rapidminer
RapidMiner merupakan perangkat lunak yang bersifat terbuka (open source) RapidMiner adalah sebuah solusi untuk melakukan analisis terhadap data mining, text mining, dan analisis prediksi. RapidMiner menggunakan berbagai teknik deskriptif dan prediksi dalam memberikan wawasan kepada pengguna sehingga dapat membuat keputusan yang paling baik. RapidMiner memiliki kurang lebih 500 operator data mining, termsuk operator untuk input, output, data preprocessing dan visualisasi. RapidMiner merupakan software yang berdiri sendiri untuk analisis data dan sebagai mesin data mining yang dapat diintegrasikan pada produknya sendiri. RapidMiner ditulis dengan menggunakan bahasa java sehingga dapat bekerja di semua sistem operasi.
RapidMiner sebelumnya bernama YALE (Yet Another Learning Environment), dimana versi awalnya mulai dikembangkan pada tahun 2001 oleh RalfKlinkenberg, Ingo Mierswa, dan Simon Fischer di Artificial Intelligence Unit
dari University of Dortmund. RapidMiner didistribusikan dibawah lisensi AGPL(GNUAffero General Public License) versi 3. Hingga saat ini telah ribuan aplikasi yang dikembangkan menggunakan RapidMiner di lebih 40 negara. RapidMiner sebagai software open source untuk data mining tidak perlu diragukan lagi karena software ini sudah terkemuka di dunia. RapidMiner menempati peringkat pertama sebagai software data mining pada polling oleh KD nuggets, sebuah portal data mining pada 2010-2011. RapidMiner menyediakan GUI (Graphical User Interface) untuk merancang sebuah pipeline analitis. GUI ini akan menghasilkan file XML (Extensible Markup Language) yang mendefinisikan proses analitis keinginan pengguna untuk diterapkan ke data. File ini kemudian dibaca oleh RapidMiner untuk menjalankan analisis secara otomatis. (Aprilla Dennis, 2013).
RapidMiner memiliki beberapa sifat sebagai berikut:
1. Ditulis dengan bahasa pemrograman java sehingga dapat dijalankan di berbagai sistem operasi.
2. Proses penemuan pengetahuan dimodelkan sebagai operator trees.
3. Representasi XML internal untuk memastikan format standar pertukaran data.
4. Bahasa scripting memungkinkan untuk eksperimen skala besar dan otomatisasi eksperimen.
5. Konsep multi-layer untuk menjamin tampilan data yang efisien dan menjamin penanganan data.
6. Memiliki GUI, Command Line Mode, dan Java API yang dapat dipanggil dari program lain.
Beberapa fitur dari RapidMiner, antara lain :
1. Banyaknya algoritma data mining, seperti decision tree dan self-organization map.
2. Bentuk grafis yang cnggih, seperti tumpang tindih digram histogram, tree chart dan 3D Scatter plots.
3. Banyaknya variasi plugin, seperti text plugin untuk melakukan analisis teks.
4. Menyediakan prosedur data mining dan machine learning termasuk: ETL ( Extraction, Transformation, Loading), data preprocessing, visualisasi, modelling dan evaluasi.
5. Proses data mining tersusun atas operator-operator yang nestable, dideskripsikan dengan XML, dan dibuat dengan GUI.
6. Mengintegrasikan proyek data mining Weka dan statistika R.
A. System Requirment
Sebelum melakukan instalasi software RapidMiner, terdapat beberapa spesifikasi minimal yang harus dimiliki komputer pengguna. Spesifikasi minimal bergantung pada komputer dan sistem operasi yang akan diinstal. Berikut ini beberapa spesifikasi minimal yang dibutuhkan software RapidMiner (Aprilla Dennis, 2013) :
1. Sistem Operasi
RapidMiner merupakan software yang multiplatform, sehingga software dapat dijalankan pada berbagai sistem operasi. Berikut ini beberapa jenis sistem operasi yang dapat diinstal RapidMiner:
1. Microsoft Windows (x86-32) : Windows Xp, Windows Server 2003, Windows Vista, Windows Server 2008, Windows 7.
2. Microsoft Windows (x64) : Windows Xp untuk x64, Windows Server 2003 untuk x64, Windows Server 2008 untuk x64, Windows 7 untuk 64. 3. Unix sistem 32 atau 64 bit.
4. Linux sistem 32 atau 64 bit.
5. Appple Macintosh sistem 32 atau 64 bit.
Sebagai bahan pertimbangan, kami merekomendasikan untuk penggunaan sistem 64 bit. Hal ini dikarenakan jumlah mksimum yang dapat digunakan oleh RapidMiner terbatas pada sistem operasi dengan sistem 32, yaitu hanya sebesar 2GB.
Selain itu, pengguna server RapidAnalytics dalam kombinasi dengan RapidMiner dapat memaksimalkan proses analisis pada RapidMiner, meskipun tugas analisis sudah banyak dapat dijalankan dengan RapidMiner Deskrop Client. Dalam hal ini proses analisa dirancang dengan RapidMiner, kemudian dieksekusi oleh server RapidAnalytics.
B. Rumus Presisi, Akurasi dan Recall
1. Presisi : Tingkat ketepatan antara informasi yang diminta oleh pengguna dengan jawaban yang diberikan oleh sistem.
2. Akurasi : Tingkat kedekatan antara nilai prediksi dengan nilai aktual. 3. Recall : Tingkat keberhasilan sistem dalam menemukan kembali sebuah
informasi. Nilai Sebenarnya TRUE FALSE Nilai Prediksi TRUE TP (True Positive) FP (False Positive) FALSE FN (False Negative) TN (True Negative) Presisi = 𝑇𝑃 𝑇𝑃 + 𝐹𝑃 Akurasi = 𝑇𝑃 + 𝑇𝑁 𝑇𝑃 + 𝐹𝑃 + 𝐹𝑁 + 𝑇𝑁 Recall = 𝑇𝑃 𝑇𝑃+𝐹𝑁 2.2 Penelitian Terdahulu
Beberapa penelitian mengenai prediksi tingkat kompetensi karyawan ataupun yang mendekati penelitian tersebut.
1. Algoritma C4.5 Untuk Penilaian Kinerja Karyawan (Windy Julianto, Rika Yunitarini & Mochamad Kautsar Sophan, 2014). Berdasarkan evaluasi yang dilakukan dapat diketahui bahwa proses pembentukan pohon menggunakan
teknik pruning memiliki kecepatan yang lebih tinggi karena penyederhanaan pohon, tetapi tidak selalu memilki akurasi yang lebih besar. Pohon keputusan Partisi A menggunakan teknik pruning dengan jumlah data taining lebih besar daripada data testing memiliki akurasi tertinggi dibandingkan dengan pohon keputusan yang lain, yaitu mencapai 90%. 2. Kajian Komparasi Penerapan Algortma C4.5, Neural Network , Dan Svm
Dengan Teknik Pso Untuk Pemilihan Karyawan Teladan PT. Xyz (Rudi Apriyadi Raharjo, 2017). Dari pengukuran kinerja ketiga algoritma yang telah dilakukan dengan menggunakan teknik PSO dan berdasarkan jumlah data maka dapat disimpulkan bahwa Algoritma C4.5 memiliki kemampuan dalam pengambilan keputusan untuk menentukan karyawan teladan yang diterima dan yang ditolak.
3. Implementasi Data Mining dengan Algoritma C4.5 untuk Memprediksi Tingkat Kelulusan Mahasiswa (David Hartanto Kamagi, Seng Hansun, 2014). Aplikasi desktop berhasil memprediksi kelulusan mahasiswa dengan presentase 87.5% dari enam puluh data training dan empat puluh data testing. Hasil prediksi kelulusan dari aplikasi penelitian ini dapat membantu bagian program studi untuk mengetahui status kelulusan mahasiswa. Hal ini dapat menjadi rekomendasi pengambilan mata kuliah bagi mahasiswa untuk semester berikutnya seperti skripsi dan magang. Dengan hal tersebut mahasiswa bisa lulus tepat waktu.
4. Pengaruh Kompetensi Terhadap Kinerja Karyawan Pada PT. Frisian Flag Indonesia (Marliana Budhiningtias Winanti, Program Studi Manajemen Informatika, Universitas Komputer Indonesia). Kompetensi karyawan yang meliputi kompetensi intelektual, kompetensi emosional dan kompetensi sosial pada karyawan PT. Frisian Flag Indonesia wilayah Jawa Barat rata-rata skornya termasuk dalam kategori tinggi. Kompetensi intelektual lebih tinggi dibandingkan kompetensi emosional dan kompetensi sosial, hal ini berarti karyawan PT. Frisian Flag Indonesia wilayah Jawa Barat memiliki semangat kerja, pengetahuan, kepedulian dan pemahaman permasalahan yang tinggi dibandingkan kemampuan karyawan dalam memahami lingkungan secara objektif dan moralis, pengendalian emosional dan
membangun jaringan kerja sama serta mempengaruhi rekan kerja atau bawahan.
5. Application Of Data Mining Algorithm To Recipient Of Motorcycle Installment (Harry Dhika, Fitriana Destiawati, 2015). Penerapan algoritma data mining terhadap penerima kredit motor memiliki tingkat akurasi yang cukup tinggi yaitu 87% atau sekitar 217 konsumen. Sedangkan yang ditolak sebesar 16% atau sebanyak 6 konsumen yang ditolak pengajuan kreditnya dari 224 konsumen. Kategori peneitian ini masuk dalam klasifikasi baik dengan presentase 0.80-0.90. Dari hasil tersebut maka perlu terus dikembangkan dan dikomparasikan dengan beberapa algoritma lain sehingga hasil akurasi bisa jauh lebih baik lagi.
6. Sistem Pendukung Keputusan Pemilihan Karyawan Teladan Dengan Metode Smart / Simple Multi Attributte Rating Technique (Suryanto, Muhammad Safrizal, 2015). Berdasarkan penelitian berupa kuesioner yang dilakukan terhadap Admin didapatkan hasil persentase sistem berada pada kisaran angka 83,57% sesuai pada realitas jawaban yang diharapkan, sehingga sistem ini sudah dikatakan user interfae dan Manager didapatkan hasil persentase sistem berada pada kisaran angka 83% sesuai pada realitas jawaban yang diharapkan, sehingga sistem ini sudah dikatakan layak digunakan.
7. SPK Pemilihan Calon Pendonor Darah Potensial dengan Algoritma C4.5 dan Fuzzy Tahan (Mahmud Yunus, Harry Soekotjo Dahlan, dan Purnomo Budi Santoso, 2014). Proses pembentukan pohon keputusan dengan algoritma data mining C4.5 diakukan pada data kasus transaksi donor darah yang terjadi pada tahun 2010 s/d 2011, menghasilkan 134 aturan keputusan dengan rincian (1) 26 aturan keputusan ‘Ya’ dan (2) 108 aturan ‘Tidak’, dengan rata-rata waktu pembelajaran 3 menit 2,57 detik.
8. Analisis komparasi algoritma klasifikasi data mining untuk prediksi mahasiswa non aktif (Hastuti, K. 2012). Hasil dari proses klasifikasi di evaluasi menggunakan cross validation, confusion matrix, ROC Curve dan T-Test untuk mengetahui algoritma mana yang paling tepat dan akurat. Hasil dari studi ini di dapatkan bahwa algoritma decision tree merupakan
algoritma yang paling akurat, namun demikian algoritma decision tree tidak dominan terhadap algoritma lainnya.
9. Rancang Bangun Aplikasi Data Mining untuk Memprediksi Hasil Belajar Siswa Sekolah Menengah Atas Berbasis Web dengan Algortima K-NN (Riveranda, Rois, Saf, & Zul, 2016). Dari hasil uji confusion matrix setelah 3 kali pengujian berdasarkan nilai K, maka didapat nilai K5 (79,34%) yang mereka terapkan untuk algoritma K-NN.
10. Analisis Profil Mahasiswa Politeknik Negeri Batam dengan Teknik Data Mining Asosiasi dan Clustering (Sari & Jannah, 2016). Data mining dapat digunakan untuk mengelompokkan, mengidentifikasi pola – pola tersembunyi dari gaya belajar mahasiswa, menemukan perilaku mahasiswa yang tidak diinginkan serta menganalisis profil mahasiswa.
11. Educational Data Mining & Students Performance Prediction (Abu Saa, A, 2016). Menggunakan data mining dengan teknik naive bayes classifier untuk mengetahui pola-pola yang tersembunyi dan berpengaruh dalam kemampuan siswa. Mencoba menelusuri apakah ada kaitan nya antara kemampuan siswa, kondisi kejiwaan siswa, dan tingkat kemampuan sosial ekonomi keluarga dalam kegiatan belajar.
12. Data Mining untuk Memprediksi Prestasi Siswa Berdasarkan Sosial Ekonomi, Motivasi, Kedisiplinan dan Prestasi Masa Lalu (Heri Susanto, Sudiyatno, 2014). Menggunakan data mining dan memakai 3 algoritma sebagai perbandingan yaitu J48, CHAID, Regresi Ganda dan hasilnya algoritma J48 lebih unggul di antara ketiga nya karena tingkat akurasi nya 95,7%.
13. Mapping Students Performance Based on Data Mining Appraoch (Harwati, Ardita Permana Alfiani, Febriana Ayu Wulandari, 2015). Improvisasi kinerja siswa dengan menggunakan 300 siswa, algoritma yang dipakai adalah K-Mean Clustering. Atribut yang digunakan yaitu jenis kelamin, tempat tinggal, GPA, nilai – nilai ujian dan hasil nya ditemukan siswa pintar (45,74%), siswa standar (33,33%), siswa rendah (20,92%).
14. Framework for Students Academic Performance Analysis Using Naive Bayes Classifier (Azwa Abdul Aziz, Nur Hafiza Ismail, Fadhilah Ahmad,
Hasni Hassan, 2014). Metode yang dipakai menggunakan naive bayes klasifikasi. Data yang digunakan sebagai bahan penelitian yaitu data kampus selama 6 tahun ke belakang 2006 – 2012 dan atribut yang mereka gunakan yaitu penghasilan keluarga, jenis kelamin, tempat tinggal.
15. Penerapan Algoritma C4.5 untuk Memprediksi Penerimaan Calon Pegawai Baru di PT WISE (Fandy Ferdian Haryanto, 2017). Implementasi Algoritma C4.5 untuk melakukan prediksi terhadap calon pegawai baru pada PT WISE telah berhasil dilakukan. Hasil tingkat keberhasilan prediksi calon pegawai baru di PT WISE secara keseluruhan yang telah diukur menggunakan ten-fold cross validation adalah sebesar 71%. Penelitian ini melihat data mining dalam memprediksi penerimaan calon pegawai baru menggunakan Algoritma C4.5.
16. Prediksi Kelulusan Mahasiswa dengan Metode Algoritma C4.5 (Jajam Haerul Jaman, 2013). Dalam penelitian ini penulis melakukan model penelitian Algoritma C4.5 yang di analisis adalah data dari mahasiswa angkatan tahun 2008 Fakultas Ilmu Komputer Universitas Singaperbangsa Karawang, dari hasil analisis ternyata bahwa untuk kelulusan yang dilihat dari gender perempuan lebih besar persentase nya dibandingkan dengan gender laki – laki, kemudian nilai gain yang didapat dari usia pada mahasiswa yang bekerja lebih kepada mahasiswa dengan kategori usia 1, dan nilai gain yang didapat dari usia pada mahasiswa yang tidak bekerja lebih kepada mahasiswa dengan kategori usia 3. Penelitian ini melihat data mining dalam memprediksi kelulusan mahasiswa menggunakan Algoritma C4.5.
17. Penerapan Data Mining untuk Memprediksi Prestasi Akademik Mahasiswa Berdasarkan Dosen, Motivasi, Kedisiplinan, Ekonomi, dan Hasil Belajar (Eka Sabna, 2016). Berdasarkan analisis data menggunakan Algoritma Decision Tree untuk memprediksi prestasi akademik berdasarkan sosial ekonomi, motivasi, peran dosen, disiplin dan hasil belajar masa lalu diperoleh hasil : variabel hasil belajar masa lalu adalah variabel yang menentukan potensi seseorang berhasil atau tidak dalam prestasi akademik. Hal ini dibuktikan bahwa Hasil Belajar menjadi mode yang terpilih/awal.
Variabel Peran Dosen menjadi variabel kedua menentukan prestasi akademik. Variabel Disiplin menjadi variabel ketiga menentukan prestasi akademik. Hasil akurasi klasifikasi menggunakan metode Area Under Curve (AUC) memperoleh nilai 65%. Penelitian ini melihat data mining dalam memprediksi prestasi akademik mahasiswa menggunakan Algoritma C4.5.
18. Penerapan Algoritma C4.5 untuk Penentuan Jurusan Mahasiswa (Liliana Swastina, 2013). Dari hasil uji Algoritma Decision Tree C4.5 memprediksi lebih akurat dari pada Algoritma Naive Bayes dalam penentuan kesesuaian jurusan dan rekomendasi jurusan mahasiswa. Dengan demikian dapat disimpulkan bahwa Algoritma Decision Tree C4.5 akurat diterapkan untuk penentuan kesesuaian jurusan mahasiswa dengan tingkat keakuratan 93,31% dan akurasi rekomendasi jurusan sebesar 82,64%. Penelitian ini melihat data mining dalam penentuan jurusan mahasiswa menggunakan Algoritma C4.5.
19. Aplikasi Data Mining dengan Metode Classification Berbasis Algoritma C4.5 (Rizky Tahara Shita, 2013). Implementasi Classifiacation berbasis Algoritma C4.5 pada aplikasi sangat membantu dalam menganalisis perkiraan keterlambatan laporan survey dengan cara membentuk pohon keputusan yang memanfaatkan data permohonan yang ditunjang dengan aplikasi berbasis web, sehingga pihak terkait dapat lebih cepat dan mudah dalam mendapatkan informasi untuk menunjang keputusan secara mobile. Penelitian ini melihat data mining classification berbasis Algoritma C4.5.
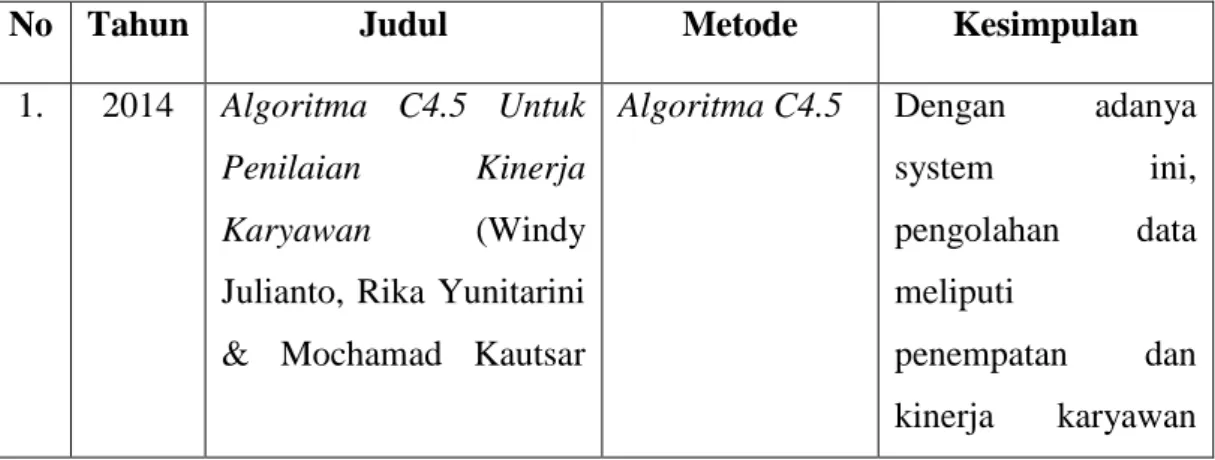
Tabel 2.2 : Rangkuman Kajian Penelitian
No Tahun Judul Metode Kesimpulan
1. 2014 Algoritma C4.5 Untuk Penilaian Kinerja Karyawan (Windy Julianto, Rika Yunitarini & Mochamad Kautsar
Algoritma C4.5 Dengan adanya
system ini,
pengolahan data meliputi
penempatan dan kinerja karyawan
Sophan) dapat dilakukan dengan mudah dan cepat.
2. 2017 Kajian Komparasi Penerapan Algoritma C4.5 , Neural Network, Dan Svm Dengan Teknik Pso Untuk Pemilihan Karyawan Teladan PT.Xyz (Rudi Apriyadi Raharjo) Algoritma C4.5, Neural Network Dan Svm Ketiga algoritma (C4.5, Neural Network, dan SVM) dapat digunakan dalam memutuskan Karyawan Teladan di PT. XYZ. Ketiga algoritma ini dikomparasi kemudian diuji akurasinya. Tingkat akurasi tertinggi lah yang digunakan dalam menentukan Karyawan Teladan. 3. 2014 Implementai Data Mining dengan Algoritma C4.5 untuk Memprediksi Tingkat Kelulusan Mahasiswa (David Hartanto Kamagi, Seng Hansun).
Algoritma C4.5 Data mining dengan algoritma C4.5 dapat diimplementasikan untuk memprediksi tingkat kelulusan mahasiswa dengan empat kategori yaitu lulus cepat, lulus tepat, lulus terlambat dan drop out. Attribute yang paling berpengaruh
dalam hasil prediksi adalah IPS enam. 4. 2016 Pengaruh Kompetensi
Terhadap Kinerja Karyawan Pada PT. Frisian Flag Indonesia ( Marliana Budhiningtias Winanti, Program Studi Manajemen Informatika, Unversitas Komp uter Indonesia) Struktural Equation Modeling (SEM) Kompetensi memiliki pengaruh yang positif dan signifikan terhadap kinerja karyawan PT. Frisian Flag Indonesia wilayah Jawa Barat. Artinya kompetensi karyawan menstimulir optimasi pembentukan kinerja karyawan PT. Frisian Flag Indonesia wilayah Jawa Barat. 5. 2015 Application Of Data Mining Algorithm To Recipient Of Motorcycle Installment (Harry Dhika, Fitriana Destiawati).
Algoritma C4.5 Penerapan algoritma
data mining
terhadap penerima kredit motor memiliki tingkat akurasi yang cukup tinggi yaitu 87% atau sekitar 217 konsumen. Sedangkan yang ditolak sebesar 16% atau sebenyak 6
konsumen yang ditolak pengajuan kreditnya dari 224 konsumen. 6. 2015 Sistem Pendukung Keputusan Pemilihan Karyawan Teladan Dengan Metode Smart / Simple Multi Attribute Rating Technique (Suryanto, Muhammad Safrizal) Smart / Simple Multi Attribute Rating Technique Aplikasi Sistem Pendukung Keputusan Pemilihan Karyawan Teladan ini telah berhasil dibangun untuk Metro Plaza Swalayan pemilihan karyawan untuk menghasilkan keputusan yang lebih objektif, terkomputerisasi dan mengurangi terjadiya human error. 7. 2014 SPK Pemilihan Calon Pendonor Darah Potensial dengan Algoritma C4.5 dan Fuzzy Tahani (Mahmud Yunus, Harry Soekotjo Dahlan, dan Purnomo Budi Santoso). Algoritma C4.5 dan Fuzzy Tahani Akurasi hasil prediksinya adalah (a) 90,56% untuk semua golongan darah; (b) 88,64% untuk golongan darah A; (c) 93,33% untuk golongan darah B; (d) 84,62% untuk golongan
darah AB dan (e) 91,03% untuk golongan darah O. Rata-rata tingkat akurasi prediksi adalah sebesar 89,64%. 8. 2012 8Analisis komparasi algoritma klasifikasi data mining untuk prediksi mahasiswa non aktif (Hastuti, K.).
Algoritma C4.5 Hasil dari proses klasifikasi di evaluasi
menggunakan cross validation,
confusion matrix, ROC Curve dan
T-Test untuk
mengetahui
algoritma mana yang paling tepat dan akurat. Hasil dari studi ini di dapatkan bahwa algoritma decision tree merupakan algoritma yang paling akurat, namun demikian algoritma decision tree tidak dominan terhadap algoritma lainnya.
Aplikasi Data Mining untuk Memprediksi Hasil Belajar Siswa Sekolah Menengah Atas Berbasis Web dengan Algortima K-NN (Riveranda, Rois, Saf, & Zul).
confusion matrix setelah 3 kali pengujian
berdasarkan nilai K, maka didapat nilai K5 (79,34%) yang mereka terapkan untuk algoritma K-NN. 10. 2016 Analisis Profil Mahasiswa Politeknik Negeri Batam dengan Teknik Data Mining Asosiasi dan Clustering (Sari & Jannah).
Algoritma C4.5 Data mining dapat digunakan untuk mengelompokkan, mengidentifikasi pola – pola tersembunyi dari gaya belajar mahasiswa, menemukan perilaku mahasiswa yang tidak diinginkan serta menganalisis profil mahasiswa. 11. 2016 Educational Data Mining & Students Performance Prediction (Abu Saa, A).
Algoritma Naive fBayes
Menggunakan data mining dengan teknik naive bayes classifier untuk mengetahui
pola-pola yang
tersembunyi dan berpengaruh dalam
kemampuan siswa. Mencoba
menelusuri apakah ada kaitan nya antara kemampuan siswa, kondisi kejiwaan siswa, dan tingkat kemampuan sosial ekonomi keluarga dalam kegiatan belajar. 12. 2014 Data Mining untuk
Memprediksi Prestasi Siswa Berdasarkan Sosial Ekonomi, Motivasi, Kedisiplinan dan Prestasi Masa Lalu
(Heri Susanto, Sudiyatno). Algoritma J48, CHAID, Regrsi Ganda Menggunakan data mining dan memakai 3 algoritma sebagai perbandingan yaitu J48, CHAID,
Regresi Ganda dan hasilnya algoritma J48 lebih unggul di antara ketiga nya karena tingkat akurasi nya 95,7%.
13. 2015 Mapping Students Performance Based on Data Mining Appraoch (Harwati, Ardita Permana Alfiani, Febriana Ayu Wulandari). Algoritma K-Mean Improvisasi kinerja siswa dengan menggunakan 300 siswa, algoritma yang dipakai adalah K-Mean Clustering. Atribut yang
digunakan yaitu jenis kelamin, tempat tinggal, GPA, nilai – nilai ujian dan hasil nya ditemukan siswa pintar (45,74%), siswa standar (33,33%), siswa rendah (20,92%).
14. 2014 Framework for Students Academic Performance Analysis Using Naive Bayes Classifier (Azwa Abdul Aziz, Nur Hafiza Ismail, Fadhilah Ahmad, Hasni Hassan). Algoritma Naive Bayes Metode yang dipakai menggunakan naive bayes klasifikasi. Data yang digunakan sebagai bahan penelitian yaitu data kampus selama 6 tahun ke belakang 2006 – 2012 dan atribut yang mereka gunakan yaitu penghasilan keluarga, jenis kelamin, tempat tinggal. 15. 2017 Penerapan Algoritma C4.5 untuk Memprediksi Penerimaan Calon Algoritma C4.5 Implementasi Algoritma C4.5 untuk melakukan
Pegawai Baru di PT WISE (Fandy Ferdian Haryanto).
prediksi terhadap calon pegawai baru pada PT WISE telah berhasil dilakukan. Hasil tingkat keberhasilan prediksi calon pegawai baru di PT WISE secara keseluruhan yang telah diukur menggunakan ten-fold cross validation adalah sebesar 71%. Penelitian ini melihat data mining dalam memprediksi penerimaan calon pegawai baru menggunakan Algoritma C4.5. 16. 2013 Prediksi Kelulusan Mahasiswa dengan Metode Algoritma C4.5 (Jajam Haerul Jaman).
Algoritma C4.5 Hasil analisis ternyata bahwa untuk kelulusan yang dilihat dari gender perempuan
lebih besar
persentase nya dibandingkan
dengan gender laki – laki, kemudian nilai gain yang didapat
dari usia pada mahasiswa yang bekerja lebih kepada mahasiswa dengan kategori usia 1, dan nilai gain yang didapat dari usia pada mahasiswa yang tidak bekerja lebih kepada mahasiswa
17. 2016 Penerapan Data Mining untuk Memprediksi Prestasi Akademik Mahasiswa Berdasarkan Dosen, Motivasi, Kedisiplinan, Ekonomi, dan Hasil Belajar (Eka Sabna).
Algoritma C4.5 Hal ini dibuktikan bahwa Hasil Belajar menjadi mode yang terpilih/awal. Variabel Peran Dosen menjadi variabel kedua menentukan prestasi akademik. Variabel Disiplin menjadi variabel ketiga menentukan prestasi akademik. Hasil akurasi klasifikasi menggunakan
metode Area Under
Curve (AUC)
memperoleh nilai 65%. Penelitian ini melihat data mining dalam memprediksi
prestasi akademik mahasiswa menggunakan Algoritma C4.5. 18. 2013 Penerapan Algoritma C4.5 untuk Penentuan Jurusan Mahasiswa (Liliana Swastina).
Algoritma C4.5 Dari hasil uji Algoritma Decision
Tree C4.5
memprediksi lebih akurat dari pada Algoritma Naive Bayes dalam penentuan kesesuaian jurusan dan rekomendasi jurusan mahasiswa. Dengan demikian dapat disimpulkan bahwa Algoritma Decision Tree C4.5 akurat diterapkan untuk penentuan kesesuaian jurusan mahasiswa dengan tingkat keakuratan 93,31% dan akurasi rekomendasi jurusan sebesar 82,64%. Penelitian ini melihat data mining dalam penentuan jurusan mahasiswa menggunakan