v
PERNYATAAN KEASLIAN PENELITIAN
Saya yang bertandatangan dibawah ini menyatakan bahwa, skripsi ini merupakan karya saya sendiri (ASLI), dan isi dalam skripsi ini tidak terdapat karya yang pernah diajukan oleh orang lain untuk memperoleh gelar akademis di suatu institusi pendidikan tinggi manapun, dan sepanjang pengetahuan saya juga tidak terdapat karya atau pendapat yang pernah ditulis dan/atau diterbitkan oleh orang lain, kecuali yang secara tertulis diacu dalam naskah ini dan disebutkan dalam daftar pustaka. Segala sesuatu yang terkait dengan naskah dan karya yang telah dibuat adalah menjadi tanggungjawab saya pribadi.
Bekasi, 28 Oktober 2018
Dede Sulaeman Ma’ruf NIM: 311410565
vi
Puji syukur penulis panjatkan kehadirat Allah SWT yang telah melimpahkan segala rahmat dan hidayah-Nya, sehingga tersusunlah Skripsi yang berjudul “ANALISIS DATA MINING UNTUK MENENTUKAN KELAYAKAN CALON KREDIT SEPEDA MOTOR MENGGUNAKAN METODE NAIVE BAYES STUDI KASUS FIF MAJALENGKA”.
Skripsi tersusun dalam rangka melengkapi salah satu persyaratan dalam rangka menempuh ujian akhir untuk memperoleh gelar Sarjana Komputer (S.Kom.) pada Program Studi Teknik Informatika di Sekolah Tinggi Teknologi Pelita Bangsa. Penulis sungguh sangat menyadari, bahwa penulisan Skripsi ini tidak akan terwujud tanpa adanya dukungan dan bantuan dari berbagai pihak. Sudah selayaknya, dalam kesempatan ini penulis menghaturkan penghargaan dan ucapan terima kasih yang sebesar-besarnya kepada :
a. Bapak Dr. Ir. Suprianto, M.P selaku Ketua STT Pelita Bangsa.
b. Bapak Aswan Supriyadi Sunge, S.E., M.Kom selaku Ketua Program Studi Teknik Informatika STT Pelita Bangsa.
c. Bapak Donny Maulana, S.Kom., M.Msi selaku Pembimbing Utama yang telah banyak memberikan arahan dan bimbingan kepada penulis dalam penyusunan Skripsi ini.
d. Bapak Hamzah M. Mardi Putra, S.K.M., M.M selaku Pembimbing Kedua yang telah banyak memberikan arahan dan bimbingan kepada penulis dalam penyusunan Skripsi ini.
e. Seluruh Dosen STT Pelita Bangsa yang telah membekali penulis dengan wawasan dan ilmu di bidang teknik informatika.
f. Seluruh staf STT Pelita Bangsa yang telah memberikan pelayanan terbaiknya kepada penulis selama perjalanan studi jenjang Strata 1.
g. Rekan-rekan mahasiswa STT Pelita Bangsa, khususnya angkatan 2014, yang telah banyak memberikan inspirasi dan semangat kepada penulis untuk dapat menyelesaikan studi jenjang Strata 1.
vii
h. Ibu dan Ayah tercinta yang senantiasa mendoakan dan memberikan semangat dalam perjalanan studi Strata 1 maupun dalam kehidupan penulis.
Akhir kata, penulis mohon maaf atas kekeliruan dan kesalahan yang terdapat dalam Skripsi ini dan berharap semoga Skripsi ini dapat memberikan manfaat bagi khasanah pengetahuan Teknologi Informasi di lingkungan STT Pelita Bangsa khususnya dan Indonesia pada umumnya.
Bekasi, 28 Oktober 2018
viii
PERSETUJUAN ... iii
PENGESAHAN ... iv
PERNYATAAN KEASLIAN PENELITIAN ... v
KATA PENGANTAR ... vi
DAFTAR ISI ... viii
DAFTAR TABEL ... xii
DAFTAR GAMBAR ... xiii
DAFTAR LAMPIRAN ... xiv
ABSTRACT ... xv ABSTRAK ... xvi BAB I PENDAHULUAN ... 1 1.1 Latar Belakang ... 1 1.2 Identifikasi Masalah ... 3 1.3 Rumusan Masalah ... 3 1.4 Batasan Masalah ... 4
1.5 Tujuan dan Manfaat ... 4
1.5.1 Tujuan ... 4
1.5.2 Manfaat ... 5
ix
BAB II TINJAUAN PUSTAKA ... 7
2.1 Kajian Pustaka ... 7
2.2 Dasar Teori ... 9
2.2.1 Data Mining ... 9
2.2.2 Metode Pelatihan ... 10
2.2.3 Pengelompokan Data Mining ... 10
2.2.4 Tahap-tahap Data Mining ... 11
2.2.5 Naive Bayes ... 13
2.3 Obyek Penelitian ... 15
2.3.1 Sejarah FIF ... 15
2.3.2 Visi dan Misi ... 16
2.3.3 Struktur Organisasi ... 17
BAB III METODE PENELITIAN... 19
3.1 Jenis Penelitian ... 19
3.2 Tempat dan Waktu Penelitian ... 19
3.2.1 Tempat Penelitian... 19
3.2.2 Waktu Penelitian ... 19
3.3 Populasi dan Sampel Penelitian ... 20
3.3.1 Populasi ... 20
3.3.2 Sampel ... 20
x
3.6 Variabel Penelitian ... 24
3.7 Metode Analisis Data ... 25
3.7.1 Persamaan Metode Naive Bayes ... 25
3.7.2 Alur Metode Naive Bayes ... 29
3.8 Tahap Penelitian ... 31
3.9 Instrumen Penelitian... 32
3.9.1 Bahan... 32
3.9.2 Peralatan ... 33
BAB IV HASIL DAN PEMBAHASAN ... 34
4.1 Penentuan Kriteria ... 34
4.2 Perhitungan Naive Bayes ... 34
4.2.1 Menghitung Probabilitas Kelas ... 35
4.2.2 Menghitung Probabilitas Masing-masing Atribut ... 35
4.2.3 Menghitung Probabilitas Akhir Untuk Setiap Kelas ... 37
4.2.4 Kasus Perhitungan Naive Bayes ... 37
4.3 Implementasi Klasifikasi Naive Bayes pada Rapid Miner ... 39
4.3.1 Akurasi Prediksi ... 41
BAB V PENUTUP ... 44
5.1 Kesimpulan ... 44
xi
xii
Tabel 3. 1 Waktu Penelitian ... 20
Tabel 3. 2 Kuesioner ... 22
Tabel 3. 3 Atribut Data yang Digunakan ... 25
Tabel 4. 1 Kriteria yang Digunakan ... 34
Tabel 4. 2 Probabilitas Kelas ... 35
Tabel 4. 3 Atribut Karakter ... 35
Tabel 4. 4 Atribut Pendidikan ... 36
Tabel 4. 5 Atribut Pekerjaan ... 36
Tabel 4. 6 Atribut Tanggungan ... 36
Tabel 4. 7 Atribut Rumah... 36
Tabel 4. 8 Atribut Penghasilan ... 37
xiii
DAFTAR GAMBAR
Gambar 2. 1 Tahap-tahap Data Mining ... 12
Gambar 2. 2 Struktur Organisasi ... 17
Gambar 3. 1 Rancangan Penelitian ... 23
Gambar 3. 2 Alur Metode Naive Bayes ... 29
Gambar 3. 3 Tahap Penelitian ... 32
Gambar 4. 1 Proses Rapid Miner ... 40
Gambar 4. 2 Hasil Prediksi Rapid Miner ... 40
Gambar 4. 3 Proses Training dan Testing ... 41
Gambar 4. 4 Accuracy/Akurasi ... 42
xiv
Sampel Data Training ... 48 Hasil Data Testing ... 58
xv
ABSTRACT
Determining the feasibility of applying for motorbike credit at a leasing company is very important, given that if there is a decision-making error it will have an impact on the company's losses which in this case is FIF Majalengka.
Budiman, General Manager, Marketing of Fideral International Finance (FIF) Majalengka, approximately 70% of motorcycle sales through a finance company
(leasing) and the remaining 30% cash. Currently technology can provide fast and accurate information, especially credit or leasing. Data mining is related to the search for data to find patterns or knowledge from the overall data, large data sets can produce a data that results can provide new knowledge information. In this research will be discussed about the design of data mining using the Naive Bayes Classifier algorithm to calculate the probability of the feasibility of the feasibility of prospective motorcycle loans whether feasible or not feasible.
xvi
Penentuan kelayakan pengajuan kredit sepeda motor pada sebuah perusahaan leasing adalah hal yang sangat penting, mengingat jika terjadi kesalahan pengambilan keputusan maka akan berdampak pada kerugian perusahaan yang pada kasus ini adalah FIF Majalengka. Budiman General Manager Marketing
Fideral International Finance (FIF) Majalengka, sekitar 70% penjualan motor
melalui perusahaan pembiayaan (leasing) dan 30% sisanya tunai. Saat ini teknologi dapat memberikan informasi yang cepat dan akurat khususnya diperkreditan atau
leasing. Data mining berhubungan dengan pencarian data untuk menemukan pola
atau pengetahuan dari data keseluruhan, kumpulan data yang besar dapat menghasilkan sebuah data yang hasilnya dapat memberikan informasi pengetahuan yang baru. Pada penelitian ini akan dibahas tentang perancangan data mining menggunakan algoritma Naive Bayes Classifier untuk menghitung probabilitas kemungkinan kelayakan calon kredit sepeda motor apakah layak atau tidak layak. Kata kunci : Data Mining, Naive Bayes Classifier, Kelayakan Kredit
1
BAB I
PENDAHULUAN
1.1 Latar Belakang
Minat masyarakat pada kepemilikan kendaraan bermotor masih terbilang tinggi dan cukup banyak yang menggunakan jasa kredit dalam pembeliannya. Perusahaan Leasing adalah badan usaha di luar Bank dan Lembaga Keuangan Bukan Bank yang khusus didirikan untuk melakukan kegiatan usaha. Penulis membahas kegiatan usaha perusahaan Leasing di bidang pembiayaan konsumen, yaitu pembiayaan kredit motor bagi konsumen yang tertera sesuai Peraturan Presiden Republik Indonesia Nomor 9 Tahun 2009 tentang Lembaga Pembiayaan Konsumen (Tanjung, 2017).
Asosiasi Industri Sepeda Motor Indonesia (AISI) mencatat data penjualan sepeda motor yang terjual pada bulan Januari hingga Juni 2018 mencapai 3.002.753 unit atau naik 11,1% dari periode sama tahun lalu sebesar 2.700.546 unit. Di semester I – 2018, total penjualan AHM masih merajai pasar sepeda motor nasional, yakni mencapai 2,23 juta unit atau naik 11,5% dari periode sama tahun lalu sebesar 2,005 juta unit. Adapun pesaing terdekat Honda, yakni Yamaha mencatatkan penjualan sebesar 690.944 unit atau naik 12,3% dari periode sama tahun lalu sebesar 614.895 unit (Tribunnews.com, 2018).
Budiman General Manager Marketing Fideral International Finance (FIF) Majalengka, sekitar 70% penjualan motor melalui perusahaan pembiayaan (leasing) dan 30% sisanya tunai. Bapak Endang dari bagian administrasi Fideral
International Finance (FIF) Majalengka menyatakan setiap hari rata- rata
pengajuan kredit sepeda motor sebanyak 50 – 100 pengajuan untuk wilayah Kabupaten Majalengka. Calon nasabah yang mengajukan kredit motor berasal dari berbagai macam latar belakang pendidikan, pekerjaan, tangungan, rumah, penghasilan, riwayat kredit maupun karakternya. Namun dalam menentukan layak atau tidak layak calon kredit sepeda motor di FIF Majalengka masih belum akurat, bahkan ada yang berniat untuk melakukan penipuan sehingga risiko kredit macet yang tinggi.
Guna memperoleh nilai prediksi yang akurat diperlukan metode yang tepat agar dapat menghasilkan nilai prediksi dengan tingkat akurasi tinggi. Saat ini banyak permasalahan nyata yang diselesaikan dengan metode softcomputing dari pada hardcomputing. Penelitian yang dilakukan oleh Arifin yang berjudul Human
Face Detection Using Bayesian Method, untuk foto ukuran close-up mampu
dideteksi dengan akurasi 100%. Penelitian lain yang dilakukan oleh Nugroho berjudul Case Based Reasoning untuk Kelayakan Kredit Sepeda Motor mempunyai akurasi 85%, dalam penelitian tersebut menggunakan metode fuzzy yang digabungkan dengan metode naive bayes dalam membangun sistem Case Based
Reasoning (CBR) (Nugroho & Suryati, 2013).
Berdasarkan penjelasan di atas, bahwa jumlah pengajuan kredit motor yang tinggi dan terus meningkat, serta kemampuan metode naive bayes yang mencapai
3
akurasi prediksi sampai 100%, telah memberikan alasan yang sangat kuat. Maka dari itu judul penelitian yang akan diambil yaitu “Analisis Data Mining Untuk Menentukan Kelayakan Calon Kredit Sepeda Motor Menggunakan Metode Naive
Bayes Studi Kasus FIF Majalengka”. Penelitian ini menggunakan algoritma naive bayes classifier sebagai salah satu algoritma klasifikasi data mining untuk
menentukan kelayakan calon kredit sepeda motor dengan akurat.
1.2 Identifikasi Masalah
Berdasarkan latar belakang yang telah disampaikan diatas, maka daftar masalah yang akan dijadikan acuan dalam penelitian ini adalah :
1. Tingginya pengajuan kredit tidak sebanding dengan jumlah karyawan yang ada.
2. Risiko kredit macet yang tinggi, karena penentuan kelayakan kredit didasar dari penilaian karyawan semata.
3. Belum diterapkan metode naive bayes untuk menentukan keleyakan calon kredit sepeda motor.
1.3 Rumusan Masalah
Dalam penyusunan penelitian ini, maka penulis memberikan rumusan masalah yang dijadikan acuan dasar dalam penyusunan penelitian yaitu :
1. Bagaimana menentukan tingginya pengajuan kredit agar sebanding dengan jumlah karyawan yang ada ?
2. Bagaimana mengatasi risiko kredit yang macet ?
3. Bagaimana menerapkan data mining menggunakan metode naive bayes untuk menentukan kelayakan calon kredit sepeda motor ?
1.4 Batasan Masalah
Dari pemaparan latar belakang diatas dapat dijadikan landasan untuk menentukan batasan masalah dalam penelitian yang akan dilakukan. Adapun batasan tersebut sebagai berikut :
1. Klasifikasi dibentuk berdasarkan data historis kelayakan calon kredit sepeda motor FIF Majalengka.
2. Atribut pembentuk klasifikasi yang digunakan berupa latar belakang pendidikan, pekerjaan, tanggungan, rumah, penghasilan, riwayat kredit dan karakter.
3. Data yang digunakan hanya kasus dari kelayakan calon kredit sepeda motor FIF Majalengka.
1.5 Tujuan dan Manfaat
1.5.1 Tujuan
Berdasarkan masalah yang telah di rumuskan sebelumnya, maka tujuan penyusunan dari laporan ini adalah :
1. Dapat menyetarakan pengajuan kredit dengan jumlah karyawan.
2. Membantu mencegah perusahaan leasing FIF Majalengka, salah dalam menentukan kelayakan kredit motor yang berujung pada kerugian keuangan.
3. Menggunakan sebuah perhitungan yang tepat dan efektif untuk menganalisa setiap data pengajuan kredit yang datang, sesuai dengan kriteria yang sudah ditentukan pihak perusahaan juga mempertimbangkan data masa lalu.
5
1.5.2 Manfaat
Penelitian ini dilakukan dengan harapan dapat memberikan manfaat, diantaranya :
1. Bagi Peneliti :
a. Dapat menambah wawasan tentang data mining khususnya klasifikasi
naive bayes.
b. Menjadi referensi bagi peneliti berikutnya. 2. Bagi Perusahaan :
a. Dapat mempermudah dan membantu untuk mengambil keputusan dalam menentukan kelayakan calon kredit sepeda motor.
b. Menghindari manipulasi data maupun cara yang subyektif untuk mengambil keputusan dalam menentukan kelayakan calon kredit sepeda motor.
c. Diharapkan metode Naive Bayes Classification dapat membantu untuk mengambil keputusan dalam menentukan calon kredit sepada motor. 3. Bagi Institusi:
a. Sebagai bahan referensi karya ilmiah khususnya dengan metode yang sama atau berbeda bagi penulis lainnya yang ingin mengkaji penelitian sejenis.
1.6 Sistematika Penulisan
Dalam penelitian ini penulis membagi beberapa bab untuk mempermudah dalam penyusunan dan mempermudah pembaca untuk memahaminya, berikut pembagian bab tersebut :
BAB I PENDAHULUAN
Bab ini meliputi uraian mengenai latar belakang masalah, identifikasi masalah, batasan masalah, rumusan masalah, tujuan dan manfaat penelitian, dan sistematika penulisan.
BAB II TINJAUAN PUSTAKA
Dalam bab ini menjelaskan tentang hal-hal yang berkaitan dengan teori konsep model data mining, teori yang berkaitan dengan penelitian, konsep aplikasi dan peralatan pendukungnya.
BAB III METODE PENELITIAN
Bab ini meliputi jenis penelitian, tempat dan waktu penelitian, variabel yang digunakan, metode pengumpulan data dan metode naive
bayes yang digunakan dalam penelitian.
BAB IV HASIL DAN PEMBAHASAN
Pada bab ini peneliti menguraikan masalah pokok dari obyek penelitian, bagaimana menerapkan sebuah model data mining dengan
metode naive bayes kedalam suatu kasus untuk menentukan kelayakan
calon kredit sepeda motor pada FIF majalengka. BAB V PENUTUP
Pada bab ini meliputi uraian mengenai kesimpulan dan koreksi beserta saran-saran untuk peneliti yang akan melakukan penelitian berikutnya.
7
BAB II
TINJAUAN PUSTAKA
2.1 Kajian Pustaka
Dibawah ini adalah beberapa penelitian tentang data mining ataupun mendekati penelitian yang digunakan sebagai bahan referensi:
1. Algoritma Klasifikasi Naive Bayes Untuk Menilai Kelayakan Kredit ( Claudia Clarentia Ciptohartono, 2014).
Penelitian ini membuktikan bahwa algoritma naive bayes dapat diterapkan untuk menilai kelayakan kredit pada BCA Finance Jakarta. Dan pengolahan data awal merupakan tahapan yang sangat mempengaruhi hasil akurasi yang baik sehingga akurasi akhir yang dihasilkan termasuk kategori Excellent. Penilaian kelayakan kredit pada BCA Finance Jakarta pada data awal dengan pre-processing menghasilkan akurasi sebesar 85,57% sedangkan setelah dilakukan pengolahan data awal dan dengan pre-processing menghasilkan akurasi sebesar 92,53%.
2. Implementasi Algoritma Naive Bayes Dalam Penentuan Pemberian Kredit (Muhammad Husni Rifqo & Ardi Wijaya, 2017).
Dari hasil evaluasi penelitian ini bahwa model naive bayes mampu menganalisa pelanggan yang baik dan pelanggan yang buruk baik menggunakan data Agiing leasing ACC maupun menggunakan data credit
akurasi yang baik. Banyaknya record dan atribut pada sebuah dataset mempengaruhi tingkat akurasi dari model naive bayes ini.
3. Sistem Pendukung Keputusan Kelayakan Kredit Motor Menggunakan
Metode Naive Bayes Pada NSC Finance Cikampek (Qonita Tanjung, 2017).
Pada penelitian ini mendapatkan hasil analisa metode naive bayes dengan cepat, apakah pengaju kredit layak atau tidak layak dengan menggunakan 15.625 data training atau dataset dan 100 data testing yang dipilih secara random. Dari pengujian yang dilakukan dengan membandingkan hasil analisa sistem dengan aplikasi pendukung Rapidminer didapat tingkat akurasi sebesar 99% dan eror sebesar 1%.
4. Penentuan Kelayakan Kredit Dengan Algoritma Naive Bayes Classfier
Studi Kasus Bank Mayapada Mitra Usaha Cabang PGC (Nia Nuraeni,
2017).
Dalam penelitian ini didapat hasil bahwa metode naive bayes dapat digunakan untuk menentukan kelayakan kredit dengan nilai akurasi algoritma klasifikasi Naive Bayes Classifier adalah 89.33%, Sementara untuk evaluasi menggunakan ROC Curve untuk model klasifikasi Naive
Bayes Classifier nilai AUC adalah 0.955 dengan tingkat diagnosa Excellent Classification.
Dari semua penelitian dan metode yang digunakan diatas terbukti penggunaan metode Naive Bayes memiliki banyak kelebihan didalam hal prediksi dengan tingkat akurasi yang baik, oleh karena itu metode Naive Bayes dipilih untuk digunakan dalam penelitian ini.
9
2.2 Dasar Teori
2.2.1 Data Mining
Data mining adalah proses menelusuri pengetahuan baru, pola dan tren yang
dipilah dari jumlah data yang besar yang disimpan dalam repositori atau tempat penyimpanan dengan menggunakan teknik pengenalan pola serta statistik dan teknik matematika. Data mining menganalisis data menggunakan tool untuk menemukan pola dan aturan dalam himpunan data. Perangkat lunak bertugas untuk menemukan pola dengan mengidentifikasi aturan dan fitur pada data (Rifqo, Wijaya, & Pseudocode, 2017).
Data Mining dikenal dengan istilah pattern recognition merupakan suatu
metode yang digunakan untuk pengolahan data, guna menemukan pola yang tersembunyi dari data yang diolah. Data yang diolah dengan teknik data mining ini kemudian menghasilkan suatu pengetahuan baru yang bersumber dari data lama, hasil dari pengolahan data tersebut dapat digunakan dalam menentukan keputusan di masa depan (Putri & Santoso, 2016).
Data mining adalah suatu konsep yang digunakan untuk menemukan
pengetahuan yang tersembunyi di dalam sekumpulan data. Data mining merupakan proses semi otomatik yang menggunakan teknik statistik, matematika, kecerdasan buatan, dan machine learning untuk mengekstrasi dan mengidentifikasi informasi pengetahuan potensial dan berguna yang tersimpan di dalam database besar. Data
mining adalah bagian dari proses KDD (Knowledge Discovery in Databases) yang
terdiri dari beberapa tahapan seperti pemilihan data, pra-pengolahan, transformasi,
Data mining adalah proses yang menggunakan teknik statistik, matematika,
kecerdasan buatan, dan machine learning untuk mengekstraksi dan mengidentifikasi informasi yang bermanfaat dan pengetahuan yang terakit dari berbagai database besar (Novianti, Rismawan, & Bahri, 2016)
Jadi dapat disimpulkan bahwa data mining adalah serangkaian proses untuk menganalisa kumpulan data untuk menemukan hubungan yang tidak terduga dan meringkasnya, mencari pengetahuan yang tidak akan diketahui secara manual untuk dapat dipahami dan bermanfaat bagi pemilik data.
2.2.2 Metode Pelatihan
Secara garis besar metode pelatihan yang digunakan dalam teknik-teknik data mining dibedakan ke dalam dua pendekatan, yaitu (Ridwan, Suyono, & Sarosa, 2013) :
1. Unsupervised learning, metode ini diterapkan tanpa adanya latihan (training) dan tanpa ada guru (teacher). Guru di sini adalah label dari data. 2. Supervised learning, yaitu metode belajar dengan adanya latihan dan pelatih. Dalam pendekatan ini, untuk menemukan fungsi keputusan, fungsi pemisah atau fungsi regresi, digunakan beberapa contoh data yang mempunyai output atau label selama proses training.
2.2.3 Pengelompokan Data Mining
Ada beberapa teknik yang dimiliki data mining berdasarkan tugas yang bisa dilakukan, yaitu (Ridwan et al., 2013):
11
1. Deskripsi
Para peneliti biasanya mencoba menemukan cara untuk mendeskripsikan pola dan trend yang tersembunyi dalam data.
2. Estimasi
Estimasi mirip dengan klasifikasi, kecuali variabel tujuan yang lebih kearah numerik dari pada kategori.
3. Prediksi
Prediksi memiliki kemiripan dengan estimasi dan klasifikasi, hanya saja prediksi hasilnya menunjukkan sesuatu yang belum terjadi (mungkin terjadi di masa depan).
4. Klasifikasi
Dalam klasifikasi variabel, tujuan bersifat kategorik. Misalnya kita akan mengklasifikasikan pendapatan dalam tiga kelas yaitu pendapatan tinggi, pendapatan sedang, dan pendapatan rendah.
5. Clustering
Clustering lebih ke arah pengelompokan record, pengamatan atau kasus
dalam kelas yang memiliki kemiripan. 6. Asosiasi
Mengidentifikasi hubungan antara berbagai peristiwa yang terjadi pada satu waktu.
2.2.4 Tahap-tahap Data Mining
Sebagai suatu rangkaian proses, Data Mining dapat dibagi menjadi beberapa tahap proses. Tahap-tahap tersebut bersifat interaktif, pemakai terlibat
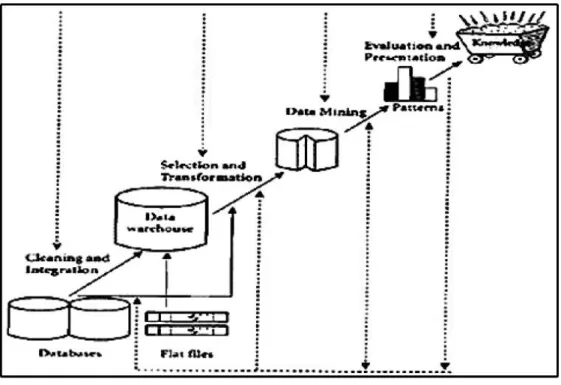
langsung atau dengan perantaraan knowledge base. Adapun tahapan - tahapan dalam proses data mining dapat dilihat pada Gambar dibawah ini (Prathama et al., 2013) :
Gambar 2.1 Tahap-tahap Data Mining
Penjelasan tahap – tahap data mining adalah sebagai berikut (Ridwan et al., 2013) :
1. Pembersihan data (Data Cleaning)
Pembersihan data merupakan proses menghilang-kan noise dan data yang tidak konsisten atau data tidak relevan.
2. Integrasi data (Data Integration)
Integrasi data merupakan penggabungan data dari berbagai database ke dalam satu database baru.
13
3. Seleksi data (Data Selection)
Data yang ada pada database sering kali tidak semuanya dipakai, oleh karena itu hanya data yang sesuai untuk dianalisis yang akan diambil dari
database.
4. Transformasi data (Data Transformation)
Data diubah atau digabung ke dalam format yang sesuai untuk diproses dalam Data Mining.
5. Proses Mining
Merupakan suatu proses utama saat metode diterapkan untuk menemukan pengetahuan berharga dan tersembunyi dari data. Beberapa metode yang dapat digunakan berdasarkan pengelompokan Data Mining.
6. Evaluasi pola (Pattern Evaluation)
Untuk mengidentifikasi pola-pola menarik ke dalam knowledge based yang ditemukan.
7. Presentasi pengetahuan (Knowledge Presentation)
Merupakan visualisasi dan penyajian pengetahuan mengenai metode yang digunakan untuk memperoleh pengetahuan yang diperoleh pengguna. 2.2.5 Naive Bayes
Naive Bayes merupakan suatu bentuk klasifikasi data dengan menggunakan metode probabilitas dan statistik. Metode ini pertama kali dikenalkan oleh ilmuwan Inggris Thomas Bayes, yaitu digunakan untuk memprediksi peluang yang terjadi di
masa depan berdasarkan pengalaman di masa sebelumnya sehingga dikenal sebagai teorema bayes (Nuraeni, 2017).
Naive Bayes merupakan salah satu algoritma dalam teknik data mining yang
menerapkan teori Bayes dalam klasifikasi. Teorema keputusan Bayes adalah pendekatan statistik yang fundamental dalam pengenalan pola (pattern
recoginition). Naive Bayes didasarkan pada asumsi penyederhanaan bahwa nilai
atribut secara konditional saling bebas jika diberikan nilai output. Dengan kata lain diberikan nilai output, probabilitas mengamati secara bersama adalah produk dari probabilitas individu (Ridwan et al., 2013) .
Naive Bayes Classifier adalah salah satu algoritma dalam teknik data mining yang menerapkan teori bayes dalam klasifikasi. Naive Bayes Classifer
merupakan pengklasifikasian statistik yang dapat digunakan untuk memprediksi probabilitas keanggotaan suatu class. Teori keputusan bayes merupakan pendekatan statistik yang fundamental dalam pengenalan pola (pattern
recognition), teori bayesian pada dasarnya adalah kemungkinan kejadian di masa
depan yang bisa dihitung dengan menentukan frekuensi pengalaman sebelumnya. Penggunaan algoritma bayes dalam hal klasifikasi harus mempunyai masalah yang bisa dilihat statistiknya (Ciptohartono, 2013).
Naive Bayes Classifier merupakan pengklasifikasi probabilitas sederhana
berdasarkan pada teorema Bayes. Teorema Bayes dikombinasikan dengan “Naive” yang berarti setiap atribut/variabel bersifat bebas (independent). Naive Bayes
Classifier dapat dilatih dengan efisien dalam pembelajaran terawasi (supervised learning) (Effendi, 2016).
15
Klasifikasi-klasifikasi Bayes adalah klasifikasi statistik yang dapat memprediksi kelas suatu anggota probabilitas. Untuk klasifikasi Bayes sederhana yang lebih dikenal sebagai Naive Bayesian Classifier dapat diasumsikan bahwa efek dari suatu nilai atribut sebuah kelas yang diberikan adalah bebas dari atribut-atribut lain, asumsi ini disebut class conditional independence yang dibuat untuk memudahkan perhitungan-perhitungan. Dalam Naive Bayes di asumsikan prediksi atribut adalah tidak tergantung pada kelas atau tidak dipengaruhi atribut lain (Darujati & Gumelar, 2016).
Pengklasifikasi bayesian adalah pengklasifikasi statistik dan didasarkan pada teorema bayes. Teori keputusan bayes adalah pendekatan statistik yang
fundamental dalam pengenalan pola (pattern recognition), penggunaan algoritma
ini dalam hal klasifikasi harus mempunyai masalah yang bisa dilihat statistiknya. Misalkan X adalah set atribut data dan h kelas variabel dan jika kelas memiliki hubungan dengan atribut maka diperlukan X dan h sebagai variabel acak dan menangkap hubungan peluang P(h|X) ini peluang posterior untuk h dan sebaliknya perior P(h) (Rifqo et al., 2017).
Dapat disimpulkan bahwa naive bayes merupakan sebuah teknik klasifikasi probabilistik berdasarkan teorema bayes dengan menggunakan asumsi tidak adanya keterkaitan antar atribut dalam proses klasifikasinya.
2.3 Obyek Penelitian
2.3.1 Sejarah FIF
PT Federal Internasional Finance didirikan dengan nama Mitrapusaka Artha Finance pada tanggal 1 Mei 1989 kemudian berganti nama menjadi FIF pada
tahun 1991. FIF mengawali usaha dibidang pembiayaan konsumen, sewa guna usaha, anjak piutang, kemudian pada tahun 1996 FIF memutuskan untuk berfokus pada pembiayaan sepeda motor Honda. Tepat di ulang tahun yang ke-24 pada tahun 2013 FIF mengeluarkan new identity yaitu FIFGROUP dengan logo sidik jari berwarna biru. FIFGROUP mempunyai 2 lini usaha, yaitu FIFASTRA yang bergerak pada pembiayaan sepeda motor Honda baik baru maupun bekas berkualitas dan SPEKTRA yang bergerak pada pembiayaan multiguna. FIFGROUP merupakan salah satu perusahaan pembiayaan terbesar di Indonesia terbukti dengan mempunyai 169 kantor cabang, 390 point of service, lebih dari 15ribu orang karyawan yang tersebar di seluruh Indonesia dan juga mencetak banyak prestasi dan penghargaan dari sejumlah institusi terpercaya.
2.3.2 Visi dan Misi
1. Visi
Menjadi pemimipin industri yang dikagumi secara nasional.
2. Misi
17
2.3.3 Struktur Organisasi
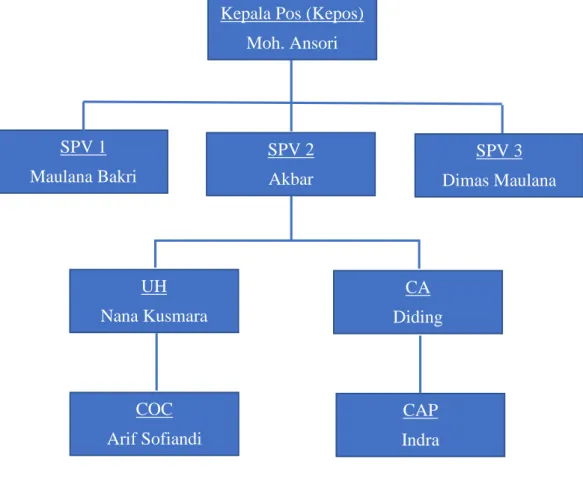
Gambar 2.2 Struktur Organisasi
Fungsi dan tugas dari masing – masing bagan adalah sebagai berikut : 1. Kepala Pos (KEPOS)
Pemberi acc / izin untuk tim kredit setiap orde yang diinput kedalam sistem dan mengontrol tim kolektor dikantor maupun dilapangan.
2. SPV 1
Mencetak bahan tagihan untuk kolektor setiap hari, yang sudah terlambat tiga bulan keatas dan pengurusan asuransi kehilangan dan kematian.
Kepala Pos (Kepos) Moh. Ansori SPV 1 Maulana Bakri SPV 2 Akbar SPV 3 Dimas Maulana UH Nana Kusmara CA Diding COC Arif Sofiandi CAP Indra
3. SPV 2
Mencetak bahan tagihan untuk kolektor setiap hari, yang sudah terlambat satu sampai dua bulan.
4. SPV 3
Mencetak bahan tagihan untuk kolektor setiap hari, yang sudah terlambat 6 hari sampai 1 bulan.
5. Kepala Pinjaman Dana Tunai
Pemberi acc dari hasil survei dilapangan dan menganalisa layak atau tidaknya diberikan pasilitas pinjaman, dan menginput ke sistem setiap kontrak (berkas akad).
6. Analisa Credit (CA)
Memberi acc DP atau uang muka setiap akad kredit sepeda motor baru, dan menganalisa hasil survei dan menginputnya kesistem untuk di acc oleh kepala pos (KEPOS).
7. Credit Control (COC)
Memasukkan data konsumen yang telah di acc oleh kepos dan menelpon kepada setiap costumer / konsumen untuk memastikan unit sepeda motor / elektronik yang dikredit konsumen sampai dengan untuk ketangan costumer / konsumen.
8. Credit Analisis Poom
Mengarsipkan berkas yang telah diinput dan mencocokkan no kontrak / no rekening untuk pembayaran konsumen / costumer.
19
BAB III
METODE PENELITIAN
3.1 Jenis Penelitian
Penelitian ini bersifat deskriptif yaitu penelitian yang mengambarkan tentang suatu keadaan tanpa menganalisis lebih lanjut atau dengan cara pendekatan cross sectional (suatu penelitian untuk mempelajari dinamika toleransi atara faktor-faktor resiko dengan cara pendekatan atau pengumpulan data dan pengumpulan observasi data) untuk mengetahui karakteristik kelayakan calon kredit sepeda motor di FIF Majalengka.
3.2 Tempat dan Waktu Penelitian
3.2.1 Tempat Penelitian
Tempat penelitian dilaksanakan di wilayah kerja FIF Majalengka, Jalan Ahmad Yani Jatiwangi (Jl. Raya Cirebon – Bandung) Kabupaten Majalengka. 3.2.2 Waktu Penelitian
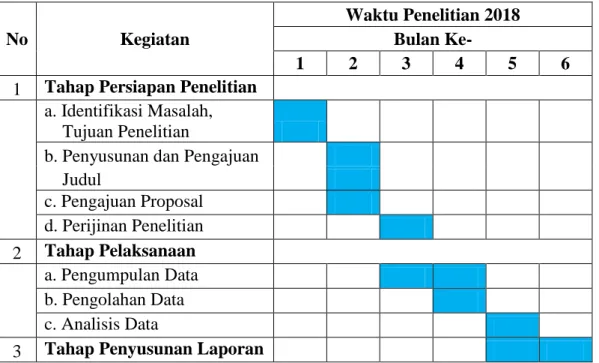
Waktu yang digunakan untuk penelitian ini dilakukan selama 6 bulan, terhitung dari tanggal 02 Mei sampai 30 Oktober 2018. Adapun rincian waktu penelitian dapat dilihat pada tabel dibawah ini :
Tabel 3. 1 Waktu Penelitian
No Kegiatan
Waktu Penelitian 2018 Bulan Ke-
1 2 3 4 5 6
1 Tahap Persiapan Penelitian
a. Identifikasi Masalah,
Tujuan Penelitian
b. Penyusunan dan Pengajuan
Judul c. Pengajuan Proposal d. Perijinan Penelitian 2 Tahap Pelaksanaan a. Pengumpulan Data b. Pengolahan Data c. Analisis Data
3 Tahap Penyusunan Laporan
3.3 Populasi dan Sampel Penelitian
3.3.1 Populasi
Menurut Sugiyono dalam (Tanjung, 2017) populasi adalah bukan hanya orang, tetapi juga obyek dan benda-benda alam yang lain. Populasi juga bukan sekedar jumlah yang ada pada obyek/subyek yang dipelajari, tetapi meliputi seluruh karakteristik/sifat yang dimiliki oleh subyek atau obyek itu.
Populasi dalam penelitian ini adalah bagian Kepala Pinjaman Dana Tunai dan Analisa Credit pada FIF Majalengka sebanyak 250 data.
3.3.2 Sampel
Menurut Sugiyono dalam (Tanjung, 2017) “sampel adalah bagian dari jumlah dan karakteristik yang dimiliki oleh populasi tersebut.”
21
Sampel pada penelitian ini adalah mengambil data sampel calon kredit sepeda motor yang telah ditentukan kelayakannya dengan jumlah sampel 250, dari 2 karyawan yang menjabat sebagai Kepala Pinjaman Dana Tunai dan Analisa
Credit Pada FIF Majalengka.
3.4 Metode Pengumpulan Data
Untuk mendapatkan data-data yang dapat menunjang penelitian ini, peneliti menggunakan beberapa metode pengumpulan data sebagai berikut :
1. Observasi
Observasi dilakukan langsung di FIF Majalengka yang beralamat di Jalan Ahmad Yani Jatiwangi (Jl. Raya Cirebon – Bandung), Kabupaten Majalengka, yang bertujuan untuk memperoleh data secara langsung berupa dokumen pendukung yang berhubungan dengan pemberian pinjaman kredit motor.
2. Kuesioner
Langkah selanjutnya peneliti menyebar kuesioner kepada responden yaitu karyawan yang menjabat sebagai Kepala Pinjaman Dana Tunai dan Analis
Credit yang menentukan secara langsung apakah pemohon kredit layak atau
tidak berdasar kriteria-kriteria yang sudah ditentukan dengan mengisi 8 pertanyaan yang diajukan penulis dengan jawaban ya atau tidak. Adapun pertanyaan-pertanyaan yang diajukan dapat dilihat pada tabel dibawah ini :
Tabel 3. 2 Kuesioner
No Pertayaan Jawaban
Ya Tidak 1 Apakah nasabah harus mengisi surat permohonan
kredit
dan membawa seluruh persyaratan pengajuan kredit?
2 Apakah nasabah yang sebelumnya sudah pernah mengajukan kredit dengan pembayaran buruk atau masih berjalan, bisa mengajukan kredit lagi?
3 Apakah Pendidikan tinggi memperbesar
kemungkinan
kelayakan nasabah?
4 Apakah besarnya nilai jaminan mempengaruhi
kelayakan nasabah menerima kredit?
5 Apakah karakter nasabah berpengaruh dalam
penilaian
kelayakan?
6 Apakah jumlah tanggungan nasabah berpengaruh
dalam
menilai kelayakan?
7 Apakah proses pengajuan kredit tidak akan
dilanjutkan
(ditolak) jika ditemukan kejanggalan dan atau
pengisian
data tidak benar?
8 Apakah pekerjaan tetap (PNS/BUMN/dll)
memperbesar
kemungkinan kelayakan nasabah dibanding
karyawan
kontrak?
3. Studi Pustaka
Peneliti melakukan studi kepustakaan melalui literatur-literatur atau referensi-referensi yang ada di perpustakaan dan internet.
23
3.5 Rancangan Penelitian
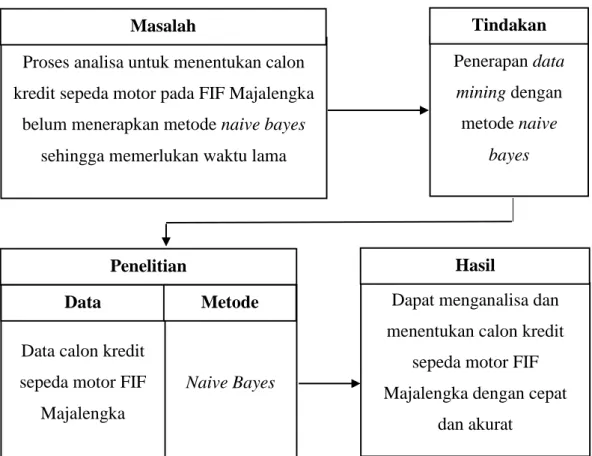
Rancangan dalam penelitian dibuat agar langkah-langkah dalam penelitian tidak keluar dari pokok pembahasan dan mudah dipahami, urutan langkah-langkah dibuat secara sistematis sehingga dapat dijadikan pedoman yang jelas dan mudah untuk menyelesaikan permasalahan yang ada.
Gambar 3. 1 Rancangan Penelitian
Rancangan penelitan diatas dapat dijelaskan sebagai berikut : 1. Masalah
Pada penelitian ini belum diterapkannya metode naive bayes sehingga memerlukan waktu lama untuk menentukan kelayakan calon kredit sepeda motor pada FIF Majalengka.
Proses analisa untuk menentukan calon kredit sepeda motor pada FIF Majalengka
belum menerapkan metode naive bayes sehingga memerlukan waktu lama
Penerapan data mining dengan metode naive bayes Penelitian Naive Bayes
Data calon kredit sepeda motor FIF
Majalengka
Data Metode
Tindakan Masalah
Dapat menganalisa dan menentukan calon kredit
sepeda motor FIF Majalengka dengan cepat
dan akurat Hasil
2. Tindakan
Metode yang digunakan untuk menganalisa dan menentukan kelayakan calon kredit sepeda motor pada FIF Majalengka adalah metode Data Mining
Classification Naive Bayes.
3. Penelitian
Data untuk menentukan kelayakan calon kredit sepeda motor diambil langsung dari FIF Majalengka dan dilakukan pengolahan data dengan membentuk data training secara random, dianalisa menggunakan metode
Naive Bayes Classification untuk menentukan kelayakan calon kredit
sepeda motor. 4. Hasil
Dapat Menganalisa hasil pengolahan data dan tingkat akurasi untuk menentukan kelayakan calon kredit sepeda motor dengan cepat dan akurat.
3.6 Variabel Penelitian
Variabel penelitian yang akan digunakan sebagai atribut data untuk proses
data mining klasifikasi adalah Karakter, Pendidikan, Pekerjaan, Tanggungan,
Rumah, Penghasilan, Riwayat Kredit dan Hasil Prediksi. Hasil Prediksi adalah variabel target penelitian yang berisi 2 nilai kelas, yaitu “LAYAK” dan “TIDAK LAYAK”.
25
Tabel 3. 3 Atribut Data yang Digunakan
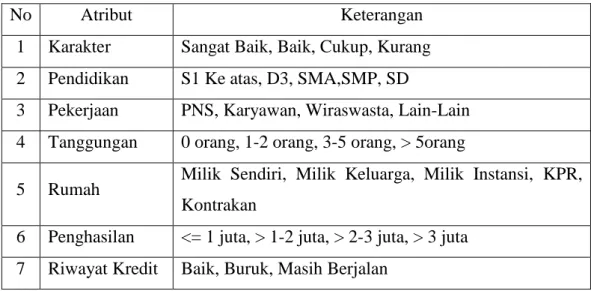
No Atribut Keterangan
1 Karakter Sangat Baik, Baik, Cukup, Kurang 2 Pendidikan S1 Ke atas, D3, SMA,SMP, SD
3 Pekerjaan PNS, Karyawan, Wiraswasta, Lain-Lain 4 Tanggungan 0 orang, 1-2 orang, 3-5 orang, > 5orang
5 Rumah Milik Sendiri, Milik Keluarga, Milik Instansi, KPR, Kontrakan
6 Penghasilan <= 1 juta, > 1-2 juta, > 2-3 juta, > 3 juta 7 Riwayat Kredit Baik, Buruk, Masih Berjalan
3.7 Metode Analisis Data
Metode analisis data menggunakan Naive Bayes Classifier (NBC) yang merupakan sebuah pengklasifikasi probabilitas sederhana yang mengaplikasikan
Teorema Bayes dengan asumsi ketidaktergantungan (independen) yang tinggi.
Keuntungan penggunaan NBC bahwa metode ini hanya membutuhkan jumlah data pelatihan (training data) yang kecil untuk menentukan estimasi parameter yang diperlukan dalam proses pengklasifikasian. Karena yang diasumsikan sebagai variabel independen, maka hanya varian dari suatu variabel dalam sebuah kelas yang dibutuhkan untuk menentukan klasifikasi, bukan keseluruhan dari matriks kovarians.
3.7.1 Persamaan Metode Naive Bayes
Bentuk umum atau persamaan dari teorema Bayes adalah :
𝑃(𝐻|𝑋) =
𝑃(𝑋|𝐻). 𝑃(𝐻)
𝑃(𝑋)
Keterangan :
X : Data dengan class yang belum diketahui
H : Hipotesis data X merupakan suatu class spesifik
P(H|X) : Probabilitas hipotesis H berdasar kondisi X (posteriori probability)
P(H) : Probabilitas hipotesis H (prior probability)
P(X|H) : Probabilitas X berdasarkan kondisi pada hipotesis H P(X) : Probabilitas X
Untuk menjelaskan metode Naive Bayes, perlu diketahui bahwa proses klasifikasi memerlukan sejumlah petunjuk untuk menentukan kelas apa yang cocok bagi sample yang dianalisis tersebut. Karena itu, metode
Naive Bayes di atas disesuaikan sebagai berikut:
(𝐶|𝐹1…𝐹𝑛) = 𝑃(𝐶)𝑃(𝐹1…𝐹𝑛|𝐶) 𝑃(𝐹1…𝐹𝑛)
Di mana Variabel C merepresentasikan kelas, sementara variabel “F1 ... Fn” merepresentasikan karakteristik petunjuk yang dibutuhkan untuk melakukan klasifikasi. Maka rumus tersebut menjelaskan bahwa peluang masuknya sampel karakteristik tertentu dalam kelas C (Posterior) adalah peluang munculnya kelas C (sebelum masuknya sampel tersebut, seringkali disebut prior), dikali dengan peluang kemunculan karakteristik-karakteristik sampel pada kelas C (disebut juga likelihood), dibagi dengan peluang kemunculan karakteristik-karakteristik sampel secara global (disebut juga
27
Posterior
= 𝑝𝑟𝑖𝑜𝑟 𝑥 𝑙𝑖𝑘𝑒𝑙𝑖ℎ𝑜𝑜𝑑𝑒𝑣𝑖𝑑𝑒𝑛𝑐𝑒
Nilai Evidence selalu tetap untuk setiap kelas pada satu sampel. Nilai dari posterior tersebut nantinya akan dibandingkan dengan nilai-nilai
posterior kelas lainnya untuk menentukan ke kelas apa suatu sample akan
diklasifikasikan. Penjabaran lebih lanjut rumus Naive Bayes tersebut dilakukan dengan menjabarkan (𝐶|𝐹1,…,) menggunakan aturan perkalian sebagai berikut:
𝑃(𝐶|𝐹1,…,𝐹𝑛 = 𝑃(𝐶)𝑃(𝐹1,…,𝐹𝑛|𝐶) = 𝑃(𝐶)𝑃(𝐹1|𝐶)𝑃(𝐹2,…,𝐹𝑛|𝐶,𝐹1) = 𝑃(𝐶)𝑃(𝐹1|𝐶)𝑃(𝐹2|𝐶,𝐹1 )𝑃(𝐹3,…,𝐹𝑛|𝐶,𝐹1,𝐹2
= (𝐶)𝑃(𝐹1|𝐶)𝑃(𝐹2|𝐶,𝐹1 )𝑃(𝐹3|𝐶,𝐹1,𝐹2)𝑃(𝐹4,…,𝐹𝑛|𝐶,𝐹1,𝐹2,𝐹3) = 𝑃(𝐶)𝑃(𝐹1|𝐶)𝑃(𝐹2|𝐶,𝐹1)𝑃(𝐹3|𝐶,𝐹1,𝐹2)…𝑃(𝐹𝑛|𝐶,𝐹1,𝐹2,𝐹3,…,𝐹𝑛−1)
Dapat dilihat bahwa hasil penjabaran tersebut menyebabkan semakin banyak dan semakin kompleksnya faktor - faktor syarat yang mempengaruhi nilai probabilitas, yang hampir mustahil untuk dianalisa satu persatu. Akibatnya, perhitungan tersebut menjadi sulit untuk dilakukan. Di sinilah digunakan asumsi independensi yang sangat tinggi, bahwa masing-masing petunjuk (F1,F2...Fn) saling bebas (independen) satu sama lain. Dengan asumsi tersebut, maka berlaku suatu kesamaan sebagai berikut:
𝑃(𝐹𝑖|𝐹 𝑗) = (𝐹𝑖 ∩ 𝐹𝑗) 𝑃(𝐹𝑗)
=
𝑃(𝐹𝑖) 𝑃(𝐹𝑗) 𝑃(𝐹𝑗)=
𝑃(𝐹𝑖) untuk I ≠ j, sehingga: 𝑃(𝐹𝑖 | 𝐶, 𝐹𝑗) = 𝑃(𝐹𝑖|𝐶)Dari persamaan di atas dapat disimpulkan bahwa asumsi independensi
naive tersebut membuat syarat peluang menjadi sederhana, sehingga
perhitungan menjadi mungkin untuk dilakukan. Selanjutnya, penjabaran
P(F1,…,Fn | C) dapat disederhanakan seperti berikut:
P(F1 … Fn | C) = P(F1 | C) P(F2 | C) … P(Fn | C) P(F1 … Fn | C) =
∏
𝑛𝑖=1𝑃 ( 𝐹𝑖 | 𝐶)Dengan kesamaan di atas, persamaan teorema bayes dapat dituliskan sebagai berikut: P(F1 … Fn | C) = 1 𝑃(𝐹1,𝐹2,… ,𝐹𝑛)
∏
𝑃 ( 𝐹𝑖 | 𝐶) 𝑛 𝑖=1 P(F1 … Fn | C) =𝑃(𝐶) 𝑍∏
𝑃 ( 𝐹𝑖 | 𝐶) 𝑛 𝑖=1Persamaan di atas merupakan model dari teorema Naive Bayes yang selanjutnya akan digunakan dalam proses klasifikasi dokumen data.
29
3.7.2 Alur Metode Naive Bayes
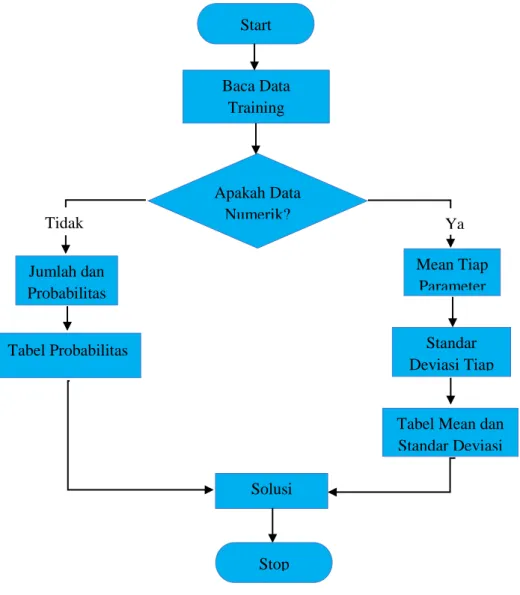
Gambar 3. 2 Alur Metode Naive Bayes
Keterangan alur metode Naive Bayes (Saleh, 2015):
1. Baca data training
2. Hitung jumlah dan probabilitas, namun apabila data numerik maka : a. Cari nilai mean dan standar deviasi dari masing masing parameter yang
merupakan data numerik.
Start Apakah Data Numerik? Baca Data Training Mean Tiap Parameter Standar Deviasi Tiap Parameter Tabel Mean dan Standar Deviasi Jumlah dan Probabilitas Tabel Probabilitas Solusi Tidak Ya Stop
Adapun persamaan yang digunakan untuk menghitung nilai rata-rata hitung
(mean) dapat dilihat sebagai berikut :
µ
=
∑𝑛1=1𝑥𝑖 𝑛 atauµ =
𝑥1+ 𝑥2 + 𝑥3+ ... + 𝑥𝑛 𝑛 dimana:µ:
Rata-rata hitung (mean)𝑥
𝑖:
Nilai sampel ke-i𝑛:
Jumlah sampleDan persamaan untuk menghitung nilai simpangan baku (standar deviasi) dapat dilihat sebagai berikut:
σ
=
√
∑𝑛1=1(𝑥𝑖−µ) 2 𝑛−1 dimana:σ
:
Standar deviasi𝑥
𝑖:
Nilai x ke-iµ:
Rata-rata hitung𝑛:
Jumlah sample31
b. Cari nilai probabilistik dengan cara menghitung jumlah data yang sesuai dari kategori yang sama dibagi dengan jumlah data pada kategori tersebut.
3. Mendapatkan nilai dalam tabel mean, standart deviasi dan probabilitas. 4. Solusi kemudian dihasilkan.
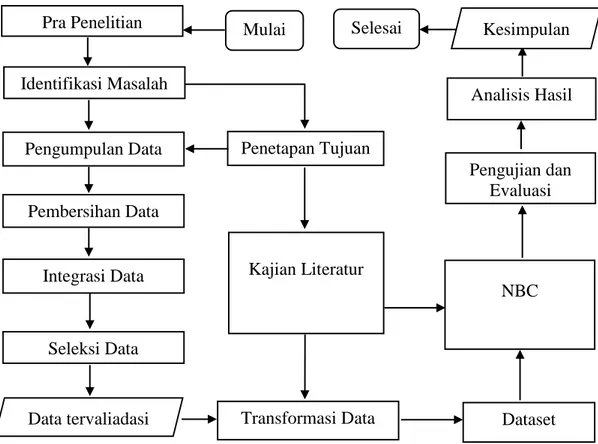
3.8 Tahap Penelitian
Pada penelitian ini, tahapan penelitian yang dilakukan adalah seperti pada Gambar 3.3 penelitian ini secara garis besar meliputi beberapa kegiatan inti yaitu pembuatan proposal, pengumpulan data, pengolahan data, implementasi NBC, pengujian, dan analisis hasil. Pada tahap pengolahan ada beberapa kegiatan sesuai dengan tahapan yang ada pada data mining, yaitu pembersihan data, integrasi data, seleksi data, transformasi data, dan pembentukan dataset yang dalam penelitian akan digunakan sebagai data training dan data testing (Ridwan et al., 2013).
Gambar 3. 3 Tahap Penelitian
3.9 Instrumen Penelitian
Berdasarkan permasalahan yang telah diuraikan sebelumnya, maka bahan dan peralatan yang diperlukan untuk penelitian ini meliputi :
3.9.1 Bahan
Dalam penelitian ini bahan yang dibutuhkan adalah data sekunder berupa data kelayakan pemberian kredit sepeda motor untuk digunakan sebagai instrumentasi guna memperoleh data untuk menentukan calon kelayakan pemberian kredit sepeda motor FIF Majalengka.
Seleksi Data Identifikasi Masalah Pengumpulan Data Pembersihan Data Integrasi Data Penetapan Tujuan Kajian Literatur Transformasi Data Data tervaliadasi Pengujian dan Evaluasi NBC Dataset Analisis Hasil
33
3.9.2 Peralatan
Peralatan dalam penelitian ini meliputi kebutuhan perangkat lunak dan kebutuhan perangkat keras. Dibawah ini merupakan peralatan atau tools yang dibutuhkan, diantaranya:
1. Kebutuhan Perangkat Lunak: a) Microsoft Office Word 2013
Software ini digunakan untuk mengolah laporan hasil penelitian. b) Microsoft Office Excel 2013
Software ini digunakan sebagai media penulisan dan pengolahan
dataset, data training dan data testing.
c) Sistem operasi Microsoft Windows 10 Sistem Operasi yang digunakan peneliti. d) Rapid Miner Studio 7.6
Tools yang akan digunakan untuk mengolah data, penerapan
algoritma naive bayes dan mengetahui akurasi dari algoritma yang digunakan terhadap data yang sedang diteliti.
2. Kebutuhan Perangkat Keras:
a) Prosesor AMD A8-4500 1.90 GHz b) AMD Radeon 8750M 2GB DDR3 c) LCD 14-inchi HD
d) RAM 4GB DDR3 e) HDD 500 GB
34
BAB IV
HASIL DAN PEMBAHASAN
4.1 Penentuan Kriteria
Dalam menentukan seseorang layak atau tidak layak menerima kredit sepeda motor ada beberapa kriteria yang digunakan oleh pihak FIF Majalengka, kriteria yang digunakan adalah sebagai berikut :
Tabel 4. 1 Kriteria yang Digunakan
Karakter Sangat Baik, Baik, Cukup, Kurang Pendidikan S1 Ke atas, D3, SMA,SMP, SD
Pekerjaan PNS, Karyawan, Wiraswasta, Lain-Lain Tanggungan 0 orang, 1-2 orang, 3-5 orang, > 5orang
Rumah Milik Sendiri, Milik Keluarga, Milik Instansi, KPR, Kontrakan
Penghasilan <= 1 juta, > 1-2 juta, > 2-3 juta, > 3 juta Riwayat Kredit Baik, Buruk, Masih Berjalan
4.2 Perhitungan Naive Bayes
Dataset yang digunakan sebagai data training adalah sebanyak 250 data
(lampiran 1) yang diambil dari data kelayakan kredit sepeda motor terdahulu yang telah ditentukan kelayakannya. Sedangkan untuk data testing yang akan ditentukan kelayakannya berjumlah 50 data (lampiran 2).
35
4.2.1 Menghitung Probabilitas Kelas
Tahap pertama perhitungan untuk menentukan kelayakan dengan metode Naive Bayes adalah dengan mencari probabilitas dari masing-masing kelas. Dalam menentukan kelayakan kredit sepeda motor akan ditentukan 2 kelas yaitu kelas “Layak” dan “Tidak Layak”. Cara perhitungannya adalah dengan mencari berapa jumlah data yang layak dan tidak layak dari total keseluruhan data training, lalu membaginya dengan total keseluruhan data. Hasil dari perhitungan tersebut dapat dilihat pada tabel berikut :
Tabel 4. 2 Probabilitas Kelas
Kelas
Layak Tidak Layak
Layak 137/250 Tidak Layak 113/250
4.2.2 Menghitung Probabilitas Masing-masing Atribut
Cara mencari probabilitas suatu atribut adalah dengan membandingkan atribut dari data testing dengan atribut dari data training. Berapa jumlah atribut dengan kelas ”Layak” yang berada pada data training, kemudian bagi dengan probabilitas kelas “Layak”. Begitu juga dengan mencari probabilitas untuk kelas “Tidak Layak”.
1. Karakter
Tabel 4. 3 Atribut Karakter
Karakter Sangat Baik Baik Cukup Kurang
Layak 45/137 53/137 34/137 5/137
2. Pendidikan
Tabel 4. 4 Atribut Pendidikan
Pendidikan S1 Ke atas D3 SMA SMP SD
Layak 20/137 20/137 36/137 28/137 33/137
Tidak Layak 29/113 18/113 22/113 20/113 24/113
3. Pekerjaan
Tabel 4. 5 Atribut Pekerjaan
Pekerjaan PNS Karyawan Wiraswasta Lain-Lain
Layak 20/137 31/137 26/137 60/137
Tidak Layak 21/113 33/113 15/113 44/113
4. Tanggungan
Tabel 4. 6 Atribut Tanggungan
Tanggungan 0 orang 1-2 orang 3-4 orang > 5 orang
Layak 48/137 30/137 26/137 33/137
Tidak Layak 18/113 9/113 40/113 46/113
5. Rumah
Tabel 4. 7 Atribut Rumah
Rumah Kontrak Milik
Sendiri Milik keluarga Milik Instansi KPR Layak 30/137 24/137 37/137 22/137 24/137 Tidak Layak 25/113 21/113 25/113 16/113 26/113
37
6. Penghasilan
Tabel 4. 8 Atribut Penghasilan
Penghasilan <= 1 juta > 1-2 juta > 2-3 juta > 3 juta
Layak 17/137 44/137 29/137 47/137
Tidak Layak 32/113 27/113 26/113 28113
7. Riwayat Kredit
Tabel 4. 9 Atribut Riwayat Kredit
Riwayat Kredit Baik Buruk Masih Berjalan
Layak 133/137 2/137 2/137
Tidak Layak 17/113 66/113 30/113
4.2.3 Menghitung Probabilitas Akhir Untuk Setiap Kelas
Untuk menghitung probabilitas akhir pada setiap kelas, perlu menggunakan
data training yang terdapat pada tabel 4.2 dan mengubahnya menjadi nilai yang
sudah ditentukan pada proses 4.2.2 sesuai dengan atribut masing-masing. Lalu dari masing-masing atribut dan nilai probabilitas kelas dikalikan. Dari kedua hasil yang sudah ditentukan pada tiap kelas, bandingkan nilai yang paling tinggi. Jika kelas “Layak” bernilai paling tinggi maka hasilnya “Layak”, begitu pula sebaliknya.
4.2.4 Kasus Perhitungan Naive Bayes
Untuk memudahkan dalam pemahaman perhitungan Naive Bayes, secara manual akan dibuat studi kasus sebagai berikut dengan rulenya berupa data training pada (lampiran 1) :
Terdapat seorang yang akan mengajukan kredit yang bernama Bapak Wahyu dengan data sebagai berikut :
Karakter Pendidik-an Pekerja-an Tanggung-an Rumah Peng-hasilan Riwayat Kredit Prediksi
Kurang SMP PNS Lebih Dari
5 orang KPR > 3 juta Buruk ?
Data Testing : X = (Karakter = “Kurang”, Pendidikan = “SMP”, Pekerjaan = “PNS”, Tanggungan = “Lebih Dari 5 orang”, Rumah = “KPR”, Penghasilan = “> 3 juta”, Riwayat Kredit = “Buruk”)
Tahap 1 menghitung jumlah kelas atau prediksi P(Ci)
P(Layak) = 137/250 = 0.548 P(Tidak Layak) = 113/250 = 0.452
Tahap 2 menghitung jumlah kasus yang sama dengan kelas yang sama
P(X|Ci)
P(Karakter= “Kurang” | Layak)= 5/137 = 0.0364
P(Karakter= “Kurang” | Tidak Layak)= 95/113 = 0.8407 P(Pendidikan= “SMP” | Layak)= 28/137= 0.2043
P(Pendidikan= “SMP” | Tidak Layak)= 20/113 = 0.1769 P(Pekerjaan= “PNS” | Layak)= 20/137 = 0.1459
P(Pekerjaan= “PNS” | Tidak Layak)= 21/113 = 0.1858
P(Tanggungan= “Lebih Dari 5 orang” | Layak)= 33/137= 0.2408
P(Tanggungan= “Lebih Dari 5 orang” | Tidak Layak)= 46/113 = 0.4070 P(Rumah= “KPR” | Layak)= 24/137= 0.1751
39
P(Rumah= “KPR” | Tidak Layak)= 26/113= 0.2300 P(Penghasilan= “> 3 juta” | Layak)= 47/137= 0.3430 P(Penghasilan= “> 3 juta” | Tidak Layak)= 28/113= 0.2477 P(Riwayat Kredit)= “Buruk” | Layak)= 2/137= 0.0145
P(Riwayat Kredit)= “Buruk” | Tidak Layak)= 66/113= 0.5840
Tahap 3 mengkalikan semua hasil atribut LAYAK dan TIDAK LAYAK
P(X|Layak) = 0.0364 * 0.2043 * 0.1459 * 0.2408 * 0.1751* 0.3430 * 0.0145 = 0.00000022
P(X|Tidak Layak) = 0.8407 * 0.1769 * 0.1858 * 0.4070 * 0.2300 * 0.2477 * 0.5840 = 0.00037417
Tahap 4 membandingkan nilai kelas LAYAK dengan TIDAK LAYAK
P(X | Ci) * P(Ci)
P(X | Layak) * P(Layak) = 0,00000029 * 0.548= 0,00000012056
P(X | Tidak Layak) * P(Tidak Layak) = 0,00037417 * 0.452= 0,00016912484
Jadi, untuk Karakter = “Kurang”, Pendidikan = “SMP”, Pekerjaan = “PNS”, Tanggungan = “Lebih Dari 5 orang”, Rumah = “KPR”, Penghasilan = “> 3 juta”, Riwayat Kredit = “Buruk”, maka hasilnya adalah “Tidak Layak”.
4.3 Implementasi Klasifikasi Naive Bayes pada Rapid Miner
Uji coba dilakukan untuk mengetahui apakah perhitungan yang telah dilakukan diatas sesuai untuk menentukan kelayakan calon kredit sepeda motor. Uji
coba dilakukan dengan menentukan 50 data testing yang telah dipilih (lampiran 2) dengan kasus yang dihitung manual yaitu satu data. Data testing tersebut akan dicari nilai prediksinya menggunakan Rapid Miner 7.6.
Gambar 4. 1 Proses Rapid Miner
41
Dari keterangan gambar 4.2 hasil testing data yang dilakukan dengan menggunakan Rapid Miner mengahasilkan prediksi yang sama dengan kasus perhitungan manual yaitu “Tidak Layak”.
4.3.1 Akurasi Prediksi
Proses klasifikasi dengan Rapid Miner menggunakan metode Naive Bayes yang digunakan untuk mengklasifikasi data kelayakan calon kredit sepeda motor pada peneltitan ini.
Gambar 4. 3 Proses Training dan Testing
1. Accuracy/akurasi
Dengan mengetahui jumlah data yang di klasifikasikan secara benar maka dapat diketahui akurasi hasil prediksi yaitu 94.00% dari hasil data testing.
Gambar 4. 4 Accuracy/Akurasi
Hasil analisa antara data yang di tes dengan data training pada Rapid Miner dapat dilihat di lampiran 2. Untuk menghitung akurasinya sebagai berikut:
Jumlah data yang diuji : 50 Jumlah data yang diprediksi benar : 47
Jumlah data yang diprediksi salah : 3
Akurasi = Jumlah data yang diprediksi benar/jumlah data yang diuji*100% = (47/50)*100% = 94%
Eror = Jumlah data yang diprediksi salah/jumlah data yang diuji*100% = (3/50)*100% = 6%
Dari perhitungan tersebut dapat disimpulkan bahwa klasifikasi dengan menggunakan metode Naive Bayes untuk menentukan kelayakan calon kredit sepeda motor menghasilkan tingkat akurasi sebesar 94% dan tingkat error 6%.
43
Gambar 4. 5 Kurva ROC
Kurva ROC digunakan untuk mengekspresikan data, garis horizontal mewakili nilai false Layak dan garis vertikal mewakili nilai true Layak. Dari gambar 4.5 dapat diketahui bahwa nilai Area Under Curve (AUC) model algoritma
naive bayes adalah 0.938, hal ini menunjukan bahwa model algoritma naive bayes
44
BAB V
PENUTUP
5.1 Kesimpulan
Berdasarkan hasil penelitian yang telah dilakukan mengenai penentuan kelayakan calon kredit sepeda motor dengan metode Naive Bayes pada FIF Majalengka, maka terdapat beberapa saran yang perlu diperhatikan :
1. Dari hasil penelitian membuktikan bahwa algoritma Naive Bayes dapat diterapkan untuk menentukan kelayakan calon kredit sepeda motor di FIF Majalengka dengan tingginya pengajuan kredit menjadi sebanding dengan jumlah karyawan yang ada, dan pengolahan data awal merupakan tahapan yang sangat mempengaruhi hasil akurasi yang baik sehingga akurasi akhir yang dihasilkan termasuk kategori excellent dengan nilai akurasi 94%. 2. Berdasarkan penelitian yang dilakukan, didapatkan hasil untuk menentukan
kelayakan calon kredit sepeda motor dengan cepat dan akurat, dari pengujian yang dilakukan dengan membandingkan data training dengan
data testing menggunakan aplikasi pendukung Rapid Miner didapat tingkat
akurasi sebesar 94% dan eror sebesar 6% sehingga dapat mengatasi risiko kredit yang macet.
3. Proses Data Mining dengan metode Naive Bayes memanfaatkan data
training untuk menghasilkan probabilitas setiap kriteria untuk class yang
berbeda, sehingga nilai-nilai probabilitas dari kriteria tersebut dapat dioptimalkan untuk menentukan kelayakan calon kredit sepeda motor
45
berdasarkan proses klasifikasi yang dilakukan oleh metode Naive Bayes itu sendiri.
5.2 Saran
Berdasarkan hasil penelitian yang telah dilakukan mengenai penentuan kelayakan calon kredit sepeda motor dengan metode Naive Bayes pada FIF Majalengka, maka terdapat beberapa saran yang perlu diperhatikan :
1. Pada penelitian ini belum dibuatkannya sistem pendukung keputusan untuk menentukan kelayakan calon kredit sepeda motor dan dapat dikembangkan dengan metode klasifikasi data mining lainnya agar bisa dilakukan perbandingan.
2. Penentuan data training dapat mempengaruhi hasil pengujian, karena pola data training tersebut akan dijadikan sebagai rule untuk menentukan kelas pada data testing. Sehingga besar atau kecilnya persentase tingkat akurasi dipengaruhi juga oleh penentuan data training.
3. Tidak berlaku jika probabilitas kondisionalnya adalah nol pada metode
46
DAFTAR PUSTAKA
Ciptohartono, C. C. (2013). BAYES UNTUK MENILAI KELAYAKAN KREDIT, 1–6.
Darujati, C., & Gumelar, A. B. (2016). PEMANFAATAN TEKNIK SUPERVISED UNTUK KLASIFIKASI TEKS BAHASA, (May).
Effendi, H. (2016). SISTEM PAKAR DIAGNOSIS PENYAKIT INFEKSI SALURAN, 284–290.
Novianti, B., Rismawan, T., & Bahri, S. (2016). IMPLEMENTASI DATA MINING DENGAN ALGORITMA C4 . 5 UNTUK PENJURUSAN SISWA ( STUDI KASUS : SMA NEGERI 1 PONTIANAK ), 4(3).
Nugroho, F. X. H., & Suryati, P. (2013). Aplikasi Sistem Pendukung Keputusan Pengajuan Kredit Sepeda Motor, 2013(November), 121–125.
Nuraeni, N. (2017). Penentuan Kelayakan Kredit Dengan Algoritma Naïve Bayes Classifier : Studi Kasus Bank Mayapada Mitra Usaha Cabang PGC, III(1), 9– 15.
Prathama, A. A., Toba, H., Prof, J., Suria, D., & Bandung, N. (2013). Sistem Pendukung Keputusan untuk Seleksi Administrasi Penerimaan Pegawan dengan Pohon Keputusan ID3 ( Studi Kasus PT Jasamedika Saranatama ), 3, 117–131.
Putri, D. L., & Santoso. (2016). Implementasi Algoritma K-Means Untuk Pengelompokan Penyakit Pasien ( Studi Kasus : Puskesmas Kajen ) K-Means
47
Algorithm Implementation for Classification of Disease Patient ( Case Study : Health Centers Kajen Regency Pekalongan ), 1.
Ridwan, M., Suyono, H., & Sarosa, M. (2013). Penerapan Data Mining Untuk Evaluasi Kinerja Akademik Mahasiswa Menggunakan Algoritma Naive Bayes Classifier, 7(1), 59–64.
Rifqo, M. H., Wijaya, A., & Pseudocode, J. (2017). IMPLEMENTASI ALGORITMA NAIVE BAYES DALAM PENENTUAN PEMBERIAN KREDIT, IV(September), 120–128.
Saleh, A. (2015). Implementasi Metode Klasifikasi Naïve Bayes Dalam Memprediksi Besarnya Penggunaan Listrik Rumah Tangga, 2(3), 207–217. Tanjung, Q. (2017). Sistem pendukung keputusan kelayakan kredit motor
Sampel Data Training
No Karakter Pendidikan Pekerjaan Tanggungan Rumah Penghasilan Riwayat Hasil Kredit
1 Baik D3 Karyawan Lebih Dari
5 orang Kontrak > 2-3 juta Baik Layak 2 Sangat
Baik SMA Wiraswasta
Lebih Dari 5 orang
Milik
Instansi > 3 juta Baik Layak 3 Kurang D3 Wiraswasta Lebih Dari
5 orang Kontrak > 2-3 juta
Masih Berjalan
Tidak Layak 4 Sangat
Baik SD Wiraswasta 0 orang Kontrak > 2-3 juta Baik Layak 5 Kurang S1 Ke atas PNS 0 orang Milik
Sendiri > 3 juta
Masih Berjalan
Tidak Layak 6 Kurang S1 Ke atas Wiraswasta Lebih Dari
5 orang
Milik
Instansi > 3 juta Buruk
Tidak Layak 7 Kurang D3 Lain-Lain 3-4 orang Milik
Instansi <= 1 juta Baik
Tidak Layak 8 Baik SMP Lain-Lain 0 orang Milik
Instansi > 1-2 juta Baik Layak 9 Kurang S1 Ke atas Lain-Lain 0 orang Milik
Keluarga > 3 juta
Masih Berjalan
Tidak Layak
10 Cukup SMA PNS 3-4 orang Milik
Sendiri > 1-2 juta Baik Layak 11 Kurang SD Karyawan 3-4 orang Kontrak <= 1 juta Baik Tidak Layak 12 Kurang D3 PNS 3-4 orang Kontrak > 3 juta Buruk Tidak Layak 13 Kurang SMA PNS Lebih Dari
5 orang
Milik
Sendiri > 1-2 juta Baik
Tidak Layak
14 Cukup SMP PNS 1-2 orang Milik
Sendiri > 1-2 juta Baik Layak 15 Cukup SD Lain-Lain 3-4 orang Milik
Instansi <= 1 juta Baik
Tidak Layak 16 Kurang SMP Karyawan 3-4 orang Kontrak > 1-2 juta Buruk Tidak Layak 17 Sangat
Baik SMP Wiraswasta 1-2 orang Kontrak > 2-3 juta Baik Layak 18 Cukup D3 PNS 0 orang KPR > 2-3 juta Baik Layak 19 Kurang S1 Ke atas PNS 3-4 orang Kontrak > 2-3 juta Buruk Tidak Layak 20 Kurang SD Lain-Lain 3-4 orang Kontrak <= 1 juta Baik Tidak Layak 21 Cukup S1 Ke atas Karyawan 3-4 orang Milik
Instansi > 2-3 juta
Masih Berjalan
Tidak Layak 22 Cukup SMA Lain-Lain 3-4 orang KPR <= 1 juta Baik Tidak Layak 23 Sangat
Baik SD Lain-Lain 3-4 orang
Milik
Instansi > 1-2 juta Baik Layak 24 Kurang SD Lain-Lain Lebih Dari
5 orang Kontrak <= 1 juta Baik
Tidak Layak
49
25 Baik SMA Lain-Lain 0 orang Milik
Instansi > 1-2 juta Baik Layak 26 Sangat
Baik SMA Lain-Lain 1-2 orang
Milik
Sendiri > 2-3 juta Baik Layak 27 Kurang S1 Ke atas Karyawan Lebih Dari
5 orang
Milik
Sendiri > 2-3 juta Buruk
Tidak Layak 28 Sangat
Baik SMA Lain-Lain 1-2 orang
Milik
Sendiri <= 1 juta Baik Layak 29 Kurang D3 Karyawan 3-4 orang Milik
Keluarga > 1-2 juta Buruk
Tidak Layak
30 Baik D3 PNS 3-4 orang Milik
Sendiri > 3 juta Baik Layak 31 Kurang SMA Karyawan 0 orang Milik
Keluarga > 2-3 juta
Masih Berjalan
Tidak Layak 32 Kurang SD Lain-Lain Lebih Dari
5 orang
Milik
Keluarga > 2-3 juta Buruk
Tidak Layak 33 Sangat
Baik S1 Ke atas Lain-Lain
Lebih Dari
5 orang Kontrak > 3 juta Baik Layak
34 Kurang SD PNS 3-4 orang Milik
Keluarga > 1-2 juta Buruk
Tidak Layak 35 Kurang S1 Ke atas Wiraswasta 3-4 orang KPR > 2-3 juta Masih
Berjalan
Tidak Layak 36 Sangat
Baik SMA Wiraswasta 3-4 orang
Milik
Keluarga > 3 juta Baik Layak 37 Kurang SMA Wiraswasta 3-4 orang Kontrak > 2-3 juta Buruk Tidak Layak 38 Sangat
Baik SMP Karyawan 3-4 orang
Milik
Sendiri > 2-3 juta Baik Layak 39 Sangat
Baik SD Lain-Lain 0 orang
Milik
Keluarga > 3 juta Baik Layak 40 Sangat
Baik D3 Wiraswasta 0 orang Kontrak > 3 juta Baik Layak 41 Sangat
Baik SMA Karyawan 0 orang
Milik
Sendiri > 3 juta Buruk Layak 42 Sangat
Baik SMA Lain-Lain 1-2 orang KPR > 1-2 juta Baik Layak 43 Kurang S1 Ke atas Wiraswasta 0 orang Milik
Keluarga > 2-3 juta
Masih Berjalan
Tidak Layak 44 Baik SMA Karyawan 3-4 orang Milik
Instansi <= 1 juta Baik Layak
45 Cukup SD PNS Lebih Dari
5 orang KPR > 2-3 juta
Masih Berjalan
Tidak Layak 46 Cukup S1 Ke atas Lain-Lain 1-2 orang Milik
Keluarga <= 1 juta Baik Layak 47 Cukup SD Lain-Lain Lebih Dari
5 orang Kontrak > 1-2 juta Buruk
Tidak Layak 48 Cukup SMA Lain-Lain 1-2 orang Milik
Keluarga <= 1 juta Baik Layak 49 Kurang D3 Karyawan Lebih Dari
5 orang KPR > 3 juta Buruk
Tidak Layak 50 Kurang SMA Lain-Lain 0 orang Kontrak > 1-2 juta Buruk Tidak Layak