8
LANDASAN TEORI
2.1 Teori Basis Data 2.1.1 Pengertian Data
Pengertian Data menurut Whitten et al. (2004, p23), data adalah fakta mentah mengenai orang, tempat, kejadian, dan hal-hal penting yang dalam organisasi. Tiap fakta, tanpa disertai fakta lainnya, secara relatif tidak ada artinya.
Pengertian Data menurut Atzeni et al. (2003, p2) data adalah merupakan suatu bentuk penyimpanan informasi yang harus diterjemahkan terlebih dahulu untuk menghasilkan informasi.
Data sendiri tidak mempunyai makna, tetapi setelah diterjemahkan dan dihubungkan dengan benar, data menghasilkan informasi yang memungkinkan kita dalam meningkatkan pengetahuan.
2.1.2 Pengertian Sistem
Pengertian sistem menurut pendapat O’Brien (2002, p8) sistem secara sederhana dapat diartikan sebagai sebuah kumpulan dari elemen – elemen yang saling berhubungan atau berinteraksi yang menbentuk suatu kesatuan.
Pengertian sistem menurut Mulyadi (1997, p2) pada dasarnya sistem adalah sekelompok unsur yang berhubungan erat satu dengan yang lainnya, yang berfungsi untuk mencapai tujuan tertentu.
2.1.3 Pengertian Basis Data dan Sistem Basis Data
Menurut Atzeni et al. (2003, p2) basis data adalah suatu koleksi data, digunakan dalam menampilkan informasi yang diinginkan kepada sebuah sistem informasi.
Menurut Connoly dan Begg (2002, p14) basis data merupakan suatu kumpulan data yang terhubung secara logic, dan deskripsi dari data tersebut yang dirancang untuk memenuhi kebutuhan informasi dari suatu organisasi. Artinya basis data merupkan tempat penyimpanan data yang besar, dimana dapat digunakan secara simultan oleh banyak pengguna.
2.1.4 Sistem Manajemen Basis Data (DBMS)
Menurut Connolly dan Begg (2002, p16) DBMS adalah sebuah sistem perangkat lunak yang memungkinkan pengguna untuk mendefinisika, menciptakan, memelihara, dan mengontrol akses ke dalam basis data.
Menurut Atzeni et al. (2003, p2) DBMS adalah sistem perangkat lunak yang mempu yi kemampuan untuk mengatur basis data yang sangat besar, terbagi, dan memastikan reabilitas dan keamanan data.
Menurut Connolly dan Begg (2002, p16) disebutkan bahwa DBMS menyediakan fasilitas-fasilitas sebagai berikut :
a. Data Definition Language (DDL) b. Data Manipulation Language (DML)
c. Akses control, terdiri dari Security system, Integrity Sytem, Concurrency Control System, Recovery Control Sytem, User Accessible Catalog
2.1.5 Data Definition Language (DDL)
Data Definition Language adalah bahasa yang memungkinkan administrator basis data atau pengguna untuk mendeskripsikan dan menamai entitas, atribut, dan hubungan dari entitas yang dibutuhkan oleh aplikasi, bersama dengan semua batasan integritas dan keamanan yang terkait (Connolly dan Begg , 2002, p40)
2.1.6 Data Manipulation Languag (DML)
Data Manipulation Language adalah bahasa yang menyediakan kumpulan operasi untuk mendukung operasi manipulasi dan sederhana pada data yang tersimpan di dalam basis data. (Connolly dan Begg, 2002, p41)
Operasi dari Data Manipulation Language biasanya mencakup operasi seperti :
a. Memasukan data baru ke dalam basis data
b. Memodifikasi data yang tersimpan di dalam basis data c. Mengambil data yang tersimpan di dalam basis data d. Menghapus data dari basis data
2.1.7 Komponen dari Lingkungan DBMS
Menurut Connolly dan Begg (2002, p18) terdapat lima komponen utama di dalam suatu lingkungan DBMS. Lima komponen utama yang terdapat pada system manajemen basis data antara lain :
1. Hardware (Perangkat Keras) 2. Software (Perangkat Lunak)
3. Data 4. Procedures 5. People
Komponen terakhir pada DBMS adalah orang atau user yang terlibat dalam sistem tersebut, yang dapat dikelompokan menjadi tiga jenis user yaitu : a. Application programmer
b. End–User
c. Data dan Database Administrator
2.1.8 Kelebihan dan kekurangan Sistem Basis Data
Menurut Connolly dan Begg (2002, p25) sistem basis data mempunyai beberapa keuntungan antara lain :
a. Control of Data Redudancy b. Data Consistency
c. Sharing of Data
d. Improved Data Integrity e. Improved Scurity
f. Improved Data Accesibility and Responsiveness g. Increased Productivity
h. Increased Concurrency
i. Improved Backup dan Recovery Services
Sedangkan, menurut Connolly dan Begg (2002, pp29-30) sistem manajeman basis data juga memiliki beberapa kekurangan seperti :
a. Complexity b. Size
c. Cost of DBMS d. Cost of Conversion e. Performance
2.1.9 Model Relational Database Management System (RDBMS) 2.1.9.1 Struktur Data Relational (Connolly and Begg, 2002, p 72)
a. Relasi, direpresentasikan sebagai tabel b. Atribut adalah kolom pada tabel c. Tuple adalah baris pada tabel (record)
d. Domain adalah himpunan nilai dari satu atau lebih atribut e. Derajat (Degree) adalah banyaknya atribut/kolom pada tabel f. Cardinality adalah banyaknya tuple atau baris pada tabel
g. Relational Database adalah kumpulan relasi ternormalisasi dengan nama relasi yang jelas
Kunci Relasi (Relational Keys) 1. Superkey
Sebuah atribut atau himpunan yang mengidentifikasi secara unik tuple – tuple yang ada dalam relasi
2. Candidate key
Superkey yang tidak bisa di urai lagi, tidak bisa di komposisi 3. Primary key
Candidate key yang dipilih untuk identifikasi tuple secara unik dalam suati relasi
4. Alternate key
Candidate key yang tidak terpilih sebagai primary key 5. Foreign key
Atribut atau himpunan atribut dalam relasi yang dibandingkan dengan candidate key pada beberapa relasi
2.1.9.2 Integrasi Relasi (Relational Integrity)
Menurut Connolly and Begg (2002, p81) integrasi relasi terbagi atas: a. Null
b. Entity Integrity
Pada relasi dasar, tidak ada atribut ataupun primary key yang bernilai Null
c. Referential Integrity
Jika terdapat foreign key dalam suatu relasi, maka nilai foreign key tersebut akan dibandingkan (match) dengan nilai candidate key dari beberapa tuple pada relasi itu sendiri atau nilai foreign key harus Null seluruhnya.
d. Enterprise Constraint
View (Connolly and Begg, 2002, p83)
Hasil dinamik dari satu atau lebih operasi relasional yang dilakukan pada relasi dasarnya untuk menghasilkan relasi yang lain. View merupakan relasi virtual yang tidak harus ada dalam basis data, tetapi dihasilkan dari request. Kegunaan view, antara lain :
1. Menyediakan mekanisme keamanan yang fleksibel dan baik dengan menyembunyikan bagian database dari user tertentu
2. Mengijinkan user untuk mengakses data dengan berbagai cara, sehingga data yang sama dapat dilihat oleh user yang berbeda dengan cara yang berbeda pada saat yang sama.
3. Menyederhanakan operasi yang rumit pada relasi dasar.
2.1.10 Entity Relationship Modelling Tipe Entitas (Entity Type)
Konsep dasar dari Model ER adalah tipe entitas, yaitu kumpulan dari objek-objek dengan sifat (properti) yang sama, yang diidentifikasi oleh enterprise mempunyai eksistensi yang independent. Keberadaannya dapat berupa fisik maupun abstrak.
Entity Occurrence, yaitu pengidentifikasian objek yang unik dari sebuah type entity. Setiap entity diidentifikasikan dan disertakan propertinya.
Tipe Relasi (Relationship Type)
Tipe relasi adalah kumpulan keterhubungan yang mempunyai arti (meaningfull associations) antara entitas yang ada.
Relationship occurrence yaitu keterhubungan yang diidentifikasi secara unik yang meliputi keberadaan tiap entitas yang berpartisipasi.
Atribut
Merupakan sifat-sifat (properti) dari sebuah entitas atau tipe relasi. Atribut domain adalah himpunan nilai yang diperbolehkan untuk satu atau lebih atribut. Macam-macam atribut :
1. Simple Attribute 2. Composite Attribute 3. Single-valued Attribute 4. Multi-valued Attribute 5. Derived Attribute Kunci (Keys) 1. Candidate Key
Jumlah minimal atribut-atribut yang dapat mengidentifikasikan setiap kejadian/record secara unik.
2. Primary Key
Candidate key yang dipilih untuk mengidentifikasikan setiap kejadian /record dari suatu entitas secara unik.
3. Composite Key
Strong and Weak Entity Types
Strong entity type yaitu entitas yang keberadaannya tidak bergantung pada entitas lainnya, dan terkadang disebut dengan parent, owner, dominant sedangkan weak entity type adalah entitas yang keberadaannya bergantung pada entitas lain, dan juga sering disebut child, dependent, subordinate.
Structural Constraint
Batasan utama pada relationship disebut dengan multiplicity, yaitu jumlah(range) dari kejadian yang mungkin terjadi pada suatu entitas yang terhubung ke satu kejadian dari entitas lain yang berhubungan melalui suatu relasi. Relasi yang paling umum adalah binary relationship. Macam-macam binary relationship antara lain :
1. one – to – one ( 1 : 1 ) 2. one – to – many ( 1 : * ) 3. many – to – many ( * : *)
Multiplicity dibentuk dari dua macam batasan pada relasi : 1. Cardinality
Menjelaskan jumlah maksimum dari kejadian relasi yang mungkin untuk entitas yang berpartisipasi di dalam relasi tersebut.
2. Participation
Menetapkan apakah seluruh atau sebagian entitas yang berpartisipasi dalam suatu relasi.
Masalah pada ER Modelling
Beberapa masalah yang dihadapi dengan model ER dianaranya : 1. Fan Traps
Fan traps adalah sebuah kondisi dimana sebuah model merepresentasikan sebuah relasi antara tipe entitas, tetapi jalur antara entitas ambigu.
2. Chasm Traps
Chasm traps adalah kondisi dimana sebuah model menunjukan keberadaan suatu relasi antar tipe entitas, tetapi jalurnya tidak terdapat antara occurrence entitas tertentu.
2.1.11 Normalisasi
Normalisasi merupakan sebuah teknik untuk menghasilkan sebuah kumpulan dari relasi-relasi dengan atribut-atribut yang diinginkan, berdasarkan kebutuhan data perusahaan. (Connolly and Begg, 2002, p376)
Tahapan-tahapan normalisasi, antara lain : 1. Bentuk Normal pertama (1NF)
Sebuah tabel dinyatakan mempunyai bentuk normal pertama jika sebuah tabel memiliki domain yang sederhana dan tidak terdapat repeating group. Jadi aturan yang berlaku pada 1NF adalah mendefinisikan primary key, tidak adanya repeating group, dan semua atribut non-key harus bergantung pada atribut primary key.
Bentuk ini mempunyai syarat yaitu data harus memenuhi kriteria 1NF dan tidak memiliki ketergantungan parsial (data hanya bergantung pada sebagian primary key). Jadi, bentuk normal kedua adalah berdasarkan konsep full funcional dependency (ketergantungan fungsional secara utuh) pada seluruh primary key dari relasi tersebut. 3. Bentuk Normal Ketiga (3NF)
Sebuah tabel dikatakan memenuhi bentuk normal ketiga jika semua atribut non-key dari suatu relasi bersifat mutually independent. Dengan demikian tidak ada atribut non-key yang bersifat functional dependent terhadap atribut non-key yang lain. Jadi aturan yang berlaku adalah harus sudah berada dalam bentuk normal kedua dan tidak ada ketergantungan transitif (dimana field non-key tergantung pada field non-key lainnya.)
2.1.12 Siklus Hidup Basis Data
Siklus Hidup Basis Data merupakan komponen mendasar suatu sistem informasi, dimana pengembangan atau pemakaiannya harus dilihat dari perspektif yang lebih luas berdasarkan kebutuhan organisasi.
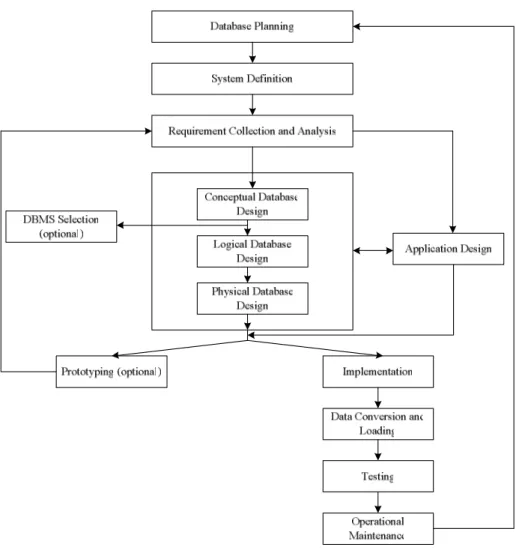
Tahapan database lifecycle seperti terlihat pada gambar 2.1, antara lain: 1. Database Planning (Perencanaan database)
Merupakan aktivitas manajemen yang memungkinkan tahapan dari siklus hidup basis data direalisasikan se-efektif dan se-efisien mungkin. Perencanaan basis data harus terintegrasi dengan keseluruhan strategi sistem informasi dari organisasi.
Gambar 2.1 Database Application Lifecycle (sumber Connoly and Begg (2002, p 272))
2. System Definition (Definisi Sistem)
Menjelaskan batasan-batasan dan cakupan dari aplikasi basis data dan sudut pandang user (user view) yang utama. User view mendefinisikan apa yang diwajibkan dari suatu aplikasi basis data dari perspektif aturan kerja khusus (seperti manajer atau supervisor) atau area aplikasi interface (seperti marketing, personalia, atau stock control). Aplikasi basis data dapat memiliki satu atau lebih user view.
3. Requirement Collection and Analysis (Analisis dan Pengumpulan Kebutuhan)
Suatu proses pengumpulan dan analisa informasi mengenai bagian oraganisasi yang didukung oleh aplikasi basis data, dan menggunakan informasi tersebut untuk identifikasi kebutuhan user akan sistem yang baru.
4. Database Design
Merupakan suatu proses pembuatan, sebuah desain database yang akan mendukung tujuan dan operasi suatu enterprise. Tujuan utamanya adalah merepresentasikan data dan relasi antar data yang dibutuhkan oleh seluruh area aplikasi utama dan user group, menyediakan model data yang mendukung segala transaksi yang diperlukan pada data, dan menspesifikasikan desain minimal yang secara tepat disusun untuk memenuhi kebutuhan performa yang ditetapkan pada sistem (misal waktu respon).
Pendekatan dalam desain basis data, antara lain : Top-down, Bottom-up, Inside-out, Mixed.
Data Modelling memiliki dua kegunaan utama, yaitu membantu dalam memahami arti (semantik) dari data dan memfasilitasi komunikasi mengenai informasi yang dibutuhkan. Pembuatan model data dapat menjawab pertanyaan mengenai entitas, relasi dan atribut.
Tiga fase desain basis data: Conceptual database design, Logical database design, Physical database design.
5. DBMS selection (optional)
Pemilihan DBMS yang tepat untuk mendukung aplikasi basis data. Dapat dilakukan kapanpun sebelum menuju desain logikal asalkan terdapat cukup informasi mengenai kebutuhan sistem.
6. Application Design (Desain Aplikasi)
Desain user interface dan program aplikasi yang menggunakan dan memproses data. Desain basis data dan aplikasi merupakan aktifitas paralel yang meliputi dua aktifitas penting, yaitu transaction design dan user interface design.
7. Prototyping (optional)
Membuat model karja suatu aplikasi basis data. Terdapat dua macam strategi prototyping yang digunakan saat ini, yaitu requirement prototyping dan evolutionary prototyping
8. Implementation
Merupakan realisasi fisik dari basis data dan desain aplikasi. Implementasi database dicapai dengan menggunakan :
1. DDL untuk membuat skema basis data dan file basis data yang kosong.
2. DDL untuk membuat user view yang diinginkan.
3. 3GL dan 4GL untuk membuat program aplikasi, termasuk transaksi basis data disertakan dengan menggunakan DML, atau ditambahkan pada bahasa pemrograman.
9. Data Conversion and Loading
Pemindahan data yang ada kedalam database baru dan mengkonversikan aplikasi yang ada agar dapat digunakan pada basis data yang baru. Tahapan ini dibutuhkan ketika sistem basis data baru menggantikan sistem yang lama. DBMS biasanya memiliki utilitas yang memanggil ulang file yang sudah ada kedalam basis data baru.
10. Testing
Suatu proses eksekusi program aplikasi dengan tujuan untuk menemukan kesalahan. Pengujian hanya akan terlihat jika terjadi kesalahan software. 11. Operational maintenance
Suatu proses pengawasan dan pemeliharaan sistem setelah instalasi meliputi :
a. Pengawasan performa sistem, jika performa menurun, maka memerlukan perbaikan atau pengaturan ulang database.
b. Pemeliharaan dan pembaharuan aplikasi basis data (jika dibutuhkan). c. Penggabungan kebutuhan baru kedalam aplikasi database.
2.1.13 Desain Metodologi Konseptual, Logikal, dan Fisikal Basis Data
Desain metodologi adalah pendekatan terstruktur yang menggunakan prosedur, teknik, tool, dan dokumentasi untuk mendukung dan memfasilitasi proses desain. (Connolly and Begg, 2002, p418)
Menurut Connolly dan Begg (2002, pp422-502), proses perancangan dibagi ke dalam tiga tahap utama, yaitu tahap konseptual, tahap logikal, dan
tahap pisikal. Langkah-langkah dalam perancangan basis data adalah sebagai berikut:
a. Desain Konseptual Basis Data
Perancangan konseptual basis data merupakan proses membangun model dari data yang digunakan pada perusahaan, terbebas dari semua pertimbangan pisikal, seperti tujuan DBMS, program aplikasi, bahasa pemrograman yang digunakan, platform piranti keras, masalah tampilan. (Connolly and Begg, 2002, p)
Perancangan konseptual basis data meliputi langkah-langkah sebagai berikut :
Langkah 1 : Membangun model data konseptual basis data untuk setiap view
1.1 Identifikasi tipe entitas
Tujuannya adalah untuk mengidentifikasikan tipe-tipe entitas yang dibutuhkan. (Connolly and Begg, 2002, p424))
Langkah pertama adalah mendefinisikan objek-objek utama di mana pengguna mempunyai ketertarikan dengan objek tersebut. Objek-objek inilah yang disebut tipe-tipe entitas untuk model.
1.2 Identifikasi tipe relationship
Tujuannya untuk mengidentifikasikan hubungan atau relationship penting yang ada di antara tipe-tipe entitas yang telah diidentifikasikan. (Connolly and Begg, 2002, p424)
1.3 Mengidentifikasi dan menghubungkan atribut dengan entitas atau tipe relationship
Tujuannya untuk menghubungkan atribut dengan entitas atau tipe relationship yang sesuai dan mendokumentasikan detail dari setiap atribut..
1.4 Menentukan domain atribut
Tujuannya untuk menentukan domain untuk atribut-atribut dalam model data konseptual lokal. Selain itu, juga didokumentasikan setiap detail dari domain tersebut. Domain merupakan sekumpulan nilai-nilai dari satu atau lebih atribut yang menggambarkan nilai yang dimiliki.
1.5 Menentukan atribut candidate key, primary key, dan alternate key Tujuannya adalah untuk mengidentifikasikan candidate key setiap tipe entitas, jika terdapat lebih dari satu candidate key, pilih satu untuk dijadikan primary key, yang lainnya sebagai alternate key.
Cara untuk memilih primary key dari candidate key adalah sebagai berikut:
a. Candidate key dengan set atribut yang minimal b. Candidate key yang nilainya jarang berubah c. Candidate key yang karakternya paling sedikit
d. Candidate key yang mempunyai nilai maksimum paling kecil e. Candidate key yang mudah digunakan dari sudut pandang user 1.6 Mempertimbangkan penggunaan konsep enchanced modelling
Tujuannya untuk mempertimbangkan penggunaan dari konsep enchanced modelling seperti spesialisasi, generalisasi, agregasi(aggregation), dan komposisi(composition).
1.7 Memeriksa model dari redudancy
Tujuannya adalah untuk memeriksa apabila ada redundancy pada model data. Pada langkah ini, model konseptual diuji untuk memeriksa apakah terdapat redudancy atau perulangan dalam data dan memindahkannya jika ada. Pada langkah ini terdapat dua aktivitas, yaitu:
a. Menguji ulang hubungan one-to-one b. Menghilangkan hubungan yang redundan c. Mempertimbangkan dimensi waktu
1.8 Memvalidasi model konseptual dari transaksi pengguna (user) Tujuannya untuk memastikan apakah model konseptual telah mendukung transaksi yang dibutuhkan oleh perusahaan.
Untuk memastikan bahwa model data lokal konseptual benar-benar mendukung transaksi di view, digunakan dua macam pendekatan, yaitu:
a. Mendeskripsikan transaksi-transaksi
b. Menggunakan jalu-jalur (pathway) transaksi
1.9 Me-review model data konseptual dengan pengguna
Tujuannya adalah untuk memastikan bahwa model tersebut sudah merupakan representasi sebenarnya dari permintaan data oleh perusahaan.
Model data konseptual juga mencakup diagram ER dan dokumentasi pendukung yang mendeskripsikan model data. Bila terdapat kejanggalan pada model data, maka harus dibuat perubahan yang sesuai.
b. Desain Logikal Basis Data
Tujuan dari tahapan ini yakni menerjemahkan model data menjadi sebuah model data logikal dan kemudian memvalidasi model tersebut untuk memeriksa apakah strukturnya sudah tepat dan mampu mendukung transaksi-transaksi yang dibutuhkan.
Desain logikal basis data terdiri dari langkah-langkah sebagai berikut:
Langkah 2 : Membangun dan memvalidasi model data lokal logikal untuk setiap view
2.1 Menghilangkan fitur-fitur yang tidak sesuai dengan model relasional
Tahap ini merupakan tahap penyesuaian dari model data lokal konseptual agar bisa digunakan dengan lebih mudah oleh sistem.
Penghilangan fitur yang tidak kompatibel memiliki empat tahapan, yaitu:
a. Menghilangkan relasi many to many ( *:* )
b. Menghilangkan relasi rekursif many to many ( *:* ) c. Menghilangkan tipe relasi kompleks
2.2 Mendapatkan relasi untuk model data logikal
Tujuannya membuat hubungan untuk model data logikal untuk merepresentasikan entiti-entiti, relationships, dan atribut-atribut yang sudah diidentifikasi.
Relasi yang dimiliki oleh setiap entitas ditunjukkan oleh mekanisme dari primary key atau foreign key.
2.3 Memvalidasi transaksi dengan menggunakan normalisasi
Pada tahap ini, dilakukan validasi terhadap transaksi di model data lokal logikal menggunakan teknik normalisasi untuk mengembangkan model data sehingga terhindar dari duplikasi data yang tidak diperlukan
2.4 Memvalidasi relasi dengan transaksi pengguna
Tujuannya adalah untuk memastikan bahwa hubungan-hubungan dalam model data logikal mendukung transaksi yang dibutuhkan oleh view.
2.5 Mendefinisikan integrity constraints
Integrity constraint adalah batasan-batasan yang digunakan untuk menjaga agar basis data tidak menjadi inkonsisten. Ada lima tipe dari integrity constraint, antara lain:
a. Required data ( data atau nilai yang valid ) b. Batasan atribut domain
c. Entity integrity ( primary key tidak boleh null ) d. Referential integrity
2.6 Memeriksa model data lokal logikal dengan pengguna
Pada tahap ini dilakukan kaji ulang untuk memastikan bahwa model data lokal logikal sudah sesuai dengan apa yang dibutuhkan oleh pengguna.
Langkah 3 : Membangun dan memvalidasi model data global logikal 3.1 Menggabungkan model data logikal
Pada tahap ini, digabungkan model data logikal individual ke dalam model data logikal global organisasi.
3.2 Memvalidasi model data global lokal
Memvalidasi relasi yang telah dibuat dari model data global dengan menggunakan teknik normalisasi dan memastikan bahwa relasi ini telah mendukung transaksi yang diperlukan.
3.3 Memeriksa untuk kemungkinan perubahan di masa mendatang Memastikan apakah ada perubahan yang signifikan yang dapat diperkirakan dan memastikan apakah model data logikal global ini dapat mendukung perubahan-perubahan ini.
3.4 Memeriksa model data global logikal dengan pengguna
Tujuan dari tahap ini adalah untuk memastikan bahwa model data logikal global merupakan representasi nyata dari organisasi.
c. Desain Fisikal Basis Data
Perancangan basis data fisikal merupakan proses untuk menghasilkan suatu deskripsi mengenai implementasi dari basis data pada secondary storage.
Deskripsi ini menjelaskan tentang hubungan dasar, file organisasi, dan indeks yang digunakan untuk mengakses data secara efisien, serta batasan-batasan integritas yang berhubungan dan pengukuran keamanan atau sekuriti.
Langkah-langkah dari merancang model data fisikal meliputi langkah-langkah sebagai berikut:
Langkah 4 : Menerjemahkan model data logikal untuk DBMS yang digunakan
Tujuannya untuk menghasilkan suatu skema basis data relasional dari model data logikal yang dapat diimplementasikan dalam target DBMS.
Aktivitas-aktivitas dalam tahapan ini mencakup, antara lain: 4.1 Mendesain relasi dasar
Tujuannya untuk menentukan bagaimana representasi dari hubungan dasar diidentifikasikan dalam model data logika dalam target DBMS.
4.2 Mendesain representasi dari derived data
Tujuannya untuk menentukan bagaimana merepresentasikan data yang dihasilkan dari model data logikal dalam target DBMS. Desain dari derived data harus didokumentasikan dengan tujuan untuk memilih rancangan yang sesuai. Contoh dari deriver atau calculated attributes, misalnya jumlah karyawan yang bekerja di satu cabang tertentu.
Tujuannya untuk mendesain batasan-batasan umum untuk target DBMS.
Rancangan dari batasan atau constraint ini tergantung dari pilihan DBMS, beberapa sistem menyediakan fasilitas lain daripada mendefinisikan batasan-batasan umum.
Langkah 5 : Mendesain gambaran fisik mengenai basis data
Tujuannya untuk menentukan organisasi file yang optimal untuk menyimpan hubungan dasar dan indeks yang dibutuhkan untuk mencapai hasil performa yang maksimal, yakni cara bagaimana relasi dan tuple disimpan di secondary storage.
Langkah ini meliputi aktivitas-aktivitas sebagai berikut: 5.1 Analisa transaksi-transaksi
Untuk membuat sebuah desain basis data fisikal yang efentif maka kita harus mengetahui transaksi atau query yang akan dijalankan dalam basis data.
5.2 Memilih organisasi file yang digunakan
Tujuannya adalah untuk menentukan organisasi file yang tepat dan efisien untuk setiap relasi dasar. Salah satu dari tujuan utama dari perancangan basis data fisikal adalah untuk menyimpan dan mengakses data dengan cara yang efisien.
Ada lima tipe organisasi file, yakni Heap, Hash, Indexed Sequenced Access Method (ISAM), B-Tree, Clusters.
5.3 Memilih indeks yang akan digunakan
Tujuannya untuk menentukan apakah menambahkan indeks akan meningkatkan performa dari sistem.
5.4 Memperkirakan disk space yang diperlukan
Tujuannya untuk memperkirakan jumlah ruang atau space dari disk yang akan dibutuhkan untuk mendukung implementasi basis data pada secondary storage.
Perkiraan perlu dibuat untuk menentukan apakah konfigurasi piranti keras yang telah ada mampu mendukung implementasi basis data atau apakah dibutuhkan piranti keras yang baru.
1. Menghitung tempat penyimpanan untuk menyimpan data
Langkah-langkah yang dapat digunakan untuk memperkirakan jumlah tempat yang dibutuhkan untuk menyimpan data pada tabel :
a. Tentukan jumlah baris yang akan digunakan pada tabel : Jumlah baris pada tabel = Num_Rows
b. Jika terdapat panjang yang tetap dan variabel panjang kolom pada definisi tabe, hitung tempat penyimpanan untuk setiap kelompok kolom dalam baris data. Ukuran kolom tergantung pada tipe data dan perincian panjang. Banyaknya kolom = Num_Cols dan banyaknya variabel panjang kolom = Num_Variable_Cols. Maksimal ukuran semua variabel panjang kolom = Max_Var_Size.
c. Jika terdapat panjang kolom yang tetap pada tabel, sebuah bagian baris, dikenal dengan null bitmap, disiapkan menangani kemungkinan null pada kolom. Untuk menghitung ukurannya: Null Bitmap = 2 + ( ( Num_Cols + 7 ) / 8 ), hanya bilangan bulat pada ekspresi tersebut yang harus digunakan. d. Jika terdapat variabel panjang kolom pada tabel, tentukan
berapa banyak tempat penyimpan yang digunakan untuk menyimpan kolom dalam baris.
Total ukuran variabel panjang kolom (Variable_Data_Size) = 2 + (Num_Variable_Cols x 2) + Max_Var_Size
Jika tidak terdapat variabel panjang kolom jadikan Variable_Data_Size menjadi nol.
e. Menghitung ukuran baris : Total Ukuran Baris (Row_Size) = Fixed_per_page + Variable_Data_Size + Null_Bitmap + 4
Nilai akhir yaitu 4, mewakili header baris data.
f. Menghitung jumlah baris per halaman (8096 bytes per halaman) : Jumlah Baris per halaman (Row_per_page) = (8096) / ( Row_Size + 2 )
g. Jika sebuah clustered index akan dibuat ada tabel, hitung jumlah baris cadangan yang kosong per halaman, tergantung pada penerapan fill factor. Jika tidak ada clustered index yang akan dibuat, tetapkan fill factor menjadi 100.
Banyaknya Baris yang Kosong per halaman (Free_Rows_per_page) = 8096 x (( 100 – FillFactor ) / 100) / Row_Size
Fill Factor digunakan pada penghitungan nilai bilangan bulat daripada persentase.
h. Menghitung banyaknya halaman yang dibutuhkan untuk menyimpan semua baris:
Banyaknya Baris (Num_Page) = Num_Rows / (Rows_per_page – Free_Rows_per_page)
Perkiraan banyaknya halaman harus dibulatkan ke atas pada keseluruhan jumlah halaman terdekat.
i. Terakhir, menghitung jumlah tempat penyimpanan yang dibutuhkan untuk menyimpan data pada tabel (total 8192 bytes per halaman): Ukuran Tabel (Bytes) = 8192 x Num_Pages
Tempat penyimpanan untuk menyimpan data = Data_Space_Used
2. Menghitung tempat yang digunakan untuk menyimpan clustered index
Tahap-tahap yang dapat digunakan untuk memperkirakan jumlah tempat yang dibutuhkan untuk menyimpan clustered index
a. Penentuan clustered index dapat termasuk panjang yang tetap dan variabel panjang kolom untuk memperkirakan ukuran
dari clustered index, harus menentukan tempat untuk setiap kelompok kolom yang ditempatkan dalam baris indeks.
Banyaknya kolom per kunci indeks = Num_Ckey_Size
Jumlah bytes pada semua panjang kolom kunci yang tetap = Fixed_Ckey_Size
Maksimal ukuran semua variabel panjang kolom kunci = Max_Var_Ckey_Size
b. Jika terdapat panjang kolom yang tetap pada clustered index, bagian pada baris indeks disiapkan untuk null bitmap, penghitungan ukuran : Index null bitmap (Cindex_null_Bitmap) = 2 + ( ( Num_Ckey_Cols + 7 ) / 8 )
Hanya bagian bilangan bulat pada ekspresi di atas yang harus digunakan.
c. Jika terdapat variabel panjang kolom pada indeks, tentukan berapa banyak tempat penyimpanan yang digunakan untuk menyimpan kolom dalam baris indeks :
Total Ukuran Panjang Variabel Panjang Kolom (Vrbl_Ckey_Size) : 2 + (Num_Variabel_Ckey_Cols x 2) + Max_Var_Ckey_Size
Jika tidak ada variabel panjang kolom, set Variable_Ckey_Size jadi nol.
Total Ukuran Kolom Indeks (Cindex_Row_Size) = Fixed_Ckey_Size + Variabel_Ckey_Size + Cindex_Null_Bitmap + 1 + 8
e. Menghitung banyaknya baris indeks per halaman (8096 bytes bebas per halaman) :
Banyaknya Baris Indeks per halaman (Cindex_Rows_per_page) = 8096 / ( Cindex_Row_size + 2 )
f. Menghitung banyaknya halaman yang dibutuhkan untuk menyimpan semua baris indeks pada tiap level indeks
Banyaknya Halaman (level 0) (Num_Pages_Clevel_0) = (Data_Spaced_Used) / 8192 / Cindex_Rows_per_pages
Banyaknya Halaman (level 1) (Num_Pages_Clevel_1) = Num_Pages_Clevel_0 / Cindex_Rows_per_pages
Ulangi perhitungan yang kedua, membagi jumlah perhitungan halaman dari level n sebelumnya dengan Cindex_Rows_per_page sampai jumlah halaman untuk level n (Num_Pages_Clevel_n) sama dengan satu (halaman sumber indeks). Sebagai contoh, untuk menghitung jumlah halaman yang dibutuhkan untuk level indeks kedua :
Banyaknya Halaman (level 2) (Num_Pages_Clevel_2) = Num_Pages_Clevel_1 / Cindex_Rows_per_pages
Jumlahkan banyaknya halaman yang dibutuhkan untuk menyimpan setiap level indeks:
Total Banyaknya Halaman (Num_Cindex_Pages) = Num_Pages_Clevel_0 + Num_Pages_Clevel_1 + Num_Pages_Clevel_2 + … + Num_Pages_Clevel_n
g. Menghitung ukuran dari clustered index (total 8192 bytes per halaman) : Ukuran clustered index (bytes) = 8192 x Num_Cindex_pages
3. Menghitung tempat yang digunakan untuk menyimpan setiap tambahan clustered index
Tahap-tahap yang digunakan untuk memperkirakan jumlah tempat penyimpanan yang dibutuhkan untuk menyimpan setiap tambahan nonclustered index.
a. Definisi nonclustered index dapat termasuk panjang yang tetap. Untuk memperkirakan ukuran nonclustered index, harus dihitung tempat penyimpanan untuk setiap kelompok kolom yang ditempatkan dalam baris indeks.
Banyaknya kolom pada kunci indeks = Num_Keys_Cols Jumlahkan bytes pada kunci indeks = Fixed_Key_Size
Banyaknya variabel panjang kunci kolom = Max_Var_Key_Size
b. Jika terdapat panjang kolom yang tetap pada indeks, bagian baris indeks disimpan untuk menyimpan kolom dalam baris indeks.
Hanya bagian bilangan bulat pada ekspresi di atas harus digunakan.
c. Jika terdapat variabel panjang kolom pada indeks, tentukan berapa banyak tempat penyimpanan yang digunakan untuk menyimpan kolom dalam baris indeks:
Total Ukuran Variabel Panjang Kolom (Variable_Key_Size) = 2 + (Num_Variable_Keys_Cols x 2) + Max_Var_key_Size d. Menghitung ukuran baris indeks nonleaf
Total Ukuran Baris Indeks (NL_Index_Row_Size) = Fixed_Key_Size + Variabel_Key_Size + Index_Null_Bitmap + 1 + 8
e. Menghitung banyaknya baris indeks nonleaf per halaman : Banyaknya baris indeks nonleaf per halaman (NL_Index_Per_Page) = 8096 / ( NL_Index_Row_Size + 2 ) f. Menghitung ukuran baris indeks leaf
Total Ukuran Baris Leaf (Index_Row_Size) = Cindex_Row_Size + Fixed_Key_Size + Variable_Key_Size + Index_Null_Bitmap + 1
g. Menghitung jumlah baris indeks level leaf per halaman :
Jumlah Baris Indeks Level Leaf per halaman (Index_Rows_Per_Page) = 8096 / ( Index_Row_Size +2 ) h. Menghitung jumlah baris indeks kosong cadangan per
halaman berdasarkan pada fill factor yang ditetapkan untuk nonclustered index
Jumlah Baris Indeks Kosong Cadangan per halaman (Free_Indes_Rows_Per_Page) = 8096 x ( (100 – fill factor)/ 100 ) / Index_Row_Size
Fill factor digunakan pada perhitungan sebuah nilai bulat pada persentase.
i. Menghitung jumlah halaman yang dibutuhkan untuk menyimpan semua baris indeks pada tiap level indeks :
Jumlah Halaman (level 0) (Num_Pages_Level_0) = Num_Rows / (Index_Rows_Per_Pages – Free_Index_Rows_Per_Page)
Jumlah Halaman (level 1) (Num_Pages_Level_1) = Num_Page_Level_0 / NL_Index_Row_Per_Page
Ulangi perhitungan kedua, membagi jumlah halaman dari level n saebelumnya dengan NL_Index_Row_Per_Page sampai jumlah halaman yang dibutuhkan untuk menyimpan setiap level indeks :
Total Jumlah Halaman (Nim_Index_Pages) = Nim_Pages_Level_0 + Nim_Pages_Level_0 + … + Nim_Pages_Level_n
j. Terakhir menghitung ukuran nonclustered index : Ukuran nonclustered index = 8192 x Num_Index_Pages
4. Menghitung ukuran tabel
Menghitung ukuran tabel (bytes) = Data_Space_Used + Clustered_Index_Size + Nonclustered_Index_Size + … n
Langkah 6 : Merancang view dari pengguna (user views)
Tujuan dari langkah ini adalah untuk merancang view pengguna yang teridentifikasi selama pengumpulan permintaan dan tahap analisis dari siklus hidup perkembangan sistem basis data
Langkah 7 : Merancang mekanisme sekuriti
Tujuannya untuk merancang mekanisme sekuriti atau keamanan untuk basis data seperti yang telah diminta oleh pengguna pada tahapan awal siklus hidup perkembangan sistem basis data.
Relational DBMS menyediakan dua tipe dari keamanan basis data, yakni keamanan sistem dan keamanan data.
Langkah 8 : Mempertimbangkan pengenalan dari redundansi yang terkontrol
Dilakukan normalisasi dengan tujuan agar dapat menngkatkan performa dari sistem dengan menghilangkan redudansi.
Langkah 9 : Memonitor dan mengatur sistem operasional
Memonitor dan meningkatkan performa dari sistem dengan memperbaiki desain yang tidak sesuai atau perubahan kebutuhan.
2.1.14 Fourth Generation Language (4GLs)
Menurut Connolly dan Begg (2002, p42), dibandingkan dengan 3 rd GL yang merupakan bahasa pemrograman prosedural, 4th GL merupakan bahasa pemrograman prosedural : user mendefinisikan apa yang akan dilakukan dan bukan bagaimana.
Keunggulan yang ditawarkan oleh 4th GL adalah penggunaan baris kode yang lebih sedikit dibanding 3rd GL yang berarti peningkatan produktifitas. Contoh dari 4th GL : SQL
2.1.15 Data Flow Diagram
Menurut Syahroni (2003), Data Flow Diagram digunakan oleh para perancang sistem untuk memudahkan penggambaran suatu sistem yang ada atau sistem baru yang akan dikembangkan secara logika tanpa memperhatikan lingkungan fisik dimana data tersebut mengalir atau lingkungan fisik dimana data tersebut akan disimpan.
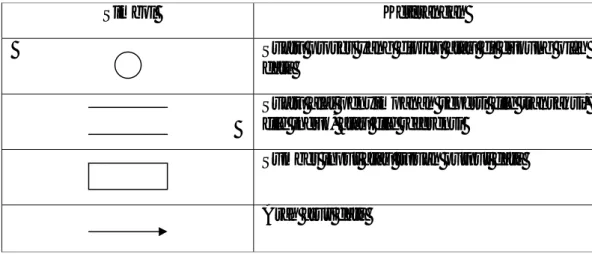
Data Flow Diagram merupakan alat yang cukup populer sekarang, karena dapat menggambarkan aliran data di dalam suatu sistem dengan terstruktur dan jelas. Dalam menggambarkan sistem perlu dilakukan pembentukan simbol. Berikut ini simbol-simbol yang sering digunakan dalam Data Flow Diagram (DFD) :
1. Kesatuan luar atau batasan (external entity or boundary)
Setiap sistem pasti memiliki batas sistem yang memisahkan suatu sistem dengan lingkungan luarnya. Sistem akan menerima input
dan menghasilkan output bagi lingkungan luarnya. Kesatuan luar merupakan kesatuan di lingkungan luar sistem yang dapat berupa orang, organisasi, atau sistem lain yang berada di lingkungan luarnya yang akan memberikan input serta menerima output dari sistem.
2. Aliran data (data flow)
Aliran data pada diagram aliran data diberi simbol panah seperti pada gambar. Aliran data ini mengalir diantara proses, penyimpanan data, dan kesatuan luar. Aliran data ini menunjukkan arus atau aliran data yang dapat berupa masukkan untuk sistem atau hasil proses sistem dan dapat berbentuk diantaranya, formulir atau dokumen yang digunakan, laporan tercetak yang dihasilkan oleh sistem, tampilan atau output di layar komputer yang dihasilkan oleh sistem, masukkan oleh komputer, komunikasi ucapan, surat-surat atau memo, data yang dibaca atau direkam pada suatu file, surat isian yang dicatat pada buku agenda, dan transmisi data dari satu komputer ke komputer yang lain.
3. Proses
Suatu proses ialah kegiatan atau kerja yang dilakukan orang, mesin, atau komputer dari hasil suatu arus data yang masuk ke dalam proses untuk dihasilkan arus data yang akan keluar dari proses. Suatu proses dapat ditunjukkan dengan simbol lingkaran.
4. Penyimpanan data (data store)
Tempat penyimpanan data yang digunakan sistem. Proses dapat mengambil data dari atau memberikan data ke data store. Berikut ini gambar notasi untuk data store.
Menurut Hall (2001, p69), diagram arus data adalah pencerminan proses, sumber-sumber data dan arus data dalam sebuah sistem dengan menggunakan simbol-simbol.
Tabel 2.1 Tabel Notasi dalam DFD
Simbol Keterangan Suatu proses yang dipicu atau di dukung oleh
data
Suatu alat penyimpanan seperti file transaksi, file induk, atau file referensi
Sumber input atau tujuan output data
Arah arus data
2.1.1.6 State Transition Diagram
Menurut Yourdan (1989, p259), State Transition Diagram (STD) merupakan sebuah perilaku model yang bergantung pada sekumpulan keadaan sistem, dimana keadaan tersebut adalah setiap modus perilaku sistem yang diamati. Komponen-komponen utama dalam STD antara lain :
1. Keadaan sistem (system state)
Merupakan keadaan yang terjadi di dalam sistem pada waktu tertentu. Keadaan sistem dilambangkan dengan bentuk seperti gambar berikut.
Gambar 2.6 Notasi Keadaan Sistem
2. Perubahan keadaan (change of state)
Gambar 2.7 Notasi Perubahan Keadaan
3. Kondisi dan aksi
Gambar 2.8 Notasi Kondisi dan Aksi
Menurut Pressman (2001, p317), State Transition Diagram (STD) menggambarkan kebiasaan dari suatu sistem dengan menggambarkan kondisi dan kejadian yang menyebabkan perubahan suatu kondisi.
2.2 Teori-teori Khusus Berhubungan dengan Topik 2.2.1 Pengertian Sumber Daya Manusia
Sumber Daya Manusia (SDM) merupakan bagian yang penting didalam suatu perusahaan. Menurut Bronzite (2000, p 12), Human Resources atau sumber daya manusia adalah departemen yang bertanggung jawab untuk menandakan individu dan menilai kualitas dari seorang individu dalam suatu tim, menyiapkan mereka agar dapat bekerja di dalam kondisi tertentu, memberikan berbagai macam program pelatihan, dan sebaik mungkin menangani segala masalah yang terjadi pada setiap individu.
2.2.2 Pengertian Pengembangan Sumber Daya Manusia
Pengembangan sumber daya manusia adalah proses peningkatan kualitas manusia dan transformasi potensi manusia menjadi angkatan kerja yang produktif. Yang dalam identifikasinya yang lebih teknis bahwa pengembangan sumber daya manusia adalah sebuah proses dimana terjadi kegiatan melengkapi kegiatan seseorang dengan pengalaman belajar yang relevan guna pertumbuhan pribadi dan profesionalisme, baik melalui kegiatan pendidikan formal maupun melalui jalur latihan kerja. (www.organisasi.org)
2.2.3 Pengertian Sistem Informasi Sumber Daya Manusia
Sistem Informasi Sumber Daya Manusia adalah komponen – komponen yang terkait, yang bekerja bersama untuk mengumpulkan, memproses, menyimpan, dan menyebarkan informasi untuk mendukung pengambilan
keputusan, koordinasi, kontrol, analisis, dan pengambaran aktivitas Manajemen Sumber Daya Manusia pada perusahaan. (Dessler, 2003, p 5)
2.2.4 Pengertian Manajemen Sumber Daya Manusia
Menurut Dessler (2003, p 3) Manajemen Sumber Daya Manusia adalah proses mendapatkan, melatih, menilai, memberi balas jasa kepada pekerja, dan terlibat kedalam hubungan kerja mereka, kesehatan, dan keamanan, serta masalah kebijakan dan keadilan.
Menurut A.F. Stoner (www.organisasi.org) Manajemen Sumber Daya Manusia adalah suatu prosedur yang berkelanjutan yang bertujuan untuk memasok suatu organisasi atau perusahaan dengan orang-orang yang tepat untuk ditempatkan pada posisi dan jabatan yang tepat pada saat organisasi memerlukannya.
Departemen Sumber Daya Manusia memiliki peran, fungsi, tugas dan tanggung jawab sebagai berikut : (sumber: www.organisasi.org)
1. Melakukan persiapan dan seleksi tenaga kerja (Preparation and Selection) a. Persiapan
Dalam proses persiapan dilakukan perencanaan kebutuhan akan sumber daya manusia dengan menentukan berbagai pekerjaan yang mungkin timbul. Yang dapat dilakukan adalah dengan melakukan perkiraan / forecast akan pekerjaan yang lowong, jumlahnya, waktu, dan lain sebagainya. Ada dua faktor yang perlu diperhatikan dalam melakukan persiapan, yaitu faktor internal seperti jumlah kebutuhan karyawan baru, struktur organisasi, departemen yang ada, dan lain-lain. Faktor
eksternal seperti hukum ketenagakerjaan, kondisi pasa tenaga kerja, dan lain sebagainya.
b. Rekrutmen tenaga kerja (Recruitment)
Rekrutmen adalah suatu proses untuk mencari calon atau kandidat pegawai, karyawan, buruh, manajer, atau tenaga kerja baru untuk memenuhi kebutuhan sdm oraganisasi atau perusahaan. Dalam tahapan ini diperluka analisis jabatan yang ada untuk membuat deskripsi pekerjaan (job description) dan juga spesifikasi pekerjaan (job specification).
c. Seleksi tenaga kerja (Selection)
Seleksi tenaga kerja adalah suatu proses menemukan tenaga kerja yang tepat dari sekian banyak kandidat atau calon yang ada.
2. Pengembangan karyawan (Development and Evaluation)
Tenaga kerja yang bekerja pada organisasi atau perusahaan harus menguasai pekerjaan yang menjadi tugas dan tanggung jawabnya. Untuk itu diperlukan suatu pembekalan pelatihan agar tenaga kerja yang ada dapat lebih menguasai dan ahli di bidangnya masing-masing serta meningkatkan kinerja yang ada.
3. Memberikan kompensasi dan proteksi pada pegawai (Compensation and Protection)
Kompensasi adalah imbalan atas kontribusi kerja pegawai secara teratur dari organisasi atau perusahaan. Kompensasi yang tepat sangat penting dan disesuaikan dengan kondisi pasar tenaga kerja yang ada pada lingkungan eksternal. Kompensasi yang tidak sesuai dengan kondisi yang ada dapat menyebabkan masalah ketenaga kerjaan di kemudian hari atau pun dapat menimbulkan kerugian pada organisasi atau perusahaan.
Proteksi juga perlu diberikan kepada pekerja agar dapat melaksanakan pekerjaannya dengan tenang sehingga kinerja dan kontribusi perkerja tersebut dapat tetap maksimal dari waktu ke waktu.
2.2.5 Pelatihan Pekerja
Menurut Dessler (2003, p187), pelatihan adalah proses mengajarkan pekerja dengan kemampuan dasar yang mereka perlukan dalam pekerjaan mereka.
Program pelatihan pekerja terdiri dari lima langkah : 1. Needs analysis
Mengidentifikasi kemampuan kerja spesifik yang diperlukan, menganalisa kemampuan dan kebutuhan prospektif trainee.
2. Instructional design
Menentukan, mengkompilasim, dan menghasilkan isi dari program pelatihan, temasuk latihan dan kegiatan dalam pelatihan.
3. Validation step
Menemukan bugs yang ada diluar jalur pelatihan dan mempresentasikannya kepada representative audience yang kecil
4. Implementation
Mengimplementasikan program yang menjadi sasaran pelatihan. 5. Evaluation and follow-up
Manajemen kesuksesan dan kegagalan program pelatihan
2.2.6 Promosi dan Pengembangan Karir
Menurut Dessler (2003, p277), promosi adalah proses penaikan posisi atau jabatan ke jenjang yang lebih tinggi dan lebih bertanggung jawab. Sedangkan mutasi adalah mempekerjakan ulang pada posisi yang sama atau lebih tinggi pada bagian atau divisi lain dalam perusahaan.
Menurut Dessler (2003, p274), pengembangan karir merupakan suatu proses dalam diri seseorang untuk peka terhadap atribut karir yang berhubungan dan tingkatan level yang dapat dikontribusikan ke dalam pemenuhan karirnya.
Di dalam pengembangan karir, pekerja akan lebih diarahkan dan dibekali dengan informasi mengenai alur karirnya dengan posisinya yang sekarang dan segala aktivitas yang berhubungan erat dengan karirnya.
Manfaat perencanaan karir :
1. Mengembangkan para karyawan uang dapat dipromosikan. 2. Menurunkan perputaran
3. Mengungkap potensi karyawan 4. Mendorong pertumbuhan 5. Mengurangi penimbunan