BAB 2
LANDASAN TEORI
2.1 Plagiarisme
Plagiarisme berasal dari kata Latin, “plagiarius”, yang berarti “pencuri”. Plagiarisme didefinisikan sebagai tindakan atau praktik mengambil dan mengumpulkan atau menyampaikan pemikiran, tulisan atau hasil karya orang lain selayaknya hasil karya diri sendiri tanpa persetujuan dari pemilik hasil karya tersebut. Dengan kata lain, mempraktikkan plagiarisme berarti mencuri hasil karya atau kepemilikan intelektual orang lain. Ide atau materi apapun yang diambil dari sumber lain untuk penggunaan secara tertulis maupun lisan harus disetujui oleh pemilik hasil karya tersebut, kecuali informasi tersebut merupakan pengetahuan umum.
Plagiarisme tidak selalu disengaja atau mencuri sesuatu dari orang lain. Praktik ini dapat bersifat tidak disengaja, kebetulan, dan dapat mencakup pencurian sendiri (self stealing). Berikut ini beberapa tipe plagiarisme.
a. Kebetulan (accidental)
Praktik plagiarisme ini dapat terjadi karena kurangnya pengetahuan akan plagiarisme dan pemahaman mengenai penulisan referensi.
b. Tidak disengaja (unintentional)
Ketersediaan informasi dalam jumlah yang sangat besar mempengaruhi pemikiran sehingga ide yang sama dapat dihasilkan secara tertulis maupun lisan sebagai milik pribadi.
c. Disengaja (intentional)
Tindakan menyalin sebagian atau keseluruhan hasil karya orang lain secara sengaja tanpa mengikutsertakan nama pemilik hasil karya.
d. Diri sendiri (self plagiarism)
Penggunaan hasil karya yang dibuat diri sendiri dalam bentuk lain tanpa menunjuk hasil karya asli.
Plagiarisme mencakup hal-hal berikut ini, tanpa persetujuan secara penuh atau sepantasnya dari sumber aslinya.
a. Menyalin isi tekstual (copy-paste).
b. Menggunakan ide atau konsep yang mirip dan tidak termasuk pengetahuan umum.
c. Menggunakan secara sebagian atau keseluruhan program komputer, algoritma, atau fungsi yang ditulis oleh orang lain.
d. Menggunakan secara sebagian atau keseluruhan dari sumber apapun, esai atau hasil karya lain yang dapat dinilai, termasuk buku, jurnal, artikel surat kabar, catatan dari dosen, hasil karya mahasiswa saat ini atau di masa lampau, situs web, maupun basis data.
e. Melakukan parafrase terhadap hasil karya orang lain.
f. Menggunakan komposisi musik, audio, visual, grafis, dan model fotografis. g. Menggunakan realia, yaitu objek atau aktifitas yang digunakan untuk
menghubungkan pengajaran di kelas dengan kehidupan nyata, artifak, kostum, model, dan lain-lain.
h. Menggunakan referensi berupa link sumber yang tidak dapat diakses atau tidak beroperasi lagi.
i. Menggunakan referensi yang materinya tidak tersedia pada sumber aslinya. j. Menerjemahkan isi dari suatu hasil karya tanpa mengikutsertakan referensi
atas hasil karya asli yang diterjemahkan.
2.2 Fungsi Hash
Fungsi hash adalah fungsi matematis yang digunakan untuk mengubah data menjadi bilangan bulat yang relatif kecil yang dapat berfungsi sebagai indeks pada array. Nilai yang dikembalikan oleh fungsi hash disebut dengan nilai hash, kode hash, jumlah hash, atau hash.
Fungsi hash pada umumnya digunakan untuk mempercepat pencarian pada tabel atau operasi perbandingan data, seperti mencari informasi tertentu dalam basis data, mendeteksi bagian yang mirip atau diduplikasi dari suatu berkas yang besar, mencari bagian yang sama pada barisan DNA, dan lain-lain.
Fungsi hash sering kali dihubungkan dengan perhitungan jumlah bit dari segmen pada data komputer yang dikalkulasi sebelum dan sesudah transmisi atau penyimpanan untuk memastikan bahwa data bebas dari kesalahan (checksum), pemeriksaan digit, fungsi acak, kode perbaikan kesalahan, dan fungsi hash kriptografi. Walaupun konsep-konsep tersebut saling melengkapi, setiap konsep mempunyai kegunaan dan persyaratannya sendiri.
Secara umum, ada teori dari fungsi hash yang dikenal sebagai fungsi
perfect hash untuk kelompok data apapun. Fungsi perfect hash menjamin bahwa
tidak akan dihasilkan nilai hash yang sama dari kelompok dengan elemen-elemen yang berbeda. Pada kenyataannya, sangatlah sulit menemukan fungsi
Pada praktiknya, sebuah fungsi perfect hash adalah fungsi hash yang menghasilkan nilai-nilai hash yang sama sedikit mungkin untuk himpunan data yang berbeda.
2.2.1 ASCII
Nilai hash yang akan dicari dengan fungsi hash dalam algoritma
Rabin-Karp merupakan representasi dari nilai ASCII (American Standard Code for Information Interchange) yang menempatkan angka numerik pada karakter,
angka, tanda baca, dan karakter-karakter lainnya. Dengan menstandarisasi nilai-nilai yang digunakan untuk karakter-karakter ini, ASCII memungkinkan komputer dan program komputer untuk saling bertukar informasi. ASCII menyediakan 256 kode yang dibagi ke dalam dua himpunan yaitu standard dan diperluas yang masing-masing terdiri dari 128 karakter. Himpunan ini merepresentasikan total kombinasi dari 7 atau 8 bit, yang kemudian menjadi angka dari bit dalam 1 byte. ASCII standard menggunakan 7 bit untuk tiap kode dan menghasilkan 128 kode karakter dari 0 sampai 127 (heksadesimal 00H sampai 7FH). Himpunan ASCII yang diperluas menggunakan 8 bit untuk tiap kode dan menghasilkan 128 kode tambahan dari 128 sampai 255 (heksadesimal 80H sampai FFH).
2.2.2 Rolling hash
Algoritma Rabin-Karp menggunakan fungsi hash yang disebut dengan rolling hash untuk menentukan apakah kata-kata yang dicocokkan sama. Rolling
blok yang digerakkan melewati input secara keseluruhan. Beberapa fungsi hash memungkinkan rolling hash untuk dikomputasi dengan cepat. Nilai hash yang baru dapat dengan cepat dihitung dari nilai hash yang lama dengan cara menhilangkan nilai lama dari kelompok hash dan menambahkan nilai baru ke dalam kelompok tersebut.
Kunci dari performa algoritma Rabin-Karp adalah komputasi yang efektif dari nilai hash dari substring-substring yang berurutan pada teks. Algoritma
Rabin-Karp melakukan perhitungan nilai hash dengan memperlakukan setiap substring sebagai sebuah angka dengan basis tertentu, di mana basis yang
digunakan pada umumnya merupakan bilangan prima yang besar. Misalnya, jika
substring yang ingin dicari adalah “dia” dan basis yang digunakan adalah 101,
nilai hash yang dihasilkan adalah 100 x 1012 + 105 x 1010 + 97 x 1010 = 1030802 (nilai ASCII dari ‘d’ adalah 100, ‘i’ adalah 105, dan nilai ASCII dari ‘a’ adalah 97).
Secara teknis, algoritma hash ini mirip dengan angka dalam representasi sistem non-desimal. Keuntungan yang penting dari representasi ini adalah bahwa nilai hash dari substring berikutnya dapat dihitung dari nilai sebelumnya hanya dengan melakukan operasi angka konstan, tanpa bergantung pada panjang dari
substring-substring tersebut. Misalnya, jika akan dicari pola dengan panjang
empat dari teks “katak”, nilai hash dari “atak” dapat dihitung dari “kata” (substring sebelumnya) dengan mengurangi angka yang ditambahkan untuk huruf ‘k’ pada “kata”, yaitu 107 x 1014 (107 adalah nilai ASCII dari ‘k’ dan 101 adalah basis yang digunakan), mengalikannya dengan basisnya, kemudian menambahkan huruf ‘k’ pada “atak”, yaitu 107 x 1010 = 107. Jika substring yang
dicari merupakan substring yang panjang, algoritma ini memerlukan waktu komputasi yang jauh lebih cepat dibandingkan dengan algoritma hash lain.
Secara teoritis, ada algoritma-algoritma hash lain yang dapat menyediakan komputasi ulang yang lebih baik dengan mengalikan nilai-nilai
ASCII dari semua karakter sehingga pemindahan kelompok substring dapat
dilakukan dengan membagi karakter pertama dan mengalikannya dengan karakter terakhir. Akan tetapi, terdapat kendala pada ukuran dari tipe data integer yang terbatas dan perlunya menggunakan aritmatika modular untuk memperkecil nilai hash. Di pihak lain, fungsi hash lain yang menghasilkan nilai hash dengan menambahkan nilai-nilai ASCII dapat mengakibatkan banyak nilai hash yang sama dan memperlambat algoritma ini. Oleh karena itu, fungsi hash yang dipilih merupakan fungsi hash yang cocok digunakan untuk algoritma Rabin-Karp.
2.2.3 Kriteria Fungsi Hash
Agar dapat diterapkan pada fungsi rolling hash, fungsi hash harus memenuhi beberapa kriteria sebagai berikut.
• Nilai hash dapat dikomputasi secara efisien dengan fungsi hash. • Mempunyai tingkat pembedaan yang tinggi untuk kata.
• Hash(y[j+1...j+m]) harus dapat dengan mudah dikomputasi dari
hash(y[j...j+m-1]) dan y[j+m], di mana hash(y[j+1...j+m]) =
2.3 Algoritma Rabin-Karp
Algoritma Rabin-Karp adalah algoritma pencarian kata yang mencari sebuah pola berupa substring dalam sebuah teks menggunakan hashing. Algoritma ini jarang digunakan untuk pencocokan pola tunggal, akan tetapi algoritma ini sangat penting dan sangat efektif untuk pencocokan kata dengan pola banyak.
Salah satu aplikasi praktis dari algoritma Rabin-Karp adalah dalam pendeteksian plagiarisme. Algoritma ini dapat dengan cepat melakukan pencarian kata atau frasa terhadap sebuah makalah atau karya tulis yang sama dengan sumber materi. Untuk menghindari kegagalan pendeteksian plagiarisme karena perbedaan yang tidak signifikan, algoritma ini dapat dimodifikasi sehingga tidak memeriksa detail seperti huruf kapital dan tanda baca dengan menghilangkan pemeriksaan detail-detail tersebut terlebih dahulu.
Karena jumlah dari kata-kata yang akan dicari sangat besar, algoritma pencarian kata lain tidak praktis untuk digunakan dalam pendeteksian plagiarisme. Untuk teks dengan panjang n dan pola dengan panjang m, waktu komputasi rata-rata dan terbaiknya adalah O(n), sedangkan performa waktu komputasi terburuknya adalah O((n-m+1)m). Akan tetapi, algoritma ini memiliki suatu kelebihan yang unik, yang memungkinkannya untuk menemukan kata-kata k dalam waktu komputasi rata-rata O(n), berapapun besarnya k.
Permasalahan mendasar dari algoritma ini adalah menemukan substring dengan panjang m, yang disebut dengan pola, dalam sebuah teks dengan panjang n, misalnya menemukan kata “mencari” dalam kalimat “algoritma Rabin-Karp digunakan untuk mencari kata dalam teks”. Salah satu algoritma yang paling
sederhana adalah dengan memeriksa substring pada semua kemungkinan posisi. Algoritma ini sering disebut dengan algoritma Brute Force. Berikut ini adalah
pseudocode yang digunakan.
Algoritma ini bekerja dengan baik pada sebagian besar kasus praktis, tapi akan mengakibatkan waktu komputasi yang relatif lama untuk kasus-kasus tertentu, seperti mencari kata yang terdiri dari 10.000 karakter ‘a’ yang diikuti dengan sebuah karakter ‘b’ dalam sebuah kata yang terdiri dari 10.000.000 karakter ‘a’. Dalam kasus ini, algoritma ini akan beroperasi dengan waktu komputasi terburuknya, yaitu O(nm). Algoritma Rabin-Karp menfokuskan optimasi pada baris 3 – 6.
Algoritma Rabin-Karp mempercepat pengujian kemiripan untuk pola dari
substring dalam teks dengan menggunakan fungsi hash. Fungsi hash adalah
fungsi yang mengubah setiap kata dalam suatu nilai numerik, yang disebut nilai
hash. Misalnya, hash(“kata”) = 5. Rabin-Karp menggunakan fakta bahwa jika
dua kata merupakan kata yang sama, maka nilai hash dari kedua kata tersebut akan sama juga. Karenanya, untuk memeriksa kecocokan kata, hanya diperlukan perhitungan nilai hash dari substring yang akan dicari dengan kata-kata yang mempunyai nilai hash yang sama. Akan tetapi, ada permasalahan yang ditimbulkan dengan cara ini. Karena jenis kata yang berbeda sangatlah banyak, untuk menjaga nilai hash agar tetap kecil, beberapa kata yang berbeda perlu
1 function BruteForce(string s[1..n], string sub[1..m]) 2 for i from 1 to n-m+1
3 for j from 1 to m
4 if s[i+j-1] ≠ sub[j]
5 jump to next iteration of outer loop
6 return i 7 return not found
diberi nilai hash yang sama, yang berarti jika nilai hash sama, kata tersebut belum tentu sama. Untuk itu, diperlukan fungsi hash yang dapat dihandalkan agar untuk data masukan yang ada, hal ini tidak akan sering terjadi, sehingga algoritma ini mempunyai waktu pencarian rata-rata yang baik.
Berikut ini adalah langkah-langkah yang perlu diperhatikan dalam pencocokan kata dengan algoritma Rabin-Karp.
1. Menghilangkan tanda baca dan mengubah teks sumber dan kata yang ingin dicari menjadi kata-kata tanpa huruf kapital.
2. Menentukan panjang dari teks sumber dan kata yang ingin dicari.
3. Mencari nilai hash dari kata yang ingin dicari dan teks sumber dengan menggunakan fungsi hash yang telah ditentukan.
4. Melakukan iterasi dari indeks i=0 sampai dengan i=n-m+1 untuk membandingkan nilai hash dari kata yang ingin dicari dengan nilai hash dari teks sumber pada indeks i sampai dengan i+m-1. Jika nilai hash yang dibandingkan mempunyai nilai yang sama, maka akan diperiksa lebih lanjut apakah kata yang dicari sama dengan bagian teks dari sumber pada indeks i sampai dengan i+m-1. Jika kata-kata tersebut memang sama, maka telah ditemukan kata-kata yang cocok. Sebaliknya, jika nilai hash yang dibandingkan mempunyai nilai yang tidak sama, dilanjutkan dengan membandingkan nilai hash dari kata yang dicari dengan nilai hash dari teks sumber pada indeks berikutnya.
Berikut ini adalah pseudocode dari algoritma Rabin-Karp.
Baris 2, 3, dan 6 masing-masing memerlukan waktu komputasi O(m). Akan tetapi, baris 2 dan 3 hanya dieksekusi sekali, dan baris 6 hanya dieksekusi jika nilai hash-nya cocok (karena jika dua kata berbeda, maka nilai hash dari kata-kata tersebut pasti berbeda), akan tetapi kasus ini jarang terjadi. Baris 4 dieksekusi selama n kali, tapi hanya memerlukan waktu konstan. Jadi, permasalahan sekarang hanya terdapat pada baris 8.
Jika dilakukan komputasi untuk nilai hash dari substring s[i+1..i+m], maka diperlukan waktu komputasi O(m). Karena komputasi ini terjadi untuk setiap perulangan, algoritma ini memerlukan waktu komputasi terburuk O(mn). Trik yang digunakan untuk mengatasi masalah ini adalah dengan menggunakan keuntungan bahwa variabel hs telah mempunyai nilai hash dari s[i..i+m-1]. Jika nilai hash berikutnya dapat dihitung dengan waktu konstan, maka permasalahan telah terpecahkan.
Untuk itu, digunakan cara hash yang disebut rolling hash. Salah satu cara yang sederhana adalah dengan menambahkan nilai dari tiap karakter dalam
substring. Kemudian, formula berikut digunakan untuk menghitung nilai hash
dengan waktu konstan.
s[i+1..i+m] = s[i..i+m-1] – s[i] + s[i+m] 1 function RabinKarp(string s[1..n], string sub[1..m]) 2 hsub := hash(sub[1..m]) 3 hs := hash(s[1..m]) 4 for i from 1 to n-m+1 5 if hs = hsub 6 if s[i..i+m-1] = sub 7 return i 8 hs := hash(s[i+1..i+m]) 9 return not found
Fungsi sederhana ini dapat diterapkan pada algoritma Rabin-Karp, walaupun pernyataan pada baris 6 akan tetap dieksekusi lebih sering daripada penggunaan fungsi rolling hash lain yang lebih kompleks, karena peluang terjadinya nilai hash yang sama akan lebih besar. Akan tetapi, penggunaan fungsi
rolling hash ini tetap lebih unggul dibandingkan dengan penggunaan fungsi rolling hash dengan modulo, karena waktu komputasinya jauh lebih rendah
dibandingkan dengan operasi modulo.
2.4 Dasar Rekayasa Perangkat Lunak
Menurut IEEE (The Institute of Electrical and Electronic Engineers), rekayasa perangkat lunak adalah penerapan dari pendekatan yang sistematis, disiplin, dan dapat diukur kualitasnya terhadap pengembangan, pengoperasian, dan pemeliharaan perangkat lunak, yang merupakan aplikasi dari rekayasa perangkat lunak (Pressman, 2005, p53).
2.4.1 Daur Hidup Perangkat Lunak
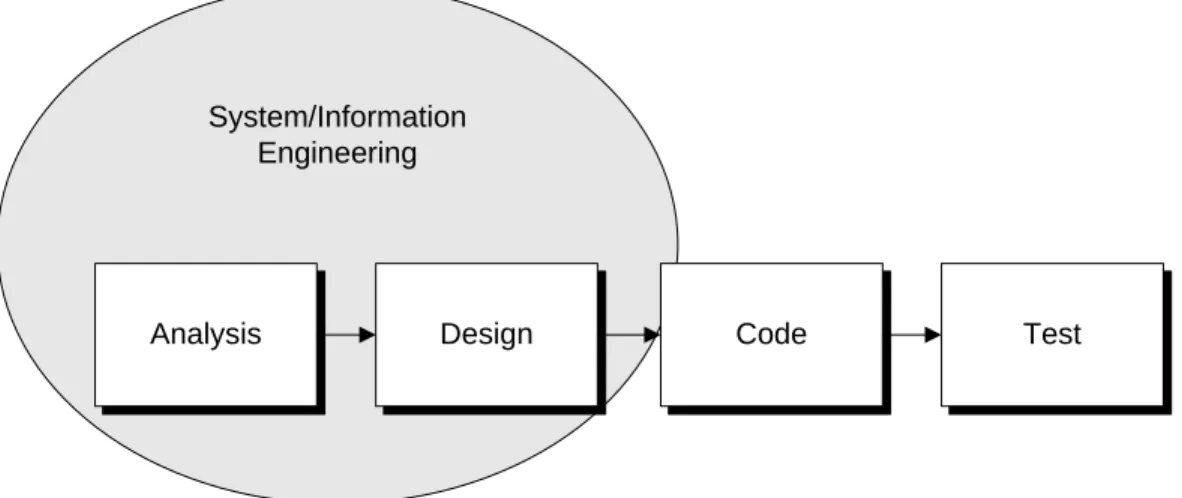
Salah satu model rekayasa perangkat lunak adalah model air terjun (Waterfall model). Model ini sering disebut juga daur hidup klasik atau model linier sekuensial. Model air terjun mengusulkan pendekatan yang sistematis dan sekuensial terhadap pengembangan perangkat lunak yang dimulai dari tingkat sistem dan berkembang ke tahap analisis, desain, pengkodean, pengujian, dan pemeliharaan. Menurut Pressman (2005, p79-80), model air terjun terdiri dari beberapa aktivitas sebagai berikut.
Analysis
System/Information Engineering
Design Code Test
Gambar 2.1 Model Proses Waterfall
Sumber: Pressman (2001, p29) • Rekayasa dan pemodelan sistem/informasi
Karena perangkat lunak merupakan bagian dari sistem yang lebih besar (atau bisnis), rekayasa perangkat lunak dimulai dengan menentukan kebutuhan untuk semua elemen sistem kemudian mengalokasikan sub himpunan-sub himpunan dari kebutuhan ini ke dalam perangkat lunak. Paradigma sistem ini penting karena perangkat lunak harus berinteraksi dengan elemen-elemen lain, seperti perangkat keras, manusia, dan basis data. Analisis dan rekayasa sistem mencakup kebutuhan-kebutuhan pada tingkat sistem dan analisis serta desain tingkat atas dalam jumlah kecil. Rekayasa informasi mencakup kebutuhan-kebutuhan pada tingkat strategis bisnis dan area bisnis.
• Analisis kebutuhan perangkat lunak
Proses pengumpulan kebutuhan diintensifikasikan dan difokuskan secara spesifik pada perangkat lunak. Untuk dapat memahami sifat dari perangkat lunak yang akan dibuat, analis harus mengerti domain informasi serta fungsi, sifat, performa, dan antarmuka dari perangkat lunak. Kebutuhan-kebutuhan untuk
sistem dan perangkat lunak didokumentasikan dan didiskusikan dengan pelanggan.
• Desain perangkat lunak
Desain perangkat lunak sebenarnya terdiri dari beberapa proses yang difokuskan pada empat atribut dari perangkat lunak, yaitu struktur data, arsitektur perangkat lunak, representasi antarmuka, dan detail prosedural (algoritma). Proses desain menerjemahkan kebutuhan ke dalam representasi dari perangkat lunak yang dapat dinilai kualitasnya sebelum tahap pengkodean dimulai. Seperti halnya kebutuhan perangkat lunak, desain didokumentasi dan menjadi bagian dari konfigurasi perangkat lunak.
• Pengkodean
Desain diterjemahkan ke dalam bentuk yang dapat dikenal oleh mesin. Tahap pengkodean melakukan tugas ini. Jika desain dibuat secara mendetail, pengkodean dapat dilakukan dengan mudah.
• Pengujian
Setelah kode telah dihasilkan, pengujian program dimulai. Proses pengujian difokuskan pada logika internal dan fungsi-fungsi eksternal dari perangkat lunak. Pengujian logika internal bertujuan untuk memastikan bahwa seluruh pernyataan telah diuji, sedangkan pengujian fungsi-fungsi eksternal bertujuan untuk mencari kesalahan teknis dan memastikan bahwa masukan yang telah ditentukan akan menghasilkan hasil aktual sesuai dengan hasil yang diinginkan.
• Pemeliharaan
Perangkat lunak kemungkinan besar akan mengalami perubahan setelah disampaikan kepada pelanggan. Perubahan tersebut dapat disebabkan oleh beberapa hal, di antaranya ditemukannya kesalahan pada perangkat lunak, perangkat lunak ingin disesuaikan untuk mengakomodasi perubahan pada lingkungan eksternal, dan pelanggan memerlukan peningkatan fungsi atau performa karena ditemukannya kebutuhan baru.
2.5 Unified Modeling Language (UML)
Menurut Booch, et.al. (1999, p14), Unified Modeling Language merupakan suatu bahasa untuk menggambarkan, menetapkan, membangun, dan mendokumentasikan artefak-artefak dari suatu sistem piranti lunak. UML mendefinisikan sembilan tipe diagram, tetapi dalam perancangan aplikasi, tidak semua diagram digunakan. Diagram-diagram yang digunakan antara lain Use
Case Diagram, Sequence Diagram, dan Activity Diagram.
2.5.1 Use Case Diagram
Use case menunjukkan hubungan interaksi antara aktor dengan use case
dalam suatu sistem (Mathiassen, 2000, p343) yang bertujuan untuk menentukan bagaimana aktor berinteraksi terhadap suatu sistem. Aktor merupakan suatu kesatuan berupa orang atau sistem lain yang berhubungan dengan sistem.
Berikut ini adalah tiga komponen yang mewakili komponen-komponen sistem.
Gambar 2.2 Notasi use case diagram
Sumber: Mathiassen (2000, p343)
Menurut Schneider dan Winters, beberapa hal yang perlu diperhatikan
dalam pembuatan use case diagram adalah (Schneider dan Winters, 1997, p26). 1. Aktor: segala sesuatu yang berhubungan dengan sistem dan melaksanakan
use case yang bersangkutan.
2. Precondition: kondisi awal yang harus dimiliki aktor untuk masuk ke dalam sistem dan terlibat dalam suatu use case.
3. Postcondition: kondisi akhir atau hasil yang akan diterima oleh aktor setelah menjalankan use case.
4. Flow of Events: kegiatan-kegiatan yang dilakukan pada sebuah proses use
case.
5. Alternative Paths: kegiatan yang terdiri dari serangkaian kejadian berbeda yang digunakan dalam Flow of Events.
2.5.2 Sequence Diagram
Sequence diagram menggambarkan bagaimana objek-objek saling
berinteraksi satu sama lain melalui pesan pada use case atau operasi. Sequence
berurutan (Whitten et al., 2004, p441). Berikut ini beberapa notasi dari sequence
diagram.
Gambar 2.3 Notasi sequence diagram
Sumber: Whitten (2004, p441)
2.5.3 Activity Diagram
M enurut Whitten et al. (2004, p442) activity diagram digunakan untuk menggambarkan urutan aliran kegiatan-kegiatan dari sebuah proses bisnis atau sebuah use case. Diagram ini juga digunakan untuk memodelkan aksi dan hasil ketika operasi berlangsung.
Gambar 2.4 Notasi activity diagram
2.6 Pseudocode
Menurut Pressman (2005, p350), pseudocode adalah suatu bahasa sederhana yang menggunakan kosakata dari sebuah bahasa (seperti bahasa Inggris) dan perintah (syntax) dari bahasa lain (seperti suatu bahasa pemrograman terstruktur).
Pseudocode dapat digunakan sebagai alternatif dalam rekayasa perangkat
lunak selain alat bantu berupa diagram. Tidak ada standarisasi tertentu yang diterapkan dalam penulisan pseudocode. Pemrogram dapat menulis pseudocode dalam bahasa tertentu yang disukai dan memadukannya dengan bahasa pemrograman tertentu. Selain itu, pemrogram juga bebas menggunakan teknik dan aturannya sendiri. Pseudocode itu sendiri dapat mengandung kata-kata kunci yang digunakan dalam bahasa pemrograman tertentu.
2.7 Interaksi Manusia dan Komputer
Menurut Schneiderman (2005, p4), interaksi manusia dan komputer merupakan disiplin ilmu yang berhubungan dengan perancangan, evaluasi, dan implementasi dari sistem komputer interaktif yang digunakan oleh manusia serta studi fenomena-fenomena besar yang berhubungan dengannya.
Interaksi manusia dan komputer ditekankan pada pembuatan antarmuka pemakai. Antarmuka pemakai dibuat sedemikian rupa sehingga pemakai dapat menggunakan perangkat lunak yang dibuat dengan baik.
2.7.1 Program Interaktif
Menurut Schneiderman (2005, p15), sebuah program yang interaktif harus bersifat user friendly. Adapun beberapa kriteria yang harus dipenuhi oleh program yang user friendly adalah sebagai berikut.
• Waktu pembelajaran yang relevan. • Penyajian informasi secara cepat. • Tingkat kesalahan pemakaian rendah.
• Penghafalan setelah pemakaian secara berulang-ulang dalam jangka waktu tertentu.
• Kepuasan subjektif pemakai terhadap berbagai aspek dari sistem.
2.7.2 Pedoman Perancangan Antarmuka
Dalam perancangan perangkat lunak, telah diperhatikan aspek-aspek perancangan perangkat lunak yang baik, sehingga informasi yang akan disampaikan dapat diterima dengan baik Selain itu, dalam perancangan perangkat lunak, digunakan antarmuka yang sederhana dengan tampilan yang interaktif. Berikut ini pedoman-pedoman yang digunakan dalam perancangan perangkat lunak.
• Delapan aturan emas (Eight Golden Rules)
Perancangan sistem interaksi manusia dan komputer yang baik memenuhi kriteria-kriteria dalam delapan aturan emas, yaitu konsisten dalam perancangan sistem, memungkinkan pengguna untuk menggunakan shortcut, menyediakan umpan balik yang informatif, merancang dialog yang menghasilkan keadaan
akhir, mendukung pengguna menguasai sistem, mengurangi kemungkinan kesalahan saat pemakaian, memberikan kesempatan bagi pemakai untuk memperbaiki kesalahan aksi, dan mengurangi beban ingatan jangka pendek. • Teori waktu respon
Menurut Schneiderman (2005, p352), waktu respon dalam sistem komputer adalah jumlah detik dari saat pengguna program memulai aktivitas sampai program menampilkan hasilnya di layar atau printer. Pemakai lebih menyukai waktu respon yang pendek. Waktu respon yang lama akan mengakibatkan pemakai menunggu dan kehilangan keinginan untuk menggunakan perangkat lunak. Oleh karena itu, waktu respon harus relevan dengan tugas yang dikerjakan dan pemakai harus diberi tahu mengenai penundaan yang panjang.