i
PREDIKSI IPK DAN MASA STUDI CALON MAHASISWA
BARU MENGGUNAKAN JARINGAN SYARAF TIRUAN
PROPAGASI BALIK
SKRIPSI
Diajukan Untuk Memenuhi Salah Satu Syarat Memperoleh Gelar Pendidikan Sarjana Komputer Program Studi Informatika
Ninda Mawarni (165314112)
PROGRAM STUDI INFORMATIKA FAKULTAS SAINS DAN TEKNOLOGI
UNIVERSITAS SANATA DHARMA YOGYAKARTA
ii
PREDICTION OF GPA AND STUDY PERIOD OF NEW STUDENT CANDIDATE USING NEURAL NETWORK BACKPROPAGATION
THESIS
Present as Partial Fulfillment of the Requirement To Obtain Sarjana Komputer Degree in Informatics Major
Ninda Mawarni (165314112)
INFORMATICS MAJOR
FACULTY OF SCIENCE AND TECHNOLOGY SANATA DHARMA UNIVERSITY
YOGYAKARTA 2020
v MOTO
HIDUPLAH SEAKAN KAMU MATI ESOK HARI, DAN BELAJARLAH SEOLAH KAMU HIDUP SELAMANYA
viii ABSTRAK
Indeks Prestasi Akademik (IPK) dan masa studi merupakan dua komponen penting yang merepresentasikan kualitas seorang mahasiswa. Kedua hal tersebut juga merupakan tolok ukur yang masuk dalam evaluasi suatu program studi di universitas yang nantinya akan menghasilkan akreditasi program studi. IPK dan masa studi dapat memberikan gambaran bagaimana jaminan mutu dan kualitas di suatu universitas dijaga dan dikembangkan.
Penelitian ini bertujuan untuk memprediksi IPK dan Masa Studi calon mahasiswa baru menggunakan jaringan syaraf tiruan propagasi balik. Data yang akan digunakan dalam penelitian ini berjumlah 2426 data mahasiswa angkatan 2001 - 2015 Fakultas Sains dan Teknologi USD dimana variabel yang digunakan meliputi nilai ujian masuk tertulis (nilai penalaran verbal. Kemampuan numerik, penalaran mekanik, hubungan ruang, dan bahasa inggris), asal daerah, jurusan SMA/SMK, pendidikan ayah, pendidikan ibu, dan jumlah saudara. Diharapkan melalui penelitian ini akan didapatkan suatu model jaringan syaraf tiruan yang optimal untuk memprediksi IPK dan masa studi calon mahasiswa baru.
Hasil percobaan yang dilakukan untuk dua model prediksi menunjukkan bahwa untuk model prediksi masa studi menghasilkan akurasi optimal 49,5446% dimana arsitektur optimal yang dihasilkan yaitu neuron pada hidden layer 1 sebanyak 50 neuron, hidden layer 2 sebanyak 25 neuron, fungsi training trainlm, fungsi aktivasi logsig dengan 5-fold. Sedangkan untuk model prediksi IPK dihasilkan akurasi optimal sebesar 52,149% dimana arsitektur optimal yang dihasilkan yaitu jumlah hidden layer 1 sebanyak 45 neuron, fungsi training traingdx, fungsi aktivasi logsig dengan 5-fold.
ix ABSTRACT
Grade Point Average (GPA) and study period are two important components that represent the quality of a student. Both of these are also benchmarks that are included in the evaluation of a study program at a university which will produce study program accreditation. The GPA and study period can provide an overview of how quality assurance and quality at a university is maintained and developed.
This study aims to predict the GPA and Study Period prospective new students using a back propagation neural network. The data to be used in this study amounted to 2426 data from 2001-2015 students of the Faculty of Science and Technology of the USD where the variables used included the value of the written entrance exam (verbal reasoning value. Numerical ability, mechanical reasoning, spatial relations, and English), regional origin , majoring in SMA / SMK, father's education, mother's education, and number of siblings. Hopefully this research an optimal neural network model will be obtained to predict the GPA and the period of study for prospective new students.
The results of experiments conducted for two prediction models show that for the prediction model the study period produces an optimal accuracy of 49.5446% where the optimal architecture produced is 50 neurons in hidden layer 1, 25 neurons in hidden layer 2, training trainlm function, logig activation function with 5-fold. As for the GPA prediction model the optimal accuracy is 52.149% where the optimal architecture produced is the number of hidden layer 1 as many as 45 neurons, the training function of the traingdx, the 5-fold logsig activation function.
x
KATA PENGANTAR
Puji syukur saya panjatkan ke hadirat Tuhan Yang Maha Esa, karena dengan karunia-Nya saya dapat menyelesaikan tugas akhir dengan sangat baik.
Saya sebagai penulis menyadari bahwa pengerjaan tugas akhir ini dapat berjalan dengan baik karena bimbingan dan bantuan dari berbagai pihak. Maka dalam kesempatan ini, perkenankanlah saya mengucapkan terima kasih kepada:
1. Dr.Cyprianus Kuntoro Adi, S.J. M.A., M.Sc. selaku dosen pembimbing tugas akhir yang telah sabar dan memberikan perhatian untuk membimbing saya dalam penyusunan tugas akhir.
2. Robertus Adi Nugroho S.T., M.Eng., selaku Ketua Program Studi Informatika yang selalu memberikan dukungan, perhatian serta saran kepada mahasiswa yang berjuang mengerjakan tugas akhir.
3. Orang tua tercinta Ibu Tri Aprilita yang telah senantiasa memberikan doa, dukungan dalam bentuk moral maupun materi, serta dorongan yang besar kepada saya, sehingga saya dapat menyelesaikan tugas akhir ini.
4. Klaudia dan Yuni, teman seperjuangan dari masa semester awal hingga bersama-sama dalam pengerjaan skripsi ini tanpa berhenti menyemangati satu sama lain.
5. Derek Silva yang telah memberikan semangat, motivasi dan menguatkan saya setiap harinya untuk menyelesaikan tugas akhir ini.
6. Hananto Widigdo yang telah membantu saya untuk memberikan pencerahan terhadap problem yang saya hadapi selama penulisan dan penyusunan tugas akhir ini.
7. Teman – teman Prodi Informatika angkatan 2016 yang selalu menyemangati dan memotivasi penulis serta berjuang bersama untuk menyelesaikan tugas akhir ini.
8. Semua pihak yang tidak dapat disebutkan satu persatu yang telah banyak membantu penulis dalam pembuatan tugas akhir ini.
Penulis menyadari bahwa masih banyak kekurangan pada Tugas Akhir ini. Mengingat keterbatasan pengetahuan dan pengalaman saya, maka saya
xi
mengharapkan kritik dan saran atas Tugas Akhir ini. Akhir kata, saya mengharapkan Tugas Akhir ini dapat bermanfaat bagi banyak pihak dan bagi para pembacanya.
Penulis
xii DAFTAR ISI
SAMPUL... i
COVER...ii
HALAMAN PERSETUJUAN PEMBIMBING...iii
HALAMAN PENGESAHAN...iv
MOTO...v
PERNYATAAN KEASLIAN KARYA... vi
LEMBAR PERNYATAAN PERSETUJUAN PUBLIKASI ILMIAH UNTUK KEPENTINGAN AKADEMIS... vii
ABSTRAK...viii ABSTRACT...ix KATA PENGANTAR... x DAFTAR ISI...xii DAFTAR GAMBAR... xv DAFTAR TABEL...xvii BAB I... 1 PENDAHULUAN...1 1.1. Latar Belakang... 1 1.2. Rumusan Masalah... 2 1.3. Tujuan... 3 1.4. Manfaat Penelitian... 3 1.5. Batasan Masalah...3 1.6. Sistematika Penulisan...3 BAB II...5 TINJAUAN PUSTAKA...5
2.1. Jaringan Syaraf Tiruan... 5
2.1.1. Konsep Dasar Pemodelan Jaringan Syaraf Tiruan... 7
xiii
2.1.3. Fungsi Aktivasi...10
2.1.4. Bias dan Threshold...11
2.1.5. Metode Pelatihan Jaringan Syaraf Tiruan... 12
2.2. Propagasi Balik... 12
2.2.1. Fungsi Aktivasi Dalam Propagasi Balik...13
2.2.2. Standar Pelatihan Propagasi Balik...14
2.2.3. K-Fold Cross Validation... 17
2.2.4. Evaluasi... 18
BAB III...20
METODOLOGI PENELITIAN...20
3.1. Gambaran Umum Sistem... 20
3.2. Data... 21
3.2.1. Preprocessing Data... 23
3.2.2. Pengelompokan Dan Komposisi Data...27
3.3. Model Propagasi Balik...30
3.3.1. Pembelajaran Model...32
3.4. Kebutuhan Sistem... 38
3.5. Perancangan Antarmuka Sistem... 39
3.5.1. Panel Data Mentah... 39
3.5.2. Panel Data Olah...39
3.5.3. Panel Training... 40
3.5.4. Panel Uji Data Tunggal... 40
BAB IV... 41
HASIL DAN ANALISIS... 41
4.1. Data Preprocessing...41
4.1.1.Data Cleaning... 41
4.1.2.Data Selection... 41
xiv
4.2. Prediksi...46
4.2.1. Model Prediksi Masa Studi...46
4.2.2. Model Prediksi IPK... 51
4.3. Arsitektur Optimal... 55
4.3.1. Model Prediksi Masa Studi...55
4.3.2. Model Prediksi IPK... 57
4.4. Uji Data Tunggal...60
4.5. Analisis Hasil Percobaan Terhadap Hasil Penelitian Terkait... 62
BAB V...64 PENUTUP...64 5.1. Kesimpulan... 64 5.2. Saran...64 DAFTAR PUSTAKA... 65 LAMPIRAN...67
xv
DAFTAR GAMBAR
Gambar 2.1 Model Tiruan Sebuah Neuron ... 7
Gambar 2.2 Single Layer Network (Siang, 2009) ... 8
Gambar 2.3 Multi Layer Network (Siang, 2009) ...9
Gambar 2.4 Bias (Siang, 2009)... 11
Gambar 2.5 Arsitektur Propagasi Balik (Siang, 2009)...13
Gambar 2.6 Ilustrasi K-Fold Cross Validation ... 18
Gambar 3.1 Gambaran Umum ... 20
Gambar 3.2 Ilustrasi Kelompok Data Aturan 3-Fold Untuk Model Prediksi Masa Studi ...28
Gambar 3.3 Ilustrasi Kelompok Data Aturan 3-Fold Untuk Model Prediksi IPK ...28
Gambar 3.4 Ilustrasi Kelompok Data Aturan 5-Fold Untuk Model Prediksi Masa Studi ...29
Gambar 3.5 Ilustrasi Kelompok Data Aturan 5-Fold Untuk Model Prediksi IPK...29
Gambar 3.6 Rancangan Arsitektur Untuk Pelatihan ... 30
Gambar 3.7 Contoh Arsitektur ... 33
Gambar 3.8 Rancangan Tampilan Antarmuka ...39
Gambar 4.1 Grafik Akurasi Percobaan Satu Hidden Layer Masa Studi Dengan Fungsi Aktivasi Tansig Dan 3-Fold ...47
Gambar 4.2 Grafik Akurasi Percobaan Satu Hidden Layer Masa Studi Dengan Fungsi Aktivasi Tansig Dan 5-Fold ...47
xvi
Gambar 4.3 Grafik Akurasi Percobaan Satu Hidden Layer Masa Studi Dengan
Fungsi Aktivasi Logsig Dan 3-Fold ...48
Gambar 4.4 Grafik Akurasi Percobaan Satu Hidden Layer Masa Studi Dengan Fungsi Aktivasi Logsig Dan 5-Fold ...49
Gambar 4.5 Grafik Akurasi Percobaan Dua Hidden Layer Masa Studi Dengan Fungsi Aktivasi Tansig Dan 3-Fold ...50
Gambar 4.6 Grafik Akurasi Percobaan Satu Hidden Layer IPK Dengan Fungsi Aktivasi Tansig Dan 3-Fold ...51
Gambar 4.7 Grafik Akurasi Percobaan Satu Hidden Layer IPK Dengan Fungsi Aktivasi Tansig Dan 5-Fold ...52
Gambar 4.8 Grafik Akurasi Percobaan Satu Hidden Layer IPK Dengan Fungsi Aktivasi Logsig Dan 3-Fold ...52
Gambar 4.9 Grafik Akurasi Percobaan Satu Hidden Layer IPK Dengan Fungsi Aktivasi Logsig Dan 5-Fold ...53
Gambar 4.10 Grafik Akurasi Percobaan Dua Hidden Layer IPK Dengan Fungsi Aktivasi Tansig Dan 3-Fold ...54
Gambar 4.11 Arsitektur Optimal Model Prediksi Masa Studi ... 55
Gambar 4.12 Akurasi Model Prediksi Masa Studi Setelah Penambahan IP Semester 1 dan 2 ...57
Gambar 4.13 Arsitektur Optimal Model Prediksi IPK ...57
Gambar 4.14 Akurasi Model Prediksi IPK Setelah Penambahan IP Semester 1 dan 2 ... 59
Gambar 4.15 Uji Data Tunggal Kelas Tepat Model Prediksi Masa Studi ... 60
Gambar 4.16 Uji Data Tunggal Kelas Terlambat Model Prediksi Masa Studi ...60
xvii
Gambar 4.18 Uji Data Tunggal Kelas Kurang Model Prediksi IPK ...61 Gambar 4.19 Uji Data Tunggal Kelas CUKUP Model Prediksi IPK ... 62 Gambar 4.20 Uji Data Tunggal Kelas Memuaskan Model Prediksi IPK ... 62
xviii
DAFTAR TABEL
Tabel 2.1 Confusion Matrix ...18
Tabel 3.1 Atribut Penelitian ... 21
Tabel 3.2 Contoh Data Penelitian ...23
Tabel 3.3 Contoh Data untuk Cleaning ...23
Tabel 3.4 Transformasi Atribut Asal Daerah ... 25
Tabel 3.5 Transformasi Atribut Jurusan saat SMA atau SMK ...25
Tabel 3.6 Transformasi Atribut Pendidikan Ayah dan Pendidikan Ibu ... 26
Tabel 3.7 Transformasi Kelas IPK ...26
Tabel 3.8 Transformasi Kelas Masa Studi ... 27
Tabel 3.9 Karakteristik Jaringan Syaraf Tiruan ... 32
Tabel 3.10 Inisiasi Bobot dari Input ke Hidden Layer ...33
Tabel 3.11 Inisiasi Bobot dari Hidden Layer ke Output Layer ...34
Tabel 3.12 Hasil Perubahan Bobot Dan Bias Dari Input Layer ke Hidden Layer ... 36
Tabel 3.13 Hasil Perubahan Bobot Dan Bias Dari Input Layer ke Hidden Layer .... 38
Tabel 4.1 Perhitungan rata - rata atribut yang memiliki missing value ...41
Tabel 4.2 Perankingan Atribut Berdasarkan Information Gain Untuk Model Prediksi Masa Studi ...42
Tabel 4.3 Perankingan Atribut Berdasarkan Information Gain Untuk Model Prediksi IPK ... 42
xix
Tabel 4.4 Hasil Percobaan Kombinasi Atribut Pada Model Prediksi Masa Studi ... 43
Tabel 4.5 Hasil Percobaan Kombinasi Atribut Pada Model Prediksi Masa Studi ... 44
Tabel 4.6 Contoh Data Model Prediksi Masa Studi Sebelum Transformasi ...45
Tabel 4.7 Contoh Data Model Prediksi Masa Studi Sesudah Transformasi ... 45
Tabel 4.8 Contoh Data Model Prediksi IPK Sebelum Transformasi ... 45
Tabel 4.9 Contoh Data Model Prediksi IPK Sesudah Transformasi ...46
Tabel 4.10 Confussion Matrix Fold Pertama Model Prediksi Masa Studi ...55
Tabel 4.11 Confussion Matrix Fold Kedua Model Prediksi Masa Studi ... 55
Tabel 4.12 Confussion Matrix Fold Ketiga Model Prediksi Masa Studi ... 55
Tabel 4.13 Confussion Matrix Fold Keempat Model Prediksi Masa Studi ... 56
Tabel 4.14 Confussion Matrix Fold Kelima Model Prediksi Masa Studi ...56
Tabel 4.15 Confussion Matrix Fold Pertama Model Prediksi IPK ... 58
Tabel 4.16 Confussion Matrix Fold Kedua Model Prediksi IPK ...58
Tabel 4.17 Confussion Matrix Fold Ketiga Model Prediksi IPK ...58
Tabel 4.18 Confussion Matrix Fold Keempat Model Prediksi IPK ...58
1 BAB I PENDAHULUAN 1.1. Latar Belakang
Indeks Prestasi Kumulatif (IPK) dan masa studi merupakan dua komponen penting yang merepresentasikan kualitas seorang mahasiswa. IPK sendiri didapat berdasarkan hasil indeks prestasi setiap semester yang diakumulasikan dalam sebuah transkrip nilai. IPK dinilai begitu penting terlebih saat seorang mahasiswa memasuki dunia pekerjaan dimana dewasa ini, banyak sekali perusahaan yang menetapkan minimal IPK 2,75 bagi calon pelamar agar bisa melamar di perusahaannya. Selain IPK, Masa studi juga merupakan hal yang sangat penting bagi seorang mahasiswa dan ikut andil dalam proses kelulusan mahasiswa.
Menurut Peraturan Menteri Riset,Teknologi dan Pendidikan Tinggi Republik Indonesia Nomor 44 Tahun 2015 Tentang Standar Nasional Pendidikan Tinggi Pasal 16 Ayat 1D menyatakan bahwa masa studi bagi seorang calon sarjana adalah maksimal 7 tahun dengan banyak sks minimal 144 sks dan minimal IPK 2,00. Bagi mahasiswa yang tidak memenuhi syarat tersebut kemungkinan dapat dikenai drop out (DO).
Selain penting bagi mahasiswa, IPK dan masa studi juga penting bagi program studi di suatu universitas. IPK dan masa studi mahasiswa merupakan dua tolok ukur yang masuk dalam evaluasi program studi yang nantinya akan menghasilkan akreditasi suatu program studi. IPK dan masa studi dapat memberikan gambaran bagaimana program studi di suatu universitas dapat mengembangkan kompetensi yang ada pada mahasiswa dan bagaimana jaminan mutu dan kualitas di dalam sebuah universitas dijaga dan dikembangkan.
IPK dan masa studi mahasiswa merupakan bagian yang tidak dapat diabaikan dalam sistem pembelajaran di universitas. Oleh sebab itu, diperlukan suatu prediksi yang memungkinkan pihak program studi di universitas untuk mengetahui gambaran kualitas seorang mahasiswa sedari dini dan dapat meningkatkan presentasi lulusan yang memenuhi standar mutu perguruan tinggi. prediksi ini mencakup berapa IPK yang mungkin
dihasilkan serta berapa lama seorang calon mahasiswa akan menempuh pendidikan di program studi tersebut. Jika pihak program studi dapat memprediksi IPK dan masa studi seorang calon mahasiswa, hal ini akan membantu dalam pencegahan untuk memperoleh mahasiswa yang memiliki IPK rendah dan mahasiswa yang lama dalam menempuh proses pendidikan.
Terdapat beberapa metode untuk prediksi IPK dan masa studi. Salah satu metode prediksi yang dapat digunakan adalah metode Jaringan Syaraf Tiruan Backpropagation. Berdasarkan jurnal penelitian yang ditulis oleh Dwi Kartini (2017), Metode Jaringan Syaraf Tiruan mampu menghasilkan akurasi 99% menggunakan layer input 4, 1 hidden layer dengan 10 neuron serta layer output sebanyak 1 dimana atribut yang digunakan adalah nilai indeks prestasi semester 1 sampai dengan 4, yang menandakan bahwa metode ini sangat baik jika digunakan sebagai metode untuk prediksi. Sedangkan menurut Lillyan Hadjaratie (2011), Metode jaringan syaraf tiruan mampu memberikan akurasi 93.34% bagi data testing untuk memprediksi nilai IPK mahasiswa menggunakan atribut nilai mata kuliah. Adapun input node yang digunakan adalah 16, 1 hidden layer dengan 15 node, serta 3 node output. Berdasarkan dua jurnal tersebut, dapat disimpulkan bahwa metode jaringan syaraf tiruan dinilai sangat baik dalam hal prediksi. Selain itu, menurut Han dan Kember (2001), Jaringan syaraf tiruan memiliki keunggulan dalam prediksi dan klasifikasi pada data yang belum diberikan pada pembelajaran sebelumnya (data baru) sehingga sangat baik jika digunakan dalam prediksi IPK dan masa studi calon mahasiswa baru dengan mempelajari pola pembelajaran data terdahulu.
1.2. Rumusan Masalah
1. Bagaimana model arsitektur jaringan syaraf tiruan yang dapat memberikan hasil prediksi IPK dan masa studi calon mahasiswa baru secara optimal?
2. Berapa besar akurasi yang dihasilkan dari model arsitektur jaringan syaraf tiruan yang dibentuk?
1.3. Tujuan
Tujuan dari penelitian ini adalah untuk :
1. Memprediksi besarnya IPK dan masa studi mahasiswa baru Fakultas Sains dan Teknologi Universitas Sanata Dharma menggunakan jaringan syaraf tiruan propagasi balik.
2. Mengetahui model arsitektur jaringan syaraf tiruan yang memberikan hasil optimal pada prediksi.
1.4. Manfaat Penelitian
Informasi yang dihasilkan dapat digunakan sebagai bahan pertimbangan apakah seorang calon mahasiswa baru dapat diterima atau tidak dalam suatu program studi mengacu pada IPK yang akan dihasilkan dan lama masa studi yang akan ditempuh.
1.5. Batasan Masalah
Adapun batasan masalah dari penelitian ini adalah :
1. Data yang digunakan merupakan data nilai TPA ujian masuk, asal daerah, jurusan SMA atau SMK, pendidikan ayah, pendidikan ibu, jumlah saudara, masa studi, dan IPK mahasiswa Fakultas Sains dan Teknologi Universitas Sanata Dharma angkatan 2001 - 2015.
2. Data mahasiswa yang digunakan adalah mahasiswa yang diterima melalui jalur ujian masuk tertulis.
1.6. Sistematika Penulisan
Sistematika Penulisan yang digunakan dalam penelitian ini yaitu : BAB I PENDAHULUAN
Bab ini berisi tentang latar belakang, rumusan masalah, tujuan, manfaat, batasan masalah dan sistematika penulisan.
BAB II TINJAUAN PUSTAKA
Bab ini berisi tentang teori - teori yang menjadi dasar penelitian prediksi IPK dan masa studi calon mahasiswa baru menggunakan jaringan syaraf tiruan propagasi balik.
BAB III METODOLOGI PENELITIAN
Bab ini berisi tentang gambaran umum sistem yang akan dibangun dan dan tahap-tahap prediksi IPK dan masa studi calon mahasiswa baru menggunakan jaringan syaraf tiruan. Selain itu terdapat juga perancangan desain antarmuka sistem yang akan dibuat.
BAB IV HASIL DAN ANALISA
Bab ini akan membahas implementasi dari tahapan - tahapan algoritma yang digunakan serta desain sistem yang sudah dirancang. Pada bab ini juga akan dibahas hasil beserta akurasi prediksi dari proses implementasi algoritma.
BAB V PENUTUP
Bab ini berisi tentang kesimpulan yang dapat ditarik dari proses percobaan. Selain itu, terdapat juga saran yang digunakan sebagai bahan acuan pengembangan sistem yang dibuat.
5 BAB II
TINJAUAN PUSTAKA
Bab ini akan membahas dasar teori serta penelitian terdahulu yang akan digunakan dalam proses penyusunan dan pembahasan penelitian yang didalamnya mencakup pengertian Jaringan Syaraf Tiruan dan konsep peramalan/prediksi.
2.1. Jaringan Syaraf Tiruan
Jaringan Syaraf Tiruan (artificial neural network) atau disingkat dengan JST adalah sistem komputasi dimana arsitektur dan operasi diilhami dari pengetahuan tentang sel syaraf biologi di dalam otak (Kristanto, 2004). Jaringan Syaraf Tiruan dapat digambarkan sebagai model matematis dan komputasi untuk fungsi aproksimasi nonlinear, klasifikasi data, cluster dan regresi non parametrik atau sebagai sebuah simulasi dari koleksi model syaraf biologi. Siang (2009) menyatakan bahwa Jaringan Syaraf Tiruan dibentuk sebagai generalisasi model matematika dari jaringan biologi, dengan asumsi bahwa :
a. Pemrosesan informasi terjadi pada banyak elemen sederhana (neuron).
b. Sinyal dikirimkan antar neuron neuron melalui penghubung -penghubung.
c. Penghubung antar neuron memiliki bobot yang akan memperkuat atau memperlemah sinyal.
d. Untuk menentukan output, setiap neuron menggunakan fungsi aktivasi (biasanya bukan fungsi liniear) yang dikenakan pada jumlahan input yang diterima. Besarnya output ini selanjutnya dibandingkan dengan suatu batas ambang.
Jaringan syaraf sangat ditentukan oleh 3 hal yakni : a. Pola hubungan antar neuron (arsitektur jaringan).
b. Metode untuk menentukan bobot penghubung (metode training/learning).
c. Fungsi aktivasi
Di dalam jaringan syaraf tiruan, neuron merupakan suatu hal yang sangat penting. Neuron merupakan unit pemroses informasi yang menjadi dasar dalam operasi jaringan syaraf tiruan (Siang, 2009). Neuron memiliki elemen - elemen pembentuk antara lain :
a. Himpunan unit - unit yang dihubungkan dengan jalur koneksi. b. Suatu unit penjumlahan yang akan menjumlahkan input - input
sinyal yang sudah dikalikan dengan bobotnya.
c. Fungsi aktivasi yang nantinya akan menentukan apakah sinyal inputan dari suatu neuron akan diteruskan ke neuron - neuron lainnya atau tidak.
Pada umumnya, jaringan syaraf tiruan memiliki 2 lapisan yakni input layer dan output layer. Namun dewasa ini, dalam perkembangannya jaringan syaraf tiruan juga memiliki suatu layer antara input layer dan output layer yakni hidden layer. Berikut ini adalah penjelasan tentang lapisan - lapisan dalam jaringan syaraf tiruan (Kusumadewi, 2003) :
a. Input Layer berisi node - node yang masing - masing menyimpan sebuah nilai masukan yang tidak berubah pada fase latih dan hanya bisa berubah jika diberikan nilai masukan baru. Node pada lapisan ini tergantung pada banyaknya input dari suatu pola. b. Hidden Layer, Lapisan ini tidak pernah muncul sehingga
dinamakan hidden layer. Akan tetapi semua proses pada fase pelatihan dan fase pengenalan dijalankan pada lapisan ini. Jumlah lapisan ini tergantung dari arsitektur yang dirancang, tetapi pada umumnya terdiri dari satu lapisan hidden layer.
c. Output layer berfungsi untuk menampilkan hasil perhitungan sistem oleh fungsi aktivasi pada hidden layer berdasarkan input yang diterima.
2.1.1. Konsep Dasar Pemodelan Jaringan Syaraf Tiruan
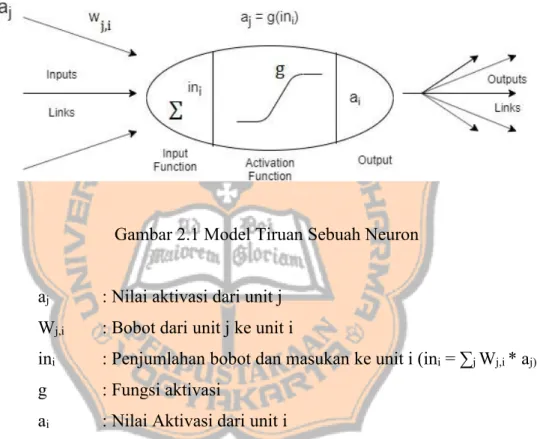
Menurut Setiowati (2014) tiruan neuron dalam jaringan syaraf tiruan adalah sebagai elemen pemroses yang dapat berfungsi seperti halnya sebuah neuron dalam manusia. Sejumlah sinyal input a dikalikan dengan masing - masing bobot w. Setelah itu, dilakukan penjumlahan dari seluruh hasil perkalian. Keluaran dari proses ini kemudian dilalukan kedalam fungsi aktivasi untuk mendapatkan tingkatan derajat sinyal keluarannya F(a,w). Berikut ini gambar model tiruan neuron (Setiowati, 2014):
Gambar 2.1 Model Tiruan Sebuah Neuron
aj : Nilai aktivasi dari unit j Wj,i : Bobot dari unit j ke unit i
ini : Penjumlahan bobot dan masukan ke unit i (ini= ∑jWj,i* aj) g : Fungsi aktivasi
ai : Nilai Aktivasi dari unit i
Kumpulan neuron yang dibuat menjadi sebuah jaringan akan berfungsi sebagai alat komputasi yang jumlah dan struktur jaringannya akan berbeda - beda untuk setiap problem.
2.1.2. Arsitektur Jaringan Syaraf Tiruan
Terdapat beberapa arsitektur jaringan yang cukup sering dipakai dalam jaringan syaraf tiruan menurut Siang (2009) antara lain :
a. Jaringan Layar Tunggal (Single Layer Network)
Dalam jaringan ini, sekumpulan input neuron dihubungkan langsung dengan sekumpulan outputnya. Dalam beberapa model (misal perceptron), hanya ada sebuah unit neuron output.
Gambar 2.2 Single Layer Network (Siang, 2009)
Gambar 2.2 menunjukkan arsitektur jaringan dengan n unit input (x1,x2,…xn) dan m buah unit output (Y1,Y2,…Ym). Dalam jaringan dengan arsitektur ini, semua unit input dihubungkan dengan semua unit output meskipun dengan bobot yang berbeda - beda.
Besaran Wj,i menyatakan bobot hubungan antara unit ke-i dalam unit input dengan unit ke-j dalam output yang masing - masing bobot saling independen. Selama proses pelatihan, bobot - bobot ini akan dimodifikasi untuk meningkatkan keakuratan hasil.
b. Jaringan Layar Jamak (Multi Layer Network)
Jaringan layar jamak merupakan perluasan dari layar tunggal. Dalam jaringan ini, selain unit input dan output, terdapat beberapa unit -unit lain (-unit tersembunyi/ hidden layer).Unit tersembunyi ini tidak saling berhubungan dalam satu layar sama halnya dengan unit input dan unit output.
Gambar 2.3 Multi Layer Network (Siang, 2009)
Gambar 2.3 adalah jaringan dengan n buah unit input (x1,x2,…,xn), layar tersembunyi yang terdiri dari p buah unit (z1,…..zp) dan m buah unit output (Y1,Y2…,Ym). Jaringan layar jamak dapat menyelesaikan masalah yang lebih kompleks dibandingkan dengan layar tunggal, meskipun seringkali proses pelatihan lebih kompleks dan lama.
c. Jaringan Reccurent
Model jaringan ini mirip dengan jaringan layar tunggal ataupun ganda. Hanya saja, terdapat neuron output yang memberikan sinyal pada unit input (sering disebut feedback floop).
2.1.3. Fungsi Aktivasi
Dalam jaringan syaraf tiruan, fungsi aktivasi dipakai untuk menentukan keluaran suatu neuron dimana jika net =∑ Xi * Wi maka fungsi aktivasinya adalah f(net) = f( ∑ Xi* Wi). Beberapa fungsi aktivasi yang sering dipakai sebagai berikut (Siang, 2009) :
a. Fungsi threshold (batas ambang)
a x a x jika jika 0 1 f(x)
{
………(1)Untuk beberapa kasus, fungsi ini dibuat tidak berharga 0 atau 1 akan tetapi berharga -1 atau 1 ( sering disebut sebagai threshold bipolar) sehingga : a x a x jika jika 1 1 f(x)
{
………..…….(2) b. Fungsi sigmoid x e 1 1 f(x) ………..(3)Fungsi sigmoid sering dipakai karena nilai fungsinya yang terletak antara 0 dan 1 yang dapat diturunkan dengan mudah
f’(x) = f(x) (1-f(x))……….……….(4)
c. Fungsi identitas
Fungsi identitas sering dipakai apabila keluaran yang diinginkan berupa sembarang bilangan real ( bukan hanya pada range [0,1] atau [-1, 1]).
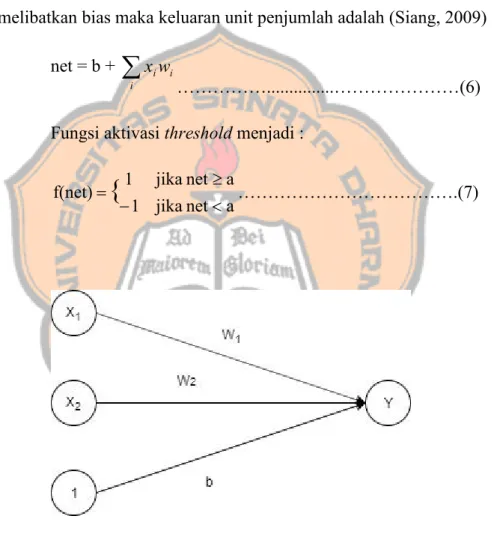
2.1.4. Bias Dan Threshold
Dalam suatu jaringan seringkali ditambahkan sebuah unit masukan yang nilainya selalu 1 yang biasa disebut dengan Bias (Gambar 2.4). Bias berfungsi untuk mengubah nilai threshold menjadi 0 (bukan a). jika melibatkan bias maka keluaran unit penjumlah adalah (Siang, 2009)
net = b + i i i w x
………...………(6) Fungsi aktivasi threshold menjadi :a net a net jika jika 1 1 f(net)
{
……….(7)2.1.5. Metode Pelatihan Jaringan Syaraf Tiruan 2.1.5.1. Metode Pelatihan Terbimbing
Metode Pelatihan terbimbing menurut Setiowati (2014) adalah metode pelatihan yang memasukkan target keluaran dalam data pelatihannya. Dalam pelatihan terbimbing, terdapat sejumlah pasangan data (masukan - target keluaran) yang dipakai untuk melatih jaringan hingga diperoleh bobot yang diinginkan. Pasangan data tersebut berfungsi sebagai “guru” guna melatih jaringan hingga diperoleh bentuk yang terbaik serta memberikan informasi yang jelas tentang bagaimana sistem harus mengubah dirinya untuk meningkatkan unjuk kerjanya (Siang, 2009). Terdapat beberapa model jaringan yang menggunakan metode ini antara lain Jaringan Perceptron, Adaline, dan Backpropagation (Setiowati, 2014). 2.1.5.2. Metode Pelatihan Tak Terbimbing
Menurut Setiowati (2014) metode pelatihan tak terbimbing adalah metode pelatihan yang tidak memerlukan target pada keluarannya. Proses pelatihan didasarkan pada proses transformasi dari bentuk kontinyu ke bentuk diskrit yang dikenal dengan kuantisasi vektor. (Siang, 2009) Perubahan bobot dilakukan berdasarkan parameter tertentu dan jaringan dimodifikasi menurut ukuran paramater tersebut. Model jaringan yang menggunakan metode ini adalah model jaringan umpan balik (Feedforward network).
2.2. Propagasi Balik
Propagasi balik adalah model jaringan dengan metode terbimbing yang paling banyak digunakan. Propagasi balik melatih jaringan untuk mendapatkan keseimbangan antara kemampuan jaringan untuk mengenali pola yang digunakan selama pelatihan serta kemampuan jaringan untuk memberikan respon yang benar terhadap pola masukan yang serupa (tapi tidak sama) dengan pola yang dipakai selama pelatihan (Siang, 2009).
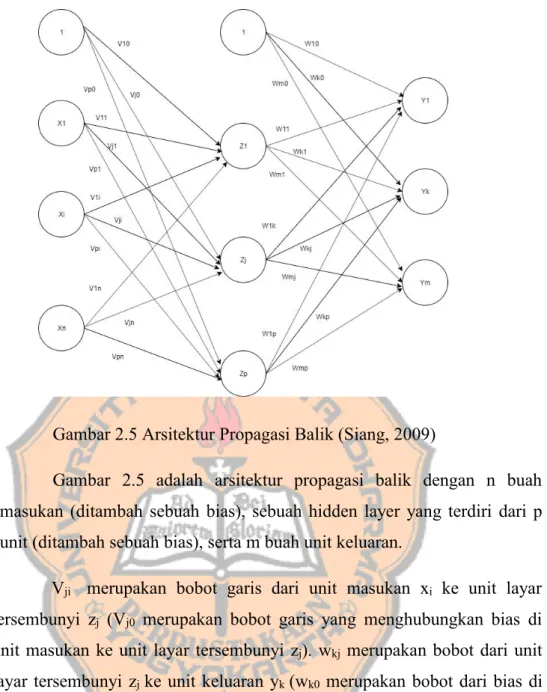
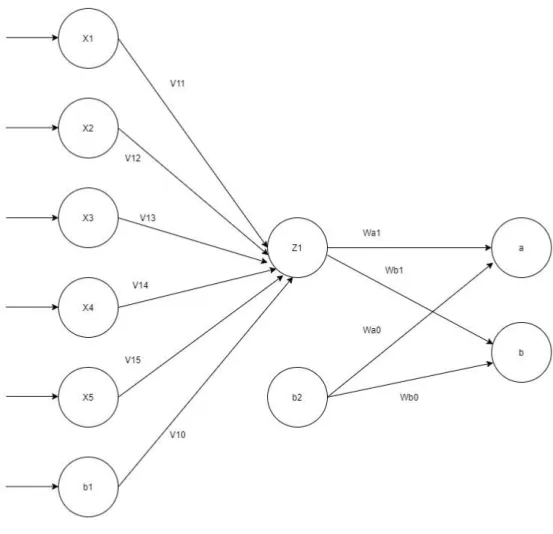
Gambar 2.5 Arsitektur Propagasi Balik (Siang, 2009)
Gambar 2.5 adalah arsitektur propagasi balik dengan n buah masukan (ditambah sebuah bias), sebuah hidden layer yang terdiri dari p unit (ditambah sebuah bias), serta m buah unit keluaran.
Vji merupakan bobot garis dari unit masukan xi ke unit layar tersembunyi zj (Vj0 merupakan bobot garis yang menghubungkan bias di unit masukan ke unit layar tersembunyi zj). wkj merupakan bobot dari unit layar tersembunyi zjke unit keluaran yk(wk0 merupakan bobot dari bias di layar tersembunyi ke unit keluaran zk).
2.2.1. Fungsi Aktivasi Dalam Propagasi Balik
Menurut Siang (2009), dalam propagasi balik, fungsi aktivasi yang dipakai harus memenuhi beberapa syarat yaitu : kontinyu, terdiferensial dengan mudah, dan merupakan fungsi yang tidak turun. Salah satu fungsi yang memenuhi ketiga syarat ini adalah fungsi sigmoid biner yang memiliki range (0,1).
f(x) = x e 1 1 ………..(8) dengan turunan f’(x) = f(x)(1-f(x))………..…(9)
Fungsi lain yang sering digunakan adalah fungsi sigmoid bipolar yang bentuk fungsinya mirip dengan fungsi sigmoid biner tapi dengan range (-1,1). f(x) = 1 1 2 ex ………..……..……(10) dengan turunan f’(x) = 2 f(x)) f(x))(1 (1 ……..……...(11)
Fungsi sigmoid memiliki nilai maksimum =1 sehingga untuk pola yang targetnya >1, pola masukan dan keluaran harus terlebih dahulu ditransformasikan sehingga semua polanya memiliki range yang sama seperti fungsi sigmoid yang dipakai. Alternatif lain adalah menggunakan fungsi aktivasi sigmoid hanya pada layar yang bukan layar keluaran. Pada layar keluaran, fungsi aktivasi yang dapat digunakan adalah fungsi identitas f(x)=x ………..(12) (Siang, 2009)
2.2.2. Standar Pelatihan Propagasi Balik
Pelatihan propagasi balik memiliki 3 fase (Siang, 2009) yakni : a. Fase 1 : Propagasi maju
Selama propagasi maju, sinyal masukan (=xi) dipropagasikan ke layar tersembunyi menggunakan fungsi aktivasi yang ditentukan. Keluaran dari setiap unit layar tersembunyi (=zj) tersebut selanjutnya dipropagasikan maju lagi ke layar tersembunyi di atasnya menggunakan fungsi aktivasi yang ditentukan demikian seterusnya hingga menghasilkan keluaran jaringan (=yk).
Berikutnya, keluaran jaringan dibandingkan dengan target yang harus dicapai (=tk). selisih antara tk- ykadalah kesalahan yang terjadi. Jika kesalahan ini lebih kecil dari batas toleransi yang ditentukan, maka iterasi dihentikan. Akan tetapi jika kesalahan masih lebih besar dari toleransi, maka bobot setiap garis dalam jaringan akan dimodifikasi untuk mengurangi kesalahan yang terjadi.
b. Fase II : Propagasi mundur
Berdasarkan kesalahan tk- yk,dihitung faktor δk(k=1,2,…,m) yang dipakai untuk mendistribusikan kesalahan di unit yk ke semua unit tersembunyi yang terhubung langsung dengan yk. δk juga dipakai untuk mengubah bobot garis yang berhubungan langsung dengan unit keluaran.
Dengan cara yang sama, dihitung faktor δj di setiap unit di layar tersembunyi sebagai dasar perubahan bobot semua garis yang berasal dari unit tersembunyi di layar di bawahnya. Demikian seterusnya hingga faktor δ di unit tersembunyi yang berhubungan langsung dengan unit masukan dihitung.
c. Fase III : Perubahan bobot
Setelah semua faktor δ dihitung, bobot semua garis dimodifikasi bersamaan. Perubahan bobot suatu garis didasarkan atas faktor δ neuron di layar atasnya. Sebagai contoh, perubahan bobot garis yang menuju ke layar keluaran didasarkan atas δkyang ada di unit keluaran.
Ketiga fase ini diulang - ulang terus hingga kondisi penghentian dipenuhi. Umumnya kondisi penghentian yang sering dipakai adalah jumlah iterasi atau kesalahan. Iterasi akan dihentikan jika jumlah iterasi yang dilakukan sudah melebihi jumlah maksimum iterasi yang ditetapkan atau jika kesalahan yang terjadi sudah lebih kecil dari batas toleransi yang diijinkan.
Algoritma pelatihan propagasi balik dengan fungsi aktivasi sigmoid bipolar adalah sebagai berikut :
Langkah 0 : inisialisasi semua bobot dengan bilangan acak kecil
Langkah 1 : jika kondisi penghentian belum terpenuhi, lakukan langkah 2 - 8
Langkah 2 : untuk setiap pasang data pelatihan, lakukan langkah 3 - 8. Fase I : Propagasi maju
Langkah 3 : tiap unit masukan menerima sunyal dan meneruskannya ke unit tersembunyi di atasnya.
Langkah 4 : hitung semua keluaran di unit tersembunyi zj( j=1,2,…p) z_netj= vj0+
n i 1xivji……….(13) zj= f(z_netj) = j z_net 1 1 e ……….(14)Langkah 5 : hitung semua keluaran jaringan di unit yk(k=1,2,…,m) y_netk= wko+
p j j kj w z 1 ……….………(15) yk= f(y_netk) = k y_net 1 1 e ………..….….(16)Fase II : Propagasi mundur
Langkah 6 : hitung faktor δ unit keluaran berdasarkan kesalahan setiap unit keluaran yk(k=1,2,…m)
δk= (tk- yk) f’(y_netk) = (tk-yk) yk(1-yk)……….….(17)
δk merupakan unit kesalahan yang akan dipakai dalam perubahan bobot layar di bawahnya (langkah 7).
Hitung semua perubahan bobot wkj (yang akan dipakai nanti untuk merubah bobot wkj) dengan laju percepatan α
Δ wkj= α δkzj ; k=1,2,…,m ; j= 0,1,…, p ………..…….……(18)
Langkah 7 : hitung faktor δ unit tersembunyi berdasarkan kesalahan di setiap unit tersembunyi zj(j=1,2,…,p)
δ_netj=
m k 1 kwkj ………..………...(19) Faktor δ unit tersembunyi :Hitung suku perubahan bobot vji (yang akan dipakai nanti untuk merubah bobot vji)
Δ vji= α δjxi; j=1,2,…,p ; i = 0,…,n………..…….….…..(21)
Fase III : Perubahan bobot
Langkah 8 : hitumg semua perubahan bobot Perubahan bobot garis yang menuju unit keluaran :
Wkj(baru) = wkj(lama) + Δwkj (k=1,2,…,m ; j=0,1,…,p).…..(22) Perubahan bobot garis yang menuju ke unit tersembunyi :
Vji(baru) = vji(lama) + Δvji (j=1,2,..,p ; I=0,1,…, n)…...…..(23)
Setelah pelatihan selesai dilakukan, jaringan dapat dipakai untuk pengenalan pola. Dalam hal ini, hanya propagasi maju (langkah 4 dan 5) saja yang dipakai untuk menentukan keluaran jaringan.
2.2.3. K-Fold Cross Validation
K-fold cross validation merupakan salah satu metode yang bisa digunakan untuk menilai atau memvalidasi keakuratan sebuah sistem. Dalam validasi ini, data akan dipartisi secara acak kedalam k partisi (D1,D2…Dk, masing - masing D memiliki jumlah data yang sama). Pembagian data dari k-fold cross validation dapat dilihat pada gambar 2.6.
Cara pembagian data dalam k-fold cross validation yakni dengan menentukan terlebih dahulu nilai K yang akan digunakan. Kemudian membagi seluruh data sebanyak K yang sudah ditentukan. Setelah itu kombinasi dengan aturan model training 2/3 dari nilai K dan 1/3 menjadi model testing (Febianto, 2019).
Gambar 2.6 Ilustrasi K-Fold Cross Validation
2.2.4. Evaluasi
Pengujian tingkat keberhasilan suatu sistem dapat dilakukan melalui evaluasi. Hal ini sangat penting untuk mengetahui seberapa baik suatu sistem dalam mengklasifikasikan suatu data (Febianto, 2019). Confusion matrix merupakan salah satu metode yang digunakan untuk mengukur kinerja suatu metode klasifikasi. Terdapat 4 kategori dalam confusion matrix pada Tabel 2.1.
Tabel 2.1 Confusion Matrix
Positif Negatif
Positif TP (True Positif) FN (False Negatif) Negatif FP (False Positif) TN (True Negatif)
Nilai akurasi dapat dihitung dengan cara :
Akurasi = x 100% TN FN FP TP TN TP
Keterangan :
TP = jumlah positif yang diklassifikasikan sebagai positif FP = jumlah positif yang diklassifikasikan sebagai negatif FN= jumlah negatif yang diklassifikasikan sebagai positif TN= jumlah negatif yang diklassifikasikan sebagai negatif
20 BAB III
METODOLOGI PENELITIAN
Pada Bab ini akan menjelaskan analisa sistem yang meliputi gambaran umum sistem yang dibuat, data dan metode preprocessing data, algoritma propagasi balik yang digunakan beserta perhitungan manual dan perancangan antarmuka sistem.
3.1. Gambaran Umum Sistem
Penelitian ini bertujuan untuk memprediksi IPK dan Lama Masa Studi Mahasiswa di Fakultas Sains dan Teknologi berdasarkan nilai TPA Ujian Masuk tertulis calon mahasiswa baru beserta asal daerah, jurusan yang ditempuh saat SMA atau SMK, pendidikan ayah, pendidikan ibu, serta jumlah saudara. Diharapkan hasil prediksi yang dihasilkan dapat memberikan gambaran IPK dan masa studi seorang calon mahasiswa dan digunakan sebagai rekomendasi penerimaan calon mahasiswa baru di Fakultas Sains dan Teknologi Universitas Sanata Dharma. Gambar 3.1 merupakan gambaran umum dari tahapan – tahapan yang akan dilakukan pada penelitian.
3.2. Data
Data yang digunakan pada penelitian ini merupakan data nilai TPA ujian tertulis calon mahasiswa baru, asal daerah, jurusan SMA atau SMK, pendidikan ayah, pendidikan ibu, serta jumlah saudara, IPK dan masa studi mahasiswa Fakultas Sains dan Teknologi Universitas Sanata Dharma Angkatan tahun 2001 - 2015. Data diambil dari Biro Administrasi Perencanaan dan Sistem Informasi (BAPSI) Universitas Sanata Dharma bulan Maret 2020 dengan jumlah data 2426, dimana sebanyak 1745 data digunakan untuk model prediksi IPK dan 2426 data digunakan untuk model prediksi masa studi. Tabel 3.1 memberikan penjelasan masing – masing atribut digunakan dalam penelitian ini.
Tabel 3.1 Atribut Penelitian
No. Nama Keterangan
1. Penalaran Verbal Jumlah soal yang dijawab benar untuk
soal Penalaran Verbal
(1/2/3/4/5/6/7/8/9/10)
2. Kemampuan Numerik Jumlah soal yang dijawab benar untuk
soal Kemampuan Numerik
(1/2/3/4/5/6/7/8/9/10)
3. Penalaran Mekanik Jumlah soal yang dijawab benar untuk
soal Penalaran
Mekanik(1/2/3/4/5/6/7/8/9/10)
4. Hubungan Ruang Jumlah soal yang dijawab benar untuk
soal Hubungan Ruang
(1/2/3/4/5/6/7/8/9/10)
5. Bahasa Inggris Jumlah soal yang dijawab benar untuk soal Bahasa Inggris (1/2/3/4/5/6/7/8/9/10) 6. Asal Daerah Asal Daerah (Pulau) Calon Mahasiswa
Baru
(Jawa/Sumatra/Kalimantan/Sulawesi/Papu a/Bali,NTT,NTB,Maluku/Luar Negeri)
7. Jurusan saat SMA atau SMK
Jurusan yang ditempuh oleh Calon Mahasiswa Baru saat SMA atau SMK (IPA/IPS/BAHASA/SMK).
8. Pendidikan Ayah Pendidikan terakhir ayah mahasiswa
(Tidak Lulus
SD/SD/SMP/SMA/DII/DIII/DIV/S1/S2/S 3)
9. Pendidikan Ibu Pendidikan terakhir ibu mahasiswa (Tidak Lulus
SD/SD/SMP/SMA/DII/DIII/DIV/S1/S2/S 3)
10. Jumlah Saudara Saudara seayah atau seibu yang dimiliki mahasiswa (1/2/3/4/5/6/7/……);
11. IP Semester 1 Indeks Prestasi Mahasiswa pada semester 1 (Digunakan Sebagai Pembanding Arsitektur Optimal)
12. IP Semester 2 Indeks Prestasi Mahasiswa pada semester 2 (Digunakan Sebagai Pembanding Arsitektur Optimal)
13. IPK IPK yang dihasilkan oleh mahasiswa (3.00<=IPK<=4.00/2,75<=IPK<3/
2<=IPK<2,75)
14. Masa Studi Apakah Mahasiswa Lulus dengan Tepat Waktu (6-8 Semester)/ Lulus dengan tidak tepat waktu (8<masa studi<=14)/ Drop Out
Tabel 3.2 adalah contoh data yang digunakan dalam penelitian ini sebelum dilakukan proses preprocessing yakni sebagai berikut :
Tabel 3.2 Contoh Data Penelitian N o. Penala ra n V er ba l K em am pu a n N um er ik Pe na la ra n M ek an ik H ub un ga n R ua ng Ba ha sa In gg ri s A sa l D ae ra h Ju ru sa n SM A /S M K Pe nd id ik an A ya h Pe nd id ik an ib u Ju m la h sa ud ar a IP K M A SA ST U D I 1. 7 8 10 10 9 Jakarta Pusat IPS S1 S1 2 2,6 11 2. 10 7 8 10 6 Kulon Progo
IPS D III D III 1 3,28 8
3. 6 8 8 5 4 Lampung Tengah IPA D II D II 3 2,3 12 4. 8 8 4 8 8 Yogyakarta IPA D II D II 2 3,43 11 5. 6 8 8 6 5 Klaten IPA S2 D II 2 3,39 8 3.2.1. Preprocessing Data
Pada tahapan ini akan dilakukan proses KDD (Knowledge Discovery in Database) dimana terdapat beberapa tahapan yaitu :
A. Data Cleaning
Tahap data cleaning digunakan untuk membersihkan noise serta data yang inkonsisten. Pada umumnya data yang dibersihkan merupakan data yang memiliki missing value. Pada penelitian ini akan dilakukan data cleaning dikarenakan terdapat beberapa data yang tidak memiliki nilai pada atribut tertentu. Tabel 3.3 merupakan contoh data yang akan dikenai cleaning.
Tabel 3.3 Contoh Data untuk Cleaning
N o. Penala ra n V er ba l K em am pu a n N um er ik Pe na la ra n M ek an ik H ub un ga n R ua ng Ba ha sa In gg ri s A sa l D ae ra h Ju ru sa n SM A /S M K Pe nd id ik an A ya h Pe nd id ik an ib u Ju m la h sa ud ar a IP K M A SA ST U D I 1. 7 8 10 10 9 Jakarta Pusat IPS S1 S1 2 2,6 11
Pada data Tabel 3.3, data nomor 2 memiliki missing value pada atribut pendidikan ayah sehingga data nomor 2 perlu dilakukan pembersihan. Cleaning untuk atribut pendidikan ayah akan dilakukan dengan cara mengidentifikasi rata rata dari atribut tersebut. Setelah mengetahui rata -rata atribut, langkah selanjutnya adalah mengisi missing value dengan data yang bernilai rata - rata atribut. Misalkan rata - rata atribut pendidikan ayah adalah 5,3 maka dibulatkan menjadi 5. Kemudian dicari data pada atribut pendidikan ayah yang memiliki nilai 5, misalkan dalam hal ini 5 mewakili D II maka missing value akan diganti dengan D II.
B. Atribute Selection
Atribute Selection dilakukan untuk memilih atribut yang relevan dan menghapus data yang tidak digunakan dalam penelitian. Pada penelitian ini akan dilakukan atribute selection untuk menentukan atribut mana yang relevan digunakan untuk masing - masing model prediksi (model prediksi IPK dan model prediksi masa studi). Atribute selection dilakukan dengan cara menginputkan satu per satu atribut pada model prediksi kemudian akan dilihat atribut mana saja yang menghasilkan akurasi terbaik untuk model prediksi.
C. Data Transformation
Data Transformation adalah proses pengubahan skala data asli ke dalam bentuk yang dapat diterima oleh system yang dibuat. Berikut ini transformasi yang dilakukan pada penelitian ini :
1. Transformasi pada Atribut Asal Daerah :
Nilai pada atribut asal daerah terlebih dahulu akan diubah berdasarkan pulau dari daerah tersebut. Misalkan “Klaten” akan diubah menjadi “Jawa”, “Pontianak” akan diubah menjadi “Kalimantan” dan seterusnya. Setelah diubah menurut pulau, langkah selanjutnya adalah melakukan transformasi nama provinsi ke dalam bentuk nominal. Tabel 3.4 merupakan bentuk transformasi atribut asal daerah.
Tabel 3.4 Transformasi Atribut Asal Daerah Asal Daerah Transformasi
Jawa 1 Sumatra 2 Kalimantan 3 Sulawesi 4 Papua 5 Bali,NTT,NTB,Maluku 6 Luar Negeri 7
2. Transformasi pada Atribut Jurusan saat SMA atau SMK
Nilai pada atribut jurusan saat SMA atau SMK akan ditransformasikan kedalam 4 nilai numerik. Tabel 3.5 merupakan hasil transformasi atribut jurusan saat SMA atau SMK.
Tabel 3.5 Transformasi Atribut Jurusan saat SMA atau SMK No. Jurusan Saat SMA atau SMK Transformasi
1. IPA 1
2. IPS 2
3. BAHASA 3
4. SMK 4
3. Transformasi pada Atribut Pendidikan Ayah dan Pendidikan Ibu Nilai pada atribut pendidikan ayah dan pendidikan ibu akan ditransformasikan ke dalam 9 nilai numerik yang direpresentasikan dalam Tabel 3.6.
Tabel 3.6 Transformasi Atribut Pendidikan Ayah dan Pendidikan Ibu Pendidikan Transformasi Tidak Lulus SD 1 SD 2 SMP/SLTP 3 SMA/SLTA/SMK 4 D II 5 D III 6 D IV/ S1 7 S2 8 S3 9
4. Transformasi pada Kelas IPK dan Masa Studi
Output yang dihasilkan pada penelitian ini diharapkan dapat memprediksi IPK dan Lama Masa Studi Mahasiswa. Masing - masing kelas akan diprediksi menggunakan model prediksi yang berbeda dengan target kelas yang berbeda pula. Transformasi kelas model prediksi IPK direpresentasikan pada Tabel 3.7 sedangkan untuk kelas model prediksi masa studi digambarkan pada Tabel 3.8.
Tabel 3.7 Transformasi Kelas IPK
Kelas Transformasi Target
3,00<=IPK<=4,00 (Memuaskan) 2 (1,0) 2,75<IPK<3,00 (Cukup Memuaskan) 1 (0,1) 2<=IPK<2,75 (Kurang Memuaskan 0 (0,0)
Tabel 3.8 Transformasi Kelas Masa Studi
Kelas Transformasi Target
6<=Masa Studi <=8 (Tepat) 3 (1,1) 8<Masa Studi<=14 (Terlambat) 1 (0,1) Drop Out 0 (0,0) 5. Data Normalization
Data yang telah ditransformasi kedalam bentuk numerik kemudian akan dinormalisasi menggunakan min-max normalization untuk mendapatkan bentuk data yang optimal digunakan dalam prediks dengan mengubahnya ke dalam range 0 sampai 1. Berikut adalah rumus min-max normalization : b data data b a data x X min) max ( ) min)( ( ' ...(24) Dengan X’ merupakan data hasil normalisasi dan x adalah data asli. a adalah data maksimum yang diharapkan dan b adalah data minimum yang diharapkan. Datamax adalah nilai data terbesar dan datamin adalah nilai data terkecil dari data yang digunakan.
3.2.2. Pengelompokan Dan Komposisi Data
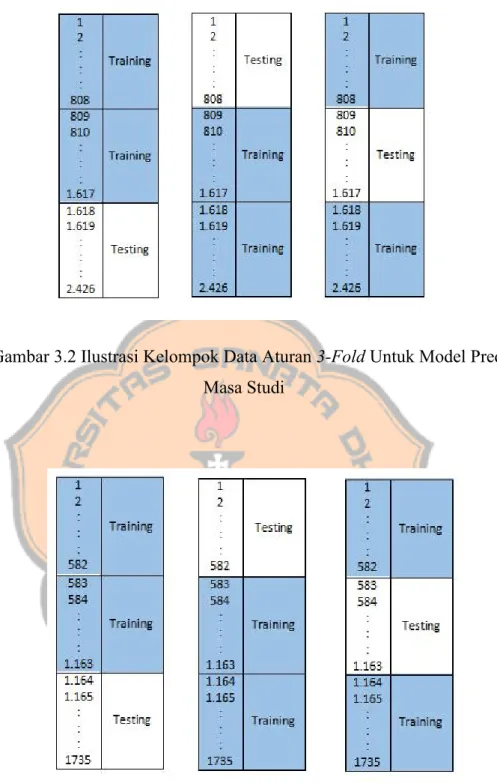
Data akan dikelompokkan menjadi 2 yakni data training dan data testing yang dibagi menggunakan aturan 3-Fold dan 5-Fold. Jumlah data masing – masing kelompok ditentukan yakni dari jumlah data merupakan data training dan dari jumlah data merupakan data testing. Berikut adalah gambar ilustrasi pembagian data menggunakan aturan 3-Fold untuk masing - masing model prediksi :
Gambar 3.2 Ilustrasi Kelompok Data Aturan 3-Fold Untuk Model Prediksi Masa Studi
Gambar 3.3 Ilustrasi Kelompok Data Aturan 3-Fold Untuk Model Prediksi IPK
Setelah dilakukan percobaan menggunakan 3 fold, data kemudian akan dikenakan percobaan kembali menggunakan 5fold. Data pertama -tama akan dibagi menjadi 5 bagian. Setelah dibagi, langkah selanjutnya adalah melakukan penentuan data training dan data testing. Berikut adalah
ilustrasi pembagian data menggunakan aturan 5-fold untuk masing - masing model prediksi:
Gambar 3.4 Ilustrasi Kelompok Data Aturan 5-Fold Untuk Model Prediksi Masa Studi
Gambar 3.5 Ilustrasi Kelompok Data Aturan 5-Fold Untuk Model Prediksi IPK
3.3. Model Propagasi Balik
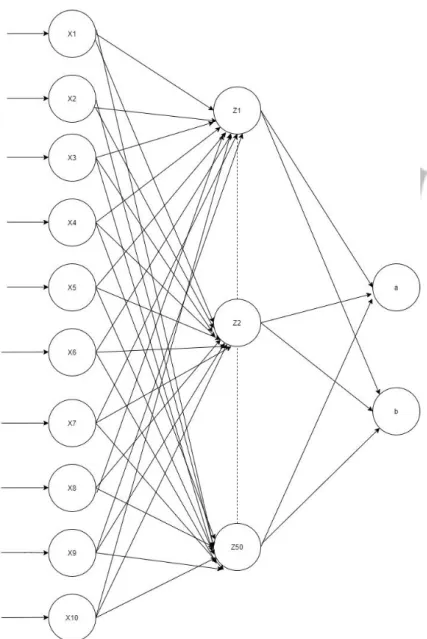
Pembentukkan model jaringan propagasi balik dimaksudkan untuk menentukan arsitektur jaringan seperti apa yang dapat digunakan untuk proses prediksi secara optimal. Pembentukan model arsitektur yang berbeda - beda akan memberikan hasil akurasi yang berbeda - beda pula. Gambar 3.6 adalah rancangan arsitektur jaringan syaraf tiruan yang akan dibentuk pada penelitian ini.
Penjelasan mengenai gambar arsitektur tersebut :
1. X1,X2,X3,X4,X5,X6,X7,X8,X9, dan X10 merupakan lapisan input dalam jaringan syaraf tiruan berupa nilai atribut yang digunakan dalam penelitian. Nilai – nilai atribut ini direpresentasikan yaitu : X1= Penalaran Verbal, X2= Kemampuan Numerik, X3= Penalaran Mekanik, X4=Hubungan Ruang, X5= Bahasa Inggris, X6= Asal Daerah, X7=Jurusan saat SMA atau SMK, X8=Pendidikan Ayah, X9= Pendidikan Ibu, dan X10=Jumlah Saudara. Atribut - atribut ini tidak digunakan seluruhnya melainkan akan diseleksi menggunakan arsitektur di atas untuk memperoleh atribut yang menghasilkan akurasi tertinggi.
2. Z1,Z2,…., Z50 merupakan Hidden Layer yang akan digunakan untuk memproses nilai masukan. Dalam Penelitian ini akan digunakan 1 hidden layerdan 2 hidden layerdimana jumlah neuron yang digunakan divariasi jumlahnya yaitu 5,10,15,20,25,30,35,40,45, dan 50. Variasi jumlah neuron pada hidden layer dimaksudkan untuk mencari arsitektur seperti apa yang optimal untuk sebuah prediksi.
3. a dan b merepresentasikan output untuk hasil prediksi IPK dan Masa Studi dimana lapisan output memiliki 2 neuron.
Selain pembentukan model jaringan, penentuan karakteristik jaringan juga dilakukan dalam penelitian ini. Secara singkat dalam penelitian ini akan digunakan jaringan syaraf tiruan dengan karakteristik – karakteristik yang tertera pada Tabel 3.9.
Tabel 3.9 Karakteristik Jaringan Syaraf Tiruan
Karakter Spesifikasi
Arsitektur Jaringan Multi Layer Algoritma Pembelajaran Propagasi balik Jumlah Node Input
Jumlah Hidden Layer Jumlah Node Hidden Layer
10 Node (jumlahnya akan diseleksi selama Pelatihan) 1 dan 2
5,10,15,20,25,30,35,40,45,50 Node
Jumlah Node Lapisan Output 2 Node
Fungsi Aktivasi Logsig (Sigmoid Biner) dan Tansig (Sigmoid Bipolar)
Toleransi Error 0.001 Laju Pembelajaran 0.1
Maksimum Epoch 1000
3.3.1. Pembelajaran Model
Setelah model jaringan yang digunakan dalam penelitian ditentukan, langkah selanjutnya adalah melakukan proses pembelajaran model. Hal ini bertujuan untuk menghasilkan suatu model jaringan yang mampu dengan baik memprediksi suatu data. Dalam propagasi balik terdapat 3 fase penting untuk pembelajaran model. Pertama adalah fase propagasi maju (feedforward) dimana pada proses ini input bersama dengan bobotnya akan dipropagasikan menuju layer output melalui hidden layer dengan menggunakan suatu fungsi aktivasi. Fase kedua adalah melakukan proses perhitungan error. Perhitungan error dilakukan dengan menghitung perbedaan keluaran yang dihasilkan dengan target yang diharapkan. Setelah proses perhitungan error selesai, langkah selanjutnya adalah melakukan propagasi mundur dimana pada proses ini akan dilakukan perubahan bobot dan bias guna memperkecil nilai error. Setelah bobot dan bias baru didapat, jaringan akan
melakukan proses pembelajaran kembali ke propagasi maju menggunakan bobot dan bias yang baru. Fase ini akan terus berulang sampai error yang dihasilkan lebih kecil dari toleransi error yang telah ditetapkan atau sudah mencapai nilai epoch tertentu. Gambar 3.7 adalah contoh perhitungan propagasi balik menggunakan 1 data untuk penelitian dengan 1 hidden layer.
Gambar 3.7 Contoh Arsitektur 1. Inisiasi Bobot
Input Data : [7 10 10 9 9 ]; Target [1 1]
Tabel 3.10 Inisiasi Bobot dari Input ke Hidden Layer
V0 V1 V2 V3 V4 V5
Tabel 3.11 Inisiasi Bobot dari Hidden Layer ke Output Layer
W0 W1
a -0.04 -0.104
b 0.13 0.02
2. Keluaran di hidden layer
a) Z1_in = V10 + V11*X1 + V12 *X2 + V13 *X3 + V14 *X4 + V15*X15
= -1.72
Z1= logsig (-1.72) = 0.15
3. Keluaran di output layer a) a_in = Wa0 + Wa1*Z1
= -0.0556 a = logsig (-0.0556) =0,486 b) b_in = Wb0 + Wb1*Z1 = 0.133 b = logsig (0,133) =0.533
4. Penghitungan error MSE (E) = (( ) ( ) ) 2 1 t a 2 t b 2 b a = (
1 0,486
(1 0,533) ) 2 1 2 2 = 0,2415. Perubahan bobot dan bias Rumus Perubahan Bobot
w E W Wnew old
Rumus Perubahan Bias
b E b bnew old
a) Perubahan bobot dan bias Wa1 dan Wa0 perubahan bobot di Wa1, maka :
1 Wa E = 1 _ _ Wa in a x in a a x a E a E = (taa) = ( 1 0.486) = 0.514 ) 1 ( _in a a a a = 0.486(10.486) =0.2498
1 1 _ Z Wa in a = 0.15
Lalu gabungkan semua
1 Wa E = 0.514 x 0.2498 x 0.15 = 0.0190 Maka, 1 1 1 Wa E Wa Wa new old = (0.104)(0.1)0.019 = -0.1059
Dengan cara yang hampir sama maka akan diperoleh bobot dan bias baru sebagai berikut :
Tabel 3.12 Hasil Perubahan Bobot Dan Bias Dari Input Layer ke Hidden Layer
W0 W1
a -0,016 -0,1059
b 0.11837 0,0183
a) Perubahan bobot dari hidden ke input perubahan bobot di V11 : 11 V E = 11 _ 1 _ 1 1 1 V in Z x in Z Z x Z E 1 1 1 Z E Z E Z E a b
1 _ _ 1 Z in a in a a a E Z Ea a 1 1 _ Wa Z in a Sehingga, 1 _ _ 1 Z in a x in a a x a E Z Ea = 0.514 x 0.2498 x -0,104 = -0,0133
Dengan cara yang hampir sama, maka diperoleh
1 _ _ 1 Z in b x in b b x b E Z Eb =0.467 x 0.249 x 0.02 =0.00232 Maka, 00232 . 0 ) 0133 , 0 ( 1 Z E = -0,01098 ) 1 1 ( 1 _ 1 1 Z Z in Z Z =0.1275 1 11 _ 1 X V in Z =7 Maka 11 V E = 7 1275 , 0 01098 , 0 x x = -0,00979
Sehingg bobot V11 yang baru adalah
11 11 11 V E V V new old
= 0.03 - (0.1* (-0,00979)) = 0.030979
Dengan cara yang sama, maka akan diperoleh nilai bobot baru seperti Tabel 3.13.
Tabel 3.13 Hasil Perubahan Bobot Dan Bias Dari Input Layer ke Hidden Layer
V0 V1 V2 V3 V4 V5
Z1 0.04139 0,030979 -0.1986 0,21139 -0.0675 -0.13745
Setelah mendapatkan bobot dan bias yang baru, jaringan akan melakukan proses feed forward kembali menggunakan bobot dan bias yang baru dan dihitung kembali besarnya error. Jika error masih lebih besar dari toleransi error yang ditetapkan, maka jaringan akan melakukan backward lagi. Proses ini akan terus berulang sampai syarat pemberhentian terpenuhi.
3.4. Kebutuhan Sistem
1. Perangkat Keras :
Processor : Intel Core i3 7thGen Memory : 4 GB Hard Drive : 500 GB 2. Perangkat Lunak : Microsoft Windows 10 Microsoft Excel MatlabR2014b
3.5. Perancangan Antarmuka Sistem
Gambar 3.8 Rancangan Tampilan Antarmuka
Gambar 3.8 merupakan rancangan tampilan antarmuka sistem yang akan dibuat. Terdapat 4 panel yang ada pada tampilan, yakni panel raw data, panel preprocessing data, panel train dan panel single data test. Berikut adalah penjelasan fungsi masing - masing panel yang ada :
3.5.1. Panel Data Mentah
Panel Data Mentah digunakan untuk sarana menampilkan source code data excel yang digunakan sebagai data training. Data ini merupakan data sebenarnya yang belum dikenai preprocessing. Cara untuk menampilkan data pada panel ini adalah dengan menekan button upload. 3.5.2. Panel Data Olah
Panel ini akan menampilkan data yang sudah dilakukan preprocessing. Proses preprocessing akan dilakukan setelah menekan button preprocessing.
3.5.3. Panel Training
Panel training dimaksudkan untuk melakukan proses training data. Terdapat dropbox yang berfungsi untuk memilih jumlah hidden layer neuron. Pilihan jumlah hidden layer neuron terdiri dari 5,10,15,20,25,30,35,40,45, dan 50. Kemudian terdapat dropbox lainnya untuk memilih fungsi training, fungsi aktivasi dan jumlah fold. Terdapat button train yang digunakan untuk memulai proses training data prediksi. Setelah proses training berakhir, akan muncul hasil akurasi dari model prediksi yang dibuat.
3.5.4. Panel Uji Data Tunggal
Panel ini bertujuan untuk menguji data tunggal sehingga diketahui kelas dari data tunggal tersebut. Terdapat textbox yang masing - masing merepresentasikan atribut yang diperlukan untuk proses prediksi. Button prediksi digunakan untuk memprediksi inputan data tunggal. Hasil dari testing ini akan menampilkan hasil kelas prediksi untuk inputan data tersebut.
41 BAB IV
HASIL DAN ANALISIS
Bab ini akan membahas tentang hasil perancangan sistem yang dibuat dan implementasi algoritma propagasi balik yang dilakukan sesuai dengan gambaran umum penelitian
4.1. Data Preprocessing 4.1.1. Data Cleaning
Pada tahapan cleaning data, penulis melakukan penggantian missing value dilakukan dengan menghitung nilai rata rata atribut -atribut yang memiliki missing value. Pada data kategorikal, data diubah terlebih dahulu ke bentuk numerik agar dapat dihitung rata - ratanya. Tabel 4.1 adalah hasil perhitungan rata - rata masing - masing atribut yang memiliki missing value.
Tabel 4.1 Perhitungan rata - rata atribut yang memiliki missing value
Atribut Rata - rata
Asal Daerah Jawa
Jurusan SMA/SMK IPS
Pendidikan Ayah D II
Pendidikan Ibu SMA
4.1.2. Atribute Selection
Seleksi atribut pada penelitian ini dilakukan melalui 2 tahapan. Tahap pertama adalah merangking atribut data berdasarkan information gain. Tabel 4.2 adalah rangking atribut yang dilakukan melalui aplikasi Weka berdasarkan information gain untuk model prediksi Masa Studi sedangkan Tabel 4.3 adalah perangkingan atribut untuk model prediksi IPK.
Tabel 4.2 Perankingan Atribut Berdasarkan Information Gain Untuk Model Prediksi Masa Studi
No Atribut 1 Asal Daerah 2 Kemampuan Numerik 3 Jurusan SMA/SMK 4 Jumlah Saudara 5 Penalaran Verbal 6 Hubungan Ruang 7 Bahasa Inggris 8 Pendidikan Ibu 9 Pendidikan Ayah 10 Penalaran Mekanik
Tabel 4.3 Perankingan Atribut Berdasarkan Information Gain Untuk Model Prediksi IPK No Atribut 1 Bahasa Inggris 2 Kemampuan numerik 3 Penalaran Verbal 4 Jurusan SMA/SMK 5 Hubungan Ruang 6 Pendidikan Ibu 7 Pendidikan Ayah 8 Penalaran Mekanik 9 Asal Daerah 10 Jumlah Saudara
Langkah selanjutnya adalah mereduksi atribut menggunakan algoritma propagasi balik dalam sistem yang dibuat. Reduksi dimulai dari atribut yang memiliki ranking terendah. Kombinasi atribut yang menghasilkan akurasi tertinggi untuk masing - masing model prediksi kemudian akan digunakan sebagai atribut penelitian. Hasil percobaan kombinasi atribut yang digunakan pada model prediksi masa studi direpresentasikan pada Tabel 4.4.
Tabel 4.4 Hasil Percobaan Kombinasi Atribut Pada Model Prediksi Masa Studi
Atribut Akurasi
Asal Daerah, Penalaran Verbal, Jurusan SMA/SMK, Bahasa Inggris,
Kemampuan Numerik, Hubungan Ruang, Jumlah Saudara, Pendidikan
Ayah, Pendidikan Ibu, Penalaran Mekanik
45,4249% (trainlm)
Asal Daerah, Penalaran Verbal, Jurusan SMA/SMK, Bahasa Inggris, Kemampuan Numerik, Hubungan Ruang, Jumlah Saudara, Pendidikan
Ayah, Pendidikan Ibu
45,2604% (trainlm)
Asal Daerah, Penalaran Verbal, Jurusan SMA/SMK, Bahasa Inggris, Kemampuan Numerik, Hubungan Ruang, Jumlah Saudara, Pendidikan
Ayah
45,4245% (trainlm)
Penalaran Verbal, Asal Daerah, Jurusan SMA/SMK, Bahasa Inggris, Kemampuan Numerik, Hubungan
Ruang, Jumlah Saudara
46,3319 % (trainlm)
Kemampuan Numerik, Jumlah Saudara, Hubungan Ruang, Penalaran
Verbal, Asal Daerah, Jurusan SMA/SMK
45,8372 % (trainlm)
Asal Daerah, Jurusan SMA/SMK, Jumlah Saudara, Kemampuan Numerik,
Penalaran Verbal
45,5074% (trainlm) Jurusan SMA/SMK, Asal Daerah,
Jumlah Saudara, Kemampuan Numerik
49,0515% (trainlm) Jurusan SMA/SMK, Jumlah Saudara,
Asal Daerah 48,5156%(trainlm) Jumlah Saudara, Asal Daerah 48,969%
(trainlm)
Jumlah Saudara 48,1859%
(trainlm)
Dari hasil percobaan di Tabel 4.4, dapat diketahui bahwa kombinasi atribut yang menghasilkan akurasi tertinggi untuk model prediksi masa studi adalah atribut Jurusan SMA/SMK, Asal Daerah, Jumlah Saudara dan Kemampuan Numerik. Kemudian dilakukan
percobaan yang sama untuk model prediksi IPK. Hasil percobaan kombinasi atribut yang digunakan pada model prediksi IPK direpresentasikan pada Tabel 4.5. Berdasarkan hasil percobaan di Tabel 4.5 dapat diketahui bahwa kombinasi atribut yang menghasilkan akurasi tertinggi untuk model prediksi IPK adalah atribut Hubungan Ruang, Penalaran Verbal, dan Bahasa Inggris.
Tabel 4.5 Hasil Percobaan Kombinasi Atribut Pada Model Prediksi Masa Studi
Atribut Akurasi
Hubungan Ruang, Bahasa Inggris, Kemampuan Numerik, Pendidikan Ibu,
Jumlah Saudara, Penalaran Verbal, Penalaran Mekanik, Jurusan SMA/SMK,
Pendidikan Ayah, Asal Daerah
49,8553 % (trainlm)
Hubungan Ruang, Bahasa Inggris, Kemampuan Numerik, Pendidikan Ibu,
Penalaran Verbal, Penalaran Mekanik, Jurusan SMA/SMK, Pendidikan Ayah,
Asal Daerah
49, 7965 % (trainlm)
Hubungan Ruang, Bahasa Inggris, Kemampuan Numerik, Pendidikan Ibu,
Penalaran Verbal, Penalaran Mekanik, Jurusan SMA/SMK, Pendidikan Ayah,
50,2547 % (trainlm) Hubungan Ruang, Bahasa Inggris,
Kemampuan Numerik, Pendidikan Ibu, Penalaran Verbal, Jurusan SMA/SMK,
Pendidikan Ayah,
50,1394 % (trainlm) Bahasa Inggris, Hubungan Ruang,
Kemampuan Numerik, Penalaran Verbal, Jurusan SMA/SMK, Pendidikan Ibu
49,1668 % (trainlm) Penalaran Verbal, Bahasa Inggris,
Hubungan Ruang, Kemampuan Numerik, Jurusan SMA/SMK
50,4292 % (trainlm) Penalaran Verbal, Bahasa Inggris,
Hubungan Ruang, Jurusan SMA/SMK 50,655 %(trainlm)
Hubungan Ruang, Penalaran Verbal,
Bahasa Inggris 51,9769 %(trainlm)
Hubungan Ruang, Bahasa Inggris 51,5169 %
(trainlm)
Bahasa Inggris 50,2003%
4.1.3. Data Transformation
Transformasi data dilakukan dengan ketentuan - ketentuan yang sudah dijelaskan pada bab 3. Tabel di bawah ini adalah contoh hasil proses transformasi data untuk masing - masing model prediksi :
Tabel 4.6 Contoh Data Model Prediksi Masa Studi Sebelum Transformasi No Jurusan SMA/SMK Asal Daerah Jumlah Saudara Kemampuan Numerik Kelas 1. SMK Sumatra 1 4 Tepat
2. IPA Jawa 0 7 Terlambat
3. BAHASA Sumatra 3 6 DO
Tabel 4.7 Contoh Data Model Prediksi Masa Studi Sesudah Transformasi No Jurusan
SMA/SMK DaerahAsal SaudaraJumlah KemampuanNumerik Kelas
1. 1 0.1667 0.0714 0.4444 3
2. 0 0 0 0.6667 1
3. 0.3333 0.1667 0.2143 0.5556 0
Tabel 4.8 Contoh Data Model Prediksi IPK Sebelum Transformasi No Hubungan Ruang Penalaran Verbal Bahasa Inggris Kelas 1. 6 7 4 Kurang 2. 7 4 4 Cukup 3. 7 5 5 Memuaskan
Tabel 4.9 Contoh Data Model Prediksi IPK Sesudah Transformasi No Hubungan
Ruang PenalaranVerbal BahasaInggris Kelas
1. 0.5556 0.6667 0.3333 0
2. 0.6667 0.3333 0.3333 1
3. 0.6667 0.4444 0.4444 2
4.2. Prediksi
Setelah melalui proses preprocessing sampai tahapan normalisasi, langkah selanjutnya adalah melakukan pelatihan menggunakan jaringan syaraf tiruan propagasi balik berdasarkan kriteria arsitektur yang sudah ditentukan pada bab 3 dimana fungsi training yang digunakan adalah trainlm, trainrp, trainbfg, trainscg, traincgb, traincgf, traincgp, trainoss dan traingdx.
Selain fungsi training yang divariasi, jumlah hidden layer dan neuron pada hidden layer juga di variasi pada kelipatan 5 (5,10,15,20,25,30,35,40,45,50) dengan fungsi aktivasi logsig dan juga tansig. Hal ini bertujuan untuk menemukan arsitektur jaringan syaraf tiruan yang optimal untuk masing - masing prediksi.
4.2.1. Model Prediksi Masa Studi a. Satu Hidden Layer
Data yang digunakan pada percobaan ini sebanyak 2.426 dengan atribut sebanyak 4 atribut untuk menghasilkan luaran prediksi predikat masa studi dengan menggunakan 1 Hidden Layer yang jumlah nodenya divariasi. Fungsi aktivasi pada percobaan ini juga divariasi yakni tansig dan logsig. Berikut adalah hasil percobaan menggunakan 1 Hidden Layer dengan 3-Fold :
Gambar 4.1 Grafik Akurasi Percobaan Satu Hidden Layer Masa Studi Dengan Fungsi Aktivasi Tansig Dan 3-Fold
Dapat dilihat melalui gambar 4.1 bahwa akurasi pada percobaan 1 Hidden Layer menggunakan 3-fold menghasilkan akurasi tertingi pada fungsi aktivasi trainlm yakni sebesar 49,0515% dimana jumlah node pada hidden layer 1 sebesar 50 node. Kemudian dilakukan percobaan yang sama dengan 5-fold menghasilkan grafik sebagai berikut :
Gambar 4.2 Grafik Akurasi Percobaan Satu Hidden Layer Masa Studi Dengan Fungsi Aktivasi Tansig Dan 5-Fold
Gambar 4.2 menunjukkan bahwa akurasi tertinggi pada percobaan yang sama dengan 5-fold adalah 49,2173% dengan fungsi training trainlm dimana jumlah neuron pada hidden layer 1 sebanyak 15 neuron. Dari dua percobaan dengan fungsi aktivasi tansig diperoleh bahwa percobaan dengan 5-fold menghasilkan akurasi lebih tinggi dibandingkan dengan 3-fold.
Langkah selanjutnya adalah melakukan percobaan dengan mengubah fungsi aktivasi. Fungsi aktivasi yang digunakan adalah logsig dengan variasi jumlah neuron pada hidden layer dan variasi fungsi training yang digunakan. Berikut adalah grafik hasil percobaan fungsi aktivasi logsig dengan fold = 3 :
Gambar 4.3 Grafik Akurasi Percobaan Satu Hidden Layer Masa Studi Dengan Fungsi Aktivasi Logsig Dan 3-Fold
Gambar 4.3 menunjukkan akurasi tertinggi masing - masing fungsi training dimana akurasi tertinggi 48,3101% terdapat pada fungsi training trainlm dengan jumlah node pada hidden layer sebanyak 50. Selanjutnya
dilakukan percobaan yang sama dengan 5-fold. Hasil percobaan dengan 5-fold direpresentasikan pada Gambar 4.4.
Gambar 4.4 Grafik Akurasi Percobaan Satu Hidden Layer Masa Studi Dengan Fungsi Aktivasi Logsig Dan 5-Fold
Gambar 4.4 menunjukkan grafik akurasi tertinggi untuk masing -masing fungsi trining. Melalui grafik akurasi tersebut dapat dilihat bahwa akurasi tertinggi terdapat pada percobaan dengan fungsi training trainglm yakni sebesar 49,382% dengan jumlah neuron hidden layer 1 sebanyak 50 neuron.
Dari 4 percobaan di atas, dapat disimpulkan bahwa akurasi tertinggi terdapat pada percobaan dengan fungsi aktivasi logsig, 5-fold, fungsi training trainlm dan jumlah node pada hidden layer 1 sebanyak 50 node. Variasi jumlah neuron pada hidden layer 1, variasi fungsi aktivasi, dan fungsi training pada percobaan ini kemudian akan dipakai pada percobaan dengan dua hidden layer.