PEMERIKSAAN KEANGGOTAAN ELEMEN PADA
HIMPUNAN DENGAN BLOOM FILTER
ADI RISWANTO
DEPARTEMEN MATEMATIKA
FAKULTAS MATEMATIKA DAN ILMU PENGETAHUAN ALAM INSTITUT PERTANIAN BOGOR
BOGOR 2015
PERNYATAAN MENGENAI SKRIPSI DAN
SUMBER INFORMASI SERTA PELIMPAHAN HAK CIPTA
Dengan ini saya menyatakan bahwa skripsi berjudul Pemeriksaan Keanggotaan Elemen pada Himpunan dengan Bloom Filter adalah benar karya saya dengan arahan dari komisi pembimbing dan belum diajukan dalam bentuk apa pun kepada perguruan tinggi mana pun. Sumber informasi yang berasal atau dikutip dari karya yang diterbitkan maupun tidak diterbitkan dari penulis lain telah disebutkan dalam teks dan dicantumkan dalam Daftar Pustaka di bagian akhir skripsi ini.
Dengan ini saya melimpahkan hak cipta dari karya ilmiah saya kepada Institut Pertanian Bogor.
Bogor, Januari 2015
Adi Riswanto
ABSTRAK
ADI RISWANTO. Pemeriksaan Keanggotaan Elemen pada Himpunan dengan
Bloom Filter. Dibimbing oleh FAHREN BUKHARI dan ELIS KHATIZAH.
Pemeriksaan keanggotaan suatu elemen sering kali dilakukan pada beberapa aplikasi. Waktu yang diharapkan untuk melakukan pemeriksaan tersebut adalah waktu minimal dengan kesalahan pemeriksaan minimal. Sebagai contoh, pada web
browser Google Chrome yang membutuhkan waktu yang singkat untuk melakukan
pemeriksaan terhadap URL jahat. Algoritma yang umum digunakan untuk melakukan pemeriksaan keanggotaan tersebut adalah algoritma Sequential Search dan Binary Search. Namun kedua algoritma tersebut masih kurang efisien. Algoritma yang ditawarkan menjadi solusi adalah Bloom Filter, yaitu suatu struktur data yang mampu melakukan pemeriksaan keanggotaan dengan efisien, walaupun menghasilkan kesalahan dalam hasil pemeriksaan tersebut. Kesalahan pemeriksaan yang terjadi salah satunya adalah false positive; yakni kesalahan penentuan suatu elemen yang bukan anggota suatu himpunan dianggap sebagai anggota himpunan. Karya ilmiah ini bertujuan untuk menjelaskan cara kerja algoritma Bloom Filter pada pemeriksaan keanggotaan elemen dalam himpunan, menghitung peluang terjadinya false positive, dan meminimalkan peluang tersebut.
Kata kunci: algoritma, bloom filter, false positive, himpunan
ABSTRACT
ADI RISWANTO. Examination of Membership Elements in a Set using The Bloom Filter Method. Supervised by FAHREN BUKHARI and ELIS KHATIZAH.
Examination of membership elements is often executed on several applications. Expected time to perform such examination is a minimum time with minimal errors. For example, the Google Chrome web browser takes a short time to do an examination of malicious URLs. The common algorithms used to perform examination of the membership are called the Sequential Search and Binary Search. However, the algorithms are considered inefficient. The Bloom Filter is considered offering the solution. It is a data structure which is able to do examination of membership within short time, but producing errors. One of the errors is assosiated with a false positive. A claim that an element to be part of the set when it was not the member. This paper aims to explain the procedure of the Bloom Filter algorithm on the membership examination of elements in a set. Also, this work is intended calculate the probability of false positives, and to minimize the probability.
PEMERIKSAAN KEANGGOTAAN ELEMEN PADA
HIMPUNAN DENGAN BLOOM FILTER
ADI RISWANTO
Skripsi
sebagai salah satu syarat untuk memperoleh gelar Sarjana Sains
pada
Departemen Matematika
DEPARTEMEN MATEMATIKA
FAKULTAS MATEMATIKA DAN ILMU PENGETAHUAN ALAM INSTITUT PERTANIAN BOGOR
BOGOR 2015
Judul Skripsi : Pemeriksaan Keanggotaan Elemen pada Himpunan dengan Bloom
Filter
Nama : Adi Riswanto NIM : G54100062
Disetujui oleh
Dr Ir Fahren Bukhari, MSc Elis Khatizah, MSi
Pembimbing I Pembimbing II
Diketahui oleh
Dr Toni Bakhtiar, MSc Ketua Departemen
PRAKATA
Puji dan syukur penulis panjatkan kepada Allah SWT atas segala nikmat, karunia, dan pertolongan-Nya sehingga penulisan karya ilmiah ini berhasil diselesaikan. Shalawat dan salam semoga senantiasa tercurahkan kepada Nabi Muhammad SAW. Judul dari karya ilmiah ini adalah Pemeriksaan Keanggotaan Elemen pada Himpunan dengan Bloom Filter. Terima kasih penulis ucapkan kepada:
1 Bapak Dr Ir Fahren Bukhari, MSc dan Ibu Elis Khatizah, MSi selaku pembimbing pertama dan pembimbing kedua yang telah sabar membimbing penulis dalam menyusun karya ilmiah ini,
2 Bapak Muhammad Ilyas, MSi MSc selaku dosen penguji yang telah banyak memberi saran dalam penulisan karya ilmiah ini,
3 Bapak, ibu, kakak, adik, dan seluruh keluarga atas doa dan kasih sayangnya. 4 Delis, Lilis, Rendi, Dadan, Kamil, Eric, Fikri, Tri, Safiih, Imad, Irfan C, Eka, Nyoman, Bella, Mira, Leny, dan semua teman-teman Matematika 47 atas segala dukungan, bantuan, dan ketulusan hati yang telah diberikan,
5 Satelit Gumatika dan seluruh pengurus Gumatika,
6 Vallian, Ade, Desi M, Fitri, Antik, Rodua, Utet, Manova, dan keluarga mahasiswa Pangandaran yang lain atas doa dan dukungannya,
7 H. Kariman dan H. Rosyid beserta keluarga atas rasa kekeluargaan yang telah diberikan,
8 Semua dosen dan staf Departemen Matematika serta pihak lain yang telah secara langsung atau tidak langsung membantu dalam penulisan karya ilmiah ini.
Penulis menyadari bahwa dalam penulisan skripsi ini masih jauh dari kesempurnaan. Kritik, saran, dan masukan yang bersifat membangun sangat penulis harapkan demi penyempurnaan di masa mendatang.
Semoga karya ilmiah ini bermanfaat.
Bogor, Januari 2015
DAFTAR ISI
DAFTAR GAMBAR vi PENDAHULUAN 1 Latar Belakang 1 Tujuan 2 TINJAUAN PUSTAKA 2 Hashing 2 Fungsi Hash 2 Sequential Search 4 Binary Search 5 BLOOM FILTER 5Standard Bloom Filter 5
False Positive 8
Peminimalan Peluang False Positive 9
Counting Bloom Filter 11
Counter untuk Counting Bloom Filter 12
SIMPULAN DAN SARAN 13
Simpulan 13
Saran 14
DAFTAR PUSTAKA 14
DAFTAR GAMBAR
1 Contoh perfect hashing 3
2 Ilustrasi tabel array 7
3 Ilustrasi penyisipan elemen pada Bloom Filter 7
4 Item false positive 8
1
PENDAHULUAN
Latar Belakang
Suatu algoritma pada aplikasi dituntut untuk tetap bersifat skalabilitas, artinya algoritma tersebut tetap memiliki performa/kinerja yang tinggi walau jumlah data ditambah. Namun pada kenyataannya jika banyaknya data ditambah maka kinerja suatu algoritma akan menurun. Hal ini dapat terjadi karena operasi-operasi yang terjadi dalam algoritma tersebut, seperti operasi penambahan data atau operasi pemeriksaan data. Operasi pemeriksaan data dapat menghabiskan waktu yang lama jika jumlah data sangat banyak. Bagi aplikasi seperti web browser Google Chrome yang perlu waktu singkat untuk melakukan pemeriksaan URL jahat, pencocokan secara cepat dalam pemeriksaan keanggotaan pada sebuah data merupakan kebutuhan yang penting.
Struktur data yang umum digunakan adalah Binary Search (pohon pencarian biner). Namun struktur data tersebut memerlukan waktu yang cukup lama untuk menambahkan elemen maupun untuk memeriksa apakah suatu elemen berada dalam himpunannya atau tidak (Guo et al 2010). Meski demikian, pohon pencarian biner masih lebih efisien dibandingkan dengan algoritma Sequential Search (pencarian berurut) yang perlu melakukakan pemeriksaan pada setiap elemen tabel
array. Algoritma pohon pencarian biner ini bekerja dengan prinsip divide and conquer, yaitu sebuah masalah atau tujuan diselesaikan dengan cara mempartisi
masalah menjadi bagian yang lebih kecil. Algoritma ini membagi sebuah tabel
array menjadi dua dan memroses satu bagian dari tabel itu saja.
Solusi yang ditawarkan untuk menangani masalah waktu penambahan elemen dan pengujian elemen dalam himpunan adalah dengan algoritma Bloom
Filter. Bloom Filter adalah sebuah ruang efisien probabilistik data yang
dikemukakan oleh Burton Howard Bloom pada tahun 1970 yang digunakan untuk memeriksa apakah suatu elemen berada di dalam himpunan atau tidak. Bloom Filter memanfaatkan hashing untuk membuat setiap elemen menjadi unik. Meski memiliki banyak kelebihan, dalam Bloom Filter terdapat suatu kelemahan yaitu terjadinya tabrakan hash (collision) yang dapat menyebabkan kesalahan dalam hasil pemeriksaan. False positive adalah kesalahan yang terjadi jika suatu elemen bukan merupakan anggota dari himpunan namun pemeriksaan pada Bloom Filter menghasilkan bahwa elemen tersebut merupakan anggota dari himpunan, misal pada web browser Google Chrome suatu URL yang tidak jahat namun dianggap sebagai URL jahat.
Pada karya ilmiah ini akan dibahas algoritma Bloom Filter, perhitungan peluang kesalahan false positive, dan peminimalan terjadinya false positive tersebut.
2
Tujuan
Tujuan penyusunan karya ilmiah ini adalah:
1 Menjabarkan cara kerja algoritma Bloom Filter pada pemeriksaan keanggotaan suatu elemen dalam himpunan.
2 Menghitung peluang false positive.
3 Meminimalkan peluang terjadinya false positive.
4 Menjabarkan cara kerja algoritma Counting Bloom Filter.
5 Memilih ukuran counter yang sesuai untuk Counting Bloom Filter.
TINJAUAN PUSTAKA
Hashing
Fungsi hash adalah fungsi yang menerima masukan dengan panjang sembarang dan menransformasikannya menjadi keluaran dengan panjang tetap yang disebut nilai hash. Ide dasar fungsi hash adalah suatu nilai hash berlaku sebagai representasi yang sederhana dari suatu input dan dapat digunakan hanya jika nilai hash tersebut dapat diidentifikasi secara unik dengan input tersebut. Fungsi hash banyak digunakan untuk mempercepat pencarian data dalam tabel data atau pembandingan data seperti di dalam basis data. Fungsi ini juga digunakan untuk mencari duplikasi atau kesamaan (rekaman) dalam arsip komputer yang besar, menemukan goresan-goresan yang sama dalam sebuah DNA, dan sebagainya.
Hashing digunakan sebagai alat untuk mengasosiasikan satu himpunan atau
data dengan identifier. Hash table adalah sebuah struktur data yang terdiri atas sebuah tabel dan fungsi yang bertujuan untuk memetakan nilai kunci yang unik untuk setiap input menjadi nilai hash yang kemudian dilokasikan dalam sebuah tabel. Pemetaan fungsi hash yang digunakan bukanlah pemetaan satu-satu sehingga antara dua input yang tidak sama dapat dibangkitkan nilai hash yang sama. Hal ini menyebabkan terjadinya tabrakan (collision) dalam penempatan suatu input.
Fungsi Hash
Fungsi Modulo
Fungsi modulo merupakan jenis fungsi hash yang nilai hash-nya didapat dengan cara mencari sisa bagi hasil nilai kunci dengan suatu nilai tertentu 𝑓(𝑘𝑒𝑦) = 𝑘𝑒𝑦 𝑚𝑜𝑑 𝑚. Nilai 𝑚 dapat berupa dua kemungkinan, yaitu banyaknya ruang alamat yang tersedia atau bilangan prima terdekat yang berada di atas nilai banyaknya data. Banyaknya ruang alamat disesuaikan dengan 𝑛.
Fungsi Pemotongan
Fungsi pemotongan merupakan jenis fungsi hash yang nilai hash-nya didapat dengan memotong nilai kunci ke jumlah digit tertentu yang lebih pendek.
3
Fungsi Pelipatan
Fungsi pelipatan adalah fungsi hash yang nilai hash-nya didapat dengan melakukan pelipatan terhadap record kunci dengan bagian yang sama panjang, lalu setiap bagian tersebut dijumlahkan.
Fungsi Pengkuadratan
Fungsi pengkuadratan adalah fungsi hash yang nilai hash-nya didapat dengan mengkuadratkan setiap digit pembentuk kunci, lalu semua hasilnya dijumlahkan.
Fungsi Penambahan Kode ASCII
Jika kunci bukan merupakan kode numerik, nilai hash dicari dengan menjumlahkan kode ASCII dari setiap huruf pembentuk kunci.
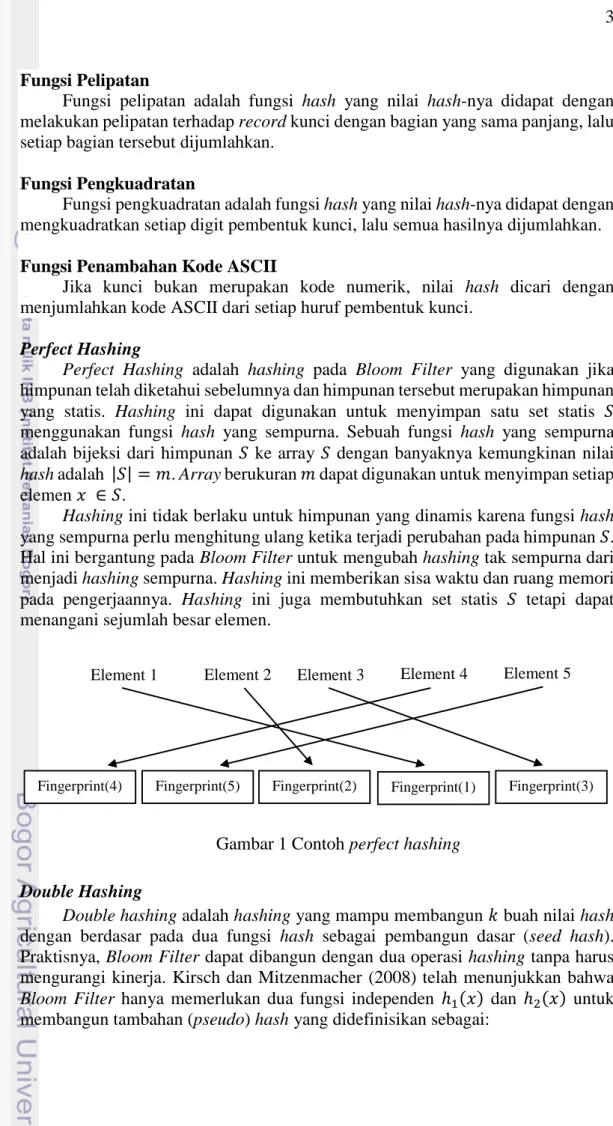
Perfect Hashing
Perfect Hashing adalah hashing pada Bloom Filter yang digunakan jika
himpunan telah diketahui sebelumnya dan himpunan tersebut merupakan himpunan yang statis. Hashing ini dapat digunakan untuk menyimpan satu set statis 𝑆 menggunakan fungsi hash yang sempurna. Sebuah fungsi hash yang sempurna adalah bijeksi dari himpunan 𝑆 ke array 𝑆 dengan banyaknya kemungkinan nilai
hash adalah |𝑆| = 𝑚. Array berukuran 𝑚 dapat digunakan untuk menyimpan setiap elemen 𝑥 ∈ 𝑆.
Hashing ini tidak berlaku untuk himpunan yang dinamis karena fungsi hash
yang sempurna perlu menghitung ulang ketika terjadi perubahan pada himpunan 𝑆. Hal ini bergantung pada Bloom Filter untuk mengubah hashing tak sempurna dari menjadi hashing sempurna. Hashing ini memberikan sisa waktu dan ruang memori pada pengerjaannya. Hashing ini juga membutuhkan set statis 𝑆 tetapi dapat menangani sejumlah besar elemen.
Gambar 1 Contoh perfect hashing
Double Hashing
Double hashing adalah hashing yang mampu membangun 𝑘 buah nilai hash dengan berdasar pada dua fungsi hash sebagai pembangun dasar (seed hash). Praktisnya, Bloom Filter dapat dibangun dengan dua operasi hashing tanpa harus mengurangi kinerja. Kirsch dan Mitzenmacher (2008) telah menunjukkan bahwa
Bloom Filter hanya memerlukan dua fungsi independen ℎ1(𝑥) dan ℎ2(𝑥) untuk
membangun tambahan (pseudo) hash yang didefinisikan sebagai:
Fingerprint(4) Fingerprint(5) Fingerprint(2) Fingerprint(1) Fingerprint(3)
4
ℎ𝑖(𝑥) = ℎ1(𝑥) + 𝑓(𝑖) ∗ ℎ2(𝑥)
dengan 𝑖 adalah indeks nilai hash, 𝑓(𝑖) dapat berupa fungsi sebarang terhadap 𝑖 (seperti 𝑖2), dan 𝑥 adalah elemen yang di-hash (Tarkoma 2012). Dalam Bloom
Filter, double hashing ini mengurangi banyaknya operasi perhitungan hash dari 𝑘 turun menjadi dua tanpa meningkatkan peluang terjadinya false positive.
Multiple Hashing
Multiple Hashing adalah hashing yang memanfaatkan gagasan bahwa
pengguna memiliki beberapa pilihan fungsi hash dan bebas untuk memilih fungsi yang sesuai. Ketika diterapkan untuk konstruksi hash table, multiple hashing menyediakan metode probabilistik untuk mengurangi dampak tabrakan (collision) dengan mengalokasikan penyebaran elemen secara cukup merata.
Simple Hash Function
Sebuah asumsi umum untuk mempertimbangkan bahwa nilai-nilai keluaran
hash adalah acak, yaitu setiap elemen hash secara independen dipetakan ke nilai hash secara seragam. Meskipun hal ini merupakan bantuan besar untuk analisis
teoritis, namun telah diketahui implementasi fungsi hash menunjukan reaksi yang acak (Tarkoma 2012).
Mitzenmacher dan Vadhan (2007) secara resmi menjelaskan ketidaksesuaian antara teori dan praktis hashing. Singkatnya, alasan mendasar bahwa fungsi hash sederhana bekerja dapat dijelaskan secara alami dari kombinasi keacakan memilih fungsi hash dan keacakan dalam data. Oleh karena itu, hanya sejumlah kecil dari keacakan dalam data yang cukup untuk meniru fungsi hash yang acak dalam praktik. Hasil ini berlaku untuk setiap teknik yang berbasis hash, dan sebagai konsekuensi praktis, mereka menyarankan bahwa fungsi sederhana (non-kriptografi misalnya CRC32) sangat cocok untuk kinerja tinggi aplikasi Bloom
Filter.
Sequential Search
Metode pencarian data berurut atau Sequential Search adalah metode yang paling sederhana pada algoritma pencarian data. Pencarian data dengan metode ini dilakukan dengan membandingkan data satu per satu dari kumpulan data (array) sampai data tersebut ditemukan (sesuai) atau tidak ditemukan (tidak sesuai). Jika data sudah ditemukan maka pencarian dihentikan. Jika belum ditemukan maka pencarian diteruskan hingga seluruh data dibandingkan. Kelebihan dari metode
Sequential Search adalah jika data yang dicari terletak di depan maka proses
pencarian akan berlangsung cepat. Namun jika data yang dicari terletak di belakang atau paling akhir maka proses pencarian akan membutuhkan waktu yang lama terlebih jika ukuran data cukup besar. Kompleksitas untuk algoritma ini adalah 𝑶(𝒏), artinya jika banyaknya elemen 𝒏 dinaikkan 𝒋 kali maka waktu menjalankan algoritma juga naik 𝒋 kali.
5
Binary Search
Binary Search adalah algoritma pencarian yang lebih efisien dibandingkan
algorima Sequential Search karena algoritma ini tidak perlu memeriksa setiap elemen dari tabel array. Pada intinya, algoritma ini menggunakan prinsip divide
and conquer, yaitu sebuah masalah atau tujuan diselesaikan dengan cara memartisi
masalah menjadi bagian yang lebih kecil. Algoritma ini membagi sebuah tabel menjadi dua dan memroses satu bagian dari tabel itu saja.
Algoritma Binary Search ini bekerja dengan cara memilih record dengan indeks tengah dari tabel dan membandingkannya dengan record yang hendak dicari. Jika record tersebut lebih rendah atau lebih tinggi, maka tabel tersebut dibagi dua dan bagian tabel yang bersesuaian akan diproses kembali secara rekursif. Algoritma ini adalah hanya bisa digunakan pada tabel yang elemennya sudah terurut secara menaik maupun menurun (Munir 2001). Kompleksitas untuk algoritma ini adalah 𝑂(𝑙𝑜𝑔 𝑛), berarti perubahan waktu lebih kecil dari perubahan masukan elemen 𝑛.
BLOOM FILTER
Standard Bloom Filter
Bloom Filter adalah struktur data ruang efisien yang mendukung permintaan
keanggotaan himpunan. Bloom Filter pertama kali dikemukakan oleh Burton H. Bloom pada tahun 1970 dan telah banyak digunakan dalam basis data seperti aplikasi jaringan, web cache sharing, dan penjaluran jaringan overlay. Standard
Bloom Filter tidak mendukung adanya operasi penghapusan elemen, namun kini
telah ada pengembangan lebih lanjut dari Bloom Filter yang mendukung operasi penghapusan (Tarkoma 2012). Agar lebih efektif, Bloom Filter telah ditingkatkan dari beberapa aspek yang berbeda untuk berbagai aplikasi. Keakuratan Bloom Filter tergantung pada ukuran filter, jumlah fungsi hash yang digunakan dalam filter, dan jumlah elemen yang ditambahkan ke himpunan.
Satu himpunan 𝑆 yang memiliki elemen sebanyak 𝑛 direpresentasikan oleh
Bloom Filter menggunakan sebuah vektor bit berukuran 𝑚 yang nilai awalnya adalah 0. Bloom Filter menggunakan fungsi hash yang bebas sebanyak 𝑘 yaitu ℎ1, ℎ2, … , ℎ𝑘 dengan kisaran nilai hash adalah berkisar dari 1 sampai 𝑚. Ketika
menyisipkan elemen 𝑥 ke 𝑆, semua bit terkait dengan elemen 𝑥 dari alamat Bloom
Filter yaitu 𝐵𝑖(𝑥) yang terdiri dari 𝑘 alamat ℎ𝑖(𝑥) untuk 1 ≤ 𝑖 ≤ 𝑘 akan berubah nilainya dari 0 menjadi 1. Untuk menanggapi setiap permintaan keanggotaan untuk elemen 𝑥, harus diperiksa apakah semua bit 𝐵𝑖(𝑥) bernilai 1. Jika tidak semua bit
bernilai 1 maka Bloom Filter akan menyimpulkan bahwa 𝑥 bukan anggota dari 𝑆, jika semua bit bernilai 1 maka Bloom Filter akan menyimpulkan bahwa 𝑥 anggota 𝑆 meskipun terdapat kemungkinan terjadinya kesalahan dalam beberapa kasus. Oleh karena itu Bloom Filter dapat menghasilkan false positive.
6
Berikut adalah algoritma penyisipan elemen pada Bloom Filter:
Algoritma 1: Penyisipan pada Bloom Filter
Data: x adalah elemen yang disisipkan ke Bloom Filter. Function: insert(x) for 𝑗 ∶ 1 … 𝑘 do 𝑖 ← ℎ𝑗(𝑥); if 𝐵𝑖 == 0 then 𝐵𝑖 ← 1; end end
Algoritma 1 menjelaskan bahwa ketika elemen 𝑥 disisipkan ke dalam suatu himpunan yang telah direpresentasikan oleh Bloom Filter, maka elemen tersebut pertama kali akan melalui tahap hashing dengan 𝑘 buah fungsi hash untuk mendapatkan nilai hash yang berkisar dari 1 sampai 𝑚. Nilai-nilai hash inilah yang kemudian menjadi indeks dari bit yang akan diubah nilainya dari 0 menjadi 1. Karena terdapat 𝑘 buah fungsi hash, maka akan ada 𝑘 buah bit dalam tabel yang akan diubah nilainya menjadi 1. Begitu seterusnya untuk penyisipan elemen yang lain. Jika elemen lain memiliki nilai hash yang sama dengan elemen-elemen sebelumnya maka bit-bit terkait tetap bernilai 1 dan kejadian ini dinamakan tabrakan hash (collision).
Algoritma 2: Pengujian elemen pada Bloom Filter Data: x adalah item yang diuji keanggotannya.
Function: ismember(x) menghasilkan benar atau salah
𝑚 ← 1; 𝑗 ← 1; while 𝑚 == 1 𝑎𝑛𝑑 𝑗 ≤ 𝑘 do 𝑖 ← ℎ𝑗(𝑥); if 𝐵𝑖 == 0 then 𝑚 ← 0; end 𝑗 ← 𝑗 + 1; end return m;
Algoritma 2 menjelaskan bahwa untuk menguji suatu elemen merupakan anggota dari suatu himpunan atau bukan, akan diperiksa apakah bit-bit yang terkait dengan elemen tersebut bernilai 1. Sama halnya dengan algoritma penyisipan, pada algoritma pengujian pun elemen yang akan diuji harus dicari nilai hash-nya terlebih dahulu untuk mengetahui indeks dari bitnya. Setelah didapat 𝑘 buah nilai hash maka langkah berikutnya adalah memeriksa nilai bit pada indeks tersebut. Jika semua bit bernilai 1 maka elemen tersebut adalah anggota dari himpunan.
Bloom Filter tak selalu menghasilkan kesimpulan yang tepat. Sebuah
permintaan keanggotaan berdasarkan Bloom Filter dapat menghasilkan salah satu dari kemungkinan hasil berikut:
7 1) Hasil yang selalu benar, yaitu jika 𝑥 ∈ 𝑆 maka 𝐵𝑖(𝑥) ≠ 0 ∀𝑖 ∈ {1,2, … , 𝑘};
dan jika 𝑥 ∉ 𝑆 maka ∃𝑖 ∈ {1,2, … , 𝑘} sehingga 𝐵𝑖(𝑥) = 0.
2) Hasil false positive, yaitu jika 𝑥 ∉ 𝑆 maka 𝐵𝑖(𝑥) ≠ 0 ∀𝑖 ∈ {1,2, … , 𝑘}.
3) Hasil false negative, yaitu jika 𝑥 ∈ 𝑆 maka ∃𝑖 ∈ {1,2, … , 𝑘} sehingga 𝐵𝑖(𝑥) = 0.
Misal terdapat suatu himpunan statis 𝑆 yang telah diketahui elemen-elemennya yaitu 𝑆 = {25, 67, 82}. Jika himpunan ini direpresentasikan oleh Bloom
Filter maka terdapat sebuah tabel array bit berukuran 𝑚 yang nilai awalnya adalah 0 dan 𝑘 buah fungsi hash. Misalkan ukuran vector bit 𝑚 = 16 dan banyaknya fungsi hash 𝑘 = 3, dengan ℎ1(𝑥) = (𝑥 𝑚𝑜𝑑 𝑚) + 1, ℎ2(𝑥) = (𝑥(𝑥 + 1)𝑚𝑜𝑑 𝑚) + 1, dan ℎ3(𝑥) = (𝑥(𝑥 + 5) 𝑚𝑜𝑑 𝑚) + 1.
Berikut ilustrasi tabel array berukuran 16 bit sebelum merepresentasikan himpunan 𝑆.
0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16
Gambar 2 Ilustrasi tabel array
Untuk merepresentasikan himpunan 𝑆 pada Bloom Filter maka Bloom Filter harus menyisipkan setiap elemen pada 𝑆 ke dalam filter menggunakan algoritma 1. Untuk elemen 25 setelah dilakukan tahap hashing maka didapat nilai hash ℎ1(25) = 10, ℎ2(25) = 11, dan ℎ3(25) = 15. Sehingga nilai pada bit-bit
berindeks 10, 11, dan 15 akan diubah nilainya menjadi 1 yaitu 𝐵10= 1, 𝐵11 = 1, dan 𝐵15 = 1. Untuk elemen 67 dan 82 dengan langkah yang sama didapat nilai hash
ℎ1(67) = 4, ℎ2(67) = 13, ℎ3(67) = 9, ℎ1(82) = 3, ℎ2(82) = 7, dan ℎ3(82) =
15. Nilai pada bit-bit berindeks 3, 4, 7, 9, 13, dan 15 akan diubah nilainya menjadi 1 yaitu 𝐵3 = 1, 𝐵4 = 1, 𝐵7 = 1, 𝐵9 = 1, 𝐵13= 1, dan 𝐵15= 1. Sehingga tabel array pada Gambar 2 setelah diperbarui nilainya disajikan pada gambar 3.
25 67 82
0 0 1 1 0 0 1 0 1 1 1 0 1 0 1 0
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16
Gambar 3 Ilustrasi penyisipan elemen pada Bloom Filter
Untuk melakukan pengujian keanggotaan elemen perlu dilakukan pemeriksaan terhadap nilai-nilai dari vektor bit pada tabel array. Misal untuk elemen 25, setelah dilakukan hashing maka akan didapat nilai hash 10, 11, dan 15. Jika bit pada indeks 10, 11, dan 15 bernilai 1 maka dipastikan elemen 25 adalah anggota dari himpunan 𝑆.
8
False Positive
Item False Positive
False positive adalah sebuah kesalahan hasil penentuan dalam Bloom Filter
yang menyatakan bahwa elemen yang merupakan anggota dari himpunan padahal sebenarnya elemen tersebut tidak berada dalam himpunan. Pada beberapa aplikasi elemen false positive ini dianggap tidak terlalu berbahaya.
Pada Gambar 3 diketahui bahwa Bloom Filter telah merepresentasikan himpunan 𝑆 = {25,67,82}. Misal pada Bloom Filter dilakukan uji permintaan untuk elemen 78 yang setelah dilakukan hashing didapat nilai-nilai hash yaitu ℎ1(78) = 15, ℎ2(78) = 3, ℎ3(78) = 11. Maka hal yang perlu dilakukan dalam
pengujian keanggotaan adalah memeriksa apakah bit-bit pada indeks 15, 3, dan 11 bernilai 1 atau tidak. Jika bit-bit tersebut bernilai 1 maka akan dilaporkan sebagai anggota dari himpunan 𝑆 dan disebut sebagai elemen false positive karena 78 sebenarnya bukan anggota dari himpunan 𝑆.
25 67 82 78 ?
0 0 1 1 0 0 1 0 1 1 1 0 1 0 1 0
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16
Gambar 4 Elemen false positive
Pada Gambar 4 terlihat bahwa bit-bit yang berhubungan dengan elemen 78 yaitu bit-bit berindeks 3, 11, dan 15 bernilai 1 karena bit-bit tersebut telah terisi oleh elemen-elemen sebelumnya. Oleh karena itu, Bloom Filter akan melaporkan bahwa 78 adalah anggota dari himpunan 𝑆 meskipun sebenarnya 78 bukan anggota dari himpunan 𝑆. Hal ini terjadi karena adanya tabrakan hash yang antara nilai-nilai
hash untuk elemen 78 dengan nilai-nilai hash dari elemen-elemen anggota
himpunan 𝑆. Misal untuk ℎ1(78) = 15 bertabrakan dengan ℎ3(25) dan ℎ3(82)
sehingga bit berindeks 15 sudah bernilai 1. Begitu pun yang terjadi dengan nilai
hash ℎ2(78) dan ℎ3(78).
Peluang False Positive
Sebuah fungsi hash diasumsikan memiliki peluang yang sama untuk memilih posisi array (bit). Banyaknya bit dalam Bloom Filter dinotasikan dengan 𝑚. Ketika melakukan penyisipan satu elemen ke dalam Bloom Filter, maka peluang bahwa nilai bit terkait tidak diubah menjadi 1 adalah
1 − 1
𝑚 . (1) Dalam Bloom Filter terdapat 𝑘 buah fungsi hash. Sehingga peluang bahwa nilai bit-bit terkait tidak diubah ke 1 adalah
9
(1 − 1 𝑚 )
𝑘
. (2) Setelah dilakukan penyisipan elemen sebanyak 𝑛 ke dalam Bloom Filter, peluang bahwa bit-bit tersebut masih bernilai 0 adalah
(1 − 1 𝑚 )
𝑘𝑛
, (3) dan peluang bahwa bit bernilai 1 adalah
1 − (1 − 1 𝑚 )
𝑘𝑛
. (4) Untuk pengujian keanggotaan sebuah elemen, jika semua posisi 𝑘 array dalam filter yang didapat dari fungsi hash bernilai 1, maka Bloom Filter menyatakan bahwa elemen tersebut merupakan milik atau anggota dari himpunan. Peluang bahwa hal ini terjadi ketika elemen tersebut sebenarnya bukan anggota himpunan adalah (1 − (1 − 1 𝑚 ) 𝑘𝑛 ) 𝑘 . (5) Suatu himpunan dapat memiliki elemen yang jumlahnya sangat besar, maka dengan membuat 𝑛 bernilai sangat besar didapat hampiran
lim 𝑛→∞(1 − 1 𝑚) 𝑘𝑛 = 𝑒−𝑘𝑛𝑚 . (6)
Sehingga didapat peluang false positive adalah
𝑝𝑓 = (1 − (1 − 1 𝑚 ) 𝑘𝑛 ) 𝑘 ≈ (1 − 𝑒−𝑘𝑛𝑚) 𝑘 . (7)
Peminimalan Peluang False Positive
Nilai peluang false positive dapat dibuat seminimal mungkin dengan menurunkan Persamaan (7) terhadap 𝑘 sehingga didapat nilai 𝑘 yang optimal.
Misalkan 𝑦 = (1 − 𝑒−𝑘𝑛𝑚)
𝑘
10 (1 − 𝑒−𝑘𝑛𝑚) 𝑘 ( 𝑘𝑛 𝑒−𝑘𝑛𝑚 𝑚 (1 − 𝑒−𝑘𝑛𝑚) + ln (1 − 𝑒−𝑘𝑛𝑚) ) . (8)
Untuk meminimalkan 𝑦, selanjutnya diberlakukan 𝑑𝑦/𝑑𝑘 = 0. Karena (1 − 𝑒−𝑘𝑛𝑚) ≠ 0, maka ( 𝑘𝑛 𝑒−𝑘𝑛𝑚 𝑚 (1 − 𝑒−𝑘𝑛𝑚) + ln (1 − 𝑒−𝑘𝑛𝑚) ) = 0 ⇔ ln (1 − 𝑒−𝑘𝑛𝑚) = − 𝑘𝑛 𝑒 −𝑘𝑛𝑚 𝑚 (1 − 𝑒−𝑘𝑛𝑚) . (9)
Selesaikan persamaan (9) maka akan didapat 𝑘 optimal, yaitu 𝑘𝑜𝑝𝑡 = 𝑚
𝑛 ln(2) ≈ 9𝑚 13𝑛. Hal ini menyebabkan peluang false positive menjadi
(1 2)
𝑘
≈ 0.6185𝑚⁄𝑛.
Dengan menggunakan fungsi hash optimal 𝑘𝑜𝑝𝑡, peluang false positive dapat dituliskan kembali dan dibatasi oleh
𝑚 𝑛 ≥
1 ln(2).
Ini berarti bahwa untuk menjaga peluang false positive bernilai tetap, banyaknya bit dari Bloom Filter harus dinaikkan secara linear dengan banyaknya elemen yang disisipkan ke dalam filter. Banyaknya bit untuk banyaknya elemen 𝑛 dan tingkat false positive 𝑝𝑓 diberikan oleh
𝑚 = −𝑛 ln(𝑝𝑓) (ln(2))2.
11
Gambar 5 Nilai peluang false positive
Gambar 5 menyajikan peluang false positive 𝑝𝑓 sebagai fungsi dari
banyaknya elemen 𝑛 dan ukuran filter 𝑚. Nilai 𝑚 dan 𝑛 yang diambil telah disesuaikan dengan banyaknya fungsi hash optimal yaitu 𝑘𝑜𝑝𝑡 =
𝑚
𝑛ln(2). Dari
grafik tersebut dapat disimpulkan bahwa peluang terjadinya false positive akan semakin tinggi bila jumlah elemen yang disisipkan semakin banyak, peluangnya akan semakin kecil jika ukuran tabel array diperbesar.
Counting Bloom Filter
Seperti telah diungkapkan sebelumnya bahwa Bloom Filter standar yang tidak mendukung operasi penghapusan di himpunan. Counting Bloom Filter yang merupakan salah satu variasi dari Bloom Filter yang mendukung adanya operasi penyisipan dan penghapusan sehingga dapat digunakan untuk himpunan yang dinamis (Jin et al 2009). Fan et al pertama kali memperkenalkan ide Counting
Bloom Filter dalam keterkaitannya dengan web cache.
Pada Counting Bloom Filter, setiap entri dalam Bloom Filter diubah menjadi sebuah counter kecil yang berasosiasi dengan bit standard Bloom Filter. Ketika satu item disisipkan, counter yang sesuai akan bertambah. Selanjutnya, jika satu item dihapus, counter yang sesuai akan berkurang.
Berikut adalah algoritma penyisipan elemen pada Counting Bloom Filter:
Banyaknya elemen yang disisipkan (n)
Pel uang f a ls e p os it iv e ( 𝑝𝑓 ) m=64 m=512 m=1024 m=2048 m=4096 20000 40000 60000 80000 100000 1.00 0.98 0.96 0.94 0.92
12
Algoritma 3: Penyisipan pada Counting Bloom Filter Data: x adalah elemen yang disisipkan.
Function: insert(x) for 𝑗 ∶ 1 … 𝑘 do 𝑖 ← ℎ𝑗(𝑥); 𝐶𝑖 ← 𝐶𝑖 + 1; if 𝐵𝑖 == 0 then 𝐵𝑖 ← 1; end end
Algoritma 3 menyajikan pseudocode operasi penyisipan untuk elemen 𝑥. Operasi akan menambahkan nilai counter pada setiap bit yang terkait dengan elemen 𝑥. Struktur Counting Bloom Filter mendukung penghapusan elemen menggunakan operasi hapus yang disajikan dalam Algoritma 4 yang menjelaskan untuk penghapusan elemen akan menurunkan nilai counter pada bit-bit terkait dan bit tersebut akan diubah nilainya menjadi 0 jika nilai counter menjadi 0.
Algoritma 4: Penghapusan elemen pada Counting Bloom Filter Data: x adalah elemen yang dhapus.
Function: delete(x) for 𝑗 ∶ 1 … 𝑘 do 𝑖 ← ℎ𝑗(𝑥); 𝐶𝑖 ← 𝐶𝑖 − 1; if 𝐶𝑖 ≤ 0 then 𝐵𝑖 ← 0; end end.
Counter untuk Counting Bloom Filter
Untuk menghindari counter yang overflow, maka pengguna perlu memilih ukuran counter yang cukup besar. Analisis yang telah dilakukan oleh Fan et al (2000) mengungkapkan bahwa 4 bit per counter akan cukup untuk sebagian besar aplikasi. Untuk menentukan ukuran counter yang baik, pengguna dapat mempertimbangkan sebuah Counting Bloom Filter untuk satu himpunan dengan 𝑛 buah elemen, 𝑘 buah fungsi hash, dan 𝑚 counters. Misalkan 𝑐(𝑖) adalah jumlah yang terkait dengan counter ke- 𝑖. Peluang bahwa counter ke- 𝑖 meningkat 𝑗 kali adalah sebuah variabel random binomial yang dapat ditulis sebagai
𝑃(𝑐(𝑖) = 𝑗) = (𝑛𝑘 𝑘𝑗) ( 1 𝑚) 𝑗(1 − 1 𝑚) 𝑛𝑘−𝑗. (10)
Peluang bahwa setiap counter setidaknya sama dengan 𝑗 dibatasi dari atas oleh 𝑚𝑃(𝑐(𝑖) = 𝑗), yang dapat dihitung dengan menggunakan Persamaan (10).
13 Nilai counter meningkat beberapa kali setiap nilai bit terkait diubah menjadi 1, yang pada mulanya semua counter diberi nilai awal 0. Peluang bahwa setiap
counter lebih besar atau sama dengan 𝑗 adalah
P(max(𝑐) ≥ 𝑗) ≤ 𝑚 (𝑛𝑘 𝑗 ) 1 𝑚𝑗 ≤ 𝑚 ( 𝑒𝑛𝑘 𝑗𝑚) 𝑗 . (11) Seperti yang telah disebutkan sebelumnya, nilai optimum dari 𝑘 adalah 𝑚
𝑛ln(2).
Asumsikan bahwa banyaknya fungsi hash kurang dari 𝑚
𝑛 ln(2), misalkan kita batasi
dengan
P(max(𝑐) ≥ 𝑗) ≤ 𝑚 (𝑒 ln (2)
𝑗 )
𝑗
. (12) Dengan 𝑗=16 kita mendapatkan
P(max(𝑐) ≥ 16) ≤ 1.37 × 10−15× 𝑚. (13) Oleh karena itu, jika kita membuat 4 bit per counter, peluang terjadinya overflow untuk nilai-nilai secara praktis dari 𝑚 selama penyisipan awal dalam filter sangatlah kecil.
Counting Bloom Filter juga mampu menjaga perkiraan banyaknya elemen.
Sebagai contoh, sisipkan elemen 𝑥 sebanyak tiga kali maka nilai bit-bit terkait berubah menjadi 1 dan nilai counter terkait bertambah 1 untuk setiap penyisipan. Oleh karena itu, 𝑘 counter terkait setidaknya bertambah tiga kali, beberapa dari
counter tersebut mungkin bertambah lebih dari tiga kali jika ada tumpang tindih
dengan unsur lain yang disisipkan. Perkiraan counter dapat ditentukan dengan mencari nilai minimum dari nilai counter di semua lokasi terkait dengan item tersebut.
SIMPULAN DAN SARAN
Simpulan
Bloom Filter adalah struktur data ruang efisien yang efektif
merepresentasikan himpunan/data dan mendukung perkiraan permintaan keanggotaan. Bloom Filter bekerja dengan berbasis tabel array memanfaatkan teknik hashing untuk membuat setiap elemen menjadi unik sehingga dapat dengan mudah menentukan keanggotaan suatu elemen. Algoritma ini dapat menghasilkan kekeliruan dalam penentuan keanggotaan suatu elemen, yang salah satunya disebut dengan false positive. Peluang munculnya false positive ini dapat dihitung dengan rumus 𝑝𝑓= (1 − (1 − 1 𝑚 ) 𝑘𝑛 ) 𝑘 ≈ (1 − 𝑒−𝑘𝑛𝑚) 𝑘
. Untuk meminimalkan terjadinya
false positive didapatkan fungsi hash optimal 𝑘𝑜𝑝𝑡 = 𝑚
𝑛 ln (2). Pada himpunan
yang dinamis dapat digunakan Counting Bloom Filter, yaitu variasi dari Bloom
14
Bloom Filter menggunakan counter yang berasosiasi dengan bit Standard Bloom Filter. Untuk membuat peluang terjadinya overflow pada counter dapat dipilih
ukuran 4 bit per counter.
Saran
Pada karya ilmiah ini telah dibahas mengenai cara kerja algoritma Bloom
Filter dalam pengujian suatu elemen dan menghitung peluang terjadinya false positive. Akan lebih baik apabila karya ilmiah ini dikembangkan dan
diaplikasikan/disimulasikan langsung pada suatu studi kasus agar lebih tergambarkan mengenai cara kerja dari algoritma Bloom Filter dan peluang nyata terjadinya false positive pada himpunan.
DAFTAR PUSTAKA
Fan L, Cao P, Almeida J, dan Broder AZ. 2000. Summary Cache: A Scalable Wide-Area Web Cache Sharing Protocol. IEEE Transactions on Networking. 8(3): 281-293. doi:10.1109/90.851975
Guo D, Liu Y, Li X, dan Yang P. 2010. False Negative Problem of Counting Bloom Filter. IEEE Transactions on Knowledge and Data Engineering. 22(5): 651-664. doi: 10.1109/TKDE.2009.209
Jin Z, Jiangxing W, Julong L, dan Jianqiang L. 2009. Performance Evaluation And Comparison of Three Counting Bloom Filter. Jurnal of Electronics (China). 26(3): 332-340. doi: 10.1007/s11767-008-0031-x
Kirsch A, Mitzenmacher M. 2008. Less Hashing, Same Performance: Building A Better Bloom Filter. Random Structures & Algorithms Archive. 33(2): 187-218. doi: 10.1002/rsa.20208
Munir R. 2001. Matematika Diskrit Vol 2. Bandung(ID): Penerbit Informatika Bandung.
Tarkoma S, Rothenberg CE, dan Lagerspetz E. 2012. Theory and Practice of Bloom Filter for Distributed System. IEEE Communication Survey & Tutorials. 14(1): 131-155. doi: 10.1109/SURV.2011.031611.00024
RIWAYAT HIDUP
Penulis dilahirkan di Ciamis pada tanggal 3 Juli 1992 dari ayah Enang Sudarna dan ibu Rasinem. Penulis adalah putra kedua dari tiga bersaudara. Tahun 2004 penulis lulus dari SD Negeri 5 Pangandaran kemudian pada tahun 2007 lulus dari SMP Negeri 1 Pangandaran. Tahun 2010 penulis lulus dari SMA Negeri 1 Pangandaran dan pada tahun yang sama penulis lulus seleksi masuk IPB melalui jalur Undangan Seleksi Masuk IPB dan diterima di Departemen Matematika, Fakultas Matematika dan Ilmu Pengetahuan Alam.
Selama mengikuti perkuliahan, penulis aktif sebagai staf Divisi Sosial dan Lingkungan Gugus Mahasiswa Matematika (Gumatika) IPB 2011/2012 dan kepala Departemen Sosial dan Lingkungan Gumatika IPB 2012/2013. Penulis juga pernah mengajar mata kuliah Landasan Matematika, Pengantar Matematika, Kalkulus, dan Kalkulus 2 di bimbingan belajar MAFIA Clubs. Penulis juga aktif mengikuti kepanitiaan sebagai staf Divisi Sponsorship Matematika Ria Pesta Sains Nasional 2012, staf Divisi Dana Usaha dan Sponsorship Masa Perkenalan Fakultas G-FORCE 48, dan staf Divisi Konsumsi Matematika Ria Pesta Sains Nasional 2013.