ANALISIS DISKRIMINAN
ANALISIS DISKRIMINAN
Di susun untuk memenuhi tugas matakuliah Analisis Statisik Multivariat Di susun untuk memenuhi tugas matakuliah Analisis Statisik Multivariat
yang dibimbing oleh Ibu Trianingsih Eni Lestari yang dibimbing oleh Ibu Trianingsih Eni Lestari
Anggota:
Anggota: Cindy Cindy Meilinda Meilinda Wijaya Wijaya (409312417678(409312417678)) Andrie
Andrie Kurniawan Kurniawan (409312417687(409312417687)) Herlin
Herlin Dwi Dwi Kartikasari Kartikasari (409312419799(409312419799)) Firqin
Firqin Setara Setara (409312419800(409312419800))
MATEMATIKA FAKULTAS MATEMATIKA DAN ILMU PENGETAHUAN MATEMATIKA FAKULTAS MATEMATIKA DAN ILMU PENGETAHUAN
ALAM UNIVERSITAS NEGERI MALANG ALAM UNIVERSITAS NEGERI MALANG
Oktober 2011 Oktober 2011
BAB I
BAB I
PENDAHULUAN
PENDAHULUAN
1.1.Latar Belakang 1.1.Latar BelakangAnalisis diskriminan merupakan teknik menganalisis data, dimana variabel dependen Analisis diskriminan merupakan teknik menganalisis data, dimana variabel dependen merupakan data kategorik (
merupakan data kategorik ( nominal dan ordinal ) nominal dan ordinal ) sedangkan variabel independen berupsedangkan variabel independen berupaa data interval atau rasio . Misalnya berdasarkan data dari nasabah peminjam kredit suatu data interval atau rasio . Misalnya berdasarkan data dari nasabah peminjam kredit suatu bank, seperti penghasilan, umur, pekerjaan, tingkat pendidikan, ingin meramalkan apakah bank, seperti penghasilan, umur, pekerjaan, tingkat pendidikan, ingin meramalkan apakah seseorang nasabah yang baru termasuk jujur atau tidak jujur. Analisis diskriminan ini seseorang nasabah yang baru termasuk jujur atau tidak jujur. Analisis diskriminan ini termasuk dalam analisis multivariat dengan metode dependensi. Ada dua metode dalam termasuk dalam analisis multivariat dengan metode dependensi. Ada dua metode dalam analisis multivariat yaitu metode dependensi dan metode interdenpendensi . Metode analisis multivariat yaitu metode dependensi dan metode interdenpendensi . Metode dependensi yaitu variabel-variabelnya tidak saling bergantung satu dengan yang lain, dependensi yaitu variabel-variabelnya tidak saling bergantung satu dengan yang lain, sedangkan metode i
sedangkan metode interdenpennterdenpendensi adalah antarvariabelnya ada densi adalah antarvariabelnya ada saling ketergantungan.saling ketergantungan. Variabel dependen adalah data kategorikal. Jika data kategorikal terdiri dari
Variabel dependen adalah data kategorikal. Jika data kategorikal terdiri dari dua kelompok dua kelompok atau kategori disebut
atau kategori disebut Two-Group Discriminant AnalysisTwo-Group Discriminant Analysis , sedangkan jika lebih dari dua, sedangkan jika lebih dari dua kategori disebut dengan
kategori disebut dengan Multiple Multiple DiscriDiscriminant minant Analysis.Analysis. Adapun yang menjadi latarAdapun yang menjadi latar belakang penelitian ini adalah terkait dengan peranan dan aplikasi analisis diskriminan belakang penelitian ini adalah terkait dengan peranan dan aplikasi analisis diskriminan yang merupakan salah satu dari t
yang merupakan salah satu dari teknik statistik multivariat yang banyak digunakan dalameknik statistik multivariat yang banyak digunakan dalam berbagai bidang ilmu yang terjadi dalam
berbagai bidang ilmu yang terjadi dalam sebuah fenomena sosiasebuah fenomena sosial, keuangan dan ekonomi.l, keuangan dan ekonomi. Analisis diskriminan digunakan asalkan pertanyaan penelitian mengarah pada
Analisis diskriminan digunakan asalkan pertanyaan penelitian mengarah pada variabel tak variabel tak bebas (
bebas (dependent variabledependent variable) yang berupa data kategori seperti : macet-lancar,untung-rugi,) yang berupa data kategori seperti : macet-lancar,untung-rugi, puas-tidak puas dan lainnya.
puas-tidak puas dan lainnya.
Analisis diskriminan adalah metode untuk mencari dasar pengelompokan individu Analisis diskriminan adalah metode untuk mencari dasar pengelompokan individu
berdasarkan lebih dari satu variabel bebas. Analisis Diskriminan dipakai untuk
berdasarkan lebih dari satu variabel bebas. Analisis Diskriminan dipakai untuk menjawabmenjawab pertanyaan bagaimana individu dapat dimasukkan ke dalam kelompok berdasarkan pertanyaan bagaimana individu dapat dimasukkan ke dalam kelompok berdasarkan beberapa variabel. Persamaan Fungsi Diskriminan yang dihasilkan untuk memberikan beberapa variabel. Persamaan Fungsi Diskriminan yang dihasilkan untuk memberikan peramalan yang paling tepat untuk mengklasifikasi individu kedalam kelompok peramalan yang paling tepat untuk mengklasifikasi individu kedalam kelompok berdasarkan skor variabel bebas .
berdasarkan skor variabel bebas . Pada penelitian bidang kesehatan , analisis Pada penelitian bidang kesehatan , analisis diskriminandiskriminan dilakukan untuk mengetahui apakah dari keempat variabel prediktor, yaitu perasaan dilakukan untuk mengetahui apakah dari keempat variabel prediktor, yaitu perasaan cemas (feeling anxious), gelisah (
cemas (feeling anxious), gelisah ( restlessrestless), depresi (), depresi (depressed depressed ), putusasa (), putusasa (hopelesshopeless) dapat) dapat menentukan apakah seorang pasien akan didiagnos
atau stress . Pada Bank, analisis diskriminan juga dilakukan untuk mengklasifikasi atau stress . Pada Bank, analisis diskriminan juga dilakukan untuk mengklasifikasi Formulir Aplikasi untuk pinjaman, kartu kredit, dan asuransi dalam kategori berisiko Formulir Aplikasi untuk pinjaman, kartu kredit, dan asuransi dalam kategori berisiko rendah atau berisiko ti
rendah atau berisiko tinggi.nggi. 1.2.Rumusan Masalah
1.2.Rumusan Masalah
1.
1. Bagaimana definisi analisis diskriminan?Bagaimana definisi analisis diskriminan?
2.
2. Apa saja halApa saja hal – – hal pokok yang mempengaruhi diskriminan analisis?hal pokok yang mempengaruhi diskriminan analisis?
3.
3. BagaimanaBagaimanaproses pengambilan keputusan untuk analisis diskriminanproses pengambilan keputusan untuk analisis diskriminan ??
4.
4. Bagaiman aplikasi dalam menganalisis model diskriminan?Bagaiman aplikasi dalam menganalisis model diskriminan?
1.3.Tujuan
1.3.Tujuan
1.
1. Mengetahui pengertian tentang analisis Mengetahui pengertian tentang analisis diskriminandiskriminan
2.
2. Untuk mengetahui tujuan Untuk mengetahui tujuan dan syarat dari dan syarat dari analisis diskriminan, menentukan banyaknyanalisis diskriminan, menentukan banyaknyaa
sampel, dan mengetahui proses-proses dalam mencari model diskriminan.
sampel, dan mengetahui proses-proses dalam mencari model diskriminan.
3.
3. MengetahuiMengetahui proses pengambilan keputusan untuk analisis proses pengambilan keputusan untuk analisis diskriminandiskriminan..
4.
BAB 2
BAB 2
PEMBAHASAN
PEMBAHASAN
2.1 DEFINISI DISKRIMINAN ANALISIS
2.1 DEFINISI DISKRIMINAN ANALISIS
Analisis diskriminan adalah teknik statistik yang sesuai ketika variabel dependen Analisis diskriminan adalah teknik statistik yang sesuai ketika variabel dependen adalah kategori (nominal atau nonmetrik) variabel dan variabel independen adalah variabel adalah kategori (nominal atau nonmetrik) variabel dan variabel independen adalah variabel metrik. Dalam banyak hal, variabel dependen terdiri dari dua kelompok atau klasifikasi metrik. Dalam banyak hal, variabel dependen terdiri dari dua kelompok atau klasifikasi (contoh. laki-laki dibandingkan perempuan atau tinggi versus rendah). Dalam kasus lain, (contoh. laki-laki dibandingkan perempuan atau tinggi versus rendah). Dalam kasus lain, lebih dari dua kelompok yang terlibat, seperti rendah, sedang, dan klasifikasi tinggi. Analisis lebih dari dua kelompok yang terlibat, seperti rendah, sedang, dan klasifikasi tinggi. Analisis diskriminan mampu menangani baik dua kelompok atau beberapa kelompok (tiga atau
diskriminan mampu menangani baik dua kelompok atau beberapa kelompok (tiga atau lebih).lebih). Ketika dua klasifikasi yang terlibat, teknik ini disebut sebagai dua kelompok analisis Ketika dua klasifikasi yang terlibat, teknik ini disebut sebagai dua kelompok analisis diskriminan. Ketika tiga atau lebih klasifikasi diidentifikasi, teknik ini disebut sebagai diskriminan. Ketika tiga atau lebih klasifikasi diidentifikasi, teknik ini disebut sebagai analisis diskriminan ganda (MDA).
analisis diskriminan ganda (MDA).
Analisis diskriminan melibatkan menurunkan suatu variat. Diskriminan variat adalah Analisis diskriminan melibatkan menurunkan suatu variat. Diskriminan variat adalah kombinasi linear dari variabel independen dua (atau lebih) yang akan membedakan terbaik kombinasi linear dari variabel independen dua (atau lebih) yang akan membedakan terbaik antara obyek (orang, perusahaan, dll) dalam kelompok didefinisikan suatu
antara obyek (orang, perusahaan, dll) dalam kelompok didefinisikan suatu prioripriori.. Diskriminasi dicapai dengan menghitung bobot untuk masing-masing variate variabel Diskriminasi dicapai dengan menghitung bobot untuk masing-masing variate variabel independen untuk memaksimalkan perbedaan antara kelompok (yaitu varians antara independen untuk memaksimalkan perbedaan antara kelompok (yaitu varians antara kelompok relatif terhadap varians dalam kelompok). Para variate untuk analisis diskriminan, kelompok relatif terhadap varians dalam kelompok). Para variate untuk analisis diskriminan, juga
juga dikenal dikenal sebagai sebagai fungsi fungsi diskriminan, diskriminan, berasal berasal dari dari persamaan persamaan seperti seperti yang yang terlihat terlihat padapada regresi berganda. Dibutuhkan bentuk sebagai berikut:
regresi berganda. Dibutuhkan bentuk sebagai berikut:
dimana dimana
= diskriminan Z skor diskriminan j fungsi untuk objek k = diskriminan Z skor diskriminan j fungsi untuk objek k
= intercept= intercept
= bobot diskriminan = bobot diskriminan untuk variabel independenuntuk variabel independen
= variabel i= variabel independenndependen untuk objek untuk objek
Analisis diskriminan adalah teknik statistik yang sesuai untuk menguji hipotesis Analisis diskriminan adalah teknik statistik yang sesuai untuk menguji hipotesis bahwa kelompok berarti satu set variabel independen untuk dua atau lebih kelompok yang bahwa kelompok berarti satu set variabel independen untuk dua atau lebih kelompok yang sama. Dengan rata-rata skor diskriminan untuk semua individu dalam suatu kelompok sama. Dengan rata-rata skor diskriminan untuk semua individu dalam suatu kelompok tertentu, kita sampai pada kelompok rata-rata. Kelompok rata-rata ini disebut sebagai suatu tertentu, kita sampai pada kelompok rata-rata. Kelompok rata-rata ini disebut sebagai suatu titik berat. Ketika analisis melibatkan dua kelompok ada dua centroid, dengan tiga kelompok titik berat. Ketika analisis melibatkan dua kelompok ada dua centroid, dengan tiga kelompok ada tiga centroid, dan sebagainya. Para centroid menunjukkan letak paling khas dari setiap ada tiga centroid, dan sebagainya. Para centroid menunjukkan letak paling khas dari setiap anggota dari kelompok tertentu, dan perbandingan dari centroid kelompok menunjukkan anggota dari kelompok tertentu, dan perbandingan dari centroid kelompok menunjukkan seberapa jauh kelompok-kelompok yang dalam bentuk
seberapa jauh kelompok-kelompok yang dalam bentuk adalah fungsi diskriminan.adalah fungsi diskriminan.
Uji untuk signifikansi statistik dari fungsi diskriminan adalah ukuran umum dari jarak Uji untuk signifikansi statistik dari fungsi diskriminan adalah ukuran umum dari jarak antara centroid kelompok, dihitung dengan membandingkan distribusi dari skor diskriminan antara centroid kelompok, dihitung dengan membandingkan distribusi dari skor diskriminan untuk kelompok. Jika tumpang tindih cukup besar, fungsi adalah diskriminator yang buruk untuk kelompok. Jika tumpang tindih cukup besar, fungsi adalah diskriminator yang buruk antara kelompok-kelompok. Dua distribusi skor diskriminan ditunjukkan pada
antara kelompok-kelompok. Dua distribusi skor diskriminan ditunjukkan pada gambar 1gambar 1 lebih menggambarkan konsep ini.
lebih menggambarkan konsep ini. Diagra Diagram m atasatas mewakili distribusi skor diskriminan untuk mewakili distribusi skor diskriminan untuk fungsi yang memisahkan kelompok-kelompok dengan baik, menunjukkan tumpang tindih fungsi yang memisahkan kelompok-kelompok dengan baik, menunjukkan tumpang tindih
minim (daerah yang diarsir) antara kelompok.
minim (daerah yang diarsir) antara kelompok. Diagram bawah Diagram bawah menunjukkan distribusi skormenunjukkan distribusi skor diskriminan pada fungsi diskriminan yang merupakan diskriminator relatif miskin antara diskriminan pada fungsi diskriminan yang merupakan diskriminator relatif miskin antara kelompok A dan B. daerah yang diarsir tumpang tindih merupakan contoh di mana kelompok A dan B. daerah yang diarsir tumpang tindih merupakan contoh di mana misclassifying objek dari grup A ke kelompok B dan
misclassifying objek dari grup A ke kelompok B dan sebaliknya dapat terjadi.sebaliknya dapat terjadi.
2.2 HAL-HAL POKOK TENTANG ANALISIS DI
2.2 HAL-HAL POKOK TENTANG ANALISIS DISKRIMINANSKRIMINAN
Tujuan Analisis Diskriminan
Tujuan Analisis Diskriminan
Karena bentuk multivariat dari analisis diskriminan adalah dependen, maka variabel
Karena bentuk multivariat dari analisis diskriminan adalah dependen, maka variabel
dependen adalah variabel yang menjadi dasar analisis diskriminan. Variabel dependen bisa
dependen adalah variabel yang menjadi dasar analisis diskriminan. Variabel dependen bisa
berupa kode grup 1 atau kode grup 2 atau lainnya, dengan tujuan diskriminan secara umum
berupa kode grup 1 atau kode grup 2 atau lainnya, dengan tujuan diskriminan secara umum
adalah :
adalah :
Ingin mengetahIngin mengetahui apakah ada ui apakah ada perbedaan perbedaan yang yang jelas antar grup pjelas antar grup pada variabelada variabel
dependen, atau bisa dikatakan apakah ada perbedaan antara anggota grup 1
dependen, atau bisa dikatakan apakah ada perbedaan antara anggota grup 1
dengan anggota grup 2.
dengan anggota grup 2.
Jika ada perbedaan, variabel independen manakah pada fungsi diskriminanJika ada perbedaan, variabel independen manakah pada fungsi diskriminan
yang membuat perbedaan tersebut.
yang membuat perbedaan tersebut.
Membuat fungsi atau model diskriminan, yang pada dasarnya mirip denganMembuat fungsi atau model diskriminan, yang pada dasarnya mirip dengan
persamaan regresi.
persamaan regresi.
Melakukan klasifikasi terhadap objek (dalam teminologi SPSS disebut baris),Melakukan klasifikasi terhadap objek (dalam teminologi SPSS disebut baris),
apakah suatu objek (bisa nama orang, nama tumbuhan, benda atau lainnya)
apakah suatu objek (bisa nama orang, nama tumbuhan, benda atau lainnya)
termasuk grup 1 atau
termasuk grup 1 atau grup 2, atau lainnya.grup 2, atau lainnya.
Syarat-Syarat yang harus Dipenuhi untuk Menggunakan Teknik Analisis Diskriminan
Syarat-Syarat yang harus Dipenuhi untuk Menggunakan Teknik Analisis Diskriminan
Variabel tergantung hanya satu dan bersifat non-metrik, artinya data harusVariabel tergantung hanya satu dan bersifat non-metrik, artinya data harus kategorikal dan berskala nominal.
kategorikal dan berskala nominal.
Variabel bebas terdiri lebih dari dua variabel dan berskala interval.Variabel bebas terdiri lebih dari dua variabel dan berskala interval.
Semua variabel prediktor sebaiknya mempunyai distribusi normal multivariat,Semua variabel prediktor sebaiknya mempunyai distribusi normal multivariat, dan
dan matrices variance-covariancematrices variance-covariance dalam kelompok harus sama untuk semuadalam kelompok harus sama untuk semua kelompok
Keanggotaan kelompok diasumsikan ekseklusif, maksudnya tidak satupun kasusKeanggotaan kelompok diasumsikan ekseklusif, maksudnya tidak satupun kasus yang termasuk dalam kelompok lebih dari satu. dan
yang termasuk dalam kelompok lebih dari satu. dan exhaustiveexhaustive secara kolektif,secara kolektif, maksudnya semua kasus merupakan anggota satu kelompok
maksudnya semua kasus merupakan anggota satu kelompok
Tidak ada korelasi antar variabel independen. Jika dua variabel independenTidak ada korelasi antar variabel independen. Jika dua variabel independen
mempunyai korelasi yang kuat, dikatakan terjadi
mempunyai korelasi yang kuat, dikatakan terjadi multikolinieritas.multikolinieritas.
Multivaria Multivariate normalityte normality, atau variabel independen seharusnya berditribusi normal., atau variabel independen seharusnya berditribusi normal.
Jika tidak berdistribusi normal, hal ini akan menyebabkan masalah pada
Jika tidak berdistribusi normal, hal ini akan menyebabkan masalah pada
ketetapan fungsi (model) diskriminan. Regresi Logistik (
ketetapan fungsi (model) diskriminan. Regresi Logistik ( Logistc Regress Logistc Regressionion) bisa) bisa
dijadikan alternative metode jika memang data tidak
dijadikan alternative metode jika memang data tidak berdistribusi normal.berdistribusi normal.
Matriks kovarians dari Matriks kovarians dari semua variabel independen seharusnysemua variabel independen seharusnya sama a sama ((equal.equal.))
Tidak adanya data yang sangat ekstrem (Tidak adanya data yang sangat ekstrem (outlier outlier ) pada variabel independen. Jika) pada variabel independen. Jika
ada data
ada data outlier outlier yang tetap diproses, Hal ini bisa berakibat berkurangnyayang tetap diproses, Hal ini bisa berakibat berkurangnya
ketetapan klasifikasi dari fungsi di
ketetapan klasifikasi dari fungsi diskriminan.skriminan.
Proses Dasar dari Diskriminan Analisis
Proses Dasar dari Diskriminan Analisis
Proses dasar analisis diskriminan meliputi :
Proses dasar analisis diskriminan meliputi :
Memisah variabel-variabel menjadi variabel dependen dan Memisah variabel-variabel menjadi variabel dependen dan variabel independen.variabel independen.
Menentukan metode untuk membuat fungsi diskriminan. Pada prinsipnya ada duaMenentukan metode untuk membuat fungsi diskriminan. Pada prinsipnya ada dua
metode dasar untuk itu, yaitu:
metode dasar untuk itu, yaitu:
1.
1. SIMULTANEOUS ESTIMATION SIMULTANEOUS ESTIMATION , di mana semua variabel dimasukkan secara, di mana semua variabel dimasukkan secara
bersama-sama kemudian dilakukan proses diskriminan.
bersama-sama kemudian dilakukan proses diskriminan.
2.
2. STEP-WISE ESTIMATION STEP-WISE ESTIMATION , dimana variabel dimasukkan satu per satu ke dalam, dimana variabel dimasukkan satu per satu ke dalam
modeldiskriminan. Pada proses ini, tentu ada variabel yang tetap ada pada model,
modeldiskriminan. Pada proses ini, tentu ada variabel yang tetap ada pada model,
dan ada kemungkinan satu atau lebih variabel independen yang ‘dibuang’ dari
dan ada kemungkinan satu atau lebih variabel independen yang ‘dibuang’ dari
model.
model.
Menguji signifikasi dari fungsi diskriminan yang telah terbentuk, menggunakanMenguji signifikasi dari fungsi diskriminan yang telah terbentuk, menggunakan
Wilk
Wilk ’s Lambda’s Lambda, Pilai,, Pilai, F-test F-test dan lainnya.dan lainnya.
Menguji Menguji ketetapan ketetapan klasifikasi klasifikasi dari dari fungsi fungsi diskriminan, diskriminan, termasuk termasuk mengetahuimengetahui
ketepatan klasifikasi secara
ketepatan klasifikasi secara individual denganindividual dengan Casewise DiagnoticsCasewise Diagnotics..
Melakukan interpretasi terhadap fungsi diskrimminan tersebut.Melakukan interpretasi terhadap fungsi diskrimminan tersebut.
Melekukan uji validasi fungsi diskriminan.Melekukan uji validasi fungsi diskriminan.
Jumlah Sampel pada
Secara pasti tidak ada jumlah sampel yang ideal pada analisis diskriminan. Setiap
Secara pasti tidak ada jumlah sampel yang ideal pada analisis diskriminan. Setiap
variabel independen sebaiknya ada 5-20 data (sampel). Dengan demikian, jika ada enam
variabel independen sebaiknya ada 5-20 data (sampel). Dengan demikian, jika ada enam
variabel independen, seharusny
variabel independen, seharusnya minimal a minimal ada 6x5=30 sampel.ada 6x5=30 sampel.
Selain itu, pada analisis diskriminan sebaiknya digunakan dua jenis sampel, yakni
Selain itu, pada analisis diskriminan sebaiknya digunakan dua jenis sampel, yakni
analysis sampel
analysis sampel yang yang digunakan digunakan untuk untuk Fungsi Fungsi DiskrimDiskriminan, inan, sertaserta holdout sample (splitholdout sample (split
sample)
sample) yang digunakan untuk menguji hasil diskriminan. Sebagai contoh, jika ada 70yang digunakan untuk menguji hasil diskriminan. Sebagai contoh, jika ada 70
sampel, maka sampel tersebut bisa dibagi dua, 35 unntuk analysis sampel dan 35 untuk
sampel, maka sampel tersebut bisa dibagi dua, 35 unntuk analysis sampel dan 35 untuk
holdout sample. Kemudian hasil fungsi diskriminan yang terjadi pada analisis sample
holdout sample. Kemudian hasil fungsi diskriminan yang terjadi pada analisis sample
dibandingkan de
dibandingkan dengan hasil fungngan hasil fungsi diskriminan si diskriminan dari holdout sampdari holdout sample, apakah terjadi perbedle, apakah terjadi perbedaanaan
yang besar atau tidak. Jika ketetapan klasifikasi kedua sampel hampir sama besar, dikatakn
yang besar atau tidak. Jika ketetapan klasifikasi kedua sampel hampir sama besar, dikatakn
fungsi diskriminan dari analisis sampel sudah valid. Inillah yang disebut proses validasi
fungsi diskriminan dari analisis sampel sudah valid. Inillah yang disebut proses validasi
silang (Cross Validation) dari fungsi diskriminan.
silang (Cross Validation) dari fungsi diskriminan.
Model dari Analisis Diskriminan
Model dari Analisis Diskriminan
Analisis diskriminan termasuk dalam
Analisis diskriminan termasuk dalam multivariate dependence method,multivariate dependence method, dengan model :dengan model :
Y
Y11 = = XX11+X+X22+…..+X+…..+Xnn
Non
Non metriks metriks Metrik Metrik
Keterangan :
Keterangan :
Variabel Independen (XVariabel Independen (X11 dan Seterusnya) adalah data metrik, yakni data berjenisdan Seterusnya) adalah data metrik, yakni data berjenis
interval atau rasio, seperti Usia seseorang, tinggi sebuah pohon, kandungan zat besi
interval atau rasio, seperti Usia seseorang, tinggi sebuah pohon, kandungan zat besi
dalam tubuh,
dalam tubuh, dan seterusnya.dan seterusnya.
Variabel Dependen (YVariabel Dependen (Y11) adalah data kategorikal atau nominal, seperti golongan) adalah data kategorikal atau nominal, seperti golongan
miskin (kode 1), golongan menengah (kode 2), golongan kaya (kode 3) dan
miskin (kode 1), golongan menengah (kode 2), golongan kaya (kode 3) dan
sebagainya. Jika data kategorikal tersebut hanya terdiri atas dua kode saja (missal
sebagainya. Jika data kategorikal tersebut hanya terdiri atas dua kode saja (missal
kode 1 untuk daerah banjir dan kode 2 untuk daerah non banjir), maka model bisa
kode 1 untuk daerah banjir dan kode 2 untuk daerah non banjir), maka model bisa
disebut Two
disebut Two-Group Discriminant Analysis-Group Discriminant Analysis. Sedang jika kode lebih dari dua kategori. Sedang jika kode lebih dari dua kategori
disebut dengan
disebut dengan Multiple Multiple DiscriminDiscriminant Analant Analysis.ysis.
Dari keterangan di atas, perhatikan adanya perbedaan dalam penempatan data yangDari keterangan di atas, perhatikan adanya perbedaan dalam penempatan data yang
sekilas mirip. Seperti
sekilas mirip. Seperti Usia seseorang (dalam tahun). Jika usia Usia seseorang (dalam tahun). Jika usia disebut secara langsungdisebut secara langsung
sekian tahun (17 tahun, 32 tahun dan sebagainya), maka data tersebut adalah rasio dan
otomatis diperlakukan sebagai variabel independen. Namun, jika usia seseorang
otomatis diperlakukan sebagai variabel independen. Namun, jika usia seseorang
dilakukan
dilakukan penggolonga penggolongan, n, dan dan dimasukkadimasukkan n dalam dalam kategori-katkategori-kategori egori tertentu,tertentu, sepertiseperti
jika
jika usia usia seseorang seseorang antara antara 15-20 15-20 tahun, tahun, ia ia digolongdigolongkankan Remaja Remaja, di atas 20 tahun, di atas 20 tahun
digolongkan dewasa, maka data seseorang
digolongkan dewasa, maka data seseorang yang berusia 17 tahun tidak ditulis ‘17’,yang berusia 17 tahun tidak ditulis ‘17’,
namun akan ditulis Remaja. Data hasil kategorisasi ini adalah data nominal dan
namun akan ditulis Remaja. Data hasil kategorisasi ini adalah data nominal dan
termasuk variabel dependen.
termasuk variabel dependen.
Dengan demikian, usia 17 tahun bisa menjadi variabel dependen atau independen
Dengan demikian, usia 17 tahun bisa menjadi variabel dependen atau independen
tergantung bagaimana data tersebut akan diperlakukan, langsung diinput apa adanya atau
tergantung bagaimana data tersebut akan diperlakukan, langsung diinput apa adanya atau
dilakukan penggolongan.
dilakukan penggolongan.
2.3 PROSES PENGAMBILAN KEPUTUSAN UNTUK ANALISIS DISKRIMINAN 2.3 PROSES PENGAMBILAN KEPUTUSAN UNTUK ANALISIS DISKRIMINAN Tahap 1
Tahap 1 Tujuan dari Analisis DiskriminanTujuan dari Analisis Diskriminan
Kajian dari tujuan untuk menerapkan analisis diskriminan lebih lanjut harus Kajian dari tujuan untuk menerapkan analisis diskriminan lebih lanjut harus mengklarifikasi sifatnya. Analisis diskriminan dapat mengatasi salah satu tujuan penelitian mengklarifikasi sifatnya. Analisis diskriminan dapat mengatasi salah satu tujuan penelitian sebagai berikut
sebagai berikut 1.
1. menentukan apakah ada perbedaan statistik yang signifikan antara profil menentukan apakah ada perbedaan statistik yang signifikan antara profil rata skor padarata skor pada satu himpunan variabel untuk dua (atau lebih) kelompok
satu himpunan variabel untuk dua (atau lebih) kelompok didefinisikandidefinisikan priori priori.. 2.
2. menentukan yang mana dari perhitungan variabel independen yang paling terjadinyamenentukan yang mana dari perhitungan variabel independen yang paling terjadinya perbedaan dalam profil skor rata-rata
perbedaan dalam profil skor rata-rata dua atau lebih kelompok.dua atau lebih kelompok. 3.
3. menetapkan jumlah dan komposisi dimensi diskriminasi antara kelompok-kelompok menetapkan jumlah dan komposisi dimensi diskriminasi antara kelompok-kelompok yang terbentuk dari
yang terbentuk dari himpunan variabel independenhimpunan variabel independen 4.
4. menetapkan prosedur untuk mengklasifikasikan objek (individu, perusahaan, produk,menetapkan prosedur untuk mengklasifikasikan objek (individu, perusahaan, produk, dll) ke dalam kelompok berdasarkan skor mereka pada sekumpulan variabel dll) ke dalam kelompok berdasarkan skor mereka pada sekumpulan variabel independen
independen Tahap 2
Tahap 2 Desain Penelitian untuk Analisis DiskriminanDesain Penelitian untuk Analisis Diskriminan 1.
1. memilih variabel memilih variabel dependen dan independendependen dan independen 2.
2. ukuran sampelukuran sampel 3.
3. pembagian sampelpembagian sampel Tahap 3
Tahap 3 Asumsi Analisis DiskriminanAsumsi Analisis Diskriminan 1.
2.
2. dampak pada interpretasidampak pada interpretasi Tahap 4
Tahap 4 Estimasi dari Estimasi dari Model Diskriminan serta Menilai Kesesuaian secara KeseluruhanModel Diskriminan serta Menilai Kesesuaian secara Keseluruhan 1.
1. memilih metode estimasimemilih metode estimasi 2.
2. signifikansi statistik signifikansi statistik 3.
3. menilai secara keseluruhan sesuai dengan modelmenilai secara keseluruhan sesuai dengan model 4.
4. casewise diagonisticcasewise diagonistic Tahap 5
Tahap 5 Interpretasi HasilInterpretasi Hasil 1.
1. bobot diskriminanbobot diskriminan 2.
2. diskriminan bebandiskriminan beban 3.
3. parsial nilai Fparsial nilai F 4.
4. interpretasi dari dua atau lebih interpretasi dari dua atau lebih fungsifungsi 5.
5. metode interpretatif metode interpretatif yang digunakanyang digunakan Tahap 6
Tahap 6 Validasi HasilValidasi Hasil 1.
1. validasi prosedurvalidasi prosedur 2.
2. membuat profil membuat profil perbedaan kelompok perbedaan kelompok
2.4
2.4 APLIKASI DALAM MENGANALISIS MODEL DISKRIMINANAPLIKASI DALAM MENGANALISIS MODEL DISKRIMINAN
1.
1. Perumusan masalahPerumusan masalah
Rumuskan permasalah yang akan dianalisis meliputi penentuan variabel independen Rumuskan permasalah yang akan dianalisis meliputi penentuan variabel independen dan variabel
dan variabel dependen.dependen. 2.
2. Uji variabelUji variabel
Menguji apakah ada variabel yang berbeda secara nyata antara satu variabel dengan Menguji apakah ada variabel yang berbeda secara nyata antara satu variabel dengan variabel lain. Men
variabel lain. Menentukan variabentukan variabel independen el independen mana ymana yang mempengang mempengaruhi variabelaruhi variabel dependen. Menguji varians dari
dependen. Menguji varians dari setiap variabel.setiap variabel. 3.
3. Melakukan analisis diskriminanMelakukan analisis diskriminan
Menentukan model diskriminan dari permasalahan yang ada. Menguji ketepatan Menentukan model diskriminan dari permasalahan yang ada. Menguji ketepatan pengklasifikasian model.
pengklasifikasian model. 4.
BAB 3 BAB 3 PENUTUP PENUTUP
Analisis diskriminan adalah teknik statistik yang sesuai ketika variabel dependen Analisis diskriminan adalah teknik statistik yang sesuai ketika variabel dependen adalah kategori (nominal atau
adalah kategori (nominal atau nonmetrik) variabel dan variabel inonmetrik) variabel dan variabel independen adalah variabendependen adalah variabell metrik. Dalam banyak hal, variabel dependen terdiri dari
metrik. Dalam banyak hal, variabel dependen terdiri dari dua kelompok atau klasifikasidua kelompok atau klasifikasi (contoh. laki-laki dibandingkan perempuan atau tinggi versus rendah).
(contoh. laki-laki dibandingkan perempuan atau tinggi versus rendah). Dengan fungsiDengan fungsi diskriminan sebagai berikut:
diskriminan sebagai berikut:
Tujuan dari an
Tujuan dari analisis diskriminan sealisis diskriminan secara umum cara umum adalahadalah mengetahui apakah adamengetahui apakah ada
perbedaan ya
perbedaan yang ng jelas antar grup pada variabel depenjelas antar grup pada variabel dependen, menentukden, menentukan model diskriminanan model diskriminan
dari suatu
dari suatu permasalahanpermasalahan. Jika . Jika model tersebut sudah diperoleh selanjutnya akan dilakukanmodel tersebut sudah diperoleh selanjutnya akan dilakukan
pengujian ketepatan klasifikasi model.
pengujian ketepatan klasifikasi model.
Model dari analisis diskriminan
Model dari analisis diskriminan dapat digudapat digunakan untuk mencnakan untuk mencari hubungan antaraari hubungan antara
variabel dependen dengan variabel
BAB II
BAB II
PEMBAHASAN
PEMBAHASAN
2.1.Analisis Diskiminan (Analisis Fungsi Pembeda ) 2.1.Analisis Diskiminan (Analisis Fungsi Pembeda )
Menurut Johnson dan Wichern (2007) Analisis Diskriminan digunakan untuk Menurut Johnson dan Wichern (2007) Analisis Diskriminan digunakan untuk mengklasifikasikan individu ke dalam salah satu dari dua kelompok atau lebih. Suatu mengklasifikasikan individu ke dalam salah satu dari dua kelompok atau lebih. Suatu fungsi diskriminan layak untuk dibentuk, bila terdapat perbedaan nilai rataan di antara fungsi diskriminan layak untuk dibentuk, bila terdapat perbedaan nilai rataan di antara kelompok-kelompok yang ada.
kelompok-kelompok yang ada.
Analisis diskriminan merupakan suatu teknis analisis multivariat yang digunakan Analisis diskriminan merupakan suatu teknis analisis multivariat yang digunakan untuk mengelompokkan atau mengklasifik
untuk mengelompokkan atau mengklasifikasi suatu objek asi suatu objek dalam dua kelompok atau lebihdalam dua kelompok atau lebih berdasarkan variabel independentnya.
berdasarkan variabel independentnya.
Sebelum fungsi diskriminan dibentuk perlu dilakukan pengujian terhadap perbedaan Sebelum fungsi diskriminan dibentuk perlu dilakukan pengujian terhadap perbedaan nilai rataan dari kelompok-kelompok tersebut. Dalam pengujian tersebut, asumsi analisis nilai rataan dari kelompok-kelompok tersebut. Dalam pengujian tersebut, asumsi analisis diskriminan yang harus dipenuhi adalah :
diskriminan yang harus dipenuhi adalah : 1.
1. Variabel independen seharusnya berdistribusi normal multivariat (Variabel independen seharusnya berdistribusi normal multivariat ( Multiv Multivariateariate Normality
Normality), jika data tidak berdistribusi normal,akan menyebabkan masalah pada), jika data tidak berdistribusi normal,akan menyebabkan masalah pada ketepatan fungsi (model) diskriminan.
ketepatan fungsi (model) diskriminan. 2.
2. Matriks varians kovarians grup dari Matriks varians kovarians grup dari semua variabel semua variabel independindependen seharusnya sama.en seharusnya sama. 3.
3. Tidak ada data yang sangat ekstrim (Tidak ada data yang sangat ekstrim ( outlier outlier ) pada variabel independen, jika ada data) pada variabel independen, jika ada data ekstrim yang tetap diproses, hal ini bisa berakibat berkurangnya ketepatan klasifikasi ekstrim yang tetap diproses, hal ini bisa berakibat berkurangnya ketepatan klasifikasi dari fungsi diskriminan.
dari fungsi diskriminan. 4.
4. Tidak ada korelasi yang kuat antar-variabel independen , jika Tidak ada korelasi yang kuat antar-variabel independen , jika dua variabel independendua variabel independen mempunyai korelasi yang kuat,dikatakan terjadi multikolinieritas. Untuk mengetahui mempunyai korelasi yang kuat,dikatakan terjadi multikolinieritas. Untuk mengetahui adanya multikolinieritas dapat dilakukan dengan melihat korelasi antar variabel adanya multikolinieritas dapat dilakukan dengan melihat korelasi antar variabel independen (r) yaitu jika ni
independen (r) yaitu jika nilai r > lai r > 0.6 menunjukkan adany0.6 menunjukkan adanya multikolinieritas.a multikolinieritas.
2.2.
2.2.Fungsi DiskriminanFungsi Diskriminan
0 0 1 1 1 ii1 2 2 2ii2 ... jj iijj Y b Y b b
b X X b
b X X
b X b X dimana : dimana :Y
Y = Nilai (skor) fungsi diskriminan dari responden ke-i= Nilai (skor) fungsi diskriminan dari responden ke-i
0 0 b
b = Intersep (konstanta), artinya jika nilai variabel= Intersep (konstanta), artinya jika nilai variabel X X
00 , maka besar nilai, maka besar nilai Y Y b
b00j j b
b = Koefisien fungsi diskriminan dari variabel ke= Koefisien fungsi diskriminan dari variabel ke-j-j
ij ij X
X = Variabel bebas ke-j dari responden ke-i , dimana i = 1,2,...,n= Variabel bebas ke-j dari responden ke-i , dimana i = 1,2,...,n
2.3.
2.3.Jumlah Sampel pada Analisis DiskriminanJumlah Sampel pada Analisis Diskriminan
Secara pasti tidak ada jumlah sampel yang ideal pada analisis diskriminan. Setiap
Secara pasti tidak ada jumlah sampel yang ideal pada analisis diskriminan. Setiap
variabel independen sebaiknya ada 5-20 data (sampel). Dengan demikian, jika ada enam
variabel independen sebaiknya ada 5-20 data (sampel). Dengan demikian, jika ada enam
variabel independen, seharusny
variabel independen, seharusnya minimal ada a minimal ada 6x5=30 sampel.6x5=30 sampel.
Selain itu, pada analisis diskriminan sebaiknya digunakan dua jenis sampel, yakni
Selain itu, pada analisis diskriminan sebaiknya digunakan dua jenis sampel, yakni
analisis sampel
analisis sampel yang yang digunakan udigunakan untuk Fungsntuk Fungsi Diskriminan, sertai Diskriminan, serta holdout sample (splitholdout sample (split
sample)
sample) yang digunakan untuk menguji hasil diskriminan. Sebagai contoh, jika ada 70yang digunakan untuk menguji hasil diskriminan. Sebagai contoh, jika ada 70
sampel, maka sampel tersebut bisa dibagi dua, 35 unntuk analysis sampel dan 35 untuk
sampel, maka sampel tersebut bisa dibagi dua, 35 unntuk analysis sampel dan 35 untuk
holdout sample. Kemudian hasil fungsi diskriminan yang terjadi pada analysis sample
holdout sample. Kemudian hasil fungsi diskriminan yang terjadi pada analysis sample
dibandingkan
dibandingkan dengan dengan hasil funghasil fungsi diskriminan si diskriminan dari hodari holdout samplldout sample, apake, apakah terjadiah terjadi
perbedaan yang besar ataukah tidak. Jika ketetapan klasifikasi kedua sampel hampir sama
perbedaan yang besar ataukah tidak. Jika ketetapan klasifikasi kedua sampel hampir sama
besar, dikatakn fungsi diskriminan dari analysis sampel sudah valid. Inillah yang disebut
besar, dikatakn fungsi diskriminan dari analysis sampel sudah valid. Inillah yang disebut
proses validasi silang (Cross Validation) dari
proses validasi silang (Cross Validation) dari fungsi diskriminan.fungsi diskriminan.
2.4.Tujuan Analisis Diskriminan
2.4.Tujuan Analisis Diskriminan
Karena bentuk multivariat dari analisis diskriminan adalah dependen, maka
Karena bentuk multivariat dari analisis diskriminan adalah dependen, maka
variabel dependen adalah variabel yang menjadi dasar analisis diskriminan. Variabel
variabel dependen adalah variabel yang menjadi dasar analisis diskriminan. Variabel
dependen bisa berupa kode grup 1 atau kode grup 2 atau lainnya, dengan tujuan
dependen bisa berupa kode grup 1 atau kode grup 2 atau lainnya, dengan tujuan
diskriminan secara umum adalah :
diskriminan secara umum adalah :
Ingin mengetahui apakah ada perbedaan yang jelas antar grup pada variabelIngin mengetahui apakah ada perbedaan yang jelas antar grup pada variabel
dependen? Atau bisa dikatakan apakah ada perbedaan antara anggota grup 1
dependen? Atau bisa dikatakan apakah ada perbedaan antara anggota grup 1
dengan anggota grup 2?
dengan anggota grup 2?
Jika ada perbedaan, variabel independen manakah pada fungsi diskriminan yangJika ada perbedaan, variabel independen manakah pada fungsi diskriminan yang
membuat perbedaan tersebut?
Membuat fungsi atau model diskriminan, yang pada dasarnya mirip denganMembuat fungsi atau model diskriminan, yang pada dasarnya mirip dengan
persamaan regresi.
persamaan regresi.
Melakukan klasifikasi terhadap objek (dalam teminologi SPSS disebut baris),Melakukan klasifikasi terhadap objek (dalam teminologi SPSS disebut baris),
apakah suatu objek (bisa nama orang, nama tumbuhan, benda atau lainnya)
apakah suatu objek (bisa nama orang, nama tumbuhan, benda atau lainnya)
termasuk grup 1 atau grup 2,
termasuk grup 1 atau grup 2, atau lainnya.atau lainnya.
2.5.Proses Dasar dari Analisis Diskriminan
2.5.Proses Dasar dari Analisis Diskriminan
Proses dasar analisis diskriminan :
Proses dasar analisis diskriminan :
Memisah variabel-variabel menjadi variabel dependen dan Variabel Independen.Memisah variabel-variabel menjadi variabel dependen dan Variabel Independen.
Menentukan metode untuk membuat fungsi diskriminan. Pada prinsipnya ada duaMenentukan metode untuk membuat fungsi diskriminan. Pada prinsipnya ada dua
metode dasar untuk itu, yaitu:
metode dasar untuk itu, yaitu:
3.
3. SIMULTANEOUS ESTIMATION, di mana semua variabel dimasukkanSIMULTANEOUS ESTIMATION, di mana semua variabel dimasukkan
secara bersama-sama kemudian dilakukan proses diskriminan.
secara bersama-sama kemudian dilakukan proses diskriminan.
4.
4. STEP-WISE ESTIMATION, dimana variabel dimasukkan satu per satu keSTEP-WISE ESTIMATION, dimana variabel dimasukkan satu per satu ke
dalam modeldiskriminan. Pada proses ini, tentu ada
dalam modeldiskriminan. Pada proses ini, tentu ada variabel yang tetap adavariabel yang tetap ada
pada model, dan ada kemungkinan satu atau lebih variabel independen
pada model, dan ada kemungkinan satu atau lebih variabel independen
yang ‘dibuang’ dari model.
yang ‘dibuang’ dari model.
Menguji signifikasi dari fungsi diskriminan yang telah terbentuk, menggunakanMenguji signifikasi dari fungsi diskriminan yang telah terbentuk, menggunakan
Wilk’s Lambda, Pilai, F test dan lainnya.
Wilk’s Lambda, Pilai, F test dan lainnya.
Menguji Menguji ketetapan ketetapan klasifikasi klasifikasi dari dari fungsi fungsi diskriminan, termasdiskriminan, termasuk muk mengetahuiengetahui
ketetpan klasifikasi secara individual dengan casewise Diagnotics.
ketetpan klasifikasi secara individual dengan casewise Diagnotics.
Melakukan interpretasi terhadap fungsi diskrimminan tersebut.Melakukan interpretasi terhadap fungsi diskrimminan tersebut.
Melekukan uji validasi fMelekukan uji validasi fungsi diskriminan.ungsi diskriminan.
a.
a. Algoritma Pokok Analisis dan Model MatematikaAlgoritma Pokok Analisis dan Model Matematika
Secara ringkas, langkah-langkah dalam analisis diskriminan adalah
Secara ringkas, langkah-langkah dalam analisis diskriminan adalah sebagsebagai berikut:ai berikut: 1.
1. Pengecekan adanya kemungkinan hubungan linier antara variabel penjelas. Untuk Pengecekan adanya kemungkinan hubungan linier antara variabel penjelas. Untuk point
point ini, dilakukan dengan bantuan matriks korelasi (pembentukan matriks korelasiini, dilakukan dengan bantuan matriks korelasi (pembentukan matriks korelasi sudah difasilitasi pada analisis diskriminan). Pada output SPSS, matriks korelasi bisa sudah difasilitasi pada analisis diskriminan). Pada output SPSS, matriks korelasi bisa dilihat pada
dilihat pada Pooled Within-Groups MatricesPooled Within-Groups Matrices.. 2.
0 0 1 1 22 1 1 1 1 22 :: :: H H H H
Diharapkan dari uji ini adalah hipotesis nol ditolak, sehingga kita mempunyai Diharapkan dari uji ini adalah hipotesis nol ditolak, sehingga kita mempunyai informasi awal bahwa variabel yang sedang diteliti memang membedakan kedua informasi awal bahwa variabel yang sedang diteliti memang membedakan kedua kelompok. Pada SPSS, uji ini dilakukan secara univariate (jadi yang diuji bukan kelompok. Pada SPSS, uji ini dilakukan secara univariate (jadi yang diuji bukan berupa vektor), dengan bantuan tabel
berupa vektor), dengan bantuan tabel Tests of Equality of Group MeansTests of Equality of Group Means .. 3.
3. Dilanjutkan pemeriksaan asumsi Dilanjutkan pemeriksaan asumsi homoskehomoskedastisitas, dengan ujidastisitas, dengan uji Box’s MBox’s M. Diharapkan. Diharapkan dari uji ini hipotesisi nol tidak ditolak (
dari uji ini hipotesisi nol tidak ditolak ( H H 0 0 ::
1 1
22).). 4.4. Pembentukan model diskriminanPembentukan model diskriminan a.
a. Kriteria Fungsi Linier FisherKriteria Fungsi Linier Fisher
Pembentukan Fungsi Pembentukan Fungsi Linier (teoritis)Linier (teoritis)
Fisher mengelompokkan suatu observasi berdasarkan nilai skor yang Fisher mengelompokkan suatu observasi berdasarkan nilai skor yang dihitung dari suatu fungsi linier
dihitung dari suatu fungsi linierY Y
''X X dimanadimana ''menyatakan vektormenyatakan vektor yang berisi koefisien-koefisien variabel penjelas yang membentuk yang berisi koefisien-koefisien variabel penjelas yang membentuk persamaan linier terhadap variabel respon,persamaan linier terhadap variabel respon, ' '
1 1 , , ,,...,, 22 p p
1 1 2 2 X X X X X X
k k XX menyatakan matriks data padakelomok ke-k menyatakan matriks data padakelomok ke-k
1 111 1122 11 2 211 2222 22 1 1 22 X X . . .. X X . . .. . . . . .. . . . . .. . . . . .. . . . . .. .. .. k k kk ppkk k k kk ppkk k k n n kk nn kk nnppkk X X X X X X X X X X X X X X X X
1 1, 2,, 2, ....,...., 1 1, 2,, 2, ....,...., 1 1, 2, 2 i i nn j j pp k k
ijk ijk XX menyatakan observasi ke-i menyatakan observasi ke-i variabel ke-j pada kelompok ke-k variabel ke-j pada kelompok ke-k
Di bawah asumsi
Di bawah asumsi X X k k N N ( ( . . )) k k
k k makamaka2 2 1 1 1 1 2 2 ( ( )) ( ( )) E E X X E E X X
dandan kk E X E ( ( X kk kk) ) ( ( X X kk kk)) '' ;; 1 1 22
1 1 .. . . ;; .. k k k k k k pk pk
adalah vektor rata-rata tiap
adalah vektor rata-rata tiap variable X pada kelompok ke-k variable X pada kelompok ke-k
1 111 1122 11 2 222 2222 . . .. . . . . . . .. . . . . . . . . . . .. . . . . . . . . . . .. . . . . . . . . .. .. p p pp pp
1 1 22 1 1 22 1 1 22 11 22 variavariansi vnsi variabariabel jel j apabapabila j ila j =j=j kov
kovariarians ans vavariariabel bel j j dan j dan j apaapabila j ¹jbila j ¹j
{
{
j j jj
Fisher mentransformasikan observasi-observasi x yang multivariate Fisher mentransformasikan observasi-observasi x yang multivariate menjadi
menjadi
observas
observasi i y yang univariate. Dari y yang univariate. Dari persamaanpersamaan Y Y
X X diperolehdiperoleh;; ( ( ) ) ( ( ' ' ) ) '' k kyy E E Y Y kk E E X X kk
2 2 v vaarr( ( ' ) ' ) ' ' ;; Y Y X X
ky ky adalah rata-rata Y yang diperoleh dari X yang termasuk dalamadalah rata-rata Y yang diperoleh dari X yang termasuk dalam kelompok ke-k kelompok ke-k 2 2 Y Y
adalah varians Y dan diasumsikan sama untuk kedua kelompok.adalah varians Y dan diasumsikan sama untuk kedua kelompok. Kombinasi linier yang terbaik menurut
Kombinasi linier yang terbaik menurut Fisher adalah yang dapatFisher adalah yang dapat memaksimumkan rasio antara jarak kuadrat rata-rata Y
memaksimumkan rasio antara jarak kuadrat rata-rata Y yang diperolehyang diperoleh dari x dari
dari x dari kelompok 1 dan 2 dengan varians Y, atau dirumuskan sebagaikelompok 1 dan 2 dengan varians Y, atau dirumuskan sebagai berikut: berikut: 11 2 2 2 2 11 22 11 22 2 2 ( ( )) ''( ( ))( ( )) '' '' Y
Y Y Y
Y Y
Jika
Jika( ( 1 1
22))
makapersamaan di atas menjadimakapersamaan di atas menjadi2 2 ( ( )) ''
. Karena. Karena ΣΣ adalahadalah matriks definit positif, maka menurut teori pertidaksamaanmatriks definit positif, maka menurut teori pertidaksamaan Cauchy- Cauchy-Schwartz
Schwartz, rasio, rasio
2 2 ( ( )) ''
dapat dimaksimumkan jikadapat dimaksimumkan jika1 1 11 1 1 22 ' ' c c cc ( ( ))
dengan memilih c=1, menghasilkan kombinasi linier yang disebut dengan memilih c=1, menghasilkan kombinasi linier yang disebut
kombinasi linier Fisher sebagai berikut: kombinasi linier Fisher sebagai berikut:
1 1 1 1 22 ' ' ( ( )) Y Y
X X
X X Pembentukan Fungsi Linier (dengan bantuan SPSS)Pembentukan Fungsi Linier (dengan bantuan SPSS)
Pada output SPSS, koefisien untuk tiap variabel yang masuk dalam Pada output SPSS, koefisien untuk tiap variabel yang masuk dalam
model dapat dilihat pada tabel
model dapat dilihat pada tabel Canonical Discriminant FunctionCanonical Discriminant Function Coefficient
Coefficient . Tabel ini akandihasilkan pada output apabila pilihan. Tabel ini akandihasilkan pada output apabila pilihan Function Coefficient
Function Coefficient bagianbagian Unstandardized Unstandardized diaktifkan.diaktifkan.
Menghitung discriminant scoreMenghitungdiscriminant score
Setelah dibentuk fungsi liniernya, maka dapat dihitung skor Setelah dibentuk fungsi liniernya, maka dapat dihitung skor diskriminan untuk tiap observasi dengan memasukkan nilai-nilai diskriminan untuk tiap observasi dengan memasukkan nilai-nilai variabel
variabel penjelasnypenjelasnya.a.
Menghitung cutting scoreMenghitungcutting score Cutting score
Cutting score (m) dapat dihitung dengan rumus sebagai berikut(m) dapat dihitung dengan rumus sebagai berikut
1 1 1 1 2 2 22 1 1 22 Y Y Y Y n n nn m m n n nn
k k nn adalah jumlah sampel pada kelompok ke-k, k=1,2adalah jumlah sampel pada kelompok ke-k, k=1,2 Kemudian nilai-nilai
Kemudian nilai-nilai discriminant scorediscriminant score tiap observasi akantiap observasi akan dibandingkan dengan
dibandingkan dengan cutting cutting scorescore, , sehingga sehingga dapatdapat diklasifikasikan suatu observasi akan termasuk ke dalam kelompok diklasifikasikan suatu observasi akan termasuk ke dalam kelompok yang mana. Suatu observasi dengan karakteristik
yang mana. Suatu observasi dengan karakteristik xx akanakan diklasifikasikan sebagai anggota kelompok kode 1 jika diklasifikasikan sebagai anggota kelompok kode 1 jika
1 1 1 1 22 ( ( )) '' ,, y
y
x x m
m selain itu dimasukkan ke dalam kelompok selain itu dimasukkan ke dalam kelompok 2(kodenol). Penghitungan m dilakukan secara manual, karena 2(kodenol). Penghitungan m dilakukan secara manual, karenaSPSS tidak mengeluarkan output m. Namun, kita dapat SPSS tidak mengeluarkan output m. Namun, kita dapat menghitung m dengan bantuan tabel
menghitung m dengan bantuan tabel Function at Group CentroidsFunction at Group Centroids dari output SPSS.
dari output SPSS.
Penghitungan Hit Penghitungan Hit RatioRatio (dalam model regresi logistik disebut(dalam model regresi logistik disebut percentage
percentage correct correct ))
Setelah semua observasi diprediksi keanggotaannya, dapatdihitung Setelah semua observasi diprediksi keanggotaannya, dapatdihitung
hit ratio
hit ratio, , yaitu yaitu rasio rasio antara antara observasi observasi yang yang tepattepat pengklasifikasianny
pengklasifikasiannya a dengan total dengan total seluruh observasi.seluruh observasi. b.
b. KriteriaKriteria posterior posterior probabilitprobabilityy
Aturan pengklasifikasian yang ekivalen dengan model linier Fisher adalah Aturan pengklasifikasian yang ekivalen dengan model linier Fisher adalah berdasarkan nilai peluang suatu observasi dengan karakteristik tertentu (x) berdasarkan nilai peluang suatu observasi dengan karakteristik tertentu (x) berasal dari suatu kelompok. Nilai peluang ini disebut
berasal dari suatu kelompok. Nilai peluang ini disebut posterior posterior probabilityprobability dan bisa ditampilkan pada sheet SPSS dengan mengaktifkan option dan bisa ditampilkan pada sheet SPSS dengan mengaktifkan option probabilities of group membership padabagian Save di kotak dialog utama. probabilities of group membership padabagian Save di kotak dialog utama.
( ( )) ( ( )) ( ( )) k k k k k k k k k k p p f f xx P P k k xx p p f f xx
Dimana Dimana k k pp adalahadalah prior pr prior probabilityobability kelompok ke-k dankelompok ke-k dan
1 1 1 1 2 2 22 1 1 11 ( ( ) ) eexxp p ( ( ) ) ( ( )); ; 00,,11 2 2 (2 (2 )) k k p p k k k k f f x x x x x x k k
Suatu observasi dengan karakteristik x akan diklasifikasikan sebagai anggota Suatu observasi dengan karakteristik x akan diklasifikasikan sebagai anggota
kelompok 0 jika
kelompok 0 jika P P k ( 0 ( k
0 ) x x P )
P k ( 1 ( k
1 ))xx ..b.
b. Aplikasi dengan Menggunakan SPSSAplikasi dengan Menggunakan SPSS KASUS
KASUS
Sebuah perusahaan bergerak dalam penjualan Air Mineral Dalam Kemasan
Sebuah perusahaan bergerak dalam penjualan Air Mineral Dalam Kemasan
mengumpulkan data sekelompok konsumen air mineral dengan variabel berikut;
mengumpulkan data sekelompok konsumen air mineral dengan variabel berikut;
Kode 0 = SEDIKIT (konsumne yang termasuk tipe sedikit minum air
Kode 0 = SEDIKIT (konsumne yang termasuk tipe sedikit minum air
mineral)
mineral)
Kode 1 = BANYAK (konsumen yang termasuk tipe bnayak minum air
Kode 1 = BANYAK (konsumen yang termasuk tipe bnayak minum air
Mineral)
Mineral)
Usia konsumen (tahun)Usia konsumen (tahun)
Berat badan konsumen (kilogram)Berat badan konsumen (kilogram)
Tinggi badan konsumen (centimeter)Tinggi badan konsumen (centimeter)
Pendapatan konsumen (ribuan Pendapatan konsumen (ribuan rupiah/bulan)rupiah/bulan)
Jam kerja konsumen dalam sehari (jam)Jam kerja konsumen dalam sehari (jam)
Kegiatan olahrKegiatan olahraga konaga konsumen dalam sumen dalam sehari sehari (jam)(jam)
Dari kasus diatas
Dari kasus diatas akan dilakukan analisis diskriminan untuk mengetahui:akan dilakukan analisis diskriminan untuk mengetahui:
Apakah ada perbedaan yang signifikan antara konsumen yang banyak minum Apakah ada perbedaan yang signifikan antara konsumen yang banyak minum airair mineral dengan konsumen yang sedikit minum air mineral?
mineral dengan konsumen yang sedikit minum air mineral?
Jika ada perbedaan yang signifikan, variabel apa saja yang membuat perilakuJika ada perbedaan yang signifikan, variabel apa saja yang membuat perilaku konsumsi air mineral mereka berbeda?
konsumsi air mineral mereka berbeda?
Membuat model diskriminan dua faktor (tipe sedikit dan Membuat model diskriminan dua faktor (tipe sedikit dan tipe banyak) untuk kasustipe banyak) untuk kasus tersebut
tersebut
Menguji ketepatan model (fungsi) diskriminanMenguji ketepatan model (fungsi) diskriminan
TAHAPAN PENGUJIAN ANALISIS DISKRIMINAN TAHAPAN PENGUJIAN ANALISIS DISKRIMINAN
A.
A. MENGUJI VARIABELMENGUJI VARIABEL
MENILAI VARIABEL YANG LAYAK UNTUK ANALISIS MENILAI VARIABEL YANG LAYAK UNTUK ANALISIS Dari SPSS diperoleh output sebagai berikut,
Dari SPSS diperoleh output sebagai berikut,
Tests of Equality of Group Means Tests of Equality of Group Means
..994455 44..224477 11 7733 ..004433 ..993344 55..117733 11 7733 ..002266 ..994466 44..118866 11 7733 ..004444 ..889944 88..665566 11 7733 ..000044 1 1..000000 ..000000 11 7733 ..999944 ..994466 44..118833 11 7733 ..004444 USIA USIA BERAT BERAT TINGGI TINGGI INCOME INCOME JAMKERJA JAMKERJA OLAHRAGA OLAHRAGA Wilks' Wilks' L Laammbbddaa FF ddff 11 ddff 22 SSiigg..
Analisis Analisis
Tabel diatas adalah hasilpengujian untuk setiap
Tabel diatas adalah hasilpengujian untuk setiap variabel bebas yang ada.variabel bebas yang ada. Keputusan bisa diambil lewat dua cara.
Keputusan bisa diambil lewat dua cara.
Dengan angka Wilk’s Dengan angka Wilk’s LambdaLambda Angka
Angka wilk’s Lambda berkisar antara 0 wilk’s Lambda berkisar antara 0 sampai 1. Jika angsampai 1. Jika angka mendekati ka mendekati 0 maka data0 maka data tiap group cenderung berbeda, sedangkan jika angka mendekati 1 maka data tiap tiap group cenderung berbeda, sedangkan jika angka mendekati 1 maka data tiap group cenderung sama.
group cenderung sama.
Dari tabel terlihat angka Wilk’s Lambda berkis
Dari tabel terlihat angka Wilk’s Lambda berkisar antara 0.894 sampai 1.000. Dariar antara 0.894 sampai 1.000. Dari kolom sign
kolom signifikan ifikan dilihat bahwa handilihat bahwa hanya vya variable Jam Keariable Jam Kerja yang rja yang cenderung cenderung tidak tidak berbeda. Hal ini berarti jam kerja untuk mereka yang sedikit atau banyak berbeda. Hal ini berarti jam kerja untuk mereka yang sedikit atau banyak mengkons
mengkonsumsi air umsi air mineral tidak mineral tidak berbeda secara nyata.berbeda secara nyata.
Dengan F testDengan F test
Perhatikan angka signifikan. Perhatikan angka signifikan. Jika sig. > 0.05 berarti
Jika sig. > 0.05 berarti tidak ada perbedaan antar gruptidak ada perbedaan antar grup Jika sig < 0.05 berarti
Jika sig < 0.05 berarti ada perbedaan antar grupada perbedaan antar grup Analisis dari data diatas adalah
Analisis dari data diatas adalah
Variabel Usia, angka sig. < 0.05 (yaitu; 0.043). Variabel Usia, angka sig. < 0.05 (yaitu; 0.043). Hal ini berarti Hal ini berarti ada perbedaanada perbedaan antar grup, atau
antar grup, atau usia responden memengaruusia responden memengaruhi banyak sedikitnyahi banyak sedikitnya mengkons
mengkonsumsi air umsi air mineral.mineral.
Variabel Berat, angka sig. < 0.05 (yaitu; Variabel Berat, angka sig. < 0.05 (yaitu; 0.026). Hal ini berarti 0.026). Hal ini berarti ada perbedaanada perbedaan antar grup, atau
antar grup, atau berat badan responden memengaruhi banyak sedikitnyaberat badan responden memengaruhi banyak sedikitnya mengkons
mengkonsumsi air umsi air mineral.mineral.
Variabel Tinggi, angka sig. < 0.05 (yaitu; 0.044). Variabel Tinggi, angka sig. < 0.05 (yaitu; 0.044). Hal ini berarti Hal ini berarti ada perbedaanada perbedaan antar grup, atau
antar grup, atau tinggi responden memengaruhi banyak sedikitnyatinggi responden memengaruhi banyak sedikitnya mengkons
mengkonsumsi air umsi air mineral.mineral.
Variabel Income, angka sig. < 0.05 (yaitu; 0.004). Hal Variabel Income, angka sig. < 0.05 (yaitu; 0.004). Hal ini berarti adaini berarti ada perbedaan antar grup, atau
perbedaan antar grup, atau income responden memengaruhi banyincome responden memengaruhi banyak sedikitnyaak sedikitnya mengkons
mengkonsumsi air umsi air mineral.mineral.
Variabel Jam Kerja, angka sig. > 0.05 (yaitu; 0.994). Hal ini berarti tidak adaVariabel Jam Kerja, angka sig. > 0.05 (yaitu; 0.994). Hal ini berarti tidak ada perbedaan antar grup, atau
perbedaan antar grup, atau jam kerja responden tidak memengaruhi banyak jam kerja responden tidak memengaruhi banyak sedikitnya mengkon
Variabel Olah Raga, angka sig. < 0.05 (yaitu; 0.44). Hal ini berarti adaVariabel Olah Raga, angka sig. < 0.05 (yaitu; 0.44). Hal ini berarti ada perbedaan antar grup, atau
perbedaan antar grup, atau olah raga responden memengaruhi banyak olah raga responden memengaruhi banyak sedikitnya mengkons
sedikitnya mengkonsumsi air umsi air mineral.mineral.
Dari 6 varible tersebut ada lima variabel berbeda secara signifikan untuk dua group Dari 6 varible tersebut ada lima variabel berbeda secara signifikan untuk dua group diskriminan, yaitu USIA, BERAT, TINGGI, INCOME, OLAH RAGA. Dengan demikian diskriminan, yaitu USIA, BERAT, TINGGI, INCOME, OLAH RAGA. Dengan demikian sedikit atau banyaknya konsumsi air mineral
sedikit atau banyaknya konsumsi air mineral dipengaruhi oleh variabel-variabel tersebut.dipengaruhi oleh variabel-variabel tersebut. UJI VARIANS DARI SETIAP VARIABEL
UJI VARIANS DARI SETIAP VARIABEL,,
Uji selanjutnya adalah menguji varians dari setiap variabel. Dapat dilakukan dengan dua Uji selanjutnya adalah menguji varians dari setiap variabel. Dapat dilakukan dengan dua
cara yaitu dengan Box’s M a
cara yaitu dengan Box’s M atau dilihat dari tau dilihat dari output LOG DETERMINANoutput LOG DETERMINANT.T. Analisis diskriminan mempunyai asumsi bahwa:
Analisis diskriminan mempunyai asumsi bahwa:
Varians variabel bebas untuk tiap grup seharusnya sama. Jika demikian,Varians variabel bebas untuk tiap grup seharusnya sama. Jika demikian, seharusny
seharusnya varians dari a varians dari responden yang sedikit mengkonsuresponden yang sedikit mengkonsumsi air msi air mineral samamineral sama dengan varians dari responden yang banyak mengonsumsi air
dengan varians dari responden yang banyak mengonsumsi air mineral.mineral.
Varians diantara variabel-variabel bebas seharusnya juga sama. Jika Varians diantara variabel-variabel bebas seharusnya juga sama. Jika demikian,demikian, seharusny
seharusnya varians dari a varians dari income sama dengan varians dari olah raga.income sama dengan varians dari olah raga. Kedua pengertian diatas bisa disimpulkan, seharusnya
Kedua pengertian diatas bisa disimpulkan, seharusnya group covariance matricesgroup covariance matrices adalah relatif sama, yang di uji dengan alat Box’s M dengan ketentuan:
adalah relatif sama, yang di uji dengan alat Box’s M dengan ketentuan:
HIPOTESISHIPOTESIS
:: group covariance matricesgroup covariance matrices adalah relatif samaadalah relatif sama
:: group covariance matricesgroup covariance matrices adalah berbeda secara nyataadalah berbeda secara nyata
Keputusan dengKeputusan dengan dasar signifikansi an dasar signifikansi (lihat angka sig.)(lihat angka sig.) Jika sig >0.05 berarti
Jika sig >0.05 berarti diterimaditerima Jika sig<0.05 berarti
Jika sig<0.05 berarti ditolak ditolak
Dari SPSS diperoleh output sebagai berikut Dari SPSS diperoleh output sebagai berikut
Analisis Analisis
Dari tabel terlihat bahw
Dari tabel terlihat bahwa angka siga angka sig. > . > 0,05, yaitu 0.163 yang 0,05, yaitu 0.163 yang menerimamenerima berartiberarti groupgroup covariance matrices
covariance matrices adalah relatif sama. Hal ini berarti data di atas sudah memenuhiadalah relatif sama. Hal ini berarti data di atas sudah memenuhi asumsi analisis diskriminan.
asumsi analisis diskriminan.
Analisis Analisis
Terlihat angka log determinant untuk kategori SEDIKIT (14,081) dan BANYAK (14,520) Terlihat angka log determinant untuk kategori SEDIKIT (14,081) dan BANYAK (14,520)
tidak berbeda banyak, sehingga
tidak berbeda banyak, sehingga group covariance matricesgroup covariance matrices akan relatif sama untuk keduaakan relatif sama untuk kedua grup.
grup. B.
B. MELAKUKAN ANALISIS DISKRIMINANMELAKUKAN ANALISIS DISKRIMINAN Dari SPSS diperoleh output sebagai berikut
Dari SPSS diperoleh output sebagai berikut
Test Results Test Results 29.866 29.866 1.297 1.297 21 21 19569.371 19569.371 .163 .163 Box's M Box's M Ap Approx.prox. df df11 df df22 Sig. Sig. F F T
Tests ests null hynull hypothesis of pothesis of equequal populal populatatioion covn cov ariariance matrices.ance matrices.
Log Determinants Log Determinants 6 6 1144..008811 6 6 1144..552200 6 6 1144..770066 MINUM MINUM .00 .00 1.00 1.00 Pooled within-groups Pooled within-groups Rank Rank Log Log Determinant Determinant Th
The ranks and natural loe ranks and natural logarithms garithms oof f determinantsdeterminants prin
Analisis Analisis
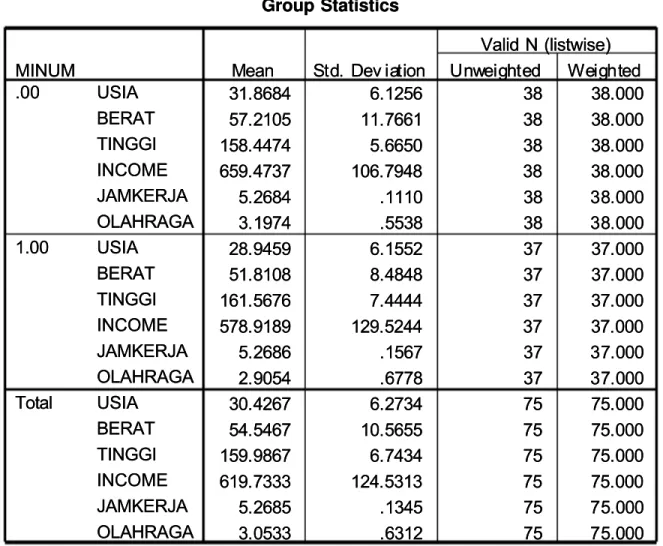
Tabel GROUP STATISTICS pada dasarnya berisi data statistic yang utama, yaitu rata Tabel GROUP STATISTICS pada dasarnya berisi data statistic yang utama, yaitu rata -rata-rata
dan standar deviasi dari kedua grup konsumen. dan standar deviasi dari kedua grup konsumen.
Misalnya, Konsumen yang termasuk tipe SEDIKIT meminum air mineral mempunyai Misalnya, Konsumen yang termasuk tipe SEDIKIT meminum air mineral mempunyai berat badan rata-rata 57,21 kilogram. Sedangkan konsumen yang termasuk tipe berat badan rata-rata 57,21 kilogram. Sedangkan konsumen yang termasuk tipe BANYAK meminum air mineral mempunyai berat badan rata-rata
BANYAK meminum air mineral mempunyai berat badan rata-rata 51,81 kilogram.51,81 kilogram.
Terlihat bahwa ada 38 responden yang tergolong sedikit mengonsumsi air mineral, Terlihat bahwa ada 38 responden yang tergolong sedikit mengonsumsi air mineral, sedangkan 37 responden lainnya tergolong banyak mengonsumsi air mineral. Semua sedangkan 37 responden lainnya tergolong banyak mengonsumsi air mineral. Semua variabel terisi angka 38
variabel terisi angka 38 atau 37, maka pada kasus ini atau 37, maka pada kasus ini tidak ada data yang hilang, sehinggatidak ada data yang hilang, sehingga total data untuk semua variabel adalah 75 buah. Tentu
total data untuk semua variabel adalah 75 buah. Tentu ini adalah keadaan yang ideal.ini adalah keadaan yang ideal.
Group Statistics Group Statistics 3 311..8866884 4 66..1122556 6 338 8 3388..000000 5 577..2211005 5 1111..7766661 1 338 8 3388..000000 1 15588..4444774 4 55..6666550 0 338 8 3388..000000 6 65599..4477337 7 110066..7799448 8 338 8 3388..000000 5 5..2266884 4 ..1111110 0 338 8 3388..000000 3 3..1199774 4 ..5555338 8 338 8 3388..000000 2 288..9944559 9 66..1155552 2 337 7 3377..000000 5 511..8811008 8 88..4488448 8 337 7 3377..000000 1 16611..5566776 6 77..4444444 4 337 7 3377..000000 5 57788..9911889 9 112299..5522444 4 337 7 3377..000000 5 5..2266886 6 ..1155667 7 337 7 3377..000000 2 2..9900554 4 ..6677778 8 337 7 3377..000000 3 300..4422667 7 66..2277334 4 775 5 7755..000000 5 544..5544667 7 1100..5566555 5 775 5 7755..000000 1 15599..9988667 7 66..7744334 4 775 5 7755..000000 6 61199..7733333 3 112244..5533113 3 775 5 7755..000000 5 5..2266885 5 ..1133445 5 775 5 7755..000000 3 3..0055333 3 ..6633112 2 775 5 7755..000000 USIA USIA BERAT BERAT TINGGI TINGGI INCOME INCOME JAMKERJA JAMKERJA OLAHRAGA OLAHRAGA USIA USIA BERAT BERAT TINGGI TINGGI INCOME INCOME JAMKERJA JAMKERJA OLAHRAGA OLAHRAGA USIA USIA BERAT BERAT TINGGI TINGGI INCOME INCOME JAMKERJA JAMKERJA OLAHRAGA OLAHRAGA MINUM MINUM .00 .00 1.00 1.00 Total Total M
Meeaan n SStdtd. . DDeevv iaiatitioon n UnUnwweeigighhteted d WeWeigighthteedd Valid N (listwise) Valid N (listwise)