Bab III Studi Kasus
III.1 Decline Rate
Studi kasus akan difokuskan pada data penurunan laju produksi (decline rate) di 31 lokasi sumur reservoir panas bumi Kamojang, Garut. Persoalan mendasar dalam penilaian kinerja reservoir adalah menghitung umur produktif reservoir dan mengestimasi kapasitas produksi dalam t-jangka waktu ke depan. Parameter yang paling sederhana dalam penghitungan ini adalah laju produksi. Cara yang rasional dalam menjawab persoalan di atas dengan menggunakan perhitungan adalah memplot variabel laju produksi terhadap waktu atau terhadap produksi kumulatif. Perluasan kurva produksi terhadap waktu dapat menunjukkan umur ekonomi reservoir. Plot laju produksi terhadap waktu pada umumnya akan menunjukkan laju produksi yang cukup tinggi pada awal produksi dan terus menurun seiring pertambahan waktu.
Decline curve analysis digunakan untuk estimasi perhitungan cadangan yang diamati di suatu lapangan, mencerminkan tingkat keekonomian lapangan tersebut dan memprediksi kinerja produksi suatu lapangan berdasarkan data historis. Perhitungan decline curve didasarkan pada penurunan laju produksi. Dengan menggunakan asumsi bahwa laju produksi secara kontinu mengikuti trend yang sudah ada, maka besarnya cadangan panas bumi dapat diperkirakan dari model trend laju penurunan produksi.
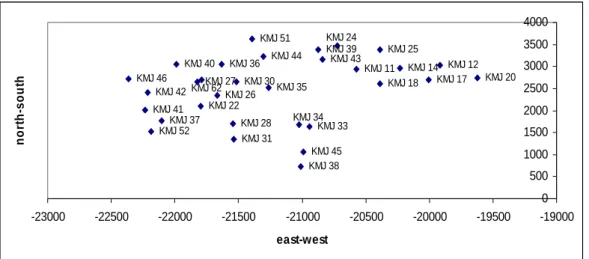
Data yang digunakan adalah data produksi dari 31 sumur panas bumi yang berlokasi di Kamojang Jawa Barat yang di ambil dari tesis Isnani (2005). Nilai decline rate setiap sumur diperoleh dari perhitungan logaritma normalisasi uji produksi yang diregresikan terhadap waktu. Lokasi sumur dinyatakan dengan koordinat easting dan Northing dengan satuan meter. Area pengamatan berkisar antara -22500 sampai -19500 easting, dan 700 sampai 3700 northing. Laju penurunan produksi sumur dianalisis dengan menggunakan laju penurunan eksponensial. KMJ – xx menyatakan sumur panas bumi Kamojang, KMJ–01 artinya sumur panas bumi kamojang nomor 1.
III.2 Penaksiran Model Semivariogram
Tabel III.1 memperlihatkan koordinat dan laju penurunan pada 31 sumur produksi. Gambar III.1 menunjukkan lokasi sumur produksi. Sari numerik data decline rate memperlihatkan nilai skewness cukup besar yang menunjukkan bahwa distribusi data tidak simetris. Untuk itu dilakukan transformasi sedemikian sehingga distribusi data hasil transformasi lebih simetris. Dalam hal ini bentuk transformasi yang dipilih adalah z* ( )s = 3 z( )s , dengan adalah nilai decline rate di lokasi yang berkoordinat
( )s
z ( , )
=
s x y . Dengan bentuk distribusi yang
simetris, penaksiran semivariogram menggunakan penaksir robust dapat dilakukan.
Tabel III.1 Lokasi dan nilai decline masing-masing sumur
Koordinat No Sumur
X (m) Y (m)
Decline rate perbulan
(z) Data transformasi (z*) 1 KMJ 26 -21664 2344 0.004 0.1587401 2 KMJ 22 -21795 2089 0.0032 0.1473613 3 KMJ 30 -21519 2652 0.010656 0.2200551 4 KMJ 62 -21786.4 2697.55 0.000894 0.0963339 5 KMJ 27 -21827 2651 0.00449 0.164974 6 KMJ 35 -21261 2517 0.020705 0.2745944 7 KMJ 36 -21631 3051 0.003641 0.1538415 8 KMJ 40 -21989 3058 0.00528 0.1741318 9 KMJ 44 -21305 3230 0.01502 0.2467308 10 KMJ 51 -21391 3626 0.003841 0.1566083 11 KMJ 37 -22107 1779 0.00173 0.1200463 12 KMJ 52 -22186 1526 0.003631 0.1537005 13 KMJ 41 -22233 2015 0.00177 0.1209645 14 KMJ 42 -22216 2398 0.015377 0.2486703 15 KMJ 46 -22363 2714 0.00702 0.1914751 16 KMJ 28 -21545 1710 0.00142 0.1123991 17 KMJ 31 -21536 1351 0.00303 0.1447041 18 KMJ 34 -21026 1689 0.00691 0.1904698 19 KMJ 33 -20945 1628 0.0219 0.2797787 20 KMJ 43 -20842 3168 0.003779 0.1557611 21 KMJ 39 -20876 3388 0.01506 0.2469496 22 KMJ 24 -20721 3466 0.00019 0.057489 23 KMJ 25 -20385 3392 0.01135 0.2247322 24 KMJ 11 -20576 2943 0.00151 0.1147252 25 KMJ 14 -20229 2966 0.00243 0.1344421 26 KMJ 12 -19917 3033 0.005025 0.1712821 27 KMJ 17 -20008 2704 0.00082 0.093599 28 KMJ 18 -20385 2613 0.00065 0.0866239 29 KMJ 20 -19621 2749 0.00374 0.1552234 30 KMJ 45 -20991 1059 0.004454 0.1645319 31 KMJ 38 -21011 725 0.005836 0.1800411
KMJ 38 KMJ 45 KMJ 20 KMJ 18 KMJ 17 KMJ 12 KMJ 14 KMJ 11 KMJ 25 KMJ 24 KMJ 39 KMJ 43 KMJ 33 KMJ 34 KMJ 31 KMJ 28 KMJ 46 KMJ 42 KMJ 41 KMJ 52KMJ 37 KMJ 51 KMJ 44 KMJ 40 KMJ 36 KMJ 35 KMJ 27 KMJ 62 KMJ 30 KMJ 22 KMJ 26 0 500 1000 1500 2000 2500 3000 3500 4000 -23000 -22500 -22000 -21500 -21000 -20500 -20000 -19500 -19000 east-west no rt h-s o u th
Gambar III.1. Lokasi sumur produksi
Tabel III.2 Sari numerik data decline rate
Univariate Statistics Decline Average 0.00610835 Median 0.003841 Minimum 0.000190 Maximum 0.021900 Range 0.021710 Variance 0.000034341 Skewness 1.468 Kurtosis 1.327
Tabel III.3 Sari numerik data hasil transformasi
Univariate Statistics data transformasi Average 0.165838071 Median 0.1566083 Minimum 0.0574890 Maximum 0.2797787 Range 0.2222898 Standard Deviation 0.0556255788 Variance 0.0030942050 Skewness 0.370 Kurtosis -0.281
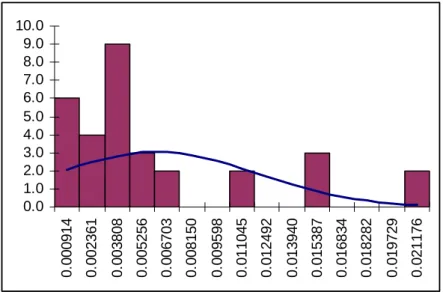
0.0 1.0 2.0 3.0 4.0 5.0 6.0 7.0 8.0 9.0 10.0 0. 00 09 14 0. 00 23 61 0. 00 38 08 0. 00 52 56 0. 00 67 03 0. 00 81 50 0. 00 95 98 0. 01 10 45 0. 01 24 92 0. 01 39 40 0. 01 53 87 0. 01 68 34 0. 01 82 82 0. 01 97 29 0. 02 11 76
Gambar III.2. Histogram data decline rate
0.0 1.0 2.0 3.0 4.0 5.0 6.0 7.0 8.0 0. 06 48 98 6 0. 07 97 17 9 0. 09 45 37 3 0. 10 93 56 6 0. 12 41 75 9 0. 13 89 95 2 0. 15 38 14 5 0. 16 86 33 9 0. 18 34 53 2 0. 19 82 72 5 0. 21 30 91 8 0. 22 79 11 1 0. 24 27 30 4 0. 25 75 49 8 0. 27 23 69 1
Gambar III.3. Histogram data hasil transformasi
Dari gambar histogram terlihat bahwa data hasil transformasi menunjukkan distribusi yang lebih simetris dan lebih mendekati distribusi normal dibandingkan dengan data sebelum transformasi.
Selanjutnya data hasil teransformasi dijadikan input untuk menghitung semivariogram eksperimental robust. Semivariogram eksperimental dihitung dalam empat arah utama yaitu Barat-Timur (BT), Utara-Selatan (US), Timur
Laut-Barat Daya (TLBD), dan Barat Laut-Tenggara (BLTG). Toleransi azimut yang digunakan adalah 10 derajat. Dalam setiap arah, lokasi dibagi ke dalam beberapa kelas jarak, dengan lebar setiap kelas jarak adalah 290 m (toleransi yang digunakan adalah ±145 m).
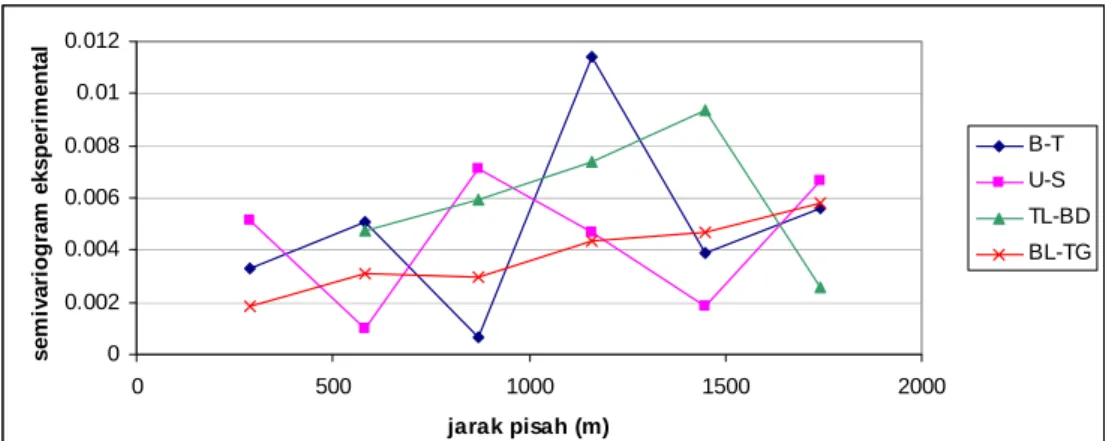
Tabel berikut memperlihatkan nilai semivariogram eksperimental untuk keempat arah tersebut yang dihitung dengan menggunakan rumus pada persamaan 2.7.
Tabel III.4 Semivariogram eksperimental untuk empat arah Barat-Timur (BT)
kelas h γˆ( )h # pasangan lokasi
290 0.003319 5 580 0.005084 10 870 0.000632 6 1160 0.011409 8 1450 0.003861 7 1740 0.005574 7 Utara-Selatan (US)
kelas h γˆ( )h #pasangan lokasi
290 0.00512 4 580 0.001011 8 870 0.007136 8 1160 0.004706 4 1450 0.001879 5 1740 0.006636 6
Timur Laut- Barat Daya (TLBD) kelas h γˆ( )h #pasangan lokasi
580 0.00474 6 870 0.005918 6 1160 0.007352 7 1450 0.00939 14 1740 0.002543 12 Barat Laut-Tenggara (BLTG) kelas h γˆ( )h #pasangan lokasi
290 0.001825 3 580 0.003126 7 870 0.002974 9 1160 0.00438 6 1450 0.004648 6 1740 0.005782 6
0 0.002 0.004 0.006 0.008 0.01 0.012 0 500 1000 1500 2000 jarak pisah (m) sem iv ar io g ra m eksp er im en ta l B-T U-S TL-BD BL-TG
Gambar III.4. Plot semivariogram eksperimental untuk keempat arah
Nilai semivariogram eksperimental untuk keempat arah tidak terlalu jauh berbeda, sehingga dapat kita anggap semivariogram tersebut isotropik. Maka, semivariogram eksperimental dapat dihitung dengan hanya memperhatikan jarak pisah antar lokasi. Dengan demikian, diperoleh semivariogram eksperimental isotropik sebagai berikut
Tabel III.5 Semivariogram eksperimental isotropik
kelas h γˆ( )h 290 0.0018338 580 0.0028488 870 0.0029736 1160 0.006212 1450 0.0046484 1740 0.0038184 0 0.001 0.002 0.003 0.004 0.005 0.006 0.007 0 200 400 600 800 1000 1200 1400 1600 1800 lag (m) sem iv ar io g ram eks p e ri m e n ta l
Selanjutnya akan dicari model semivariogram yang dapat memodelkan semivariogram eksperimental dengan menggunakan regresi median melaui kopula. Pertama-tama akan ditaksir fungsi distribusi dari h yang merupakan jarak pisah antara dua sumur dan fungsi distribusi dari T = 2 * ( ) * ( ) 1 2 0.457 ⎛ − + ⎞ ⎜ ⎜ ⎝ ⎠ s s h Z Z ⎟
⎟, dengan s, s +h∈D. Terlebih dahulu kita tinjau statistik deskriptif dari h sebagai berikut
Tabel III.6 Statistik deskriptif h
Univariate Statistics h Count 160 Sum 179,345.81 Average 1,120.9113 Median 1,137.30 Minimum 222.61 Maximum 1,878.70 Range 1,656.09 Standard Deviation 463.16454 Variance 214,521.38793 Skewness -0.076 Kurtosis -1.161 25th Percentile 717.10 75th Percentile 1,514.08 |h| 0 200 400 600 800 1000 1200 1400 1600 1800 2000
Distribusi dari h diasumsikan normal dengan mean 1120.9113 dan variansi 214521.39. Asumsi ini diuji dengan uji Kolmogorov-Smirnov. Statistik uji bagi
uji Kolmogorov-Smirnov adalah S = i
( )
i*( )
i
sup F h −F h , dengan F adalah fungsi distribusi kumulatif empirik dari h dan F* adalah fungsi distribusi yang dihipotesiskan, dalam hal ini normal dengan mean dan variansi seperti tersebut di atas. Hasil perhitungan menghasilkan S = 0.076. Pada uji Kolmogorov-Smirnov, untuk tingkat keberartian 5% dan n > 40 , hipotesis bahwa h berdistribusi normal dengan mean 1120.91 dan variansi 214521.39 ditolak jika S > 1.36
n dengan n adalah banyaknya pasangan lokasi sumur yang diikutkan dalam penghitungan semivariogram. (dalam kasus ini n = 160). Didapatkan 1.36
n =
0.108. Maka hipotesis bahwa h berdistribusi normal dengan mean 1120.91 dan variansi 214521.39 tidak ditolak. Dengan demikian, distribusi tersebut dapat digunakan untuk memodelkan distribusi dari h .
Selanjutnya akan diselidiki fungsi distribusi dari T =
2 * ( ) * ( ) 1 2 0.457 ⎛ − + ⎞ ⎜ ⎟ ⎜ ⎟ ⎝ ⎠ s s h Z Z .
Statistik deskriptif dari T adalah sebagai berikut
Tabel III.7 Statistik deskriptif T
Univariate Statistics Count 160 Sum 1.255843915 Average 0.00784902447 Median 0.003595175 Minimum 0.000000785 Maximum 0.054060000 Range 0.054059215 Standard Deviation 0.009933334596 Variance 0.000098671136 Skewness 1.866 Kurtosis 3.826 25th Percentile 0.000755788 75th Percentile 0.011086000
0.0 10.0 20.0 30.0 40.0 50.0 60.0 70.0 80.0 90.0 0 .00 18 02 75 9 0 .00 54 06 70 7 0 .00 90 10 65 4 0 .01 26 14 60 2 0 .01 62 18 55 0 0 .01 98 22 49 7 0 .02 34 26 44 5 0 .02 70 30 39 3 0 .03 06 34 34 0 0 .03 42 38 28 8 0 .03 78 42 23 6 0 .04 14 46 18 3 0 .04 50 50 13 1 0 .04 86 54 07 9 0 .05 22 58 02 6 T
Gambar III.7. Histogram T
Fungsi distribusi dari T diasumsikan Weibull ,yaitu G T( )= −1 e−( / )tθ τ ,dengan parameter θ =0.0063 dan τ =0.586. Parameter θ dan τ ditaksir dari data. Asumsi ini juga diuji dengan uji Kolmogorov-Smirnov. Perhitungan menghasilkan S = 0.047. Dengan tingkat keberartian 5% didapatkan titik kritis yang sama seperti sebelumnya yaitu 0.108. Maka hipotesis bahwa T berdistribusi Weibull dengan parameter θ =0.0063 dan τ =0.586 tidak ditolak. Dengan demikian, distribusi tersebut dapat digunakan untuk memodelkan distribusi dari T.
Selanjutnya kopula yang menggambarkan distribusi bivariat antara U =F(h )
dan akan dimodelkan dengan salah satu dari kopula yang dikenal yaitu
kopula Clayton. Parameter ( )
=
V G T
α dari kopula Clayton akan ditaksir dengan
menggunakan metode maximum likelihood sebagai berikut:
1. hitung nilai CDF untuk masing-masing pasangan ui =F(hi )
i
)
dan , dengan i = 1, 2,...,n, di mana n adalah banyaknya pasangan lokasi yang diikutkan dalam penghitungan semivariogram yaitu n = 160,
( ) = i
v G T
2. selanjutnya bentuk fungsi
(
n i i i 1 ln L ln c(u , v ) | = =∑
α (3.1)dengan 2 C(u, v) c(u, v) u v ∂ =
∂ ∂ , turunan kedua dari kopula C(u,v) (dalam hal ini kopula Clayton),
3. cari ˆα yang memaksimumkan fungsi (3.1), ˆα yang didapat adalah penaksir bagi α.
Dari perhitungan yang dilakukan, didapatkan ˆα = 0.0571. Dengan demikian,
kopula yang akan digunakan adalah C(u,v) =
(
)
1 0.0571 0.0571 0.0571
1 −
− + − −
u v .
Selanjutnya, kecocokkan kopula ini akan diuji dengan menggunakan uji
Khi-kuadrat. Pertama-tama, daerah domain kopula, yaitu persegi ,
dipartisi menjadi 25 persegi yang luasnya sama. Untuk setiap persegi, frekuensi titik (u
2 [0,1] [0,1]× ∈ R
i, vi) dihitung. Persegi dengan frekuensi yang kecil (kurang dari 5)
digabung dengan persegi yang lain. Lalu terapkan uji khi-kuadrat. Dari hasil pengujian, didapatkan nilai p-value sebesar 0.79. Dengan tingkat keberartian 0.05, hipotesis bahwa kopula dari u dan v adalah Clayton dengan parameter
tidak ditolak. Maka, kopula ini dapat digunakan.
0.0571 α =
Sekarang yang akan dilakukan adalah menentukan model semivariogram melalui regresi median kopula. Untuk kopula Clayton, yang merupakan solusi bagi persamaan v ( , ) 0.5 ∂ = ∂uC u v adalah
(
)
1 /( 1) 1 − (0.5− + 1) − = + − v u α α α α. Dengandemikian,didapatkanmodel semivariogram isotropik yaitu γ( h)=
1( ), 0 0, 0 − > = ⎧⎪ ⎨ ⎪⎩ h h G v
atau, dengan u=F
( )
h , G T( )= −1 e−( / )tθ τ di mana θ =0.0063 dan ,dan , model semivariogram tersebut dapat dituliskan sebagai
0.586 τ = 0.0571 α = (h ) γ =
(
0.0571)
17.51 1.71 1 1 0.038 ln 0.0063 0 0,
0
,
− − ⎛ ⎛ ⎞⎞ − + ⎜ ⎜ ⎟⎟ ⎜ ⎝ ⎠⎟ ⎝− ⎠>
=
⎧
⎪
⎨
⎪⎩
h
h
u (3.2) dengan( )
2 1 1 1120.91 exp 2 463.16 463.16 2 −∞ ⎛ ⎛ − ⎞ ⎞ = = ⎜⎜− ⎜ ⎟ ⎟⎟ ⎝ ⎠ ⎝ ⎠∫
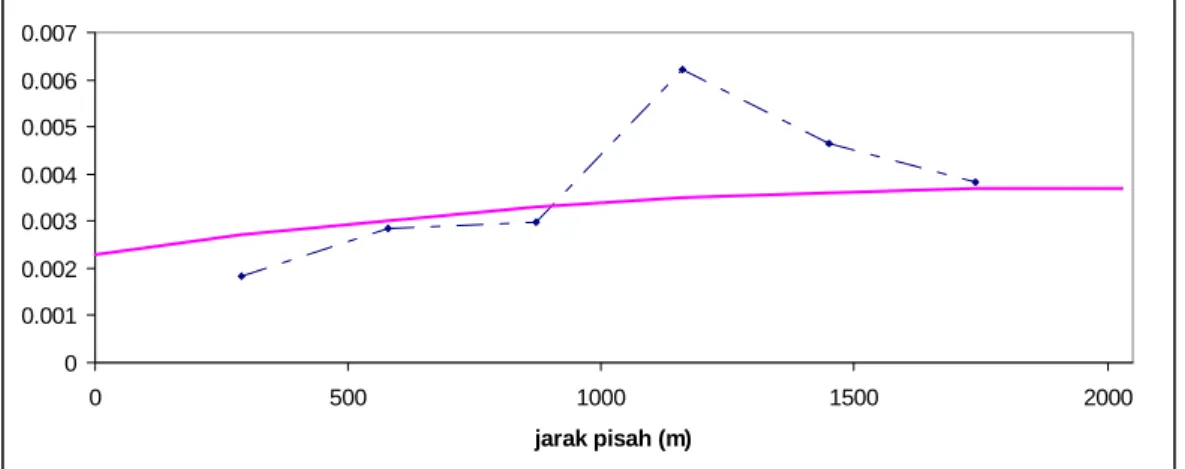
h h x u F dx π .Plot semivariogram eksperimental isotropik (garis putus-putus) bersama dengan model semivariogram (garis solid) yang diperoleh adalah sebagai berikut
0 0.001 0.002 0.003 0.004 0.005 0.006 0.007 0 500 1000 1500 2000 jarak pisah (m)
Gambar III.8. Plot model semivariogram dan semivariogram eksperimental isotropik
III.3 Validasi Silang
Model semivariogram yang diperoleh harus diuji validitasnya. Untuk itu dilakukan uji validasi silang (Kitanidis, 1997). Hipotesis yang diuji adalah bahwa z* merupakan realisasi dari proses spasial intrinsik dengan semivariogram γ(h )
seperti pada persamaan 3.2. Pertama-tama lokasi sampel diberi nomor dari 1 sampai 31. Kemudian taksir nilai z* di dengan hanya menggunakan nilai z* di
melalui ordinary kriging. Maka didapatkan dan
2 s 1 s ˆz *( )s2 =z * ( )s1
( )
(
2 K 2 2 2 1σ s = γ s −s
)
. Hitung galat δ =2 z * ( ) z * ( )s2 −ˆ s2 dan galat standar 22 2
K( )2 δ ε =
σ s . Prosedur yang sama dilakukan untuk menghitung galat yang
lainnya. Untuk lokasi sampel ke-i, estimasi nilai dengan menggunakan (i-1) data pertama, lalu hitung nilai galat dan galat standar
i ˆz *( )s i z * ( ) z * ( )i ˆ i δ = s − s dan i i 2 K( )i δ ε =
σ s , untuk i = 1, 2, ..., 31. Maka didapatkan nilai galat dan galat standar seperti pada tabel berikut
Tabel III.8 Galat dan galat standar no z* ˆz * z*-ˆz * σˆK K ˆ (z*- z*) ˆ ε = σ ε 2 2 0.147361 0.15874 -0.01138 0.073342 -0.15515 0.02407 3 0.220055 0.15376 0.066295 0.066989 0.989641 0.97939 4 0.096334 0.18072 -0.08439 0.061388 -1.37463 1.889621 5 0.164974 0.1483 0.016674 0.056983 0.292613 0.085622 6 0.274594 0.16584 0.108754 0.060315 1.803108 3.251198 7 0.153842 0.17765 -0.02381 0.060526 -0.39336 0.154732 8 0.174132 0.16263 0.011502 0.059879 0.192083 0.036896 9 0.246731 0.18027 0.066461 0.060933 1.090719 1.189667 10 0.156608 0.1963 -0.03969 0.062005 -0.64014 0.409776 11 0.120046 0.17097 -0.05092 0.062622 -0.81319 0.661282 12 0.153701 0.15595 -0.00225 0.060933 -0.03692 0.001363 13 0.120964 0.15223 -0.03127 0.057755 -0.54135 0.293058 14 0.24867 0.14993 0.09874 0.05739 1.720514 2.960167 15 0.191475 0.17633 0.015145 0.058342 0.259592 0.067388 16 0.112399 0.16808 -0.05568 0.059579 -0.93457 0.873426 17 0.144704 0.15377 -0.00907 0.060135 -0.15076 0.022728 18 0.19047 0.1661 0.02437 0.060714 0.401386 0.161111 19 0.279779 0.17547 0.104309 0.057675 1.808561 3.270892 20 0.155761 0.1991 -0.04334 0.060443 -0.71702 0.514119 21 0.24695 0.18182 0.06513 0.057874 1.125369 1.266455 22 0.057489 0.19773 -0.14024 0.057443 -2.44139 5.960408 23 0.224732 0.16049 0.064242 0.059352 1.082393 1.171575 24 0.114725 0.18849 -0.07376 0.058023 -1.2713 1.616209 25 0.134442 0.16981 -0.03537 0.058781 -0.60169 0.362029 26 0.171282 0.16288 0.008402 0.059401 0.141447 0.020007 27 0.093599 0.16574 -0.07214 0.058237 -1.23875 1.534497 28 0.086624 0.15687 -0.07025 0.057032 -1.2317 1.517075 29 0.155223 0.14836 0.006863 0.059077 0.116177 0.013497 30 0.164532 0.17777 -0.01324 0.060336 -0.21941 0.048139 31 0.180041 0.16824 0.011801 0.059937 0.196892 0.038767
Selanjutnya hitung statistik
m 1 i i 2 1 Q m 1 = = ε −
∑
dan m 2 1 i 2 1 Q m 1 = i = ε−
∑
, dalam hal ini m = 31 . Uji validasi dapat didasarkan pada atatistik Q1 ataupun Q2. Dari tabel diatas, kita peroleh nilai Q1 = -0.05136 dan Q2 = 1.013. Model semivariogram akan
ditolak jika |Q1| >
2 2
0.365
m 1− = 30 = . Dengan demikian, jika Q1 yang
digunakan sebagai statistik uji, model semivariogram tidak ditolak. Jika yang digunakan sebagai statistik uji adalah Q2, model semivariogram ditolak jika Q2 > U atau Q2 < L, dengan nilai U dan L dapat dilihat pada tabel di lampiran H. Untuk
m = 30, didapatkan L = 0.56 dan U=1.57. Dengan demikian, jika Q2 yang
digunakan sebagai statistik uji, model semivariogram juga tidak ditolak. Berdasarkan hasil uji validasi silang, model semivariogram dapat digunakan untuk memodelkan struktur dependensi data. Jadi hipotesis bahwa z* merupakan realisasi dari proses spasial intrinsik dengan semivariogram γ(h ) seperti pada persamaan 3.2 tidak ditolak.
III.4 Tinjauan Model Semivariogram
Sekarang akan ditinjau sifat-sifat model semivariogram yang diperoleh pada persamaan 3.2. Perhatikan bahwa
( )
1 1 x 1120.9113 2lim u lim F lim exp dx 1
2 463.16454 463.16454 2 →∞ →∞ →∞ −∞ ⎛ ⎛ − ⎞ ⎞ = = ⎜⎜− ⎜ ⎟ ⎟⎟ π ⎝ ⎝ ⎠ ⎠
∫
h h h h h = . Maka,( )
( )
(
(
(
)
)
)
1.71 17.51 0.0571 u 1 u 1lim lim lim 0.006345 ln 1 1 0.0382u
0.0037251 − − →∞γ = → γ = → − − + = h h h
Dengan demikian, model semivariogram tersebut terbatas di atas. Menurut Armstrong (1998), model semivariogram yang terbatas di atas adalah model semivariogram dari proses spasial yang stasioner. Maka proses spasial {Z*(s),s∈D} bisa dianggap merupakan proses yang stasioner.
Karena lim
( )
0.0037251→∞γ =
h h , model semivariogram tersebut dikatakan
memiliki sill sebesar 0.0037251. Sill merupakan batas atas bagi semivariogram. Berdasarkan persamaan 2.4, pada proses stasioner, sill adalah kovariogram pada
h = 0 atau . Dengan kata lain, sill adalah variansi dari Z*. Selain itu berlaku juga (0) C
( )
0 lim+ 0.0023 → γ = hh , berarti terdapat nugget effect pada model
semivariogram. Nugget effect mengindikasikan adanya ketidak kontinuan peubah
acak regional, di mana dapat berbeda dengan berapapun kecilnya
jarak
* ( )s
Z Z* ( ')s
h = s s− ' . Nilai kovariogram turun dari 0.0037251 pada h = 0 menjadi 0.0014 ketika h bergeser sedikit lebih besar dari 0. Nilai korelogram turun dari
1 pada h = 0 menjadi 0.3784 ketika nilai h bergeser sedikit lebih besar dari 0.
Ini berarti korelasi antara dan sudah cukup kecil walaupun lokasi
dan ’ berdekatan.
* ( )s
Z Z* ( ')s
s s
Pada h = 1164.336 m, nilai semivariogram adalah 0.0035 yang merupakan 95% dari nilai sill. Pada jarak ini, nilai korelogram adalah 0.0604. Nilai korelogram
pada h yang lebih besar dari 1164.336 lebih kecil dari 0.0604 karena
korelogram adalah fungsi turun terhadap h . Maka dapat disimpulkan bahwa korelasi spasial antara dua lokasi sumur dengan jarak pisah ( h ) yang lebih besar
atau sama dengan 1164.336 sudah sangat kecil. Jarak h = 1164.336 m ini
disebut practical range.
III.5 Penaksiran dengan Ordinary Kriging
Setelah diperoleh model semivariogram, dilanjutkan dengan estimasi kriging pada sumur yang dekat dengan lokasi pengeboran, yaitu sumur yang lokasinya di koordinat -22687.5 ≤ x ≤ -21567.5 dan 1175 ≤ y ≤ 2365. Berikut adalah lokasi yang diestimasi KMJ 38 KMJ 45 KMJ 20 KMJ 18 KMJ 17 KMJ 12 KMJ 14 KMJ 11 KMJ 25 KMJ 24 KMJ 39 KMJ 43 KMJ 33 KMJ 34 KMJ 31 KMJ 28 KMJ 46 KMJ 42 KMJ 41 KMJ 52 KMJ 37 KMJ 51 KMJ 44 KMJ 40 KMJ 36 KMJ 35 KMJ 27 KMJ 62 KMJ 30 KMJ 22 KMJ 26 0 500 1000 1500 2000 2500 3000 3500 4000 -23000 -22500 -22000 -21500 -21000 -20500 -20000 -19500 -19000 Barat-Timur Ut ar a -S e la ta n koordinat sumur lokasi yang ditaksir
225 224 223 222 221 220 219 218 217 216 215 214 213 212 211 210 209 208 207 206 205 204 203 202 201 200 199 198 197 196 195 194 193 192 191 190 189 188 187 186 185 184 183 182 181 180 179 178 177 176 175 174 173 172 171 170 169 168 167 166 165 164 163 162 161 160 159 158 157 156 155 154 153 152 151 150 149 148 147 146 145 144 143 142 141 140 139 138 137 136 135 134 133 132 131 130 129 128 127 126 125 124 123 122 121 120 119 118 117 116 115 114 113 112 111 110 109 108 107 106 105 104 103 102 101 100 99 98 97 96 95 94 93 92 91 90 89 88 87 86 85 84 83 82 81 80 79 78 77 76 75 74 73 72 71 70 69 68 67 66 65 64 63 62 61 60 59 58 57 56 55 54 53 52 51 50 49 48 47 46 45 44 43 42 41 40 39 38 37 36 35 34 33 32 31 30 29 28 27 26 25 24 23 22 21 20 19 18 17 16 15 14 13 12 11 10 9 8 7 6 5 4 3 2 1 1132.5 1332.5 1532.5 1732.5 1932.5 2132.5 2332.5 -22728 -22528 -22328 -22128 -21928 -21728 -21528 Barat-Timur Ut a ra -S e la ta n
Lokasi yang Diestimasi
Gambar III.10. Penomoran kokasi yang diestimasi
Banyaknya titik yang akan diestimasi adalah 225 titik. Penaksiran dilakukan
dengan menggunakan ordinary kriging pada lokasi yang diestimasi untuk
menaksir nilai Z*. Dari taksiran nilai Z* dapat diperoleh nilai taksiran decline rate
( ) dilokasi tersebut dengan menggunakan persamaan 2.18 dan simpangan
baku krigingnya dapat dihitung dengan menggunakan persamaan 2.19. Tabel nilai data hasil estimasi ordinary kriging dapat dilihat pada lampiran E. Pada halaman
berikut akan ditampilkan peta hasil estimasi decline rate dengan
menggunakan ordinary kriging pada lokasi-lokasi yang diestimasi yang
digambarkan dalam 225 grid. Z( )s
Berikut ini adalah peta kontur nilai decline rate hasil estimasi ordinary kriging beserta peta kontur simpangan baku krigingnya.
0.00 45 0.005 0.005 0.0 05 0.005 0.005 0.0 05 0.00 55 0.00 55 0.0055 0.0055 0.0 055 0.006 0.006 0.006 0.0065 0.0065 0.00 65 -2.26 -2.25 -2.24 -2.23 -2.22 -2.21 -2.2 -2.19 -2.18 -2.17 -2.16 x 104 1200 1400 1600 1800 2000 2200
Gambar III.12. Peta kontur nilai decline rate (perbulan) hasil estimasi ordinary kriging 0 .0 04 5 0. 004 5 0.00 45 0 .0 0 4 5 0 .00 46 0 .0 04 6 0.0046 0.0 046 0 .0 0 47 0 .0 04 7 0.0047 0.0047 0 .0 0 4 8 0 .0 04 8 0.0048 0.0048 0.0049 0 .0 04 9 0 .0 0 4 9 0.00 5 -2.26 -2.25 -2.24 -2.23 -2.22 -2.21 -2.2 -2.19 -2.18 -2.17 -2.16 x 104 1200 1400 1600 1800 2000 2200
Gambar III.13. Peta kontur simpangan baku kriging hasil estimasi ordinary kriging
Berdasarkan peta nilai decline rate hasil estimasi maupun peta kontur terlihat bahwa nilai decline rate yang terendah berada pada koordinat
dan 1685
22.168 x 21.968
− ≤ ≤ − ≤ ≤y 1770 (di sekitar pusat daerah yang
diestimasi). Nilai taksiran decline rate di daerah ini yaitu adalah sekitar 0.0045/bulan. Semakin jauh titik estimasi dari pusat daerah yang diestimasi, semakin besar nilai taksiran decline rate di titik tersebut. Hasil kriging mean menunjukkan taksiran mean dari decline rate adalah 0.0062937/bulan. Selain itu, peta kontur simpangan baku kriging menunjukkan bahwa semakin jauh lokasi yang diestimasi dari lokasi sumur (lokasi sampel), semakin besar nilai simpangan baku kriging di lokasi itu. Hal ini menunjukkan bahwa semakin jauh lokasi yang diestimasi dari lokasi sampel, tingkat ketakpastian dalam penaksiran semakin tinggi.
III.6 Penaksiran dengan Sequential Kriging
Sebelum melakukan sequential kriging, data sampel terlebih dahulu diurutkan berdasarkan jarak lokasi sumur (lokasi observasi) terhadap tehadap titik yang akan diestimasi, sehingga akan terdapat sampel dengan urutan yang berbeda-beda untuk setiap titik yang akan diestimasi. Alasan pengurutan ini adalah karena lokasi observasi yang berada dekat dengan lokasi yang akan diestimasi mempunyai korelasi yang lebih tinggi dengan lokasi estimasi dibandingkan dengan lokasi observasi yang jauh dari lokasi estimasi tersebut. Artinya titik lokasi observasi yang berada jauh dari lokasi estimasi memberi pengaruh yang relatif kecil terhadap nilai decline rate di titik yang akan diestimasi. Titik-titik lokasi observasi yang jauh dari titik estimasi dan pengaruhnya kecil dapat disisihkan sehingga tidak diikutsertakan dalam estimasi.
Lokasi estimasi masih sama dengan lokasi estimasi sebelumnya. Data sampel dibagi ke dalam 31 subset sehingga setiap subset merupakan datum tunggal. Berdasarkan persamaan 2.24 sequential kriging dilakukan untuk mengestimasi
dalam 31 langkah sebagai berikut:
( )
0* s
( )
( )
( )
( )
( )
( )
( )( )
( )
( )
( )
( )( )
( )
( )
( )
( )
( )
( )
( )
(1) 0 01 1 (2) (1) 1 0 0 2 2 2 (3) (2) 2 0 0 3 3 3 (30) (29) (29) 0 0 30 30 30 (31) (30) (30) 0 0 31 31 31 ˆ * * ˆ* ˆ* ( * ˆ* ) ˆ* ˆ* ( * ˆ* ) ˆ* ˆ* ( * ˆ* ˆ* ˆ* ( * ˆ* = = + − = + − = + − = + − s s s s s s s s s s s s s s s s s s Z Z Z Z Z Z Z Z Z Z Z Z Z Z Z Z Z Z ρ θ θ θ θ ) ) (3.3) .dengan jarak s0−s1 ≤ s0−s2 ≤ ≤... s0−sn , Zˆ *( )
s0 (k−1) adalah estimasidengan menggunakan (k-1) data,
( )
0* s
Z Z* s
( )
i adalah data observasi darilokasi sampel terdekat ke-i dari titik yang akan diestimasi,
merupakan selisih antara nilai data terdekat ke-i dengan estimasi data ke-i menggunakan (k-1) data, dan
( )
ˆ( )
( 1)( *Z si −Z* si k− )
i
θ adalah bobot sequential kriging dari data subset ke-i. Bobot sequential kriging adalah :
2 2 02 01 12 12 3 2 03 01 13 2 23 12 13 13 4 2 04 01 14 2 24 12 14 3 34 13 14 14 5 2 05 01 15 2 25 12 15 3 35 13 15 4 45 14 15 15 0 01 1 2 1 1 ( ) 1 1 ( ( )) 1 1 ( ( ) ( )) 1 1 ( ( ) ( ) ( 1 1 1 = − − = − − − − = − − − − − − = − − − − − − − − = − − − k k k k θ ρ ρ ρ ρ θ ρ ρ ρ θ ρ ρ ρ ρ θ ρ ρ ρ θ ρ ρ ρ θ ρ ρ ρ ρ θ ρ ρ ρ θ ρ ρ ρ θ ρ ρ ρ θ ρ ρ ρ ρ θ ρ ρ ρ ρ )) 1 1 1 2 30 31 2 0,31 01 1,31 ,31 1 1,31 2 1,31 ( ) 1 ( ) 1 − = = ⎛ − ⎞ ⎜ ⎟ ⎝ ⎠ ⎛ ⎞ = ⎜ − − − ⎟ − ⎝ ⎠
∑
∑
k m mk m k m m m m m θ ρ ρ ρ θ ρ ρ ρ θ ρ ρ ρ ρ (3.4) Kompleksitas komputasi sequential kriging jauh lebih kecil daripada kompleksitas komputasi ordinary kriging. Pada ordinary kriging, untuk menyelesaikanpersamaan 2.17 dengan metode eliminasi Gauss-Jordan diperlukan operasi tambah sebanyak 1
(
n 1)
3 1(
n 1)
2 5(
n 13 + +2 + −6 +
)
dan operasi perkalian sebanyak(
) (
3)
2(
1
n 1 n 1 n 1
3 + + + −3 +
)
1
, dengan n adalah ukuran sampel. Sehingga total banyaknya operasi yang dilakukan dalam ordinary kriging adalah
(
)
3(
)
2(
2 3 7
n 1 n 1 n 1
3 + +2 + −6 +
)
operasi. Dalam kasus ini n sama dengan 31,sehingga total banyaknya operasi pada jika menggunakan ordinary kriging adalah 23344 operasi. Sedangkan dalam sequential kriging, diperlukan sebanyak
2
1 1
n
2 + n operasi perkalian dan sebanyak 2 2
1 1
n n
2 +2 − operasi tambah pada 1
persamaan 3.3, dan sebanyak n2+ − operasi perkalian serta sebanyak n 2 operasi tambah pada persamaan 3.4. Sehingga total banyaknya operasi pada agoritma sequential kriging adalah
2 n −n
2
3n + − operasi. Untuk n = 31, total n 3 banyaknya operasi jika menggunakan sequential kriging adalah 2911 operasi. Jadi, banyaknya operasi pada algoritma metode sequential kriging lebih sedikit dari banyaknya operasi pada algoritma ordinary kriging, sehingga kompleksitas komputasinya lebih kecil.
Setelah diperoleh taksiran nilai Z dengan sequential kriging, nilai taksiran * decline rate ( ) dapat dihitung dengan menggunakan persamaan 2.37 dan standar deviasi krigingnya dapat dihitung dengan menggunakan persamaan 2.38. Nilai estimasi decline rate hasil estimasi sequential kriging dapat dilihat pada lampiran F. Pada halaman berikut akan ditampilkan peta hasil estimasi decline rate ( ˆz ) pada lokasi-lokasi yang diestimasi yang digambarkan dalam 225 grid.
Berikut ini adalah peta kontur hasil nilai decline rate hasil estimasi sequential kriging beserta peta kontur simpangan baku krigingnya.
0.0045 0.0 045 0.0 05 0.005 0.005 0. 005 0.005 0.005 0.0 05 0.0 05 5 0.00 55 0.0055 0.0055 0.0 055 0.006 0.006 0.006 0.0065 0.0065 -2.26 -2.25 -2.24 -2.23 -2.22 -2.21 -2.2 -2.19 -2.18 -2.17 -2.16 x 104 1200 1400 1600 1800 2000 2200
Gambar III.15. Peta kontur nilai decline rate (perbulan) hasil estimasi sequential kriging 0.00 48 0.00 48 0.0 048 0 .0 0 4 8 0 .00 4 85 0 .00 48 5 0.004 85 0.0 04 85 0.0 04 85 0 .0 04 9 0 .00 4 9 0.0049 0.0049 0. 00 495 0 .00 4 95 0.00495 0.004 95 0 .0 0 5 0 .00 5 0.005 0.005 0 .0 0 5 0 5 0 .00 5 0 5 0.00505 0.00505 0. 0 05 1 0.0 051 0.0051 0.005 15 0 00 5 15 0.0 052 -2.26 -2.25 -2.24 -2.23 -2.22 -2.21 -2.2 -2.19 -2.18 -2.17 -2.16 x 104 1200 1400 1600 1800 2000 2200
Gambar III.16. Peta kontur simpangan baku kriging hasil estimasi sequential kriging
Berdasarkan gambar-gambar di atas, terlihat bahwa hasil estimasi dengan menggunakan sequential kriging tidak jauh berbeda dengan hasil estimasi dengan menggunakan ordinary kriging. Demikian juga kontur simpangan baku krigingnya menunjukkan pola yang sama yaitu semakin jauh lokasi yang diestimasi dari lokasi sumur (lokasi sampel), semakin besar nilai simpangan baku kriging di lokasi itu. Namun, penggunaan sequential kriging untuk mengestimasi nilai decline rate lebih menguntungkan karena kompleksitas komputasinya lebih kecil sehingga akan menghemat komputasi.
Kompleksitas komputasi sequential kriging masih dapat dikurangi lagi. Sebagai ilustrasi, tinjau lokasi estimasi ke-136 di koordinat x = -21968, y = 1175. Nilai estimasi decline rate di titik tersebut dengan menggunakan ordinary kriging adalah 0.005093/bulan, sedangkan jika menggunakan sequential kriging diperoleh nilai taksiran sebesar 0.0050499/bulan yang tidak jauh berbeda dengan hasil ordinary kriging. Selanjutnya perhatikan gambar berikut
-0.05 0 0.05 0.1 0.15 0.2 0.25 0 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 data subset bobo t s e que nt ia l k ri g in g .
Gambar III.17. Bobot sequential kriging subset data untuk titik estimasi dengan koordinat x = -21968, y = 1175
Dari gambar di atas, terlihat bahwa pada titik estimasi dengan koordinat x = -21968 dan y = 1175, bobot sequential kriging subset data pada taksiran nilai
Z* di titik tersebut cenderung semakin mendekati nol seiring dengan semakin besarnya indeks subset. Hal ini berarti data observasi yang lokasinya jauh dari titik yang diestimasi nilai bobotnya mendekati nol sehingga dapat diabaikan. Hal ini pun berlaku pada seluruh 225 titik estimasi.
Sekarang tinjau gambar berikut
0.15 0.152 0.154 0.156 0.158 0.16 0.162 0.164 0.166 0.168 0 1 2 3 4 5 6 7 8 9 10111213141516171819202122232425262728293031 Iterasi N il a i t a ksi ra n Z *( s0)
Gambar III.18. Taksiran nilai Z* di titik estimasi dengan koordinat x = -21968, y = 1175 dengan menggunakan sequential kriging dalam 31 iterasi
Gambar di atas adalah gambar taksiran sequential kriging dari nilai di titik dengan koordinat x = -21968 dan y = 1175 dalam 31 iterasi. Terlihat bahwa mulai iterasi ke-15, taksiran nilai sudah mulai stabil di sekitar suatu nilai tertentu. Hal ini pun berlaku pada seluruh 225 titik estimasi di mana taksiran nilai mulai stabil setelah iterasi tertentu. Mengingat pada sequential kriging ini data observasi diurutkan berdasarkan jaraknya dari titik estimasi, maka kestabilan nilai taksiran setelah iterasi tertentu disebabkan oleh kecilnya bobot data observasi yang lokasinya jauh dari titik estimasi. Hal ini sesuai dengan ilustrasi pada gambar III.17. Oleh karena itu kita bisa melakukan pemotongan iterasi pada algoritma sequential kriging, di mana ketika taksiran nilai sudah mulai stabil di sekitar nilai tertentu iterasi akan dihentikan. Dengan demikian, data observasi yang
Z*
Z*
Z*
Z*
bobotnya kecil tidak diikutsertakan. Hal ini akan lebih mengurangi banyaknya operasi dalam sequential kriging.
Sekarang akan dilakukan sequential kriging dengan pemotongan iterasi untuk menaksir nilai decline rate masih di lokasi estimasi yang sama seperti sebelumnya. Pada kasus ini, untuk setiap titik estimasi, iterasi dihentikan jika
(i) (i 1) 6
0 0
ˆ ˆ
z * (s ) −z * (s ) − < ×1 10 ,− dengan adalah taksiran nilai Z* pada iterasi ke-i, dan yang diambil sebagai taksiran nilai di titik tersebut adalah . Berikut adalah peta kontur hasil estimasi sequential kriging dengan pemotongan iterasi (i) 0 ˆz * (s ) Z * (i) 0 ˆz *(s ) 0.0045 0.0 045 0 .004 5 0.005 0.005 0.005 0 .00 5 0.005 0.005 0.0 05 0.00 55 0.00 55 0.0055 0.0055 0.0 055 0.006 0.006 0.006 0.0065 0.0065 -2.26 -2.25 -2.24 -2.23 -2.22 -2.21 -2.2 -2.19 -2.18 -2.17 -2.16 x 104 1200 1400 1600 1800 2000 2200
Gambar III.19. Peta kontur taksiran nilai decline rate menggunakan sequential kriging dengan pemotongan iterasi
0.0 048 0.004 8 0 .00 4 8 0.00 48 0 .00 4 85 0 .00 4 85 0.004 85 0.0 04 85 0 .00 4 8 5 0 .00 4 9 0.00 49 0.0049 0.0 049 0 .0 04 95 0.0 04 95 0.00495 0.00 495 0 .0 05 0 .00 5 0.005 0.005 0 .0 0 5 0 5 0 .0 05 05 0.005 05 0.00505 0 .0 05 1 0 .00 5 1 0.0051 0.0 0515 0 .00 5 15 0.0 052 -2.26 -2.25 -2.24 -2.23 -2.22 -2.21 -2.2 -2.19 -2.18 -2.17 -2.16 x 104 1200 1400 1600 1800 2000 2200
Gambar III.20. Peta Kontur Taksiran Simpangan Baku Kriging
Menggunakan Sequential Kriging dengan Pemotongan Iterasi
Dari gambar III.19 terlihat bahwa peta kontur taksiran nilai decline rate menggunakan sequential kriging dengan pemotongan iterasi tidak berbeda secara signifikan dengan peta kontur nilai decline rate menggunakan sequential kriging yang biasa. Demikian juga dengan peta kontur simpangan baku krigingnya. Dengan demikian, kita dapat menggunakan sequential kriging dengan pemotongan iterasi karena hasilnya tidak jauh berbeda dan kompleksitas komputasinya lebih kecil.