TUGAS SISTEM DATABASE II
Review of:
Distributed Database Management System
Aspects of the Design of Distributed Databases
A New Data Re-Allocation Model for Distributed
Database Systems
Disusun oleh :
Felisita Tri Ayuningrum (11.6647)
Muhammad Miftakhul Romadlon (11.6800)
Yosefina Irwan (11.6961)
Kelompok 10 - 3KS1
SEKOLAH TINGGI ILMU STATISTIK
JAKARTA
DAFTAR ISI
Abstract 1
1. PENDAHULUAN 2
2. ISI DAN PEMBAHASAN 3
2.1 Distributed Data Proccessing 3
2.2 Apa yang dimaksud dengan Sistem Database Terdistribusi? 4 2.3 Keuntungan dan kerugian dari Database Terdistribusi 5
2.4 Distributed Database Design 7
2.5 Alternative Desain Strategy 7
2.5.1 Top down design 7
2.5.2 Bottom-Up Desain 9
2.6 Transparansi SGBDD 9
2.7 Data Independence 9
2.8 Network Transparency 10
2.9 Transparansi dalam replikasi 10
2.10 Transparansi fragmentasi 10
2.11 Fragmen 11
2.12 Pernyataan Masalah dan Persyaratan Informasi 11
2.12.1 Deskripsi Masalah dan Notasi 11
2.12.2 Persyaratan Informasi 13
2.12.3 Informasi Database 13
2.12.4 Informasi Perilaku Query 14
2.12.5 Informasi Situs 15
2.12.6 Informasi Jaringan 16
2.13 Model yang Diusulkan dan Fungsi Biaya 17
2.14.1 Model yang Diusulkan 17
2.14 Prioritas Fragmen (FP) 19
2.15 Fungsi Harga 20
2.16 The Proposed Algorithm (Algoritma yang Diusulkan) 20
2.17 Experimental Results (Hasil Experimental) 25
2.17.1 Initial Allocation (Alokasi Awal) 25
2.17.2 Re-Allocation Process (Proses Pengalokasian Kembali) 25
2.18 Performance Evaluation (Evaluasi Kinerja) 26
3. PENUTUP 26
3.1 Kesimpulan 26
3.2 Kelebihan dan Kelemahan Paper 29
2.10 Transparansi fragmentasi 29
DAFTAR PUSTAKA 30
Data-data yang telah terdistribusi akan diproses oleh system yang dapat didistribusikan di antara beberapa komputer, serta dapat diakses dari salah satu komputer tersebut.
Permasalahan desain database terdistribusi adalah dengan melibatkan pengembangan model global, fragmentasi, dan alokasi data. Siswa diberikan model entity-relationship konseptual untuk database dan deskripsi dari transaksi serta lingkungan jaringan generik. Pendekatan bertahap mengenai solusi untuk masalah ini dijelaskan berdasarkan nilai rata-rata asumsi mengenai beban kerja dan layanan. Sebuah sistem manajemen database terdistribusi (SGBDD) adalah perangkat lunak sistem yang memungkinkan proses manajemen dan pendistribusian BDD secara transparan kepada pengguna (user). Sebuah SGBDD terdiri dari sebuah database tunggal yang didekomposisi menjadi fragmen dengan kemungkinan beberapa fragmen dikalikan, dan setiap fragmen atau salinan dari fragmen disimpan pada satu atau lebih situs di bawah kendali DBMS lokal. Setiap situs mampu memproses permintaan pengguna di sistem lokal, independen dari jaringan, dan mampu berpartisipasi dalam pengolahan data di situs lain dalam jaringan. Selain itu, untuk mengatakan bahwa suatu DBMS sudah terdistribusi maka CLE seharusnya memiliki permintaan global yang minim.
Sistem database terdistribusi (SBDD) memiliki dua pendekatan untuk memenuhi pengolahan data, yaitu: sistem teknologi dan database jaringan komputer. Sistem database telah berevolusi dari pengolahan data dimana setiap aplikasi berfungsi untuk mendefinisikan dan memelihara data aplikasinya sendiri, serta aplikasi lain berfungsi untuk mendefinisikan dan mengelola data secara terpusat. Orientasi baru ini menyebabkan data independen, aplikasi tersebut menjadi kebal terhadap perubahan organisasi data fisik atau logis dan sebaliknya. Sebuah motivasi utama dalam menggunakan sistem database adalah integrasi data dan memberikan akses terpusat dan dikendalikan untuk data. Di sisi lain, teknologi jaringan komputer mempromosikan hal yang bertentangan dari berbagai upaya sentralisasi database. Hal ini terlihat sukar khususnya untuk memahami bagaimana kedua pendekatan yang kontras ini dapat diringkas dalam sebuah teknologi yang lebih kuat dan lebih menjanjikan dari keduanya. Salah satu kunci untuk memahaminya adalah kesadaran bahwa tujuan yang paling penting dari teknologi database adalah tidak terpusat, tapi terintegrasi. Selain itu penting untuk digarisbawahi pula bahwa tidak ada istilah-istilah yang tidak melibatkan istilah lain dalam pemahaman database terdistribusi.
Masalah desain penting yang berdampak besar terhadap kinerja DDBS dan mengarah ke solusi optimal terutama di dalam lingkungan terdistribusi yang dinamis adalah masalah fragmentasi, replikasi, dan alokasi.
Ada tiga masalah penting yang harus diperhitungkan dalam mendesain suatu database terdistribusi. Pertama, bagaimana relasi global harus difragmentasi. Kedua, berapa banyak salinan fragment yang harus direplikasi. Ketiga, teknik apa yang akan digunakan untuk mengalokasikan fragmen ke situs jaringan yang berbeda dan informasi apa yang akan difragmentasi dan dialokasikan.
sekali yang benar-benar optimal. Kualitas metode heuristik ditentukan oleh hasil yang diperoleh dari metode tersebut. Model yang diusulkan di dalam paper ini lebih kepada pendekatan heuristik daripada pendekatan probabilitas, meskipun sedikit menggabungkan kedua konsep tersebut.
2. ISI DAN PEMBAHASAN 2.1 Distributed Data Proccessing
Pengolahan Data Terdistribusi adalah salah satu istilah yang psering disalahgunakan dalam ilmu komputer dalam beberapa tahun terakhir. Istilah tersebut digunakan untuk merujuk pada berbagai sistem seperti sistem multiprosesor, pengolahan data dan jaringan komputer terdistribusi. Pemrosesan terdistribusi adalah sebuah konsep yang sulit untuk memberikan definisi yang tepat, sehingga kami memberi definisi dalam hal sistem database terdistribusi. Sebuah sistem komputasi terdistribusi terdiri sejumlah elemen pengolahan otonom (tidak harus homogen) yang saling berhubungan dengan jaringan komputer dan bekerja sama dalam melaksanakan tugas-tugas (task) dari setiap pengguna. Dengan “pengolahan elemen” berarti komputer dapat menjalankan program-programnya masing-masing.
menggunakan metode ini berubah menjadi lebih baik dan sistem tersebut lebih aman. Dari perspektif global, dapat dikatakan bahwa alasan utama untuk pemrosesan terdistribusi adalah karena terdapat masalah besar dan rumit yang kita hadapi saat ini, yaitu menggunakan variasi aturan terkenal yaitu “divide et impera”. Jika perangkat lunak didistribusikan, maka pengolahan yang dibutuhkan dapat dibuat secara baik. Oleh karena hal itu, maka terdapat pencerahan untuk memecahkan masalah-masalah rumit. Pemecahan masalah dalam hal ini dilakukan dengan berbagi bagian yang lebih kecil, yang dapat diselesaikan oleh kelompok perangkat lunak yang berbeda serta terletak di komputer yang berbeda dan menghasilkan sistem yang berjalan pada lebih banyak elemen pengolahan, tetapi dapat secara efektif melakukan tugas bersama.
2.2 Apa yang dimaksud dengan Sistem Database Terdistribusi?
Kami mendefinisikan database terdistribusi sebagai kumpulan database logika yang saling terkait dan didistribusikan melalui jaringan komputer. Sebuah manajemen database terdistribusi didefinisikan sebagai sistem perangkat lunak yang memungkinkan manajemen database terdistribusi dan membuat distribusi transparan kepada pengguna (user).
Figure 1.1 Environment SBDD
2.3 Keuntungan dan kerugian dari Database Terdistribusi
Keuntungan:
- Local Autonomy. Pengguna database layaknya seperti perhentian tertentu dalam jaringan, yang memiliki kontrol data lokal, karena desentralisasi organization. Data lokal disimpan secara lokal, di mana data secara logic berada dalam banyak kasus serta dalam melaksanakan pengolahan yang telah tersimpan.
Contoh : pemerintahan di Indonesia khususnya untuk setiap daerah diberikan suatu wewenang untuk melaksanakan otonomi daerah, yaitu dalam daerah tersebut dapat mengolah data ataupun hal-hal yang terkait di daerahnya sendiri dan tetap berpedoman dan bertanggung jawab terhadap daerahnya.
- Performance Improvement. Eksekusi paralel dari beberapa tugas di tempat yang berbeda, dapat mengurangi konflik akses data dan dapat meningkatkan baik kecepatan pelaksanaan operasi pada database dan kecepatan akses ke informasi yang tersimpan.
sehingga meningkatkan pelaksanaan informasi dari setiap daerah dan kecepatan akses juga lebih cepat.
- Improving safety and available. Terdapat peningkatan keamanan dalam penggunaan system database terdistribusi dan kesalahan pun dapat diminimalisir, yaitu dalam hal kesalahan yang terjadi ketika data yang direplikasi pada beberapa node, maka akan terjadi tidak tersedianya data dari sekumpulan data yang ada ataupun masalah jaringan, yaitu data tidak dapat diakses (unavailable).
- Expandability. Dalam lingkungan terdistribusi jauh lebih mudah untuk meningkatkan ukuran database.
- Partabilitas. Organisasi yang secara geografis telah didistribusikan melalui operasi dan data dapat disimpan secara normal di tempat yang sama.
Kerugian :
- Complexity. Permasalahan dalam SBDD lebih kompleks daripada yang terpusat, termasuk masalah bersama, dan masih belum terselesaikan dalam lingkungan terpusat. Masalahnya adalah kompleksitas programmer dan bukan pengguna. - Economic. Jika database Anda secara geografis tersebar, maka dibutuhkan
aplikasi yang digunakan untuk tempat penyimpanan data dan mengakses data, sehingga hal-hal tersebut akan meningkatkan biaya komunikasi, membutuhkan tambahan hardware dan software, yang meningkatkan biaya .
- Distribution Control. Hal ini, yang juga merupakan keuntungan, menyebabkan masalah waktu dan koordinasi .
- Security. Hal ini juga diketahui kesulitan dalam mempertahankan kontrol yang memadai keamanan jaringan, sehingga dalam database terdistribusi.
- Adoption technology is difficult. Banyak perusahaan telah berinvestasi dalam sistem database mereka yang tidak didistribusikan. Saat ini tidak ada alat atau teknologi yang membantu pengguna untuk mengkonversi database terpusat database terdistribusi .
Sistem komputasi terdistribusi dirancang dengan melibatkan pengambilan keputusan tentang penempatan data dan program dalam node jaringan computer serta desain jaringan itu sendiri. Dalam kasus database terdistribusi, dengan asumsi bahwa jaringan yang telah dirancang sudah dan terdapat salinan dari perangkat lunak DBMS pada setiap node dalam jaringan di mana data disimpan, ditujukan untuk memusatkan perhatian kita pada distribusi data.
2.5 Alternative Desain Strategy
Ada dua strategi utama untuk desain database terdistribusi yaitu desain top down dan desain bottom-up.
Seperti nama yang telah diberikan kepada kedua design tersebut, maka strategi ini adalah pendekatan yang sangat berbeda dengan proses desain. Tapi sebagian besar aplikasi tidak begitu sederhana sehingga cocok sekali diterapkan dalam salah satu strategi ini, sehingga sangat penting untuk mengetahui bahwa strategi ini harus digunakan bersama-sama sebagai pelengkap satu sama lain.
2.5.3 Top down design
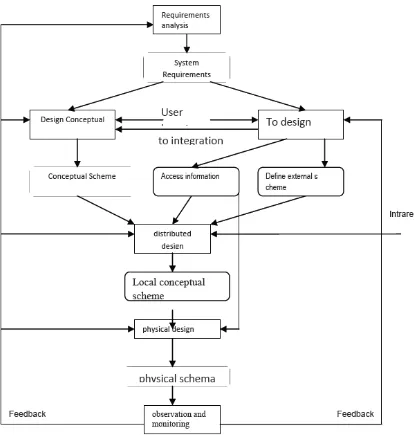
fragmen, dan mereka didistribusikan. Kegiatan desain sehingga didistribusikan terdiri dari dua langkah: fragmentasi dan alokasi. Langkah terakhir dalam proses desain adalah desain fisik, yang membuat hubungan antara skema konseptual dan perangkat penyimpanan fisik lokal pada node yang sesuai data. Entri dalam proses ini adalah skema konseptual lokal dan pola akses informasi. Berikut skema pendekatan top down design.
Figure 1.2 Top-Down design process
2.5.2 Bottom-Up Desain
sudah ada, dan kegiatan desain harus menyadari dan integrasi. Pendekatan bottom-up cocok untuk lingkungan tersebut. Titik awal dalam merancang bottom-up adalah skema konseptual lokal. Proses ini terdiri dalam integrasi skema lokal dalam skema konseptual global.
2.6 Transparansi SGBDD
SGBDD Transparansi mengacu pada pemisahan semantik tingkat tinggi dari sistem implementasi pada tingkat yang rendah. Dengan kata lain, menyembunyikan rincian implementasi transparan kepada pengguna. Keuntungan dari situs transparan DBMS adalah portabilitas, reconfigurabilitatea, menyediakan lingkungan pengembangan untuk aplikasi yang kompleks.
2.7 Data Independence
Independensi data adalah bentuk dasar dari SGBDD transparansi. Hal ini mengacu pada kekebalan aplikasi untuk mengubah pengguna dalam mendefinisikan dan mengorganisasi data, dan sebaliknya .
Anda dapat menyorot dua jenis data independen :
Independensi data logis mengacu pada kekebalan aplikasi pengguna dari perubahan dalam struktur logika database. Jika aplikasi bekerja dengan subset dari atribut dari sebuah hubungan, tidak akan sakit untuk menambahkan atribut baru ke hubungan yang sama.
Physical data independence mengacu menyembunyikan rincian struktur penyimpanan untuk aplikasi pengguna. Aplikasi ini tidak perlu dimodifikasi setiap kali ada perubahan dalam organisasi data.
2.8 Network Transparency
perbedaan (dalam hal pengguna) antara aplikasi menggunakan database terpusat dan orang-orang yang menggunakan database terdistribusi. Jenis transparansi disebut transparansi jaringan.
2.9 Transparansi dalam replikasi
Hal ini diperlukan bahwa data yang didistribusikan oleh cara replikatif antara mesin pada jaringan. Jadi data yang sama akan ditemukan di banyak mobil. Hal ini meningkatkan kinerja sistem karena tuntutan yang berbeda dan bersaing pengguna dapat lebih mudah puas. Sebagai contoh, data yang sering diakses oleh pengguna dapat menyimpan mobilnya, dan bahwa pengguna lain dengan persyaratan akses yang sama. Jika node jaringan tidak tersedia, data dapat diakses dari lokasi lain. Data apa yang harus direplikasi di banyak anak-anak sangat tergantung pada aplikasi yang mengaksesnya. Replikasi data tetapi menyebabkan beberapa masalah update. Fakta bahwa pengguna tidak tahu berapa banyak salinan yang dibuat dan tidak tahu apa-apa tentang keberadaan mereka, kita dapat memanggil replikasi transparan ( replikasi Transparansi).
2.10 Transparansi fragmentasi
Hal ini dimaksudkan bahwa setiap objek database yang akan dibagi menjadi fragmen kecil dan setiap fragmen diperlakukan sebagai objek database yang terpisah. Hal ini disebabkan oleh alasan kinerja, ketersediaan dan kehandalan. Juga, fragmentasi dapat mengurangi efek negatif dari replikasi.
2.11 Fragmen
keputusan migrasi dibuat dengan memilih situs Sj yang memiliki biaya pembaruan permintaan tertinggi untuk fragmen Fi untuk dipilih sebagai calon lokasi untuk menyimpan Fi fragmen untuk meminimalkan komunikasi biaya.
Model ini menggunakan Fragment Prioritas (FP) teknik untuk menghindari duplikasi fragmen (yang bisa terjadi pada tahap alokasi awal) dan situs kendala pelanggaran setiap kali mereka terjadi.
2.12 Pernyataan Masalah dan Persyaratan Informasi
2.12.1 Deskripsi Masalah dan Notasi
Model yang diusulkan di dalam paper ini mengasumsikan jaringan yang terkoneksi penuh terdiri dari situs S = {S1, S2, …., Sm}, di mana setiap situs memiliki kapasitas (C), fragment limit (FL) dan sistem database lokal. Sebuah hubungan antara dua situs Si
dan Sj memiliki bilangan positif (CCij) yang terkait yang mewakili
biaya transfer data dari situs Si ke Sj. Setiap situs memiliki
seperangkat query Q = {Q1, Q2, ..., Qk} yang dianggap sebagai
pertanyaan yang paling sering dieksekusi yang dihitung dari lebih dari 75% pengolahan situs di DDBS. Setiap query Qk dapat
dijalankan di situs manapun dengan frekuensi tertentu, frekuensi eksekusi k query di situs m dapat direpresentasikan oleh matriks m x k (QFij). Misal S mengandung satu set fragmen F = {F1, F2, ..., Fn)
merepresentasikan partisi hubungan selama fase fragmentasi desain DDBS. Untuk membuat alokasi lebih efsien kita perlu menentukan tidak hanya jumlah salinan untuk setiap fragmen tetapi juga menemukan alokasi yang tepat untuk masing-masing di situs menurut informasi query yang dikumpulkan.
Ada dua defnisi optimal menurut [24]. Pertama, biaya minimal (biaya penyimpanan setiap fragmen Fi di situs Sk + biaya
biaya komunikasi data). Kedua, kinerja (meminimalkan waktu respon dan memaksimalkan sistem throughput.
Penulis di dalam paper ini mengadopsi defnisi yang pertama (biaya minimal) untuk pengukuran yang optimal. Dengan demikian, masalah optimalitas sesuai dengan model yang diusulkan di dalam paper ini bisa didefnisikan sebagai minimalisasi biaya komunikasi dalam proses pengalokasian ulang fragmen Fi ke situs Sj.
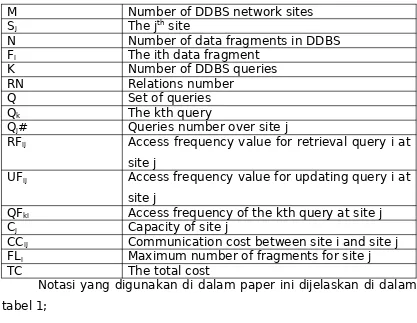
Tabel 1. Notasi Model
M Number of DDBS network sites Sj The jth site
N Number of data fragments in DDBS Fi The ith data fragment
RFij Access frequency value for retrieval query i at
site j
UFij Access frequency value for updating query i at
site j
QFki Access frequency of the kth query at site j
Cj Capacity of site j
CCij Communication cost between site i and site j
FLi Maximum number of fragments for site j
TC The total cost
Notasi yang digunakan di dalam paper ini dijelaskan di dalam tabel 1;
2.12.2 Persyaratan Informasi
2.12.3 Informasi Database
Biasanya relasi terdiri dari banyak fragmen. Masing-masing memiliki ukuran Z(Fi) yang perlu ditentukan sebelumnya karena
memainkan peran kunci dalam menghitung biaya komunikasi.
Z (Fi) = Card (Fi) * L (Fi) , i = 1,…, n.
Dimana L adalah panjang fragmen tuple dan kartu (Fi) adalah kardinalitas fragmen (yaitu jumlah record fragmen), panjang (Fi) dapat dihitung dengan menggunakan rumus berikut:
Length (Fi) = Σ LA , 1 <= A <= h.
Dimana h adalah jumlah atribut untuk fragmen itu dan A menunjukkan kepada atribut Ath. Jadi, Z (F
i) = n * Σ Lj, dimana n
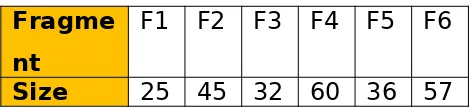
adalah jumlah record fragmen. Untuk menyederhanakan model yang diusulkan ini, penulis akan menganggap fragmen ukuran diberikan seperti yang ditunjukkan pada tabel 2.
Tabel 2. Ukuran Fragmen
Fragme nt
F1 F2 F3 F4 F5 F6
Size 25 45 32 60 36 57
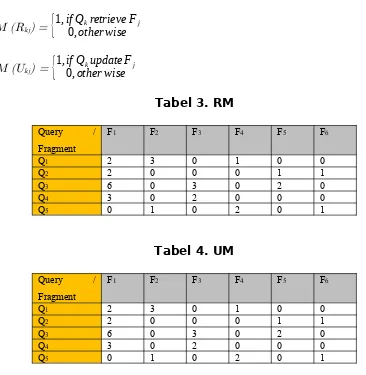
Kita juga perlu mendefnisikan matriks Xij yang menunjukkan
tugas fragmen ke situs. Matriks ini akan ditentukan oleh Retrieval Matrix (RM) dan akan digunakan pada tahap alokasi awal.
Xij =
{
1,if Fiis assigned¿ S¿0,other wise¿
2.12.4 Informasi Perilaku Query
pertanyaan. Unsur-unsur Rkj atau UKJ di RM atau UM masing-masing,
memberikan frekuensi akses fragmen Fj oleh query k.
RM (Rkj) =
{
Sebagai contoh pada Tabel 3, query Q1 mengambil fragmen F1 dua kali, tiga kali F2 dan F4 hanya sekali. Hal ini juga, update fragmen F3 dua kali dan F5 sekali dalam Tabel 4. Namun, untuk setiap permintaan yang dipekerjakan di situs manapun, harus memiliki nilai frekuensi di situs tersebut. Dengan demikian, kita harus mendefnisikan Frekuensi Matrix untuk Query (QF) yang menunjukkan frekuensi pelaksanaan query di setiap situs (Tabel 5 menggambarkan ini).
Tabel 5. Frekuensi Query
Query / Site S1 S2 S3 S4
Q1 0 2 3 1
Q3 2 0 1 0
Q4 3 0 4 0
Q5 1 1 0 2
2.12.5 Informasi Situs
Pada bagian ini informasi situs direpresentasikan dalam model pengalokasian ulang ini dengan kendala situs, sistem harus memenuhi constraint kapasitas situs (C) dan batas fragmen (FL) yang merepresentasikan ukuran maksimum dan jumlah fragmen yang dapat dihandle oleh suatu situs. Kendala yang digunakan untuk mengelola proses alokasi dijelaskan pada bagian yang lain.
Persamaan (1), menunjukkan bahwa setiap fragmen F harus dialokasikan untuk setidaknya satu situs di tahap alokasi awal. Persamaan (2), menyatakan bahwa tidak ada situs akan menerima lebih dari kapasitasnya. Persamaan (3), menyatakan bahwa setiap situs tidak akan menangani lebih dari angka yang diberikan fragmen (FL) dan akhirnya persamaan (4), menyatakan bahwa fragmen akan dialokasikan untuk hanya satu situs di fase alokasi pos (re-alokasi) . Tabel 6 menggambarkan batas kendalan model re-alokasi ini.
2.12.6 Informasi Jaringan
Dalam pendekatan yang diusulkan oleh penulis diasumsikan bahwa situs jaringan DDBS terhubung jaringan secara penuh. Dan setiap link antara situs Si dan Sj memiliki nilai biaya komunikasi (CCij) mewakili biaya komunikasi di antara mereka seperti yang ditunjukkan pada Gambar 1.
Gambar 2. Situs Jaringan
F1, F2 18 F6
9
5 4 11
F3
16 F4, F5
Untuk menyederhanakan model re-alokasi tersebut, matriks biaya komunikasi diberikan sebagai matriks simetris, yaitu biaya komunikasi antara situs Si dan Sj adalah sama seperti antara
situs Si dan Sj dan biaya komunikasi dalam situs yang sama adalah
nol seperti yang ditunjukkan dalam tabel 7.
Tabel 7. Matriks Biaya Komunikasi
Sites S1 S2 S3 S4
S1 0 5 9 18
S2 5 0 16 4
S3 9 16 0 11
S4 18 4 11 0
s4
s1
s3
Setelah menerapkan algoritma minimum [20] pada matriks biaya komunikasi, kita memperoleh Matrix Biaya Jarak (DM) seperti pada (Tabel 8).
Tabel 8. Matriks Biaya Jarak
Sites S1 S2 S3 S4
S1 0 5 9 9
S2 5 0 14 4
S3 9 14 0 11
S4 9 4 11 0
2.13 Model yang Diusulkan dan Fungsi Biaya
Pada bagian ini, model yang diusulkan bersama dengan fungsi biaya yang akan digunakan untuk menghitung biaya fragmen re-alokasi akan disajikan.
2.13.1 Model yang Diusulkan
Model yang diusulkan ini mengasumsikan bahwa ada informasi yang dikumpulkan tentang frekuensi update yang terlibat dalam alokasi fragmen di seluruh situs. Untuk menyelesaikan proses alokasi, setiap fragmen harus ditugaskan untuk satu atau lebih situs di DDBS pada tahap alokasi awal. Namun, karena masalah alokasi melibatkan pemikiran untuk menemukan distribusi fragmen yang optimal di seluruh situs. Kemudian untuk himpunan fragmen dengan ukuran yang berbeda, dan sejumlah situs jaringan dimana setiap situs memiliki sejumlah query yang dieksekusi, model alokasi optimal akan meminimalkan total biaya pembaruan di seluruh jaringan tanpa melanggar kendala situs.
semua fragmen didistribusikan untuk menggunakan mereka setiap kali sebuah proses re-alokasi diperlukan. Untuk menghasilkan tahap awal distribusi fragmen (yang mungkin mengandung fragmen duplikasi), teknik yang diusulkan akan mengasumsikan bahwa fragmen telah didistribusikan di situs jaringan yang berbasis pada pengambilan matriks yang diberikan (RM) dan matriks permintaan frekuensi (QF) yang diuraikan dalam bagian III. B.2. Pendekatan yang diusulkan mengasumsikan bahwa, query pengambilan akan ditangani dengan tanpa biaya komunikasi dengan mengalokasikan setiap fragmen ke situs yang meminta. Sebagai contoh, fragmen F3 di RM (tabel 3), bisa diminta oleh permintaan Q3 dan Q4 saja. Dan karena permintaan Q3 dan Q4 diterbitkan di situs S1 dan S3, maka F3 fragmen akan dialokasikan untuk kedua situs.
Sebuah teknik baru untuk re-alokasi fragmen yang dihasilkan dari tahap awal dengan cara yang non-redundant disajikan dalam paper ini. Teknik re-alokasi ini dilakukan dengan menggunakan matriks pembaruan hanya bersama dengan frekuensi query, karena query update biasanya menimbulkan biaya lebih dari query pengambilan. Oleh karena itu, tabel 4 dan 5, yaitu UM dan QF matriks akan digunakan sebagai masukan untuk membangun sebuah matriks baru yang disebut Matriks Frekuensi Pembaruan Fragmen, FUFM (tabel 10) sebagai dasar untuk re-alokasi. Matriks FUFM dapat didefnisikan sebagai nilai-nilai pembaruan permintaan di situs tertentu untuk fragmen yang terkena dampak.
kandidat, maka fragmen akan bermigrasi ke situs dengan nilai biaya pembaruan tertinggi berikutnya. Selain itu, jika ada lebih dari satu situs yang memiliki nilai biaya pembaruan yang sama untuk fragmen tertentu, prosedu rFragments Prioritas (FP) akan dijalankan pada situs tersebut untuk mengalokasikan fragmen itu ke situs dengan nilai FP tertinggi dan kemudian tindakan ini jaminan bahwa saat ini salinan fragmen akan menjadi satu-satunya copy di seluruh jaringan. Tahapan sistem yang diusulkan penulis digambarkan pada Gambar 2. yang diinginkan. Ini digunakan jika ada permintaan untuk fragmen Fi yang sama lebih dari satu situs yang memiliki nilai biaya pembaruan yang sama untuk fragmen itu. Dengan demikian, untuk menghindari duplikasi fragmen atas situs, FP akan dihitung untuk setiap situs dan akan digunakan untuk membuat keputusan tentang alokasi fragmen Fi ke situs yang memiliki nilai FP tertinggi.
FP (Sj,Fi) = Σ (QFhi * QShi ) * DMj,h , 1 < = j< = m (1)
QShi = Σ RMhi + Σ UMhi, 1 < = h < = h (2)
Pada bagian ini dibahas mengenai biaya yang dikenakan oleh query dalam proses mengakses dan memperbarui fragmen pada situs tertentu. Seperti disebutkan sebelumnya, untuk melakukan perhitungan FUPM, kita mengambil matriks FUFM sebagai masukan dan menggunakan fungsi biaya berikut:
CUFT = Σ Σ (QFi * UF(Fi)) (3)
DMij = Min (CCij), 1 <= i, j <= m (4)
FUPM= Σ CUFT (Fi) * DMjj’ ,1 <= j, j’ <= m (5)
Σ Max (FUPMij), 1 <= i <= n (6)
Persamaan (3) digunakan untuk menghasilkan tabel CUFT, Persamaan (4) menerapkan "minimum" algoritma biaya komunikasi matriks, Persamaan (5) digunakan untuk membangun FUPM dan akhirnya Persamaan (6) merupakan keputusan re-alokasi. Secara umum, proses redistribusi dapat dianggap optimal ketika mencapai skema alokasi yang menghasilkan total biaya pembaruan minimal untuk query. Karena masalah ini praktis tak dapat dihitung, maka dengan demikian penulis memutuskan di sini untuk menggunakan metode heuristik sebagai gantinya.
2.16 The Proposed Algorithm (Algoritma yang Diusulkan)
Pada paper ini terdapat lima langkah dalam algoritma model yang disusulkan untuk mengalokasikan kembali (re-allocation), yaitu Distance matrix formation, The sum of retrival and update cost calculation, Computation of the pay update cost for sites to access fragments, Allocation of the fragment Fi to the site incurring the highest update cost, dan If more than one site require then use fragment priority procedure Allocate-FP(Sj,Sj+1,Fi,FUPM_value); Output is an allocation of the intended fragment to its new site
Selain lima langkah itu juga terdapat initial allocation phase dan re-allocation phase. Berikut ini adalah bagian-bagian algoritmanya:
For each relation {1,… , K}
{QN = { Q1……, Qn} // a set of queries F = { F1……., Fn } // DDBS fragments S = { S1…….., Sm} // a set of network sites
RM matrix, UM matrix, QF matrix and communication cost matrix Output: fragment reallocation scheme
Input dalam algoritma ini adalah satu set query, fragment DDBS, satu set situs jaringan (network sites) dari setiap relasi.
Outputnya adalah skema pengalokasian kembali fragment
Initial Allocation Phase
Begin
Start initial allocation using RM and QF matrices Build Distance Cost matrix (DM) = min (CCM) Calculate_DM(CCM);
Calculate_CUFT (QFM, FUFM); Calculate_FUPM (DM, CUTF); End
Pada fase initial allocation dimulai dengan mengalokasikan database menggunakan matriks RM dan QF. Lalu membangun DM yang nilainya sama dengan nilai CCM yang paling kecil. Setelah mendapatkan DM hitung DM(CCM), CUFT(QFM, FUFM), dan FUPM(DM, CUTF).
Step 1
// Distance matrix formation Min(CCM);{
Langkah pertama pada algoritma ini adalah menghitung jarak formasi matriks dengan menggunakan fungsi Min(CCM).
Fungsi tersebut nantinya akan memberikan output berupa jarak matriks dan nilai tekecilnya.
Step 2
// The sum of retrieval and update cost calculation Calculate_CUFT (QFM,FUFM);
Langkah kedua adalah menghitung jumlah perhitungan biaya retrieval dan update dengan menggunakan fungsi Calculate_CUFT(QFM, FUFM)
Fungsi tersebut akan menghasilkan output berupa table CUFT.
Step 3
Langkah ketiga adalah menghitung biaya update untuk situs yang mengakses fragment-fragment dengan menggunakan fungsi Calculate_FUPM(CCM, SRUM) yang menghasilkan FUPM.
Re- Allocation Phase
Start the post-allocation or re-allocation phase using (FUPM) matrix
Step 4
// Allocation of the fragment Fi to the site incurring the highest update cost Begin
If Sj.Fi (FUPM_value) = Sj+!.Fi (FUPM_value) FP (Sj,Sj+1,Fi,FUPM_value); update tertinggi, kemudian mengalokasikan fragment Fi ke situs tersebut.
Step 5
// If more than one site require the same fragment then use fragment priority procedure
Allocate-FP(Sj,Sj+1,Fi,FUPM_value);
//Output is an allocation of the intended fragment to its new site
Begin
For i=1 to n do // attributes
update cost for fragment (Sj). Allocate Fi to Sj (v) // allocate the fragment i to the corresponding site Sj (v) If many sites require one fragment Fi
Run FP procedure at all sites that require Fi Allocate fragment to sj that has maximum FP ENDFOR; fragment yang sama. Jika ada maka gunakan prosedur prioritas fragment untuk mengalokasikannya dengan menggunakan fungsi Allocate-FP(Sj,Sj+1,Fi,FUPM_value);
Outputnya adalah alokasi fragment yang dimaksudkan untuk situs baru. 2.17 Experimental Results (Hasil Experimental)
2.17.1 Initial Allocation (Alokasi Awal)
Hasil dari Retrieval Matrix (RM) menunjukkan query setiap Qk untuk
mendapatkan kembali (retrieve) setiap fragment Fi. Sedangkan hasil Query Frequency
matriks tersebut digunakan dalam paper ini untuk memperoleh tabel initial allocation (Tabel 9). Dengan tabel ini kita dapat melihat setiap fragment terdapat pada situs mana saja. Misalnya F1 terdapat pada situs 2, 3, 4. Hal ini akan menyebabkan masalah duplikasi fragment. Oleh karena itu masalah ini akan diselesaikan dengan proses selanjutnya yaitu proses pengalokasian kembali (re-allocation).
2.17.2 Re-Allocation Process (Proses Pengalokasian Kembali)
Proses pengalokasian kembali merupakan solusi untuk menangani duplikasi fragment. Sedikit berbeda dengan tabel initial allocation yang didapakan dari RM dan QF, proses ini menggunakan Fragment Update Frequeancy Matrix (Tabel 10) yang didapatkan dari Update Matrix dan QF Matrix. Hasil dari Update Matrix (UM) menunjukkan query setiap Qk untuk melakukan update pada setiap fragment Fi.
Kemudian FUFM matrix dapat disederhanakan menjadi Cumulative Update Frequency Table Matrix (Tabel 11) dengan melakukan perkalian setiap nilai QF dengan F kemudian menjumlahkan hasilnya suntuk setiap S yang sama. Setelah didapatkan CUFT Matrix, apabila dikalikan dengan Distance Cost Matrix (DM) maka akan didapatkan Fragment Update Pay Matrix (tabel 12).
dialokasikan, akan didapatkan tabel 13 yaitu Fragment Allocation sebagai hasil dari eksperimen paper ini.
2.18 Performance Evaluation (Evaluasi Kinerja)
Permasalahan yang akan diatasi oleh paper ini adalah mengalokasikan kembali fragment, yaitu dengan menggunakan metode probabilities atau heuristic. Pendekatan yang digunakan adalah keduanya, tetapi lebih mengarah ke pendekatan heuristic untuk meningkatkan performa DDBS secara dinamis dan meminimalkan biaya komunikasi serta permintaan waktu respon.Untuk meminimalkan biaya komunikasi, maka biaya update harus diperbesar. Bukti dari teori ini adalah:
Dengan asumsi bahwa ∑ ∑ ∑ QFjk * UMkl konstan, maka terbukti untuk mendapatkan biaya komunikasi minimal harus memaksimalkan ∑ ∑ QFhk * UMkl.
Selain meminimalkan matriks biaya komunikasi untuk mendapatkan Distance Cost Matrix merupakan factor utama dalam meningkatkan kinerja DDBS. Namun dalam model yang digunakan proses pengalokasin kembali didasarkan pada biaya update hanya dikarenakan operasi update dikenakan biaya lebih dari pengambilan, terutama ketika fragment direplikasi di beberapa situ pada initial allocation.
Model dalam paper ini digunakan untuk menemukan metode pengalokasian fragment kembali yang paling optimal untuk meningkatkan kinerja DDBS dengan meminimalkan biaya komunikasi dan waktu respon query. Sehingga didapatkan data yang lebih baik dengan mempertahankan satu copy fragment di DDBS setelah proses alokasi.
Tabel 14 dan gambar 3 menunjukkan perbedaan pada initial allocation yang menghasilkan 19 alokasi sedangkan fragment allocation hanya menghasilkan 6 alokasi.
Gambar 5. Allocation Process
III PENUTUP
3.1 Kesimpulan
1. Manajemen internal database terdistribusi bersifat menuntut dan umumnya sulit, karena kita telah memastikan bahwa:
• Distribusi transparan (tak terlihat dan tidak mengganggu) - pengguna harus dapat berinteraksi dengan sistem seolah-olah mereka adalah non-terdistribusi (monolitik)
• Transaksi juga harus memiliki struktur yang transparan (tak terlihat dan tidak mengganggu).
2. Tentu saja setiap transaksi harus menjaga integritas database, meskipun banyaknya partisi. Untuk ini mereka biasanya dibagi subtranzacţii, masing-masing bekerja dengan hanya satu partisi.
3. Pada bagian kesimpulan dapat dikatakan penggunaan model dinamis pengalokasian kembali dengan metode heuristik dapat menemukan solusi optimal untuk pengalokasian kembali fragment dalam lingkungan DDBS . 4. Untuk mendapatkan biaya komunikasi yang minimal maka biaya update harus
dimaksimalkan.
6. Jika ada lebih dari satu situs yang memiliki nilai biaya pembaruan yang sama untuk fragmen tertentu , maka fragmen yang akan dialokasikan ke situs optimal sesuai dengan prosedur Fragment Priority ( FP ).
7. Hasil dari model ini menjamin tidak adanya duplikasi fragment melalui penggunaan prosedur FP yang menghasilkan kompleksitas komputasi rendah. Karena pendekatan yang digunakan sederhana dan efisien.
3.2 Kelebihan dan Kelemahan Paper
Kelebihan metode yang digunakan dalam paper ini antara lain:
1. Proses pengalokasian kembali merupakan metode dinamis berdasarkan informasi yang diekstraksi (pengambilan dan pembaruan nilai-nilai frekuensi) dari DDBS yang ada. Jadi, setiap perubahan situs query dan frekuensi akan memiliki efek pada proses pengalokasian kembali.
2. Menjamin tidak ada fragment yang duplikasi (duplikasi hanya diperbolehkan pada tahap initial allocation). Sedangkan pada fase pasca alokasi hanya duplikasi primary key di situs yang diperbolehkan.
3. Kompleksitas komputasi kurang. Karena pendekatan yang digunakan sederhana tapi efisien.
DAFTAR PUSTAKA
[1] Abdalla H, "An Efficient Approach for Data Placement in Distributed Systems", Fifth FTRA International Conference on Multimedia and Ubiquitous Engineering, (2011).
[2] Abdalla H, “Using a Greedy-Based Approach for Solving Data Allocation Problem in a Distributed Environment”, to appear in the Proceedings of the 2008 International Conference on Parallel and Distributed Processing Techniques and Applications (PDPTA'08), (2008). [3] Brunstrom A, Leutenegger ST and Simha R, “Experimental Evaluation of Dynamic Data Allocation Strategies in a Distributed Database With Changing Workloads”, in Proceedings of the 1995 International Conference on Information and Knowledge Management, Baltimore,MD, USA, (1995), pp. 395-402.
[4] Apers P, “Data Allocation in Distributed Databases”, ACM Trans. Database Systems, vol. 13, no. 3, (1988) September, pp. 263-304.
[5] Abiteboul S, Bonifati A, Cobena G, Manolescu I and Milo T, “Dynamic XML Documents with Distribution and Replication”, Proc. 2003 ACM SIGMOD Int’l Conf. Management of Data, (2003), pp. 527-538.
[6] Wilson B and Navathe SB, “An Analytical Framework for the Redesign of Distributed Databases”,, in Proceedings of the 6th Advanced Database Symposium, Tokyo, Japan, (1986), pp. 77-83.
[7] Chiu G and Raghavendra C, “A Model for Optimal Database Allocation in Distributed Computing Systems”, Proc. IEEE INFOCOM 1990, vol. 3, (1990) June, pp. 827-833.[8] Chu WW, “Optimal File Allocation in Multiple Computer Systems”, IEEE Transaction on Computers, vol. C-18, no. 10, (1969).
[9] Cormen TH, Leisorson CE, Rivest RL and Stein C, “Introduction to Algorithms 2nd Edition”, McGraw Hill (2001).
[10] Lin WJ and Veeravalli B, “A Dynamic Object Allocation and Replication Algorithm for Distributed System with Centralized Control”, International Journal of Computer and Application, vol. 28, no. 1, (2006), pp. 26-34.
[11] Karimi Adl R and Rouhani Rankoohi SMT, “A new ant colony optimization based algorithm for data allocation problem in distributed databases”, Knowl Inf Syst 2009, vol. 20,
(2009) January 23, pp. 349–373.
[13] Hababeh IO, Ramachandran M and Bowring N, “A high-performance computing method for data allocation in distributed database systems”, Springer J Supercomput, vol. 39,
(2007), pp. 3-18.
[14] Singh A and Kahlon KS, "Non-replicated Dynamic Data Allocation in Distributed Database Systems", IJCSNS International Journal of Computer Science and Network Security, vol. 9, no. 9, (2009) September, pp. 176-180.
[15] Sleit A, AlMobaideen W, Al-Areqi S and Yahya A, "A Dynamic Object Fragmentation and Replication Algorithm In Distributed Database Systems", American Journal of Applied Sciences, vol. 4, no. 8, (2007), pp. 613-618.
[16] John LS, “A Generic Algorithm for Fragment Allocation in Distributed Database System”, ACM (1994).
[17] Tâmbulea L and Horvat M, "Dynamic Distribution Model in Distributed Database", Int. J. of Computers, Communications & Control, ISSN 1841-9836, E-ISSN 1841-9844, Vol. III,
(2008), Suppl. issue: Proceedings of ICCCC 2008, pp. 512-515.
[18] Tamhankar A and Ram S, “Database Fragmentation and Allocation: An Integrated Methodology and Case Study,” IEEE Trans. Systems,Man and Cybernetics—Part A, vol. 28, no. 3, (1998) May.
[19] Ozsu MT and Valduriez P, “Principles of Distributed Database Systems”, 2nd ed.Prentice-Hall International Editions, (1999).
[20] Toadere T, “Graphs. Theory, Algorithms and Applications”, Editura Albastra, Cluj-Napoca, ROMANIA, (2002).
[21] Upadhyaya S and Lata S, "Task allocation in Distributed computing VS distributed database systems: A Comparative study", IJCSNS International Journal of Computer Science and Network Security, vol. 8, no. 3, (2008) March.
[22] Ulus T and Uysal M, “Heuristic Approach to Dynamic Data Allocation in Distributed Database Systems”, Pakistan Journal of Information and Technology, vol. 2, no. 3, (2003), pp. 231-239.
[23] Rivera-Vega PI, Varadarajan R and Navathe SB, “Scheduling Data Redistribution in Distributed Databases”, in IEEE Proceedings of the Sixth International Conference on Data Engineering, (1990), pp. 166-173.
[24] Dowdy LW and Foster DV, “Comparative models of the file assignment problem,” ACM Computing Survey, vol. 14, no. 2, (1982), pp. 287-313.