BAB II
KAJIAN TEORITIS 2.1 Pengindeksan Subjek
Dalam ilmu perpustakaan indeks memiliki arti yang lebih luas. Ada dua unsur penting dalam kegiatan pengindeksan, yakni orang yang membuat indeks (indexer) dan objek yang di indeks. Objek yang diindeks meliputi buku, artikel, jurnal, atau laporan. Indeks yang dihasilkan diharapkan berguna sebagai sarana penelusuran informasi yang dibutuhkan. Istilah indeks diperoleh melalui proses pengindeksan.
Menurut Clevelend (2001: 97), “indexing is the process identifying information in a knowledge record (text or nontext) an organizing the pointers to that
information in to searchable file”. Defenisi di atas dapat diartikan bahwa pengindeksan adalah proses identifikasi informasi dalam sebuah catatan pengetahuan baik teks ataupun non-teks dan pengorganisasian nilai-nilai informasi untuk pencarian file. Dari pendapat di atas bahwa pengindeksan adalah kegiatan pengorganisasian nilai-nilai informasi.
“Indeks merupakan hasil utama dari proses analisis dokumen, dibuat untuk keperluan temu kembali informasi dalam suatu pangkalan data atau dalam majalah sekunder tercetak. Suatu indeks harus memberikan kemungkinan bagi pengguna untuk dapat mengakses suatu dokumen, maupun sekumpulan secara efesien.” (Konfhage dalam Andriaty (2002 : 1) )
Pendapat tersebut dapat dinyatakan bahwa indeks merupakan hasil dari proses analisis dokumen untuk dapat diakses oleh pengguna dalam pencarian informasi. Dari kedua pendapat di atas dapat dinyatakan bahwa pengindeksan adalah proses identifikasi dan analisis dokumen dalam kegiatan pengorganisasian nilai-nilai informasi yang mampu mewakili isi dokumen agar dapat diakses oleh pengguna dalam keperluan penelusuran informasi. Dengan demikian, indeks sangat penting dalam penentuan representasi dokumen tertentu dalam temu kembali informasi.
Indeks ada dua jenis yaitu indeks subjek dan indeks pengarang. Jika atribut tersebut adalah subjek, maka indeks yang mewakilinya disebut indeks subjek. Jika atribut tersebut adalah pengarang, maka indeks yang mewakilinya disebut indeks pengarang. Pada perpustakaan dan pusat informasi kedua indeks di atas digunakan dalam proses temu kembali informasi. Untuk menghasilkan indeks subjek dilakukan kegiatan pengindeksan subjek. Pengindeksan subjek menghasilkan deskripsi indeks yang merupakan wakil ringkas isi dokumen. Pengindeksan subjek dapat dilakukan dengan dua cara yaitu pengindeksan secara manual dan otomatis.
2.1.1 Pengindeksan Subjek Secara Manual
Pengindeksan secara manual menggunakan pengetahuan indexer untuk menganalisis topik sebuah karya.
“Human indexer use their knowledge to find the “aboutness” of the writing they are analyzing and find concept within the writing. Human indexing tends to “focus on larger documentary units, such as complete periodical articles, complete chapter in collection, or even complete monographs” (Anderson dan Perez dalam Shield, 2005: 1).
Defenisi di atas dapat diartikan bahwa pengindeks (indexer) menemukan
konsep dalam tulisan dan kemudian menggunakan istilah dalam pencarian sebuah karya. Pengindeksan secara manual cenderung fokus dalam jenis bahan dokumen yang besar, seperti artikel terbitan berkala yang lengkap, koleksi per bab atau koleksi monograf yang lengkap. Dari pendapat di atas dapat dinyatakan bahwa pengindeksan secara manual adalah proses analisis subjek yang mana pengindeks (indexer) mempelajari isi dokumen untuk mengidentifikasi konsep-konsep penting yang dibahas dalam dokumen.
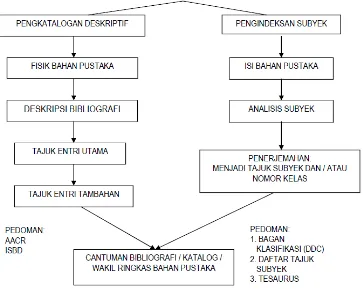
klasifikasi, daftar tajuk subyek dan thesaurus. Kedua kegiatan ini menghasilkan cantuman bibliografi atau sering disebut katalog yang merupakan wakil ringkas bahan pustaka.
Keterkaitan kegiatan pengatalogan dengan pengindeksan subjek dapat dilihat pada gambar berikut :
Gambar. 1. Keterkaitan Kegiatan Pengindeksan Subjek dalam Pengatalogan (Pangaribuan, 2010: 2).
Kegiatan pengindeksan subjek secara manual mencakup : 1. Memahami isi bahan pustaka
2. Analisis subjek 3. Penerjemahan
1. Memahami Isi Bahan Pustaka
bertujuan menggunakan kata-kata (istilah) yang seragam untuk bahan pustaka perpustakaan mengenai subyek tertentu. Subyek adalah topik yang merupakan kandungan informasi (content) dalam bahan pustaka.
2. Analisis Subyek
Dalam penentuan subyek buku atau bahan pustaka lainnya diperlukan analisis subyek. Kegiatan analisis subyek memerlukan kemampuan yang memadai, sebab di sinilah pengindeks dituntut kemampuannya untuk menentukan subyek apa yang dikandung dalam bahan pustaka yang diolah. Ada tiga hal yang mendasar perlu dikenali pengindeks dalam menganalisis subyek (Pangaribuan 2010: 3) yakni :
A. Jenis konsep B. Jenis subyek C. Urutan sitasi
A. Jenis konsep
Dalam satu bahan pustaka dapat dibedakan tiga jenis konsep (Miswan 2003: 4) yaitu:
1. Disiplin ilmu, yaitu istilah yang digunakan untuk satu bidang atau cabang ilmu pengetahuan. Disiplin ilmu dapat dibedakan menjadi 2 kategori: a. Disiplin fundamental, yang meliputi bagian-bagian utama ilmu
pengetahuan. Oleh para ahli disiplin fundamental dikelompokkan menjadi tiga yakni ilmu-ilmu sosial, ilmu-ilmu pengetahuan alam, dan ilmu-ilmu kemanusiaan.
b. Sub disiplin, merupakan bidang spesial dalam satu disiplin fundamental. Misalnya dalam disiplin ilmu fundamental alam, sub disiplinnya terdiri atas fisika, kimia, biologi, dsb.
2. Fenomena (topik yang dibahas), merupakan wujud/benda yang menjadi objek kajian dari disiplin ilmu.
3. Bentuk ialah cara bagaimana suatu subyek dasajikan. Dibedakan menjadi tiga jenis:
a. Bentuk fisik, yakni medium atau sarana yang digunakan dalam menyajikan suatu subyek. Misalnya dalam bentuk buku, majalah, pita rekaman, dan sebagainya.
c. Bentuk intelektual, yaitu aspek yang ditekankan dalam pembahasan suatu subyek. Misalnya Filsafat Sejarah disini yang menjadi subyeknya adalah sejarah sedangkan filsafat adalah bentuk intelektual.
Dari pernyataan di atas dapat dinyatakan bahwa dalam menganalisis subjek berdasarkan konsep terkandung tiga jenis konsep yaitu berdasarkan disiplin ilmu, fenomena dan bentuk. Ketiga konsep tersebut dapat membantu pengindeks dalam menentukan subjek dari dokumen.
B. Jenis subjek
Dalam kegiatan analisis subyek dokumen terdapat dalam bermacam-macam jenis subyek. Secara umum digolongkan dalam 4 kelompok (Yuslina 2011: 12) yaitu:
1. Subyek dasar, yaitu subyek yang hanya terdiri dari satu disiplin ilmu atau sub disiplin ilmu saja. Misalnya, Pengantar Ekonomi, yaitu menjadi subyek dasaranya Ekonomi.
2. Subyek sederhana, yaitu subyek yang hanya terdiri dari satu faset yang berasal dari satu subyek dasar (Faset ialah sub kelompok klas yang terjadi disebabkan oleh satu ciri pembagian. Tiap bidang ilmu mempunyai faset yang khas sedangkan fokus ialah anggota dari satu faset). Misalnya, Pengantar ekonomi Pancasila terdiri dari subyek dasar ekonomi dan faset Pancasila.
3. Subyek majemuk, yaitu subyek yang terdiri dari subyek dasar disertai fokus dari dua atau lebih faset. Misalnya, Hukum adat di Indonesia. Subyek dasarnya yaitu Hukum dan dua fasetnya yaitu Hukum Adat (faset jenis) dan Indonesia (faset tempat).
4. Subyek kompleks, yaitu subyek yang terdiri dari dua atau lebih subyek dasar dan saling berinteraksi antara satu sama lain. Misalnya, Pengaruh Agama Hindu Terhadap Agama Islam. Disini terdapat dua subyek dasar yaitu Agama Hindu dan Agama Islam.
Untuk menentukan subyek yang diutamakan dalam subyek kompleks terdapat
Abu Merapi. (3). Fase alat, yaitu subyek yang digunakan sebagai alat untuk menjelaskan atau membahas subyek lain. Disini subyek yang diutamakan ialah subyek yang dibahas atau dijelaskan. Misalnya, Penggunaan Alat Kimia Dalam Analisis Darah. Disini yang diutamakan adalah Darahbukan Kimia. (4). Fase perbandingan, yaitu dalam satu dokumen/bahan pustaka terdapat berbagai subyek tanpa ada hubungannya antara satu sama lain.
C. Urutan sitasi
Agar diperoleh suatu urutan yang baku dan taat azas/konsistensi dalam penentuan
subyek dan (nomor kelas) maka Ranganathan menggunakan konsep yang dikenal Urutan
Sitasi. Menurutnya ada 5 (lima) faset yang mendasar yang dikenal dengan akronim
P-M-E-S-T Ranganathan dalam (Pangaribuan 2010: 5) yaitu:
P - Personality (Wujud) M - Matter (Benda) E - Energy (Kegiatan) S - Space (Tempat) T - Time (Waktu)
Contoh: Konstruksi Jembatan Beton Tahun 20-an di Indonesia. P – Personality = Jembatan
M – Matter = Beton E – Energy = Konstruksi S – Space = Indonesia T – Time = Tahun 20-an
3. Penerjemahan
Setelah mengetahui subyek suatu bahan pustaka melalui analisis subyek, selanjutnya menerjemahkan ke dalam kata-kata atau lambang-lambang yang terdapat dalam bahasa indeks(index language). Bahasa Indeks merupakan bahasa yang terawasi (control language). Beberapa sistem bahasa indeks adalah sebagai berikut:
Subyek misalnya Sears List Subject Headings edited by Barbara M. Wesby (1997), pedoman tajuk subyek untuk Perpustakaan (PTSP) oleh Perpustakaan Nasional RI (1994), daftar tajuk subyek untuk Perpustakaan, edisi ringkas oleh J.N.B. Tairas dan Soekarman K. (1990), dll.
2. Thesaurus, yaitu suatu daftar kosakata atau istilah dengan menyebutkan istilah GU (Gunakan Untuk), RL (Ruang Lingkup), IK (Istilah Khusus), IB (Istilah Berhubungan). Misalnya: Makrotesaurus adalah Daftar Istilah Pembangunan Ekonomi dan Sosial (1997).
2.1.1.1 Thesaurus Sebagai Alat Temu Kembali Informasi
Menurut Sri Rohyanti Z.: 2002: 1, “Thesaurus adalah kamus kata-kata dan ungkapan yang dikumpulkan menurut kesamaan artinya dan sinonimnya. Dalam dunia perpustakaan, dokumntasi dan informasi”. Dari pendapat tersebut dapat dinyatakan bahwa thesaurus merupakan kumpulan kosa kata yang mempunyai arti dan sinonim. Kamus Amerika Webster’s dalam Sri Rohyanti Z. (2002: 1) “juga mendefinisikan thesaurus sebagai suatu ‘buku yang berisi kata atau informasi mengenai bidang subyek tertentu atau suatu kelompok konsep, seperti kamus
sinonim”.
Menurut Fungsi dan kegunaan thesaurus terletak pada struktur yang mengaitkan satu konsep dengan konsep lainnya melalui berbagai hirarki dan maknanya. Di dalam definisi yang dibuat oleh World Science Information System of Unesco (UNISIST) dalam Andi (2011: 1)” menyatakan bahwa sebuah thesaurus
dapat didefinisikan baik dari segi fungsi maupun strukturnya”.
1. Dari segi fungsi, sebuah thesaurus adalah alat pengendali terminologi yang digunakan dalam penerjemahan dari bahasa alamiah di dalam dokumen, indeks, atau pengguna menjadi sebuah bahasa sistem (bahasa dokumentasi, bahasa informasi) yang lebih terbatas.
Dari penyataan diatas dapat dinyatakan bahwa thesaurusadalah himpunan kata-kata terkendali yang berhubungan satu sama lain secara semantik dan hierarkis, yang dapat dipergunakan untuk menterjemahkan bahasa sehari-hari ke dalam bahasa indeks dalam bidang ilmu pengetahuan tertentu. Thesaurus dipergunakan secara luas untuk mengendalikan kosa kata (vocabulary control) dalam sistem terkoordinasi, kemudian menggunakan sistem komputerisasi dan sistem Pre –coordinate.
Adapun manfaat dan peran dari thesaurus menurut Andi (2011: 2). Ada beberapa manfaat dari thesaurus diantaranya adalah:
1. Menyediakan sebuah kosakata yang berstandar untuk bidang tertentu, sehingga para pengindeks (manusia) dapat secara konsisten menetapkan istilah yang akan dipakai sebagai indeks.
2. Menjadi sebuah panduan bagi pengguna sistem informasi ketika memilih istilah untuk digunakan dalam pencarian berdasarkan subjek.
3. Menjadi sumber bagi istilah-istilah yang sudah terstandardisasi di bidang pengetahuan tertentu.
4. Menyediakan hirarki berkelas sehingga sebuah proses pencarian dapat diperluas atau dipersempit.
Dari pendapat tersebut dapat dinyatakan bahwa thesaurus memiliki manfaat yaitu menyediakan kosakata yang berstandar, sebagai panduan bagi pengguna sistem informasi ketika memilih istilah dalam pencarian berdasarkan subjek, sumber istilah-istilah standar di bidang pengetahuan dan menyediakan hirarki atau hubungan antar kosakata.
Dalam kaitanya dengan pengelolaan informasi, thesaurus berperan penting di dalamnya diantaranya:
1. Sebagai sarana temu kembali informasi yang berbasis komputer.
2. Sebagai pedoman dalam mengolah dokumen seperti pembuatan indeks dan penentuan tajuk.
3. Mempermudah dalam mengelola data yang telah ada.
4. Mempercepat diketemukannya informasi yang di cari.(Andi 2011: 3)
Dalam proses temu kembali informasi berbasis komputer, pemakai harus menyediakan pertanyaan (query) yang diperlukan dengan menggunakan kata kunci (keyword). Thesaurus menyediakan daftar kata-kata kunci yang disusun secara alpabetis dengan sinonim yang berdekatan dan sering dikembangkan untuk mencakup beberapa indikasi dari istilah yang luas (broader term) dan istilah khusus (narrower term). Dengan kata lain bahwa thesaurus dalam fungsinya sebagai sarana temu kembali informasi, bahwa kosa kata yang terdapat dalam thesaurus dapat dipergunakan sebagai kata kunci (keyword) untuk membuat pertanyaan (query) dalam proses temu kembali informasi seperti dilakukan dalam pengoperasiaan Boolean Logic.
2.1.2 Pengindeksan Subjek Secara Automasi
Pengindeksan subjek secara otomatis identik dengan penggunaan komputer. Pengindeksan subjek secara otomatis dapat memperkecil beban kerja indekser. Dalam hal ini, indekser dituntut memiliki keahlian di bidang komputer.
“Menurut Anderson dan Perez dalam Shield (2005: 1); automatic indexing often refers to indexing done by computer algorithms. Obviously, humans are involved with creating the programs for the computers, and in setting the parameters, but the work is done by computers”.
Dapat diartikan pengindeksan subjek secara otomatis sering mengacu kepada alogaritma atau statistika komputer. Secara jelas, manusia dilibatkan dalam penciptaan program komputer, dan pengaturan tolak ukur, tetapi pekerjaan tetap diselesaikan dengan komputer. Berdasarkan uraian di atas, maka dapat dinyatakan bahwa pengindeksan subjek secara otomatis diselesaikan dengan komputer serta penerapan algoritma dan statistika komputer. Menurut Diakoft (2004: 85) dalam (Shield 2005: 3) pengindeksan secara automatis memiliki ciri-ciri antara lain adalah : lebih canggih, sangat baik untuk materi yang sama, sangat murah serta mampu untuk menyaring istilah seperti halnya pengelompokan kata.
Dengan mengetahui jenis pengindeksan akan lebih membantu untuk mengetahui perbedaan utama serta pengertian dari pengindeksan itu sendiri.
Pengindeksan manual dilakukan oleh manusia. Pengindeksan manual menggunakan pengetahuan untuk menganilisis isi dokumen yang dapat menemukan konsep-konsep dalam tulisan dan menggunakan istilah untuk membantu pengguna dalam penelusuran informasi. “Human indexing tends to focus on larger documentary units, such as complete periodical articles, complete chapters in
collections, or even complete monographs”(Anderson dan Perez) dalam (Shield 2005:1). Pengertian tersebut dapat diartikan bahwa pengindeksan manual fokus kepada jenis dokumen seperti artikel jurnal dan bahan monograf yang lengkap. Dari pendapat tersebut dapat dinyatakan bahwa pengindeksan manual merupakan kegiatan indeks yang lebih fokus terhadap bahan pustaka yang di indeks seperti terbitan berkala dan bahan monograp lengkap. Seorang pengindeks secara manual harus memiliki pengalaman dan pengetahuan dalam mengindeks dokumen. Fidel dalam Shield 2005: 1 mengatakan bahwa pengindeksan manual tidak konsisten.
Pengindeksan otomatis merujuk pada pengindeksan yang dilakukan secara
alogaritma komputer.
Menurut Fidel dalam Shield (2005:1),”on the one hand, she says it is the most user-centered approach because of its dynamic, helpful, and flexible nature. One the other hand, indexing is based solely on the text stored and is completely immune to the particular group of users and their queires”.
Pendapat tersebut dapat diartikan bahwa pengindeksan otomatis mengacu kepada pendekatan yang berpusat pada pengguna karena dinamis, bermanfaat dan alamiah. Pengindeksan otomatis dibagi ke dalam 4 pendekatan yaitu statistik, sintaksis, sistem semantik dan dasar ilmu pengetahuan.
Pengindeksan subjek secara manual dengan otomatis menunjukkan keunggulan dan kelemahan dalam setiap pengindeksan. Adapun keunggulan dan kelemahan dapat dilihat dari beberapa variabel, yaitu : biaya (cost), waktu (time), kemampuan mengindeks (extent of indexable matter), kelengkapan (exhaustifity), istilah khusus (specifity), kemampuan menampilkan indeks saat menelusur
display syntax), manajemen kosakata (vocabulary management), penggantian (surrogation).
Keunggulan dan kelemahan dapat diuraikan sebagai berikut :
“Cost, Human Indexing-Expensive per unit Idexed because it Is labor-Intensive. Automatic Indexing-Inexpensive per unit Idexed.
Who’wins’?
Depends on what you are seeking,” Anderson dan Perez dalam Shield (2005: 5).
Dari variabel biaya dapat diuraikan bahwa pembuatan indeks manual lebih mahal diakibatkan tenaga kerja yang susah diperoleh karena dibutuhkan seorang pengindeks yang berpengalaman dan kompeten. Sedangkan biaya pengindeksan otomatis tidak mahal. Dengan demikian keunggulan pengindeksan tergantung pada apa yang dicari oleh penelusur.
“Time, Human Indexing-Involues more time per unit indexed.can indexing large amounts of material in short amount of time.
Who wins?
Once again, it depends on what the needs are,” Anderson dan Perez dalam Shield (2005: 5).
Dari variabel waktu dapat diuraikan bahwa pengindeksan manual
membutuhkan waktu yang lama. Sedangkan proses pengindeksan sejumlah materi secara otomatis dilakukan dalam waktu singkat. Dengan demikian pengindeksan yang unggul juga tergantung oleh materi yang dicari penelusur.
“Extent Of Indexable Matter, Human Indexing may be limited to abstract or summarization of text. Automatic Indexing routinely based on complete text. Who Wins?
Automatic indexing can index more of the indexable matter,” Anderson dan Perez dalam Shield (2005: 5).
“Exhaustifity, Human Indexing, tends to be more selective. Automatic Indexing, considers most of the words in indexible material.
Who wins?
Automatic indexing is by nature more exhaustive,” Anderson dan Perez dalam Shield (2005: 5).
Dari variabel kelengkapan bahwa pengindeksan manual lebih cenderung untuk selektif. Sedangkan pengindeksan otomatis membutuhkan banyak pertimbangan mengenai kata-kata dalam pengindeksan dokumen. Dalam hal ini pengindeksan otomatis jauh lebih unggul karena jauh lebih lengkap kata-kata yang akan dijadikan indeks subjek.
“Specificity, Human Indexing use more generic terminology, smaller vocabulary. Automatic Indexing uses very specific terminology, larger vocabulary.
Who wins?
Automatic indexing has a higher specificity,” Anderson dan Perez dalam Shield (2005: 5).
Dari variabel kekhususan kata bahwa pengindeksan manual menggunakan istilah-istilah umum dan kosakata yang lebih sempit (khusus). Sedangkan pengindeksan otomatis menggunakan istilah-istilah umum dan kosakata yang luas. Dalam hal ini pengindeksan otomatis lebih unggul karena memiliki kekhususan yang lebih tinggi karena menggunakan kosakata yang umum dan istilah-istilah yang luas.
“Browsable displayed indexes, Human Indexing use multi-term context-providing headings. Automatic Indexing limited use of term combinations. Who wins?
Depends on what you are seeking,” Anderson dan Perez dalam Shield (2005: 5).
Dari variabel kemampuan menampilakan indeks saat menelusur bahwa pengindeksan manual menggunakan multi term/multi istilah konteks dan menyediakan tujuan. Sedangkan pengindeksan otomatis membatasi penggunaan kombinasi istilah gabungan dari penentuan jenis pengindeksan. Dengan demikian keunggulan pengindeksan tergantung pada kemampuan sipenelusur.
selecting, combining, manipulating, and weighing terms. Usually limited to key-words in, out of, or along-side context.
Who wins?
Human indexing has an advantage here,” Anderson dan Perez dalam Shield (2005: 5).
Dari variabel pencarian dan penampilan sintaksis bahwa pengindeksan manual menggunakan pola sintaksis yang lebih luas dan dapat menyesuaikan dengan cepat untuk memasukan istilah-istilah batu, seperti tajuk subjek yang lama. Sedangkan pengindeksan otomatis jauh lebih canggih dalam penyeleksian, pengkombinasian dan penimbangan istilah selalu terbatas. Dalam hal pencarian dan penampilan sintaksis maka pengindeksan manual jauh lebih unggul dibandingkan pengindeksan otomatis.
“Vocabulary Management,Human Indexing can cross-reference, link synonyms or like terms, point to related terms easily. Automatic Indexing being experimented with.
Who wins?
Human indexing currently has batter vocabulary management,” Anderson dan Perez dalam Shield (2005: 5).
Dari variabel manajemen kosakata bahwa pengindeksan manual dapat dibuat
cross reference, menghubungkan sinonim/istilah yang sama dan dapat menunjukkan istilah-istilah dengan mudah. Sedangkan pengindeksan otomatis, manajemen kosa kata dilakukan dengan melakukan uji coba. Dalam hal ini pengindeksan manual lebih unggul.
“Surrogation, Human Indexing not often used by human indexing. Automatic Indexing being used frequently – often as visual display, such as icons or graphs.
Who wins?
Automatic indexing often uses surrogation, while human indexing does not,” Anderson dan Perez dalam Shield (2005: 5).
Dari pernyataan di atas bahwa pengindeksan otomatis memiliki lebih banyak Keunggulan daripada pengindeksan manual. Keunggulan itu dapat dilihat dari berbagai aspek antara lain, biaya, waktu, kemampuan mengindeks, kelengkapan, spesifikasi, kemampuan menampilkan indeks saat menelusur, pencarian dan penampilan sintaksis, dan penggantian (surrogation).
2.2 Teknik Pengindeksan Subjek pada Artikel Ilmiah
Artikel ilmiah merupakan karya tulis yang banyak dimanfaatkan kalangan sivitas akademik untuk bahan rujukan dalam melakukan penelitian. Untuk memudahkan penelusuran artikel ilmiah, diperlukan indeks subjek. Indeks subjek tersebut dibutuhkan dalam rangka memperkecil waktu pencarian serta memaksimalkan keberhasilan penelusuran artikel. Oleh karena itu penggunaan indeks subjek dalam penelusuran artikel menjadi sangat penting.
“Menurut Cortez (2007: 3), ada cara pengindeksan subjek pada artikel. Adapun langkah-langkah tersebut adalah: memilih jurnal elektronik yang akan di indeks subjeknya. Kemudian pilih 1 atau 2 tesaurus atau daftar kontrol vacabulary yang spesifik (misalnya: ERIC atau Medical Subject Heading) untuk topik jurnal dan satu lagi tesaurus yang umum (misalnya: Library of Congres Subject Headings)”.
Dari pernyataan di atas dapat dinyatakan bahwa teknik pengindeksan subjek pada artikel ilmiah dapat dilakukan dengan memilih jurnal yang akan diindeks, kemudian memasukkan istilah ke dalam bahasa indeks yang dikonsultasikan dengan kosa kata terkendali seperti ERIC, Library of Congres Subject Headings, dll. Dalam teknik pengindeksan dikenal istilah kebijakan pengindeksan (indexing policy). Ini berarti sampai sejauh atau sedalam mana pengindeks melakukan analisis dan
suatu dokumen dan hanya mengambil konsep yang ada dalam tema utama. Pengindeksan mendalam biasanya dilakukan oleh lembaga-lembaga penerbit informasi, misalnya pengindeks jurnal. Penerbit indeks jurnal biasanya menetapkan konsep yang diambil dari sub-sub bab dari suatu artikel pada jurnal.
2.3 Bahasa Indeks
Pengindeksan secara manual dan otomatis akan menghasilkan bahasa indeks. Bahasa indeks merupakan istilah atau kata yang dipilih menjadi representasi isi dari dokumen. Istilah tersebut boleh berupa istilah alami atau bahasa alamiah (natural language) dan kosa kata terkendali (controlled vocabulary). Bahasa alamiah adalahbahasa asli dari dokumen itu sendiri. Sedangkan kosa kata terkendali adalah istilah yang terkontrol karena telah dikonsultasikan kepada tesaurus.
Ditinjau dari sisi sistem temu kembali informasi, tesaurus adalah suatu daftar pengendali (authority list) istilah-istilah khusus yang digunakan dalam sistem temukembali informasi. Akan tetapi bila ditinjau dari segi fungsinya tesaurus adalah saranapengawasan istilah yang digunakan untuk penerjemahan bahasa alamiah dokumen kebahasa yang lebih terkendali. Tesaurus berisi sejumlah istilah indeks
denganmenggunakan bahasa yang terkendali, sehingga sering disebut juga dengan bahasaterkontrol (controlled language). Tujuan utama tesaurus adalah juga untukmemudahkan temu kembali dokumen, dan untuk mencapai konsistensi dalampengindeksan dokumen pada sistem simpan dan temu kembali informasi.
2.3.1 Bahasa Alamiah (Natural Language/Uncontrolled Vocabulary)
Menurut Lancaster, 1986 : 159 dalam Hasugian, 2003 : 5“bahasa alamiah adalah bahasa dari dokumen yang diindeks”. Dari pendapat tersebut dapat dinyatakan bahwa bahasa alamiah adalah bahasa asli dokumen itu sendiri. Biasanya bahasa tersebut merupakan bahasa yang tidak terkendali (uncontrolled vocabulary). Bahasa alamiah yang dihasilkan dari dokumen masih akan dicocokkan dengan tesaurus kemudian dijadikan indeks subjek dari dokumen tersebut.
terkecuali stopword atau daftar kata umum yangtidak digunakan dalam penelusuran” (Rowley, 1992 : 272). Dari pendapat tersebut dapat dinyatakan bahwa pengindeksan bahasa ilmiah adalah pengindeksan yang menghilangkan stopword dan tidak menggunakannya sebagai istilah indeks.
Bahasa alamiah memiliki kelebihan dan kelemahan. Kelebihan dari bahasa alamiah adalah:
1. Bahasa alamiah dapat dengan mudah dimengerti oleh pengguna tanpa harus memerluka pelatihan khusus, dan berbagai nuansa makna dapat diekspresikan dengan lebih leluasa (Meadow, 1992 : 37-38).
Dari pendapat tersebut dapat dijelaskan bahwa bahasa almiah mudah dimengerti oleh pengguna tanpa memerlukan pelatihan khusus, sehinggga memudahkan bagi pengguna dalam penelusuran dapat mengekspresikan gagasan, perasaan dan keinginan untuk mendapatkan dokumen yang diinginkannya. Bagi praktisi dan ilmuwan, hal ini juga memberi keuntungan karena istilah yang digunakan kurang lebih sama dengan istilah yang terdapat dalam dokumen.
2. Bahasa alamiah memiliki spesifikasi (specification) yang tinggi
(Lancaster, 1977 : 23) dalam (Hasugian 2003: 6).
Dari pendapat tersebut dapat dijelaskan bahwa spesifikasi istilah muncul karena dapat menggunakan seluruh istilah yang terdapat dalam dokumen sebagai kata kunci. Spesifikasi istilah akan memudahkan pencarian untuk mendapatkan ketepatan (precision) yang tinggi. Semakin tinggi spesifikasi istilah yang digunakan dalam penelusuran, maka akan semakin tinggi ketepatan, sedangkan perolehan (recall) akan semakin rendah. Sebaliknya bila spesifikasi istilah rendah, maka perolehan akan semakin tinggi, sedangkan ketepatan cenderung rendah.
Selain memiliki sejumlah kelebihan, bahasa alamiah juga memiliki berbagai kelemahan, beberapa diantaranya adalah :
1. Bahasa almiah tidak atau kurang ringkas (lack of consiseness) (Meadow, 1992 : 38).
Dari pendapat tersebut dapat dijelaskan bahwa penelusuran cenderung akan menggunakan kata-kata yang sering digunakan atau istilah yang familiar. Istilah yang digunakan penelusur sering berupa kata atau istilah berbeda atau tidak standard sehingga sering terjadi kehilangan informasi saat penelusuran. Sebagai contoh, seorang penelusur mungkin akan menggunakan kata kunci kesusastraan dalam penelusuran informasi mengenai dunia sastra, yang bisa jadi tidak akan menghasilkan dokumen yang diinginkan karena dalam dokumen tersebut tidak ada kata kesusastraan, yang hanya adalah sastra.
2. Mempunyai ambiguitas (ambiguity) yang tinggi. (Meadaw, 1992 : 37) Dari pendapat. tersebut dapat dinyatakan bahwa Ambiguitas adalah kata atau istilah yang dapat memiliki lebih dari satu arti sehingga mengakibatkan kerancuan. Ambiguitas dapat terjadi karena sinomim atau homograf. Sinonim yaitu bentuk kata
yang berbeda tetapi artinya sama, dapat menyebabkan terpencarnya informasi mengenai topik yang sama.
3. Kesulitan komputer untuk menginterpretasikan teks (Meadew, 1992 : 37) Dari pendapat tersebut dapat dijelaskan bahwa ketidakmampuan sistem menyerap atau menangkap makna dari suatu pernyataan. Hal ini terjadi karena dalam memproses bahasa alami, komputer tidak bisa bekerja sebagaimana otak manusia, terkecuali komputer tersebut dilengkapi dengan suatu knowledge base.
2.3.2 Kosa Kata Terkendali (Control Vocabulary)
Kosa kata terkendali merupakan kosakata yang terkontrol karena telah dikonsultasikan kepada tesaurus. Proses pembuatan indeks yang menggunakan bahasa terkontrol dilakukan oleh pengindeks yang dianggap cukup menguasai suatu subjek tertentu. Proses ini melibatkan kemampuan intelektualitas dari pengindeks untuk menentukan kata atau istilah apa yang dianggap bisa mewakili isi dokumen sebagai temu kembali informasi.
Kosa kata terkendali yang dihasilkan dalam pengindeksan subjek memiliki kelebihan dan kelemahan. Kelebihan kosa kata terkendali dapat diuraikan sebagai berikut:
1. Proses penelusuran dan temu kembali informasi lebih efisien (Korfhage, 1997 : 24).
Dari pendapat tersebut dapat dijelaskan bahwa dengan menggunakan kosa kata terkontrol seperti indeks subjek atau tesaurus dalam penelusuran, maka ketepatan dari dokumen yang terambil dengan kebutuhan pengguna dapat diperoleh dalam waktu yang relatip singkat.
2. Memudahkan penelusuran dengan menyatukan istilah terkait secara semantis (Lancaster, 1977: 2) dalam (Hasugian 2003: 8) .
Dari pendapat tersebut dapat dijelaskan bahwa suatu kosa kata atau indeks subjek tertentu mempunyai hubungan makna dengan indeks yang lain, sehingga dapat digunakan untuk memperkuat pencarian.
3. Memiliki ambiguity yang sangat kecil. Ambiguitas atau kerancuan dapat diminimize dengan sekecil mungkin karena kosa kata dapat mengontrol
sinonim dan homograf.
Selain memiliki kelebihan bahasa terkendali juga memiliki kelemahan antara lain:
suatu periode tertentu harus diperbaharui untuk bisa menyesuaikan diri sesuai perkembangan (Muddamalle, 1998: 881)
2. Kurangnya spesifikasi dalam kosa kata. Berbeda dengan bahasa alamiah, dimana penelusur dapat menggunakan secara bebas kosa kata yang spesifik. Akan tetapi pada kosa kata terkontrol, spesifikasi istilah ditentukan oleh ketersediaannya pada indeks subjek atau tesaurus.
3. Kosa kata terkontrol memiliki struktur yang tidak lengkap. Artinya rincian subjek adalah sangat terbatas untuk pencarian atau penelusuran komprehensif.
Dari pendapat di atas dapat dinyatakan bahwa kosa kata terkendali memiliki kelebihan dan kelemahan. Kelebihan dari kosa kata terkendali dapat dilihat dari segi proses penelusuran lebih efisien,penelusuran komprehensif, ambiguity yang kecil. Sedangkan kelemahan kosa kata terkendali dapat dilihat dari segi pembaharuan kosa kata yang harus dilakukan setiap saat, kurangnya spesifikasi dalam kosa kata serta kosa kata terkontrol memiliki struktur tidak lengkap.
2.4 Dalil Zipf’s
2.4.1 Pengertian dan Sejarah Zifp’s
Dalil Zipf’s memiliki peranan penting dalam pengindeksan subjek. Menurut Hasugian, 1999: 1, dalil Zipf’s digunakan untuk mengetahui subjek suatu dokumendengan memberi peringkat kata dalam literatur, distribusi frekwensi kata denganperingkat kata (word frequency). Dari pernyataan di atas dapat dinyatakan bahwa dalil Zipf’s digunakan untuk mengetahui indeks subjek suatu dokumen denganmelihat frekwensi kata.
Dalil Zipf diperkenalkan pertama sekali oleh George Kingsley Zipf, disingkatZipf. Biodata singkat Zipf adalah sebagai berikut:
kanker, meninggalkan seorang istri dan empat orang anak,” (Hartinah, 2002: 2).
Zipf mulai terkenal dalam bidang bibliometrika setelah karyanya yang berjudul The Psycho-biology of Language, terbit pada tahun 1935. Zipf melalui karya tersebut membawa studi bahasa ke dalam suatu kondisi ilmu eksakta dengan memakai prinsip-prinsip statistik. Empat belas tahun kemudian, Zipf semakin terkenal dengan bukunya yang berjudul, Human Behavior and Principle of Least Effort yang terbit pada tahun 1949. Karya tersebut menyatakan bahwa seseorang lebih mudah untuk memilih dan menggunakan kata-kata umum, yang lebih familiar dari pada kata-kata yang tidak dikenalnya, dengan demikian kemungkinan pemunculan kata-kata umum yang lebih familiar dalam suatu karya biasanya lebih tinggi dari pada kata-kata yang tidak dikenalnya. Sekalipun Zipf adalah seorang ahli bahasa dan filsafat, namun ia tertarik untuk melakukan teknik pengukuran (matrics) terhadap dokumen atau literatur dengan memakai pendekatan statistik.
Zipf berhasil melakukan observasi atau pemeriksaan terhadap sebuah novel yang berjudul Ulysses, karangan James Joice yang pada saat itu merupakan salah satu
pemegang hadiah nobel. Hasil observasinya menyatakan bahwa terdapat 29.899 kata yang berlainan dalam karya tersebut, sedangkan jumlah kata seluruhnya adalah 260.430. Dalam hasil pemeriksaan atau observasinya, Zipf juga menemukan beberapa kata yang berkali-kali digunakan (di ulang), dan kata-kata yang penggunaanya rendah, bahkan ada kata yang hanya digunakan sekali. Kata yang dimaksudkannya adalah kumpulan huruf yang diapit oleh dua spasi. Kata bergaris hubung dianggap satu kata, dan tanda kutip dianggap bagian dari satu kata. Semua kata fonetik yang dianggapkata berbeda, kata sandang (stopword) tidak dipergunakan dan diabaikan oleh Zipf. Kemudian Zipf membuat perhitungan peringkat kata. Perhitungan peringkat kata ini yang akhirnya dikenal dengan sebutan dalil Zipf’s.
2.4.2 Perkembangan dan Aplikasi Dalil Zipf’s
“Bila jumlah pengulangan setiap kata yang berlainan terdapat pada sebuah teks dihitung serta hasilnya dituangkan kedalam sebuah tabel, dengan peringkat I merupakan kata yang memiliki frekuensi pengulangan paling tinggi dan demikian seterusnya dan bila peringkat susunan jajaran itu disebut ranking (r) dan jumlah pengulangan kata disebut frekuensi (f) maka r x f = k (konstanta),” (Sulistyo-Basuki, 1988:70).
Dari pendapat di atas dapat dinyatakan bahwa rumus dalil Zipf’s I digunakan hanya untuk kata-kata yang muncul dengan frekuensi tinggi. Perhitungan setiap kata
yang berbeda cara menulisnya dianggap kata berbeda dan frekuensi pengulangan yang
sama memperoleh peringkat yang berbeda pula.
Satu lagi rumus Zipf’s tentang kata yang memiliki frekuensi pengulangan yang rendah, rumus ini disebut sebagai Dalil Zipf’s II. Dalil Zipf’s II ini sama sekali tidak memiliki hubungan dengan dalil Zipf’s I. Karena dalil kedua ini hanya berlaku bagi kata-kata yang muncul dengan frekuensi rendah. Dalil kedua ini telah diperbaiki oleh Booth dengan rumus sebagai berikut:
I1 / In = n (n-1)/ 2
Dimana I1 adalah kata yang diulang 1 (satu) kali sedangkan In adalah kata
yang diulang n kali. Rumus Booth dalam (Mustafa 2009: 5)juga menyebutkan adanya titik frekuensi antara kata yang berfrekuensi tinggi dengan kata yang berfrekuensi rendah. Titik frekuensiini terjadi pada saat peralihan dari kata yang memiliki frekuensi khusus ke kata yang memiliki frekuensi pengulangan yang sama.
2.4.2.1 Titik Transisi
Goffman salah seorang peminat hukum Zipf yang telah melakukan serangkaian penelitian dan mengembangkan teori untuk menentukan isi dokumen berdasarkan hukum Zipf. Goffman menemukan fenomena yang disebut sebagai titik transisi. Titik transisi yaitu titik teoritis dimana terjadi perubahan dari frekuensi tinggi ke frekuensi rendah, diduga merupakan daerah yang memuat kata-kata yang menunjukkan isi dokumen.
yang biasa diabaikan dalam pengindeksan karena hanya berupa kata bantu, misalnya
the, of, and, dll dalam bahasa Inggris).
Untuk menentukan titik transisi dipakai rumus ABC yang terkenal dalam pelajaran matematika SMA. Selanjutnya untuk mendapatkan nilai n1,2 berlaku
perhitungan rumus ABC sebagai berikut:
n
1,2=
−𝑏𝑏±√𝑏𝑏2−4𝑎𝑎𝑎𝑎 2𝑎𝑎
Keterangan:
n1,2 = titik transisi ; a = 1 ; b = 1 dan c = - 2 I1
“Menurut Pao dalam Hasugian (1999:9) menyatakan bahwa setelah diperoleh titik transisi ( dari nilai n di atas), dengan mengambil jumlah kata yang sama di atas dan di bawah titik tersebut, maka diperoleh daerah transisi. Kata-kata yang berada pada daerah transisi setelah dikurangi dengan kata-kata buangan (stopword), merupakan istilah indeks dokumen.”
Dari pendapat di atas dapat dinyatakan bahwa untuk memperoleh titik transisi menggunakan rumus ABC, kemudian mengambil jumlah kata yang di atas dan di bawah titik transisi yang disebut daerah transisi. Kata-kata pada daerah transisi merupakan indeks subjek dari dokumen itu sendiri tetapi kata-kata yang termasuk stopword tidak diikutsertakan.
2.4.3 Prosedur Penentuan Indeks Subjek dengan Dalil Zipf’s
Ada beberapa langkah yang harus ditempuh untuk menentukan indeks subjeksuatu artikel dengan menggunakan dalil Zipf’s yaitu:
1. Memilih dokumen. Dalam memilih dokumen peneliti biasanya memilih dokumen elektronik, karena lebih mudah diolah dalam menghitung frekuensi kata.
diketik disamping setiap kata (mulai dari frekuensi kata tertinggi sampai ke frekuensi rendah).
3. Menentukan titik transisi dari suatu dokumen. Untuk menentukan titik transisi, dipergunakan rumus dari dalil Zipf II yang sudah dikembangkan yaitu rumus ABC yaitu:
n
1,2=
−𝑏𝑏±√𝑏𝑏2−4𝑎𝑎𝑎𝑎
2𝑎𝑎
Diketahui bahwa nilai a dan b merupakan nilai konstanta yaitu 1, c adalah -2 x I1, sehingga menghasilkan rumus sebagai berikut :
n
1,2=
−1±�1+8I1 2𝑎𝑎
4. Penentuan daerah transisi. Dilakukan dengan cara mengambil 10 kata diatasdan 10 kata di bawah titik transisi.
5. Penentuan indeks dokumen. Kata-kata yang terdapat pada daerah transisi, setelah kata buangan (stopword) dihilangkan selanjutnya dijadikan menjadi indeks dokumen.
6. Interpretasi terhadap indeks dokumen.Setelah indeks dokumen diperoleh, maka selanjutnya diinterpretasikan atau dinilai apakah indeks tersebut benar-benar dapat menggambarkan isi atau subjek dari artikel atau dokumen yang sebenarnya, (Hasugian, 1999: 11)
Berdasarkan penjelasan di atas bahwa untuk menentukan indeks suatu artikel terlebih dahulu memilih dokumen, biasanya dokumen berupa artikel elektronik. Menghitung jumlah dan frekunsi kata dapat dilakukan dengan bantuan komputer dengan memakai program Microsoft word. Menentukan titik transisi dapat dilakukan
dengan memakai rumus ABC. Menentukan daerah transisi dapat dilakukan dengan mengambil 10 kata diatas dan 10 kata di bawah titik transisi. Menentukan indeks dokumen dilakukan dengan cara membuang stopword (kata buangan). Interpretasi terhadap indeks dokumen apakah indeks tersebut benar-benar dapat menggambarkan isi atau subjek dari artikel atau dokumen yang sebenarnya.
2.5 Masa Depan Pengindeks
Sejalan dengan berkembangnya teknologi informasi dewasa ini, tentunya tingkat keprofesionlan pengindeks sangat dituntut. Untuk mencapai tingkat efektifitas pemakaian indeks tentunya profesional indeks harus benar-benar bercermin pada user sebagai pemakai informasi yang dihasilkan, agar hasil yang dicapai benar-benar maksimal dan berdaya guna. Visi indeks sebenarnya sudah digambarkan oleh Paul Otlet (pelopor Universal Decimal Classification dan pendiri International Federation for Information and Documentation) sejak tahun 1934. Otlet dalam Margono (1999: 3) lebih menekankan pentingnya mekanisme pengolahan indeks dalam suatu mesin secara simultan bagi pengembangan indeks secara menyeluruh dengan sistem teks.
Oleh sebab itu upaya yang dapat dilakukan oleh profesional indeks dalam mengontrol hasil olahannya, antara lain:
1. Tujuan Pembuatan Indeks
Tujuan ini harus disesuaikan dengan pengindeks (berdasarkan standard atau thesaurus), organisani, user, dan perkembangan ilmu pengetahuan. Hal tersebut tidak mudah dicapai oleh profesional indeks, sebab standard yang biasa dipakai jauh lebih lama daripada perkembangan ilmu pengetahuan yang ada. Oleh sebab itu bagi
profesional indeks tidak harus mengacu pada thesaurus saja tetapi pada mengikuti perkembangan ilmu yang melalui subject headings dan kepopuleran ilmu pengetahuan yang sedang berkembang pada saat ini.
2. Teknologi
related, seealso). Sementar penelusuran yang dilakuakan melalui indeks dapat memberikan seluruh informasi yang terkait secara lengkap, tinggal pengguna memilih alternatif artikel yang tepat. Oleh sebab itu masa depan indekser tetap cerah karena masih banyak informasi yang belum terolah.
3. Etika
Diharapkan pengindeks benar-benar dapat mengikuti perkembangan ilmu pengetahuan sesuai dengan bidangnya sehingga ilmu pengetahuan yang sedang berkembang di masyarakat dapat dijadikan sebagai kata kunci yang penting. Diluar negeri justru indeks dikerjakan oleh ilmuwan yang bersangkutan, disamping mereka mengerjakan penelitian, mereka juga membuat indeks (indeks dikerjakan oleh sarjana tamatan S1 – S3 , dimana S1 merupakan tahap mencari pengalaman dan S2-S3
merupakan subject specialist). Berbeda dengan peneliti di Indonesia, di mana mereka justru kurang memahami indeks dengan benar.
4. Pendidikan profesi
Menurut Wallis (1997: 190) dalam (Margono 1999: 4), “professional indeks dibagi menjadi dua yaitu pengindeks terakreditasi (accredited indexers) yaitu pengindeks yang lulus test berdasarkan standard British Society (BS), yang mencerminkan pekerjaan mengindeks dengan teori mengindeks yang benar; dan pengindeks terdaftar (registered indexers) yaitu pengindeks yang membuktikan pengalamannya berdasarkan keahlian/ilmu pengetahuan yang dimiliki melalui prosedur pengindeksan yang diterapkan oleh British Society”.
Indexer di Indonesia hampir sebagian besar tidak memiliki pendidikan sebagai pengindeks professional seperti di atas. Indexer tersebut lebih menilai dan mengukur hasil yang diolah oleh pengindeks berdasarkan keyakinan bahwa pekerjaan yang dilakukan oleh pengindeks akan berjalan dengan baik asalkan sejalan dengan thesaurus yang diigunakan tanpa meninjau lebih lanjut apakah hasil kerja tersebut benar-benar bermanfaat bagi user.
Melihat kenyataan tersebut sebaiknya PDII-LIPI mulai membekali pengindeksnya melalui kursus yang berhubungan dengan status indekser di atas. Diharapkan indekser yang dimaksud dapat berkiprah lebih jauh untuk dapat membuat standard indeks Indonesia dimasa mendatang, apakah sebagai pengindeks