BAB II
LANDASAN TEORI
2.1 Laptop
Laptopadalah komputer pribadi yangportableatau mudah dibawa kemana-mana. Nama laptop itu sendiri diambil dari cara orang menggunakan komputer pribadi ini. Dahulu komputer pribadi ini sering digunakan di atas pangkuan, maka
kemudian diberi namaLap Top= Atas Pangkuan.
Laptop atau komputer jinjing adalah komputer bergerak yang berukuran relatif kecil dan ringan, beratnya berkisar dari 1 sampai dengan 6 kg, tergantung
ukuran, bahan, dan spesifikasi laptop tersebut. Sumber daya laptop berasal dari baterai atau adaptor A/C yang dapat digunakan untuk mengisi ulang baterai dan menyalakanlaptop tersebut. Baterailaptoppada umumnya dapat bertahan sekitar 1 hingga 6 jam sebelum akhirnya habis, tergantung dari cara pemakaian,
spesifikasi, dan ukuran baterai.Laptopterkadang disebut juga dengannotebook.
Sebagai komputer pribadi, laptop memiliki fungsi yang sama dengan komputer pada umumnya. Komponen yang terdapat di dalamnya sama persis
dengan komponen pada komputer, hanya saja ukurannya diperkecil, dijadikan
lebih ringan, lebih tidak panas, dan lebih hemat daya.
dengan papan sentuh yang berfungsi sebagai pengganti mouse. Papan ketik dan mousetambahan dapat dipasang melaluiusb portjika tersedia.
Berbeda dengan komputerdesktop,laptopmemiliki komponen pendukung yang didesain secara khusus untuk mengakomodasi sifat komputer jinjing yang
portable. Sifat utama yang dimiliki oleh komponen penyusun laptop adalah ukuran yang kecil, hemat konsumsi energi, dan efisien. Laptop biasanya berharga lebih mahal, tergantung dari merek dan spesifikasi komponen penyusunnya,
walaupun demikian harga laptop pun semakin mendekati komputer desktop seiring dengan semakin tingginya tingkat permintaan konsumen.
Desain yang semakin ramping, bobot yang semakin ringan dan
kemampuan menghemat daya menjadi bagian terpenting dalam perkembangan
laptop berikutnya. Laptop yang seperti kita lihat saat ini memiliki desain yang sangt tipis, bobot yang sangat ringan, tampilan layar yang besar serta kemampuan
kiner yang super canggih ditambah lagi kemampuan hardisk dalam menyimpan data yang lebih banyak. Maka kemudian penggunaan laptop pun menjadi sebuah trend baru ditengah-tengah pengguna Portable Computer. Berbagai varian dan merek pun muncul sebagai pilihan dari para pengguna komputerportable.
2.2 Minat
Arti minat menurut kamus umum Bahasa Indonesia berarti kesukaan
(kecenderungan hati) kepada sesuatu atau keinginan. Menurut Slameto (1991)
minat adalah suatu rasa lebih suka dan rasa keterikatan pada suatu hal atau
aktivitas, tanpa ada yang menyuruh. Minat pada dasarnya adalah penerimaan akan
suatu hubungan antara diri sendiri dengan sesuatu diluar diri. Semakin kuat atau
sesuatu barang atau kegiatan yang dapat memberi pengaruh terhadap pengalaman
yang distimuli oleh kegiatan itu sendiri”.
Berdasarkan dua definisi di atas tentang minat, maka dapat disimpulkan
minat merupakan suatu keinginan yang cenderung menetap pada diri seseorang
untuk mengarahkan pada suatu pilihan tertentu sebagai kebutuhannya, kemudian
dilanjutkan untuk diwujudkan dalam tindakan yang nyata dengan adanya
perhatian pada objek yang diinginkannya itu untuk mencari informasi sebagai
wawasan bagi dirinya.
2.3 Atribut
Dalam arti sempit, atribut adalah keseluruhan karakteristik yang melekat pada
produk tersebut. Sedangkan dalam arti luas, atribut merupakan keseluruhan faktor
yang dipertimbangkan konsumen untuk membeli suatu produk (Suliyanto,
2005:30). Atribut merupakan indikator yang memungkinkan terjadinya
pengukuran pengaruh pada variabel. Konsumen melihat suatu produk atau jasa
sebagai sekelompok atribut. Mereka akan kesulitan membandingkan banyak
produk secara keseluruhan. Jadi, konsumen membutuhkan pendekatan yang lebih
sederhana.
Pertama konsumen menentukan beberapa merek, yang mereka anggap
memenuhi kriterianya. Kedua konsumen melakukan evaluasi terhadap faktor
produk atau atribut, meliputi tingkat kepentingan atribut yang digunakan oleh
seorang konsumen disebut sebagai kriteria pemilihan konsumen.
2.4 Nilai Guna (Utilitas)
Teori nilai guna (utilitas) yaitu teori ekonomi yang mempelajari kepuasan atau
kenikmatan yang diperoleh seorang konsumen dari mengkonsumsi barang-barang.
Kalau kepuasan itu semakin tinggi maka semakin tinggi nilai gunanya. Sebaliknya
semakin rendah kepuasan dari suatu barang maka nilai guna semakin rendah pula.
Nilai guna dibedakan menjadi dua pengertian:
a. Nilai Guna Marginal
Nilai guna marginal adalah pertambahan atau pengurangan kepuasan
akibat adanya pertambahan atau pengurangan penggunaan satu unit barang
tertentu.
b. Total Nilai Guna
Total nilai guna yaitu keseluruhan kepuasan yang diperoleh dari
mengkonsumsi sejumlah barang-barang tertentu.
Jika konsumen membeli barang karena mengharap memperoleh nilai
gunanya, tentu saja secara rasional konsumen berharap memperoleh nilai guna
optimal. Secara rasional nilai guna akan meningkat jika jumlah komoditas yang
dikonsumsi meningkat.
2.5 Matriks Bujur Sangkar
Informasi dalam bidang sains dan matematika seringkali ditampilkan dalam
bentuk baris-baris dan kolom-kolom yang membentuk jajaran empat persegi
panjang yang disebut matriks. Matriks seringkali merupakan tabel-tabel data
numerik yang diperoleh melalui pengamatan fisik, tetapi dapat juga muncul dalam
Jika adalah matriks bujur sangkar dan jika matriks yang ukurannya
sama sedemikian rupa sehingga = = , maka disebut dapat dibalik
(invertible) dan disebut invers dari . Suatu matriks bujur sangkar dapat
dibalik, jika dan hanya jikadet( ) ≠ 0. Jika dapat dibalik, maka
= 1
det ( ) ( )
Sumber: Anton (1987:75)
2.6 Uji Validitas dan Reliabilitas
Sugiyono (2006:267), berpendapat bahwa instrumen (kuesioner) harus diuji.
Instrumen yang baik harus memenuhi dua persyaratan penting yaitu valid dan
reliabel.
Uji validitas atau kesasihan digunakan untuk mengetahui seberapa tepat
suatu alat ukur mampu melakukan fungsi. Alat ukur yang dapat digunakan dalam
pengujian validitas suatu kuesioner adalah angka hasil korelasi antara skor
pernyataan dan skor keseluruhan penyataan reseponen terhadap informasi dalam
kuesioner.
Perhitungan uji validitas ini dilakukan dengan bantuan program Statistical product and Service Solution (SPSS). Pengujian reliabilitas bertujuan untuk mengetahui konsistensi atau keteraturan hasil pengukuran suatu instrumen apabila
instumen tersebut digunakan lagi sebagai alat ukur suatu objek atau responden.
Menurut Sugiyono (2006:220), “instrumen yang reliabel adalah instrumen yang
bila digunakan beberapa kali untuk mengukur objek yang sama, akan
Kategori koefisien korelasi berdasarkan Sugiyono (2006:216) adalah sebagai
berikut:
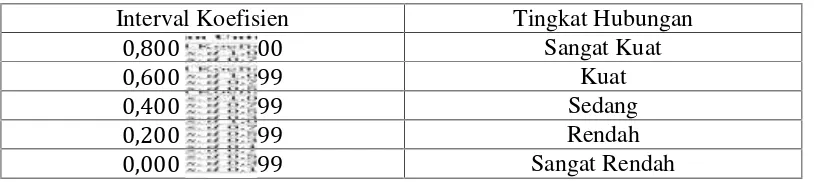
Tabel 2.1 Pedoman Untuk Memberikan Interpretasi Koefisien Korelasi Interval Koefisien Tingkat Hubungan
0,800 . 1,000 Sangat Kuat
0,600 . 0,799 Kuat
0,400 . 0,599 Sedang
0,200 . 0,399 Rendah
0,000 . 0,199 Sangat Rendah
2.7Uji Kendall’s W
Uji Kendall’s W diperkenalkan secara terpisah oleh Kendall dan Babington-Smith
pada tahun 1939 dan Wallis pada tahun 1939 sehingga disingkat dengan nama
Kendall’s W. Uji Kendall’s W merupakan uji nonparametrik yang digunakan
untuk menguji keselarasan terhadap penilaian yang diberikan oleh sekelompok
subjek terhadap atribut-atribut yang dianggap penting.
Nilai dari statistik Kendall’s W berkisar antara 0 dan 1. Jika nilai dari
statistik Kendall’s W adalah 1, maka terjadi keselarasan sempurna terhadap
penilaian yang diberikan oleh sekelompok subjek pada atribut-atribut. Jika nilai
dari statistik Kendall’s W adalah 0, maka tidak terjadi keselarasan terhadap
penilaian yang diberikan oleh sekelompok subjek. Hipotesis nol yang diuji pada
uji Kendall’s W adalah terjadi tidak adanya keselarasan terhadap penilaian yang
diberikan sekelompok subjek pada atribut-atribut.
Berikut rumus untuk menghitung statistik Kendall’s W (Siegel, 1985):
Keterangan:
= Nilai statistikKendall’s W
= Jumlah rangking pada atribut ke-i= 1, 2, ... ,k
= Rangking rata-rata
= Jumlah atribut yang diteliti
= Jumlah responden atau elemen dalam sampel
Untuk nilai diperoleh dari
= ( + 1) 2
Uji statistik yang digunakan adalah uji statistik chi-kuadrat. Nilai dari uji
statistik chi-kuadrat digunakan untuk menentukan apakah hipotesis nol diterima
atau ditolak. Berikut rumus untuk menghitung nilai uji statistik chi-kuadrat
= ( − 1)
Nilai uji statistik chi-kuadrat kemudian dibandingkan dengan nilai kritis
berdasarkan tabel nilai kritis chi-kuadrat. Berikut aturan keputusan berdasarkan
uji statistik chi-kuadrat
Jika ≤nilai kritis, hipotesis nol diterima
Jika >nilai kritis, hipotesis nol ditolak
2.8 Analisis Konjoin
Analisis konjoin adalah suatu teknik yang secara spesifik digunakan untuk
memahami bagaimana keinginan atau minat konsumen terhadap suatu produk atau
jasa dengan mengukur tingkat kegunaan dan nilai kepentingan relatif berbagai
atribut suatu produk. Analisis konjoin yang mulai dikembangkan pada tahun
1970-an ini mulai banyak digunakan pada bidang ilmu yang terkait dengan
persepsi seseorang, seperti pemasaran, sosial politik dan psikologi. Pada bidang
konsumen akan sebuah produk baru. Analisis konjoin sangat berguna untuk
membantu bagaimana seharusnya karakteristik produk baru, membuat konsep
produk baru, mengetahui pengaruh tingkat harga serta memprediksi tingkat
penjualan atau penggunaan (Santoso, 2010).
2.8.1 Manfaat Analisis Konjoin
Analisis konjoin digunakan untuk membantu mendapatkan kombinasi atribut
produk laptop baru maupun lama yang paling disukai konsumen. Dalam prosesnya analisis konjoin akan memberikan ukuran kuantitatif terhadap tingkat
kegunaan dan kepentingan relatif suatu atribut dibandingkan dengan atribut lain.
Tujuan penggunaan analisis konjoin terutama dalam riset pemasaran yaitu untuk
mengetahui persepsi konsumen terhadap laptop. Oleh karena itu, penggunaan analisis konjoin sangat membantu penelitian dalam pemasaran. Terutama untuk
mengetahui penting atau tidak suatu atribut beserta level pada produklaptop.
Manfaat yang dapat diambil produsen dari penggunaan analisis konjoin ini
adalah produsen dapat mencari solusi kompromi yang optimal dalam merancang
dan mengembangkan suatu produk. Analisis ini dapat juga dimanfaatkan untuk
merancang harga, memprediksi tingkat penjualan atau penggunaan produk, uji
coba konsep produk baru, dan merancang strategi promosi. Atribut-atribut yang
digunakan dalam analisis konjoin berskala kategorik, sehingga dibutuhkan peubah
boneka untuk mewakili taraf-tarafnya ke dalam model.
2.8.2 Tahapan Analisis Konjoin
Adapun tahapan-tahapan analisis konjoin meliputi beberapa langkah yaiatu:
1. Mengidentifikasi atribut
5. Interpretasi Hasil
6. Penilaian keandalan dan kesahian
2.8.2.1 Mengidentifikasi Atribut
Langkah awal dalam melakukan analisis konjoin yaitu mengidentifikasi kumpulan
dari atribut-atribut dimana setiap atribut terdiri atas beberapa taraf/level. Informasi
mengenai atribut yang mewakili preferensi konsumen bisa diperoleh melalui
diskusi dengan pakar, eksplorasi data skunder, atau melakukan tes awal.
Kemudian atribut yang sudah dianggap mewakili ditentukan skalanya.
Skala atribut dibagi menjadi dua yaitu skala kualitatif atau non metrik atau
kategori (nominal dan ordinal) dan skala kuantitatif atau metrik (interval dan
rasio).
Banyaknya tingkatan atribut menentukan banyaknya parameter yang akan
diperkirakan dan juga mempengaruhi banyaknya stimulus yang akan dievaluasi
oleh responden. Untuk meminimumkan tugas evaluasi responden, dan harus bisa
memperkirakan parameter seakurat mungkin, perlu membatasi banyaknya
tingkatan/level dari atribut. Utility atau parth-worth function untuk level suatu
objek mungkin tidaklinear (non-linear).
2.8.2.2 Merancang Kombinasi Atribut (Stimuli)
Ada dua cara pembentukan stimuli dalam analisis konjoin yaitu :
1. Full-profile
Pendekatan kombinasi lengkap (full profile) juga disebut evaluasi banyak faktor (multiple-factor-evaluation) yaitu jika ada k atribut dan ada l level yang diteliti dapat mengevaluasi semua stimuli yang muncul dengan l1 x
Tentunya terkadang banyaknya stimuli membuat bingung
responden dalam menilai, untuk mengatasi masalah ini dapat digunakan
SPSS dengan menggunakan pendekatan full profile namun desain yang digunakan bukan full factor design melainkan fractional factorial design. Dengan design ini, sebagian dari seluruh kombinasi produk dipilih yang
benar-benar berpengaruh terhadap efek utama. Efek interaksi tidak
diperhatikan. Desain seperti ini dikenal dengan nama Orthogonal array. Dalam tabel Orthogonal Array, keseimbangan dicapai karena setiap tingkat faktor/atribut terjadi pada jumlah yang sama dengan setiap tingkat
dari masing-masing faktor lainnya. Catatan bahwa semua faktorial lengkap
di mana terdapat jumlah yang sama berulang untuk setiap kombinasi
faktor-tingkat adalah orthogonal array. Beberapa faktorial adalah orthogonal array, beberapa tidak.
Orthogonal Array memungkinkan desain yang mengasumsikan bahwa semua interaksi yang tidak penting bisa diabaikan. Orthogonal
Array dibentuk dari basic full fractional design dengan mengganti suatu faktor baru untuk seleksi interaksi efek yang dianggap bisa diabaikan.
Metode yang lain untuk mengurangi banyaknya inetraksi dengan
melakukan survey terhadap konsumen.
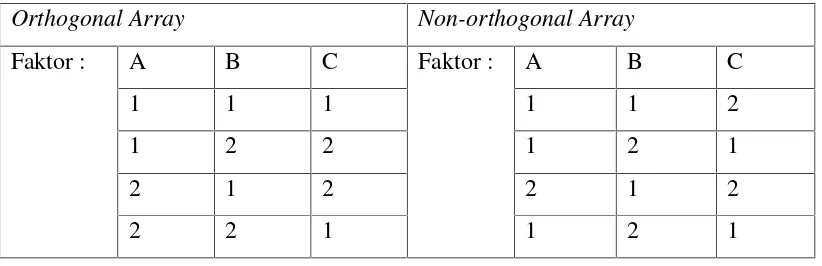
Tampak bahwa dalam desain orthogonal Array, jumlah kemunculan dari setiap level suatu atribut selalu tidak sama. Berikut
contoh desain orthogonal Array dan bukan orthogonal Array. Tabel sebelah kiri menunjukkan bahwa setiap level dari masing-masing atribut
muncul satu kali, sebaliknya pada tabel sebelah kanan, kombinasi 1 2 1
Tabel 2.2 ContohOrthogonal ArraydanNon-orthogonal Array
Orthogonal Array Non-orthogonal Array
Faktor : A B C Faktor : A B C
1 1 1 1 1 2
1 2 2 1 2 1
2 1 2 2 1 2
2 2 1 1 2 1
2. Pairwise Combination
Melalui pendekatan ini, stimuli yang diperingkatkan dilakukan dengan
cara memberikan peringkat pada setiap kombinasi taraf/level dari dua
atribut, mulai dari yang paling disukai sampai pada yang paling tidak
disukai. Jika banyaknya atribut ada -buah, maka kombinasi taraf/level
atribut yang harus dievaluasi responden adalah sebanyak:
c = ( ) pasangan.
Kelebihan pendekatan pasangan adalah bahwa pendekatan ini lebih
mudah bagi responden untuk memberikan pertimbangan. Tetapi
kelemahan relatifnya ialah bahwa pendekatan ini memerlukan lebih
banyak evaluasi.
2.8.2.3 Menentukan Jenis Data
Data yang diperlukan dalam analisis konjoin dapat berupa data non-metrik (data
berskala nominal atau ordinal atau kategorial) maupun data metrik (data berskala
interval atau rasio).
1. Data non-metrik
Untuk memperoleh data dalam bentuk non-metrik, responden diminta
untuk membuat ranking atau mengurutkan stimulus yang paling disukai
disukai deberi nilai dimulai dari 1 dan seterusnya hingga ranking terakhir stimulus yang paling tidak disukai.
2. Data Metrik
Untuk memperoleh data dalam bentuk metrik, responden diminta untuk
memberikan nilai atau rating terhadap masing-masing stimulus. Dengan cara ini, responden akan memberikan penilaian terhadap masing-masing
stimulus secara terpisah. Pemberian nilai atau rating dapat dilakukan melalui beberapa cara, yaitu:
a. Menggunakan skala likert mulai dari 1 hingga 5 (1 = paling tidak
disukai dan 5 = paling disukai).
b. Menggunakan nilai rangking terbalik, artinya untuk stimulus yang
paling disukai diberi nilai tertinggi setara dengan jumlah stimulusnya,
sedangkan stimulus yang paling tidak disukai diberi nilai satu.
2.8.2.4 Memilih Prosedur Analisis Konjoin
Model dasar analisis konjoin secara matematis sebagai berikut (Supranto, 2004):
( ) =
di mana:
( ) = Utilitas total dari tiap-tiap stimuli
= Utilitas dari atribut ke- ( = 1, 2, 3, ... ,k) dan
level ke-j (j = 1, 2, 3, ... , )
= Banyaknya level dari atribut
= Banyaknya atribut
= Peubah boneka atribut ke- level ke- (bernilai 1, jika level ke- dari
Rumus untuk nilai kepentingan relatif adalah :
= ∑
di mana:
= Bobot kepentingan relatif untuk tiap atribut
= Range nilai kepentingan untuk tiap atribut
Range nilai kepentingan relatif tiap atribut dapat dicari dengan rumus :
= { ( ) – ( )}
Beberapa prosedur yang berbeda tersedia untuk mengestimasi model dasar
yang paling sederhana, dan sangat populer yaitu dummy variable regression, artinya suatu regresi, variabel bebasnya merupakan variabeldummy.
Untuk membangun model regresi yang peubah bebasnya mengandung
variabel kualitatif, salah satunya adalah menggunakan peubah boneka. Peubah
boneka merupakan cara yang sederhana untuk mengkuantifikasi variabel yang
kualitatif. Untuk variabel kualitatif yang mempunyai kategori bisa dibangun
− 1 peubah boneka. Peubah boneka ini biasanya mengambil nilai 1 atau 0.
Kedua nilai yang diberikan tidak menunjukkan bilangan (numerik) tetapi hanya
sebagai identifikasi kelas atau kategorinya. Di dalam literatur Supranto (2004)
menyebutkan bahwa :
1. Atribut yang mempunyai dua taraf diberi kode 1 untuk salah satu taraf
dan 0 untuk lainnya.
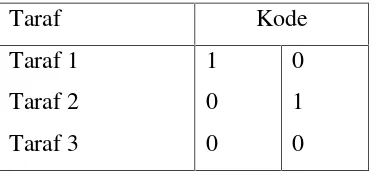
2. Atribut yang mempunyai dari tiga taraf, pengkodeannya sebagai
Tabel 2.3 Pengkodean taraf/level
Taraf Kode
Taraf 1
Taraf 2
Taraf 3
1
0
0
0
1
0
Untuk taraf lebih dari tiga, pengkodean dilakukan dngan cara yang sama
sehingga setiap faktor memiliki − 1 peubah boneka. Banyaknya peubah boneka
sama dengan banyaknya kategori (taraf) dikurangi satu.
Jika data yang digunakan berasal dari penilaian stimuli yang telah
dirancang sebelumnya dan penilaian dilakukan dengan menggunakan skala
metrik, maka regresi dapat dihitung langsung dengan menggunakan pendekatan
Ordinary Least Square(OLS). Jika penilaian stimuli menggunakan urutan stimuli, maka data tersebut harus ditransformasi terlebih dahulu dengan monotomic regression atau multidimensional scalling, kemudian analisis dilanjutkan dengan regresi peubah boneka. Namun, jika data diperoleh melalui penilaian secara
terpisah dari masing-masing taraf/level atribut yang dikenal dengan istilah
discrete choice, analisis yang dapat digunakan adalah model logit.
2.8.2.5 Interpretasi Hasil
Untuk menginterpretasikan hasil analisis, dilakukan pada semua tingkat
kepentingan atribut dengan membuat grafik perbandingan antara nilai kepentingan
dari tiap-tiap atributnya. Interpretasi dari hasil berikutnya juga dilakukan dengan
2.8.2.6 Penilaian Keandalan Dan Kesahihan
Uji keandalan terhadap hasil konjoin untuk mengetahui apakah prediksi yang
telah dilakukan mempunyai ketepatan yang tinggi dengan kenyataannya. Pada uji
ketepatan prediksi ini akan dilakukan pengukuran korelasi secara Pearson maupunKendall dengan bantuan SPSS. Pada pengukuran tersebut akan diketahui seberapa kuat hubungan antara estimasi dan actualnya atau seberapa tinggi Predictive accuracynya.
2.9 Tahapan Pengambilan Sampel
2.9.1 Populasi dan Sampel
Populasi adalah wilayah generelisasi yang terdiri atas; obyek/subyek yang
mempunyai kuantitas dan karakteristik tertentu yang ditetapkan oleh peneliti
untuk dipelajari dan kemudian ditarik kesimpulannya. Sampel merupakan bagian
dari populasi yang mempunyai ciri-ciri atau keadaan tertentu yang akan diteliti
karena tidak semua data dan informasi akan diproses dan tidak semua orang atau
benda akan diteliti melainkan cukup dengan menggunakan sampel yang
mewakilinya (Sugiyono, 2006).
Dalam pelaksanaan penelitian, ruang lingkup populasi merupakan area
yang amat luas batasnya sehingga penggunaan populasi sebagi instrumen
penelitian sangat sulit dilakukan. Oleh karena itu, untuk memenuhi kelayakan
dalam pelaksanaan penelitian, ditentukan populasi sasaran (target population),
yaitu populasi yang digunakan untuk mengeneralisasi hasil penelitian.
2.9.2 Teknik Penarikan Sampel
Masalah sampel akan terjadi bila jumlah populasi terlalu besar dan menyebar
pengambilan sampel dilakukan dengan teknik penarikan sampel bertingkat
proposional (propotional stratified random sampling). Ada beberapa syarat yang
harus terpenuhi terlebih dahulu untuk menggunakan teknik ini antara lain
(Singarimbun dan Effendi, 1989:162-163):
1. Adanya kriteria yang jelas yang akan dipergunakan sebagai dasar untuk
menstratifikasi populasi ke dalam lapisan-lapisan.
2. Adanya data pendahuluan dari populasi mengenai kriteria yang
dipergunakan untuk menstratifikasi.
3. Jumlah satuan elementer dari setiap strata (ukuran setiap subpopulasi)
harus diketahui dengan pasti. Hal ini diperlukan agar peneliti dapat
membuat kerangka sampling untuk setiap subpopulasi atau strata yang akan dijadikan sumber dalam menentukan sampel atau responden.
Untuk mendapatkan sampel yang benar-benar mewakili seluruh populasi,
maka dalam penelitian ini teknik penentuan jumlah sampel menggunakan rumus
slovin yang mempunyai syarat ukuran populasi diketahui dan taraf kesalahan ditentukan. Rumus
Slovin sebagai berikut:
= 1 +
Sumber: Umar (2004:108)
Keterangan :
= Ukuran Sampel
= Ukuran Populasi
= Persen Kelonggaran ketidaktelitian karena kesalahan pengambilan