133
PEMBENTUKAN THESAURUS YANG SENSITIF TERHADAP TINGKAT
POLARITAS REVIEW PADA CROSS-DOMAIN SENTIMENT CLASSIFICATION
Putu Praba Santika, Agus Zainal Arifin,Diana Purwitasari Jurusan Teknik Informatika, Institut Teknologi Sepuluh Nopember Kampus ITS Keputih, Sukolilo, Surabaya 60111, Jawa Timur, Indonesia
Email: [email protected]
ABSTRAK
Ketidaksesuaian antara isi opini dan rating yang diberikan pada review produk mungkin terjadi karena diberikan secara terpisah. Pendekatan Machine Learning dapat dilakukan untuk klasifikasi sentimen yang terdapat pada opini untuk mendapatkan rating. Idealnya classifier dilatih dengan data yang sudah diketahui polaritasnya dari domain yang sama dengan domain yang akan diuji, sehingga diperlukan data latih tersendiri. Pelabelan secara manual pada pembuatan data latih sangat menghabiskan waktu dan biaya. Untuk menghidari pelabelan secara manual, dilakukan dengan pendekatan cross-domain sentiment classification.
Pendekatan ini hanya membedakan polaritas opini menjadi positif dan negatif. Hal ini menyebabkan kerancuan, sehingga perlu digunakan rentang nilai untuk menunjukkan tingkat polaritas suatu opini. Penelitian ini bertujuan untuk mengusulkan pendekatan pengukuran tingkat polaritas review pada cross-domain sentiment classification agar dapat melakukan klasifikasi pada domain yang berbeda. Metode yang digunakan adalah membuat thesaurus
yang sensitif terhadap tingkat polaritas sentimen digunakan dalam features expansion untuk menambahkan feature baru pada Review. Review yang sudah ditambah feature baru digunakan pada training dan testing.
Hasil pengujian menunjukkan bahwa rata-rata akurasi pada pengujian cross-domain sentiment classification yang menerapkan features expansion dengan memanfaatkan
thesaurus yang sensitif terhadap sentiment 8.17% lebih baik dari pada yang tidak menerapkan features expansion. Penelitian ini membuktikan bahwa klasifikasi pada domain yang berbeda dapat dilakukan dengan menerapkan features expansion dengan memanfaatkan
thesaurus yang sensitif terhadap tingkat polaritas sentiment.
Kata kunci: cross-domain, machine learning, sentiment classification, tingkat polaritas.
1. Pendahuluan
Tren berbelanja secara online
membuat pembeli produk atau jasa mengekpresikan opini mengenai produk atau jasa dengan menuliskan review secara
online pula. Calon pembeli dapat memanfaatkan review dari pembeli produk atau jasa sebelumnya sebagai pertimbangan sebelum memutuskan menggunakan produk atau jasa tersebut
(D’Avanzo & Pilato, 2014). Sebanyak 80% calon pembeli mempertimbangkan review sebelum memutuskan untuk membeli atau menggunakan produk atau jasa (Pang & Lee, 2008) (D'avanzo & Kuflik, 2013).
134
layanan. Saat ini, rating atau penilain tingkat kepuasan pengguna terhadap suatu produk harus diberikan secara manual oleh penulis opini. Ketidaksesuaian antara isi opini dan nilai tingkat kepuasan mungkin terjadi, sehingga diperlukan pemberian tingkat kepuasan secara otomatis terhadap opini tersebut. Opinion Mining adalah suatu cara untuk mengidentifikasi opini terhadap suatu subjek kemudian mengevaluasi polaritas dari opini tersebut (Tsytsarau & Palpanas, 2012). Dengan
opinion mining dapat diketahui polaritas sebuah ulasan produk. Polaritas review menunjukkan apakah ulasan tersebut mengandung opini positif atau negatif. Klasifikasi dapat dilakukan berdasarkan sentimen yang terdapat pada opini tersebut. Turney melakukan klasifikasi terhadap review untuk merekomendasikan atau tidak suatu produk dilakukan dengan cara menghitung rata-rata nilai orientasi semantiknya (Turney, 2002). Orientasi simantik dihitung berdasarkan kedekatan dengan kata “excellent” dikurangi
kedekatan dengan “poor”. Machine Learning juga digunakan untuk melakukan klasifikasi terhadap sentimen. Metode
Machine Learning memberikan tingkat akurasi yang lebih tinggi. (Pang, Lee, & Vaithyanathan, 2002).
Pada pendekatan machine learning idealnya classifier dilatih dengan data yang sudah diketahui polaritasnya dari domain yang sama dengan domain yang akan diuji. Classifier yang dilatih kemudian diuji dengan data dari domain yang berbeda akan memberikan hasil yang buruk (Whitehead & Yaeger, 2009). Hal ini terjadi karena fitur yang terdapat pada domain sumber (domain yang digunakan untuk pelatihan) tidak cocok dengan fitur yang terdapat pada domain tujuan (domain yang diuji).
Untuk dapat melakukan opinion mining atau sentiment analysis diperlukan data latih yang sudah diketahui polaritasnya. Untuk masing-masing
domain diperlukan data latih tersendiri (Blitzer, Dredze, & Pereira, 2007). Pelabelan fitur secara manual pada pembuatan data latih sangat menghabiskan waktu dan biaya. Untuk menghidari pelabelan secara manual, dilakukan penelitian agar dapat menggunakan data latih dari domain yang sudah tersedia untuk menangani klasifikasi pada domain yang berbeda. Klasifikasi sentimendengan menggunakan data latih dari domain yang berbeda dengan domain data yang akan diuji disebut cross-domain sentiment classification.
Cross-domain classification atau
transfer learning berfokus pada
menganalisa data dari sebuah domain kemudian hasilnya digunakan untuk melakukan klasifikasi pada domain yang berbeda. Secara umum Cross-domain sentiment classification memanfaatkan data berlabel dari domain sumber ditambah data yang belum berlabel dari domain target untuk melakukan transfer learning.
Whitehead (Whitehead & Yaeger, 2009) melakukan penelitian dengan menggunakan data dari beberapa domain berbeda digabungkan untuk digunakan sebagai data latih. Penggunaan gabungan data dari beberapa domain terbukti meningkatkan akurasi namun tidak terlalu signifikan. Penggunaan gabungan data dari beberapa domain berbeda sangat terpengaruh oleh kesamaan antara fitur pada data latih hasil penggabungan dengan fitur yang terdapat pada data dari domain yang akan diuji. Metode lain untuk menangani masalah cross-domain adalah dengan memanfaatkan feature expansion
(Bollegala, Weir, & Carroll, 2013). Ketidak cocokan fitur pada domain yang berbeda ditangani dengan membuat
135 ditambahkan pada vektor fitur untuk
menjembatani domain sumber dan domain tujuan.
Penelitian tersebut hanya membedakan polaritas opini menjadi dua, yaitu positif dan negatif. Walaupun opini sebenarnya hanya bernada sedikit positif, namun jika menggunakan pendekatan tersebut, opini akan dianggap menjadi positif sehingga menimbulkan kerancuan (Okanohara & Tsujii, 2005). Untuk mengatasi kerancuan ini perlu digunakan rentang nilai untuk menunjukkan tinggkat polaritas suatu opini.
Pada penelitian ini dikembangkan metode yang dapat menunjukkan tingkat poaritas opini suatu produk, tanpa harus memberikan label terhadap data latih pada domain tersebut. Sebelum dilakukan klasifikasi, review mengalami feature
expansion dengan memanfaatkan
thesaurus yang sensitif terhadap tingkat polaritas sentimen.
2. Tinjauan Pustaka 2.1. Opinion Mining
Opinion mining / Sentiment analysis bertujuan untuk mengidentifikasi pendapat yang dikemukakan pada suatu subjek tertentu dan mengevaluasi polaritas pendapat ini. Polaritas sentimen adalah titik pada skala evaluasi yang sesuai dengan evaluasi positif atau negatif tentang makna sentimen ini.
Tujuan dari Opinion mining adalah untuk membuat komputer mampu mengenali dan mengekspresikan emosi. Tugas dasar dalam analisis sentimen adalah mengelompokkan teks kalimat atau dokumen dan menentukan pendapat yang dikemukakan dalam kalimat atau dokumen tersebut apakah bersifat positif atau negatif. Sebuah pikiran, pandangan, atau sikap berdasarkan emosi, disebut sentimen. Jadi
Opinion mining juga disebut sebagai analisis sentiment (Khan, Baharudin, Khan, & Malik, 2009). Sentiment analysis juga
dapat menyatakan perasaan emosional sedih, gembira, atau marah.
Sentiment analysis mengidentifikasi informasi subjektif dari dokumen tekstual menggunakan pengolahan bahasa alami (natural language processing) dan teknik
data mining. Fokus utama dari analisis sentimen untuk menentukan sikap pembicara atau penulis terhadap beberapa topik, atau polaritas kontekstual keseluruhan dokumen. Sikap dapat berupa penilaian atau evaluasi yang dilakukan oleh penulis, atau efek emosional. (Kurian, 2014)
Salah satu penerapan sentiment analysis adalah pada pemberian rating produk. Pengguna dapat secara tidak sengaja memberikan rating rendah, padahal review
yang diberikan sangat positif. Kesalahan ini dapat diatasi dengan melakukan klasifikasi terhadap sentiment review, sehingga dapat memberikan rating secara otomatis (Pang & Lee, 2008).
2.2 Cross-Domain Sentiment
Classification
Pada pendekatan machine learning idealnya classifier dilatih dengan data yang sudah diketahui polaritasnya dari domain yang sama dengan domain yang akan diuji. Classifier yang dilatih kemudian diuji dengan data dari domain yang berbeda akan memberikan hasil yang buruk (Whitehead & Yaeger, 2009). Hal ini terjadi karena fitur yang terdapat pada domain sumber (domain yang digunakan untuk pelatihan) tidak cocok dengan fitur yang pada domain tujuan (domain yang diuji).
136
tingkat korelasi yang sama dengan label kelas yang sama di target domain (Kurian, 2014).
Tantangan yang terdapat pada pendekatan machine learning adalah bagaimana memanfaatkan data yang telah memiliki label sentimen dalam satu domain (yaitu domain sumber) agar dapat digunakan untuk melakukan klasifikasi sentimen di domain lain (yaitu domain target). Konsep
cross-domain sentiment classification
digunakan untuk menangani masalah ini. Data dari sebuah domain dianalisis kemudian hasilnya digunakan untuk melakukan klasifikasi pada domain yang berbeda.
3. Desain Sistem
Proses-proses yang dilalui pada pengukuran tingkat polaritas review pada
cross-domain sentiment classification
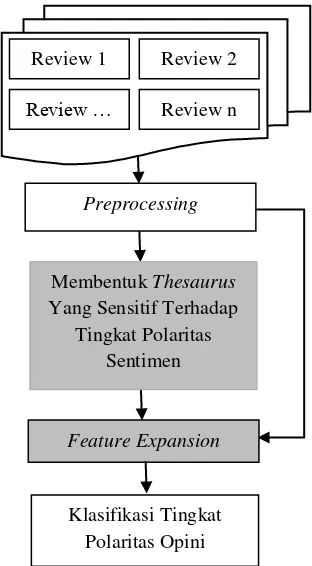
disusun sesuai framework pada Gambar 1.
Gambar 1. Tahapan Klasifikasi Tingkat Polaritas Opini
2.1 Tahap Preprocessing
Pada tahap preprocessing, review dipecah menjadi kalimat. Selanjutnya kata-kata dalam kalimat tersebut ditandai sesuai dengan jenis katanya. Tahapan penandaan jenis kata ini disebut Part-of-Speech Tagging.
Untuk setiap kata yang sudah ditandai jenis katanya kemudian dicek apakah kata tersebut sudah tidak mengandung angka dan karakter khusus, bukan merupakan
stopword, dan jenis katannya atau Part-of-Speech nya sudah sesuai dengan jenis kata yang akan digunakan pada tahap pembentukan thesaurus yang sensitif terhadap tingkat polaritas sentiment. Jika semua syarat tersebut terpenuhi maka kata tersebut dimasukkan kedalam daftar unigram yang berbentuk list, banyaknya kemunculan kata ini dalam kalimat juga disimpan dalam list terpisah.
Setelah terbentuk unigram, kemudian dilanjutkan dengan dengan membentuk
bigram. Bigram dibentuk dengan
menggabungkan dua buah unigram yang berurutan. Bigram dan dan banyaknya kemunculan bigram dalam kalimat juga disimpan dalam list yang sebelumnya sudah berisi unigram. ID dari setiap elemen list ini merupakan kode dari unigram atau bigram
tersebut. Kode unigram, bigram serta banyak kemunculannya dalam dokumen
review dicatat sebagai kode penyusun teks review tersebut.
3.2 Tahap Pembentukan Thesaurus yang Sensitif Terhadap Tingkat Polaritas Sentimen
Thesaurus yang sensitif terhadap tingkat polaritas sentiment didapat dengan mencari hubungan antar lexical elements.
Tahapan yang dilakukan untuk membentuk
thesaurus yang sensitif terhadap tingkat polaritas sentiment adalah menghitung banyaknya kemunculan masing-masing
lexical elements dengan sentiment emlement
dalam review. Review … Review n
Feature Expansion
Klasifikasi Tingkat Polaritas Opini Review 1 Review 2
Membentuk Thesaurus
Yang Sensitif Terhadap Tingkat Polaritas
Sentimen
137 Banyaknya kemunculan antara lexical
elements u dan sentiment elements w
dilambangkan dengan c(u,w). Banyaknya kemunculan antara lexical elements u dan
sentiment elements w digunakan untuk menghitung Pointwise Mutual Information
(PMI) antara lexical elements u dan
sentiment elements w dilambangkan dengan
f(u,w) sesuai persamaan 1.
𝑓(𝑢, 𝑤) = log ( 𝑐(𝑢,𝑤)𝑁 ∑𝑛𝑖=1𝑐(𝑖,𝑤)
𝑁 ×
∑𝑚𝑗=1𝑐(𝑢,𝑗) 𝑁
),
(1)
Dengan banyaknya lexical element u dan
sentiment element w dinotasikan dengan n
dan m. Sedangkan N dihitung dengan menggunakan persamaan 2,
𝑁 = ∑ ∑𝑚 𝑐(𝑖, 𝑗) 𝑗=1 𝑛
𝑖=1 .
(2)
Pointwise Mutual Information digunakan untuk mengetahui keterkaitan antara sebuah lexical elements dan sentiment elements. Selanjutnya, nilai keterkaitan anatara sebuah lexical elements dan
sentiment elements digunakan untuk melakukan perhitungan nilai kemiripan antar lexical elements.
Untuk menghitung kemiripan antara lexical element u dan lexical element v
digunakanpersamaan 3
𝜏(𝑣, 𝑢) = ∑𝑤∈{ 𝑥| 𝑓(𝑣,𝑥)>0𝑓(𝑢,𝑤) ∑𝑤∈{ 𝑥| 𝑓(𝑢,𝑥)>0𝑓(𝑢,𝑤)
(3)
dimana f(u,w) pada persamaan 3 dihitung sesuai dengan persamaan 1.
3.3 Tahap Feature Expansion
Sebuah review d dimodelkan dalam set {w1, w2, …, wN} dimana w1 merupakan
unigram atau bigram pada review d. dimana
dj adalah banyaknya kemunculan unigram
atau bigram wj pada review d. Kandidat yang akan digunakan untuk melakukan ekspansi terhadap semua base entry dihitung dengan persamaan 4.
𝑠𝑐𝑜𝑟𝑒 (𝑢𝑖, 𝑑) = ∑ 𝑑𝑗𝜏(𝑤𝑗,𝑢𝑖) 𝑁
𝑗=1 ∑𝑁𝑙=1𝑑𝑙
(4)
Skor ui diurutkan secara menurun, kemudian dipilih k buah yang terbaik. Base entry yang terpilih untuk review d
dilambangkan dengan 𝑣𝑑𝑟 dengan nilai r
berupa rentang dari 1 sampai k. Vektor review d yang awalnya hanya berisi {w1, w2, …, wN} digabungkan dengan base entry yang terpilih, sehingga menjadi {w1, w2, …, wN, 𝑣𝑑1, 𝑣𝑑2, … , 𝑣𝑑𝑘}, vektor ini disebut sebagai d’.
Nilai N elemen pertama pada d’ sama dengan nilai N elemen pertama pada vektor
d yaitu banyaknya kemunculan wi pada
review d. Sedangkan untuk elemen ke N+1
sampai k pada vektor d’ berisi nilai skor yang dihasilkan pada Persamaan 4 untuk masing masing base entry yang terpilih.
3.4 Tahap Klasifikasi Tingkat Polaritas Opini
Untuk mengetahui tingkat polaritas suatu review dilakukan melalui metode klasifikasi multi class. Untuk melakukan klasifikasi digunakan L1 regularized logistic regression. Class yang ingin dibentuk adalah class sesuai dengan tingkatan polaritasnya yaitu (1,2,3,4,5).
Untuk melakukan klasifikasi, terdapat dua langkah yang harus dilakukan, yaitu
training dan testing. Tahap training,
classifier dilatih dengan vektor d’ yang merupakan vektor review digabungkan dengan vektor hasil ekspansi nya. Langkah selanjutnya adalah menggunakan classifier
yang telah dilatih untuk menentukan class
138
4. HASIL UJI COBA DAN
PEMBAHASAN
Pada ujicoba ini digunakan data review produk pada web Amazon yang telah diambil dan digunakan dalam penelitian yang dilakukan oleh McAuley (McAuley & Leskovec, 2013) , kemudian diperbaharui pada penelitian (McAuley, Pandey, & Leskovec, 2015). Domain yang dipilih adalah Book, CDs & Vinyl, Electronics, Home & Kitchen karena memiliki komentar terbanyak. Keempat domain ini digunakan sebagai domain sumber dan domain tujuan secara bergantian, sehingga didapat 12 kombinasi domain sumber dan domain target.
Untuk masing-masing domain produk diambil secara acak 100 review yang memiliki rating 1, 100 review yang memiliki rating 2, 100 review yang memiliki rating 3, 100 review yang memiliki rating 4, 100 review yang memiliki rating 5. Sehingga terdapat 500 review yang terbagi dalam 5 rating yang berbeda. Review ini disebut sebagai labeled review karena telah memiliki tingkat polaritas. Selain itu diambil 1000 review lain tanpa memperhatikan rating dari review tersebut. Review ini disebut sebagai
unlabeled review, karena dianggap tidak memiliki tingkat polaritas.
Dalam pengujian terdapat tiga buah parameter yang dikombinasikan untuk mencapai akurasi maksimal. Ketiga parameter tersebut adalah k yaitu banyaknya fitur atau lexical elements yang akan diambahkan pada review, c yaitu
regularization parameter, dan eps yaitu kriteria terminasi pada proses training. Ketiga variable ini diberikan nilai awal seperti ditunjukkan pada tabel 1.
Banyaknya fitur atau lexical element
yang akan diambahkan pada review (k) ditentukan pada rentang antara 1 sampai 100 dengan kenaikan 1 karena penambahan
lexical element yang terlalu banyak pada
review akan menyebabkan akurasi menurun. Akurasi menurun karena semakin banyak
lexical element yang ditambahkan, maka semakin besar kemungkinan terdapat lexical element yang sebenarnya tidak memiliki kaitan erat dengan review, namun ikut ditambahkan pada review. Nilai
regularization parameter (c) ditetapkan pada rentang antara 1 sampai 20 dengan kenaikan 1 karena nilai regularization parameter yang telalu kecil menyebabkan model klasifikasi yang terbentuk pada saat training menjadi overfiting, sebaliknya jika terlalu besar, maka akan terbentuk model klasifikasi yang underfiting.
Tabel 1. Parameter yang Dioptimasi dan Nilainya
Parameter Nilai Parameter
K {1, 2, 3, … , 100}
C {1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16, 17, 18, 19, 20}
Eps { 0,01; 0,02; 0,03; 0,04; 0,05; 0,06; 0,07; 0,08; 0,09; 0,1}
Pengujian pertama bertujuan untuk mendapatkan nilai akurasi maksimum untuk masing-masing kombinasi domain sumber dan target pada kasus cross-domain sentiment classification yang menerapkan
feature expansion dengan memanfaatkan
thesaurus yang sensitif terhadap tingkat polaritas sentimen. Nilai ketiga parameter dikombinasikan dan digunakan dalam melakukan cross-domain sentiment classification untuk masing-masing kombinasi domain yang tersedia, yaitu
Book, CDs & Vinyl, Electronics, Home & Kitchen. Masing-masing akurasi dicatat, kemudian diurutkan berdasarkan nilai akurasi secara menurun. Hasil akurasi maksimum dan kombinasi nilai parameter untuk masing-masing kombinasi domain ditunjukkan pada Tabel 2.
Tabel 2 menunjukkan akurasi maksimum didapat pada kombinasi domain
139 Sedangkan akurasi terendah didapat pada
kombinasi domain CDs & Vinyl sebagai domain sumber dan domain Home & Kitchen sebagai domain target. Akurasi yang diperoleh sebesar 30%. Rata-rata akurasi pada pengujian cross-domain sentiment classification yang menerapkan
features expansion dengan memanfaatkan
thesaurus yang sensitif terhadap sentiment untuk semua kombinasi domain adalah 48.75%.
Tabel 2. Hasil Cross-Domain Sentiment Classification dengan Menerapkan
Feature Expansion Domain
Pengujian kedua bertujuan untuk mendapatkan nilai akurasi maksimum untuk masing-masing kombinasi domain sumber dan target pada kasus cross-domain
sentiment classification tanpa menerapkan
feature expansion. Nilai ketiga parameter dikombinasikan dan digunakan dalam melakukan cross-domain sentiment classification untuk masing-masing kombinasi domain yang tersedia, yaitu
Book, CDs & Vinyl, Electronics, Home & Kitchen dengan menggunakan kombinasi nilai parameter yang telah disebutkan sebelumnya. Untuk pengujian pada kasus
cross-domain sentiment classification tanpa menerapkan feature expansion nilai parameter k selalu bernilai 0. Parameter k
bernilai 0 berarti tidak ada lexical elements
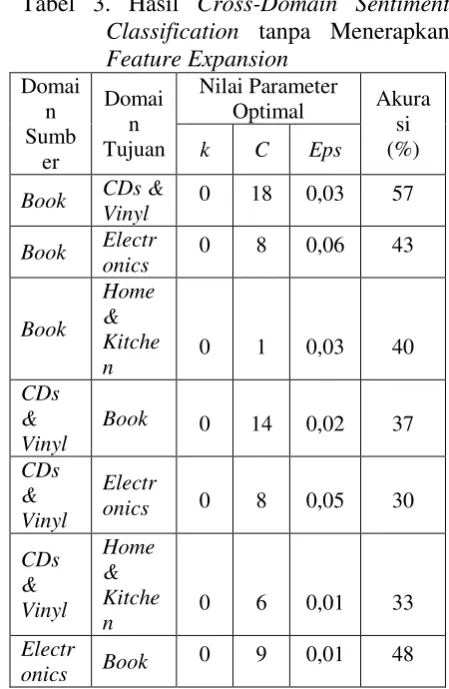
yang ditambahkan pada review tersebut. Masing-masing akurasi dicatat, kemudian diurutkan berdasarkan nilai akurasi secara menurun. Hasil akurasi maksimum dan kombinasi nilai parameter untuk masing-masing kombinasi domain ditunjukkan pada tabel 3.
Tabel 3. Hasil Cross-Domain Sentiment Classification tanpa Menerapkan
140
Akurasi terbaik yang diperoleh sebesar 57%. Akurasi terbaik didapat pada Sedangkan akurasi terendah didapat pada kombinasi domain Electronics sebagai domain sumber dan domain CDs & Vinyl
sebagai domain target. Akurasi yang diperoleh sebesar 22%. Rata-rata akurasi pada pengujian cross-domain sentiment classification tanpa menerapkan features expansion untuk semua kombinasi domain adalah 40,58%.
Pada pengujian cross-domain sentiment classification yang menerapkan
features expansion dengan memanfaatkan
thesaurus yang sensitif terhadap tingkat polaritas sentimen, kombinasi CDs & Vinyl sebagai domain sumber dan
Electronics sebagai domain target, menghasilkan nilai akurasi yang sangat rendah, akurasi yang didapat hanya sebesar 26%. Nilai akurasi ini bahkan lebih rendah dibandingkan pengujian cross-domain sentiment classification tanpa menerapkan
features expansion, yaitu 28%.
Akurasi yang didapat pada kombinasi
CDs & Vinyl sebagai domain sumber dan domain Home & Kitchen sebagai domain target sangat rendah disebabkan oleh kurangnya informasi sentiment element, sehingga belum mampu memunculkan keterkaitan antara lexical element penyusun
review dengan lexical element kandidat yang ditambahkan pada review dalam proses
feature expansion. Hal ini akan menyebabkan skor keterkaitan menjadi rendah. Dalam prosesnya, feature expansion
akan mengurutkan skor keterkaitan antara
lexical element penyusun review dengan
lexical element yang menjadi kandidat. Kemudian dipilih sebanyak k lexical element baru dengan skor tertinggi yang digunakan untuk ditambahkan pada review. Walaupun skor keterkaitan untuk lexical element kandidat kecil, jika lexical element
kandidat tersebut termasuk dalam k lexical element kandidat dengan nilai tertinggi, maka terpaksa fitur tersebut digunakan.
Lexical element terpaksa ditambahkan pada
review tersebut juga tampak dari nilai parameter k yaitu parameter yang menyatakan banyaknya jumlah lexical element yang harus ditambah. Pada kombinasi CDs & Vinyl sebagai domain sumber dan domain Home & Kitchen
sebagai domain target akurasi maksimal didapat pada parameter k bernilai 1. Nilai k sangat kecil, yaitu hanya bernilai 1 karena ternyata penambahan lebih banyak lexical element pada review malah menurunkan nilai akurasi. Lexical element dengan skor keterkaitan rendah terhadap review, berarti
lexical element tersebut tidak memiliki hubungan rengan review tersebut. Penambahan lexical element yang tidak memiliki berkaitan dengan review malah menyebabkan hasil klasifikasi menurun. Hal ini dapat dilihat pada salah satu contoh
141 0615391206A388T8QB30Y6U11
ditunjukkan pada Tabel 4.
Tabel 4. Lexical Element Dengan Skor Tertinggi pada Review 0615391206A388T8QB30Y6U11
Kode lexical
element Skor Keterkaitan
17289 0,0606
17284 0,0328
3640 0,0113
3639 0,0099
17286 0,0097
30260 0,0076
17281 0,0066
4971 0,0057
2303 0,0056
30266 0,005
Pada kombinasi domain Home & Kitchen
sebagai domain sumber dan Book sebagai domain target, sepuluh lexical element
dengan skor tertinggi pada review 0001714384A19HM4UCA0MC9R1
ditunjukkan pada tabel 5
Pada contoh review dari kombinasi domain Home & Kitchen sebagai domain sumber dan Book sebagai domain target, skor keterkaitan antara lexical element yang ditambahkan memiliki keterkaitan yang erat dengan review, hal ini ditunjukkan dengan skor keterkaitan yang tinggi. Keterkaitan antara review dan lexical element tidak harus memiliki kesamaan arti, atau sinonim, namun kedekatan lebih pada kesamaan tingkat polaritas antara review dengan
lexical element tersebut. Tambahan lexical element yang memiliki keterkaitan erat akan membantu proses training dan testing pada tahap klasifikasi.
Tabel 5. Lexical Element Dengan Skor Tertinggi pada Review 0001714384A19HM4UCA0MC9R 1
Kode lexical element Skor Keterkaitan
4970 5.504
3640 1.793
17287 1.4212
2303 0.7981
2306 0.7534
2308 0.5544
4969 0.5415
3634 0.5384
1 0.4506
4966 0.3424
5. KESIMPULAN
Pada paper ini diusulkan cross-domain sentiment classification yang menerapkan
feature expansion dengan memanfaatkan
thesaurus yang sensitif terhadap tingkat polaritas sentiment. Thesaurus yang sensitif terhadap tingkat polaritas sentiment dibentuk dengan menghitung keterkaitan anatara lexical elements dan sentiment elements. Keterkaitan antar lexical elements
dihitung dengan membagi jumlah nilai keterkaitan sentiment elements yang pernah muncul bersama kedua lexical elements
dibagi dengan jumlah semua nilai keterkaitan dengan semua sentiment elements. Keterkaitan antar lexical elements
142
DAFTAR PUSTAKA
[1] Blitzer, J., Dredze, M., & Pereira, F. (2007). Biographies, Bollywood, Boom-boxes and Blenders: Domain Adaptation for Sentiment Classification. The 45th Annual Meeting of the Association of Computational Linguistics (pp. 440– 447). Prague: Association for Computational Linguistics.
[2] Bollegala, D., Weir, D., & Carroll, J. (2013). Cross-Domain Sentiment Classification Using a Sentiment Sensitive Thesaurus. IEEE Transactions On Knowledge And Data Engineering, 1719-1731. [3] D’Avanzo, E., & Pilato, G. (2014).
Mining social network users opinions to aid buyers shopping decisions. Computers in Human Behavior.
[4] D'avanzo, E., & Kuflik, T. (2013). E-Commerce Websites Services Versus Buyers Expectations: An Empirical Analysis Of The Online Marketplace. International Journal of Information Technology & Decision Making.
[5] Dave, K., Lawrence, S., & Pennock, D. (2003). Mining the Peanut Gallery: Opinion Extraction and Semantic Classification of Product Reviews. WWW2003. Budapest: ACM.
[6] Khan, K., Baharudin, B., Khan, A., & Malik, F. (2009). Mining Opinion from Text Documents: A Survey.
IEEE International Conference on
Digital Ecosystems and
Technologies (pp. 217-222). IEEE. [7] Kurian, N. (2014). Cross Domain
Sentiment Classification: Current Solutions. International Journal of Advanced Research in Computer Engineering & Technology (IJARCET), 1747-1750.
[8] Liu, B. (2010). Sentiment Analysis: A Multi-Faceted Problem. IEEE Intelligent Systems.
[9] McAuley, J., & Leskovec, J. (2013). Hidden factors and hidden topics: understanding rating dimensions with review text. 7th ACM conference on Recommender systems
(pp. 165-172). New York: ACM. [10] McAuley, J., Pandey, R., &
Leskovec, J. (2015). Inferring networks of substitutable and complementary products. Knowledge Discovery and Data Mining.
[11] Okanohara, D., & Tsujii, J. (2005). Assigning Polarity Scores to Reviews Using Machine Learning Techniques. Lecture Notes in Computer Science, 314-325.
[12] Pang, B., & Lee, L. (2008). Opinion Mining and Sentiment Analysis.
Foundations and Trends in
Information Retrieval, 1-135.
[13] Pang, B., Lee, L., & Vaithyanathan, S. (2002). Thumbs up?: sentiment classification using machine learning techniques. Empirical Methods in Natural Language Processing (pp. 79-86). ACM.
[14] Tsytsarau, M., & Palpanas, T. (2012). Survey on Mining Subjective Data on the Web. Data Mining and Knowledge Discovery, 478-514. [15] Turney, P. D. (2002). Thumbs up or
thumbs down?: semantic orientation applied to unsupervised classification of reviews. ACL '02 Proceedings of the 40th Annual Meeting on Association for Computational Linguistics (pp. 417-424). Stroudsburg.
[16] Whitehead, M., & Yaeger, L. (2009). Building a General Purpose Cross-Domain Sentiment Mining Model. [17] World Congress on Computer
Science and Information