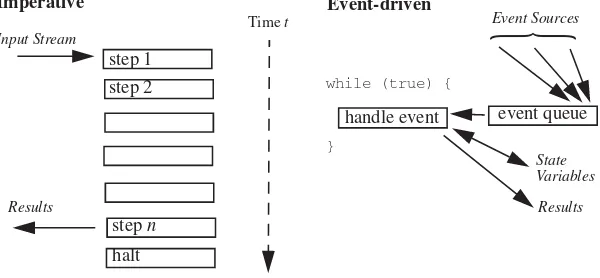
X
Programming
Languages
The area of Programming Languages includes programming paradigms, language imple-mentation, and the underlying theory of language design. Today’s prominent paradigms include imperative (with languages like COBOL, FORTRAN, and C), object-oriented (C++ and Java), functional (Lisp, Scheme, ML, and Haskell), logic (Prolog), and event-driven (Java and Tcl/Tk). Scripting languages (Perl and Javascript) are a variant of imperative programming for Web applications. Event-driven programming is useful in Web-based and embedded applications, and concurrent programming serves applications in parallel computing environments. This section also provides a balanced treatment of the under-lying theories of language design and implementation such as type systems, semantics, memory management, and compilers.
90 Imperative Language Paradigm Michael J. Jipping and Kim Bruce Introduction • Data Bindings: Variables, Type, Scope, and Lifetime • Control Structures • Best Practices • Research Issues and Summary 91 The Object-Oriented Language Paradigm Raimund Ege
Introduction • Underlying Principles • Best Practices • Language Implementation Issues • Research Issues
92 Functional Programming Languages Benjamin Goldberg
Introduction • History of Functional Languages • The Lambda Calculus: Foundation of All Functional Languages • Pure Versus Impure Functional Languages • SCHEME: A Functional Dialect of LISP • Standard ML: A Strict Polymorphic Functional
Language • Nonstrict Functional Languages • HASKELL: A Nonstrict Functional Language • Research Issues in Functional Programming
93 Logic Programming and Constraint Logic Programming Jacques Cohen Introduction • An Introductory Example • Features of Logic Programming Languages • Historical Remarks • Resolution and Unification • Procedural
Interpretation: Examples • Impure Features • Constraint Logic Programming • Recent Developments in CLP (2002) • Applications • Theoretical Foundations • Metalevel Interpretation • Implementation • Research Issues • Conclusion
94 Scripting Languages Robert E. Noonan and William L. Bynum Introduction • Perl • Tcl/Tk • PHP • Summary
95 Event-Driven Programming Allen B. Tucker and Robert E. Noonan Foundations: The Event Model • The Event-Driven Programming
96 Concurrent/Distributed Computing Paradigm Andrew P. Bernat and Patricia Teller
Introduction • Hardware Architectures • Software Architectures • Distributed Systems • Formal Approaches • Existing Languages with Concurrency Features • Research Issues • Summary
97 Type Systems Luca Cardelli
Introduction • The Language of Type Systems • First-Order Type Systems • First-Order Type Systems for Imperative Languages • Second-Order Type
Systems • Subtyping • Equivalence • Type Inference • Summary and Research Issues
98 Programming Language Semantics David A. Schmidt
Introduction • A Survey of Semantics Methods • Semantics of Programming Languages • Applications of Semantics • Research Issues in Semantics
99 Compilers and Interpreters Kenneth C. Louden Introduction • Underlying Principles • Best Practices • Incremental Compilation • Research Issues and Summary
100 Runtime Environments and Memory Management Robert E. Noonan and William L. Bynum
90
Imperative Language
Paradigm
Michael J. Jipping
Hope College
Kim Bruce
Williams College
90.1 Introduction
90.2 Data Bindings: Variables, Type, Scope, and Lifetime
Binding Time •Variables •Types • Scope • Execution Units: Expressions, Statements, Blocks, and Programs
90.3 Control Structures
Conditional Structures• Iterative Structures • Unconstrained Control Structures: Goto and Exceptions •Procedural Abstraction •Data Abstraction
90.4 Best Practices
Data Bindings: Variables, Types, Scope, and Lifetime •Execution Units • Control Structures • Procedural Abstraction •Data Abstraction and Separate Compilation 90.5 Research Issues and Summary
90.1 Introduction
In the 1940s, John von Neumann pioneered the design of basic computer architecture by structuring computers into two major units: a central processing unit (CPU), responsible for computations, and a data storage unit, or memory. This architecture is demand driven, based on a command and instruction-oriented computing model. The basic unit cycle of execution, typically composed of a single instruction, consists of four steps:
1. Obtain the addresses of the result and operands. 2. Obtain the operand data from the operand location(s). 3. Compute the result data from the operand data. 4. Store the result data in the result location.
Note in this sequence how separation of the execution unit from the memory unit has structured the sequence. Data must be located and piped from memory, operated on, and transferred back to memory to be available for the next operation. All operations in a von Neumann machine operate this way, in a stepwise, structured manner. The von Neumann model has been the basis of nearly every computer built since the 1940s.
In this chapter we address the fundamental principles underlying imperative programming languages and examine the way the constructs of imperative languages are represented in several languages. We devote special attention to features of more modern imperative programming languages, among them support for abstract data types and newer control constructs such as iterators and exception handling. Ex-amples in this chapter are given in a variety of imperative programming languages, including FORTRAN, Pascal, C, C++, MODULA-2, and Ada 83. In the Best Practices section we explore in more detail the languages FORTRAN IV (chosen for historical reasons), C and C++ (its imperative parts), and Ada 83.
90.2 Data Bindings: Variables, Type, Scope, and Lifetime
In this section we discuss some of the fundamental properties of imperative programming languages. In particular, we address issues related to binding time, the properties of variables,types, scope, and lifetime.
90.2.1 Binding Time
We will find it useful to classify many of the differences in programming languages based on the notion of binding time. Abindingis the association of an attribute to a name. The time at which a binding takes place is an important consideration. There are many times when a binding can occur. Some of these follow:
r Language definition: when the language is designed. An example is the binding of the constant
name true to the corresponding Boolean value.
r Language implementation: when a compiler or interpreter is written. An example is the binding of
the representation of values of various types.
r Compile time: when a program is being translated into machine language. For example, the type
of a variable in a statically typed language is bound at compile time. In statically typed languages, overloaded functions are bound at compile time.
r Load time: when the executable machine language image of the program is loaded into the memory
for execution by the execution unit. The location of global variables is bound at load time.
r Procedure or function invocation time: the time a program is being executed. Actual parameters
are bound to formal parameters and local variables are bound to locations at procedure invocation time.
r Run time: any time during the execution of a program. A new value can be bound to a variable at
run time. In dynamically typed languages, overloaded functions are bound at run time.
As we examine fundamental issues in the definition of imperative programming languages, we will keep in mind the distinctions between languages based on differences in binding time.
90.2.2 Variables
Imperative languages support computation by executing commands whose purpose is to change the underlying state of the computer on which they are executed. Thestateof a computer encompasses the contents of memory and also includes both data which are about to be read from outside of the computer and data which have been output.
Variablesare central to the definition of imperative languages as they are objects whose values are dependent on the contents of memory. A variable is characterized by its attributes, which generally include its name, location in memory, value, type, scope, and lifetime.
the left of the assignment symbol is its location (sometimes called the l-value ofx), whereas the meaning of the occurrence on the right side is its value, that is, the value stored at the location corresponding tox (sometimes called the r-value). The location of global variables is bound at load time, whereas the location of local variables and reference parameters is typically bound at procedure entry. The value of the variable can be changed at any point during execution of the program.
90.2.3 Types
Types in programming languages are abstractions which represent sets of values and the operations and relations which are applicable to them. Types can be used to hide the representation of the primitive values of a language, allow type checking at either compile time or run time, help disambiguate overloaded operators, and allow the specification of constraints on the accuracy of computations. Types also can play an important role in compiler optimization.
Types in a programming language include both simple and composite types. The use ofsimple types such as integer, real, Boolean, and character types allows the user to abstract away from the actual com-puter representation of these values, which may differ from comcom-puter to comcom-puter. The operations on simple types may or may not be supported directly by the underlying hardware. For instance, many early microprocessors supported only real or floating-point operations in software.
Some languages (e.g., those derived from Pascal) allow the programmer to define their own simple enumeratedtypes by simply listing the values of the type. The ordering of elements in this enumeration is significant as these types typically support successor and predecessor functions as well as ordering relations. Later we will discuss mechanisms for supportingabstract data types, another way of constructing types which can be used as though they were primitive to a language.
Many languages support the creation ofsubrangetypes, which allows a programmer to define a new type as a copy of a type with a subset of its values. The new type comes equipped with the same operators as its parent type and is usually compatible with the original type.
Composite or structured data typescan be created from simple types usingtype constructors. Typical composite types include arrays, records (or structures), variant records (or unions), sets, subranges, pointer types, and, in a few languages, function or procedure types. For instance, arrays are typically constructed from two types: a subrange type which provides the set of indices of the array, and another type representing the values stored in the array. Not all languages support all these type constructors. For instance, function and procedure types are provided by MODULA-2 but are not available in Ada 83. Many languages support strings as special types of composite types, for instance, as arrays of characters, but they may also be provided as builtin types.
Most imperative languages bind types to variables statically. These bindings are usually specified in declarations, but some languages, such as FORTRAN, allow implicit declaration of variables, with the type binding determined by the name of the identifier (e.g., in FORTRAN if the name starts withIthroughN then the variable is an integer, otherwise real).
An important issue in type-checking programming languages is type equivalence. When do two terms have equivalent types? The two extremes in the definitions oftype equivalenceare structural and name equivalence:
r Structural equivalence: Two types are said to bestructurally (or domain) equivalentif they have the
same structure. That is, they are built from the same type constructors and builtin types in the same way.
r Name equivalence: Two types arename equivalentif they have the same name.
Inequivalent types may be compatible in certain situations. For instance, two types are assignment compatible if an expression of one type may be assigned to a variable of another. For instance, in Pascal a subrange of integer is assignment compatible with integer, even though the types are not equivalent.
An application of these ideas can be found in the rules for determining whether a particular actual parameter may be used in a procedure call for a particular formal parameter. In Pascal, if the formal parameter is a reference parameter then the actual parameter must be a variable of equivalent type. If the formal parameter is a value parameter then the actual parameter must be assignment compatible.
As mentioned earlier, some languages support the creation of subrange types. The new subrange type is usually assignment compatible with the original type. Because of this compatibility, the new type is called asubtypeof the parent in Ada. Another mechanism available in Ada, calledderived typing, defines a new type by constructing an exact copy of a type that already exists. However, the resulting new type is distinct and is not type equivalent or even assignment compatible with the existing type.
The type equivalence rules are the cause of one of the greatest limitations in the use of Pascal. If a formal parameter has an array type, then the actual parameter must have an equivalent type. In particular, the subscript ranges of the two arrays must be identical. Thus, it is impossible to write a procedure in Pascal which can be used to sort different-sized arrays of real numbers. (Actually, the current ANSI standard Pascal provides a special mechanism to allow exceptions to this rule.)
Ada escapes from this problem by designating some properties of types to be static, while others are dynamic. For example, in a type defined to be a subrange of integers, the underlying static type is integer while the subrange bounds are a dynamic property. Only the static properties of types are considered at compile time by the type checker, whereas restrictions due to dynamic properties are checked at run time.
Consider the following Ada declarations as an example of type bindings: type COINS is (PENNY, NICKEL, DIME, QUARTER); subtype SILVER is COINS range (NICKEL..QUARTER); type CHANGE is new COINS;
C1, C2; COINS; S: SILVER; CH: CHANGE;
COINSis an enumerated type, defined by the programmer to allow assignments such as C1 := DIME;
SILVERis a subrange ofCOINS, which includes only the valuesNICKEL,DIME, andQUARTER.CHANGE
is a derived type taken fromCOINS.
Because Ada employs name equivalence, onlyC1andC 2are equivalent, butSis assignment compatible with them. If Ada used structural equivalence, then variablesC1,C2, andCHwould be equivalent.
90.2.4 Scope
The scope of a binding is the area or section of a program in which that particular binding is effective. The method and extent ofscope rulesthat define a binding scope will, to a large degree, affect the usefulness and applicability of a language. If, for instance, the rules allow the scope of a binding to be determined by the execution path of a program, the language might be more flexible, yet the code becomes harder to understand.
with TEXT_IO; use TEXT_IO; procedure SCOPED is
package INT_IO is new INTEGER_IO (integer); use INT_IO; I,J: integer;
procedure P is begin put (J); new_line; end P;
begin J := 0; I := 10;
declare -- Block 1 J: integer;
begin
j := I; -- reference point A P;
end;
put (J); new_line; declare -- Block 2
I: Integer begin
I := 5
J := I + 1; -- reference point B P;
end;
put (J); new_line; end;
FIGURE 90.1 Scoping rules in Ada.
As an example of scope rules in Ada, consider the code in Figure 90.1. Static scope rules are determined by the program block structure, which does not change while the program runs. Therefore, the call to procedurePprints the variableJdefined in the outer, main program, no matter where it is called from. Likewise, the assignment in block 1 at reference point A changesJfrom the block and not from the main program. Dynamic scope rules, on the other hand, typically follow dynamic call paths to determine variable bindings. If Ada used dynamic scope rules, the first call toPfrom block 1 would print the value 10 corresponding to theJfrom block 1, whereas the second call toPwould print the value 3 corresponding to theJfrom the main program.
90.2.5 Execution Units: Expressions, Statements, Blocks, and Programs
Anexpressionis a program phrase which returns a value. Expressions are built up from constants and variables using operators. As described earlier, variables may represent two values, depending on context: their location and the value stored at that location. Operators may be builtin, like the arithmetic and comparison operators, or may be user-defined functions.
Reflecting the sequential order of von Neumann computation, an imperative language specifies the order in which operations are evaluated. Typically, evaluation order is determined by precedence rules. A typical precedence rule set for arithmetic expressions might be the following:
1. Subexpressions inside parentheses are evaluated first (according to the precedence rules). 2. Instances of unary negation are evaluated next.
Although procedure rules are commonly used by imperative languages, some languages use other conven-tions to avoid precedence rules. For example, PostScript uses postfix notation for expressions, while LISP uses prefix notation. APL evaluates all expressions from right to left without regard to precedence, using only parentheses to change the evaluation order.
The fundamental unit of execution in an imperative programming language is thestatement. A statement is an abstraction of machine language instructions, grouped together to form a single logical activity.
The simplest and most fundamental statement in imperative programming languages is the assignment statement. This statement, typically written in the formx := eorx = ewithxa variable (or other expression representing a location) andean expression, is usually interpreted by evaluatingeand copying its value into the location represented byx. This is known as thecopy semanticsfor assignment.
Less common are languages which use the sharing interpretation of assignment. In these languages, variables generally represent references to objects which contain the actual values. The assignmentx:=y would then be interpreted as binding the object referred to byy toxrather than its value. Since both variables refer to the same object, they share the same value. If the value of one is changed, the value of the other will also change. This is thesharing semanticsfor assignment.
Declarations and statements may be grouped together to form ablock. Procedure and function bodies are represented as blocks, whereascontrol structures(discussed subsequently) can also be understood as acting on blocks of statements (generally without declarations). The most general form of a block contains adeclarativesection, which contains the declarations that define the bindings that are effective in the block, and anexecutablesection, which contains the statements over which the binding is to hold, i.e., the scope of the declarations.
In so-called block-structured languages (including most languages descended from ALGOL 60, e.g., Pascal, Ada, and C), blocks may be nested. Within any block, therefore, there can be two kinds of bindings in force: local bindings, which are specified by the declarative sections associated with the block, and nonlocal bindings(also known asglobalbindings), which are bindings defined by declarative sections of blocks within which the specific block is nested.
Consider again the code fromFigure 90.1. The first two assignments of the main program assignJfrom the main program the value 0 andIfrom the main program the value 10. The next assignment assigns
the value 10, derived from the globalI, to the variableJfrom the first inner block. When the definition
of the second inner block is encountered, the variableIis found in the local scope, whileJis found in the outerscope, that of the main program. The value 6 will be printed forJat the end of the main program.
90.3 Control Structures
By adopting the semantics of the basic execution cycle of a von Neumann architecture, an imperative language adopts a strict sequential ordering for its statements. By default, the next statement to execute is the next physical statement in the program. Control structures in imperative languages provide ways to alter this strict sequential ordering. The most common control structures areconditional structuresand iterative structures.Unconstrained control structuresare also allowed in most languages through the use of goto statements.
90.3.1 Conditional Structures
Conditional control structures (also known asselection statement) determine whether or not a block of statements is executed based on the result of one or several tests. These structures fall into one of two classes:
90.3.1.1 If Statements
programmer may provide another block of statements which can be executed only if the test evaluates to false. The following is a simple example from Ada:
if (x = 2) then y := 3; else
y := 6; end if;
The variableyis set to either 3 or 6 depending on the value ofx.
In most languages, if statements can be nested within other control structures, including other if statements. However, nested if statements can result in awkward, deeply nested code. Thus, many languages provide a special construct (e.g.,elsifin Ada) to representelse ifconstructs without requiring further nesting. The two Ada examples given next are equivalent semantically, though the first, which useselsif, is easier to read than the second, which uses nested conditionals:
if (x = 2) then if (x = 2) then
y := 3; y := 3;
elsif (x = 3) then else
y := 15; if (x = 3) then
elsif (x = 5) then y := 15;
y :=18; else
else if (x = 5) then
y := 6; y := 18;
end if; else
y := 6; end if; end if; end if;
90.3.1.2 Case Statements
This conditional combines case-by-case expression examination with a restricted multiway conditional. This conditional may be seen to be simply a syntactic convenience, but in many cases its implementation results in a much faster determination at run time of the actual block of code to be executed. Consider the following case statement from Ada:
case y is
when 2 => y := 3; when 3 => y := 15; when 15 => y := 18; when others => y := 6; end case;
An expression (yin this case) of an ordinal type occurs after the keywordcase. Eachwhenclause contains
a guard, which is a list of one or more constants of the same type as the expression. Most languages require that there be no overlap between these guards. The expression after the keywordcaseis evaluated, and the resulting value is compared to the guards. The block of statements connected with the first matched alternative is executed. If the value does not correspond to any of the guards, the statements in theothers
C’s switch statement differs from the case previously described in that if the programmer does not explicitly exit at the end of a particular clause of the switch, program execution will continue with the code in the next clause.
90.3.2 Iterative Structures
One of the most powerful features of an imperative language is the specification ofiterationor statement repetition. Iterative structures can be classified as either definite or indefinite, depending on whether the number of iterations to be executed is known before the execution of the iterative command begins:
r Indefinite iteration: The different forms of indefinite iteration control structures differ by where
the test for termination is placed and whether the success of the test indicates the continuation or termination of the loop. For instance, in Pascal thewhile-docontrol structure places the test before the beginning of the loop body (a pretest), and a successful test determines that the execution of the loop shall continue (a continuation test). Pascal’srepeat-untilcontrol structure, on the other hand, supports a posttest, which is a termination test. That is, the test is evaluated at the end of the loop and a success results in termination of the loop.
Some languages also provide control structures which allow termination anywhere in the loop. The following example is from Ada:
loop ...
exit when test; ...
end loop
Theexit when teststatement is equivalent toif test then exit.
A few languages also provide a construct to allow the programmer to terminate the execution of the body of the loop and proceed to the next iteration (e.g., C’scontinuestatement), whereas some provide a construct to allow the user to exit from many levels of nested loop statements (e.g., Ada’s namedexitstatements).
r Definite iteration: The oldest form of iteration construct is the definite or fixed-count iteration
form, whose origins date back to FORTRAN. This type of iteration is appropriate for situations where the number of iterations called for is known in advance. A variable, called theiteration control variable(ICV), is initialized with a value and then incremented or decremented by regular intervals for each iteration of the loop. A test is performed before each loop body execution to determine if the ICV has gone over a final, boundary value. Ada provides fixed-count iteration as a for loop; an example is shown next.
for i in 1..10 loop y := y + i; z := z * i; end loop;
Here,iis initialized to 1, and incremented by 1 for each iteration of the loop, until it exceeds 10.
Note that this type of loop is a pretest iterative structure and is essentially syntactic sugar for an equivalentwhileloop.
Some modern programming languages have introduced a more general form of for loop called an iteratorconstruct. Iterators allow the programmer to control the scheme for providing the iteration control variable with successive values. The following example is from CLU [Liskov et al. 1977]. We first define the iterator:
string_chars = iter (s : string) yields (char); index: Int := 1;
limit: Int := string$size (s); while index <= limit do
yield (string$fetch(s, index)); index := index + 1;
end;
end string_chars;
which can be used in aforloop as follows:
for c: char in string_chars(s) do LoopBody end;
When the for loop controlled by an iterator is encountered, control is passed to the iterator, which runs until ayieldstatement is executed. The value associated with theyieldstatement is used as the initial
value of the iterator control variablec, and the body of the loop is executed. Control is then passed back
to the iterator, which resumes execution with the statement following theyield. Control is passed to the loop body each time a yield statement is executed and back to the iterator each time the loop body finishes execution. Thus, iterators behave as a restricted form of coroutine, passing control back and forth between the two blocks of code. The loop is terminated when the iterator runs to completion. In the preceding examples this will occur whenindex > limit.
90.3.3 Unconstrained Control Structures: Goto and Exceptions
Unconstrained control structures, generally known as goto constructs, cause control to be passed to the statement labeled by theidentifieror line number given in the goto statement. Dijkstra [1968] first ques-tioned the use of goto statements in his famous letter, “Goto statement considered harmful,” to the editor of theCommunications of ACM. The controversy over the goto mostly centers on readability of code and handling of the arbitrary transfer of control into and out of otherwise structured sections of program code.
For example, if a goto statement passes control into the middle of a loop block, how is the loop to be initialized, especially if it is a fixed-count loop? Even worse, what happens when a goto statement causes control to enter or exit in the middle of a procedure or function? The problems with readability arise because a program with many goto statements can be very hard to understand if the dynamic (run time) flow of control of the program differs significantly from the static (textual) layout of the program. Programs with undisciplined use of gotos have earned the name ofspaghetti codefor their similarity in structure to a plate of spaghetti.
Although some argue for the continued importance of goto statements, most languages either greatly restrict their use (e.g., do not allow gotos into other blocks) or eliminate them altogether. In order to handle situations where gotos might be called for, other, more restrictive language constructs have been introduced to make the resulting code more easily readable. These include thecontinueandexit
statements (particularly labeledexitstatements) referred to earlier.
Another construct which has been introduced in some languages in order to replace some uses of the goto statement is theexception. An exception is a condition or event that requires immediate action on the part of the program. An exception israisedorsignaledimplicitly by an event such as arithmetic overflow or an index out of range error, or it can be explicitly raised by the programmer.
appropriate handler generally starts with the routine which is executing when the exception is raised. If no appropriate handler is found there, the search continues with the routine which called the one which contained the exception. The search continues through the chain of routine calls until an appropriate handler is found, or the end of call chain is passed without finding a handler.
If no handler is found the program terminates, but if a handler is found the code associated with the handler is executed. Different languages support different models for resuming execution of the program. The termination model of exception handling results in termination of the routine containing the handler, with execution resuming with the caller of that routine. The continuation model typically resumes execution at the point in the routine containing the handler which occurs immediately after the statement whose execution caused the exception.
The following is an example of the use of exceptions in Ada (which uses the termination model): procedure pop(s: stack) is
begin
if empty(s) then raise emptyStack else ...
end;
procedure balance (parens: string) return boolean is pStack: stack
begin ...
if ... then pop(s) ... exception
when emptyStack => return false end
Many variations on exceptions are found in existing languages. However, the main characteristics of exception mechanisms are the same. When an exception is raised, execution of a statement is abandoned and control is passed to the nearest handler. (Here “nearest” refers to the dynamic execution path of the program, not the static structure.) After the code associated with the handler is executed, normal execution of the program resumes.
The use of exceptions has been criticized by some as introducing the same problems as goto statements. However, it appears that disciplined use of exceptions for truly exceptional conditions (e.g., error handling) can result in much clearer code than other ways of handling these problems.
We complete our discussion of control structures by noting that, although many control structures exist, only a very few are actually necessary. At the one extreme, simple conditionals and a goto statement are sufficient to replace any control structure. On the other hand, it has been shown [Boehm and Jacopini 1966] that a two-way conditional and a while loop are sufficient to replace any control structure. This result has led some to point out that a language has no need for a goto statement; indeed, there are languages that do not have one.
90.3.4 Procedural Abstraction
Support for abstraction is very useful in programming languages, allowing the programmer to hide details and definitions of objects while focusing on functionality and ease of use.Procedural abstraction[Liskov and Guttag 1986] involves separating out the details of an execution unit into a procedure and referencing this abstraction in a program statement or expression. The result is a program that is easier to understand, write, and maintain.
one that is simpler. In practice, it typically replaces a block of statements with a single statement or expression.
Thedefinitionof a procedure binds the abstraction to a name and to an executable block of statements called thebody. These bindings are compile-time, declarative bindings. In Ada, such a binding is made by specifying code such as the following:
procedure area (height, width: real; result: out real) is begin
result := height * width; end;
Theinvocationof a procedure creates an activation of that procedure at run time. Theactivation recordfor a procedure contains data bound to a particular invocation of a procedure. It includes slots for parameters, local variables, other information necessary to access nonlocal variables, and data to enable the return of control to the caller. In languages supporting recursive procedures, more than one activation record can exist at the same time for a given procedure. In those languages, the lifetime of the activation record is the duration of the procedure activation.
Although scoping rules provide access to nonlocal variables, it is generally preferable to access nonlocal information viaparameterpassing. Parameter-passing mechanisms can be classified by the direction in which the information flows:in parameters, where the caller passes data to the procedure, but the procedure does not pass data back;out parameters, where the procedure returns data values to the caller, but no data are passed in; andin out parameters, where data flow in both directions.
Formal parametersare specified in the declaration of a procedure. Theactual parametersto be used in the procedure activation are specified in the procedural invocation. The procedure passing mechanism creates an association between corresponding formal and actual parameters. The precise information flow which occurs during procedure invocation depends on the parameter passing mechanism.
The association or mapping of formal to actual parameters can be done in one of three ways. The most common method ispositional parameter association, where the actual parameters in the invocation are matched, one by one in a left-to-right fashion, to the formal parameters in the procedural definition. Named parameter associationalso can be used, where a name accompanies each actual parameter and determines to which formal parameter it is associated. Using this method, any ordering can be used to specify parameter values. Finally,default parameter associationcan be used, where some actual parameter values are given and some are not. In this case, the unmatched formal parameters are simply given a default value, which is generally specified in the formal parameter declaration.
Note that in a procedural invocation, the actual parameter for an in parameter may be any expression of the appropriate type, since data do not flow back, but the actual parameter for either an out or an in out parameter must be a variable, because the data that are returned from a procedural invocation must have somewhere to go.
Parameter passing is usually implemented as being one of copy, reference, and name. There are two copy parameter passing mechanisms. The first, labeledcall-by-value, copies a value from the actual to the formal parameter before the execution of the procedure’s code. This is appropriate for in parameters. A second mode, calledcall-by-result, copies a value from the formal parameter to the actual parameter after the termination of the procedure. This is appropriate for out parameters. It is also possible to combine these two mechanisms, obtainingcall-by-value-result, providing a mechanism which is appropriate for in out parameters.
Thecall-by-referencepasses the address of the actual parameter in place of its value. In this way, the transfer of values is not by copying but occurs by virtue of the formal parameter and the actual parameter referencing the same location in memory. Call-by-reference makes the sharing of values between the formal and actual a two-way, immediate transfer, because the formal parameter becomes an alias for the actual parameter.
generally more difficult for programmers to understand. In call-by-name, the actual parameter is re-evaluated every time the formal parameter is referenced. If any of the constituents of the actual parameter expression has changed in value since the last reference to the formal parameter, a different value may be returned at successive accesses of the formal parameter. This mechanism also allows information to flow back to the main program with an assignment to a formal parameter. Although call-by-name is no longer used in most imperative languages, a variant is used in functional languages which employ lazy evaluation (seeChapter 92).
Several issues crop up when we consider parameters and their use. The first is a problem calledaliasing, where the same memory location is referenced with two or more names. Consider the following Ada code:
procedure MAIN is a: integer;
procedure p(x, y: in out integer) is begin
a := 2; x := y + a; end;
begin a := 10; p(a,a); ... end;
During the call ofp(a,a)the actual parameterais bound to both of the formal parametersxandy. Becausexandyare in out parameters, the value forawill change after the procedure returns. It is not clear, however, which valueawill have after the procedure call. If the parameter passing mechanism is call-by-value-result then the semantics of this program depend on the order in which values are copied back to the caller. If they are copied into the parameters from left to right, the value of awill be 10
after the call. The results with call-by-reference will be unambiguous (though perhaps surprising to the programmer), with the value ofabeing 4 after the call. In Ada, a parameter specified to be passed as in out may be passed using either call by value-result or call by reference. The preceding code provides an example where, because of aliasing, these parameter passing mechanisms give different answers. Ada terms such programs to be erroneous and considers them not to be legal, even though the compiler may not be able to detect such programs.
Most imperative programming languages support the use of procedures as parameters (Ada is one of the few exceptions). In this case the parameter declaration must include a specification of the number and types of parameters of the procedure parameter. MODULA-2, for example, supports procedure types which may be used to specify procedural parameters. There are few implementation problems in supporting procedure parameters, though the implementation must ensure that nonlocal variables are accessed properly in the procedure passed as a parameter.
There are two kinds of procedural abstractions. One kind, usually known simply as aprocedure, is an abstraction of a program statement. Its invocation is like a statement, and control passes to the next statement after the invocation. The other type is called avalue returning procedureorfunction. Functions are abstractions for an operand in an expression. They return a value when invoked, and, upon return, evaluation of the expression containing the call continues.
To avoid confusion, most languages allow a name to be bound to only one procedural abstraction within a particular scope. Some languages, however, permit theoverloadingof names. Overloading permits several procedures to have the same name as long as they can be distinguished in some manner. Distinguishing characteristics may include the number and types of parameters or the data type of the return value for a function. In some circumstances, overloading can increase program readability, whereas in others it can make it difficult to understand which operation is actually being invoked.
Program mechanisms to support concurrent execution of program units are discussed inChapter 98. However, we mention brieflycoroutines [Marlin 1980], which can be used to support pseudoparallel execution on a single processor. The normal behavior for procedural invocation is to create the procedural instance and its activation record (runtime environment) upon the call and to destroy the instance and the activation record when the procedure returns. With coroutines, procedural instances are first created and then invoked. Return from a coroutine to the calling unit only suspends its execution; it does not destroy the instance. A resume command from the caller results in the coroutine resuming execution at the statement after the last return.
Coroutines provide an environment much like that of parallel programming; each coroutine unit can be viewed as a process running on a single processor machine, with control passing between processes. Despite their interesting nature (and clear advantages in writing operating systems), most programming languages do not support coroutines. MODULA-2 is an example of a language which supports coroutines. As mentioned earlier, iterators can be seen as a restricted case of coroutines.
90.3.5 Data Abstraction
Earlier in this chapter, we introduced the idea of data types as specifying a set of values and operations on them. Here we extend that notion of values and operations to abstract data types and their definitional structures in imperative languages.
The primitive data types of a language are specified by both a set of values and a collection of operations which may be applied to them. Clearly, the set of integers would be useless without the simultaneous provision of operation on those integers. It is characteristic of primitive data types that the programmer is not allowed access to their representations.
Many modern programming languages provide a mechanism for a programmer to specify a new type which behaves as though it were a primitive type. An abstract data type (ADT) is a collection of data objects and operations on those data objects whose representation is hidden in such a way that the new data objects may be manipulated only using the operations provided in the ADT. ADTs abstract away the implementation of a complex data structure in much the same way primitive data types abstract away the details of the underlying hardware implementation.
Thespecificationof an ADT presents interface details relevant to the users of the ADT, whereas the implementation contains the remaining implementation details that should not be exported to users of the ADT.Encapsulationinvolves the bundling that together of all definitions in the specification of the ADT in one place. Because the specification does not depend on any implementation details, the implementation of the ADT may be included in the same program unit with the specification or it may be contained in a separately compiled unit. This encapsulation of the ADT typically supports information hiding so that the user of the ADT (1) need not know the hidden information in order to use the ADT, and (2) is forbidden from using the hidden information so that the implementation can be changed without impact on correctness to users of the ADT (at least if the specifications of the operations are still satisfied in the new implementation). Of course, one would expect a change in implementation to affect the efficiency of programs using the ADT. A further advantage of information hiding is that, by forbidding direct access to the implementation, it is also possible to protect the integrity of the data structure.
operations init, push, pop, top, and empty. A MODULA-2 specification for a stack of integers resembles the following:
DEFINITION MODULE StackADT; TYPE stack;
PROCEDURE init (VAR s: stack);
PROCEDURE push (VAR s: stack; elt: INTEGER); PROCEDURE pop (VAR s: stack);
PROCEDURE top (s: stack): INTEGER; PROCEDURE empty (s: stack): BOOLEAN END StackADT.
Note the declaration includes the type name and proceduralheadersonly. The typestackincluded in the preceding specification is called anopaquetype in MODULA-2, because users cannot determine the actual implementation of the type from the specification. This ADT specification uses information hiding to get rid of irrelevant detail. Now, this specification can be placed in a separate file and made available to programmers. By including the following declaration:
FROM StackADT IMPORT stack, init, push, pop, top, empty;
at the beginning of a module, a programmer could use each of these names as though the complete specification was included in the module. Thus, the user can write
var s1, s2: Stack; begin
push(s1, 15); push(s2, 20);
if not empty(s1) then pop(s1) ...
is such a module.
In MODULA-2 the complete definitions of the typestackand its associated operations are provided
in an implementation module, which typically is stored in a separate file. IMPLEMENTATION MODULE StackADT;
TYPE stack = POINTER TO stackRecord; stackRecord = RECORD
top: 0..100;
values: ARRAY[1..100] of INTEGER; END;
PROCEDURE init(VAR s: stack); BEGIN
ALLOCATE(s, SIZE(stackRecord)); S∧.top :=0
END
PROCEDURE push (VAR s: stack; elt: INTEGER); BEGIN
S∧.top := S∧.top + 1;
S∧.value[S∧.top] := elt
END;
PROCEDURE pop(VAR s: stack); ... PROCEDURE top(s: stack): INTEGER; ... PROCEDURE empty(s: stack) BOOLEAN; ... END StackADT.
The specification module must be compiled before any module that imports the ADT and before its implementation module, but importing modules and the implementation module of the ADT can be compiled in any order. As previously suggested, the implementation is irrelevant to writing and compiling a program using the ADT, though, of course, the implementation must be compiled and present when the final program is linked and loaded in preparation for execution.
There is one important implementation issue which arises with the use the language mechanisms supporting ADTs. When compiling a module which includes variables of an opaque type imported from an ADT (e.g., stack), the compiler must determine how much space to reserve for these variables. Either the language must provide a linguistic mechanism to provide the importing module with enough information to compute the size required for values of each type or there must be a default size which is appropriate for every type defined in an ADT. CLU and MODULA-2 use the latter strategy. Types declared as CLU clusters are represented implicitly as pointers, whereas in MODULA-2 opaque types must be represented explicitly using pointer types as in theStack ADTexample just given. In either case, the
compiler need reserve for a variable of these types only an amount of space sufficient to hold a pointer. The memory needed to hold the actual data pointed to is allocated from the heap at run time. As discussed later, Ada uses a language mechanism to provide size information for each type to importing units.
The definition of ADTs can beparameterized in several languages, including CLU, Ada, and C++. Consider the definition of thestackADT. Although the preceding example was specifically given for an integer data type, the implementations of the data type and its operations do not depend essentially on the fact that the stack holds integers. It would be more desirable to provide a parameterized definition of
stackADT which can be instantiated to create a stack of any typeT.
Allocating space for these parameterized data types raises the same problems as previously discussed for regular ADTs. C++and Ada resolve these difficulties by requiring parameterized ADTs to be in-stantiated at compile time, whereas CLU again resolves the difficulty by implementing types as implicit references.
90.4 Best Practices
In this section, we will examine three quite different imperative languages to evaluate how the features of imperative languages have been implemented in each. The example languages are FORTRAN (FORTRAN IV for illustrative purposes), Ada 83, and C++. We chose FORTRAN to give a historical perspective on early imperative languages. Ada 83 is chosen as one of the most important modern imperative languages which supports ADTs. C++might be considered a controversial choice for the third example language, as it is a hybrid language that supports both ADT-style and object-oriented features. Nevertheless, the more modern feature contained in the C++language design makes it a better choice than its predecessor, C (though many of the points that will be made about C++also apply to C). In this discussion we ignore most of the object-oriented features of C++, as they are covered in more detail inChapter 96.
90.4.1 Data Bindings: Variables, Types, Scope, and Lifetime
Like most imperative languages, all three of our languages use static binding and static scope rules. FORTRAN is unique, however, because it supports theimplicit declaration of variables. An identifier whose name begins with any of the lettersIthroughLis implicitly declared to be of type integer, whereas any other identifier is implicitly declared to be of type real. These implicit declarations can be overridden by explicit declaration. Therefore, in the fragment:
INTEGER A I = 0 A = I
Aand Iare integer variables, while Band Care of type real. Most other statically typed languages (including Ada and C++) requireexplicit declarationof each identifier before use. Aside from provid-ing better documentation, these declarations lessen the danger of errors due to misspellprovid-ings of variable names.
FORTRAN has a relatively rich collection of numerical types, including integer,double precision(real), andcomplex.Logical(Boolean) is another builtin type, but FORTRAN IV provided no direct support for characters. However, characters could be stored in integer variables. (Thecharacterdata type was added by FORTRAN 77). FORTRAN IV supported arrays of up to three dimensions but did not support records. Strings were represented as arrays of integers. FORTRAN IV did not provide any facilities to define new named types.
Later languages provided much richer facilities for defining data types. Pascal, C, MODULA-2, Ada, and C++all provided a full range of primitive types as well as constructors for arrays, records (structures in C and C++), variant records (unions in C and C++), and pointers (access types in Ada). All provided facilities for naming new types and for constructing types hierarchically (constructing nested types). Variant records or unions opened up holes in the static type systems of most of these languages, but Ada (and CLU before it) provided restrictions on the access to variants and builtin run time checks in order to prevent type insecurities.
The scope rules for each language, though static in nature, differ significantly. In FORTRAN, the rules are the simplest. The unit of scope for an identifier is either the main program or the procedural unit in which it is declared. Declarations of procedures (subroutines) and functions are straightforward as well in FORTRAN, with no nesting and all parameters passed by reference. Whereas FORTRAN does not support access to nonlocal variables through scoping rules, it allows the programmer to explicitly declare that certain variables are to be more globally available. When two subprograms need to share certain variables, they are listed in acommonstatement which is included in each subprogram. If different combinations of subprograms need to share different collections of variables, several distinct common blocks can be set up, with each subprogram specifying which blocks it wishes access to.
Ada (like Pascal) supportsnested declarationsof procedures and functions. As a result, block structure becomes extremely important to scope determination.
Whereas C and C++do not provide for nested procedures and functions, they do share with Ada the ability to include declaration statements in local blocks of code. In C++, blocks are syntactically enclosed in bracket{. . .}symbols, and any declarations that occur between the symbols hold for the duration of the block. Consider the following code:
for (i = 0; i<20; i++) { int i = 1, j;
j = 0;
while (i < 25) { j += i*2; i ++; }
}
One might think that when the inner loop is done, the outer loop also will be done, becauseihas the
value 26. But since the inner block of statements redeclaredi, the scope rules state that the new, inneri
was manipulated, leaving the outeriuntouched and free to correctly manipulate the for loop.
In FORTRAN IV the lifetime of all variables is the lifetime of the program. As a result, all memory in a program could be statically allocated, including activation records. Because each subprogram has only one activation record, FORTRAN could not support recursion.
pointers to stack-allocated memory). The lifetime of these variables is generally from the time that the programmer executes a creation instruction until a corresponding destruction statement is executed.
90.4.2 Execution Units
FORTRAN and Ada make a strong distinction between expressions and statements, with expressions sim-ply returning a value, but with statements forming the basic unit for program execution. In C and C++, however, these two units of execution are merged, with statements treated as expressions. The statement
x = 5assigns the value 5 to the variablex. But, in C++, the=sign is also an operator, and this assignment statement is actually an expression that returns the value being assigned. Thus, the statementy = x = 5
assigns the value 5 toboth xandy, because the value 5 is assigned toxand the expressionx=5 returns 5, which is assigned toy. Although interesting, it can also be very confusing. Because many expressions will have side effects, the order of evaluation will affect the value returned from an expression. Consider the code
if ( (y = ++x) == (x + 6)) { ... }
This code actually has two statements embedded in it; first,++xincrementsx, then this value is assigned toy, then the value assigned is tested against the value ofx + 6. If the compiler decides to change the order in which the subexpressions are evaluated (a not unheard of occurrence in C++compilers), it may change whether the guard on the if statement is true or false.
Allowing statements to be part of expressions also means that typographical errors are more likely to give rise to syntactically correct (but logically incorrect) statements. For instance, if one of the = signs in
if (x == 6) { ... }
is omitted, then it will assign of value 6 toxand the conditional will always evaluate to true as all non-0 integers in C and C++are treated as representing true.
90.4.3 Control Structures
Because FORTRAN was one of the earliest high-level languages, it is not surprising that its control structures are much closer to the underlying machine language instructions. Aside from the do loop (which was similar to the for loop in Pascal and Ada), most other control structures were based on the use of goto statements. Thus, the if statement of FORTRAN IV evaluated an integer expression and, depending on whether the result was negative, zero, or positive, resulted in a jump to one of three statement labels included with the statement. Aside from the usual goto statement, FORTRAN IV also included assigned and computed gotos, which provided some of the flexibility of case statements. FORTRAN 77 and the more recent FORTRAN 90 provide more modern control structures such as the if and while statements of other languages.
The control constructs in Ada are similar to those of Pascal, including if, case, while, and for loops, as well as indefinite loops, which are terminated with exit statements. Several of these were described earlier in the general discussion of control structures.
C and C++include if statements and a switch construct which is similar to the case statement. The while loop is similar to that in Pascal and Ada, but for the loops in C and C++are more general than those in most other languages. For loops have the form:
for (E1; E2; E3) S;
whereE1is initialization code,E2is a test for termination,E3contains code to update variables for the next iteration of the loop, andSrepresents the code to be executed each time through the loop. The test for termination is executed before the update code. Thus, a statement of the form
will result inSbeing executed once for each value ofifrom 1 to 10. (The expressioni+ +is an expression which increments the value ofi.) However, much more flexible statements are also possible
for (i = 1; not done and i < 1024; i = 2 * i) S;
This statement repeatedly executesSwhileiranges through the powers of 2 from 1 to 1024. If done is ever true, it will terminate early.
90.4.4 Procedural Abstraction
Each of Ada, FORTRAN, C, and C++provides procedural abstraction. Ada and FORTRAN distinguish between functions and procedures, whereas C and C++do not since procedures are just functions which return an element of type void. FORTRAN IV also supported single-line statement functions, which could be defined local to a program or subprogram. As noted earlier, Ada, C, and C++all support recursive functions and procedures, whereas FORTRAN does not.
The languages differ in minor ways in how they return values from functions. FORTRAN, like Pascal, treats the name of the function as a pseudovariable which can be assigned to. An explicit return statement returns control to the calling program unit. When the function returns, the last value stored in the function name is returned as the value of the function. Ada, C, and C++use return statements of the form return exp to return control to the calling program unit. The value of the expression associated with the return statement is the value returned from the function.
Most programming languages provide system-defined overloaded functions, such as arithmetic oper-ators (+,−,∗, etc.) and comparison functions (e.g.,=,<, etc.). Ada and C++are relatively unusual, though, in allowing user-defined overloading. In both, the compiler must be able to disambiguate at com-pile time whichever of the versions of the overloaded operator are called for at each of its occurrences. C++determines which version is called for by looking at the number and types of the actual parameters. Ada goes further and can also use the return type to determine which version works in the particular context in which it is found. Thus, in Ada one may overload the+operator to take two integer parameters and return a user-defined rational type, even though there already exists a built-in version of+which takes two integer parameters and returns an integer. If+occurs in a context in which only an integer result would make sense, the builtin version would be selected. If+occurs in a context in which only a rational value would make sense the user-defined version would be selected. If the system cannot tell which should be used, then an error will occur at compile time.
Unlike FORTRAN, Pascal, and C, both Ada and C++provide language support for exceptions. Ada and C++both use the termination model for program resumption after handling the exception.
90.4.5 Data Abstraction and Separate Compilation
FORTRAN provides support for separate compilation of subroutines and functions but provides no type checking across compilation unit boundaries. Thus, the main program may call a functionFwith two real parameters, but the definition of F in a separately compiled unit may have only one formal parameter, and it might be an integer. Because FORTRAN does not support the definition of new named types, it provides no support for abstract data types.
C and C++provide slightly better support for separate compilation by allowing the programmer to put external function and procedure declarations in a header file, which may be included into compilation units which use them. The header files are treated as though they were textually part of the compilation unit into which they are included. C provides no support for abstract data types, though C++does provide strong support through its class facilities. C++classes give the programmer control over which aspects of a data type the user will be allowed to see and use. Because C++is described in some depth inChapter 96, we omit a detailed description here.
implementation sections. The interface of a unit may be explicitly imported into another compilation unit with ausesstatement. This provides for separate, but not independent, compilation without requiring the programmer to create individual header files by hand. These units generally do not provide support for information hiding.
Ada provides both separate compilation and strong support for abstract data types. Like MODULA-2’s modules described earlier, Ada packages come in two separately compiled units, the specification and body. Only items listed in the nonprivate part of the package specification are accessible at compile time to units which import the package. The following is an Ada package specification for stacks:
package StackADT is
type stack is private;
procedure push(s: in out stack; elt: in integer); procedure pop(s: in out stack);
procedure top(s: in stack) return integer; procedure empty(s: in stack) return boolean; private
type stack is record top: integer := 0;
values: array (1..100) of integer end record
end StackADT;
The private section of a package specification is necessary to provide a description of private types. This is necessary so that importing programs know how much space to provide for a variable of that type. This is not as clean as the MODULA-2 solution, since any change of representation of the type will require the recompilation of the specification and hence of any program which imports the package. For this particular representation of stack, no initialization routine is necessary because top is initialized to 0 in the declaration of the type.
If the implementation of the private variable is a pointer, then only partial type information need be provided. That is, if we replace the private part of the preceding example by
private
type stackRecord;
type stack is access StackRecord; end StackADT;
then this would provide sufficient information for importing programs to determine the memory needs for a variable of this type (i.e., the amount of space necessary to hold a pointer).
An implementation of the original package specification is given next: package body StackADT is
procedure push (s: in out stack; elt: in integer) is begin
s.top := s.top + 1; s.value[s.top] := elt end push;
procedure pop(s: in out stack); ... function top(s: in stack): integer; ... function empty(s: in stack) boolean; ... end StackADT;
e.g.,StackADT.stackandStackADT.push. The package name prefix can be omitted if use Stack-ADTis also included at the beginning of the unit.
Both Ada and C++provide mechanisms for supporting parameterized packages (or classes in the case of C++). The C++template mechanism is quite primitive, with template instantiations being treated as being similar to compile-time macroexpansions. The template is never type checked, only its instantiations. Ada also requires its generic packages to be instantiated at compile time, but the generics are type checked before, rather than after, instantiation. Thus, a generic package can be compiled and later used in another until which does not have access to the implementation.
The following is an example of the header of a genericBinarySearchTreepackage: generic
type Element is private;
with function LessThan (x, y: Element) return boolean; package BinarySearchTree is
type BSTree is private; ...
end BinarySearchTree;
This can be used in another unit by instantiating it with a type and appropriate function, for example, package PeopleDict is new BinarySearchTree(People, PeopleComp)
wherePeopleCompis a function taking pairs of typePeopleand returning a Boolean.PeopleDict
can then be used like any other package. The ability to require generic package instantiations to include necessary functions and values as well as types ensures that they will not be instantiated with types which do not support the appropriate operations.
90.5 Research Issues and Summary
Research issues in imperative languages in recent years have tended to focus on many of the new con-structs presented in this chapter. These include support for exceptions, iterators, abstract data types, and parameterized or generic types. It is fair to say that most current research in programming languages is devoted to implementation and environment issues or to other programming paradigms. There are not many new concepts currently being introduced into imperative programming languages. Many languages which formerly were purely imperative have recently been extended to include object-oriented concepts (e.g., Object Pascal, Objective C, C++, Ada 95). Another series of extensions has provided features for concurrent and distributed programming. Discussions of these two different kinds of extensions can be found inChapters 96and98of this Handbook.
From our earlier discussion, it is clear that support for abstraction plays an important role in imperative language design and use. Variables abstract away details of memory usage; data types (and in particular abstract data types) abstract from the representation of values to provide support for operations that are independent from the actual implementation; execution units abstract away details of machine instruction execution and expression computation while providing clean interfaces for sharing information between caller and callee.
are moving forward to a time when most programmers will see such secure languages as assisting them in their goal of creating correct and efficient software, rather than getting in the way. (SeeChapter 104for a further discussion of type systems.)
We have surveyed the class of programming languages modeled after the sequential organization of the von Neumann architecture. The imperative programming language paradigm is characterized by its sequential, stepwise statement execution.
As discussed in theSection 90.4the imperative programming constructs are implemented in a variety of ways in different languages. There are many languages to choose from; choosing the right language for the applications at hand is an important first step to software implementation.
It could be argued that the object-oriented paradigm is simply a minor variation on the imperative paradigm in which remote procedure and function calls replace the more familiar imperative calls. However, the object-oriented paradigm requires an entirely different way of thinking about the organization of a program, with the traditional conception of a program as a series of operations being applied to values replaced in the object-oriented view by an organization of more distributed responsibility. In this view, values (typically referred to as objects) are responsible for knowing how to perform their own operations, and the programmer is responsible for bringing together a group of objects with appropriate capabilities and organizing a program which relies on these distributed capabilities to accomplish a task. Subtyping and inheritance provide important organizing tools and promote code reuse in ways unavailable in traditional imperative languages.
Most programmers today are initially taught to program in imperative languages. Thus, these languages reflect the way that most programmers currently think about algorithm construction and program ex-ecution. Whether this will continue in the face of the challenge of the object-oriented paradigm will be interesting to see.
Defining Terms
Abstract data type: A collection of data type and value definitions and operations on those definitions which behaves as a primitive data type. The specifications of these types, values, and operations are generally collected in one place, with the implementations hidden from the user.
Binding: A connection between an abstraction used in the language and a data object as it exists in the computer hardware. The usage, establishment, and number of these bindings characterize the various imperative languages and affect their ease of use and performance.
Control structures: Structures or statements that alter the strict sequential ordering in an imperative pro-gram, presenting alternatives to sequential control. Control structures can be conditional, iterative, or unconstrained.
Derived type: A new data type constructed by copying a type that already exists. The resulting new type is distinct and not identified as being copied from the existing type, though operations on the old type are automatically inherited in the new type.
Identifier: The name bound to an abstraction.
Parameters: Data objects passed between the caller and the called procedural abstraction.
Procedural abstraction: Separating out the details of an execution unit in such a way that it may be invoked in a program statement or expression.
Scope rules: Rules in a language that define the area or section of a program in which a particular binding is effective.
Subtype: A new data type defined as a copy of another defined type, typically with a restricted subset of its values. It may generally be used in the same contexts as its parent type.
Type: A collection of values with an associated collection of primitive operations on those values. Type equivalence: Rules that govern when variables or values from two different data types may be used
together.
References
Boehm, C. and Jacopini, G. 1966. Flow diagrams, Turing machines, and languages with only two formation rules.Commun. ACM9(5):366–371.
Dijkstra, E. W. 1968. Goto statement considered harmful.Commun. ACM11(3):147–148.
Liskov, B. H. and Guttag, J. V. 1986.Abstraction and Specification in Program Development. MIT Press, Cambridge, MA.
Liskov, B., Snyder, A., Atkinson, R., and Schaffert, C. 1977. Abstraction mechanisms in CLU.IEEE Trans. Software Eng. SE-5(6):546–558.
Marlin, C. D. 1980.Coroutines. Lecture notes in computer science 95. Springer–Verlag, New York.
Further Information
A good examination of imperative languages, as well as other paradigms, can be found in the following texts:
Dershem, H. L. and Jipping, M. J. 1995.Programming Languages: Structures and Models, 2nd ed. PWS, Boston, MA.
Louden, K. C. 2003.Programming Languages: Principles and Practice, 2nd ed. PWS-Kent, Boston, MA. Pratt, T. W. and Zelkowitz, M. V. 2001.Programming Languages: Design and Implementation, 4th ed.
Prentice Hall, Englewood Cliffs, NJ.
Sebesta, R. 2003.Concepts of Programming Languages, 2nd ed. Benjamin-Cummings.