BAB 2
LANDASAN TEORI
2.1 Kata baku dan tidak baku Bahasa Indonesia
Kata merupakan bentuk yang sangat kompleks yang tersusun atas beberapa unsur. Kata dalam bahasa Indonesia terdiri atas satu suku kata atau lebih. Kata merupakan bagian yang sangat penting dalam kehidupan berbahasa. Bidang atau kajian mengenai kata telah banyak diselidiki oleh para ahli bahasa. Penyelidikan tersebut menghasilkan berbagai teori-teori antara yang satu dengan yang lain berbeda-beda. Perbedaan ini terjadi karena adanya perbedaan sudut pandang antara ahli bahasa yang satu dengan yang lainnya. Adanya perbedaan konsep antara ahli yang satu dengan yang lainnya tentu akan membingungkan dalam kegiatan pembelajaran. Untuk mengurangi kebingungan tersebut, dikelompokanlah jenis kata yaitu kata baku dan kata tidak baku. Kata baku dan tidak baku sering dijadikan sebagai pembahasan dalam mata pelajaran bahasa Indonesia. Kata baku dan tidak baku dalam bahasa Indonesia berhubungan dengan penyerapan kosakata bahasa asing dan berhubungan juga dengan kaidah penulisan yang benar.
Banyak anak-anak yang belum mengetahui mana yang menjadi kata baku dan mana yang menjadi kata tidak baku dari sebuah kata. Hal ini dikarenakan penggunaan kata baku tidak begitu sering diterapkan kepada anak dalam bentuk penulisan. Selain pada anak-anak, penggunaan kata baku juga sering salah penggunaannya oleh orang yang sudah dewasa, akan tetapi kesalahan tersebut sudah lebih minim daripada kesalahan yang ditemukan pada anak yang berusia 9 sampai 15 tahun.
2.2 Speech Recognition
Speech Recognition pertama kali muncul di tahun 1952 dan terdiri dari device untuk pengenalan satu digit yang diucapkan. Kemudian pada tahun 1964, muncul IBM Shoebox. Salah satu teknologi yang cukup terkenal di Amerika dalam bidang kesehatan adalah Medical Transcriptionist (MT) merupakan aplikasi komersial yang menggunakan speech recognition. Sekarang banyak aplikasi yang dikembangkan menggunakan speech recognition, antara lain di bidang kesehatan terdapat MT, di bidang militer terdapat High-performance fighter aircraft, Training air traffic controllers, sampai pada alat yang membantu orang-orang yang memiliki kesulitan dalam menggunakan tangan, maka diciptakannya komputer yang dapat dioperasikan menggunakan deteksi pengucapan user (Sunny, A.S. 2009). Speech recognition merupakan teknik dimana perangkat akan mengenali masukan berupa suara, setelah itu perangkat melakukan respon yang sesuai dengan masukan suara tersebut (Syarif, A., Daryanto, T. & Arifin, M.J. 2011). Output yang dihasilkan perangkat dapat berupa output penulisan teks maupun output runnning program.
Untuk membangun sistem pengenalan suara ini, dibutuhkan model akustik, model bahasa, dan kamus. Setelah itu maka akan dilakukan dua proses lanjutan yaitu tahap pembelajaran dan tahap pengujian.
2.2.1 Model akustik , model bahasa dan kamus a. Model Akustik
Pada tahap pertama pemrosesan sinyal suara input adalah dengan melakukan ekstraksi kepada sinyal suara tersebut. Setelah itu dilanjutkan dengan pembangunan model yang terdiri atas Hidden state (tidak dapat diamati /Hidden) dan feature vector (dapat diamati/observable). Pembangunan model berarti pembangunan data probabilitas transisi antar Hidden state serta data probabilitas emisi (emission) yaitu pembangkitan feature vector oleh Hidden state. Model akustik dapat dinyatakan dalam bentuk tied-state N-phone atau monophone. Jika nilai N adalah dua, model tersebut berbentuk tied-state biphone.
b. Model Bahasa
Model bahasa digunakan dalam speech recognition untuk membantu menentukan probabilitas dari urutan hipotesis kata. Selain itu, probabilitas model bahasa dan model akustik akan membuat system membatasi ruang pencarian selama pengenalan ke arah hanya urutan kata yang memiliki kemungkinan yang besar untuk benar. Jadi, hal ini akan mengurangi ruang pencarian kata sehingga proses pencarian lebih cepat dan tepat. Model bahasa dapat dibangun dengan dua pendekatan, yaitu model bahasa berbasiskan rules dan model bahasa statistik. Model bahasa berbasis rules artinya terdapat rules statis yang didefinisikan. Sedangkan, model bahasa statistic akan memberikan probabilitas dari suatu urutan kata.
1. Model Bahasa berbasis Rules
2. Model Bahasa berbasis Statistik
Model bahasa berdasarkan statistik memberikan nilai probabilitas dari suatu urutan kata. Model N-gram adalah yang paling sering digunakan karena menghasilkan solusi yang lebih baik dan fleksibel. Model bahasa N-Gram digunakan untuk menyediakan sistem pengenal dengan nilai probabilitas urutan kata tersebut muncul bersama-sama. Model bahasa N-Gram digunakan untuk menyediakan sistem pengenal dengan nilai probabilitas urutan kata tersebut muncul bersama-sama. Nilai ini diperoleh dari teks latih yang besar yang menggunakan bahasa yang sama. Jika kita menganggap bahwa W adalah urutan kata, w merupakan kata-kata dalam W, dan q adalah jumlah kata, nilai P(W) dapat dilihat pada persamaan berikut.
P(W) = P(w1,w2,…,wq) =
π
i=1P(wi|wi-n+1,…,wi-1)Untuk memperoleh nilai probabilitas P (wi | wi-2 wi-1) dalam kasus trigram, dilakukan dengan hanya menghitung jumlah masing-masing kemunculan tiga kata secara berturut-turut dalam data latih. Jika N(a,b) menyatakan jumlah kemunculan a,b berturut-turut pada data latih, rumus matematisnya dapat dilihat pada persamaan :
P(w1|wi-2, w1-1) =
3. Kamus
Kamus akan memberikan daftar kata yang dapat dikenali oleh sistem beserta cara pengucapannya. Kata-kata yang dikenali oleh sistem pengenal suara bergantung pada kamus.
Q
N(wi-2, wi-1, wi)
2.3 Microsoft Speech Application Programming Interface (SAPI)
Speech Application Programming Interface (SAPI) merupakan Application Programming Interface (API) yang dikembangkan oleh Microsoft yang dapat digunakan untuk pengembangan speech recognition dengan sistem operasi yang berbasis windows. Speech Aplication Programming Interface (SAPI) diperkenalkan oleh Microsoft pada tahun 1995. SAPI memungkinkan sistem akan mengenali input suara dari sipengguna dan kemudian akan menghasilkan ouput berupa text. Dengan kata lain Speech Application Programming Interface (SAPI) ini dapat mengubah sinyal suara menjadi text melalui proses ekstraksi yang terjadi di dalamnya. Dalam speech recognition, speech to text terdapat beberapa modul yang disebut engines (Permadi. T, 2008). SAPI telah digunakan dalam windows XP, windows vista, dan windows seven. Banyak versi dari Speech Application Programming Interface (SAPI), diantaranya adalah Speech Application Programming Interface (SAPI) 1, Speech Application Programming Interface (SAPI) 3, Speech Application Programming Interface (SAPI) 4, dan versi terbaru Speech Application Programming Interface (SAPI) 5. Komponen yang terdapat pada Speech Application Programming Interface (SAPI) adalah sebagai berikut.
1. Voice Command
Sebuah obyek level tinggi untuk perintah dan kontrol menggunakan pengenalan suara.
2. Voice Dictation
Sebuah obyek level tinggi untuk continous dictation speech recognition. 3. Voice Talk
Sebuah obyek level tinggi untuk speech synthesis. 4. Voice Telephony
Sebuah obyek untuk menulis aplikasi telepon berbasiskan pengenalan suara. 5. Direct Speech Recognition
6. Direct Text to Speech
Sebuah obyek sebagai mesin yang mengontrol synthesis. 7. Audio Object
Untuk membaca dari audio device atau sebuah file audio.
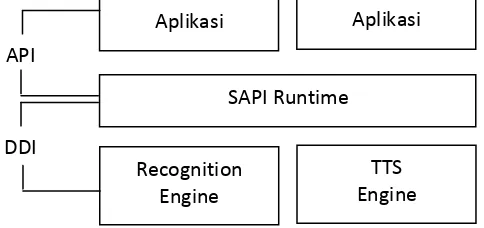
Speech Application Programming Interface (SAPI) terdiri dari 2 antarmuka yaitu Application Programming Interface dan Device Driver Interface (DDI) (Permadi. T, 2008) Arsitektur SAPI ini dapat dilihat pada gambar 2.1.
2.3.1 Application Programming Interface (API)
Dalam API terdapat fungsi-fungsi/ perintah-perintah untuk menggantikan bahasa yang digunakan dalam system calls dengan bahasa yang lebih terstruktur dan mudah dimengerti oleh programmer. Fungsi yang dibuat dengan menggunakan API tersebut kemudian akan memanggil system calls sesuai dengan sistem operasinya.
Keuntungan memprogram dengan menggunakan API adalah :
a. Portabilitas dimana programmer yang menggunakan API dapat menjalankan programnya dalam sistem operasi mana saja apabila API sudah ter- install dalam sistem operasi tersebut. Sedangkan system call berbeda antar sistem operasi, dengan catatan dalam pengaplikasiannya ada kemungkinan untuk berbeda.
Gambar 2.1. Arsitektur SAPI Aplikasi Aplikasi
SAPI Runtime
Recognition Engine
TTS Engine API
b. Lebih mudah dimengerti. API menggunakan bahasa yang lebih terstruktur dan
mudah dimengerti daripada bahasa system call. Hal ini sangat penting dalam hal editing dan pengembangan.
System call interface ini berfungsi sebagai penghubung antara API dan system call yang dimengerti oleh sistem operasi. System call interface ini akan menerjemahkan perintah dalam API dan kemudian akan memanggil system calls yang diperlukan.
2.3.2 Device Driver Interface (DDI)
Device Driver Interface (DDI) berfungsi untuk menerima data masukan yang berupa suara dari Speech Application Programming Interface (SAPI) dan mengembalikan phrase pada level SAPI paling dasar.
2.4 Penelitian Terdahulu
Dalam membangun aplikasi dalam penelitian ini, penulis menggunakan referensi dari beberapa penelitian terdahulu yang telah pernah dilakukan. Adapun penelitian terdahulu yang dimaksud, dapat dilihat pada tabel 2.1.
Tabel 2.1. Penelitian Terdahulu
Peneliti Terdahulu Judul
Permadi, T. 2008.
Pemanfaatan Microsoft Speech
Application Programming Interface Pada
Pembuatan Aplikasi Perintah Suara.
Junaedih. 2007. Implementasi Speech Recognition Menggunakan SAPI 5 dan Visual Basic
6.0 Pada Pembuatan Aplikasi Kalkulator
Noertjahyana, A. & Adipranata, R. 2003 Implementasi Sistem Pengenalan Suara Menggunakan SAPI 5.1 dan DELPHI 5