LAPORAN PRAKTIKUM III
PL2202 METODE ANALISIS PERENCANAAN II
ANALISIS REGRESI
MENGIDENTIFIKASI SEKTOR-SEKTOR YANG MEMPENGARUHI HARGA PDRB PROVINSI LAMPUNG
Oleh :
I Gede Adi Saputra 22116145
Nurulia Indarti 22116151
Kelas C: Jum’at, 16.00 - 17.00
Asisten Praktikum :
Yabes Davin Arne Hasiholan Tambun 22115064
Rohmayati 22115045
PROGRAM STUDI PERENCANAAN WILAYAH DAN KOTA JURUSAN TEKNOLOGI INFRASTRUKTUR DAN KEWILAYAHAAN
i
DAFTAR ISI
DAFTAR ISI ... i
DAFTAR TABEL ... ii
DAFTAR GAMBAR ... iii
BAB I PENDAHULUAN ... 1
1.1 Latar Belakang ... 1
1.2 Rumusan Masalah ... 2
1.3 Tujuan dan Sasaran ... 2
1.3.1 Tujuan ... 2
1.3.2 Sasaran ... 2
1.4 Ruang Lingkup Penelitian ... 3
1.4.1 Ruang Lingkup Materi ... 3
1.4.2 Ruang Lingkup Wilayah ... 3
1.5 Metodologi Penelitian ... 4
1.6 Sistematika Penulisan ... 4
BAB II DASAR TEORI ... 5
2.1 Tinjauan PDRB ... 6
2.2 Teori Analisis Regresi ... 7
2.2.1 Persamaan Regresi ... 8
2.2.2 Seleksi Variabel Predictor... 10
ii
2.2.4 Pengujian Residual Error ... 10
2.2.5 Variabel Dummy dan Musim ... 10
2.3 Penggunaan Analisis Regresi dengan Aplikasi SPSS ... 10
BAB III INPUT DAN ANALISIS DATA ... 16
3.1 Input Data ... 16
3.2 Analisis Output Data ... 17
3.3 Interpretasi Terhadap Bidang Perencanaan Wilayah dan Kota ... 24
BAB IV KESIMPULAN DAN SARAN ... 24
4.1 Kesimpulan ... 25
4.2 Saran ... 26
LAMPIRAN ... 26
iii
DAFTAR TABEL
Tabel 3.1 Descriptive Statistics ... 23
Tabel 3.2 Correlations ... 23
Tabel 3.3 Variables faured Removed ... 24
Tabel 3.4 Coefficients ... 24
Tabel 3.5 Model Summary ... 25
Tabel 3.6 Excluded Variables ... 25
Tabel 3.7 Collinearity Diagnostics ... 26
DAFTAR GAMBAR Gambar 2.1 Langkah Regresi Linier... 4
Gambar 2.2 Kotak Dialog Regresi Linier ... 11
Gambar 2.3 Kotak Dialog Statistik ... 13
Gambar 2.4 Kotak Dialog Plot ... 14
Gambar 2.5 Kotak Dialog Save ... 15
Gambar 3.1 Normal P-P Plot Regresion Standarized Residual ... 17
1
BAB I
PENDAHULUAN
Pada bab Pendahuluan akan dipaparkan mengenai latar belakang, rumusan masalah, tujuan dan sasaran, ruang lingkup penelitan yang meliputi ruang lingkup materi, ruang lingkup wilayah, dan waktu, serta metodologi dan sistematika dari penulisan laporan ini.
1.1 Latar Belakang
2
pengembangan wilayah yang dimilikinya yaitu potensi sumber daya alam, sumber daya manusia, dan sumber daya modal berupa teknologi. Proses pertumbuhan ekonomi dipengaruhi oleh dua macam faktor, yaitu faktor ekonomi dan faktor non ekonomi. Faktor ekonomi yang mempengaruhi pertumbuhan ekonomi suatu negara adalah sumber alam, sumber daya manusia, modal usaha, teknologi dan sebagainya. Selain itu, perlu ditunjang oleh faktor-faktor non ekonomi, seperti lembaga sosial, sikap budaya, nilai moral, kondisi politik dan kelembagaan dari negara tersebut. Pembangunan ekonomi dalam konteks regional (tata ruang/ spasial), pada dasarnya sama dengan pembangunan nasional secara keseluruhan, dalam arti sama-sama mau mengatasi kemiskinan, penggangguran, ketimpangan dan sebagainya. Permasalahan-permasalahan tersebut, melalui proses pembangunan akan dipecahkan dengan menentukan target-target tertentu, seperti pertumbuhan ekonomi, pengurangan angka kemiskinan, pengangguran dan lain-lain.
1.2 Rumusan Masalah
Berdasarkan latar belakang tersebut diatas dapat dirumuskan permasalahan yaitu: Bagaimana pengaruh variabel-variabel bebas terhadap harga Produk Domestik Regional Bruto di Provinsi Lampung ?
1.3 Tujuan dan Sasaran 1.3.1 Tujuan
3
1.3.2 Sasaran
Teridentifikasi variabel-variabel yang mempengaruhi harga Produk Domestik Regional Bruto di Provinsi Lampung.
1.4 Ruang Lingkup Penelitian
Ruang lingkup dari penelitian ini terdiri atas ruang lingkup materi, ruang lingkup wilayah, dan ruang lingkup waktu.
1.4.1 Ruang Lingkup Materi
Analisis regeresi berganda terhadap variabel-variabel yang mempengaruhi Produk Domestik Regional Bruto di Provinsi Lampung. Terdapat 11 variabel yang dimasukkan ke program SPSS dan 15 obyek berupa kabupaten atau kota. Variable tersebut yaitu PDRB, UMR, Luas Areal Perkebunan, Produksi Pangan, Indeks Kemahalan Konstruksi, Jumlah Tenaga Kerja, Jumlah Lahan Pertanian, Jumlah Penggunaan Listrik, Jumah Pengeluaran Rumah Tangga, Prosuksi daging Ternak, dan Produksi Budidaya Ikan.
1.4.2 Ruang Lingkup Wilayah
Wilayah orientasi studi (pengambilan data) terbatas pada Provinsi Lampung. Jumlah data yang diambil sebanyak 15 Kabupaten/Kota dan terdapat 11 variabel.
4
Metoda pengumpulan data menggunakan pengumpulan data sekunder dengan mencari variabel-variabel yang ada pada data Provinsi Lampung. Kemudian variabel-variabel tersebut diolah menggunakan SPSS untuk direduksi dianalisis.
1.6 Sistematika Penulisan
Sistematika penulisan laporan penelitian ini terbagi menjadi lima bab, yaitu pendahuluan, dasar teori, input dan analisis data, serta kesimpulan dan saran.
Pada Bab I (Pengantar) akan dibahas mengenai latar belakang pengangkatan aspek laporan penelitian ini, rumusan masalah, tujuan dan sasaran yang ingin dicapai dari, ruang lingkup penelitian yang terdiri dari: ruang lingkup materi, ruang lingkup wilayah, dan ruang lingkup waktu, metodologi penelitian yang mencakup metode pengumpulan dan analisis data, serta sistematika penulisan.
Pada Bab II (Dasar Teori) akan disajikan penjelasan umum dan aspek-aspek yang akan dikaji dengan menggunakan berbagai literatur sebagai sumbernya berupa teori analisis mengenai substansi penelitian, teori analisis faktor yang digunakan mengenai metode analisis pada kuliah Metode Analisis Perencanaan (MAP) 2, dan teori analisis yang menjelaskan langkah-langkah analisis dalam menggunakan SPSS.
Bab III (Input dan Analisis Data) akan menjabarkan dan menganalisis masalah-masalah yang telah dirumuskan mengenai tabel input data yang berisi variabel-variabel yang akan diuji. Setelah itu bagaimana analisis data tersebut, analisis output data berupa penginterpretasian dan penganalisisan data setelah data tersebut diolah menggunakan SPSS, dan interpretasi hasil analisis tersebut terhadap bidang Perencanaan Wilayah dan Kota.
5
BAB II
DASAR TEORI
Pada bab ini akan dipaparkan mengenai metode analisis regresi berganda, rumus perhitungan, langkah-langkah analisis. Kemudian akan dipaparkan pula mengenai cara penggunaan SPSS terkait dengan analisis regresi berganda.
2.1 Tinjauan Produk Domestik Regional Bruto (PDRB)
Kuncoro (2001) menyatakan bahwa pendekatan pembangunan tradisional lebih dimaknai sebagai pembangunan yang lebih memfokuskan pada peningkatan PDRB (Produk Domestik Regional Bruto) suatu provinsi, kabupaten, atau kota. Sedangkan pertumbuhan ekonomi dapat dilihat dari pertumbuhan angka PDRB.
Produk Domestik Regional Bruto (PDRB) menurut BPS didefinisikan sebagai jumlah nilai tambah yang dihasilkan oleh seluruh unit usaha dalam suatu wilayah, atau merupakan jumlah seluruh nilai barang dan jasa akhir yang dihasilkan oleh seluruh unit ekonomi di suatu wilayah. Cara perhitungan PDRB dapat diperoleh melalui tiga pendekatan (Robinson Tarigan, 2008), yaitu:
1. Pendekatan Produksi
Pendekatan ini menghitung nilai tambah dari barang dan jasa yang diproduksi oleh suatu kegiatan ekonomi di daerah tersebut dikurangi biaya antar masing-masing total produksi bruto tiap kegiatan subsektor atau sektor dalam jangka waktu tertentu. Nilai tambah merupakan selisih antara nilai produksi dan nilai biaya antara yait bahan baku/penolong dari luar yang dipakai dalam proses produksi.
2. Pendekatan Pendapatan
6
upah, gaji, dan surplus usaha, penyusutan, pajak tidak langsung neto pada sektor pemerintah dan usaha yang sifatnya tidak mencari untung, surplus usaha tidak diperhitungkan. Surplus usaha meliputi bunga yang dibayarkan neto, sewa tanah, dan keuntungan.
3. Pendekatan Pengeluaran
Pendekatan ini menjumlahkan nilai penggunaan akhir dari barang dan jasa yang diproduksi di dalam negeri. Jika dilihat dari segi penggunaan maka total penyediaan/produksi barang dan jasa itu digunakan untuk konsumsi rumah tangga, konsumsi lembaga swasta yang tidak mencari untung, konsumsi pemerintah, pembentukan modal tetap bruto (investasi), perubahan stok, dan ekspor neto.
2.2 Teori Analisis Regresi Berganda
Metoda analisis regresimemberikan suatu persamaan yang menggambarkan sifat hubungan antara dua variabel. Metoda analisis regresi memberikan ukuran variansi yang memungkinkan untuk memperkirakan keakuratan sebagaimana jauh persamaan regresi dapat memprediksi nilai variabel kriteria bukan sekedar teknik pencocokan pola. Regresi sederhana hanya mempersoalkan hubungan antara 2 variabel, yaitu variabel dependen Y dan variabel independen X. Namun penggunaan variabel independen tunggal untuk menduga varibel dependen seringkali kurang realistis. Maka dari itu digunakan metoda analisis regresi berganda dalam peramalan kausal.
Metoda analisis regresi berganda merupakan perluasan dari konsep regresi sederhana. Metoda regresi berganda mengestimasikan nilai suatu variabel kriteria berdasarkab banyak (lebih dari satu) variabel prediktor. Metoda ini mengurangi kesalahan dalam memprediksi dan dapat menghitung variansi yang lebih besar dari variabel kriteria.
7
❖ Y’=a+b1X1+b2X2+………+bkXk
✓ Y’ adalah nilai prediksi dari variabel
✓ a, b merupakan koefisien yang ditentukan berdasarkan data sampel.
❖ Persamaan tersebut dipikirkan sebagai suatu estimasi yang sebenarnya dari persamaan populasi:
μY= + 1X1+ 2X2+………+ kXk
2.2.2 Seleksi Variabel Prediktor
1. Membuat Daftar Panjang Variabel Prediktor: • Teori
• Logika
• Arahan Pakar • Ketersediaan Data
• Kendala Waktu dan Biaya
2. Membuat Daftar Pendek Variabel Prediktor: Long List Short List
1. Persamaan Regresi hendaknya mempunyai variabel prediktor sesedikit mungkin variabel prediktor dengan variansi sangat kecil harus dihapus
2. Seleksi Variabel Prediktor dapat dilakukan dalam berbagai cara:
▪ Plot Variabel Bebas terhadap Variabel Terikat ▪ Hitung Inter Korelasi
▪ Analisis Faktor
▪ Melalui prosedur lain, diantaranya “Stepwise”
Terdapat tiga pengolahan data dengan SPSS, yaitu forward elimination, backward elimination, dan stepwise elimination. Berikut ini merupakan prosedur dari tiga cara pengolahan data tersebut.
8
1. Regresikan Variabel Kriteria dengan Variabel Prediktor yang mempunyai Korelasi Terbesar.
2. Hitung Error masing-masing Obyek.
3. Amati Korelasi Variabel Prediktor Sisa dengan Error Pilih Variabel Prediktor dengan Korelasi Tertinggi.
4. Regresikan Variabel Kriteria dengan 2 variabel prediktor tersebut hitung Error R2.
5. Cari Variabel Prediktor sisa yang mempunyai korelasi tertinggi terhadap Error.
6. Regresikan dengan variabel Kriteria bersama dengan variabel regreser sebelumnya sampai R2 relatif tidak meningkat lagi
• Backward Eliminaton
Merupakan kebalikan dari forward elimination.
1. Mulai dengan Regresikan Variabel Kriteria dengan seluruh Variabel Prediktor.
2. Hapus satu persatu yang paling tidak dapat digunakan untuk prediksi.
3. Prosedur berakhir sampai eliminasi Variabel Prediktor akan mengorbankan sejumlah variansi yang cukup berarti
• Stepwise Elimination
Hampir sama dengan forward, hanya variabel yang telah dimasukkan dalam model regresi bisa dikeluarkan lagi dari model.
Metode ini dimulai dengan memasukkan variabel bebas yang mempunyai korelasi paling kuat dengan variabel dependen. Kemudian setiap kali pemasukkan variabel bebas yang lain dilakukan pengujian untuk tetap memasukkan variabel bebas atau mengeluarkannya
2.2.3 Permasalahan Multicolinearity
Terdapat beberapa kondisi permasalahan multicolinearity, yaitu: ➢ Dua Variabel Independent terkorelasi sempurna
9
➢ Suatu kombinasi linier dari beberapa variabel independent terkorelasi sempurna atau mendekati sempurna dengan variabel independent lain.
➢ Suatu kombinasi linier dari satu subset variabel independent terkorelasi sempurna atau mendekati sempurna dengan kombinasi linier dari subset variabel independent lain.
Apabila Multicollinearity terjadi dalam model regresi berganda maka tidak dimungkinkan menghasilkan solusi Least Square. Solusi Least Square dipengaruhi oleh Error yang berlebihan. Kestabilan model regresi berganda dipengaruhi oleh multicollinearity standard error koefisien dipengaruhi oleh korelasi variabel bebas semakin besar korelasi, maka koefisien semakin tidak stabil. Pengaruh hal tersebut pada peramalan yaitu terjadinya “Over Estimate”.
2.2.4 Pengujian Residual Error
▪ Model dikatakan baik apabila errornya random ▪ Alat untuk menganalisis Error adalah:
o Menggambarkan Error untuk penyelidikan secara visual. o Mempelajari Outokorelasi dari Error
o Mempelajari Statistik Durbin –Watson: • 0<DW<4
• DW= 2 error acak tidak ada autokorelasi
• DW <1 error sistematis autokorelasi positif
• Dw sekitar 3 error sistematis autokorelasi negatif
2.2.5 Variabel Dummy dan Musim
➢ Regresi Berganda memungkinkan untuk mempertimbangkan musim dengan memperkenalkan Variabel Dummy:
• D1= 1 bila bulan yang diinginkan,
10
➢ Suatu Variabel Dummy equivalen dengan variabel regresor baru. ➢ Bila digunakan 12 Variabel Dummy untuk 12 periode bulanan akan
dihadapi masalah Multicolloniarity gunakan (p-1) variabel dummy untuk menunjukkan p periode yang berbeda.
2.3 Penggunaan Analisis Regresi Berganda dengan Aplikasi SPSS
Analisis regresi berganda merupakan perluasan dari konsep regresi sederhana. Regresi berganda mengestimasikan nilai suatu variabel dependen (kriteria) berdasarkan banyak variabel independen (prediktor). Metode yang digunakan dalam analisis regresi berganda dalam SPSS adalah metode stepwise, dimana variabel bebas dimasukkan satu persatu dari variabel yang tidak memiliki korelasi dengan variabel dependen dapat dikeluarkan.
Berikut ini merupakan langkah-langkah proses analisis regresi berganda dengan penggunaan SPSS.
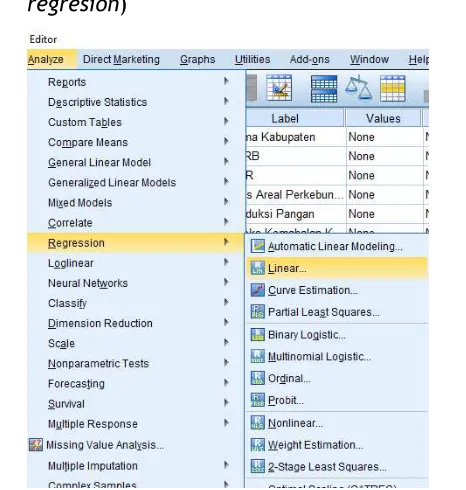
1. Klik AnalyzeRegression Linear (akan muncul kotak dialog linier regresion)
11
2. Masukkan variabel dependen (PDRB) dalam data yang ingin diolah ke dalam kotak Dependent. Kemudian masukan semua variabel independent ke kolom independent. setelah itu masukan variabelm nama kabupaten ke kolom case labels. Dan pada metode pilih stepwise.
3. Klik Statistics centang estimates, model fit, R squared change, descriptive, collinearity diagnostics, dan centang durbin-watson
kemudian klik continue.
12
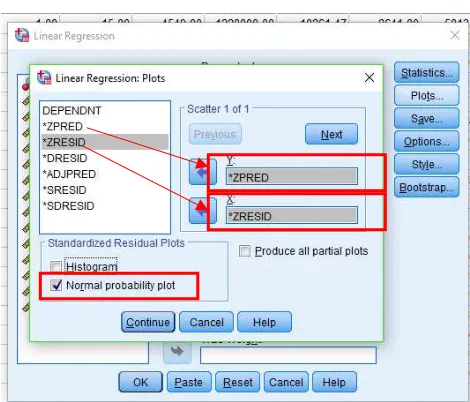
4. Klik Plots Masukan ZPRED ke kolom Y dan ZRESID ke kolom X. kemudian pada stanadarized residual plots centang normal Probaabillity plot dan klik continue.
Gambar 3. Kotak dialog statistics
13
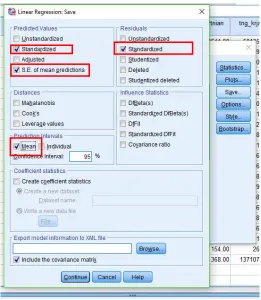
5. Klik Save, Pada bagian Predicted Values klik Standardized dan S.E. of mean predictions.Pada bagian Residuals klik Standardized. Pada bagian Prediction Intervals klik Means Continue OK
Setelah langkah-langkah telah dilakukan, maka akan keluar output SPSS sebagai berikut.
1. Descriptive Statistics
Tabel ini menunjukkan variabel-variabel yang akan dianalisis. N merupakan jumlah objek dalam data yang akan dianalisis.
2. Correlation
Tabel ini menjelaskan korelasi masing-masing variabel dengan variabel lainnya. Jika nilai korelasi >0,5 maka hubungannya cukup kuat,
14
sedangkan jika nilai korelasi <0,5 hubungannya lemah. Tabel di atas juga menunjukkan korelasi antara variabel dependen dengan variabel bebas.
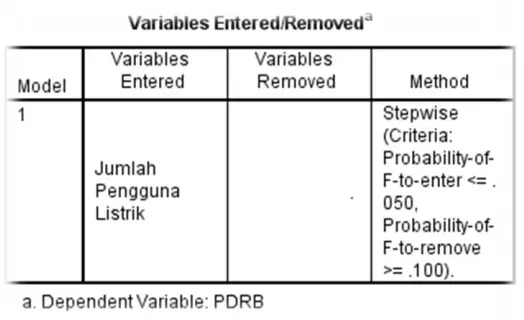
3. Variables Entered/Removed
Tabel ini menunjukkan variabel independen apa saja yang mempengaruhi variabel dependen dalam data yang kita pergunakan dalam analisis.
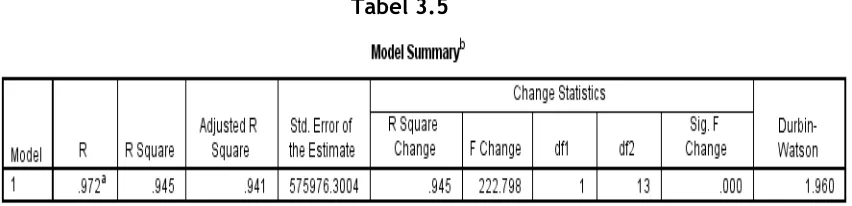
4. Model Summary
Tabel ini menunjukkan jumlah variabel predictor yang terbentuk dan seberapa persen variabel predictor tersebut menjelaskan variabel dependen. Apabila nilai Durbin Watson <2 maka tidak terdapat autokorelasi antar variabel.
5. Annova
Tabel ini menunjukkan nilai signifikansi pada model-model yang dapat digunakan dalam analisis. Apabila nilai signifikansi <0,5 maka model tersebut dapat dianalisis lebih lanjut, sebaliknya apabila nilai signifikansi >0,5 maka model tersebut tidak dapat diolah lebih lanjut.
6. Coeficients
Tabel ini menunjukkan model yang dapat dibuat berdasarkan banyaknya variabel predictor. Nilai VIF menunjukkan ada tidaknya multicollinearity antar variabel. Apabila nilai VIF <5 maka tidak terdapat multicollinearity antar variabel, sehingga model dapat dianalisis lebih lanjut.
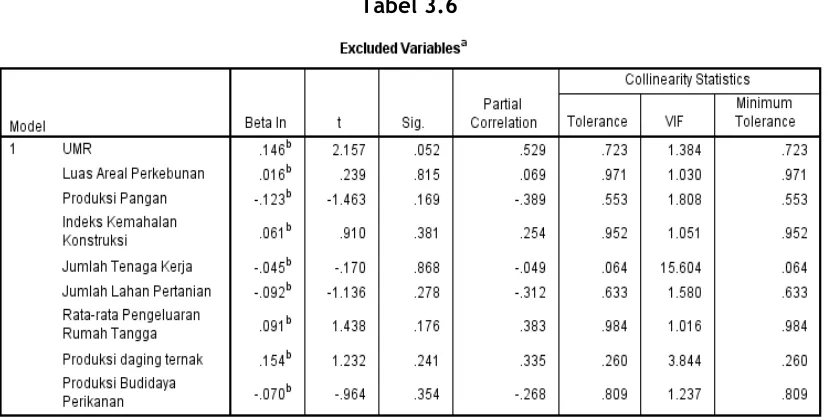
7. Excluded Variables
15
yang ada di kolom t. Variabel yang memiliki nilai t paling tinggi dikeluarkan menjadi variabel predictor.
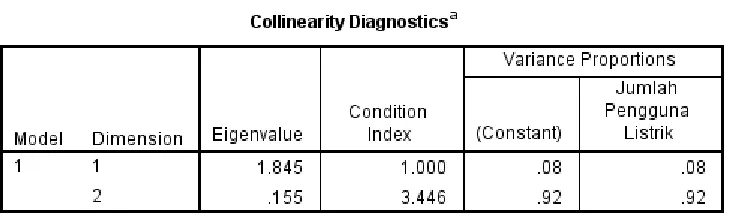
8. Collinearity Diagnostics
Pada tabel ini dapat dilihat nilai eigen value. Pada tabel ini juga dapat dilihat ada atau tidaknya multicollinearity dengan syarat nilai Condition Index <15 menandakan bahwa tidak terdapat multicollinearity.
9. Kurva P-P Plot
16
BAB III
INPUT DAN ANALISIS DATA
Bab ini memuat input data yang digunakan berupa variabel-variabel yang menjadi acuan dalam penentuan hubungan serta analisis regresi yang dilakukan untuk mengetahui keterkaitan antar variabel. Output dari SPSS dan Hasil dari proses analisis kemudian diinterpretasikan dengan Perencanaan Wilayah dan Kota.
3.1 Input Data
Sumber data yang digunakan berasal dari Badan Pusat Statistik Provinsi Lampung dan Badan Pusat Statisik Kabupaten/kota. Data tersebut ditampilkan dalam bentuk tabel input yang berisi variabel-variabel yang akan dianalisis. Data yang digunakan terdiri dari 10 variabel dan 24 objek yang berupa kota dan kabupaten di Lampung.
3.2 Analisis Output Data
Analisis output data yang digunakan pada praktikum kali ini adalah Regresi Berganda. Dalam statistik, Fungsi Analisis Regresi berganda adalah untuk mengetahui karakteristik, arah, dan pola serta keterkaitan antar variabel dependen dengan independen. Dalam hal ini, kami ingin mengetahui variabel – variabel apa saja yang dapat mempengaruhi PDRB (Produk Domestik Regional Bruto) di Provinsi Lampung. Jika sudah diketahui variabel-variabel yang paling berpengaruh, maka akan diketahui variabel yang hubunganya sangat erat dengan PDRB sehingga variabel tersebut dapat dikembangkan dalam rangka peningkatan PDRB.
17
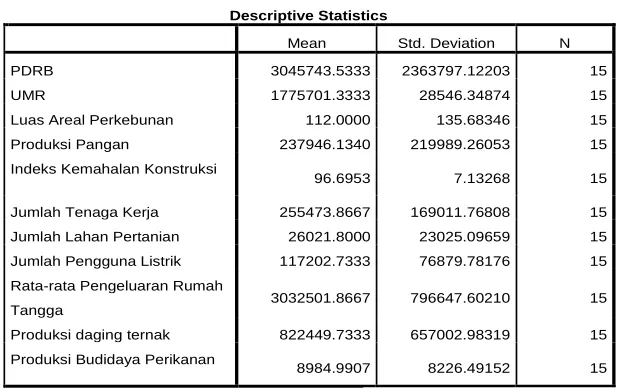
Tabel 3.1 Descriptive Statistics
Tabel diatas menunjukan jumlah data atau variabel yang digunakan dalam proses analisis ini yaitu berjumlah 11 diantaranya PDRB, UMR, luas areal perkebunan, produksi pangan, indeks kemahalan konstruksi, jumlah tenaga kerja, jumlah lahan pertanian, jumlah pengguna listrik, rata-rata pengeluaran rumah tangga, produksi daging ternak, dan produksi budidaya perikanan. Kolom paling kanan (N) merupakan jumlah sampel atau objek, dalam hal ini adalah jumlah kabupaten/Kota di provinsi Lampung yaitu berjumlah 15 ojek.
Selanjutnya variabel-variabel tersebut akan dihitung nilai korelasinya antar satu variabel dengan variabel lainnya dengan menggunakan SPSS untuk mendapatkan variabel yang paling memengaruhi PDRB
Tabel 3.2 Correlations (data terlampir)
Dari tabel 3.2, kita dapat mengetahui korelasi antar seluruh variabel. Pada baris diagonal terdapat angka 1,000 yang berarti korelasi antar variabel dengan dirinya sendiri sangat kuat. Korelasi antar variabel dapat dikatakan kuat jika nilainya > 0,5 sedangkan jika nilainya < 0,5 maka korelasi antar dua
Descriptive Statistics
Mean Std. Deviation N
PDRB 3045743.5333 2363797.12203 15
UMR 1775701.3333 28546.34874 15
Luas Areal Perkebunan 112.0000 135.68346 15 Produksi Pangan 237946.1340 219989.26053 15 Indeks Kemahalan Konstruksi
96.6953 7.13268 15
Jumlah Tenaga Kerja 255473.8667 169011.76808 15 Jumlah Lahan Pertanian 26021.8000 23025.09659 15 Jumlah Pengguna Listrik 117202.7333 76879.78176 15 Rata-rata Pengeluaran Rumah
Tangga 3032501.8667 796647.60210 15 Produksi daging ternak 822449.7333 657002.98319 15 Produksi Budidaya Perikanan
8984.9907 8226.49152 15
18
variabel tersebut dinilai lemah. Dari tabel Correlations, maka variabel yang mempunyai korelasi yang tinggi dengan variabel dependen PDRB adalah yaitu jumlah tenaga kerja dan jumlah pengguna listrik dan produksi daging ternak.
Tabel 3.3
Tabel Variables Entered/Removed diatas menunjukkan variabel independen yang mempengaruhi variabel dependen. Jadi berdasarkan SPSS dengan metode Stepwise diperoleh 4 variabel independen yang mempengaruhi variabel dependen PDRB yaitu jumlah pelanggan air, jumlah produksi padi, jumlah penduduk dan indek produksi cabai. Hal ini juga sesuai dengan hasil analisis korelasi sebelumnya. Berikutnya akan dicari variabel predictor yang akan digunakan dalam penelitian ini.
Tabel 3.4
Sumber: Output SPSS, 2018
19
Berdasarkan tabel Model Summary, dapat diketahui jumlah variabel predictor yang terbentuk dan berapa persen variabel predictor tersebut menjelaskan variabel dependen yang ada. Pada tabel ini hanya terdapay satu model, nilai Adjusted R Square adalah 0,945. Hal ini berarti variabel predictor Jumlah Pengguna Listrik menjelaskan 94,5% variabel dependen PDRB. Untuk nilai Durbin Watson, jika nilainya <2 maka tidak terdapat autokorelasi antar variabel. Pada model ini, nilai Durbi-Watsonnya adalah 1.960 berarti tidak ada autokorelasi antar variabel sehingga error pada model tersebut bersifat acak. Berikutnya akan dilakukan analisis menggunakan Anova untuk melihat signifikansinya.
Tabel 3.5
Tabel Coefficient menunjukkan model yang dapat dibuat berdasarkan banyaknya variabel predictor yang digunakan. Nilai VIF pada model sebesar 1,000. Karena nilai < 5 maka tidak terdapat multikolineariti antar variabel. Maka model ini dapat digunakan.
Melalui tabel diatas juga dapat dilihat hubungan antar variabel bebas yang digunakan dengan variabel dependennya, baik itu korelasi positif atau korelasi negatif. Korelasi ini dilihat dari nilai B yang tertera pada tabel. Berdasarkan nilai B maka diperoleh model sebagai berikut:
Y = a + b1X1
Y = -457104,987 + 29,887 X1
Dimana Y : Nilai PDRB
20
X1 : Jumlah Pengguna Listrik
Jadi variabel dependen PDRB dipengaruhi oleh satu variabel predictor yaitu jumlah pengguna Listrik. Artinya, apabila terdapat peningkatan pada Pengguna Listrik maka PDRB juga meningkat. Begitu juga sebaliknya apabila jumlah pengguna Listrik mengalami penurunan maka PDRB juga menurun.
Tabel 3.6
Tabel exclude variables menunjukkan variabel apa saja yang paling berhubungan dengan variabel dependen. Hal ini dapat dilihat melalui nilai yang terdapat pada kolom t. Nilai yang paling tinggi terdapat pada variabel UMR dengan nilai sebesar 2.157. Pada tabel ini tidak terdapat variabel jumlah Pengguna Listrik karena variabel ini telah terlebih dahulu dikeluarkan oleh SPSS menjadi variabel predictor.
21
Tabel 3.7
Pada tabel diatas penulis memilih model 1 karena merupakan model tunggal, dan berdasarkan nilai analisis sebelumnya model tersebut mampu menjelaskan variabel dependen PDRB. Sedangkan dimensi yang diambil adalah dimensi 1 karena nilai eigenvalueya > 1 yaitu sebesar 1,845. Dimensi 1 ini menunjukkan dataran (1 dimensi) dalam ruang multidimensi. Pada tabel ini juga untuk menunjukan apakah terdapat multikolineariti atau tidak. berdasarkan tabel tersebut diketahui tidak terdapat multikolineriti, hal ini karena nilai Condition Indez < 15 yang berarti tidak terdapat multikolineariti. Pada model 1 dimensi 1, nilai Condition Indexnya adalah 1,000 Hal ini juga berarti model tersebut tidak memiliki multikolineariti antara variabel independenya. Pada analisis berikutnya akan ditampilkan diagram yang menunjukkan persebaran seluruh variabel yang digunakan dimana selisih antara kuadrat jarak titik-titik variabel dan membentuk garis minimal.
22
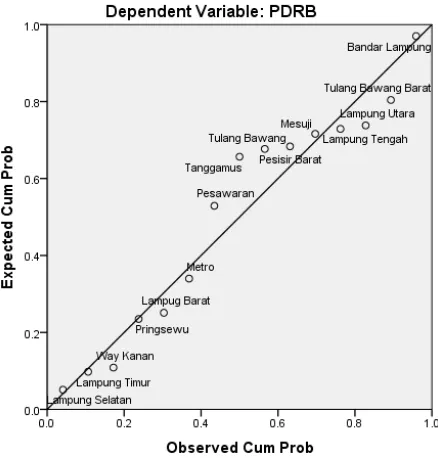
Gambar 3.1
Gambar 3.2
23
Berdasarkan gambar scatterplots diatas,gambar pertama menginterpretasikan persebaran data yang mendekati garis linier yang artinya objek data memiliki deviasi yang tidak signifikan. Sedangkan pada gambar kedua terlihat bahwa data titik objek setiap variabel tersebar secara acak dan tidak membentuk sebuah pola. Hal ini berarti data yang digunakan dalam perhitungan ini adalah acak, tidak membentuk sebuah pola sehingga dapat dikatakan mewakili sebuah sampel.
3.3 Interpretasi Terhadap Bidang Perencanaan Wilayah dan Kota
24
BAB IV
KESIMPULAN DAN SARAN
4.1 Kesimpulan
Berdasarkan hasil perhitungan dan anlisis yang telah dilakukan, didapatkan bahwa variabel yang mempengaruhi Produk domestik regional bruto adalah jumlah Jumlah Pengguna Listrik. Model yang terbentuk dari hasil proses SPSS adalah:
Y = -457104,987 + 29,887 X1
Y adalah variabel dependen, yaitu Produk domestik regional bruto, dan X1 adalah Jumlah Pengguna Listrik. Berdasarkan model regresi Y diatas,
dapat disimpulkan bahwa variabel Jumlah Pengguna Listrik memiliki karakteristik hubungan yang bersifat searah dengan nilai PDRB dan memiliki arah hubungan yang positif atau berbanding lurus dengan indeks PDRB. Artinya jika Jumlah Pengguna Listrik mengalami peningkatan, maka nilai PDRB akan naik pula, begitupun sebaliknya, jika jumlah Pengguna Listrik Menurun maka akan berdampak pada penurunan nilai PDRB.
4.2 Saran
25
27
DAFTAR PUSTAKA
William H. Kruskal and Judith M. Tanur, ed. (1978), "Linear Hypotheses," International Encyclopedia of Statistics. Free Press, v. 1,
Evan J. Williams, "I. Regression," pp. 523–41
Lindley, D.V. (1987). "Regression and correlation analysis," New Palgrave: A Dictionary
of Economics, v. 4, pp. 120–23
irkes, David and Yadolah Dodge, Alternative Methods of Regression. ISBN 0-471-56881-3
Chatfield, C. (1993) "Calculating Interval Forecasts," Journal of Business and Economic
Statistics, 11. pp. 121–135.
Corder, G.W. and Foreman, D.I. (2009).Nonparametric Statistics for Non-Statisticians: A Step-by-Step Approach Wiley, ISBN 978-0-470-45461-9