38 http://research.pps.dinus.ac.id
OPTIMASI ALGORITMA
SUPPORT VECTOR MACHINE
(SVM)
MENGGUNAKAN
ADABOOST
UNTUK PENILAIAN RISIKO KREDIT
Defri Kurniawan1 dan Catur Supriyanto21,2Program Pascasarjana Magister Teknik Informatika Universitas Dian Nuswantoro
Abstract
Support Vector Machine (SVM) is an algorithm proposed by many researchers in the field of data mining credit risk. But the difficulty of determining the parameters of an ideal is the problem of research in improving the accuracy of SVM. In this study, the use of AdaBoost is proposed to improve the accuracy of SVM with the selection of the kernel, the value of the parameter C, and the appropriate iteration. The results showed that the use of Boosting (AdaBoost-SVM) has better accuracy than Bagging optimization model (Bagging-SVM) and SVM with conventional C's election. Using AdaBoost able to correct errors on the base SVM classifiers. And SVM without optimization into the model with the lowest accuracy followed by Bagging-SVM.
Keywords: credit risk, data mining, support vector machine, AdaBoost-SVM, Bagging-SVM
1. PENDAHULUAN
1.1. Latar Belakang
Sesuai dengan Pasal 1 angka 2 Undang-udang Nomor 10 tahun 1998 tentang perbankan: “Bank adalah badan usaha yang menghimpun dana dari masyarakat dalam bentuk simpanan dan menyalurkannya kepada masyarakat dalam bentuk kredit dan atau bentuk-bentuk lainnya dalam rangka meningkatkan taraf hidup rakyat banyak”. Hal ini menyebabkan masyarakat memerlukan bantuan untuk meningkatkan usahanya, tentu memerlukan modal dengan bantuan dari bank. Secara otomatis akan terwujud adanya suatu hubungan hukum berupa perjanjian kredit [1]. Pihak bank berkedudukan sebagai kreditor (pemberi pinjaman) sedangkan para nasabahnya berkedudukan sebagai debitor (peminjam).
Pengelolaan risiko kredit telah dianggap sebagai tugas yang paling penting bagi perusahaan dan lembaga keuangan lainnya [2]. Hal ini terlihat dengan banyaknya pembangunan ekonomi yang inovatif dan berkesinambungan, maka dengan demikian risiko kredit terlibat lebih luas dalam berbagai bidang ekonomi nasional. Dalam lingkup global, risiko kredit terus mengalami peningkatan sejak tahun 1990-an [3]. Dan di tingkat Asia, krisis keuangan Asia juga disebabkan oleh masalah risiko kredit pada tahun 1997 [4]. Maka bagaimana mencegah dan mengendalikan risiko kredit dengan efektif telah menjadi isu yang menantang [2]. Dan menjadi sangat penting bagi management resiko.
Risiko kredit adalah salah satu risiko yang paling penting dan bentuk tertua di pasar keuangan [3]. Dengan kata lain, resiko kredit disebut sebagai resiko kerugian ketika seorang peminjam tidak melunasi kontrak hutangnya [4]. Dalam beberapa tahun mendatang, pengukuran dan pengelolaan risiko kredit akan menjadi subjek yang paling menantang dalam risiko penelitian [3]. Oleh sebab itu telah menjadi kebutuhan yang sangat penting dalam teori dan prakteknya.
http://research.pps.dinus.ac.id , 39 menangani penilaian resiko kredit [5]. Model pendekatan kecerdasan buatan lainnya adalah dengan data mining yang dianggap dapat mendukung kegiatan kredit komersial [6]. Karena data mining memiliki mekanisme pembelajaran mandiri setelah dilakukan suatu proses pelatihan (training).
Penelitian dengan data mining mengenai resiko kredit telah banyak dilakukan dengan berbagai metode. Berdasarkan review penelitian data mining tentang resiko kredit yang telah dilakukan pada tahun 2000 sampai dengan 2010, menunjukkan algoritma Support Vector Machine (SVM) merupakan teknik yang banyak diusulkan oleh para peneliti [7]. SVM masuk dalam sepuluh algoritma terbaik dalam penanganan resiko kredit [8]. SVM menunjukkan ketahanan dan kemampuan generalisasi yang lebih tinggi dibandingkan dengan algoritma yang lain [4]. SVM mempunyai akurasi klasifikasi yang lebih stabil dibandingkan dengan algoritma yang lain [9]. Keunggulan-keunggulan SVM tersebut menjadikan SVM sebagai algoritma yang layak untuk dijadikan solusi dalam menangani resiko kredit.
Beberapa penelitian komparasi berusaha membandingkan kemampuan SVM dengan beberapa algoritma yang lain. Pada penelitian T Warren Liao dan Evangelas Triantaphyllou tahun 2007 membandingkan algoritma data mining LDA, QDA, LOG, KNN, NB, TAN, C45, CBA, NN dan SVM, menunjukkan akurasi SVM menduduki peringkat kedelapan dari sepuluh algoritma tersebut dengan akurasi 84,6% [6]. Dan penelitian Jozef Zurada tahun 2011, menunjukkan performa SVM belum bisa mengungguli LR, NN, kNN pada Quinlan data set [10]. Walaupun terdapat beberapa keunggulan, namun akurasi SVM belum menunjukkan hasil yang diharapkan dengan nilai akurasi yang lebih baik dari algoritma yang lain dalam penentuan kelayakan kredit data mining.
Salah satu perkembangan utama machine learning pada dekade terakhir ini adalah metode ensemble yang memiliki akurasi tinggi dengan cara menggabungkan cukup banyak komponen pengklasifikasi [11]. Metode ensemble yang dapat digunakan untuk meningkatkan akurasi suatu pengklasifikasi adalah Bagging dan Boosting [12]. Penggunaan boosting lebih dipilih karena berfokus pada misclassified tuples dan memiliki kecenderungan peningkatan akurasi yang lebih tinggi daripada Bagging. AdaBoost adalah algortima Boosting yang popular.
SVM merupakan algoritma yang sensitif terhadap pemilihan perameter yang digunakan [9]. Parameter C dianggap dapat meningkatkan akurasi pada SVM [10]. Namun sulitnya menentukan parameter C yang tepat menjadi kendala dalam meningkatkan akurasi SVM [13]. Pemilihan parameter C yang tepat diharapkan dapat diterapkan pada penelitian ini.
Pada penelitian ini AdaBoost akan diterapkan untuk meningkatkan akurasi SVM. Agar dapat membuktikan bahwa penggunaan Boosing lebih baik dari Bagging dan AdaBoost dapat memperbaiki kesalahan dari pengklasifikasi dasar. Maka hasil akurasi AdaBoost akan dibanding dengan penggunaan Bagging dan SVM tunggal.
1.2. Rumusan Masalah
Berdasarkan uraian latar belakang di atas, maka rumusan masalah yaitu:
a. Risiko kredit disebut sebagai resiko kerugian ketika seorang peminjam tidak melunasi kontrak hutangnya. Di lain pihak pengendalian risiko tidak mudah untuk dilakukan.
b. Saat ini masih terjadi kesulitan dalam menentukan parameter yang ideal bagi SVM sehingga akurasinya hanya mencapai 84,6%.
1.3. Tujuan
Tujuan penelitian ini adalah untuk:
a. Memudahkan pengendalian risiko kredit
40 http://research.pps.dinus.ac.id 1.4. Manfaat
Manfaat dari penelitian ini meliputi:
a. Manfaat dari penelitian ini diharapkan dapat digunakan sebagai model untuk memberikan penilaian kredit pada perusahaan dan lembaga keuangan agar dapat membuat suatu perbaikan berupa kebijakan dalam penentuan pemberian kredit
b. Manfaat bagi iptek hasil penelitian ini diharapkan dapat memberikan kontribusi penelitian pada upaya peningkatan akurasi algoritma Support Vector Machine (SVM) pada data mining yang berkaitan dengan resiko kredit (credit risk).
2. LANDASAN TEORI
2.1. Data Mining
Data mining merupakan suatu cara dalam penggalian informasi dari sejumlah data yang biasanya tersimpan dalam repositori dengan menggunakan teknologi pengenalan pola, statistik dan teknik matematika [23]. Penggunaan data mining telah muncul untuk diterapkan di berbagai bidang, baik dari bidang akademis, bisnis ataupun kegiatan medis pada khususnya [24]. Secara umum, data mining dikenal dengan proses penggalian data.
2.2. Algoritma Support Vector Machine (SVM)
Support Vector Machine (SVM) merupakan salah satu dari sepuluh algoritma terbaik data mining [8]. SVM disampaikan pada tahun 1992 oleh Vladimir Vapnik dan rekannya, Bernhard Boser dan Isabelle Guyon, meskipun dasar untuk SVM telah ada sejak 1960-an [12]. Metode ini menjadikan SVM sebagai metode baru yang menjanjikan untuk klasifikasi data, baik linier maupun nonlinier.
Langkah awal suatu algoritma SVM adalah pendefinisian persamaan suatu hyperplane pemisah yang dituliskan dengan:
……….……….1)
W adalah suatu bobot vektor, yaitu W = {W1, W2,…,Wn}; n adalah jumlah atribut dan b merupakan suatu skalar yang disebut dengan bias. Jika berdasarkan pada atribut A1, A2 dengan permisalan tupel pelatihan X = (x1, x2), x1 dan x2 merupakan nilai dari atribut A1 dan A2, dan jika b dianggap sebagai suatu
bobot tambahan w0, maka persamaan suatu hyperplane pemisah dapat ditulis ulang sebagai berikut:
……….……… 2)
Setelah persamaan dapat didefinisikan, nilai x1 dan x2 dapat dimasukkan ke dalam persamaan untuk
http://research.pps.dinus.ac.id , 41 Gambar 1: Pemisahan Dua Kelas Data Dengan Margin Maksimum
Pada Gambar 1, SVM menemukan hyperplane pemisah maksimum, yaitu hyperplane yang mempunyai jarak maksimum antara tupel pelatihan terdekat. Support vector ditunjukkan dengan batasan tebal pada titik tupel. Dengan demikian, setiap titik yang terletak di atas hyperplane pemisah memenuhi rumus:
……….………3)
Sedangkan, titik yang terletak di bawah hyperplane pemisah memenuhi rumus:
……… 4)
Melihat dua kondisi di atas, maka didapatkan dua persamaan hyperplane yaitu:
H1: w0 + w1x1 + w2x2 ≥ 1 untuk yi = +1 ……….. (5)
H2: w0 + w1x1 + w2x2 ≤ -1 untuk yi = -1 ……….. (6)
Perumusan model SVM menggunakan trik matematika yaitu formula Lagrangian. Berdasarkan Lagrangian formulation, Maksimul Margin Hyperplane (MMH) dapat ditulis ulang sebagai suatu batas keputusan (decision boundary) yaitu:
(7)
yi adalah label kelas dari support vector Xi. XT merupakan suatu tupel test. αi dan b0 adalah parameter
numerik yang ditentukan secara otomatis oleh optimalisasi algoritma SVM dan l adalah jumlah vector support.
Adanya hyperplane yang maksimum mampu memberikan akurasi yang lebih baik pada data yang dapat dipisahkan secara linier, namun hal tersebut tidak berlaku bagi data yang tidak dapat dipisahkan secara linier [25]. Model pembelajaran SVM memperkenalkan istilah penalti untuk klasifikasi kesalahan dalam fungsi objektif dengan menggunakan parameter biaya [14]. Dengan adanya parameter biaya terhadap kesalahan, maka fungsi optimasi SVM menjadi:
42 http://research.pps.dinus.ac.id ξi≥0,1≤m≤l merupakan variabel slack untuk memungkinkan kesalahan beberapa klasifikasi dan C
yang disebut sebagai parameter biaya untuk mengontrol keseimbangan antara margin dan kesalahan klasifikasi [13]. Dengan demikian pembatas pada dua kelas diberi suatu tambahan berupa variable slack ξi
sehingga margin pembatas menjadi:
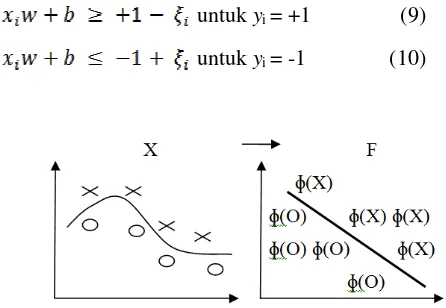
untuk yi = +1 (9)
untuk yi = -1 (10)
Gambar 2. Suatu Kernel Mengubah Problem yang Tidak Liner Menjadi Linier Dalam Ruang Baru
Pada Gambar 2 memperlihatkan adanya permasalahan klasifikasi tidak dapat diselesaikan secara linier pada sampel data X. Pengubahan dari problem data non linier ke linier membutuhkan hitungan yang komplek. Maka diperlukan trik matematika lain yang dapat mempermudah perhitungan, dalam hal ini suatu penggunaan kernel mulai diterapkan. Terdapat 3 persamaan pada kernel SVM yang dapat digunakan yaitu:
a. Polinomial Kernel
b. Kernel Berbasis Gaussian Radial (RBF) c. Sigmoid Kernel
Salah satu kernel yang populer digunakan di SVM adalah kernel RBF, yang memiliki parameter yang dikenal sebagai Gaussian width, σ [
11
]. Sangat berbeda dengan RBF Network, SVM dengan kernel RBF atau biasa disingkat RBFSVM dapat secara automatis menentukan jumlah dan lokasi dari pusat dan nilai-nilai bobot.2.3. AdaBoost
AdaBoost merupakan salah satu dari beberapa varian tentang ide boosting [26]. Ide boosting berasal dari suatu cabang pada penelitian machine learning yang dikenal sebagai computational learning theory. Konsep AdaBoost muncul dari pertanyaan Kearns dan Valiant pada tahun 1988 [8]. Apakah suatu pembelajaran lemah dapat ditingkatkan menjadi suatu pembelajaran yang kuat. Jawaban pertanyaan di atas dijawab oleh Schapire dengan membangun suatu algoritma boosting untuk yang pertama kali. Selanjutnya algoritma ini dikembangkan lagi oleh Freund dan Schapire dengan mengajukan konsep Adaptive Boosting yang dikenal dengan nama AdaBoost.
http://research.pps.dinus.ac.id , 43 yang lain untuk meningkatkan performa klasifikasi. Tentunya secara intuitif, penggabungan beberapa model akan membantu jika model tersebut berbeda satu sama lain. Sehingga masing-masing punya bagian kerja sendiri-sendiri.
AdaBoost dan variannya telah sukses diterapkan pada beberapa bidang (domain) karena dasar teorinya kuat, prediksi yang akurat dan kesederhanaan yang besar [8]. Langkah-langkah algoritma AdaBoost adalah [11]:
a. Input: Suatu kumpulan sample pelatihan dengan label {(x1,y1),…,(xN, yN)}, suatu ComponentLearn Algoritma, jumlah perputaran T.
b. Initialize: Bobot suatu sample pelatihan: = 1 / N, untuk semua i = 1,…,N. c. Do for t = 1,…,T.
1) Gunakan ComponentLearn Algoritma untuk melatih suatu komponen klasifikasi, ht , pada sample
bobot pelatihan.
2) Hitung kesalahan pelatihannya pada ht :
3) Tetapkan bobot untuk component classifier
4) Update bobot sample pelatihan , i = 1,…,N Ct adalah suatu konstanta
normalisasi d. Output: f(x) = sign(
2.4. Bagging
Bagging dan Boosting memiliki kesamaan pendekatan dalam pengambilan keputusan dengan menggunakan beberapa suara yang digabung menjadi prediksi tunggal [
26
]. Namun perbedaan terletak dari cara mereka mengambil prediksi tunggal tersebut. Pada Bagging, model menerima bobot yang sama dari suara terbanyak. Sedangkan pada Boosting, bobot digunakan untuk memberikan pengaruh pada perbaikan bobot selanjutnya.44 http://research.pps.dinus.ac.id Gambar 3 Algoritma Bagging
2.5. OPTIMASI ALGORITMA SUPPORT VECTOR MACHINE (SVM) MENGGUNAKAN
ADABOOST UNTUK PENILAIAN RESIKO KREDIT
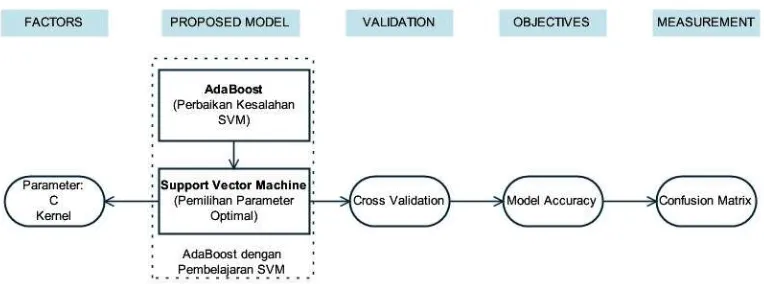
Kerangka pemikiran dari penelitian optimasi algoritma Support Vector Machine (SVM) menggunakan adaboost untuk penilaian resiko kredit ini adalah sebagai berikut.
Gambar 4Kerangka Pemikiran
3. METODE PENELITIAN
3.1. Pengumpulan dan Pengolahan Data
http://research.pps.dinus.ac.id , 45 klasifikasi di bidang financial yang banyak digunakan oleh para peneliti, dengan jumlah data dan atribut yang tidak begitu besar. Sehingga tidak terlalu lama dalam proses eksekusi.
Data terdiri dari 14 atribut dengan tipe Categorical, Integer, dan Real. Jumlah data sebanyak 690 baris. Data diklasifikasikan ke dalam 2 kelas, yaitu kelas Positif(+) dan Negatif(-). Data kelas + terdiri dari 307 data atau 44.5% dari keseluruhan data, sedangkan data kelas – terdiri dari 383 data atau sebanyak 55.5% dari keseluruhan data. Data Australian Credit Approval tidak memiliki nilai dari suatu atribut yang tidak terisi (missing value atribute) ataupun nilai keluaran (output) yang tidak terisi (missing value label). Sehingga teknik replace missing value pada pre-processing data yaitu tidak dilakukan.
Pengolahan data awal yang dilakukan adalah mengubah tipe data keluaran dari tipe Integer ke tipe Binomial. Hal ini dilakukan untuk memperjelas pekerjaan suatu algortima yang digunakan, bahwa keluaran kelas adalah biner (positif atau negatif), bukan merupakan regresi.
3.2. Pemodelan
AdaBoost dengan pembelajaran SVM diusulkan untuk meningkatkan akurasi pengklasifikasi SVM. SVM digunakan untuk mengatasi kelemahan pembelajaran Pohon Keputusan dan Jaringan Syaraf Tiruan yang telah marak digunakan [27] Ketika keduanya digunakan sebagai pembelajaran lemah pada AdaBoost.
Pada penelitian [16], penggunaan Boosting dengan pembelajaran SVM telah dilakukan. Hasil penelitian ini, menunjukkan metode yang diusulkan mempunyai kemampuan belajar kompetitif dan memperoleh akurasi yang lebih baik dari SVM. Algoritma AdaBoost-SVM yang digunakan sebagai berikut:
Tabel 1. Algoritma Boost-SVM Begin
Diberikan data (x1,y1),…,(x2,y2), xi ϵ X, yi ϵ {+1,-1}
Inisialisasi: D1(i) = 1 / Ɩ
For k = 1,…,K
Pilih data pelatihan menurut bobot masing-masing Dt. Latih SVM
Dapatkan pembelajaran SVM: hk:X->{+1,-1}
Prediksi sample menggunakan pembelajaran
Hitung bobot pembelajaran βk menggunakan tingkat errornya
Perbarui bobot tiap sample:
Zk adalah factor normalisasi
end loop
Keluaran pembelajaran terakhir:
46 http://research.pps.dinus.ac.id Kinerja klasifikasi SVM tergantung pada pemilihan C [13]. Nilai C dapat didefinisikan sebelumnya (secara manual) maupun melalui prosedur tuning. Selain parameter C, pemilihan kernel juga berpengaruh pada kinerja klasifikasi SVM [14]. Sedangkan pada AdaBoost jumlah putaran atau iterasi yang cukup besar dapat mengurangi tingkat kesalahan pengklasifikasi dasar [15]. Parameter yang telah dipelajari tersebut akan digunakan sebagai penelitian untuk dapat meningkatkan akurasi pengklasifikasi dasar SVM, melalui pemilihan kernel, nilai parameter C dan iterasi yang tepat.
3.3. Pengujian Model
Pengujian dilakukan pada pengklasifikasi dasar SVM yaitu SVM Linier (tanpa optimasi), SVM optimasi dengan pemilihan nilai parameter C=30 dan AdaBoost-SVM. Berikutnya hasil percobaan dibandingkan dengan model optimasi lainnya yaitu penggunaan Bagging, untuk menguji apakah Boosting lebih baik dari Bagging.
4. HASIL DAN PEMBAHASAN
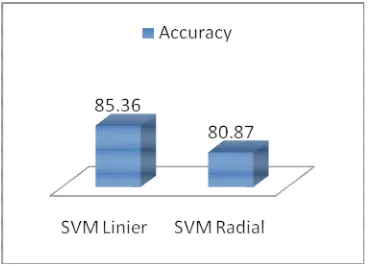
Pada langkah awal penelitian, pemilihan kernel dilakukan pada pembelajaran SVM. Perbandingan dilakukan antara kernel dasar (linier) dan kernel RBFSVM.
Gambar 5. Perbandingan Akurasi Kernel Liner dan RBF Pada SVM
Pada perbandingan di atas hasil akurasi SVM dengan kernel linier lebih baik dari pada kernel RBF dengan data kredit Australia. Maka SVM dengan kernel linier akan dicari lebih lanjut parameter yang ke-2 yaitu nilai parameter C untuk dapat memperoleh akurasi yang lebih baik.
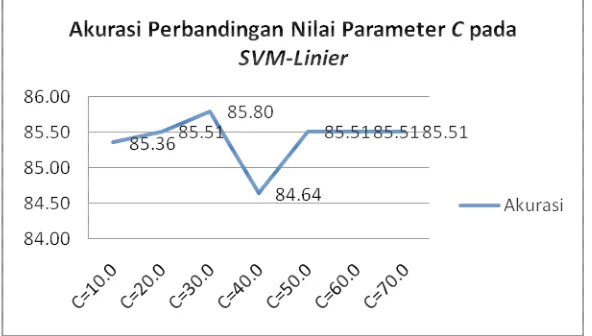
Pemilihan nilai parameter C akan dipilih dengan melihat implikasi terhadap hasil akurasi yang paling tinggi terhadap nilai C yang diberikan. Nilai C ditentukan sebelumnya dengan mencari tahu nilai C dari 1 sampai dengan 70, nilai C sampai dengan 70. Berhenti pada nilai 70 disebabkan pada nilai C dari 50 sampai dengan 70 mengalami nilai yang stagnan terus (tidak ada perubahan).
http://research.pps.dinus.ac.id , 47
Gambar 6: Akurasi Perbandingan Nilai Parameter C pada SVM
Linier
Hasil percobaan nilai C dengan akurasi yang paling tinggi didapat oleh C dengan nilai 30 dengan akurasi 85.80. Akurasi ini lebih baik dibandingkan dengan SVM tanpa optimasi nilai parameter C. Dengan didapatkannya parameter optimasi SVM dengan akurasi yang lebih baik, yaitu menggunakan kernel linier dan parameter C dengan nilai 30. Maka selanjutnya paremeter-parameter pada SVM tersebut akan digunakan sebagai base classifier dari pembelajaran AdaBoost.
Berdasarkan [15], tingkat kesalahan base classifier dapat dikurangi dengan memperbesar iterasi yang tepat pada AdaBoost. Maka pada percobaan selanjutnya, pemilihan iterasi K digunakan untuk memperoleh hasil yang lebih baik. Hasil akurasi diperbandingkan pada setiap akurasi.
Tabel 2: Perbandingan Hasil Akurasi Terhadap Iterasi K Pada AdaBost-SVM
Iterasi K=1 K=2 K=3 K=4 K=5 K=6 K=7 K=8 K=9 K=10 K=20 K=30
Akurasi 85.80 85.80 85.80 85.80 85.80 85.80 86.09 86.09 86.09 86.09 86.09 86.09
Dalam percobaan ini, iterasi AdaBost dimulai dari angka 1 sampai dengan nilai default putarannya yaitu 10. Setelah putaran ke-7 angka akurasi baru meningkat, dalam hal ini berarti AdaBoost telah dapat memperbaiki kesalahan pada SVM. Sampai dengan nilai K=10 (default), angka akurasi tidak berubah. Kemudian dilanjutkan pada nilai K=20 dan K=30 berhenti karena tidak ada perubahan pada nilai akurasi tersebut.
48 http://research.pps.dinus.ac.id
Hasil penelitian menunjukkan bahwa AdaBoost-SVM memiliki akurasi yang lebih baik dari pada model optimasi lainnya yaitu penggunaan Bagging maupun SVM Optimasi dengan pemilihan nilai C secara konvensional. Penggunaan AdaBoost mampu memperbaiki kesalahan pada model SVM Optimasi. Dan SVM tanpa optimasi menjadi model dengan akurasi terendah disusul dengan Bagging-SVM.
5. PENUTUP
5.1. Kesimpulan
Pada kesimpulan penelitian ini, menunjukkan bahwa penggunaan Boosting dalam hal ini AdaBoost-SVM memiliki akurasi yang lebih baik dari model Bagging-SVM. Penggunaan Boosting dapat dikatakan lebih baik dari Bagging. Dan Bagging-SVM mempunyai nilai akurasi dibawah SVM dengan pemilihan parameter C yang tepat, Sedangkan pengaturan nilai parameter C terbukti dapat meningkatkan akurasi SVM dasar.
5.2. Saran
Rekomendasi dari penelitian ini dengan melihat atas segala kekurangan dan sebagai bahan pekerjaan selanjutnya. Maka diperlukan penggunaan metode atau algoritma khusus untuk mencari nilai parameter C yang optimal, bukan lagi dilakukan secara manual.
DAFTAR PUSTAKA
[1] Setyawan, Aneka Masalah Hukum dan Hukum Acara Perdata. Bandung, Indonesia: Alumni, 1992. [2] Ning LIU, En jun XIA, and Li YANG, "Research and application of PSO-BP Neural Networks in
Credit Risk Assessment," in International Symposium on Computational Intelligence and Design, Beijing, 2010, pp. 103 - 106.
[3] Haiying Ma and Yu Guo, "Credit Risk Evaluation Based On Artificial Intelligence Technology," in International Conference on Artificial Intelligence and Computational Intelligence, Beijing, 2010, pp. 200 - 203.
[4] Hong Yu, Xiaolei Huang, Xiaorong Hu, and Hengwen Cai, "A Comparative Study on Data Mining Algorithms for Individual Credit Risk Evaluation," in International Conference on Management of e-Commerce and e-Government, Beijing, 2010, pp. 35 - 38.
[5] Jiun Yao Chiu, Yan Yan, Gao Xuedong, and Rung Ching Chen, "A New Method for Estimating Bank Credit Risk," in International Conference on Technologies and Applications of Artificial Intelligence, Taichung, 2010, pp. 503 - 507.
[6] T Warren Liao and Evangelos Triantaphyllou,. USA: World Scientific Publishing Co. Pte. Ltd., 2007, vol. 6, ch. 2, p. 113.
http://research.pps.dinus.ac.id , 49 Operations Management, Kuala Lumpur, 2011, p. 420.
[8] Xindong Wu and Vipin Kumar, The Top Ten Algorithms in Data Mining.: CRC Press, 2009.
[9] Defu Zhang, Huang Hongyi, Qingshan Chen, and Yi Jiang, "A Comparison Study of Credit Scoring Models," in Third International Conference on Natural Computation, China, 2007.
[10] Jozef Zurada and K Niki Kunene, "Comparisons of the Performance of Computational Intelligence Methods fo rLoan Granting Decisions," in Proceedings of the 44th Hawaii International Conference on System Sciences, Hawaii, 2011, p. 8.
[11] Xuchun Li, Lei Wang, and Eric Sung, "AdaBoost with SVM-based component classifiers," Engineering Applications of Artificial Intelligence, vol. 21, pp. 785 - 795, 2008.
[12] Jiawei Han and Micheline Kamber, Data Mining Concepts and Techniques, 2nd ed. San Francisco, United State America: Morgan Kaufmann Publishers, 2007.
[13] Yan Li-mei, "Parameter Selection Problems in Support Vector Machine," in World Congress on Computer Science and Information Engineering, 2009, pp. 351-355.
[14] Yulin Dong, Zhonghang Xia, Manghui Tu, and Guangming Xing, "An Optimization Method for Selecting Parameters in Support Vector Machines," in Sixth International Conference on Machine Learning and Applications, 2007.
[15] Xiaodan Wang, Chongming Wu, Chunying Zheng, and Wei Wang, "Improved Algorithm For AdaBoost With SVM Base," in Proc. 5th IEEE Int. Conf. on Cognitive Informatics (ICCI'06), 2006, pp. 948-952.
[16] Xiaolong Zhang and Fang Ren, "Improving Svm Learning Accuracy with Adaboost," in Fourth International Conference on Natural Computation, 2008, pp. 221-225.
[17] Malayu S.P. Hasibuan, Dasar-dasar Perbankan. Jakarta: Bumi Aksara, 2004.
[18] Suhardjono, Manajemen Perkreditan Usaha Kecil dan Menengah. Jakarta: UPP AMP YKPN Ikut
[21] Ruddy Tri Santoso, Kredit Usaha Perbankan. Yogyakarta: Andi Yogyakarta, 1996.
[22] Jozef Zurada, "Could Decision Trees Improve the Classification Accuracy and Interpretability of Loan Granting Decisions," in Interpretability of Loan Granting Decisions, Hawaii, 2010, pp. 1 - 9. [23] Daniel T Larose, Data Mining Methods and Models. Hoboken, New Jersey, United State of America:
John Wiley & Sons, Inc., 2006.
[24] Florin Gurunescu, Data Mining Consepts, Models and Techniques, 12th ed. Verlag Berlin Heidelberg, Germany: Springer, 2011.
[25] Burgers C,., 1998, ch. 2(2), pp. 121–167.
[26] Ian H Witten, Eibe Frank, and Mark A Hall, Data Mining Practical Machine Learning Tools and Techniques, 3rd ed. USA: Morgan Kaufmann Publishers, 2011.