Dalam kurun waktu terakhir, pertambahan jumlah dokumen karya ilmiah berbahasa Indonesia
meningkat sangat pesat. Tanpa ada pengubahan dalam sistem pemerolehan informasi, volume
data yang meningkat dapat mengakibatkan turunnya performa sistem pemerolehan informasi,
terutama dalam hal waktu retrieval.
Salah satu metode yang diusulkan untuk mempersingkat waktu retrieval adalah
pengelompokan koleksi. Dalam tugas akhir ini, G-Means dipilih sebagai algoritma pemodelan
cluster. Keuntungan implementasi G-Means adalah kemampuan algoritma ini untuk memilih
jumlah cluster yang paling optimal.
Hasil pengelompokan koleksi kemudian diuji dalam lingkungan sistem pemerolehan informasi
untuk melihat seberapa baik pengelompokan koleksi dalam mempersingkat waktu retrieval, dan
seberapa besar pengaruhnya terhadap precision.
Data yang digunakan adalah karya ilmiah berbahasa Indonesia sebanyak 100 karya. Dari
hasil pengujian, ditemukan bahwa waktu retrieval lebih singkat hingga 16,3%, dengan rerata
waktu retrieval sebesar 12,88 detik dan precision sebesar 47%.
In recent years, Indonesian-written scientific papers grow significantly in term of number.
Without any improvement in information retrieval systems, increasing data volume could lead to
poor system performance, especially in its retrieval time.
One proposed method to improve retrieval time is collection clustering. G-Means was chosen
for cluster modeling algorithm, as it can determine number of generated clusters automatically.
Clustering collection results are tested in information retrieval system to find how significant
clustering can reduce retrieval time, and whether it has impact to systemâs average precision.
We use 100 Indonesian scientific papers as collection. Based from the results, retrieval time
gain 16.3% faster, with average retrieval time is about 12,88 seconds and average precision is
about 47%.
CLUSTER DENGAN G-MEANS CLUSTERING
SKRIPSI
Diajukan untuk memenuhi salah satu syarat
memperoleh gelar Sarjana Teknik Informatika (S.Kom.)
Program Studi Teknik Informatika
Disusun Oleh :
AGUSTINUS AGRI ARDYAN
NIM : 125314109
PROGRAM STUDI TEKNIK INFORMATIKA
JURUSAN TEKNIK INFORMATIKA
FAKULTAS SAINS DAN TEKNOLOGI
UNIVERSITAS SANATA DHARMA
YOGYAKARTA
THESIS
Presented as partial fulfillment of the requirements
To obtain the Bachelor Degree of Computer (S.Kom.)
In Informatics Engineering
Written by :
AGUSTINUS AGRI ARDYAN
NIM : 125314109
DEPARTMENT OF INFORMATICS ENGINEERING
FACULTY OF SCIENCE AND TECHNOLOGY
SANATA DHARMA UNIVERSITY
YOGYAKARTA
vi
HALAMAN MOTTO
vii
HALAMAN PERSEMBAHAN
Penelitian ini dipersembahkan untuk :
Allah Bapa, Putera dan Roh Kudus atas berkat dan bimbinganNya
Kedua orangtuaku, Mikael âPaeâ Santosa dan Fransiska
âIbukâ
Tasri Aryani yang
dengan sabar selalu membimbing langkahku
Adikku, Philipus âBro' Agri Adhiatma, yang selalu menghibur setiap saat
Teman-teman Teknik Informatika yang selalu suportif dan memberikan banyak
sekali pengalaman dan ilmu baru.
Kepada segenap masyarakat yang terpanggil dan ikut berkontribusi dalam
kemajuan ilmu pengetahuan.
viii
DAFTAR ISI
SISTEM PEMEROLEHAN INFORMASI KARYA ILMIAH BERBASIS
CLUSTER DENGAN G-MEANS CLUSTERING ... i
CLUSTER BASED INFORMATION RETRIEVAL SYSTEM FOR
SCIENTIFIC PAPER RETRIEVAL USING G-MEANS CLUSTERING ... ii
HALAMAN PERSETUJUAN SKRIPSI ... iii
HALAMAN PENGESAHAN SKRIPSI ... iv
PERNYATAAN KEASLIAN KARYA ... v
HALAMAN MOTTO ... vi
HALAMAN PERSEMBAHAN ... vii
DAFTAR ISI ... viii
DAFTAR GAMBAR ... xii
DAFTAR TABEL ... xiv
DAFTAR PERSAMAAN ... xviii
ABSTRAK ... xix
ABSTRACT ... xx
LEMBAR PERNYATAAN PERSETUJUAN PUBLIKASI... xxi
KATA PENGANTAR ... xxii
BAB I PENDAHULUAN ... 1
1.1. Latar Belakang ... 1
1.2. Rumusan Masalah ... 2
1.3. Tujuan Penelitian ... 2
1.4. Batasan Masalah ... 3
1.5. Metodologi Penelitian ... 3
1.6. Sistematika Penulisan ... 5
BAB II LANDASAN TEORI ... 7
2.1. Konsep Pemerolehan Informasi ... 7
2.1.1. Operasi Teks ... 7
2.1.1.1. Stopword ... 7
2.1.1.2. Stemming ... 7
ix
2.1.2. Term-Document Matrix ... 10
2.1.3. TF-IDF sebagai Metode Pembobotan ... 11
2.1.4. Evaluasi Pemerolehan Informasi ... 12
2.2. Konsep Pengelompokan Dokumen ... 12
2.2.1. Clustering dalam Pemerolehan Informasi... 12
2.2.2. Hipotesis Cluster ... 13
2.2.3. K-Means ... 13
2.2.4. G-Means ... 15
2.2.5. Evaluasi Cluster ... 18
2.2.5.1. Purity ... 18
BAB III ANALISIS DAN PERANCANGAN SISTEM ... 19
3.1. Analisis Sistem ... 19
3.1.1. Deskripsi Sistem ... 19
3.1.1.1. Sub Sistem Pengelompokan Dokumen ... 19
3.1.1.2. Sub Sistem Pencarian Dokumen ... 23
3.1.2. Data yang Digunakan ... 26
3.1.3. Analisis Kebutuhan Pengguna ... 26
3.2. Perancangan Sistem ... 26
3.2.1. Data Flow Diagram ... 26
3.2.1.1. Diagram Konteks ... 26
3.2.1.2. Overview DFD ... 27
3.2.1.3. DFD Level 2 ... 28
3.2.2. Diagram Berjenjang ... 30
3.2.3. Deskripsi Proses ... 30
3.2.3.1. Deskripsi Proses 1 : Pengelompokan Dokumen ... 30
3.2.3.2. Deskripsi Proses 2 : Pencarian Dokumen ... 31
3.2.4. Rancangan Basis Data ... 33
3.2.4.1. Desain Konseptual ... 33
3.2.4.2. Desain Logikal ... 33
3.2.4.3. Desain Fisikal ... 34
3.2.5. Rancangan Antarmuka Pengguna ... 37
3.2.5.1. Antarmuka Pengelompokan Dokumen ... 37
x
BAB IV IMPLEMENTASI SISTEM ... 38
4.1. Struktur Data ... 38
4.2. Implementasi Basis Data ... 39
4.3. Implementasi Pengelompokan Dokumen ... 39
4.3.1. Implementasi G-Means ... 39
4.4. Implementasi Pencarian Dokumen ... 48
4.4.1. Implementasi Preprocessing Query ... 48
4.4.2. Implementasi Pencarian Berbasis Cluster dan Konvensional ... 50
4.5. Implementasi Antarmuka Pengguna... 51
4.5.1. Implementasi Antarmuka Pengelompokan Dokumen ... 51
4.5.2. Implementasi Antarmuka Pencarian Dokumen ... 52
BAB V ANALISIS HASIL PENELITIAN ... 54
5.1. Analisis Hasil Sistem ... 54
5.1.1. Hasil Pengelompokan Dokumen ... 54
5.1.1.1. Purity ... 58
5.1.2. Hasil Pengujian Pencarian Dokumen berdasar Kueri Pengguna ... 59
5.1.2.1. Pencarian dengan query data i i g ... 59
5.1.2.2. Pencarian dengan query aï e ayes ... 64
5.1.2.3. Pencarian dengan query klasifikasi ... 68
5.1.2.4. Pencarian dengan query siste pe duku g keputusa ... 73
5.1.2.5. Pencarian dengan query jari ga ko puter ... 78
5.1.2.6. Pencarian dengan query data i i g e ggu aka k- ea s ... 82
5.1.2.7. Pencarian dengan query kesehata a usia ... 86
5.1.2.8. Pencarian dengan query diag osa pe yakit ... 90
5.1.2.9. Pencarian dengan query t p udp ... 94
5.1.2.10. Pencarian dengan query ireless ... 98
5.2. Pembahasan ... 102
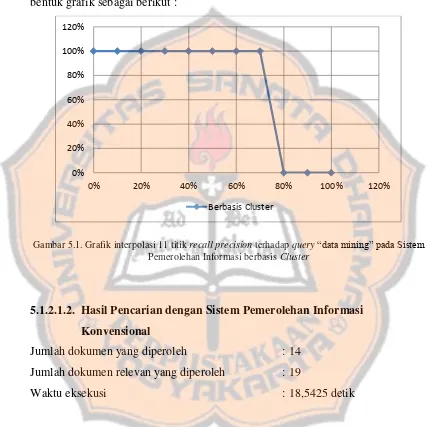
5.2.1. Rerata Interpolasi 11 Titik Recall â Precision ... 102
5.2.1.1. Sistem Pemerolehan Informasi berbasis Cluster ... 102
5.2.1.2. Sistem Pemerolehan Informasi Konvensional ... 103
5.2.2. Waktu Eksekusi ... 105
5.3. Kelebihan dan Kekurangan Sistem ... 107
xi
5.3.2. Kekurangan Sistem ... 107
BAB VI KESIMPULAN DAN SARAN ... 108
6.1. Kesimpulan ... 108
6.2. Saran ... 108
xii
DAFTAR GAMBAR
Gambar 2.1. Visualisasi term-document matrix... 11
Gambar 2.2. Pseudocode algoritma K-Means (Manning et al, 2008) ... 13
Gambar 2.3. Visualisasi proses yang terjadi dalam algoritma K-Means (Manning et al, 2008) ... 14
Gambar 2.4. Visualisasi G-Means dalam suatu dataset 2 dimensi dengan 1000 point. Algoritma G-Means mencoba mencari normalitas dalam sebaran titik pada suatu cluster (Hamerly et al., 2004) ... 15
Gambar 3.1. Alur proses pengklusteran dokumen ... 20
Gambar 3.2. Alur proses pencarian dokumen ... 24
Gambar 3.3. Sistem Pemerolehan Informasi Konvensional (Baeza, 1999)... 25
Gambar 3.4. Sistem Pemerolehan Informasi Berbasis Cluster ... 25
Gambar 3.5. Diagram konteks dari sistem yang akan dibangun ... 26
Gambar 3.6. Overview DFD dari sistem yang akan dibangun ... 27
Gambar 3.7. DFD level 2 dari proses pengelompokan dokumen ... 28
Gambar 3.8. DFD level 2 dari proses pencarian dokumen ... 29
Gambar 3.9. Diagram berjenjang dari sistem yang akan dikembangkan ... 30
Gambar 3.10. ERD untuk sistem yang akan dibangun ... 33
Gambar 3.11. Model relasional untuk sistem yang akan dibangun ... 33
Gambar 3.12. Rancangan antarmuka pengguna untuk proses pengelompokan dokumen ... 37
Gambar 3.13. Rancangan antarmuka pengguna untuk proses pencarian dokumen ... 37
Gambar 4.1 Struktur data untuk term list yang menggunakan LinkedList dan document list yang menggunakan ArrayList ... 38
Gambar 4.2. Struktur data untuk master term list yang berupa HashMap ... 39
Gambar 4.3 Capture screen antarmuka subsistem pengelompokan dokumen (1) ... 51
Gambar 4.4. Capture screen antarmuka subsistem pengelompokan dokumen (2) ... 52
Gambar 4.5. Capture screen antarmuka subsistem pencarian dokumen ... 52
Gambar 4.6. Implementasi antarmuka pengguna subsistem pencarian dokumen berbasis cluster ... 53
Gambar 4.7. Implementasi antarmuka pengguna subsistem pencarian dokumen berbasis cluster ... 53
Gambar 5.1. Grafik interpolasi 11 titik recall precision terhadap query data i i g pada Sistem Pemerolehan Informasi berbasis Cluster ... 61
Gambar 5.2. Grafik interpolasi 11 titik recall precision terhadap query data i i g pada Sistem Pemerolehan Informasi Konvensional ... 64
Gambar 5.3. Grafik interpolasi 11 titik recall precision terhadap query aï e ayes pada Sistem Pemerolehan Informasi berbasis Cluster ... 66
xiii
Gambar 5.5. Grafik interpolasi 11 titik recall precision terhadap query klasifikasi pada
Sistem Pemerolehan Informasi berbasis Cluster ... 70
Gambar 5.6. Grafik interpolasi 11 titik recall precision terhadap query klasifikasi pada Sistem Pemerolehan Informasi Konvensional ... 72
Gambar 5.7. Grafik interpolasi 11 titik recall precision terhadap query siste pe duku g keputusa pada âiste Pe eroleha I for asi er asis Cluster ... 75
Gambar 5.8. Grafik interpolasi 11 titik recall precision terhadap query siste pe duku g keputusa pada âiste Pe eroleha I formasi Konvensional ... 78
Gambar 5.9. Grafik interpolasi 11 titik recall precision terhadap query jari ga ko puter pada âiste Pe eroleha I for asi er asis Cluster ... 80
Gambar 5.10. Grafik interpolasi 11 titik recall precision terhadap query jari ga ko puter pada âiste Pe eroleha I for asi Ko e sio al ... 82
Gambar 5.11. Grafik interpolasi 11 titik recall precision terhadap query aï e ayes pada Sistem Pemerolehan Informasi berbasis Cluster ... 84
Gambar 5.12. Grafik interpolasi 11 titik recall precision terhadap query data i i g menggunakan k- ea s pada âiste Pe eroleha I for asi Ko e sio al ... 86
Gambar 5.13. Grafik interpolasi 11 titik recall precision terhadap query kesehata a usia pada âiste Pe eroleha I for asi er asis Cluster ... 88
Gambar 5.14. Grafik interpolasi 11 titik recall precision terhadap query aï e ayes pada Sistem Pemerolehan Informasi Konvensional ... 90
Gambar 5.15. Grafik interpolasi 11 titik recall precision terhadap query diag osa pe yakit pada âiste Pe eroleha I for asi er asis Cluster ... 92
Gambar 5.16. Grafik interpolasi 11 titik recall precision terhadap query diag osa pe yakit pada âiste Pe eroleha I for asi Ko e sio al ... 94
Gambar 5.17. Grafik interpolasi 11 titik recall precision terhadap query t p udp pada Sistem Pemerolehan Informasi berbasis Cluster ... 96
Gambar 5.18. Grafik interpolasi 11 titik recall precision terhadap query t p udp pada Sistem Pemerolehan Informasi Konvensional ... 98
Gambar 5.19. Grafik interpolasi 11 titik recall precision terhadap query ireless pada Sistem Pemerolehan Informasi berbasis Cluster ... 100
Gambar 5.20. Grafik interpolasi 11 titik recall precision terhadap query ireless pada Sistem Pemerolehan Informasi Konvensional ... 102
Gambar 5.21. Grafik rerata interpolasi 11 titik recall precision kedua jenis sistem ... 104
Gambar 5.22 Grafik rerata waktu retrieval kedua jenis sistem (1) ... 106
xiv
DAFTAR TABEL
Tabel 2.1. Tabel kombinasi awalan dan akhiran yang tidak diijinkan ... 8
Ta el 2.2. Cara Me e tuka Tipe A ala U tuk a ala te- ... 9
Tabel 2.3. Awalan yang diijinkan dihapus berdasarkan Tipe Awalannya ... 10
Tabel 2.4. Perancangan term document matrix ... 10
Tabel 3.1. Kebutuhan fungsional pengguna sistem ... 26
Tabel 3.2. Desain basis data untuk Sistem Pemerolehan Informasi berbasis Cluster pada level fisikal untuk relasi Cluster ... 34
Tabel 3.3. Desain basis data untuk Sistem Pemerolehan Informasi berbasis Cluster pada level fisikal untuk relasi Documents ... 34
Tabel 3.4. Desain basis data untuk Sistem Pemerolehan Informasi berbasis Cluster pada level fisikal untuk relasi Centroid ... 35
Tabel 3.5. Desain basis data untuk Sistem Pemerolehan Informasi berbasis Cluster pada level fisikal untuk relasi Term... 35
Tabel 3.6. Desain basis data untuk Sistem Pemerolehan Informasi berbasis Cluster pada level fisikal untuk relasi Term_Document ... 36
Tabel 3.7. Desain basis data untuk Sistem Pemerolehan Informasi berbasis Cluster pada level fisikal untuk relasi Stopword_Ina ... 36
Tabel 3.8. Desain basis data untuk Sistem Pemerolehan Informasi berbasis Cluster pada level fisikal untuk relasi Rootword_Ina ... 36
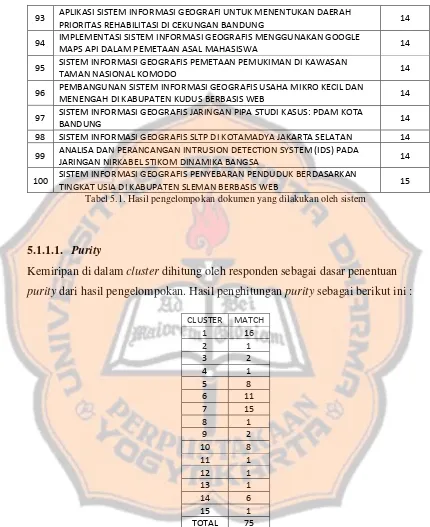
Tabel 5.1. Hasil pengelompokan dokumen yang dilakukan oleh sistem ... 58
Tabel 5.2. Hasil penghitungan dokumen-dokumen yang sesuai dengan cluster yang ditempati ... 58
Tabel 5.3. Hasil pencarian dengan query data i i g pada âiste Pe eroleha Informasi berbasis Cluster ... 60
Tabel 5.4. Penghitungan recall - precision terhadap query data i i g pada âiste Pemerolehan Informasi berbasis Cluster ... 60
Tabel 5.5. Interpolasi 11 titik recall precision terhadap query data i i g pada âiste Pemerolehan Informasi berbasis Cluster ... 61
Tabel 5.6. Hasil pencarian dengan query data i i g pada âiste Pe eroleha Informasi Konvensional... 62
Tabel 5.7. Penghitungan recall - precision terhadap query data i i g pada âiste Pemerolehan Informasi Konvensional ... 63
Tabel 5.8. Interpolasi 11 titik recall precision terhadap query data i i g pada âiste Pemerolehan Informasi berbasis Cluster ... 63
Tabel 5.9. Hasil pencarian dengan query aï e ayes pada âiste Pe eroleha Informasi berbasis Cluster ... 64
Tabel 5.10. Penghitungan recall - precision terhadap query aï e ayes pada âiste Pemerolehan Informasi berbasis Cluster ... 65
xv
Tabel 5.12. Hasil pencarian dengan query aï e ayes pada âiste Pe eroleha Informasi Konvensional... 66 Tabel 5.13. Penghitungan recall - precision terhadap query aï e ayes pada âiste Pemerolehan Informasi Konvensional ... 67 Tabel 5.14. Interpolasi 11 titik recall precision terhadap query aï e ayes pada âiste Pemerolehan Informasi Konvensional ... 67 Tabel 5.15. Hasil pencarian dengan query klasifikasi pada âiste Pe eroleha
Informasi berbasis Cluster ... 69 Tabel 5.16. Penghitungan recall - precision terhadap query klasifikasi pada âiste Pemerolehan Informasi berbasis Cluster ... 69 Tabel 5.17. Interpolasi 11 titik recall precision terhadap query klasifikasi pada âiste Pemerolehan Informasi berbasis Cluster ... 69 Tabel 5.18. Hasil pencarian dengan query klasifikasi pada âiste Pe eroleha
Informasi Konvensional... 71 Tabel 5.19. Penghitungan recall - precision terhadap query klasifikasi pada âiste Pemerolehan Informasi Konvensional ... 72 Tabel 5.20. Interpolasi 11 titik recallprecision terhadap queryâklasifikasiâ pada Sistem
Pemerolehan Informasi Konvensional ... 72 Tabel 5.21. Hasil pencarian dengan query siste pe duku g keputusa pada âiste Pemerolehan Informasi berbasis Cluster ... 74 Tabel 5.22. Penghitungan recall - precision terhadap query siste pe duku g
keputusa pada âiste Pe eroleha I for asi er asis Cluster ... 74 Tabel 5.23. Interpolasi 11 titik recall precision terhadap query siste pe duku g
keputusa pada âiste Pe eroleha I for asi er asis Cluster ... 75 Tabel 5.24. Hasil pencarian dengan query siste pe duku g keputusa pada âiste Pemerolehan Informasi Konvensional ... 77 Tabel 5.25. Penghitungan recall - precision terhadap query siste pe duku g
keputusa pada âiste Pe eroleha I for asi Ko e sio al ... 77 Tabel 5.26. Interpolasi 11 titik recall precision terhadap query siste pe duku g
keputusa pada âiste Pe eroleha I for asi Ko e sio al ... 78 Tabel 5.27. Hasil pencarian dengan query jari ga ko puter pada âiste
Pemerolehan Informasi berbasis Cluster ... 79 Tabel 5.28. Penghitungan recall - precision terhadap query jari ga ko puter pada Sistem Pemerolehan Informasi berbasis Cluster ... 79 Tabel 5.29. Interpolasi 11 titik recall precision terhadap query jari ga ko puter pada Sistem Pemerolehan Informasi berbasis Cluster ... 79 Tabel 5.30. Hasil pencarian dengan query jari ga ko puter pada âiste
xvi
Tabel 5.34. Penghitungan recall - precision terhadap query data i i g e ggu aka k
-ea s pada âiste Pe eroleha I for asi erbasis Cluster ... 83 Tabel 5.35. Interpolasi 11 titik recall precision terhadap query data i i g
menggunakan k- ea s pada âiste Pemerolehan Informasi berbasis Cluster ... 83 Tabel 5.36. Hasil pencarian dengan query data i i g e ggu aka k- ea s pada Sistem Pemerolehan Informasi Konvensional ... 84 Tabel 5.37. Penghitungan recall - precision terhadap query data i i g e ggu aka k -means pada âiste Pe eroleha I for asi Ko e sio al ... 85 Tabel 5.38. Interpolasi 11 titik recall precision terhadap query data i i g
menggunakan k- ea s pada âiste Pe eroleha I for asi Ko e sio al ... 85 Tabel 5.39. Hasil pencarian dengan query kesehata a usia pada âiste
Pemerolehan Informasi berbasis Cluster ... 87 Tabel 5.40. Penghitungan recall - precision terhadap query kesehata a usia pada Sistem Pemerolehan Informasi berbasis Cluster ... 87 Tabel 5.41. Interpolasi 11 titik recall precision terhadap query kesehata a usia pada Sistem Pemerolehan Informasi berbasis Cluster ... 87 Tabel 5.42. Hasil pencarian dengan query kesehata a usia pada âiste
Pemerolehan Informasi Konvensional ... 88 Tabel 5.43. Penghitungan recall - precision terhadap query kesehata a usia pada Sistem Pemerolehan Informasi Konvensional ... 89 Tabel 5.44. Interpolasi 11 titik recall precision terhadap query aï e ayes pada âiste Pemerolehan Informasi Konvensional ... 89 Tabel 5.45. Hasil pencarian dengan query diag osa pe yakit pada âiste Pe eroleha Informasi berbasis Cluster ... 90 Tabel 5.46. Penghitungan recall - precision terhadap query diag osa pe yakit pada Sistem Pemerolehan Informasi berbasis Cluster ... 91 Tabel 5.47. Interpolasi 11 titik recall precision terhadap query diag osa pe yakit pada Sistem Pemerolehan Informasi berbasis Cluster ... 91 Tabel 5.48. Hasil pencarian dengan query diag osa pe yakit pada âiste Pe eroleha Informasi Konvensional... 93 Tabel 5.49. Penghitungan recall - precision terhadap query diag osa pe yakit pada Sistem Pemerolehan Informasi Konvensional ... 93 Tabel 5.50. Interpolasi 11 titik recall precision terhadap query diag osa pe yakit pada Sistem Pemerolehan Informasi Konvensional ... 93 Tabel 5.51. Hasil pencarian dengan query t p udp pada âiste Pe eroleha I for asi berbasis Cluster ... 95 Tabel 5.52. Penghitungan recall - precision terhadap query t p udp pada âiste
Pemerolehan Informasi berbasis Cluster ... 95 Tabel 5.53. Interpolasi 11 titik recall precision terhadap query t p udp pada âiste Pemerolehan Informasi berbasis Cluster ... 95 Tabel 5.54. Hasil pencarian dengan query t p udp pada âiste Pe eroleha I for asi Konvensional ... 96 Tabel 5.55. Penghitungan recall - precision terhadap query t p udp pada âiste
xvii
xviii
DAFTAR PERSAMAAN
Persamaan 2.1. Rumus pembobotan TF-IDF (Savoy, 1993) ... 11
Persamaan 2.2. Rumus penghitungan skor dan perankingan dokumen terhadap query 12 Persamaan 2.3. Rumus penghitungan nilai recall (Manning et al, 2008) ... 12
Persamaan 2.4. Rumus penghitungan nilai precision (Manning et al, 2008) ... 12
Persamaan 2.5. Rumus Uji Statistik Anderson Darling ... 16
Persamaan 2.6. Rumus Uji Statistik Anderson Darling ... 17
Persamaan 2.7. Rumus mencari anak cluster (Hamerly et al., 2004) ... 17
Persamaan 2.8. Rumus proyeksi vektor-vektor di X ke vektor v ... 17
Persamaan 2.9. Rumus penghitungan nilai purity ... 18
xix
ABSTRAK
Dalam kurun waktu terakhir, pertambahan jumlah dokumen karya ilmiah
berbahasa Indonesia meningkat sangat pesat. Tanpa ada pengubahan dalam
sistem pemerolehan informasi, volume data yang meningkat dapat mengakibatkan
turunnya performa sistem pemerolehan informasi, terutama dalam hal waktu
retrieval.
Salah satu metode yang diusulkan untuk mempersingkat waktu retrieval
adalah pengelompokan koleksi. Dalam tugas akhir ini,
G-Means dipilih sebagai
algoritma pemodelan cluster. Keuntungan implementasi
G-Means adalah
kemampuan algoritma ini untuk memilih jumlah cluster yang paling optimal.
Hasil pengelompokan koleksi kemudian diuji dalam lingkungan sistem
pemerolehan informasi untuk melihat seberapa baik pengelompokan koleksi
dalam mempersingkat waktu retrieval, dan seberapa besar pengaruhnya terhadap
precision.
Data yang digunakan adalah karya ilmiah berbahasa Indonesia sebanyak
100 karya. Dari hasil pengujian, ditemukan bahwa waktu retrieval lebih singkat
hingga 16,3%, dengan rerata waktu retrieval sebesar 12,88 detik dan precision
sebesar 47%.
xx
ABSTRACT
In recent years, Indonesian-written scientific papers grow significantly in
term of number. Without any improvement in information retrieval systems,
increasing data volume could lead to poor system performance, especially in its
retrieval time.
One proposed method to improve retrieval time is collection clustering.
G-Means was chosen for cluster modeling algorithm, as it can determine number of
generated clusters automatically. Clustering collection results are tested in
information retrieval system to find how significant clustering can reduce
retrieval
time, and whether it has impact to systemâs average
precision.
We use 100 Indonesian scientific papers as collection. Based from the
results, retrieval time gain 16.3% faster, with average retrieval time is about
12,88 seconds and average precision is about 47%.
xxii
KATA PENGANTAR
Puji dan Syukur saya panjatkan kepada Tuhan Yang Maha Esa, atas berkat
dan kuasa-Nya yang diberikan sehingga penelitian ini dapat berhasil dan selesai.
Penelitian ini tidak mungkin diselesaikan tanpa adanya keterlibatan dan dukungan
dari banyak pihak. Dalam penyelesaian penelitian ini, saya ingin mengucapkan
terima kasih sebesar-besarnya kepada pihak-pihak tersebut, antara lain :
1.
Bapak Sudi Mungkasi, S.Si, M.Sc.Math., Ph.D. selaku dekan Fakultas Sains
dan Teknologi, Universitas Sanata Dharma.
2.
Ibu Dr. Anastasia Rita Widiarti selaku Ketua Program Studi Teknik
Informatika, Universitas Sanata Dharma
3.
Bapak J.B. Budi Darmawan, M.Sc. selaku dosen pembimbing penelitian.
Beliau memberikan banyak masukan dan saran serta pembelajaran yang amat
sangat berharga dalam penelitian ini.
4.
Bapak Puspaningtyas Sanjoyo Adi, S.T., M.T., selaku dosen penguji skripsi,
atas saran dan kritik yang diberikan untuk menunjang skripsi ini.
5.
Ibu Sri Hartati Wijono, S.Si., M.Kom. selaku dosen penguji skripsi, atas saran
dan kritik yang diberikan untuk menunjang skripsi ini.
6.
Keluarga yang tercinta, Bapak, Mikael Santosa, Ibu, Fransiska Tasri Aryani,
dan Adik, Philipus Agri Adhiatma yang selalu memberi dukungan terbaik dan
kasih sayang.
7.
Adika Dwi Ananda Putra (Dika), yang telah berbaik hati meminjami unit
komputer untuk menyelesaikan penelitian ini.
1
BAB I
PENDAHULUAN
1.1.
Latar Belakang
Jumlah publikasi karya ilmiah dari Indonesia terus bertambah dari tahun
ke tahun. Dari tahun 2011 hingga 2016, prosiding KNSI menampung 1590 karya
ilmiah, SRITI menampung 51 karya ilmiah pada tahun 2016. Sementara itu,
terdapat 110 karya ilmiah dipublikasikan di JUTI, jurnal teknologi informasi ITS,
sejak 2010 hingga 2016 dan 51 karya ilmiah pada JURTEK Akprind dari tahun
2014 hingga 2016. Jumlah karya ilmiah yang tidak termasuk dalam publikasi
tersebut tentunya jauh lebih besar lagi.
Dengan pertambahan jumlah karya ilmiah yang tersebut, permasalahan
yang muncul berasal dari besarnya volume data yang ada. semakin besar suatu
koleksi dokumen, maka proses pemerolehan informasi cenderung makin
membutuhkan waktu yang lebih banyak (Grossman
et al.
, 2004).
Untuk itu, diperlukan pengembangan dalam sistem pemerolehan
informasi. Salah satu pengembangan yang dapat dilakukan antara lain dengan
mengelompokkan koleksi dokumen yang ada. Antar dokumen dalam satu
kelompok memiliki kemiripan yang semirip-miripnya, dan antar dokumen dalam
kelompok yang berbeda memiliki ketidakmiripan yang sejauh-jauhnya. Sehingga
sistem tidak membutuhkan waktu eksekusi yang lama, karena tiap koleksi sudah
dibagi menjadi kelompok-kelompok yang seragam, atau yang disebut juga dengan
2
Tiap
cluster
direpresentasikan dengan satu centroid. Pengelompokan akan
dilakukan dengan algoritma Means. Keuntungan menggunakan algoritma
G-Means adalah selain melakukan pengelompokan, algoritma ini juga dapat
menghitung jumlah
cluster
yang optimum dengan melihat apakah suatu
cluster
sudah terdistribusi normal atau belum.
Setelah terbentuk kelompok-kelompok dokumen, maka tiap
query
dari
user
akan dicocokan dengan
centroid
tiap
cluster
saja. Kluster yang memiliki skor
paling tinggi dengan
query
pencarian akan dicatat, lalu isi dari
cluster
itulah yang
akan diberikan skor terhadap
query
dari pengguna, lalu kemudian ditampilkan.
1.2.
Rumusan Masalah
1.
Bagaimana hasil dan kualitas
cluster
yang dihasilkan dari proses
pengelompokan dokumen oleh sistem?
2.
Bagaimana pengaruh pengelompokan dokumen dalam sistem pemerolehan
informasi berbasis
cluster
terhadap waktu
retrieval
dan dampaknya terhadap
precision
?
1.3.
Tujuan Penelitian
1.
Mengetahui hasil evaluasi dan kualitas
cluster
yang dihasilkan dari proses
3
2.
Mengetahui seberapa baik sistem pemerolehan informasi berbasis
cluster
dalam menurunkan waktu
retrieval
, dan seberapa besar pengaruhnya
terhadap
precision
.
1.4.
Batasan Masalah
1.
Dokumen yang digunakan sebagai korpus adalah karya ilmiah dalam bentuk
digital yang diambil dari prosiding berbagai seminar.
2.
Dokumen yang digunakan sebagai korpus adalah dokumen yang
menggunakan bahasa Indonesia.
3.
Dokumen yang digunakan sebagai korpus untuk penelitian ini diambil
secara acak.
4.
Dokumen digital yang digunakan sebagai korpus dalam penelitian ini telah
diubah menjadi format TXT.
5.
Pengelompokan dokumen dalam karya tulis ini tidak menggunakan data
training.
1.5.
Metodologi Penelitian
Langkah-langkah metodologi penelitian yang dilakukan dalam penelitian ini
adalah sebagai berikut :
1.
Studi Pustaka
Studi pustaka dilakukan untuk mengumpulkan teori-teori yang mendukung
penelitian ini. Teori tersebut antara lain mengenai pemerolehan informasi
(
information retrieval
),
clustering
dokumen dengan menggunakan G-Means,
dan informasi lain yang mendukung implementasian pemerolehan informasi
4
2.
Pembangunan Sistem Pemerolehan Informasi berbasis
Cluster
Pembangunan sistem pemerolehan informasi berbasis
cluster
ini
menggunakan metode
Framework for the Application System Technique
(FAST) dengan tahap sebagai berikut:
a.
Analisis Sistem
1)
Analisis Masalah
Hal yang dilakukan dalam tahap ini adalah analisis masalah yang
dapat dipecahkan dengan pembangunan sistem.
2)
Analisis Kebutuhan
Hal yang dilakukan dalam tahap ini adalah identifikasi kebutuhan
sistem dengan mengumpulkan data kebutuhan pengguna sistem yang
kemudian dimodelkan dalam diagram
Use Case
.
b.
Desain Sistem
1)
Logical
Design
Hal yang dilakukan dalam tahap ini adalah penggambaran model data,
proses dan antarmuka dalam bentuk logical.
2)
Physical
Design
and Integration
Implementasi secara teknis dengan pembuatan desain antarmuka
pengguna secara fisik dan desain basis data apabila diperlukan.
3)
Construction and Testing
Pengembangan rancangan ke dalam program dengan menggunakan
bahasa pemrograman Java, dan MySQL sebagai pengelola basis
datanya.
3.
Uji Coba Relevansi terhadap Pengguna
Uji coba terhadap pengguna dilakukan untuk melihat unjuk kerja sistem
5
uji relevansi. Hasil dari uji coba ini akan menjadi sumber data untuk analisis
hasil uji coba.
4.
Analisis Hasil Uji Coba Relevansi
Analisis hasil uji coba dilakukan dengan melihat data yang didapatkan dari
uji coba pengguna. Tujuan dari analisis ini adalah untuk mendapatkan
kesimpulan dari tujuan penelitian.
1.6.
Sistematika Penulisan
1.
BAB I
: PENDAHULUAN
Berisi pendahuluan berupa permasalahan yang melatarbelakangi penelitian ini,
tujuan dari penelitian ini, batasan-batasan yang ada dalam penelitian, serta
sistematika dokumen proposal ini.
2.
BAB II
: TINJAUAN PUSTAKA
Berisi jabaran konsep dan hasil penelitian dari peneliti lain yang berkaitan
dengan penelitian ini. Isinya antara lain konsep dasar pemerolehan informasi,
stemming
, eliminasi
stopword
,
term
weighting, evaluasi hasil pemerolehan
informasi, serta konsep dasar pengelompokan teks, dan algoritma G-Means
untuk pemodelan data dan pemilihan jumlah
cluster
optimum.
3.
BAB III
: ANALISIS DAN PERANCANGAN
Bab ini berisi gambaran umum dari sistem yang akan dibangun, analisis
kebutuhan sistem dan rancangan basis data untuk sistem tersebut.
4.
BAB IV : IMPLEMENTASI
Bab ini berisi jabaran dari implementasi pemodelan G-Means
dalam bahasa
6
5.
BAB V
: ANALISIS HASIL PENELITIAN
Bab ini berisi hasil pengujian sistem, serta pembahasan dari hasil pengujian
tersebut.
6.
DAFTAR PUSTAKA
Berisi referensi pustaka yang digunakan dalam penulisan karya ilmiah ini.
7.
LAMPIRAN
7
BAB II
LANDASAN TEORI
2.1.
Konsep Pemerolehan Informasi
Pemerolehan informasi (
Information Retrieval
) adalah kumpulan berbagai
algoritma dan teknologi untuk melakukan pemrosesan, penyimpanan, dan temu
kembali informasi pada suatu koleksi data yang besar dan tidak terstruktur
(Manning
et al
, 2008).
Jenis informasi tersebut beragam, bisa berupa teks dokumen, halaman web,
maupun objek multimedia seperti foto dan video.
2.1.1.
Operasi Teks
2.1.1.1.
Stopword
Stopword
adalah suatu kata yang sangat sering muncul dalam berbagai
dokumen adalah diskriminator yang buruk dan tidak berguna dalam temu kembali
informasi.
Stopword
perlu dieliminasi untuk mengurangi waktu eksekusi
query
dengan cara menghindari proses
list
yang panjang (Butcher
et al.,
2010).
Pembuangan
stopword
ini akan mengurangi ukuran indeks, meningkatkan
efisiensi dan keefektifan dari pemerolehan informasi (Croft
et al.,
2010). Contoh
stopword
dalam bahasa Indonesia, yaitu kata ganti orang (âakuâ, âkamuâ, âkitaâ,
dsb.), konjungsi (âdanâ, âatauâ, dsb.), dan beberapa kata lainnya.
2.1.1.2.
Stemming
Stemming
adalah proses pengenalan suatu kata.
Stemming
sering
melibatkan pemisahan kata dari imbuhan dan tanda baca (Göker
et al,
2009).
Menurut Agusta (2010), pola suatu kata dalam bahasa Indonesia adalah
sebagai berikut :
8
2.1.1.2.1.
Algoritma Nazief
â
Adriani sebagai Algoritma
Stemming
Algoritma
Stemming
Nazief
â
Adriani diperkenalkan oleh Nazief dan Adriani
(1996). Algoritma ini memiliki tahap-tahap sebagai berikut ini :
1.
Cari kata yang akan diistem dalam basis data kata dasar. Jika ditemukan maka
diasumsikan kata adalah
root word
. Maka algoritma berhenti.
2.
Selanjutnya adalah pembuangan
Inflection Suffixes
(â
-
lahâ, â
-
kahâ, â
-
kuâ, â
-muâ, atau â
-
nyaâ). Jika berupa
particles
(â
-
lahâ, â
-
kahâ, â
-
tahâ atau â
-
punâ)
dan terdapat
Possesive Pronouns
(â
-
kuâ, â
-
muâ, atau â
-
nyaâ)
, maka langkah
ini diulangi lagi untuk menghapus
Possesive Pronouns
.
3.
Hapus
Derivation Suffixes
(â
-
iâ, â
-
anâ atau â
-
kanâ). Jika kata ditemukan di
kamus, maka algoritma berhenti. Jika tidak maka ke langkah 3a berikut ini :
a.
Jika â
-
anâ telah dihapus dan huruf terakhir dari kata tersebut adalah â
-
kâ,
maka â
-
kâ juga ikut dihapus. Jika kata tersebut ditemukan dalam kamus
maka algoritma berhenti. Jika tidak ditemukan maka lakukan langkah 3b.
b.
Akhiran yang dihapus (â
-
iâ, â
-
anâ atau
â
-
kanâ) dikembalikan, lanjut ke
langkah 4.
4.
Hapus
Derivation Prefix
. Jika pada langkah 3 ada sufiks yang dihapus maka
pergi ke langkah 4a, jika tidak pergi ke langkah 4b.
a.
Periksa tabel kombinasi awalan-akhiran yang tidak diijinkan pada
Tabel2.1. Jika ditemukan maka algoritma berhenti, jika tidak, pergi ke langkah
4b. Tabel kombinasi awalan-akhiran yang tidak diijinkan ditampilkan pada
tabel berikut ini :
Awalan Akhiran yang tidak diizinkan
[image:33.595.85.513.189.719.2]be-
-i
di-
-an
ke-
-i, -kan
me-
-an
se-
-i, -kan
Tabel 2.1. Tabel kombinasi awalan dan akhiran yang tidak diijinkan
b.
Tentukan tipe awalan kemudian hapus awalan. Jika awalan kedua sama
9
c.
Jika root word belum juga ditemukan lakukan langkah 5, jika sudah maka
algoritma berhenti..
5.
Jika semua langkah telah selesai tetapi tidak juga berhasil maka kata awal
diasumsikan sebagai root word. Proses selesai.
Tipe awalan ditentukan melalui langkah-langkah berikut:
1.
Jika awalannya adalah: â
di-
â, âke
-
â, atau âse
-
â maka tipe awalannya secara
berturut-
turut adalah âdi
-
â, âke
-
â, atau âse
-
â.
2.
Jika awalannya adalah âte
-
â, âme
-
â, âbe
-
â, atau âpe
-
â
maka dibutuhkan sebuah
proses tambahan untuk menentukan tipe awalannya.
3.
Jika dua karakter pertama bukan âdi
-
â, âke
-
â, âse
-
â, âte
-
â, âbe
-
â, âme
-
â, atau
âpe
-
â maka berhenti.
4.
Dengan melihat Tabel 2.2, j
ika tipe awalan adalah ânoneâ maka berhenti. Jika
tipe awalan adalah bukan ânoneâ maka awalan dapat dilihat pada
Tabel 2.4.Hapus awalan jika ditemukan.
Tipe-tipe awalan dapat dilihat dalam tabel berikut ini :
Karakter huruf setelah awalan
Tipe awalan
Set 1
Set 2
Set 3
Set 4
â
-r-
â
â
-r-
â
â
â
None
â
-r-
â
â
â
ter-luluh
[image:34.595.86.515.235.621.2]â
-r-
â
not (vowel or â
-r-
â)
â
-er-
â
vowel
Ter
â
-r-
â
not (vowel
or â
-r-
â)
â
-er-
â
not vowel ter-
â
-r-
â
not (vowel or â
-r-
â)
not â
-er-
â
â
Ter
not (vowel or â
-r-
â)
â
-er-
â
vowel
â
None
not (vowel or â
-r-
â)
â
-er-
â
not vowel
â
Te
Tabel 2.2. Cara Menentukan Tipe Awalan Untuk awalan âte-â
Awalan yang diijinkan dihapus berdasarkan tipe awalannya ditunjukkan
pada tabel berikut ini :
Tipe Awalan Awalan yang harus dihapus
di-
di-
ke-
ke-
se-
se-
10
ter-
ter-
[image:35.595.89.519.229.713.2]ter-luluh
ter
Tabel 2.3. Awalan yang diijinkan dihapus berdasarkan Tipe Awalannya
2.1.1.3.
Tokenisasi
Tokenisasi adalah proses pemisahan kata dari kumpulannya, sehingga
menghasilkan suatu kata yang berdiri sendiri, baik dalam bentuk perulangan
maupun tunggal. Proses ini juga akan menghilangkan tanda baca maupun karakter
yang ada pada kata tersebut dan semua huruf menjadi huruf kecil. (Manning
et al
,
2008).
Contoh dari input dan output dari tokenisasi adalah sebagai berikut :
Input : Suatu deret angka genap
Output : suatu, deret, angka, genap
2.1.2.
Term
-Document Matrix
Term-document
matrix
adalah matriks yang memperlihatkan frekuensi
kemunculan suatu
term
didalam suatu dokumen. Dalam
term-document matrix
,
baris-baris menunjukkan
term
dalam suatu koleksi dan kolom menunjukkan
dokumen. (Manning
et al
, 2008).
Contoh perancangan matriks
term
-
document
diperlihatkan seperti berikut ini :
doc 1 doc 2 doc 3 doc 4 doc 5 doc 6
term 1 1 2 2 1 1 0
term 2 0 4 4 1 2 0
term 3 2 5 0 1 3 0
term 4 3 1 0 0 1 1
term 5 2 0 2 0 0 1
term 6 1 0 1 1 3 2
Tabel 2.4. Perancangan termdocumentmatrix
Sehingga matriks
term-document
nya (matriks M) akan menjadi seperti berikut ini
11
[
]
Gambar 2.1. Visualisasi term-documentmatrix
2.1.3.
TF-IDF sebagai Metode Pembobotan
Terms Frequency
â
Inverse Documents Frequency
(TF-IDF) adalah skema
pembobotan
term
yang paling populer dalam ranah pemerolehan informasi
(Baeza
â
Yates, 1999).
Rumus pembobotan TF-IDF menurut Savoy (1993) adalah sebagai berikut :
Persamaan 2.1. Rumus pembobotan TF-IDF (Savoy, 1993)
Dimana,
, dan
Keterangan :
ï·
w
= bobot
term
(T
j) pada dokumen D
iï·
tf
ij= frekuensi kemunculan
term
(T
j) pada dokumen D
iï·
m
= jumlah dokumen D
ipada kumpulan dokumen
ï·
df
j= jumlah dokumen yang mengandung
term
(T
j)
ï·
idf
j= invers frekuensi dokumen (
inverse document frequency
)
ï·
max tf
i= frekuensi
term
terbesar dalam suatu dokumen
Dari penghitungan nilai TF-IDF ini, scoring atau penilaian terhadap
query
12
â
Persamaan 2.2. Rumus penghitungan skor dan perankingan dokumen terhadap query
2.1.4.
Evaluasi Pemerolehan Informasi
Pengukuran hasil relevansi dapat dilakukan dengan penghitungan
recall
dan
precision
. Recall digunakan untuk mengukur seberapa baik suatu sistem
melakukan pencarian terhadap dokumen yang relevan terhadap suatu
query
pengguna. Sementara itu,
precision
digunakan untuk melihat seberapa baik sistem
pemerolehan informasi mengeliminasi dokumen yang tidak relevan (Croft
et al.
,
2010).
Rumus dari
recall
dan
precision
adalah sebagai berikut (Manning
et al
, 2008) :
â
â
Persamaan 2.3. Rumus penghitungan nilai recall (Manning et al, 2008)
â
â
Persamaan 2.4. Rumus penghitungan nilai precision (Manning et al, 2008)
2.2.
Konsep Pengelompokan Dokumen
2.2.1.
Clustering
dalam Pemerolehan Informasi
Algoritma
clustering
mengelompokan sekumpulan dokumen ke dalam
suatu subset atau
cluster
. Tujuan algoritma
clustering
dalam pemerolehan
informasi bertujuan untuk mengelompokan sekumpulan dokumen yang koheren
secara internal, namun memiliki perbedaan jauh dengan dokumen dari
cluster
yang lain. Dengan kata lain, antar dokumen di dalam satu
cluster
yang sama
13
cluster
yang berbeda seharusnya memiliki tingkat perbedaan yang
setinggi-tingginya (Manning
et al
, 2008).
2.2.2.
Hipotesis
Cluster
Hipotesis
cluster
berisi tentang asumsi dasar yang dibuat ketika menerapkan
clustering
dalam pemerolehan informasi. Hipotesis
cluster
menyebutkan bahwa
dokumen dalam
cluster
yang sama akan memiliki keidentikan sifat, berkenaan
dengan relevansi terhadap kebutuhan informasi (Manning
et al
, 2008).
2.2.3.
K-Means
K-Means adalah salah satu algoritma
flat clustering
yang paling penting
(Manning
et al
, 2008). Tujuan K-Means adalah meminimalkan rata-rata kuadrat
jarak Euclidean dokumen terhadap
centroid
(pusat
cluster
) dokumen tersebut
(Manning
et al
, 2008).
Algoritma k-Means ditunjukkan dalam gambar berikut ini :
Gambar 2.2. Pseudocode algoritma K-Means (Manning et al, 2008)
Dalam bukunya, Manning (2008) menjabarkan langkah dari algoritma
K-Means. Pertama-tama, dilakukan pemilihan pusat
cluster
K secara acak dari
14
untuk meminimalkan RSS (
residual sum of squares
). Setelah itu, tiap dokumen
ditempatkan pada
cluster
yang memiliki
centroid
terdekat dengan dokumen
tersebut. Proses kembali lagi ke iterasi pergerakan pusat
cluster
.
Visualisasi proses yang terjadi dalam k-Means ditampilkan dalam gambar berikut
ini :
15
Ada beberapa cara penghentian iterasi, antara lain :
ï·
Banyak iterasi I yang telah ditetapkan sebelumnya. Ketika iterasi telah
mencapai langkah ke-i, maka proses akan berhenti.
ï·
Penempatan dokumen dalam suatu
cluster
(fungsi partisi γ) tidak berubah
-ubah lagi.
ï·
Centroid µ
ktida
k berubah lagi. Hal ini sama dengan γ tidak berubah.
ï·
Berhenti ketika nilai RSS dibawah batas yang ditentukan.
2.2.4.
G-Means
Algoritma G-Means diperkenalkan oleh Greg Hamerly dan Charles Elkan
dari University of California pada tahun 2004. G-Means adalah algoritma
pengembangan dari K-Means yang memiliki fitur penghitungan jumlah
cluster
yang optimum dengan menggunakan uji statistik untuk memutuskan apakah suatu
pusat
cluster
perlu dipecah menjadi dua pusat
cluster
(Hamerly
et al.
, 2004).
Algoritma G-Means akan dimuai dari jumlah pusat
cluster
yang kecil,
misalnya satu atau dua. Tiap iterasi dimulai dengan pengelompokan data
menggunakan K-Means seperti biasa untuk mendapatkan himpunan anggota tiap
cluster
, selanjutnya algoritma ini akan memecah pusat
cluster
menjadi dua apabila
suatu
cluster
nampak tidak terdistribusi normal.
Visualisasi G-Means dalam suatu dataset 2 dimensi dengan 1000 point
ditampilkan dalam gambar berikut ini :
16
Algoritma G-Means dapat dilihat sebagai berikut (Hamerly
et al.
, 2004) :
1.
Pilih C sebagai sekumpulan pusat
cluster
(centroid) awal
2.
Lakukan K-Means pada dataset X dengan C sebagai pusat-pusat
cluster
nya.
3.
x
iadalah sekumpulan
datapoint
yang menjadi member centroid c
j, dimana { x
i| class(x
i) = j }
4.
Gunakan uji statistik untuk melihat apakah tiap { x
i| class(x
i) = j } mengikuti
distribusi normal (pada suatu
confidence level
α).
5.
Jika data terlihat terdistribusi normal, maka c
jtidak berubah. Namun jika
sebaliknya, maka c
jdiganti menjadi dua pusat
cluster
6.
Ulangi langkah no. 2 hingga tidak ada lagi pusat
cluster
yang ditambahkan.
Terdapat dua hipotesis dalam uji statistik pada no. 4, yaitu sebagai berikut
(Hamerly
et al
., 2004) :
ï·
H
0: data disekitar pusat
cluster
terdistribusi normal
ï·
H
1: data disekitar pusat
cluster
tidak terdistribusi normal
Jika H
0diterima, maka pusat
cluster
tidak perlu dipisah lagi menjadi dua.
Sementara itu, jika H
1diterima, maka pusat
cluster
harus dipecah menjadi dua.
Uji statistik yang digunakan adalah adalah uji Anderson-Darling, dengan formula
sebagai berikut :
Persamaan 2.5. Rumus Uji Statistik Anderson Darling
17
â
[
Persamaan 2.6. Rumus Uji Statistik Anderson Darling
X adalah subset dengan pusat
cluster
C. Tiap instance dari X diwakili
dengan x
i, x
i+1, â¦,x
n-1,x
n. Sementara itu, z
iadalah hasil dari fungsi distribusi
kumulatif untuk distribusi normal baku terhadap nilai x
i.
Untuk melakukan uji statistik diatas, dilakukan langkah seperti berikut ini
(Hamerly
et al.
, 2004) :
1.
Ambil suatu subset X
2.
Pilih level signifikan α untuk uji.
3.
Dari pusat
cluster
tersebut, ambil dua buah âanakâ pusat
cluster
, dinotasikan
dengan c1 dan c2. Caranya dengan menggunakan rumus c±m, dimana m
adalah random atau dengan rumus berikut :
â
Persamaan 2.7. Rumus mencari anak cluster (Hamerly et al., 2004)
Dimana,
m = vector anak
s = eigenvalue terbesar yang didapat dari data
λ
= principal component utama, yaitu eigenvector dengan eigenvalue
terbesar
4.
Jalankan K-Means pada X dengan dua
centroid
tersebut (c1 dan c2).
5.
Hitung nilai vektor v dengan v = c1
â
c2.
6.
Proyeksikan X ke v, menjadi X
â
, dengan rumus sebagai berikut
â â
Persamaan 2.8. Rumus proyeksi vektor-vektor di X ke vektor v
18
8.
Hitung z
idengan rumus z
i= F(x
i).
9.
Hitung
. Apabila
berada pada daerah non-kritis, maka H
0diterima. Sebaliknya apabila
berada di dalam daerah kritis, maka H
1diterima dan pusat
cluster
yang baru adalah c1 dan c2.
2.2.5.
Evaluasi
Cluster
2.2.5.1.
Purity
Purity
adalah salah satu pengukuran dalam evaluasi
cluster
. Untuk
menghitung
purity
, tiap
cluster
diberikan label kelas berdasarkan label yang
paling sering muncul dalam
cluster
tersebut, dan kemudian akurasi
cluster
dihitung dengan jumlah data yang benar dibagi dengan banyak data (Chen, 2010).
Rentang
purity
dari 0 hingga 1. Semakin besar nilai
purity
, semakin baik
cluster
tersebut. Formula
purity
adalah sebagai berikut (Chen, 2010) :
â | |
19
BAB III
ANALISIS DAN PERANCANGAN SISTEM
3.1.
Analisis Sistem
3.1.1.
Deskripsi Sistem
Sistem yang akan dikembangkan dalam penelitian ini adalah sebuah sistem
pengelompokan koleksi dan pencarian dokumen berdasarkan input
query
pengguna. Sistem ini terdiri dari dua sub sistem, yaitu sub sistem pengelompokan
dokumen dan sub sistem pencarian dokumen.
3.1.1.1.
Sub Sistem Pengelompokan Dokumen
Sub sistem pengelompokan dokumen bertindak sebagai modul
clustering
dokumen. Nantinya koleksi dokumen yang diunggah oleh
User
ke dalam sistem
mula-mula diproses oleh subsistem ini. Proses yang terjadi adalah tokenisasi,
eliminasi
stopword
,
stemming
, lalu dilanjutkan dengan pembangunan
term
-document
matrix
.
Dalam
penelitian
ini,
kolom
dalam
term
-
document
matrix
akan
merepresentasikan
term
, selanjutnya disebut atribut atau feature. Sementara baris
dalam
term
-
document
matrix
akan merepresentasikan dokumen. Dari
term
-document
matrix
inilah akan dilakukan pengelompokan koleksi.
Jumlah
cluster
optimum akan dicari secara otomatis oleh sistem menggunakan
algoritma G-Means, yaitu pemodelan
cluster
dengan memperhitungkan
kenormalan distribusi dari tiap anggota
cluster
terhadap pusatnya masing-masing.
20
Normalitas distribusi tiap
cluster
akan dihitung dengan menggunakan test
statistik, dimana akan digunakan uji Anderson-Darling untuk menentukan apakah
cluster
sudah terdistribusi normal atau belum. Apabila suatu
cluster
belum
terdistribusi normal, maka suatu
cluster
akan dipecah menjadi dua, dan seterusnya
hingga terdistribusi normal.
Alur subsistem ini ditunjukkan dalam gambar berikut ini :
Input dokumen karya ilmiah
Operasi tokenizing
Operasi stopword
Operasi stemming
Penghitungan tf, df dan w
Pembangunan term-document matrix
Implementasi G-Means untuk pemodelan cluster
Pengklusteran Dokumen
Simpan data cluster dan membernya, serta centroidnya
Feature selection
21
3.1.1.1.1.
Clustering dengan G-Means
Penggunaan algoritma G-Means serta parameter-parameter yang digunakan dalam
penelitian ini adalah sebagai berikut :
1.
Ambil suatu subset X
Subset X pada saat ini adalah seluruh dataset yang ada. Dataset ini
dianggap sebagai satu
cluster
. Karena hanya terdapat satu
cluster
saja,
centroid dari
cluster
ini adalah rerata dari tiap atribut dari dataset tersebut.
2.
Pilih level signifikan α untuk uji.
Level signifikan
α
dalam penelitian ini diinisalisasi dengan nilai 0.05.
Nilai ini nantinya akan dibandingkan dengan p-value dari hasil penghitungan
uji statistik Anderson
â
Darling.
3.
Dari pusat
cluster
(
centroid
)
yang dibentuk pada point 1 tadi, ambil dua buah
âanakâ pusat
cluster
, dinotasikan dengan c1 dan c2. Caranya dengan
menggunakan rumus pada Persamaan 2.1.
4.
Jalankan K-Means pada X dengan dua
centroid
tersebut (c1 dan c2).
K-Means dilakukan pada
cluster
yang diobservasi. Parameter jumlah
cluster
(k) memiliki nilai 2, dan seed untuk centroid awal adalah c1 dan c2.
Kriteria penghentian iterasi dalam tahap ini adalah sebagai berikut :
a.
Jumlah iterasi telah melewati batas iterasi yang ditentukan, yaitu 1000 kali
iterasi, atau,
b.
Salah satu
cluster
kehilangan seluruh anggotanya (empty
cluster
), atau,
c.
Cluster
sudah konvergen, ditandai dengan
centroid
dan anggota
cluster
tidak mengalami perubahan. Dengan kata lain, memiliki nilai dan jumlah
yang sama dengan iterasi sebelumnya.
22
6.
Proyeksikan X ke v, menjadi X
â
, dengan rumus pada Persamaan 2.8.
7.
Normalisasi X` sehingga memiliki rerata 0 dan varian 1.
Normalisasi untuk mengubah Xâ sehingga memiliki rerata 0 dan varian 1
dilakukan dengan menggunakan normalisasi
z-score
, yaitu normalisasi dengan
rumus berikut ini :
Persamaan 3.1. Rumus penghitungan normalisasi z-score pada suatu data
Dimana,
-
s
i= nilai normalisasi di titik data ke i dalam suatu atribut
-
x
i= nilai awal data di titik data ke i dalam suatu atribut
-
µ = nilai atribut dari atribut dimana terdapat data i
-
= nilai standar deviasi dari atribut dimana terdapat data i
8.
Hitung z
idengan rumus z
i= F(x
i).
Penghitungan
Cummulative Distribution Function
(CDF) menggunakan
java library yang dikhususkan untuk statistika, yaitu jdistlib.
9.
Hitung
. Apabila
berada pada daerah non-kritis, maka H
0diterima. Sebaliknya apabila
berada di dalam daerah kritis, maka H
1diterima dan pusat
cluster
yang baru adalah c1 dan c2.
Penghitungan p-value akan digunakan untuk mengetahui apakah nilai
berada pada daerah kritis atau non-kritis. Penghitungan p-value
dilakukan dengan java library yang dikhususkan untuk statistika, yaitu jdistlib.
Apabila nilai p-value lebih besar sama dengan nilai
α
, maka H
0diterima, yang
artinya
cluster
tidak perlu dipecah menjadi dua
cluster
. Begitu pula
sebaliknya, maka H
1diterima, yang artinya
cluster
perlu dipecah menjadi dua
23
3.1.1.2.
Sub Sistem Pencarian Dokumen
Sub sistem pencarian dokumen berfungsi untuk mencari dokumen yang
memiliki kemiripan atau relevan dengan
query
yang diberikan oleh pengguna
sistem.
Query
hanya akan dicocokkan dengan
centroid
tiap
cluster
dengan
menggunakan operator boolean AND, dengan menggunakan Persamaan 2.2 untuk
menghitung skor.
Cluster
yang memiliki
centroid
dengan skor yang tertinggi
terhadap
query
pencarian
user
akan dicatat oleh sistem. Apabila tidak ada
kecocokan dengan semua centroid, maka dicoba pencocokan dengan
menggunakan operator OR.
Apabila sudah ditemukan
cluster
yang sesuai, dokumen yang berada dalam
cluster
tersebut akan dibobot ulang oleh sistem menggunakan TF-IDF untuk
kemudian ditampilkan urut ke pengguna berdasarkan bobot terhadap
query
yang
diberikan oleh pengguna. Jumlah dokumen untuk penghitungan IDF didasarkan
pada jumlah dokumen yang berada pada
cluster
terpilih.
Aktor yang terlibat dalam sistem ini adalah
User
.
User
adalah aktor yang
memiliki wewenang untuk melakukan pencarian dokumen dengan memberikan
input berupa
query
pencarian pada sistem. Selain itu,
user
memiliki wewenang
untuk memulai proses
clustering
dokumen.
24 Input query pencarian
Operasi tokenizing
Operasi stopword
Operasi stemming
Penghitungan tf, df, w
Pembangunan term-query matrix
Pembobotan cluster terhadap kueri, dengan membandingkan centroid terhadap kueri, dapat ditemukan bobot yang paling besar (cluster yg paling mirip
dgn kueri)
Load document id dari cluster yang paling mirip
Hitung ulang bobot document member cluster tadi terhadap kueri
Tampilkan hasil pencarian ke user
Pencarian
Gambar 3.2. Alur proses pencarian dokumen
Subsistem ini memiliki dua opsi untuk
retrieval
, yaitu
retrieval
berbasis
cluster
dan
retrieval
tanpa
cluster
. Retrieval berbasis
cluster
selanjutnya disebut
dengan Sistem Pemerolehan Informasi berbasis
Cluster
, sementara
retrieval
tanpa
cluster
disebut dengan Sistem Pemerolehan Informasi Konvensional.
25
Text database Index
Index Text operation
Query operation Indexing DB Manager Module
Searching
Ranking User interface
Inverted file
Text Text
Logical view Ranked docs
feedback User need
Logical operation
query
Retrieved docs
Gambar 3.3. Sistem Pemerolehan Informasi Konvensional (Baeza, 1999)
Text database Text operation
Query operation Indexing DB Manager
Module
Searching
Ranking
User interface
Inverted file
Text Text
Logical view Ranked docs
feedback User need
Logical operation
query
Retrieved docs
Clustering
Cluster Member (Documents)
Cluster Member (Documents)
Cluster Index (Centroid)
Cluster Index (Centroid)
26
3.1.2.
Data yang Digunakan
Data yang digunakan dalam penelitian ini adalah 100 karya ilmiah
berbahasa Indonesia yang diambil dari berbagai prosiding dan jurnal.
3.1.3.
Analisis Kebutuhan Pengguna
Kebutuhan yang dibutuhkan tiap aktor dalam sistem ini disajikan dalam tabel
berikut ini :
Pengguna Sistem
Kebutuhan
User
1.
Melakukan
clustering
dokumen
2.
Melakukan pencarian dengan menggunakan
query
3.
Melihat isi dokumen
Tabel 3.1. Kebutuhan fungsional pengguna sistem
3.2.
Perancangan Sistem
3.2.1.
Data Flow Diagram
3.2.1.1.
Diagram Konteks
Diagram konteks atau diagram aliran data pada level 0 untuk sistem yang akan
dibangun, ditampilkan pada gambar berikut ini :
Dokumen Sistem Pemerolehan Informasi
koleksi
cluster
User query pencarian
list dokumen Sistem
pemerolehan informasi
27
3.2.1.2.
Overview
DFD
Overview
dari diagram aliran data untuk sistem yang akan dibangun, ditampilkan
pada gambar berikut ini :
D o k u m e n S is te m P e m e ro le h an In fo rm as i k o le k si cl u ste r 1 . P e n g e lo m p o k an d o k u m e n S is te m P e m e ro le h a n Inf o rm as i U se r q u e ry p e n car ian li st d o k u m e n 2 . P e n car ian d o k u m e n T e rm C lu ste r Re co rd C e n tr o id Te rm li st Kolek si, ind
ex cluste r cen tro id In d e x d o k u m e n ce n tr o id Ind ex d ok um en D o k u m e n se su ai in d e x cl u st e r
28
3.2.1.3.
DFD Level 2
3.2.1.3.1.
DFD Proses 1
: Pengelompokan Dokumen
Diagram aliran data pada level 2 untuk proses pengelompokan dokumen
ditampilkan pada gambar berikut :
Dokumen Sistem Pemerolehan Informasi koleksi
1.2. pembobotan
1.3. Pengelompokan
dokumen 1.1. preprocessing
Term
Cluster
Record Centroid Token list,
koleksi
Tf,df,w, term-document
matrix, koleksi
Term list
Index dok umen
Koleksi, index cluster
centroid
29
3.2.1.3.2.
DFD Proses 2
: Pencarian Dokumen
Diagram aliran data pada level 2 untuk proses pencarian dokumen ditampilkan
pada gambar berikut :
User Sistem Pemerolehan Informasi
query
1.2. Pembobotan query
1.3. Pemilihan cluster
termirip 1.1. Preprocessing query
Term
Cluster
Record Centroid Token list
TF-IDF query
df
Index dok umen
Dokumen
sesuai index cluster
centroid
1.4. Perankingan dokumen Index
cluster, TF-IDF query Dokumen
terurut
30
3.2.2.
Diagram Berjenjang
Diagram berjenjang (hierarchial chart) dari system yang akan dibangun ini
ditampilkan pada gambar berikut :
Sistem pemerolehan
informasi
1. Pengelompokan
dokumen
2. Pencarian dokumen
1.1. preprocessing
1.2. pembobotan
1.3. Pengelompokan
dokumen
2.1. Preprocessing
query
2.2. Pembobotan
query
2.3. Pemilihan cluster
termirip
2.4. Perankingan
dokumen Level 0
Level 1
Level 2
Gambar 3.9. Diagram berjenjang dari sistem yang akan dikembangkan
3.2.3.
Deskripsi Proses
3.2.3.1.
Deskripsi Proses 1 : Pengelompokan Dokumen
3.2.3.1.1.
Deskripsi Proses 1.1
: Preprocessing
Preprocessing
dilakukan
untuk
menghilangkan
stopword
dan
menyederhanakan bentuk-bentuk
term
dengan cara
stemming
. Preprocessing ini
berguna untuk mengurangi dimensi matriks
term
-
document
.
Setelah semua
term
diubah menjadi bentuk kata dasarnya, selanjutnya
dilakukan tokenisasi. Dalam sistem ini, token yang diambil adalah semua token
yang mengandung alfabet saja. Apabila token terdiri dari karakter alphanumeric
atau numerik, maka token akan dibuang. Setiap token akan dicatat
31
Selain itu, jumlah dokumen yang mengandung token tersebut akan dicatat juga.
Jumlah ini menghasilkan nilai
document
frequency (DF).
Hasil dari proses ini adalah TF, DF, dan token-token yang nantinya akan
dibobot oleh proses selanjutnya.
3.2.3.1.2.
Deskripsi Proses 1.2
: Pembobotan
Input dari proses pembobotan adalah nilai-nilai TF tiap dokumen, DF tiap
term
, serta token
list
. Token
list
selanjutnya disebut
term
list
. Pembobotan
dilakukan dengan rumus pada Persamaan 2.1.
Metode yang digunakan untuk pembob