SISTEM INFORMASI GEOGRAFIS PEMETAAN PERSEBARAN ALUMNI DENGAN ANALISA CLUSTERING
Teks penuh
Gambar
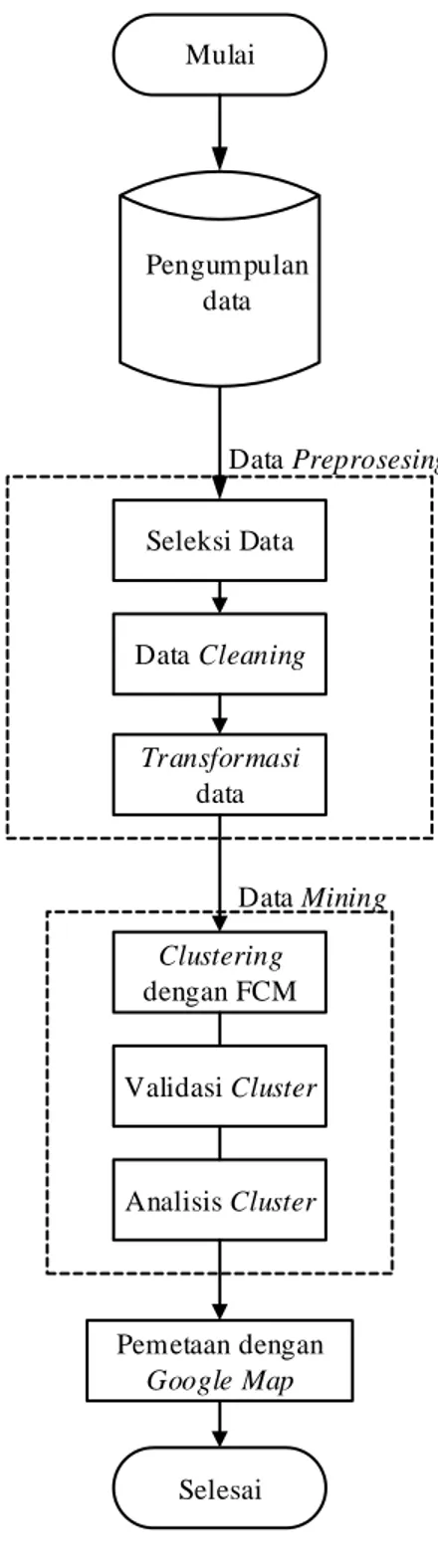
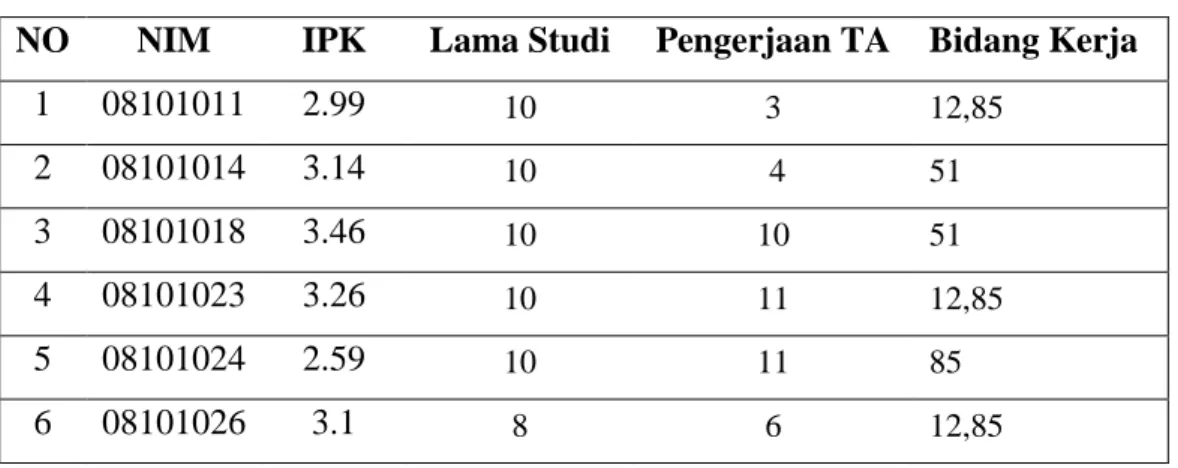
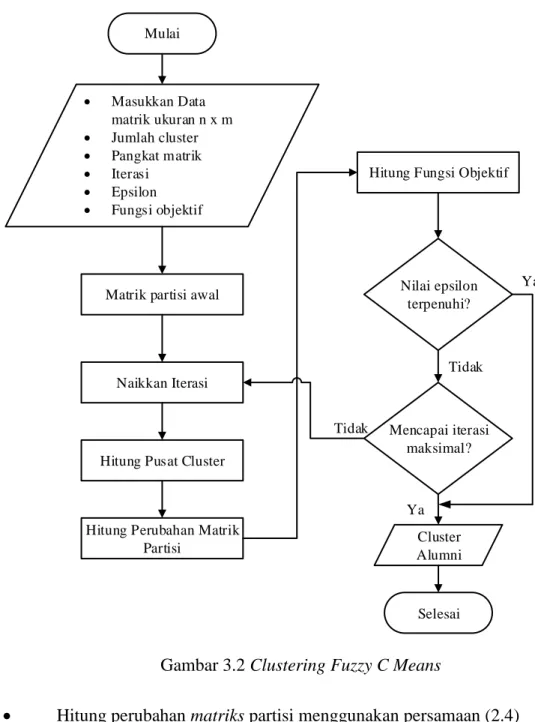
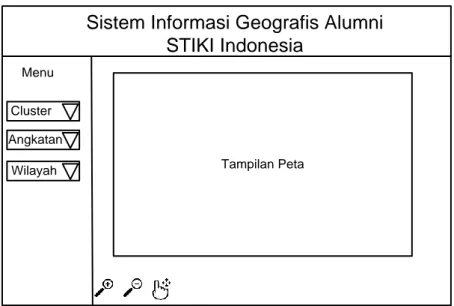
Dokumen terkait
1). Survei dan pemetaan ini bertujuan untuk memberikan informasi yang jelas tentang persebaran industri konveksi berdasarkan lokasi di Kecamatan Kedungwuni Kabupaten
Dari hasil penelitian dapat disimpulkan bahwa pemetaan persebaran industri yang dilakukan dengan menggunakan program arc view 3.3 memiliki keunggulan yaitu dapat lebih
Pengujian fungsi sistem informasi geografis pariwisata Pulau Bintan ini dilakukan dengan menggunakan metode Black Box. Pengujian dilakukan pada fungsi-fungsi sistem
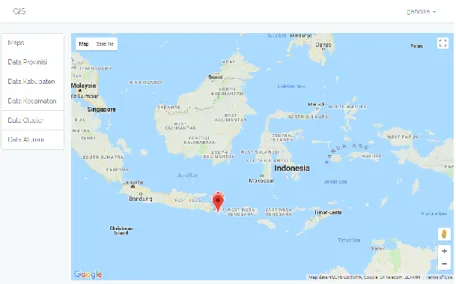
Sistem Informasi Geografis Sebaran Alumni berhasil dibuat dengan hasil system berbasis web, dimana sistem berbasis web tersebut dapat diintegrasikan dengan google map sehingga
Hasil dari semua tahapan penelitian didapatkan tampilan Sistem Informasi Geografis Pemetaan Penyebaran Penyakit Menggunakan Google Map API Berbasis Web Menggunakan
Berdasarkan hasil pengujian dengan teknik black box testing pada tabel 1, dapat disimpulkan bahwa aplikasi atau sistem informasi geografis cuaca pada data curah hujan
Tampilan halaman utama merupakan halaman menu utama admin jika sudah masuk login ke dalam aplikasi web browser pemetaan persebaran fasilitas umum di Propinsi
Berdasarkan analisa yang telah dilakukan pada sistem informasi geografis untuk pemetaan perkebunan kelapa sawit di Kabupaten Pasaman Barat pada bab sebelumnya maka dapat
