6
BAB II. LANDASAN TEORI
2.1. Information Retrieval
Menurut Manning, Raghavan, dan Schutze (2009), information retrieval merupakan proses mencari materi yang tidak terstruktur yang dapat memenuhi kebutuhan materi dari sekumpulan besar materi.
2.2. MachineLearning
Machine learning merupakan pendekatan di mana sekumpulan data digunakan untuk menyetel parameter yang ada pada sebuah model adaptif. Model yang telah diberikan training tersebut kemudian dapat digunakan untuk mengkategorikan data lainnya (Bishop, 2006).
Machine learning dimulai dari tahap training, dengan menggunakan sekumpulan data training untuk menyetel parameter dalam model adaptif. Setelah dilakukan training, tahap testing dilangsungkan menggunakan sekumpulan data testing untuk menguji apakah model yang telah diberikan training dapat digunakan dengan baik untuk mengkategorikan data.
Dalam machine learning, dikenal istilah supervised learning dan unsupervised learning. Supervised learning merupakan penerapan machine learning dengan data training berupa input vector beserta nilai targetnya. Unsupervised learning merupakan merupakan machine learning di mana data training tidak diberi nilai target.
2.3. Classification
Menurut Manning, Raghavan, dan Schutze (2009), classification merupakan proses menentukan suatu objek termasuk ke dalam kategori/kelas yang mana. Objek yang diklasifikasikan dapat berupa teks, gambar, suara, dan lain-lain.
Istilah labeling merupakan proses menghubungkan suatu objek dengan kelasnya (Manning, Raghavan, & Schutze, 2009). Oleh karena itu, labeling dan classification mempunyai pengertian yang sama.
2.3.1. Single-Label Classification
Menurut Tsoumakas dan Katakis(2007), single-label classification merupakan proses learning di mana masing-masing data memiliki asosiasi dengan satu label l dari sekumpulan label L yang tidak saling berhubungan.
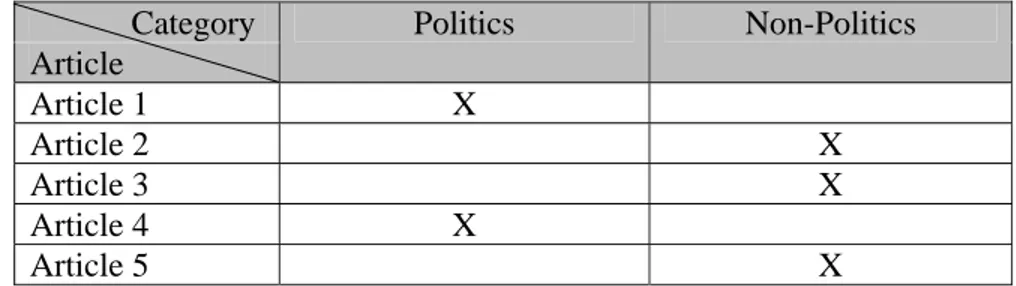
Contoh single-label classification dapat dilihat pada tabel 2.1.
Tabel 2.1. Contoh Single-Label Classification (dua kelas)
Category Politics Non-Politics Article Article 1 X Article 2 X Article 3 X Article 4 X Article 5 X
2.3.2. Multi-Class Classification
Menurut Tsoumakas dan Katakis (2007), multi-class classification merupakan single-label classification di mana data yang ada dikelompokkan ke dalam salah satu elemen dari himpunan label L (|L| > 2).
Tabel 2.2. Contoh Multi-Class Classification
2.3.3. Multi-Label Classification
Menurut Manning, Raghavan, dan Schutze (2009), multi-label classification merupakan classification di mana satu data dapat dihubungkan dengan lebih dari satu label.
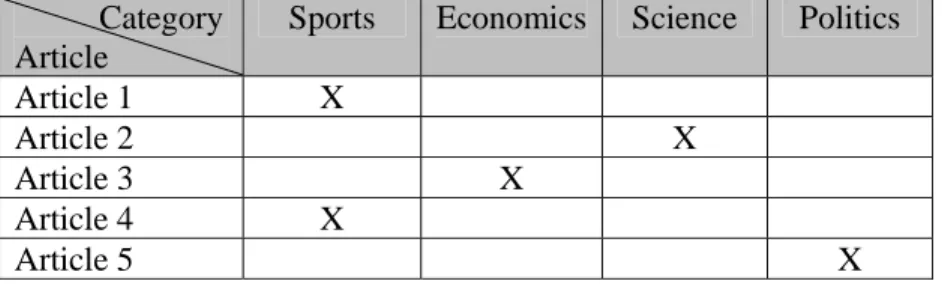
Contoh multi-labelclassification dapat dilihat pada tabel 2.3.
Tabel 2.3. Contoh Multi-Label Classification
Category Article
Sports Economics Science Politics
Article 1 X X
Article 2 X X
Article 3 X X
Article 4 X X
Article 5 X X X
Menurut Tsoumakas dan Katakis (2007), terdapat 2 pendekatan utama terhadap multi-label classification. Pendekatan pertama yaitu problem transformation, di mana objek multi-label diubah menjadi single-label dahulu, kemudian diklasifikasikan seperti layaknya objek single-label biasa. Output dari pendekatan ini adalah objek dengan satu label. Pendekatan kedua adalah algorithm adaptionmethods yang menggunakan algoritma yang telah disesuaikan untuk melakukan klasifikasi secara langsung dari objek multi-label.
Category Article
Sports Economics Science Politics
Article 1 X
Article 2 X
Article 3 X
Article 4 X
Spolaor, Cherman, Monard, & Lee (2013) mengkombinasikan kedua pendekatan di atas. Kumpulan objek multi-label melalui problem transformation untuk menjadi kumpulan objek single-label terlebih dahulu. Hal ini dilakukan agar dapat menerapkan algoritma feature selection hanya cocok untuk single-label classification. Setelah dilakukan feature selection, data kemudian diklasifikasikan menggunakan algoritma yang sudah disesuaikan untuk menghasilkan output objek multi-label.
2.3.4. Problem Transformation
Problem transformation merupakan salah satu pendekatan dalam multi-label classification. Problem transformation adalah mentransformasi masalah multi-label classification menjadi satu atau lebih single-label classification(Tsoumakas & Katakis, 2007).
2.3.5. FeatureExtraction
Feature extraction atau indexing merupakan proses mengambil bagian-bagian tertentu yang mencirikan suatu objek dan merepresentasikannya ke dalam sebuah matriks(Manning, Raghavan, & Schutze, 2009).
Dalam klasifikasi teks, feature yang biasa digunakan adalah term (istilah). Istilah dapat berupa kata atau frasa benda yang terdapat di dalam dokumen tersebut (Joachimes, 1997).
2.3.6. FeatureSelection
Feature selection merupakan proses memilih sebagian dari istilah (fitur) yang muncul di data training dalam klasifikasi. Tujuan utama feature selection adalah mengurangi ukuran fitur yang digunakan dalam proses klasifikasi untuk
mempercepat waktu klasifikasi tersebut dengan mengorbankan akurasi sekecil-kecilnya. Dalam beberapa kasus, feature selection tidak menyebabkan penurunan akurasi yang berarti atau bahkan dapat meningkatkan akurasi dari klasifikasi dengan membuang fitur noise(Guyon & Elisseeff, 2003).
2.3.7. Classifier
Menurut Manning, Raghavan, dan Schutze, (2009), classifier merupakan fungsi yang memetakan dokumen ke dalam kelas/kategori/label. Classifier dibangun dengan melakukan supervised learning dengan training set yang sudah diberi label terlebih dahulu. Kumpulan dokumen lain yang berlaku sebagai test set kemudian diklasifikasikan menggunakan classifier yang sudah dibangun untuk mengukur waktu yang diperlukan dan akurasinya.
2.3.8. Kombinasi Algoritma Multi-Label Classification
Spolaor, Cherman, Monard, & Lee (2013) membuat model multi-label classification yang terdiri dari tahap problem transformation, feature selection, dan classification. Masing-masing tahap tersebut dapat dilakukan dengan menerapkan algoritma yang sesuai dengan tahap terkait. Penelitian tersebut dilakukan dengan menganggap proses feature extraction sudah dilakukan secara terpisah.
Kombinasi algoritma didefinisikan sebagai kombinasi dari algoritma problem transformation, algoritma feature selection, dan algoritma classification sesuai dengan penelitian Spolaor, Cherman, Monard, dan Lee (2013).
2.3.9. Classification Evaluation
Kecepatan klasifikasi dapat dilihat dari jumlah waktu training (training time) dan waktu testing (testing time). Waktu training adalah waktu yang diperlukan untuk komputasi setelah diketahui istilah mana saja yang terkait suatu dokumen (setelah feature extraction) hingga pembentukan classifier, sedangkan waktu testing adalah waktu yang diperlukan untuk komputasi setelah pembentukan classifier hingga semua dokumen diberi label (Jiang, Tsai, & Lee, 2012; Xu, 2012). Semakin cepat training dan testing dilakukan, maka algoritma semakin baik.
Ukuran yang digunakan untuk mengevaluasi akurasi multi-label classification berbeda dengan klasifikasi single-label karena harus mempertimbangkan hasil labeling yang hanya benar bagian. Akurasi dapat diukur menggunakan ukuran hamming loss yang digunakan oleh (Lopez, Prieta, Ogihara, & Wong, 2012; Spolaor, Cherman, Monard, & Lee, 2013; Rokach, Schclar, & Itach, 2014; Yu, Pedrycz, & Miao, 2014).
Hamming loss merupakan ukuran banyaknya label yang salah dibanding dengan jumlah seluruh label yang ada. Hamming loss didefinisikan sebagai:
1 | ∆ |
| |
Di mana:
Karena hamming loss menyatakan kesalahan pemberian label, semakin kecil hamming loss, akurasi suatu klasifikasidianggap semakin baik (Spolaor, Cherman, Monard, & Lee, 2013).
2.4. ScholarlyJournal
Menurut Reitz (2014)Scholarly journal (artikel jurnal)adalah publikasi periodik yang memuat artikel berisi penelitian atau komentar mengenai perkembangan dalam rumpun ilmu tertentu. Artikel jurnal biasanya diakses dalam bentuk digital dari bibliographic database.
Bibliographic database merupakan database berisi deskripsi seragam untuk dokumen tipe tertentu. Bibliographic databasebiasanya menyediakan layanan untuk mempermudah menemukan dokumen seperti pencarian berdasarkan pengarang, tahun terbit, atau kata kunci tertentu (Reitz, 2014).
2.5. Dewey Decimal Classification
Dewey Decimal Classification (DDC) merupakan standar pengorganisasian pengetahuan yang paling banyak digunakan untuk klasifikasi di seluruh dunia. DDC dipublikasikan oleh Online Computer Library Center, Inc (OCLC).
Dalam DDC, pada first summary, dokumen dibagi ke dalam 10 kelas utama. Dalam second summary, masing-masing kelas utama tersebut dibagi lagi ke dalam 10 kelas lagi, sehingga terdapat 100 kelas. Dalam third summary, masing-masing kelas dibagi lagi menjadi 10 kelas, sehingga terdapat 1000 kelas (OCLC, 2015). Pembagian kelas menurut DDC dapat dilihat pada lampiran.
2.6. TermFrequency (TF)
TF merupakan frekuensi kemunculan suatu term (istilah) dalam sebuah dokumen. TF menunjukkan relevansi suatu istilah terhadap dokumen (Joachimes, 1997). TF bisa langsung digunakan sebagai bobot suatu istilah dalam klasifikasi yang tidak melalui feature selection(Joachimes, 1997; Jiang, Tsai, & Lee, 2012). TF juga dapat digunakan sebagai input untuk menghitung pembobotan dengan algoritma feature selection(Spolaor, Cherman, Monard, & Lee, 2013; Uysal & Gunal, 2012).
2.7. TermExtraction
Dalam text classification, secara umum feature extraction melibatkan mengekstrak feature berupa istilah yang tercantum dalam teks tersebut dan bobot untuk istilah tersebut. Salah satu bobot yang digunakan adalah TF(Joachimes, 1997).
Dalam penelitian ini, proses ekstraksi istilah dilakukan dengan menggunakan tool SQL Server Integration Services. Tool ini menghasilkan daftar istilah beserta frekuensi kemunculannya dalam sebuah dokumen berdasarkan dua langkah utama, yaitu POS Tagging dan Noun Phrase Detection.
2.7.1. POSTagging
Menurut Brill (1994), POS Tagging merupakan proses mengkategorikan setiap kata dalam suatu kalimat ke dalam kelas kata-(part-of-speech)-nya. Metode POS Tagging yang banyak dipakai adalah POS Tagging yang dikemukakan oleh (Brill, 1994)yang merupakan penyempurnaan metode POS Tagging sebelumnya (Brill, 1992).
Metode Brill(1994) memberikan tag untuk kata-kata yang sudah diketahui menggunakan kamus, kemudian memberikan tag untuk kata-kata yang belum diketahui berdasarkan huruf kapital, tag di depan dan belakangnya.Setelah itu, dilakukan revisi terhadap tag-tag yang tidak sesuai dengan rule yang telah disediakan.
2.7.2. NounPhrase Detection
Noun Phrase Detection dilakukan untuk mengekstrak frasa benda yang terdapat dalam suatu kalimat. Salah satu metode noun phrase detection adalah metode yang dikemukakan oleh Voutilainen, (1993). Metode ini menekankan pada morphological analysis (analisa susunan kelas kata yang mungkin dalam suatu kalimat) dan lexicon analysis (analisa pendekatan arti kata) untuk memperoleh frasa benda.
Gabungan dari kata benda dan frasa benda membentuk daftar istilah yang dipakai dalam feature extraction dari sebuah dokumen/teks.
2.8. Vector Space Model
Dalam klasifikasi, sebuah dokumen perlu direpresentasikan sebagai kumpulan berbagai istilah dan bobot masing-masing istilah tersebut. Salah satu cara untuk merepresentasikan dokumen sebagai kumpulan istilah adalah dengan menggunakan vector space model.
Dalam vector space model, sebuah dokumen dianggap sebagai vektor, di mana masing-masing komponen vektor tersebut mewakili satu istilah yang terdapat dalam kamus, beserta bobot dari istilah tersebut (Manning, Raghavan, & Schutze, 2009).
Representasi matriks dari vector space model dapat dilihat pada gambar 2.1, sedangkan representasi grafis dari vector space model dapat dilihat pada gambar 2.2.
…
…
…
…
Gambar 2.1. Vector Space Model Berisi Bobot Istilah dalam Dokumen
Gambar 2.2. Representasi Grafis Vector Space Model
2.9. Pengukuran
Jarak
2.9.1. Euclidean Distance
Euclidean distance merupakan fungsi jarak yang paling sering digunakan. Euclidean distance dihitung dengan mengukur garis lurus yang
menghubungkan dua titik (Black, 2004). Berikut persamaan Euclidean distance antara titik p dan q pada N dimensi:
Di mana:
2.9.2. Manhattan Distance
Manhattan distance merupakan jarak yang diukur mengikuti arah sumbu-sumbu tegak lurus (Black, 2006). Manhattan distance antara titik p dan q pada N dimensi dihitung menggunakan rumus:
| |
Di mana:
Gambar 2.3. Jenis-jenis Pengukuran Jarak
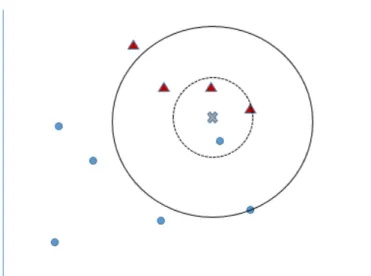
2.10. k-Nearest Neighbor
Algoritma k-nearest neighbor (kNN) biasa digunakan dalam machine learning untuk melakukan klasifikasi objek berdasarkan data training yang jaraknya paling dekat dengan objek. Untuk memperoleh data training yang jaraknya paling dekat dengan objek D, dibuat sebuah lingkaran dengan objek D sebagai titik pusatnya. Jari-jari lingkaran terus ditingkatkan sampai terdapat data training sejumlah k di dalam lingkaran tersebut (Shi & Nickerson, 2006).
Gambar 2.4 mengilustrasikan kNN untuk k=3 dan k=5.
2.11. Label Powerset (LP)
LP merupakan salah satu algoritma problem transformation. LP mentransformasikan data dengan banyak label menjadi data dengan satu label dengan menganggap setiap kombinasi unik dari label yang ada sebagai satu label tersendiri (Tsoumakas, Katakis, & Vlahavas, 2009). Algoritma LP memiliki keuntungan, yaitu memperhatikan ketergantungan antar label, di mana satu label lebih mungkin dikombinasikan dengan satu label dibandingkan dengan label lainnya. Meskipun demikian, kekurangan LP adalah jumlah kelas yang dihasilkan cukup besar.
Beberapa penelitian menggunakan LP untuk transformasi pada berbagai algoritma multi-label classification, di antaranya Spolaor, Cherman, Monard, dan Lee (2013) yang menggabungkan LP-ReliefF dengan BRkNN dan Trohidis, Tsoumakas, Kalliris, dan Vlahavas (2008) yang menggabungkan LP-CHI2 dengan SVM.
2.12. ReliefF
ReliefF merupakan algoritma feature selection yang mengukur kualitas atribut (W[A]) berdasarkan besarnya perbedaan nilai atribut tersebut antara instances yang berdekatan (Kononenko, 1994).
Algoritma ReliefF dimulai dari pemilihan suatu instanceRi secara acak,
kemudian mencari hits, yaitu k-nearest neighbors untuk kelas yang sama (Hj) dan
misses, yaitu k-nearest neighbors untuk kelas yang berbeda (Mj(C)). Jika nilai
atribut A untuk setiap neighbor sekelas (Hj) berbeda dengan Ri, maka atribut A
kualitas (W[A]) berkurang. Sebaliknya jika nilai atribut A untuk setiap neighbor beda kelas (Mj(C)) berbeda dengan Ri, maka atribut A dianggap berkualitas baik
karena memisahkan dua instance yang memang berbeda, sehingga kualitas (W[A]) meningkat. Berikut pseudocode untuk algoritma ReliefF:
1. 0.0; 2. 1 3. ; 4. ; 5. 6. 7. 1 8. ∑ , , . 9. ∑ ∑ , , / . ; 10. ;
Fungsi diff(A,I1,I2) merupakan fungsi untuk menghitung jarak antara dua
instance dalam Manhattan distance. Nilainya untuk atribut nominal:
, , 0; , ,
1; Dan untuk atribut numerik:
, , | , , |
max min
Beberapa penelitian menggunakan ReliefF sebagai algoritma feature selection dalam klasifikasi single-label maupun multi-label. Kumari, Nath, dan Chaube (2015) menggabungkan ReliefF dengan algoritma learning Rotation Forest dan memperoleh akurasi di atas 85%.
Spolaor, Cherman, Monard, dan Lee (2013) menggunakan algoritma ReliefF berpasangan dengan BR dan LP dalam algoritma klasifikasi multi-label BRkNN. Algoritma tersebut memilih lebih sedikit istilah dibandingkan dengan algoritma Information Gain (IG). Oleh karena itu, algoritma ini bisa membuat klasifikasi lebih cepat. Meskipun demikian, algoritma ini sendiri cukup kompleks sehingga feature selection sendiri mungkin memakan waktu yang lama.
2.13. Distinguishing Feature Selector (DFS)
DFS merupakan algoritma feature selection untuk memilih fitur dengan memberi bobot tinggi pada fitur pembeda dan mengeliminasi fitur yang tidak informatif (Uysal & Gunal, 2012).
Ranking istilah dalam DFS dilakukan dengan mempertimbangkan kriteria berikut:
1. Sebuah istilah yang sering muncul di suatu kelas dan tidak muncul di kelas lain adalah distinctive, sehingga skor tinggi.
2. Sebuah istilah yang jarang muncul di suatu kelas dan tidak muncul di kelas lain adalah irrelevant, sehingga skor rendah.
3. Sebuah istilah yang sering muncul di semua kelas adalah irrelevant, sehingga skor rendah.
4. Sebuah istilah yang muncul di beberapa kelas adalah relatively distinctive, sehingga diberi skor relatif tinggi.
Sehingga bobot suatu istilah dengan DFS dihitung dengan rumus berikut: |
Di mana:
|
|
|
Setelah nilai DFS diperoleh, sejumlah istilah yang memiliki nilai DFS tertinggi dipilih untuk digunakan dalam klasifikasi.
Terdapat penelitian yang menggunakan DFS. Uysal dan Gunal (2014) menggabungkan DFS dengan algoritma classifier,Genetic Algorithm Latent Semantic Indexing (GALSF). Hasilnya penelitian tersebut, algoritma DFS + GALSF lebih akurat dibandingkan dengan CHI2 + GALSF.
Alenezi dan Magel, (2013) membandingkan akurasi DFS dengan 4 algoritma feature selection lain, yaitu LOR, X2, TFRF, MI. Kelima feature selection tersebut dikombinasikan dengan classifier Naive Bayes. Dari penelitian tersebut diketahui bahwa DFS unggul ketika menggunakan dataset Maemo.
Meskipun DFS cukup akurat, namun sejauh pengetahuan penulis, selama ini DFS hanya digunakan untuk feature selection dalam single-label classification.
2.14. Fuzzy Similarity Measure
Fuzzy Similarity Measure(Saracoglu, Tutuncu, & Allahverdi, 2008) merupakan ukuran yang digunakan untuk menentukan kemiripan antara suatu dokumen dengan kategori yang ada.
Misalkan himpunan data training , , , , … , , terdiri dari dua komponen: dokumen ( ) dan label vector ( ). Untuk setiap
dokumen training , merupakan vektor dengan komponen sejumlah p yang menggambarkan apakah suatu dokumen termasuk atau tidak termasuk suatu kategori ( , , … , ). yi dinyatakan dengan rumus:
1,
0,
Distribusi term pada kategori (dt dan dd) dihitung menggunakan rumus: , ∑ ∑ , ∑ ∑ Di mana: 1, 0 0, 0
Derajat keanggotaan istilah pada kategori dapat dihitung menggunakan rumus: , , max , , , max , ,
Derajat keanggotaan istilah t terhadap dokumen d dapat dihitung menggunakan rumus:
max
Fuzzy similarity dari dokumen d terhadap kategori dapat dihitung menggunakan rumus:
, ∑ ,
∑ ,
Di mana:
2.15. Fuzzy Similarity k-Nearest Neighbor (FSkNN)
FSkNN (Jiang, Tsai, & Lee, 2012) merupakan pengembangan dari algoritma MLkNN (Zhang & Zhou, 2007) dengan menambahkan fuzzy similarity measure(Saracoglu, Tutuncu, & Allahverdi, 2008) untuk mengurangi cost mencari k-nearest neighbors. Setelah menghitung fuzzy similarity measure, dokumen dikelompokkan ke dalam cluster. Hanya dokumen training dalam cluster yang memiliki kemiripan dengan dokumen melebihi batas tertentu yang digunakan untuk mencari k-nearest neighbor. Dokumen testing diberi label berdasarkan perkiraan maximum a posteriori.
Pada penelitian Jiang, Tsai, dan Lee (2012), FSkNN digunakan begitu saja tanpa melakukan tahap pendahuluan dalam klasifikasi seperti problem transformation dan/atau feature selection. Sejauh pengetahuan penulis, belum ada penelitian lain yang menggunakan algoritma ini dengan langkah-langkah tersebut.
2.15.1. Tahap Training
Tahap training dari FSkNN dilakukan dengan mengelompokkan dokumen ke dalam cluster, kemudian menentukan prior dan likelihood.
Dokumen dikelompokkan ke dalam cluster berdasarkan fuzzy similarity measure terlebih dahulu. Kemudian derajat keanggotaan dokumen d dalam sebuah kategori dihitung menggunakan rumus berikut:
,
max ,
Pseudocode berikut menunjukkan cara pengelompokkan dokumen ke dalam cluster: 1. , 1 2. , 1 3. 4. 5. , 1 6. , 1 7. 8. Di mana: P(Hj) merupakan prior probability dari sebuah variabel acak termasuk
kategori j, yang dihitung menggunakan rumus:
1 ∑
2
0 1 1
Di mana:
s = smoothing constant dan y = label vector
Misalkan merupakan himpunan k-nearest neighbors untuk dokumen testing (dengan Euclidean distance), dan , , … , merupakan label-count vector untuk , likelihood dihitung dengan terlebih dahulu mendefinisikan:
,
Di mana:
1 1, 0, Kemudian perhitungan likelihood:
1 , 1 ∑ , 0 , 1 ∑ , Untuk e = 0,1,…,k dan j=1,2,…,p.
2.15.2. Tahap Testing
Tahap testing dilakukan untuk menentukan dokumen testingdt termasuk kategori yang mana. Dalam tahap ini diperlukan perhitungan estimasi maximum a posteriori.
Misalkan , , … , merupakan himpunan k-nearest neighbors untuk dokumen (menggunakan Euclidean distance), dan
, , … , merupakan label-count vector untuk dt yang dihitung menggunakan rumus:
Maximum a posteriori (MAP) dihitung menggunakan rumus:
1, 1| 0|
0, 0| 1|
0,1 , Di mana:
0,1 0 1
Berdasarkan teorema Bayes, rumus MAP tersebut dapat diubah menjadi:
1, 1 | 1 0 | 0
0, 0 | 0 1 | 1
0,1 ,
Pseudocode berikut menunjukkan langkah-langkah yang dilakukan dalam tahap testing:
1. , 1 2. 1 . , , … , . , , … , 3. , , , . 4. , 1 . 5. ,
2.16. Storyboard
Storyboard adalah outline rancangan grafis yang mendeskripsikan proyek secara rinci, menggunakan kata-kata dan sketsa untuk setiap tampilan layar, suara, dan pilihan navigasi, hingga warna dan corak, konten teks, atribut dan font, bentuk tombol, styles, respon, dan perubahan suara.
Pendekatan storyboard yang rinci tepat digunakan untuk membangun prototype dengan cepat dan mengkonversikannya menjadi sebuah sistem jadi (Vaughan, 2008).
2.17. Unified Modeling Languange (UML)
Menurut Whitten dan Bentley (2007), Unified Modeling Language (UML) adalah sekumpulan aturan perancangan model untuk menggambarkan bagaimana suatu sistem perangkat lunak bekerja dari segi objek.
UML terdiri dari berbagai diagram untuk menggambarkan cara kerja suatu perangkat lunak dan interaksinya dengan pengguna. Berikut adalah beberapa diagram UML:
2.17.1. Use Case Diagram
Use case diagram adalah diagram dalam UML yang digunakan untuk menggambarkan interaksi antara sistem dan sistem eksternal atau pengguna (Whitten & Bentley, 2007). Use case diagram menunjukkan siapa pengguna sistem dan bagaimana cara pengguna tersebut berinteraksi dengan sistem.
Gambar 2.5. menunjukkan notasi yang digunakan dalam use case diagram, sedangkan gambar 2.6. menunjukkan contoh penggunaan use case diagram.
Gambar 2.5. Notasi Use Case Diagram
Classification System
Upload File
Admin
Gambar 2.6. Contoh Use Case Diagram
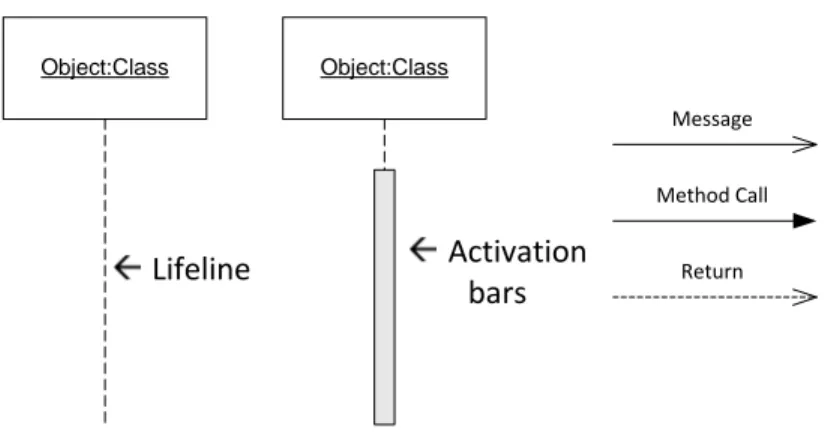
2.17.2. Sequence Diagram
Sequence Diagram adalah sebuah diagram UML yang menggambarkan interaksi antar objek dalam urutan waktu (Whitten & Bentley, 2007).
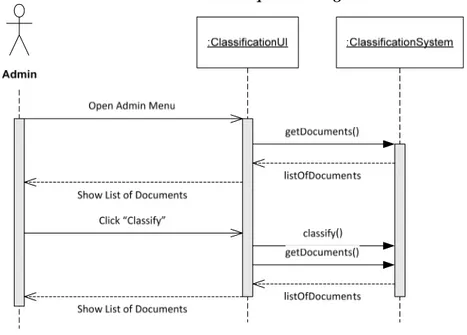
Gambar 2.7. menunjukkan notasi sequence diagram, sedangkan gambar 2.8. menunjukkan contoh penggunaan sequence diagram.
Object:Class Object:Class Lifeline Activation bars Message Method Call Return
Gambar 2.7. Notasi Sequence Diagram
Gambar 2.8. Contoh Sequence Diagram
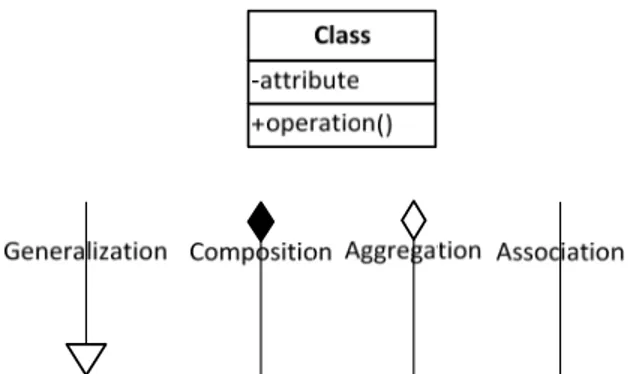
2.17.3. Class Diagram
Class diagram adalah diagram UML yang digunakan untuk menggambarkan struktur objek statis suatu sistem, menunjukkan objek kelas lain yang menyusun suatu kelas, dan hubungan antar objek (Whitten & Bentley, 2007).
Gambar 2.9. menunjukkan notasi yang digunakan dalam class diagram, sedangkan gambar 2.10. menunjukkan contoh penggunaan class diagram.
Gambar 2.9. Notasi Class Diagram
2.18. Data Modeling
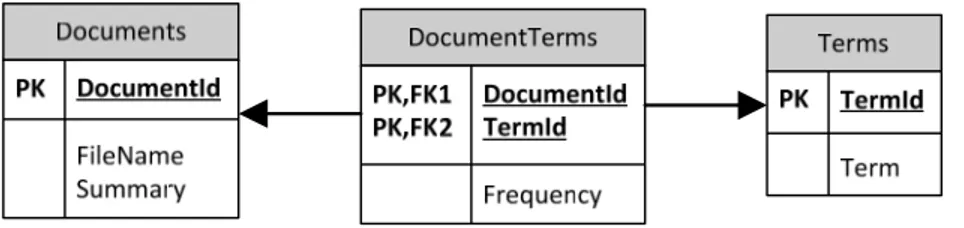
Data Modeling adalah teknik untuk mengatur dan mendokumentasikan data dalam suatu sistem. Ada beberapa notasi untuk data modeling. Model aktual dari data modeling disebut Entity Relationship Diagram (ERD).
ERD adalah data model yang menggunakan beberapa notasi untuk menggambarkan data dalam konteks entitas dan hubungan antar data tersebut (Whitten & Bentley, 2007).
Paling tidak 3 komponen berikut ada di dalam sebuah ERD (Whitten & Bentley, 2007):
1. Entitas
Entitas adalah sebuah kelas dari orang, tempat, objek, kejadian atau konsep yang dibutuhkan untuk memperoleh dan menyimpan data.
2. Atribut
Atribut adalah bagian tertentu dari data sebuah entitas yang akan disimpan nilainya. Sebagai contoh, entitas student dapat dideskripsikan dengan atribut-atribut berikut: nama, alamat, tanggal lahir, gender, dll.
Sebuah entitas dapat memiliki ribuan atau jutaan instance. Oleh karena itu, perlu adanya satu atau lebih atribut unik untuk mengidentifikasi suatu instance. Atribut unik ini disebut dengan key. Key yang paling sering digunakan untuk mengidentifikasi instance adalah primary key.
3. Relationship
Sebuah relationship dalam ERD adalah hubungan bisnis alami antara satu atau lebih entitas. Secara grafis, relationship dinyatakan dalam bentuk garis yang menghubungkan lebih dari satu entitas. Contoh ERD ditunjukkan dalam gambar 2.11.