Penerapan Data Mining Dalam Pengelompokan Kota
Berdasarkan Provinsi Yang Tanggap Terhadap Ancaman
Narkotika Dengan Menggunakan K-Medoids
Ilfi Rahmadani
1, Saifullah
2, Heru Satria Tambunan
3, Irfan Sudahri Damanik
4,
Ilham Syahputra Saragih
51
Jurusan Sistem Informasi, STIKOM Tunas Bangsa Pematangsiantar
1
ilfirahmadani24@gmail.com
Abstract
Narcotics is a problem that is not uncommon to be heard again by the public inside and outside the country. Especially at this time the development of Indonesia's population is very rapid so it is vulnerable to the threat of narcotics. There are several parties who take advantage of this development, especially the narcotics dealers, who are trying to destroy the younger generation by smuggling narcotics into the country and this is a potential market for illicit drug trafficking. The role of the community is very important in responding to this especially at the city / district level. To solve this problem the writer uses the K-Medoids method to classify cities that are responsive to the threat of narcotics. K-Medoids is one of the methods that exist in data mining by using clustering or grouping techniques. In this method the data that has been collected will be processed through the calculation process first by following the steps in the calculation process of the K-Medoids method that has been set so that it can get effective and accurate results. Using the K-Medoids method can find out the number of groupings in cities / districts that have high or low responsiveness. If a city has a low responsiveness to the threat of narcotics, it can help the City / District National Narcotics Agency (BNNK) to improve or add facilities such as UKS, socialize to the community and others in a City / Regency that has a low level of responsiveness to the threat narcotics, and increase public awareness of the dangers of narcotics. And if the city has a high response to the threat of narcotics, it is expected that the people in the city can maintain and increase their responsiveness (level of awareness) to the threat of narcotics. The results of grouping from the RapidMiner tools with the calsulation of k-medoids obtained a high clusters (C1) of 7 and a low cluster (C2)
of 26.
Keywords: K-Medoids Method, City / District, Response, Narcotics.
1. Pendahuluan
Dengan pertumbuhan penduduk yang sangat besar di Indonesia ada beberapa pihak yang memanfaatkan perkembangan ini apalagi Indonesia mempunyai banyak pulau–pulau kecil yang sangat banyak sehingga dapat dimanfaatkan oleh pihak-pihak tertentu terutama pihak pengedar narkotika yang berupaya untuk menghancurkan generasi muda dengan menyeludupkan narkotika ke dalam negeri dan membuat pasar potensial bagi peredaran gelap narkotika. Hal ini dikarenakan narkoba telah menjadi masalah yang serius, melibatkan jejaring dan pelaku trans-nasional, serta perputaran uang yang besar, dan teknologi yang canggih yang berdampak pada ke rusakan yang bersifat multi-dimensional. Kerusakan tersebut mengakibatkan pelemahan karakter individu yang berarti melemahkan ketahanan keluarga dan masyarakat sebagai awal dari kehancuran bangsa. Oleh karena itu Badan Narkotika Nasional banyak berperan penting untuk melaksanakan tugasnya di bidang pencegahan dan pemberdayaan masyarakat melalui diseminasi informasi dan advokasi, pemberdayaan peran serta masyarakat, bidang rehabilitasi melalui penguatan lembaga instansi pemerintah dan komponen masyarakat, bidang
pemberantasan melalui pelaksanaan intelijen dan penyidikan jaringan peredaran gelap narkotika. Peran masyarakat juga sangat dibutuhkan oleh Badan Narkotika Nasional untuk membantu mereka dalam melaksanakan tugas dan mewujudkan kota yang tanggap (memiliki tingkat kesadaran yang tinggi) terhadap ancaman narkotika agar kejahatan narkotika bisa di selesaikan secara bersama-sama (bukan hanya menjadi tanggung jawab BNN satu–satunya) mulai dari bagian atas (pemerintah) sampai ke bagian bawah (masyarakat).
Ada beberapa teknik untuk melakukan pengelompokan, diantaranya K-Means, dan K-Medoids. Pada penelitian ini, penulis menggunakan metode K-Medoids untuk mengelompokkan data. Ada beberapa penelitian yang memiliki penyelesaian dengan metode yang sama, dan ada pula yang menggunakan perbandingan seperti penelitian yang dilakukan oleh [1] dengan hasil penelitian bahwa „algoritma K-Medoids lebih baik dalam melakukan pengelompokan pada data sebaran Anak Cacat dibandingkan dengan algoritma K-Means’.
2. Tinjauan Pustaka
2.1. Data Mining
Menurut Tacbir (dalam [2]) „data mining adalah proses yang menggunakan teknik statistik, matematika, kecerdasan buatan, dan machine learning untuk mengekstraksi dan mengidentifikasi informasi yang bermanfaat dan pengetahuan yang terkait dari database yang besar‟. “Tujuan dari data mining yaitu mencari trend atau pola yang diinginkan dalam database besar untuk membantu dalam pengambilan keputusan pada waktu yang akan datang”[3].
2.2 Clustering
Menurut Juneidi et.al (dalam [1]) “Clustering merupakan suatu proses pengelompokan data, observasi, atau mengelompokan kelas yang memiliki kesamaan objek”. “Berbeda dengan proses klasifikasi, clustering tidak mempunyai target variable dalam melakukan. Clustering sering dilakukan sebagai langkah awal dalam proses data
mining”[1].
Gambar 2.1. Contoh Clustering
(Sumber : Nango ( dalam Defiyanti & Jajuli, 2017))
Menurut Nango (dalam [4]) „Adapun tujuan dari data clustering ini adalah untuk meminimalisasikan objective function yang diset dalam proses clustering, yang pada umumnya berusaha meminimalisasikan variasi di dalam suatu cluster dan memaksimalisasikan variasi antar cluster‟
.
2.3 K-Medoids
Menurut Furqon dkk (dalam [3]) „Algoritma K- Medoids memiliki kelebihan untuk mengatasi kelemahan pada pada algoritma K-Means yang sensitive terhadap noise dan
outlier, dimana objek dengan nilai yang besar yang memungkinkan menyimpang pada
dari distribusi data. Kelebihan lainnya yaitu hasil proses clustering tidak bergantung pada urutan masuk dataset‟. Langkah- langkah algoritma K-Medoids, yaitu:
2. Alokasikan setiap data (objek) ke cluster terdekat menggunakan persamaan ukuran jarak Euclidian Distance dengan persamaan:
……… (2)
3. Pilih secara acak objek pada masing-masing cluster sebagai kandidat medoid baru. 4. Hitung jarak setiap objek yang berada pada masing-masing cluster dengan kandidat
medoid baru.
5. Hitung total simpangan (S) dengan menghitung nilai total distance baru-total distance lama. Jika S < 0, maka tukar objek dengan data cluster untuk membentuk sekumpulan k objek baru sebagai medoid.
6. Ulangi langkah 3 sampai 5 hingga tidak terjadi perubahan medoid, sehingga didapatkan cluster beserta anggota cluster masing-masing.
2.4 Pemodelan Metode
Setiap metode atau algoritma memiliki pemodelan masing-masing yang sesuai dengan proses pengerjaannya. Pada penelitian ini penulis menggunakan metode
K-Medoids untuk mengelompokkan kota berdasarkan provinsi yang tanggap terhadap
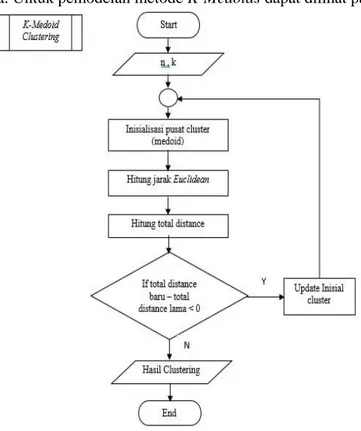
ancaman narkotika. Untuk pemodelan metode K-Medoids dapat dilihat pada Gambar 2.2.
Gambar 2.2. Flowchart Metode K-Medoids
(Sumber: [3])
Gambar 2.2 ini menjelaskan bagaimana langkah-langkah metode K-Medoids yang dimulai dari menentukan jumlah data yang akan dicluster atau dikelompokkan, kemudian menetapkan nilai k yang akan dicari. Menentukan nilai centroid awal yang sudah ditentukan secara random berdasarkan nilai variable data yang dicluster sebanyak k yang ditentukan sebelumnya. Pilih secara acak objek masing-masing cluster sebagai kandidat
medoid baru kemudian hitung jarak setiap objek yang berada pada masing-masing cluster
dengan kandidat medoid baru. Lalu hitunglah total simpangan (S) dengan menghitung nilai total distance baru-total distance lama. Jika S < 0, maka tukar objek dengan data cluster untuk membentuk sekumpulan k objek baru sebagai medoid baru. Setelah itu ulangi langkah dari menentukan medoid hingga selesai sampai hasil yang didapatkan
tidak terjadi perubahan medoid sehingga didapatkan cluster beserta anggota cluster masing-masing.
3. Hasil Dan Pembahasan
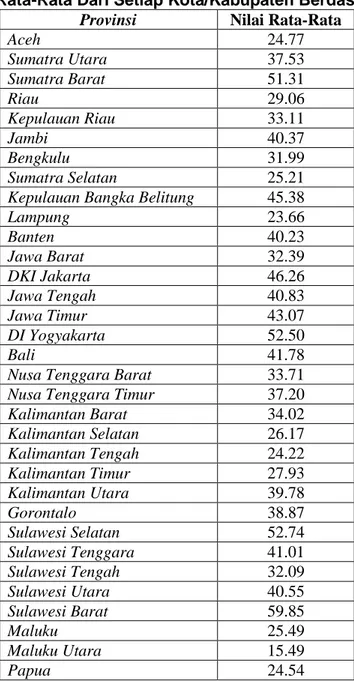
Pada bagian ini penulis akan menguraikan penyajian hasil penelitian. Berikut ini data hasil rata-rata dari setiap Kota/Kabupaten berdasarkan provinsi yang tanggap terhadap ancaman narkotika sebagai berikut:
Tabel 1. Hasil Rata-Rata Dari Setiap Kota/Kabupaten Berdasarkan Provinsi
Provinsi Nilai Rata-Rata
Aceh 24.77 Sumatra Utara 37.53 Sumatra Barat 51.31 Riau 29.06 Kepulauan Riau 33.11 Jambi 40.37 Bengkulu 31.99 Sumatra Selatan 25.21
Kepulauan Bangka Belitung 45.38
Lampung 23.66 Banten 40.23 Jawa Barat 32.39 DKI Jakarta 46.26 Jawa Tengah 40.83 Jawa Timur 43.07 DI Yogyakarta 52.50 Bali 41.78
Nusa Tenggara Barat 33.71
Nusa Tenggara Timur 37.20
Kalimantan Barat 34.02 Kalimantan Selatan 26.17 Kalimantan Tengah 24.22 Kalimantan Timur 27.93 Kalimantan Utara 39.78 Gorontalo 38.87 Sulawesi Selatan 52.74 Sulawesi Tenggara 41.01 Sulawesi Tengah 32.09 Sulawesi Utara 40.55 Sulawesi Barat 59.85 Maluku 25.49 Maluku Utara 15.49 Papua 24.54
Setelah data sudah diketahui hasilnya data tersebut akan masuk ke dalam proses perhitungan sesuai dengan metode atau algoritma yang akan digunakan untuk memecahkan masalah tersebut. Pada proses perhitungan pada metode K-Medoids ini dimulai dari melakukan inisialisasi pusat cluster sebanyak k (jumlah cluster) yang ingin digunakan. Disini penulis menggunakan 2 cluster dalam melakukan inisialisasi. Pemilihan setiap cluster untuk menentukan medoid dilakukan secara acak seperti pada tabel 3.2 di bawah ini:
Tabel 2. Medoids Awal
Nama Provinsi Nilai Rata-Rata
C1 Sulawesi Barat 59,85
C2 Maluku Utara 15,49
Setelah medoid awal sudah ditentukan kemudian hitunglah nilai jarak terdekat setiap data (objek) ke cluster terdekat menggunakan persamaan ukuran jarak Eulidian
Distance. Berikut ini perhitungan dengan persamaan (2):
…
Untuk hasil medoid awal yang sudah dihitung melalui persamaan dapat dilihat pada tabel 3.3 berikut ini:
Tabel 3. Hasil Perhitungan Iterasi 1 PROVINSI JARAK KE MEDOID TERDEKAT CLUSTER YANG DIKETAHUI C1 C2 ACEH 35.08 9.28 9.28 2 SUMATRA UTARA 22.32 22.04 22.04 2 … … … … … PAPUA 35.31 9.05 9.05 2
Setelah itu hitung seluruh jumlah C1 dan C2 lalu jumlahkan keseluruhannya untuk mendapatkan nilai costnya. Pada hasil iterasi 1 ini total cost yang didapat sebanyak 1463.88. Setelah hasil dari jarak terdekat pada medoid awal sudah didapatkan pada iterasi ke-1 kemudian pilih secara acak objek pada masing-masing cluster sebagai kandidat
medoid baru untuk proses perhitungan pada iterasi ke-2.
Tabel 4. Medoid Baru (Non-Medoid 1)
Nama Provinsi Nilai Rata-Rata
C1 Sulawesi Selatan 52.74
C2 Lampung 23.66
Hitung kembali jarak dari setiap objek pada masing-masing cluster menggunakan
medoid baru yang ada pada tabel 4.5 sebagai berikut:
…
0.88
Berikut ini seluruh hasil dari medoid baru untuk perhitungan iterasi ke-2:
Tabel 5. Hasil Perhitungan Iterasi 2 PROVINSI JARAK KE MEDOID TERDEKAT CLUSTER YANG DIKETAHUI C1 C2
ACEH 27.97 1.11 1.11 2 SUMATRA UTARA 15.21 13.87 13.87 2 … … … … … PAPUA 28.20 0.88 0.88 2
Kemudian hitung total simpangan (S) dengan menghitung nilai total cost baru dengan total cost lama. Total cost baru diambil dari iterasi ke-2 dan total cost lama diambil dari iterasi ke-1, sehingga hasil yang diperoleh yaitu:
S = 990.20 - 1463.88 = - 473.68.
Jika hasil S < 0, maka tukar nilai objek dengan menentukan medoid baru hingga nilai S > 0. Karna hasil simpangan masih dibawah 0 jadi proses perhittungan akan dilanjutkan ke iterasi 3 dengan menggunakan medoid baru. Pada penelitian ini penulis melakukan penelitian sampai iterasi 4, karna pada iterasi 4 hasil perhitungan simpangan yang di dapatkan di atas nilai 0 maka proses perhitungan selesai dilakukan. Dengan jumlah simpangan
S = 657,464 – 608,954 = 48.51
Dengan hasil simpangan yang sudah diatas 0 maka proses perhitungan cluster dihentikan sehingga jumlah cluster yang didapatkan dapat dilihat pada tabel 3.6 dibawah ini:
Tabel 6. Hasil Pengklusteran Dengan K-Medoids Provinsi Jarak Ke Medoid Terdekat Cluster Yang Diketahui C1 C2 Aceh 20.607 15.597 15.597 2 Sumatra Utara 7.85 2.84 2.84 2 Sumatra Barat 5.93 10.94 5.93 1 Riau 16.32 11.31 11.31 2 Kepulauan Riau 12.27 7.26 7.26 2 Jambi 5.01 0.00 0.00 2 Bengkulu 13.39 8.38 8.38 2 Sumatra Selatan 20.17 15.16 15.16 2
Kepulauan Bangka Belitung 0.00 5.01 0.00 1
Lampung 21.72 16.71 16.71 2 Banten 5.15 0.14 0.14 2 Jawa Barat 12.99 7.98 7.98 2 DKI Jakarta 0.88 5.89 0.88 1 Jawa Tengah 4.55 0.46 0.46 2 Jawa Timur 2.31 2.7 2.31 1 DI Yogyakarta 7.12 12.13 7.12 1 Bali 3.6 1.41 1.41 2
Nusa Tenggara Barat 11.67 6.66 6.66 2
Nusa Tenggara Timur 8.18 3.17 3.17 2
Provinsi Jarak Ke Medoid Terdekat Cluster Yang Diketahui Kalimantan Selatan 19.21 14.2 14.2 2 Kalimantan Tengah 21.16 16.15 16.15 2 Kalimantan Timur 17.45 12.44 12.44 2 Kalimantan Utara 5.6 0.59 0.59 2 Gorontalo 6.51 1.5 1.5 2 Sulawesi Selatan 7.36 12.37 7.36 1 Sulawesi Tenggara 4.37 0.64 0.64 2 Sulawesi Tengah 13.29 8.28 8.28 2 Sulawesi Utara 4.83 0.18 0.18 2 Sulawesi Barat 14.47 19.48 14.47 1 Maluku 19.89 14.88 14.88 2 Maluku Utara 29.89 24.88 24.88 2 Papua 20.84 15.83 15.83 2
Dari tabel di atas dapat diketahui bahwa total provinsi yang memiliki ketanggapan yang tinggi terhadap ancaman narkotika (C1) ada sebanyak 7 provinsi dan total provinsi yang memiliki ketanggapan yang rendah terhadap ancaman narkotika (C2) sebanyak 26 provinsi.
4. Kesimpulan
Berdasarkan pembahasan yang ada, skripsi ini menarik beberapa kesimpulan sebagai berikut:
1. Pada studi kasus ini dengan menggunakan metode K-Medoids dapat dilihat berapa banyak provinsi yang ada di Indonesia ini yang memiliki ketanggapan yang tinggi (C1) dan rendah (C2) terhadap ancaman narkotika.
2. Hasil pengelompokan dari tools RapidMiner dengan perhitungan K-Medoids diperoleh
cluster tinggi (C1) sebanyak 7, yaitu: Sumatra Barat, Kepulauan Bangka Belitung,
DKI Jakarta, Jawa Timur, DI Yogyakarta, Sulawesi Selatan, dan Sulawesi Barat sedangkan cluster rendah (C2) sebanyak 26 provinsi, yaitu: Aceh, Sumatra Utara, Riau, Kepulauan Riau, Jambi, Bengkulu, Sumatra Selatan, Lampung, Banten, Jawa Barat, Jawa Tengah, Bali, Nusa Tenggara Barat, Nusa Tenggara Timur, Kalimantan Barat, Kalimantan Selatan, Kalimantan Tengah, Kalimantan Timur, Kalimantan Utara, Gorontalo, Sulawesi Tenggara, Sulawesi Tengah, Sulawesi Utara, Maluku, Maluku Utara dan Papua.
Daftar Pustaka
[1] D. Marlina, N. F. Putri, A. Fernando, and A. Ramadhan, “Implementasi Algoritma K-Medoids dan K-Means untuk Pengelompokkan Wilayah Sebaran Cacat pada Anak,” vol. 4, no. 2, pp. 64–71, 2018. [2] A. N. Khomarudin, “Teknik Data Mining : Algoritma K-Means Clustering,” pp. 1–12, 2016. [3] D. F. Pramesti, M. T. Furqon, and C. Dewi, “Implementasi Metode K-Medoids Clustering Untuk
Pengelompokan Data Potensi Kebakaran Hutan / Lahan Berdasarkan Persebaran Titik Panas ( Hotspot ),” vol. 1, no. 9, pp. 723–732, 2017.
[4] S. Defiyanti and M. Jajuli, “Optimalisasi K - Medoid Dalam Pengklasteran Mahasiswa Pelamar Beasiswa Dengan Cubic Clustering Criterion,” vol. 3, no. 1, pp. 211–218, 2017.