Sistem Automatic Music Emotion Classification
Ali Akbar – NIM : 23507042Program Studi Informatika, Institut Teknologi Bandung Jl. Ganesha 10, Bandung
E-mail : [email protected]
Abstrak
Kenyataan bahwa musik terkait dengan emosi adalah fakta yang umum dan tidak dapat dibantah. Penggunaan musik pada kehidupan sehari-hari berdasarkan emosi yang terkandung di dalamnya sudah banyak dilakukan. Akan tetapi, analisa emosi musik di komputer adalah hal yang sulit dilakukan [1]. Makalah menjabarkan hasil studi sistem automatic music emotion classification ( klasifikasi emosi musik otomatis). Tujuan dari studi ini adalah untuk membuat sebuah usulan sistem automatic music emotion classification (AMEC). Sistem ini adalah sistem yang dapat mendeteksi secara otonom mood atau emosi yang terkandung di dalam musik. Studi literatur dilakukan terhadap setiap bagian dari sistem ini, kemudian dirumuskan pendekatan yang dinilai terbaik pada rancangan ini.
Kata kunci : music, mood, emotion, system
1. Pendahuluan
Musik adalah seni, hiburan dan aktivitas manusia yang melibatkan suara-suara yang teratur. Secara khusus, musik diartikan sebagai ilmu dan seni suara, yaitu berupa bentuk dan sinkronisasi suara-suara yang membentuk harmoni nada-nada sehingga terdengar estetik [2].
Elemen terkecil dari musik adalah nada. Nada adalah suara yang memiliki nilai frekuensi tertentu. Dalam musik, nada berada pada ruang dua dimensi, dimensi vertikal dan horizontal. Dimensi vertikal atau dimensi nada menyatakan nada-nada yang ada atau berbunyi pada suatu waktu tertentu. Dimensi horizontal atau dimensi waktu adalah bagaimana nada-nada tersebut berubah sejalan dengan waktu.
Musik berkaitan erat dengan psikologi manusia. Kenyataan bahwa musik dapat terkait emosi atau mood tertentu adalah fakta yang umum diketahui dan tidak dapat dibantah. Penelitian penelitian eksperimental memperkuat kenyataan ini [3]. Dari sudut pandang psikologi musik, emosi merupakan salah satu cara penggolongan musik yang paling penting. Huron mengemukakan bahwa karena fungsi utama dari musik adalah sosial dan psikologis, penggolongan musik yang paling penting adalah: style, emosi, genre dan similarity [4].
Sistem automatic music emotion classification (AMEC) adalah sistem yang dapat melakukan
klasifikasi terhadap musik berdasarkan emosi atau mood yang terkait dengan musik tersebut. Sistem ini masuk dalam bahasan bidang music information retrieval. Dalam jurnal khusus music information retrieval, SIGMIR, banyak makalah dan penelitian yang dipublikasikan membahas berbagai aspek dari klasifikasi musik berdasarkan emosi ini.
Penangkapan emosi dalam musik bersifat subjektif. Satu individu dapat menangkap pesan emosi yang berbeda dari individu lain dari musik yang sama. Yang et al. membahas khusus masalah ini pada [5]. Solusi yang ditempuh para peneliti adalah dengan membuat ‘ground truth’ untuk data penilaian musik [6][7]. Pada bidang musik sendiri belum dirumuskan formulasi sebagai dasar penentuan klasifikasi emosi. Sehingga, pendekatan yang dapat dilakukan untuk mengklasifikasikan musik ke dalam kategori emosi adalah dengan bergantung pada pembelajaran terhadap penilaian subjektif oleh manusia.
Makalah ini mengajukan sebuah rancangan sistem AMEC. Sistem ini dirancang untuk dapat melakukan klasifikasi emosi terhadap musik secara umum. Sistem ini memakai pendekatan machine learning, sehingga sistem terbagi atas dua fase, pelatihan dan penggunaa. Penilaian subjektif ‘ground truth’ diberikan sebagai data pelatihan sistem AMEC untuk menghasilkan suatu model klasifikasi. Model inilah yang akan
digunakan classifier untuk mengklasifikasikan musik berdasarkan emosi.
Dalam makalah ini, bagian 3 membahas gambaran umum sistem AMEC ini. Bagian-bagian selanjutnya akan membahas masing-masing permasalahan yang ada pada sistem AMEC ini.
2. Latar Belakang
Tak terhitung banyaknya upaya para filsuf, penulis dan pemusik untuk mencoba menjelaskan keterkaitan antara musik dengan emosi, tapi tidak menghasilkan kesepakatan. Pada beberapa tahun belakangan ini, perkembangan pada bidang psikologi kognitif menunjukkan kembalinya ketertarikan pada bidang ini. Pada makalahnya di tahun 2003, Grund bahkan mencatatnya dalam wish list utama penelitian dalam bidang psikologi musik [9].
Jumlah music psychologist, yang mengkhusus-kan penelitiannya pada seputar msuik dan keterkaitannya dengan emosi terus bertambah. Walaupun begitu, hanya sedikit pembahasan teoritis mengenai respon emosi terhadap musik yang ditulis berdasarkan perspektif psikologi musik yang dapat dijadikan acuan dalam studi empiris lebih lanjut [10].
Diantara pemicunya yang terkenal adalah penelitian Hevner pada tahun 1936 yang berjudul ‘Studi eksperimental mengenai elemen ekspresi di dalam musik’ (‘Experimental studies of the elements of expression in music’) [8]. Hevner melakukan penelitian dengan melakukan eksperimen dimana pendengar diminta menuliskan kata sifat yang muncul di pikiran mereka yang paling deskriptif terhadap musik yang diperdengarkan. Eksperimen ini dilakukan utuk memperkuat hipotesis bahwa musik benar-benar membawa arti emosional. Hevner menemukan adanya kluster kata sifat merumuskan delapan kata sifat utama yang ditempatkannya di dalam sebuah lingkaran. Dia juga menemukan dalam sebuah kelompok yang mempunyai latar belakang kultural yang sama, pelabelan emosi musik cenderung konsisten antar tiap individunya [11].
Keterkaitan antara musik dengan emosi/mood ini telah banyak digunakan dalam berbagai kesempatan oleh manusia. Misalnya, pada film,
musik digunakan untuk mempertegas suasana pada scene-scene tertentu: musik yang dramatis digunakan untuk melatar belakangi scene yang menegangkan, musik yang bersemangat untuk scene perang, musik yang menyenangkan digunakan sebagai latar belakang scene humor, dsb. Di beberapa tempat di Tokyo, setiap pagi diputar musik yang tenang sekaligus bersemangat, untuk membuat penduduk lebih tenang dan bersemangat. Pada kafe-kafe, diputar musik bernuansa romantis. Masih banyak lagi contoh yang tidak dapat disebutkan di sini. Karena itu, klasifikasi musik berdasarkan keterkaitannya dengan emosi tertentu menjadi penting.
Klasifikasi musik berdasarkan emosi dapat dilakukan secara manual dan subjektif oleh manusia, seperti yang banyak dilakukan pada kasus pemilihan musik untuk latar belakang suatu film. Biasanya pada tim pembuat film tersebut terdapat tim kecil yang khusus bertugas untuk menangani masalah pemilihan, bahkan pembuatan, musik latar belakang. Dapat dilihat pada film-film yang telah dibuat bahwa emosi atau mood yang digerakkan oleh musik latar tersebut seringkali benar-benar mengena sesuai dengan emosi yang diinginkan pada scene-scene tertentu pada film tersebut.
Pertanyaan yang sering muncul adalah apakah klasifikasi tersebut memang benar-benar dapat diterapkan secara global, sehingga klasifikasi tersebut tidak spesifik untuk segolongan manusia tertentu dan musik-musik tertentu. Jika hal tersebut benar, maka dapat dibuat pengklasifikasi musik yang dibantu dengan komputer, sehingga klasifikasi musik berdasarkan emosi dapat dilakukan secara otomatis. Dengan adanya sistem klasifikasi musik otomatis ini, proses-proses seperti pemilihan musik untuk film dapat sangat terbantu.
J. Skowronek, et al. dalam penelitiannya melakukan analisis apakah dari penilaian subjektif klasifikasi emosi musik dapat dibuat suatu ‘ground truth’ sebagai acuan untuk mengembangkan sistem deteksi emosi secara otomatis. Pada eksperimen yang dilakukan, mereka mengumpulkan 60 potongan musik berdurasi 20 detik. Kemudian dievaluasi oleh sekelompok orang sedemikan sehingga satu potongan musik terevaluasi oleh 4 orang. Kesimpulan yang didapatkan oleh penelitian itu adalah bahwa klasifikasi ini mungkin dilakukan, dan disarankan untuk memilih label emosi/mood
yang mudah dipahami oleh subjek yang mengevaluasi [6]. Penelitian yang dilakukan Skorownek ini dan penelitian lain yang sejenis memberikan dasar pada pengembangan sistem klasifikasi emosi pada musik secara otomatis. Didasari oleh hasil penelitian tersebut, pada tahun 2007 MIREX (Music Information Retrieval Evaluation eXchange), sebuah kompetisi tahunan yang bertujuan untuk melihat kemajuan dalam bidang music information retrieval (MIR), melombakan pembuatan sistem klasifikasi musik berdasarkan emosi ini. Dengan 11 peserta, pemenang dari MIREX 2007 berhasil menghasilkan ketepatan 60% dalam melakukan klasifikasi [7].
3. Gambaran Umum Sistem
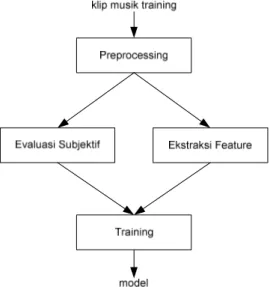
Sistem AMEC yang akan diusulkan di makalah ini adalah sistem yang berbasiskan pembelajaran terhadap klasifikasi musik yang sudah ada, yang diklasifikasikan secara subyektif. Sistem AMEC ini terbagi atas dua fase, yaitu fase pelatihan seperti pada Gambar 1 dan fase classifier, seperti pada Gambar 2, yang menggunakan model dari hasil training di bagian pertama.
Gambar 1 Fase Pelatihan
Pada fase pelatihan, diberikan sejumlah klip (potongan) musik untuk menjadi bahan pelatihan. Kemudian dilakukan preprocessing untuk mempermudah pemrosesan berikutnya. Dari hasil preprocessing ini kemudian dilakukan ekstraksi feature. Selain itu, dilakukan pula
evaluasi secara subjektif untuk melabeli klip musik pelatihan dengan label emosi tertentu. Evaluasi secara subjektif ini dilakukan terhadap hasil preprosesing agar degradasi yang terjadi juga mempengaruhi evaluasi subjektif. Kemudian dilakukan pembelajaran untuk menghasilkan model yang akan digunakan oleh classifier untuk dapat mengklasifikasikan klip musik tertentu.
Pada fase classifier, sistem AMEC ini dapat digunakan untuk melakukan pelabelan klasifikasi emosi suatu klip musik tertentu. Klip musik diolah dulu oleh preprosesor dan diekstraksi featurnya dengan cara yang sama dengan pada fase pelatihan. Kemudian, terhadap feature hasil ekstraksi akan dilakukan classifying, pengklasifikasian dengan menggunakan model hasil dari fase pelatihan.
Gambar 2 Fase Classifier
4. Label Klasifikasi Emosi
Salah satu permasalahan dalam AMEC ini adalah taksonomi dari muatan emosi musik. Pembagian label klasifikasi emosi musik tidak dapat dilakukan sembarangan. Tanpa pembagian label yang tepat dan hati-hati, mudah terjadi label klasifikasi yang saling beririsan satu sama lain, sehingga sulit untuk mengklasifikasikan musik ke dalam label-label tersebut.
Dalam psikologi musik, pendekatan tradisional pelabelan emosi adalah dengan menggunakan label sifat, seperti sedih, suram dan murung. Akan tetapi, pelabelan ini berlainan dalam setiap
Preprocessing klip musik Ekstraksi Feature Classifying kelas model
penelitian. Tidak ada standar taksonomi emosi yang disepakati oleh semua pada saat ini. Akan tetapi, daftar kata sifat Hevner yang dikemukakan pada tahun 1936 menjadi basis bagi penelitian selanjutnya.
Hevner membagi klasifikasi emosi menjadi 64 kata sifat, yang dikelompokkan menjadi 8 cluster, yaitu sober, gloomy, longin, lyrical, sprightly, joyous, restless dan robust [12]. Kemudian pengelompokan tersebut diperbaiki oleh Farnsworth dan dikelompokkan ulang menjadi 10 cluster, seperti dapat dilihat pada Tabel 1.
Tabel 1 Klasifikasi Emosi Farnsworth [8] A cheerful,gay,happy B fanciful, light C delicate, graceful D dreamy, leisurely E longing, pathetic F dark, depressing G sacred, spiritual H dramatic, emphatic I agitated, exciting J frustated
Karena sistem klasifikasi seperti klasifikasi Hevner/Farnsworth dan pengembangannya masih saling tumpang tindih antara satu cluster, maka klasifikasi tersebut susah untuk diaplikasikan dalam suatu sistem AMEC. Sebagai contoh, AMG (allmusicguide.com) yang memakai daftar kata sifat turunan dari Hevner memiliki sekitar 200 buah label emosi musik [13]. Seperti yang disimpulkan oleh J. Skowronek, et al. pada penelitiannya, pada pengaplikasian klasifikasi musik, lebih baik memakai sistem klasifikasi emosi yang sederhana, terdiri atas sedikit cluster yang dapat dengan mudah dibedakan [6].
Banyak peneliti yang akhirnya mengikuti saran Skowronek, dan menyederhanakan pelabelan emosinya menjadi hanya beberapa cluster (di antaranya: [8][14][15]). Misalnya, dalam MIREX 2007 bagian Automatic Mood Detection, label emosi yang digunakan hanya dibagi lima cluster [7] (lihat Tabel 2), atau MoodLogic yang hanya membaginya menjadi lima: aggresive, upbeat, happy, romantic, mellow dan sad [16].
Tabel 2 Cluster Emosi MIREX 2007 [7] Cluster_1 passionate, rousing,
confident,boisterous, rowdy Cluster_2 rollicking, cheerful, fun, sweet,
amiable/goodnatured Cluster_3 literate, poignant, wistful,
bittersweet, autumnal, brooding Cluster_4 humorous, silly, campy, quirky,
whimsical, witty, wry
Cluster_5 aggressive, fiery, tense/anxious, intense, volatile visceral
Selain masalah ambiguitas, kategorisasi yang berdasarkan Hevner ini memiliki kekurangan lain, yaitu bahwa kategorisasi ini sama sekali tidak menunjukkan stimulus terkait yang menimbulkan suatu emosi tertentu. Keterkaitan ini dapat sangat membantu dalam pemodelan komputasi. Pada sekitar tahun 90an, Thayer mengajukan pendekatan lain terhadap kategorisasi emosi musik [17]. Thayer mengajukan model dua dimensi yang memetakan emosi musik. Tidak seperti Hevner yang mempergunakan kata sifat yang secara kolektif membentuk suatu pola emosi, pendekatan dua dimensi ini mengadopsi teori yang menyatakan bahwa emosi disebabkan oleh dua faktor: stress (senang/cemas) dan energi (kalem/energetik). Dengan begitu, Thayer membagi kategori emosi musik menjadi empat cluster, contentment (kepuasan), depression (depresi), exuberance (gembira) dan anxious/frantic (cemas/kalut), seperti pada Gambar 3.
Gambar 3 Model Emosi Thayer [12] Model Thayer ini juga banyak diadopsi pada penelitian mengenai emosi dalam musik. Istilah yang digunakan utuk menyebut dua dimensi emosi musik seringkali berlainan, tetapi esensinya sama seperti model Thayer ini. Misalnya, Pohle et al. dalam [18] menggunakan istilah mood (dari senang, netral sampai sedih) dan emosi (dari lembut, netral sampai agresif). Y.H. Yang dalam beberapa papernya yang berkenaan dengan klasifikasi emosi menyebutnya arousal (tingkat emosi) dan valence (lihat Gambar 4) [5][19][20].
Gambar 4 Model Y.H. Yang [5]
Kelemahan dari model-model yang mengadopsi Thayes dibandingkan dengan Hevner adalah pembagian yang kaku, pasti 4 cluster. Dengan begitu, model ini tidak dapat dikembangkan untuk kebutuhan yang lebih spesifik, yang membutuhkan pembagian cluster yang berbeda. Walaupun begitu, hal ini dapat sedikit diatasi dengan menggeser batas antara valence positif-negatif dan arousal high-low.
Dalam rancangan yang diusulkan, klasifikasi emosi yang ingin dicapai tidaklah spesifik untuk satu tujuan tertentu. Model klasifikasi emosi yang dipilih haruslah dapat diaplikasikan secara umum untuk emosi yang ada dalam semua musik. Model yang dipilih juga harus cukup sederhana, mudah dipahami dan tidak ambigu agar memudahkan klasifikasi subjektif yang dilakukan sebagai bahan pelatihan.
Atas dasar kebutuhan pada rancangan ini, maka model klasifikasi yang dipakai adalah model klasifikasi yang dipakai oleh Yang. Klasifikasi Yang ini diambil karena dimensinya lebih jelas daripada model aslinya yang dibuat oleh Thayer.
5. Musik Masukan
Musik yang diolah oleh sistem AMEC ini adalah musik dalam bentuk digital. Terdapat dua kategori format utama untuk musik dalam bentuk digital, yaitu:
1. Musik dalam bentuk data akustik atau audio, yaitu rekaman permainan musik tersebut dalam bentuk suara. Format ini dapat dibagi atas dua kelompok besar, yaitu melodi monofonik satu suara/channel dan musik yang mixed multichannel.
Gambar 5 Suara Sebagai Sinyal Digital [21] 2. Musik dalam bentuk simbolik, yaitu
informasi mengenai nada-nada yang membentuk suatu musik tertentu. Format yang umum digunakan yang masuk kategori ini adalah MIDI. Data MIDI ini dapat berupa permainan musik yang direkam dalam bentuk MIDI atau partitur musik yang dibuat oleh pengarang lagu.
Gambar 6 Musik Simbolik (divisualisasikan dalam bentuk partitur)
Beberapa penelitian seputar bidang AMEC menggunakan representasi simbolik. Liu [22] mengemukakan sebuah sistem mood recognition dengan classifier berupa fuzzy classifier dipergunakan untuk mengklasifikasikan waltz karya Johann Strauss ke dalam lima cluster emosi. Sistem Liu mengekstraksi feature-feature dari file MIDI lagu-lagu Johann Strauss. Katayose juga mengemukakan sitem ekstraksi emosi untuk musik pop, dimana data suara monofonik dikonversi menjadi kode musik terlebih dahulu. Kemudian, feature-feature musik seperti melodi, ritme dan lainnya diekstraksi dari kode musik tersebut [12].
Penelitian-penelitian tersebut menghasilkan hasil yang baik, tetapi penelitian tersebut berkonsentrasi pada representasi simbolik, karena sulitnya mengekstraksi feature-feature musik yang berguna dari data musik dalam bentuk akustik. Akan tetapi, musik yang ada di dunia nyata bukanlah dalam bentuk simbolik, dan saat ini belum ada sistem transkripsi yang dapat mentranslasikannya ke dalam representasi simbolik dengan baik.
Penentuan format mana yang dipakai tergantung pada konteks sistemnya. Pada sistem AMEC yang diusulkan ini, karena sistemnya dibuat untuk penggunaan secara umum, maka sistem AMEC ini harus dapat menerima format dalam bentuk data akustik atau audio. Permasalahan apakah data akustik tersebut dikonversi dulu menjadi data simbolik akan dibahas pada bagian preprosesor.
Panjang Klip Musik
Selain masalah format, hal lain yang perlu diperhatikan adalah panjangnya klip musik masukan. Emosi yang terkandung dalam satu musik tertentu seringkali tidak hanya satu. Pada bagian tertentu, satu musik bisa saja cenderung calm atau peaceful, kemudian berubah ke arah valence negatif. Sebagai contoh, potongan lagu “1812 Overture” di [12] diklasifikasikan seperti pada Gambar 7. Atas dasar pertimbangan yang sama dengan pertimbangan pemilihan format, maka panjang klip musik tidak dibatasi. Pemotongan akan dilakukan secara internal, dan akan dibahas pada bagian preprosesor.
Lirik
Sebagian dari musik mengandung kata-kata yang dinyanyikan oleh manusia. Kata-kata tersebut disebut dengan lirik. Rangkaian lirik membawa emosi tersendiri, dapat sejalan dan saling menguatkan dengan emosi pada musik itu sendiri, dapat juga tidak [23]. Pada sistem AMEC ini, lirik diabaikan, karena permasalahan speech recognition dari nyanyian, dan kemudian ekstraksi emosi dari kata-kata memerlukan pembahasan tersendiri. Oleh karena itu, maka lirik dalam musik diabaikan, dan pada penilaian subjektif yang diberikan pada pelatihan, diharapkan penilaian subjektif yang diberikan didapatkan dari penilaian musik saja, tidak menilai emosi yang dibawa oleh liriknya.
6. Feature Musik
Dalam proses pelatihan serta klasifikasi, sistem AMEC perlu melakukan ekstraksi feature yang mempunyai level lebih tinggi dari musik yang diolah. Feature ini mempermudah dilakukannya pelatihan dengan mengkaitkan feature-feature tersebut dengan cluster emosi dari musik yang diproses, dibandingkan dengan mengolah musik apa adanya.
Banyak feature yang dapat diekstraksi dari sebuah klip musik, dari mulai feature yang paling sederhana seperti nada, tempo dan nada dasar, feature yang lebih tinggi seperti tangga nada (mayor/minor), ritme, beat, akor sampai pada feature seperti chord progression, bentuk melodi, genre, dan sebagainya. Tidak semua feature tersebut memiliki andil pada emosi yang terkandung pada musik. Misalnya, Blood mengemukakan pada hasil penelitiannya bahwa tingkat disonansi akor sangat berpengaruh besar pada emosi antara cluster pleasant dan unpleasant, tetapi tidak berpengaruh antara cluster sad dan happy (lihat Gambar 8).
Gambar 8 Contoh dari akor dengan versi paling konsonan (akor triad mayor, Diss0) sampai ke yang paling disonan (akor -13, Diss5), dan keterkaitannya dengan rating pleasant (+5) /
unpleasant (-5) dan sad (+5) / happy (-5) [24]. Hevner dalam hasil penelitiannya mengemuka-kan hubungan antara cluster kategori emosi yang dirumuskannya dengan beberapa feature (lihat Tabel 3). Terdapat lima feature yang ditelitinya, yaitu mode, tempo, pitch (tinggi nada), ritme, harmoni dan bentuk melodi. Dengan menggunakan cara klasifikasi Hevner, semua feature yang mungkin berpengaruh besar harus diteliti. Karena cara klasifikasi yang digunakan Gambar 7 Mood dalam potongan “1812 Overture” [12]
pada sistem AMEC ini adalah model klasifikasi Yang, yang diturunkan dari model Thayer, feature musik yang diperlukan untuk mengklasifikasi emosi dapat dibagi menjadi dua: 1. Feature yang berpengaruh terhadap dimensi
Arousal,
2. Feature yang menyebabkan perbedaan emosi yang ditimbulkan, emosi positif atau negatif (dimensi Valence).
Secara umum, dimensi Arousal lebih mudah untuk dibedakan dibandingkan dengan dimensi Valence [12]. Dimensi arousal berkenaan dengan ‘energi’ yang ada pada suatu musik. Jika musik tersebut lebih berenergi, maka tingkat arousalnya lebih besar. Berbeda dengan dimensi Arousal, dimensi Valence tidak dapat dengan mudah dijelaskan seperti itu.
Secara garis besar, feature yang dibutuhkan untuk mendeteksi emosi dapat dibagi tiga: 1. Intensitas
2. Timbre dan tekstur 3. Ritme
Feature intensitas adalah feature utama yang digunakan untuk mengukur Arousal. Cara ekstraksi feature ini yang paling sederhana adalah dengan mengukur MSE loudness dan volume dari musik. Walaupun feature ini adalah feature paling utama yang mempengaruhi Arousal, tetapi Arousal juga dapat dipengaruhi oleh kedua jenis feature lainnya.
Feature yang mempengaruhi Valence utamanya berasal dari feature timbre dan tekstur serta ritme. Kedua jenis feature ini relatif lebih susah untuk diukur jika dibandingkan dengan feature intensitas.
Salah satu feature yang termasuk dalam feature timbre dan tekstur adalah tangga nada. Lagu yang menggunakan tangga nada mayor cenderung memiliki valence positif, sedangkan lagi yang menggunakan tangga nada minor
sebagian besar memiliki valence yang cenderung negatif. Akan tetapi, feature mode adalah feature yang susah untuk diekstraksi.
Karena hubungan antara ketiga jenis feature tersebut dengan dimensi Arousal maupun Valence tidak dapat dipastikan, maka pada proses pelatihan, seluruh feature dipelajari hubungannya dengan kedua dimensi, Arousal dan Valence.
7. Preprosesor dan Teknik Ekstraksi Feature Preprosesor dan teknik yang digunakan dalam ekstraksi feature sangat berkaitan satu sama lain. Preprosesor harus menyesuaikan klip musik menjadi sesuai dengan kebutuhan pada proses ekstraksi feature. Begitu pula sebaliknya, teknik ekstraksi feature yang digunakan harus dapat mengolah musik hasil preproses sehingga menghasilkan feature yang diinginkan.
Preprosesor
Seperti dijelaskan pada bagian sebelumnya, ekstraksi feature dari data simbolik seperti MIDI lebih mudah dilakukan dibandingkan dengan dari data akustik. Akan tetapi, sampai saat ini belum ada cara sistem transkripsi data akustik yang mumpuni untuk mengkonversinya menjadi data simbolik. Oleh karena itu, preprosesor pada sistem AMEC ini tidak mengubah representasi musik masukan, tetap sebagai data akustik. Untuk menyeragamkan serta menyederhanakan pemrosesan berikutnya, data akustik di-sampling ulang menjadi 16-bit, mono, 16 kHz. Downsampling dari stereo menjadi mono dilakukan dengan menggabungkan kedua channel audio menjadi satu channel. Downsampling stereo menjadi mono ini tidak berpengaruh terhadap ekstraksi feature untuk klasifikasi emosi karena dua channel suara stereo tersebut hanya berfungsi menyimpan kesan ‘ruang’ bagi pendengar musik.
Tabel 3 Rangkuman hubungan cluster emosi – feature yang disimpulkan Hevner [34]. (Nomer di sebelah feature mengindikasikan bobot relatif dari tiap feature untuk setiap cluster emosi.
Klip musik masukan dipotong-potong menjadi potongan 30 detik untuk memperkecil perubahan emosi yang ada dalam satu klip, mengadopsi cara yang digunakan dalam MIREX 2007. Liu dalam [12] mengemukakan cara yang lebih baik untuk memotong berdasarkan emosi yang terkandung di dalamnya. Cara itu disebutnya sebagai ‘Mood Tracking’. Pada setiap perubahan feature yang cukup drastis, klip musik dipotong, sehingga menghasilkan potongan-potongan yang masing-masing hanya membawa satu emosi. Cara ini tidak diterapkan dalam sistem AMEC ini agar tidak memperumit permasalahan. Ekstraksi Feature
Hasil pengolahan preprosesor berupa data akustik, sehingga teknik ekstraksi feature yang digunakan haruslah teknik ekstraksi yang berbasiskan pada data akustik. Untuk itu, sistem AMEC ini menggunakan dua toolkit yang dapat digunakan secara bebas: PsySound [36] dan Marsyas [33]. Total 45 buah feature yang termasuk pada kelompok feature yang dibahas di bagian sebelumnya diekstraksi.
PsySound mengekstraksi feature-feature berdasarkan model psikoakustik [35], sehingga feature yang dihasilkan relevan dengan persepsi emosi. Feature tersebut mencakup: loudness, sharpness, lebar warnasuara, volume, disonansi spektrum dan akor.
Marsyas adalah framework generik untuk aplikasi audio [33]. Marsyas menghasilkan 19 feature tekstural, 6 feature ritmis (dengan deteksi beat dan tempo) dan 5 feature berkenaan dengan pitch.
8. Algoritma Klasifikasi dan Pelatihannya Semua algoritma machine learning yang mampu mempelajari data dengan dimensi besar (vektor feature yang digunakan berdimensi 45) dapat digunakan, seperti SVM (Support Vector Machines), C4.5, naive bayes, ANN, k-Nearest Neighbor, dan sebagainya. Untuk menilai algoritma yang paling tepat untuk sistem AMEC ini, sistem ini harus diimplementasikan, kemudian diuji dan dinilai ketepatan hasil klasifikasinya.
9. Kesimpulan
Rancangan sistem automatic music emotion
classification yang diajukan sudah mencakup seluruh bagian dari sebuah sistem yang lengkap. Setiap bagian telah dianalisis dan diambil pendekatan yang paling sesuai, kecuali pada algoritma klasifikasi. Pemilihan algoritma klasifikasi yang sesuai memerlukan adanya pengujian untuk masing-masing algoritma klasifikasi yang mungkin digunakan.
Sistem ini perlu diimplementasikan dan diuji terlebih dahulu, sebelum dikembangkan lebih lanjut. Misalnya, dengan memasukkan algoritma ‘Mood Tracking’ untuk memotong klip musik, ataupun memperbaiki rancangan dengan umpan balik dari hasil pengujian.
10. Daftar Pustaka
[1] C.-C Liu, Y.-H. Yang, P.-H. Wu, H.-H. Chen. (2006). Detecting and classifying emotion in popular music. Proc. 9th Joint Int. Conf. Information Sciences / 7th Int. Conf. Computer Vision, Pattern Recognition and Image Processing 2006
(JCIS/CVPRIP'06), Kaohsiung, Taiwan, pp. 996-999.
[2] B. Klein. (2007). Music Definition.
http://www.bklein.de/music_definition.htm Diakses: Februari 2007.
[3] CTV News. (2002). Study explains link between music and emotion.
http://www.ctv.ca/servlet/ArticleNews/story/ CTVNews/1039741748103_21/?hub=Healt h. Diakses: Oktober 2007.
[4] D.Huron. (2000). Perceptual and Cognitive Applications in Music Information Retrieval. International Symposium on Music
Information Retrieval (ISMIR) 2000. [5] Y.-H. Yang, Y.-F. Su, Y.-C. Lin, H.-H.
Chen. (2007). Music emotion recognition: The role of individuality. Proc. ACM SIGMM Int. Workshop on Human-centered Multimedia 2007, in conjunction with ACM Multimedia (ACM MM/HCM'07),
Augsburg, Germany, pp. 13-21.
[6] J. Skowronek, M.E. McKinney, S. van de Par. (2006). Ground Truth for Automatic Music Mood Classification. International Symposium on Music Information Retrieval (ISMIR) 2006.
http://ismir2006.ismir.net/PAPERS/ISMIR0 6105_Paper.pdf. Diakses: September 2007.
[7] Music Information Retrieval eXchange (MIREX) 2007.
http://www.music-ir.org/mirex/2007. Diakses: Desember 2007. [8] O. Li. (2003). Detecting Emotion in Music.
International Symposiun on Music Information Retrieval 2003.
[9] C.M. Grund. (2006). A Philosophical Wish List for Research in Music Information Retrieval. International Symposium on Music Information Retrieval (ISMIR) 2006.
http://ismir2006.ismir.net/PAPERS/ISMIR0 6149_Paper.pdf . Diakses: Oktober 2007. [10]M.M. Lavy. (2001). Emotion and the
Experience of Listening to Music: A Framework for Empirical Research. Jesus College, Cambridge.
http://www.scribblin.gs/miscellanea/mlavy-thesis-noapp.pdf. Diakses: Oktober 2007. [11]K. Hevner. Experimental studies of the
element sof expression in music. American Journal of Psychology,48:246–268,1936. [12]D. Liu, L. Lu, H.-J. Zhang. (2003).
Automatic Mood Detection from Acoustic Music Data. ISMIR 2003.
http://ismir2003.ismir.net/papers/Liu.PDF. Diakses: November 2007.
[13]AllMusicGuide (AMG). Explore by Moods.
http://wm02.allmusic.com/cg/amg.dll?p=am g&sql=75:. Diakses: Januari 2008.
[14]M.I. Mandel, G.E. Poliner, D.P.W. Ellis (2006). Support vector machine active learning for music retrieval. Multimedia Systems, Vol.12(1). Aug.2006.
http://www.ee.columbia.edu/~dpwe/pubs/M andPE06-svm.pdf. Diakses: Desember 2007. [15]N. Corthaut, Govaerts, S., dan Duval, E.
(2006). Moody Tunes: The Rockanango Project . ISMIR 2006.
http://ismir2006.ismir.net/PAPERS/ISMIR0 688_Paper.pdf. Diakses: Oktober 2007. [16]MoodLogic. http://www.moodlogic.com.
Diakses: Januari 2008
[17]R. E. Thayer. (1989). The biopsychology of mood and arousal. Oxford University Press. [18]Pohle, Pampalk, dan Widmer. (2005).
Evaluation of Frequently Used Audio Features for Classification of Music into Perceptual Categories.
[19]Y.-H. Yang, Y.-C. Lin, Y.-F. Su, and H.-H. Chen, "Music emotion classification: A
regression approach," in Proc. IEEE Int. Conf. Multimedia and Expo. 2007 (ICME'07), Bejing, China, pp. 208-211. [20]Y.-H. Yang, C.-C Liu, and H.-H. Chen, "Music emotion classification: A fuzzy approach," in Proc. ACM Multimedia 2006 (ACM MM'06), Santa Barbara, CA, USA, pp. 81-84.
[21]Langi, Armein (2006). Introduction to Multimedia Data Compression. DSP Research and Technology IURC Microelectronics ITB.
[22]D. Liu, N. Y. Zhang, H. C. Zhu, (2003). Form and mood recognition of Johann Strauss’s waltz centos. Chinese Journal of Electronics, 3.
[23]Taylor, Ken (2006) . Music, Meaning and Emotion: Interview With Peter Kivy .
http://theblog.philosophytalk.org/2006/09/m usic_meaning_a.html. Diakses: Oktober 2007.
[24]A.J. Blood, R.J. Zatorre, P. Bermudez, A.C. Evans. (1999). Emotional responses to pleasant and unpleasant music correlate with activity in paralimbic brain regions. Nature Neuroscience, 2, 382-387.
http://www.zlab.mcgill.ca/docs/Blood_et_al _1999.pdf. Diakses: Desember 2007. [25]Blood, A.J. & Zatorre, R.J. (2001 )
Intensely pleasurable responses to music correlate with activity in brain regions implicated with reward and emotion. Proceedings of the National Academy of Sciences, 98, 11818-11823. (Didapatkan dari
http://www.zlab.mcgill.ca/docs/Blood_and_ Zatorre_2001.pdf)
[26]Dawson, Terence. Music: Emotion and Feeling.
http://www.victorianweb.org/authors/wilde/ dawson2.html . Diakses: Oktober 2007. [27] Worth, Sarah E. (2007). Music, Emotion
and Language: Using Music to Communicate .
http://www.bu.edu/wcp/Papers/Aest/AestW ort.htm . Diakses: Oktober 2007.
[28]American Association for Artificial Intellig ence. AI Applications In Music.
http://www.aaai.org/aitopics/html/music.htm l . Diakses: Oktober 2006.
Intelligence.
http://music.arts.uci.edu/dobrian/CD.music.a i.htm .
[30] Kawakimi. (1975). Arranging Popular Music: A Practical Guide. Yamaha Music Foundation .
[31] Kheng, Loh Phaik. 1991. A Handbook of Music Theory. Muzikal .
[32]Pope, A.T., Holm, F., Kouznetsov, A. (2004). Feature Extraction and Database Design for Music Software. Proc. 2004 Int’l Computer Music Conference. University of Miami.
http://fastlabinc.com/PopeHolmKouznetsov _icmc2.pdf. Diakses: November 2007. [33]Music Analysis, Retrieval, and Synthesis for
Audio Signals (MARSYAS).
http://marsyas.sness.net. Diakses: Desember 2007.
[34]E.Farrar. (2002). A Method for Mapping Expressive Qualities of Music to Expressive Qualities of Animation. Advanced
Computing Center for the Arts and Design, The College Of Arts, The Ohio State University.
http://accad.osu.edu/~efarrar/thesis/proposal 120602.pdf. Diakses: Januari 2008.
[35]D. Cabrera. (1999). Psysound: A computer program for psychoacoustical analysis. Proceedings of the Australian Acoustical Society Conference, Melbourne, 24-26 November 1999, pp 47-54.
http://members.tripod.com/~densil/software/ PsySound.PDF. Diakses: Januari 2008. [36]PsySound3. http://psysound.org. Diakses:
![Tabel 1 Klasifikasi Emosi Farnsworth [8]](https://thumb-ap.123doks.com/thumbv2/123dok/4823156.3455675/4.918.487.785.118.309/tabel-klasifikasi-emosi-farnsworth.webp)
![Gambar 5 Suara Sebagai Sinyal Digital [21]](https://thumb-ap.123doks.com/thumbv2/123dok/4823156.3455675/5.918.146.421.119.347/gambar-suara-sebagai-sinyal-digital.webp)
![Gambar 8 Contoh dari akor dengan versi paling konsonan (akor triad mayor, Diss0) sampai ke yang paling disonan (akor -13, Diss5), dan keterkaitannya dengan rating pleasant (+5) / unpleasant (-5) dan sad (+5) / happy (-5) [24]](https://thumb-ap.123doks.com/thumbv2/123dok/4823156.3455675/6.918.499.782.571.812/gambar-contoh-konsonan-disonan-keterkaitannya-rating-pleasant-unpleasant.webp)
![Tabel 3 Rangkuman hubungan cluster emosi – feature yang disimpulkan Hevner [34].](https://thumb-ap.123doks.com/thumbv2/123dok/4823156.3455675/7.918.136.780.147.270/tabel-rangkuman-hubungan-cluster-emosi-feature-disimpulkan-hevner.webp)
